
23. Collections
Objectives
In this chapter you’ll learn:
• The nongeneric and generic collections that are provided by the .NET Framework.
• To use class Array’s static methods to manipulate arrays.
• To use enumerators to “walk through” a collection.
• To use the foreach statement with the .NET collections.
• To use nongeneric collection classes ArrayList, Stack, and Hashtable.
• To use generic collection classes SortedDictionary and LinkedList.
The shapes a bright container can contain!
—Theodore Roethke
I think this is the most extraordinary collection of talent, of human knowledge, that has ever been gathered together at the White House—with the possible exception of when Thomas Jefferson dined alone.
—John F. Kennedy
Outline
23.1 Introduction
23.2 Collections Overview
23.3 Class Array and Enumerators
23.4 Nongeneric Collections
23.4.1 Class ArrayList
23.4.2 Class Stack
23.4.3 Class Hashtable
23.5 Generic Collections
23.5.1 Generic Class SortedDictionary
23.5.2 Generic Class LinkedList
23.6 Covariance and Contravariance for Generic Types
23.7 Wrap-Up
23.1 Introduction
Chapter 21 discussed how to create and manipulate data structures. The discussion was “low level,” in the sense that we painstakingly created each element of each data structure dynamically with new and modified the data structures by directly manipulating their elements and references to their elements. For the vast majority of applications, there’s no need to build custom data structures. Instead, you can use the prepackaged data-structure classes provided by the .NET Framework. These classes are known as collection classes—they store collections of data. Each instance of one of these classes is a collection of items. Some examples of collections are the cards you hold in a card game, the songs stored in your computer, the real-estate records in your local registry of deeds (which map book numbers and page numbers to property owners), and the players on your favorite sports team.
Collection classes enable programmers to store sets of items by using existing data structures, without concern for how they’re implemented. This is a nice example of code reuse. Programmers can code faster and expect excellent performance, maximizing execution speed and minimizing memory consumption. In this chapter, we discuss the collection interfaces that list the capabilities of each collection type, the implementation classes and the enumerators that “walk through” collections.
The .NET Framework provides three namespaces dedicated to collections. Namespace System.Collections contains collections that store references to objects. We included these because there’s a large amount of legacy code in industry that uses these collections. Most new applications should use the collections in the System.Collections.Generic namespace, which contains generic classes—such as the List<T> and Dictionary<K, V> classes you learned previously—to store collections of specific types. The System.Collections.Specialized namespace contains several collections that support specific types, such as strings and bits. You can learn more about this namespace at msdn.microsoft.com/en-us/library/system.collections.specialized.aspx. The collections in these namespaces provide standardized, reusable components; you do not need to write your own collection classes. These collections are written for broad reuse. They’re tuned for rapid execution and for efficient use of memory. As new data structures and algorithms are developed that fit this framework, a large base of programmers already will be familiar with the interfaces and algorithms implemented by those data structures.
23.2 Collections Overview
All collection classes in the .NET Framework implement some combination of the collection interfaces. These interfaces declare the operations to be performed generically on various types of collections. Figure 23.1 lists some of the interfaces of the .NET Framework collections. All the interfaces in Fig. 23.1 are declared in namespace System.Collections and have generic analogs in namespace System.Collections.Generic. Implementations of these interfaces are provided within the framework. Programmers may also provide implementations specific to their own requirements.
Fig. 23.1. Some common collection interfaces.

In earlier versions of C#, the .NET Framework primarily provided the collection classes in the System.Collections and System.Collections.Specialized namespaces. These classes stored and manipulated object references. You could store any object in a collection. One inconvenient aspect of storing object references occurs when retrieving them from a collection. An application normally needs to process specific types of objects. As a result, the object references obtained from a collection typically need to be downcast to an appropriate type to allow the application to process the objects correctly.
The .NET Framework also includes the System.Collections.Generic namespace, which uses the generics capabilities we introduced in Chapter 22. Many of these classes are simply generic counterparts of the classes in namespace System.Collections. This means that you can specify the exact type that will be stored in a collection. You also receive the benefits of compile-time type checking—the compiler ensures that you’re using appropriate types with your collection and, if not, issues compile-time error messages. Also, once you specify the type stored in a collection, any item you retrieve from the collection will have the correct type. This eliminates the need for explicit type casts that can throw InvalidCastExceptions at execution time if the referenced object is not of the appropriate type. This also eliminates the overhead of explicit casting, improving efficiency and type safety. Generic collections are especially useful for storing structs, since they eliminate the overhead of boxing and unboxing.
This chapter demonstrates collection classes Array, ArrayList, Stack, Hashtable, generic SortedDictionary, and generic LinkedList—plus built-in array capabilities. Namespace System.Collections provides several other data structures, including BitArray (a collection of true/false values), Queue and SortedList (a collection of key/value pairs that are sorted by key and can be accessed either by key or by index). Figure 23.2 summarizes many of the collection classes. We also discuss the IEnumerator interface. Collection classes can create enumerators that allow programmers to walk through the collections. Although these enumerators have different implementations, they all implement the IEnumerator interface so that they can be processed polymorphically. As we’ll soon see, the foreach statement is simply a convenient notation for using an enumerator. In the next section, we begin our discussion by examining enumerators and the capabilities for array manipulation. [Note: Collection classes directly or indirectly implement ICollection and IEnumerable (or their generic equivalents ICollection<T> and IEnumerable<T> for generic collections).]
