
CHAPTER 12
DATABASE SECURITY
After reading this chapter, the reader will understand:
- Importance of database security for organizations
- Security issues
- Types of threats that could adversely affect the database system
- Role of DBA in database security
- The role of database audit for finding the illegal and unauthorized operations
- Authorization, authorizer, access matrix, and authorization tree
- Various access privileges that a user can have on a relation
- Authentication and various methods to authenticate a user
- Access control and main approaches in DBMS for access control including discretionary access control (DAC), mandatory access control (MAC), and role-based access control (RBAC)
- Granting and revoking privileges to database users
- Implementing multilevel security using Bell–LaPadula model
- Multilevel relations and polyinstantiation
- Creating and destroying roles, and granting and revoking privileges to/from roles
- Access control policies for web applications
- The importance and use of encryption and decryption in communication
- Two encryption techniques, namely, symmetric key encryption and public key encryption
- Digital signatures
- Statistical databases and statiscal queries
Database system manages large bodies of information, which is vital to organizations. Any unauthorized access or manipulation of the database, therefore, spells trouble for the organization. Thus, database should be protected from the persons who are not authorized to access either certain parts of the database or the whole database. In other words, protecting database against unauthorized access or manipulation is a major concern.
In this chapter, we discuss various security issues, the types of threats to the database, and the role of DBA in implementing database security. In addition, we discuss how the user is restricted to access only certain portion of the database.
This chapter also discusses how DBMS maintains secrecy of data during transmission. For this, encryption and decryption algorithms are discussed in Section 12.6. Finally, we discuss some aspects of security in specialized database, such as statistical database.
12.1 SECURITY ISSUES
The security of data is the most important, yet, least talked about issue that organizations face while implementing a database system. Database security covers the following issues.
- Privacy: Only authorized persons should be allowed to access the database. In addition, only the part of the database that is required for the functions they perform should be available to them. In other words, users are allowed to access only the information that is pertinent to their jobs.
- Database integrity: Database should be protected from improper modifications, either intentional or accidental, to maintain database integrity. Only the type of operations that need to be performed by the user should be allowed to them. For example, an employee who does not belongs to accounts department should not be allowed to modify the balance sheet of the organization. The employees of accounts department only should be allowed to do so.
- Database availability: Security should not restrict the authorized users to perform their actions on the part of the database available to them. For example, an accounts department employee should not be restricted to update the balance sheet.
There are various types of threats that adversely affect the database system. These threats can be classified into two categories, namely, accidental and malicious or intentional threats.
Accidental
- Due to any system error, a user can get access to the portion of the database that should not be accessible to him.
- Some people have good intentions and motives; yet do not have full understanding of what they are doing. Assume that an employee shares a password with his co-worker so that he can get something done, and regardless of his intention he runs an update query without proper
WHEREclause or noWHEREclause at all. His actions can negatively affect the database. - Improper authorization can be accidentally assigned to a user by the authorizer. Such incidents could lead to security violations.
- Concurrent usage of the database could lead to database inconsistency, if proper synchronization mechanism is not implemented.
- Failure of the memory protection hardware could result in diversified response from the database.
Malicious or Intentional
- Hackers, an ex-employee looking for revenge, or even a regular employee can get into the system parts that they are not authorized to access. They could then intentionally update or even delete the secret and precious information from the database.
- Authorized user of an organization could give valuable information to the competitors for personal gain.
- Programmers and/or developers of database development team could easily access database files, although not authorized to do so, and can update the data.
Threats, either accidental or intentional, can cause some extent of damage to the database. Impact of threats on the database heavily depends on the type of data affected. In order to protect database against these types of threats, various steps can be taken. Some measures are access control and encryption, which we discuss in this chapter.
Things to Remember
Though, DBMS includes a database security and authorization subsystem for ensuring security of database, some additional security features are also required by operating system. For instance, operating system must restrict any unauthorized user to directly access the files belonging to the database.
12.2 ROLE OF DBA IN DATABASE SECURITY
As discussed in Chapter 01, the database administrator (DBA) is the central authority that is responsible to manage the database system. The DBA is responsible for the overall security of the database system. The two main responsibilities of DBA are managing user accounts and performing database audit.
Managing User Accounts
It includes creation and deletion of accounts as well as granting and revoking privileges to/from the accounts. For this, the DBA has a system or superuser account in the DBMS, which provides powerful capabilities to control access to the database. He must restrict the user’s access to the data so that the user, can perform only the necessary action on the portion of the database to which they are authorized. For this, the DBA deals with the following.
- Creation of user account: Creates a new account and password for an individual user or a group of users to allow them to access the database. This step is used to control access to the database system as a whole.
- Granting of privileges: Grants certain privileges to certain accounts.
- Revoking of privileges: Revokes or cancels the privileges previously granted to certain accounts.
- Classification of user accounts: Assign user accounts to different security classification levels.
Note that privilege is a kind of permission that allows users to access certain data items in a specified mode (like read, modify, or alter). Granting and revoking of privileges are used to control discretionary authorization, and classification of user accounts is used to control mandatory authorization.
Further, user accounts and passwords have to be kept confidential. The DBMS maintains an encrypted table with two fields, namely, Account_Number and Password to keep track of database users and their passwords. At the time of creation of a new account, a new entry is inserted into the table and at the time of deletion of an account, the corresponding entry must be deleted from the table.
