
Chapter 26. Hash Values
The Verification Standard
Information in this chapter:
• Hash values
• How hash values are used in digital forensics
Hash values play an important role in digital forensics, especially in verifying that a forensic image of digital evidence is exactly the same as the original; a digital fingerprint, if you will. When asked on the witness stand, any examiner should be able to show that he or she took the proper steps to verify the evidence collected using hash values for verification of the forensic copy against the original evidence.
But to ignore the benefit of hash values in a case beyond simply verifying evidence does them a great disservice. If a particular file is of interest in your case, hash values can be used to find that file buried just about anywhere in a computer, even if the name of the file has been changed. Hash values can be used to link one device to another, such as a USB thumb drive to a computer, which can be particularly useful in cases that involve data theft or the distribution of contraband. Likewise, hash values can be used to help prove that something does not exist on a computer or other digital device. A good examiner knows the importance of hash values and how to use them. In this chapter we will highlight some of the more common uses of hash values and how you can put them to work in a case, and we will share some examples of how we have used them ourselves.
Keywords
Hash Values, Verification, Computer Forensics
Introduction
When asked on the witness stand, any examiner should be able to show that he or she took the proper steps to verify the evidence collected using hash values for verification of the forensic copy against the original evidence.
In Chapter 4 (in the section “Acquisition Best Practices”), we saw that hash values play an important roles in forensics, especially in verifying that a forensic image of digital evidence is exactly the same as the original; a digital fingerprint, if you will.
Ignoring the benefit of using hash values in a case beyond simply verifying evidence does them a great disservice. If a particular file is of interest in your case, hash values can be used to find that file buried just about anywhere in a computer, even if the name of the file has been changed. Hash values can be used to link one device to another, such as a USB thumb drive to a computer, which can be particularly useful in cases that involve data theft or the distribution of contraband. Likewise, hash values can be used to help prove that something does not exist on a computer or other digital device. A good examiner knows the importance of hash values and how to use them. In this chapter we will highlight some of the more common uses of hash values and how you can put them to work in a case, and we will share some examples of how we have used them ourselves.
26.1. Hash values
The process of hashing, as used in digital forensics, is a mathematical algorithm performed against a file, a group of files, or the contents of an entire hard drive. This hash value is the digital version of a thumbprint, allowing for that file or hard drive to be uniquely identified as it exists at the time it was hashed. Basically, you have a perfect snapshot in time of the data, which is an absolute must if the evidence itself, or any examination that is performed on the evidence, is going to be used in your case or the courtroom. The two types of hashes you will encounter in computer forensics are
• Message Digest 5 (MD5)
• Secure Hash Algorithm 1 (SHA1)
They both serve the same function in the verification of evidence and they aid in the examination of digital evidence.
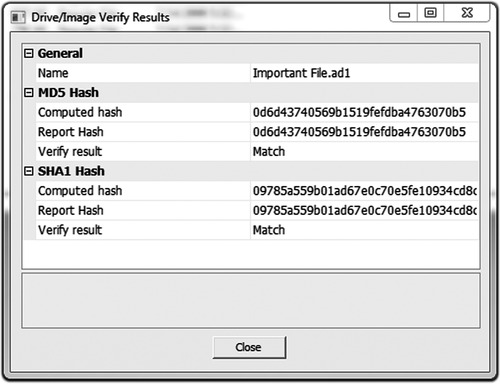
The purpose of Fig. 26.1 is to familiarize legal professionals with what a hash value looks like so they can identify it when they see it in a warrant or forensic reports.
26.2. How hash values are used in digital forensics
When a hard drive is hashed for verification purposes, the hashing process looks at all of the data on the hard drive and creates a “digital thumbprint” for it. At this point, the hashing process has performed its primary function, which is the verification of the data on the hard drive; the perfect snapshot in time of the data has been created. At this point, only the hard drive has a hash value. All of the files and documents that reside on the hard drive do not yet have a hash value. A forensic examiner can hash all of the files on the hard drive, giving each and every file a unique digital “thumbprint,” or hash value.
Think of it like this: Imagine you are packing boxes in preparation to move. When packing your office, you clear off all the papers on your desk and put them in one box, and label it “Office Papers.” This box of items now has a unique name, allowing you to identify it, so that it will be put in the correct room when you are unpacking. However, in the process of unpacking, you have to read each sheet of paper to know where it belongs since they are not labeled. This would be like hashing a hard drive for verification and preservation purposes. The hard drive has a unique hash value based on its data, which allows it to be identified, but the individual items inside the hard drive do not. Using the same scenario, let’s imagine this time that before placing your papers in the box, you label each paper with a unique name. You labeled the box, so you know which room it belongs in, and since you also labeled each individual paper with a unique name, you are able to quickly organize and find a particular paper of interest. This is akin to the process of hashing the contents of a hard drive. Since all of the files and documents are hashed and now have their own “digital thumbprint,” it is now possible to quickly and accurately locate a particular file of interest. The following sections show some of the ways in which hash values aid in digital forensics analysis.
