
Data must sometimes be interlaced to get it into a form that can be easily handled. By understanding how to interlace and de-interlace data, a most productive solution can be found for solving an expression.
The instructions in this chapter are easier to understand through visualization, and each processor has its set of instructions that it handles, but here is where data swizzling can easily be confusing: converting data from the output of one instruction and used as the input of another.
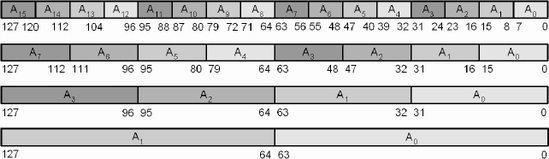
As a guide to assist you in remembering big- versus little-endian orientations, the following are the placement of bytes within the 64-bit data diagrams used in this chapter. Keep in mind that each 64-bit block is a repeat of the previous block.
Little-Endian
0x88,0x99,0xaa,0xbb,0xcc,0xdd,0xee,0xff (8-bit)
0x9988, 0xbbaa, 0xddcc, 0xffee (16-bit)
0xaab9988, 0xffeeddcc (32-bit)Big-Endian
0x88,0x99,0xaa,0xbb,0xcc,0xdd,0xee,0xff (8-bit)
0x8899, 0xaabb, 0xccdd, 0xeeff (16-bit)
0x8899aabb, 0xccddeeff (32-bit)The one thing to remember here is that the data elements are isolated from each other. The An placement of each element is related to its position. For example, when related to a quad vector:
So that means that Aw Az Ay Ax are visually on the far right just like A3 A2 A1 A0 for little-endian, and Ax, Ay, Az, Aw are on the far left just like A0, A1, A2, A3 for big-endian.
As long as you get the element positions correct for your processor, then the data flow represented by the arrows in the diagrams will be correct.
Note
The bit indicators on the diagrams in this section are in little-endian byte order.
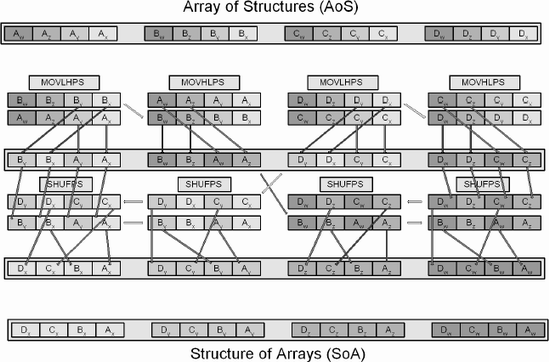
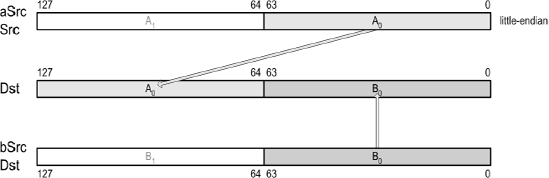
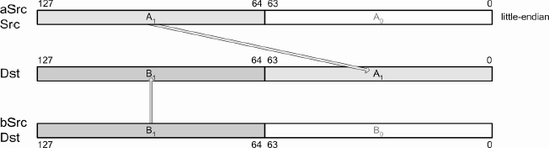
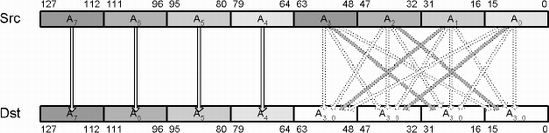
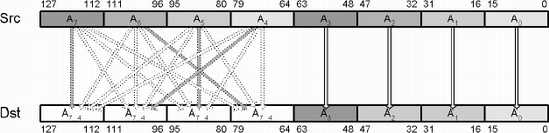
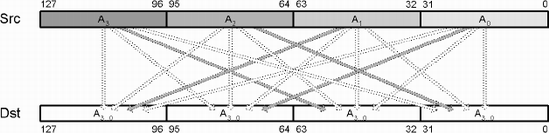
Quite often, data needs to be migrated from one form to another, and a single instruction may not be sufficient. For instance, a matrix is made up of four vectors: Axyzw, Bxyzw, Cxyzw, Dxyzw. This is known as an Array of Structures (AoS). But mathematical operations are typically between like terms such as AxBxCxDx, AyByCyDy, etc. This is known as a Structure of Arrays (SoA), which is more matrix friendly (and efficient) due to the simultaneous operation upon the same elements. To get the data from one form to another requires the data to be manipulated.
The following is one such example.
Before exploring various methods of converting data, let us first examine the method most often needed: The endian conversion! The handling of big- and little-endian was initially discussed in Chapter 3 but let us re-examine.
If your application is designed to be multiplatform, then having multiple endian declarations might make your life easier. Having Endian16(), Endian32(), Endian64(), and Endian128() conversion functions are one thing, but having extra declarations such as BigEndian64() versus LittleEndian64() that map to either a stub macro or an Endian64 converter will save you some time. The data file being read will be in a known endian orientation. The target platform knows what it needs, so if the big-endian label is used if the source data is known to be big-endian and vice versa for little-endian, then the use of that declaration will resolve any confusion. This will work for any platform!
Table 6-1. Correlation between little- and big-endian orientation and whether a byte swap or a stub function is implemented
These endian wrappers are shown only for little-endian as this book is mostly meant for little-endian. If you are truly interested, my Vector Game Math Processors book contains both sets.
#define VMP_LITTLE_ENDIAN
This is oversimplifying it and there are better methods such as the BSWAP instruction on the 80×86, but this is a generic method for cross-platform portability.
Example 6-1. Generic 32-bit endian conversion
int32 VMP_ENDIAN32(int32 val)
{
uint8 buf[4];
buf[ 0 ]=*(((uint8*)&val)+3); // = [3]
buf[ 1 ]=*(((uint8*)&val)+2); // = [2]
buf[ 2 ]=*(((uint8*)&val)+1); // = [1]
buf[ 3 ]=*(((uint8*)&val)+0); // = [0]
return *(int32*)buf;
}Example 6-2. Generic 16-bit endian conversion
int16 VMP_ENDIAN16(int16 val)
{
uint8 buf[2];
buf[ 0 ]=*(((uint8*)&val)+1); // = [1]
buf[ 1 ]=*(((uint8*)&val)+0); // = [0]
return *(int16*)buf;
} The typecasting camouflages it a bit, but it is merely a byte read-write with inverse offsets. I will leave the actual endian implementation up to you! Just remember that it is preferable to have the tools handle your endian conversion so that a game application does not have to. And since tools exercise the same data over and over for the length of a project, you might as well make them as efficient as possible.
For cross-platform compatibility I refer to the following as a little pretzel logic. It looks a little twisted, but if you dig a little deeper it becomes what it is — slicker 'n snail snot!
Example 6-3. KariType.h
#ifdef VMP_LITTLE_ENDIAN // Little-endian processor
// Big-endian data on little-endian processor
#define VMP_BIG_ENDIAN32 VMP_ENDIAN32
#define VMP_BIG_ENDIAN16 VMP_ENDIAN16
// Little-endian data on little-endian processor
#define VMP_LITTLE_ENDIAN32 // stub
#define VMP_LITTLE_ENDIAN16 // stub
#endifNote that same endian to same endian assignment merely stubs out the macro, so no conversion is needed or implemented. One only needs to know what byte order the data is in and what order is needed, and use the appropriate macro. It will then be cross-platform compatible to all other platforms as long as the endian flag is set properly for that platform.
Neat, huh? No extra #ifdef cluttering up the code!
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
BSWAP |
|
|
|
|
|
|
|
|
|
|
bswap | rDst(32/64) | [Un]signed |
This general-purpose instruction does a big/little-endian conversion. It reverses the byte order of a 32-bit or 64-bit register.
D31-D24 | D23-D16 | D15-D8 | D7-D0 | |
|---|---|---|---|---|
BEFORE | D | C | B | A |
AFTER | A | B | C | D |
bswap eax
This is used in the conversion of communications messages from big-endian platforms such as Unix or Macintosh, or file formats such as TIFF, MIDI, etc.
Flags: None are altered by this opcode. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
- | - | - | - | - | - | |
The C code equivalent is slow, especially when compared to the speed of a BSWAP instruction. I normally do not believe in in-line assembly as it makes code less portable to other platforms, but here is one of my rare exceptions. Note that compiling C with optimization set for speed should truly embed the Endian32 function into your code like a macro.
Example 6-4. BSWAP-based 32-bit endian conversion
int32 VMP_ENDIAN32(int32 val)
{
_asm {
mov eax,val
bswap eax
mov val,eax
};
return val;
}For those of you working with an embedded 8086...80386 processor, a 16-bit endian conversion can be accomplished with a ROR, which would have the same effect as an XCHG; however, it is more efficient depending on the processor manufacturer and model.
When using that same technique for 32-bit endian conversion, it should be noted that the ROR will cause a stall performing an operation with the EAX register after the write to the AX. So use the BSWAP on the Pentiums!
pswapd destination, source (2×32-bit) (2×SPFP)
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PSWAPD |
|
|
3DNow!+ pswapd mmxDst, mmxSrc/m64 | [Un]signed | 64 |
Single-precision |
pswapd mm0,mm1
If this functionality is needed, it can be emulated with the following:
movq mm0,mm1 ; y x punpckldq mm1,mm1 ; x x punpckhdq mm0,mm1 ; x y
punpcklbw destination, source (8×8-bit) (16×8-bit)