Database Audit
In order to access the database, the user must log in to the DBMS by entering the account number and password. The DBMS verifies the account number and password and allows the user to access the database if the combination is found valid, otherwise access is denied. When a user logs in successfully, the DBMS records its account number and the terminal ID from where the user logs in. The DBMS keeps track of all the operations applied from that terminal and associate them with the user’s account until the user logs off. Thus, in case, the database is tampered with any update operation, the DBA can find out the user who is responsible for that tampering.
To keep track of all the changes (insert/delete/update) applied to the database, system log that includes an entry for each update operation can be used. The entry in the system log can be further modified to include user’s account number and terminal ID from where the changes have been applied. In case of database tampering, a review of log is carried out to examine all the operations applied to the database during certain period of time. This review of log is called database audit. It helps the DBA to find out the illegal or unauthorized operation and the account number used to perform this operation. A database log that is mainly used for database security is generally called an audit trail.
12.3 AUTHORIZATION
Authorization is the granting of privileges to users, which enable them to access certain portion of the database. Since database users perform different roles, they are permitted to access only the part of database that is pertinent to their job. In addition, each user is allowed to perform only the necessary operation on the database that is required to perform their function. Such type of permission is given to database users by granting different privileges to them. The person who is responsible for granting privileges to database users is called authorizer. The DBA assign privileges to different users; however, the owner of relation can also assign privileges, since the owner has all the privileges on his relations.
The authorization information is maintained in a table called access matrix, which the database system consults each time an access request is issued in the system. The columns of access matrix represent objects and rows represent subjects. Here, object is any part of the database that needs to be protected from unauthorized access. For example, a file or a relation and its attribute can be considered as an object. Subject is an active user or account who operates on various objects in the database. An application program can also be considered as a subject. Each subject is given some access rights on some or all objects. The type of access that a subject has with respect to an object is represented by an entry in the access matrix at the intersection of the corresponding row and column. Figure 12.1 shows an example of access matrix with some access rights for listed subjects with respect to various objects.
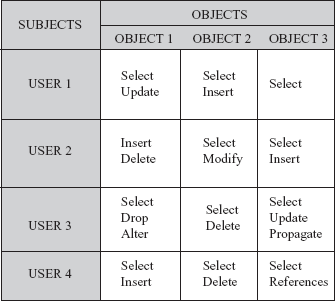
Fig. 12.1 Access matrix
In terms of a relation as an object, a user can have following access privileges on a relation.
- SELECT: A user having select privilege on relation
Ris allowed to select or retrieve tuples fromR. - MODIFY: A user having modify privilege on relation
Ris allowed to modify the tuples ofR. This privilege is further divided into three types, namely,INSERT,UPDATE, andDELETE. User having any of the privilege is allowed to apply the corresponding command toR. For instance, user havingINSERTprivilege is allowed to insert new tuples inR. - REFERENCES: A references privilege on
Rallows the user to reference the attribute ofRwhile specifying integrity constraints. This privilege can also be restricted to some specific attributes ofR. - DROP: A drop privilege allows the user to delete existing relation of the database.
- ALTER: A user having alter privilege on relation
Ris allowed to add new attributes to the relationR. The user is also allowed to drop or delete the existing attributes ofR. - PROPAGATE ACCESS CONTROL: A user having propagate right on relation
Ris allowed to pass all or part of his privileges onRto other users.
Note that, in addition to these privileges, a user may have the privileges to define indexes, execute certain application programs, and so on.
Authorization Tree
Propagate access control allows the users to pass either entire or part of their rights to other users, who may also be allowed to pass their rights as well. Such a series of authorization from one user to another user leads to a tree termed as authorization tree. Database users become the nodes in the tree with authorizer as the root node. Edge from one node to another node exists if rights are passed from one user to another user represented by these two nodes. For example, consider an authorization tree shown in Figure 12.2.
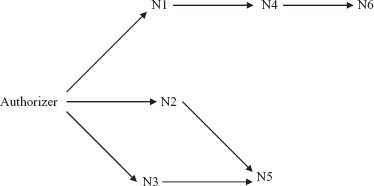
Fig. 12.2 Authorization tree
Here, authorizer assigns some access rights to the users represented by the nodes N1, N2, and N3. N1 assigns access rights to N4, which in turn assigns access rights to N6. Further, N2 and N3 together assign access rights to N5.
A user has some access rights, if there is any path from the root node (that is, authorizer) to the node representing that user. Thus, to revoke access rights from a user, all the incoming edges to that user in authorization tree should be removed. Returning to our example, suppose that authorizer revokes the access rights from N3. In this situation, N5 loses its access rights that are granted by N3; however, it retains those rights that are granted by N2. Further, if the authorizer revokes the access rights from N2 also, then N5 loses all of its access rights. However, if authorizer revokes access rights from N1, then both N4 and N6 lose their authorization, since both N4 and N6 has their access rights from N1.
12.4 AUTHENTICATION
Authorization allows the database users to access certain part of database. However, before accessing the database, users need to identify themselves to the system to confirm their correctness. The process of verifying the identity of a user is termed as authentication. Various methods can be used to authenticate a user, such as a secret password, some physical characteristics of the user, a smart card, or a key given to the user.
