
CHAPTER 6
Design Science on Trillions Mountain
We are as gods, we might as well get good at it.
—WHOLE EARTH CATALOG
If we are going to play god by creating an ecology of trillions of information devices, the first requirement is not hubris, but humility. Ecosystems are big complex things, and the ones we’re familiar with have had millions of years in which to achieve the refinement that we see today. It is vitally important that we take our first steps into pervasive computing carefully and correctly because the processes we set in motion now will have huge implications later. The stakes are high. If pervasive computing arrives without adequate principles in place to guide it, it will quickly result in incoherent, unmanageable, malignant complexity, which is another way of saying “not much will actually happen that is good and some very bad things may happen as well.” Among other important things, the viability of vast new markets is at stake. If, on the other hand, its development is guided by principled design science, technology and information will coalesce into a coherent, evolutionary, organic whole—a working information model of and for the world.
The foundations of this design science are largely in place. They come from a merging of the study of ecological patterns in Nature; from the long and evolved practices of the design professions; from the traditional sciences; and from a commitment to the search for underlying Architecture to provide structure. Yet the evolution of the discipline is not complete.
BEYOND DESIGN THINKING TO DESIGN SCIENCE
Design thinking is an au courant term used by business schools and corporations as some sort of Next Big Thing. Like most Next Big Things, it will most likely become an old obvious thing as soon as the next Next Big Thing comes along. In its present form, the methods and practices of design thinking are a far cry from those of the rigorous and well-defined methodologies of lean manufacturing and process engineering to which it is sometimes compared. It is more like a good marketing campaign to raise awareness of what designers have been working toward for some time, with the added insight that design shouldn’t just be left to professional designers.
Facing the levels of complexity and dynamism toward which we are headed, intuitive, seat-of-the-pants approaches to design will no longer do. A genuine design science—along the lines of what Buckminster Fuller had in mind—will need to be put into practice. Fuller called his approach Comprehensive Anticipatory Design Science. And in typical Fuller form, each word is important:
The natural sciences—physics, biology, chemistry, and astronomy—deal with what is. Design science deals with what might be. Its domain is human artifice in all its forms, the artificial world rather than the natural world.
This kind of science involves a systematic process of inquiry and exposition about all things made by human hands, a process that embraces the full range of human modes of thought—rational, intuitive, emotional, methodical—just as in the natural sciences. It implies the belief that there are objective design principles out there waiting to be discovered—analogous to the laws of physics. For some people, the term design science may evoke the image of a process in which the cultural, humanistic, and aesthetic components are stripped out until there is nothing left but sterile mechanism, devoid of human life and passion. Such thinking is wrong for two reasons. First, measuring something does not kill it. In coming to understand the structure and function of plants, the botanist need not lose sight of the beauty of flowers or the wonder of their relationships with the rest of the living world. Quite the opposite—the deeper the understanding, the greater the wonder. Similarly, our ability to precisely describe the process of creating artifacts is a token of our deepening understanding and appreciation of those processes. Second, in every science our knowledge is imperfect and limited. This is true even in the most mature of physical sciences. It is most certainly true in design science. As we apply science to the process of building, we inevitably reach the limits of what we know to be correct—often sooner than we would hope. At this point, the intuitions of the experienced practitioner, the passions of the artist, and the simple joy of creative desire find ample room to play their part. Human needs and desires defy simple classification, and no matter how rationalized it is, design is always for and about people.
Design science rejects a purely relativist view of traditional design thinking. In design science we avoid notions such as “liking” a design for personal or superficially stylistic reasons. There will always be a variety of good designs—some better than others; bounded rationality and the sheer diversity of problem situations suffice to ensure that. But there are also wrong designs. It’s not just a matter of preference. Nor is it to claim that only mechanical experiments or design methods are valid ways of arriving at the right design. Intuitive methods have a place in all areas of science. But it is to say that, given a proper statement of goals and a sufficiently broad and careful consideration of the entire situation—technical, human, and market—it is possible to establish principled, professional, systematic techniques that rationally select some designs over others.
Not all design choices are objective—even in principle. One should consider the design process as one of using up degrees of freedom. At every stage of the process, one makes choices that embrace certain options and close off others. When one decides to commit to a new project for building, say, a refrigerator, one closes off the option of having the project be about washing machines. Deciding that the refrigerator will be propane powered ensures that it will be suitable for certain markets (say, recreational vehicles) but not others, and so on. Each such decision reduces one’s options. A design scientist will seek, at each step of the way to provide principled, scientific answers to these questions whenever possible. However, rarely if ever will scientific methods alone fill in all the details of the territory. There are almost always degrees of freedom remaining after all objective criteria have been satisfied. There is room to spend these final degrees of freedom on the pursuit of novelty, pure aesthetics, and other aspects of the design team’s artistic and creative impulses. Science and rationality should always come first, but they rarely have the last word.
MAKE THE RIGHT THING
The Crystal Palace exhibition of 1851 exposed the human weakness for celebrating what can be done with technology, with little thought about what should be done. We need to remind ourselves that even though we may have some prowess in making things right, we need to put equal emphasis on making the right things.
