
CHAPTER 3
The Tyranny of the Orthodoxy
At any given moment there is an orthodoxy, a body of ideas which it is assumed that all right-thinking people will accept without question. It is not exactly forbidden to say this, that or the other, but it is “not done” to say it. . . . Anyone who challenges the prevailing orthodoxy finds himself silenced with surprising effectiveness. A genuinely unfashionable opinion is almost never given a fair hearing, either in the popular press or in the highbrow periodicals.
—GEORGE ORWELL
INFORMATION INTERRUPTUS
On November 6, 2008, an AOL staffer named Kelly posted a message on the America Online (AOL) customer-relations blog called “People Connection.”

AOL Hometown was an online tool that let AOL members build and maintain their own web sites hosted on AOL’s system. Many of AOL’s customers had embraced Hometown as a repository for priceless personal information. The service was once wildly popular. As early as 2001, it is reported to have hosted more than 11 million web pages.
The first official notice of the impending demise of the service appears to have been posted on September 30, 2008, along with a procedure for retrieving user data (during the 30-day period before the plug was pulled). This procedure involved the use of a low-level file transfer protocol called “FTP,” which a typical AOL Hometown user had probably never heard of.1 In any event, many of the users apparently didn’t get the memo. User comments on Kelly’s post expressed disbelief, grief, and finally outrage. AOL member “Rick” was brief and to the point:
Things like this is why I left AOL, they think they own your internet expereince!
A user named “Gloria” was more typical:
What happened to my web page on my husband, Bob ——, that took me many years to put together on his career and which meant a lot to me and to the aviation community. I noticed with 9.0 I lost the left margin and the picture of him exiting the X-1. I need to restore it to the internet as it is history. Please tell me what to do. I will be glad to retype it, I just don’t want it lost to the world.
I need help.
Gloria—
AOL member “Pat” was even more distraught:
Well I am also so surprised to see all our work is gone, why didn’t they notify everyone on the update through email I never even knew this was going to happen to even get a chance to save my webpage..Also is anyone getting any answers as to where or how we can get our work back..there has to be a way and something saved on there end. AOL not for nothing this was an awful decision to make and you have hurt many people who cherish there pictures, there life stories and just plain old happiness . . . It like stealing our hearts and souls without our knowledge . . . I WANT MY WEBPAGE INFO BACK I never gave you permission to destroy it..we should all file one big lawsuit against you for this. ANY LAWYERS OUT THERE THAT CAN HELP..EMAIL US ALL for one class action..or we get a second chance to get our work back.
And then there was the unfortunate case of “Alice”:
It is so sad that I have lost all my saved all pages from my daughter. That’s all i had left all her memories now I have nothing at all. I lost my daughter 2 years ago, and I needed those pages. I beg you is there any way I can get them back pleaseee. It will be very much appreciated.
In all, nearly 30 user comments were posted that day and the next, and then the comments abruptly ceased.2 One person said, “You gave us ample notice,” though that may have been sarcasm. Most comments complained of receiving no notice at all.
AOL posted no response at all to the comments. As of this writing, a Google search of the string “http://hometown.aol.com” still produces more than 9 million hits. Most of these are links to content once found on Hometown. None of them work. Nor, ironically, does the so-called permalink that AOL thoughtfully included in their original termination notice.3 Instead, at least at this writing, the link (and, apparently, all other Hometown URLs) redirect to a newer AOL service called Lifestream. We’re sure they will do better this time.
In the meantime, staff blogger Kelly was busy elsewhere on the system. On December 2, 2008, she filed the post, “Ficlets Will Be Shut Down Permanently,” and the next day she posted, “Circavie Will Be Shut Down Permanently.” It’s hard to deduce what “Circavie” was; apparently it allowed one to create timelines of events and embed them on other web pages. An interesting idea, though few users took the trouble to protest its disappearance. Ficlets, however, was another story. This was a place for sharing works of very short fiction, and it clearly meant a great deal to some AOL users. In the comments attached to AOL’s announcement of Ficlets’ demise, “Brebellez” wrote:
****SOBS!!!!****
What? This is the only place that I’m on CONSTANTLY!! Its the only ‘happy place’. could you please give me one thing? tell me, why. why is this horrid, horrid thing happening!!??
And a user named Alexa said:
I feel like I lost a family member. Or several.
I’m completely overwhelmed by my shock.
I just . . .
I just really hate this.
Kevin, thanks for creating the one thought-provoking, creative site on the Internet and the only decent thing AOL has ever brought me.
AOL—a pox on your house.
