
![]()
Migrating to Exadata
Finally, the big day is here. Your Exadata Database Machine is installed, configured, tuned, tweaked, and ready to go. By now, you have probably invested many, many hours learning about Exadata, proving its value to the company, and planning how you will make the most of this powerful database platform. No doubt, it has been a long road to travel, but you are not there quite yet. Now the real work begins—migration. After all, the budget owners need to be shown that all that money invested is invested well and pays off !
This was a much more difficult chapter to write than expected since is nearly impossible to count all the migrations Enkitec has done over the years. But when you consider all the various versions of Oracle, the migration tools available, and the change they have undergone from one version to the next, it became clear that the scope had to be narrowed somewhat. So, to keep this interesting and save trees, the focusing will be on versions 11.2 and 12.1 (Enterprise Edition) for the majority of this chapter. Along the way, you can learn more about how to make the most of the features available in previous versions of the Oracle database. “Previous versions of Oracle” is always in relation to the currently supported version. At the time of writing, 11.2.0.3+ and 12.1.0.1+ were in error correction support, although you should check Doc ID 742060.1 for a more accurate overview. You can also check My Oracle Support Note 888828.1 for the support status of Oracle releases as well as the Certification Matrix on My Oracle Support.
There are many methods, tools, and techniques for migrating your database from legacy hardware to Exadata, but, generally speaking, they fall into two broad categories: physical migration and logical migration, and these can be combined. While there are several factors that determine which method is best, the decision-making process is usually dominated by one factor: the available downtime to complete the move. A secondary factor is the skill set of your team. Some of the content covered in this chapter is beyond what would be expected as business as usual from a database administrator. It might require a little time to upskill team members to be able to work with some of these tools confidently.
The good news is that there are several strategies to help you get to Exadata. Each method comes with its own pros and cons. In this chapter, you can read plenty about each of these methods. You will read about reasons why you might use one over the other, the relative advantages and disadvantages, and common pitfalls you should watch out for.
![]() Note Migrating your applications to Oracle Exadata from non-Oracle platforms is out of the scope of this chapter.
Note Migrating your applications to Oracle Exadata from non-Oracle platforms is out of the scope of this chapter.
Once you have a good understanding what Exadata is and how it works, you are ready to start thinking about how you are going to get your database moved. Let’s circle back to the two general categories-logical migration and physical migration. Logical migration involves extracting the data from one database and loading it into another. Physical migration refers to lifting the database, block by block, from one database server and moving it to another. The data access characteristics of your database are a key consideration when deciding which migration method is best, primarily because of the way the data is accessed on Exadata. OLTP databases tend to use single block reads and update data across all tables, whereas Data Warehouse (DW) databases are typically optimized for full table scans and only update current data, if any.
Exadata uses Smart Flash Cache on the storage cells to optimize single-block reads and improve the overall performance for OLTP databases. For DW databases, Exadata uses Smart Scan technology to optimize full table scans. Beginning with Exadata version 11.2.3.3.x, Smart Scans scan flash and disk storage concurrently for higher throughput. The details of Smart Scans and Flash Cache optimization methods are covered in Chapters 2 and 5 as well as Chapter 16. A logical migration gives you the opportunity to make changes to your database and optimize it for the Exadata platform. Such changes might include resizing extents, implementing or redesigning your current partitioning schemes, and compressing tables using Hybrid Columnar Compression (HCC). These are all very important storage considerations for large tables and especially so for DW databases.
Because OLTP applications tend to update data throughout the database, HCC compression might not be a good fit depending on the implementation of your partitioning schema. In worst-case scenarios, HCC could actually degrade performance. And while large extents are beneficial for DW databases, there are fewer benefits for OLTP databases, which use mostly index-based access and “random” single-block reads. Beginning with 11.2.0.2, Oracle creates partitions as 8MB extents to allow better full-segment scan performance (documented in My Oracle Support Doc ID 1295484.1).
Physical migration, by its very nature, allows no changes to be made to the storage parameters for tables and indexes in the database, while logical migration allows much more flexibility in redefining storage, compression, partitioning, and more.
The most impressive way to migrate your database to Exadata is a combination of logical and physical migration, as described in various white papers on the Oracle web site. One example involving Golden Gate for a near-zero downtime migration between a big endian platform and Exadata describes how you can make use of an intermediate database as a staging area. If you roll the intermediary database forward to a known SCN, you can start the extraction of transactions on the source at that very same SCN. While the Golden Gate extract process is capturing changes on the source, you convert the intermediary database to Exadata using the Transportable Tablespace Technology, described later in this chapter. After the endianness conversion is complete and the tablespaces are plugged into an otherwise empty database on Exadata, you start the transfer and application of captured transactions Golden Gate was mining at the source. The Golden Gate apply process will update the Exadata database with all changes that happened on the source while the intermediary database has been migrated. Before getting too deep into technical aspects of a combined logical and physical migration, let’s start by covering the essentials first.
Logical Migration
Regardless of the technology used, logical migration consists of extracting objects from the source database and reloading them into a target database. Even though logical migration strategies tend to be more complicated than physical strategies, they are often preferable because of the following advantages:
- Staged Migration: Tables and partitions that are no longer taking updates can be moved outside of the migration window, reducing the volume to be moved during the final cut over.
- Selective Migration: Often the source database has obsolete user accounts and database objects that are no longer needed. With the logical method, these objects may be simply omitted from the migration. The old database may be kept around for some time in case you later decide you need something that did not migrate.
- Platform Differences: Data is converted to target database block size automatically. Big-endian to little-endian conversion is handled automatically.
- Exadata Hybrid Columnar Compression (HCC) can be configured before data is moved. That is, the tables may be defined with HCC in the Exadata database so that data is compressed as it is loaded into the new database.
- Extent Sizing: Target tables, partitions, and indexes may be pre-created with optimal extent sizes (Oracle uses 8MB by default since 11.2.0.2 for partitions, for example) before the data is moved. Refer to Chapter 16 for a discussion about the relevance of extent sizes for Smart Scans.
- Allows Merging of Databases: This feature is particularly important when Exadata is used as a consolidation platform. If your Exadata is model V2 or X2-2, memory on the database servers may be a somewhat limiting factor. V2 database servers are configured with 72G of RAM each, while X2-2 comes with 96G of RAM per server (upgradable). This might be sufficient memory when dealing with 10 or fewer moderate- to large-sized databases, but it is becoming fairly common to see 15 or more databases on a server in Oracle 11.2. For example, Enkitec worked on a project where Exadata was used to host PeopleSoft HR and Financials databases. The implementer requested 15 databases for this effort. Add to this the 10 databases in their plan for other applications, and SGA memory became a real concern. The solution, of course, is to merge these other separate databases together, allowing them to share memory more efficiently. The problem of merging databases is addressed with Oracle 12c and Pluggable Databases. These can be the perfect vehicle for merging and consolidating databases. Memory shortage is less of an issue with the X3 and later compute nodes. They are equipped with 256GB of RAM by default, upgradable to 768GB per node. The X3-8 and X4-8 have 2TB of DRAM per server. Each X4-8 compute node can be equipped with up to 6TB of DRAM for a total of 12TB of RAM per cluster.
- Pre-ordering: If using the Create Table as Select method or Insert into as Select method (CTAS or IAS) over a database link, the data may also be sorted as it is loaded into the target database to improve index efficiency, optimize for Exadata Storage Indexes, and achieve better compression ratios.
There are basically two approaches for logical migration. One involves extracting data from the source database and loading it into the target database. This is often referred to as the “Extract and Load method.” Tools commonly used in this approach are Data Pump, Export/Import, and Create Table as Select (CTAS) (or Insert ... as Select-IAS) through a database link. The other method is to replicate the source database during normal business operations. When the time comes to switch to the new database, replication is cancelled and client applications are redirected to the new database. This technique is often referred to as the “Replication-Based method.” Tools commonly used in the Replication-Based method are Oracle Streams, Oracle Data Guard (Logical Standby), and Oracle Golden Gate. It is also possible to use a combination of physical and logical migration, such as copying (mostly) read-only tablespaces over well ahead of the final cutover and applying changes to them via some replication method like Streams. Note that Oracle Streams is deprecated in 12c and did not receive any enhancements.
Extract and Load
Generally speaking, the Extract and Load method requires the most downtime of all the migration strategies because once the extract begins and for the duration of the migration, all DML activity must be brought to a stop. Data warehouse environments are the exception to the rule because data is typically organized in an “age-in/age-out” fashion. Since data is typically partitioned by date range, static data is separated from data that is still undergoing change. This “read-only” data may be migrated ahead of time, outside the final migration window, perhaps even during business hours. The biggest advantage of the Extract and Load strategy is its simplicity. Most DBAs have used Data Pump or CTAS for one reason or another, so the tool set is familiar. Another big advantage is the control it gives you. One of the great new features Exadata brings to the table is Hybrid Columnar Compression (HCC). Since you have complete control over how the data is loaded into the target database, it is a relatively simple task to employ HCC to compress tables as they are loaded in. Extract and Load also allows you to implement partitioning or change partitioning strategies. Loading data using CTAS allows you to sort data as it is loaded, which improves the efficiency of Exadata’s storage indexes. One could argue that all these things could be done post migration, and that is true, but why move the data twice when it can be incorporated into the migration process itself? In some situations, it may not even be possible to fit the data onto the platform without applying compression. In the next few sections, you can read about several approaches for performing Extract and Load migrations.
Data Pump
Data Pump is an excellent tool for moving large quantities of data between databases. Data Pump consists of two programs, expdp and impdp. Both are documented in the Utilities Guide. The expdp command is used to extract database objects out of the source database. It can be used to dump the contents of an entire database or, more selectively, by schema or by table. Like its predecessor Export (exp), Data Pump extracts data and saves it into a portable data file. This file can then be copied to Exadata and loaded into the target database using the impdp command. Data Pump made its first appearance in Oracle 10g, so if your database is version 9i or earlier, you will need to use the old Export/Import (exp/imp) instead. Export and Import have been around since Oracle 7, and, although they are getting a little long in the tooth, they are still very effective tools for migrating data and objects from one database to another. Even though Oracle has been talking about dropping exp and imp for years now, they are still part of the base 12c install.
First, you can read about Data Pump and how it can be used to migrate to Exadata. After covering the new tool set, you can have a look at ways to migrate older databases using Export and Import. Keep in mind that new features and parameters are added to Data Pump with each major release. Check the Oracle documentation for capabilities and features specific to your database version.
From time to time in this chapter, you will see reference to tests and timings we saw in our lab. Table 13-1 shows some of the relevant characteristics of the servers and databases we used for these tests. The LAB112 database is the source database and not on Exadata. DB12C is the target (Exadata) database.
Table 13-1. Lab Configuration
|
Database |
DB Version |
Platform |
|---|---|---|
|
LAB112 |
11.2.0.4 |
Oracle Linux 6, 64 bit |
|
DB12C |
12.1.0.2 |
Oracle Linux 6, 64 bit |
Before continuing, let’s take a look at some of the most relevant Data Pump parameters to know about. Here are some of the key parameters that are useful for migrating databases.
- COMPRESSION: Data Pump compression is a new 11g feature. In 10g you had the ability to compress metadata, but in 11g this capability was extended to table data as well. Valid options are ALL, DATA_ONLY, METADATA_ONLY, and NONE. Using the COMPRESSION=ALL option Data Pump reduced the size of a test export from 13.4G to 2.5G, a compression ratio of over five times. That is a very significant saving in storage. When testing with compression turned on, we fully expected it to slow down the export, but instead it actually reduced our export time from 39 minutes to just over 9 minutes. This cannot be expected to always be the case, of course. Compression effectiveness is highly dependent on the actual data. On our test system, the export was clearly I/O-bound. But it does point out that compression can significantly reduce the storage requirements for exporting your database without necessarily slowing down the process. Unfortunately, the ability to compress table data on the fly was not introduced until release 11gR1. If your database is 10g and you need to compress your dump files before transferring them to Exadata, you will need to do that using external tools like gzip, zip, or compress. Note that the use of the data COMPRESSION option in Data Pump requires Oracle Advanced Compression licenses.
- COMPRESSION_ALGORITHM: Oracle 12c gives you finer granularity about the algorithm used when compressing dump files. You can choose between basic, low, medium, and high compression. As with any compression, you trade file size for (CPU) time. You should test if compressing your dump files more aggressively is worth the effort. The use of this parameter requires the Advanced Compression Option.
- FLASHBACK_TIME, FLASHBACK_SCN: It may come as a surprise that Data Pump does not guarantee the read consistency of your export by default. To export a read-consistent image of your database, you must use either the FLASHBACK_SCN or the FLASHBACK_TIME parameter. If you use FLASHBACK_TIME, Data Pump looks up the nearest System Change Number (SCN) corresponding to the time you specified and exports all data as of that SCN. FLASHBACK_TIME can be passed in to Data Pump as follows:
FLASHBACK_TIME="to_timestamp('05-JUN-2014 21:00:00','DD-MON-YYYY HH24:MI:SS')" - If you choose to use FLASHBACK_SCN, you can get the current SCN of your database by running the following query:
SQL> select current_scn from v$database; - FULL, SCHEMAS, TABLES: These options are mutually exclusive and specify whether the export will be for the full database, a selection of schemas, or a selection of individual tables. Note that certain schemas, such as SYS, MDSYS, CTXSYS, and DBSNMP, are never exported when doing a full database export. The FULL keyword has been enhanced in 12c and allows you to incorporate transportable tablespace technology where applicable.
- PARALLEL: The PARALLEL parameter instructs Data Pump to split the work up into multiple parts and run them concurrently. PARALLEL can vastly improve the performance of the export process. If you are planning on using the PARALLEL keyword, do not forget to specify multiple output files using the %U identifier in the dump file name.
- NETWORK_LINK: This parameter specifies a database link in the target database to be used for the export. It allows you to export a database from a remote server, pulling the data directly through the network via database link (defined in the target database). According to the Utilities Guide, there is no dump file involved when using the parameter with impdp. The network link is used by Grid Control to automate the migration process using the Import from Database process as well as for the Transportable Tablespaces with Cross-Platform Backups and the new 12c Full Transportable import.