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PUNPCKLBW |
|
|
|
|
|
|
|
|
|
MMX | punpcklbw mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | punpcklbw xmmDst, xmmSrc/m128 | [Un]signed | 128 |
punpcklbw mm0,mm1 punpcklbw xmm0,xmm1
This is one of the more popular instructions as it is extremely useful in the expansion of an unsigned data value. By interlacing a value of zero with an actual value, an 8-bit value is expanded to 16 bits.
A = 0x00000000 B = 0x44332211 D = 00 44 00 33 00 22 00 11 0044 0033 0022 0011 punpcklbw mm0,mm0 ; {w w z z y y x x} ← {u t s r w z y x}
punpckhbw destination, source (8×8-bit) (16×8-bit)

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PUNPCKHBW |
|
|
|
|
|
|
|
|
|
MMX | punpckhbw mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | punpckhbw xmmDst, xmmSrc/m128 | [Un]signed | 128 |
punpckhbw mm0,mm1
punpckhbw xmm0,xmm1
fooa qword 0ffffa5a55a5a0000h
foob qword 08000003f007f00ffh
movq mm7,fooa
movq mm6,foob
punpckhbw mm7,mm6
; 80 00 00 3f 00 7f 00 ff ff ff a5 a5 5a 5a 00 00
; became
; 80 ff 00 ff 00 a5 3f a5
punpckhbw mm0,mm0 ; {u u t t s s r r} ← {u t s r w z y x}punpcklwd destination, source (4×16-bit) (8×16-bit)

