
CHAPTER 15
INFORMATION RETRIEVAL
After reading this chapter, the reader will understand:
- Information retrieval process and information retrieval system
- Differences between database system and information retrieval system
- Vector space model for document representation
- TF/IDF based ranking
- Similarity based retrieval, cosine similarity, and relevance feedback
- Performance measures, recall, and precision
- Inverted index
- Signature files
- Working of web search engines
Any web page, usually designed in HTML or XML, is considered to be a document. The web documents may be multimedia objects such as images or video clips or it may also contain data in the form of text. There are billions of documents on the Web, which is the biggest source of information. However, unlike structured data in relational databases, textual data is unstructured. The management of such a large number of documents in DBMS is a big challenge, and therefore, becomes a point of interest for database researchers.
Retrieving text information from such a gigantic digital library is a difficult task. The process of extracting information from unstructured textual data is referred to as information retrieval (IR). The emphasis in information retrieval system is different from the one in database systems. The main emphasis is on querying based on keywords and ranking documents on the basis of their relevance to the query. This chapter discusses IR systems and its various features.
15.1 INFORMATION RETRIEVAL SYSTEMS
Information retrieval is the process of searching for documents, information within the documents or within the databases. The process of information retrieval consists of locating relevant documents based on user inputs. The users of IR systems request to retrieve a particular set of documents by providing a set of words or keywords. Information retrieval system locates and returns the documents whose associated keywords match with the given keywords. For example, the keywords ‘computer memory’ and ‘memory system’ may be used to locate articles/documents describing memory system of the computer.
There is much similarity between database systems and IR systems, such as both have the common objective of supporting searches over collection of data. However, several issues that IR systems are dealing with are not addressed in database systems and vice versa. Some of these issues are listed in Table 15.1.
Table 15.1 Differences between database system and IR system
| Database System | IR System |
|---|---|
| Data in database system is rigidly structured and supports search based on very general class of queries. | IR system deals with unstructured data and supports approximate searching based on the keywords. |
| It supports the notion of transaction and its associated requirements, such as concurrency control and durability. | Notion of transaction is less significant in IR system and it is mainly designed to handle read mostly workload. |
| Database systems do not order the search result in terms of its relevance to the query. | Ranking of search documents in terms of their relevance to the keyword is the main feature of IR system. |
IR systems support search based on query expressions, which are formed using keywords and logical connectives ‘and’, ‘or’, and ‘not’. For example, a user may ask to retrieve documents that contain the keywords ‘mobile technology or CDMA’, or documents containing keywords ‘health and wealth’, or even the documents containing keywords ‘computer but not software’. If a query contains keywords without any of the logical connectives, it is assumed to have ‘and’ implicitly connecting the keywords.
Information retrieval based on keywords are not only used for retrieving textual data, but can also be used for retrieving other types of objects such as audio or video objects. Such specialized multimedia objects have descriptive keywords associated with them. For example, a song can be associated with several related keywords such as title, movie name, and actors.
Information retrieval systems also support full text retrieval in which each word in the document is considered to be a keyword. Full text retrieval is essential for unstructured data, since it is possible that document does not contain information about words that are keywords. Note that in full text retrieval where each word is a keyword, we can use term to refer words in a document.
IR system typically locates and returns all the documents relevant to query. In information retrieval, a query does not uniquely identify a single document. Instead a collection of document may match the given query. More sophisticated IR systems rank the resultant documents in the order of their relevance to the query. The top-ranked documents are then shown to the user as the query result. The relevance of a document to a query is estimated by using information such as a term occurrence. Ranking the document in the order of their relevance to the query is discussed in Section 15.3.
Learn More
Documents are added to IR system frequently and indexes that are used to locate the documents are updated periodically. Therefore, if indexes are not up to date, it might be possible that documents that are highly relevant to a given query are available in the IR system but are not retrieved in the query result.
15.1.1 Document Representation
As we know, Web contains billions of documents, which contain important information and data. We need a simple model to handle them with ease. One of the most widely used models is vector space model. In this model, each document is transformed from full text version to a document vector, which describes the contents of the document. Each word that appears in the collection of documents corresponds to a dimension in the vector, and each document is represented as a vector with one entry per word. For instance, if a given word t appears n times in a document d, the vector for document d contains value n in position t. The document vector for any document d contains nonzero value for the word that appears in d.
