
Incident Management
In ITIL terminology, an incident is defined as an unplanned interruption to an IT service, a reduction in the quality of an IT service, or a failure of a CI that has not yet impacted an IT service (for example, failure of one disk from a mirror set).
This is an important definition; because the incident is an interruption to service, restoring the service or improving the quality of the service to agreed levels resolves the incident. Note that incident resolution does not necessarily include understanding why the fault occurred or preventing its recurrence; these are matters for problem management. By understanding this distinction, you can see that resolving an incident does not need the skill that resolving a problem requires. If the service can be restored by a simple reboot, then the user can be instructed to do this by the service desk staff, without involving the more skilled (and therefore more expensive) second-line technicians.
From the user and business perspectives, the focus is on being able to get back to work, and there is little interest in the cause of the failure. Repeat occurrences will impact their work and increase the number of calls to the service desk so an investigation of the cause, and the permanent resolution of the underlying problem, will be required, but this can take place without impacting the users.
The incident management process is responsible for progressing all incidents from when they are first reported until they are closed. Some organizations may have dedicated incident management staff, but the most common approach is to make the service desk responsible for the process.

The Purpose of Incident Management
The purpose of incident management is to restore normal service operation as quickly as possible and minimize the adverse impact on business operations, thus ensuring that agreed levels of service quality are maintained. Normal service operation is defined as an operational state where services and CIs are performing within their agreed service and operational levels.
As explained, by focusing on service restoration, incident management enables the business to return to work quickly, thus ensuring that the impact on business processes and deadlines is reduced.
The Objectives of Incident Management
The objectives of the incident management process are to ensure that all incidents are efficiently responded to, analyzed, logged, managed, resolved, and reported upon. By carrying out these tasks in an efficient and effective manner and by ensuring that affected customers are updated as required, the IT service provider aims to improve customer satisfaction, even though a fault has occurred. At all times during the incident management process, the needs of the business must be considered; business priorities must influence IT priorities.
The Scope of Incident Management
Incident management encompasses all incidents: all events have a real or potential impact on the quality of the service. Incidents will mostly be logged as the result of a user contacting the service desk, but event management tools may report an incident following an alert (see the discussion of event management in Chapter 12); often there will be a link between the event system and incident management tool so that events meeting certain criteria can automatically generate an incident log. Third-party suppliers may notify the service desk of a failure, or technical staff may notice that an error condition has arisen and log an incident.
Requests may be logged and managed at the service desk, but it is important to differentiate between these requests and incidents; in the case of requests, no service has been impacted. Incident and problem management seek to reduce the number of incidents over time, whereas the IT service provider may want to handle increasing numbers of requests through the service desk and the request fulfillment process as a quick, efficient, and customer-focused method of dealing with them.
Efficient incident management delivers several benefits to the business; it reduces the cost of incident resolution by resolving incidents quickly, using less-skilled staff. Where incidents need to be escalated, the resolution is faster (because the relevant information required will have been gathered and an initial diagnosis will have been made). Faster incident resolution means a faster return to work for the affected users. Effective incident management improves the overall efficiency of the organization because nonproductive users are a cost to the company.
Incident prioritization is based on business priorities, which ensures that resources are allocated to maximize the business benefit. The data gathered by the service desk about the numbers and types of incidents can be analyzed to identify training requirements or potential areas for improvement.
As highlighted in the discussion of the service desk in Chapter 10, incident management is one of the most visible processes, as well as one that all users understand the need for. So, it is one of the easier areas to improve, because an improved incident resolution service has easily understood benefits for the business.
Basic Concepts for Incident Management
ITIL describes a number of basic concepts to keep in mind when implementing the incident management process. They are covered in the following sections.
Timescales
Time is of the essence in incident management because every incident represents some loss or deterioration of service. Every aspect of the process needs to be optimized to produce the fastest end result. Service-level agreements, operational-level agreements, and underpinning contracts will define how long a support group or third-party has to complete each step, with measurable targets.
Service management tool sets should be configured to capture how long it takes to log and escalate an incident, how many incidents are resolved within the first few minutes without requiring escalation, and how long support teams take to respond to and to fix incidents. These times should be monitored, and steps should be taken to identify bottlenecks or underperforming teams so that improvement actions can be taken.