What goals, processes, and guidelines will lead us to the right things—made right? At this point in the book, readers may already have formed some answers of their own. If we’ve been convincing, those answers will have drawn on the history of designing, the pervasive effects of technological revolutions, the inevitable and exponential proliferation of digital devices, and personal experience with information products, for better and for worse. We’ve argued that whether the reader’s self-definition is as a “scientist” or not, there is reason to believe that scientific thinking, as embodied in the concept of design science, is a viable way to manage complex problems and generate solutions—products, environments, messages, systems—that are conducive to a good society in a deeply technological era.
A thorough and detailed description of how to design on Trillions Mountain is beyond the scope of any one book. Indeed, some of the design problems are yet to be discovered. We can, however, describe some qualities of design in a connected world. These descriptions emphasize process over product, and the evolution of process over the repetition of process. Through consideration of the process, qualities of the practice can be discerned. Design on Trillions Mountain will incorporate:
- Deeply interdisciplinary methods
- Focusing on humans
- Interaction physics
- Information-centric interaction design
- Computation in Context
Deeply Interdisciplinary Methods
We have already discussed the necessity of building bridges between disciplines in order to solve complex problems that reach simultaneously into the social, technological, physiological, and ethical dimensions of human life.
We have also acknowledged the inherent difficulty of interdisciplinary practice—the way it misaligns with the specialization and the narrow focus of traditional professional training. Indeed, this misalignment is one that contrasts design science with respect to traditional science.
Interdisciplinary practice on Trillions Mountain will have to be deeply interdisciplinary. It will not be enough to occasionally bring separate specialists together for an interdisciplinary interlude. Depth isn’t achieved by sprinkling on interdisciplinary fairy dust. It requires a thorough transformation of professional practice. And it will continue to require this transformation until our education systems find a way to integrate the generalized with the specialized in the core curriculum.
We will see a broad spectrum of professionals working together—not three varieties of engineers, or just 2-D and 3-D designers. We are already seeing this trend in companies that propel innovation. Their staffs include, yes, different flavors of designers and engineers, but also psychologists, anthropologists, sociologists, and game developers. And we should expect to see historians, biologists, economists, filmmakers, and more. It might be better to imagine a professional environment that maintains contact with not only narrow disciplinary organizations, but also mash-up organizations dedicated to cross-linking.
Jeff Senn is the Chief Technology Officer of MAYA Design.
Focusing on Humans
If we are going to design for Trillions in a way that is human-literate, rather than forcing people to become ever more computer-literate, we need to keep the human at the center of the process. We need a vision of how we will come to understand not just people and their needs and desires, but also how they will be affected by the myriad devices that will become intimate parts of their everyday lives. While laboratory user studies are standard practice in the current paradigm, Trillions will force us out of the laboratory and into the field. As the information itself takes center stage and the devices that mediate the information recede into the woodwork (sometimes literally), the user experience ceases to be a direct consequence of the design of individual devices. Instead, it becomes an emergent property—a complex interaction that is difficult to measure and even more difficult to design. Studying one product in isolation, unconnected from its “social life,” will no longer suffice.
To add to the challenge, the range of potential products that have become technically feasible is becoming nearly boundless. Instead of being limited by the properties of materials and the realities of manufacturing, we increasingly find ourselves in a position in which we have the technical means to produce pretty much anything we can imagine. And, in the words of Han Solo, we can imagine a lot. Sizing up the market to decide where to invest one’s efforts and capital has always been a core challenge of business, even when the range of possibilities was severely bounded. Now that so many of the bounds have been lifted, the challenge is that much greater. Remember the stuff in the Crystal Palace?
Both of these new challenges—designing for an emergent user experience, and identifying promising opportunities in an increasingly unbounded and unstructured space of possibilities—are challenges that are not likely to be successfully met by seat-of-the-pants methods. Fortunately, the range of systematic methodologies available to design professionals has kept pace with the need.
The word systematic in the previous sentence may raise red flags with readers from a certain background. In many industries, there is a regrettable tradition of treating usability and market research issues as simple matters of process engineering, in the same category as ISO-9000 certification or stage-gate model management techniques. Treated in this way, usability issues tend to be viewed by engineering and marketing teams not as the essential processes that they are, but as just so many bureaucratic obstacles to be avoided on the way to the market. Worse, the mechanical application of cookbook processes to this class of problem (often in the form of so-called “voice of the customer” methodologies) tends to lead to what amounts to games of Twenty Questions between engineers and users. Such techniques may have had some efficacy in a simpler age, but given the complexities we now face, executing such methods effectively is generally prohibitively time consuming and expensive.
Not surprisingly, the free-thinking, agile world of the tech industries has not in general succumbed to this particular trap. Unfortunately, they have often erred in the opposite direction. The mantra in Silicon Valley has long been ship early, ship often. Agile manufacturing techniques, “extreme programming” methodologies, instant customer feedback via social networks, and free design advice from an army of bloggers conspire to make the temptation to use paying customers as beta testers nearly irresistible. This can be good, and it can be bad. If “ship early, ship often” is interpreted as the willingness to expose not-quite-feature-complete but well-tested products to the healthy pressures of real users, everybody wins. But if it is used as an excuse for shipping half-baked, flaky products; using your customers as unpaid quality-assurance staff—and counting on ever-lowering expectations of quality in a slipshod marketplace numbed by crashing TVs and bug-filled software—it is another matter entirely.