When exporting, it might be a good idea to create a number of export dump files. The first one could be the metadata-only export dump you take off the whole database. This way you can create a valid DDL file (SQLFILE=...) of the database or a subset. A clever combination of the SQLFILE and INCLUDE/EXCLUDE parameters, for example, allows you to create the DDL for all users and their grants without extracting that information using DBMS_METADATA. This is also useful for removing hints from views: The LONG data type used for the column TEXT in DBA_VIEWS requires some clever coding to read the full text in 11.2 (if the view’s code fits into 4,000 characters, you can retrieve it from DBA_VIEWS.TEXT_VC in 12.1). Dumping the DDL of all views of a schema in a single file allows you to use perl, awk or sed to globally search and replace text. Another export could be a small sample of the schema(s) you want to import. The SAMPLE keyword can be used during the export to limit the amount of data in the dump file. You could use such a file on a development system to hone the procedure. The final export file would then contain everything you need to get across to the Exadata system.
![]() Note When using a dump file on Exadata, either during export or import, you should consider using the Database File System (DBFS) to store the file. The number of disks available in the DBFS_DG greatly surpasses the number of internal disks on the compute node. Beginning with Grid Infrastructure 12.1.0.2, you also have the option to use the ASM Cluster File System (ACFS).
Note When using a dump file on Exadata, either during export or import, you should consider using the Database File System (DBFS) to store the file. The number of disks available in the DBFS_DG greatly surpasses the number of internal disks on the compute node. Beginning with Grid Infrastructure 12.1.0.2, you also have the option to use the ASM Cluster File System (ACFS).
Now let’s turn our attention to the import process. Schema-level import is usually preferable when migrating databases. It allows you to break the process up into smaller, more manageable parts. This is not always the case, and there are times when a full database import is the better choice. Most of the tasks you already read about here apply to both schema-level and full-database imports. Throughout this section, you should see notes about any exceptions you will need to be aware of. If you choose not to do a full database import, be aware that system objects including roles, public synonyms, profiles, public database links, system privileges, and others will not be imported. You will need to extract the DDL for these objects using the SQLFILE parameter and a FULL=Y import. The required export can be performed as a metadata-only export. You can then execute the DDL against the target database to create the missing objects. Let’s take a look at some of the impdp parameters useful for migrating databases.
- REMAP_SCHEMA: As the name implies, this parameter tells Data Pump to change the ownership of objects from one schema to another during the course of the import. This is particularly useful for resolving schema conflicts when merging multiple databases into one Exadata database. When importing into a 12c PDB, this might not even be required.
- REMAP_DATAFILE: Data files can be renamed dynamically during the import process using this parameter. This allows ASM to automatically organize and name the data files according to Oracle Managed Files (OMF) rules.
- REMAP_TABLESPACE: This option changes the tablespace name reference for segments from one tablespace to another. It is useful when you want to physically relocate tables from one tablespace to another during the import.
- SCHEMAS: Lists schemas to import.
- SQLFILE: Instead of importing anything into the database, Object definitions (DDL) are written to an SQL script. This can be quite useful for pre-building objects if you want to make changes to their physical structure, such as partitioning or using HCC compression. Note that beginning with Oracle 12c, you can use the TRANSFORM parameter (described later) to change further physical structure, most notably the compression level.
- TABLE_EXISTS_ACTION: The action to take if the imported object already exists. Valid keywords are APPEND, REPLACE, SKIP, and TRUNCATE. Skip is the default.
- TABLES: A list of tables to import. For example, TABLES=MARTIN.T1,MARTIN.T2
- TRANSFORM: This parameter allows you to make changes to segment attributes in object-creation DDL statements, like storage attributes. This provides a convenient way to optimize extent sizes for tables when they are created in Exadata. Oracle 12c greatly enhances the potential of the parameter. You can now request that the logging attribute of the segment you are importing is set to NOLOGGING using the DISABLE_ARCHIVE_LOGGING parameter. Be careful in environments where you already implemented a physical standby database—the NOLOGGING operation will corrupt data files on the standby.
- Additional new parameters allow you to change the compression level of a segment using the TABLE_COMPRESSION_CLAUSE as well as a change of the LOB type (basic/secure file) on the fly using the LOB_STORAGE keyword. There are other parameters that might be useful in your situation, so have a look at the specifics in the documentation.
- LOGTIME: a very useful addition in Oracle 12c allows you to request timestamps to be emitted in the Data Pump log files. This is a very convenient way to forecast the time the process will take in case it is repeated.
- NETWORK_LINK: This parameter has already been covered in the previous section.
Before you begin importing schemas into your Exadata database, be aware that Data Pump only creates tablespaces automatically when a full database import is done. If you are importing at the schema or table level, you have to create your tablespaces manually. To do this, generate the DDL for tablespaces using the import Data Pump parameters FULL=yes and SQLFILE={your_sql_script}. This produces a script with the DDL for all objects in the SQL file (including data files). You may notice that in the CREATE TABLESPACE DDL the data-file file names are fully qualified. This is not at all what you want because it circumvents OMF and creates hard-coded file names that cannot easily be managed. The REMAP_DATAFILE parameter allows you to rename your data files to reflect the ASM disk groups in your Exadata database. The syntax looks like this:
REMAP_DATAFILE='/u02/oradata/LAB112/example01.dbf':'+DATA'
An alternative is to use REMAP_TABLESPACE. One final note before moving on to Export/Import. Character set translation between the source and target databases is done automatically with Data Pump. Please make sure the character set of the source database is a subset of the target database, or something may be lost in translation. For example, it is OK if your source database is US7ASCII (7 bit) and the target database is WE8ISO8859P15 (8 bit). However, migrating between different 8-bit character sets or going from 8 bit to 7 bit may cause special characters to be dropped.
Another reference that matters is version compatibility. When in doubt, consult Doc ID 553337.1, which explains the compatibility of Data Pump for the different Oracle versions out there.
If the database you are migrating to Exadata is a release prior to version 10g, Data Pump is not an option. Instead you need to work with its predecessors, Export (exp) and Import (imp). Export/Import features have not changed much since Oracle 9.2, but if you are migrating from a previous release, you will notice that some features may be missing. Hopefully, you are not still supporting 8i databases, or even 7.x, but not to worry. Even though some options such as FLASHBACK_SCN and PARALLEL are not options in these older releases, there are ways to work around these missing features. Speaking of releases, MOS Doc ID 132904.1 has a compatibility matrix for the different versions of the export and import tools as well as some other background information we take for granted in this section.
PARALLEL is strictly a Data Pump feature, but you can still parallelize database exports by running concurrent schema exports. This is a much less convenient way of “parallelizing” your export process. If you have to parallelize your export process in this way, you have to do the work of figuring out which schemas, grouped together, are fairly equal in size to minimize the time it takes for all of them to complete.
COMPRESSION is another feature missing from Export. This has never been much of an issue for DBAs supporting Unix/Linux platforms. These systems provide the ability to redirect the output from Export through the compress or gzip commands by means of a named pipe, something like this (the $ sign is the shell prompt, of course):
oracle@solaris:~$ mkfifo exp.dmp
oracle@solaris:~$ ls -l exp.dmp
prw-r--r-- 1 oracle oinstall 0 Jun 20 20:08 exp.dmp
oracle@solaris:~$ cat exp.dmp | gzip > exp_compressed.dmp.gz &
[1] 5140
oracle@solaris:~$ exp system file=exp.dmp owner=martin consistent=y statistics=none
> log=exp_compressed.dmp.log
[...]
oracle@solaris:~$ ls -lh *exp_compressed*
-rw-r--r-- 1 oracle oinstall 16M Jun 20 20:12 exp_compressed.dmp.gz
-rw-r--r-- 1 oracle oinstall 1.4K Jun 20 20:12 exp_compressed.dmp.log
The REMAP_TABLESPACE parameter is not available in Export/Import. To work around this, you have to generate a SQL file using the INDEXFILE parameter, which produces a SQL script like Data Pump’s SQLFILE parameter. You can then modify tablespace references and pre-create segments in the new tablespace as needed. Using the IGNORE parameter will allow Import to simply perform an insert into the tables you manually created ahead of time. The REMAP_SCHEMA parameter takes on a slightly different form in Import. To change the name of a schema during import, use the FROMUSER and TOUSER parameters.
There is one limitation with Export/Import that cannot be escaped. Import does not support Exadata HCC. Our tests show that when importing data using Import, the best table compression you can expect to get is about what you would get with tables compressed for OLTP (also known in 11g as “Advanced Compression”), an extra licensable feature. It does not matter if a table is configured for any one of the four HCC compression modes available on Exadata (Query Low/High and Archive Low/High). This is because HCC compression can only occur if the data is direct-path inserted, using syntax like insert /*+ APPEND */, for example. According the Exadata User’s Guide, conventional inserts and updates work, but do not allow you to achieve the same compression savings. This “reduced compression ratio” is actually the same as the OLTP compression provided by the Advanced Compression option, which HCC falls back to for normal inserts. By the way, Import will not complain or issue any warnings to this effect. It will simply import the data at a much lower compression rate, silently eating up far more storage than you planned or expected. There is nothing you can do about it other than rebuild the affected tables after the import is complete. The important bit to understand is that you cannot exploit Exadata’s HCC compression using Export/Import.
The Export/Import approach also does not support Transparent Data Encryption (TDE). If your database uses TDE, you need to use Data Pump to migrate this data. If you are importing at the schema level, system objects such as roles, public synonyms, profiles, public database links, and system privileges will not be imported. System objects like these can be extracted by doing a full database import and with the INDEXFILE parameter to extract the DDL to create these objects. This step is where the most mistakes are made. It is a tedious process and careful attention must be given so that nothing falls through the cracks. Fortunately, there are third-party tools that do a very good job of comparing two databases and showing you where you missed something. Most of these tools also provide a feature to synchronize the object definitions across to the new database.
If you are still thinking about using Export/Import, note that as the data loading with Import does not use direct-path load inserts, it will have a much higher CPU usage overhead due to undo and redo generation and buffer cache management. You would also have to use a proper BUFFER parameter for array inserts (you will want to insert thousands of rows at a time) and COMMIT=Y (which will commit after every buffer insert) so you do not fill up the undo segments with one huge insert transaction.
When to Use Data Pump or Export/Import
Data Pump and Export/Import are volume-sensitive operations. That is, the time it takes to move your database will be directly tied to its size and the bandwidth of your network. For OLTP applications, there can be a fair bit of downtime. As such, it is better suited for smaller-sized databases. It is also well suited for migrating large DW databases, where read-only data is separated from read-write data. Take a look at the downtime requirements of your application and run a few tests to determine whether Data Pump is a good fit. Another benefit of Data Pump and Export/Import is that they allow you to copy over all the objects in your application schemas easily, relieving you from manually having to copy over PL/SQL packages, views, sequence definitions, and so on. It is not unusual to use Export/Import for migrating small tables and all other schema objects, while the largest tables are migrated using a different method.
In cases where Transportable Database or Transportable Tablespace is not applicable, (in other words, objects that cannot be transported and/or converted) you might end up with a two-pronged approach. In the first move, you ensure that the data files are converted and plugged in. In the second part of the migration, you move the non-transportable components across. Interestingly, in Oracle 12c, the Transportable Tablespace option is combined with the logical export in a new feature name Full Transportable Export/Import.
What to Watch Out for When Using Data Pump or Export/Import
Character-set differences between the source and target databases are supported, but if you are converting character sets, make sure the character set of the source database is a subset of the target. If you are importing at the schema level, check to be sure you are not leaving behind any system objects, like such as roles and public synonyms, or database links and grants. Remember that HCC is only effectively applied with Data Pump. Be sure you use the consistency parameters of Export (CONSISTENT=Y) or Data Pump (FLASHBACK_SCN/FLASHBACK_TIME) to ensure that your data is exported in a read-consistent manner. Do not forget to take into account the load you might be putting on the network.
Data Pump and Export/Import methods also might require you to have some temporary disk space (both in the source and target server) for holding the dumpfiles. Note that using Data Pump’s table data compression option requires you to have Oracle Advanced Compression licenses both for the source and target database (only the metadata_only compression option is included in the Enterprise Edition license).
Copying Data over a Database Link
When extracting and copying very large amounts of data—many terabytes—between databases, database links may be a very useful option. Unlike with the default Data Pump option (that is, not using the network link clause), with database links you read your data once (from the source), transfer it immediately over the network, and write it once (into the target database). With traditional Data Pump, Oracle would have to read the data from source and then write it to a dumpfile. Then you need to transfer the file with some file-transfer tool (or do the network copy operation using NFS) and then read the data from the dumpfile before writing it into the target database tables. In addition to the extra disk I/O done for writing and reading the dumpfiles, you would need extra disk space for holding these files during the migration. Now you might say “Hold on.” Data Pump does have the NETWORK_LINK option and the ability to transfer data directly over database links, but there is a slight caveat.
Data Pump in Oracle 12c allows for a few optimizations, but there is a very important downside to the network link method: You cannot import a table with parallelism. With Data Pump and the network link option, each segment has its own (and only) worker process for writing data. Now, before discarding Data Pump, you should read about what it has to offer.
Very importantly for Exadata, impdp in 12c allows you to use direct path inserts. This is crucial for HCC compressed data. Remember from the HCC chapter that, in order to achieve compression, you need to use direct path inserts. With traditional inserts, you create blocks flagged for OLTP compression, resulting in segments larger than they need to be. Here is a demonstration showing that HCC compression works with impdp. The first step is to create a database link in the destination database.
CREATE DATABASE LINK sourcedb
CONNECT TO source:user
IDENTIFIED BY source:password
USING 'tns_alias';
Before launching impdp, you could now make use of your DDL file to pre-create the tables you want to import. With a little editing, you can add HCC compression to specific segments before starting the import. In 12c this has become easier using the TABLE_COMPRESSION_CLAUSE of the TRANSFORM option to impdp.
