
CHAPTER 16
OBJECT-BASED DATABASES
After reading this chapter, the reader will understand:
- The need for object-based databases
- Two streams of object-based databases, that are object-relational and object-oriented databases
- Extension of SQL to support complex data types and object-oriented features, such as inheritance
- Defining structured data types using row and array type constructors
- Defining methods on the structured types
- The concept of type inheritance and table inheritance The concept of object identifier (OID) and reference types in SQL
- Characteristics of object-oriented databases including persistence and versioning
- The standard model of OODBMS, that is, the ODMG object model
- Various concepts and technologies related to object model, such as objects, literals, interface, inheritance, etc.
- Representation of the structure of an object-oriented database using object definition language (ODL)
- Querying object-oriented databases using object query language (OQL)
- Similarities and differences between OODBMS and ORDBMS
Traditional database applications like airline reservation and employee management consist of data-processing tasks with relatively simpler data types such as integers, dates, and strings, which are well suited to the relational model. However, complex database applications such as Computer Aided Design (CAD), Computer Aided Software Engineering (CASE), and Geographical Information System (GIS) demand the use of complex data types to represent multivalued attributes, composite attributes, and inheritance. Such features can be easily represented in the E-R and Extended E-R model, but are difficult to translate into relational model using simpler SQL data types. Thus, the need of a new database model that allows us to deal with complex data types arose.
The new database model proposed was based on the concept of object, since objects represent complex data types naturally. The concept of object was implemented in the database system in two ways, which resulted in object-relational and object-oriented systems. These object-based database systems provide a richer type system including complex data types and object orientation. This chapter discusses both of them in detail.
16.1 NEED FOR OBJECT-BASED DATABASES
Relational databases systems suffer from certain limitations, which led to the development of object-based database systems. The main disadvantage of relational databases is that they represent entities and relationships among them in the form of two-dimensional tables. Thus, any kind of complex data such as multivalued and composite attributes are difficult to represent in such databases. For example, consider the multivalued attributes Phone and Email_id from the E-R model of Online Book database. Representation of such attributes in relational model results in the decomposition of relation into several relations (because 1NF states that all the attributes must have atomic values). However, creation of a new relation for each multivalued attribute may be expensive and artificial in some cases.
Learn More
Some of the object-based database systems that were created for experimental purposes include ORION system developed at MCC, ODE system at AT&T Bell Labs, the IRIS system developed at Hewlett-Packard laboratories, and OPENOODB at Texas Instruments, etc.
Similarly, consider an example of a composite attribute Address. We can view entire address as an atomic data item of type string. However, answering the queries that need to access the street, city, state, and zip code individually becomes difficult. Alternatively, if we represent the address by breaking it into the components (street, city, state, and zip code), it will make the queries more complicated as the user has to mention each field individually in the query. A better option is to represent these attributes as structured data types, which allow a type Address with subparts street, city, state, and zip_code.
Another limitation of relational model is that concepts like inheritance are difficult to represent in it. The inheritance hierarchy needs to be represented with a series of tables. In order to ensure data consistency and integrity, referential integrity constraints must also be set up. With complex type systems, E-R model concepts such as multivalued and composite attributes, generalization and specialization can be directly represented without a complex translation to the relational model.
Relational database systems may not be suitable for certain applications, but they have so many advantages. That is why many commercial DBMS products are basically relational but also support object-oriented concepts.
Another major reason for the development of object-based databases is the increasing use of object-oriented programming languages in software development. Traditional databases seem to be difficult to use with software applications that are developed in object-oriented languages such as C++, Smalltalk, or Java. Object-oriented databases are designed so that they can be directly integrated with the applications that are developed using object-oriented programming language.
16.2 OBJECT RELATIONAL DATABASE SYSTEMS
Object relational database systems (ORDBMS) are the relational database systems that have been extended to include the features of object-oriented paradigm. The SQL:1999 extends the SQL to support the complex data types and object-oriented features such as inheritance. In this section, we discuss implementation of these features in SQL.
16.2.1 Structured Types
In addition to built-in data types, SQL:1999 allows us to create new types which are called user-defined types in SQL. Structured type is a form of user-defined type that allows representing complex data types. Using structured types, composite attributes as well as multivalued attributes of E-R diagrams are represented efficiently.
Using Type Constructors
Structured data types are defined using type constructors, namely, row and array. Row type is used to specify the type of a composite attribute of a relation. A row type can be specified using the syntax given here.
CREATE TYPE <Type_Name> AS [ROW] (<attribute1> <data_type1>, <attribute2> <data_type2>, : <attributen> <data_typen>, );
NOTE The keyword ROW is optional.
For example, a row type to represent a composite attribute Address with component attributes HouseNo, Street, City, State, and Zip can be specified as follows.
CREATE TYPE AddressType AS (HouseNo VARCHAR(30), Street VARCHAR(15), City VARCHAR(12), State VARCHAR(6), Zip INTEGER(6));
We can now use the defined type (that is, AddressType) as a type for an attribute while creating a relation. For example, a relation PUBLISHER can be created by declaring an attribute Paddress of type AddressType as shown here.
