
If you are interested in programming the FPU (floating-point unit) in assembly, you are either bored or deeply disturbed. My apologies to those few of you writing compilers or low-level operating system kernels who actually need to know how to do this! Then again, you may just be curious. Other books tend to stick this topic in the section beginning with "F," or somewhere buried in the back in an appendix, and maybe 1% of the readers actually even glance at it. Some people have been known to tape those pages together or just rip them out of their book (not my book) altogether. If C/C++ is good enough for you to handle your floating-point math, then just skip this section.
Wait!
 There are a couple items you REALLY NEED TO KNOW! Stuff not in the standard runtime C libraries. Something to make your code just a bit faster and better!
There are a couple items you REALLY NEED TO KNOW! Stuff not in the standard runtime C libraries. Something to make your code just a bit faster and better!
My gosh! You're still reading this? You must be indeed interested in floating-point math. So we will chat about a couple items but we are not going to go into very much detail — only enough to take advantage of some enhanced functionality.
These are the three methods available to use for floating-point calculation: 3DNow!, SSE, and SSE2 packed instructions; run-time C libraries; and of course, ye old floating-point coprocessor known as the FPU (floating-point unit), for which most whom program it directly have a love/hate relationship. This book should help you get over that, at least in part.
It is strongly recommended that if you only have generic floating-point programming in mind (whether it be single-precision floating-point or double-precision floating-point), then just use your higher level language such as C/C++ instead. It will be much easier and any optimization will be merely that of intermixing general-purpose instructions with floating-point instructions.
Working with the SIMD instructions for floating-point support is much easier than working with the FPU, but the FPU has some helpful features. Fortunately, most of the hard work of directly programming the FPU has been done for you already and is available in libraries such as the runtime library for the C programming language. The FPU has so many nuances that it could take a several hundred-page book to understand all the feature sets, controls, exception handling, etc. This chapter is going to describe how floating-point works in general and paint some broad strokes as to how to use the FPU, especially the few instructions that can be of use but are not utilized by off-the-shelf libraries. If you indeed want to do in-depth programming I suggest you download the various technical manuals and application notes from the manufacturer.
Workbench Files: Benchx86chap08projectplatform
project | platform | |
|---|---|---|
Boolean Logic | fas | vc6 |
vc.net |
Before digging very deeply let us first examine the floating-point number and its sub-components.

The FPU supports three sizes of floating-point numbers, as shown below.
Data Size | C reference | Assembler | Bytes |
|---|---|---|---|
(float) | 4 | ||
(double) | 8 | ||
Double Extended-Precision | --- | REAL10 | 10 |
You are probably familiar with the single- and double-precision but not the double extended-precision. Did you know that when you do a floating-point calculation that the data is actually expanded into the 10-byte (80-bit) form — double extended-precision floating-point — as it is pushed on the FPU stack?

The larger the number of bits used to store the number, the higher the precision of that number.
The exponent is a base-2 power representation stored as a binary integer. The significand (mantissa) really consists of two components: a J-bit and a binary fraction.
For the single-precision value, there is a hidden integer bit (1.) leading the 23 bits of the mantissa, thus making it a 24-bit significand. The exponent is 8 bits, thus having a bias value of 127. The magnitude of the supported range of numbers is 2×10–38 to 2×1038.
For double-precision values, there is a hidden integer bit (1.) leading the 52 bits of the mantissa, thus making it a 53-bit significand. The exponent is 11 bits, thus having a bias value of 1023. The magnitude of the supported range of numbers is 2.23×10–308 to 1.8×10308.
For the 80-bit version, the extra bits are primarily for protection against precision loss from rounding and over/underflows. The leading integer bit (1.) is the 64th bit of the significand. The exponent is 15 bits, thus having a bias value of 32767. The magnitude of the supported range of numbers is 3.3×10–4932 to 1.21×104932.
The product of the exponent and significand result in the floating-point value.
A zero exists in two forms (±0): positive zero (+0) and negative zero (–0). Both of these are valid indications of zero. (The sign is ignored!)
For double-precision and single-precision floating-point numbers, the integer bit is always set to one. (It just is not part of the 64 or 32 bits used to encode the number.) For double extended-precision the bit is encoded as part of the number and so denormalized numbers apply. These are very small non-zero numbers represented with an exponent of zero and thus very close to the value of zero and considered tiny. Keep in mind for the FPU that the single-precision and double-precision numbers are expanded into double extended-precision where the integer bit is one of the 80 bits and thus denormalized numbers exist for the calculations. Upon saving the single- or double-precision floating-point number back to memory the bit is stripped out as an imaginary bit, which is set!
Programmers are also usually aware that floats cannot be divided by zero or process a square root of negative because an exception error would occur.
Table 8-1. Single-precision floating-point number representations. ±Sign bit. xe Exponent. Note: The integer bit of (1) 1.### is implied for single-precision and double-precision numbers.
± | xe | Significand | NaN (Not a Number) | |
|---|---|---|---|---|
0 | 255 | 1.1xxx... | 0 11111111 1xxxxxxxx... 7FC00000-7FFFFFFFh | QNaN |
0 | 255 | 1.0xxx... | 0 11111111 0xxxxxxx...1 7F800001h-7FBFFFFFh | SNaN |
0 | 255 | 1.000... | 0 11111111 000... 7f800000h | + ∞ |
0 | 1...254 | 1.xxx | 0 11111110 xxxxxx... 00000001h-7F7FFFFFh | + Normalized Finite |
0 | 0 | 0.xxx | (Not SPFP) | + Denormalized (Tiny) |
0 | 0 | 0 | 00000000h | + Positive Zero |
1 | 0 | 0 | 80000000h | – Negative Zero |
1 | 0 | 0.xxx | 1000 0000 0 xxx 80000001h-807FFFFFh | – Denormalized (Tiny) |
1 | 1...254 | 1.xxx | 1 11111110 xxxxxx... FF000000h-FF7FFFFFh | – Normalized Finite |
1 | 255 | 1.000... | 1 11111111 000... FF800000h | - ∞ |
1 | 255 | 1.0xxx... | FF800001h-FFBFFFFFh | SNaN |
1 | 255 | 1.1xxx... | FFC00000h-FFFFFFFFh | QNaN |
There are two types of NaNs (non-numbers): The quiet NaNs known as QNaNs and the signalling NaNs known as SNaNs.
QNaN
The QNaN has the most significant fraction bit set and is a valid value to use in most floating-point instructions even though it is not a number. A QNaN is an unordered number due to not being a real floating-point value.
