
The topic of floating-point was discussed back in Chapter 8, "Floating-Point Anyone?" As the same methodologies of SIMD processing learned in Chapter 7, "Integer Math," apply for packed floating-point, it does not matter whether one is calculating the sum or the product. However, there is one exception. With integer addition, the data width increases by one bit. With integer multiplication, the data width increases by 2N bits. With floating-point, the number occupies the same number of bits. So with that said, let's jump right into packed floating-point addition.
The samples are actually three different types of examples: a standard single data element solution; a 3D value, typically an {XYZ} value; or a 4D value, {XYZW}. Integer or fixed point is important, but in terms of fast 3D processing, single-precision floating-point is of more interest.
Workbench Files:Benchx86chap12projectplatform
Add/Sub | project | platform |
|---|---|---|
3D Float | vas3d | vc.net |
4vec Float | qvas3d |

3DNow! | pfadd mmxDst, mmxSrc/mm64 | Single-precision | 64 |
SSE | addps xmmDst, xmmSrc/m128 | Single-precision | 128 |
SSE2 | addpd xmmDst, xmmSrc/m128 | Double-precision | 128 |
This vector instruction is a parallel operation that uses an adder on each of the source floating-point blocks aSrc (xmmSrc) and bSrc (xmmDst) and stores the result in the destination Dst (xmmDst).
The instructions may be labeled as packed, parallel, or vector, but each block of floating-point bits is in reality isolated from one another.
The following are 64/128-bit single- and double-precision summation samples.
64-bit single-precision floating-point

128-bit single-precision floating-point

128-bit double-precision floating-point


SSE | addss | xmmDst, xmmSrc/m32 | Single-precision | 128 |
SSE2 | addsd | xmmDst, xmmSrc/m64 | Double-precision | 128 |
This vector instruction is a scalar operation that uses an adder with the source scalar xmmSrc and the source floating-point value in the least significant block within xmmDst and stores the result in the destination xmmDst. The upper float elements are unaffected.

3DNow! | pfsub mmxDst, mmxSrc/m64 | Single-precision | 64 |
SSE | subps xmmDst, xmmSrc/m128 | Single-precision | 128 |
SSE2 | subpd xmmDst, xmmSrc/m128 | Double-precision | 128 |
This vector instruction is a parallel operation that subtracts each of the source floating-point blocks aSrc (xmmSrc) from bSrc (xmmDst) with the result stored in the destination Dst (xmmDst).
Note
Be careful here as A – B ≠ B – A.
The register and operator ordering is as follows:

The instructions may be labeled as packed, parallel, or vector, but each block of floating-point bits is in reality isolated from one another.
64-bit single-precision floating-point

128-bit single-precision floating-point

128-bit double-precision floating-point


SSE | subss xmmDst, xmmSrc/m32 | Single-precision | 128 |
SSE2 | subsd xmmDst, xmmSrc/m64 | Double-precision | 128 |
This vector instruction is a scalar operation that subtracts the least significant source floating-point block of xmmSrc from the same block in xmmDst and stores the result in the destination xmmDst. The upper float elements are unaffected.

3DNow! | pfsubr mmxDst, mmxSrc/m64 | Single-Precision | 64 |
This vector instruction is a parallel operation that subtracts each of the source floating-point blocks bSrc (mmxDst) from aSrc (mmxSrc) with the result stored in the destination Dst (mmxDst).
The register and operator ordering is as follows:
The instructions may be labeled as packed, parallel, or vector, but each block of floating-point bits is in reality isolated from one another.
A typical subtraction uses an equation similar to {a=a–b}, but what happens if the equation {a=b–a} is needed instead? This instruction solves that situation by limiting any special handling needed to exchange values between registers such as the following:

or

By now you should be very aware that you should be using assertions in your code such as the ASSERT_PTR4 for normal pointers and ASSERT_PTR16 for pointers to vectors to ensure they are properly aligned in memory, so I will try not to bore you with it much anymore in print. You should also by now be aware of the penalties for dealing with out of alignment memory. Keep these in mind when writing your own code. There is also a limitation on the use of the term const to help make the printed code less wordy and more clear.
You will find that for purposes of cross-platform compatibility, these functions return no arguments. They are instead written as procedures where the first argument points to a buffer that the result is stored in. This is not written to make your life confusing. It is written this way because of one particular processor: the 80×86. Due to its MMX versus FPU usage an EMMS instruction must be called to reset that functionality as a clean slate, so only one of them can be used at a time. By not returning a value such as a float or array of floats, it minimizes the risk that the programmer might accidentally try to use the returned value while in the wrong mode. In this way the vmp_SIMDEntry() and vmp_SIMDExit() procedure calls are made to assist in switching between FPU and MMX mode of operation. Since most of you will be focused upon float and not integer or fixed-point vector math, that will be the focus, but the principles are the same!
The simple addition and subtraction of a single (scalar) float has been included here as a reference.
The above are simple scalar addition and subtraction using single-precision floats. Now view the addition of two vectors containing a three-cell {XYZ} float.
Example 12-4. ...chap12vas3dVas3D.cpp
void vmp_VecSub(vmp3DVector * const pvD,
const vmp3DVector * const pvA,
const vmp3DVector * const pvB)
{
pvD->x = pvA->x - pvB->x;
pvD->y = pvA->y - pvB->y;
pvD->z = pvA->z - pvB->z;
}Now view the addition and subtraction of two vectors containing a four-cell (quad) {XYZW} single-precision float. For the sample cross-platform libraries there is a differentiation as a Vec is a standard 3D tri-elemental value, and a QVec is a full four-quad float vector. The Vec is more oriented to the AoS (Array of Structures) approach, and the QVec would work best in a SoA (Structure of Arrays). These concepts will be discussed later.
Now examine these functions closer using x86 assembly. As MMX does not support floating-point, only 3DNow!, SSE, and above can be utilized. 3DNow! supports 64-bit so two loads must be handled simultaneously and two stores, but it is a simple matter of adding the two pairs of floats to each other. This example shows that three floats {XYZ} are being used and the fourth element {W} is being ignored.
mov eax,vA ; Vector A mov ebx,vB ; Vector B mov edx,vD ; Vector destination
Example 12-7. ...chap12vas3dVas3DX86M.asm
movq mm0,[eax] ; vA.xy {Ay Ax}
movq mm2,[ebx] ; vB.xy {By Bx}
movd mm1,(vmp3DVector PTR [eax]).z ; {0 Az}
movd mm3,(vmp3DVector PTR [ebx]).z ; {0 Bz}
pfadd mm0,mm2 ; {Ay+By Ax+Bx}
pfadd mm1,mm3 ; {0+0 Az+Bz}
movq [edx],mm0 ; {Ay+By Ax+Bx}
movd (vmp3DVector PTR [edx]).z,mm1 ; {0 Az+Bz}For subtraction, the functions are virtually identical to the addition functions, except for the exchanging of a PFSUB for the PFADD.
Example 12-8. ...chap12vas3dVas3DX86M.asm
movq mm0,[eax] ; vA.xy {Ay Ax}
movq mm2,[ebx] ; vB.xy {By Bx}
movd mm1,(vmp3DVector PTR [eax]).z ; {0 Az}
movd mm3,(vmp3DVector PTR [ebx]).z ; {0 Bz}
pfsub mm0,mm2 ; {Ay-By Ax-Bx}pfsub mm1,mm3 ; {0-0 Az-Bz}
movq [edx],mm0 ; {Ay-By Ax-Bx}
movd (vmp3DVector PTR [edx]).z,mm1 ; {0 Az-Bz}A quad vector access is not much different. Instead of loading a single float for each vector, a double float pair is loaded instead using a MOVQ instead of a MOVD.
The SSE processor in the following code snippet can load 128 bits at a time, so the entire 96-bit vector can be loaded at once including an extra 32 bits. This introduces a problem of contamination when the 96-bit value is written to memory as 128 bits. The solution is to read those destination bits, preserve the upper 32 bits, and write the newly merged 128 bits. Keep in mind efficient memory organization and memory tail padding previously discussed in Chapter 4, "Bit Mangling." Data can be misaligned or aligned, but 128-bit alignment would be preferable.
You now need to review two SSE instructions: MOVAPS and MOVUPS. This was introduced in Chapter 3, "Processor Differential Insight."
MOVAPS — is for use in aligned memory access of single-precision floating-point values.
