
CHAPTER 18
LEADING DATABASE SYSTEMS
After reading this chapter, the reader will understand:
- History of PostgreSQL
- psql, a client application that facilitate user interaction with PostgreSQL server
- Some features of PostgreSQL including the query-rewrite system
- History of Oracle
- Oracle’s Interface
- Some object-relational features of Oracle
INSTEAD OFtrigger and Data Guard feature of Oracle- History of Microsoft SQL Server
- SQL Server Management Studio
- Establishing connection with SQL Server
- Transact-SQL that is used for data access in SQL Server
- History of IBM DB2
- Managing all the DB2 objects visually through Control Center
- Some features of IBM DB2
In this chapter, we focus on the leading database systems that implement the database features discussed so far in the book. This chapter covers the four leading database systems—PostgreSQL, Oracle, Microsoft SQL Server, and IBM DB2. Out of these, PostgreSQL is the open-source database system whereas others are the three most widely used commercial database systems. In addition to discussing some unique features of each database system, the brief history and the interfaces to interact these databases are also discussed here.
18.1 POSTGRESQL
PostgreSQL is the most advanced and widely used open-source object-relational database system. It comes with a BSD license that allows everyone to use, modify, and distribute its code and documentation for any purpose without any charge. The current version of PostgreSQL (version 8.3) is fully ACID compliant and has full support for foreign keys, joins, triggers, views, stored procedures, multiversion concurrency control, and write-ahead logging. It includes most of the SQL92 and SQL99 data types and allows users to define new data types also. In addition, it has interfaces for many programming languages like C, C++, Java, Perl, and Python, and it runs on almost all the major operating systems including Linux, UNIX, Solaris, Apple Macintosh OS X, and Windows.
PostgreSQL is highly scalable in terms of the number of concurrent users it can handle and the amount of data it can manage. It supports database of virtually any size, and a table in PostgreSQL can contain any number of rows. However, there is an upper limit on the size of a table (32TB), row (1.6TB), and field (1GB).
18.1.1 History of PostgreSQL
PostgreSQL was developed at the University of California at Berkeley (UCB) and is a descendant of Postgres, a database server developed at UCB under the Professor Michael Stonebraker. He started the development of Postgres in 1986 as a follow-up project to Ingres, another database system developed under him at UCB. Version 1 of Postgres was released in 1989, and since then it has undergone many major releases.
Until 1994, Stonebraker and his students continued working on the project and added various useful features to the subsequent versions of Postgres. Later, Illustra Information Technologies developed Postgres into a commercial product. Illustra was later purchased by Informix, which in turn was purchased by IBM in 2001.
In 1995, two students—Andrew Yu and Jolly Chen—at Berkeley added SQL capabilities to Postgres and gave it a new name, Postgres95. The Postgres95 was released to the Web in 1996 and left the development at Berkeley. The system began a new life in the open source world, and a global development team (consisting of a group of dedicated developers from around the world) was formed. These developers devoted themselves to keep the development of the system continued.
Initially, the developers of global development team did not understand the code of system inherited from the Berkeley. Thus, they aimed at fixing bugs in the system reported by its users, instead of adding new capabilities. However, fixing some bugs in the system required extensive research and several reports were duplicated. So, they first cut down the duplicates and aimed to fix the simple bugs. A new version of system was released every three to five months, where each version fixed some problems existing in the previous version. In late 1996, the system was renamed to PostgreSQL to reflect the relationship between the Berkeley’s Postgres and the newer versions of Postgres with SQL capabilities.
Slowly, the developers gained the knowledge of the code, which enabled them to fix complicated bugs and add new features thereby improving the system in every area. Thus, every new release of the system not only fixed the bugs in the previous version but also added various new useful features. Today, each new version is a major improvement over the previous one.
18.1.2 PostgreSQL Interface
PostgreSQL employs a client/server architecture in which clients send their requests to the server, which processes the requests and returns the result back to the client. To facilitate the user interaction with the PostgreSQL server, several client applications have been developed. One such client application is psql, which is an interactive terminal and allows executing SQL commands.
When psql application is started, it asks for some information, including the name of the server machine, database name (default is postgres) to which to connect, the port (default is 5432) where server is receiving requests, the username (default is postgres), and the password. Figure 18.1 shows the psql client application. Note that the default information for each field is shown in [] (square brackets) and we can simply press the Enter key to let psql accept the default information.
PostgreSQL server can manage several databases, and to work with a particular database, we need to connect to it. To create a new database through psql, the CREATE DATABASE command is used. Once the database is created, we can connect to it using c followed by the database name. Figure 18.2 shows the commands to connect to a database onlinebook and create a table PUBLISHER in the database.