“Kevin” is Kevin Lawver, the actual developer of Ficlets, who posted a comment himself, which began:
I knew this was coming, I just didn’t know the day. I tried, with the help of some great people, to get AOL to donate ficlets to a non-profit, with no luck. I asked them just to give it to me outright since I invented it and built it with the help of some spectacular developers and designers. All of this has gone nowhere.
Kevin revealed that he had exported all of the contributions and has led a volunteer effort to reestablish the Ficlets community elsewhere. And he added, “I’m disappointed that AOL’s turned its back on the community, although I guess I shouldn’t be surprised.”
Forever Is a Long Time
In fairness, sudden suspensions of service are not unique to America Online. And, at least these were “free” services. The same cannot be said in the case of on-line e-book retailer Fictionwise, who, in January 2009 (shortly before being bought by Barnes & Noble), announced that its customers would lose access to certain texts they had purchased because one of the company’s “digital rights management” providers had gone out of business, leaving the encrypted products orphaned. Many customers had interpreted their user agreement to mean that their Fictionwise e-books would remain on their virtual bookshelf “forever.” In its FAQ, the management of Fictionwise helpfully observed: “Forever is a long time.”
One month earlier, Google had shut down its scientific research service Google Research Datasets (although, in this case, at least Google had followed its common practice of labeling the service as “experimental”). In an online article on the shutdown, Wired magazine noted that “the service was going to offer scientists a way to store the massive amounts of data generated in an increasing number of fields,” but that “the dream appears to have fallen prey to belt-tightening at Silicon Valley’s most innovative company.” Then, in rapid succession, the company killed Google Video, Google Catalog Search, Google Notebook, Google Mashup Editor, and Jaiku, a rival of the Twitter microblogging service, among other “side” projects. Explaining the closings, one of the search giant’s product managers said, “At Google, we like to launch early, launch often, and to iterate our products. Occasionally, this means we have to re-evaluate our efforts and make difficult decisions to be sure we focus on products that make the most sense for our users.”
Welcome to the future.
We do not mean to be overly harsh on the businesses cited in these stories. After all, they are only corporations trying to do what corporations are legally required to do: Maximize return for their stockholders. But, these experiments from the early days of the web are reasonably accurate harbingers of how we comport ourselves today, and their outcomes portend what we may expect in the future.
Of course “information interruptus” isn’t caused solely by changes in corporate policy. There are other factors, like the small matter of bugs. Late in 2008, certain models of Microsoft’s Zune music player simply stopped working thanks to a leap-year glitch in the device’s internal clock driver. Did what was then the world’s largest software company offer an official fix? Yes. Owners afflicted by the problem were instructed to run the battery all the way down and then wait until after the New Year to turn the device back on.
The fact is that we’re babes in the woods of information. Computing complexity is already far beyond the ability of most normal people to manage, and we’ve scarcely gotten started. You used to be able to go into your grandparents’ attic and find the photo box full of family images. Now everybody takes pictures with perishable cell phones that they don’t know how to sync. When they do use a full-fledged digital camera, they store the pictures on perishable hard drives that almost nobody ever backs up.4 Whole lifetimes of personal history vanish every day. What happens when popular “free” media-sharing sites like Flickr or Picassa or YouTube stop producing value for their owners’ stockholders and get taken down?
Sterling companies like Yahoo! and Google wouldn’t do that, you might say.
They most certainly would, we reply. Not just “would”—will.
Or how about just catastrophic accidental data loss? It can’t happen to companies that big, you might believe. Really? On May 14, 2009, 14 percent of the users of “the Internet’s biggest property” lost Google Search and other core services for a full hour when the company made a technical networking mistake, and it wasn’t the first time.5
Figure 3.1 When scenarios like Pete’s TV occur, it makes you wonder how much time we spend using, waiting for, and fixing our technology. We imagine it looks something like this.

The Dark Side of “Convergence”
The suspension of various services does not make America Online a special villain in the computing landscape. They’re just another company making it up as they go along—which is, of course, the problem. Still, there’s special symbolic significance when AOL drops the guillotine on its users because the company was once the poster child for a phenomenon called “convergence.” AOL’s merger with Time Warner in 2000 (consummated in 2001, just in time for the dot-com collapse) was trumpeted, by its champions, as the beginning of a new era of human experience in which knowledge, entertainment, and commerce would be “synergistically” fused together by digital information technology and networks. Even at the time, however, some observers were not particularly sanguine about it. Commenting on the merger before its rapid collapse, Lawrence Lessig wrote:
Though I don’t (yet) believe this view of America Online (AOL), it is the most cynical image of Time Warner’s marriage to AOL: the forging of an estate of large-scale networks with power over users to an estate dedicated to almost perfect control over content. That content will not be “broadcast” to millions at the same time; it will be fed to users as users demand it, packaged in advertising precisely tailored to the user. But the service will still be essentially one-way, and the freedom to feed back, to feed creativity to others, will be just about as constrained as it is today.