SNaN
The SNaN has the most significant fraction bit reset (clear) and typically signals an invalid exception when used with floating-point instructions. SNaN values are never generated by the result of a floating-point operation. They are only operands supplied by software algorithms. A SNaN is an unordered number due to not being a real floating-point value.
NaN
The NaN (Not ANumber) is a number that is either a QNaN or SNaN.
Unordered
An unordered number is a number that is valid or a QNaN. (It is not SNaN.)
Ordered
An ordered number is a valid number that is not NaN (neither QNaN nor SNaN).
Table 8-2. Single-precision floating-point to hex equivalent
Value | Hex | Sign Exp Sig. |
|---|---|---|
–1.0 | 0×BF800000 | 1 7F 000000 |
0.0 | 0×00000000 | 0 00 000000 |
0.0000001 | 0×33D6BF95 | 0 67 56BF95 |
1.0 | 0×3F800000 | 0 7F 000000 |
2.0 | 0×40000000 | 0 80 000000 |
3.0 | 0×40400000 | 0 80 800000 |
4.0 | 0×40800000 | 0 81 000000 |
Table 8-3. Double-precision floating-point to hex equivalent
Value | Hex |
|---|---|
–1.0 | 0×BFF00000 00000000 |
0.0 | 0×00000000 00000000 |
1.0 | 0×3FF00000 00000000 |
Table 8-4. Double extended-precision floating-point to hex equivalent
Value | Hex |
|---|---|
–1.0 | 0×BFFF8000 00000000 |
0.0 | 0×00000000 00000000 |
1.0 | 0×3FFF8000 00000000 |

The floating-point unit has eight data registers, {ST(0), ST(1), ST(2), ST(3), ST(4), ST(5), ST(6), ST(7)}, and Status, Control Word, Tag Word, IP, Data Pointer, and Op Code Registers.
Table 8-5. (16-bit) FPU status register
Def. | Code | Bit | Description |
|---|---|---|---|
00001h | 0 | Invalid operation (exception) | |
FPU_DE | 00002h | 1 | Denormalized operand (exception) |
FPU_ZE | 00004h | 2 | Zero divide (exception) |
FPU_OE | 00008h | 3 | Overflow (exception) |
FPU_UE | 00010h | 4 | Underflow (exception) |
FPU_PE | 00020h | 5 | Precision (exception) |
FPU_SF | 00040h | 6 | Stack fault |
FPU_ES | 00080h | 7 | Error summary status |
FPU_C0 | 00100h | 8 | (C0) Condition Code Bit#0 |
FPU_C1 | 00200h | 9 | (C1) Condition Code Bit#1 |
FPU_C2 | 00400h | 10 | (C2) Condition Code Bit#2 |
11-13 | Top of stack pointer | ||
FPU_C3 | 04000h | 14 | (C3) Condition Code Bit#3 |
FPU_B | 08000h | 15 | FPU busy bit |
The FPU has condition code bits contained within the status register. These bits match 1:1 with the EFLAGS of the CPU. They can be copied to the AX register using the FSTSW AX instruction followed by a SAHF instruction to place them into the EFLAGS register.
Table 8-6. (16-bit) FPU control word
Def. | Code | Bit | Description |
|---|---|---|---|
FPU_IM | 00001h | 0 | Invalid operation |
FPU_DM | 00002h | 1 | Denormalized operand |
FPU_ZM | 00004h | 2 | Zero divide |
FPU_OM | 00008h | 3 | Overflow |
FPU_UM | 00010h | 4 | Underflow |
FPU_PM | 00020h | 5 | Precision |
FPU_PC | 00300h | 8,9 | Precision control |
FPU_RC | 00c00h | 10,11 | Rounding control |
FPU_X | 01000h | 12 | Infinity control |
Now would be a good time to talk about FPU exceptions. The FPU uses exceptions for invalid operations in a manner similar to how the CPU uses exceptions.
Most of the single- and double-precision floating-point functionality is covered by the C runtime math library, which can be accessed in the file: #include <math.h>.
FPU | fld | source | Single-precision | 32 |
Double-precision | 64 | |||
Extended-precision | 80 |
The floating-point load instruction loads the value in memory, expands it to an 80-bit double extended-precision floating-point form, and pushes it on the stack, thereby making it addressable by the FPU as register ST(0).
float a;
double b;
__asm {
fld a ; Load SPFP 32-bit to 80-bit
fld b ; Load DPFP 64-bit to 80-bit
fadd
};The CPU handles integer addition through a simple process of D = A + B
...which is in reality:
add edx,ebx ; D = D + B
The FPU, however, has its registers as entries on a stack. Thus, values are pushed on a stack and an operation is performed upon the values stored at the top of the stack.
A standard calculator operates as:
The FPU behaves like an RPN (Reverse Polish Notation) calculator. Arguments are "pushed" on the stack and then the operation is performed.
And in the case of the FPU:
There are eight floating-point data registers, which are treated like a circular stack. The stack pointer ST(0) references the register number that is at the top of the stack.
ST(0) | 2.0 |
ST(1) | 1.0 |
ST(2) | |
ST(3) | |
ST(4) | |
ST(5) | |
ST(6) | |
ST(7) |
As values are loaded they are pushed onto the top of the stack, and the other items on the stack are pushed down, leaving the new item addressed as ST(0) and the other items addressed as ST(1)...ST(7). A maximum of eight values can be pushed on the FPU stack, as the ninth item generates an FPU error: #IS aka: 1#IND "Stack overflow or underflow."
If the stack had only one or no arguments pushed, the operation would have generated a stack underflow due to the missing argument.
As mentioned, ST(0) references the top of the stack but the stack is really a rotating queue. Let us examine a simple addition operation again but step by step: 1 + 2 + 5 thus 1 2 + 5 +.
a = 1; b = 2; c = 5;
fld a
fld b
fadd
fld c
fadd
fst d ; Save float to memory.1.0 | 2.0 | FADD | 5.0 | FADD | FST | |
ST(0) | 1.0 | 2.0 | 3.0 | 5.0 | 8.0 | 8.0 |
ST(1) | 1.0 | 3.0 | ||||
ST(2) | ||||||
ST(3) | ||||||
ST(4) | ||||||
ST(5) | ||||||
ST(6) | ||||||
ST(7) | 2.0 | 5.0 | 5.0 |
First, the value of 1 was loaded and thus pushed onto the stack. Then, the value of 2 was loaded and thus pushed onto the stack.
The FADD operation actually caused the stack to unwind. The 2.0 was retrieved from ST(0), and the stack was rolled back one slot, then summed with the new ST(0) value 1.0 and the result written back to ST(0). The effect is the result was stored for the next operation, but the old ST(0) was rolled into ST(7) and the other slots rolled down by one. If a new value is loaded and processed, the same kind of operation occurs. Notice the activity of ST(0) and ST(7).