Learn More
PostgreSQL standard distribution does not come with any graphical interface tool; however, several graphical tools have been developed for database administration as well as database design. pgAdmin and Data Architect are graphical tools for database administration and database design, respectively.
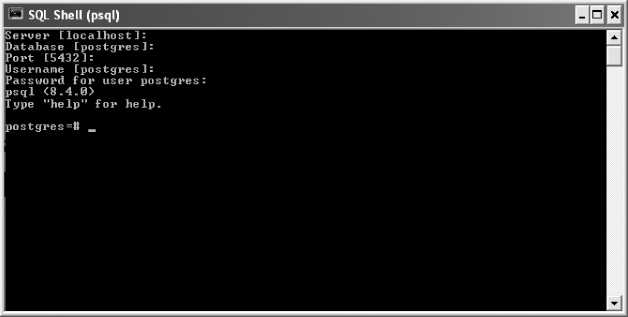
Fig. 18.1 psql client application
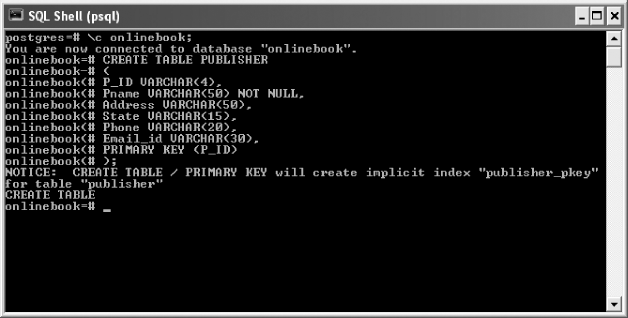
Fig. 18.2 Creating a database, connecting to it, and creating a table
The client application psql is widely used for entering SQL commands interactively. However, it is not ideal for writing applications. Fortunately, PostgreSQL provides interfaces for many programming languages including C, C++, Java, Perl, and Python. The language interfaces allow passing queries from applications to PostgreSQL server and receiving the results back. Programming-language interfaces for some popular languages are shown in Table 18.1.
NOTE pgAdmin is an open source GUI for database administration.
Table 18.1 Programming language interfaces for some languages
| Programming Language Interfaces | Programming Language |
|---|---|
| LIBPQ, ECPG, LIBPGEASY | C |
| LIBPQ++ | C++ |
| JDBC | Java |
| PERL | Perl |
| PYTHON | Python |
18.1.3 Some Features of PostgreSQL
PostgreSQL is rich in features that an organization looks for in a database system. The data types in PostgreSQL include integer, numeric, Boolean, date, varchar, etc., and it also allows defining new types as per the needs of specific applications.
To maintain data integrity, PostgreSQL allows applying SQL constraints such as unique, primary key, foreign key with restricting and cascading updates/deletes, check, and not null. It also supports triggers, which are executed automatically as a result of SQL DML statements. Note that the trigger functions cannot be written in plain SQL; rather they are written in a procedural language such as PL/pgSQL (similar to PL/SQL) or in C.
PostgreSQL supports a rule system (also called query-rewrite system) which allows users to define how SQL queries on a given table or view should be modified into alternate queries. The modified queries are then submitted for the execution. Using rules is advantageous in many situations. For example, suppose a new edition of an existing book in the BOOK relation of Online Book database is published. In this case, it is required to have information about the new edition in the BOOK relation instead of having information about the old edition. Further, it is required to keep the information of old edition in some other relation. To perform all this, we can declare a new relation, say oldEditions, having the same attributes as that of the BOOK relation and define the following rule.
CREATE RULE editions AS ON INSERT TO BOOK WHERE new.Book_title = old.Book_title DO INSERT INTO oldEditions VALUES ( old.ISBN, old.Book_title, old.Category, old.Price, old.Copyright_date, old.Year, old.Pagecount, old.P_ID );
Now, a query to insert the information of a new edition of book into the BOOK relation automatically transfers the information of old edition of the book into the oldEditions relation.
Rules are also used by PostgreSQL to implement views. For instance, consider the following query to define a view on BOOK relation of Online Book database.
CREATE VIEW bookview AS SELECT ISBN, Book_title, Category FROM BOOK;
PostgreSQL might convert this query into the following alternate queries.
CREATE TABLE bookview ( ISBN VARCHAR(15), Book_title VARCHAR(50), Category VARCHAR(20) );
CREATE RULE QueryView AS ON SELECT TO bookview DO INSTEAD SELECT ISBN, Book_title, Category FROM BOOK;
This rule definition redirects all the select queries on bookview to the underlying base relation BOOK. Similarly, rules can be defined to handle update queries on the bookview. Some additional features of PostgreSQL are as follows:
- Extensibility: Since the source code of PostgreSQL is available (without any cost) under the BSD license, staff of any organization can extend the features of PostgreSQL as well as add new features to it to meet their needs.