Password Authentication
It is the simplest and most commonly used authentication scheme. In this scheme, the user is asked to enter the user name and password to log in into the database. The DBMS then verifies the combination of user name and password to authenticate the user, and allows him the access to the database if he is the legitimate user, otherwise access is denied. Generally, password is asked once when a user log in into the database; however, this process can be repeated for each operation when the user is trying to access sensitive data.
Though, the password scheme is widely used by database systems, this scheme has some limitations. In this method, the security of database completely relies on the password. Thus, password itself needs to be secured from unauthorized access. One simple way to secure the password is to store them in an encrypted form. Further, care should be taken to ensure that password would never be displayed on the screen in its decrypted (non-encrypted) form. Encryption and decryption are discussed in detail in the Section 12.6.
Physical Characteristics of User
In this method, the physical characteristics of the users such as fingerprints, voiceprint, length of fingers of hand, face structure, and so on are used for the identification purpose. These characteristics of users are known to be unique, and have a very low probability of duplication. Thus, security of database is relatively high in this scheme as compared to the password scheme. However, this method requires the use of some special hardware and software to identify physical characteristics of the user, which incurs extra cost to the organization.
Smart Card
In this method, a database user is provided with a smart card that is used for identification. The smart card has a key stored on an embedded chip, and the operating system of smart card ensures that the key can never be read. Instead, it allows data to be sent to the card for encryption or decryption using that private key. The smart card is programmed in such a way that it is extremely difficult to extract values from smart card, thus, it is considered as a secure device.
12.5 ACCESS CONTROL
Restricting unauthorized access to the database is the main issue in developing secure DBMS. As discussed earlier, most database users need only a small portion of database to perform their job. Allowing them access to the whole database is undesirable. Thus, an organization should develop effective security policy to enable a group of users to access only a required portion of the database. Security policies of the organizations depend on the type of data maintained by them, hence, they vary from organization to organization. Further, once the security policy is developed, it should be enforced to achieve the level of security required. Two main approaches in DBMS for access control are discretionary access control and mandatory access control.
12.5.1 Discretionary Access Control
Discretionary access control (DAC) is enforced in a database system by granting and revoking privileges to/from the users. Different users have different access privileges on the object (either a base table or a view) of the database. GRANT and REVOKE commands of data manipulation language corresponds to grant and revoke privileges, respectively.
The syntax to grant some privileges to a user is
GRANT <privilege_list> ON <relation or view_name> TO <user_list> [WITH GRANT OPTION];
Suppose DBA decides to allow USER1 to create relations. For this, he issues the following GRANT statement.
GRANT createtab TO USER1;
After this, USER1 can create relations. Further, suppose he creates a relation R1 and decides to give some privileges to USER2 and issues the following statement.
GRANT SELECT, INSERT, UPDATE ON R1 TO USER2;
Since, the user who creates a relation automatically has all privileges on it; hence, the USER1 — owner of the relation—is allowed to grant privileges to other users on that relation. The preceding statement allows USER2 to retrieve tuples of relation R1. In addition, USER2 can also insert new tuples into R1 and can update any existing tuple. However, USER2 is not allowed to propagate SELECT, INSERT, and UPDATE privileges on R1 to other users.
Further, USER1 issues the following statement to allow USER3 to SELECT, DELETE, and UPDATE any tuple of R1. In addition, it enables USER3 to further propagate its privileges on R1 to other users (notice the WITH GRANT OPTION).
GRANT SELECT, DELETE, UPDATE ON R1 TO USER3 WITH GRANT OPTION;
It is also possible to restrict a user to access only few attributes or tuples of a relation. Following statement allow USER4 to UPDATE only A1 and A2 attributes of relation R1.
GRANT UPDATE (A1,A2) ON R1 TO USER4;
Only INSERT or UPDATE privilege can be given on a set of attributes of a relation. SELECT and DELETE privilege on a set of attributes can easily be specified by creating views containing that set from the base relation and granting privilege on that view.
Learn More
Techniques have been developed to limit the propagation of privileges, but still not implemented in most of the DBMSs. For example, horizontal propagation of n (an integer number) restricts the user with the GRANT OPTION on an object to propagate his privileges to at most n other users.
A user who creates a view has only those privileges on the view that he has on each base relations or views which were used to define the view. In addition, the privileges with respect to the view held by its creator changes over time as he gains or loses privileges on the underlying base relations or views. For example, suppose that the creator of a view loses GRANT privilege on the base relations of a view. It implies that all the users lose privileges on that view, since all of them were granted privileges from its owner. Similarly, if the creator of a view gains some more privileges on the base relations then he automatically gains additional privilege on the view also.
In order to create a view, the user must have SELECT privilege on all the base relations involved in creating the view. In case, the owner of a view loses SELECT privilege on the underlying base relations then the view may be dropped.
To cancel or revoke the previously assigned privileges from a user, the REVOKE command is used. The syntax to revoke some privilege from the user is
REVOKE <privilege_list> ON <relation or view_name> FROM <user_list>;
For example, the following statement revokes the privileges of USER2 on relation R1.
REVOKE SELECT, INSERT, UPDATE ON R1 FROM USER2;
Similarly, the following REVOKE statement revokes the privileges of USER4.