Incident Models
Using incident models, which are incident templates prepopulated with the necessary steps to resolve common incidents, is one method of speeding up resolution. They enable faster, more consistent logging and resolution. The steps may instruct the service desk how to resolve the incident or may predefine the information to be gathered as well as the correct escalation group.
Major Incidents
All incidents should get resolved as quickly as possible, but some incidents are so serious, with such an impact on the business, that they require extra attention. The first step is to agree on exactly what is defined as a major incident. Some organizations will define all priority one incidents as major; others may restrict priority one incidents to those whose impact will be felt by the external customers. In this definition, an incident with a major impact within the organization would not normally be classed as major. An incident that (for example) prevents customers from ordering goods from the organization’s website and that is therefore affecting both revenue and reputation would be included. The definition must align with the priority scheme to avoid confusion.
The purpose of defining an incident as a major incident is so that it can receive special focus. Specific actions to be undertaken are defined in advance so that when the major incident occurs, everyone knows what they are expected to do. Typical actions might include the following:
- Notification of key contacts within the service provider organization and the business as soon as the major incident is declared
- Regular updates posted through agreed channels—intranet, key users, and so on
- Recorded greeting put on the service desk number to inform callers that the incident has occurred and is being dealt with to reduce the number of calls being handled by the desk
- Appointment of a major incident manager (this may be the service desk manager) and the appointment of a separate team to focus on resolving the incident
As with any incident, some major incidents can be resolved without understanding the cause (perhaps by restarting a server); some require the underlying cause to be understood. In the second case, problem management would become involved. It is essential, however, that the focus of incident management remains on restoring service as quickly as possible.
As we discussed in Chapter 10, a major responsibility of the service desk is communicating with the users; this is particularly true in the case of major incidents. Regular updates should be provided. The service desk staff members are also accountable for ensuring that the incident record is kept up-to-date throughout the incident, although it may be the technicians in other teams who actually enter the information. An accurate record is essential during the incident so that there is no confusion; it will also be used after the incident is resolved, as part of the major incident review. Regular updates showing the steps taken and whether they were successful will allow improvements to be identified for future events.
Incident Status
Incident management tracks incidents through their lifecycle, moving from when the incident is identified through diagnosis and resolution and finally closure. Incident management must ensure that incidents are resolved as quickly as possible and so will remind resolving groups of the associated target times, making sure no incident is forgotten or ignored.
Most service management tool sets will allow a number of statuses to be defined for each incident to facilitate progress tracking. Typical statuses include the following:
- If the user is unhappy, the call is put back into In Progress, and further work is carried out to resolve it.
- The service desk should attempt to contact users to obtain permission to close calls before the automated closure, especially for high-impact incidents, where the user may not be aware of the resolution.
Expanded Incident Lifecycle
The expanded incident lifecycle is used by the service design availability management process and within CSI. The expanded lifecycle breaks down each step of the process so that they can be examined to understand the reasons for the failed targets. For example, the diagnosis of the incident may ascertain very quickly that the resolution requires the restoration of data, which takes three hours; this information would be used to pinpoint where improvements should be made. Delays in any step of the lifecycle can be analyzed, and improvements can be implemented to speed up resolution; implementing a knowledge base or storing spare parts on-site are two typical measures that are taken to shorten the diagnosis and repair steps.
Managing Incidents
We are going to look at the lifecycle of an incident and each of the process steps that take place. Refer to the flow chart pictured in Figure 11.1.
FIGURE 11.1 Incident management process flow
Based on Cabinet Office ITIL® material. Reproduced under license from the Cabinet Office.