- Cross-platform: PostgreSQL is available for almost all the major operating systems. Though earlier versions were made ‘Windows compatible’ via the Cygwin framework, version 8.0 and higher have native Windows support.
- GUI support: PostgreSQL supports graphical user interface (GUI) along with the command-line interface. Several commercial as well as open-source GUI tools are available for database design and administration.
18.2 ORACLE
There are several DBMSs available in the market today, out of which Oracle is the most popular one. It was the first commercial relational database management system. Today, Oracle technology can be found in almost every industry. The latest release of this database is Oracle 11g.
18.2.1 History of Oracle
In 1977, Larry Ellison with his two friends—Bob Miner and Ed Oates—started software development laboratories (SDL). They realized that there was a great potential in relational database model and there were no commercial relational database products in the market. Thus, they committed themselves to build a commercial RDBMS and came out with a version of Oracle in 1979. This version supported only the basic SQL functionalities of queries and joins, and did not support the advanced concepts like transactions.
Learn More
First version of Oracle was written in Assembly language and was never released. The version of Oracle released in 1979 was version 2.0.
In 1982, the company was renamed to Oracle Corporation to indicate its close relationship with its product Oracle. Though the Oracle Corporation was initially a much smaller company, it did not confine itself to relational database server only. With time, it started providing query and analysis tools, application software for enterprise resource planning and customer-relationship management, and application server with close integration to the database server.
Today, with the wide range of services and products, Oracle Corporation has become the second largest independent software company in the world. It is serving over three lacs customers in more than 145 countries.
18.2.2 Oracle’s Interface
There are several tools available to access a database created in Oracle. The most popular and simplest tool is SQL*PLUS, which allows users to interactively query the database using SQL commands as well as executing PL/SQL programs. When SQL*PLUS is started, it asks the users to log on by providing the username and password. Note that Oracle provides some default usernames including SYS, SYSTEM, SYSMAN, and DBSNMP, and during installation, it asks for a password for these default usernames.
When the required information is provided in the dialog box, Oracle performs several checks to determine the authenticity of the user. If the username and password provided are invalid, then the user is not allowed to log on. Otherwise, the SQL plus window appears (see Figure 18.3), which is a command-line interpreter. Note that the version of Oracle along with some additional information is also displayed in the window.
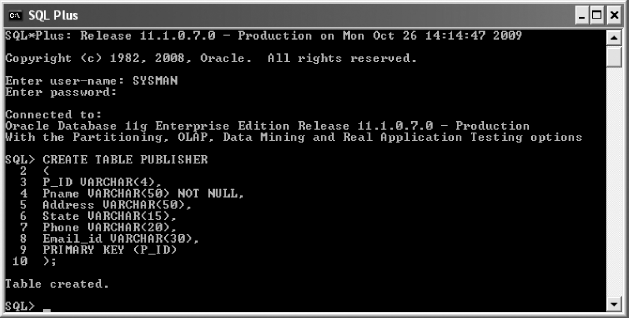
Fig. 18.3 SQL Plus window
18.2.3 Some Features of Oracle
Oracle supports all the core features of SQL99 in addition to object-relational features. Some object-relational features that Oracle supports are as follows:
- Defining types: New types can be defined as objects in Oracle using the syntax shown here.
CREATE TYPE newtype AS OBJECT ( Declarations of attributes and methods ) ; /
Note that the use of slash (/) is mandatory at the end of the type definition. It lets Oracle to process the type definition. Once a type is defined, it can be used like other types of SQL. For instance, we may use
newtypewhile defining other object-types. - Dropping types: The new types defined by the users can be dropped by using the syntax shown here.
DROP TYPE newtype;
Note that before dropping a specific type, we must drop all the types that are using it; otherwise, the query to drop a type fails.
- Defining methods: Oracle allows declaring methods in
CREATE TYPEstatement usingMEMBER FUNCTIONorMEMBER PROCEDURE. These methods are then defined separately in aCREATE TYPE BODYstatement or in a programming language like Java or C. - Nested tables: Oracle supports nested tables, which means in a relation, the value of an attribute in one tuple can be an entire table.
- XML as a data type: Oracle has XML as its native data type which is used to store XML documents.
Oracle also supports some constructs which are, in syntax and functionality, specific to Oracle. One such construct is OLAP operations. We have already discussed OLAP operations, including rollup, cube, and ranking in Chapter 14.
NOTE Version 6 or higher of Oracle supports PL/SQL and Java as its procedural languages. PL/SQL was the Oracle’s original procedural language used for defining stored procedures.
