
![]()
What Is Exadata?
No doubt, you already have a pretty good idea what Exadata is or you wouldn’t be holding this book in your hands. In our view, it is a preconfigured combination of hardware and software that provides a platform for running Oracle Database (either version 11g Release 2 or version 12c Release 1 as of this writing). Since the Exadata Database Machine includes a storage subsystem, different software has been developed to run at the storage layer. This has allowed Oracle product development to do some things that are just not possible on other platforms. In fact, Exadata really began its life as a storage system. If you talk to people involved in the development of the product, you will commonly hear them refer the storage component as Exadata or SAGE (Storage Appliance for the Grid Environment), which was the code name for the project.
Exadata was originally designed to address the most common bottleneck with very large databases—the inability to move sufficiently large volumes of data from the disk storage system to the database server(s). Oracle has built its business by providing very fast access to data, primarily through the use of intelligent caching technology. As the sizes of databases began to outstrip the ability to cache data effectively using these techniques, Oracle began to look at ways to eliminate the bottleneck between the storage tier and the database tier. The solution the developers came up with was a combination of hardware and software. If you think about it, there are two approaches to minimize this bottleneck. The first is to make the pipe between the database and storage bigger. While there are many components involved and it’s a bit of an oversimplification, you can think of InfiniBand as that bigger pipe. The second way to minimize the bottleneck is to reduce the amount of data that needs to be transferred. This they did with Smart Scans. The combination of the two has provided a very successful solution to the problem. But make no mistake—reducing the volume of data flowing between the tiers via Smart Scan is the golden goose.
In this introductory chapter, we will review the components that make up Exadata, both hardware and software. We will also discuss how the parts fit together (the architecture). In addition, we will talk about how the database servers talk to the storage servers. This is handled very differently than on other platforms, so we will spend a fair amount of time covering that topic. We will also provide some historical context. By the end of the chapter, you should have a pretty good feel for how all the pieces fit together and a basic understanding of how Exadata works. The rest of the book will provide the details to fill out the skeleton that is built in this chapter.
An Overview of Exadata
A picture is worth a thousand words, or so the saying goes. Figure 1-1 shows a very high-level view of the parts that make up the Exadata Database Machine.

Figure 1-1. High-level Exadata components
When considering Exadata, it is helpful to divide the entire system mentally into two parts, the storage layer and the database layer. The layers are connected via an InfiniBand network. InfiniBand provides a low-latency, high-throughput switched fabric communications link. Redundancy is provided through multiple switches and links. The database layer is made up of multiple Sun servers running standard Oracle 11g or 12c software. The servers are generally configured in one or more Real Application Clusters (RAC), although RAC is not actually required. The database servers use Automatic Storage Management (ASM) to access the storage. ASM is required even if the databases are not configured to use RAC. The storage layer also consists of multiple Sun x86 servers. Each storage server contains 12 disk drives or 8 flash drives and runs the Oracle storage server software (cellsrv). Communication between the layers is accomplished via iDB, which is a network-based protocol that is implemented using InfiniBand. iDB is used to send requests for data along with metadata about the request (including predicates) to cellsrv. In certain situations, cellsrv is able to use the metadata to process the data before sending results back to the database layer. When cellsrv is able to do this, it is called a Smart Scan and generally results in a significant decrease in the volume of data that needs to be transmitted back to the database layer. When Smart Scans are not possible, cellsrv returns the entire Oracle block(s). Note that iDB uses the RDS protocol, which is a low-latency, InfiniBand-specific protocol. In certain cases, the Oracle software can set up remote direct memory access (RDMA) over RDS, which bypasses doing system calls to accomplish low-latency, process-to-process communication across the InfiniBand network.
History of Exadata
Exadata has undergone a number of significant changes since its initial release in late 2008. In fact, one of the more difficult parts of writing this book has been keeping up with the changes in the platform during the project. Following is a brief review of the product’s lineage and how it has changed over time:
- V1: The first Exadata was released in late 2008. It was labeled as V1 and was a combination of HP hardware and Oracle software. The architecture was similar to the current X5 version, with the exception of Flash, which was added to the V2 version. Exadata V1 was marketed exclusively as a data warehouse platform. The product was interesting but not widely adopted. It also suffered from issues resulting from overheating. The commonly heard description was that you could fry eggs on top of the cabinet. Many of the original V1 customers replaced their V1s with V2s or X2-2s.
- V2: The second version of Exadata was announced at Open World in 2009. This version resulted from a partnership between Sun and Oracle. By the time the announcement was made, Oracle was already in the process of attempting to acquire Sun Microsystems. Many of the components were upgraded to bigger or faster versions, but the biggest difference was the addition of a significant amount of solid state-based storage. The storage cells were enhanced with 384G of Exadata Smart Flash Cache. The software was also enhanced to take advantage of the new cache. This addition allowed Oracle to market the platform as more than a Data Warehouse platform, opening up a significantly larger market.
- X2: The third edition of Exadata, announced at Oracle Open World in 2010, was named the X2. Actually, there were two distinct versions of the X2. The X2-2 followed the same basic blueprint as the V2, with up to eight dual-socket database servers. The CPUs were upgraded to hex-core models, where the V2s had used quad-core CPUs. The other X2 model was named the X2-8. It broke the small 1U database server model by introducing larger database servers with 8×8 core CPUs and a large 1TB memory footprint. The X2-8 was marketed as a more robust platform for large OLTP or mixed workload systems due primarily to the larger number of CPU cores and the larger memory footprint. In 2011, Oracle changed the hardware in the X2-8 to 8x10-core CPUs and 2TB of memory per node. For customers that needed additional storage, storage expansion racks (racks full of storage servers) were introduced. In January 2012, Oracle increased the size of the high-capacity disks from 2TB to 3TB.
- X3: In 2012, Oracle announced the Exadata X3. The X3 was the natural progression of the hardware included in the X2 series. Compute node updates included eight-core Intel Sandy Bridge CPUs and increased memory, up to 256GB per server (although it originally was equipped with 128GB per server for a short time). Storage servers saw upgrades to CPUs and memory, and flash storage increased to 1.6TB per server. The X3-2 family also introduced a new size—the eighth rack. X3-8 racks saw the same improvements in the storage servers, but the compute nodes in X3-8 racks are the same as their X2-8 counterparts.