REVOKE UPDATE (A1,A2) ON R1 FROM USER4;
12.5.2 Mandatory Access Control
Mandatory access control (MAC) enforces multilevel security by classifying subjects (for example, database users, programs, etc.) and objects (for example, relations, views, etc.) of database system in different security classes. The Bell–LaPadula model is commonly used to implement multilevel security. In this model, each object is assigned a security class (for example, top secret, secret, confidential, and unclassified) and each subject has some clearance (generally the same as security classes). The class assigned to a subject or an object, say Z, is denoted as class(Z). The security classes are assumed to form a hierarchy as top secret (TS) > secret (S) > confidential (C) > unclassified (U). It means the class TS is the highest level and U is the lowest level. In other words, the data of class TS is much more sensitive than class S data and so on. This model imposes two rules on subjects to access objects.
- Subject
Sis allowed to read objectOif and only if the clearance level ofSis greater than or equal to the classification level ofO, that isclass(S) >= class(O). This property is known as simple security property. - Subject
Sis allowed to write objectOif and only if the clearance level ofSis less than or equal to the classification level ofO, that isclass(S) <= class(O). This property is known as star property (*-property).
These two rules in combination with discretionary access control, enforce additional security for database. Thus, in order to retrieve or write an object, the subject should have necessary access privileges on the object and in addition, the security classes of subject, and object must satisfy the stated rules. The first rule or simple security property is very obvious, which states that a subject can read an object whose security classification is lower than or equal to the security clearance of subject itself. For example, a subject with clearance level TS can read object of all classes (including TS) but the subject should have required access privileges (through GRANT command) on that object. The second rule or star property restricts a subject from writing an object whose security classification is lower than the security clearance of the subject. For example, a subject with clearance S can write objects of class TS and class S, since object with TS or S classification is at higher or equal classification than that of subject clearance. However, subject with clearance S cannot write objects of class C and class U.
Multilevel Relations and Polyinstantiation
To implement mandatory access control in relational DBMS, attribute values and tuples are considered as objects and therefore, assigned a security class. Each attribute in a relation is associated with a classification attribute, say Y, and each attribute value is associated with a corresponding security classification. In addition, a tuple classification attribute, say TY, is added to the relation to classify each tuple as a whole. This situation leads to a multilevel relation. A multilevel relation schema R with m attributes would be represented as
R(A1, Y1, A2, Y2, …, Am, Ym, TY)
where, Yi represents the classification attribute associated with attribute Ai, and TY is tuple classification attribute. The value of tuple classification attribute for each tuple is the highest level of all classification attribute value associated with the attributes within that tuple.
The set of attributes that would have served as the primary key in the regular relation is termed as an apparent key in a multilevel relation. For multilevel relations, entity integrity rules ensures that the set of attributes of apparent key must not be null and security classification of each attribute of apparent key should be same within each individual tuple. In addition, security classification of all other attributes’ values must be greater than or equal to that of the apparent key. Thus, any user who is permitted to see any attribute of tuple is also allowed to see the key value of that tuple.
To understand this concept, consider the modified form of Online Book database in which only selected attributes and tuples are taken from PUBLISHER relation (see Figure 12.3) for simplicity. The apparent key of the PUBLISHER relation is P_ID, and classification attribute value of each attribute is written next to the attribute value.

Fig. 12.3 An instance of PUBLISHER relation
In response to the query SELECT * FROM PUBLISHER, the users with clearance S and TS get all the rows, since all the tuple classifications are less than or equal to S and TS. However, the users with clearance C are not allowed to see the third row. Moreover, they are not allowed to see the value of attribute Pname in second row, since it has higher classification in second row. The value for the attribute Pname in second row would appear to be null [see Figure 12.4(a)]. Similarly, the users with clearance U get only first row, and in that the value of attribute State appears to be null [see Figure 12.4(b)].
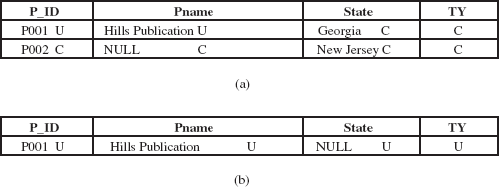
Fig. 12.4 (a) Appearance for clearance level C. (b) Appearance for clearance level U
Further, assume that a user with clearance U is trying to insert a new row <P002, Wesley Publications, Nevada, U>. There arises a problem in choosing between the following two alternatives:
- If the user is allowed to insert that row, the relation will contain two distinct tuples with
P_ID = “P002”, which violates the primary key constraint. - On the other hand, if the user is denied to insert the new row because of violation of primary key constraint, the user with clearance U deduce that there exist a publisher with
P_ID = “P002”, whose classification is higher than U. Doing so violates the principle that users should not be able to deduce any information about objects of higher classification level. This flow of information from higher classification level to a lower classification level, through indirect means, is called covert channel.
This problem can be solved by treating the combination of P_ID and TY as primary key for the relation, instead of just P_ID, and allowing the user to insert the new tuple. The relation instance after insertion is shown in the Figure 12.5.

Fig. 12.5 Relation PUBLISHER after insertion
Note The two tuples having same value for the attribute P_ID is revealed to user according to their clearance level.
Multilevel relation has a surprising property that the users of different security classes view a different collection of tuples within the same relation. For example, in the relation instance, shown in the Figure 12.5, two tuples have same value for apparent key but users with different clearance level view different values in other attributes for P_ID = “P002”. This concept is called polyinstantiation.