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PUNPCKLWD |
|
|
|
|
|
|
|
|
|
MMX | punpcklwd mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | punpcklwd xmmDst, xmmSrc/m128 | [Un]signed | 128 |
punpcklwd mm0,mm1
punpcklwd xmm0,xmm1
fooa qword 0ffffa5a55a5a0000h
foob qword 08000003f007f00ffh
movq mm7,fooa
movq mm6,foob
punpcklwd mm7,mm6
; 8000 003f 007f 00ff ffff a5a5 5a5a 0000
; became
; 007f 5a5a 00ff 0000
punpcklwd xmm0,xmm0 ; {w w z z y y x x} ← {u t s r w z y x}punpckhwd destination, source (4×16-bit) (8×16-bit)
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PUNPCKHWD |
|
|
|
|
|
|
|
|
|
MMX | punpckhwd mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | punpckhwd xmmDst, xmmSrc/m128 | [Un]signed | 128 |
punpckhwd mm0,mm1
punpckhwd xmm0,xmm1
punpckhwd xmm0,xmm0 ; {u u t t s s r r} ← {u t s r w z y x}punpckldq destination, source (2×32-bit) (4×32-bit)
unpcklps destination, source (4×SPFP)

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PUNPCKLDQ |
|
|
|
|
|
|
|
|
| |
UNPCKLPS |
|
|
|
|
|
MMX | punpckldq mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE | unpcklps xmmDst, xmmSrc/m128 | Single-precision | 128 |
SSE2 | punpckldq xmmDst, xmmSrc/m128 | [Un]signed | 128 |
punpckldq mm0,mm1 unpcklps xmm0,xmm1 punpckldq xmm0,xmm1
If a "splat" functionality is needed, it can be emulated with the following:
punpckldq mm0,mm0 ; 64-bit {x x} A = {y x}
punpckldq xmm0,xmm0 ; 128-bit {y y x x} A = {w z y x}punpckhdq destination, source (2×32-bit) (4×32-bit)
unpckhps destination, source (4×SPFP)
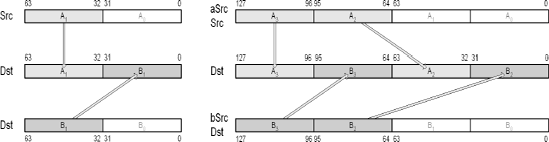
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PUNPCKHDQ |
|
|
|
|
|
|
|
|
| |
UNPCKHPS |
|
|
|
|
|
MMX | punpckhdq mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE | unpckhps xmmDst, xmmSrc/m128 | Single-precision | 128 |
SSE2 | punpckhdq xmmDst, xmmSrc/m128 | [Un]signed | 128 |
punpckhdq mm0,mm1
unpckhps xmm0,xmm1
punpckhdq xmm0,xmm1
fooa qword 0ffffa5a55a5a0000h
foob qword 08000003f007f00ffh
movq mm7,fooa
movq mm6,foob
punpckhdq mm7,mm6
; 8000003f 007f00ff ffffa5a5 5a5a0000
; becomes
; 007f00ff 5a5a0000If a "splat" functionality is needed, it can be emulated with the following:
punpckhdq mm0,mm0 ; 64-bit {y y} ← {y x}
punpckhdq xmm0,xmm0 ; 128-bit {w w z z} ← {w z y x}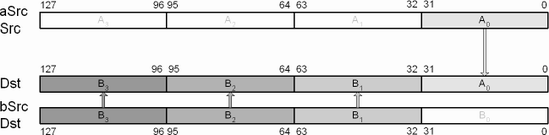
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVSS |
|
|
|
|
|
SSE | movss xmmDst, xmmSrc/m32 | Single-precision | 128 |
" | movss xmmDst/m32, xmmSrc |
This SSE instruction copies the least significant single-precision floating-point scalar value from 32-bit memory aSrc and copies it to destination Dst. Source and destination can be XMM register, XMM to 32-bit memory, or 32-bit memory to XMM scalar copy.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVQ2DQ |
|
|
|
|
SSE | movq2dq xmmDst, mmxSrc(mmx/m32) | [Un]signed | 128 |
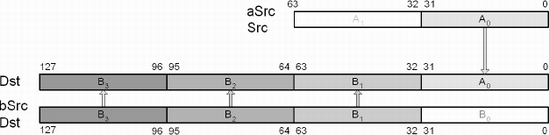
This SSE instruction copies the least significant 32-bit unsigned scalar value from MMX or 32-bit memory aSrc and copies it to XMM destination Dst. Other elements remain unchanged.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVDQ2Q |
|
|
|
|
SSE | movdq2q mmxDst, (xmmSrc/m32) | [Un]signed | 128 |
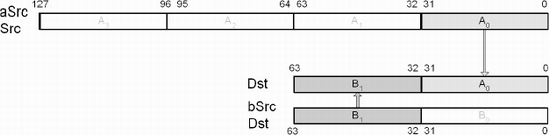
This SSE instruction copies the least significant 32-bit unsigned scalar value from XMM or 32-bit memory aSrc to the least significant 32-bit element of the MMX destination Dst. The other element of Dst remains unchanged.