MOVUPS — is for use in unaligned memory access of single-precision floating-point values.
One other item that should be brought to light is the special handling required by vectors versus quad vectors. As previously discussed in Chapter 4, the vector is three single-precision floats 96 bits in size, but when accessed as a vector, 128 bits are accessed simultaneously. This means that those extra 32 bits must be preserved and not destroyed. Also, the data contained within it must not be expected to be a float; it should be garbage data to that particular expression but valid data to another expression, and thus must be treated as such. Therefore, the easiest method is to clear and then restore those bits. The following declarations work nicely as masks for bit blending just for that purpose:
himsk32 DWORD 000000000h, 000000000h, 000000000h,
0FFFFFFFFh ; Save upper 32 bits
lomsk96 DWORD 0FFFFFFFFh, 0FFFFFFFFh, 0FFFFFFFFh,
000000000h ; Save lower 96 bitsAlso note that if bits are being preserved with a mask, then others are being cleared to zero. Of course it depends upon the endian type byte ordering of the platform but for x86 it is as listed!
Example 12-10. ...chap12vas3dVas3DX86M.asm
movupsxmm2,[edx] ; vD.xyzw {Dw Dz Dy Dx}movupsxmm0,[ebx] ; vB.xyzw {Bw Bz By Bx}movupsxmm1,[eax] ; vA.xyzw {Aw Az Ay Ax} andps xmm2,OWORD PTR himsk32 ; {Dw 0 0 0} addps xmm0,xmm1 ; {Aw+Bw Az+Bz Ay+By Ax+Bx} andps xmm0,OWORD PTR lomsk96 ; {0 Az+Bz Ay+By Ax+Bx} orps xmm0,xmm2 ; {Dw Az+Bz Ay+By Ax+Bx}movups[edx],xmm0 ; {Dw Dz Dy Dx}
By replacing the MOVUPS marked in bold with MOVAPS the data must be properly aligned or an exception will occur, but the application will run more smoothly. This is where two versions of the function would work out nicely. One is for when data alignment is unknown, and the other is for when alignment is guaranteed.
Example 12-11. ...chap12vas3dVas3DX86M.asm
movapsxmm2,[edx] ; vD.xyzw {Dw Dz Dy Dx}movapsxmm0,[ebx] ; vB.xyzw {Bw Bz By Bx}movapsxmm1,[eax] ; vA.xyzw {Aw Az Ay Ax} andps xmm2,OWORD PTR himsk32 ; {Dw 0 0 0} addps xmm0,xmm1 ; {Aw+Bw Az+Bz Ay+By Ax+Bx} andps xmm0,OWORD PTR lomsk96 ; {0 Az+Bz Ay+By Ax+Bx} orps xmm0,xmm2 ; {Dw Az+Bz Ay+By Ax+Bx}movaps[edx],xmm0 ; {Dw Dz Dy Dx}
The code looks almost identical, so from this point forward, the book will only show the aligned code using MOVAPS.
And for quad vectors, it is even easier as there is no masking of the fourth float {W}; just read, evaluate, and then write! Of course the function should have the instructions arranged for purposes of optimization but here they are left in a readable form.
Scalar addition and subtraction of vectors are also a relative simple matter for vector math instructions to handle. Scalar math appears in one of two forms: either a single element processed within each vector, or one element is swizzled, shuffled, or splat (see Chapter 6, "Data Conversion") into each element position and applied to the other source vector. When this type instruction is not supported by a processor, the trick is to replicate the scalar so it appears as a second vector.
Example 12-14. ...chap12qvas3dQVas3D.cpp
void vmp_VecSubScalar(vmp3DVector * const pvD,
const vmp3DVector * const pvA, float fScalar)
{
pvD->x = pvA->x - fScalar;
pvD->y = pvA->y - fScalar;
pvD->z = pvA->z – fScalar;
}Did that look strangely familiar? The big question now is, "How do we replicate a scalar to look like a vector since there tends not to be mirrored scalar math on processors?" Typically a processor will interpret a scalar calculation as the lowest (first) float being evaluated with a single scalar float. This is fine and dandy, but there are frequent times when a scalar needs to be replicated and summed to each element of a vector. So the next question is how do we do that?
With the 3DNow! instruction set it is easy. Since the processor is really a 64-bit half vector, the data is merely unpacked into the upper and lower 32 bits.
movd mm2,fScalar ; fScalar {0 s}
punpckldq mm2,mm2 ; fScalar {s s}Then it is just used twice, once with the upper 64 bits and then once with the lower 64 bits.
pfadd mm0,mm2 ; {Ay+s Ax+s}
pfadd mm1,mm2 ; {Aw+s Az+s}With the SSE instruction set it is almost as easy. The data is shuffled into all 32-bit floats.
movss xmm1,fScalar ; {0 0 0 s}
shufps xmm1,xmm1,00000000b ; {s s s s}Now the scalar is the same as the vector.
addps xmm0,xmm1 ; {Aw+s Az+s Ay+s Ax+s}Any questions?
The addition and subtraction of simultaneous vectors are a relatively simple matter for vector math instructions to handle. SSE3 added simultaneous functionality, while older versions have to simulate it.