12.5.3 Comparing MAC and DAC
Discretionary access control policies are generally very effective and flexible. Due to their high degree of flexibility, they are well suited for large variety of applications. However, DAC suffers with certain weaknesses. Their vulnerability to malicious attacks, such as Trojan horse, is the major limitation of DAC. Trojan horse is a program to breach security of computer system. Using Trojan horse scheme, an unauthorized user can change application program of DBMS to infer sensitive data from authorized user. This is because the discretionary models do not impose any control on flow of information, once it has been accessed by authorized users. In contrast, mandatory access control policies overcome such problems of DAC. MAC control any illegal flow of information using the two rules discussed earlier. Thus, MAC ensures a high degree of protection, which makes them suitable for highly secure applications, such as military applications. However, due to their rigid nature, mandatory policies are applicable to a very few applications.
12.5.4 Role-Based Access Control
Role-based access control (RBAC) emerged as an alternative approach to traditional DAC and MAC. This approach restricts the system access to authorized users only. It appears to be a promising approach for controlling what information computer users can utilize, the programs that they can run, and the modifications that they can make. In RBAC, permissions to perform certain operations are associated with arbitrary roles and these roles are assigned to database users based on their responsibilities in the organization. Only the operations that need to be performed by the members of a role are granted to the role. Further, granting of user membership to roles can be limited. Some roles can only be occupied by a certain number of users at any given point of time. For example, the role of principal can be granted to only one user at a time.
Roles can be created and destroyed using CREATE ROLE and DESTROY ROLE commands, respectively. The GRANT and REVOKE commands can then be used to assign and revoke privileges from roles. Since, users are not assigned to the permissions directly; they acquire a set of permissions through their assigned roles. It reduces the amount of administrative effort required to add or delete accounts of database users. In addition, roles can be updated without updating the privileges for every user on an individual basis. Note that roles can be granted to users with the permission to pass on their role to other users. Database users establish sessions during which they are mapped to an activated subset of the set of roles they belong to.
Under RBAC, roles can have overlapping responsibilities and permissions, that is, users belonging to different roles may need to perform common operations. In this situation, it would be inefficient and administrative cumbersome to repeatedly specify those operations for each role. Alternatively, role hierarchies can be established to provide the natural structure of an organization. In the role hierarchy, a role may contain other roles that means, one role implicitly includes the operations that are associated with another role. Usually, roles in the hierarchy include the operations that are associated to the lower level roles.
The RBAC model is policy neutral that means individual RBAC policy can support a mandatory policy, while other can support discretionary policy. In addition, RBAC can also support user-defined or organization-specific policies. Several other desirable features of RBAC such as flexibility, better management, and administrative support make them suitable for implementing security plan for web-based applications.
12.5.5 Access Control Policies for Web Applications
With the rapid growth of web-based applications for commercial purpose, there is a need to develop security standards for them. Usually, the set of authorizations developed by DBA for access control is well suited for traditional database applications. However, such policy is not well applicable for dynamic web applications, since data must also be protected during its transmission over insecure links. For example, transmission of credit card number for an electronic transaction over Internet must be secure.
Various content publishing sites are available over Internet that enables Internet users to share their knowledge, experience, and opinions. Thus, not only data but also their views must be protected in such type of applications. Hence, a prime importance is the support for content-based access control. In content-based access control, access to an object partially or entirely depends on its contents in the system. Note that the policy for one object can depend on the contents of other objects in the system. For example, the policy depends on the contents of objects owned by the user requesting access.
Another related requirement is the heterogeneity of the subjects, in which access control policies are based on user’s qualifications and characteristics. Suppose, there is an online catalog document that lists available goods sold on the Internet. The access control policy requires that only premium members can view the special discount price information. When a regular member views the document, any such information provided for premium members should be hidden.
It is common to develop web documents using Extensible Markup Language (XML), thus, XML can be very effective in the access control policy for web applications. An XML-based language is developed to specify security policies to be enforced on specific accesses to XML documents. This language is called as XML access control language (XACL). It provides a sophisticated access control mechanism that enables secure browsing and updating of XML documents. In addition, major approach to protect data during transmission is encryption of data before transmission and then decryption of the data to recover original data at the destination.
12.6 ENCRYPTION
Encryption is a means of maintaining security of data in an insecure environment, such as while transmitting data over an insecure communication link. It involves applying an encryption algorithm to the data or plaintext using a pre-specified encryption key. The algorithm produces encrypted version of the plaintext as the output. For example, assume that the encryption algorithm substitutes each character of plaintext with the next third character in the alphabetical sequence. In this algorithm, three is the key for circularly shifted alphabets. Thus, we have the following substitution format.
plaintext: a b c d e f g h i j k l m n o p q r s t u v w x y z
ciphertext: d e f g h i j k l m n o p q r s t u v w x y z a b c
Learn More
Over two thousand years ago, Julius Ceasar, a commander of Roman army, used encryption to convert his message into ciphertext by a substitution of three so that he could communicate with his troops securely.
By this substitution, the text principle becomes sulqflsoh. It is difficult for an unauthorized user or intruder to understand the meaning of sulqflsoh. This encrypted data needs to be decrypted using a decryption algorithm to recover the original data. The decryption algorithm requires decryption key to decrypt the encrypted data. Note that without correct decryption key, the algorithm cannot produce the original data. However, by looking at the frequently occurring pattern and by making guesses at common letters, intruders may be able to guess what substitution is being made. Thus, a good encryption algorithm should have the following features:
- Security should not depend only on the secrecy of the algorithm, rather it should also depend on the encryption key.