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVLPS |
|
|
|
|
|
SSE | movlps xmmDst, mSrc64 | Single-precision | 128 |
" | movlps mDst64, xmmSrc |
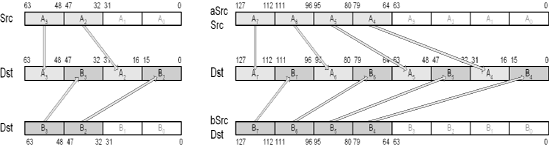
This SSE instruction copies the two least significant single-precision floating-point values from XMM source register or 32-bit memory aSrc to the two least significant single-precision floating-point elements of the XMM destination Dst. The other elements of Dst remain unchanged.
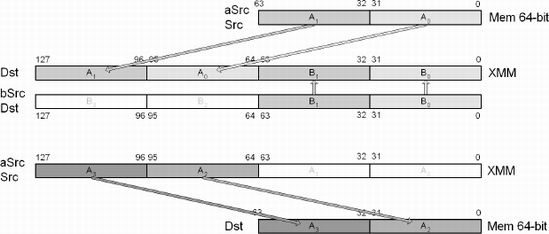
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVHPS |
|
|
|
|
|
SSE | movhps xmmDst, m64 | Single-precision | 128 |
" | movhps m64, xmmSrc |
When the source is memory, this SSE instruction copies the two single-precision floating-point values from 64-bit memory aSrc and copies them to the two most significant single-precision floating-point elements within an XMM register specified by Dst. When aSrc is an XMM register, the two most significant single-precision floating-point values are copied to 64-bit memory Dst.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVLHPS |
|
|
|
|
|
SSE | movlhps xmmDst, xmmSrc | Single-precision | 128 |
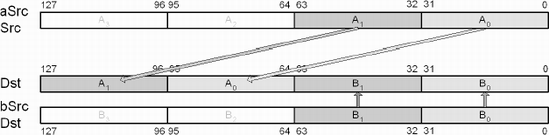
This SSE instruction copies the two least significant single-precision floating-point values from XMM source register aSrc to the two most significant single-precision floating-point elements of the XMM register destination Dst. The other elements of Dst remain unchanged.
movlhps xmm0,xmm0 ; {y x y x} ← {w z y x}
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVHLPS |
|
|
|
|
|
SSE | movhlps xmmDst, xmmSrc | Single-precision | 128 |
This SSE instruction copies the two most significant single-precision floating-point values from the XMM register aSrc to the two least significant single-precision floating-point elements of destination XMM register Dst. The other elements of Dst remain unchanged.
movhlps xmm0,xmm0 ; {w z w z} ← {w z y x}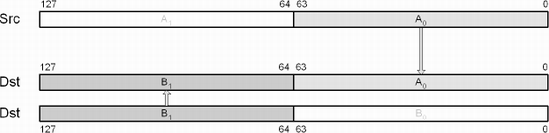
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVSD |
|
|
|
|
SSE2 | movsd xmmDst, xmmSrc/m64 | Double-precision | 128 |
" | movsd xmmDst/m64, xmmSrc |
When the source is memory, this SSE2 instruction copies the double-precision floating-point value from 64-bit memory aSrc and copies it to the least significant double-precision floating-point element of the XMM destination register specified by Dst. The upper double-precision floating-point value is unchanged. When aSrc is an XMM register, the lower double-precision floating-point value is copied to 64-bit memory.
Note
This MOVSD instruction should not be confused with the string instruction MOVSD. This instruction uses XMM registers, not general-purpose registers, and does not work with the REP prefix.
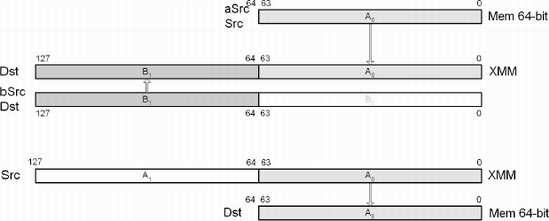
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVLPD |
|
|
|
| ||||||
MOVSD |
|
|
|
|
SSE2 | movsd xmmDst, mSrc64 | Double-precision | 128 |
" | movsd mSrc64, xmmSrc | ||
" | movlpd xmmDst, mSrc64 | ||
" | movlpd mSrc64, xmmSrc |
The MOVLPD instruction copies the double-precision floating-point value from 64-bit memory aSrc to the lower 64 bits of the XMM register or from the lower 64 bits of the XMM register to 64-bit memory. The upper double-precision floating-point value in the XMM register is unchanged when the destination is the XMM register.
Note
The MOVLPD and MOVSD instructions appear to be functionally identical. However, the MOVSD can optionally move XMM to XMM, while the MOVLPD cannot!
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVHPD |
|
|
|
|
SSE2 | movhpd xmmDst, m64 | Double-precision | 128 |
" | movhpd m64, xmmSrc |
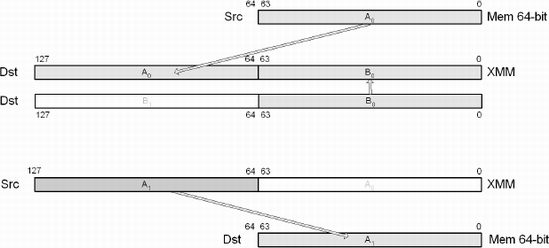
The MOVHPD instruction copies the double-precision floating-point value from 64-bit memory aSrc to the upper 64 bits of the XMM register or from the upper 64 bits of the XMM register to 64-bit memory. The upper double-precision floating-point value in the XMM register is unchanged when the destination is the XMM register.
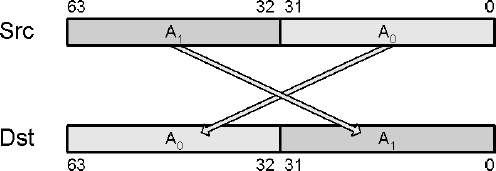
The various manufacturers refer to the swapping of data values by different terms: swizzle, shuffle, splat, etc. Some of these replicate a data value into two or more destination locations. In a few hybrid cases the functions use a defined distribution or a custom-defined interlacing of source arguments such as was discussed in the previous section.
The splat functionally is similar to a bug hitting the windshield of an automobile at 70 mph.
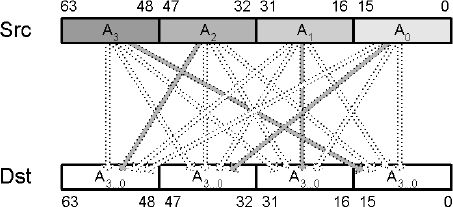
A bit sequence is used to indicate which source elements are mapped to which destination elements.