Oracle has extensive support for triggers. Row level triggers and statement level triggers that Oracle supports are already discussed in Chapter 05. Both types of triggers are defined to execute either before or after some DML operation on a table. Oracle also allows creating triggers for views that are not subject to a DML operation. Recall from Chapter 05 that it is not always possible for Oracle to translate an update query (a DML operation) on a view to its underlying base table. Therefore, Oracle allows users to create INSTEAD OF trigger on a view to specify the actions that need to be taken on the base table as a consequence of DML operation on the view. Now, whenever the DML operation for which trigger is defined is performed on the view, Oracle executes the trigger and not the DML operation.
Some additional features of Oracle are as follows:
- It provides support for embedding structured query language (SQL) in programming languages. For example, to embed SQL in Java, it supports SQLJ.
- It allows referencing external sources (such as flat files) in the
FROMclause of a query. It is particularly important for ETL process in a data warehouse. - It allows executing queries that need data from tables residing at different sites. It has in-built capability to optimize such queries, that is, it attempts to minimize the amount of data transfer in order to evaluate the query successfully and efficiently.
- It provides a standby database feature known as Data Guard. A standby database is a copy of the regular database maintained on a separate system. In case, a catastrophic failure occurs at the site where the regular database is maintained, the standby database is activated, which then takes over the processing. This feature minimizes the effect of failure and thus, provides high availability of the database.
18.3 MICROSOFT SQL SERVER
SQL Server is a relational model database server developed by Microsoft. It is used to generate databases that can be accessed from desktops or laptops or through handheld devices like PocketPCs and PDAs. The latest release of this software is SQL Server 2008.
18.3.1 History of Microsoft SQL Server
In 1980s, Microsoft and IBM announced a joint development agreement, which was the beginning of OS/2 operating system (a successor to MS-DOS operating system). However, soon after the declaration, IBM announced to launch a special higher-end version of OS/2 which would include an SQL RDBMS called OS/2 Database Manager. That announcement aroused a need of database management product for Microsoft; because otherwise no one would buy Microsoft OS/2.
At that time, Sybase had developed (but not yet shipped) a DataServer product for the systems running UNIX operating system. The pre-release version of the DataServer gained a good reputation because of its support for client/server computing and for some new innovative features including stored procedures and triggers.
Microsoft proposed a deal to Sybase that would be beneficial for both the organizations. Sybase was a small organization at that time and the credibility and royalties for its technology that Microsoft could bring was of prime importance for Sybase. Thus, both Microsoft and Sybase signed a deal in 1987 and as a result, Microsoft got exclusive rights to Sybase’s DataServer product for all of its operating systems. Microsoft also signed a deal with Ashton-Tate because Ashton-Tate’s dBASE product also had a good reputation in PC data products.
In 1989, Ashton-Tate/Microsoft SQL Server version 1.0 was shipped. However, as anticipated, the sales records of the product were not impressive. Therefore, Ashton-Tate started refocusing on its core dBASE desktop product, and Microsoft and Ashton-Tate ended their agreement.
NOTE Though Sybase was not a part of the product’s name, its role in the product was significant.
In 1990, Microsoft shipped the SQL Server 1.1 as an upgrade to Ashton-Tate/Microsoft SQL Server 1.0. SQL Server 1.1 had support for a new client platform Windows 3.0 (Microsoft’s new operating system). Slowly, many Windows-based applications were developed that were supporting SQL Server, and SQL Server became one of the leading database products for Windows-based application.
Initially, Microsoft depended entirely on Sybase for fixing the bugs in the product, since it has no right to access the source code. However, in 1991, Microsoft got rights to fix the bugs, and the developers at Microsoft became experts of SQL Server code. In the same year, Microsoft released SQL Server 1.11, another small upgraded version.
At the same time, developers at Microsoft were involved in the development of a new operating system named Microsoft Windows NT (NT for new technology). SQL Server would, no doubt, be moved to this new operating system. The first version of Windows NT was not expected for two years. In the meantime, engineers at Microsoft and Sybase worked together on new version of SQL Server which was shipped in 1992.
Learn More
Microsoft decided to focus on developing a new version of Windows since Windows 3.0 was a big success but OS/2 was not up to the expectations. Microsoft and IBM declared the end of their joint development agreement.
After that, Sybase started working on the new version of its product named System 10, and Microsoft focused on developing SQL Server for Windows NT. Microsoft shipped the beta version of SQL Server for Windows NT in October 1992. It was a major hit and surveys showed that most of the customers upgraded (or planned to upgrade) to SQL Server for Windows NT.