Even more dubious is the expectation that such run-it-up-the-flagpole techniques will lead to true innovation. We have already spoken about the conservative nature of the wisdom of crowds. For all its efficiencies, market forces always produce local hill climbing. They will very effectively determine the relative merits of BlackBerry versus Palm smartphones. But they will never lead us to the iPhone.
Figure 6.1 Shifting complexity: the International 420 and the Transition Rig

David Bishop is a MAYA Fellow, Senior Practitioner, and Researcher at MAYA.
It is tempting to conclude that only someone like Steve Jobs will lead us to the iPhone, and there is no doubt that hiring this person is the most efficient path to that kind of innovation. Unfortunately, such people are a bit hard to find. The suite of participatory user-centered techniques that the design community has evolved in recent years is motivated precisely by the need to fill this gap.
All of science is based on cycles of HYPOTHESIS >> MODEL >> TEST >> NEW HYPOTHESIS, and design science is no exception. In designing on Trillions Mountain, the TEST part isn’t the only place where user-focused work need apply. Instead, it must begin at the beginning of a design cycle and be carried through to the end, often bridging to the next, follow-on cycle.
During the HYPOTHESIS stage the designer has available a number of open-ended user-centered design techniques, going under such labels as participatory design, cooperative design, and co-creation.2 These methods are the methodological descendants of techniques such as brainstorming and synectics that were developed throughout the 1950s and 1960s under the broad label of design methods. The difference is that these contemporary techniques place a far greater emphasis on active participation by end users out in the field.
During the early iterations of the process, user engagement may involve just a few tries on a really informal task—“here, put these things into separate piles; you decide how many piles”—to check out some first guesses about how a user will perceive her options. Later, during more formal activities, there may be more detailed video data gathering, with a larger sample, to settle disagreements that have arisen among the design team. Later still may come preference interviews regarding the more superficial aspects of the design, where preference is the issue.
When performed in this continual integrated way, something interesting happens to user research efforts. They lead to creative divergence as well as convergence. The traditional view of user studies is that they are a tool for convergence: to focus in on the one right answer to questions like “exactly how far apart should those screen buttons be?” But now they have become, especially at the early stages of a project, tools for divergence, a way to reveal the questions that we didn’t even know we should ask; a way to reveal unmet or unvoiced needs.
The data so obtained are then passed through the MODEL stage of the process. This is a process of summarization, generalization, and abstraction from raw observation. Once again, the nature of the work product varies by iteration. The outcomes of the early stages may be captured in a form no more sophisticated than digital snapshots of whiteboard sketches, or stapled-together piles of sticky notes. Later on, we will see sketches evolve to foam models or interactive mock-ups of screen interactions. In all cases, care is taken that divergent paths be preserved so that the structure of the “space of possibilities” is not lost. The reason for this is that the goal is not to converge on a single product. Rather, it is to evolve an architecture that defines an entire family of potential products. We will have more to say on this topic presently.
Interaction Physics
Material objects follow the laws of physics. Always. If an item loses its support, the item falls. If two items rub together, they get hot. If the lights go out, the items disappear from view. The chains of cause and effect, action and reaction, work so consistently that we can act with precision and confidence. We have a pretty good idea how physical stuff will behave. We and our ancestors have been accumulating intuitions about such things for millions of years.
When it comes to design in cyberspace things are different. The rules are not forced upon us. We have choices to make. In the case of a simulation, the task may be obvious—make the virtual thing behave just like a real thing would. We just copy the laws of nature. But design is not all simulation. We now have the opportunity to design things that were not possible before the information era. What happens to a number when you let go of it? When an idea becomes important, does it look any different? How does color overtake and inhabit space? In a virtual world, what happens to Wile E. Coyote when he runs off a cliff?
So we have to invent the physics, and it’s not a task to be taken lightly. For starters, it isn’t easy. An interaction physics is not the same things as the more familiar notion of user interface guidelines. The difference is this: Guidelines are suggestions, to be used when they seem appropriate and to be eschewed when they are inconvenient. That is not how a physics works. Physical laws admit no exceptions. Gravity may not always be convenient, but you can count on it. So, if we are going to devise an interaction physics, we need to be prepared to commit to living with every rule we make under every single circumstance. Moreover, just as in physical law, no rule must ever contradict any other rule. Anyone who has ever attempted this realizes that you can’t make very many such rules without violating one or the other of these strictures. One quickly runs out of degrees of freedom. The bottom line is that finding a set of rules that qualify as an interaction physics and is also useful is no easy task. And so, it is rarely even attempted.
As a result, we have come to a point in the computer industry in which users have come to expect very little consistency in their interactions with devices. Everybody knows the drill: You download a new app, or you press MENU on yet another new remote control in your living room, and you immediately go into puzzle-solving mode—sorting through the dozen or so familiar patterns that the designer might have chosen—trying to get into her head so as to get some traction on the guessing game to follow. Worse, if it is not a device that you use every day, you will probably end up playing the game over and over—there are just too many permutations to remember them all. It is credit to human cleverness that we get by at all.
