
Chapter 7
Latches and Spinlocks
WHAT’S IN THIS CHAPTER?
- Recognizing the symptoms of latch and spinlock contention
- Describing the types of systems which are susceptible to latch and spinlock contention
- Descriptions of latch types and modes
- Common contention-prone scenarios and how to resolve them
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
The wrox.com code downloads for this chapter are found at www.wrox.com/remtitle.cgi?isbn=1118177657 on the Download Code tab. The code is in the Chapter 7 download and individually named according to the names throughout the chapter.
OVERVIEW
When I speak to database consultants, many of them are familiar with SQL Server’s locking behavior, and can even describe many of the principles covered in Chapter 6. They’re far less confident about latches, however. Similarly, comparatively few can talk at any length about spinlocks, which are a very related topic. In light of this, I consider this chapter to be an important inclusion in this book.
The idea of this chapter is to offer practical advice to users trying to resolve issues identified to be related to both latch and spinlock behavior. We begin by describing some of the scenarios you might find yourself in, and the kind of symptoms you might see that betray a latch or spinlock problem. Even if they all seem alien (you might have never yet experienced latch contention) it would be useful to have a passing familiarity with these symptoms so that you can recognize various problems when you see them. By looking at the kinds of environments that lend themselves to latch and spinlock contention, you can assess your own situation and weigh the importance of this knowledge in your own skill set.
After introducing the symptoms, the chapter takes a detailed look at latches — what they are, how they work, and how to track them down using DMVs and extended events. The chapter also contains some real-world examples of latch contention, explaining how to resolve them
SYMPTOMS
In an ideal system, the number of transactions per second increases as traffic increases, and adding extra processor threads can help to resolve this. Having more processor threads should result in better performance, but it could lead to latch and spinlock contention instead. Over recent years, processors have not increased significantly, but the number of processors per server, cores per processor, and threads per core through hyperthreading have all been increasing, resulting in systems that are often scaled up by adding processor threads.
So it’s important to recognize the signs of latch and spinlock contention.
Recognizing Symptoms
If your transactions per second figure is dropping as you enable extra processor threads, and your average latch waits are increasing at a rate greater than the throughput, then you quite possibly have a problem with latch contention. Consider the following two images. One represents how you want your system to behave, and the other, the effect of latch contention.
Both images show the number of transactions per second and average latch time (how to get this information will be shown soon).
Figure 7-1 represents the behavior that you should see when adding threads.

However, your chart may look more like the one shown in Figure 7-2. Notice the number of transactions per second starting to decrease after a point, and the number of latches increasing significantly.
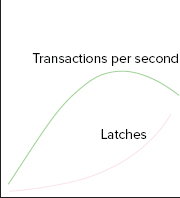
In Figure 7-1, the ideal behavior shows the average latch time increasing a little as the number of processors increases, but not significantly. The number of transactions per second is happily increasing, suggesting that the processors are not conflicting with each other too much; and the more processors there are, the more can be done.
But in Figure 7-2, adding processors was proving useful but only up to a point. The effect of latch waits started to kick in, preventing the benefit of extra processors from being realized. It even got to the unhappy point of reducing the amount of work that could actually be done. This caused problems, rather than solving them. With the system spending so long waiting, the impact on real work becomes negative.
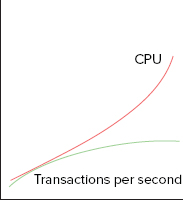
In order for spinlock contention to be a concern, behavior as described by the chart shown in Figure 7-3 would be exhibited, with the CPU rising exponentially as the load increases, with transactions dropping as with the latches. Keep in mind that you should also eliminate other factors that may be responsible for the increased CPU load.
Sometimes the obvious needs to be stated — you need a benchmark to tell you what “good performance” looks like, to weigh against what you’re seeing when troubleshooting. When you examine a system without any historical background, you can sometimes recognize undesirable behavior, but a particular system could easily exhibit symptoms that are typical for it. Doctors use benchmarks when testing their patients — some of whom exhibit levels that are not typical across a broad population but are fine for them.
When you, in your role as database surgeon, open Performance Monitor, or PerfMon, and start looking at the various levels, it helps to know what those levels were before the problems started.
Measuring Latch Contention
A latch is like a lock on a piece of memory. As more threads get involved, they will start to compete to access the same pieces of memory, causing blocking. Blocking due to latch contention is exhibited in waits; but unlike a lock, a latch can be released as soon as the physical operation is completed.
The main sources of data about latches are two DMVs called sys.dm_os_wait_stats and sys.dm_os_latch_stats. The details of the values stored in these DMVs will be examined later in an explanation of latch modes and latch types, but for the purposes of recognizing the symptoms, a brief explanation will suffice. The DMVs are restarted when the service restarts, or when the DBCC SQLPERF command is called to clear them, as in the following code (code file Ch7Symptoms.sql):
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);Among the columns of the DMV sys.dm_os_wait_stats are ones called wait_type, wait_time_ms and waiting_tasks_count. These three columns represent the wait type, the total number of milliseconds that have been spent waiting on this wait type, and the number of times this type of wait has occurred, respectively. Wait types that associate with latches start with LATCH_, PAGELATCH_, or PAGEIOLATCH_.
Dividing the total wait time by the number of waits will give an average wait time (I’d recommend wrapping the waiting_tasks_count column in the NULLIF function to avoid a division by zero error). By querying this DMV repeatedly over time (as in the following example, code file Ch7Symptoms.sql, further illustrated in Figure 7-4), a picture can be built up of the frequency of latch waits, along with the amount of time the system must wait for these latches. This picture allows a database administrator to understand what kind of behavior is being exhibited — whether it matches Figure 7-1 or Figure 7-2.

SELECT
wait_type,
wait_time_ms,
waiting_tasks_count,
wait_time_ms / NULLIF(waiting_tasks_count,0) AS avg_wait_time
FROM sys.dm_os_wait_stats
WHERE wait_type LIKE 'LATCH_%'
OR wait_type LIKE 'PAGELATCH_%'
OR wait_type LIKE 'PAGEIOLATCH_%';The DMV called sys.dm_os_latch_stats lists similar statistics for latch classes. This will be described further later in the chapter.
Measuring Spinlock Contention
For the time being, you can think of a spinlock as a latch, except that if the memory needing access is not available, the spinlock will keep checking it (known as spinning) for a while. There is slightly more to it, but that will be kept for later in the chapter.