- It should be simple for authorized user to encrypt and decrypt the data.
- It should be extremely difficult for an unauthorized user to guess the encryption key.
Most encryption algorithms belong to one of the two categories, namely, symmetric key encryption, or public key encryption.
12.6.1 Symmetric Key Encryption
The type of encryption in which the same key is used for both encryption and decryption of data is called symmetric key encryption. Data Encryption Standard (DES) is a well known example of symmetric key encryption. In 1977, the U.S. government developed DES, which was widely adopted by the industry for use in security products. The DES algorithm is parameterized by a 56-bit encryption key. The DES algorithm has a total of 19 distinct stages and encrypts the plaintext in blocks of 64 bits, producing 64 bits of ciphertext. The first stage is independent of key and performs transposition on the 64-bit plaintext. The last stage is exact inverse of first stage transposition. The preceding stage of last one exchanges the first 32 bits with the next 32 bits. The remaining 16 stages perform encryption by using parameterized encryption key. Since, the algorithm is symmetric key encryption; it allows decryption to be done with the same key as encryption. All the steps of algorithm are run in the reverse order to recover the original data.
With the increasing speed of computer, it is estimated that a special-purpose chip can crack DES in under a day by searching 256 possible keys. Thus, after questioning the adequacy of DES, the National Institute of Standards and Technology (NIST) adopted Rijndael algorithm (by V. Rijmen and J. Daemen) in 2000 as a new symmetric encryption standard called advanced encryption standard (AES). It supports key lengths of 128, 192, and 256 bits and specifies the block size of 128 bits. Since the key length is 128-bit, there are 2128 possible keys. It is estimated that a fast computer that can crack DES in 1 second could take trillion of years to crack 128-bit AES key. The main problem with symmetric algorithm is that the key must be shared among all the authorized users. This increases the chance of key becoming known to an intruder.
12.6.2 Public Key Encryption
In 1976, Diffie and Hellman introduced a new concept of encryption called public key encryption. It is based on mathematical functions rather than operations on bit patterns. Unlike DES and AES, it uses two different keys for encryption and decryption. These two keys are referred to as the public key (used for encryption) and the private key (used for decryption). Each authorized user has a pair of public key and private key. The public key of each user is known to everyone, whereas, the private key is known to its owner only, thus, avoiding the weakness of DES. Assume that E and D represent the public encryption key and the private decryption key, respectively. It must be ensured that deducing D from E should be extremely difficult. In addition, the plaintext that is encrypted using the public key Ei requires the private key Di to decrypt the data.
NOTE The keys are referred to as public key and private key instead of secret key (the key used in conventional encryption) to distinguish them from conventional symmetric-key encryption.
Now suppose that a user A wants to transfer some information to user B securely. The user A encrypts the data by using public key of B and sends the encrypted message to B. On receiving encrypted message, B decrypts it by using his private key. Since decryption process requires private key of user B, which is known only to B, the information is transferred securely. RSA is a well known example of public key encryption.
RSA Algorithm
In 1978, a group at M.I.T. discovered a strong method for public key encryption. It is known as RSA, the name derived from the initials of the three discoverers: Ron Rivest, Adi Shamir, and Len Adleman. It is the most widely accepted public key scheme, in fact most of the practically implemented security is based on RSA. The algorithm requires keys of at least 1024 bits for good security. This algorithm is based on some principles from number theory, which states that determining the prime factors of a number is extremely difficult. The algorithm follows the following steps to determine the encryption key and decryption key.
- Take two large distinct prime numbers, say m and n (about 1024 bits).
- Calculate p = m * n and q = (m – 1)*(n – 1).
- Find a number which is relatively prime to q, say D. That number is decryption key.
- Find encryption key E such that E * D = 1 mod q.
Using these calculated keys, a block B of plaintext is encrypted as Te = BE mod p. To recover the original data, compute B = (Te)D mod p. Note that E and p are needed to perform encryption, whereas, D and p are needed to perform decryption. Thus, the public key consists of (E, p), and the private key consists of (D, p). An important property of RSA algorithm is that the roles of E and D can be interchanged. Note that the number theory suggests that it is very hard to find prime factors of p. Thus, it is extremely difficult for an intruder to determine decryption key D using just E and p, because it requires factoring p which is very hard.
Learn More
The first public key encryption algorithm was the knapsack algorithm. Its inventor Ralph Merkle offered a $100 reward for the one who could break it. Adi Shamir (one of the inventors of RSA algorithm) broke it and collected $100. Ralph Merkle modified the algorithm and offered a $1000 reward this time. Unfortunately, Ralph Merkle had to pay $1000 to Ronald Rivest (again one of the inventors of RSA algorithm) for breaking the knapsack algorithm.
12.6.3 Digital Signatures
Digital signature is a very useful application of public key encryption technique. Like a physical handwritten signature, digital signatures are used to verify the authenticity of electronic document. In other words, digital signatures play the role of physical signatures in verifying electronic documents. The private key of the user is used to digitally sign an electronic document, and the signed document can be made public. Any user can easily verify the authenticity of the document by using the public key that means it can be easily verified that the data is originated by the person who claims for it. However, no one can sign the document without having the private key.
Digital signatures also ensure non-repudiation. It means that no party or person can later deny that he never created such a document which is digitally signed by him. In case, he claims that he did not create that document, it can be easily proved that he must have created the document (unless their private key was not stolen).