By the late 1993, both Sybase and Microsoft were successful companies in their own rights. Sybase had earned a good position in the database market. Similarly, Microsoft had also earned a good name in the software market. The SQL Server products of Microsoft became a direct competitor of Sybase SQL Server products for UNIX or other platforms. Both organizations decided to develop their own products and declared an end of their joint development in 1994. Since then Microsoft has been shipping the SQL Server products independently.
18.3.2 Microsoft SQL Server’s Interface
SQL Server contains SQL Server Management Studio that provides a variety of functionality for managing the server using GUI. SQL Server Management Studio is the tool that allows creating, editing, and deleting database objects like tables, views, procedures, triggers, etc. When it is started, the Connect to Server dialog box (see Figure 18.4) appears.
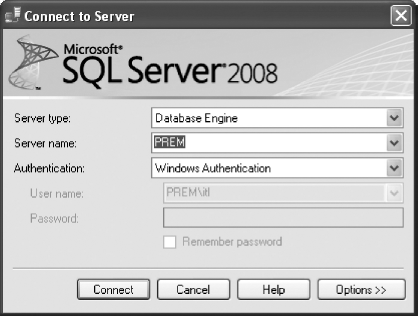
Fig. 18.4 Connect to Server dialog box
Here, we need to provide the following information to connect to the SQL Server.
- Server type: The subsystem of SQL Server into which we have to log in.
- Server name: The SQL Server into which we have to log in. Note that SQL Server allows multiple instances of SQL Server to run simultaneously and by default, the instance of the server carries the same name as the name of the machine on the network. To get connected to the SQL Server on the same computer from which we are trying to connect, we can use its name.
- Authentication: The authentication type using which we want to log in. There are two options which are Windows Authentication and SQL Server Authentication. With the Windows Authentication, user name and password are not required. Instead, the user is validated through the Windows domain. On the other hand, with the SQL Server Authentication, the user name and password specific to SQL Server needs to be provided.
After providing the correct information, the interactive sessions with SQL Server are allowed. There is a New Query button at the top left corner of the Management Studio by clicking on which a new Query window is opened. In this window, statements are executed using the SQL Server’s native language Transact-SQL (or T-SQL). T-SQL provides SELECT, INSERT, UPDATE, and DELETE statements to manipulate data in addition to other types of commands such as creating a database or table, granting rights to users, and so on.
Figure 18.5 shows the Query window in which a T-SQL command has been executed to create the PUBLISHER relation. Note that after writing a query in the Query window, we click the Execute button on the toolbar in order to execute the query.
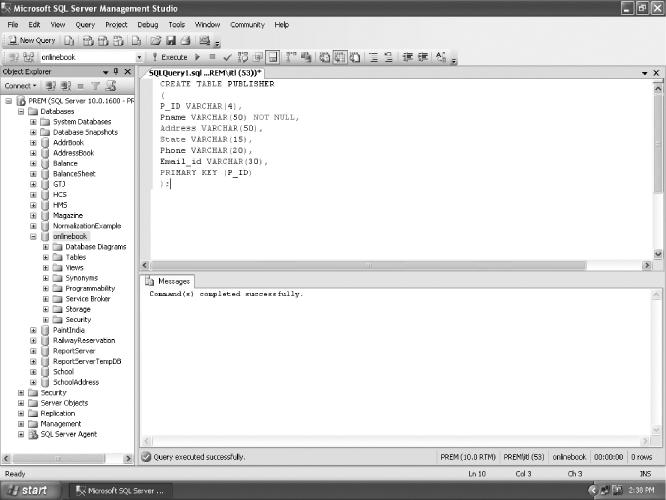
Fig. 18.5 SQL Server Management Studio
18.3.3 Some Features of Microsoft SQL Server
T-SQL is the core language that is used in SQL Server for data access. It is a common language runtime (CLR) compliant language, which means, a .NET language. SQL Server 2008 introduces several new T-SQL programmability features and enhances some existing ones. Some of its key features are as follows:
- It allows initializing variables as a part of the variable declaration statements, whereas in earlier versions, separate
DECLAREandSETstatements had to be used. - New compound assignment operators are introduced, which include
+=(plus equals),-=(minus equals),*=(multiplication equals),/=(division equals), and%=(modulo equals). These assignment operators can be used wherever assignment is allowed. These operators help abbreviating the code of assignments. - Four new date and time data types are introduced, namely,
DATE,TIME,DATETIME2, andDATETIMEOFFSET. These data types provide improved accuracy and support for larger date and a time zone element. Some new functions that operate on these new types are also introduced and existing ones are enhanced. - SQL Server’s new data compression feature helps reducing the size of tables, indexes or a subset of their partitions. Although space savings that can be achieved depends on the schema and data distribution, one can expect 50% to 70% reduction. SQL backups can also be compressed to significantly save space on disk media.