Consider a set of text documents shown in Figure 15.1. Each document in the set can be represented as a document vector, which is shown in Figure 15.2. In this representation, each row corresponds to a document and each dimension corresponds to a term in the collection of document. Such vector representation of the documents is called vector space model.
| ID | Document contents |
|---|---|
| A | computer keyboard mouse memory mobile |
| B | keyboard language memory device driver |
| C | mouse CPU keyboard mobile mouse |
Fig. 15.1 Text documents with some records

Fig. 15.2 Example of a document vector
This model is widely used for information retrieval, indexing, and relevance ranking. However, it has some limitations as well that are given as follows:
- Representation of long documents is poor because of their poor similarity values.
- Similar context documents having different term vocabulary cannot be associated.
- The order of term appearance in the document is lost in this representation.
15.1.2 TF/IDF-Based Ranking
In document vector, the value for a term is the number of occurrences of that word in the document or simply the term frequency (TF). It gives the impression that higher the TF, more relevant the document is. However, just counting the number of occurrences is not a good idea. It is because some words appear more frequently in the document than other words. Secondly, number of occurrences also depends on the length of the document.
However, TF can be used in measuring the relevance R of a document d to a given term t using the following formula.
R(d, t) = log (1 + a(d, t)/a(d))
where a(d, t) represents TF (the number of times term t appears in the document d) and a(d) represents total number of terms in the documents. Relevance of document R(d, t) increases with TF. However, it is not directly proportional to TF because the formula takes the document length into account.
Many systems refine the result by considering the document more relevant if the term occurs in the title, or the heading, or the author list.
Some common words that appear in almost all the documents are not very useful in searches. For instance, all textual documents in English contain words such as ‘a’, ‘an’, ‘the’, ‘and’, and so on. Set of these most common words, called stop words, are defined by IR systems, and documents are preprocessed to ignore these words while searching.
Even after ignoring stop words, all the terms used as keywords are not equally significant. This is because some terms appear more frequently than others in the set of documents. Suppose a query contains two terms ‘MBA’ and ‘course’, it is likely to have much more frequency of occurrence of term ‘course’ than ‘MBA’. To get better results, we should give more importance to the term ‘MBA’ than the term ‘course’.
This can be achieved by assigning weights to terms in the document vector by using inverse document frequency (IDF). IDF of a term t is defined as 1/a (t), where a(t) represents total number of documents that contains the term t. The relevance of a document d to a query Q is defined as
This approach of using term frequency and inverse document frequency as a measure of the relevance of a document is called TF/IDF approach.
15.1.3 Similarity-Based Retrieval
Certain IR systems allow similarity-based retrieval whereby users can retrieve documents that are similar to a given document d. Similarity between two documents may be defined on the basis of common terms. The set of n terms in the document d with highest values of a(d, t)* IDF(t) are used as a query to find other relevant documents. The document that is most similar to the query is ranked highest.
Consider n terms t1, t2,…, tn that appear in the collection of documents. The document vector for the document collection can be visualized as an n -dimensional space, in which each dimension corresponds to a term. Any document d is represented by a point in this space, with the value of jth coordinate of the point being R(d, tj). For a two-dimensional space, Figure 15.3 shows document vector for two documents d1 and d2, along with a query Q.
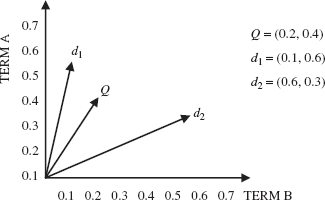
Fig. 15.3 Document similarity
Similarity between two documents d1 and d2 is defined by cosine similarity metric as
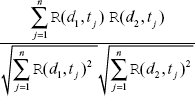
where, R(d, t) = A(d, t) * IDF (t). Note that the metric derives its name ‘cosine similarity’ from the fact that it computes the cosine of the angle between two vectors, each of which represents a document.
