
This chapter involves math related to whole numbers that you learned in grade school: the processes of addition and subtraction. There you learned about the number line in which numbers just go on forever in positive and negative directions. In computers, as the numbers increase in a positive or negative amount they actually approach a limit (the end of their finite space). Upon reaching the end of the world (Flat Earth Society), they overflow and wrap to the opposite end of the number line (quantum physics, or was that string theory?). Well, anyway, your integer range of numbers is limited by the size of the data used to store them.
Workbench Files:Benchx86chap07projectplatform
project | platform | |
|---|---|---|
Boolean Logic | pas | vc6 |
vc.net |
We learned negation with the NEG instruction in Chapter 4, "Bit Mangling," and binary multiplication (2N) and division using bit shifting in Chapter 5, "Bit Wrangling."
We can add 8-, 16-, 32-, and 64-bit numbers, and 4-bit if you include BCD (binary-coded decimal) discussed later in Chapter 15.
The EFLAGS Overflow, Sign, Zero, Auxiliary Carry, Parity, and Carry are all altered when using the general-purpose instructions.
Whether the numbers overflow the binary limit of the destination operand | |
Sign | Set to the resulting value of the MSB (most significant bit) |
Zero | Set if the result is a value of zero |
Aux. Carry | Set as a result of a carry of the low-order nibble |
Parity | |
Carry | Any mathematical carry results of the mathematical operation |
ADD destination, source
add | rmDst(8/16/32/64), #(8/16/32) | Signed |
add | rmDst, rSrc(8/16/32/64) | |
add | rDst, rmSrc(8/16/32/64) |
The ADD general-purpose instruction logically sums the 8-, 16-, 32-, or 64-bit source to the destination, saves the result in destination, and sets the flags accordingly. An 8-bit source immediate value can be sign extended to 16-, 32-, or 64-bit value. A 32-bit source immediate value can be sign extended to a 64-bit destination.
d = a + b | d = b | so | d = a + d = d + a | d += a |
adc | rmDst(8/16/32/64), #(8/16/32) | Signed |
adc | rmDst, rSrc(8/16/32/64) | |
adc | rDst, rmSrc(8/16/32/64) |
The ADC general-purpose instruction does exactly the same operation but with one difference. The carry value of 0 or 1 is added to the ending result: d = a + b + (carry)
Flags: The flags are set as a result of the addition operation. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
× | × | × | × | × | × | |

When adding a series of numbers one typically uses the non-carry ADD first, followed by ADC for each additional calculation, taking into account the resulting Carry flag.
a = a + b + c + d + e
a = a ADD b ADC c ADC d ADC e
mov eax,0000a5a5h
add eax,00000ff0h
adc eax,0000ff00h
adc eax,000ff000h
adc eax,00ff0000h
; Add two 64 #'s ecx:ebx + edx:eax
add ebx,eax ; Carry results from lower 32 bits.
adc ecx,edx ; Add upper 32 bits + carry
; or when using a 64-bit processor
add rbx,rax ; 64 bits
; and then add with carry for a 128-bit summation.
adc rcx,rdxSums for really big numbers can be calculated in this way. Need a number 8000 bits long? You can do it in assembly by continuously adding the carry of previous arithmetic operations onto a current operation.
inc | rmDst(8/16/32/64) | (Un)signed |
The INC general-purpose instruction is very similar to the ADD instruction, adding a value of 1 to the 8-, 16-, 32-, or 64-bit destination. The result is saved in the destination: d = a + 1.
Flags: The flags are set as a result of the addition operation. Note that the Carry flag is unaffected. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
× | × | × | × | × | - | |
It is recommended that an ADD instruction be used instead of an INC since flag dependencies can cause stalling due to previous writes to the EFLAG registers.
inc eax
Use this instead:
add eax,1
Various forms of indirect memory reference, such as the following, are still allowed:
inc [eax] inc [eax+ebx*4]
This applies to all the general-purpose registers.