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PINSRW |
|
|
|
|
|
|
MMX+ | pinsrw mmxDst, r32, # | [Un]signed | 64 |
" | pinsrw mmxDst, m16, # | " | " |
SSE2 | pinsrw xmmDst, r64, # | " | 128 |
" | pinsrw xmmDst, m32, # | " | " |
For 64-bit data there exist four output elements and so an immediate value of 0...3; thus two bits are needed to identify which element is the destination. The two least significant bits of the index are masked to only allow a selectable value of 0...3. With 128-bit data there exist eight output elements and therefore a value of 0...7; thus three bits are used to select the destination.
pinsrw mm0,eax,01b ; 1 {3...0}The lower 16 bits of the general-purpose register are assigned to one of the four destination 16-bit values selected by the index.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PSHUFW |
|
|
|
|
|
|
MMX+ | pshufw mmxDst, (mmxSrc/m64), # | [Un]signed | 64 |
SSE | pshufw mmxDst, (mmxSrc/m64), # | [Un]signed | 64 |
The immediate value indicates which source index is mapped to each of the destination elements. The immediate value is a single 8-bit byte; with four possible source elements needing two bits each, that leaves a maximum of four remappable elements. There are 4×4×4×4 = 44= 256 possible patterns.
pshufw mm0,mm1,10000111b ; 2 0 1 3
pshuflw destination, source, #
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PSHUFLW |
|
|
|
|
SSE2 | pshuflw xmmDst, (xmmSrc/m128), # | [Un]signed | 128 |
The immediate value indicates which source index is mapped to each of the destination elements. The immediate value is a single 8-bit byte; with four possible source elements needing two bits each, that leaves a maximum of four remappable elements. This is similar in functionality to PSHUFW; the lower four 16-bit elements are remappable but the upper four elements are straight mappings and thus a direct copy.
pshuflw xmm0,xmm1,01001110b ; 1 0 3 2
pshufhw destination, source, #
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PSHUFHW |
|
|
|
|
SSE2 | pshufhw xmmDst, (xmmSrc/m128), # | [Un]signed | 128 |
The immediate value indicates which source index is mapped to each of the destination elements. The immediate value is a single 8-bit byte, and with four possible source elements needing two bits each, that leaves a maximum of four remappable elements. This is similar in functionality to PSHUFW; the upper four 16-bit elements are remappable but the lower four elements are straight mappings and thus a direct copy.
pshufhw xmm0,xmm1,11000110b ; 3 0 1 2
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PSHUFD |
|
|
|
|
SSE2 | pshufd xmmDst, (xmmSrc/m128), # | [Un]signed | 128 |
pshufd xmm0,xmm1,01001110b ; 1 0 3 2
The immediate value indicates which source index is mapped to each of the destination elements. The immediate value is a single 8-bit byte, and with four possible source elements needing two bits each, that leaves a maximum of four remappable elements.

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
SHUFPS |
|
|
|
|
|
SSE | shufps xmmDst, (xmmSrc/m128), # | Single-precision | 128 |
The immediate value is split between where the two lowest elements are selectable from the destination and the two highest elements of the destination are selectable from the source. The immediate value is a single 8-bit byte; with four possible source elements needing two bits each, that leaves a maximum of four remappable elements.
shufps xmm0,xmm1,11100100b ; 3 2 1 0 {3...0}
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVSLDUP |
|
|
SSE3 | movsldup xmmDst,(xmmDst/m32) | Single-precision | 128 |
The even single-precision floating-point elements from the source are replicated so element #0 is copied to the two lower destination elements and the source element #2 is copied to the upper two destination elements.

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVSHDUP |
|
|
SSE3 | movshdup xmmDst, (xmmSrc/m32) | Single-precision | 128 |
The odd single-precision floating-point elements from the source are replicated so element #1 is copied to the two lower destination elements and the source element #3 is copied to the upper two destination elements.


