
![]()
Storage Layout
In Oracle 10gR1, Oracle introduced Automatic Storage Management (ASM) and changed the way we think of managing database storage. Exadata is the first Oracle product to rely completely on ASM to provide database storage. Without ASM, databases would not be capable of utilizing the Exadata storage servers at all. Because of this, ASM is a hard requirement for running Exadata. While ASM may not be a new technology, the storage servers are a concept that had not been used prior to Exadata.
Looking at all the various intricacies of cell storage can be a little daunting at first. There are several layers of abstraction between physical disks and the ASM disk groups many DBAs are familiar with. If you’ve never worked with Oracle’s ASM product, there will be a lot of new terms and concepts to understand there as well. In Chapter 8, we discussed the underlying layers of Exadata storage from the physical disks up through the cell disk layer. This chapter will pick up where Chapter 8 left off and discuss how cell disks are used to create grid disks for ASM storage. We’ll briefly discuss the underlying disk architecture of the storage cell and how Linux presents physical disks to the application layer. From there, we’ll take a look at the options for carving up and presenting Exadata grid disks to the database tier. The approach Oracle recommends is to create a few large “pools” of disks across all storage cells. While this approach generally works well from a performance standpoint, there are reasons to consider alternative strategies. Sometimes, isolating a set of storage cells to form a separate storage grid is desirable. This provides separation from more critical systems within the Exadata enclosure so that patches may be installed and tested before they are implemented in production. Along the way, we’ll take a look at how ASM provides fault resiliency and storage virtualization to databases. Lastly, we’ll take a look at how storage security is implemented on Exadata. The storage cell is a highly performant, highly complex, and highly configurable blend of hardware and software. This chapter will take a close look at how all the various pieces work together to provide flexible, high-performance storage to Oracle databases.
When Linux boots up, it runs a scan to identify disks attached to the server. When a disk is found, the operating system determines the device driver needed and creates a block device called a LUN for application access. While it is possible for applications to read and write directly to these block devices, it is not a common practice. Doing so subjects the application to changes that are complicated to deal with. For example, because device names are dynamically generated on bootup, adding or replacing a disk can cause all of the disk device names to change. ASM and databases need file permissions to be set that will allow read/write access to these devices as well. In earlier releases of ASM, system administrators managed disk name persistency via native Linux utilities such as ASMLib and udev. Exadata shields system administrators and DBAs from these complexities through various layers of abstraction. Cell disks provide the first abstraction layer for LUNs. Cell disks are used by cellsrv to manage I/O resources at the storage cell. Grid disks are the next layer of abstraction and are the disk devices presented to the database servers as ASM disks. Figure 14-1 shows how cell disks and grid disks fit into the overall storage architecture of an Exadata storage cell.
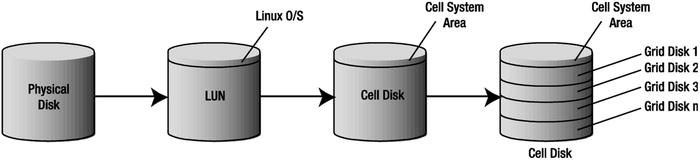
Figure 14-1. The relationship between physical disks and grid disks
With the introduction of ASM, Oracle provided a way to combine many physical disks into a single storage volume called a disk group. Disk groups are the ASM replacement for traditional file systems and are used to implement Oracle’s SAME (Stripe and Mirror Everything) methodology for optimizing disk performance. As the name implies, the goal of SAME is to spread I/O evenly across all physical disks as visible from the ASM instance. Virtualizing storage in this way allows multiple databases to share the same physical disks. It also allows physical disks to be added or removed without interrupting database operations. If a disk must be removed, ASM migrates its data to the other disks in the disk group before it is dropped. When a disk is added to a disk group, ASM automatically rebalances data from other disks onto the new disk to ensure that no single disk contains more data than the others. In a very basic ASM configuration, LUNs are presented to ASM as ASM disks. ASM disks are then used to create disk groups, which in turn are used to store database files such as data files, control files, and online redo logs. The Linux operating system presents LUNs to ASM as native block devices such as /dev/sda. Exadata virtualizes physical storage through the use of grid disks and ASM disk groups. Grid disks are used for carving up cell disks similar to the way partitions are used to carve up physical disk drives. Figure 14-2 shows the relationship between cell disks, grid disks, and ASM disk groups. It is important to remember that ASM disks on Exadata are different from ASM disks on a standard system in that they are not physically mounted on the database server. All ASM disks on Exadata are accessed via the iDB protocol.

Figure 14-2. ASM disk group with its underlying grid disks and cell disks
Before we talk in more detail about grid disks, let’s take a brief detour and talk about how disk redundancy is handled in the ASM architecture. ASM uses redundant sets of ASM disks called failure groups to provide mirroring. Traditional RAID1 mirroring maintains a block-for-block duplicate of the original disk. ASM failure groups provide redundancy by assigning ASM disks to failure groups and guaranteeing that the original and any mirror copies of a block do not reside within the same failure group. It is critically important to separate physical disks into separate failure groups. Because each of the storage servers is an independent Linux system (that could fail at any moment), Exadata breaks each of the disks from a storage server into a fail group. This ensures that two disks on a single storage server will never contain two copies of the same block. For example, the following listing shows the fail groups and grid disks for storage cells 1-3. As the names imply, these fail groups correspond to storage cells 1–3. These fail groups were created and named automatically by ASM when the grid disks were created.
SYS:+ASM1> select failgroup, name from v$asm_disk order by 1,2
FAILGROUP NAME
----------- ----------------------
CELL01 DATA_CD_00_CELL01
CELL01 DATA_CD_01_CELL01
CELL01 DATA_CD_02_CELL01
CELL01 DATA_CD_03_CELL01
...
CELL02 DATA_CD_00_CELL02
CELL02 DATA_CD_01_CELL02
CELL02 DATA_CD_02_CELL02
CELL02 DATA_CD_03_CELL02
...
CELL03 DATA_CD_00_CELL03
CELL03 DATA_CD_01_CELL03
CELL03 DATA_CD_02_CELL03
CELL03 DATA_CD_03_CELL03
Figure 14-3 shows the relationship between the DATA disk group and the failure groups, CELL01, CELL02, and CELL03. Note that this does not indicate which level of redundancy is being used, only that the DATA disk group has its data allocated across three failure groups.

Figure 14-3. ASM failure groups CELL01–CELL03
There are three types of redundancy in ASM: External, Normal, and High:
- External Redundancy: No redundancy is provided by ASM. It is assumed that the storage array, usually a SAN, is providing adequate redundancy—in most cases, RAID1, RAID10, or RAID5. This has become the most common method where large storage area networks are used for ASM storage. In the Exadata storage grid, ASM provides the only mechanism for mirroring. If External Redundancy were used on Exadata, the loss of a single disk drive would mean a catastrophic loss of the entire ASM disk group using that disk. It also means that even the temporary loss of a storage cell (reboot, crash, or the like) would make all disk groups using storage on the failed cell unavailable for the duration of the outage and possibly require a database recovery.
- Normal Redundancy: Normal Redundancy maintains two copies of data blocks in separate failure groups. Until Oracle 12c, databases will always attempt to read from the primary copy of a data block first. Secondary copies are only read when the primary blocks are unavailable or corrupted. At least two failure groups are required for Normal Redundancy, but many more may be used. For example, an Exadata full rack configuration has 14 storage cells, and each storage cell constitutes a failure group. When data is written to the database, the failure group used for the primary copy of every other block rotates from failure group to failure group in a round-robin fashion. This ensures that disks in all failure groups participate in read operations.