The main DMV for spinlocks is sys.dm_os_spinlock_stats. The metrics of concern for spinlocks are around collisions and spins_per_collision, which are both columns in this DMV, along with the name column for the type of spinlock. Collisions and spins will be described later in the chapter. Here is an example of using sys.dm_os_spinlock_stats (code file Ch7Symptoms.sql), further illustrated in Figure 7-5:
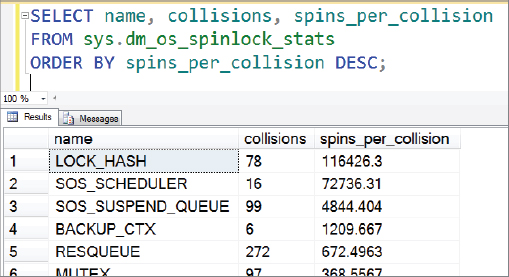
SELECT name, collisions, spins_per_collision
FROM sys.dm_os_spinlock_stats
ORDER BY spins_per_collision DESC;The sys.dm_os_spinlock_stats DMV can also be cleared using DBCC SQLPERF.
Contention Indicators
Locks are used to maintain the ACID properties of a transaction, but latches are used to provide consistency over a memory operation. A spinlock should be considered as similar, in that a resource is needed for a particular operation, but is not available.
Therefore, when you see higher than normal wait stats associated with latches and spinlocks, you may need to investigate further.
However, only seeing higher than normal wait stats does not in and of itself indicate a contention problem. It is perfectly reasonable to expect that if your system is busier now than when you took your benchmark, your wait stats would be higher. You should look for the proportion of wait stats compared to others, and compare this to the throughput being achieved. You might also want to consider how many transactions per second you’re managing to achieve as you increase the load, and the effect of extra processors.
One strong indicator of latch contention can be seen when the proportion of latch-related wait stats increases unreasonably as your throughput increases, as shown in Figure 7-2.
For spinlock contention, a strong indicator is the number of spins per collision increasing, typically combined with increased CPU. Spinning is an activity that requires CPU effort, so if spinning increases disproportionally, CPU is likely to do the same. CPU may go up simply because of a busier system, but if the transactions per second counters are leveling off while CPU is increasing, then this would suggest the CPU is being used for something else — such as spinning. This is the behavior shown by the graph in Figure 7-3.
SUSCEPTIBLE SYSTEMS
In SQL Server, you lock something to use it. A latch is similarly applied to a piece of memory when it is used. In the physical world, suppose you want to sit in a chair. If it isn’t occupied, then you have no problem. At home, even if you live with family, the chances of finding the chair unoccupied are relatively good. If you have people over, however, the chance of finding the chair occupied increases quickly. If there’s a party going on, the chair might be occupied quite a lot. Even if people tend to sit down for just a few moments and then get up again, with enough people interested in sitting down now and then, the chance of the chair being occupied increases; and if that chair happens to be particularly popular (maybe it’s a lot more comfortable than the other chairs), then you might have a great deal of chair-use contention.
In terms of latches and spinlocks, recall that a process uses a piece of memory and then releases it. Contention occurs when a process tries to use a piece of memory and finds that another process has already acquired a latch on it. If SQL Server were using only one processor core, there shouldn’t be a problem (you can sit where you like if you’re the only person at home); but that’s yesterday’s server, not today’s. Increasingly, we’re seeing systems with a number of cores that seem ridiculous; and much like we used to talk about memory in megabytes rather than gigabytes, the numbers available now will seem tiny in the future. It is already common to see six- or eight-core processors. Even my laptop, a few years old, is a quad-core machine, raised to eight through hyperthreading.
Furthermore, there are systems that encourage the use of a particular piece of memory. For example, when a lot of processes are trying to push data into a table, and that table always inserts data into the same page, latch contention could result. Database administrators don’t always know exactly what the applications that use their databases are trying to do, but they often have a good idea of which tables meet these conditions, and therefore whether they might be candidates for latch contention.
I imagine by now you’re convinced that latch contention is a very real possibility for your systems, and that if you’re not suffering from it yet, it’s only a matter of time. I think it’s a good time to introduce what latches and spinlocks are, and take a deeper look at them.
UNDERSTANDING LATCHES AND SPINLOCKS
To understand latches and spinlocks, you will need to consider their actual definitions, and consider why they are required in SQL Server.
Definitions
You might recall from the discussion about locks that they are vital to the protection of data. In fact, it was suggested that without locks, there is no guarantee of data integrity, and all would be chaos. Latches perform the same function, but at another level. While locks protect our data from a logical perspective, ensuring that no one accesses the same table (or whatever) during someone else’s transaction, latches do this for memory.
Books Online describes latches as “lightweight synchronization primitives that are used by the SQL Server engine to guarantee consistency of in-memory structures.” In other words, despite the fact that you might think of your data as living in tables and indexes, these tables and indexes must be implemented in memory in order to enable the database engine to work its magic. To be used at all, data needs to be loaded off disk into RAM, making it available when needed. Latches protect this process of loading the data, and protect the data that has been already loaded. Similar to locks, latches are acquired when required, and have modes with various levels of compatibility. You’ll learn more about these modes in a minute, and about some of the techniques that the SQL Server engine uses to efficiently manage latches.
You may already be thinking that because you can, to a certain extent, avoid locking trouble by simply setting the appropriate isolation level in your application, you ought to be able to do the same with latches. You can’t.
A latch is an internal object, used by the SQL Server engine. It is not something that you, the database developer, can directly influence. If you need to get data from a particular page, the SQL Server engine needs to acquire a latch. You have no choice over this. Nor can you tell it what kind of latch to acquire — that’s determined by the SQL Server engine. The difference is that this is not just about the protection of data, it’s about the protection of server memory. Although you might be willing to tolerate dirty reads, and choose your locking strategy accordingly, you don’t have that luxury with latches.
Spinlocks are a similar concept to latches, in that they are also lightweight synchronization primitives, but they act slightly differently. A lot of the effects can seem similar, and the kinds of systems that can exhibit spinlock contention are similar to those that can exhibit latch contention.
The main difference between a spinlock and a latch is this: If a thread fails to acquire a latch immediately, it yields, enabling the CPU to be used for other things. If a thread fails to acquire a spinlock, the thread starts looping (spinning), checking the resource repeatedly, with the expectation that it will become available soon. It won’t spin forever, though. After a bit of time, it will back off, at which point it yields to other processes on the CPU.