The important item to remember is that with regular data expansion, the enlarging of the data size from a lower bit count to a higher bit count of an unsigned number only requires a 128-bit value of zero. This needs to be interlaced with the value and when the bit size is doubled, a zero is in effect, moved into the upper bits. When working with signed values, instructions such as those that follow are needed so that the sign bit is replicated into the upper bits. Note the size differential in the following diagrams. A data element is being doubled in size: to word from byte or dword from word. Also, a possible change in sign may occur, which is denoted with a from/to (±).
cbw | Signed | 16 |
cwde | Signed | 32 |
cdqe | Signed | 64 |
The CBW general-purpose instruction converts the (7+1)-bit signed value in the AL register to a (15+1)-bit signed value in the AX register.
The CWDE general-purpose instruction converts the (15+1)-bit signed value in the AX register to the (31+1)-bit signed value in the EAX register.
The CDQE general-purpose instruction converts the (31+1)-bit signed value in the EAX register to the (63+1)-bit signed value in the RAX register.
Flags: None are altered by this opcode. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
- | - | - | - | - | - | |
Conversion of signed 8-bit to 16-bit
To convert a signed value of [-128...0...127] to a 16-bit value. This only works with the AL to AX register, and is most efficient if the data value originated in the AL; if not, then the MOVSX is best.
Conversion of signed 16-bit to 32-bit
To convert a signed value of [-32768...0...32767] to a 32-bit value.
Best | Worst | |||
|---|---|---|---|---|
cwde | movsx eax,ax | shl eax,16 sar eax,16 | ror eax,16 sar eax,16 | |
P bytes | 1 | 3 | 6 | 6 |
R bytes | 1 | 4 | 6 | 6 |
MOVSX destination, source
movsx | rDst16, rmSrc8 | Signed |
movsx | rDst32, rmSrc(8/16) | |
movsx | rDst64, rmSrc(8/16) | |
movsxd | rDst64, rmSrc32 |
These general-purpose instructions are very similar to CBW and CWDE except that they are a lot more versatile in which other registers can be sign extended to the same or a different register instead of just the AL or AX. A (7+1)-bit signed value can be converted to a (15+1)-bit or (31+1)-bit signed value. A (15+1)-bit signed value is converted into a (31+1)-bit signed value.
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
|---|---|---|---|---|---|---|
Flags: None are altered by this opcode. | ||||||
- | - | - | - | - | - | |
Conversion of signed 8-bit to 16-bit
To convert a signed value of [-128...0...127] to a 16-bit value. If working with AX,AL then use the CBW instruction as it is more efficient. I recommend using 32-bit form, as it is the best.
Best | (+Best+) | Worst | ||
|---|---|---|---|---|
movsx ax,bl | movsx eax,bl | mov eax,ebx shl eax,24 sar eax,24 | mov ax,bx shl ax,8 sar ax,8 | |
P bytes | 4 | 3 | 8 | 11 |
R bytes | 3 | 4 | 11 | 8 |
Conversion of signed 8-bit to 32-bit
Best | Worst | ||
|---|---|---|---|
movsx eax,bl | mov eax,ebx shl eax,24 sar eax,24 | mov al,bl (stall) shl eax,24 sar eax,24 | |
P bytes | 3 | 8 | 10 |
R bytes | 4 | 11 | 8 |
Conversion of signed 16-bit to 32-bit
Best | Worst | ||
|---|---|---|---|
movsx eax,bx | mov eax,ebx shl eax,16 sar eax,16 | mov ax,bx (stall) shl eax,16 sar eax,16 | |
P bytes | 3 | 8 | 9 |
R bytes | 4 | 11 | 10 |
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
MOVZX |
|
|
|
|
|
|
|
|
|
|
movzx | rDst16, rmSrc8 | Unsigned |
movzx | rDst32, rmSrc(8/16) | |
movzx | rDst64, rmSrc(8/32) |
This instruction converts an unsigned value into a larger unsigned value. An 8-bit unsigned value can be converted to a 16-bit or 32-bit unsigned value. A 16-bit unsigned value is converted into a 32-bit unsigned value.
Flags: None are altered by this opcode. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
- | - | - | - | - | - | |
Conversion of same unsigned 8- to 16-bit register (no move)
To convert an unsigned number (0...255) to a 16-bit.
Best | (+Best+) | Worst | ||
|---|---|---|---|---|
movzx ax,al | movzx eax,al | and ax,00ffh | and eax,000ffh | |
P bytes | 4 | 3 | 4 | 5 |
R bytes | 3 | 4 | 3 | 6 |
Conversion of same unsigned 8- to 32-bit register (no move)
To convert an unsigned number (0...255) to a 32-bit.
Best | Worst | |
|---|---|---|
movzx eax,al | and eax,000ffh | |
P bytes | 3 | 5 |
R bytes | 4 | 6 |
Conversion of unsigned 8-bit to 16-bit
To convert an unsigned value of (0...255) to a 16-bit value. I recommend using the 8- to 32-bit form.
Best | Worst | |||
|---|---|---|---|---|
movzx ax,bl | xor ax,ax mov al,bl | sub ax,ax mov al,bl | mov ax,bx and ax,0ffh | |
P bytes | 4 | 5 | 5 | 7 |
R bytes | 3 | 4 | 4 | 5 |
Conversion of unsigned 8-bit to 32-bit
Best | Worst | |||
|---|---|---|---|---|
movzx eax,bl | xor eax,eax mov al,bl | sub eax,eax mov al,bl | mov eax,ebx and eax,0ffh | |
P bytes | 3 | 4 | 4 | 7 |
R bytes | 4 | 5 | 5 | 9 |
Conversion of unsigned 16-bit to 32-bit
Best | Worst | ||
|---|---|---|---|
movzx eax,bx | xor eax,eax mov ax,bx | mov eax,ebx and eax,0ffffh | |
P bytes | 3 | 5 | 7 |
R bytes | 4 | 5 | 9 |
cwd | Signed |
cdq | Signed |
cqo | Signed |
The general-purpose CWD, CDQ, and CQO instructions are typically used for preparation of a number before a division. The integer division requires:
AX or DX:AX or EDX:EAX or RDX:RAX
You would get the same result by multiplying two numbers together.
Flags: None are altered by this opcode. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
- | - | - | - | - | - | |
Best | Worst | ||
|---|---|---|---|
cwd | mov edx,eax sar dx,16 | mov dx,ax sar dx,16 | |
P bytes | 2 | 6 | 7 |
R bytes | 1 | 6 | 5 |
Best | Worst | |
|---|---|---|
cdq | mov edx,eax sar edx,31 sar edx,1 | |
P bytes | 1 | 7 |
R bytes | 2 | 10 |