This, Lessig went on to say, was the “future of the Internet” that we seemed to be choosing (or that we were having chosen for us): “Take the Net, mix it with the fanciest TV, add a simple way to buy things, and that’s pretty much it.” As it turned out, AOL’s merger with Time Warner was a catastrophic failure. That’s one face of the dark side of convergence: the inevitable vagaries of highly speculative business dealings. Even if publicly traded companies were not bound by law to put shareholder value above all else, there would still be an obvious conflict in conducting the core affairs of humanity’s information-future in the volatile milieu of competing board rooms.
The increasing flakiness and frustration of computerized products are another glimpse of the dark side. Televisions didn’t freeze and need to be rebooted before “convergence.” Why are we going backwards? The simple answer is that we’re incorporating badly designed complexity into virtually everything. Most people’s experience will jibe with this statement: “Computerizing any device makes it far more complex than it was before, and the predictable side-effects of that complexity are that the device becomes harder to use and its reliability goes down.” But most people have not yet experienced, or imagined, a world crippled by the uncountable interactions among trillions of improperly complex and thus unreliable devices.
The Complexity Cliff
There is strong temptation to assume that minor annoyances like a frozen plasma TV represent the last few bugs that need to be squashed before we perfect the wonderful new technologies that will make life in the twenty-first century a thing of beauty and a joy forever. The thesis of this book is precisely the opposite. These examples of information interruptus are merely the first dim glimpses of looming disaster.
Put bluntly, we are heading, as a civilization, toward a cliff. The cliff has a name, but it is rarely spoken.
Its name is complexity.
Computing is making our lives vastly better along certain dimensions but noticeably worse along others. We’re like the frog in the pot of water on the stove with the temperature going up one degree at a time. By the time the frog feels enough discomfort to think about jumping out, the frog is scalded. In five years, people won’t think any harder about rebooting their phones and TVs—even their household heating plants–than they think today about rebooting their PCs. Only 20 years ago, rebooting a TV or a phone or a furnace was unthinkable. Today, our time and attention are drained daily by products that force consumers to understand technical things they shouldn’t have to think about. And it’s about to get much worse. We tell ourselves that this goes hand in hand with progress. It doesn’t, but manufacturers with quarterly profit targets need us to accept that story. The human beings are babysitting the machines, playing handmaiden to tools that aren’t good enough to get along in the world on their own.
Today, the price of underestimated and ill-managed complexity is usually only inconvenience or annoyance—mild words that don’t capture the frustration and lost productivity of a really bad day in the digital revolution. To make the same point in another way: There is an unspoken reasoning behind deciding how “good” to make usability; that it depends on the “cost” of failure or an error. Something like annoyance is near one end of the cost spectrum and death is at the other end. So, historically, the first human factors studies were done for military aircraft cockpits. But is there a point where countless annoyances become equivalent to one death?
The time is not far off when the price of undesigned, ill-managed complexity will be much, much higher than inconvenience or annoyance. It’s not the worst thing in the world that a brand-new plasma TV locks up and won’t respond to its controls. We could live with it, though we shouldn’t have to. But how about the same scenario in a city’s traffic control system? How about waiting ten minutes for an ambulance to reboot? With current ways of thinking about computing technologies, we could easily “brick” all the lights in a next-generation skyscraper that uses wireless systems to control illumination. Or the elevators. Or the ventilation. It is quite within the realm of possibility that such a technical glitch could render a modern smart building—or an entire campus of such buildings—uninhabitable for months.6
If we’re going to embrace, in blind faith, the limitless extension of our current technologies, then we have to consider the possibility (among many others) of people dying in skyscrapers because some pervasive, emergent, undesigned property of a building’s systems—or an entire city’s systems—starts a chaotic cascade of failures. To some readers these dire hypotheticals will ring of Chicken Little. But they’re quite reasonable extrapolations of what we know today—if only we’ll admit that we know it.
And all this before we’ve even mentioned malice. Every day brings another story of computer systems and infrastructure under attack. The vulnerability that makes these attacks so easy is largely due to our thoughtless use of unnecessary and badly designed complexity, usually for no better reason than that it’s cheap or “free.” But complexity is never free. In fact, it’s quite expensive indeed. Among many other liabilities, it gives attackers plenty of vectors in, and plenty of places to hide and operate once they are in.