Now let us try that again but this time: 1 + 2 + 5 thus 1 2 5 + +.
fld a
fld b
fld c
fadd
fadd
fst d ; Save float to memory.1.0 | 2.0 | 5.0 | FADD | FADD | FST | |
ST(0) | 1.0 | 2.0 | 5.0 | 7.0 | 8.0 | 8.0 |
ST(1) | 1.0 | 2.0 | 1.0 | |||
ST(2) | 1.0 | |||||
ST(3) | ||||||
ST(4) | ||||||
ST(5) | ||||||
ST(6) | 5.0 | 5.0 | ||||
ST(7) | 5.0 | 7.0 | 7.0 |
All three values are pushed on the stack and they are popped as the stack gets rolled and processed. Upon completion of the floating-point operation, the value is exported in one of the forms while being popped off the stack and put back into system memory.
Be careful when mixing your operators due to rules of precedence:
Warning
There seems to be some confusion or encoding errors in some of the macro assemblers in regard to the "P" suffix. If you try to assemble your code and get an error on one of the FPU instructions, try the alternative (with or without P).
FPU | fst | source | Single-precision | 32 |
Double-precision | 64 | |||
Extended-precision | 80 |
The FST instruction copies the truncated integer from ST(0) to 16/32/64-bit memory and leaves the FPU stack intact.
The FSTP instruction is similar to FST, but it pops the value off the FPU stack.
FPU | fild | mSrc(16/32/64) | Signed | 80 |
The integer load instruction loads the 16/32/64-bit integer in the 80-bit double extended-precision floating-point value.
FPU | fist | mSrc(16/32/64) | Signed | 80 |
fistp | mSrc(16/32/64) |
The FIST instruction copies the integer from ST(0) to 16/32/64-bit memory. The FISTP instruction does the same, only it pops the value off the FPU stack.
SSE3-FPU | fisttp mDst{16/32/64} | Signed | 80 |
The FISTTP instruction is similar to FISTP, but it copies the truncated integer from ST(0) to 16/32/64-bit memory and it pops the value off the FPU stack. This instruction was introduced with SSE3.
Some FPU values are predefined constants that get loaded into stack register ST(0) and as such do not need to be loaded from memory.
FPU | fxch | Extended-precision | 80 |
fxch st(i) |
The FXCH instruction can be used to exchange any of the stack registers {ST(1) ... ST(7)} with stack register ST(0). The default (with no parameter) is ST(1) and ST(0). The stack exchange value must be valid before the exchange to be valid after the swap.
Since floats and doubles are pretty much handled for you there is no real need to pick them apart as scalar libraries have been written for you by compiler manufacturers. If you want to use the double extended-precision, then you have a lot of work that you will need to do since standard C compilers do not tend to support it and thus you need to do the math yourself using FPU instructions.
FPU | fincstp |
The FINCSTP instruction effectively rolls the stack. The value indexed by ST(0) becomes ST(7), but the data does not become invalidated. A valid stack argument in ST(0) gets rolled to ST(7). As the data is still valid, it is still eligible for exchange with the FXCHG instruction.
FPU | fdecstp |
The FDECSTP instruction effectively rolls the stack. The value indexed by ST(0) becomes ST(1) and ST(7) becomes ST(0), but the data retains its valid/invalid state. A valid stack argument in ST(0) gets rolled to ST(1). As the data is still valid, it is still eligible for exchange with the FXCHG instruction.
FPU | fwait |
" | wait |
The FWAIT instruction is used to wait for the FPU (floating-point unit) operation to complete. Without it, an operation that is in effect can be preempted by a new floating-point calculation pushed on the FPU stack.
Whenever MMX and FPU instructions are both used within the same thread there must be a switch-over by the CPU calling the EMMS instruction. The 3DNow! instruction set has the fast instruction FEMMS. Having to switch back and forth is time consuming and a burden on the CPU, so whenever possible the instructions should be grouped by type or kept in separate threads.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
EMMS |
|
|
|
|
|
|
|
|
| |
FEMMS |
|
|
|
FPU | fchs | Extended-precision | 80 |
This instruction performs a one's complement on the sign bit in ST(0). This effectively two's complements the value in the ST(0) register.
FPU | fabs | Extended-precision | 80 |
This instruction clears (resets) the sign bit in ST(0).

FPU | faddp | Extended-precision | 80 | |
" | fadd | mSrc(32/64) | ||
fadd | st(0)Dst, st(i)Src | |||
" | fadd | st(i)Dst, st(0)Src | ||
" | faddp | st(i)Dst, st(0)Src | ||
" | fiadd | mSrc(32/64) | Signed |
The FADD instruction performs a summation of the source to the destination and stores the result in the destination. If no destination is specified, the default is ST(0).
FADDP performs the same operation, but it pops ST(0) off the stack and pushes the result back onto the stack at ST(0).
The FIADD instruction performs the same operation as FADD except the source value is a 16/32-bit integer.
fs REAL4 2.0
fldpi ; ST(0) = π (PI) 3.1415926535897932
fldpi
faddp ; ST(0) = 2π = π+π
fadd fsFPU | fsubp | Extended-precision | 80 | |
" | fsub | mSrc(32/64) | ||
" | fsub | st(0)Dst, st(i)Src | ||
" | fsub | st(i)Dst, st(0)Src | ||
" | fsubp | st(i)Dst, st(0)Src | ||
" | fisub | mSrc(32/64) | Signed |
The FSUB instruction subtracts the source from the destination and stores the result in the destination. If no destination is specified, the default is ST(0).
FSUBP performs the same operation, but it pops ST(0) off the stack and stores the result in ST(0).
The FISUB instruction performs the same operation as FSUB except the source value is a 16/32-bit integer.
FPU | fsubrp | Extended-precision | 80 | |
" | fsubr | mSrc(32/64) | ||
" | fsubr | st(0)Dst, st(i)Src | ||
" | fsubr | st(i)Dst, st(0)Src | ||
" | fsubrp | st(i)Dst, st(0)Src | ||
" | fisubr | mSrc(32/64) | Signed | |
The FSUBR instruction is a reverse subtraction where the destination is subtracted from the source and the result is stored in the destination. If no destination is specified, the default is ST(0).
Instead of D = (B) + (– A), the expression D = (– B) + A is used.
FSUBRP performs the same operation, but it pops ST(0) off the stack and stores the result in ST(0).
The FISUBR instruction performs the same operation as FSUBR except the source value is a 16/32-bit integer.