- X4: Oracle released the Exadata X4 in 2013. It followed the traditional new features: processing increased to 2x12 core CPUs, the ability to upgrade to 512GB of memory in a compute node was added, and flash and disk storage increased. The X4-2 also saw a new model of high-capacity disk, trading out the 600GB, 15,000 RPM disks for 1.2TB, 10,000 RPM disks. These disks were a smaller form factor (2.5” vs 3.5”). The other notable change with the X4-2 was the introduction of an active/active InfiniBand network connection. On the X4-2, Oracle broke the bonded connection and utilized each InfiniBand port independently. This allowed for increased throughput across the InfiniBand fabric.
- X5: In early 2015, Oracle announced the sixth generation of Exadata, the X5-2. The X5-2 was a dramatic change in the platform, removing the high-performance disk option in favor of an all-flash, NVMe (Non-Volatile Memory Express) model. High-capacity disk sizes were not changed, leaving them at 4TB per disk. Once again, the size of the flash cards doubled, this time to 6.4TB per storage server. Memory stayed consistent with a base of 256GB, upgradeable to 768GB, and the core count increased to 18 cores per socket. Finally, the requirement to purchase racks in predefined sizes was removed. The X5-2 rack could be purchased with any configuration required—a base rack begins with two compute nodes and three storage servers. Beyond that, any combination of compute and storage servers can be used within the rack. This removed discussions around Exadata configurations being “balanced” based on the workload. As was seen by many deployments before the X5, every workload is a little bit different and has different needs for compute and storage.
Alternative Views of What Exadata Is
We have already given you a rather bland description of how we view Exadata. However, like the well-known tale of the blind men describing an elephant, there are many conflicting perceptions about the nature of Exadata. We will cover a few of the common descriptions in this section.
Data Warehouse Appliance
Occasionally, Exadata is described as a data warehouse appliance (DW Appliance). While Oracle has attempted to keep Exadata from being pigeonholed into this category, the description is closer to the truth than you might initially think. It is, in fact, a tightly integrated stack of hardware and software that Oracle expects you to run without a lot of changes. This is directly in line with the common understanding of a DW Appliance. However, the very nature of the Oracle database means that it is extremely configurable. This flies in the face of the typical DW Appliance, which typically does not have a lot of knobs to turn. However, there are several common characteristics that are shared between DW Appliances and Exadata:
- Exceptional Performance: The most recognizable characteristic of Exadata and DW Appliances in general is that they are optimized for data warehouse type queries.
- Fast Deployment: DW Appliances and Exadata Database Machines can both be deployed very rapidly. Since Exadata comes preconfigured, it can generally be up and running within a week from the time you take delivery. This is in stark contrast to the normal Oracle clustered database deployment scenario, which generally takes several weeks.
- Scalability: Both platforms have scalable architectures. With Exadata, upgrading is done in discrete steps. Upgrading from a half-rack configuration to a full rack increases the total disk throughput in lock step with the computing power available on the database servers.
- Reduction in TCO: This one may seem a bit strange, since many people think the biggest drawback to Exadata is the high price tag. But the fact is that both DW Appliances and Exadata reduce the overall cost of ownership in many applications. Oddly enough, in Exadata’s case, this is partially thanks to a reduction in the number of Oracle database licenses necessary to support a given workload. We have seen several situations where multiple hardware platforms were evaluated for running a company’s Oracle application and have ended up costing less to implement and maintain on Exadata than on the other options evaluated.
- High Availability: Most DW Appliances provide an architecture that supports at least some degree of high availability (HA). Since Exadata runs standard Oracle 12c or 11g software, all the HA capabilities that Oracle has developed are available out of the box. The hardware is also designed to prevent any single point of failure.
- Preconfiguration: When Exadata is delivered to your data center, an Oracle engineer will be scheduled to assist with the initial configuration. This will include ensuring that the entire rack is cabled and functioning as expected. But like most DW Appliances, the work has already been done to integrate the components. Hence, extensive research and testing are not required. Having the operating system preinstalled and everything cabled and ready to go in the rack speeds up the time from delivery to implementation immensely.
Regardless of the similarities, Oracle does not consider Exadata to be a DW Appliance, even though there are many shared characteristics. Generally speaking, this is because Exadata provides a fully functional Oracle database platform with all the capabilities that have been built into Oracle over the years, including the ability to run any application that currently runs on an Oracle database and, in particular, to deal with mixed workloads that demand a high degree of concurrency, which DW Appliances are generally not equipped to handle.
OLTP Machine
This description of OLTP Machine is a bit of a marketing ploy aimed at broadening Exadata’s appeal to a wider market segment. While the description is not totally off base, it is not as accurate as some other monikers that have been assigned to Exadata. It brings to mind the classic quote:
It depends on what the meaning of the word “is” is.
—Bill Clinton
In the same vein, OLTP (Online Transaction Processing) is a bit of a loosely defined term. We typically use the term to describe workloads that are very latency-sensitive and characterized by single-block access via indexes. But there is a subset of OLTP systems that are also very write-intensive and demand a very high degree of concurrency to support a large number of users. Exadata was not designed to be the fastest possible solution for these write-intensive workloads, although the latest flash improvements in the X5 models definitely perform better than previous generations. It is worth noting, however, that very few systems fall neatly into these categories. Most systems have a mixture of long-running, throughput-sensitive SQL statements and short-duration, latency-sensitive SQL statements—which leads us to the next view of Exadata.
Consolidation Platform
This description of Consolidation Platform pitches Exadata as a potential platform for consolidating multiple databases. This is desirable from a total cost of ownership (TCO) standpoint, as it has the potential to reduce complexity (and, therefore, costs associated with that complexity), reduce administration costs by decreasing the number of systems that must be maintained, reduce power usage and data center costs through reducing the number of servers, and reduce software and maintenance fees. This is a valid way to view Exadata. Because of the combination of features incorporated in Exadata, it is capable of adequately supporting multiple workload profiles at the same time. Although it is not the perfect OLTP Machine, the Flash Cache feature provides a mechanism for ensuring low latency for OLTP-oriented workloads. The Smart Scan optimizations provide exceptional performance for high-throughput, DW-oriented workloads. Resource Management options built into the platform provide the ability for these somewhat conflicting requirements to be satisfied on the same platform. In fact, one of the biggest upsides to this ability is the possibility of totally eliminating a huge amount of work that is currently performed in many shops to move data from an OLTP system to a DW system so that long-running queries do not negatively affect the latency-sensitive workload. In many shops, simply moving data from one platform to another consumes more resources than any other operation. Exadata’s capabilities in this regard may make this process unnecessary in many cases.