![]() Note When creating the database link, you can specify the database link’s TNS connect string directly with a USING clause, like this:
Note When creating the database link, you can specify the database link’s TNS connect string directly with a USING clause, like this:
CREATE DATABASE LINK ... USING '(DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = source-host)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORA10G)))'
That way, you do not have to set up tnsnames.ora entries in the database server.
Once the setup is completed, execute impdp like so:
[oracle@enkdb03 ~]$ impdp network_link=dplink remap_schema=martin:imptest > schemas=martin directory=imptest logfile=nlimp.log
When examining the sessions on the system you will see the master as well as the import slaves. In one particular instance the following was recorded:
IMPTEST@DB12C1:1> @as
SID SERIAL# USERNAME PROG SQL_ID SQL_TEXT
----- ---------- ------------- ---------- ------------- -----------------------------
1240 59677 IMPTEST udi@enkdb0 7wn3wubg7gjds BEGIN :1 := sys.kupc$que_int...
264 16273 IMPTEST oracle@enk 9qhxsv2smtyw9 INSERT /*+ APPEND
1499 9287 IMPTEST oracle@enk bjf05cwcj5s6p BEGIN :1 := sys.kupc$...
As you can see from the little SQL snippet and its output direct path inserts are possible with Data Pump. If you do not use a Data Guard standby database or similar redo-based replication tool you might even consider operating this in NOLOGGING mode. Another 12c enhancement allows you to specify the operation in that fashion without modifying the table DDL:
[oracle@enkdb03 ~]$ impdp network_link=dplink remap_schema=martin:imptest schemas=martin
> directory=imptest logfile=nlimp2.log table_exists_action=replace
> transform=disable_archive_logging:Y
Just be careful when you have any kind of redo-based standby database. All loads using NOLOGGING will not make it across to the standby database and you have to take a backup from SCN to get it back in sync. The important downside with the Data Pump approach using a network link is that you cannot make use of intra-segment parallelism. Read on if you want to know more about intra-segment parallelism.
Achieving High-Throughput CTAS or IAS over a Database Link
While the previous examples are simple, they may not give you the expected throughput, especially when the source database server is not in the same network segment as the target. The database links and the underlying TCP protocol must be tuned for high-throughput data transfer. The data transfer speed is limited, obviously, by your networking equipment throughput and is also dependent on the network roundtrip time (RTT) between the source and target database.
When moving tens of terabytes of data in a short time, you obviously need a lot of network throughput capacity. You must have such capacity from end to end, from your source database to the target Exadata cluster. This means that your source server must be able to send data as fast as your Exadata cluster has to receive it, and any networking equipment (switches, routers) in between must also be able to handle that (in addition to all other traffic that has to flow through them). Dealing with corporate network topology and network hardware configuration is a very wide topic and out of the scope of this book, but it is very important to touch on the subject of the network hardware built in to Exadata database servers here.
In addition to the InfiniBand ports, Exadata clusters also have built-in Ethernet ports. Table 13-2 lists all the Ethernet and InfiniBand ports.
Table 13-2. Exadata Ethernet and InfiniBand Ports in Each Database Server

The database servers and cells each have one more administrative Ethernet port for server management (ILOM). Note that there was no X5-8 at the time of writing.
Note that the X2 and earlier generations use PCIe version 2.0, while the X3 and later use PCIe version 3 for higher throughput per PCI lane. However, up to the X3 generation the InfiniBand cards are capable of using PCIe version 2.0 and 8 lanes, which means the maximum bandwidth of the InfiniBand card communicating with its PCI bus is limited to 8 x 500MB = 4000MB (roughly 4GB). Quadruple Data Rate (QDR) InfiniBand throughput with a four times link aggregate as used with Exadata has a maximum data rate of 40Gb/s, or 5GB/s. This might explain the active/passive configuration of InfiniBand up to the X3 generation.
Table 13-2 shows the number of network ports per database server. While Exadata V2 does not have any 10GbE ports, it still has 4 × 1GbE ports per database server. With eight database servers in a full rack, this would add up to 32 × 1 GbE ports, giving you a maximum theoretical throughput of 32 gigabits per second when using only Ethernet ports. With various overheads, three gigabytes per second of transfer speed would theoretically still be achievable if you manage to put all of the network ports equally into use and there are no other bottlenecks. This would mean that you have to either bond the network interfaces in an all-active configuration or route the data transfer of different datasets via distinct different network interfaces. Different dblinks’ connections can be routed via different IPs or Data Pump dumpfiles transferred via different routes. Thankfully, current Exadata systems can use 10Gb/s Ethernet either using the built-in ports with a copper connection or, alternatively, make use of the two optical ports for the same theoretical bandwidth. On the dash-8 systems, you are really spoiled for network ports.
Because this is rather complicated, companies migrating to Exadata often used the high-throughput bonded InfiniBand links for migrating large datasets with low downtime. Unfortunately, the existing database networking infrastructure in most companies does not include InfiniBand (in old, big, iron servers). The standard usually is a number of switched and bonded 1GbE Ethernet ports or 10GbE ports in some cases. That is why, for Exadata V1/V2 migrations, you would have had to either install an InfiniBand card into your source server or use a switch capable of both handling the source Ethernet traffic and flowing it on to the target Exadata InfiniBand network.
Luckily, the Exadata X2 and newer releases both have 10GbE ports included in them, so you do not need to go through the hassle of getting your old servers InfiniBand-enabled anymore and can resort to 10GbE connections (if your old servers or network switches have 10GbE Ethernet in place).
If you are going to migrate your system to Exadata using a network link as the primary means of getting data across, you might consider checking the bandwidth with iperf, an open source tool for measuring throughput. The tool is prominently featured in a MOS note: How to use iperf to test network performance, ID: 1507397.1 detailing how to troubleshoot the RAC interconnect traffic and lost packets. In our opinion, it is well worth using.
This leads us to software configuration topics for high network throughput for database migrations. This chapter does not aim to be a network tuning reference, but we would like to explain some challenges we have seen. Getting the Oracle database links throughput right involves changing multiple settings and requires manual parallelization. Hopefully, this section will help you avoid reinventing the wheel when dealing with huge datasets and low downtime requirements. Before starting to tune the database for best throughput, you should ensure that the network connection provides enough throughout and lower-enough latency for the migration.
In addition to the need for sufficient throughput capacity at the network hardware level, there are three major software configuration settings that affect Oracle’s data transfer speed:
- Fetch array size (arraysize)
- TCP send and receive buffer sizes
- Oracle Net Session Data Unit (SDU) size
With regular application connections, the fetch array size has to be set to a high value, ranging from hundreds to thousands, if you are transferring lots of rows. Otherwise, if Oracle sends too few rows out at a time, most of the transfer time may end up being spent waiting for SQL*Net packet ping-pong between the client and server.
However, with database links, Oracle is smart enough to automatically set the fetch array size to the maximum—it transfers 32,767 rows at a time. As a result, we do not need to tune it ourselves.
Tuning TCP Buffer Sizes
The TCP send and receive buffer sizes are configured at the operating-system level, so every O/S and hardware device has different settings for it. In order to achieve higher throughput, the TCP buffer sizes might have to be increased in both ends of the connection. You can read about a Linux example here; for other operating systems, please refer to your networking documentation. The Pittsburgh Supercomputing Center’s “Enabling High Performance Data Transfers” page is used as a reference (http://www.psc.edu/networking/projects/tcptune/) here.
As a first step, you have to determine the maximum buffer size TCP (per connection) in your system. On the Exadata servers, just keep the settings for TCP buffer sizes as they were set during standard Exadata install. On Exadata, the TCP stack has already been changed from generic Linux defaults. Please do not configure Exadata servers settings based on generic database documentation (such as the “Oracle Database Quick Installation Guide for Linux”).
Many non-Exadata systems are configured conservatively for networking in the 100Mbit/s or 1Gbit/s range. The use of 10Gbit/s Ethernet can be optimized by setting parameters in the operating system to enlarge send and receive buffers. A useful figure in this context is the Bandwidth Delay Product (BDP). The BDP is the maximum amount of data “on the wire” at a given point in time, and your non-Exadata systems network configuration should take it into account. Some time ago, starting with the 2.6.18 kernel used in Red Hat Linux 5.x, Linux introduced automatic tuning of the send and receive buffers. Tuning of the buffers can be checked in /proc/sys/net/ipv4/tcp_moderate_rcvbuf; it should be set to a value of 1. The recommendations commonly found when researching the topic state that you should not try to outsmart Linux and stick with the default.
The optimal buffer sizes are dependent on your network roundtrip time (RTT) and the network link maximum throughput (or desired throughput, whichever is lower). The optimal buffer size value can be calculated using the BDP formula, also explained in the “Enabling High Performance Data Transfers” document mentioned earlier in this section. Note that changing the kernel parameters shown earlier means a global change within the server. If your database server has a lot of processes running, the memory usage may rise thanks to the increased buffer sizes. Hence, you might not want to increase these parameters until the actual migration happens.
Before you change any of the socket buffer settings mentioned above at the O/S level, there is some good news if your source database is Oracle 10g or newer. Starting from Oracle 10g, it is possible to make Oracle request a custom buffer size itself when a new process is started. You can do this by changing the listener.ora configuration file on the server side (source database) and tnsnames.ora (or the raw TNS connect string in database link definition) in the target database side. The target database acts as the client in the database link connection pointing from target to source. This is well documented in the Optimizing Performance section of the Oracle Database Net Services Administrator’s Guide, section “Configuring I/O Buffer Space.”
Additionally, you can reduce the number of system calls Oracle uses for sending network data by increasing the SDU size. This requires a change in listener.ora and setting the default SDU size in server-side sqlnet.ora. You should also edit your client configuration files accordingly. Please refer to the Oracle documentation for more details. Note that in Oracle 12c, the maximum size of the SDU has been increased from 32kb to 2MB for 12c-to-12c communication.
Following is an example that shows how to enable the large SDU on the source database. First of all, you need a listener. Thinking about the migration, you might want to use a new listener instead of modifying an existing one. This also means you do not interfere with your regular listener, which can be a burden if you use dynamically registered databases. In the example, you will see the listener defined as SDUTEST on the source database:
$ cat listener.ora
LISTENER_sdutest =
(DESCRIPTION_LIST =
(DESCRIPTION =
(SDU = 2097152)
(ADDRESS =
(PROTOCOL = TCP)
(HOST = sourcehost)
(PORT = 2521)
(SEND_BUF_SIZE=4194304)
(RECV_BUF_SIZE=1048576)
)
)
)
SID_LIST_listener_sdutest =
(SID_DESC=
(GLOBAL_DBNAME=source)
(ORACLE_HOME = /u01/app/oracle/product/12.1.0.2/dbhome_1)
(SID_NAME = source1)
)
In addition to the listener.ora file you need to set the default SDU to 2M as well in sqlnet.ora:
DEFAULT_SDU_SIZE=2097152
You might want to store the listener.ora and the sqlnet.ora files in their proper TNS_ADMIN directory and not interfere with the other listeners. If you plan on modifying the networking parameters for the duration of the migration only then it is of course fine to modify the default listeners.
The tnsnames.ora file on Exadata (as client) would refer to a database similar to this example:
$ cat tnsnames.ora
source =
(DESCRIPTION =
(SDU=2097152)
(ADDRESS =
(PROTOCOL = TCP)
(HOST = sourcehost)
(PORT = 2521)
(SEND_BUF_SIZE=1048576)
(RECV_BUF_SIZE=4194304)
)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = source)
)
)
With these settings, when the database link connection is initiated in the target (Exadata) database, the tnsnames.ora connection string additions will make the target Oracle database request a larger TCP buffer size for its connection. Thanks to the SDU setting in the target database’s tnsnames.ora and the source database’s sqlnet.ora, the target database will negotiate the maximum SDU size possible.
![]() Note If you have done SQL*Net performance tuning in old Oracle versions, you may remember another SQL*Net parameter: TDU (Transmission Data Unit size). This parameter is obsolete and is ignored starting with Oracle Net8 (Oracle 8.0).
Note If you have done SQL*Net performance tuning in old Oracle versions, you may remember another SQL*Net parameter: TDU (Transmission Data Unit size). This parameter is obsolete and is ignored starting with Oracle Net8 (Oracle 8.0).
It is possible to ask for different sizes for send and receive buffers. This is because, during the data transfer, the bulk of data will move from source to target direction. Only some acknowledgement and “fetch more” packets are sent in the other direction. That is why you see the send buffer larger in the source database (listener.ora) as the source will do mostly sending. On the target side (tnsnames.ora), the receive buffer are configured to be larger as the target database will do mostly receiving. Note that these buffer sizes are still limited by the O/S-level maximum buffer size. As you read in the previous section, that number is automatically tuned on Linux. Other operating systems may be different.
If you choose the extract-load approach for your migration, there is one more bottleneck to overcome in case you plan to use EHCC. You probably want to use EHCC to save the storage space and also get better data-scanning performance (compressed data means fewer bytes to read from disk). Note that faster scanning may not make your queries significantly faster if most of your query execution time is spent in operations other than data access, such as sorting, grouping, joining, and any expensive functions called either in the SELECT list or filter conditions. However, EHCC compression requires many more CPU cycles than the classic block-level de-duplication, since the final compression in EHCC is performed with CPU intensive algorithms (currently LZO, Zlib, or BZip, depending on the compression level). Also, while decompression can happen either in the storage cell or database layer, the compression of data can happen only in the database layer. Thus, if you load lots of data into an EHCC compressed table using a single session, you will be bottlenecked by the single CPU (core) you are using. Therefore, you will almost definitely need to parallelize the data load to take advantage of all the database layer’s CPUs for more efficient and faster compression.
This sounds very simple—just add a PARALLEL flag to the target table or a PARALLEL hint into the query, and you should be all set, right? Or maybe use the PARALLEL keyword in impdp to get the work done in parallel? Unfortunately, things are a little more complex than that. There are a couple of issues to solve; one of them is easy, but the other one requires some effort.
The next few sections will not reference imdp for a simple reason: When importing using imdp over a network link, the tool cannot perform intra-segment parallelism. It will import segments in parallel—respecting the parallel clause—but none of the segments will be imported in parallel. Instead, the focus is on how to use your own DIY intra-segment parallelism with insert statements across the database link.