Because we have no control over latching behavior or spinlocks, it isn’t possible to demonstrate the impact of various latch scenarios using a real system, as shown for locks in Chapter 6. Instead, the following section presents a simulated example that uses real concepts.
Latching Example
All of the code in this section uses the Ch7Understanding.sql code file.
To begin, suppose you have a table that contains a single row of data. The following code will set up such an environment.
CREATE DATABASE LatchInAction;
GO
USE LatchInAction;
CREATE TABLE dbo.LatchTable
( COL1 INT
,COL2 INT
);
INSERT INTO dbo.LatchTable ( COL1, COL2 )
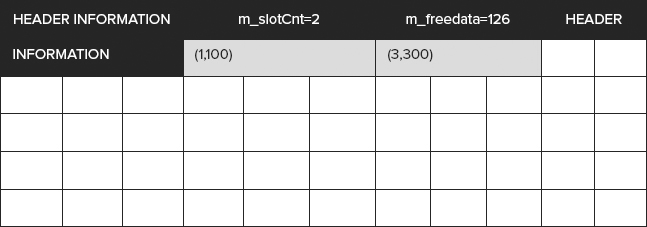
VALUES (1,100);Running DBCC IND will provide information about the pages that are used in the table. You will use the PagePID value of the row which has a PageType value of 1. The PageType column is the tenth column returned, so you may need to scroll. In my system, the value I’m looking for is 73, as seen in Figure 7-6.

DBCC IND(LatchInAction,'dbo.LatchTable',-1);Now run DBCC PAGE to get the output of the table. Before doing that, though, you need to use DBCC TRACEON(3604) to output the results to the screen.
DBCC TRACEON(3604);
DBCC PAGE('LatchInAction',1,73,1);The output is shown in Figure 7-7.

The noteworthy elements for this example are:
- In the PAGE HEADER section, the values m_slotCnt = 1 and m_freeData = 111
- In the DATA section, in Slot 0, the value Length 15
- In the OFFSET TABLE section, the Offset 96
This tells us that there is a single row (slot) in the page. This is Slot 0, which is 15 bytes long. This row starts at position 96 in the page. From position 111 on is empty (freedata). Not coincidentally, 111 = 96 + 15.
You can picture the page as in Figure 7-8.
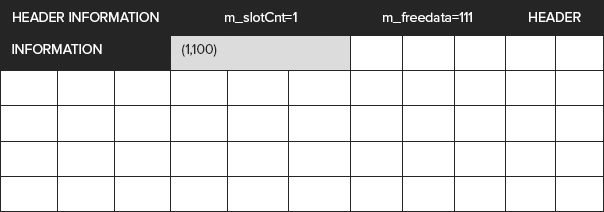
Consider that the white text on black background indicates the page header information, including the offset table. The grey background is the row containing (1,100), at position 96. The white background blocks are freedata, waiting to be allocated to further slots.
Now you can try doing some inserts, from two different sessions:
/*TRANSACTION 1 SESSION 1*/
INSERT INTO LatchTable
VALUES (2,200);
/*TRANSACTION 2 SESSION 2*/
INSERT INTO LatchTable
VALUES (3,300);These inserts are concurrent and are received by the Lock Manager at the same time. Neither row exists, so there is no Exclusive (X) lock available on the row just yet. Both sessions receive an Intent Exclusive (IX) lock on the page, which are compatible with one another.
The transactions now proceed to the Buffer Manager to write their respective rows. The page is in memory, and both start to read it. The following two sections describe what can happen next. In the first fictitious scenario, latches do not exist. Then, once you have seen the problem that causes, the second section demonstrates how latches prevent it.
Without Latching
This part of the example represents a world without latches. Assume that the row containing the values (2,200) in Transaction 1 arrived at the page a fraction of a second before Transaction 2, when the values (3,300) are written. Transaction 1 writes to Slot 1, as seen in Figure 7-9 and Figure 7-10.


The update has gone through, as you have a second row in the page in slot 1 with the hex values 02 and c8 (which are the values 2 and 200, respectively). However, the page header is not yet updated. They still appear as in Figure 7-7. m_freedata is still 111, and the m_slotcnt value is still 1.
Before the header information is written, Transaction 2 arrives and wants to write a row with its values (3,300). Without a mechanism to stop it, Transaction 2 queries the m_freedata and m_slotcnt values, and writes its data into Slot 1, as seen in Figure 7-11 and Figure 7-12.


Before the “2,200” transaction could update the metadata, the “3,300” transaction had arrived. This second transaction checked the m_freedata field, found the location to write the row, and made the change. By now Transaction 1 has updated the header information, but this is also overwritten by Transaction 2. The change made by Transaction 1 is gone, and we have a lost update, as seen in Figure 7-13 and Figure 7-14.

This scenario reflects one of the prime uses for latches — serializing writes to prevent lost updates.
As mentioned before, you won’t be able to repeat this demonstration. SQL Server wouldn’t let you. In order to present it here, the output had to be massaged. Now take a look at what actually happens in a normal, i.e., latched, scenario. This you will be able to repeat.
With Latching
When these same steps are performed on a real SQL Server database, the behavior is affected by latches.
When Transaction 1 (2,200) gets to the page of memory, it acquires a latch. This is an EX latch, which you’ll learn more about soon. A moment later, however, Transaction 2 (3,300) will also want an EX latch, which it won’t be able to get. It has to wait for Transaction 1 to finish its business with that page (though not the whole transaction), and you will begin to see waits in sys.dm_os_wait_stats showing this.
With latches, Transaction 1 holds the EX latch for as long as it is needed to both write the row and update the page header and offset. Only then does it release the latch and allow another transaction in. Because of this, the page is never seen in the state shown in Figure 7-10 earlier.
Note that the 2,200 transaction does not wait for the completion of its transaction before releasing the latch. The latch isn’t tied to the transaction in that sense. It’s not a lock, designed to protect the integrity of the transaction; it’s a latch, designed to protect the integrity of the memory. Handling the lock behavior, snapshot versions, and so on — that’s all separate from this, but it may increase the amount of work that needs to be done by the process that has taken out the latch.