Since Exadata is delivered as a preconfigured, integrated system, there are very few options available. As of this writing, there are five standard versions available. They are grouped into two major categories with different model names (the X5-2 and the X4-8). The storage tiers and networking components for the two models are identical. The database tiers, however, are different.
The X5-2 comes in five flavors: eighth rack, quarter rack, half rack, full rack, and an elastic configuration. Table 1-1 shows the amount of storage available with each option on an Exadata X5-2. The system is built to be upgradeable, so you can upgrade later from a quarter rack to half rack, for example. Here is what you need to know about the different options:
- Eighth Rack: The X5-2 Eighth Rack ships with the exact same hardware as a Quarter Rack. On the database tier, half of the CPU cores are disabled via the BIOS. On the storage servers, half the hard disks, flash disks, and CPU cores are disabled as well. This gives all of the redundancy of a quarter rack for a lower cost. If customers want to upgrade from an Eighth Rack to a Quarter Rack, it is simply a matter of running a few scripts to enable the hardware. This configuration was introduced with the X3 model and was not available in the V1, V2, or X2 models. High-capacity models provide roughly 30TB of usable disk space when configured for normal redundancy (also known as double mirroring). When the extreme flash version is selected, users are provided with around 8TB of usable space with normal redundancy.
- Quarter Rack: The X5-2 Quarter Rack comes with two database servers and three storage servers. The high-capacity version provides roughly 63TB of usable disk space if it is configured for normal redundancy. The high-performance version provides roughly one-fourth of that or about 17TB of usable space, again if configured for normal redundancy.
- Half Rack: The X5-2 Half Rack comes with four database servers and seven storage servers. The high-capacity version provides roughly 150TB of usable disk space if it is configured for normal redundancy. The extreme flash version provides roughly 40TB of usable space if configured for normal redundancy.
- Full Rack: The X5-2 Full Rack comes with eight database servers and fourteen storage servers. The high-capacity version provides roughly 300TB of usable disk space if it is configured for normal redundancy. The extreme flash version provides about 80TB of usable space if configured for normal redundancy.
- Elastic Configuration: The Exadata X5-2 model removed the requirement for standard configurations and allowed customers to size an Exadata rack specific for their needs. It starts with a base rack of three storage servers and two compute servers. Beyond that, any combination of servers can be placed in the rack, with a limit of 22 compute servers or 18 storage servers. For a very small, compute-intensive database, a rack with 10 compute servers and 5 storage servers could be ordered and delivered from the factory.
Table 1-1. Usable Disk Space by Exadata Model

Oracle offers an InfiniBand expansion switch kit that can be purchased when multiple racks need to be connected together. These configurations have an additional InfiniBand switch called a spine switch. This switch is used to connect additional racks. There are enough available connections to connect as many as eight racks, although additional cabling may be required depending on the number of racks you intend to connect. The database servers of the multiple racks can be combined into a single RAC database with database servers that span racks, or they may be used to form several smaller RAC clusters. Chapter 15 contains more information about connecting multiple racks
The Exadata X4-8 is Oracle’s answer to databases that require large memory footprints. The X4-8 configuration has two database servers and an elastic number of storage cells. At the time of this writing, the X4-8 model currently in production utilizes X5-2 storage servers. It is effectively an X5-2 rack, but with two large database servers instead of the smaller database servers used in the X5-2. As previously mentioned, the storage servers and networking components are identical to the X5-2 model. There are no rack-level upgrades specific to X4-8 available. If you need more capacity, your option is to add another X4-8, a storage expansion rack, or additional storage cells.
Exadata Storage Expansion Rack X5-2
Beginning with the Exadata X2 model, Oracle began to offer storage expansion racks to customers who were challenged for space. The storage expansion racks are basically racks full of storage servers and InfiniBand switches. Just like Exadata, storage-expansion racks come in various sizes. If the disk size matches between the Exadata and storage-expansion racks, the disks from the expansion rack can be added to the existing disk groups. If customers wish to mix high-capacity and high-performance disks, they must be placed into different disk groups, due to the difference in performance characteristics between the disk types. Table 1-2 lists the amount of disk space available with each storage-expansion rack. Here is what you need to know about the different storage options:
- Quarter Rack: The X5-2 quarter rack storage expansion includes four storage servers, two InfiniBand switches, and one management switch.
- Half Rack: The X5-2 half rack storage expansion includes nine storage servers, three InfiniBand switches, and one management switch.
- Full Rack: The X5-2 full rack storage expansion includes eighteen storage servers, three InfiniBand switches, and one management switch.
Table 1-2. Usable Disk Space by Storage Expansion Rack X5 Model

Upgrades
Eighth racks, quarter racks, and half racks may be upgraded to add more capacity. The current price list has three options for upgrades, the half-rack to full-rack upgrade, the quarter-rack to half-rack upgrade, and the eighth-rack to quarter rack- upgrade. The options are limited in an effort to maintain the relative balance between database servers and storage servers. These upgrades are done in the field. If you order an upgrade, the individual components will be shipped to your site on a big pallet and an Oracle engineer will be scheduled to install the components into your rack. All the necessary parts should be there, including rack rails and cables. Unfortunately, the labels for the cables seem to come from some other part of the universe. When we did the upgrade on our lab system in 2010, the lack of labels held us up for a couple of days.
The quarter-to-half upgrade includes two database servers and four storage servers along with an additional InfiniBand switch, which is configured as a spine switch. The half-to-full upgrade includes four database servers and seven storage servers. Eighth-to-quarter upgrades do not include any additional hardware because it was already included in the shipment of the eighth rack. This upgrade is simply a software fix to enable the resources that were disabled during the initial configuration of the eighth rack. None of the upgrade options require any downtime, although extra care should be taken when racking and cabling the new components, as it is very easy to dislodge the existing cables, not to mention adding the InfiniBand spine switch to the bottom of the rack.