Issue 1: Making Sure the Data Load Is Performed in Parallel
The problem here is that while parallel query and Data Definition Language (DDL) statements are enabled by default for any session, parallel execution of Data Manipulation Language (DML) statements is not. Therefore, parallel CTAS statements will run in parallel from end to end, but the loading part of parallel IAS statements will be done in serial! The query part (SELECT) will be performed in parallel, as the slaves pass the data to the single Query Coordinator (QC) and it is the single process, which is doing the data loading (including the CPU-intensive compression).
This problem is simple to fix, though; you will just need to enable parallel DML in your session. Let’s check the parallel execution flags in the session first:
SQL> SELECT pq_status, pdml_status, pddl_status, pdml_enabled
2> FROM v$session WHERE sid = SYS_CONTEXT('userenv','sid'),
PQ_STATUS PDML_STATUS PDDL_STATUS PDML_ENABLED
--------- ----------- ----------- ---------------
ENABLED DISABLED ENABLED NO
The parallel DML is disabled in the current session. The PDML_ENABLED column is there for backward compatibility. Let’s enable PDML:
SQL> ALTER SESSION ENABLE PARALLEL DML;
Session altered.
SQL> SELECT pq_status, pdml_status, pddl_status, pdml_enabled
2> FROM v$session WHERE sid = SYS_CONTEXT('userenv','sid'),
PQ_STATUS PDML_STATUS PDDL_STATUS PDML_ENABLED
--------- ----------- ----------- ---------------
ENABLED ENABLED ENABLED YES
After enabling parallel DML, the INSERT AS SELECTs are able to use parallel slaves for the loading part of the IAS statements.
There is another important aspect to watch out for regarding parallel inserts. In the next example, a new session has been started (thus the PDML is disabled), and the current statement is a parallel insert. You can see a “statement-level” PARALLEL hint was added to both insert and query blocks, and the explained execution plan output (the DBMS_XPLAN package) shows us that parallelism is used. However, this execution plan would be very slow loading into a compressed table, as the parallelism is enabled only for the query (SELECT) part, not the data loading part!
How can that be? Pay attention to where the actual data loading happens—in the LOAD AS SELECT operator in the execution plan tree. This LOAD AS SELECT, however, resides above the PX COORDINATOR row source (this is the row source that can pull rows and other information from slaves into QC). Also, in line 3, you see the P->S operator, which means that any rows passed up the execution plan tree from line 3 are received by a serial process (QC).
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | | | 6591 (100) | |
| 1 | LOAD AS SELECT | | | | | |
| 2 | PX COORDINATOR | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 10M | 1268M | 6591 (1) | 00:00:01 |
| 4 | PX BLOCK ITERATOR | | 10M | 1268M | 6591 (1) | 00:00:01 |
|* 5 | TABLE ACCESS STORAGE FULL | T1 | 10M | 1268M | 6591 (1) | 00:00:01 |
-------------------------------------------------------------------------------------------------
... continued from previous output:
-----------------------------
TQ |IN-OUT| PQ Distrib |
-----------------------------
| | |
| | |
Q1,00 | P->S | QC (RAND) |
Q1,00 | PCWP | |
Q1,00 | PCWC | |
Q1,00 | PCWP | |
-----------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - storage(:Z>=:Z AND :Z<=:Z)
Note
-----
- Degree of Parallelism is 8 because of hint
The output of the plan table was too wide to put it into a single row; therefore, the remaining information (which is very important!) has been wrapped around.
The message “Degree of Parallelism is 8 because of hint” means that a request for running some part of the query with parallel degree 8 was understood by Oracle, and this degree was used in CBO calculations when optimizing the execution plan. However, as explained above, this does not mean that this parallelism was used throughout the whole execution plan. It’s important to check whether the actual data loading work (LOAD AS SELECT) is done by the single QC or by PX slaves.
Let’s see what happens with parallel DML enabled:
SQL> alter session enable parallel dml;
Session altered.
SQL> insert /*+ monitor append parallel(8) */ into t1 select /*+ parallel(8) */ * from t2
SQL Plan Monitoring Details (Plan Hash Value=3136303183)
====================================================================================
| Id | Operation | Name | Rows | Cost | Time |
| | | | (Estim) | | Active(s) |
====================================================================================
| 0 | INSERT STATEMENT | | | | 1 |
| 1 | PX COORDINATOR | | | | 1 |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 10M | 3764 | 1 |
| 3 | LOAD AS SELECT | | | | 3 |
| 4 | OPTIMIZER STATISTICS GATHERING | | 10M | 3764 | 3 |
| 5 | PX BLOCK ITERATOR | | 10M | 3764 | 2 |
| 6 | TABLE ACCESS STORAGE FULL | T2 | 10M | 3764 | 3 |
===================================================================================
The requested DOP in this case is eight, just as before, but compare the two plans. The execution plan is taken from a SQL Monitor report from a 12c database. You can see an extra step—gathering statistics. This is a new feature ensuring that you have accurate statistics in a newly created or populated segment.
You will need to see the parallel distribution as well to follow the discussion. Here it is—this time taken from DBMS_XPLAN.DISPLAY_CURSOR from an 11.2 database:
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes || TQ |IN-OUT| PQ Distrib |
------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | | || | | |
| 1 | PX COORDINATOR | | | || | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 10M| 1268M|| Q1,00 | P->S | QC (RAND) |
| 3 | LOAD AS SELECT | | | || Q1,00 | PCWP | |
| 4 | PX BLOCK ITERATOR | | 10M| 1268M|| Q1,00 | PCWC | |
|* 5 | TABLE ACCESS STORAGE FULL| T1 | 10M| 1268M|| Q1,00 | PCWP | |
------------------------------------------------------------------------------------------------
In this second case represented by the two execution plans on this page, the LOAD AS SELECT operator has moved down the execution plan tree; it is not a parent of PX COORDINATOR anymore. How you can read this simple execution plan is that the TABLE ACCESS STORAGE FULL sends rows to PX BLOCK ITERATOR (which is the row source who actually calls the TABLE ACCESS and passes it the next range of data blocks to read). PX BLOCK ITERATOR then sends rows back to LOAD AS SELECT, which then immediately loads the rows to the inserted table, without passing them to QC at all. All the SELECT and LOAD work is done within the same slave—there is no inter-process communication needed. How can you tell? It is because the IN-OUT column says PCWP (Parallel operation, Combined With Parent) for both operations, and the TQ value for both of the operations is the same (Q1,00). This indicates that parallel execution slaves do perform all these steps under the same Table Queue node, without passing the data around between slave sets.
The actual execution plan when reading data from a database link looks like this:

In this example, because parallel DML is enabled at the session level, the data loading is done in parallel; the LOAD AS SELECT is a parallel operation (the IN-OUT column shows PCWP) executed within PX slaves and not the QC.
Note that DBMS_XPLAN shows the SQL statement for sending to the remote server over the database link (in the Remote SQL Information section above). Instead of sending PARALLEL hints to the remote server, an undocumented SHARED hint is sent, which is an alias of the PARALLEL hint. Note the output is from 12c, where this load as select operation triggers a stats-gathering operation.
This was the easier issue to fix. If your data volumes are really big, there is another problem to solve with database links, which we will now explain.
Issue 2: Achieving Fully Parallel Network Data Transfer
Another issue with database links and parallel execution is that even if you manage to run parallel execution on both ends of the link, it is the QCs that actually open the database link and manage the network transfer. The Parallel Execution (PX) slaves cannot somehow magically open their own database link connections to the other database—all traffic flows through the single query coordinator of a query. So you can run your CTAS/IAS statement with hundreds of PX slaves; however, you still only have one single database link connection for the network transfer. While you can optimize the network throughput by increasing the TCP buffer and SDU sizes, there is still a limit of how much data the QC process (on a single CPU) is able to ingest.
Figure 13-1 illustrates how the data flows through a single QC despite all the parallel execution.
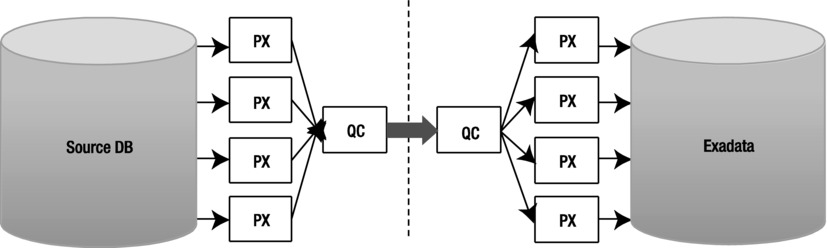
Figure 13-1. Data flow is single-threaded through query coordinators
In addition to the single QC database link bottleneck, sending data (messages) between the QC and PX slaves takes some extra CPU time. This is where fine-tuning the parallel_execution_message_size parameter has helped a little in the past. However, starting from Oracle 11.2, its value defaults to 16KB anyway, so there probably will not be any significant benefit in adjusting this further. If you are doing parallel data loads across multiple nodes in a RAC instance, there will still be a single QC per query with a single network connection. So, if the QC runs in node 1 and the parallel slaves in node 2, the QC will have to send the data it fetches across the database link to the PX slaves over the RAC interconnect as PX messages.
Should you choose to use database links with parallel slaves, you should run multiple separate queries in different instances and force the PX slaves to be in the same instance as the QC, using the following command:
SQL> ALTER SESSION SET parallel_force:local = TRUE;
Session altered.
This way, you will avoid at least the RAC inter-instance traffic and remote messaging CPU overhead, but the QC to PX slave intra-instance messaging (row distribution) overhead still remains here.
Despite all these optimizations and migration of different large tables using parallel queries in different instances, you may still find that a single database link (and query coordinator) does not provide enough throughput to migrate the largest fact tables of your database within your downtime. As stated earlier, the database links approach is best used for the few huge tables in your database, and all the rest can be exported/imported with Data Pump. Perhaps you only have a couple of huge fact tables, but if you have eight RAC instances in the full rack Exadata cluster, how could you make all the instances transfer and load data efficiently? You would want to have at least one parallel query with its query coordinator and database link per instance and likely multiple such queries if a single QC process cannot pull and distribute data fast enough.
The obvious solution here is to take advantage of partitioning, as your large multi-terabyte tables are likely partitioned in the source database anyway. You simply copy the huge table as multiple independent separate parts. However, there are a couple of problems associated with this approach.
The first issue is that when performing the usual direct path load insert (which is needed for HCC and for NOLOGGING loads where applicable), your session would lock the table it inserts into exclusively for itself. Nobody else can modify or insert into that table while there is an uncommitted direct path load transaction active against that table. Note that others can still read that table, as SELECT statements do not take enqueue locks on tables they select from.
How do you work around this concurrency issue? Luckily, the Oracle INSERT syntax allows you to specify the exact partition or subpartition where you want to insert by name:
INSERT /*+ APPEND */
INTO
fact PARTITION ( Y20080101 )
SELECT
*
FROM
fact@sourcedb
WHERE
order_date >= TO_DATE('20080101 ', 'YYYYMMDD ')
AND order_date < TO_DATE('20080102', 'YYYYMMDD ')
With this syntax, the direct-path insert statement would lock only the specified partition, and other sessions could freely insert into other partitions of the same table. Oracle would still perform partition key checking to ensure that data is not be loaded into wrong partitions. If you attempt to insert an invalid partition key value into a partition, Oracle returns the error message
ORA-14401: inserted partition key is outside specified partition.
Note that you cannot use the PARTITION ( partition_name ) syntax in the SELECT part of the query. The problem here is that the query generator (unparser), which composes the SQL statement to be sent over the database link, does not support the PARTITION syntax. If you try it, you will get an error:
ORA-14100: partition extended table name cannot refer to a remote object.
That is why you have to rely on the partition pruning on the source database side—for example, by adding filter predicates to the WHERE condition so that only the data in the partition of interest is returned. In the example just shown, the source table is range-partitioned by order_date column. Thanks to the WHERE clause passed to the source database, the partition pruning optimization in that database will only scan through the required partition and not the whole table.
Note the absence of the BETWEEN clause in this example, as it includes both values in the range specified in the WHERE clause, whereas Oracle Partitioning option’s “values less than” clause excludes the value specified in DDL from the partition’s value range.
It is also possible to use subpartition-scope insert syntax to load into a single subpartition (thus locking only a single subpartition at time). This is useful when even a single partition of data is too large to be loaded fast enough via a single process/database link, allowing you to split your data into even smaller pieces. Just be careful not to have too many (small) subpartitions—you may not be able to Smart Scan them later. Here is the above example again, this time for a subpartition insert:
INSERT /*+ APPEND */
INTO
fact SUBPARTITION ( Y20080101_SP01 )
SELECT
*
FROM
fact@sourcedb
WHERE
order_date >= TO_DATE('20080101 ', 'YYYYMMDD ')
AND order_date < TO_DATE('20080102', 'YYYYMMDD ')
AND ORA_HASH(customer_id, 63, 0) + 1 = 1
In this example, the source table is still range-partitioned by order_date, but it is hash-partitioned to 64 subpartitions. As it is not possible to send the SUBPARTITION clause through the database link either, you have used the ORA_HASH function to fetch only the rows belonging to the first hash subpartition of 64 total subpartitions. The ORA_HASH SQL function uses the same kgghash() function internally, which is used for distributing rows to hash partitions and subpartitions. If there were 128 subpartitions, you would need to change the 63 in the SQL syntax to 127 (n – 1).
As you would need to transfer all the subpartitions, you can copy other subpartitions in parallel, depending on the server load of course, by running slight variations of the above query and changing only the target subpartition name and the ORA_HASH output to corresponding subpartition position:
INSERT /*+ APPEND */
INTO
fact SUBPARTITION ( Y20080101_SP02 )
SELECT
*
FROM
fact@sourcedb
WHERE
order_date >= TO_DATE('20080101 ', 'YYYYMMDD ')
AND order_date < TO_DATE('20080102', 'YYYYMMDD ')
AND ORA_HASH(customer_id, 63, 0) + 1 = 2
At the end of the day, you need to execute 64 slight variations of that script:
... INTO fact SUBPARTITION ( Y20080101_SP03 ) ... WHERE ORA_HASH(customer_id, 63, 0) + 1 = 3 ...