- High Redundancy: High Redundancy is similar to Normal Redundancy except that three copies of data blocks are maintained in separate failure groups.
In order for ASM to maintain sanity regarding where the primary and secondary copies of data reside, each disk has a set number of partners where the redundant copy could be. By default, each disk will have eight partners. This number is the same regardless of whether Normal or High Redundancy is used. The partner relationship between disks can be seen by querying the x$kfdpartner view inside of the ASM instance. For example, looking at disk 0 in the DATA disk group, we can see the eight partner disks:
SQL> select g.name "Diskgroup", d.disk_number "Number", d.name "Disk"
2 from v$asm_diskgroup g, v$asm_disk d
3 where g.group_number=d.group_number
4 and g.name='DATA'
5 and d.name='DATA_CD_00_ENKCEL01'
6 /
Diskgroup Number Disk
------------------------------ ----------- -------------------
DATA 0 DATA_CD_00_ENKCEL01
SQL> select g.name "Diskgroup", d.name "Disk", p.number_kfdpartner "Partner", d.FAILGROUP "Failgroup"
2 from x$kfdpartner p, v$asm_disk d, v$asm_diskgroup g
3 where p.disk = 0
4 and g.name='DATA'
5 and p.grp=g.group_number
6 and d.group_number = g.group_number
7 and p.number_kfdpartner=d.disk_number
8 ORDER BY p.number_kfdpartner
9 /
Diskgroup Disk Partner Failgroup
------------------------------ ------------------------------ ----------- ---------
DATA DATA_CD_02_ENKCEL02 13 ENKCEL02
DATA DATA_CD_03_ENKCEL02 14 ENKCEL02
DATA DATA_CD_06_ENKCEL02 17 ENKCEL02
DATA DATA_CD_07_ENKCEL02 18 ENKCEL02
DATA DATA_CD_05_ENKCEL03 28 ENKCEL03
DATA DATA_CD_06_ENKCEL03 29 ENKCEL03
DATA DATA_CD_08_ENKCEL03 31 ENKCEL03
DATA DATA_CD_11_ENKCEL03 34 ENKCEL03
The partner disks are balanced evenly across the remaining two storage cells on the quarter rack shown above. Whenever ASM places a primary copy of data on DATA_CD_00_ENKCEL01, the secondary (or tertiary copy in High Redundancy disk groups) will be placed on one of the eight disks listed by the second query above. From a disk failure standpoint, the partner disks are crucial. In a Normal Redundancy disk group, only one disk that contains portions of the data can be offline. In a High Redundancy disk group, a disk and one of its eight partners can be offline because a third copy of the data exists. If ASM is unable to reach any of the copies of data, the entire disk group will be taken offline in an attempt to prevent possible data loss or corruption.
No matter the number of copies of data, Oracle ASM in version 11g will only read from the primary copy of data. If a disk fails, ASM will look for the redundant copy. In Oracle 12c, an “even read” feature has been introduced. In the event of a disk failure, ASM will attempt to keep disk I/O balanced by reading both primary and secondary copies of all data, regardless of the status of the primary copy.
Grid Disks
Grid disks are created within cell disks, which you may recall are made up of physical disks. Grid disks can either reside on hard-disk-based or flash-based cell disks. In a simple configuration, one grid disk can be created per cell disk. Typical configurations have multiple grid disks per cell disk. The CellCLI command list griddisk displays the various characteristics of grid disks. For example, the following output shows the relationship between grid disks and cell disks, the type of device on which they are created, and their size:
[enkcel03:root] root
> cellcli
CellCLI: Release 11.2.1.3.1 - Production on Sat Oct 23 17:23:32 CDT 2010
Copyright (c) 2007, 2009, Oracle. All rights reserved.
Cell Efficiency Ratio: 20M
CellCLI> list griddisk attributes name, celldisk, disktype, size
DATA_CD_00_cell03 CD_00_cell03 HardDisk 1282.8125G
DATA_CD_01_cell03 CD_01_cell03 HardDisk 1282.8125G
...
FLASH_FD_00_cell03 FD_00_cell03 FlashDisk 4.078125G
FLASH_FD_01_cell03 FD_01_cell03 FlashDisk 4.078125G
...
ASM doesn’t know anything about physical disks or cell disks. Grid disks are what the storage cell presents to the database servers (as ASM disks) to be used for Clusterware and database storage. ASM uses grid disks to create disk groups in the same way conventional block devices are used on a non-Exadata platform. To illustrate this, the following query shows what ASM disks look like on a non-Exadata system:
SYS:+ASM1> select path, total_mb, failgroup
from v$asm_disk
order by failgroup, group_number, path;
PATH TOTAL_MB FAILGROUP
--------------- ---------- ---------
/dev/sdd1 11444 DATA01
/dev/sde1 11444 DATA02
...
/dev/sdj1 3816 RECO01
/dev/sdk1 3816 RECO02
...
The same query on Exadata reports grid disks that have been created at the storage cell:
SYS:+ASM1> select path, total_mb, failgroup
from v$asm_disk
order by failgroup, group_number, path;
PATH TOTAL_MB FAILGROUP
------------------------------------------------------------ -------- ----------o/192.168.12.9;192.168.12.10/DATA_CD_00_CELL01 3023872 CELL01
o/192.168.12.9;192.168.12.10/DATA_CD_01_CELL01 3023872 CELL01
o/192.168.12.9;192.168.12.10/DATA_CD_02_CELL01 3023872 CELL01
...
o/192.168.12.9;192.168.12.10/RECO_CD_00_CELL01 756160 CELL01
o/192.168.12.9;192.168.12.10/RECO_CD_01_CELL01 756160 CELL01
o/192.168.12.9;192.168.12.10/RECO_CD_02_CELL01 756160 CELL01
...
o/192.168.12.11;192.168.12.12/DATA_CD_00_CELL02 3023872 CELL02
o/192.168.12.11;192.168.12.12/DATA_CD_01_CELL02 3023872 CELL02
o/192.168.12.11;192.168.12.12/DATA_CD_02_CELL02 3023872 CELL02
...
o/192.168.12.11;192.168.12.12/RECO_CD_00_CELL02 756160 CELL02
o/192.168.12.11;192.168.12.12/RECO_CD_01_CELL02 756160 CELL02
o/192.168.12.11;192.168.12.12/RECO_CD_02_CELL02 756160 CELL02
...
o/192.168.12.13;192.168.12.14/DATA_CD_00_CELL03 3023872 CELL03
o/192.168.12.13;192.168.12.14/DATA_CD_01_CELL03 3023872 CELL03
o/192.168.12.13;192.168.12.14/DATA_CD_02_CELL03 3023872 CELL03
...
o/192.168.12.13;192.168.12.14/RECO_CD_00_CELL03 756160 CELL03
o/192.168.12.13;192.168.12.14/RECO_CD_01_CELL03 756160 CELL03
o/192.168.12.13;192.168.12.14/RECO_CD_02_CELL03 756160 CELL03
...
o/192.168.12.15;192.168.12.16/DATA_CD_00_CELL04 3023872 CELL04
o/192.168.12.15;192.168.12.16/DATA_CD_01_CELL04 3023872 CELL04
o/192.168.12.15;192.168.12.16/DATA_CD_02_CELL04 3023872 CELL04
...
o/192.168.12.15;192.168.12.16/RECO_CD_00_CELL04 756160 CELL04
o/192.168.12.15;192.168.12.16/RECO_CD_01_CELL04 756160 CELL04
o/192.168.12.15;192.168.12.16/RECO_CD_02_CELL04 756160 CELL04
...
o/192.168.12.17;192.168.12.18/DATA_CD_00_CELL05 3023872 CELL05
o/192.168.12.17;192.168.12.18/DATA_CD_01_CELL05 3023872 CELL05
o/192.168.12.17;192.168.12.18/DATA_CD_01_CELL06 3023872 CELL05
...
o/192.168.12.17;192.168.12.18/RECO_CD_00_CELL05 756160 CELL05
o/192.168.12.17;192.168.12.18/RECO_CD_01_CELL05 756160 CELL05
o/192.168.12.17;192.168.12.18/RECO_CD_02_CELL05 756160 CELL05
...