12.7 STATISTICAL DATABASE
A statistical database contains confidential information about individuals or events. These databases are mainly used to generate statistical information about the stored information. Such databases accept only statistical queries, which involve statistical functions such as SUM, AVG, COUNT, MIN, MAX, and so on. However, users are not allowed to retrieve information about a particular individual.
Consider a relation BankEmp with the attributes ECode, EName, Sex, State, Salary, Branch, and Designation. Using statistical queries, one can retrieve the number of clerks, maximum salary, average salary of clerks, and so on. However, users are not allowed to retrieve the salary of a particular employee.
Implementing security in such a database raises new problems because it is possible to infer the information about specific individuals from a sequence of statistical queries. For example, suppose that the user is interested in retrieving the salary of John Macmillan living in New York, who is a Clerk in Los Angeles branch. User issues a statistical query to count the number of clerks in Los Angeles branch who are living in New York. The query can be defined as
SELECT COUNT (*) FROM BankEmp WHERE (State = ‘New York’ AND Sex = ‘M’ AND Designation = ‘Clerk’ AND Branch = ‘Los Angeles’);
If the result of this query is 1, the next statistical query can be issued with the same condition to find the salary of John Macmillan. The query can be defined as
SELECT SUM (Salary) FROM BankEmp WHERE (State = ‘New York’ AND Sex = ‘M’ AND Designation = ‘Clerk’ AND Branch = ‘Los Angeles’);
Even if the result of the first query is not 1 but a small value, say 4 or 5, the approximate salary of John Macmillan could be inferred by applying MAX, MIN, and AVG functions in statistical queries.
One possible approach to prevent the chances of inferring information about individual is to reject certain statistical queries. For example, if the number of tuples specified by selection condition falls below a particular number, say n, the statistical query can be rejected. Alternatively, by rejecting the sequence of statistical queries from the same user that refers to the same set of tuples, it is possible to prevent retrieval of individual information. Another approach is database partitioning, in which records are classified and stored in small size groups. In this case, any statistical query can refer to complete group or set of groups, but the query referring to the subset of any group is rejected.
- Database security is a crucial issue, and it covers the privacy, database integrity, and database availability.
- Privacy states that only authorized persons should be allowed to access the database.
- Database integrity states that database should be protected from improper modifications, either intentional or accidental, to maintain database integrity.
- Availability states that security should not restrict the authorized users to perform their actions on the part of the database available to them.
- Threats are classified in two categories, namely, accidental and malicious or intentional threats.
- The DBA plays an important role in the database security. He is responsible for the overall security of the database system. Main responsibilities of the DBA are managing user accounts and database audit.
- Managing user accounts includes creation of user accounts, granting of privileges, and classification of user accounts.
- To keep track of all the changes (insert/delete/update) applied to the database, system log—that includes an entry for each update operation—can be used. In case of database tampering, a review of log is carried out to examine all the operations applied to the database during certain period of time. This review of log is called database audit.
- Authorization is the granting of privileges to users, which enables them to access certain portion of the database. The person who is responsible for granting privileges to database users is called authorizer.
- The authorization information is maintained in a table called access matrix, which the database system consults each time an access request is issued in the system. The columns of access matrix represent objects and rows represent subjects.
- Propagation of authorization from one user to another user leads to a tree termed as authorization tree.
- Before accessing the database, users need to identify themselves to the system to confirm their correctness. The process of verifying the identity of a user is termed as authentication. Various methods can be used to authenticate a user such as secret password, some physical characteristics of a user, smart card, or a key given to the user.
- Discretionary access control and mandatory access control are the two approaches for access control in DBMS.
- Discretionary access control (DAC) is enforced in a database system by granting and revoking privileges from the users.
- Mandatory access control (MAC) enforces multilevel security by classifying subjects (for example, database users, programs, etc.) and objects (for example, relations, views, etc.) of database system in different security classes. Further, it prohibits the flow of information from higher to lower security level.
- To implement MAC in relational DBMS, tuples and attribute values are considered as objects. Therefore, each attribute in a relation is associated with a classification attribute, and a tuple classification attribute is added to the relation. This situation leads to multilevel relations.
- An alternative approach to traditional DAC and MAC are role-based access control (RBAC). In RBAC, permissions to perform certain operations are associated with arbitrary roles, and these roles are assigned to database users based on their responsibilities in the organization.
- With the rapid growth of web-based applications for commercial purpose, there is a need to develop security standards for them. Major approach to protect data during transmission is encryption of data before transmission and then decryption of the data to recover original data at the destination.
- Encryption involves applying an encryption algorithm to the data or plaintext using a pre-specified encryption key. The algorithm produces encrypted version of the plaintext as the output. Most encryption algorithm belongs to one of the two categories, namely, symmetric key encryption, or public key encryption.
- Digital signature is a very useful application of public key encryption technique. Like a physical handwritten signature, digital signatures are used to verify the authenticity of electronic document.
- A statistical database contains confidential information about individuals or events. These databases are mainly used to generate statistical information about the stored information.