... INTO fact SUBPARTITION ( Y20080101_SP04 ) ... WHERE ORA_HASH(customer_id, 63, 0) + 1 = 4 ...
...
... INTO fact SUBPARTITION ( Y20080101_SP64 ) ... WHERE ORA_HASH(customer_id, 63, 0) + 1 = 64 ...
If your table’s hash subpartition numbering scheme in the subpartition name does not correspond to the real subpartition position (the ORA_HASH return value), you will need to query DBA_TAB_SUBPARTITIONS and find the correct subpartition_name using the SUBPARTITION_POSITION column.
There is one more catch. While the order_date predicate will be used for partition pruning in the source database, the ORA_HASH function won’t; the query execution engine just does not know how to use the ORA_HASH predicate for subpartition pruning. In other words, the above query will read all 64 subpartitions of a specified range partition, and then the ORA_HASH function will be applied to every row fetched and the rows with non-matching ORA_HASH result will be thrown away. So, if you have 64 sessions, each trying to read one subpartition with the above method, each of them would end up scanning through all subpartitions under this range partition, meaning 64 × 64 = 4096 subpartition scans.
It is possible to work around this problem by creating views on the source table in the source database. Start by creating a view for each subpartition, using a script, of course, to generate the create view commands. The view names would follow a naming convention such as V_FACT_Y2008010_SP01, and each view would contain the SUBPARTITION ( xyz ) clause in the view’s SELECT statement.
Remember, these views have to be created in the source database to avoid an issue with database links syntax restriction. When it is time to migrate, the insert-into-subpartition statements executed in the target Exadata database would reference appropriate views depending on which subpartition is required. This means that some large fact tables would have thousands of views on them. The views may be in a separate schema as long as the schema owner has select privileges on the source table. Also, you probably do not have to use this trick on all partitions of the table since, if your largest tables are time-partitioned by some order_date or similar, you can probably transfer much of the old partitions before the downtime window. Consequently, you do not need to use such cunning but time-consuming workarounds.
The techniques just discussed may seem quite complicated and time-consuming, but if you have tens or hundreds of terabytes of raw data to extract, transfer, and compress (all of which has to happen very fast), such measures are going to be useful. We have used these techniques for migrating VLDB data warehouses up to 100TB in size (compressed with old-fashioned block compression) with raw data sets exceeding a quarter of a petabyte. You might ask yourself now if the approach just shown is worth it. Read more in the next section about when it is feasible to go with database links and when it is not.
When to Use CTAS or IAS over Database Links
If you have allocated plenty of downtime, the database to be migrated is not too big, and you do not want or need to perform a major reorganization of your database schemas, you probably do not have to use data load (IAS/CTAS) over database links. A full Data Pump export/import is much easier if you have the time; everything can potentially be exported and imported with a simple command.
However, if you are migrating VLDBs with low downtime windows, database links can provide one performance advantage—with database links you can create your own intra-table parallelism that is not available with Data Pump import over a network link. Compared to the “classic” Data Pump export with a dump file, both the network link option as well as the database link technique offer the significant advantage that no disk space is needed for the exported data. You do not have to dump the data to a disk file just to copy it over and reload it back in the other server. Also, you do not need any intermediate disk space for keeping dumps when using database links. With database links, you read the data from disk once (in the source database), transfer it over the network, and write it to disk once in the target.
Transferring lots of small tables (or table partitions) may actually be faster with the Export/Import or Data Pump method. Also, the other schema objects (views, sequences, PL/SQL, and so on) have to be migrated anyway. From that point of view, it might be a good idea to transfer only the large tables over database links and use Export/Import or Data Pump for migrating everything else. Clever use of the INCLUDE (or, depending on use case, EXCLUDE) parameter in Data Pump can make the migration a lot less problematic. Also remember that the SQLFILE option can be used to create scripts for specific database objects. If you needed all the grants from a database before a schema import, you could use the following example (assuming that the dump is a metadata-only dumpfile from a full database export):
[oracle@enkdb03 ~]> impdp sqlfile=all_grants.sql dumpfile=metadata.dmp
> directory=migration_dir logfile=extract_grants.log include=GRANT
You can query the dictionary views DATABASE_EXPORT_OBJECTS, SCHEMA_EXPORT_OBJECTS, and TABLE_EXPORT_OBJECTS respectively, depending on the mode (FULL, SCHEMA, or TABLE) chosen, for objects to be included or excluded.
What to Watch Out for When Copying Tables over Database Links
Copying tables during business hours can impact performance on the source database. It can also put a load on the network, sometimes even when dedicated network hardware is installed for reducing the impact of high-throughput data transfer during production time. Table 13-3 shows a summary of the capabilities of each of these Extract and Load methods.
Table 13-3. When to Use Extract and Load
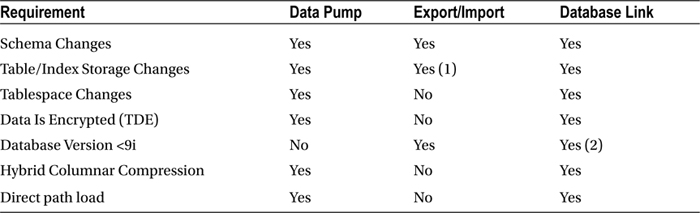
1. It is possible to change the object creation DDL by running imp with show=y option to extract the DDL statements, modifying the script and creating the objects manually in Sqlplus. Data Pump has made such tasks much easier thanks to its TRANSFORM parameter.
2. Support for connections to old clients is described in Client / Server Interoperability Support Matrix for Different Oracle Versions (Doc ID 207303.1).
Generally speaking, replication-based migration is done by creating a copy of the source database and then keeping it in sync by applying changes to the copy, or “target database.” There are two very different methods for applying these changes.
Physical replication ships redo information to the target where it is applied to the database using its internal recovery mechanisms. This is called “Redo Apply.” You can read more about how that works in the “Physical Migration” section later in this chapter. With logical replication, changes to the source database are extracted as SQL statements from the redo stream and executed on the target database. The technique of using SQL statements to replicate changes from source to target is called “SQL Apply.” Back in the nineties when Oracle 7 and 8 were all the rage, it was common practice among DBAs to use snapshots to keep tables in a remote database in sync with master tables in the source database. These snapshots used triggers to capture changes to the master table and execute them on the target. Snapshot logs were used to queue up these changes when the target tables were unavailable so they could be executed at a later time. It was a simple form of logical replication. Of course, this was fine for a handful of tables, but it became unwieldy when replicating groups of tables or entire schemas. In later releases, Oracle wrapped some manageability features around this technology and branded it ”Simple Replication.” Its next evolution step, “Advanced Replication,” was hot in 8, but is now deprecated in 12c and slated for a replacement with Oracle Golden Gate.
Even back in the early days of database replication, there were companies that figured out how to mine database redo logs to capture DML more efficiently and less intrusively than triggers could. Today there are several products on the market that do a very good job of using this “log-mining” technique to replicate databases. The advantage logical replication has over physical replication is in its flexibility. For example, logical replication allows the target to be available for read access. In some cases, it also allows you to implement table compression and partitioning in the target database. In the next few sections, we will introduce several tools that support replication-based migration.
Oracle Streams and Golden Gate
Oracle Streams is included in the base RDBMS product and was introduced as a new feature in version 9i. Although still present in 12.1—the current production release of the database software at the time of writing—it has been deprecated. Deprecation of a feature means that developers and administrators alike should try to remove dependencies on it as it will disappear at some stage in the future.
Golden Gate started out as an independent product but has been acquired by Oracle. Both products—Streams and Golden Gate—replicate data in much the same way by mining redo information, although their implementations are different. For the purpose of the database migration, a copy of the source database is created (the target) and started up. This may be done from a full database backup using Recovery Manager or by using Data Pump to instantiate a select number of schemas if it is not the entire database that you want to migrate. Then changes in the source database are extracted, or mined, from the redo logs. The changes are then converted to equivalent DML and DDL statements and executed in the target database. Oracle calls these steps Capture, Propagation, and Apply.
Regardless of which product you use, the target database remains online and available for applications to use while replication is running. New tables may be created in the target schema or in other schemas, although that is not recommended by Oracle. Any restrictions on the target are limited to the tables being replicated. This is particularly useful when your migration strategy involves consolidation—taking schemas from multiple source databases and consolidating them into one (pluggable?) database. Because of its extremely high performance and scalability, most companies use Exadata for database consolidation to at least some degree, so this is a very useful feature. If you read between the lines, you realize that this means you can migrate multiple databases concurrently.
Another capability of both Streams and Golden Gate is the ability to transform data on the fly. This is not something normally associated with database migration, but it is available should it be needed. Since both tools use SQL Apply to propagate data changes to the target, you can implement changes to the target tables to improve efficiencies. For example, you can convert conventional target tables to partitioned tables. You can also add or drop indexes and change extent sizes to optimize for Exadata. Be aware that even though replication provides this capability, it can get messy, especially if the number of changes is high. If you are planning a lot of changes to the source tables, consider implementing them before you begin replication.
Tables in the target database may be compressed using Exadata HCC. Be prepared to test performance when inserting data and using HCC compression. As you saw in Chapter 3, compressing is a CPU-intensive process, much more so than Basic and OLTP compression. However, the rewards are usually significant in terms of storage savings and query performance, depending on the nature of the query of course. Please remember that if conventional inserts or updates are executed on HCC compressed tables, Oracle switches to OLTP compression (for the affected rows) and your compression ratio drops significantly. Direct path inserts can be done by implementing the insert append hint as follows:
SQL> insert /*+ append */ into my_hcc_table select ...;
SQL> insert /*+ append_values */ into my_hcc_table values ( <array of rows> );
Note that the append_values hint only works from Oracle 11gR2 onward. Unlike mentioned in the first edition of this book, Golden Gate now supports reading from compressed tables, it does so now. The only way to add support for Basic, Advanced (OLTP), and EHCC is to configure the new integrated capture mechanism. Unlike the classic capture, which mines online redo logs, integrated capture interacts directly with the log-mining server to receive changes to data in form of a Logical Change Record (LCR).
![]() Note You cannot use classic capture for use with an Oracle 12c Multi-Tenant database.
Note You cannot use classic capture for use with an Oracle 12c Multi-Tenant database.
As for Streams, the documentation reads that direct path inserts are not supported in 10g databases. 11g does provide limited support through the Direct Path API. Once again, make sure you check the Oracle documentation to see what is supported for your database version. If in doubt, run a few tests to see whether you do get the level of compression you expect. However, a big improvement is that Oracle 11.2 allows Streams to capture data from tables compressed with basic table compression and OLTP compression. From Oracle 11.2.0.2 patchset onward, Streams/XStream can also capture changes made to HCC compressed tables. The Oracle Streams Concepts and Administration Guide explains this in more detail in Appendix B.
Streams has supported most of Oracle’s data types, and the list increased with every release. The following is a quick summary of the benefits common to both Oracle Streams and Golden Gate:
- Support for failover (Oracle RAC environments)
- Support for multi-tenant databases
- Support for table partitioning (target tables)
- Support for HCC compression although you may not get the best loading compression ratio compared to CTAS or IAS
- Support for storage changes for tables and indexes (target tables)
- Ability to change indexing strategy (target tables)
- Read access to the target tables during migration
- Support for endian differences between source and target
- Support for (some) character set differences between source and target
- Support for different database block sizes between source and target
- Support for change capture on the target server, reducing the performance impact on the source system
- Not difficult to set up
- Database version-agnostic
- Very little downtime to switch over
- Support exists in Oracle Enterprise Manager.
Disadvantages common to both Streams and Golden Gate include the following:
- Replicated tables must have a primary or unique key. If there is no primary key on the source table, you must provide a list of columns that provide uniqueness. If no such combination exists, the table cannot be replicated.
- Some data types are not supported for replication.
- Log mining on the source system can impact performance. Consider moving the change capture to the target system.
- Logical replication in general is more complex than other migration strategies.
Disadvantages of Streams compared to Golden Gate:
- Streams is deprecated in Oracle 12c. It is still available (unlike Change Data Capture—CDC) but cannot support multi-tenant databases as documented in Appendix B of the Streams Concepts and Administration Guide. Golden Gate is generally seen as the replacement for Streams.
- Data mining can heavily impact performance on the source database.
- It is more complex to set up and maintain.
- DDL is supported but problematic.
- If replication breaks, fixing it can be messy. It is often easier to rebuild the target from scratch.
- SQL Apply is more prone to falling behind the source than Golden Gate.
- Streams tends to require much more CPU resources than Golden Gate.
Advantages of Streams over Golden Gate:
- Streams is included with your database license, while Golden Gate is sold separately.
- All process information is stored in the database, providing convenient remote access.
So which should you use, Streams or Golden Gate? On the one hand, there is the technical aspect. We have spoken with clients and colleagues who have used both products. In every case, they are using the product for simple replication to a remote site much like you would for database migration. The feedback we get is overwhelmingly in favor of Golden Gate. These users cite Golden Gate’s ease of use, stability, and performance as the most important reasons. In addition to this, Golden Gate supports non-Oracle database sources. Streams runs inside the Oracle database and has not been ported to any other database platform. As mentioned, Streams is included in your Oracle database license. Golden Gate is not, and the cost based on the total number of cores on the source and target servers is not trivial. If you have need for data replication beyond your Exadata migration, the investment may be well worth it. If you are faced with a one-time migration, Streams may be a better fit for cost (neglecting the fact that the team needs to familiarize itself with the tool). But then, on the other hand, Streams has been dropped in favor of Golden Gate. Many readers will still be on 11g Release 2, so the fact that Streams has been deprecated might not affect you straight away. However, the time will come where lack of support of some of the more interesting 12c features in Streams becomes a limiting factor.
When to Use Streams or Golden Gate
Streams and Golden Gate both provide a lot of flexibility with near-zero downtime. They are well suited for migrations that require changes to the target tables. This includes resizing table and index extents, implementing partitioning strategies, and compressing tables. They also allow you to change schemas, tablespaces, and disk groups, among other things.