CREATE TABLE PUBLISHER( P_ID VARCHAR(20), Pname VARCHAR(50), Paddress AddressType);
The attribute Paddress in the PUBLISHER relation is now a composite attribute having HouseNo, Street, City, State, and Zip as its components.
The row types discussed so far have names associated with them. SQL provides an alternative way of defining composite attributes by using unnamed row types. To illustrate this, consider the following declaration.
CREATE TABLE PUBLISHER( P_ID VARCHAR(20), Pname VARCHAR(50), Paddress ROW (HouseNo VARCHAR(30), Street VARCHAR(15), City VARCHAR(12), State VARCHAR(6), Zip INTEGER(6)));
Note that the attribute Paddress has unnamed type and rows of the relation also have an unnamed type.
Now in order to access the components of a composite attribute “dot” notation is used. For example, Paddress.City returns the city component of the Paddress attribute. For example, consider the following query.
SELECT Paddress.HouseNo, Paddress.City FROM PUBLISHER;
In addition to creating an attribute of user-defined type in a relation, SQL also allows creating a relation whose rows are of a user-defined type. For example, we can define a type PublisherType, which can be further used to create a relation PUBLISHER as follows.
CREATE TYPE PublisherType AS ( P_ID VARCHAR(20), Pname VARCHAR(50), Paddress AddressType);
CREATE TABLE PUBLISHER OF PublisherType;
An array type is used to specify an attribute (multivalued attribute) whose value will be a collection. For example, an author can have many phone numbers, thus, the attribute Phone can be represented using array type in the type AuthorType as follows.
CREATE TYPE AuthorType AS ( Aname VARCHAR(30) NOT NULL, State VARCHAR(15), City VARCHAR(15), Zip VARCHAR(10), Phone VARCHAR(20) ARRAY[5], URL VARCHAR(30));
Note that the attribute Phone can store at most five values. Now we can create a relation AUTHOR of type AuthorType, and can insert a row in it using the following statements.
CREATE TABLE AUTHOR OF AuthorType;
INSERT INTO AUTHOR VALUES (‘James Erin’, ‘Georgia’, ‘Atlanta’, ‘31896’, ARRAY [‘376045’, ‘376123’], ‘www.ejames.com’);
In order to access or update array elements, we use array index. For example, the following query retrieves the name and first phone number of the authors who live in Georgia.
SELECT Aname, Phone[1] FROM AUTHOR WHERE State = ‘Georgia’;
In addition to row and array type, other type constructors are set, multiset (bag), and list, but these are not the part of SQL:1999. The types defined using array, set, multiset, and list are referred to as collection types.
Defining Methods We can also define methods on the structured types. The methods are declared as part of the type definition as shown here.
Learn More
SQL:1999 allows defining constructor functions for the structured types in order to create values for their attributes. The name of constructor function is same as that of structured type and it may or may not have arguments. The default constructor for a structured type has no arguments and it assigns default values to the attributes.
CREATE TYPE PublisherType AS ( P_ID VARCHAR(20), Pname VARCHAR(50), Paddress VARCHAR(25)) METHOD ShowName (P_ID VARCHAR(20)) RETURNS VARCHAR(50));
Here a method ShowName is declared that takes P_ID as parameter and it is supposed to return the name of the publisher. The method body is created separately as shown here.
CREATE INSTANCE METHOD ShowName(P_ID VARCHAR(20)) RETURNS VARCHAR(50) FOR PublisherType BEGIN RETURN SELF.Pname; END
In this declaration, the FOR clause indicates that the method is declared for the type PublisherType, and the keyword INSTANCE indicates that the method executes on an instance of PublisherType. Note that the method returns Pname by using the variable SELF, which refers to the current instance of PUBLISHER on which the method is invoked. For example, we can invoke the method ShowName as follows:
SELECT ShowName(‘P002’) FROM PUBLISHER;
NOTE Method body can include procedural statements as well as it can update the values of the attributes of the instance on which it is executed.
16.2.2 Inheritance
Unlike relational system, object-relational database system supports inheritance directly. In object-relational database system, inheritance can be used in two ways: for reusing and refining types (type inheritance) and for creating hierarchies of collection of similar objects (table inheritance).
NOTE SQL:1999 and SQL:2003 supports only single inheritance. Though it may be possible that future versions of SQL support multiple inheritance also.
Type Inheritance
Consider the following type definition for BookType.
CREATE TYPE BookType ( Book_title VARCHAR(50), Category VARCHAR(20), Price NUMERIC(6, 2), Copyright_date NUMERIC(4), Year NUMERIC(4), Page_count NUMERIC(4), P_ID VARCHAR(4)) NOT FINAL ;
Further, suppose that we want to store additional information in the database about the books that are textbooks. Instead of creating separate type for textbook, we can inherit BookType to define type TextBookType as shown here.