Note
There is no Carry flag set for this instruction. If a carry is needed, use ADD reg/mem, 1.
Tip
The 80×86 is one of the few processors that can perform an operation upon a memory location, not necessarily only in a register. An instruction cannot be preempted by another thread or process in the middle of its execution. It must complete its execution first!
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
XADD |
|
|
|
|
|
|
|
|
|
|
xadd | rmDst, rSrc(8/16/32/64) | Signed |
The XADD general-purpose instruction first exchanges the values in the source general-purpose register and destination just like the XCHG instruction and then logically sums the 8-, 16-, 32-, or 64-bit source to the destination, saves the result in destination, and sets the flags accordingly.
This instruction is rarely used except in the case where a register exchange needs to take place so as to preserve the old value. This is equivalent to four separate instructions:
edx = D | eax = A | ebx = tmp | |
|---|---|---|---|
OLD | NEW | ||
mov ebx,eax | OLD | NEW | NEW |
mov eax,edx | OLD | OLD | NEW |
mov edx,ebx | NEW | OLD | NEW |
add edx,eax | NEW+OLD | OLD | |
NEW+OLD | OLD |
...or two instructions by using the XCHG instruction.
As you can see, the old value is preserved in the source register, and the destination memory gets the sum of the new and old values.
Flags: The flags are set as a result of the addition operation. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
× | × | × | × | × | × | |
sub | rmDst(8/16/32/64), #(8/16/32) | Signed |
sub | rmDst, rSrc(8/16/32/64) | |
sub | rDst, rmSrc(8/16/32/64) |
The SUB general-purpose instruction logically subtracts the 8-, 16-, 32-, or 64-bit source from the destination, saves the result in destination, and sets the flags accordingly. An 8-bit immediate source value can be sign extended to 16-, 32-, or 64-bit value. A 32-bit immediate source value can be sign extended to a 64-bit destination: d = b – a.
sbb | rmDst(8/16/32/64), #(8/16/32) | Signed |
sbb | rmDst, rSrc(8/16/32/64) | |
sbb | rDst, rmSrc(8/16/32/64) |
The SBB general-purpose instruction does exactly the same thing but with one difference: The Carry flag is referred to as the borrow flag with a value of 0 or 1, which is subtracted from the ending result.
6d = b – a – (Carry)
Flags: The flags are set as a result of the subtraction operation. When carry is set (1) it indicates a borrow is needed. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
× | × | × | × | × | × | |

When subtracting a series of numbers one typically uses SUB for the first subtraction, followed by SBB for each additional subtraction, taking into account the Carry flag, which indicates a borrow is required from the next calculation.
a = a – b – c – d – e
a = a SUB b SBB c SBB d SBB e
mov eax,0000a5a5h
sub eax,00000ff0h
sbb eax,0000ff00h
sbb eax,000ff000h
sbb eax,00ff0000hdec | rmDst(8/16/32/64) | (Un)signed |
The DEC general-purpose instruction is very similar to the SUB instruction, subtracting a value of 1 from the 8-, 16-, 32-, or 64-bit destination. The result is saved in the destination: d = a – 1.
Flags: The flags are set as a result of the subtraction operation. Note that the carry is unaffected. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
× | × | × | × | × | - | |
It is recommended that a SUB instruction be used instead of a DEC since flag dependencies can cause stalling due to previous writes to the EFLAG registers.
dec eax
Use this instead:
sub eax,1
The various forms of indirect memory reference, such as the following, are still allowed:
dec [eax] dec tbl[ebx+ecx*2]
This applies to all the general-purpose registers.

#ifdef _M_IX86
#define QUICK_DECREMENT(v) __asm dec v;
#else
#define QUICK_DECREMENT(v)
EnterMutex()
v--;
ExitMutex()
#endifSome programmers will have code such as follows:
inc al
jnz $L1 ; Jump if not saturated!
dec al
$L1:
But that introduces some branching and misprediction. (Branch misprediction will be discussed in a later chapter.) A branchless code methodology can be alternatively utilized where the state of the Carry flag is taken to advantage. Remember, the INC does not affect the Carry flag but the ADD instruction does.
add al,1 sbb al,0
Instead of using an increment, a non-carry addition is used. A normal advancement of one to a value ranging from [0, 255) has a carry of zero, but upon 255+1, a carry is generated. Immediately subtracting a zero with no carry has no effect. But subtracting a zero with a carry takes that one increment back off. Normally d = a + 1 – 0c, then upon rollover d = a + 1 – 1c. In essence, a saturation is created. This same logic can be applied for 216, 232, or 264, whatever your data size is. The code is smaller and much faster.
Contrarily, a down count to the floor value of zero can be implemented utilizing this same rollback method:
sub al,1 adc al,0
The number is decremented until the floor is reached, thus initiating a borrow, and then the borrow is summed back in. Normally, d = a – 1 + 0c, then upon rollover, d = a – 1 + 1c.
At this point the focus turns to the integer addition and subtraction of numbers in parallel. With the general-purpose instructions of a processor, normal calculations of addition and subtraction take place one at a time as scalar operations. These can instead be pipelined so that multiple integer calculations can occur simultaneously, but when performing large numbers of similar type calculations there is a bottleneck of processor calculation time. By using vector calculations, multiple like calculations can be performed simultaneously. The only trick here is to remember the key phrase "multiple like calculations."
If, for example, four pairs of 32-bit words are being calculated simultaneously such as in the following addition:


...the point is that the calculations all need to use the same operator. There is an exception, but this is too early to discuss it. There are workarounds, such as if only a couple of expressions need a calculated adjustment while others do not, then adding or subtracting a zero would keep their result neutral.

Remember your algebraic law:
It is in essence a wasted calculation, but its use as a placeholder helps make SIMD instructions easier to use.
The other little item to remember is that subtraction is merely the addition of a value's additive inverse:
a–b = a+(–b)
PADDx destination, source
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PADDx |
|
|
|
|
|
|
|
|
| |
PADDQ |
|
|
|
|
MMX | padd(b/w/d/q) mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | padd(b/w/d/q) xmmDst, xmmSrc/m128 | [Un]signed | 128 |
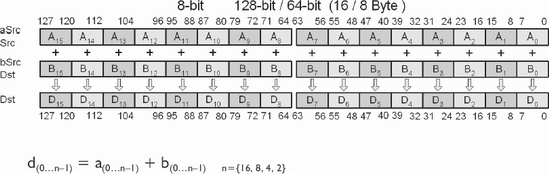
The PADDx instruction is a parallel operation that uses an adder on each of the source bit blocks aSrc (xmmSrc) and bSrc (xmmDst) and stores the result in the destination Dst (xmmDst).
The instructions may be labeled as packed, parallel, or vector, but each block of bits is in reality isolated from each other. The following is a 32-bit example consisting of four unsigned 8-bit values:

...and four signed 8-bit values:

Regardless of the decimal representation of unsigned or signed, the hex values of the two examples remains the same, which is the reason for these being [Un]signed, thus sign neutral.
Notice in the following additions of 7-bit signed values that with the limit range of –64...63 the worst case of negative and positive limit values results with no overflow.
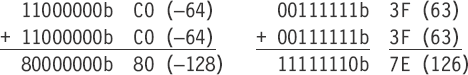
Of course, positive and negative signed values could also be intermixed without an overflow. For a 7-bit unsigned value, 0...127, there would be no overflow.
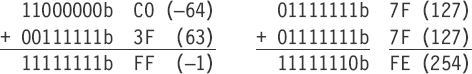
The eighth unused bit is in reality used as a buffer to prevent any overflow to a ninth bit.

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PADDSx |
|
|
|
|
|
|
|
|
| |
PADDUSx |
|
|
|
|
|
|
|
|
|
MMX | paddus(b/w) mmxDst, mmxSrc/m64 | Unsigned | 64 |
" | padds(b/w) mmxDst, mmxSrc/m64 | Signed | |
SSE2 | paddus(b/w) xmmDst, xmmSrc/m128 | Unsigned | 128 |
" | padds(b/w) xmmDst, xmmSrc/m128 | Signed |
The PADDSx (signed) and PADDUSx (unsigned) instructions are a parallel operation that uses an adder on each of the source bit block registers aSrc (xmmSrc) and bSrc (xmmDst) and stores the result in the destination Dst (xmmDst) using saturation logic to prevent any possible wraparound.
Each calculation limits the value to the extents of the related data type so that if the limit is exceeded, it is clipped inclusively to that limit. This is handled differently whether it is signed or unsigned, as they both use different limit values. Effectively, the result of the summation is compared to the upper limit with a Min expression and compared to the lower limit with a Max expression. Notice in the previous section that when two signed 8-bit values of 0x7F (127) are summed, a value of 0xFE (254) results but is clipped to the maximum value of 0x7f (127). The same applies if, for example, two values of 0x80 (–128) are summed, resulting in –256 but clipped to the minimum value of 0x80 (–128).
The instructions may be labeled as packed, parallel, or vector but each block of bits is in reality isolated from each other.
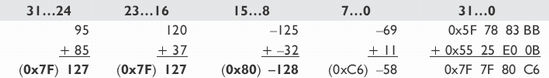
A sample use of this instruction would be for sound mixing where two sound waves are mixed into a single wave for output. The saturation point keeps the amplitude of the wave from wrapping from a positive or high level into a negative or low one, thus creating a pulse encoded harmonic, or distortion.
For saturation, the limits are different for the data size as well as for signed and unsigned.
8-bit | 16-bit | |
signed | -128...127 | -32768...32767 |
unsigned | 0...255 | 0...65535 |
PSUBx destination, source D –= A