Fig. 23.2. Some collection classes of the .NET Framework.

23.3 Class Array and Enumerators
Chapter 8 presented basic array-processing capabilities. All arrays implicitly inherit from abstract base class Array (namespace System); this class defines property Length, which specifies the number of elements in the array. In addition, class Array provides static methods that provide algorithms for processing arrays. Typically, class Array overloads these methods—for example, Array method Reverse can reverse the order of the elements in an entire array or can reverse the elements in a specified range of elements in an array. For a complete list of class Array’s static methods visit:
msdn.microsoft.com/en-us/library/system.array.aspx
Figure 23.3 demonstrates several static methods of class Array.
Fig. 23.3. Array class used to perform common array manipulations.



The using directives in lines 3–4 include the namespaces System (for classes Array and Console) and System.Collections (for interface IEnumerator, which we discuss shortly). References to the assemblies for these namespaces are implicitly included in every application, so we do not need to add any new references to the project file.
Our test class declares three static array variables (lines 9–11). The first two lines initialize intValues and doubleValues to an int and double array, respectively. Static variable intValuesCopy is intended to demonstrate the Array’s Copy method, so it’s left with the default value null—it does not yet refer to an array.
Line 16 initializes intValuesCopy to an int array with the same length as array int-Values. Line 19 calls the PrintArrays method (lines 49–74) to output the initial contents of all three arrays. We discuss the PrintArrays method shortly. We can see from the output of Fig. 23.3 that each element of array intValuesCopy is initialized to the default value 0.
Line 22 uses static Array method Sort to sort array doubleValues. When this method returns, the array contains its original elements sorted in ascending order. The elements in the array must implement the IComparable interface.
Line 25 uses static Array method Copy to copy elements from array intValues to array intValuesCopy. The first argument is the array to copy (intValues), the second argument is the destination array (intValuesCopy) and the third argument is an int representing the number of elements to copy (in this case, intValues.Length specifies all elements).
Lines 32 and 40 invoke static Array method BinarySearch to perform binary searches on array intValues. Method BinarySearch receives the sorted array in which to search and the key for which to search. The method returns the index in the array at which it finds the key (or a negative number if the key was not found). BinarySearch assumes that it receives a sorted array. Its behavior on an unsorted array is unpredictable. Chapter 20 discussed binary searching in detail.
Method PrintArrays (lines 49–74) uses class Array’s methods to loop though each array. The GetEnumerator method (line 54) obtains an enumerator for array doubleValues. Recall that Array implements the IEnumerable interface. All arrays inherit implicitly from Array, so both the int[] and double[] array types implement IEnumerable interface method GetEnumerator, which returns an enumerator that can iterate over the collection. Interface IEnumerator (which all enumerators implement) defines methods MoveNext and Reset and property Current. MoveNext moves the enumerator to the next element in the collection. The first call to MoveNext positions the enumerator at the first element of the collection. MoveNext returns true if there’s at least one more element in the collection; otherwise, the method returns false. Method Reset positions the enumerator before the first element of the collection. Methods MoveNext and Reset throw an InvalidOperationException if the contents of the collection are modified in any way after the enumerator is created. Property Current returns the object at the current location in the collection.
Common Programming Error 23.1
![]()
If a collection is modified after an enumerator is created for that collection, the enumerator immediately becomes invalid—any methods called on the enumerator after this point throw InvalidOperationExceptions. For this reason, enumerators are said to be “fail fast.”
When an enumerator is returned by the GetEnumerator method in line 54, it’s initially positioned before the first element in Array doubleValues. Then when line 56 calls MoveNext in the first iteration of the while loop, the enumerator advances to the first element in doubleValues. The while statement in lines 56–57 loops over each element until the enumerator passes the end of doubleValues and MoveNext returns false. In each iteration, we use the enumerator’s Current property to obtain and output the current array element. Lines 62–65 iterate over array intValues.
Notice that PrintArrays is called twice (lines 19 and 28), so GetEnumerator is called twice on doubleValues. The GetEnumerator method (lines 54 and 62) always returns an enumerator positioned before the first element. Also notice that the IEnumerator property Current is read-only. Enumerators cannot be used to modify the contents of collections, only to obtain the contents.
Lines 70–71 use a foreach statement to iterate over the collection elements like an enumerator. In fact, the foreach statement behaves exactly like an enumerator. Both loop over the elements of an array one by one in consecutive order. Neither allows you to modify the elements during the iteration. This is not a coincidence. The foreach statement implicitly obtains an enumerator via the GetEnumerator method and uses the enumerator’s MoveNext method and Current property to traverse the collection, just as we did explicitly in lines 54–57. For this reason, we can use the foreach statement to iterate over any collection that implements the IEnumerable interface—not just arrays. We demonstrate this functionality in the next section when we discuss class ArrayList.