There are a couple of other things worth noting about upgrades. When customers purchase an upgrade kit, they will receive whatever the current revision of Exadata is shipping. This means it is possible to end up with a rack containing X2 and X3 components. Many companies purchased Exadata V2 or X2 systems and are now in the process of upgrading those systems. Several questions naturally arise with regard to this process. One question is whether or not it is acceptable to mix the newer X5-2 servers with the older V2 or X2 components. The answer is yes, it’s OK to mix them. In the Enkitec lab environment, for example, we have a mixture of V2 (our original quarter rack) and X2-2 servers (the upgrade to a half rack). We chose to upgrade our existing system to a half rack rather than purchase another stand-alone quarter rack with X2-2 components, which was another viable option. When combining different generations into one cluster, it is important to remember that there will be different amounts of certain resources, especially on the compute nodes. Database instances running on X5 servers will have access to significantly more memory and CPU cores than they would on a V2 compute node. DBAs should take this under consideration when deciding which compute servers should host specific database services.
The other question that comes up frequently is whether or not adding additional standalone storage servers is an option for companies that are running out of space but that have plenty of CPU capacity on the database servers. If it’s simply lack of space that you are dealing with, additional storage servers are certainly a viable option. With Oracle’s new elastic configuration option, increasing components incrementally can be very easy.
Hardware Components
You have probably seen many pictures like the one in Figure 1-2. It shows an Exadata Database Machine X2-2 full rack. It still looks very similar to an X5-2 full rack. We have added a few graphic elements to show you where the various pieces reside in the cabinet. In this section, we will discuss those pieces.
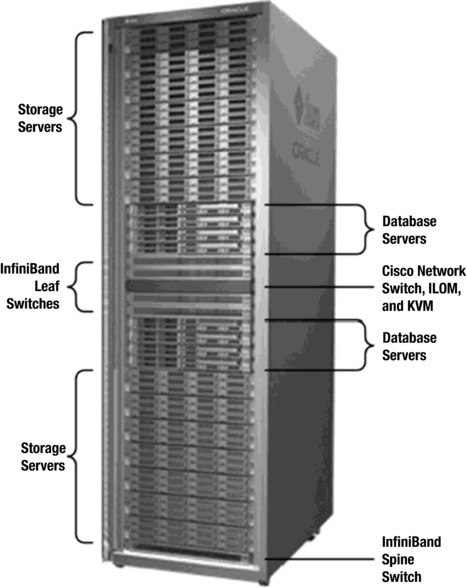
Figure 1-2. An Exadata full rack
As you can see, most of the networking components, including an Ethernet switch and two redundant InfiniBand switches, are located in the middle of the rack. This makes sense as it makes the cabling a little simpler. The surrounding eight slots are reserved for database servers, and the rest of the rack is used for storage servers, with two exceptions. The very bottom slot is used for an additional InfiniBand “spine” switch that can be used to connect additional racks, if so desired. It is located in the bottom of the rack, based on the expectation that your Exadata will be in a data center with a raised floor, allowing cabling to be run from the bottom of the rack. The top two slots are available for top-of-rack switches. By removing the keyboard, video, and mouse (KVM) switch in the V2 and X2-2 racks, Oracle is able to provide room for additional switches in the top of the rack.
Operating Systems
The current generation X5 hardware configurations use Intel-based Sun servers. As of this writing, all the servers come preinstalled with Oracle Linux 6. Older versions shipped with the option to choose between Oracle Linux 5 and Solaris 11. The release of the X5-2 model brought in Oracle Linux 6. Because of the overwhelming majority of customers that chose Linux, Oracle removed support for Solaris 11 on Intel-based Exadata systems. Beginning with Exadata storage server version 11.2.3.2.0, Oracle has announced that it intends to support one version of the Linux kernel—an enhanced version called the Unbreakable Enterprise Kernel (UEK). This optimized version has several enhancements that are specifically applicable to Exadata. Among these are network-related improvements to InfiniBand using the RDS protocol. One of the reasons for releasing the UEK was to speed up Oracle’s ability to roll out changes/enhancements to the Linux kernel and overcome the limitations in the RedHat default kernel. Oracle has been a strong partner in the development of Linux and has made several major contributions to the code base. The stated direction is to submit all the enhancements included in the UEK version for inclusion in the standard release.
Database Servers
The current generation X5-2 database servers are based on the Sun Fire X4170 M5 (Sun Fire X5-2) servers. Each server has 2×18-core Intel Xeon E5-2699 v3 processors (2.3 GHz) and 256GB of memory. They also have four internal 600GB 10K RPM SAS drives. They have several network connections including two 10Gb fiber and four 10Gb copper Ethernet ports in addition to the two QDR InfiniBand (40Gb/s) ports. Note that the 10Gb fiber ports are open and that you need to provide the correct connectors to attach them to your existing copper or fiber network. The servers also have a dedicated ILOM port and dual hot-swappable power supplies.
The X4-8 database servers are based on the Sun Fire X4800 servers. They are designed to handle systems that require a large amount of memory. The servers are equipped with 8x15-core Intel Xeon E7-8895 v2 processors (2.8 GHz) and 2 TB of memory. The X4-8 compute nodes also include seven internal 600GB 10K RPM SAS drives, along with four QDR InfiniBand cards, eight 10Gb Ethernet fiber ports, and ten 1Gb Ethernet copper ports. This gives the full rack X4-8 a total of 240 cores and 4 terabytes of memory on the database tier.
Storage Servers
The current generation of storage servers is the same for both the X5-2 and the X4-8 models. Each storage server consists of a Sun Fire X4270 M5 (Sun Fire X5-2L) and contains either 12 hard disks or 8 flash disks. Depending on whether you have the high-capacity version or the extreme flash version, the disks will either be 4TB (originally 2TB) disks or 1.6TB flash drives. Each storage server comes with 96GB (high capacity) or 64GB (extreme flash) of memory and 2x8-core Intel Xeon E5-2630 v3 processors running at 2.4 GHz. Because these CPUs are in the Haswell family, they have built-in AES encryption support, which essentially provides a hardware assist to encryption and decryption. Each storage server also contains 1.6TB Sun Flash Accelerator F160 NVMe PCIe cards. The high-capacity version contains 4 F160 PCIe cards for the Flash Cache; the extreme flash version contains 8 F160 PCIe cards, which are used both as Flash Cache and final disk storage. The storage servers come pre-installed with Oracle Linux 6.