MMX | psub(b/w/d/q) mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | psub(b/w/d/q) xmmDst, xmmSrc/m128 | [Un]signed | 128 |
This vector instruction is a parallel operation that subtracts each of the source bit blocks aSrc (xmmSrc) from bSrc (xmmDst) and stores the result in the destination Dst (xmmDst).
Note
Be careful here! The register and operator ordering is as follows:
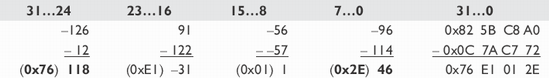
PSUBSx destination, source D –= A


Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PSUBSx |
|
|
|
|
|
|
|
|
| |
PSUBUSx |
|
|
|
|
|
|
|
|
|
MMX | psubus(b/w) mmxDst, mmxSrc/m64 | Unsigned | 64 |
psubs(b/w) mmxDst, mmxSrc/m64 | Signed | ||
SSE2 | psubus(b/w) xmmDst, xmmSrc/m128 | Unsigned | 128 |
psubs(b/w) xmmDst, xmmSrc/m128 | Signed |
This vector instruction is a parallel operation that subtracts each of the source bit blocks aSrc (xmmSrc) from bSrc (xmmDst) and stores the result in the destination Dst (xmmDst).
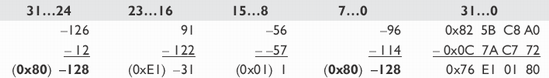
For most of the number crunching in your games or tools you will most likely use single-precision floating-point. For artificial intelligence (AI) and other high-precision calculations, you may wish to use the higher precision double-precision, but it only exists in scalar form on the FPU, except for the case of the SSE2 or above, so functionality must be emulated in a sequential fashion whenever possible. But even with the higher precision, there is still a bit of an accuracy problem.
An alternative would be to use integer calculations in a fixed-point format of zero or more places. If the data size is large enough to contain the number, then there is no precision loss!
These can get pretty verbose, as for fixed-point (integer) addition there would be support for 8-, 16-, and 32-bit data elements within a 128-bit vector and these would be signed and unsigned, with and without saturation. The interesting thing about adding signed and unsigned numbers, other than the carry or borrow, is that the resulting value will be exactly the same and thus the same equation can be used. This can be viewed in the following 8-bit example:
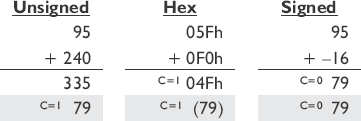
Notice that the resulting bits from the 8-bit calculation are all the same. Only the carry is different and the resulting bits are only interpreted as being signed or unsigned.
Now let's examine these functions closer. MMX and SSE2 have the biggest payoff, as 3DNow! and SSE are primarily for floating-point support.
mov ebx,pbB ; Vector B mov eax,pbA ; Vector A mov edx,pbD ; Vector Destination
The following is a 16×8-bit addition but substituting a PSUBB for the PADDB will transform it into a subtraction.
Example 7-1. ...chap07pasPAddX86M.asm
movq mm0,[ebx+0] ; Read B Data {B7...B0}
movq mm1,[ebx+8] ; {BF...B8}
movq mm2,[eax+0] ; Read A Data {A7...A0}
movq mm3,[eax+8] ; {AF...A8}
paddbpaddbFor SSE, it is essentially the same function wrapper, keeping in mind aligned memory MOVDQA versus non-aligned memory MOVDQU.
Example 7-2. ...chap07pasPAddX86M.asm
movdqa xmm0,[ebx] ; Read B Data {BF...B0 }
movdqa xmm1,[eax] ; Read A Data {AF...A0 }
paddbThe following is a master substitution table for change of functionality, addition versus subtraction (inclusive/exclusive of saturation).
Add | Sub | Add | Sub | Add | Sub | |
|---|---|---|---|---|---|---|
8-bit | paddb | psubb | paddsb | psubsb | paddusb | psubusb |
16-bit | paddw | psubw | paddsw | psubsw | paddusw | psubusw |
32-bit | paddd | psubd | ||||
64-bit | paddq | psubq |
VD[] = (vA[] + vB[] + 1) ÷ 2;
3DNow! | pavgusbmmxDst, mmxSrc/m64 | Unsigned | 64 | |