Other static Array methods include Clear (to set a range of elements to 0, false or null, as appropriate), CreateInstance (to create a new array of a specified type), IndexOf (to locate the first occurrence of an object in an array or portion of an array), LastIndexOf (to locate the last occurrence of an object in an array or portion of an array) and Reverse (to reverse the contents of an array or portion of an array).
23.4 Nongeneric Collections
The System.Collections namespace in the .NET Framework Class Library is the primary source for nongeneric collections. These classes provide standard implementations of many of the data structures discussed in Chapter 21 with collections that store references of type object. In this section, we demonstrate classes ArrayList, Stack and Hashtable.
23.4.1 Class ArrayList
In most programming languages, conventional arrays have a fixed size—they cannot be changed dynamically to conform to an application’s execution-time memory requirements. In some applications, this fixed-size limitation presents a problem for programmers. They must choose between using fixed-size arrays that are large enough to store the maximum number of elements the application may require and using dynamic data structures that can grow and shrink the amount of memory required to store data in response to the changing requirements of an application at execution time.
The .NET Framework’s ArrayList collection class mimics the functionality of conventional arrays and provides dynamic resizing of the collection through the class’s methods. At any time, an ArrayList contains a certain number of elements less than or equal to its capacity—the number of elements currently reserved for the ArrayList. An application can manipulate the capacity with ArrayList property Capacity. [Note: New applications should use the generic List<T> class introduced in Chapter 9.]
Performance Tip 23.1
![]()
As with linked lists, inserting additional elements into an ArrayList whose current size is less than its capacity is a fast operation.
Performance Tip 23.2
![]()
It’s a slow operation to insert an element into an ArrayList that needs to grow larger to accommodate a new element. An ArrayList that’s at its capacity must have its memory reallocated and the existing values copied into it.
Performance Tip 23.3
![]()
If storage is at a premium, use method TrimToSize of class ArrayList to trim an Array-List to its exact size. This will optimize an ArrayList’s memory use. Be careful—if the application needs to insert additional elements, the process will be slower, because the ArrayList must grow dynamically (trimming leaves no room for growth).
ArrayLists store references to objects. All classes derive from class object, so an ArrayList can contain objects of any type. Figure 23.4 lists some useful methods and properties of class ArrayList.
Fig. 23.4. Some methods and properties of class ArrayList.

Figure 23.5 demonstrates class ArrayList and several of its methods. Class ArrayList belongs to the System.Collections namespace (line 4). Lines 8–11 declare two arrays of strings (colors and removeColors) that we’ll use to fill two ArrayList objects. Recall from Section 10.11 that constants must be initialized at compile time, but readonly variables can be initialized at execution time. Arrays are objects created at execution time, so we declare colors and removeColors with readonly—not const—to make them unmodifiable. When the application begins execution, we create an ArrayList with an initial capacity of one element and store it in variable list (line 16). The foreach statement in lines 19–20 adds the five elements of array colors to list via ArrayList’s Add method, so list grows to accommodate these new elements. Line 24 uses ArrayList’s overloaded constructor to create a new ArrayList initialized with the contents of array removeColors, then assigns it to variable removeList. This constructor can initialize the contents of an ArrayList with the elements of any ICollection passed to it. Many of the collection classes have such a constructor. Notice that the constructor call in line 24 performs the task of lines 19–20.
Fig. 23.5. Using class ArrayList.


Line 27 calls method DisplayInformation (lines 37–54) to output the contents of the list. This method uses a foreach statement to traverse the elements of an ArrayList. As we discussed in Section 23.3, the foreach statement is a convenient shorthand for calling ArrayList’s GetEnumerator method and using an enumerator to traverse the elements of the collection. Also, line 40 infers that the iteration variable’s type is object because class ArrayList is nongeneric and stores references to objects.
We use properties Count and Capacity (line 45) to display the current number and the maximum number of elements that can be stored without allocating more memory to the ArrayList. The output of Fig. 23.5 indicates that the ArrayList has capacity 8.
In line 47, we invoke method IndexOf to determine the position of the string "BLUE" in arrayList and store the result in local variable index. IndexOf returns -1 if the element is not found. The if statement in lines 49–53 checks if index is -1 to determine whether arrayList contains "BLUE". If it does, we output its index. ArrayList also provides method Contains, which simply returns true if an object is in the ArrayList, and false otherwise. Method Contains is preferred if we do not need the index of the element.
Performance Tip 23.4
![]()
ArrayList methods IndexOf and Contains each perform a linear search, which is a costly operation for large ArrayLists. If the ArrayList is sorted, use ArrayList method BinarySearch to perform a more efficient search. Method BinarySearch returns the index of the element, or a negative number if the element is not found.
After method DisplayInformation returns, we call method RemoveColors (lines 57–63) with the two ArrayLists. The for statement in lines 61–62 iterates over ArrayList secondList. Line 62 uses an indexer to access an ArrayList element—by following the ArrayList reference name with square brackets ([]) containing the desired index of the element. An ArgumentOutOfRangeException occurs if the specified index is not both greater than 0 and less than the number of elements currently stored in the ArrayList (specified by the ArrayList’s Count property).