CREATE TYPE TextBookType UNDER BookType (Subject VARCHAR(30));
This statement creates a new type TextBookType, which inherits the attributes of BookType, plus it has one additional attribute Subject. Here, BookType is a supertype of TextBookType, and TextBookType is a subtype of BookType.
Note that the keyword NOT FINAL states that the subtypes can be created from the given type. In addition, SQL also provides FINAL keyword, which states that subtypes cannot be created from the given type.
Subtypes also inherit the methods of supertypes, in addition to their attributes. However, a subtype can override the method of supertypes just by using OVERRIDING METHOD instead of METHOD in the method declaration.
Table Inheritance
Like type inheritance, SQL also supports table inheritance, and allows us to create subtables. The concept of subtable came into existence to incorporate the implementation of generalization/specialization of an E-R diagram. To understand the table inheritance, consider the following definition of BOOK relation.
CREATE TABLE BOOK OF BookType;
Now we can define TextBook as a subtable of BOOK using the following statement.
CREATE TABLE TextBook OF TextBookType UNDER BOOK;
Some important points regarding table inheritance are given here.
- The major requirement for the table inheritance is that the type of subtable must be the subtype of the type of the parent table.
- Every tuple in the subtable also implicitly exist in the supertable; however, every tuple in the supertable corresponds to at most one tuple in each of its subtable (immediate subtable).
- A query on the parent table finds all the tuples from the parent table as well as from its subtables. However, the result of the query would include the attributes of parent table only.
- We can restrict the query to find tuples in the parent table only by using the keyword
ONLYas shown here.
SELECT Book_title FROM BOOK ONLY ;
16.2.3 Object Identity and Reference Types in SQL
In object database system, each object is assigned an object identifier (OID), which uniquely identifies the object over its entire lifetime. Database system is responsible for ensuring the uniqueness of objects by assigning a system generated OID to the objects. The value of OID is used internally by the system for object identification and to manage inter object references. However, its value is invisible to database users. Another important property of OID is immutability, which means, the value of OID of any object should not change. In addition, each OID should be used only once. In other words, even if the object is removed from the database, its OID should not be assigned to another object.
The value of OID can be used to refer to the object from anywhere in the database. In SQL:1999, every tuple in a table—defined in terms of structured type—can be treated as an object, and therefore, can be assigned a unique OID. In such tables, an attribute of a type may be a reference (specified using keyword REF) to a tuple of same (or different) table. To understand the concept, consider the type AuthorBookType and the table AuthorBook, which are shown here.
CREATE TYPE AuthorBookType AS ( Book_id REF (BookType) SCOPE BOOK, Author_id REF (AuthorType) SCOPE AUTHOR);
CREATE TABLE AuthorBook OF AuthorBookType;
In the type AuthorBookType, the keyword SCOPE specifies that the values in the attributes Book_id and Author_id are references to the rows in the BOOK and AUTHOR table, respectively. This concept of references is similar to the concept of the foreign keys. Note that the referenced table (BOOK and AUTHOR) must have an attribute that stores the identifier of the row. This attribute, known as self-referential attribute, is specified by using REF IS clause while creating the table as shown here.
CREATE TABLE AUTHOR OF AuthorType REF IS A_ID SYSTEM GENERATED ;
This statement specifies that the values of the attribute A_ID are generated automatically by the database system.
In addition to system generated identifiers, SQL also allows users to generate identifiers. In this case, we must specify the data type of self-referential attribute (using REF USING clause) in the type definition of referenced table as shown here.
CREATE TYPE BookType ( Book_title VARCHAR(50), Category VARCHAR(20), Price NUMERIC(6, 2), Copyright_date NUMERIC(4), Year NUMERIC(4), Page_count NUMERIC(4), P_ID VARCHAR(4)) REF USING VARCHAR(50);
CREATE TABLE BOOK OF BookType REF IS ISBN USER GENERATED ;
Note that in case of user generated identifiers, user must specify the value of the self-referential attribute while inserting tuple in the table. For example, the following statement inserts a tuple in the BOOK table.
INSERT INTO BOOK (ISBN, Book_title, Category) VALUES (‘001-987-760-9’, ‘C++’, ‘Textbook’);
Besides system generated and user generated identifier, we can also use the values of the primary key attribute of a table as identifiers by including the REF FROM clause in the type definition of referenced table. The table definition must include the DERIVED keyword to specify that the reference is derived as shown here.
CREATE TYPE PublisherType AS ( P_ID VARCHAR(20) PRIMARY KEY, Pname VARCHAR(50), Paddress AddressType) REF FROM (P_ID);
CREATE TABLE PUBLISHER OF PublisherType REF IS Pub_ID DERIVED ;
Here Pub_ID is the name of self-referential attribute whose values are derived from the primary key P_ID.
16.3 OBJECT-ORIENTED DATABASE MANAGEMENT SYSTEMS
Object-oriented database Management systems (OODBMS) provide a closer integration with an object-oriented programming language such as Python, C#, C++, Java, or Smalltalk. An object-oriented database system extends the concept of object-oriented programming language with persistence, concurrency control, data recovery, security, and other capabilities as shown in Figure 16.1.