But it doesn’t have to be this way, and in the world of Trillions, it can’t be this way. Our collective goal must be convergence toward a unified user experience. A common interaction physics is the golden path to this goal. Consistency builds confidence, and confidence provides feelings of control, security, and comfort. A consistent physics provides the trust that “this thing I put down today will still be there tomorrow.” Such trust is the foundation for our ability to build new things. You wouldn’t put a book under your child to boost him up in his chair if you thought the book might suddenly slide through the seat and fall through the floor. You wouldn’t attempt to build a hut, or a bridge, or a city if you couldn’t trust in a few basic rules like gravity, and inertia, and friction. Our ability to build civilization itself would be called into question if everything were as plastic as most software products.
The opposite of physics is magic. Before we had the scientific method, some wise shaman believed that if he slaughtered a goat, it would bring rain—not because he was a fool, but because a few times the rains did really come just after a goat had been slaughtered. The correct name for such behavior is superstition, and superstitious behavior is extremely common in users of complex software. You ask people why they saved that word processing document, quit the program, and then reopened the same document. They say things like “I don’t know, but for some reason I’ve found that I have to do that whenever I create new sections that have different formats.” Other users believe that the same task requires that they use three or four consecutive drop down menu choices in a fast succession of moves that seem more like an incantation than a rational interaction. It’s a vulnerability common to many life forms; research psychologists have induced superstitious behavior even in pigeons.
When users engage with a system, they naturally try to form mental models of how it operates. These models evolve with experience as each user plays a kind of guessing game with the system—trying to learn the rules of the game. The quality of the model at any given time is a major determinant of how well the user will get on with it. The existence of a physics (natural or artificial) provides a solid foundation for these models. But in the absence of a physics, there is often no self-consistent underlying model to be learned. Every tentative hypothesis by the user is eventually contradicted by some new behavior. Rather than systematically piecing together an increasingly accurate and detailed mental model of the system, the user thrashes from one crude model to another—each accounting for the most recent observations, but having very little of the predictive value that supports true fluency with the system. In these cases, users resort to keeping long lists of exceptions in their head or scribbled on sticky notes. Without a few stable, trusted, never-failing interaction “laws,” users are left to carry the burden of all those exceptions. Eventually, they give up even trying to learn new features. The ultimate result is that the most powerful features of many programs and devices go unused by most users. Consumer satisfaction, the ability to build new things from a product’s basic capabilities, the ability to perform critical but rarely encountered tasks—often the very features that differentiate a product from its competitors—are all put at risk.
It should be emphasized that although interaction physics implies strict self-consistency, it does not necessarily imply consistency with nature. There must be a physics, but not necessarily the physics. As game designers know well, users are capable of rapidly adjusting to novel—even bizarre—virtual environments and quickly becoming highly skilled in them; but only in the presence of consistency that they can count on. Gravity that works sideways? No problem. Eyes that see through disembodied floating cameras that follow your avatar? Got it!
This is fortunate. In the world of Trillions, we expect to be surrounded by embedded devices that do things that are far from natural. After all, if all we did was slavishly copy nature, what would we have gained? In such an environment, how far can we push the physics? Where will the Most Advanced become Unacceptable?
Thus, designing on Trillions Mountain won’t involve just the application of rigid interface design rules. There’s research to be done, new things to learn. As design scientists, we are left to our imagination and intelligence to propose a hypothesis that seems reasonable and testable, and then to put it through the wringer of experience. In complex systems, it is essential to get the physics straight before the designing can begin in earnest. For the people who will ultimately own, use, and live with the design, their comfort and quality of life is at stake.
Information-Centric Interaction Design
It is possible to identify four distinct stages in the evolution of human-computer interaction. The earliest of these was what might be called command-centric. When you logged into a timesharing computer in 1970, or turned on an early personal computer a decade later, your teletype machine (or its “glass” equivalent) presented you with a one-character prompt, indicating that it was time for you to type a command. You were expected to know the list of options, which generally consisted of such verbs as LIST, PRINT, DELETE, and COPY. You literally told the computer what to do, and it did it immediately and exactly. And that was the end of the story. The experience was much like using a very powerful typewriter, or perhaps running an extremely flexible slide projector. The information itself felt far away and abstract.
Stage 2 was application-centric. It first appeared in the form of an addition to the above list of commands. The newcomer was RUN, and it introduced an additional level of abstraction between the user and the computer in the form of applications—computer programs that were not part of the machine’s operating system, but were devised by third parties to perform some specific task. There were applications to read e-mail, perform word processing, manage spreadsheets, and do a thousand more tasks. At first, they had their own sets of commands, analogous to those used to control the operating system, but specialized for a specific task. The feeling here was a bit like using those remote manipulator arms in nuclear power plants. You could grab hold of your data, but only indirectly. You would say, “Please, e-mail program, show me my next unread message,” and your e-mail app would fetch it on your behalf.