MMX+ | pavgb | mmxDst, mmxSrc/m64 | Unsigned | 64 |
SSE | pavgb | mmxDst, mmxSrc/m64 | Unsigned | 64 |
SSE2 | pavgb | xmmDst, xmmSrc/m128 | Unsigned | 128 |
This SIMD instruction is a 64 (128)-bit parallel operation that sums the eight (16) individual 8-bit source integer bit blocks aSrc (xmmSrc) and bSrc (xmmDst), adds one, then divides by two and returns the lower 8 bits with the result being stored in the destination Dst (xmmDst).
![PAVGB/PAVGUSB — N×8-Bit [Un]signed Integer Average](http://imgdetail.ebookreading.net/software_development/3/9781598220025/9781598220025__3264-bit-80x86-assembly__9781598220025__figs__ch07unfig26.png)
Tip
These two instructions are remnants from the processor wars. They have two different mnemonics with two different opcodes, but they have the same functionality. PAVGB was added to the AMD instruction set, which matched the SSE instruction PAVGB but had the same functionality as AMD's PAVGUSB. If the target is 3DNow! and MMX extensions or better, use the instruction PAVGB.
MMX+ | pavgw mmxDst, mmxSrc/m64 | Unsigned | 64 |
SSE | pavgw mmxDst, mmxSrc/m64 | Unsigned | 64 |
SSE2 | pavgw xmmDst, xmmSrc/m128 | Unsigned | 128 |
This SIMD instruction is a 64 (128)-bit parallel operation that sums the four (eight) individual 16-bit source integer bit blocks aSrc (xmmSrc) and bSrc (xmmDst), adds one, then divides by two and returns the lower 16 bits with the result being stored in the destination Dst (xmmDst).
![PAVGW — N×16-Bit [Un]signed Integer Average](http://imgdetail.ebookreading.net/software_development/3/9781598220025/9781598220025__3264-bit-80x86-assembly__9781598220025__figs__ch07unfig27.png)
The simplified form of this parallel instruction individually calculates the differences of each of the packed bits, then sums the absolute value for all of them, and returns the result in the destination.
MMX+ | psadbw mmxDst, mmxSrc/m64 | Unsigned | 64 |
SSE | psadbw mmxDst, mmxSrc/m64 | Unsigned | 64 |
SSE2 | psadbw xmmDst, xmmSrc/m128 | Unsigned | 128 |
8×8-Bit Sum of Absolute Differences
Dst(15...0) = abs(Src(7...0) - Dst(7...0)) + abs(Src(15...8) -
Dst(15...8))
+ abs(Src(23...16) - Dst(23...16)) + abs(Src(31...24) - Dst(31...24))
+ abs(Src(39...32) - Dst(39...32)) + abs(Src(47...40) - Dst(47...40))
+ abs(Src(55...48) - Dst(55...48)) + abs(Src(63...56) - Dst(63...56))
Dst(63...16) = 0;
16×8-Bit Sum of Absolute Differences
Dst(31...16) = abs(Src(71...64) - Dst(71...64)) + abs(Src(79...72) -
Dst(79...72))
+ abs(Src(87...80) - Dst(87...80)) + abs(Src(95...88) - Dst(95...88))
+ abs(Src(103...96) - Dst(103...96)) + abs(Src(111...104) -
Dst(111...104))
+ abs(Src(119...112) - Dst(119...112)) + abs(Src(127...120) -
Dst(127...120))
Dst(127...32) = 0
Integer data is expanded upon the calculation of a product between two operands, and thus two operands are needed to store the result. Depending on whether the source values are small enough, the operand receiving the upper bits of the result may be ignored as it always contains a predictable amount.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MUL |
|
|
|
|
|
|
|
|
|
|
mul | rmDst(8/16/32/64) | (Un)signed |
The MUL general-purpose instruction multiplies the unsigned 8-, 16-, 32-, or 64-bit operand by the unsigned AL/AX/EAX/RAX register, saves the result based upon the bit size of the operand as indicated in the table below, and sets the flags accordingly.
8-bit | 16-bit | 32-bit | 64-bit | |
|---|---|---|---|---|
operation | AL×BL | AX×BX | EAX×EBX | RAX×RBX |
result | AX | DX:AX | EDX:EAX | RDX:RAX |