Once the latch has been released, the 3,300 transaction can get in with its own EX latch and insert its row of data, updating the header and offset accordingly, as seen in Figure 7-15 and Figure 7-16.


In short, without latching, data is lost. With latching, it’s not. It’s that simple. Regardless of what kind of isolation level is being used by the transaction, SQL Server protects data with latches.
LATCH TYPES
As you learned in the preceding section, latches exist to protect in-memory data. There are hundreds of different types of latch, most of which you are unlikely to encounter in any meaningful way when you are working with SQL Server. While latch waits will occasionally show up in sys.dm_os_wait_stats, you normally have to actively search for them. As a rule, they don’t come to you.
Typically, latches are divided into two distinct categories in SQL Server. They either serve the buffer pool, in which case they are known as BUF latches (showing up as PAGELATCH or PAGEIOLATCH in sys.dm_os_wait_stats and aggregated into the BUFFER latch class in sys.dm_os_latch_stats), or they don’t, in which case they are grouped under the non-buffer (Non-BUF) heading. This is a slight generalization, but it’s adequate for our purposes here.
If you run the following query, you will get a list of more than 150 latch types (code file Ch7LatchTypes.sql):
SELECT *
FROM sys.dm_os_latch_stats;If you order this data by any of the three numeric columns, you’ll see that by far the most common latch type is BUFFER. If you look at the contents of sys.dm_os_wait_stats, you’ll see latches that are prefixed with LATCH_, PAGELATCH_ and PAGEIOLATCH_.
The LATCH_ waits are all for the Non-BUF types. There are many of these, ensuring that the database engine can handle many of the operations it needs to perform. If you look through those latch types in sys.dm_os_latch_stats, you will see things such as BACKUP_FILE_HANDLE latches, SERVICE_BROKER latches, and even VERSIONING latches, which may be involved in your transactions depending on the isolation level.
The PAGELATCH_ latches are like those you saw in the example earlier. Data from a user object is needed, and to ensure that it can be written or read consistently, a latch is acquired. These buffer latches can be applied to all kinds of pages, including Page Free Space (PFS), Global Allocation Map (GAM), Shared Global Allocation Map (SGAM), and Index Allocation Map (IAM) pages.
The PAGEIOLATCH_ latch types are used when data is being moved from disk into RAM. An I/O operation is in play when a I/O latch is needed. In some ways, this is the easiest type latch wait to troubleshoot, as high PAGEIOLATCH wait times imply that the I/O subsystem cannot keep up. If this is the case, and you can’t mitigate the problem through I/O reduction or increased RAM, you have a nice argument for buying that faster storage you’ve been wanting.
LATCH MODES
Latch modes are far easier to contemplate than lock modes. I’m sure you remember from Chapter 6 that nasty big matrix of lock compatibilities. Latches have far fewer modes, and compatibility is much more straightforward.
If you query sys.dm_os_wait_stats as follows (code file Ch7LatchModes.sql), you’ll see the different modes listed there. This query is looking at the PAGELATCH_ latches, but you could use it for PAGEIOLATCH_ or LATCH_ instead and see the same latch modes. They are the two character combinations following the underscore.
SELECT *
FROM sys.dm_os_wait_stats
where wait_type like 'PAGELATCH%';Six latch modes are listed, usually in the following order: NL, KP, SH, UP, EX, DT. While there’s no guarantee they’ll appear in this order if you don’t specify an ORDER BY clause, this is the order you’ll likely see.
NL
NL is an internal Null latch. You don’t need to consider it. It essentially means no latch is being used, so it isn’t even recorded under normal conditions.
KP
KP is a Keep latch, used to indicate that a particular page is needed for something and shouldn’t be destroyed.
SH
This refers to a Shared latch, which is needed to read the data from a page.
UP
This is an Update latch, which indicates that a page is being updated, but not the table data within it. This is not related to the T-SQL UPDATE statement, which requires an Exclusive latch (the next mode discussed). Update latches are more common for internal operations, such as maintaining PFS pages or updating the checksum bits on a page. Because the type of data being updated is not needed to service queries, it is compatible with a shared latch, but not another Update latch.
EX
When data is being explicitly changed or added, an Exclusive latch is required. This is the most common type of latch for troubleshooting purposes, as two EX latches cannot be held on the same page at the same time. While this is also true of UP latches, EX latches are the more common of the two.
DT
The presence of this latch, the Destroy latch, means that the page is in the process of being removed from memory. A page that is deleted picks up a DT latch from the lazywriter process while the record of the page is removed. Bear in mind that this does not necessarily mean that the data is being deleted — it may simply be removed from the buffer cache, with a copy of the data still residing on the disk. However, multiple steps are involved in removing a page from the buffer cache, as the SQL Server engine maintains a hash table that lists which pages are currently in memory (otherwise, it wouldn’t know the memory address of the page). The DT latch cannot be taken out if any other kind of latch is on the page, which makes the KP latch much more significant. A page that is needed but isn’t yet being read or written would use a KP latch to prevent the DT latch from being acquired.
Latch Compatibility
The five latch types (ignoring the internal NL latch) are compatible as shown in Table 7-1. Note how much simpler it is than the lock compatibility equivalent.
TABLE 7-1: Latch Types
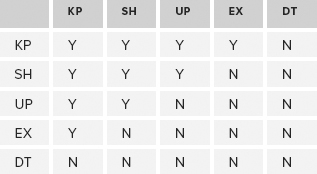
A page that has an EX latch on it can have a KP latch applied, but not any other type. Similarly, the only type of latch that can exist on a page that needs an EX latch applied is a KP latch. Unlike the lock compatibility table, there are no surprises in the latch compatibility table.
Despite the simplicity of this table, be sure you feel comfortable with the various scenarios that are possible. Consider the page with the shared latch that allows an update latch to be acquired on it (for an internal process to make a change to non-user data), but not an exclusive latch (which would mean that actual data was changing). Consider the page that is being destroyed and doesn’t allow anything else to come near it; and the update latch, which prevents other update latches.
Grant Order
In any system, particularly as the number of processor threads grows, a number of requests will be queued for a particular page. For example, a number of pages might be inserting data into a table while others are reading that data, and the data may need to be moved from disk, and so on.
For a page that has no latches on it, the first process that wants a latch will be granted one. That’s straightforward; but when more processes start coming along, the behavior is slightly different. A KP latch will skip the queue completely — unless there is a DT latch on the page, a KP latch will jump ahead and keep it alive.