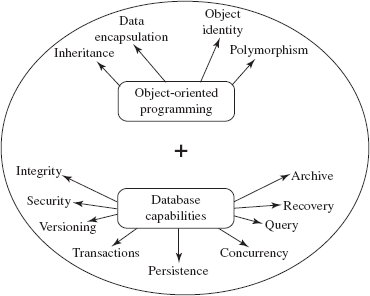
Fig. 16.1 An object-oriented database management system
Some object-oriented databases are well suited for available object-oriented programming languages while others have their own programming languages. OODBMSs are built upon the same data model as used by the object-oriented programming languages.
16.3.1 Characteristics of Object-Oriented Databases
Object-oriented databases combine the object-oriented programming concepts and database capabilities to provide an integrated application development system. In addition to basic object-oriented programming concepts such as encapsulation, inheritance, polymorphism, and dynamic binding, object-oriented database also supports persistence and versioning.
Persistence is one of the most important characteristics of object-oriented database systems. In an object-oriented programming language (OOPL), objects are transient in nature, that is, they exist only during program execution and disappear after the program terminates. In order to convert an OOPL into a persistent programming language (or database programming language), the objects need to be made persistent, that is, objects should persist even after the program termination. OO databases store persistent objects permanently on the secondary storage so that they can be retrieved and shared by multiple programs. The data stored in OO database is accessed directly from the object-oriented programming language using the native type system of the language. Whenever a persistent object is created, the system returns a persistent object identifier. Persistent OID is implemented through a persistent pointer, which points to an object in the database and remains valid even after the termination of program.
Learn More
In C++, the objects are made persistent at the time of their creation by defining them using the overloaded new operator. The overloaded new operator accepts some more arguments for specifying the database in which the object should be created. On the other hand, in Java, one or more objects are explicitly declared as persistent and all other objects that can be referred through those persistent objects also become persistent.
Another important feature of OODBMS is versioning. Versioning allows maintaining multiple versions of an object, and OODBMS provide capabilities for dealing with all the versions of the object. This feature is especially useful for designing and engineering applications in which the older version of the object that contains tested and verified design should be retained until its new version is tested and released.
16.3.2 ODMG Object Model
The object data management group (ODMG), a subgroup of the object management group (OMG), has designed the object model for object-oriented database systems. The OMG is a pool of hundreds of object vendors whose purpose is to set standards for object technology. In 1993, the first release of the ODMG was published which was called ODMG-93 or ODMG 1.0 standard. Later, it was revised into ODMG 2.0, which included a common architecture and definitions for an OODBMS, definitions for an object model, an object definition language (ODL), and object query language (OQL). Various concepts and terminologies related to object model are discussed here.
- Objects: An object is the most basic element of an object model and it consists of two components: state (attributes and relationships) and behavior (operations). An object in the object model is described by four characteristics, namely, identifier, name, lifetime, and structure.
- Identifier: Each object is assigned a unique system generated identifier (OID) that identifies it within the database.
- Name: Some objects are also assigned a unique name within a particular database that can be used to refer to that object in the program. We can use the name of an object as an entry point to the database, that is, by locating an object by its unique name we can also locate other objects that are referenced from it.
- Lifetime: The lifetime of an object specifies whether the object is persistent (that is a database object) or transient (a programming language object).
- Structure: The structure of an object specifies how the object is created using a certain type constructor. Various type constructors used in the object model are atom, tuple (or row), set, list, bag, and array. We have already discussed tuple and array type constructors in Section 16.2.1. All the basic atomic values such as integers, real numbers, Booleans, character, strings, etc. are represented using atom constructor. The list type constructor is used to represent a collection of objects in some specific order (ascending or descending), whereas, set and bag are used to represent an unordered collection of objects. Note that all the objects in a set must be distinct while a bag can have duplicate objects. The objects in the object model can be classified as atomic objects (created using atom type constructor) or collection objects (created using set, list, bag, or array type constructor).
- Literal: A literal is basically a constant value that does not have an object identifier. It can be of three types, namely, atomic, collection, and structured. Atomic literals correspond to the values of basic data types of the object model including long, short, and unsigned integers, floating point numbers, Boolean values, character, string, and enumeration type values. Collection literals define a value that is a collection of objects or values such as set, array, list, bag, etc., but the collection itself does not have an object identifier. Structured literals correspond to the values that are constructed using the tuple type constructor. Structured literals include built-in structures like
Date,Interval,Time, andTimestamp, as well as user-defined structures that can be created using thestructtype constructor. - Atomic (user-defined) objects: A user-defined object that is not a collection object is called an atomic object. In order to create object types (or instances) for atomic objects, the
classkeyword is used which specifies the properties (state) and operations (behavior) for the object types. The properties define the state of an object type and are described by attributes and relationships. Attributes specify the features of an object and can be simple, enumerated, structured, or complex type, and relationships specify how one object is related to another. In the object model, only binary relationships are explicitly represented and a pair of inverse references (specified using the keywordrelationship) is used to represent each binary relationship. In addition to properties, each object type can also have a number of operation signatures, which include name of operation, type of arguments passed, return type, and name of exceptions (optional) that can occur during operation execution. - Interface: Unlike a class that specifies both the abstract state and abstract behavior of an object type, an interface specifies only the abstract behavior of an object type. The operations that are to be inherited by the user-defined objects or other interfaces for a specific application are defined in an interface. In addition, an interface cannot be instantiated that means objects cannot be created for an interface. An interface is defined using the keyword
interface.NOTE An interface may also specify properties (along with the operations) of an object type; however, these cannot be inherited from the interface.