Flags: If the upper half of the resulting bits are 0, then the Overflow and Carry bits are set to 0; else they are set to 1. The other flags are undefined. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
× | - | - | - | - | × | |
A square operation (x2) is actually pretty simple!
mov rax,7
mul rax ; rdx:rax = rax x raxMnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
IMUL |
|
|
|
|
|
|
|
|
|
|
imul rmDst(8/16/32/64) | Signed |
imul rDst(16/32/64), rmSrc(16/32/64) | |
imul rDst(8/16/32/64), #(8/16/32) | |
imul rDst(16/32/64), rmSrc(16/32/64), #(8/16/32) |
The IMUL general-purpose instruction has three forms based upon the number of operands.
One Operand — Similar to that of the MUL instruction but deals with signed numbers. That is, it multiplies the 8-, 16-, 32-, or 64-bit signed operand by the unsigned AL/AX/EAX/RAX register, saves the result based upon the bit size of the operand as indicated in the table below, and sets the flags accordingly.
Two Operands — Used for multiplication of 16-, 32-, or 64-bit signed numbers in operand1 with the value in operand2 and stores the result in operand1. Unlike MUL, AX/EAX/RAX is not used unless it is one of the two operands. If operand2 is an immediate value, then it is sign extended to match operand1.
Three Operands — Used for multiplication of 16-, 32-, or 64-bit signed numbers in operand2 with the sign extended immediate value in operand3. The result is stored in operand1. Unlike MUL, AX/EAX/RAX is not used unless it is one of the three operands.
8-bit | 16-bit | 32-bit | 64-bit | |
|---|---|---|---|---|
result | AX | DX:AX | EDX:EAX | RDX:RAX |
Flags: If the upper half of the resulting bits are 0 then the Overflow and Carry bits are set to 0, else they are set to 1. The other flags are undefined. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
× | - | - | - | - | × | |
Packed integer multiplication is one of the mathematical equations that you will tend to use in your SIMD application either as fixed-point or just parallel integer processing. This works out nicely when it is necessary to increase the magnitude of a series of integers. The problem here comes up because fixed-point multiplication is not like floating-point multiplication. In floating-point, there is a precision loss with each calculation since a numerical value is stored in an exponential form. With fixed-point, there is no precision loss, which is great but leads to another problem. When two integers are used in a summation, the most significant bits are carried into an additional (n+1) bit. With a multiplication of two integers, the resulting storage required is (n+n=2n) bits. This poses a problem of how to deal with the resulting solution. Since the data size increases, there are multiple solutions to contain the result of the calculation.
Store upper bits.
Store lower bits.
Store upper/lower bits into two vectors.
Store even n bit elements into 2n bit elements.
Store odd n bit elements into 2n bit elements.
PMULLW destination, source
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PMULLW |
|
|
|
|
|
|
|
|
|
MMX | pmullw mmxDst, mmxSrc/m64 | [Un]signed | 64 |
MMX+ | pmullw mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | pmullw xmmDst, xmmSrc/m128 | [Un]signed | 128 |
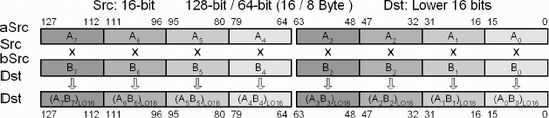
These vector instructions use a 64 (128)-bit data path and so four (eight) operations occur in parallel. The product is calculated using each of the 16-bit half-words of the multiplicand mmxSrc (xmmSrc) and the 16-bit half-words of the multiplier mmxDst (xmmDst) for each 16-bit block, and stores the lower 16 bits of each of the results in the original 16-bit half-words of the destination mmxDst (xmmDst).