Although application-centric interaction is still common, it has in many cases been supplanted (or perhaps supplemented is a better term) by stage 3 interaction, which is commonly known as document-centric interaction. Here, the applications recede into the background, and the user is encouraged to focus on the document as the unit of interaction. Instead of thinking about commands or indirect manipulation, direct manipulation is the order of the day. One can grab an image from a PC web browser, drag it out of its window and drop it into a word-processing document or onto the desktop. On an iPhone or iPad, one can flip through the albums of a music collection or scroll around on a map with the slide of a finger. The remote manipulator arms are gone, and if it weren’t for that pesky piece of glass, it feels as though you could literally get your hands on the data.
Stage 4 takes the progression to its logical conclusion. First introduced by a collaboration between MAYA and Carnegie Mellon University, this stage is known as information-centric manipulation. Like stage 3, it makes aggressive use of such direct manipulation techniques as drag-and-drop and gesture-based interaction. What distinguishes it from the document centric approach is that, rather than limiting the “currency” of manipulation to the document, it is extended to every level of detail in a display. In the information-centric approach, a display is not so much drawn as it is assembled out of more primitive graphical elements, each of which is itself a representation of a more primitive information object and is itself directly manipulable.
If the user is given, say, a document containing a table containing a list of cities, not only can the document and the table be dragged and dropped into a different context, but so can the cities. Thus, for example, a subset of the cities could be selected, dragged out of the table, and dropped into a bar graph designed to show population. Instantly, the lines that list the cities will morph into bars whose height is proportional to the city’s population. Then, perhaps, the user might use this display to select the cities with the tallest bars (and thus, the highest populations) and drag them in turn onto a map, which would automatically morph the bars into the appropriate icons and “snap” them to their proper location according to the cities’ latitudes and longitudes (Figure 6.2). This concept is kinetically illustrated online at http://trillions.maya.com/Visage_polymorphic.
Figure 6.2 Information-centric data manipulation
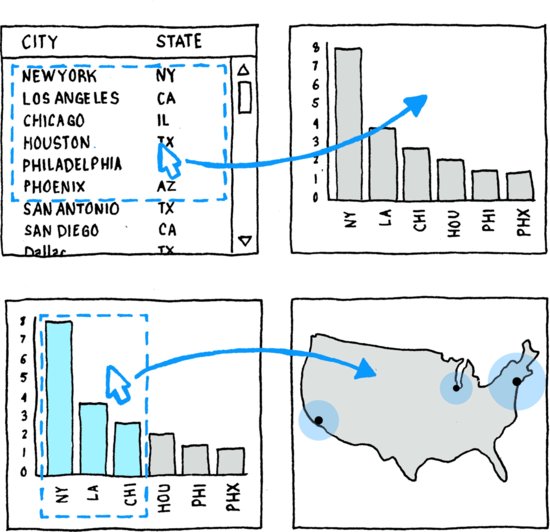
To appreciate the power of this approach, it is important to fully understand the nature of the morph operations in the above story. This operation is easy and intuitive when experienced, but it has no direct analog in the real world, and so is a bit tricky to describe. The key to the technique involves the distinction between the identity of the information object and the form in which it is presented in a given display. Information as such is invisible. Humans have no sensory apparatus to perceive it directly. And so, we use displays—whether on paper or on computer screens—as concrete, physical surrogates for the data. What computers let us do that paper never could is to dynamically change the form while maintaining the underlying identity of an information object. Thus, in our example, the row of text in the table, the bar on the bar chart, and the symbol positioned on the map are all representations of one and the same abstract information object—namely an object containing various information about a city. Each representation lets us perceive a different facet of the information we have about the city. The table shows us the city’s name, the bar shows the population, and the map icon shows us the location. Different representations are valuable for different tasks, but all ultimately refer to the same underlying object—our city object.
As should be clear, information-centric interaction design is intimately related to the ideas of persistent object identity and of cyberspace that we have discussed previously. These are powerful and somewhat radical techniques, but they are, we believe, exactly the power we need to make significant progress toward a tractable future.
Computation in Context
As we begin to develop pervasive computing systems, issues related to context awareness will increasingly come to the fore. As a result, we will need to apply significantly more precision to the notion of context than is afforded by common usage of this term. Just as in previous sections we found it useful to distinguish among people, devices and information, we may usefully identify three distinct realms of context. First, the physical context allows us to make our devices responsive to their actual, real-world locations. Second, the device context concerns the relations among information-processing systems as such—machines talking to other machines. Finally, computing systems have an information context. The study of information contexts is the province of the discipline of information architecture, which the next chapter will explore in detail but in brief may be defined as the design of information entities abstracted from the machines that process them.
Perhaps the pinnacle of eighteenth- and nineteenth-century high technology was the commercial sailing ship. The design and operation of these craft represented a subtle and challenging enterprise. This challenge was rooted in the fact that these devices needed to operate simultaneously in three distinct but interacting realms. A merchant ship is at once in the ocean, in the atmosphere, and “in” a constantly flowing current of passengers and cargo (Figure 6.3).