If the system finds a large set of documents that are similar to the query document d, it may present only a few highest ranked documents, and allow the user to select the most relevant few. After this, the system starts searching documents that are similar to d and to the selected documents. The set of documents returned by the system is likely to be what the user is looking for. This scheme of searching is called relevance feedback. This scheme can also be used to find relevant documents from a large set of documents that match the given query keywords. In this situation, an alternative approach to the relevance feedback is to allow user to filter the query by adding more keywords.
15.1.4 Performance Measures
In order to determine the accuracy or quality of retrieved result, IR system should be evaluated. The two widely used measures for evaluating the performance of IR systems are recall and precision. Precision is defined as the percentage of retrieved documents that are relevant to the query. Recall is defined as the percentage of relevant documents in the database that are retrieved in response to the query.
In information retrieval, a perfect recall of 100% means that every relevant document is retrieved but it does not guarantee that irrelevant documents are not retrieved. On the other hand, a perfect precision of 100% means that every retrieved document is relevant but it does not guarantee that all relevant documents are retrieved.
Often, there is an inverse relationship between recall and precision. It means that it is possible to increase one at the cost of other. Generally, it is relatively easy for an IR system to achieve either high recall or high precision; however, it is challenging to achieve both. Thus, instead of discussing recall and precision in isolation, either values of one measure are compared for a fixed level at the other measure. For instance, 80% recall at a level of 75% precision.
15.2 INDEXING OF TEXT DOCUMENTS
Efficient index structure plays an important role in efficient processing of queries in an IR system. Size of the index depends on the number of terms in the document collection. Thus, documents are preprocessed to eliminate irrelevant terms such as stop words. In addition, IR system may also apply stemming, in which all related terms are reduced to the simplest and the most significant form without loss of generality. For example, the terms index, indexing, and indexed stem to the simplest term index. This step provides two advantages, firstly, it reduces the number of terms for indexing, secondly, it allows user to retrieve documents that contain variant of exact query term. Two widely used indexing techniques are inverted index and signature file index.
Inverted Index
Inverted index maps each term t to a list (called inverted list) of documents that contain the term t. The entry for a document in the inverted list also provides location within the document where t occurs. The collection of inverted lists is called postings file. Consider the Figure 15.4, which shows the inverted index of our example documents shown in Figure 15.1.

Fig. 15.4 An example of inverted index
Since the term ‘computer’ occurs at location 1 in document A, the entry for document A in the inverted list for term ‘computer’ contains location 1. Similarly, the entry for document C for term ‘mouse’ contains location 1 and 4. Such a data structure not only enables fast retrieval of documents for a given query but also supports relevance ranking. However, inverted index file requires large amount of space. Sometimes the index grows up to several 100 times of the original file, which is a major disadvantage of inverted index.
An inverted list can be very large for large document collections, and thus, must be stored on disk. Mostly, a list spans multiple disk pages and is maintained as a linked list of pages. Alternatively, system might keep it in consecutive pages to minimize the I/O operations required to access the list. Further, to quickly find the inverted list for a given query keyword, a second index structure such as B+-tree or hash index is created for all the possible keywords. This index, called the lexicon, not only contains the address of inverted lists on disks, but it may also contain some additional information. For instance, in our example, each entry in the lexicon index contains address of inverted list and the number of documents in which the term occurs. Lexicon is much smaller than the postings file, and is kept in the memory. Thus, it enables quick retrieval of the inverted list for a given query term.
A query involving conjunction of several terms is evaluated by retrieving the inverted lists of the query terms one by one and intersecting them. On the other hand, a query involving disjunction of several terms is evaluated by computing union of relevant inverted lists.
Signature Files
Another index that can be created for text documents to support efficient retrieval is signature file. In this technique, each document is associated with an index record called signature of the document. Each signature is represented by a fixed size of bits called signature width.
| Word | Hash value |
|---|---|
| computer | |
| 0001 | |
| device | |
| CPU | |
| 0010 | |
| driver | |
| keyboard | |
| language | 0100 |
| mobile | |
| mouse | |
| 1000 | |
| memory | 1000 |
Fig. 15.5 Words with hash value
| ID | Document contents | Signature |
|---|---|---|
| A | computer keyboard mouse memory mobile | 1101 |
| B | keyboard language memory device driver | 1111 |
| C | mouse CPU keyboard mobile mouse | 1110 |
Fig. 15.6 An example of signature file
To calculate the signature of a document, first the hash value of each word in the document is calculated by applying a hash function. A hash function may group different words to same buckets. For instance, suppose a hash function is applied on each word in the set of documents shown in Figure 15.1, then the hash values we get for each word is shown in Figure 15.5.