- Inheritance: The object model employs two types of inheritance relationships. One is behavior inheritance or interface inheritance in which the supertype is an interface and the subtype is either a class or an interface. The behavior inheritance is specified using the colon (:) symbol. Another kind of inheritance relationship is EXTENDS relationship, which requires both the supertype and the subtype to be classes. This type of inheritance is specified using the keyword
extends, and it cannot be used for implementing multiple inheritance. However, multiple inheritance is permitted for behavior inheritance that allows an interface or a class to inherit behavior from more than one interface. Note that if a class is used as a subtype in multiple inheritance then it can inherit state and behavior from at most one other class usingextendsin addition to inheriting from several interfaces via (:). - Extents: In ODMG object model, an extent can be declared for any object type (defined using class declaration), and it contains all the persistent objects of that class. An extent is given a name and is declared using the keyword
extent. Whenever extents are declared, the database system automatically enforces set/subset relationship between the extents of a supertype and its subtype. For example, if two classes A and B define extents all_A and all_B, and B is subtype of class A, then the collection of objects in all_B must be a subset of those in all_A.
16.3.3 Object Definition Language (ODL)
Object definition language, a part of ODMG 2.0 standard, has been designed to represent the structure of an object-oriented database. ODL serves the same purpose as DDL (part of SQL), and is used to support various constructs specified in the ODMG object model. The database schema is defined independently of any programming language, and then the specific language bindings are used to map ODL constructs to the constructs in specific programming languages like C++, Java, or Smalltalk. The main purpose of ODL is to model object specifications (classes and interfaces) and their characteristics. Any class in the design process has three characteristics that are attributes, relationships, and methods. The syntax for defining a class in ODL is shown here.
class <name>
{
<list of properties>
};
Here, class is a keyword and the list of properties may be attributes, relationships, or methods. For example, consider the Online Book database and its objects BOOK, AUTHOR, PUBLISHER, and CUSTOMER. The object BOOK can be defined as shown here (for simplicity we have taken only three attributes).
class BOOK
{
attribute string ISBN;
attribute string Book_title;
attribute enum Book_type
{Novel, Textbook, Languagebook} Category;
};
In this example, a field Category as an enum is defined which can take either Novel or Textbook or Languagebook as its value. Similarly, all other objects can also be defined.
An entity in E-R data model or a tuple in relational data model corresponds to an object in object data model, and an entity set or a relation corresponds to a class.
In order to sale these books to the customers, a relationship needs to be specified between the BOOK object and the CUSTOMER object. To connect a CUSTOMER object with a BOOK object, a relationship needs to be defined in the CUSTOMER class as shown here.
relationship set <BOOK> purchases
Here, for each object of the class CUSTOMER, there is a reference to BOOK object and the set of these references is called purchases. This relationship helps us to find the books purchased by a particular customer. However, if we want to access the customers based on the book then the inverse relationship should be specified in the BOOK class as shown here.
relationship set <CUSTOMER> purchasedby
Now, this pair of inverse references (or relationships) can be connected by using the keyword inverse in each class declaration. For example, the relationship set between book and customer is specified in both BOOK and CUSTOMER classes as shown here.
class BOOK
{
…
…
relationship set <CUSTOMER> purchasedby
inverse CUSTOMER :: purchases;
};
class CUSTOMER { attribute string Cust_id; attribute string Name; attribute struct Address //structured literal {short H_no, string street, string city, string state, string country} address; relationship set <BOOK> purchases inverse BOOK :: purchasedby; … … };
Similarly, other relationship sets between book and author, book and publisher can also be specified. In addition to relationships, operations (or methods) can also be specified by including their signatures within the class declaration. The parameters specified in the methods must have one of the three different modes, namely, in, out, or inout. The in parameters are arguments to the method, the out parameters are returned from the method and a value is assigned to each out parameter that a user can process. The inout parameters combine the features of both in and out. They contain values to be passed to the method and the method can set their values as return values. For example, a method find_cust() that finds the name of the customer residing in a particular city, can be included in the CUSTOMER class definition as follows.
class CUSTOMER
{
attribute string Cust_id;
attribute string Name;
attribute struct Address //structured literal
{short H_no, string street, string city, string state,
string country} address;
relationship set <BOOK> purchases
inverse BOOK :: purchasedby;
void find_cust(in string city; out string cust_name)
raises(city_not_valid);
};
Here, the name of the city is passed as a parameter to find_cust() method and the name of the customer belonging to that city is returned. In case, an empty string is passed as a parameter for city name, an exception city_not_valid is raised.