FPU | fmulp | Extended-precision | 80 | |||
" | fmul | mSrc(32/64) | ||||
" | fmul | st(0)Dst, st(i)Src | ||||
" | fmul | st(i)Dst, st(0)Src | ||||
" | fmulp | st(i)Dst, st(0)Src | ||||
" | fimul | mSrc(32/64) | Signed |
The FMUL instruction calculates the product of the source and the destination and stores the result in the destination. If no destination is specified, the default is ST(0).
FMULP performs the same operation, but it pops ST(0) off the stack and stores the result in ST(0).
The FIMUL instruction performs the same operation as FMUL except the source value is a 16/32-bit integer.
FPU | fdivp | Extended-precision | 80 | |
" | fdiv | mSrc(32/64) | ||
" | fdiv | st(0)Dst, st(i)Src | ||
" | fdiv | st(i)Dst, st(0)Src | ||
" | fdivp | st(i)Dst, st(0)Src | ||
" | fidiv | mSrc(32/64) | Signed |
The FDIV instruction calculates the dividend of the destination quotient and source divisor and stores the result in the destination. If no destination is specified, the default is ST(0).
FDIVP performs the same operation, but it pops ST(0) off the stack and stores the result in ST(0).
The FIDIV instruction performs the same operation as FDIV except the source value is a 16/32-bit integer.
FPU | fdivrp | Extended-precision | 80 | |
" | fdivr | mSrc(32/64) | ||
" | fdivr | st(0)Dst, st(i)Src | ||
" | fdivr | st(i)Dst, st(0)Src | ||
" | fdivrp | st(i)Dst, st(0)Src | ||
" | fidivr | mSrc(32/64) | Signed |
The FDIVR instruction calculates the dividend of the source quotient and destination divisor and stores the result in the destination. If no destination is specified, the default is ST(0).
FDIVRP performs the same operation, but it pops ST(0) off the stack and stores the result in ST(0).
The FIDIVR instruction performs the same operation as FDIVR except the source value is a 16/32-bit integer.
FPU | fprem | Extended-precision | 80 |
This instruction returns the remainder from dividing the dividend ST(0) by the divisor ST(1) and stores the result in ST(0). This instruction is the equivalent of a modulus:
FPU | fprem1 | Extended-precision | 80 |
This instruction is similar to the instruction FPREM but returns the IEEE remainder from dividing the dividend ST(0) by the divisor ST(1) and stores the result in ST(0). This instruction is the equivalent of a modulus:
FPU | fsqrt | Extended-precision | 80 |
The FSQRT instruction pops the ST(0) off the stack, performs a square root operation, then pushes the result back on the stack.
FPU | fscale | Extended-precision | 80 |
The FSCALE instruction effectively shifts ST(0) by the amount set in ST(1). This is equivalent to D = D × 2A.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
F2XM1 |
|
|
|
|
|
|
|
|
|
|
FPU | f2xm1 | Extended-precision | 80 |
The F2XM1 instruction calculates 2X – 1, where the source x is ST(0) and the result is stored in ST(0).
FPU | fyl2x | Extended-precision | 80 |
The FYL2X instruction calculates y log2x, where the source y is ST(1), the source x is ST(0), and the result is stored in ST(0). The operand x must be > 0.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
FYL2XPI |
|
|
|
|
|
|
|
|
|
|
The FYL2XP1 instruction calculates y log2(x+1), where the source y is ST(1), the source x is ST(0), and the result is stored in ST(0). The operand x must be within the range –(1– (√2)/2)) ... (1 – (√2)/2).
Do not expect the resulting values from different calculations to be identical. For example, 2.0 × 9.0 is about 18.0, and 180.0 ÷ 10.0 is about 18.0, but the two 18.0 values are not guaranteed to be identical.
2.0 x 9.0 ≈ 180.0 ÷ 10.0
Let us examine a range of values 10n and compare a displacement of ±0.001 versus ±0.0000001.
Table 8-9. Note the single-precision loss between the ±0.001 displacement as the number of digits goes up in the base number. As the base number gets larger, fewer decimal places of precision can be supported. The hexadecimal numbers in bold are where the precision was totally lost.
Base number | –0.001 | +0.0 | +0.001 |
|---|---|---|---|
1.0 | 0×3F7FBE77 | 0×3F800000 | 0×3F8020C5 |
10.0 | 0×411FFBE7 | 0×41200000 | 0×41200419 |
100.0 | 0×42C7FF7D | 0×42C80000 | 0×42C80083 |
1000.0 | 0×4479FFF0 | 0×447A0000 | 0×447A0010 |
10000.0 | 0×461C3FFF | 0×461C4000 | 0×461C4001 |
100000.0 | 0×47C35000 | 0×47C35000 | 0×47C35000 |
1000000.0 | 0×49742400 | 0×49742400 | 0×49742400 |
10000000.0 | 0×4B189680 | 0×4B189680 | 0×4B189680 |
100000000.0 | 0×4CBEBC20 | 0×4CBEBC20 | 0×4CBEBC20 |
Table 8-10. This is a similar single-precision table except the displacement is between ±0.0000001. Note the larger number of hexadecimal numbers in bold indicating a loss of precision.
Base number | –0.0000001 | +0.0 | +0.0000001 |
|---|---|---|---|
1.0 | 0×3F7FFFFE | 0×3F800000 | 0×3F800001 |
10.0 | 0×41200000 | 0×41200000 | 0×41200000 |
100.0 | 0×42C80000 | 0×42C80000 | 0×42C80000 |
1000.0 | 0×447A0000 | 0×447A0000 | 0×447A0000 |
10000.0 | 0×461C4000 | 0×461C4000 | 0×461C4000 |
100000.0 | 0×47C35000 | 0×47C35000 | 0×47C35000 |
1000000.0 | 0×49742400 | 0×49742400 | 0×49742400 |
10000000.0 | 0×4B189680 | 0×4B189680 | 0×4B189680 |
100000000.0 | 0×4CBEBC20 | 0×4CBEBC20 | 0×4CBEBC20 |
Okay, one more table for more clarity.
Table 8-11. Note that accuracy of the precision of the numbers diminishes as the number of digits increases.