We use the indexer to obtain each of secondList’s elements, then remove each one from firstList with the Remove method. This method deletes a specified item from an ArrayList by performing a linear search and removing (only) the first occurrence of the specified object. All subsequent elements shift toward the beginning of the ArrayList to fill the emptied position.
After the call to RemoveColors, line 33 again outputs the contents of list, confirming that the elements of removeList were, indeed, removed.
23.4.2 Class Stack
The Stack class implements a stack data structure and provides much of the functionality that we defined in our own implementation in Section 21.5. Refer to that section for a discussion of stack data-structure concepts. We created a test application in Fig. 21.14 to demonstrate the StackInheritance data structure that we developed. We adapt Fig. 21.14 in Fig. 23.6 to demonstrate the .NET Framework collection class Stack. [Note: New applications requiring a stack class should use the generic Stack<T> class.]
Fig. 23.6. Demonstrating class Stack.


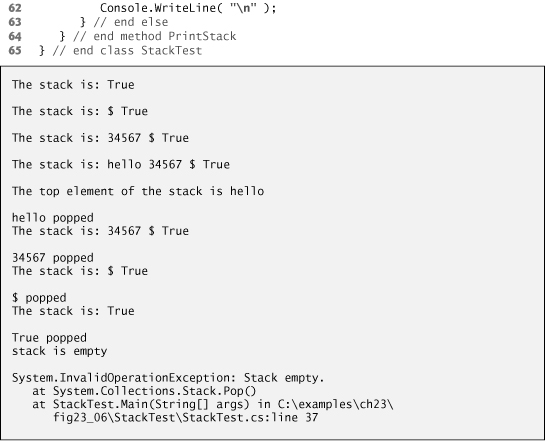
The using directive in line 4 allows us to use the Stack class with its unqualified name from the System.Collections namespace. Line 10 creates a Stack. As one might expect, class Stack has methods Push and Pop to perform the basic stack operations.
Method Push takes an object as an argument and inserts it at the top of the Stack. If the number of items on the Stack (the Count property) is equal to the capacity at the time of the Push operation, the Stack grows to accommodate more objects. Lines 19–26 use method Push to add four elements (a bool, a char, an int and a string) to the stack and invoke method PrintStack (lines 50–64) after each Push to output the contents of the stack. Notice that this nongeneric Stack class can store only references to objects, so each of the value-type items—the bool, the char and the int—is implicitly boxed before it’s added to the Stack. (Namespace System.Collections.Generic provides a generic Stack class that has many of the same methods and properties used in Fig. 23.6. This version eliminates the overhead of boxing and unboxing simple types.)
Method PrintStack (lines 50–64) uses Stack property Count (implemented to fulfill the contract of interface ICollection) to obtain the number of elements in stack. If the stack is not empty (i.e., Count is not equal to 0), we use a foreach statement to iterate over the stack and output its contents by implicitly invoking the ToString method of each element. The foreach statement implicitly invokes Stack’s GetEnumerator method, which we could have called explicitly to traverse the stack via an enumerator.
Method Peek returns the value of the top stack element but does not remove the element from the Stack. We use Peek at line 30 to obtain the top object of the Stack, then output that object, implicitly invoking the object’s ToString method. An InvalidOperationException occurs if the Stack is empty when the application calls Peek. (We do not need an exception-handling block because we know the stack is not empty here.)
Method Pop takes no arguments—it removes and returns the object currently on top of the Stack. An infinite loop (lines 35–40) pops objects off the stack and outputs them until the stack is empty. When the application calls Pop on the empty stack, an Invalid-OperationException is thrown. The catch block (lines 42–46) outputs the exception, implicitly invoking the InvalidOperationException’s ToString method to obtain its error message and stack trace.
Common Programming Error 23.2
![]()
Attempting to Peek or Pop an empty Stack (a Stack whose Count property is 0) causes an InvalidOperationException.
Although Fig. 23.6 does not demonstrate it, class Stack also has method Contains, which returns true if the Stack contains the specified object, and returns false otherwise.
23.4.3 Class Hashtable
When an application creates objects of new or existing types, it needs to manage those objects efficiently. This includes sorting and retrieving objects. Sorting and retrieving information with arrays is efficient if some aspect of your data directly matches the key value and if those keys are unique and tightly packed. If you have 100 employees with nine-digit social security numbers and you want to store and retrieve employee data by using the social security number as a key, it would nominally require an array with 1,000,000,000 elements, because there are 1,000,000,000 unique nine-digit numbers. If you have an array that large, you could get high performance storing and retrieving employee records by simply using the social security number as the array index, but it would be a large waste of memory.
Many applications have this problem—either the keys are of the wrong type (i.e., not nonnegative integers), or they’re of the right type but are sparsely spread over a large range.
What is needed is a high-speed scheme for converting keys such as social security numbers and inventory part numbers to unique array indices. Then, when an application needs to store something, the scheme could convert the application key rapidly to an index and the record of information could be stored at that location in the array. Retrieval occurs the same way—once the application has a key for which it wants to retrieve the data record, the application simply applies the conversion to the key, which produces the array index where the data resides in the array and retrieves the data.
The scheme we describe here is the basis of a technique called hashing, in which we store data in a data structure called a hash table. Why the name? Because, when we convert a key into an array index, we literally scramble the bits, making a “hash” of the number. The number actually has no real significance beyond its usefulness in storing and retrieving this particular data record.