For each word in the document, we set the bits in the signature that are set in the hash value of the word. Since, hash function may map different words to the same bit, the bit could be set multiple times by different words in the signature (until we have a unique bit for each word). Two signatures are said to be same, if at least all those bits that are set in one signature are also set in another. Signature file for the set of documents is shown in Figure 15.6.
A query involving conjunction of several terms is evaluated as follows:
- First the query signature is generated by applying hash function to each word in the query.
- Signature file is scanned and all the documents whose signature matches the query signature are retrieved.
Since the signature does not uniquely identify the words contained in a document, all the retrieved documents must be checked to determine whether they actually contain the required words. The retrieved documents that do not contain all the words in the query are called false positive.
A query involving disjunction of several terms is evaluated as follows:
- For each word in the query, a query signature is generated.
- Signature file is scanned and all the documents whose signature matches signature of any word in the query are retrieved.
Learn More
Since we need to scan the entire signature file for each query, the performance degrades if the signature file cannot fit in main memory at once. Alternatively, the signature file can be vertically partitioned into bit slices; such an index is called bit-sliced signature file. Now, for a query with n bits set in the query signature, we need to retrieve only n bit slices.
15.3 WEB SEARCH ENGINES
For a search to be successful, web search engines must find all the relevant documents in the extremely large number of documents. Documents have links (hyperlinks) to other documents, which help in locating relevant documents for a given search. Web search engines crawl the Web to locate and gather information found in the documents to a combined index. Since there is extremely large number of documents on the Web, every search engine covers only a small portion of Web. The crawlers may take several days to perform a single crawl of all the pages they cover. Crawling consists of several processes that run on multiple machines.
Crawling starts at a collection of pages with many hyperlinks. These hyperlinks are followed to find new pages. All the hyperlinks that are to be visited are stored in a database. The new hyperlinks found during a crawl are inserted into the database, and may be assigned to another crawler program, or may be visited later. All the pages found during a crawl are given to an indexing system, which creates inverted lists for the terms that occur in the document. The process is iterated, keeping track of the hyperlinks that have been visited to avoid re-visiting them in a single crawl. Since, the process retrieves enormous amount of pages, creating an index of them is an expensive task. Fortunately, the task is parallelizable, so indexing systems run on multiple machines in parallel.
To keep the index up to date, the pages are re-fetched periodically to obtain the updated information. Pages of new launched sites are added in the index, and the sites that no longer exist are discarded. Adding new pages to the index that is being used to handle queries is not a good technique because it requires concurrency control on the index, which affects the query and update performance. Alternatively, two copies of index are maintained—one is used to handle queries and another one is updated by adding new pages. The two copies are switched over periodically; with old one being updated and new one being used to handle queries.
Search engines must also support a high query rate over such vast indexes. To do so, indexes may be partitioned and kept in main memory across several machines. Each machine maintains inverted index for those terms that are mapped to that machine (for example, by hashing the term). System sends the queries to the machine that contains index for the terms that occurs in the query, thus, balancing the load among multiple machines. Note that a query may have to be sent to multiple machines if the terms it contains are handled by different machines. However, it is not a big problem because web queries rarely contain more than two terms.
Mostly search engines have several thousands of machines involved in the process of crawling, indexing, and handling the queries.
Using Hyperlink Information
As discussed earlier, all the documents retrieved in response to a query should be ranked on the basis of their relevance to the given query. Early search engines use TF/IDF-based ranking (discussed in Section 15.1.2), which uses information within the single page to estimate its relevance to a query. However, most relevant pages may not contain the search terms at all, or may have few occurrences of the query term, thus, would not be ranked higher in the result. For instance, the home page of The Times of India may not contain the term ‘newspaper’. However, it is likely that a site containing the term ‘newspaper’ has a link to the home page of The Times of India. Thus, researchers exploit the use of information hidden in hyperlinks to get better result.