KEY TERMS
- Security issues
- Privacy
- Database integrity
- Database availability
- Accidental threats
- Malicious or intentional threats
- System or superuser account
- Database audit
- Audit trail
- Authorization
- Authorizer
- Access matrix
- Objects and subjects
- Access privileges
SELECTMODIFYREFERENCESDROPALTER- Authorization tree
- Authentication
- Password authentication
- Smart card
- Access control
- Discretionary access control
GRANTandREVOKEcommandGRANTOPTION- Mandatory access control
- Bell–LaPadula model
- Security class
- Clearance
- Simple security property
- Star property
- Classification attribute
- Tuple classification
- Multilevel relation
- Apparent key
- Covert channel
- Polyinstantiation
- Trojan horse
- Role-based access control
CREATE ROLEDESTROY ROLE- XML access control language (XACL)
- Encryption
- Encryption algorithm
- Plaintext
- Encryption key
- Decryption algorithm
- Decryption key
- Symmetric key encryption
- Data encryption standard (DES)
- Rijndael algorithm
- Advanced encryption standard (AES)
- Public key encryption
- Public key
- Private key
- RSA algorithm
- Digital signatures
- Non-repudiation
- Statistical database
- Statistical queries
EXERCISES
A. Multiple Choice Questions
- Which of the following issues are covered by database security?
- Privacy
- Database integrity
- Database availability
- All of these
- _________ is responsible for overall security of the database system.
- Programmer
- Database users
- Database administrator
- None of these
- To keep track of database users and their passwords, the DBMS maintains an encrypted table with ______ fields.
- One
- Two
- Three
- Four
- When a user logs in successfully, the DBMS records its
- Account number
- Terminal ID
- Both (a) and (b)
- None of these
- Which of the following is false?
- DBA can assign privileges to different users
- A user can assign privileges to any user on any relation
- A user can assign privileges to any user on its own relations only
- All of these
- ________ is a part of database that needs to be protected from unauthorized access.
- Subject
- Object
- Both (a) and (b)
- None of these
- Which of the following access privileges a user can have on a relation?
SELECTPROPAGATE ACCESS CONTROLREFERENCES- Both (a) and (b)
- Which of the following is incorrect?
- Password itself needs to be secured from unauthorized access
- Using physical characteristics of user for identification provides relatively high security of database
- The key stored on embedded chip in the smart card cannot be read
- None of these
- Which of the following privileges can be given on a set of attributes of a relation?
SELECTINSERTUPDATE- Both (b) and (c)
- Which of the following features should not be there in an encryption algorithm?
- Encryption and decryption should be simple for authorized user
- It should require both keys for encrypting and decrypting data
- Security should not depend only on the secrecy of the algorithm
- All of these
B. Fill in the Blanks
- ___________ account in the DBMS provides powerful capabilities to control access to the database.
- A database log that is mainly used for database security is generally called an _________.
- The person who is responsible for ________ to database users is called authorizer.
- _______access control allows the users to pass their rights, either entire or part of their rights.
- The process of verifying the identity of a user is termed as __________.
- Two main approaches in DBMS for access control are _____________ and ____________.
- In order to create a view, the user must have ________ privilege on all the base relations involved in creating the view.
- In Bell–LaPadula model, each object is assigned a _________ and each subject has ________.
- _________ is a computing program to breach security of computer system.
- The type of encryption in which the same key is used for both encryption and decryption of data is called ______________.
C. Answer the Questions
- Define database security. Why is it important? How is it different from database integrity?
- Define various categories of threats.
- How DBA manages the overall database security?
- What is an audit trail? How does it help DBA in finding out unauthorized operations?
- What is authorization? How does the system maintain the authorization information? Explain with the help of an example.
- Define authentication. How does it differ from authorization? Discuss various techniques that can be used to authenticate a user.
- Explain authorization tree with the help of an example.
- Discuss various access privileges that a user can have on a relation.
- What is an access control? Discuss the two main approaches for access control in DBMS.
- How does mandatory access control provide additional security for the database?
- Access control is the feature of which category of language (DDL, DML, DCL, or DSDL)? At which level of ANSI/SPARC three-level architecture does access control work? Explain the various commands that are used for discretionary access control. Give suitable examples for each of them.
- Define the following terms.
- Subjects
- Objects
- Authorizer
- Classification attribute
- Tuple classification
- Apparent key
- Public key
- Private key
- Encryption key
- Decryption key
- Define multilevel relations. How does it lead to polyinstantiation? Explain with the help of suitable example.
- What is RBAC? How is it different from DAC and MAC? Describe the SQL commands that are used for creating and destroying roles.
- Write a short note on the following.
- Content based access control
- Statistical databases
- RSA algorithm
- Define encryption and decryption? What are the features of a good encryption algorithm? Discuss the two categories of encryption algorithm.
- What are digital signatures? How they can be used to verify the authenticity of the electronic documents?
D. Practical Questions
- Consider the relation
BankEmpintroduced in Section 12.7 and assume yourself as database administrator. Write the SQL statements to grant privileges for the following.- Allow USER1 to retrieve
ECode,EName, andSalaryonly and also allow USER1 to update theSalaryof any employee. - Allow USER2 to act as an authorizer for all privileges on
BankEmp. - Allow USER3 to retrieve or modify the relation but he should not be able to propagate privileges to other users.
Create views wherever required.
- Allow USER1 to retrieve
- Suppose using any substitution system the plaintext Strong Security becomes Fgebat Frphevgl. Using the same substitution system, compute the ciphertext for the plaintext It is really hard and also list the complete substitution format.
- Suppose you are given with two small prime numbers 11 and 3. Using RSA algorithm, compute public key and private key.