A glitch in the scheme occurs when there are collisions (i.e., two different keys “hash into” the same cell, or element, in the array). Since we cannot sort two different data records to the same space, we need to find an alternative home for all records beyond the first that hash to a particular array index. One scheme for doing this is to “hash again” (i.e., to reapply the hashing transformation to the key to provide a next candidate cell in the array). The hashing process is designed so that with just a few hashes, an available cell will be found.
Another scheme uses one hash to locate the first candidate cell. If the cell is occupied, successive cells are searched linearly until an available cell is found. Retrieval works the same way—the key is hashed once, the resulting cell is checked to determine whether it contains the desired data. If it does, the search is complete. If it does not, successive cells are searched linearly until the desired data is found.
The most popular solution to hash-table collisions is to have each cell of the table be a hash “bucket”—typically, a linked list of all the key/value pairs that hash to that cell. This is the solution that the .NET Framework’s Hashtable class implements.
The load factor affects the performance of hashing schemes. The load factor is the ratio of the number of objects stored in the hash table to the total number of cells of the hash table. As this ratio gets higher, the chance of collisions tends to increase.
Performance Tip 23.5
![]()
The load factor in a hash table is a classic example of a space/time trade-off: By increasing the load factor, we get better memory utilization, but the application runs slower due to increased hashing collisions. By decreasing the load factor, we get better application speed because of reduced hashing collisions, but we get poorer memory utilization because a larger portion of the hash table remains empty.
Computer-science students study hashing schemes in courses called “Data Structures” and “Algorithms.” Recognizing the value of hashing, the .NET Framework provides class Hashtable to enable programmers to easily employ hashing in applications.
This concept is profoundly important in our study of object-oriented programming. Classes encapsulate and hide complexity (i.e., implementation details) and offer user-friendly interfaces. Crafting classes to do this properly is one of the most valued skills in the field of object-oriented programming.
A hash function performs a calculation that determines where to place data in the hash table. The hash function is applied to the key in a key/value pair of objects. Class Hashtable can accept any object as a key. For this reason, class object defines method GetHashCode, which all objects inherit. Most classes that are candidates to be used as keys in a hash table override this method to provide one that performs efficient hash-code calculations for a specific type. For example, a string has a hash-code calculation that’s based on the contents of the string. Figure 23.7 uses a Hashtable to count the number of occurrences of each word in a string. [Note: New applications should use generic class Dictionary<K, V> (introduced in Section 17.4) rather than Hashtable.]
Fig. 23.7. Application counts the number of occurrences of each word in a string and stores them in a hash table.


Lines 4–6 contain using directives for namespaces System (for class Console), System.Text.RegularExpressions (for class Regex) and System.Collections (for class Hashtable). Class HashtableTest declares three static methods. Method CollectWords (lines 20–46) inputs a string and returns a Hashtable in which each value stores the number of times that word appears in the string and the word is used for the key. Method DisplayHashtable (lines 49–60) displays the Hashtable passed to it in column format. The Main method (lines 10–17) simply invokes CollectWords (line 13), then passes the Hashtable returned by CollectWords to DisplayHashtable in line 16.
Method CollectWords (lines 20–46) begins by initializing local variable table with a new Hashtable (line 22) that has a default maximum load factor of 1.0. When the Hashtable reaches the specified load factor, the capacity is increased automatically. (This implementation detail is invisible to clients of the class.) Lines 24–25 prompt the user and input a string. We use static method Split of class Regex in line 28 to divide the string by its whitespace characters. This creates an array of “words,” which we then store in local variable words.
Lines 31–43 loop over every element of array words. Each word is converted to lowercase with string method ToLower, then stored in variable wordKey (line 33). Then line 36 calls Hashtable method ContainsKey to determine whether the word is in the hash table (and thus has occurred previously in the string). If the Hashtable does not contain an entry for the word, line 42 uses Hashtable method Add to create a new entry in the hash table, with the lowercase word as the key and an object containing 1 as the value. Auto-boxing occurs when the application passes integer 1 to method Add, because the hash table stores both the key and value in references of type object.
Common Programming Error 23.3
![]()
Using the Add method to add a key that already exists in the hash table causes an ArgumentException.
If the word is already a key in the hash table, line 38 uses the Hashtable’s indexer to obtain and set the key’s associated value (the word count) in the hash table. We first downcast the value obtained by the get accessor from an object to an int. This unboxes the value so that we can increment it by 1. Then, when we use the indexer’s set accessor to assign the key’s associated value, the incremented value is implicitly reboxed so that it can be stored in the hash table.
Notice that invoking the get accessor of a Hashtable indexer with a key that does not exist in the hash table obtains a null reference. Using the set accessor with a key that does not exist in the hash table creates a new entry, as if you had used the Add method.