Suppose we want to store information about journals in our database. Since a journal is also a book, we can use inheritance to define the Journal class using the keyword extends as shown in this example.
class JOURNAL extends BOOK
{
attribute string VOLUME;
attribute string Emailauthor1;
attribute string Emailauthor2;
};
Learn More
Some of the object-oriented database systems also support selective inheritance, which allows a subtype to inherit only some of the functions of a supertype. The functions not to be inherited by the subtype are mentioned using the EXCEPT clause.
To implement multiple inheritances, consider a class BOOK_SOLD that stores information about the books sold and the customers who have purchased those books. This class can be derived from both BOOK and CUSTOMER classes as shown here.
class BOOK_SOLD extends BOOK : CUSTOMER
{
void purchase(in string ISBN;in string card_no;in short pin)
raises (ISBN_not_valid, card_not_valid, pin_not_valid);
};
In purchase() method, the ISBN of the book to be purchased, credit/debit card number, and the pin number of the customer are passed as arguments. If the ISBN of the book, card number, or the pin number is not correct, the exception ISBN_not_valid, card_not_valid, or pin_not_valid is raised, respectively.
Like the relation instance of a relation schema, ODL defines an extent of a class, which contains the current set of the objects of that class. For example, an extent books of the class BOOK can be defined as shown here.
class BOOK (extent books)
{
… //same as in
… //BOOK class
};
Similarly, an extent FirstCustomer of the class CUSTOMER can also be defined as shown here.
class CUSTOMER (extent FirstCustomer)
{
… //same as in
… //CUSTOMER class
};
A class with an extent can have one or more keys associated with it that uniquely identify each object in the extent. A key for a class can be declared using the keyword key. For example, the CUSTOMER class definition can be modified to include a key as shown here.
class CUSTOMER (extent FirstCustomer key Cust_id)
{
… //same as in
… //CUSTOMER class
};
Here, Cust_id has been defined as a key for the CUSTOMER class, thus, no two objects in the extent FirstCustomer can have the same value for Cust_id.
In ODL, various schema constructs like class, interface, relationships, and inheritance can be represented graphically. The graphical notations for representing ODL schema constructs are shown in Table 16.1.
Using these notations, a graphical object database schema for Online Book database can be represented as shown in Figure 16.2.
Table 16.1 Graphical notations for representing ODL schema constructs
| Schema Construct | Graphical Notation |
|---|---|
| Interface | |
| Class | |
| Relationships | 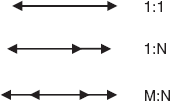 |
| Inheritance |  |

Fig. 16.2 Graphical object database schema for Online Book database
16.3.4 Object Query Language (OQL)
Object Query Language (OQL) is a standard query language designed for the ODMG object model. It resembles SQL (used for relational databases) but it also supports object-oriented concepts of the object model, such as object identity, inheritance, relationship sets, operations, etc. An OQL can query object databases either interactively (that is by writing ad hoc queries) or OQL queries can be embedded in object-oriented programming languages like C++, Java, Smalltalk, etc. An embedded OQL query results in objects that match with the type system of that programming language.
Each query in OQL needs an entry point to the database for processing. Generally, the name of an extent of a class is used as an entry point; however, any named persistent object (either an atomic object or a collection object) can also be used as a database entry point. Using an extent name as an entry point in a query returns a reference to a persistent collection of objects. In OQL, such a collection is referred to by an iterator variable (similar to tuple variable in SQL) that ranges over each object in the collection.
The basic OQL syntax is “SELECT-FROM-WHERE” as for SQL. For example, the query to retrieve the titles of all textbooks can be specified as
SELECT b.Book_title FROM books b WHERE b.Category = ‘Textbook’;
Here, books is an extent of class BOOK and b is an iterator variable. The query retrieves only the persistent objects that satisfy the condition and the collection of these objects is referred to by b. For each textbook object in b, the value of Book_title is retrieved and displayed. As the type of Book_title is a string, the result of the query is a set of strings.
NOTE An iterator variable can also be specified using other syntax such as “b in books” or “books as b”.
In order to access the related attributes and objects of the object under collection, we can specify a path expression. It starts at the persistent object name or at the iterator variable, then it is followed by zero or more relationship set names or attribute names connected using the dot notation. To understand the path expression, consider a query that displays the titles of all the books purchased by Allen, which is shown here.
SELECT b.Book_title FROM books b WHERE b.purchasedby.Name = ‘Allen’;
Here, the query retrieves a collection of all the books that are purchased by the customer Allen using the path expression b.purchasedby.Name. If Allen has purchased more than one copy of the same book the query will result in a bag of strings. With the use of DISTINCT clause the same query will return a set of strings as shown here.