Base number | +0.001 | +0.002 | +0.003 |
|---|---|---|---|
1.0 | 0×3F8020C5 | 0×3F804189 | 0×3F80624E |
10.0 | 0×41200419 | 0×41200831 | 0×41200C4A |
100.0 | 0×42C80083 | 0×42C80106 | 0×42C80189 |
1000.0 | 0×447A0010 | 0×447A0021 | 0×447A0031 |
10000.0 | 0×461C4001 | 0×461C4002 | 0×461C4003 |
100000.0 | 0×47C35000 | 0×47C35000 | 0×47C35000 |
1000000.0 | 0×49742400 | 0×49742400 | 0×49742400 |
What this means is that smaller numbers such as those that are normalized and have a numerical range from –1.0 to 1.0 allow for higher precision values, but those with larger values are inaccurate and thus not very precise. For example, the distance between 1.001 and 1.002, 1.002 and 1.003, etc. is about 0x20c4 (8,388). This means that about 8,387 numbers exist between those two samples. A number with a higher digit count such as 1000.001 or 1000.002 support about 0x11 (17), so only about 16 numbers exist between those two numbers. And a number around 1000000 identifies 1000000.001 and 1000000.002 as the same number. This makes for comparisons of floating-point numbers with nearly the same value very tricky. This is one of the reasons why floating-point numbers are not used for currency as they tend to lose pennies. Binary-coded decimal (BCD) and fixed-point (integer) are used instead.
So when working with normalized numbers {–1.0 ... 1.0}, a comparison algorithm with a precision slop factor (accuracy) of around 0.0000001 should be utilized. When working with estimated results, a much smaller value should be used. The following function returns a Boolean true : false value to indicate that the two values are close enough to be considered the same value. Normally you would not compare two floating-point values except to see if one is greater than the other for purposes of clipping. You almost never use a comparison of the same value as shown here. It is only used in this book for purposes of comparing the results of C code to assembly code to see if you are getting results from your algorithms in the range of what you expected.
Example 8-1. vmp_IsFEqual() — Compares two single-precision floating-point values and determines if they are equivalent based upon the precision factor or if one is less than or greater than the other.
bool vmp_IsFEqual(float fA, float fB, float fPrec)
{
// The same so very big similar numbers or very small
// accurate numbers.
if (fA == fB) return true;
// Try with a little precision slop!
return (((fA-fPrec)<=fB) && (fB<=(fA+fPrec)));
}Making the call for single-precision floating-point numbers is easy:
#define SINGLE_PRECISION 0.0000001f if (!vmp_IsFEqual(f, f2, SINGLE_PRECISION))
For a fast algorithm that uses estimation for division or square roots, then merely reduces the precision to something less accurate:
#define FAST_PRECISION 0.001f
This book will discuss these fast estimate algorithms in later chapters. For vector comparisons, this book uses the following code:
Example 8-2. Compare two {XYZ} vectors using a specified precision factor.
bool vmp_IsVEqual(const vmp3DVector * const pvA,
const vmp3DVector * const pvB, float fPrec)
{
ASSERT_PTR4(pvA); // See explanation of assert macros
ASSERT_PTR4(pvB); // later in this chapter!
if ( !vmp_IsFEqual(pvA->x, pvB->x, fPrec)
|| !vmp_IsFEqual(pvA->y, pvB->y, fPrec)
|| !vmp_IsFEqual(pvA->z, pvB->z, fPrec))
{
return false;
}
return true;
}When dealing with quad vectors (vmp3DQVector) an alternative function is called:
Example 8-3. Compare two {XYZW} vectors using a specified precision factor.
bool vmp_IsQVEqual(const vmp3DQVector *const pvA,
const vmp3DQVector *const pvB,
float fPrec)...and a fourth element {.w} is tested:
|| !vmp_IsFEqual(pvA->w, pvB->w, fPrec)
FPU | ftst | Extended-precision | 80 |
This instruction compares 0.0 with the value in FPU register ST(0) and sets the FPU code flags {C0, C2, and C3} with the results. (The state of the sign bit is ignored, allowing 0.0 = ±0.0.) If register ST(0) contains NaN an unordered condition is set.
A ? B | C3 (Zero) | C2 (Parity) | C1 (Oflow) | C0 (Carry) |
|---|---|---|---|---|
Flags: The condition flag C0 is cleared. | ||||
Unordered | 1 | 1 | 0 | 1 |
0.0 = ST(0) | 1 | 0 | 0 | 0 |
0.0 > ST(0) | 0 | 0 | 0 | 1 |
0.0 < ST(0) | 0 | 0 | 0 | 0 |
FPU | fcom | mSrc(32/64) | Extended-precision | 80 |
fcom | st(i) | |||
fcom | ||||
fcomp | mSrc(32/64) | |||
fcomp | st(i) | |||
fcomp | ||||
fcompp | ||||
This ordered instruction compares the value of ST(0) with ST(i) or 32/64-bit memory and sets the condition flags. If no source operand is specified, ST(1) is used as a default. This instruction has the same functionality as FUCOM, but exceptions occur for operands with NaN. QNaN or SNaN values both set an unordered condition but generate an exception. The FCOMP instruction pops ST(0) off the stack, while FCOMPP pops ST(0) and ST(1) off the stack. (The state of the sign bit is ignored if zero, allowing 0.0 = ±0.0.)
A? B | C3 (Zero) | C2 (Parity) | C1 (Oflow) | C0 (Carry) |
|---|---|---|---|---|
Flags: The condition flag C1 remains unchanged. | ||||
Unordered | 1 | 1 | – | 1 |
0.0 = ST(0) | 1 | 0 | – | 0 |
0.0 > ST(0) | 0 | 0 | – | 1 |
0.0 < ST(0) | 0 | 0 | – | 0 |
FPU | fucom | st(i) | Extended-precision | 80 | |
fucom | |||||
fucomp | st(i) | ||||
fucomp | |||||
fucompp | |||||
This unordered instruction compares the value of ST(0) with ST(i) and sets the condition flags. If no source operand is specified, ST(1) is used as a default. This instruction has the same functionality as FCOM, but exceptions only occur for operands with SNaN. A QNaN or SNaN sets the condition to unordered but the QNaN value is valid in comparisons. The FUCOMP instruction pops ST(0) off the stack, while FUCOMPP pops ST(0) and ST(1) off the stack. (The state of the sign bit is ignored if zero, allowing 0.0 = ±0.0.)
A ? B | C3 (Zero) | C2 (Parity) | C1 (Oflow) | C0 (Carry) |
|---|---|---|---|---|
Flags: The condition flag C1 remains unchanged. | ||||
Unordered | 1 | 1 | – | 1 |
0.0 = ST(0) | 1 | 0 | – | 0 |
0.0 > ST(0) | 0 | 0 | – | 1 |
0.0 < ST(0) | 0 | 0 | – | 0 |
FPU | fcomi | st, st(i) | Extended-precision | |
fcomip | st, st(i) | |||
fucomi | st, st(i) | |||
fucomip | st, st(i) |
The FCOMI and FCOMIP instructions have identical functionality to the FCOM and FCOMP instructions, except that the EFLAGS are set instead of the FPU conditional flags.