What to Watch Out for with Streams and Golden Gate
Since Streams and Golden Gate propagate database changes by means of redo, you must prevent NOLOGGING operations at the source database. This can be done at the tablespace level using alter tablespace force logging or at the database level using alter database force logging. Here are a few examples of NOLOGGING operations that you must prevent:
- CREATE TABLE newtab NOLOGGING AS select * from ...
- insert /*+ append */ ... (for tables in nologging mode) or
- insert /*+ append nologging */(specifically overriding the default logging operation)
- Direct path SQL*Loader (for tables in nologging mode)
Note that some large DW databases are designed to use NOLOGGING for large data loads to save CPU and disk space (fewer archive logs generated). These databases rely on incremental backups plus data reloads as a recovery strategy. In such databases, forcing redo logging for everything may cause unacceptable performance degradation and archive log generation. In those cases, it makes sense to configure the ETL engine to perform loads to both the old and new DW system during the transition period. Although it appears trivial to change from nologging to logging load operations, it can prove impossible to change, especially in silo’d organizations. Instead, you may have to use alter database force logging if you use a replication method that relies on mining the redo logs.
Logical Standby
Another type of replication potentially useful for database migration is a logical standby database. Logical standby is a built-in feature of the Oracle database. It was introduced in version 9i release 2 as an extension or additional feature of Data Guard (formerly Standby Database). On the surface, this strategy sounds a lot like Streams and Golden Gate in that it is basically performing the same task. Changes to the source database are mined from the redo (or archived redo) and converted to SQL statements and executed on the target database. As in other logical replication methods, the database is open and available while replication is running.
Logical standby is far more restrictive than Streams or Golden Gate. Because the logical standby is actually instantiated from a physical, block-for-block copy of the source database, several rules come into play. The database version must be the same for the source and the target databases, even down to the patch level.
Oracle supports heterogeneous configurations for primary and logical standby database in the same Data Guard configuration. The master note can be found on My Oracle Support: Data Guard Support for Heterogeneous Primary and Logical Standbys in Same Data Guard Configuration (Doc ID 1085687.1). Reading this note reveals a matrix of supported combinations of operating systems for Oracle Data Guard. Before you get your hopes too high, however, there are only a precious few exceptions to the rule that you cannot have Data Guard between different platforms or even endiannesses.
It might surprise you to know that while indexes and materialized views can easily be created in the target database, implementing a partitioning strategy is more difficult. You have to pause replication, recreate the table with partitions, and then resume replication. If your replicated table is out of sync with the primary, you are in trouble. The DBMS_LOGSTDBY.INSTANTIATE_TABLE procedure normally used to get things back in order removes the existing table on the standby and replaces it with the table as it exists on the primary.
Table compression is not 100% supported, either. Remember that HCC compression only works with direct path load, and logical standby applies changes using conventional inserts. Worse, a bulk update is replicated using row-by-row updates. Implementing EHCC is often a very important performance strategy for Exadata. The lack of support for this feature is a significant downside for logical standby and a one-shot approach to migrating. You can, of course, issue a number of alter table move commands once the cutover is complete to achieve the correct compression ratio.
The list of unsupported data types is found in Appendix C in the Data Guard Concepts and Administration Guide.
Creating a logical standby database is more involved than creating its cousin, the physical standby database. There are a lot of steps in configuring and instantiating a logical standby. Listing all of them would extend the chapter even further. The high-level steps have to suffice:
- Create a physical standby database (note that this is covered a little later in the “Physical Standby” section).
- Stop redo apply on the physical standby database.
- Configure Log Miner in the primary database.
- Convert the physical standby database to a logical standby.
- Open the logical standby database and restart redo apply.
- Verify that the logical standby database is applying changes from the source.
Logical standby uses the SQL Apply instead of Redo Apply technology to replicate changes from the source database to the target. As mentioned earlier, changes in the source database are converted to SQL statements and shipped to the target for execution. Although this may sound fairly straightforward, there are some interesting implications because of how it is implemented. Here are a few things to keep in mind for DML statements:
- Batch updates are executed one row at a time. So, if you are updating 100,000 records with just one command, you will apply 100,000 individual commands on the standby.
- Direct path inserts are performed in conventional manner.
- Parallel DML is not executed in parallel.
DDL statements are replicated without any special configuration requirements. However, there are some considerations for DDL statements:
- Parallel DDL is not executed in parallel.
- CTAS is executed as create table, insert, insert, insert.
You should keep a close eye on your apply process on the standby database to ensure that bulk operations do not interfere with performance too much. When a massive bulk insert into a table is replicated on the logical standby database, you will see quite a bit of overhead and performance of the queries on the logical standby will suffer due to undo application and block cleanouts.
When to Use Logical Standby
Logical standby has a very narrow list of benefits that set it apart from other, more likely, migration methods. It provides full database replication and allows read access to the standby database during replication. As such, the standby may be used to offload resource-intensive reporting operations from the production database until the time you are ready to make the final switch. Tables and materialized views may be created on the standby database, and indexes may be created or dropped to improve performance.
What to Watch Out for with Logical Standby
NOLOGGING operations do not generate enough redo, which means they will not be replicated to the standby database. As with any Data Guard setup, be sure to prevent NOLOGGING operations using the alter database force logging command in SQL*Plus on the primary and logical standby database. Considering its lack of support for modifying storage of target tables, compression, and partitioning, you might opt to use the physical standby approach instead. If you do not require full database replication, Streams and Golden Gate are excellent alternatives providing support for many of the capabilities lacking in a logical standby database.
This is a bit of “roll-your-own” method for migration. In this strategy, data changes are fed to the database through an in-house developed application. As such, it is a small task to configure the application to update Exadata tables in parallel with the current production database. Historical data is then migrated over to Exadata during normal business hours. Depending on the volume, this may take several days to several weeks. Once all tables have been migrated to Exadata, the feed to the old production system is cut and Exadata becomes the new production database.
Logical Migration Wrap Up
In most cases logical migration provides the most flexibility for reconfiguring extent sizes, implementing or modifying partitioning strategies, and compressing tables using HCC. This flexibility comes at the cost of complexity and restrictions that should be weighed and measured against the simplicity of some of the physical migration strategies presented in this chapter. At the end of the day, you want to properly size extents for large tables, implement a good partitioning strategy, and compress read-only tables using HCC compression. This can be done before you switch over to Exadata using most of the logical migration strategies discussed here.
Physical Migration
Physical database migration, as the name implies, is the process of creating a block-for-block copy of the source database (or parts of the database) and moving it to Exadata. Physical migration is a much simpler process than some of the logical migration strategies discussed earlier in this chapter. As you might expect, it does not allow for any changes to be made to the target database, other than choosing not to migrate some unnecessary tablespaces. This means that you will not be able to modify extent sizes for tables and indexes, alter your indexing strategy, implement partitioning, or apply HCC table compression. Furthermore, if your database saw the light of the day in the 7.x or 8i days, chances are that you have hundreds or even thousands of data files due to restrictions of the file systems at the time. Do you still remember the 2GB file size limit?
All tasks to simplify or “exadatarize” your database must be done post-migration. However, physical migration is, hands down, the fastest way to migrate your database to Exadata. For all physical migration strategies, except Transportable Tablespaces (TTS), the new Exadata database starts out as a single-instance database. Post-migration steps are needed to register the database and all its instances with Cluster Ready Services (Grid Infrastructure). Because physical migration creates an exact copy of the source database, the list of restrictions is very short:
- The source database version must be 11.2 or later.
- One option is to upgrade the production database to version 11.2 or later before copying it to Exadata. Upgrading is usually a quick process and is not dependent on the size of the database tables, but rather on the number of objects in the database and the options configured. (The post-upgrade recompilation of PL/SQL packages and views may take a while however.)
- The source platform must be certified for running Oracle 11.2 or later. You can check the My Oracle Support Certification Matrix to see which Linux distribution is certified for Oracle 11.2 and 12.1 respectively.
- The source platform must be little-endian. When using a hybrid solution creating a new database on Exadata and using cross-platform transportable table spaces, the source database can be on different platforms with different endianness (supported platforms are listed in v$transportable_platform view.)
There are three strategies for performing a physical migration: backup and restore, physical standby, and Cross Platform Transportable Tablespaces with incremental backups. In this section, we will discuss these strategies, how they work, and what they are best suited for.
Backup and Restore
The backup and restore strategy uses Oracle’s Recovery Manager (RMAN) to create a full backup of the source database and then restore it to the Exadata platform. Unless you plan to shut down the database during this process, the source database must be running in Archivelog mode. The backup and restore process can be done in one pass using a full backup. This is the best way to move smaller databases to Exadata since smaller databases take much less time. Larger databases may take hours to back up and restore. For these databases, the process can be done in two passes by taking a full backup followed by an incremental backup.
Full backup and restore are well understood processes and are not listed in detail here. One of the rules with RMAN backup and restore/recovery was that you could not cross platforms with it. There were a few exceptions, documented in MOS Doc ID 1079563.1 “RMAN DUPLICATE/RESTORE/RECOVER Mixed Platform Support,” but they are hardly worth mentioning since there are so few of them. What is more interesting is a new 12c feature where you create cross-platform backups using backup sets and offload the conversion to the destination database. The current implementation does not support moving to a different endiannes, which makes the feature less attractive for migrations to Exadata and, for the same reason, is not covered here.
Please note that unless your source database is a 12c database, you will not immediately be able to make use of the new multi-tenant database architecture. An 11.2 database will first have to be migrated to 12c before you can convert it into a Pluggable Database (PDB). If you are happy to keep using the database as a non-CDB, then no further action is needed. If, however, you are consolidating multiple databases into a single Container Database as PDBs, then further steps are needed.
RMAN is used to create a full backup of the database to be migrated. The backup files are staged in a file system or otherwise made accessible to Exadata. The backup is then restored to the Exadata platform. Note that this is the section about the full restore, which cannot overcome a difference in the database endianness. You can, however, perform cross-platform conversion as long as the endianness stays the same. This involves extra steps not covered in this chapter. In other words, you cannot convert the database from big endian (for example, SPARC) to little endian (for example, Intel = Exadata), but you can convert from Windows to Linux. The high-level steps restoring a backup on Exadata are as follows:
- Perform pre-migration tasks:
- Create an entry in the tnsnames.ora file for your database on Exadata (optional).
- Copy the password file and parameter file (init.ora or spfile) to Exadata.
- Restrict user and application access to the database.
- Take a full database backup.
- Copy the files to Exadata (not required if backup resides on a shared file system or NFS).
- On Exadata, start the database into nomount mode using the adapted server parameter file.
- Restore the control file.
- Mount the database.
- Restore the database.
- Recover the database.
- Perform post-migration tasks:
- Convert the database to RAC and create service names.
- Reconfigure client tnsnames.ora files, configuration files for connecting to the Exadata database.
- Make the database available to users and applications.
As you can see, this is a fairly straightforward process. After following these, you have an exact copy of your production database running on Exadata. There are a few things to keep in mind, though. If your source database uses file systems for database storage or if you are using ASM but the disk group names are different on Exadata, you may redirect the restored files to the new disk group names by changing the db_create_file_dest and db_recovery_file_dest parameters in the init.ora file before starting the restore process. Table 13-4 shows how these parameters can be used to remap disk group names from the source database to Exadata.
Table 13-4. Remap Disk Groups
|
Init.ora Parameters |
Source Database |
Exadata Database |
|---|---|---|
|
db_create_file_dest |
'+DATA_FILES' |
'+DATA' |
|
db_recovery_file_dest |
'+RECOVERY_FILES' |
'+RECO' |
If your database uses multiple ASM disk groups to store your database files, use the RMAN db_file_name_convert clause—part of the restore command—to remap the file names to ASM disk groups. For example:
db_file_name_convert=
('+DATA_FILES/exdb/datafile/system.737.729723699','+DATA')
db_file_name_convert=
('+DATA_FILES1/exdb/datafile/sysaux.742.729723701','+DATA')
The attentive reader will now undoubtedly point out that the use of the RMAN duplicate command can achieve the exact same thing, and that is, of course, correct. However, in our experience, management is notoriously cautious about access to production, even for a (non-active) duplication process. The extra steps just explained in the procedure above are often worth it—the backup may even exist already and only needs to be rolled forward with the use of archived logs. And, as an added benefit, it was not even necessary to “touch” the production system, an action that normally requires elaborate change control processes.
If the database you need to migrate is large and the time to migrate is limited, you might consider using the incremental backup and restore strategy to reduce downtime for the final switch to Exadata. Alas, the incremental method does not support endian format conversion either (but there is a way around that which you will read about later). Here are the basic steps:
- Perform pre-migration tasks:
- Create an entry in the tnsnames.ora file for your database on Exadata (optional).
- Copy the password file and parameter file (init.ora or spfile) to Exadata.
- Create a level 0 backup of the database.
- Copy the backup files to Exadata (not required if backup resides on a shared file system or NFS).
- On Exadata, start the database in nomount mode.
- Restore the control file.
- Mount the database.
- Restore the database.
- Restrict user and application access to the database.
- Create an incremental level 1 backup of the source database.
- Copy the incremental backup files to Exadata.
- Recover the database (applying incremental backup and archived redo logs) until the cutover date.
- Perform post-migration tasks:
- Convert the database to RAC and create service names.
- Reconfigure client tnsnames.ora files.
- Make the database available to users and applications.
You certainly noticed that the steps for the incremental backup method are almost identical to the full backup method. The important difference is the downtime required. The bulk of the time for migrating the database is in the full backup itself. This could take hours to complete and, with the full backup method, that is all database downtime. The incremental backup method uses a level 0 backup instead of a full backup. Actually, the level 0 backup is the same as the full backup except that it has special properties that allow it to be used as a baseline to which incremental backups can be applied. Thus, using the incremental method, the database remains online for users during the longest part of the migration.