Figure 6.3 The three environments of a sailing ship

It may seem peculiar to speak of the ships as being “in” the flow of cargo rather than the converse, but this is a perfectly sensible and useful description of the situation. The peculiarity comes from thinking only of the goods and passengers who are on a particular ship. Think instead about the continuous flow of all the people and things in the world that are on their way, right now, from one place to another. Ships are unquestionably “in” that flow. From the point of view of a ship and its designers, this stream of commerce is as real and as important a context as wind or current: Its pressures shape the holds and staterooms and decks just as surely as the imperatives of hydro- and aerodynamics determine the streamlines of the hull and the catenaries of the sails.
The need to balance the often-conflicting design constraints imposed by these three contexts, combined with the reality that sailing ships spent most of their lives operating without infrastructural support, raised naval architecture to a level of art unmatched in its day. The sense of appreciation—even awe—that many people feel in the presence of a gathering of tall ships reflects an intuitive recognition of the success of their designers in meeting the challenges of this multiply constrained design space.
As designers of information devices, we are embarking on a great enterprise whose challenges are, in certain ways, reminiscent of those of our seafaring past. No longer can computer designers make the simplifying assumption that their creations will spend their lifetimes moored safely to the desk of a single user or plying the familiar channels of a particular local network. Nor will most devices be tethered to some remote corporate cloud service. It seems clear that, before long, most computing will happen in situ and that most computing devices will find themselves operating in diverse and changing contexts. Context awareness will soon become a hallmark of effective information products and services.
Talk of context-aware computing has become common. Yet such discussions nearly always significantly understate the issue. Each of these realms— physical, device, and information—presents a unique set of challenges. But they are not independent, and we treat them so at our peril. Thus there is a compelling need for the development of a framework within which we can begin to reason about information systems in the large—dealing at once with context awareness in each of the three realms.
Physical Context
The physical context is the first and most obvious of our three contexts of computation. This is what is most commonly meant when the term context aware is encountered in the literature. It is about imbuing our devices with a sense of place by the most literal interpretation of that phrase. But even here the notion of context is not simple. We can mean many things by physical context. Most obvious, perhaps, is geographic location. Here we are heir to a rich and sophisticated body of work inherited from the disciplines of cartography and navigation. As the etymology of the word “geometry” demonstrates, we have been measuring the earth for a very long time. Consequently, we are not lacking for well-developed standards for denoting locations on the earth’s surface.
Indeed, there is an embarrassment of riches in this regard: The novice soon discovers that referencing a spot on the earth is no simple matter of latitude and longitude. Various geographic, geodetic, and geocentric coordinate systems are in common use—each optimized for a different purpose. Although practice in this area can be extremely complex, it is for the most part well defined, with precise—if not always simple—mathematics defining the relations involved. The field of geographic information systems (GIS) is quite mature; we have comprehensive (if sometimes overly complex) standards for the machine representation and interchange of geographic information of all sorts.
However, as we move beyond mere geolocation to the more interesting problem of denoting geographic features (whether natural, man-made, or political), the situation rapidly becomes murky. Suppose, to pick one of the easier cases, we wish to refer in an unambiguous way to, say, Hanover, Pennsylvania. Should we simply use the place name? If so, we will have to devise a way to indicate whether we mean the Hanover near Wilkes-Barre, the one by Allentown, or the one at York (this is assuming we don’t mean Hanover Green, Hanover Junction, Hanoverdale, or Hanoverville). We could use latitude/longitude, but what point on the earth, exactly, should we choose to represent Hanover?5 If we do not choose precisely the same coordinates, comparing two references to the same location becomes an exercise in trigonometry.
If we look to other challenges, such as denoting street addresses, we discover similar issues. There is no shortage of schemes for encoding these kinds of data, and there exist many high-quality databases of such information. However, each such database is a referential island, defining a local namespace adequate to support a particular application, but nearly useless for enabling the kinds of large-scale, open information spaces implied by the pervasive computing agenda.
But there is more to place than mere geography. Human artifice has structured space in many complex ways, creating new challenges. Consider a large skyscraper. It may have 100 floors, each having 100 rooms. Already today, each room likely contains multiple networked processors—smoke detectors, door locks, building alarms, lighting controllers, thermostats. A single building may easily contain tens of thousands of embedded computers. To do its job, each of these processors must in some sense be “aware” of its location. But location means different things to different devices. To some it is room number; to others it is floor, distance from a fire exit, topological location on a local area network, or proximity to a window. The state of the art in such systems is such that each device is imbued with its requisite address by an installer on a ladder—often keeping paper records of his progress. Standardization efforts are underway within the relevant industry trade groups, but they are proceeding with little thought to how such standards might fit into a larger ecology. It will not be long before the tens of thousands of processors in each office building become tens of millions, and it will not end there. When light switches built into modular room dividers are expected to turn on neighboring lights, how will they determine what lights are neighboring? When sensors in office chairs are able to identify their occupants by weight, how will this information be made available to nearby devices, and how will nearby be defined and determined? When every manufactured thing, from soda cans to soap dispensers joins the network, what role will context play? There are soap dispensers, sold in grocery stores today, that have a small processor, a sensor to allow hands-free operation, and a power supply. With just the one small step of adding communications to the mix, we could easily have the means to enhance our parenting skills with respect to our kids’ hand-washing habits. But how will we capture the dispenser’s physical location, and how will we control how afar the resulting information should be allowed to roam?