Tying it all together, Figure 14-4 shows how the layers of storage fit together, from the storage cell to the ASM disk group. Note that the Linux operating system partitions on the first two cell disks in each storage cell are identified by a darkened partition. We’ll talk a little more about the operating system partitions later in this chapter and in much more detail in Chapter 8.
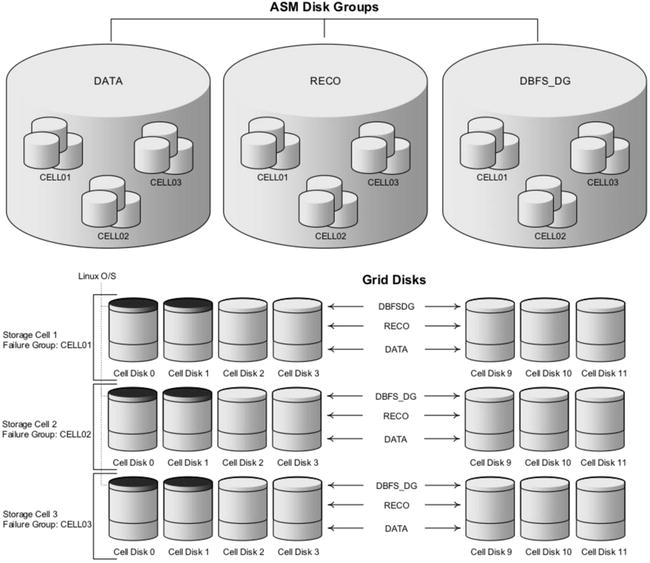
Figure 14-4. Storage on Exadata
Storage Allocation
Disk drives store data in concentric bands called tracks. Because the outer tracks of a disk have more surface area, they are able to store more data than the inner tracks. As a result, data transfer rates are higher for the outer tracks and decline slightly as you move toward the innermost track. Figure 14-5 shows how tracks are laid out across the disk surface from fastest to slowest.

Figure 14-5. Disk tracks
Exadata provides two policies for allocating grid disk storage across the surface of disk drives. The first method is the default behavior for allocating space on cell disks. It has no official name so, for purposes of this discussion, I’ll refer to it as the default policy. Oracle calls the other allocation policy interleaving. These two allocation policies are determined when the cell disks are created. Interleaving must be explicitly enabled using the interleaving parameter of the create celldisk command. For a complete discussion on creating cell disks, refer to Chapter 8.
Fastest Available Tracks First
The default policy simply allocates space starting with the fastest available tracks first, moving inward as space is consumed. Using this policy, the first grid disk created on each cell disk will be given the fastest storage, while the last grid disk created will be relegated to the slower, inner tracks of the disk surface. When planning your storage grid, remember that grid disks are the building blocks for ASM disk groups. These disk groups will, in turn, be used to store tables, indexes, online redo logs, archived redo logs, and so on. To maximize database performance, frequently accessed objects (such as tables, indexes, and online redo logs) should be stored in the highest priority grid disks. Low priority grid disks should be used for less performance-sensitive objects such as database backups, archived redo logs, and flashback logs. Figure 14-6 shows how grid disks are allocated using the default allocation policy.

Figure 14-6. The default allocation policy
Table 14-1 shows the performance effect on the ASM disk groups from the first to the last grid disk created when using the default allocation policy. You won’t find the term “I/O Performance Rating” in the Oracle documentation. It’s a term I’m coining here to describe the relative performance capabilities of each disk group due to its location on the surface of the physical disk drive.
Table 14-1. I/O Performance—Default Allocation Policy
|
ASM Disk Group |
I/O Performance Rating |
|---|---|
|
DATA |
1 |
|
RECO |
2 |
|
DBFS_DG |
3 |
The other policy, interleaving, attempts to even out performance of the faster and slower tracks by allocating space in an alternating fashion between the slower and faster tracks of the disks. This is achieved by splitting each cell disk into two regions—an outer region and an inner region. Grid disks are slices of cell disks that will be used to create ASM disk groups. For example, the following command creates 12 grid disks (one per physical disk; see Figure 14-4) on Cell03 to be used for the DATA disk group:
CellCLI> CREATE GRIDDISK ALL HARDDISK PREFIX=DATA, size=744.6813G
These grid disks were used to create the following DATA disk group. Notice how each grid disk was created on a separate cell disk:
SYS:+ASM2> select dg.name diskgroup,
substr(d.name, 6,12) cell_disk,
d.name grid_disk
from v$asm_diskgroup dg,
v$asm_disk d
where dg.group_number = d.group_number
and dg.name ='DATA'
and failgroup = 'CELL03'
order by 1,2;
DISKGROUP CELL_DISK GRID_DISK
---------- ------------ ---------------------
DATA CD_00_CELL03 DATA_CD_00_CELL03
DATA CD_01_CELL03 DATA_CD_01_CELL03
DATA CD_02_CELL03 DATA_CD_02_CELL03
DATA CD_03_CELL03 DATA_CD_03_CELL03
...
DATA CD_10_CELL03 DATA_CD_10_CELL03
DATA CD_11_CELL03 DATA_CD_11_CELL03
Using interleaving in this example, DATA_CD_00_CELL03 (the first grid disk) is allocated to the outer most tracks of the outer (fastest) region of the CD_00_CELL03 cell disk. The next grid disk, DATA_CD_01_CELL03, is created on the outermost tracks of the slower, inner region of cell disk CD_01_CELL03. This pattern continues until all 12 grid disks are allocated. When the next set of grid disks is created for the RECO disk group, they start with the inner region of cell disk 1 and alternate from inner to outer region until all 12 grid disks are created. Figure 14-7 shows how the interleaving policy would look if two grid disk groups were created.

Figure 14-7. The interleaving allocation policy
Table 14-2 shows the performance effect on the ASM disk groups from the first to the last grid disk created when the interleaving allocation policy is used.
Table 14-2. I/O Performance—Interleaving Policy
|
ASM Disk Group |
I/O Performance Rating |
|---|---|
|
DATA |
1 |
|
RECO |
1 |
|
DBFS_DG |
2 |
As you can see, the main difference between the default policy and the interleaving policy is that default provides finer-grained control over ASM disks. With the default policy you have the ability to choose which set of grid disks will be given the absolute fastest position on the disk. The interleaving policy has the effect of evening out the performance of grid disks. In practice, this gives the first two sets of grid disks (for DATA and RECO) the same performance characteristics. This may be useful if the performance demands of the first two disk groups are equal. In our experience, this is rarely the case. Usually there is a clear winner when it comes to the performance demands of a database environment. Tables, indexes, and online redo logs (the DATA disk group) have much higher performance requirements than database backups, archived redo logs, and flashback logs, which are usually stored in the RECO disk group. Unless there are specific reasons for using interleaving, we recommend using the default policy.