The FUCOMI and FUCOMIP instructions have identical functionality to the FUCOM and FUCOMP instructions, except that the EFLAGS are set instead of the FPU conditional flags.
Flags: The flags are set as a result of the addition operation. | ||||||
|---|---|---|---|---|---|---|
Flags | O.flow | Sign | Zero | Aux | Parity | Carry |
0 | - | × | - | × | × | |
This unordered instruction loads the 16/32-bit integer from memory, converts it to double extended-precision floating-point, compares it to the value in the ST(0) register and sets the condition flags. A QNaN or SNaN value sets the condition to unordered, but the QNaN value is valid in comparisons and a SNaN generates an exception. The FICOMP instruction pops ST(0) off the stack. (The state of the sign bit is ignored if zero, allowing 0.0 = ±0.0.)
A ? B | C3 (Zero) | C2 (Parity) | C1 (Oflow) | C0 (Carry) |
|---|---|---|---|---|
Flags: The condition flag C1 remains unchanged. | ||||
Unordered | 1 | 1 | – | 1 |
0.0 = ST(0) | 1 | 0 | – | 0 |
0.0 > ST(0) | 0 | 0 | – | 1 |
0.0 < ST(0) | 0 | 0 | – | 0 |
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
FCMOVx |
|
|
|
|
|
|
|
|
|
|
FPU | fcmovb | st(0), st(i) | Extended-precision | 80 |
" | fcmove | st(0), st(i) | " | " |
" | fcmovbe | st(0), st(i) | " | " |
" | fcmovu | st(0), st(i) | " | " |
" | fcmovnb | st(0), st(i) | " | " |
" | fcmovne | st(0), st(i) | " | " |
" | fcmovnbe | st(0), st(i) | " | " |
" | fcmovnu | st(0), st(i) | " | " |
The EFLAGS are examined and the FPU moves the value from ST(i) to ST(0) if the condition is met.
Left and right columns are complemented instructions. If conditional set...
FCMOVNBE | If above. ZF=0, CF=0 op1 > op2 |
FCMOVNB | If above or equal. CF=0 op1 ≥ op2 |
FCMOVE | Set if equal. ZF=1 op1 = op2 |
FCMOVU | If parity. PF=1 If parity even. |
FCMOVBE | If Below or Equal. ZF=1, CF=1 op1 ≤ op2 |
FCMOVB | If below. CF=1 op1 < op2 |
FCMOVNE | Set if not equal. ZF=0 op1 ≠ op2 |
FCMOVNU | If not parity. PF=0 If parity odd. |
A ? B | C3 (Zero) | C2 (Parity) | C1 (Oflow) | C0 (Carry) |
|---|---|---|---|---|
Flags: The condition flags C0, C2, and C3 remain unchanged. C0 is cleared if stack underflow occurred. | ||||
Unordered | – | – | 0 | – |
One other feature of the FPU that can be taken advantage of is the BCD capability. BCD can be loaded, calculations performed, and data written back out. It allows for 18 4-bit BCD digits plus a sign bit within a number to be processed simultaneously. Due to precision loss, a number represented by BCD and utilizing BCD math is the safest method of representing monetary values (money) without losing pennies. This will be discussed in Chapter 15, "Binary-Coded Decimal."

Figure 8-4. Ten-byte BCD data storage. The MSB in the far left byte (byte #9) is the sign bit and the rightmost eight bytes (#8...0) contain the BCD value pairs. The 18th BCD digit resides in the upper nibble of byte #8 and the first BCD digit resides in the lower nibble of byte #0.
FPU | fbld | source | BCD | 80 |
The binary-coded decimal (BCD) load instruction loads the 80-bit value in memory, expands it to an 80-bit double extended-precision floating-point form, and pushes it on the stack, thereby making it addressable by the FPU as register ST(0).
TBYTE bcd
REAL8 f
fbld tbyte ptr bcd ; Load (10 byte) BCD
fstp f ; Write 64-bit double-precisionFor more detail see Chapter 15.
FPU | fbstp | destination | BCD | 80 |
The binary-coded decimal (BCD) save instruction reads the 80-bit value in register ST(0) and pops it off the stack, then saves to memory.
For more detail see Chapter 15.
FPU | fptan | Extended-precision | 80 |
The partial tangent of the source radians in ST(0) is calculated, then stored in ST(0).
FPU | fpatan | Extended-precision | 80 |
The value of the divisor ST(0) is divided into the quotient ST(1), and the resulting value is stored into the unwound stack into ST(0).



The standard C math library contains these functions:
float cos(float x); | double cos(double x); |
float sin(float x); | double sin(double x); |
You should already be familiar with the fact that the angle is not passed into those functions in degrees but instead in radians. If you recall, π (PI) is equivalent to 180° and 2π to 360°. By using the following macro, an angle in degrees can be converted to radians:
#define PI 3.141592f #define DEG2RAD(x) ((x) * (PI/180.0F))
...and used in the calculations. It can then be converted from radians back to degrees:
#define RAD2DEG(x) ((x) * (180.0f/PI))
...if needed for printing or other purposes.
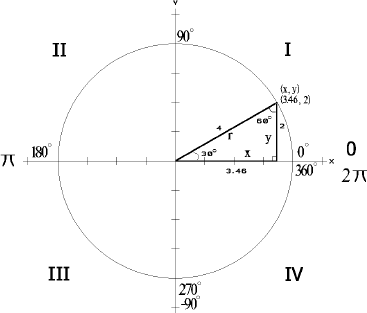
For a simple 2D rotation the use is merely:
x = cos(fRadian); y = sin(fRadian);
There is one thing that has always bothered me about these two functions: When a cosine is needed, a sine is typically needed as well, and that one is in reality 90 degrees out of phase of the other, which means that they share similar algorithms. As the following equation shows, subtracting an angle from 90 degrees results in the alternate angle. So, for example, a sin(30°) is equal to the cos(60°). As the angles of a triangle always add up to 180 degrees, that would mean that the two angles are really not that far from each other, and mathematical operations to find one of the angles can be slightly adapted to find the other angle without having to do twice the work.
But I find something really interesting. In Intel's wisdom they not only support the sine and cosine on their FPU (floating-point unit) but they also support the combination sine-cosine, which returns both results. What I find amazing is that very few programmers actually take advantage of it! In addition, I am upon occasion called in to review other programmer's code and I quite consistently have to recommend calling the sine and cosine functions only once in their matrix algorithms.