We are about to meld superminiaturized computing and communication devices into the very fabric of the physical world, ushering in the age of Trillions. This will create a planetary ocean of awareness and intelligence with the potential to transform civilization. We’re not going to “decide” whether or not to do this. The process, as we have seen, is already well underway. Obviously, it will make us vastly more dependent upon digital technology than we are right now. More importantly, the technology itself will be vastly more dependent upon the core design principles and engineering intelligence of its creators.
We’re heading into a world of malignant complexity, the kind that grows like cancer from flawed architectural principles—or from none at all. But we can still choose not to go there. Complexity itself is inevitable. Dysfunctional complexity isn’t.
THE KING AND THE MATHEMATICIAN
This steady creep of increasing complexity has been quietly feeding on itself, and soon it will hit its exponential inflection point and lift off like a rocket. If we wait until then to change our relationship to information technology, we’ll be engulfed by the explosion of our own creations and their interactions with each other.
Now, we do understand that this will sound completely ridiculous to many readers. There you are, wirelessly trading securities on your laptop, searching the web for any information your heart desires, meeting up with everybody you’ve ever known on social networks, streaming feature films on your mobile phone. And we’re saying that information technology is seriously broken, that we’re headed for technology dystopia if we don’t rethink it. Yes, on its face that sounds absurd. Exponential growth is counterintuitive, and counterintuitive things often seem nonsensical until, like boomerangs, they come circling back around to hit you in the head.
The salient feature of exponential curves is that for quite a while they look just like ordinary, tame, linear ramps, and then suddenly they bend upwards and go almost vertical. In the early phases of such growth, it’s basically impossible for people to believe that the pleasant warmth they’re feeling will suddenly burst into a firestorm and incinerate them.
To illustrate this phenomenon, one of your math teachers may have told you the story of the king, the mathematician and the chessboard. A king offers his court mathematician a reward for something good that he’s done. The mathematician can have anything he wants, but he asks only that one grain of rice be placed on the first square of a chessboard, two grains of rice on the next square, four grains on the next, and so on—simply that the grains of rice be doubled for each successive square (Figure 3.2). The King bursts out laughing. He thinks the mathematician is a fool but for his own amusement he orders that the request be fulfilled.
Figure 3.2 Grains of rice on the King’s chessboard
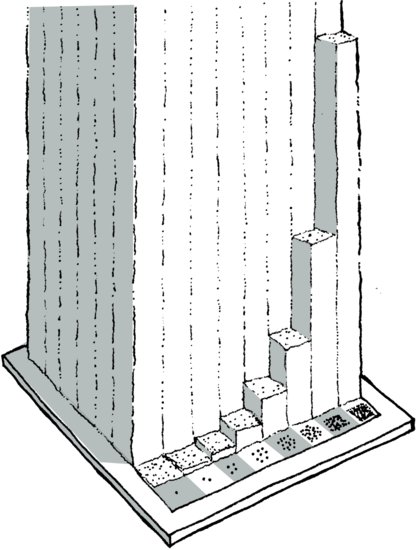
About halfway through the chessboard, the King isn’t so amused anymore. All the rice in the palace is gone, and the King has had to send out for more. A few more squares later, the King realizes that there aren’t enough grains of rice in his entire kingdom to fulfill the mathematician’s simple request. “Actually, Sire,” the mathematician informs him, “there aren’t enough grains of rice in the universe.” Depending upon which version of the story you hear, the mathematician then marries the King’s beautiful daughter or gets his head chopped off.
On the great chessboard of information and computing, we haven’t reached the halfway mark yet, and so it seems laughable that our presently dependable systems could suffocate on their own proliferation.
Every time we hang a fancy digital TV, or stop our work to reboot a crawling laptop, or waste half a day trying to get a wireless network running, or lose the precious contents of a computer hard drive, we are experiencing the leading edge of an imminent, full-scale collision of unimaginably complex systems with ordinary people who don’t have—and never will have, and shouldn’t need to have—the ability to cope with complexity of that sort.
When our world literally doesn’t work for people anymore, we’ll be ready to make changes. Unfortunately, that’s going to be tough. We’ll be stuck because the number of embedded, networked microprocessors controlling and sensing the physical world and all its processes will have multiplied like the grains of rice on the mathematician’s chessboard. But these grains of computing will be connected to each other, interacting and producing incalculable network effects. It will be the most complex system ever created by human beings—by a long shot—and when bad architecture rears its head in a structure like that, the potential for catastrophe is something we don’t even know how to talk about.
If complexity is our destiny, and ill-designed complexity is the death of us, what does well-designed complexity look like? It should look a lot like life. A trillion-node network is still unimaginable to most designers, but we have trillions of cells in each of our bodies. The rules that govern biological development—the genetic code—are simple, yet they give rise to fantastic (and highly functional) complexity and diversity. In life, limitless complexity is layered upon carefully constrained simplicity. John Horton Conway’s Game of Life is built on the idea of establishing a simple set of rules, yet those rules create far-reaching consequences. Explore the Game of Life online at http://trillions.maya.com/Game_of_Life.