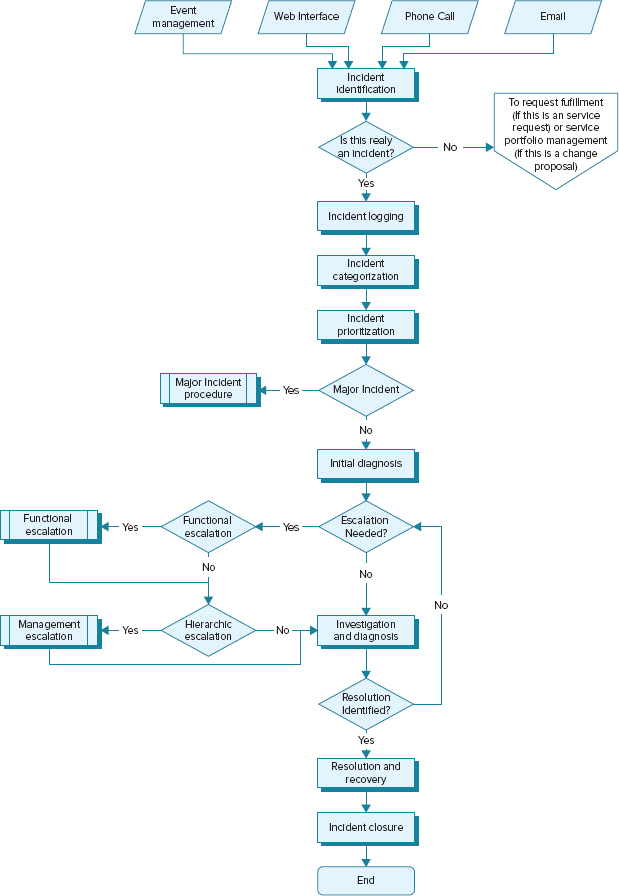
Step 1: Incident Identification
Incident management is a reactive process; we cannot start to resolve an incident until we know it has occurred. As we said earlier, it is essential that incidents are resolved in the shortest possible time, because each represents business disruption. Whenever possible, therefore, we should be trying to realize that an incident has occurred before the user notices or, failing that, before they have reported it to the service desk. Chapter 12, on event management, shows how monitoring tools can be used to identify failures. The event management process should link directly to incident management so that any incidents spotted are worked on immediately and resolved quickly.
Where event management is not in place, incidents will be identified by users contacting the service desk.
Step 2: Incident Logging
The incident record contains all the information concerning a particular incident; details of when it was logged, assigned, resolved, and closed may be required for service-level management reporting. Details of symptoms and the affected equipment may be used by problem management. Steps taken to resolve the incident may be used to populate a knowledge base. It is essential therefore that all relevant information is added to the record as it progresses through its lifecycle.
A good integrated service management tool makes good recordkeeping much easier, because it can automatically populate the record with user details (from Active Directory or a similar tool) and equipment and warranty details (based on the CI number). Automatic date and time stamping of each update and identification of who made the update will both improve the completeness of the information in the record.
Service management tool sets differ, but a typical list of required information in an incident record would include the following:
- Unique reference number, generated automatically
- Incident category (covered in the next section)
- Incident impact, urgency, and priority
- Date/time of every update, from logging to closure
- Name of who logged and updated the incident
- Method of notification (telephone, automatic, email, in person, and so on)
- Full user contact details
- Symptoms, questions asked by the service desk, and the answers given by the user
- Steps taken to try to resolve the incident (successful or otherwise)
- Incident status (covered earlier)
- Related CI/problem/known error
- Assignee group and individual
- Closure category
Step 3: Incident Categorization
Incidents are categorized during the logging stage. This can be helpful in guiding the service desk agent to the correct known error entry or the appropriate support team for escalation. A simple category structure should be used, however; too complex a scheme leads to incidents all being logged as “other” or “miscellaneous” because the agent does not want to spend the time considering which category is correct. This makes later analysis very difficult. A multilevel scheme, as shown in Figure 11.2, achieves granularity without facing the service desk agent with a long list to choose from. Incidents should be recategorized during investigation and on resolution, if the original choice was incorrect. (The service desk agent will have chosen the most appropriate category based on the information available at the time, but further investigation may have shown that, for example, a printer fault was actually a cabling fault.)
FIGURE 11.2 Multilevel incident categorization
Based on Cabinet Office ITIL® material. Reproduced under license from the Cabinet Office.

Step 4: Incident Prioritization
Incidents need to be prioritized to ensure that the most critical incidents are dealt with first. It is often said that all users believe that their own incident is the highest priority, so it is important to agree during service-level negotiations what criteria should be used to decide priority.
The ITIL framework recommends that two factors should be considered: business impact and urgency (how quickly the business needs a resolution). Business impact can be assessed by considering a number of factors: the number of people affected, the criticality of the service, the financial loss being incurred, damage to reputation, and so on. Dependent on the type of organization, other factors such as health and safety (for a hospital or a railway company or similar) and potential breach of regulations (financial institutions, and so on) may be considered.
During the life of an incident, it may be necessary to adjust the priority of an incident if the assessment of the impact changes or a resolution becomes more urgent.