Line 45 returns the hash table to the Main method, which then passes it to method DisplayHashtable (lines 49–60), which displays all the entries. This method uses read-only property Keys (line 56) to get an ICollection that contains all the keys. Because ICollection extends IEnumerable, we can use this collection in the foreach statement in lines 56–57 to iterate over the keys of the hash table. This loop accesses and outputs each key and its value in the hash table using the iteration variable and table’s get accessor. Each key and its value is displayed in a field width of -12. The negative field width indicates that the output is left justified. A hash table is not sorted, so the key/value pairs are not displayed in any particular order. Line 59 uses Hashtable property Count to get the number of key/value pairs in the Hashtable.
Lines 56–57 could have also used the foreach statement with the Hashtable object itself, instead of using the Keys property. If you use a foreach statement with a Hashtable object, the iteration variable will be of type DictionaryEntry. The enumerator of a Hashtable (or any other class that implements IDictionary) uses the DictionaryEntry structure to store key/value pairs. This structure provides properties Key and Value for retrieving the key and value of the current element. If you do not need the key, class Hashtable also provides a read-only Values property that gets an ICollection of all the values stored in the Hashtable. We can use this property to iterate through the values stored in the Hashtable without regard for where they’re stored.
Problems with Nongeneric Collections
In the word-counting application of Fig. 23.7, our Hashtable stores its keys and data as object references, even though we store only string keys and int values by convention. This results in some awkward code. For example, line 38 was forced to unbox and box the int data stored in the Hashtable every time it incremented the count for a particular key. This is inefficient. A similar problem occurs in line 56—the iteration variable of the foreach statement is an object reference. If we need to use any of its string-specific methods, we need an explicit downcast.
This can cause subtle bugs. Suppose we decide to improve the readability of Fig. 23.7 by using the indexer’s set accessor instead of the Add method to add a key/value pair in line 42, but accidentally type:
table[ wordKey ] = wordKey; // initialize to 1
This statement will create a new entry with a string key and string value instead of an int value of 1. Although the application will compile correctly, this is clearly incorrect. If a word appears twice, line 38 will try to downcast this string to an int, causing an InvalidCastException at execution time. The error that appears at execution time will indicate that the problem is at line 38, where the exception occurred, not at line 42. This makes the error more difficult to find and debug, especially in large software applications where the exception may occur in a different file—and even in a different assembly.
23.5 Generic Collections
The System.Collections.Generic namespace contains generic classes that allow us to create collections of specific types. As you saw in Fig. 23.2, many of the classes are simply generic versions of nongeneric collections. A couple of classes implement new data structures. Here, we demonstrate generic collections SortedDictionary and LinkedList.
23.5.1 Generic Class SortedDictionary
A dictionary is the general term for a collection of key/value pairs. A hash table is one way to implement a dictionary. The .NET Framework provides several implementations of dictionaries, both generic and nongeneric, all of which implement the IDictionary inter-face (described in Fig. 23.1). The application in Fig. 23.8 is a modification of Fig. 23.7 that uses the generic class SortedDictionary. Generic class SortedDictionary does not use a hash table, but instead stores its key/value pairs in a binary search tree. (We discuss binary trees in depth in Section 21.7.) As the class name suggests, the entries in Sorted-Dictionary are sorted in the tree by key. When the key implements generic interface IComparable<T>, the SortedDictionary uses the results of IComparable<T> method CompareTo to sort the keys. Notice that despite these implementation details, we use the same public methods, properties and indexers with classes Hashtable and SortedDictionary in the same ways. In fact, except for the generic-specific syntax, Fig. 23.8 looks remarkably similar to Fig. 23.7. This is the beauty of object-oriented programming.
Fig. 23.8. Application counts the number of occurrences of each word in a string and stores them in a generic sorted dictionary.


Line 6 contains a using directive for the System.Collections.Generic namespace, which contains class SortedDictionary. The generic class SortedDictionary takes two type arguments—the first specifies the type of key (i.e., string) and the second the type of value (i.e., int). We have simply replaced the word Hashtable in line 13 and lines 23–24 with SortedDictionary<string, int> to create a dictionary of int values keyed with strings. Now, the compiler can check and notify us if we attempt to store an object of the wrong type in the dictionary. Also, because the compiler now knows that the data structure contains int values, there’s no longer any need for the downcast in line 40. This allows line 40 to use the much more concise prefix increment (++) notation. These changes result in code that can be checked for type safety at compile time.
Static method DisplayDictionary (lines 51–63) has been modified to be completely generic. It takes type parameters K and V. These parameters are used in line 52 to indicate that DisplayDictionary takes a SortedDictionary with keys of type K and values of type V. We use type parameter K again in line 59 as the type of the iteration key. This use of generics is a marvelous example of code reuse. If we decide to change the application to count the number of times each character appears in a string, method DisplayDictionary could receive an argument of type SortedDictionary<char, int> without modification. The key-value pairs displayed are now ordered by key, as shown in Fig. 23.8.
Performance Tip 23.6
![]()
Because class SortedDictionary keeps its elements sorted in a binary tree, obtaining or inserting a key/value pair takes O(log n) time, which is fast compared to linear searching, then inserting.
Common Programming Error 23.4
![]()
Invoking the get accessor of a SortedDictionary indexer with a key that does not exist in the collection causes a KeyNotFoundException. This behavior is different from that of the Hashtable indexer’s get accessor, which would return null.