Other latches will wait, joining the queue (even if there is compatibility between the two — another slight difference between lock behavior and latch behavior). When the current latch is released, the first latch in the queue can be granted, but here something special happens. Any other latch in the queue that is compatible with that first latch (which is being granted) will be allowed, even if there are incompatible locks in front of it. It’s like the nightclub bouncer who takes the first person in the queue but also looks through it for anyone else who can be let in. This way, the next latch type in line is always granted, but there’s an opportunity for other latches to jump in through the closing door at the same time. Typically, latches are taken out for short periods, so the incompatible latches shouldn’t have to wait for too long, depending on what’s going on. The algorithm might not seem fair, but it does make sure that concurrency can apply when possible.
Latch Waits
You’ve already looked at wait types such as PAGELATCH_EX and PAGEIOLATCH_SH, but there’s more to discuss about this in order to provide a complete picture of the information in sys.dm_os_wait_stats. As described earlier, some latches can come into contention with one another. This is intended and necessary as part of the need to serialize access. However, as with locking, this does raise the prospect of blocking, and consequently latch waiting.
A latch wait can be defined as a latch request that cannot be granted immediately. This could result from one of two reasons. First, the latch is already being accessed. As stated earlier, new latches are evaluated at the closure of the existing request. The second reason follows from the first. When the wait list is accessed following the closure of the previous latch, the next wait in that list may be a conflicting lock with other waits. If you refer back to the grant order example, when an EX request is processed, no other latch may be granted at the same time.
Unfortunately, there are side effects to keeping latches lightweight. They do not provide full blocking task information when forced to wait. Blocking task information is only known when the latch is held in one of the write latch modes — namely, UP, EX, and DT. Given that only one task can hold a latch in one of these modes at any one time, identifying it as the blocker is relatively straightforward. Suppose the blocker is a read latch (either KP or SH) — this latch could be held by many tasks simultaneously, so identifying the task that is the blocker is not always possible. When the blocker is known, all waiting tasks will report that the one task is the cause of the block. Logically, then, the wait type is that of the requester, not the blocker.
It is possible for this blocking information to change during a single task’s wait. Consider this example: A UP latch has been granted. Another task has requested a DT latch and therefore has been forced to wait. At this point the blocker is reported, as the latch held is a UP latch. By definition this can only be a single task. Before the UP latch has been released, a KP latch sneaks in and is granted (remember that KPs don’t respect the FIFO rules). The UP latch is then released, leaving the KP in place to do its thing. It can no longer be guaranteed that this KP is the only latch in play. The DT latch is still forced to wait because the KP is already there. However, now there is no serialized write latch mode in effect and the blocking information is lost. What can be said though at this point is that the blocker is either a KP latch or a SH latch.
It is also possible for a task to be shown to block itself in certain scenarios (although it is somewhat of an illusion, as the blocking is probably being done by internal threads that belong to the database engine rather than the actual task). This is due to the asynchronous nature of data access. Again, this is probably best illustrated with an example. Consider this scenario: A read request is made to the Buffer Manager, but when the hash table is checked, it is found that the page doesn’t exist in memory. An I/O request is scheduled and a PAGIOLATCH_EX latch is taken (assume granted) on a BUF structure to allow the page to be read into the data page for the buffer. The task that initiated the request will then submit an SH latch to read the data. However, this can appear as being blocked by the EX latch if there is a lag retrieving the page from disk.
SUPERLATCHES/SUBLATCHES
If you think about what kinds of pages would have latches applied to them frequently, it’s easy to consider the exclusive latches on insert pages; but a far more commonly latched page would be the root page of a frequently used index. Every time a seek is performed on an index, the root page must be read to help point the way to the page containing the rest of the data. Even tables that are frequently written to have a lot of shared access (for reading) on the root page of the indexes on those tables. The root pages probably don’t need to change very often at all, but they need to be read repeatedly.
The queuing method of accepting all compatible latches each time the latching check is done only helps so far. It’s still a lot of work to manage all this. Enter the SuperLatch (or sublatch). SuperLatches improve the performance of systems with 32 or more logical processors by promoting a single latch into an array of sublatches, one for each CPU core. This way, each core can easily acquire a sublatch without having to apply the shared latch to the page, because it’s already taken out.
The PSS SQL blog site has some useful diagrams showing how this looks, which they have generously let us use here (see Figure 7-17 and Figure 7-18) from http://blogs.msdn.com/b/psssql/archive/2009/01/28/hot-it-works-sql-server-superlatch-ing-sub-latches.aspx.

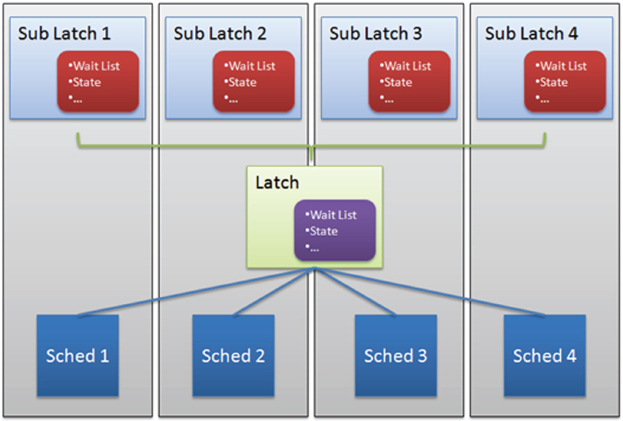
In the original scenario, there would be a single latch with a wait list of items trying to reach it. When the latch is released, the single wait list can be examined for compatible latches again, and the shared latch re-acquired. As a SuperLatch, the SuperLatch remains acquired, and each sublatch is handled by a processor. The sublatch then resides inside a single-processor microcosm, in a cache local to the CPU, sort of like the chair in your house when you’re the only person home — so that processor has much freer access to the page as long as the sublatch is shared.
The problem appears when a processor needs an exclusive latch. To do this, the SuperLatch must coordinate with all the sublatches to ensure that they’re all converted to exclusive latches when the time is right. It’s a lot more expensive than acquiring a regular exclusive latch; so if this happens often enough, the SuperLatch is demoted to an ordinary latch. SuperLatches are useful, but only on pages that are almost always read-only.