Just like the way index of a book keeps links to related topics in the book, good web pages are linked too. In fact, the web pages are classified into two types, authorities and hubs. The hub is a page that itself may not contain the actual information on a topic, but stores links to many related pages that contain actual information. On the other hand, authority is a page that contains actual information on a topic; however, it may not contain links to other related pages.
The relationship between hubs and authorities influences a link-based search algorithm, the HITS algorithm, which retrieves highly relevant pages in response to a given query. The algorithm represents the web as a directed graph with each node corresponding to a web page. If there is a hyperlink from page X to page Y, there exists an edge in the graph between the two corresponding nodes.
The HITS algorithm proceeds in two steps, namely, sampling step and iteration step. In the sampling step, the algorithm collects the pages that are most relevant to the given query using some traditional method. For instance, all the web pages that contain the occurrence of query terms are collected. The resulting set of pages is called the root set. Since some relevant authoritative pages may not contain the query words, the root set may not contain all the relevant pages. However, it may be the case that some pages in the root set contain hyperlinks to those relevant authoritative pages or that some of those authoritative pages have hyperlinks to pages in the root set. Such a page is called a link page, if it is linked to some pages in the root set. All link pages are added in the root set to collect all the potentially relevant pages. The resultant set of pages is called the base set, which includes all the root pages and all the link pages. A web page in the base set is referred to as base page.
Since, the base set can be quite large, each base page is associated with a hub-prestige value and an authority-prestige value. Hub-prestige value indicates the quality of the page as a hub, and the authority-prestige value indicates the quality of the page as an authority. A hub is considered a good hub and assigned higher hub-prestige value if it stores hyperlinks to many pages with high authority-prestige value. On the other hand, an authority is considered a good authority and is assigned higher authority-prestige value if many good hubs have link to it. The pages with good authority-prestige value and hub-prestige value among the base pages are located in the iteration step.
Initially we do not know which pages are good hubs and authorities, so all the values are assigned to one. Later, authority-prestige and hub-prestige values are updated iteratively. Rather taking into account the words that occur in the base page, iteration step is concerned with the hyperlinks that the base pages store.
For instance, consider a page b in the base set with authority-prestige value Va and hub-prestige value Vh. In each iteration, the value Va is updated to the sum of Vh of all the pages that have link to b. On the other hand, the value Vh is updated to the sum of Va of all the pages that are pointed to by b.
SUMMARY
- The process of extracting information from unstructured textual data is referred to as information retrieval (IR).
- The main emphasis in IR system is on querying based on keywords and ranking documents on the basis of their relevance to the query.
- The users of IR systems request to retrieve a particular set of documents by providing a set of words or keywords. IR system locates and returns the documents whose associated keywords match with the given keywords.
- One of the main features of IR system is ranking of search documents in terms of their relevance to the query. The relevance of a document to a query is estimated by using information such as term occurrence. The top-ranked documents are shown to the user as the query result.
- IR systems also support full text retrieval in which each word in the document is considered to be a keyword. In full text retrieval where each word is a keyword, we can use term to refer words in a document.
- To handle billions of documents in Web, vector space model is used. In this model, each document is transformed from full text version to a document vector, which describes the contents of the document. Each word that appears in the collection of documents corresponds to a dimension in the vector, and each document is represented as a vector with one entry per word.
- In document vector, the value for a term is the number of occurrences of that word in the document or simply the term frequency (TF). Term frequency can be used in measuring the relevance of a document to a given term.
- All the terms that are used as keywords are not equally significant, thus, we should give more importance to significant terms to get better results. This can be achieved by assigning weights to terms in the document vector by using inverse document frequency (IDF).
- Certain IR systems allow similarity-based retrieval, whereby users can retrieve documents that are similar to a given document d. Similarity between two documents d1 and d2 is defined by cosine similarity metric.
- The two widely used measures for evaluating the performance of IR systems are recall and precision. Generally, it is relatively easy for an IR system to achieve either high recall or high precision; however, it is challenging to achieve both.