Deciding the priority must be simple, because the incident has to be logged quickly. Employing service desk staff with good business knowledge and ensuring they are trained to be aware of business impact will help a realistic assessment of business impact to be made. Table 11.1 shows a simple but very effective way to determine priority.
TABLE 11.1 Impact and urgency: a matrix for determining an incident’s priority
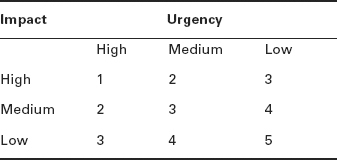
Table 11.2 shows how the determination of priority made using the matrix in Table 11.1 can in turn be employed to set a target resolution time for the incident.
TABLE 11.2 Target resolution
| Priority code | Description | Target resolution time |
| 1 | Critical | 1 hour |
| 2 | High | 8 hours |
| 3 | Medium | 24 hours |
| 4 | Low | 48 hours |
| 5 | Planning | Planned |
Many organizations struggle with applying the prioritization rules when the user reporting the fault is very senior. Some organizations will have a formal procedure in place to give these VIPs faster service; some will apply the business impact and urgency evaluation to their incident as with any other caller (although the business impact is likely to be higher with these users). There needs to be clear guidance to the service desk agent whether to (for example) prioritize a VIP’s printer fault over a fault affecting online sales.
Some organizations address this issue by formally recognizing the needs of VIPs for fast service and defining a special service level (gold service) for them within the SLA, documented in the service catalog.
Step 5: Initial Diagnosis
The initial diagnosis step refers to the actions taken at the service desk to diagnose the fault and, where possible, to resolve it at this stage. The service desk agent will use the known error database provided by problem management, incident models (covered earlier), any other diagnostic tools to assist in the diagnosis, and possible resolution. Where the service desk is unable to resolve the incident, the initial diagnosis will identify the appropriate support team for escalation.
One technique used by the service desk agent is “incident matching.” By checking for previous incidents with the same classification, the service desk agent may be able to identify a repeat incident and the appropriate resolution steps. This speeds up the resolution and increases the first-contact fix rate.
FIGURE 11.3 Incident matching
Based on Cabinet Office ITIL® material. Reproduced under license from the Cabinet Office.
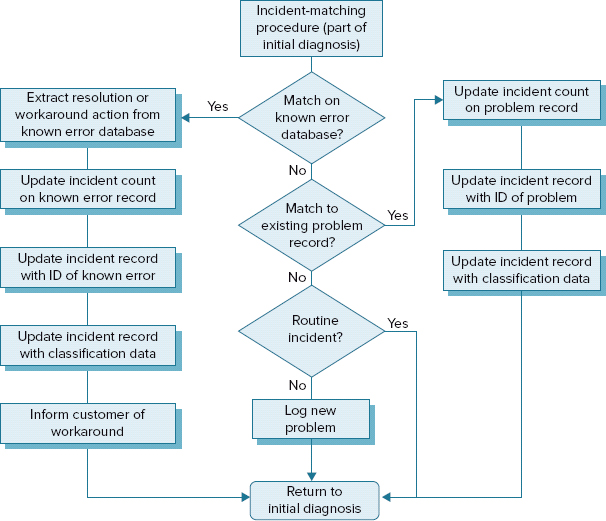
As we have stated previously, time is of the essence in incident management, so the length of time an agent has to resolve the incident will be limited. If the incident can be resolved at first line, it is far more efficient for the user and the IT provider that this is done; holding onto the call for too long, however, delays the eventual resolution. Consideration needs to be given to what the time limit should be; five to ten minutes is common.
Part of this stage is the gathering of information to assist the second-line technician in resolving the incident quickly. Again, sufficient time is required for this step; “saving” time by passing the incident to a second-line technician quickly but with sparse details is not helpful. The second-line technician will need to contact the customer to obtain the information, adding delay and frustration. Support teams should provide guidance to the service desk about the type and level of information they should be gathering.
Step 6: Incident Escalation
The ITIL framework describes two forms of escalation that may take place during incident management: functional escalation and hierarchic escalation. We will look at each of these in turn.