MMX | pmulhuw | mmxDst, mmxSrc/m64 | Unsigned | 64 |
pmulhw | mmxDst, mmxSrc/m64 | Signed | ||
MMX+ | pmulhuw | mmxDst, mmxSrc/m64 | Unsigned | 64 |
SSE2 | pmulhuw | xmmDst, xmmSrc/m128 | Unsigned | 128 |
pmulhw | xmmDst, xmmSrc/m128 | Signed |
These vector instructions use a 64 (128)-bit data path and so four (eight) operations occur in parallel. The product is calculated using each of the 16-bit half-word of the multiplicand mmxSrc (xmmSrc) and the 16-bit half-word of the multiplier mmxDst (xmmDst) for each 16-bit block, and stores the upper 16 bits of each of the results in the original 16-bit half-words of the destination mmxDst (xmmDst).



Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PMULHRW |
|
|
|
3DNow! | pmulhrw mmxDst, mmxSrc/m64 | Signed | 64 |
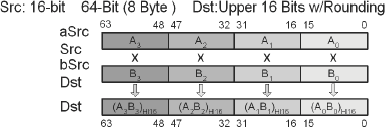
This vector instruction uses a 64-bit data path and so four operations occur in parallel. The product is calculated using each of the unsigned 16-bit half-words of the multiplicand mmxDst and the 16-bit half-word of the multiplier mmxSrc for each 16-bit block, sums 00008000 hex to the 32-bit product, and stores the resulting upper 16 bits in the destination mmxDst (xmmDst).
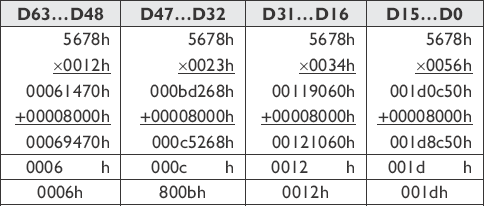
Dst(15...0) = UPPER16((Dst(15...0) x Src(15...0)) + 0x8000) Dst(31...16) = UPPER16((Dst(31...16) x Src(31...16)) + 0x8000) Dst(47...32) = UPPER16((Dst(47...32) x Src(47...32)) + 0x8000) Dst(63...48) = UPPER16((Dst(63...48) x Src(63...48)) + 0x8000)
An interesting thing about the SSE instruction set is that it is primarily designed for floating-point operations. The MMX instruction set handles most of the packed integer processing except the case of unsigned 16-bit multiplication. This was not resolved until a later release of extensions for the MMX by AMD and the SSE by Intel, but this is only 64 bits. Intel came back with the SSE2 instruction set with a complete set of packed instructions for supporting 128 bits.
mov ebx,phB ; Vector B mov eax,phA ; Vector A mov edx,phD ; Vector Destination
The instruction PMULLW is the [un]signed multiplication storing the lower 16 bits; PMULHW is the signed multiplication storing the upper 16 bits; and PMULHUW is the unsigned multiplication storing the upper 16 bits. The following function is designed to return only 16 bits of the resulting product, and selection of the appropriate instruction will return that value. Using the following code shell but with the PMULLW instruction calculates the lower bits, while PMULHW calculates the upper bits. PMULHW calculates the upper signed bits and PMULHUW the upper unsigned bits. The following code is designed for use with the 64-bit MMX register and is used in pairs for 128-bit support.
Example 7-3. ...chap7pmdPMulX86M.asm
movq mm0,[ebx+0] ; Read B Data {3...0}
movq mm1,[ebx+8] ; {7...4}
movq mm2,[eax+0] ; Read A Data {3...0}
movq mm3,[eax+8] ; {7...4}
pmullw mm0,mm2
pmullw mm1,mm3movq [edx+0],mm0 ; Write D ??? 16 bits {3...0}
movq [edx+8],mm1 ; (upper or lower) {7...4}
To return 16 high signed integer bits, use PMULH instead of PMULLW.
pmulhwmm0,mm2 ; SIGNED HIGH {3...0}pmulhwmm1,mm3 ; {7...4}
To return 16 unsigned high integer bits, use PMULHUW instead of PMULLW.
pmulhuwmm0,mm2 ; UNSIGNED HIGH {3...0}pmulhuwmm1,mm3 ; {7...4}
With the release of the SSE2 instruction set, Intel handles 128 bits simultaneously using the XMM registers. These same instructions can be used with 128-bit data.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PMULUDQ |
|
|
|
|
SSE2 | pmuludq mmxDst, mmxSrc/m64 | Unsigned | 64 |
pmuludq xmmDst, xmmSrc/m128 | Unsigned | 128 |
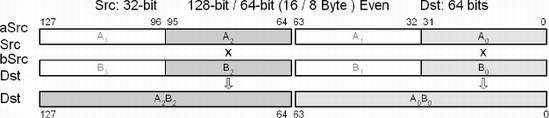
This vector instruction calculates the product of the (even) lower 32 bits of each set of 64 (128) bits of the multiplicand aSrc (xmmSrc) and the lower 32 bits of the multiplier bSrc (xmmDst) for each 64 (128)-bit block, and stores each full 64 (128)-bit integer result in the destination Dst (xmmDst).