InfiniBand
One of the more important hardware components of Exadata is the InfiniBand network. It is used for transferring data between the database tier and the storage tier. It is also used for interconnect traffic between the database servers, if they are configured in a RAC cluster. In addition, the InfiniBand network may be used to connect to external systems for such uses as backups. Exadata provides redundant 36-port QDR InfiniBand switches for these purposes. The switches provide 40 Gb/Sec of throughput. You will occasionally see these switches referred to as “leaf” switches. In addition, each database server and each storage server are equipped with Dual-Port QDR InfiniBand Host Channel Adapters. If you are connecting multiple Oracle Engineered Systems racks together, an expansion (spine) switch is available.
Flash Cache
As mentioned earlier, each storage server comes equipped with 3.2TB of flash-based storage. This storage is generally configured to be a cache. Oracle refers to it as Exadata Smart Flash Cache (ESFC). The primary purpose of ESFC is to minimize the service time for single block reads. This feature provides a substantial amount of disk cache, about 44.8TB on a half-rack configuration.
Disks
Oracle provides two options for disks. An Exadata Database Machine may be configured with either high-capacity drives or all flash drives. As previously mentioned, the high-capacity option includes 4TB, 7200 RPM drives, while the extreme flash option includes 1.6TB NVMe flash drives. If customers wish to mix drive types, it must be accomplished using different ASM diskgroups for each storage type. With the large amount of Flash Cache available on the storage cells, it seems that the high-capacity option would be adequate for most read-heavy workloads. The Flash Cache does a very good job of reducing the single-block-read latency in the mixed-workload systems we have observed to date.
Bits and Pieces
The package price includes a 42U rack with redundant power distribution units. Also included in the price is an Ethernet switch. The spec sheets don’t specify the model for the Ethernet switch, but, as of this writing, a switch manufactured by Cisco (Catalyst 4948) is being shipped. To date, this is the one piece of the package that Oracle has agreed to allow customers to replace. If you have another switch that you like better, you can remove the included switch and replace it (at your own cost). Models prior to the X3-2 included a KVM unit as well. Due to the larger database server size in the X2-8, X3-8, and X4-8, no KVM is provided. Beginning with the X3-2, Oracle has removed the KVM in favor of leaving the top two rack units available for top-of-rack switches. The package price also includes a spares kit that includes an extra flash card and an extra disk drive. The package price does not include SFP+ connectors or cables for the 10Gb Ethernet ports. These are not standard and will vary based on the equipment used in your network. These SFP+ ports are intended for external connections of the database servers to the customer’s network.
The software components that make up Exadata are split between the database tier and the storage tier. Standard Oracle database software runs on the database servers, while Oracle’s disk management software runs on the storage servers. The components on both tiers use a protocol called iDB to talk to each other. The next two sections provide a brief introduction to the software stack that resides on both tiers.
Database Server Software
As previously discussed, the database servers run Oracle Linux. The database servers also run standard Oracle 11g Release 2 or Oracle 12c Release 1 software. There is no special version of the database software that is different from the software that is run on any other platform. This is actually a unique and significant feature of Exadata, compared to competing data warehouse appliance products. In essence, it means that any application that can run on Oracle 11gR2/12cR1 can run on Exadata without requiring any changes to the application. While there is code that is specific to the Exadata platform, iDB for example, Oracle chose to make it a part of the standard distribution. The software is aware of whether it is accessing Exadata storage, and this “awareness” allows it to make use of the Exadata-specific optimizations when accessing Exadata storage.
Oracle Automatic Storage Management (ASM) is a key component of the software stack on the database servers. It provides file system and volume management capability for Exadata storage. It is required because the storage devices are not visible to the database servers. There is no direct mechanism for processes on the database servers to open or read a file on Exadata storage cells. ASM also provides redundancy to the storage by mirroring data blocks, using either normal redundancy (two copies) or high redundancy (three copies). This is an important feature because the disks are physically located on multiple storage servers. The ASM redundancy provides mirroring across the storage cells, which allows for the complete loss of a storage server without an interruption to the databases running on the platform. Other than the operating system disks on the database servers, there is no form of hardware- or software-based RAID that protects the data on Exadata storage servers. The data mirroring protection is provided exclusively by ASM.
While RAC is generally installed on Exadata database servers, it is not actually required. However, RAC does provide many benefits in terms of high availability and scalability. For systems that require more CPU or memory resources than can be supplied by a single server, RAC is the path to those additional resources.
The database servers and the storage servers communicate using the Intelligent Database protocol (iDB). iDB implements what Oracle refers to as a function shipping architecture. This term is used to describe how iDB ships information about the SQL statement being executed to the storage cells and then returns processed data (prefiltered, for example), instead of data blocks, directly to the requesting processes. In this mode, iDB can limit the data returned to the database server to only those rows and columns that satisfy the query. The function shipping mode is only available when full scans are performed. iDB can also send and retrieve full blocks when offloading is not possible (or not desirable). In this mode, iDB is used like a normal I/O protocol for fetching entire Oracle blocks and returning them to the Oracle buffer cache on the database servers. For completeness, we should mention that it is really not a simple one-way-or-the-other scenario. There are cases where we can get a combination of these two behaviors. We will discuss that in more detail in Chapter 2.
iDB uses the Reliable Datagram Sockets (RDS) protocol and, of course, uses the InfiniBand fabric between the database servers and storage cells. RDS is a low-latency, low-overhead protocol that provides a significant reduction in CPU usage compared to protocols such as UDP. RDS has been around for some time and predates Exadata by several years. The protocol facilitates an option to use direct memory access model for interprocess communication, which allows it to avoid the latency and CPU overhead associated with traditional TCP traffic.
It is important to understand that no storage devices are directly presented to the operating systems on the database servers. Therefore, there are no operating-system calls to open files, read blocks from them, or perform the other usual tasks. This also means that standard operating-system utilities like iostat will not be useful in monitoring your database servers, because the processes running there will not be issuing I/O calls to the database files. Here’s some output that illustrates this fact:
ACOLVIN@DBM011> @whoami
USERNAME USER# SID SERIAL# PREV_HASH_VALUE SCHEMANAME OS_PID
--------------- ----------- ----------- ----------- --------------- ---------- -----------
ACOLVIN 89 591 36280 1668665417 ACOLVIN 103148
ACOLVIN@DBM011> select /* avgskew.sql */ avg(pk_col) from acolvin.skew a where col1 > 0;
...