23.5.2 Generic Class LinkedList
The generic LinkedList class is a doubly linked list—we can navigate the list both backward and forward with nodes of generic class LinkedListNode. Each node contains property Value and read-only properties Previous and Next. The Value property’s type matches LinkedList’s single type parameter because it contains the data stored in the node. The Previous property gets a reference to the preceding node in the linked list (or null if the node is the first of the list). Similarly, the Next property gets a reference to the subsequent reference in the linked list (or null if the node is the last of the list). We demonstrate a few linked-list manipulations in Fig. 23.9.
Fig. 23.9. Using LinkedLists.




The using directive in line 4 allows us to use the LinkedList class by its unqualified name. Lines 16–23 create LinkedLists list1 and list2 of strings and fill them with the contents of arrays colors and colors2, respectively. LinkedList is a generic class that has one type parameter for which we specify the type argument string in this example (lines 16 and 23). We demonstrate two ways to fill the lists. In lines 19–20, we use the foreach statement and method AddLast to fill list1. The AddLast method creates a new LinkedListNode (with the given value available via the Value property) and appends this node to the end of the list. There’s also an AddFirst method that inserts a node at the beginning of the list. Line 23 invokes the constructor that takes an IEnumerable<string> parameter. All arrays implicitly inherit from the generic interfaces IList and IEnumerable with the type of the array as the type argument, so the string array colors2 implements IEnumerable<string>. The type parameter of this generic IEnumerable matches the type parameter of the generic LinkedList object. This constructor call copies the contents of the array colors2 to list2.
Line 25 calls generic method Concatenate (lines 51–58) to append all elements of list2 to the end of list1. Line 26 calls method PrintList (lines 40–48) to output list1’s contents. Line 29 calls method ToUppercaseStrings (lines 61–73) to convert each string element to uppercase, then line 30 calls PrintList again to display the modified strings. Line 33 calls method RemoveItemsBetween (lines 76–90) to remove the elements between "BLACK" and "BROWN"—not including either. Line 35 outputs the list again, then line 36 invokes method PrintReversedList (lines 93–107) to display the list in reverse order.
Generic method Concatenate (lines 51–58) iterates over list2 with a foreach statement and calls method AddLast to append each value to the end of list1. The LinkedList class’s enumerator loops over the values of the nodes, not the nodes themselves, so the iteration variable has type T. Notice that this creates a new node in list1 for each node in list2. One LinkedListNode cannot be a member of more than one LinkedList. If you want the same data to belong to more than one LinkedList, you must make a copy of the node for each list to avoid InvalidOperationExceptions.
Generic method PrintList (lines 40–48) similarly uses a foreach statement to iterate over the values in a LinkedList, and outputs them. Method ToUppercaseStrings (lines 61–73) takes a linked list of strings and converts each string value to uppercase. This method replaces the strings stored in the list, so we cannot use an enumerator (via a foreach statement) as in the previous two methods. Instead, we obtain the first LinkedListNode via the First property (line 64), and use a while statement to loop through the list (lines 66–72). Each iteration of the while statement obtains and updates the contents of currentNode via property Value, using string method ToUpper to create an uppercase version of string color. At the end of each iteration, we move the current node to the next node in the list by assigning currentNode to the node obtained by its own Next property (line 71). The Next property of the last node of the list gets null, so when the while statement iterates past the end of the list, the loop exits.
Notice that it does not make sense to declare ToUppercaseStrings as a generic method, because it uses the string-specific methods of the values in the nodes. Methods PrintList (lines 40–48) and Concatenate (lines 51–58) do not need to use any string-specific methods, so they can be declared with generic type parameters to promote maximal code reuse.
Generic method RemoveItemsBetween (lines 76–90) removes a range of items between two nodes. Lines 80–81 obtain the two “boundary” nodes of the range by using method Find. This method performs a linear search on the list and returns the first node that contains a value equal to the passed argument. Method Find returns null if the value is not found. We store the node preceding the range in local variable currentNode and the node following the range in endNode.
The while statement in lines 85–89 removes all the elements between currentNode and endNode. On each iteration of the loop, we remove the node following currentNode by invoking method Remove (line 88). Method Remove takes a LinkedListNode, splices that node out of the LinkedList, and fixes the references of the surrounding nodes. After the Remove call, currentNode’s Next property now gets the node following the node just removed, and that node’s Previous property now gets currentNode. The while statement continues to loop until there are no nodes left between currentNode and endNode, or until currentNode is the last node in the list. (There’s also an overloaded version of method Remove that performs a linear search for the specified value and removes the first node in the list that contains it.)
Method PrintReversedList (lines 93–107) displays the list backward by navigating the nodes manually. Line 98 obtains the last element of the list via the Last property and stores it in currentNode. The while statement in lines 100–104 iterates through the list backward by moving the currentNode reference to the previous node at the end of each iteration, then exiting when we move past the beginning of the list. Note how similar this code is to lines 64–72, which iterated through the list from the beginning to the end.
23.6 Covariance and Contravariance for Generic Types
A new feature in Visual C# 2010 is covariance and contravariance of generic interface and delegate types. To understand these concepts, we’ll consider them in the context of arrays, which have always been covariant and contravariant in C#.