MONITORING LATCHES AND SPINLOCKS
In terms of monitoring latches, you’ve already been introduced to some of the DMVs. There’s more to monitoring latches than just DMVs, though. Performance Monitor also offers useful information about latches, as do extended events, which also provide information about spinlocks. Another option is to use memory dumps, but those are not covered here.
DMVs
The DMVs covered earlier are a useful point of reference. You should familiarize yourself with the contents of sys.dm_os_wait_stats, sys.dm_os_latch_stats, and sys.dm_os_spinlock_stats, and be comfortable with the output they provide. In addition, sys.dm_os_waiting_tasks will display a list of any tasks that are currently waiting on a resource, providing a useful session_id column that can be used to hook into other useful DMVs for information about sessions and the like.
sys.dm_os_wait_stats
This DMV has five columns.
- wait_type
- waiting_tasks_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
The first three were described earlier. max_wait_time_ms shows the largest wait time for a single wait since the DMV was cleared. signal_wait_time_ms is less relevant for latches, although it does get used if threads hit spinlock barriers.
sys.dm_os_latch_stats
This DMV has four columns.
- latch_class
- waiting_requests_count
- wait_time_ms
- max_wait_time_ms
These columns have all been described earlier.
sys.dm_os_spinlock_stats
This DMV has six columns.
- name
- collisions
- spins
- spins_per_collision
- sleep_time
- backoffs
A collision is recorded when a spinlock tries to acquire a resource but finds it unavailable. As a result, the spinlock starts spinning. This increases the spins but the collision has already been recorded. Usefully, this DMV also provides a spins_per_collision column, saving the user from doing the calculation.
I’m sure you can imagine that the number of spins is potentially quite large. Let’s just say that it’s a good thing that this column is a bigint type, which handles numbers up to 19 digits long. I don’t think the correct technical term is actually “gazillions,” but it feels right when you take a look at this DMV on busy systems that have been up for a while.
The sleep_time and backoffs columns simply report the amount of time that has been spent sleeping on spinlocks, and the number of backoffs.
Performance Monitor
Performance Monitor provides several useful counters to keep an eye on. Figure 7-19 shows a typical screenshot containing the list of counters in the SQLServer:Latches category for a machine.
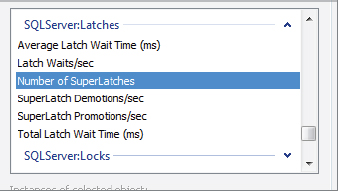
Table 7-2 describes these counters.
TABLE 7-2: Useful Performance Monitor Counters
| COUNTER | DESCRIPTION |
| Average Latch Wait Time (ms) | Average latch wait time (in milliseconds) for latch requests that had to wait |
| Latch Waits/sec | Number of latch requests that could not be granted immediately and had to wait before being granted |
| Number of SuperLatches | Number of latches that are currently SuperLatches |
| SuperLatch Demotions/sec | Number of SuperLatches that have been demoted to regular latches |
| SuperLatch Promotions/sec | Number of latches that have been promoted to SuperLatches |
| Total Latch Wait Time (ms) | Total latch wait time (in milliseconds) for latch requests that had to wait in the last second |
These performance counter values are also available using the DMV sys.dm_os_performance_counters (see Figure 7-20) (code file Ch7Monitoring.sql):

SELECT *
FROM sys.dm_os_performance_counters
WHERE object_name LIKE '%Latches%';Note that although the object_name field appears to end in the string ’Latches’, this field is actually stored as nchar(256), rather than nvarchar(256), so there is a large amount of whitespace at the end, and that last % is needed.
Extended Events
Chapter 13 is dedicated to the topic of extended events, so this section simply explains which extended events are available for latches and spinlocks. If you open the New Session Wizard for Extended Events from SQL Server 2012 Management Studio, you will reach a screen from which you select the events you wish to capture. After reaching this, first scroll the Event library section to reveal the Channel drop-down box. Then, as shown in Figure 7-21, check Debug, which is unchecked by default.

Now you can search for spinlock and latch to find a list of extended events related to these areas, as described in Table 7-3.
TABLE 7-3: Spinlock and Latch Extended Events
| EXTENDED EVENT | DESCRIPTION |
| spinlock_backoff | Spinlock backoff |
| spinlock_backoff_warning | Occurs when a spinlock backoff warning is sent to the Error Log |
| latch_acquire_time | Time taken to acquire a latch |
| latch_demoted | Occurs when a SuperLatch is demoted to an ordinary latch |
| latch_promoted | Occurs when a latch is promoted to a SuperLatch |
| latch_suspend_begin | Occurs when the executing task must suspend while waiting for a latch to become available in the requested mode |
| latch_suspend_end | Occurs when the executing task is resumed after waiting for a latch |
| latch_suspend_warning | Occurs when there is a timeout waiting for a latch possibly causing performance problems |
You should now be able to create an XE session collecting these events. Bear in mind that you would typically expect to see many more latch_acquire_time events occurring than the other event types, and you might not want to bother collecting them.
LATCH CONTENTION EXAMPLES
All of the code in this section uses the Ch7Examples.sql code file.
Earlier in the chapter, you saw a contrived example demonstrating why a latch is necessary. This section looks at a couple of examples demonstrating contention issues involving latches and spinlocks. Some of these examples are borrowed from various presentations involving the SQLCAT team at SQLBits events in the U.K., and we are indebted to Thomas Kejser in particular for his work on these.
Inserts When the Clustered Index Key Is an Identity Field
A lot of advice suggests using an identity field for the clustered index on a table. Certainly there are benefits to doing this. An identity field is typically an int or bigint type, making it relatively small compared to some other candidates for primary keys, in particular uniqueidentifier fields, which can cause frequent page splits, as well as being overly large, especially because clustered index keys appear in nonclustered indexes as well.
However, for tables that use identity fields for clustered index keys, when the number of inserts scales up, the final page will become “hot,” and contention could occur.
Consider the scenario in which a lot of processor cores are trying to insert data into the same page. The first session to reach the page in question will obtain a PAGELATCH_EX latch; but in the same moment, a large number of other threads might also be trying to acquire a PAGELATCH_EX latch. There would also be PAGELATCH_SH latches acquired at the higher index levels, to allow these pages to be traversed. If the insert needs to tip onto a new page, then a PAGELATCH_EX would be required at the next index level higher.
If sys.dm_os_waiting_tasks were queried during heavy inserts, it would likely show PAGELATCH_EX waits, with the resource_description column showing the page of note. The page could be examined, with DBCC PAGE, and identified as the table under stress.