Device Context
Just as various kinds of sensory apparatus—GPS receivers, proximity sensors, and so forth—are the means by which mobile devices will become geographically aware, another class of sensors makes it possible for devices to become aware of each other. The superficial similarity between such sensors and ordinary communications channels belies their significance. There is a fundamental difference between the mere ability to transfer data between two or more devices along preconfigured channels and the ability of a device to discover the presence of its peers and to autonomously establish such channels without the aid of some external designer. The first situation involves fixed infrastructure; the second doesn’t. And we have precious little experience with computing in the absence of fixed infrastructure.
This, the so-called service discovery problem, forms the basis for a kind of context awareness that is different from that based on physical context. A cluster of vehicles driving in convoy across the country forms a persistent context that is quite distinct from that of the countryside rolling by. Peer-to-peer communication in such circumstances is largely uncharted territory. If we ignore such rudimentary communications channels as horns, turn signals, and CB radios (which in any event involve humans in the loop), no direct communication occurs among today’s vehicles. This will certainly change soon. The question is whether the inter-vehicle systems now being developed will be isolated stunts, or whether they will be designed to evolve as part of a larger information ecology.
Even if we broaden our search to include all information-processing devices, the pickings are slim. It is surprisingly difficult to find significant instances of peer-to-peer communications that do not involve the mediation of fixed infrastructure. Anyone who has witnessed the often comic antics of two technically adept laptop users attempting to establish direct communications between their machines without the use of external media will appreciate just how primitive is the state of the art. Progress is being made, however. For example, a little-noted feature of recent versions of Apple’s OSX operating system called Airdrop allows properly-equipped computers to automatically become aware of each other’s presence, allowing painless drag-and-drop file transfers among such machines.6 Modest progress for 20 years of effort, but it is a start.
Sooner or later, the practical ability to establish zero-infrastructure ad hoc networks will be achieved. But this in itself does not get us very far toward a true realm of mobile devices. Let’s assume, for instance, that you and a friend are riding a New York subway along with 80 strangers. Let’s further assume (this being the near future) that everyone on board has in his or her pocket a cell phone that is also physically able to communicate with each of the others, and each device has succeeded in discovering the presence of the other 81. So, what do we do now? Even ignoring engineering issues, how will your friend’s device know to cooperate with yours while remaining wary of the 80 strangers? How will these devices even be identified? More basically, what exactly will constitute identity for purposes of such policy?
Before leaving this topic, we should note that device contexts are not necessarily defined by physical proximity. Devices employing a common radio channel may share a context even at great distances. In the case of wired networks, topological distances are typically (but not always) more relevant than topographic proximity.
Many other kinds of “distance” (e.g., how far am I from an Internet connection—and at what cost?) will have importance in specific situations. In general, what it means to define a “space” is precisely to define such distance measures. Building a true “cyberspace” will in large part be a process of coming to agreement on such matters.
Finally, there is the issue of mobile code. The vision of small bits of behavior moving freely from device to device raises many issues of device context awareness. Strictly speaking, code is not a device, but simply data (and therefore the subject of the following section). But the running computer programs to which such code gives rise are in effect devices. As such, they exist in contexts, raising many of the same issues of context awareness as do physical devices, as well as a few new ones: On what kind of machine am I executing? Whom am I sharing it with? What resources are available to me, and what restrictions must I observe? These are matters of context awareness no less than the more obvious ones of physical context.
Information Context
The third—and least discussed—of our three contexts is the information context in which computation takes place. The study of such contexts is the province of the discipline of information architecture, which we define as the design of information entities abstracted from the machines that process them. This topic has not received the attention that it deserves, largely due to our long habit of thinking of data as residing “in” our computers. As we have already seen, in a pervasive computing world it is useful to take quite the opposite perspective—increasingly, data are not “in” our devices any more than a phone call is “in” a cell phone. In this regard, our earlier nautical analogy is particularly evocative, suggesting a future in which computing devices float freely in a vast sea of data objects—objects whose existence and identity are quite distinct from those of the devices that process them. In this world, the data have been liberated from the devices and have claimed center stage.
This provocative image is compatible with the often-stated ideal of the computer “disappearing” or receding into the background. From this view, computing devices are seen as merely “transducers”—a sort of perceptual prosthesis. We need them in order to see and manipulate data just as we need special goggles to see infrared light. In both cases, it is the perception that is of interest, not the mediating device.
People are beginning to talk about a vapor of information following us around as we move from place to place and from device to device. But what, exactly, is this vapor? What is it made of? What are its properties? How will it know to follow us? How can we make it usable? These are strange and difficult questions, but beginning to view computing from an information-centric perspective is a first step in dispelling the strangeness.
Already, users of mobile web browsers routinely carry around replicas of web pages that are automatically cached on their devices. As it becomes easier to pass such information objects from device to device, they will begin to take on an existence (and a persistence) that is quite independent of the server machines of their origin. Services exist that extend this concept to other kinds of data, allowing appointments, to-do lists, and even editable text documents to exist as coordinated replicates on any number of mobile devices and desktops simultaneously. Today, these capabilities are typically implemented via the kinds of centralized pseudo-cloud services discussed in Chapter 3. But we will soon begin to see true peer-to-peer implementations. This mode of operation is presently the exception rather than the rule, but we are clearly heading toward patterns of normal activity that will stretch and ultimately break our present conception of the “location” of information.