Creating Grid Disks
Before we run through a few examples of how to create grid disks, let’s take a quick look at some of their key attributes:
- Multiple grid disks may be created on a single cell disk, but a grid disk may not span multiple cell disks.
- Storage for grid disks is allocated in 16M Allocation Units (AUs) and is rounded down if the size requested is not a multiple of the AU size.
- Grid disks may be created one at a time or in groups with a common name prefix.
- Grid disk names must be unique within a storage cell and should be unique across all storage cells.
- Grid disk names should include the name of the cell disk on which they reside.
Once a grid disk is created, its name is visible from ASM in the V$ASM_DISK view. In other words, grid disks = ASM disks. It is very important to name grid disks in such a way that they can easily be associated with the physical disk to which they belong in the event of disk failure. To facilitate this, grid disk names should include both of the following:
- The name of the ASM disk group for which it will be used
- The cell disk name (which includes the name of the storage cell)
Figure 14-8 shows the properly formatted name for a grid disk belonging to the TEST disk group, created on cell disk CD_00_cell03.

Figure 14-8. Grid disk naming
The CellCLI command create griddisk is used to create grid disks. It may be used to create individual grid disks one at a time or in groups. If grid disks are created one at a time, it is up to you to provide the complete grid disk name. The following example creates one properly named 400GB grid disk on cell disk CD_00_cell03. If we had omitted the size=400GB parameter, the resulting grid disk would have consumed all free space on the cell disk:
CellCLI> create griddisk TEST_CD_00_cell03 –
celldisk='CD_00_cell03', size=400G
GridDisk TEST_CD_00_cell03 successfully created
CellCLI> list griddisk attributes name, celldisk, size –
where name='TEST_CD_00_cell03'
TEST_CD_00_cell03 CD_00_cell03 400G
There are 12 drives per storage cell, and the number of storage cells varies from 3, for a quarter rack, to 14, for a full rack. That means you will be creating a minimum of 36 grid disks for a quarter rack, and up to 168 grid disks for a full rack. Fortunately, CellCLI provides a way to create all the grid disks needed for a given ASM disk group in one command. For example, the following command creates all the grid disks for the ASM disk group TEST:
CellCLI> create griddisk all harddisk prefix='TEST', size=400G
GridDisk TEST_CD_00_cell03 successfully created
GridDisk TEST_CD_01_cell03 successfully created
...
GridDisk TEST_CD_10_cell03 successfully created
GridDisk TEST_CD_11_cell03 successfully created
When this variant of the create griddisk command is used, CellCLI automatically creates one grid disk on each cell disk, naming them with the prefix you provided in the following manner:
{prefix}_{celldisk_name}
The optional size parameter specifies the size of each individual grid disk. If no size is provided, the resulting grid disks will consume all remaining free space of their respective cell disk. The all harddisk parameter instructs CellCLI to use only disk-based cell disks. Just in case you are wondering, Flash Cache modules are also presented as cell disks (of type FlashDisk) and may be used for creating grid disks as well. We’ll discuss flash disks later on in this chapter. The following command shows the grid disks created:
CellCLI> list griddisk attributes name, cellDisk, diskType, size -
where name like 'TEST_.*'
TEST_CD_00_cell03 CD_00_cell03 HardDisk 96M
TEST_CD_01_cell03 CD_01_cell03 HardDisk 96M
...
TEST_CD_10_cell03 CD_10_cell03 HardDisk 96M
TEST_CD_11_cell03 CD_11_cell03 HardDisk 96M
Grid Disk Sizing
As we discussed earlier, grid disks are equivalent to ASM disks. They are literally the building blocks of the ASM disk groups you will create. The DBFS_DG disk group is created when Exadata is installed on a site. It is primarily used to store the OCR and voting files used by Oracle Clusterware (Grid Infrastructure). However, there is no reason DBFS_DG cannot be used to store other objects such as tablespaces for the Database File System (DBFS). In addition to the DBFS_DG, (formerly SYSTEMDG) disk group, Exadata is also delivered with DATA and RECO disk groups to be used for database files and Fast Recovery Areas. But these disk groups may actually be created with whatever names make the most sense for your environment. For consistency, this chapter uses the names DBFS_DG, DATA, and RECO. If you are considering something other than the “factory defaults” for your disk group configuration, remember that a main reason for using multiple ASM disk groups on Exadata is to prioritize I/O performance. The first grid disks you create will be the fastest, resulting in higher performance for the associated ASM disk group.
![]() Note When Exadata V2 rolled out, SYSTEMDG was the disk group used to store OCR and voting files for the Oracle Clusterware. When Exadata X2 was introduced, this disk group was renamed to DBFS_DG, presumably because there was quite a bit of usable space left over that made for a nice location for a moderately sized DBFS file system. Also, the other default disk group names changed somewhat when X2 came out. The Exadata Database Machine name was added as a postfix to the DATA and RECO disk group names. For example, the machine name for one of our lab systems is ENK. So DATA became DATA_ENK, and RECO became RECO_ENK.
Note When Exadata V2 rolled out, SYSTEMDG was the disk group used to store OCR and voting files for the Oracle Clusterware. When Exadata X2 was introduced, this disk group was renamed to DBFS_DG, presumably because there was quite a bit of usable space left over that made for a nice location for a moderately sized DBFS file system. Also, the other default disk group names changed somewhat when X2 came out. The Exadata Database Machine name was added as a postfix to the DATA and RECO disk group names. For example, the machine name for one of our lab systems is ENK. So DATA became DATA_ENK, and RECO became RECO_ENK.
By the way, Oracle recommends you create a separate database for DBFS because it requires instance parameter settings that would not be optimal for typical application databases.
Following are some of the most common ASM disk groups:
- DBFS_DG: This disk group is typically the location for Clusterware’s OCR and voting files, along with the spfile for ASM. It may also be used for other files with similar performance requirements. For OCR and voting files, Normal Redundancy is the minimum requirement. Normal Redundancy will create three voting files and three OCR files. The voting files must be stored in separate ASM failure groups. Recall that on Exadata, each storage cell constitutes a failure group. This means that only Normal Redundancy may be used for an Exadata eighth or quarter rack configuration (three storage cells/failure groups). Only in half rack and full rack configurations (seven or fourteen storage cells/failure groups) are there a sufficient number of failure groups to store the required number of voting and OCR files required by High Redundancy. Table 14-3 summarizes the storage requirements for OCR and voting files at various levels of redundancy. Note that External Redundancy is not supported on Exadata. We’ve included it in the table for reference only. If a High Redundancy disk group with a suitable number of fail groups is available, the scripted installation process will move the OCR and voting disks to that disk group.
Table 14-3. OCR and Voting File Storage Requirements

- DATA: This disk group is used for storing files associated with the db_create_file_dest database parameter. These include datafiles, online redo logs, control files, and spfiles.