26.2.1. Using hash values to find hidden files
One way to try and hide a file is to rename the file extension. For instance, let’s imagine that an important picture is stolen from a server at a company and transferred to another computer. The stolen picture is named “evidence.jpg.” Since the computer that has a copy of the stolen picture on the hard drive is running the Windows operating system, it would see the file extension (jpg) and recognize the file as a picture. If the file extension were changed to “.txt,” Windows would not know it was a picture. The person who copied the stolen picture to the computer could go a step further in trying to hide the picture “evidence.jpg” by renaming the file to something innocuous, like “puppies.jpg,” and then changing the file extension, giving us “puppies.txt.” So now, when the nosy boss navigates through the files on the computer, he will not be clued in that there is a stolen picture that belongs to the company on the hard drive. In all probability it will seem to the boss, given the new name of the file and the file extension “txt,” that it is a delightful short story about the joy of puppies.
While hiding a file in this method can fool a nosy boss, it will not hide it from a competent examiner who is using hash values as a way to locate a sensitive file. This type of file hiding is common in cases with a scenario like this. Hash values allow a forensic examiner to use the hash value from a known file (in this example, evidence.jpg), and search the suspect’s computer for that sensitive file, looking for an exact match of that hash value. Since the hash value is created using the contents of the file and ignores the file name and file extension, it does not matter if someone tries to hide it using the aforementioned method, a hash value analysis will still find it, as shown in Fig. 26.2.
26.2.2. How to determine whether a file exists on a computer
Determining whether a file exists on a computer is a scenario in which hash values really shine. In forensics, when a group of files that are of particular interest is found, an examiner can run the hashing process on those files to generate the hash values for each of the files, and then put them together in what is called a hash set. That examiner can then use this hash to compare the hash values of the set against all the files on a hard drive to see if any of the files on the hard drive match any of the hash values for the files in the hash set.
26.2.3. De-duplicating data in e-discovery
Having to read the same e-mail or document multiple times is a real chore when reviewing discovery. In cases that involve electronic discovery (e-discovery), hash values allow data to be de-duplicated. After all the files are hashed in an e-discovery case, the de-duplication process finds files that have matching hash values. When multiple files with the same hash value are found, one of the files is kept, while the rest are removed from the discovery. The result is that you can still be assured you have the entirety of the discovery, since the de-duplication process only removes duplicate files that are exactly the same, so that you only have to read a particular e-mail or document once instead of multiple times.
26.2.4. The dangers of court testimony without verification
Failing to follow the basic steps of maintaining chain of custody for evidence by creating a verification hash of collected evidence leaves the question of the authenticity of the evidence open. The purpose of the hash value is to be able to, at any time, compare a file or an entire hard drive’s worth of evidence to prove that the original is identical to the evidence being presented, without alteration.
It is this process of verification hashing for evidence that allows examiners to create and work from exact copies of original evidence.
26.2.5. What if an opposing expert did not verify evidence?
It is very common, especially in civil and domestic cases, to collect evidence as a “point-in-time” snapshot. In contrast to a criminal proceeding where computers and other evidence may be seized and held by a law enforcement agency for the duration, civil collections often require that the computer be taken out of service only long enough to make the forensic copy.
In a civil litigation, taking a production e-mail server out of a corporate office for an indefinite time would create an undue burden of discovery. To ensure that the producing party is not unduly burdened by disruption to their business, which would involve loss of business, employee costs, and so on, a server or computer must be forensically imaged quickly and put back into production.
Creating a verification hash of the collected evidence is a vital step in ensuring that the collected evidence matches the original evidence at the time it is collected. It also ensures that when produced, evidence can be verified against the collected “original,” since the point-in-time snapshot in effect becomes the original evidence, even though the original media is no longer available for comparison.
In electronic discovery collections, it is common to collect a group of files, or a custodian’s e-mail, without making a forensic image of the entire hard drive where those documents reside. However, even in a case where only a set of files is to be collected, they should be collected using forensic tools that provide a hash value in a defensibly sound manner.
Summary
In this chapter we learned that hash values are used to verify that a forensic copy of a hard drive or electronic file is the same as the original, allowing the use of forensic copies for analysis and production of evidence. We also learned that hash values can be used to locate files that have been hidden by changing the file name and/or file extension to fool a computer user. Also covered in this chapter is the use of hash values in e-discovery for de-duplication where the same document or e-mail may occur multiple times in electronic discovery.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.