> strace -cp 103148
Process 103148 attached - interrupt to quit
^CProcess 103148 detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
96.76 0.000358 0 750 375 setsockopt
3.24 0.000012 0 425 getrusage
0.00 0.000000 0 53 3 read
0.00 0.000000 0 2 write
0.00 0.000000 0 24 12 open
0.00 0.000000 0 12 close
0.00 0.000000 0 225 poll
0.00 0.000000 0 48 lseek
0.00 0.000000 0 4 mmap
0.00 0.000000 0 10 rt_sigprocmask
0.00 0.000000 0 3 rt_sigreturn
0.00 0.000000 0 5 setitimer
0.00 0.000000 0 388 sendmsg
0.00 0.000000 0 976 201 recvmsg
0.00 0.000000 0 1 semctl
0.00 0.000000 0 12 fcntl
0.00 0.000000 0 31 times
0.00 0.000000 0 3 semtimedop
------ ----------- ----------- --------- --------- ----------------
100.00 0.000370 2972 591 total
In this listing we have run strace on a user’s foreground process (sometimes called a shadow process). This is the process that’s responsible for retrieving data on behalf of a user. As you can see, the vast majority of system calls captured by strace are network-related (setsockopt). By contrast, on a non-Exadata platform we mostly see disk I/O-related events, primarily some form of the read call. Here’s some output from a non-Exadata platform for comparison:
ACOLVIN@AC12> @whoami
USERNAME USER# SID SERIAL# PREV_HASH_VALUE SCHEMANAME OS_PID
------------- --------- ---------- ---------- --------------- ---------- -------
ACOLVIN 103 141 13 1029988163 ACOLVIN 57449
ACOLVIN@AC12> select /* avgskew.sql */ avg(pk_col) from acolvin.skew a where col1 > 0;
AVG(PK_COL)
-----------
16093749.8
...
[oracle@homer ~]$ strace -cp 57449
Process 57449 attached - interrupt to quit
Process 57449 detached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ---------------
99.44 0.029174 4 7709 pread
0.40 0.000117 0 3921 clock_gettime
0.16 0.000046 0 1314 times
0.00 0.000000 0 3 write
0.00 0.000000 0 7 mmap
0.00 0.000000 0 2 munmap
0.00 0.000000 0 43 getrusage
------ ----------- ----------- --------- --------- ---------------
100.00 0.029337 12999 total
Notice that the main system call captured on the non-Exadata platform is I/O-related (pread). The point of the previous two listings is to show that there is a very different mechanism in play in the way data stored on disks is accessed with Exadata.
Storage Server Software
Cell Services (cellsrv) is the primary software that runs on the storage cells. It is a multithreaded program that services I/O requests from a database server. Those requests can be handled by returning processed data or by returning complete blocks depending on the request. cellsrv also implements the I/O Resource Manager (IORM), which can be used to ensure that I/O bandwidth is distributed to the various databases and consumer groups appropriately.
There are two other programs that run continuously on Exadata storage cells. Management Server (MS) is a Java program that provides the interface between cellsrv and the Cell Command Line Interface (cellcli) utility. MS also provides the interface between cellsrv and the Grid Control Exadata plug-in (which is implemented as a set of cellcli commands that are run via ssh). The second utility is Restart Server (RS). RS is actually a set of processes that are responsible for monitoring the other processes and restarting them if necessary. ExaWatcher (previously OSWatcher) is also installed on the storage cells for collecting historical operating system statistics using standard Unix utilities such as vmstat and netstat. Note that Oracle does not authorize the installation of any additional software on the storage servers.
One of the first things you are likely to want to do when you first encounter Exadata is to log on to the storage cells and see what is actually running. Unfortunately, the storage servers are generally off-limits to everyone except the designated system administers or DBAs. Here is a quick listing showing the abbreviated output generated by a ps command on an active storage server:
> ps -eo ruser,pid,ppid,cmd
RUSER PID PPID CMD
root 5555 4823 /usr/bin/perl /opt/oracle.ExaWatcher/ExecutorExaWatcher.pl
root 6025 5555 sh -c /opt/oracle.ExaWatcher/ExaWatcherCleanup.sh
root 6026 6025 /bin/bash /opt/oracle.ExaWatcher/ExaWatcherCleanup.sh
root 6033 5555 /usr/bin/perl /opt/oracle.ExaWatcher/ExecutorExaWatcher.pl
root 6034 6033 sh -c /opt/oracle.cellos/ExadataDiagCollector.sh
root 6036 6034 /bin/bash /opt/oracle.cellos/ExadataDiagCollector.sh
root 6659 8580 /opt/oracle/../cellsrv/bin/cellrsomt
-rs_conf /opt/oracle/../cellinit.ora
-ms_conf /opt/oracle/../cellrsms.state
-cellsrv_conf /opt/oracle/../cellrsos.state -debug 0
root 6661 6659 /opt/oracle/cell/cellsrv/bin/cellsrv 100 5000 9 5042
root 7603 1 /opt/oracle/cell/cellofl-11.2.3.3.1_LINUX.X64_141206/../celloflsrv
-startup 1 0 1 5042 6661 SYS_112331_141117 cell
root 7606 1 /opt/oracle/cell/cellofl-12.1.2.1.0_LINUX.X64_141206.1/../celloflsrv
-startup 2 0 1 5042 6661 SYS_121210_141206 cell
root 8580 1 /opt/oracle/cell/cellsrv/bin/cellrssrm -ms 1 -cellsrv 1
root 8587 8580 /opt/oracle/../cellrsbmt
-rs_conf /opt/oracle/../cellinit.ora
-ms_conf /opt/oracle/../cellrsms.state