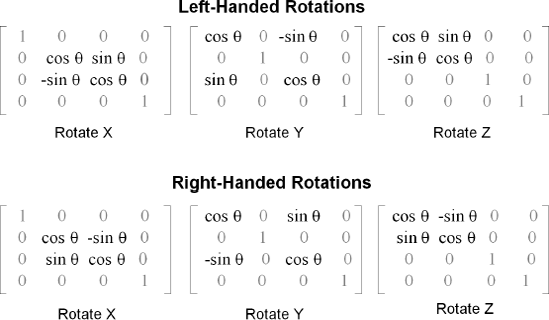
A 3D rotational matrix for an axis will use two identical cosines, a sine, and a negative sine, but why do I keep seeing these functions each called twice? I see code such as follows for a left-handed rotate X:
Mx[1][2] = sin(fRadian); Mx[2][2] = cos(fRadian); Mx[1][1] = cos(fRadian); Mx[2][1] = -sin(fRadian);
...or the just slightly better:
Mx[1][2] = sin(fRadian); Mx[2][2] = Mx[1][1] = cos(fRadian); Mx[2][1] = -sin(fRadian);
...and then you wonder why your code runs so slow! Instead, your code should be more like:
Mx[1][2] = sin(fRadian); Mx[2][2] = Mx[1][1] = cos(fRadian); Mx[2][1] = -Mx[1][2]; //-sin
...or better yet, if you are using an x86 processor use its combination sine/cosine instruction! When I work on legacy projects involving trigonometry I quite often find that I need to drop the following code snippet into the application:
sincos(&fSin, &fCos, fRadian); Mx[1][2] = fSin; Mx[2][2] = Mx[1][1] = fCos; Mx[2][1] = -fSin;
The reason will soon become evident!
Similar to the other functions in this book, the sine and cosine functions have been wrapped for extra portability and for alternate specialty function replacements. One for single-precision floating-point and another for double-precision floating-point:
Early Microsoft math libraries did not include this functionality, which is understandable as the C programming language was born in the land of UNIX and was brought forth to the x86 DOS world by other companies and eventually by Microsoft. I believe the absence of a library function for a combination sine-cosine was merely an oversight. It has recently been introduced in third-party libraries and in different forms.
void _sincos(float, float *); void a_sincos(void); // mm0 -> mm0 (cos|sin) __m64 _m_sincos(__m64); // mm0 -> mm0 (cos|sin)
inline void SinCos(float angle, float *sine, float *cosine)
I did a wildcard search on my computer for header files within various SDKs and this is all that turned up with all the compilers I work with. Apparently, most programmers up until now either did not understand the issue or did not have the ability to write FPU code! Let's fix that right now.
First, stub your cross-platform C function for sincos(). No matter the platform, you should always use something similar.
We will soon build an equivalent function using the FPU found in every 80×86 processor since the 80486, and available as an optional coprocessor before that.
FPU | fsin | Extended-precision | 80 |
The sine of the source radians in ST(0) is calculated and the result is stored in ST(0). See the table for the FSINCOS instruction for source versus destination details.
float sinf(float rad);
double sin(double rad);FPU | fcos | Extended-precision | 80 |
The cosine of the source radians in ST(0), is calculated and the result is stored in ST(0). See the table for the FSINCOS instruction for source versus destination details.
float cosf(float rad);
double cos(double rad);Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
FSINCOS |
|
|
|
|
|
|
|
|
|
|
FPU | fsincos | Extended-precision | 80 |
The FSINCOS instruction calculates the sine and cosine simultaneously for a single-precision floating-point radian in ST(0) and stores the result in ST(0). It's slower than calling just sine or cosine, but faster than calling them both consecutively.
Note
The value used for radians must be a proper floating-point normalized value between [–π, π]. If valid but out of range, a precision loss will occur.
Radians (Src) | Destination | |
|---|---|---|
ST(0) | ST(1) Cos | ST(0) Sin |
NaN | NaN | NaN |
+∞ | <Invalid> | <Invalid> |
+Finite | [–1, 1] [–π, π] | [–1, 1] [–π, π] |
+0 | +1 | +0 |
– 0 | +1 | – 0 |
– Finite | [–1, 1] [–π, π] | [–1, 1] [–π, π] |
– ∞ | <Invalid> | <Invalid> |
If the source radians are outside the allowed range of [–263, 263], the value can be reduced within range by N mod (2π).
Example 8-5. ...chap8vtrig3dVTrig3DX86.asm
void sincosf(float *pfSin, float *pfCos, float r)
{
#if 01
__asm {
fld r ; Load radians from memory
fwait ; Wait for FPU to be idle
fsincos ; ST(0)=cos ST(1)=sin
mov eax,pfSin
mov ecx,pfCos
fwait ; Wait for FPU to be idle
fstp [ecx] ; ST(0)=cos ST(1)=sin
fstp [eax] ; sin
};
#else
*pfSin = sinf(r);
*pfCos = cosf(r);
#endif
}AMD has a really nice solution for their 3DNow! functionality. It resolves the sine and cosine simultaneously using the MMX register set. Their algorithm is actually pretty cool, as what they do is ratio π (3.14159) to a value of 4. The value of {–3.14159 ... 3.14159} is effectively scaled to a value of {–4.0 ... 4.0}, which in essence makes π radians a base 2 number and thus integer math is used in conjunction with parallel floating-point math and MMX registers. Signs are tracked to encode the quadrant of the circle in which the angle resides. Since a circle is actually made up of eight quadrants (investigate the Bresenham DDA algorithm for circle plotting), then only the modulus 45° angle needs to be resolved. Using this methodology, several cos/sin functions could be processed simultaneously.

The code can be downloaded from the AMD web site (www.amd.com) and is contained within their Software Development Kit (SDK) – AMD Library Reference.
Cut and paste it into your own code. If using Direct3D, it is automatically called if you are using a processor supporting the 3DNow! instruction set; there is also an SSE version. It is a lot more efficient than having to do an FPU/MMX switch, especially as sine and cosine are processed simultaneously in parallel.
I am not telling you to reverse-engineer the DirectX library, as that would be wrong and illegal, but by setting a break point on the DirectX library function call and upon getting the break, set your view to assembly code and step into the code. You can cut and paste a copy of that code to a text editor, allowing you to edit and analyze how it works. Remember, there is more than one algorithm residing in the library as well.
The following are FPU instructions used for system administration purposes. A typical application will not need to use these. These have been left here instead of moving them to Chapter 18, "System," just to keep the FPU documentation grouped together.
FPU | finit |
fninit |
The FINIT instruction checks for pending unmasked floating-point exceptions, then initializes the FPU.