- RECO: This disk group is what used to be called Flash Recovery Area (FRA). Some time after 11gR1, Oracle renamed it to the “Fast Recovery Area”; rumor has it that the overuse of “Flash” was causing confusion among the marketing team. So to clarify, this disk group will be used to store everything corresponding to the db_recovery_file_dest database parameter. It includes online database backups and copies, copies of the online redo log files, mirror copies of the control file, archived redo logs, flashback logs, and Data Pump exports.
Recall that Exadata storage cells are actually finely tuned Linux servers with 12 internal disk drives. Oracle could have dedicated two of these internal disks to run the operating system, but doing so would have wasted a lot of space. Instead, they carved off several small partitions on the first two disks in the enclosure. These partitions, about 33GB each, create a slight imbalance in the size of the cell disks. The DBFS_DG grid disks even out this imbalance. Figure 14-9 illustrates the size imbalance.

Figure 14-9. Cell disk layout
This reserved space can be seen by running parted on one of the storage cells. The /dev/sda3 partition in the listing is the location of the cell disk. All other partitions are used by the Linux operating system:
[root@enkx3cel01 ~]# parted /dev/sda print
Model: LSI MR9261-8i (scsi)
Disk /dev/sda: 3000GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Number Start End Size File system Name Flags
1 32.8kB 123MB 123MB ext3 primary raid
2 123MB 132MB 8225kB ext2 primary
3 132MB 2964GB 2964GB primary
4 2964GB 2964GB 32.8kB primary
5 2964GB 2975GB 10.7GB ext3 primary raid
6 2975GB 2985GB 10.7GB ext3 primary raid
7 2985GB 2989GB 3221MB ext3 primary raid
8 2989GB 2992GB 3221MB ext3 primary raid
9 2992GB 2994GB 2147MB linux-swap primary raid
10 2994GB 2995GB 732MB primary raid
11 2995GB 3000GB 5369MB ext3 primary raid
You can see the smaller cell disks in the size attribute when you run the list celldisk command:
CellCLI> list celldisk attributes name, devicePartition, size –
where diskType = 'HardDisk'
CD_00_cell01 /dev/sda3 2760.15625G
CD_01_cell01 /dev/sdb3 2760.15625G
CD_02_cell01 /dev/sdc 2793.953125G
CD_03_cell01 /dev/sdd 2793.953125G
CD_04_cell01 /dev/sde 2793.953125G
CD_05_cell01 /dev/sdf 2793.953125G
CD_06_cell01 /dev/sdg 2793.953125G
CD_07_cell01 /dev/sdh 2793.953125G
CD_08_cell01 /dev/sdi 2793.953125G
CD_09_cell01 /dev/sdj 2793.953125G
CD_10_cell01 /dev/sdk 2793.953125G
CD_11_cell01 /dev/sdl 2793.953125G
Let’s take a look at a fairly typical configuration to illustrate how grid disks are allocated in the storage cell. In this example, we’ll create grid disks to support three ASM disk groups. DBFS_DG will be used for the OCR and Voting files:
- DATA
- RECO
- DBFS_DG
This storage cell is configured with 3TB sized, high-capacity disks, so the raw space per storage cell is 33.45 terabytes. Newer models with larger disk sizes distribute the additional space between the DATA and RECO grid disks. Table 14-4 shows what the allocation would look like.
Table 14-4. I/O Grid Disk Space Allocation (All Sizes Expressed in Gigabytes)

Creating a configuration like this is fairly simple. The following commands create grid disks according to the allocation in Table 14-4:
CellCLI> create griddisk all prefix='DATA' size=2607G
CellCLI> create griddisk all prefix='RECO' size=1084.4375G
CellCLI> create griddisk all prefix='DBFS_DG'
Notice that no size was specified for the DBFS_DG grid disks. When size is not specified, CellCLI automatically calculates the size for each grid disk so they consume the remaining free space on the cell disk. For example:
CellCLI> list griddisk attributes name, size
DATA_CD_00_cell01 2607G
DATA_CD_01_cell01 2607G
DATA_CD_02_cell01 2607G
...
RECO_CD_00_cell01 1084.4375G
RECO_CD_01_cell01 1084.4375G
RECO_CD_02_cell01 1084.4375G
...
DBFS_DG_CD_02_cell01 33.796875G
DBFS_DG_CD_03_cell01 33.796875G
DBFS_DG_CD_04_cell01 33.796875G
...
Creating FlashDisk-Based Grid Disks
Exadata uses offloading features like Smart Scan to provide strikingly fast I/O for direct path reads typically found in DSS databases. These features are only activated for very specific data access paths in the database. To speed up I/O performance for random reads, Exadata V2 introduced Flash Cache, a solid-state, storage-backed cache. In an X4-2 model, each storage cell comes configured with four 3.2T Flash Cache cards (2,978G usable) to augment I/O performance for frequently accessed data. When configured as Exadata Smart Flash Cache, these devices act like a large, database-aware disk cache for the storage cell. We discussed this in detail in Chapter 5. Optionally, some space from the Flash Cache may be carved out and used like high-speed, solid-state disks. The Flash Cache is configured as a cell disk of type FlashDisk, and just as grid disks are created on HardDisk cell disks, they may also be created on FlashDisk cell disks. When FlashDisks are used for database storage, it’s primarily to improve performance for highly write-intensive workloads when disk-based storage cannot keep up. The need for flash-based grid disks has diminished greatly with the advent of write-back Flash Cache. FlashDisk cell disks may be seen using the CellCLI list celldisk command, as in the following example:
CellCLI> list celldisk attributes name, diskType, size
CD_00_cel01 HardDisk 3691.484375G
CD_01_cel01 HardDisk 3691.484375G
CD_02_cel01 HardDisk 3725.28125G
...
CD_11_cel01 HardDisk 3725.28125G
FD_00_cel01 FlashDisk 186.25G
FD_01_cel01 FlashDisk 186.25G
...
FD_15_cel01 FlashDisk 186.25G
FlashDisk type cell disks are named with a prefix of FD and a diskType of FlashDisk. It is not recommended to use all of your Flash Cache for grid disks. When creating the Flash Cache, use the size parameter to hold back some space to be used for grid disks. The following command creates a Flash Cache of 512GB, reserving the remaining space for grid disks (example below from an X3-2 Exadata):
CellCLI> create flashcache all size=512G
Flash cache cel01_FLASHCACHE successfully created
Note that the create flashcache command uses the size parameter differently than the create griddisk command. When creating the flash cache, the size parameter determines the total size of the cache:
CellCLI> list flashcache detail
name: cel01_FLASHCACHE
cellDisk: FD_11_cel01,FD_03_cel01,FD_07_cel01, ...
...
size: 512G
status: normal
CellCLI> list celldisk attributes name, size, freespace –
where disktype='FlashDisk'
FD_00_cel01 22.875G 4.078125G
FD_01_cel01 22.875G 4.078125G
...
FD_15_cel01 22.875G 4.078125G
Now we can create 16 grid disks with the remaining free space on the Flash Disks, using the familiar create griddisk command. This time we’ll specify flashdisk for the cell disks to use:
CellCLI> create griddisk all flashdisk prefix='RAMDISK'
GridDisk RAMDISK_FD_00_cel01 successfully created
...
GridDisk RAMDISK_FD_14_cel01 successfully created
GridDisk RAMDISK_FD_15_cel01 successfully created
CellCLI> list griddisk attributes name, diskType, size –
where disktype='FlashDisk'
RAMDISK_FD_00_cel01 FlashDisk 4.078125G
RAMDISK_FD_01_cel01 FlashDisk 4.078125G
...