- Database mirroring feature that Microsoft introduced in SQL Server 2005 is enhanced in SQL Server 2008. This enhanced feature provides database administrators a low-cost disaster recovery solution.
18.4 IBM DB2 UNIVERSAL DATABASE
DB2 Universal Database (UDB) is one of IBM’s families of relational database management system (RDBMS) software products. It is strong enough to meet the needs of large organizations and flexible enough to serve the medium-sized and small business organizations. Initially, DB2 was available on IBM’s mainframes only, but later it spanned to a wide variety of platforms including Windows 2000, Windows XP, variants of UNIX like Linux, Solaris, AIX, HP-UX, etc. Today, different editions and versions of DB2 are available that run on devices ranging from handhelds (such as PDAs) to mainframes. In mid-2009, IBM announced version 9.7 of this product on distributed platforms.
Like the free version of Oracle and Microsoft SQL Server, a free version of DB2 called DB2 Express-C is also available. This free version has no limit on the number of concurrent users and database size, but the database engine (the software component responsible for storing, processing, and retrieving data) uses only two CPU cores and supports a maximum of 2 GB of RAM.
18.4.1 History of IBM DB2
The idea of DB2 arose in 1970 when E.F. Codd of IBM described the theory of relational databases. He published a paper “A Relational Model of Data for Large Shared Data Banks”, which proposed a new architecture for storing and managing the digital data. The new model would free the application developers from the burden of managing the data and allowed them to focus on business logic. Hence, new and powerful application could be developed more quickly and easily.
IBM implemented the new model and came up with the structured english query language (or SEQUEL) after four years. This language became the basis for SQL language standard. In 1983, IBM released its database product on multiple virtual storage (MVS) mainframe platform which was given the name DB2 (formally called Database 2). It was the first database product to use SQL.
NOTE IBM overhauled the SEQUEL and renamed as SQL to differentiate it from SEQUEL.
The development of DB2 was continued on the mainframe as well as on the distributed platforms. In 1987, the database manager in OS/2 Extended edition was the first RDBMS on distributed systems. In the next year, SQL/400 for AS/400 server was emerged. Later, new editions of DB2 supported by many other platforms including AIX, HP-UX, Solaris, Windows, and Linux were developed.
In 1996, IBM announced DB2 UDB version 5 for distributed platforms. This version of universal database supported a wide variety of hardware platforms ranging from uni-processor systems and symmetric multiprocessor (SMP) systems to massively parallel processing (MPP) systems.
NOTE For simplicity, the term “Universal Database” or UDB was dropped from the name in version 9 of DB2, thus, the terms DB2 UDB and DB2 are used interchangeably.
18.4.2 IBM DB2’s Interface
DB2 provides Control Center, a GUI tool, to manage all the DB2 objects visually. When we open the Control Center, its main interface (similar to the one shown in Figure 18.6) appears, which allows creating database objects (such as tables, view, triggers, etc.) using simple-to-use wizards.
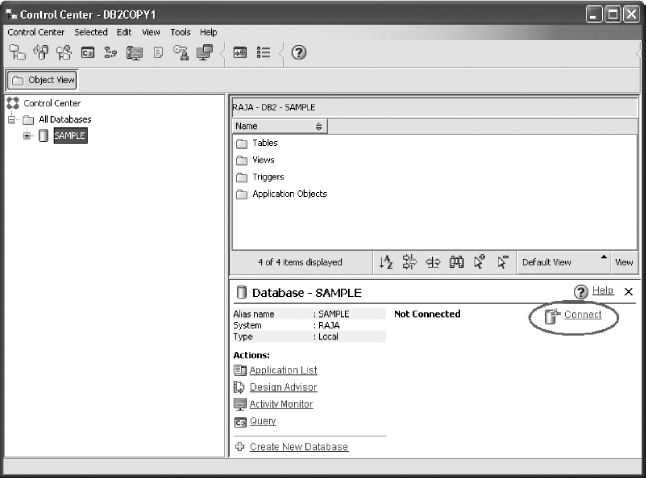
Fig. 18.6 Control Center
There are two panels in the Control Center, the left panel and the right panel. The left panel displays the folders and folders’ objects in a tree-like structure, and right clicking an item displays a popup menu listing all the actions that can be performed on the item. The right panel on the other hand displays the related objects, information, and contents of the selected item in the left panel.
Before creating database objects, we must click on Connect (encircled in Figure 18.6). Once we get connected, we can create tables, views, triggers, new databases, etc. For instance, to create a table, we expand the database folder in the left pane to see the Tables folder icon, right click on it, select Create…, and then follow the Create Table Wizard. We can create a new database by clicking on the Create New Database (see Figure 18.6) and following the wizards that appear. Figure 18.7 shows the Control Center after creating the ONBOOK database and the PUBLISHER table in it.