Block change tracking (BCT) should really be activated on the source database before the incremental level 0 is taken. When block change tracking is turned on, Oracle keeps track of all the blocks that have changed since the last level 0 backup by flipping a bit in a small bitmap file. This means that when you take an incremental level 1 backup, Oracle does not have to scan every block in the database to see which ones have changed. It simply looks them up in the block change tracking file instead. The use of a block change tracking file is almost guaranteed to reduce the time an incremental backup takes. We have seen cases where a 13TB data warehouse could be backed up incrementally using a BCT file in 15 minutes, down from 9 hours. To see if block change tracking is active, execute the following query in SQL*Plus:
SQL> SELECT status FROM v$block_change_tracking;
STATUS
----------
DISABLED
You do not have to shut down the database to activate block change tracking. It can be done at any time. To enable block change tracking, execute the following command:
SQL> ALTER DATABASE ENABLE BLOCK CHANGE TRACKING;
Database altered.
By default, the block change tracking file is created in the db_create_file_dest location. If this parameter is not set, you will need to set it or specify the file name for the block change tracking file:
ALTER DATABASE ENABLE BLOCK CHANGE TRACKING
USING FILE '/u01/app/oracle/admin/<ORACLE_SID>/bct/bct.dat';
Post-migration tasks are necessary to convert your single-instance Exadata database to a multi-instance RAC database. In order to do so, you need to add mappings for instances to online redo log threads and also add additional undo tablespaces, one per instance. It is also a very sound idea to register the new RAC database in Clusterware. Once the database is recovered and running on Exadata, you should take a full database backup. Assuming the database is running in Archivelog mode, you can do this after the database is back online and servicing end users and applications.
![]() Note A slight variation of the incremental backup is to automate the process of rolling the copy forward using the Exadata database as a Data Guard physical standby. This will be covered later in the chapter.
Note A slight variation of the incremental backup is to automate the process of rolling the copy forward using the Exadata database as a Data Guard physical standby. This will be covered later in the chapter.
When to Use Backup and Restore
Executing a simple database backup and recovery using RMAN is something all DBAs should be able to do in their sleep. This makes the backup and restore a very attractive strategy. It is best suited for OLTP databases that do not require partitioning and HCC compression straight away. It is also suitable for data warehouse databases that already run on a little-endian, 64-bit platform, post-migration steps notwithstanding.
What to Watch Out for When Considering the Backup and Restore Strategy
Incremental backup and restore does not support endianness conversion. If this is a requirement, you might be better off using the Transportable Tablespace migration strategy or revisiting some of the logical migration strategies you read about earlier in this chapter. Objects will need to be rebuilt after migration to take advantage of Exadata storage features such as HCC. The same goes for data files. If your database has a lot of version history in it then you may have lots of small data files. In the days of Solaris 2.5 and early AIX versions the file system limits mandated that you could not create data files larger than 2GB. In the Exadata age it makes sense to reorganize these fragmented data files and the segments stored on them.
Related to these points are questions about materialized views, micro-partitioning tables, block fragmentation, and so on, which could be revisited in an effort to simplify and optimize the database on the new Exadata platform. It is also likely that rows are chained across multiple blocks when a database has a lot of history to it and has never been physically been reorganized.
Transportable Tablespaces
Transportable tablespaces (TTS) can be used to migrate subsets of the source database to Exadata. To do this, you need a running database on Exadata to host these subsets of your database. We often describe TTS as a sort of “Prune and Graft” procedure. This method allows a set of tablespaces to be copied from a source database and installed into a live target database. Unlike the full backup and restore procedure described earlier, you can plug in individual tablespaces into a 12c Pluggable Database. This way, you save yourself a bit of work converting a non-CDB to a PDB. This task is further simplified if you implemented schema-level consolidation in your source database. Assume for a moment that your schemas are all nicely self-contained on their own (bigfile) tablespaces. Migrating them to Exadata is a very elegant way of migrating, isn’t it?
The standard TTS method is based on image copies of the data files. The process is fairly simple, especially if there is no Data Guard physical standby database, but there are a few things you need to be aware of before beginning. The important restrictions around the process are these, as mentioned in Chapter 15:
- Tablespaces to be migrated must be put in read-only mode during the process.
- Character sets will, ideally, be the same for the source and target databases. There are exceptions to this rule. See the Oracle documentation if you plan to change character sets during migration.
- Objects with underlying dependencies like materialized views and table partitions are not transportable unless they are contained in the same set. A tablespace set is a way of moving a group of related tablespaces together in one operation.
- Before transporting encrypted tablespaces, you must first copy the Oracle wallet to the target system and enable it for the target database. A database can only have one Oracle wallet for TDE. If the database you are migrating to already has a wallet, you will need to use Data Pump to export and import table data.
- Tablespaces that do not use block-level encryption but have tables that use column encryption cannot be transported with TTS. In this case, Data Pump is probably the best alternative.
- Tablespaces that contain XML data types are supported by TTS as of 10g Release 2. In that release, you need to use the original exp/imp utilities to extract the metadata. From 11.1 onward, you have to use expdp/impdp. There are other restrictions and caveats to transporting XML data. Refer to the Oracle XML DB Developer’s Guide for a complete listing. To list tablespaces with XML data types, run the following query:
SQL> select distinct p.tablespace:name
from dba_tablespaces p,
dba_xml:tables x,
dba_users u,
all_all_tables t
where t.table_name=x.table_name
and t.tablespace:name=p.tablespace:name
and x.owner=u.username;
- Opaque types such as RAW and BFILE are supported by TTS but are not converted cross-platform. The structure of these types is only known to the application, and any differences in endian format must be handled by the application. Types and objects are subject to this limitation whether their use of opaque types is direct or indirect.
- Database version differences are supported as long as the target database is of the same or higher version than the source database.
Cross-Platform Transportable Tablespaces (XTTS) supports conversion between most but not all platforms. To determine whether your platform is supported, run the following query:
SQL>SELECT * FROM V$TRANSPORTABLE_PLATFORM ORDER BY PLATFORM_NAME;
PLATFORM_ID PLATFORM_NAME ENDIAN_FORMAT
----------- ----------------------------------- --------------
6 AIX-Based Systems (64-bit) Big
16 Apple Mac O/S Big
21 Apple Mac O/S (x86-64) Little
19 HP IA Open VMS Little
15 HP Open VMS Little
5 HP Tru64 UNIX Little
3 HP-UX (64-bit) Big
4 HP-UX IA (64-bit) Big
18 IBM Power Based Linux Big
9 IBM zSeries Based Linux Big
10 Linux IA (32-bit) Little
11 Linux IA (64-bit) Little
13 Linux x86 64-bit Little
7 Microsoft Windows IA (32-bit) Little
8 Microsoft Windows IA (64-bit) Little
12 Microsoft Windows x86 64-bit Little
17 Solaris Operating System (x86) Little
20 Solaris Operating System (x86-64) Little
1 Solaris[tm] OE (32-bit) Big
2 Solaris[tm] OE (64-bit) Big
Exadata is little-endian, 64-bit Linux (or Solaris x86-64), so if the source database is also little-endian, tablespaces may be transported as if the platform were the same. If the source platform is big-endian, an additional step is required. To convert a tablespace from one platform to another, use the RMAN CONVERT TABLESPACE or CONVERT DATAFILE command. You may convert the endian format of files during the backup using the following command:
RMAN> CONVERT TABLESPACE payroll_data,payroll_mviews
TO PLATFORM 'Linux x86 64-bit'
FORMAT '/u01/shared_files/%U';
In this example, RMAN converts the data files to an endian format compatible with Exadata. The converted data files are uniquely named automatically (%U) and saved in the /u01/shared_files directory. This conversion can alternatively be performed on the source system as just demonstrated or the target (Exadata). The following command converts the endian format during the restore operation on Exadata:
RMAN> CONVERT DATAFILE payroll_data.dbf, payroll_mviews.dbf
FROM PLATFORM 'Solaris[tm] OE (64-bit)'
DB_FILE_NAME_CONVERT
'/u01/shared_files/payroll_data.dbf','+DATA',
'/u01/shared_files/payroll_mviews.dbf','+DATA';
This gives you the additional advantage of moving the files into ASM at the same time. A tablespace can be transported individually or as part of a transport set. Transport sets are more common because, more often than not, object dependencies exist across tablespaces. For example, there may be tables in one tablespace and dependent materialized views or indexes in another. In order to transport a tablespace, you must first put it in read-only mode. Tablespace metadata is then exported using Data Pump with the transportable_tablespaces parameter. You should also specify the TRANSPORT_FULL_CHECK parameter to ensure strict containment of the tablespaces being transported. This ensures that no dependent objects (like indexes) exist outside of the transport set. RMAN is then used to take a backup of the tablespaces in the transport set. Conversion between endian formats may be done during the RMAN backup or during the restore on the target system. Here are the steps for transporting tablespaces to Exadata:
- Identify tablespace object dependencies.
- Set tablespaces to read-only mode.
- Export metadata for the transport set using Data Pump.
- Take an RMAN backup of the tablespaces in the transport set.
- Copy the export files along with the data file backups to Exadata.
- Restore the data files from the RMAN backup to your Exadata database. If endian conversion is needed, use the CONVERT DATAFILE command to restore and convert the data files simultaneously.
- Make the tablespaces read/write again.
- Using Data Pump, import the tablespace metadata into the Exadata database using the transport_datafiles parameter. You can optionally remap the schema of the tablespace contents using the remap_schema parameter.
When to Use Transportable Tablespaces
TTS and XTTS are useful for migrating portions of the source database using the speed of RMAN. If parts of your database are ready to move to Exadata but others are not, TTS may be a good fit. Be careful, though, that some objects in the data dictionary are not migrated along—grants, privileges, PL/SQL code—, and so must be exported separately. And you also have to pre-create accounts before you can plug the tablespaces into the database. Remember the metadata-only Data Pump export? This could be a good strategy to create a SQLFILE and execute the necessary DDL commands.
What to Watch Out for with the Transportable Tablespace Strategy
Check your Oracle documentation for specific restrictions or caveats that may apply to your database. Watch out for tablespace and schema name collisions on the target (Pluggable) database. Tablespaces must be put in read-only mode for the move, so this will incur downtime for applications requiring read-write access to the tablespaces. This downtime window should not be underestimated! The tablespaces have to remain read-only for as long as it takes to migrate the copy into Exadata. For a multi-TB database, that duration can be very significant and range days, if not weeks (all depending on network throughput or alternative means of getting data to the Exadata system). You can run an RMAN backup of the tablespaces while they are in read/write mode to see how long this operation will take before deciding whether TTS is an appropriate method or not for your migration. One option to shorten the downtime window without having to resort to logical replication tools is the use of Cross-Platform Transportable Tablespaces with Incremental Backups. This will not completely eliminate the downtime window, but has the potential to shorten it considerably. If you truly require no downtime migrations, you need to use logical migration tools capturing any changes to the system while the endianness conversion to Exadata is ongoing. Only after the transportable tablespace set is completely imported into Exadata can the floodgates be opened and the replication of the changes on Exadata begin.
Cross-Platform TTS with Incremental Backups
Another option to physically migrate a subset of the database is to use a little known My Oracle Support note and the steps documented in it. There is nothing really new to this procedure as it builds on top of features already within the database—you just read about XTTS, for example. The MOS document is titled “11G - Reduce Transportable Tablespace Downtime using Cross Platform Incremental Backup” and has a Doc ID of 1389592.1. The procedure described in it applies to Oracle 11.2. The MOS document has been updated for 12c very recently, referring to another Doc ID: 2005729.1. The procedure for 12c as just mentioned requires that the source database and destination have their initialization parameter compatible set to 12.1.0 or higher. Since it is quite likely that you are moving off old hardware, it is unrealistic to assume that you upgrade your source system in place to 12c before migrating to Exadata. This section, therefore, focuses on the procedure for 11.2. Once the database is safely on the Exadata system, further steps to bring it up to a higher version can be taken.
As the name suggests, the whole idea is based on cross-platform transportable tablespaces. XTTS are not new—so why this section about incremental backups? While indeed XTTS are well known, what is new is the way you use incremental backups to roll the image copies of the data files forward. That is nothing new, either, because that is exactly what happens when you recover a database. What is truly new, however, is that you take the incremental backup on your source system and apply it on your destination Exadata database. If you consider that your source system is most likely Big Endian such as Power, or SPARC, or Itanium-based, you will start appreciating the elegance of the proposed solution.
In summary, x-platform TTS plus incremental backups allow you to migrate your big-endian database from your old hardware into Exadata, potentially at very little expense (of downtime). The amount of downtime you will incur is expected to be roughly proportional to the amount of metadata you will need to import as part of the transportable tablespace move. The procedure you are reading about is focused around these steps, most of which are initiated using a perl script named xttdriver.pl:
- Begin with a setup phase in which you set up all the needed structures, databases, and scripts.
- During the preparation phase, you create the initial image copies of the data files to migrate and transfer them to the Exadata system.
- During the roll-forward phase, you take incremental backups of the source system and apply them on the image copies of the destination system.
- When the cutover weekend has finally arrived, you put the tablespace(s) to be migrated into read-only mode, create a last incremental backup, apply it, and plug the tablespace in.
- You can verify the data file in the Exadata database before flipping the switch and making it read-write.
If you read the above bullets attentively, you will have noticed that the source system stays online and available until the cutover date. This is a huge advantage compared to the “traditional” TTS approach, where you place the tablespace into read-only mode for as long as it takes to convert all its data files.
Before Christmas 2013 (and Oracle 11.2.0.4), the procedure you read about now was slightly more involved. Instead of just a source and destination database, you had to have a conversion instance. If your destination database is 11.2.0.4 or higher, you no longer need that instance. If you want to migrate to 11.2.0.3, which we hope you do not have to do, an additional “conversion” instance is required. Furthermore, the procedure used to be supported when you migrated to Exadata only. This restriction has now been lifted as well and you can use it to migrate to 64-bit Oracle Linux.
![]() Warning The X-platform TTS + incremental backup procedure cannot perform any magic and work around the limitations of TTS. Make sure to read the previous section of this chapter and the Oracle documentation set to understand the limitations of TTS.
Warning The X-platform TTS + incremental backup procedure cannot perform any magic and work around the limitations of TTS. Make sure to read the previous section of this chapter and the Oracle documentation set to understand the limitations of TTS.