The point here is not to make a case against ever using an identity field for a clustered index. In many systems, it’s still an excellent idea. However, if you’re seeing a large amount of latch contention during busy periods of insertion into such a table, then this design choice may certainly be a contributor to the predicament.
The solution has to move the activity away from the hotspot of insertion. While this could be done by simply replacing the identity field with a new uniqueidentifier field, populated with newid() values, the same goal can be achieved in other ways. One way of spreading the load sufficiently without losing the benefits of having a small clustered index, with the data nicely arranged in a b-tree, is to introduce partitioning. This way, the table is spread across a number of b-tree structures, instead of just one. With a bit of planning, the activity can be spread across the partitions. There may still be a hotspot for each partition, but this could well be enough to relieve the stress on the problem page.
The following example assumes that eight partitions are wanted, but you could choose whatever number suited your needs. All the partitions can be put on the same filegroup; this exercise is not designed to use partitions to spread the table across multiple filegroups, but merely to make additional b-tree structures to store the table.
CREATE PARTITION FUNCTION pf_spread (TINYNT) AS RANGE LEFT FOR VALUES
(0,1,2,3,4,5,6);
CREATE PARTITION SCHEME ps_spread AS PARTITION pf_spread ALL TO (PRIMARY);To spread the data across your various partitions, you simply need to introduce into the table a column that causes the data to be distributed. In this case, ID % 8 will do nicely:
ALTER TABLE MyStressedTable
ADD PartID AS CAST(ID % 8 AS TINYINT) PERSISTED NOT NULL;Once this is done, the clustered index simply needs to be created on the partitions:
CREATE UNIQUE CLUSTERED INDEX cixMyStressedTable (ID, PartID) ON ps_spread(PartID);Now, inserts will be cycled around the eight partitions, which should enable many more inserts to be done before latch contention occurs. Going back to the analogy using the chairs at a party, this partitioning provides seven more chairs. If the number of threads being used to perform the inserts is such that there is now a very small number of threads per b-tree, then the likelihood of contention is very much reduced.
Of course, additional partitions might translate into more work finding data using the ID field. A query that simply filters on the ID field would need to search all eight partitions, despite the fact that you can see a correlation between the ID and the partition. To avoid having to search across all the partitions, code such as
SELECT *
FROM dbo.MyStressedTable
WHERE ID = @id;should be changed to
SELECT *
FROM dbo.MyStressedTable
WHERE ID = @id
AND PartID = CAST(@id % 8 AS TINYINT);Queuing
Another typical scenario that can exhibit large amounts of latch contention is a system designed to allow queuing, for similar reasons to the last example, although exhibited in a slightly different way, and certainly resolved with a different method.
Most queues are handled using a table, with numerous inserts used to push items onto the queue, and deletes using TOP to enable quickly locating the earliest row in the table. Techniques such as using the OUTPUT clause can help with concurrency, but as the load increases this kind of design can still end up showing latch contention issues.
Certainly there would be PAGELATCH_EX waits in the leaf levels, as in the last example; but from time to time, activity in the leaf levels would cause similar activity through the higher levels of the b-tree, even up to the root. This means there is potential for contention between the inserts and deletes, even if they are at opposite sides of the b-tree. A representation of this can be seen in Figure 7-22.

It’s interesting to note at this point that some of the changes required at the higher levels of a b-tree when performing inserts and deletes are simply not required when performing updates. Unless the update causes a page split by being larger than the earlier page, and provided the clustered index key values for the row being updated don’t change, an update command should not need to affect the higher levels of the clustered index at all. This is similar to changing information in the page of a book. The table of contents need not change if only the information in a particular paragraph is being updated, and no extra pages are being introduced.
To that end, one method to avoid this kind of latch contention is to pre-populate a table with a number of fixed-length columns, and then cycle through them with updates, using two sequences to help the queuing stored procedures to know which value is at the top of the queue, and which one is at the end. It is important to gauge the maximum length of the queue. The impact on the b-tree of needing to perform inserts is significant, and should be avoided with a little planning.
An approach such as this can work nicely:
CREATE SEQUENCE dbo.seqQueuePush START WITH 1 CACHE 1000;
CREATE SEQUENCE dbo.seqQueuePop START WITH 1 CACHE 1000;Unless specified otherwise, sequences are created using the bigint type, starting at the lowest possible. Because the maximum bigint is extremely large, it might be a little nicer to start with 1 and work up. Either way, it’s important to have your queue start empty, with both sequences at the same number. A cache is used to avoid a bottleneck on generating the next number. You should experiment to see what size cache suits your particular queuing system.
As well as markers to indicate the locations of the beginning and end of your queue, you need a table structure to hold it. For example, if you anticipate needing to be able to handle 10,000 messages in the queue, you should create 10,000 positions using placeholder messages. This enables the b-tree to grow to the appropriate size before the system is under load.
The following code will create the queue, and populate it with the 10,000 placeholder items.
CREATE TABLE dbo.MyQueue (ID INT, Available BIT, Message CHAR(7000));
INSERT dbo.MyQueue
SELECT TOP (10000) ROW_NUMBER() OVER (ORDER BY (SELECT 1))-1, 1, ''
FROM sys.all_columns t1, sys.all_columns t2;The message has been chosen at 7,000 characters, as it fits nicely within a single page. Note that it is CHAR(7000), not VARCHAR(7000), as the row should be fixed length. You do not want to implement compression at this point either. A bit column is used to indicate whether or not the position in the queue is taken, in case the queue fills up completely.
These 10,000 slots are numbered from 0 to 9,999. Your ever-increasing sequences will far exceed this range, but the modulo function will provide a mapping, enabling the sequence numbers to roll around to the start every 10 thousand entries.
When message 3,549,232 arrives, it would be pushed into slot 9232. If message 3,549,019 is being popped out at the time, it would be found in slot 9,019. After these two operations, the sequences would be ready to tell the system that the next slot for a push would be position 3,549,233, and for a pop it would be 3,549,020. Any delay in processing the messages that are being popped off the queue would be fine as long as the size of the queue doesn’t stretch beyond 10,000.