Functional escalation takes place when the service desk is unable to resolve the incident; this may be realized immediately because of the type of incident such as a server failure or because the service desk agent may have spent the maximum time allowed under the organization’s guidelines attempting to resolve the incident without success. It then needs to be passed to another group with a greater level of knowledge. The second-line support group that receives this escalated incident will also have a time limit for resolution, after which the incident gets escalated again to the next support level. Sometimes, as with the service desk, it is obvious that the incident will require a high level of technical knowledge, and in such a case the incident would be immediately escalated, without any attempt by second-line support staff to resolve it.
The service desk must know the correct group to escalate an incident to, to avoid unnecessary delays, so the service desk staff needs to have sufficient technical knowledge to be able to identify which incident goes to which team. Operational-level agreements will specify the responsibilities of each group. There may be occasions where cooperation between support groups is required or where the incident needs to be referred to third parties such as hardware maintenance companies. The OLAs and UCs should specify what should happen in this situation.
The second type of escalation is hierarchic escalation, which takes place for high-priority or major incidents. This escalation consists of informing the appropriate level of management about the incident so that they are aware of it. This ensures that the management is able to make any decisions that are required regarding prioritization of work, involving suppliers, and so on. In the case of a major incident, the IT director may be expected to brief the business directors about the progress of the incident; even if this is not the case, business managers may go directly to senior IT managers when a serious incident has occurred, so it is essential that the IT managers have been thoroughly briefed themselves.
It is also sometimes necessary to use hierarchic escalation when the incident is not progressing as quickly as it should or if there is disagreement among the support groups regarding to whom it should be assigned.
A good service management tool will be able to automatically escalate incidents, based on the SLA targets, updating the record with details. For example, a tool could be set to notify a team leader when 90 percent of the SLA target time had passed and to inform the team leader’s line manager when the incident breached the target.
Step 7: Investigation and Diagnosis
The major activity that takes place for every incident is investigation and diagnosis. The incident will have undergone the initial diagnosis step covered earlier; this identifies whether the service desk can resolve the incident because the incident has been seen before. The investigation and diagnosis stage here is different; it involves trying to ascertain what has happened and how the incident can be resolved.
The incident record should be updated to record what actions have been taken, and an accurate description of the symptoms, and the various actions taken, is required to prevent duplication of effort; it will also be useful when the incident is reviewed, perhaps as part of problem management. Typical investigation and diagnosis actions would include gathering a full description of the issue and its impact and urgency, creating a timeline of events, identifying possible causes such as recent changes, interrogating knowledge sources such as the known error database, and so on.
Step 8: Resolution and Recovery
Potential incident resolutions should be tested to ensure that they actually resolve the issue completely with no unintended consequences. This testing may involve the user. Other resolution actions might include the service desk agent or technician remotely taking over the user’s equipment to implement a resolution or to show the user what they need to do in the future. Once the incident is resolved, it returns to the service desk for closure.
Step 9: Incident Closure
When the incident has been resolved and the service restored, the service desk will contact the user to verify that the incident may be closed (covered earlier). This is an important step, because the fault may appear resolved to the IT department, but the user may still be having difficulties, especially if there were actually two incidents, with the symptoms of one being hidden by the other. The second incident would become apparent only after the first was resolved. The service desk may contact the user directly, or an email could be sent with a time limit when the incident will be closed, as described earlier.
The category assigned to the incident when it was logged should be reviewed. The initial incident categorization is based on the available evidence at the time; following the resolution, it may be altered to reflect the confirmed cause (covered earlier). If the underlying cause of the incident is still unknown, despite the fact it has been resolved, a problem record may be raised to investigate the underlying cause and to prevent a recurrence. Finally, a user satisfaction survey may be carried out.
Interfaces Between Incident Management and the Lifecycle Stages
Incident management is a key process that is carried out by all service providers. There are several links between the process and other processes both within service operation and within the service design stage.
Service Design
Several of the service design processes interface directly with the incident management process. These processes are among those we discussed in Chapter 10, where many of the process activities take place in the service operation lifecycle stage. Service-level management interfaces with incident management because SLAs will contain incident targets; the other service design processes may result in incidents if the processes fail to prevent a security breach, a lack of capacity, or unplanned downtime.
Service Transition
The service transition processes of SACM and change management interface with incident management; SACM provides useful information to the incident process, and changes may be the cause of incidents or the means by which incidents are resolved.
Service Operation
There is a strong interface between incident management and problem management, as we will be covering in the rest of this chapter. Access management issues may also cause incidents.