RAMDISK_FD_15_cel01 FlashDisk 4.078125G
Once the grid disks have been created, they may be used to create ASM disk groups used to store database objects just as you would any other disk-based disk group. The beauty of Flash Cache configuration is that all this may be done while the system is online and servicing I/O requests. All of the commands we’ve just used to drop and reconfigure the Flash Cache were done without the need to disable or shut down databases or cell services.
Storage Strategies
Each Exadata storage cell is an intelligent mini-SAN, operating somewhat independently of the other cells in the rack. Now this may be stretching the definition of SAN a little, but with the Cell Server software intelligently controlling I/O access we believe it is appropriate. Storage cells may be configured in such a way that all cells in the rack provide storage for all databases in the rack. This provides maximum I/O performance and data transfer rates for each database in the system. Compute nodes may also be configured to communicate with specific cell servers using the cellip.ora file. In addition, cell security may be used to restrict access to specific databases or ASM instances through use of storage realms. In this section, I’ll discuss strategies for separating cells into groups that service certain database servers or RAC clusters. To borrow a familiar term from the SAN world, this is where we will talk about “zoning” a set of storage cells to service development, test, and production environments. While both of these options are available to Exadata administrators, the methodology described in “Isolating Storage Cell Access” has been seen much more frequently across Exadata environments.
Exadata represents a substantial investment for most companies. For one reason or another, we find that many companies want to buy a full or half rack for consolidating several database environments. Exadata’s architecture makes it a very good consolidation platform. These are some of the most common configurations we’ve seen:
- A full rack servicing development, test, and production
- A full rack servicing several, independent production environments
- A half rack servicing development and test
- Isolating a scratch environment for DBA testing and deploying software patches
For each of these configurations, isolating I/O to specific database servers may be a key consideration. For example, your company may be hosting database environments for external clients that require separation from other database systems. Or your company may have legal requirements to separate server access to data. Another reason for segmenting storage at the cell level may be to provide an environment for DBA training, or testing software patches. There are two ways to isolate Exadata storage cells—by network access and by storage realm. Based on experience seen in the field, the most common method for restricting access between database servers and storage cells is via the first method described below.
Recall that ASM gains access to grid disks through the InfiniBand network. This is configured by adding the IP address of storage cells in the cellip.ora file. For example, in a full rack configuration, all 14 storage cells are listed as follows:
[enkdb02:oracle:EXDB2] /home/oracle
> cat /etc/oracle/cell/network-config/cellip.ora
cell="192.168.10.17;192.168.10.18"
cell="192.168.10.19;192.168.10.20"
cell="192.168.10.21;192.168.10.22"
cell="192.168.10.23;192.168.10.24"
cell="192.168.10.25;192.168.10.26"
cell="192.168.10.27;192.168.10.28"
cell="192.168.10.29;192.168.10.30"
cell="192.168.10.31;192.168.10.32"
cell="192.168.10.33;192.168.10.34"
cell="192.168.10.35;192.168.10.36"
cell="192.168.10.37;192.168.10.38"
cell="192.168.10.39;192.168.10.40"
cell="192.168.10.41;192.168.10.42"
cell="192.168.10.43;192.168.10.44"
The example above is from a full rack X4-2 Exadata with active – active InfiniBand links. Each line defines a single storage cell. When ASM starts up, it interrogates the storage cells on each of these IP addresses for grid disks it can use for configuring ASM disk groups. We can easily segregate storage cells to service specific database servers by removing the IP address of cells that should not be used. Obviously, this is not enforced by any kind of security, but it is an effective, simple way of pairing up database servers with the storage cells they should use for storage. Table 14-5 illustrates a configuration that splits a full rack into two separate database and storage grids. Production is configured with six database servers and eleven storage cells, while Test is configured for two database servers and three storage cells.
Table 14-5. A Storage Network Configuration
|
Production Database Servers, 1-6 |
Production Storage Cells, 1-11 |
|---|---|
|
/etc/oracle/cell/network-config/cellip.ora | |
|
cell="192.168.10.17;192.168.10.18" |
dm01cel01 192.168.10.17;192.168.10.18 |
|
cell="192.168.10.19;192.168.10.20" |
dm01cel02 192.168.10.19;192.168.10.20 |
|
cell="192.168.10.21;192.168.10.22" |
dm01cel03 192.168.10.21;192.168.10.22 |
|
cell="192.168.10.23;192.168.10.24" |
dm01cel04 192.168.10.23;192.168.10.24 |
|
cell="192.168.10.25;192.168.10.26" |
dm01cel05 192.168.10.25;192.168.10.26 |
|
cell="192.168.10.27;192.168.10.28" |
dm01cel06 192.168.10.27;192.168.10.28 |
|
cell="192.168.10.29;192.168.10.30" |
dm01cel07 192.168.10.29;192.168.10.30 |
|
cell="192.168.10.31;192.168.10.32" |
dm01cel08 192.168.10.31;192.168.10.32 |
|
cell="192.168.10.33;192.168.10.34" |
dm01cel09 192.168.10.33;192.168.10.34 |
|
cell="192.168.10.35;192.168.10.36" |
dm01cel10 192.168.10.35;192.168.10.36 |
|
cell="192.168.10.37;192.168.10.38" |
dm01cel11 192.168.10.37;192.168.10.38 |
|
Test Database Servers, 7-8 |
Test Storage Cells, 12-14 |
|
/etc/oracle/cell/network-config/cellip.ora | |
|
cell="192.168.10.39;192.168.10.40" |
dm01cel12 192.168.10.39;192.168.10.40 |
|
cell="192.168.10.41;192.168.10.42" |
dm01cel13 192.168.10.41;192.168.10.42 |
|
cell="192.168.10.43;192.168.10.44" |
dm01cel14 192.168.10.43;192.168.10.44 |
Database servers and storage cells can be paired in any combination that best suits your specific needs. Remember that the minimum requirements for Oracle RAC on Exadata requires two database servers and three storage cells, which is basically a quarter rack configuration. Table 14-6 shows the storage and performance capabilities of Exadata storage cells in quarter rack, half rack, and full rack configurations.
Table 14-6. Performance Capabities of Exadata Storage Cells (Exadata X4-2)

If some of your environments do not require Oracle RAC, there is no reason they cannot be configured with stand alone (non-RAC) database servers. If this is done, then a minimum of one storage cell may be used to provide database storage for each database server. In fact, multiple standalone database servers may even share a single storage cell. Once again, Exadata is a highly configurable system. But just because you can do something doesn’t mean you should. Storage cells are the workhorse of Exadata. Each cell supports a finite data transfer rate (MBPS) and number of I/Os per second (IOPS). Reducing the storage cell footprint of your database environment directly impacts the performance your database can yield. Finally, if a single storage cell services multiple database clusters, there are certain components that cannot be segmented (Flash Cache, Flash Log).
![]() Note Over time, Oracle has changed types of storage available to Exadata. Prior to the X4-2 release, high-performance disks had a rotational speed of 15,000 RPM. X4 storage cells (including X3-8 racks purchased after December 2013) included 10,000RPM high-density drives, and the X5 storage server replaced the high-performance disks with NVMe flash cards. The only change to the high-capacity disks has been the size, ranging from 2TB to 4TB, depending on when the Exadata was purchased.