- Efficient index structure plays an important role in efficient processing of queries in an IR system. Two widely used indexing techniques are inverted index and signature file index.
- Documents have links (hyperlinks) to other documents, which help in locating relevant documents for a given search.
- Web search engines crawl the Web to locate and gather information found in the documents to a combined index. Crawling consists of several processes that run on multiple machines.
- To keep the index up to date, the pages are re-fetched periodically to obtain the updated information.
- Just like the way index of a book keeps links to related topics in the book, good web pages are linked too. In fact, the web pages are classified into two types, authorities and hubs.
- The hub itself may not contain actual information on a topic, but stores links to many related pages that contain actual information. On the other hand, authority page is one that contains actual information on a topic; however, it may not contain links to other related pages.
- The relationship between hubs and authorities influences a link-based search algorithm, the HITS algorithm, which retrieves highly relevant pages in response to a given query.
- The HITS algorithm proceeds in two steps, namely, sampling step and iteration step.
- In the sampling step, the algorithm collects the pages that are most relevant to the given query using some traditional method. The resultant set of pages is called the base set. A web page in the base set is referred to as base page.
- Each base page is associated with a hub-prestige value and an authority-prestige value. Hub-prestige value indicates the quality of the page as a hub, and the authority-prestige value indicates the quality of the page as an authority.
- The pages with good authority-prestige value and hub-prestige value among the base pages are located in the iteration step.
KEY TERMS
- Information retrieval (IR)
- Information retrieval system
- Keywords
- Full text retrieval
- Term
- Vector space model
- Term frequency (TF)
- Stop words
- Inverse document frequency (IDF)
- Similarity-based retrieval
- Relevance feedback
- Recall
- Precision
- Stemming
- Inverted index
- Inverted list
- Postings file
- Lexicon
- Signature file
- Signature
- Signature width
- False positive
- Crawl
- Hub and authority
- HITS algorithm
- Sampling step
- Root set
- Link page
- Base set
- Base page
- Iteration step
A. Multiple Choice Questions
- Which of the following is incorrect?
- Database system deals with unstructured data
- Database system supports the notion of transaction
- Database system orders the search result according to its relevancy to query
- None of these
- Which of the following should be ignored while searching documents?
- Keywords
- Term
- Stop words
- Term frequency
- A query containing keywords without any of the logical connectives is assumed to have _______ implicitly.
- or
- and
- not
- Both (a) and (c)
- Which of the following term is not related with inverted index?
- Signature
- Postings file
- Lexicon
- Inverted list
- Which of the following is correct?
- The new hyperlinks found during crawl cannot be assigned to another crawler program
- Indexing systems cannot run on multiple machines in parallel
- While updating the index, the sites that no longer exist cannot be discarded
- Adding new pages to index in use is not a good technique
B. Fill in the Blanks
- Unlike structured data in relational databases, textual data is ___________.
- The users of IR system request to retrieve a particular set of documents by providing _________.
- IR systems also support ________ retrieval in which each word in the document is considered to be a keyword.
- In vector space model, the representation of ________ documents is poor because of their poor similarity values.
- The approach of using term frequency and inverse document frequency as a measure of the relevance of a document is called _____________.
- The two widely used measures for evaluating the performance of IR system are _________ and _________.
- IR system may also apply ________ in which all related terms are reduced to the simplest and most significant form without loss of generality.
- In signature files, each signature is represented by a fixed size of bits called __________.
- The retrieved documents that do not contain _____________ are called false positive.
- Web pages are classified into two types: _________ and ___________.
C. Answer the Questions
- Define the term information retrieval and its necessity. Mention the differences between database system and IR system.
- What are performance measures for IR systems?
- Define the following terms:
- Term frequency
- Stop words
- Cosine similarity metric
- Stemming
- Hub and authority
- How would you represent a document using vector space model? Explain with the help of suitable example. What are its limitations?
- How would you measure the relevance of a document to a given term t?
- What is similarity-based retrieval?
- What is the role of indexing in IR system? Describe the various indexing techniques used by IR system.
- Define search engine. How does a search engine search a page?
- What is a web page? How are different web pages linked? Discuss link-based search algorithm.