Unbelievable as it may sound, the very need for such a principled, designed architecture for civilization’s information systems has not yet occurred to the thought leaders of high-technology. They’re too busy remaining “competitive” as they go about their local hill climbing. But the systems themselves are growing exponentially, even in the absence of good architecture, and by the time we admit that the foundations are bad, we’ll be living in a technological dystopia more bewildering and jerry-rigged than a Rube Goldberg cartoon or Terry Gilliam’s film Brazil with its ubiquitous wacky computers and metastatic ventilation ducts.
The message of this book is not that we’re helplessly doomed, and it’s certainly not that technology per se is bad. The message is that we are indeed headed for a complexity cliff, but there’s a better path into the future, and we’re still free to take it. To get to rational complexity in information systems, certain fundamental things about the technology need to be redesigned. We’ll discuss those things in detail later in this book. But the real challenge is not the technology itself. After all, the chessboard obeys understandable rules.
The real challenge is the laughing King.
LINKS TO NOWHERE
If you examine the bibliography of any scholarly book published in the last few years, the odds are very high that, in addition to citations pointing to traditional paper documents (which routinely stay live for hundreds or thousands of years), it will also contain references in the form of web URLs. This, of course, is symptomatic of the obvious fact that the World Wide Web has very rapidly become nearly the sole source of important public information for global society. It is interesting to consider the following simple question: Fifty years from now, what percentage of these web references will still be operational?
We will be very surprised if the answer turns out to be greater than zero.
The reason is simple: URLs are fundamentally different from traditional references on ontological grounds. Traditional citations refer to published information as such. That is, if you cite, say, Moby-Dick, everyone understands that you’re not referencing a particular instance of that book. Any of the millions upon millions of more or less identical replicas of Melville’s words will (for most purposes) do equally well. A URL, on the other hand, points not to a web page that has been massively replicated like a published book but rather to a specific place in the structure of a specific server (or at best, in any of a relatively small number of redundant servers under common management) where that web page might (at the moment) be found. Such a pointer will remain relevant only as long as the owner of that “place” possesses the resources and the will to maintain the pointer. And we all know that this will not be forever. Sooner or later, all links on the World Wide Web will go dead.7
And yet, web URLs with a half-life of only a few years have become the primary way that knowledge workers around the world document their thinking and their research.
Have we completely lost our minds?
This is no way to run a civilization. We are not the first to make this observation, and there have been sporadic efforts toward data preservation. The solution to the problem, however, does not lie in acid-free paper, the archiving of floppy drives, or any of the many other schemes focused on preservation of media. Paper books have proven to be a wonderfully robust and reliable medium, but not fundamentally because of their physical longevity, admirable though it may be. The reliability stems from the fact that they are deployed as part of a bibliographic system that relies on distributed ownership and massive replication. Paper books are liquid, in the sense that they can flow freely from publisher to printer to bookseller to first purchaser (individual or library) to resale shop to giveaway shelf. In the process, the contents of the books are scattered to the far corners of the earth such that destroying the last copy—whether by natural disaster or by censorship—is in most cases nearly inconceivable. And most importantly, any single copy suffices to “resolve the link” found in a citation. None of these things is true of web information, or for that matter, any of the other information found in the many petabytes of data “safely” stored away in the world’s databases. We need an entirely new information architecture that is designed from the bottom up to support the key qualities that our paper-book system gave us: namely, information liquidity and massive replication.
THE WRONG CLOUD
The interesting thing about cloud computing is that we’ve redefined cloud computing to include everything that we already do. I can’t think of anything that isn’t cloud computing with all of these announcements. The computer industry is the only industry that is more fashion-driven than women’s fashion. Maybe I’m an idiot, but I have no idea what anyone is talking about. What is it? It’s complete gibberish. It’s insane. When is this idiocy going to stop?
—Larry Ellison, CEO, Oracle
Something Vague and Indistinct, Up in the Sky
A few years ago, computing marketers started touting the great benefits of something they were calling “the cloud.” The industry must have needed a shot in the arm because pretty soon you were nobody unless you had a big reference to the cloud on the home page of your website. Even Apple, Inc.—not often a follower of industry fashion—got into the act. Apple’s wildly successfully iPhone can keep some of its data in sync with computers if the devices share information in the Apple cloud. These days, phones and computers can do this wirelessly from arbitrary locations, which contributes to the vapory imagery.