-cellsrv_conf /opt/oracle/../cellrsos.state -debug 0
root 8588 8580 /opt/oracle/cell/cellsrv/bin/cellrsmmt
-rs_conf /opt/oracle/../cellinit.ora
-ms_conf /opt/oracle/../cellrsms.state
-cellsrv_conf /opt/oracle/../cellrsos.state -debug 0
root 8590 8587 /opt/oracle/cell/cellsrv/bin/cellrsbkm
-rs_conf /opt/oracle/../cellinit.ora
-ms_conf /opt/oracle/../cellrsms.state
-cellsrv_conf /opt/oracle/../cellrsos.state -debug 0
root 8591 8588 /bin/sh /opt/oracle/../startWebLogic.sh
root 8597 8590 /opt/oracle/../cellrssmt
-rs_conf /opt/oracle/../cellinit.ora
-ms_conf /opt/oracle/../cellrsms.state
-cellsrv_conf /opt/oracle/../cellrsos.state -debug 0
root 8663 8591 /usr/java/jdk1.7.0_72/bin/java -client -Xms256m -Xmx512m
-XX:CompileThreshold=8000 -XX:PermSize=128m -XX:MaxPermSize=256m
-Dweblogic.Name=msServer
-Djava.security.policy=/opt/oracle/../weblogic.policy
-XX:-UseLargePages -XX:Parallel
root 11449 5555 sh -c /usr/bin/mpstat -P ALL 5 720
root 11450 11449 /usr/bin/mpstat -P ALL 5 720
root 11457 5555 sh -c /usr/bin/iostat -t -x 5 720
root 11458 11457 /usr/bin/iostat -t -x 5 720
root 12175 5555 sh -c /opt/oracle/cell/cellsrv/bin/cellsrvstat
root 12176 12175 /opt/oracle/cell/cellsrv/bin/cellsrvstat
root 14386 14385 /usr/bin/top -b -d 5 -n 720
root 14530 14529 /bin/sh /opt/oracle.ExaWatcher/FlexIntervalMode.sh
/opt/oracle.ExaWatcher/RDSinfoExaWatcher.sh
root 14596 14595 /bin/sh /opt/oracle.ExaWatcher/FlexIntervalMode.sh
/opt/oracle.ExaWatcher/NetstatExaWatcher.sh 5 720
root 17315 5555 sh -c /usr/bin/vmstat 5 2
root 17316 17315 /usr/bin/vmstat 5 2
root 23881 5555 sh -c /opt/oracle.ExaWatcher/FlexIntervalMode.sh
'/opt/oracle.ExaWatcher/LsofExaWatcher.sh' 120 30
root 23882 23881 /bin/sh /opt/oracle.ExaWatcher/FlexIntervalMode.sh
/opt/oracle.ExaWatcher/LsofExaWatcher.sh 120 30
As you can see, there are a number of processes that look like cellrsvXXX. These are the processes that make up the Restart Server. The first bolded process is cellsrv itself. The next two bolded processes are the offload servers (discussed in further detail in Chapter 2), which were introduced in the 12c version of the Exadata Storage Server software. Also notice the last two bolded processes; this is the WebLogic program that we refer to as Management Server. Finally, you will see several processes associated with ExaWatcher. Note also that all the processes are started by root. While there are a couple of other semi-privileged accounts on the storage servers, it is clearly not a system that is set up for users to log on to.
Another interesting way to look at related processes is to use the ps –H command, which provides an indented list of processes showing how they are related to each other. You could work this out for yourself by building a tree based on the relationship between the process ID (PID) and parent process ID (PPID) in the previous text, but the –H option makes that a lot easier. Here’s an edited snippet of output from a ps –efH command:
cellrssrm <= main Restart Server
cellrsbmt
cellrsbkm
cellrssmt
cellrsmmt
startWebLogic.sh <= Management Server
cellrsomt
cellsrv
It’s also interesting to see what resources are being consumed on the storage servers. Here’s a snippet of output from top:
top - 12:01:30 up 19 days, 17:17, 1 user, load average: 0.49, 0.26, 0.21
Tasks: 428 total, 4 running, 424 sleeping, 0 stopped, 0 zombie
Cpu(s): 11.1%us, 1.7%sy, 0.0%ni, 83.8%id, 3.3%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 65963336k total, 21307292k used, 44656044k free, 140216k buffers
Swap: 2097080k total, 0k used, 2097080k free, 1235320k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7988 root 20 0 22.1g 7.1g 12m S 246.3 11.3 5581:38 cellsrv
7982 root 20 0 1621m 385m 21m S 5.3 0.6 851:07.47 java
8192 root 20 0 67960 5232 972 R 2.6 0.0 0:00.08 sh
394 root 20 0 13016 1408 832 R 0.7 0.0 0:01.33 top
The output from top shows that cellsrv is using more than one full CPU core. This is common on busy systems and is due to the multithreaded nature of the cellsrv process, which makes it possible to run on multiple CPU cores at the same time.
Software Architecture
In this section, we will briefly discuss the key software components and how they are connected in the Exadata architecture. There are components that run on both the database and the storage tiers. Figure 1-3 depicts the overall architecture of the Exadata platform.
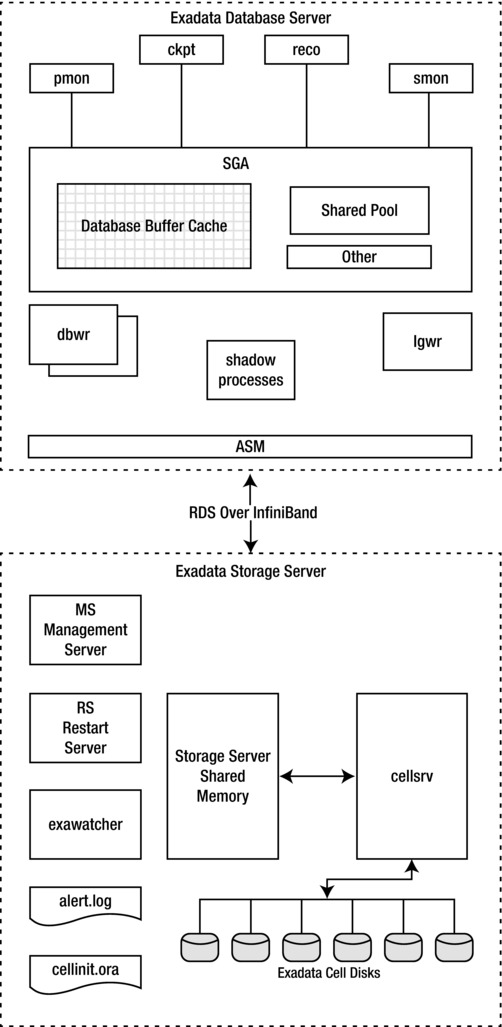
Figure 1-3. Exadata architecture diagram
The top half of the diagram shows the key components on one of the database servers, while the bottom half shows the key components on one of the storage servers. The top half of the diagram should look pretty familiar, as it is standard Oracle database architecture. It shows the System Global Area (SGA), which contains the buffer cache and the shared pool. It also shows several of the key processes, such as Log Writer (LGWR) and Database Writer (DBWR). There are many more processes, of course, and much more detailed views of the shared memory that could be provided, but this should give you a basic picture of how things look on the database server.