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PEXTRW |
|
|
|
|
|
|
MMX | pextrw r(32/64), mmxSrc, # | [Un]signed | 64 |
SSE | pextrw r(32/64), xmmSrc, # |
pextrw eax,mm1,00b ; {3...0}One of the four 16-bit values is assigned to the lower 16 bits of the general-purpose register and zero extended into the upper 16 bits for the 32-bit register, or 48 bits for the 64-bit register.
One of the eight 16-bit values is assigned to the lower 16 bits of the general-purpose register and zero extended into the upper 16 bits for the 32-bit register, or 48 bits for the 64-bit register.

Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PACKSSWB |
|
|
|
|
|
|
|
|
|
MMX | packsswb mmxDst, mmxSrc/m64 | Signed | 64 |
SSE2 | packsswb xmmDst, xmmSrc/m128 | Signed | 128 |
packsswb mm0,mm1 packsswb xmm0,xmm1
This instruction takes a word value in the range {-32768 ... 32767} and saturates it to a signed 8-bit range of {-128...127}.
fooa qword 0ffffa5a55a5a0000h
foob qword 08000003f007f00ffh
movq mm7,fooa
movq mm6,foob
packsswb mm7,mm6
; 8000 003f 007f 00ff ffff a5a5 5a5a 0000
; became
; 80 3f 7f 7f ff 80 7f 00Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PACKUSWB |
|
|
|
|
|
|
|
|
|
MMX | packuswb mmxDst, mmxSrc/m64 | [Un]signed | 64 |
SSE2 | packuswb xmmDst, xmmSrc/m128 | [Un]signed | 128 |
packuswb mm0,mm1
This instruction uses the same diagram as the 64-bit form of the PACKSSWB instruction but saturates an unsigned word with a range of {-32768...32767} to an unsigned 8-bit range of {0...255}.
packuswb xmm0,xmm1
The following instruction uses the same diagram as the 128-bit form of the PACKSSWB instruction but saturates an unsigned word with a range of {-32768...32767} to an unsigned 8-bit range of {0...255}.
fooa qword 0ffffa5a55a5a0000h
foob qword 08000003f007f00ffh
movq mm7,fooa
movq mm6,foob
packuswb mm7,mm6
; 8000 003f 007f 00ff ffff a5a5 5a5a 0000
; became
; 00 3f 7f ff 00 00 ff 00
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
PACKSSDW |
|
|
|
|
|
|
|
|
|
MMX | packssdw mmxDst, mmxSrc/m64 | Signed | 64 |
SSE2 | packssdw xmmDst, xmmSrc/m128 | Signed | 128 |
packssdw mm0,mm1 packssdw xmm0,xmm1
This instruction takes a 32-bit signed value in the range {-2147483648 ... 2147483647} and saturates it to a signed 16-bit range of {-32768... 32767}.
fooa qword 0ffffa5a55a5a0000h
foob qword 08000003f007f00ffh
movq mm7,fooa
movq mm6,foob
packssdw mm7,mm6
; 8000003f 007f00ff ffffa5a5 5a5a0000
; became
; 8000 7fff a5a5 7fff
3DMx+ | pi2fw mmxDst, mmxSrc/m64 | SPFP ← INT16 | 64 |
This instruction converts even packed signed 16-bit values into packed single-precision floating-point values and stores the result in the destination mmxDst.

SSE | cvtdq2ps xmmDst, xmmSrc/m128 | SPFP ← INT32 | 128 |
This instruction converts a packed 32-bit signed integer from source xmm to xmm single-precision floating-point destination.

SSE | cvtps2dq xmmDst, xmmSrc/m128 | INT32 ← SPFP | 128 |
This converts a packed single-precision floating-point source xmm to xmm 32-bit signed destination.
SSE | cvttps2dq xmmDst, xmmSrc/m128 | INT32 ← SPFP | 128 |
This converts a packed single-precision floating-point with truncation source xmm to xmm 32-bit signed destination.