The web retailer Amazon.com had the cloud even before Apple did. Amazon’s cloud dispenses not books and music but data storage-space and computation cycles, both by the pound, so to speak. You can buy as much or as little of each as you want at any given moment, enabling you to build expanding and contracting virtual computers.
Facebook and Microsoft have clouds of their own, of course. So does Salesforce.com and Google and Yahoo! and, one assumes, any other company worth talking about. Naturally, these clouds are all of proprietary design and built to compete with each other, not cooperate with each other. No corporate cloud possesses the inherent ability to interoperate with other clouds. And yet they’re all called “the cloud.” Strange. If their purveyors feel like allowing it, the clouds can sometimes conduct feeble interactions by means of cobbled-together “web services” and APIs that you can spend a lot of time researching and learning if you enjoy that kind of thing. Don’t memorize them, however; they will change.
Customers who know what’s good for them just choose one incarnation of “the cloud” from one vendor and stick with it.
It’s beginning to sound familiar, isn’t it? It turns out that all these clouds are what we used to call servers, and those smaller entities hurling their astral bodies up into the cloud were once known as clients. Yes, cloud computing is the same old client-server computing we’ve known for years, except pretending to be intoxicatingly new and different and liberating.
There are both technical and commercial reasons that the web has evolved this way. We will explore the technical reasons later. The commercial ones reduce to a deeply held belief on the part of content providers of all kinds that the simplest way to make money from information is to keep it tightly locked away, to be dispensed one piece at a time. This belief is correct, as far as it goes. It is the simplest way to monetize information resources. The problem, as we shall argue, is that this simplistic strategy is fundamentally incompatible with the world of Trillions. If the world is going to become one huge, vastly distributed information system, don’t we need one huge, vastly distributed database to go with it? It would be a lost business opportunity of monumental proportions if we were to use these incredible new computational capabilities in a way that perpetuates patterns of information access that evolved in a time when computers were large, expensive, centrally controlled, and few.
Today’s so-called cloud isn’t really a cloud at all. It’s a bunch of corporate dirigibles painted to look like clouds. You can tell they’re fake because they all have logos on them. The real cloud wouldn’t have a logo.
Once There Was a Real Cloud
A very long time ago, back in the 1990s, whenever somebody wanted to represent the Internet in a diagram for a brochure or a slide show, they would put in a little cartoon of a cloud. Countless presentations to venture capitalists featured little pictures of desktop computers, modems, and hard drives, all connected by wiggly lines to the cloud cartoon. In fact, for a few years there, the entire global economy pretty much consisted of nothing but images just like that. When people needed money, they would just draw a diagram where everything was connected to a cloud, and take it to the bank. Those old pictures seem quaint and naive by today’s standards, but the truth is that the cloud in the 1990s dot-com business-model diagrams was vastly better than the cloud we have today.
One of the main virtues of the old cloud was its singularity. It was a single cloud—the Internet—not many as we find today on the web.
When it appeared in a diagram, it instantly conveyed an extremely important idea: If you went into this cloud, you were automatically connected to everything else that was in the cloud. This idea has been completely lost today, but back then it was considered a beautiful thing.
This point is so important that it is worth repeating in a different way: The very heart of the miracle that is the Internet is that it is able to establish virtual connections between literally any two computers in the world such that they can communicate directly with each other. This is a truly amazing ability, and our current usage patterns of the Net have barely scratched the surface of its potential.
The other main virtue of the old cloud was that nobody owned it. It wasn’t the Microsoft Cloud or the Apple Cloud or the Google Cloud or the Amazon Cloud. It was just the Internet. The one and only Cloud of Information, property of Humanity.
Those were the days. It’s getting hard to remember them now, it being almost 20 years ago and all. But let’s think back, as our vision gets all wavy and blurry. . . .
THE DREAM OF ONE BIG COMPUTER
It was the heyday of a programming language called Java, when people were excited about things like “thin client” and “applets” and “zero-footprint.” The Net was going to be One Big Computer. PCs would be supplanted by “network appliances” that would have no local “state” at all. There would be nothing to configure because these machines wouldn’t have anything “in” them. Instead they would be “in” the information—in the cloud. You could walk up to any appliance and log on, and via the magic of the cloud, there would be your stuff.
The machines wouldn’t have anything “in” them because they wouldn’t have any storage of their own. There was an important reason for this particular detail. High-capacity hard drives were expensive and not very reliable back then. The advantages of a thin client were several, including convenience and ease of maintenance, but the key advantage was cost savings. Computers with no disks would be significantly cheaper, and thus you could have a lot more of them.