All modern smartphones and other mobile devices ship with multiple gigabytes of storage. (It is increasingly difficult for a manufacturer to even source memory chips any smaller.) All that storage represents yet another of the underutilized resources we have so often encountered in our story. In this context, what happens when we step beyond the relatively simple client-server model that dominates the web today? What happens when our pocket devices get good at communicating directly with each other? As such devices are released by the billions into the wild, it is inevitable that widespread data replication will rapidly become the norm. Popular web pages and other data objects will be replicated countless times as they flow from device to device. Explicit backup utilities will disappear—replaced by the inherent redundancy of cyberspace. Corrupted or momentarily unneeded data will be casually deleted from local devices by users confident in their ability to grab fresh copies out of the ether when needed. Damaged devices will be replaced with a shrug: The data stream will soon replenish each emptied vessel. Such a world will be characterized by the primacy of information itself, and no one will be tempted to think of data as being “in” machines.
This is not to suggest that all data will be available everywhere. Contrary to predictions that all computing devices will someday have continuous Internet access, we assume that connectivity will always be intermittent, and there will always be devices that are too small and cheap to support direct continuous access. Storage capacities, although huge, will always be finite and unevenly distributed. These and a variety of other factors, ranging from intellectual property issues to bandwidth and security policies, will guarantee that only a small subset of the aggregate data space will be immediately available to any given device at any given time. The sea of data will be far from homogenous. Natural patterns of human and machine interaction, as well as deliberate data replication, will create currents and eddies of data flow within the larger sea.
Thus, devices will find themselves at any given time in this context of the third kind, and awareness of that context will involve a whole new set of questions: What information “objects” are floating around in my immediate neighborhood? Which devices contain them? Are they in a form that I understand? What are the transactions going on among devices for which these information objects serve as currency? In the long run, this kind of context awareness may prove to be the most basic of all. Yet the current dominance of the client-server networking model found in most cloud implementations—with its assumptions of fixed infrastructure, centralized authorities, and walled-off repositories—means that this crucially important context, information-context, is not even part of the discussion today.
What About the User?
In our discussion of computing contexts, the role of the user has been conspicuously and intentionally absent—until now. Surely humans will represent an important, perhaps the ultimate, context for both devices and data. Where do people fit into our three-contexts scheme? In fact, they form a curious cut through the entire space. On the one hand, people are clearly part of the physical context. Awareness of who is present and of their needs, interests, and characteristics will surely be a hallmark of successful “smart spaces.” On the other hand, it is often useful to think of the user as a “living information device”—an architectural peer to the computers, participating in the worldwide data flow as a source and sink of data like any other system component. Yet again, we must acknowledge the user as a teleological force—the source of purpose and meaning for the system, guiding it from the outside.
All of these points of view have validity. But most importantly, we must consider people from the perspective of system usability and usefulness. We are on the verge of building systems unprecedented both in their scale and in their very nature. It is one thing to design a usable computer program. It is quite another to design a usable environment when that environment comprises innumerable semiautonomous devices mediating an unbounded swirl of constantly flowing information. Usability, or the lack thereof, will be an emergent property of such a milieu. How does one design an emergent property? The answer is not at all clear. But it is a good guess that the place to start is in defining a basic ontology of existence in this strange new world, with an eye toward imbuing that existence with a consistency of behavior that in some measure approximates the consistency that we get for free in the physical world.
While we touched on the idea of Universally Unique Identity in earlier passages, it is important to raise it again here. No amount of clever hacking will achieve our goals unless it is layered on top of a common model of identity and reference. It is unambiguous identity that is the sine qua non of “objects” of all kinds, and until we start treating information as objects, we will be stuck in an ever-growing pool of informational quicksand.
1 But our engineering staff was able to develop scanning software to identify each cover sheet, read its barcode, and direct the associated document to the correct user—quite an achievement in those primitive days.
2 Each of these terms is associated with one or more communities of adherents who attach more or less precise definitions to each term. Such distinctions are not of the essence for our purposes.
3 The research led to the development of five U.S. patents and the launch of a new product category that won an innovation award from the Consumer Electronics Association.
4 When this research study was conducted, Twitter didn’t exist yet and wouldn’t come into existence for another three years.
5 There is a U.S. Board on Geographic Names that sanctions official U.S. place names, but it treats U.S. and foreign names differently. For example, web-accessible resources from this source present unique numerical identifiers for foreign but not domestic places. The Getty Research Institute has compiled an extremely thorough thesaurus of geographic names that is both worldwide and hierarchical, and also includes unique identifiers. However, this work is not in the public domain and is not generally recognized as authoritative.
6 One of the reasons this feature is “little noted” is because it only works on the very latest hardware. Why? Because until recently, the designers of WiFi chips saw no reason to provide for simultaneous P2P and infrastructure connections.