Covariance in Arrays
Recall our Employee class hierarchy from Section 12.5, which consisted of the base class Employee and the derived classes SalariedEmployee, CommissionEmployee and Base-PlusCommissionEmployee. Assuming the declarations
SalariedEmployee[] salariedEmployees = {
new SalariedEmployee( "Bob", "Blue", "111-11-1111", 800M ),
new SalariedEmployee( "Rachel", "Red", "222-22-2222", 1234M ) };
Employee[] employees;
we can write the following statement:
employees = salariedEmployees;
Even though the array type SalariedEmployee[] does not derive from the array type Employee[], the preceding assignment is allowed because class SalariedEmployee is a derived class of Employee.
Similarly, suppose we have the following method, which displays the string representation of each Employee in its employees array parameter:
void PrintEmployees( Employee[] employees )
We can call this method with the array of SalariedEmployees, as in:
PrintEmployees( salariedEmployees );
and the method will correctly display the string representation of each SalariedEmployee object in the argument array. Assigning an array of a derived-class type to an array variable of a base-class type is an example of covariance.
Covariance in Generic Types
Covariance now also works with several generic interface and delegate types, including IEnumerable<T>. Arrays and generic collections implement the IEnumerable<T> interface. Using the salariedEmployees array declared previously, consider the following statement:
IEnumerable< Employee > employees = salariedEmployees;
Prior to Visual C# 2010, this generated a compilation error. Interface IEnumerable<T> is now covariant, so the preceding statement is allowed. If we modify method PrintEmployees as in:
void PrintEmployees( IEnumerable< Employee > employees )
we can call PrintEmployees with the array of SalariedEmployee objects, because that array implements the interface IEnumerable<SalariedEmployee> and because a Salaried-Employee is an Employee and because IEnumerable<T> is covariant. Covariance like this works only with reference types that are related by a class hierarchy.
Contravariance in Arrays
Previously, we showed that an array of a derived-class type (salariedEmployees) can be assigned to an array variable of a base-class type (employees). Now, consider the following statement, which has always worked in C#:
SalariedEmployee[] salariedEmployees2 =
( SalariedEmployee[] ) employees;
Based on the previous statements, we know that the Employee array variable employees currently refers to an array of SalariedEmployees. Using a cast operator to assign employees—an array of base-class-type elements—to salariedEmployees2—an array of derived-class-type elements—is an example of contravariance. The preceding cast will fail at runtime if employees is not an array of SalariedEmployees.
Contravariance in Generic Types
To understand contravariance in generic types, consider a SortedSet of SalariedEmployees. Class SortedSet<T> maintains a set of objects in sorted order—no duplicates are allowed. The objects placed in a SortedSet must implement the IComparable<T> interface. For classes that do not implement this interface, you can still compare their objects using an object that implements the IComparer<T> interface. This interface’s Compare method compares its two arguments and returns 0 if they’re equal, a negative integer if the first object is less than the second, or a positive integer if the first object is greater than the second.
Our Employee hierarchy classes do not implement IComparable<T>. Let’s assume we wish to sort Employees by social security number. We can implement the following class to compare any two Employees:
class EmployeeComparer : IComparer< Employee >
{
int IComparer< Employee >.Compare( Employee a, Employee b)
{
return a.SocialSecurityNumber.CompareTo(
b.SocialSecurityNumber );
} // end method Compare
} // end class EmployeeComparer
Method Compare returns the result of comparing the two Employees social security numbers using string method CompareTo.
Now consider the following statement, which creates a SortedSet:
SortedSet< SalariedEmployee > set =
new SortedSet< SalariedEmployee >( new EmployeeComparer() );
When the type argument does not implement IComparable<T>, you must supply an appropriate IComparer<T> object to compare the objects that will be placed in the Sorted-Set. Since, we’re creating a SortedSet of SalariedEmployees, the compiler expects the IComparer<T> object to implement the IComparer<SalariedEmployee>. Instead, we provided an object that implements IComparer<Employee>. The compiler allows us to provide an IComparer for a base-class type where an IComparer for a derived-class type is expected because interface IComparer<T> supports contravariance.
Web Resources
For a list of covariant and contravariant interface types in .NET 4, visit
msdn.microsoft.com/en-us/library/dd799517.aspx#VariantList
It’s also possible to create your own variant types. For information on this, visit
msdn.microsoft.com/en-us/library/dd997386.aspx
23.7 Wrap-Up
This chapter introduced the .NET Framework collection classes. You learned about the hierarchy of interfaces that many of the collection classes implement. You saw how to use class Array to perform array manipulations. You learned that the System.Collections and System.Collections.Generic namespaces contain many nongeneric and generic collection classes, respectively. We presented the nongeneric classes ArrayList, Stack and Hashtable as well as generic classes SortedDictionary and LinkedList. In doing so, we discussed data structures in greater depth. We discussed dynamically expanding collections, hashing schemes, and two implementations of a dictionary. You saw the advantages of generic collections over their nongeneric counterparts.
You also learned how to use enumerators to traverse these data structures and obtain their contents. We demonstrated the foreach statement with many of the classes of the Framework Class Library, and explained that this works by using enumerators “behind-the-scenes” to traverse the collections.