Note Over time, Oracle has changed types of storage available to Exadata. Prior to the X4-2 release, high-performance disks had a rotational speed of 15,000 RPM. X4 storage cells (including X3-8 racks purchased after December 2013) included 10,000RPM high-density drives, and the X5 storage server replaced the high-performance disks with NVMe flash cards. The only change to the high-capacity disks has been the size, ranging from 2TB to 4TB, depending on when the Exadata was purchased.
In addition to isolating storage cells by their network address, Exadata also provides a way to secure access to specific grid disks within the storage cell. An access control list (ACL) is maintained at the storage cell, and grid disks are defined as being accessible to specific ASM clusters and, optionally, databases within the ASM cluster. If you’ve already logged some time working on your Exadata system, chances are you haven’t noticed any such access restrictions. That is because, by default, cell security is open, allowing all ASM clusters and databases in the system access to all grid disks. Cell security controls access to grid disks at two levels—by ASM cluster and by database:
- ASM-Scoped Security: ASM-scoped security restricts access to grid disks by ASM cluster. This is the first layer of cell security. It allows all databases in the ASM cluster to have access to all grid disks managed by the ASM instance. For example, an Exadata full rack configuration can be split so that four database servers and seven storage cells can be used by Customer-A, and the other four database servers and seven storage cells can be used by Customer-B.
- Database-Scoped Security: Once ASM-scoped security is configured, access to grid disks may be further controlled at the database level using database-scoped security. Database-scoped security is most appropriate when databases within the ASM cluster should have access to a subset of the grid disks managed by the ASM instance. In the earlier example, Customer-A’s environment could use database-scoped security to separate database environments from one another within its half rack configuration.
Cell Security Terminology
Before we get too far along, let’s take a look at some of the new terminology specific to Exadata’s cell security:
- Storage realm: Grid disks that share a common security domain are referred to as a storage realm.
- Security key: A security key is used to authenticate ASM and database clients to the storage realm. It is also used for securing messages sent between the storage cells and the ASM and database clients. The security key is created using the CellCLI command create key. The key is then assigned to grid disks using the CellCLI assign key command.
- cellkey.ora: The cellkey.ora file is stored on the database servers. One cellkey.ora file is created for ASM-scoped security and another cellkey.ora file is created for each database requiring database-scoped security. The cellkey.ora files are used to identify security keys, the storage realm, and the unique name of the ASM cluster or database.
Table 14-7 shows the definitions for the fields in the cellkey.ora file.
Table 14-7. The Contents of the cellkey.ora File
|
Field |
Description |
|---|---|
|
key |
This is the security key generated at the storage cell with the create key command. This key is used to authenticate the ASM cluster and database to the storage realm. For ASM-scoped security, this value must match the key assigned to the ASM cluster using the assign key command. For database-scoped security, this value must match the security key assigned to the database using the assign key command. |
|
asm |
This is the unique name of the ASM cluster found in the DB_UNIQUE_NAME parameter of the ASM instance. It is used to associate the ASM cluster with the availableTo attribute of the grid disks in the storage realm. Grid disks are assigned this value using the CellCLI create griddisk and alter grid disk commands. |
|
realm |
This field is optional. If used, the value must match the realmName attribute assigned to the storage cells using the CellCLI command alter cell realmName. |
Following Oracle’s best practices is an important part of configuring cell security. It will help you avoid those odd situations where things seem to work some of the time or only on certain storage cells. Following these best practices will save you a lot of time and frustration:
- If database-scoped security is used, be sure to use it for all databases in the ASM cluster.
- Make sure the ASM cellkey.ora file is the same on all servers for an ASM cluster. This includes contents, ownership, and permissions.
- Just as you did for the ASM cellkey.ora file, make sure contents, ownership, and permissions are identical across all servers for the database cellkey.ora file.
- Ensure the cell side security settings are the same for all grid disks belonging to the same ASM disk group.
- It is very important that the cellkey.ora files and cell commands are executed consistently across all servers and cells. Use the dcli utility to distribute the cellkey.ora file and reduce the likelihood of human error.
Configuring ASM-Scoped Security
With ASM-scoped security, the ASM cluster is authenticated to the storage cell by its DB_UNIQUE_NAME and a security key. The security key is created at the storage cell and stored in the cellkey.ora file on the database server. An access control list (ACL) is defined on the storage cell that is used to verify the security key it receives from ASM. The availableTo attribute on each grid disk dictates which ASM clusters are permitted access.
Now let’s take a look at the steps for configuring ASM-scoped security:
- Find the DB_UNIQUE_NAME for your ASM cluster using the show parameter command from one of the ASM instances:
SYS:+ASM1>show parameter db_unique_name
NAME TYPE VALUE
---------------- ----------- -----
db_unique_name string +ASM - Shut down all databases and ASM instances in the ASM cluster.
- Create the security key using the CellCLI create key command:
CellCLI> create key
3648e2a3070169095b799c44f02fea9This simply generates the key, which is not automatically stored anywhere. The create key command only needs to be run once and can be done on any storage cell. This security key will be assigned to the ASM cluster in the key field of the cellkey.ora file.
- Next, create a cellkey.ora file and install it in the /etc/oracle/cell/network-config directory for each database server on which this ASM cluster is configured. Set the ownership of the file to the user and group specified during the ASM software installation. Permissions should allow it to be read by the owner of the file. For example:
key=3648e2a3070169095b799c44f02fea9
asm=+ASM
realm=customer_A_realm
> chown oracle:dba cellkey.ora
> chmod 600 cellkey.oraNote that if a realm is defined in this file, it must match the realm name assigned to the storage cells using the alter cell realm= command. Using a storage realm is optional.
- Use the CellCLI assign key command to assign the security key to the ASM cluster being configured. This must be done on each storage cell to which you want the ASM cluster to have access:
CellCLI> ASSIGN KEY -
FOR '+ASM'='3648e2a3070169095b799c44f02fea9' - Using the CellCLI create griddisk command, set the availableTo attribute for each grid disk to which you want this ASM cluster to have access. This can be done for all grid disks on the cell as follows:
CellCLI> create griddisk all prefix='DATA' -
size= 1282.8125G availableTo='+ASM' - For existing grid disks, use the alter grid disk command to set up security:
CellCLI> alter griddisk all prefix='DATA' -
availableTo='+ASM' - A subset of grid disks may also be assigned, as follows:
CellCLI> alter griddisk DATA_CD_00_cell03, -
DATA_CD_01_cell03, -
DATA_CD_02_cell03, -
...
availableTo='+ASM'
This completes the configuration of ASM-scoped cell security. The ASM cluster and all databases can now be restarted. When ASM starts up, it will check for the cellkey.ora file and pass the key to the storage cells in order to gain access to the grid disks. Keep in mind that when you use ASM scoped security, each cluster will need a different name for identification purposes.
Configuring Database-Scoped Security
Database-scoped security locks down database access to specific grid disks within an ASM cluster. It is useful for controlling access to grid disks when multiple databases share the same ASM cluster. Before database-scoped security may be implemented, ASM-scoped security must be configured and verified.
When using database-scoped security, there will be one cellkey.ora file per database, per database server, and one ACL entry on the storage cell for each database. The following steps may be used to implement simple database-scoped security for two databases, called HR (Human Resources) and PAY (Payroll). Each database has its own respective disk group (DATA_HR and RECO_HR for the Human Resources database, DATA_PAY and RECO_PAY for the Payroll database) in this example.