SELECT DISTINCT b.Book_title FROM books b WHERE b.purchasedby.Name = ‘Allen’;
If we want to retrieve a list of books purchased by Allen, we can use ORDER BY clause. For example, the following query results in a list of books purchased by Allen in the ascending order by Category and in the descending order by Price.
SELECT DISTINCT b.Book_title FROM books b WHERE b.purchasedby.Name = ‘Allen’ ORDER BY b.Category ASC, b.Price DESC ;
If the type of result returned from a query is a structure then the keyword struct need to be used within the query. For example, a query to retrieve the location of the publisher who publishes the book having ISBN either 003-456-533-8 or 001-354-921-1 in ascending order of name can be written as
SELECT struct (name:p.Pname, loc:p.Address, s:p.State, ph:p.Phone) FROM publishers p WHERE p.publishes.ISBN=‘003-456-533-8’ OR p.publishes.ISBN=‘001-354-921-1’ ORDER BY name;
Here, the type of result returned by the query is a structure that is composed of name, address, state, and phone number of the publisher. Note that publishers is an extent of PUBLISHER class and the expressions name:p.Pname, loc:p.Address, s:p.State, ph:p.Phone represent aliasing of Pname as name, Address as loc, State as s, and Phone as ph, respectively.
In addition, a number of aggregate operators like SUM, AVG, COUNT, MAX, and MIN can also be used in OQL, since most of the OQL queries result in a collection. Out of these operators, the COUNT operator returns an integer value, while other operators return the same type as the type of the operand collection. The following query returns the average price of books purchased by Allen.
AVG (SELECT b.Price FROM books b WHERE b.purchasedby.Name = ‘Allen’);
If we want a query to return only a single element from a singleton collection (that contains only one element), the keyword ELEMENT can be used. For example, the following query retrieves the single object reference to the books having price greater than $34 and less than $40.
ELEMENT (SELECT b FROM books b WHERE b.Price > 34 AND b.Price < 40);
A host language variable can also be used to hold the result of an OQL query. For example, consider the following statement in which a set<BOOK> type variable Costly_Books stores the l ist of books having price greater than $30.
Costly_Books = SELECT b.Book_title FROM books b WHERE b.Price > 30 ORDER BY b.Price DESC ;
16.4 OODBMS VERSUS ORDBMS
In the earlier sections, we have discussed the important features of both OODBMS and ORDBMS. It is clear from our discussion that the two kinds of object databases are similar in terms of their functionalities. Both the databases support structured types, object identity and reference types, and inheritance. In addition, both support a query language for accessing and manipulating complex data types, and common DBMS functionality such as concurrency control and recovery. These two databases have certain differences also which are listed in Table 16.2.
Table 16.2 Differences between OODBMS and ORDBMS
| OODBMS | ORDBMS |
|---|---|
| It is created on the basis of persistent programming paradigm. | It is built by creating object-oriented extensions of a relational database system. |
| It supports ODL and OQL for defining and manipulating complex data types. | It supports an extended form of SQL. |
| It aims to achieve seamless integration with object-oriented programming languages such as C++, Java, or Smalltalk. | Such an integration is not required as SQL:1999 allows us to embed SQL commands in a host language. |
| Query optimization is difficult to achieve in these databases. | The relational model has a very strong foundation for query optimization, which helps in reducing the time taken to execute a query. |
| The query facilities of OQL are not supported efficiently in most OODBMS. | The query facilities are the main focus of ORDBMS. The querying in these databases is as simple as in relational database system, even for complex data types and multimedia data. |
| It is based on object-oriented programming languages; any error of data type made by programmer may affect many users. | It provides good protection against programming errors. |
SUMMARY
- The concept of object was implemented in the database system in two ways, which resulted in object relational and object database systems.
- SQL:1999 extends the SQL to support the complex data types and object-oriented features.
- Structured type is a form of user-defined type that allows representing complex data types.
- Structured data types are defined using type constructors, namely, row and array. Row type is used to specify the type of a composite attribute of a relation.
- Methods can also be defined on the structured types. The methods are declared as part of the type definition.
- In object-relational database system, inheritance can be used in two ways: for reusing and refining types (type inheritance) and for creating hierarchies of collection of similar objects (table inheritance).
- A subtype can override the method of supertypes just by using
OVERRIDING METHODinstead ofMETHODin the method declaration. - The concept of subtable came into existence to incorporate the implementation of generalization/specialization of an E-R diagram.
- The value of OID can be used to refer to the object from anywhere in the database.
- The referenced table must have an attribute that stores the identifier of the row. This attribute, known as self-referential attribute, is specified by using
REF ISclause. - An object-oriented database system extends the concept of object-oriented programming language with persistence, concurrency control, data recovery, security, and other capabilities.
- Persistence is one of the most important characteristics of object-oriented database systems in which objects persist even after the program termination.
- OID is implemented through a persistent pointer, which points to an object in the database and remains valid even after the termination of program.