But then, all of a sudden, disks got absurdly large and cheap. Almost overnight, the world was awash in disk space. The thin client idea started to seem silly. Why should we rearrange the world in such a fundamental way just to save the now-trivial cost of local storage? Plus, along with CPUs boasting meaninglessly faster clock-speeds, “bigger disks” were one of the few motivators we had to get people to trade up their PCs every couple of years.
So there went the idea of network appliances.
Hard drives kept getting bigger and cheaper, but once everybody had ripped their CD collections it got harder for people to understand why they would want even higher-capacity disks. The only obvious answers were (a) to store really big files, like digital video; and (b) to move to a peer-to-peer world where every machine could be a client and a server at the same time, and participate in a global scheme of data integrity via massive, cooperative replication. Both of those activities made a great deal of sense, culturally and technically.
Unfortunately, both were also political landmines.
THE GRAND REPOSITORY IN THE SKY
Nonetheless, it was around this time that advocates of peer-to-peer (P2P), including our team here at MAYA Design, began to talk seriously about extending the Internet “cloud” metaphor to storage. We meant a genuine “cloud of information” that you and your devices could be “in” no matter where you were. In MAYA’s technical literature we half-facetiously called it GRIS—the Grand Repository In the Sky. But we thought of it not as a mere metaphor, but as something that could actually be built, or at least approximated—a vast, disembodied information space built out of P2P and massive data-replication. With the essential support of visionary clients, we started making plans to build it. The system intended to implement GRIS is called the Via Repository and is part of a larger project called Visage. Another project dating from this period sharing a similar vision (although a very different technical approach) is the OceanStore project from UC Berkeley.
This vision has many of the virtues of the thin client idea, with the additional virtue of being able to take advantage of all that ever-cheaper disk space. In this model, devices have local storage all right, and plenty of it. Arbitrarily large amounts of storage will enable more and more data replication, which means that GRIS will just keep getting better and better as its many nodes add terabytes. However, unlike the thin client idea, which is still a species of client-server computing, the GRIS model is based on radically distributed computing in which all network nodes—peers—are both clients and servers that transact with each other directly.
Like most successful complex systems, it works in a way that compares well to nature. Information rises from devices the way water vapor does and forms local clouds. Those clouds can easily fuse together to form bigger clouds with even more potential for sustaining precipitation. The digital equivalent of the Gulf Stream moves the cloud-stuff around the world. The many peers on the ground can store enough data-precipitation to survive local droughts if cloud-connection is ever interrupted, as it surely will be from time to time. And every component is a part of a sustainable ecosystem. The real cloud has the deep virtue of being able to bootstrap from zero infrastructure while remaining scalable without bound.
Exactly which information ends up being stored on which disk drive is controlled by no one—not even the owner of the disk drive. You don’t get to decide which radio waves travel through your house on the way to your neighbor’s set—your airspace is a public resource. In this vision, the extra space on your disk drive becomes the same kind of thing. This might be controversial if all that extra disk space wasn’t essentially free—but it is, and is all but guaranteed to become more so as Moore’s law ticks away.
The real cloud is made of information itself, and computing devices are transducers that make information visible and useful in various ways.
FUD AND THE BIRTH OF THE IMPOSTOR CLOUD
The computing industry loves to toss around the term paradigm shift, but (naturally and understandably) its established interests aren’t so excited when the real thing comes along. And the vision of a truly pervasive information cloud was the real thing. So, even though such “network computing” clearly represented increasingly irresistible advantages in terms of usability, convenience, and lowered costs, the industry countered with classic FUD (Fear, Uncertainty, and Doubt) about this scary, decentralized phenomenon called peer-to-peer (P2P) that could only result in the wholesale theft of intellectual property and The End of Life As We Know It.
And the client-server paradigm survived yet again.
Finally, someone in the industry had a Big Idea: All those cheap disks didn’t have to go into laptops. They could be used to build huge disk farms that would let companies offer a new service called network storage that promised the marketing equivalent of magic: It would tether users to a proprietary service, just like always, yet it would convey a vaguely “distributed” feeling that suggested openness and freedom. It worked, and soon ever-cheaper CPUs were similarly lashed together to offer remote computation as well as remote storage. The marketing fairy godmother waved her wand over the whole “new model” and pronounced it Cloud Computing.
The Rise of the Computing Hindenburgs
Earlier in this chapter, we quoted an exasperated Larry Ellison as he declared cloud computing to be nothing but empty hype. What we didn’t quote was Mr. Ellison’s next remark. After dismissing the phenomenon as ludicrous, and damning the entire industry for its triviality, Oracle’s CEO went on to say, “We’ll make cloud computing announcements. I’m not going to fight this thing.”