The bottom half of the diagram shows the components on one of the storage servers. The architecture on the storage servers is pretty simple. There is one master process (cellsrv), and the offload servers that handle all the communication to and from the database servers. There are also a handful of ancillary processes for managing and monitoring the environment.
One of the things you may notice in the architecture diagram is that cellsrv uses an init.ora file and has an alert log. In fact, the storage software bears a striking resemblance to an Oracle database. This should not be too surprising. The cellinit.ora file contains a set of parameters that are evaluated when cellsrv is started. The alert log is used to write a record of notable events, much like an alert log on an Oracle database. Note also that Automatic Diagnostic Repository (ADR) is included as part of the storage software for capturing and reporting diagnostic information.
Also notice that there is a stand-alone process that is not attached to any database instance (DISKMON), which performs several tasks related to Exadata Storage. Although it is called DISKMON, it is really a network- and cell-monitoring process that checks to verify that the cells are alive. DISKMON is also responsible to propagating Database Resource Manager (DBRM) plans to the storage servers. DISKMON also has a single slave process per instance, which is responsible for communicating between ASM and the database it is responsible for.
The connection between the database server and the storage server is provided by the InfiniBand fabric. All communication between the two tiers is carried by this transport mechanism. This includes writes via the DBWR processes and LGWR process and reads carried out by the user foreground (or shadow) processes.
Figure 1-4 provides another systematic view of the architecture, which focuses on the software stack and how it spans multiple servers in both the database grid and the storage grid.
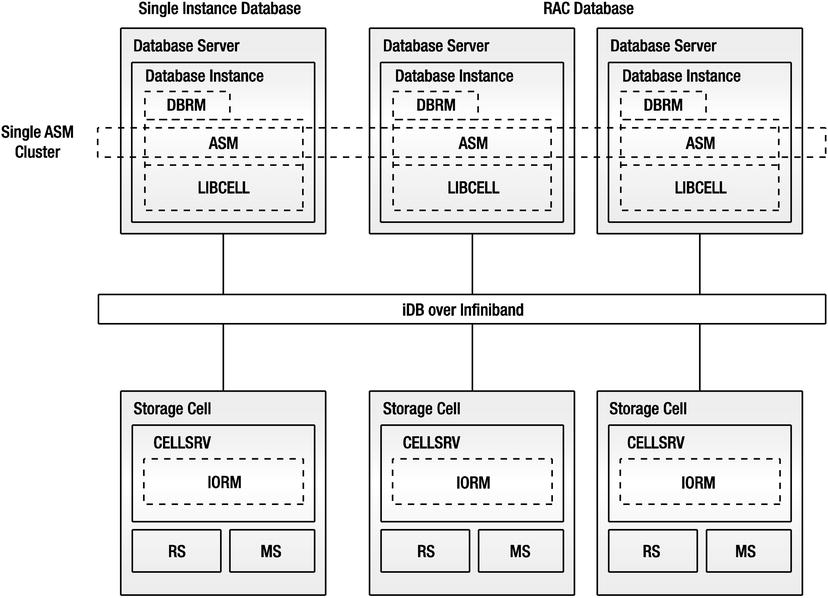
Figure 1-4. Exadata software architecture
As we’ve discussed, ASM is a key component. Notice that we have drawn it as an object that cuts across all the communication lines between the two tiers. This is meant to indicate that ASM provides the mapping between the files and the objects that the database knows about on the storage layer. ASM does not actually sit between the storage and the database, though, and it is not a layer in the stack that the processes must touch for each “disk access.”
Figure 1-4 also shows the relationship between DBRM running on the instances on the database servers and IORM, which is implemented inside cellsrv running on the storage servers.
The final major component in Figure 1-4 is LIBCELL, which is a library that is linked with the Oracle kernel. LIBCELL has the code that knows how to request data via iDB. This provides a very nonintrusive mechanism to allow the Oracle kernel to talk to the storage tier via network-based calls instead of operating system reads and writes. iDB is implemented on top of the RDS protocol provided by the OpenFabrics Enterprise Distribution. This is a low-latency, low-CPU-overhead protocol that provides interprocess communications. You may also see this protocol referred to in some of the Oracle marketing material as the Zero-loss Zero-copy (ZDP) InfiniBand protocol. Figure 1-5 is a basic schematic showing why the RDS protocol is more efficient than using a traditional TCP based protocol like UDP.
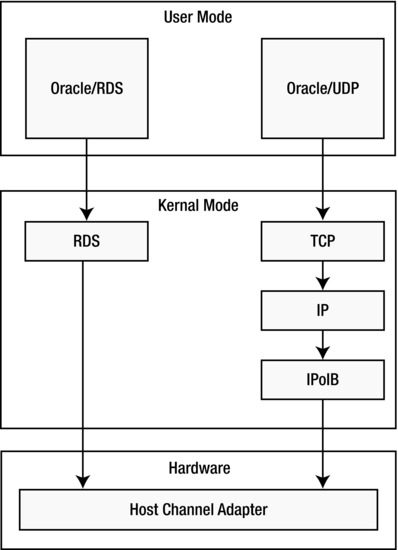
Figure 1-5. RDS schematic
As you can see from the diagram, using the RDS protocol to bypass the TCP processing cuts out a portion of the overhead required to transfer data across the network. Note that the RDS protocol is also used for interconnect traffic between RAC nodes.
Summary
Exadata is a tightly integrated combination of hardware and software. There is nothing magical about the hardware components. The majority of the performance benefits come from the way the components are integrated and the software that is implemented at the storage layer. In the Chapter 2, we’ll delve into the offloading concept, which is what sets Exadata apart from all other platforms that run Oracle databases.