SSE | cvtpi2ps | xmmDst, xmmSrc/m64 | SPFP ← INT32 | 128 |
3DNow! | pi2fd | mmxDst, mmxSrc/m64 | SPFP ← INT32 | 64 |
This instruction converts packed signed 32-bit values into packed single-precision floating-point values and stores the result in the destination MMX register mmxDst.

SSE | cvtps2pi xmmDst, xmmSrc/m64 | INT32 ← SPFP | 128 |
SSE | cvttps2pi mmxDst, mmxSrc/m64 | INT32 ← SPFP | 128 |
(the same but with truncation)
3DNow! | pf2id mmxDst, mmxSrc/m64 | INT32 ← SPFP | 64 |
This instruction converts packed single-precision values in source mmxSrc to signed (saturated) 32-bit values and stores the result in the destination mmxDst.
3DMx+ | pf2iw mmxDst, mmxSrc/m64 INT32 ← INT16 ← DPFP 64 |
This instruction converts packed single-precision values in source mmxSrc to signed (saturated) 16-bit values [-32768, 32767], then sign extends to 32 bits and stores the result in the destination mmxDst.

SSE | cvtsi2ss xmmDst, r/m32 | SPFP ← INT32 | 128 |

SSE2 | cvtdq2pd xmmDst, xmmSrc/m64 | SPFP ← INT32 | 128 |
This instruction converts a packed even signed 32-bit integer value from source xmm to destination xmm double-precision floating-point.
SSE2 | cvtpd2dq xmmDst, xmmSrc/m128 | INT32 ← DPFP | 128 |
This converts a packed double-precision floating-point from source xmm to destination even packed 32-bit signed integer.
SSE2 | cvttpd2dq xmmDst, xmmSrc/m128 | INT32 ← DPFP | 128 |
(the same but with truncation)

SSE2 | cvtpd2ps xmmDst, xmmSrc/m128 | SPFP ← DPFP | 128 |
This converts a packed double-precision floating-point from source xmm to destination xmm packed single-precision floating-point.

SSE2 | cvtps2pd xmmDst, xmmSrc/m64 | DPFP ← SPFP | 128 |
This converts a lower packed single-precision floating-point xmm source to xmm double-precision destination.

SSE2 | cvtpd2pi mmxDst, xmmSrc/m128 | INT32 ← DPFP | 64 |
This converts a packed double-precision floating-point from source xmm to destination mmx register.
SSE2 | cvttpd2pi mmxDst, xmmSrc/m128 | INT32 ← DPFP | 64 |
This converts a packed double-precision floating-point with truncation from source xmm to destination mmx register.

SSE2 | cvtpi2pd xmmDst, xmmSrc/m64 | SPFP ← INT32 | 128 |
This converts a packed 32-bit signed integer source mmx to double-precision floating-point xmm destination.

SSE | cvtss2si r32, xmmSrc/m32 | INT32 ← SPFP | 32 |
" | cvtss2si r64, xmmSrc/m32 | INT64 ← SPFP | 64 |
" | cvttss2si r32, xmmSrc/m32 | INT32 ← SPFP | 32 |
" | cvttss2si r64, xmmSrc/m32 | INT64 ← SPFP | 64 |
(the same but with truncation)

SSE2 | cvtsd2si r64, xmmSrc/m64 | INT64 ← DPFP | 64 |
" | cvtsd2si r32, xmmSrc/m64 | INT32 ← DPFP | 32 |
" | cvttsd2si r32, xmmSrc/m64 | INT32 ← DPFP | 32 |
" | cvttsd2si r64, xmmSrc/m64 | INT64 ← DPFP | 64 |
(the same but with truncation)
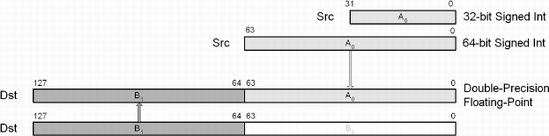
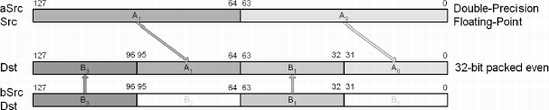
SSE2 | cvtsi2sd xmmDst, rmSrc64 | DPFP ← INT64 | 128 |
" | cvtsi2sd xmmDst, rmSrc32 | DPFP ← INT32 | 128 |

SSE2 | cvtsd2ss xmmDst, xmmSrc/m64 | SPFP ← DPFP | 128 |

Write code for your favorite processor to convert an image 256 pixels wide by 256 pixels high from 32-bit RGB data to 24-bit RGB.
Same as problem #1 but convert to 5:6:5-bit RGB (5 bits red, 6 bits green, 5 bits blue).
Convert from packed 5:5:5 RGB to 32-bit RGB.
For {SSE2} what instruction is needed to convert from a 16-bit signed number to 32-bit? Unsigned?
For {SSE2} write code snippets to pack four 128-bit vectors from packed 32-bit to packed 8-bit.
Write a function to convert a 128-bit vector of 32-bit packed integers from big-endian to little-endian and vice versa.
Same as problem #6 but 32-bit single-precision floating-point values.
Same as problem #6 but 64-bit double-precision floating-point values.
The beginning of this chapter shows a diagram for an AoS to SoA. Write it using
3DNow!
SSE
SSE2
The beginning of this chapter shows a diagram for an AoS to SoA. Write the reverse from SoA to AoS using
3DNow!
SSE
SSE2