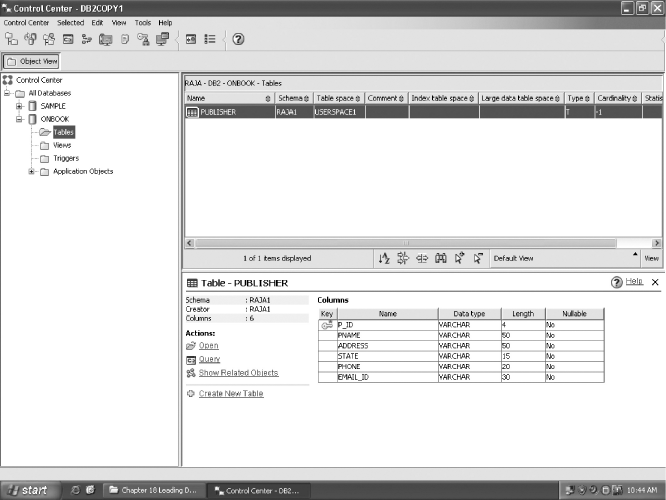
Fig. 18.7 Control Center after creation of ONBOOK database and PUBLISHER table
18.4.3 Some Features of IBM DB2
DB2 is a true client/server architecture, which allows applications running on client machines to interact with the databases residing on the server machine. It comes with an expansion of SQL which supports recursive queries, active database features (such as constraints and triggers), etc. It also includes a collection of object-oriented features that allow manipulating large objects such as text, images, video, etc. Some important features of DB2 are as follows.
Learn More
DB2 also provides a Command Editor which, unlike Control Center, is a command line tool and allows writing and executing DB2 commands and SQL statements interactively. In version 9.7, Command Editor is deprecated and may be removed from future versions.
- Scalable: DB2 runs on laptops or handheld devices to massive parallel systems with several GBs of data and many concurrent users.
- Business intelligence support: DB2 supports business intelligence applications such as data warehousing (DW) and online analytical processing (OLAP).
- Open database: It is an open database and runs on almost all the popular and widely used platforms. It also supports popular development platforms like J2EE and Microsoft.NET and has APIs for.NET CLI, Perl, Python, Java, C, C++, FORTRAN, and many other popular programming languages. This capability enables organizations to reduce cost by utilizing their current investment in hardware, software, and skills.
- Data compression technology: The data compression technology of DB2 can help reduce the storage need for data, indexes, temporary tables, and other large database objects significantly. Increased storage efficiency along with automated administration, simple deployment of virtual appliances, and improved performance reduce the cost of data management.
- Easy to use and manage: DB2 can be administered by either command-line interface or GUI. Its GUI contains several wizards that enable novice users to interact with it easily.
- Support for XML data: DB2 has native support for XML data and contains several XML functions including
xmlelement,xmlagg, andxmlattributes. - Support for user-defined types, functions, and methods: DB2 supports user-defined types and allows users to define distinct or structured types. Distinct types are based on built-in types of DB2 but user can define additional semantics to the new types. These are defined using
CREATE DISTINCT TYPEstatement, and user can use them as a type for fields of tables. Structured types are complex types and can contain more than one attribute. These are defined usingCREATE TYPEstatement and can be used to define typed tables (a table whose rows are of user-defined type) or nested attributes inside a column of table.DB2 also enables users to define their own functions and methods. Users can write functions in programming languages (such as C or Java) or scripts (such as Perl). These functions can generate either single attribute or tables as their result. To register the functions, the
CREATE FUNCTIONstatement is used and the functions can be included in SQL queries. Like functions, users can also define methods in order to define the behavior of objects. However, methods are tightly encapsulated with particular structured type. To register the methods, theCREATE METHODstatement is used.
SUMMARY
- Four leading database systems are PostgreSQL, Oracle, Microsoft SQL Server, and IBM DB2.
- PostgreSQL is the most advanced and widely used open-source object-relational database system.
- The current version of PostgreSQL (version 8.3) is fully ACID compliant and has full support for foreign keys, joins, triggers, views, stored procedures, multiversion concurrency control, and write-ahead logging.
- PostgreSQL is highly scalable in terms of number of concurrent users it can handle and the amount of data it can manage.
- PostgreSQL was developed at the University of California at Berkeley (UCB) and is a descendant of Postgres, a database server developed at UCB under the Professor Michael Stonebraker.
- To facilitate the user interaction with PostgreSQL server, several client applications have been developed. One such client application is psql, which is an interactive terminal and allows executing SQL commands.
- PostgreSQL supports a rule system (also called query-rewrite system) which allows users to define how SQL queries on a given table or view should be modified into alternate queries.