Pushing a message onto the queue is therefore as simple as incrementing the sequence, performing a modulo 10,000 on the sequence number to discover into which slot the message should be pushed, and running an UPDATE command to put the message into that appropriate slot:
DECLARE @pushpos INT = NEXT VALUE FOR dbo.seqQueuePush % 10000;
UPDATE dbo.MyQueue SET Message = @msg, Available = 0
WHERE ID = @pushpos;To pop a message from the queue, code such as this could be used:
DECLARE @poppos INT = NEXT VALUE FOR dbo.seqQueuePop % 10000;
UPDATE dbo.Queue SET Message = '', Available = 1
OUTPUT deleted.Message
WHERE ID = @poppos;Some testing could be performed to ensure that the queue is not empty, but this technique can certainly enable up to 10,000 messages in the queue at any one time, and spread a heavy load across a large number of pages. Most important, negative impact on the higher levels of the b-tree, caused by performing inserts and deletes, can be avoided.
An environment that leverages the efficiency of updates in this way has already been seen in this chapter. There was data that needs to be updated very quickly, and updates are used rather than inserts — as shown in Figure 7-23, the DMV sys.dm_os_latch_stats:

It does not contain any kind of ID field. The only fields are latch_class, waiting_requests_count, wait_time_ms, and max_wait_time_ms; and yet the data is always returned in order, and the order is meaningful. The BUFFER class is always row 28. ACCESS_METHODS_HOBT_VIRTUAL_ROOT is always row 5 (this is a non-buffer latch that exhibits waits when root splits are needed, which would occur if a traditional delete/insert queue had been implemented).
You may have noticed when querying this DMV that many of the entries are zero, but the entries are still there. This is different to, say, sys.dm_db_index_usage_stats, which only includes a row once an index is used for a scan, seek, lookup, or update operation.
The sys.dm_os_latch_stats DMV is like your queue structure. It needs to be able to respond extremely quickly, as do many of the internal mechanisms within SQL Server. To that end, it is much quicker to set bits than to squeeze them in. Incrementing a counter that is already in place is a significantly better option than trying to preserve space until it is needed, if the speed of recording the data is to be maintained.
UP Latches in tempdb
It is possible that the resource your request is waiting on might be in tempdb, rather than the database you have designed. You can see this by looking at the wait_resource field in sys.dm_exec_requests and, in particular, the first number, which indicates the database. The number 2 means that tempdb has the problem.
If PAGELATCH_UP waits are seen on the first page in any of the files in tempdb — that is, page 2:1:1 or 2:4:1 (essentially, 2:N:1 for any N) — then this indicates that the PFS (Page Free Space) page is exhibiting latch contention. This can be confirmed by looking at sys.dm_os_buffer_descriptors:
SELECT page_type
FROM sys.dm_os_buffer_descriptors
WHERE database_id = 2 AND page_id = 1;A common reaction to any kind of contention in tempdb is to increase the number of data files it uses. It is good practice to have more than one tempdb data file in a multi-threaded environment, but continually adding new files isn’t necessarily the best approach to resolve this problem.
The PFS_PAGE resource must be updated whenever data is inserted into a table without a clustered index — that is, a heap. This doesn’t imply that a heap is necessarily bad; there are many positive things about storing data outside b-trees. However, the PFS_PAGE must be consulted whenever an insert is done, to locate a page with enough free space for the insert.
At this point you’re probably thinking, “But this is tempdb.” However, you haven’t designed your database for tempdb; it’s being used to service your application, and you’ve already made sure that you don’t have latch contention in your own database.
One common cause of this type of contention is the use of multi-statement table-valued functions.
A multi-statement table-valued function declares a table variable, which is populated within the code of the function definition. Finally, the RETURN command is issued, which returns the populated table variable to the user. Examples of this can be seen in SQL Server Books Online.
This is in contrast to an inline table-valued function, which is handled very differently.
Like a scalar function, a multi-statement table-valued function is executed in a separate context. It is no coincidence that both methods use BEGIN and END and in many ways are more similar to a stored procedure. An inline function does not use BEGIN and END, and is more similar to a view in that the subquery within is extracted into the outer query, not simply the results. The tempdb database is used to store the results of multi-statement table-valued functions, and it is here that contention could occur.
Imagine a scenario in which a multi-statement table-valued function is used in a correlated subquery, such as an EXISTS clause, or in the SELECT clause. Without the ability to perform simplification on the function, the Query Optimizer may well need to call the function many times. This is commonly seen in scalar functions used in the WHERE clause, but it can also be seen when a multi-statement table-valued function is used outside the FROM clause.
The storage used by tempdb for the results of a multi-statement table-valued function must be managed, which involves the PFS_PAGE resource (using UP latches, because the information being updated is not table data, which would require an EX latch), as it determines where new records can be placed, and it marks them as free once the results have been consumed by the outer query. Even a single statement can end up having such a function called many times, causing contention even within a single query.
I’m sure you can imagine some of the ways to avoid this contention. Inline equivalents can be useful; and restructuring the query to avoid using the function in an EXISTS or SELECT clause can also be effective. That’s because latch contention is not just about the database design, but also about the way in which queries are written.
Spinlock Contention in Name Resolution
Unfortunately, developers do not always qualify their object names in their queries. This is particularly common in older applications, originally written in SQL Server 2000 or earlier, before schemas were introduced, but it also occurs in many other systems. It’s very easy to assume that dbo is the only schema used, and to omit the dbo. prefix in table names — using, for example
SELECT * FROM Customers;instead of
SELECT * FROM dbo.Customers;This is a simple error to make, and you may not notice any discernible effect on your system until it needs to scale. However, if you don’t specify the schema, the system needs to do a couple of quick checks. It has to determine your default schema, and it has to check whether there is a table with that name in your default schema. If not, it has to check the dbo schema to see if that’s what you meant.
All this can happen very quickly — so quickly that a spinlock is used. It would be rare to find that a spinlock could not be acquired immediately on such an operation, but you may well see this occurring on a system under significant load. The contention appears on the SOS_CACHESTORE spinlock type. Fortunately, it’s simple to resolve: Just ensure that you always fully qualify your table names.
SUMMARY
Latch contention is not something that can be controlled by hints in the same way that locks can. Latches are designed to protect the very internal structures within SQL Server that hold data, and they are absolutely necessary.
As the demands on your data increase, with more and more processor threads needing access, even latches can start to contend for resources. Good design decisions, both schema design and query design, can typically prevent these problems, however, and you should be able to avoid most latch contention issues through appropriate planning and awareness.