- Versioning allows maintaining multiple versions of an object, and OODBMS provide capabilities for dealing with all the versions of the object.
- The object data management group (ODMG), a subgroup of the object management group (OMG), has designed the object model for object-oriented database systems.
- An object is the most basic element of an object model and it consists of two components: state (attributes and relationships) and behavior (operations).
- Each object is assigned a unique system generated identifier OID that identifies it within the database.
- The lifetime of an object specifies whether the object is persistent (that is a database object) or transient (a programming language object).
- The structure of an object specifies how the object is created using a certain type constructor. Various type constructors used in the object model are atom, tuple (or row), set, list, bag, and array.
- A literal is basically a constant value that does not have an object identifier.
- In ODMG object model, an extent can be declared for any object type (defined using class declaration), and it contains all the persistent objects of that class. An extent is given a name and is declared using the keyword
extent. - Object definition language, a part of ODMG 2.0 standard, has been designed to represent the structure of an object-oriented database. The main purpose of ODL is to model object specifications (classes and interfaces) and their characteristics.
- OQL is a standard query language designed for the ODMG object model. It resembles SQL (used for relational databases) but it also supports object-oriented concepts of the object model, such as object identity, inheritance, relationship sets, operations, etc.
KEY TERMS
- Object relational database systems
- Object-oriented database systems
- Structured types
- Inheritance
- Type inheritance
- Table inheritance
- Object identifier (OID)
- Self-referential attribute
- Persistence
- Persistent pointer
- Versioning
- ODMG object model
- Object data management group (ODMG)
- Object management group (OMG)
- Objects
- Literal
- Atomic literals
- Collection literals
- Structured literals
- Atomic (user-defined) objects
- Interface
- Inheritance
- Behavior inheritance or Interface inheritance
- Extents
- Object definition language (ODL)
- Inverse relationship
- Object query language (OQL)
- Entry point
- Iterator variable
- Path expression
EXERCISES
A. Multiple Choice Questions
- Which of these is a complex database application?
- Computer aided design
- Computer aided software engineering
- Geographical information system
- All of these
- Which of the following type constructors is not supported by SQL:1999?
- Row
- Array
- Set
- None of these
- Which type of inheritance is supported by SQL:1999?
- Single-level
- Multiple-level
- Both (a) and (b)
- None of these
- Which of the following is not the type of an object in object model?
- Collection objects
- Structured objects
- Atomic objects
- All of these
- Which of these statements is true in reference to OID?
- OID is only system generated
- The value of OID can be changed
- The value of OID is used to manage inter object reference
- The value of OID is visible to database users
- Which of these concepts is supported by an object-oriented database?
- Inheritance
- Dynamic binding
- Versioning
- All of these
- An interface specifies __________ of an object type.
- Abstract state
- Abstract behavior
- Both (a) and (b)
- None of these
- An object in the object model is described by four characteristics, namely, identifier, name, _______ and structure.
- Attribute
- Consistency
- Lifetime
- Size
- OO databases store persistent objects
- On the secondary storage
- On the primary storage
- Either (a) or (b)
- Both (a) and (b)
- The OMG is a pool of hundreds of __________ who set standards for object technology.
- Organizations
- Object vendors
- IEEE members
- Database users
B. Fill in the Blanks
- A _________ is a form of user-defined type that helps to represent complex data types.
- SQL supports table inheritance to incorporate implementation of ____________ of an E-R diagram.
- The interface inheritance is specified using the _________ symbol.
- In OO databases, literals can be of types, namely, __________, _________, and _________.
- The _________ clause is used to specify a self-referential attribute while creating the table.
- In object database systems, each object is assigned an __________________ that uniquely identifies the object over its entire lifetime.
- In ODMG object model, an ________ of an object type contains all its persistent objects.
- To specify that the subtypes cannot be created from the given type, the ________ keyword is used.
- The objects of an object-oriented programming language are ________, whereas the objects of a database programming language are _________ in nature.
- Object-oriented databases combine the ___________ and __________ to provide an integrated application development system.
C. Answer the Questions
- Explain how the concept of object was implemented in database system.
- What were the limitations of relational database system which led to the development of object based systems?
- Define the following terms:
- Structured types
- Type inheritance
- Versioning
- Self-referential attribute
- Object ID
- Object state
- Atomic objects
- Collection objects
- What are structured types in SQL? Explain how they represent complex data types.
- Explain type inheritance with suitable example. How table inheritance is used for creating hierarchies of collections of similar objects?
- How is OID used to refer to object in the database? Explain with the help of suitable example.
- Define object-oriented database. What are its characteristics?
- State similarities and differences between objects and literals in ODMG object model.
- What does ODL stand for? Describe the purpose of ODL and also describe how multiple inheritance is implemented in ODL.
- Describe the following OQL concepts.
- Database entry points
- Iterator variables
- Path expressions
- Aggregate operators
- What are the similarities and differences between OODBMS and ORDBMS?