SSE3 | addsubps | xmmDst, xmmSrc/m128 | Single-precision | 128 |
" | addsubpd | xmmDst, xmmSrc/m128 | Double-precision | " |
This vector instruction is a parallel operation that has an even subtraction and an odd addition of the source floating-point blocks. For the even elements, subtract aSrc (xmmSrc) from bSrc (xmmDst) with the result stored in the destination Dst (xmmDst). For the odd elements, sum aSrc (xmmSrc) and bSrc (xmmDst) with the result stored in the destination Dst (xmmDst).
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
HADDPD |
|
| ||||||||
HADDPS |
|
| ||||||||
PFACC |
|
|
|
3DNow! | pfacc mmxDst, mmxSrc/m64 | Single-precision | 64 |
SSE3 | haddps xmmDst, xmmSrc/m128 | Single-precision | 128 |
" | haddpd xmmDst, xmmSrc/m128 | Double-precision | " |
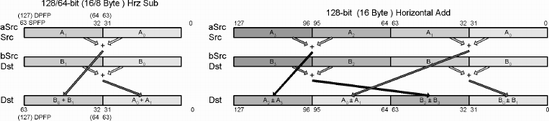
This vector instruction is a parallel operation that separately sums the odd/even pairs of the source and destination and stores the result of the bSrc (xmmDst) in the lower destination elements of Dst (xmmDst) and the result of the aSrc (xmmSrc) in the upper elements of Dst (xmmDst).

3Mx+ | pfnacc | mmxDst, mmxSrc/m64 | Single-precision | 64 |
SSE3 | hsubps | xmmDst, xmmSrc/m128 | Single-precision | 128 |
" | hsubpd | xmmDst, xmmSrc/m128 | Double-precision | " |
This vector instruction is a parallel operation that separately subtracts the (odd) element from the (even) element and stores the result of the bSrc (xmmDst) in the lower destination elements of Dst (xmmDst) and the result of the aSrc (xmmSrc) in the upper addresses of Dst (xmmDst).

3Mx+ | pfpnacc mmxDst, mmxSrc/m64 | Single-precision | 64 |
This half-vector instruction is a parallel operation that separately subtracts the upper element from the lower element of bSrc (mmxDst) and stores the result in the lower element of Dst (mmxDst). The sum of the upper and lower elements of aSrc (mmxSrc) is stored in the upper element of Dst (mmxDst).
Using only Boolean logic, how could two numbers be summed?
If your processor had no instructions for parallel subtraction, how would you find the difference of two numbers?
Invert the sign of the even-numbered elements of signed 8-bit byte, 16-bit half-word, and 32-bit word of a 128-bit data value using:
a) pseudo vector C code
b) MMX
c) SSE2
Same as problem 3 but use odd-numbered elements.
Invert the sign of all the elements of four packed single-precision floating-point values.
You have been given a 4096-byte audio sample consisting of left and right channel components with a PCM (pulse coded modulation) of unsigned 16-bit with 0x8000 as the baseline.
unsigned short leftStereo[1024], rightStereo[1024]; signed char Mono[???];
a) How many bytes is the mixed sample?
b) Write a mixer function to sum the two channels from stereo into mono and convert to a signed 8-bit sample.
Project:
You now have enough information to write an SHA-1 algorithm discussed in Chapter 5, "Bit Wrangling," for your favorite processor. Write one! HINT: Write the function code in C first.