- Oracle was the first commercial relational database management system. The latest release of this software is Oracle 11g.
- In 1977, Larry Ellison, Bob Miner, and Ed Oates started software development laboratories (SDL) and committed themselves to build a commercial RDBMS and came out with a version of Oracle two years later.
- In 1982, the company was renamed to Oracle Corporation to indicate its close relationship with its product Oracle.
- Today with wide range of services and products, Oracle Corporation has become the second largest independent software company in the world.
- There are several tools available to access a database created in Oracle. The most popular and simplest tool is SQL*PLUS, which allows users to interactively query the database using SQL commands as well as executing PL/SQL programs.
- Oracle supports all the core features of SQL99 in addition to object-relational features.
- SQL Server is a relational model database server developed by Microsoft. The latest release of this software is SQL Server 2008.
- In 1987, Microsoft signed a deal with Sybase to gain rights for Sybase’s DataServer product for all of its operating systems. Microsoft also signed a deal with Ashton-Tate because Ashton-Tate’s dBASE product also had a good reputation in PC data products.
- In 1989, Ashton-Tate/Microsoft SQL Server version 1.0 was shipped. Later, Microsoft’s agreement with Sybase and Ashton-Tate terminates and Microsoft has been shipping the SQL Server products independently.
- SQL Server contains SQL Server Management Studio that provides a variety of functionality for managing the server using GUI.
- Transact-SQL (T-SQL) is the SQL Server’s native language and provides
SELECT,INSERT,UPDATE, andDELETEstatements to manipulate data in addition to other types of commands, such as creating a database or table, granting rights to users, and so on. - SQL Server 2008 introduces several new T-SQL programmability features and enhances some existing ones.
- DB2 Universal Database (UDB) is one of IBM’s families of RDBMS software products.
- Initially, it was available on IBM’s mainframes only, but later it spanned to a wide variety of platforms. In mid-2009, IBM announced version 9.7 of this product on distributed platforms.
- Like free version of Oracle database and Microsoft SQL Server, a free version of DB2 called DB2 Express-C is also available.
- The idea of DB2 arose in 1970 when E.F. Codd of IBM described the theory of relational databases. He published a paper which proposed a new architecture for storing and managing the digital data.
- In 1983, IBM released its database product on multiple virtual storage (MVS) mainframe platform which was given the name DB2 (formally called Database 2).
- DB2 provides Control Center, a GUI tool, to manage all the DB2 objects visually. When we open the Control Center, its main interface appears which allows creating database objects using simple-to-use wizards.
- DB2 is a true client/server architecture, which allows applications running on client machines to interact with the database residing on the server machine.
KEY TERMS
- Query-rewrite systems
- Row level triggers
- Statement level triggers
INSTEAD OFtriggers- Data Guard
- Standby database
- DB2 Express-C
- Database 2
- Distinct types
- Structured types
A. Multiple Choice Questions
- Which of the following database systems support query-rewrite system?
- Oracle
- PostgreSQL
- IBM DB2
- Microsoft SQL Server
- Which of the following is the programming-language interface for C++?
- JDBC
- ECPG
- LIBPQ++
- PERL
- Which of the following is a default username provided by Oracle 11g?
- SYS
- DBSNMP
- SYSMAN
- All of these
- In which release of SQL Server, Microsoft introduced database mirroring?
- SQL Server 2000
- SQL Server 2005
- SQL Server 2008
- None of these
- In which year, IBM announced version 9.7 of DB2 on distributed platforms?
- 2006
- 2007
- 2008
- 2009
B. Fill in the Blanks
- In 1995, __________ and __________ added SQL capabilities to Postgres and gave it a new name, Postgres95.
- The most popular and simplest tool to access database created in Oracle is __________.
- Sybase had developed a __________ product for the systems running UNIX operating system.
- __________ is the core language that is used in SQL Server for data access.
- Like the free version of Oracle and Microsoft SQL Server, a free version of DB2 called __________ is also available.
C. Answer the Questions
- What information psql application asks for when it is started?
- Discuss query-rewrite system that PostgreSQL supports.
- Describe some object-relational features of Oracle.
- Write short notes on the following.
- Data Guard
- Instead of trigger
- Explain the types of authentication that can be used to log in to SQL Server 2008.
- List the new assignment operators introduced in SQL Server 2008.
- Discuss the support of IBM DB2 for user-defined types, functions, and methods.
- Create a rule in PostgreSQL for inserting the old price of book in a new relation whenever the price of a book in the
BOOKrelation is updated. - Write steps to connect to the SQL Server 2008 and then create a database and the
BOOKrelation (whose schema is given in Chapter 04) under the newly created database.