For this section, please assume that the source database resides on Solaris on SPARC (meaning big endian) and will be migrated to Exadata (meaning little endian). The source database with the ORACLE_SID “solaris” uses Oracle 11.2.0.3, while the destination database “EXA” is 11.2.0.4. A conversion instance, therefore, is not required. Be careful in Data Guard environments—the new data files are not automatically copied to the standby databases. It is your responsibility to ensure the files are physically present on all the standby databases in addition to the primary.
You start the preparation by looking up DOC ID 1389592.1 and downloading the attached zip file. At the time of writing, the file was named rman_xttconvert_2.0.zip. Stage the zip file on the source host. In the following example, we will use a new directory named xtt in the oracle user’s home directory to keep the scripts and configuration files.
With version 2 of the scripts, you have the option to transfer the files either using DBMS_FILE_TRANSFER or RMAN. The advantage of the first is that you do not need to worry how to get the data files into Exadata. On the other hand, there is a restriction with regards to the maximum file size, which cannot exceed 2 TB. That restriction renders the DBMS_FILE_TRANSFER procedure problematic, especially with bigfile tablespaces. For that reason, the RMAN method is chosen in this example.
When using the RMAN approach, you have to think about how the files can be transferred physically between the source and destination systems. For systems in clos(er) proximity, NFS might be an option. But firewalls and routing issues to the various VLAN settings often times prevent NFS from being used. The fallback alternative—especially for longer distances—is SCP. Depending on your network bandwidth, you can start multiple SCP sessions in parallel, and even compress data as it flows through the pipe. The downside to using the RMAN approach should not be concealed either: You will require a staging area on the source and destination side to hold the image copies as well as any incremental backups. Thankfully for those Exadata users that always looked for a purpose for their DBFS_DG, here is one in form of using the database filesystem option with a database in the DBFS_DG disk group as the staging area! And Oracle 12.1.0.2 Grid Infrastructure allows you to use ACFS as an alternative to DBFS.
As part of the preparation, you need to edit the xtt.properties file. It contains all the information about source and target databases, data file backup locations, and a lot more, all of which is needed for the next steps. Here is an example of the configuration file stripped of all comments:
oracle@solaris:~/xtt$ grep -i '^[a-z]' xtt.properties
tablespaces=DATA_TBS
platformid=2
dfcopydir=/u01/stage/src
backupformat=/u01/stage/src
stageondest=/u01/stage/dest
storageondest=+DATA/EXA/datafile/
backupondest=+RECO
asm_home=/u01/app/11.2.0.4/grid
asm_sid=+ASM1
parallel=8
rollparallel=4
Here, tablespaces list the tablespace to be migrated. Multiple tablespaces can be listed, but they need to be comma separated. The platform ID is the source database’s v$database.platform_id. The directory indicated by dfcopydir is the location where the image copies of the tablespaces will be placed during the prepare phase (more on that later). Likewise, backupformat takes the directory where the incremental backups are created. On the Exadata, stageondest is where the process expects the initial image copies. The converted data files will then be stored in storageondest. The location indicated by backupondest instructs the driver script to write the incremental backups during the roll-forward phase. The ASM parameters are self-describing. You can take advantage of parallel execution of some steps as well: Parallel is the degree of parallelism during the data file conversion, and roll parallel defines the level of parallelism rolling the image copies forward using the incremental backups from the source. Adjust the parameters to suit your needs. You will have to set a few other parameters should you decide to use the DBMS_FILE_TRANSFER method. These parameters are not shown here to keep it simple.
![]() Note Yes, that is correct—you can take incremental backups on the source (big endian) platform and apply them on image copies in Exadata. That is why we like the process so much.
Note Yes, that is correct—you can take incremental backups on the source (big endian) platform and apply them on image copies in Exadata. That is why we like the process so much.
With the configuration completed on the source system, copy the xtt directory to the driving Exadata compute node into the Oracle user’s home directory. Ensure that all the directories exist. You could, of course, make use of NFS as well—your directories indicated by dfcopydir, backupformat, stageondest will be the same in that case.
Once the step completes, transfer the image copies to the Exadata system to the stageondest directory. This step is optional if you are using NFS. You also need to copy the newly created metadata files and scripts to the ~/xtt directory on Exadata. After the data files have made it across, convert them to 64-bit Linux x86-64. Note that it does not matter how long this takes. The tablespace has been online read-write all the time on the source database, so there is no impact on application availability on the source at all.
The next phase is named roll-forward. You take an incremental backup of the tablespace you want to migrate with the intention to roll the image copies previously taken forward. Again, this is the biggest selling point of this technique: You take a backup on a big-endian system to roll a data file already converted to little-endian forward. The backup files alongside their meta-information and scripts need to be transferred to Exadata where they are applied. This process can be repeated many times until the next phase starts: the transport phase.
The transport phase is not really different from the traditional x-platform TTS technique: You change the tablespaces to be migrated to read-only mode on the source and take a last incremental backup, transfer, and apply it on Exadata. As soon as you set the source tablespaces to read-only mode, you incur the outage on the source. The difference compared to regular x-platform TTS is that you do not need to transfer the data files to Exadata and convert them, potentially a huge time saver. The last incremental backup ensures that your image copies in the Exadata database are 100% current. If the data owners of the tablespaces you want to import do not exist yet, create them now including grants, roles, and privileges. As soon as the final roll-forward command finishes, you can import the tablespace metadata into the Exadata database.
Once the import finished—the time for it to finish is proportional to the amount of dictionary metadata associated with the tablespaces you are importing—you can validate the tablespaces for integrity and make them read-write on the destination.
Physical Standby
In the physical standby strategy, the target database is instantiated from a full backup of the source database. The backup is restored to Exadata in the same way you would for the backup and restore strategy. Once the database is restored to Exadata, it is started in mount mode and kept in a continual state of recovery. As changes occur in the source database, redo information is generated and transmitted to the standby database, where changes are written to the standby redo logs before they are applied (Redo Apply). Unlike the backup and restore strategy, this database is kept in recovery mode for a period of time. Because redo information is constantly being applied to the standby database, conversion from big-endian to little-endian format is not supported. Standby databases have been around since version 7 of Oracle. The capability is inherent in the database architecture. Of course, back then you had to write scripts to monitor the archive log destination on the source system and then copy them (usually via FTP) to the standby system, where another script handled applying them to the standby database. In version 9i, Oracle introduced a new product called Data Guard to manage and automate many of those tedious tasks of managing and monitoring the standby environment. Today Data Guard provides the following services:
- Redo Transport Services
- Handles the transmission of redo information to the target system
- Resolves gaps in archive redo logs due to network failure
- Detects and resolves missing or corrupt archived redo logs by retransmitting replacement logs
- Apply Services
- Automatically applies redo information to the standby database in real time, whenever possible
- Can allow read-only access to the standby database during redo apply, which requires a license for the Active Data Guard option
- Provides role transition management: The role of the source and standby databases may be switched temporarily or permanently
- Switchover: gracefully switches the roles of the source and standby databases. Does not have any impact on the databases in the Data Guard configuration. Useful for undoing a migration to the old hardware if no version changes are involved
- Failover: change in roles, usually as a consequence of a site failure. Requires a re-instantiation of the former primary database either by means of Flashback Database, where applicable, or a complete rebuild. Not normally used for migrations
- Data Guard Broker:
- Simplifies the configuration and management of the standby database
- Oracle Enterprise Manager offers a graphical user interface that can assist in creating a Data Guard configuration
- Centralized console for monitoring and managing the standby database environment
- Simplifies switchover/failover of the standby database
- A very versatile command line interface exists as well.
Data Guard provides three modes of protection of the standby database:
- Maximum Availability: A good compromise between the laissez-faire approach employed by the maximum performance mode and the very strict maximum performance setting. For transactions to commit on the primary, at least one synchronized standby database must have received the relevant redo information in one of its standby redo logs. If that is not possible, the primary will still carry on. With 12c, it is possible to configure maximum availability in FASTSYNC mode. In this mode, the standby database acknowledges to the primary that it received the redo information without having to wait for I/O to complete, writing the information to disk. The slightly higher performance this mode offers might expose you to a higher risk of data loss.
- Maximum Performance: The default protection mode in Data Guard. It does not impact the availability of the primary database at all, primary and standby database operate independently of each other. The standby database can still be completely in synch with the primary using real-time redo apply.
- Maximum Protection: the only Data Guard configuration that can guarantee zero data loss. Now that sounds like a very desirable feature, but it comes at the cost of potential loss of service. If the primary standby database cannot write redo information to the standby, it will shut down. Few customers implement this protection mode. Operating in this protection mode can imply a performance penalty on the primary database.
Keep in mind that although Data Guard is an excellent tool for database migration, it is not its only purpose. Data Guard’s force is protecting databases from media corruption, catastrophic media failure, and site failure. It is an integral component in Oracle’s Maximum Availability Architecture. So, it is no surprise that some of the replication modes mentioned above make no sense in the context of database migration. Maximum performance is the replication mode most appropriate for migrating databases because it has no impact on the performance of the source database. In maximum performance mode, the source database continues to function as it always has. Transactions are not delayed by network issues or downstream replication problems. It is also worth mentioning that Data Guard fully supports either a single-instance standby or an Oracle RAC standby. And as of 11gR1, redo can be applied while the standby database is open in read-only mode provided you paid for the Active Data Guard option. There is also strong integration with Enterprise Manager Grid Control.
Interesting new features in Data Guard 12c include the Far-Sync standby configuration, allowing the database to send redo to really remote locations more easily. Support for cascading standby databases has also been greatly enhanced, but these do not add value for the average database migration and will not be covered here.
When to Use Physical Standby
The physical standby database does not allow any changes to the database (other than data file name changes). As a result, it is best suited for database migrations where no changes to the target database are required. In that respect, it is very similar to the full backup and restore you read about earlier in the chapter. If changes need to be made, they will have to be done post-migration. Generally speaking, this is less of an issue with OLTP databases because changes such as migrating to large table extent sizes, implementing partitioning, and implementing HCC are not as beneficial as they are for larger DW databases. If getting to Exadata as quickly and safely as possible is your goal, physical standby may be a good fit. With Exadata’s performance and scalability, post-migration tasks may take far less time to implement than you might expect.
What to Watch Out for When Considering the Physical Standby Strategy
There aren’t many twists or turns with the physical standby strategy. You should keep an eye on network stability and performance. While it is possible to use Oracle’s cross-platform physical standby feature for low-downtime migrations between some platforms, you have no opportunity to do such migrations across platforms with different byte order (endian orientation). There are also some Oracle version specific limitations. (Read more from My Oracle Support note 413484.1 “Data Guard Support for Heterogeneous Primary and Physical Standbys in Same Data Guard Configuration.”) If a low-downtime migration between incompatible platforms is required, you should consider the Logical Standby, Streams, or Golden Gate strategies instead.
Wrap Up Physical Migration Section
Physical migration may prove to be an easy migration option if your application schema is complex enough that you do not want to take any logical migration path. It is also very suited for the migration of lots of databases into Exadata. If you need quick results, a physical migration—“lift and shift”—is the way to go, but do not forget to simplify and optimize when you have a chance.
Also, physical migration can potentially be done with very low downtime by restoring a production copy to the Exadata database as a physical standby database and applying production archivelogs until it is time to switch over and make standby the new production database. However, this approach cannot be used between platforms with different endianness, and there are a few more Oracle version specific restrictions.
Dealing with Old Initialization Parameters
When migrating from an older version of Oracle, you might be tempted to keep all the old (undocumented) init.ora parameters for “tuning” or “stability.” The fact is that Oracle has very good default values for its parameters since 10g, especially so in 11.2 and later, which likely runs on your Exadata cluster. Whatever problems were solved by setting these undocumented parameters years ago are probably already fixed in the database code. Also, moving to Exadata brings a much bigger change than any parameter adjustment can introduce, so the stability point is also moot. As such, it is recommended not to carry over any undocumented parameters from the old databases, unless your application (such as Oracle Siebel, SAP) documentation clearly states it as a requirement for the new Oracle release you are migrating to.
Planning VLDB Migration Downtime
When you are estimating the downtime or data migration time, you should only rely on actual measurements in your environment, with your data, your network connection, database settings, and compression options. While it is possible to load raw data to a full rack at 5TB/hour (Exadata V2) or even 21.5 TB/hour (Exadata X5-2) according to Oracle, you probably are unlikely to get such loading speeds when the target tables are compressed with ARCHIVE or QUERY HIGH. No matter which numbers you find from this book or official specs, you will have to test everything out yourself, end to end. There are some temporary workarounds for improving loading rates. For example, if you have enough disk space, you can first load to non-compressed or EHCC QUERY LOW-compressed tables during the downtime window and, once in production, recompress individual partitions with higher compression rates.
Summary
In this lengthy chapter, you read a lot about the wide range of tools available for migrating your data to Exadata. You should choose the simplest approach you can as this reduces risk and can also save your own time. You might consider evaluating Data Pump as well; it is often overlooked, but it can transfer the whole database or just a schema. In 12c, the Full Transportable Export/Import leverages Transportable Tablespaces under the covers. And it can do the job fast and is even flexible when you want to adjust the object DDL metadata in the process. Often, however, this approach is not fast enough (network bandwidth!) or requires too much temporary disk space. It all depends on how much data you have to transfer and how much downtime you are allowed. When moving VLDBs that are tens or even hundreds of terabytes in size, you may have to get creative and use less straightforward approaches like database links, copying read-only data in advance, or perhaps doing a completely incremental migration using one of the replication approaches. The cross-platform transportable tablespaces plus incremental backup method is very useful, helping you with a low downtime window if the metadata export does not consume too much time.
Every enterprise’s database environments and business requirements are different, but you can use the methods explained in this chapter as building blocks. You may need to combine multiple techniques if the migrated database is very large and the allowed downtime is small. No matter which techniques you use, the most important thing to remember is to test everything—the whole migration process from end to end—preferably multiple times to iron out any problems along the way. You will likely find and fix many problems in advance thanks to systematic testing. Good luck!