The FNINIT instruction initializes the FPU without any pending checks.
FPU | fclex |
fnclex |
The FCLEX instruction checks for pending unmasked floating-point exceptions, then clears the exception flags.
The FNCLEX instruction clears the exception flags without any pending checks.
C3 (Zero) | C2 (Parity) | C1 (Oflow) | C0 (Carry) | |
|---|---|---|---|---|
Flags: The condition of flags {C0, C1, C2, C3} remain unchanged; however, the other FPU flags (PE, UE, OE, ZE, DE, IE, ES, SF, and B) are cleared. | ||||
– | – | – | – | |
FPU | ffree | st(i) |
This instruction sets the tag associated with ST(i) to an empty state.
FPU | fsave | mSrc(94/108) |
fnsave | mSrc(94/108) |
The FSAVE instruction checks for pending unmasked floating-point exceptions, saves the FPU state to 94/108-byte memory, and then reinitializes the FPU.
The FNSAVE instruction saves the FPU state to 94/108-byte memory, and then reinitializes the FPU.
The assembler typically inserts the FWAIT instruction before this instruction to ensure the FPU is ready (no instruction in process) to save.
(16-bit) Real Mode saves 94 bytes, and (32-bit) Protected Mode saves 108 bytes. The complement of this instruction is FRSTOR.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
FRSTOR |
|
|
|
|
|
|
|
|
|
|
FPU | frstor | mSrc(94/108) |
This instruction loads the FPU state from 94/108-byte memory that was saved with the instruction FSAVE or FNSAVE.
FPU | fxsave | mSrc(512) |
This instruction saves the registers {FPU, MMX, XMM, and MXCSR} to a 512-byte memory block. The complement of this instruction is FXRSTOR.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
FXRSTOR |
|
|
|
|
|
FPU | fxrstor | mSrc(512) |
This instruction loads registers from 512-byte memory saved with the FXSAVE instruction.
FPU | fstenv | mSrc(14/28) |
fnstenv | mSrc(14/28) |
The FSTENV instruction checks for pending unmasked floating-point exceptions, then masks all exceptions and saves the FPU environment to 14/28-byte memory.
The FNSTENV instruction save the FPU environment to 14/28-byte memory, then masks all floating-point exceptions.
The assembler typically inserts the FWAIT instruction before this instruction to ensure the FPU is ready (no instruction in process) to save.
The data saved is the FPU control word, status word, tag word, instruction pointer, data pointer, and last opcode. (16-bit) Real Mode saves 14 bytes, and (32-bit) Protected Mode saves 28 bytes. The complement of this instruction is FLDENV.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
FLDENV |
|
|
|
|
|
|
|
|
|
|
FPU | fldenv | mSrc(14/28) |
This instruction loads the environment from 14/28-byte memory that was saved with the instruction FSTENV or FNSTENV.
FPU | fstcw | mSrc(2) |
fnstcw | mSrc(2) |
The FSTCW instruction checks for pending unmasked floating-point exceptions, then saves the 16-bit FPU control word to memory.
The FNSTCW instruction saves the 16-bit FPU control word to memory.
The assembler typically inserts the FWAIT instruction before this instruction to ensure the FPU is ready (no instruction in process) to save.
Mnemonic | P | PII | K6 | 3D! | 3Mx+ | SSE | SSE2 | A64 | SSE3 | E64T |
|---|---|---|---|---|---|---|---|---|---|---|
FLDCW |
|
|
|
|
|
|
|
|
|
|
FPU | fldcw | mSrc(2) |
This instruction loads the 16-bit FPU control word from memory that was saved with the instruction FSTCW or FNSTCW.
FPU | fstsw | mSrc(2) |
fstsw | AX | |
fnstsw | mSrc(2) | |
fnstsw | AX |
The FPU has condition code bits contained within the status register. These bits match 1:1 with the EFLAGS of the CPU. They can be copied to memory or the AX register using this instruction. They can then be copied to the EFLAGS register using the SAHF instruction.
fstsw ax ; Copy FPU condition bits to AX register.
sahf ; Copy AH to EFLAGS.When a floating-point value becomes invalid due to overflows, etc., the easiest way to make it valid is stretch the value into a larger floating-point form, which becomes valid, and then store it back out as a valid form. Confusing?
The following is a code snippet that detects single-precision floating-point overflows. In this case, the value is radians.
OFLOW_FIXUP fRads ; Overflow fixup
Example 8-6. incx86vmp3DX86M.inc
OFLOW_FIXUP MACRO arg1
mov eax,DWORD PTR arg1 ; 03F800000h = 1.0f 0BF800000h=-1.0
and eax,07F800000h
cmp eax,07F800000h ;Check for an non-zero exponent!
jne $ok mov eax,DWORD PTR arg1
call FixupReal4
$ok: ; ST(0)= value
endmTo fix the overflow of a single-precision floating-point value, it can be expanded to double extended-precision floating-point or double-precision floating-point, such as in the following code snippet.
Example 8-7. FixupReal4
; Fixup Real4 (float)
; eax=bad float
; NOTE: ST(0) already contains the float!!!
FixupReal4 proc near
fstp qword ptr [esp-8-10] ; Save Real8 (double) & pop ST(0)
; Build a Real10
mov eax,[esp-8-10+4] ; Hi
or eax,7FFF0000h ; Set Real8 (Double)
mov dword ptr [esp-10+6],eax ; 7FFFXXXX????????????
mov eax,[esp-8-10+4] ; Real8 Hi
mov ecx,[esp-8-10+0] ; Real8 Lo
shld eax,ecx,11
shl ecx,11
mov dword ptr [esp-10+4],eax ; 7FFFHHHHHHHH????????
mov dword ptr [esp-10+0],ecx ; FFFHHHHHHHHLLLLLLLL
fld tbyte ptr [esp-10+0] ; Load Real10
ret ; ST(0)=value
FixupReal4 endpWrite a sincos function in assembly language similar to sincosf but using double-precision floating-point.
Write a floating-point equation A+B×C+D using RPN. Write it using FPU instructions.
Write a factorial program to solve for !15 using FPU instructions and taking advantage of the stack.
How much accuracy does the vmp_IsFEqual() function allow with a single-precision definition? Fast precision?
Does vmp_IsFEqual() accept a negative value for the third argument? Should there be an assertion? Why or why not?
In this chapter, vmp_IsVEqual() uses an ASSERT_PTR4(). What assertion would be used instead to force a 16-byte alignment?
Write C functions to support double-precision for:
vmp_IsDEqual() scalar double-precision
vmp_IsDVEqual() vector double-precision
vmp_IsDQVEqual() quad vector double-precision