In the following 64-bit table, the upper 32 bits {63...32}of mmxSrc and mmxDst are ignored. Note that this is not a SIMD reference but included for reference.

In the following 128-bit table, the upper odd pairs of 32 bits {127...96, 63...32} of xmmDst and xmmSrc are ignored.


Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PMADDWD |
|
|
|
|
|
|
|
|
|
MMX | pmaddwd mmxDst, mmxSrc/m64 | Signed | 64 |
SSE2 | pmaddwd xmmDst, xmmSrc/m128 | Signed | 128 |
This vector instruction calculates the 32-bit signed products of two pairs of two 16-bit multiplicands aSrc(xmmSrc) and the multiplier bSrc(xmmDst) for each bit block. The first and second 32-bit products are summed and stored in the lower 32 bits of the Dst(xmmDst). The third and fourth 32-bit products are summed and stored in the next 32 bits of the destination Dst(xmmDst). The same is repeated for the upper 64 bits for the 128-bit data model.
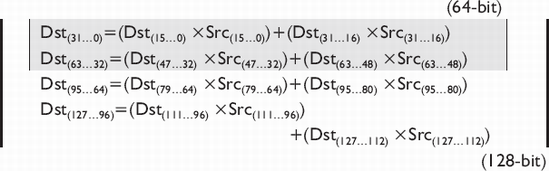
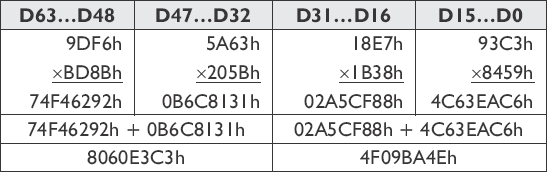

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
DIV |
|
|
|
|
|
|
|
|
|
|
div | rmDst(8/16/32/64) | (Un)signed |
The DIV general-purpose instruction divides the unsigned 16-, 32-, 64-, or 128-bit AX, DX:AX, EDX:EAX, RDX:RAX pair into the 8-, 16-, 32-, or 64-bit operand and saves the result based upon the bit size of the operand as indicated in the table below and sets the flags accordingly.
8-bit | 16-bit | 32-bit | 64-bit | |
|---|---|---|---|---|
Dividend | AX | DX:AX | EDX:EAX | RDX:RAX |
Divisor | div bl | div bx | div ebx | div rbx |
Quotient | AL | AX | EAX | RAX |
AH | DX | EDX | RDX |
Flags: All the flags are undefined. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
- | - | - | - | - | - | |
div ebx
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
IDIV |
|
|
|
|
|
|
|
|
|
|
idiv | rmDst(8/16/32/64) | Signed |
The IDIV general-purpose instruction divides the signed 16-, 32-, 64-, or 128-bit AX, DX:AX, EDX:EAX, RDX:RAX pair into the 8-, 16-, 32-, or 64-bit operand and saves the result based upon the bit size of the operand as indicated in the table below and sets the flags accordingly.
8-bit | 16-bit | 32-bit | 64-bit | |
|---|---|---|---|---|
Dividend | AX | DX:AX | EDX:EAX | RDX:RAX |
Divisor | idiv bl | idiv bx | idiv ebx | idiv rbx |
Quotient | AL | AX | EAX | RAX |
Remainder | AH | DX | EDX | RDX |
Flags: All the flags are undefined. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
- | - | - | - | - | - | |
The sign of the remainder always matches the sign of the divisor. An overflow is indicated by a Divide Error Exception instead of the Overflow flag.
Write a code snippet to saturate an unsigned 8-bit incrementing count at a value of 99.
The result of the summation of two integers increases the size of the source by one bit (the carry). How many bits are needed from the product of two 32-bit values?
What are different output methods to store the various results of a product of two integers?