- Retrieve the DB_UNIQUE_NAME for each database being configured using the show parameter command from each of the databases:
SYS:+HR>show parameter db_unique_name
NAME TYPE VALUE
---------------- ----------- -----
db_unique_name string HR
SYS:+PAY>show parameter db_unique_name
NAME TYPE VALUE
---------------- ----------- -----
db_unique_name string PAY - Shut down all databases and ASM instances in the ASM cluster.
- Create the security key using the CellCLI create key command:
CellCLI> create key
7548a7d1abffadfef95a53185aba0e98
CellCLI> create key
8e7105bdbd6ad9fa53d41736a533b9b1The create key command must be run once for each database in the ASM cluster. It can be run from any storage cell. One security key will be assigned to each database within the ASM cluster in the key field of the database cellkey.ora file.
- For each database, create a cellkey.ora file using the keys created in step 2. Install these cellkey.ora files in the ORACLE_HOME/admin/{db_unique_name}/pfile directories for each database server on which database-scoped security will be configured. Just as you did for ASM-scoped security, set the ownership of the file to the user and group specified during the ASM software installation. Permissions should allow it to be read by the owner of the file. For example:
# -- Cellkey.ora file for the HR database --#
key=7548a7d1abffadfef95a53185aba0e98
asm=+ASM
realm=customer_A_realm
# --
> chown oracle:dba $ORACLE_HOME/admin/HR/cellkey.ora
> chmod 600 $ORACLE_HOME/admin/HR/cellkey.ora
# -- Cellkey.ora file for the PAY database --#
key=8e7105bdbd6ad9fa53d41736a533b9b1
asm=+ASM
realm=customer_A_realm
# --
> chown oracle:dba $ORACLE_HOME/admin/PAY/cellkey.ora
> chmod 600 $ORACLE_HOME/admin/PAY/cellkey.oraNote that if a realm is defined in this file, it must match the realm name assigned to the storage cells using the alter cell realm= command.
- Use the CellCLI assign key command to assign the security keys for each database being configured. This must be done on each storage cell you want the HR and PAY databases to have access to. The following keys are assigned to the DB_UNIQUE_NAME of the HR and PAY databases:
CellCLI> ASSIGN KEY -
FOR HR='7548a7d1abffadfef95a53185aba0e98', –
PAY='8e7105bdbd6ad9fa53d41736a533b9b1'
Key for HR successfully created
Key for PAY successfully created - Verify that the keys were assigned properly:
CellCLI> list key
HR d346792d6adea671d8f33b54c30f1de6
PAY cae17e8fdce7511cc02eb7375f5443a8 - Using the CellCLI create disk or alter griddisk command, assign access to the grid disks to each database. Note that the ASM unique name is included with the database unique name in this assignment.
CellCLI> create griddisk DATA_HR_CD_00_cell03, -
DATA_HR_CD_01_cell03 -
size=1282.8125G -
availableTo='+ASM,HR'
CellCLI> create griddisk DATA_PAY_CD_00_cell03, -
DATA_PAY_CD_01_cell03 -
size=1282.8125G -
availableTo='+ASM,PAY' - The alter griddisk command may be used to change security assignments for grid disks. For example:
CellCLI> alter griddisk DATA_HR_CD_00_cell03, -
DATA_HR_CD_01_cell03 -
availableTo='+ASM,HR'
CellCLI> alter griddisk DATA_PAY_CD_00_cell03, -
DATA_PAY_CD_01_cell03 -
availableTo='+ASM,PAY'
This completes the configuration of database-scoped security for the HR and PAY databases. The ASM cluster and databases may now be restarted. The human resources database now has access to the DATA_HR grid disks, while the payroll database has access to the DATA_PAY grid disks.
Once implemented, cell security may be modified as needed by updating the ACL lists on the storage cells and changing the availableTo attribute of the grid disks. Removing cell security is a fairly straightforward process of backing out the database security settings and then removing the ASM security settings.
The first step in removing cell security is to remove database-scoped security. The following steps will remove database-scoped security from the system:
- Before database security may be removed, the databases and ASM cluster must be shut down.
- Remove the databases from the availableTo attribute of the grid disks using the CellCLI command alter griddisk. This command doesn’t selectively remove databases from the list. It simply redefines the complete list. Notice that we will just be removing the databases from the list at this point. The ASM unique name should remain in the list for now. This must be done for each cell you want to remove security from.
CellCLI> alter griddisk DATA_HR_CD_00_cell03, -
DATA_HR_CD_01_cell03 -
availableTo='+ASM'
CellCLI> alter griddisk DATA_PAY_CD_00_cell03, -
DATA_PAY_CD_01_cell03 -
availableTo='+ASM' - Optionally, all the databases may be removed from the secured grid disks with the following command:
CellCLI> alter griddisk all availableTo='+ASM'Assuming that these databases have not been configured for cell security on any other grid disks in the cell, the security key may be removed from the ACL list on the storage cell as follows:
CellCLI> assign key for HR='', PAY=''
Key for HR successfully dropped
Key for PAY successfully dropped - Remove the cellkey.ora file located in the ORACLE_HOME/admin/{db_unique_name}/pfile directory for the database client.
- Verify that the HR and PAY databases are not assigned to any grid disks with the following CellCLI command:
CellCLI> list griddisk attributes name, availableTo
Once database-scoped security has been removed, you can remove ASM-scoped security. This will return the system to default open security status. The following steps remove ASM-scoped security. Once this is done, the grid disks will be available to all ASM clusters and databases on the storage network.
- Before continuing with this procedure, be sure that database-scoped security has been completely removed. The list key command should display the key assignment for the ASM cluster only. No databases should be assigned keys at this point. The list griddisk command should show all the names of the grid disks assignments for the ASM cluster '+ASM'.
CellCLI> list griddisk attributes name, availableTo - Next, remove the ASM unique name from the availableTo attribute on all grid disks.
CellCLI> list griddisk attributes name, availableTo - Now, remove the ASM security from the ACL by running the following command:
CellCLI> alter griddisk all assignTo='' - The following command removes the ASM cluster assignment for select grid disks:
CellCLI> alter griddisk DATA_CD_00_cell03, -
DATA_CD_01_cell03 -
DATA_CD_02_cell03 -
DATA_CD_03_cell03 -
availableTo='' - The list griddisk command should show no assigned clients. Verify this by running the list griddisk command.
- The ASM cluster key may now be safely removed from the storage cell using the CellCLI assign key command:
CellCLI> list key detail
name: +ASM
key: 196d7983a9a33fccae276e24e7a9f89
CellCLI> assign key for +ASM=''
Key for +ASM successfully dropped - Remove the cellkey.ora file from the /etc/oracle/cell/network-config directory on all database servers in the ASM cluster.
This completes the removal of ASM-scoped security. The ASM cluster may now be restarted as well as all the databases it services.
Summary
Understanding all the various layers of the Exadata storage architecture and how they fit together is a key component to properly laying out storage for databases. In most cases, using Oracle’s default layout will be sufficient, but understanding the relationship between physical disks, LUNs, cell disks, grid disks, and ASM disk groups is absolutely necessary if you need to carve up disk storage for maximum performance and security. In this chapter, we’ve discussed what grid disks are, what they are made up of, and how they fit into the ASM storage grid. We’ve taken a look at how to create disk groups so that I/O is prioritized for performance critical data files. Carving up storage doesn’t end at the disk, so we also discussed methods for partitioning storage by cell and by grid disk within the cell.