We’ll let you draw your own conclusions from that. Meanwhile, as we watch Oracle enthusiastically enter the fray, we’re reminded of something else about all these corporate cloud-balloons: their remarkable fragility. The sight of them bobbing around up there brings to mind the massive stateliness of the Hindenburg. Like the infamous exploding zeppelin, today’s cloud computing looks substantial but it’s really a very delicate envelope of ether. All is not heavenly in the heavens. The client-server cloud uses architecture that is vulnerable to assault, and yet, as Mr. Ellison’s remarks about fashion suggest, the greatest threats may come from within. Corporate takeovers and plain old changes in business strategy bring down “web services” every day, even from the biggest names in the business. Chances are, you know about it all too well already.
Let us be clear about this: Perhaps you are enough of an optimist to be willing to assume that all of the headlines about technical, economic, and criminal vulnerabilities of these new centralized services represent temporary growing pains and that the industry will mature to the point at which these become acceptable risks. Fine. But the bottom line is that as long as you choose to trust all of your data to a single commercial entity, those data will remain available to you no longer than the lifetime of that entity and its successors. Is that good enough for you? Well, before you decide, consider the following quote from Bloomberg Businessweek:
The average life expectancy of a multinational corporation—Fortune 500 or its equivalent—is between 40 and 50 years. This figure is based on most surveys of corporate births and deaths. A full one-third of the companies listed in the 1970 Fortune 500, for instance, had vanished by 1983—acquired, merged, or broken to pieces. Human beings have learned to survive, on average, for 75 years or more, but there are very few companies that are that old and flourishing.
Yes, most companies have successors, and often they try to do the Right Thing. But when the Right Thing ceases to make economic sense, their ability to continue to do it becomes extremely limited. This is no way to run a world.
The radically distributed networking of a P2P cloud is a whole different vision altogether. P2P at the hardware level—in some forms known as mesh networking—is self-adjusting and self-healing. Its lack of central control may make it seem ethereal (it’s really a cloud, remember), but that’s what makes it so resilient. Every time a node appears or disappears, the network automatically reconfigures, and, of course, if properly designed, it scales forever. And like the Internet itself, nobody owns it. Not only can the real cloud withstand attackers, it can’t be shot down by its own proprietors either.
Today’s “cloud computing” claims to be the next big thing, but in fact it’s the end of the line (or rather “a” line). Those corporate dirigibles painted to look like clouds are tied to a mooring mast at the very top of PC Peak, which we conquered long ago. There’s nowhere left to go within that paradigm. The true P2P information cloud hovers over Trillions Mountain—the profoundly different and vastly higher mountain of the real information revolution.
Having said all of this, though, it is important not to succumb to guilt by association. Not everything going under the rubric of “cloud computing” is ill conceived. Amid all the hype can be found some genuine and important innovations. Of particular note is the emergence of a cluster of service-oriented business models, with names like Software as a Service (SaaS), Platform as a Service (PaaS), and Infrastructure as a Service (IaaS). These models amount to a kind of outsourcing in which generic but difficult-to-manage aspects of IT infrastructure are purchased as needed, rather than being provided in-house. This approach is particularly effective at lowering barriers to entry for new players. If you’re just starting a business and are trying to focus on what you really do well, pay-per-service can be a prudent and cost-effective way to manage your affairs. Further, it levels the playing field, democratizing the tools of business and allowing new entrants to keep up with their more mature competitors. The current crop of social media startups could not have become so successful so fast without this sort of business innovation.
We do not at all disparage these developments. It is just that absent the principle of data liquidity, the platforms upon which the innovations are being delivered constrain the evolution of the marketplace in dangerous ways. It is quite possible to embrace these important new business models using technical approaches that also make long-term sense.

THE CHILDREN’S CRUSADE
Basically, a lot of the problems that computing has had in the last 25 years comes [sic] from systems where the designers were trying to fix some short-term thing and didn’t think about whether the idea would scale if it were adopted. . . . It was a different culture in the ’60s and ’70s; the ARPA (Advanced Research Projects Agency) and PARC culture was basically a mathematical/scientific kind of culture and was interested in scaling, and of course, the Internet was an exercise in scaling. . . . Once you have something that grows faster than education grows, you’re always going to get a pop culture.
—Alan Kay
The Demise of Software Engineering
A plumber will never install a faucet that dips below the highest possible water level in a sink basin. Why? Because if the faucet were to become submerged, it could conceivably siphon contaminated basin water back up into the fresh water supply.
An electrician will never install a circuit breaker panel in a space unless the opposite wall is at least 36 inches away from the front of the panel. Why? So that if some future electrician were to ever inadvertently contact a live circuit while working in the panel, she would have enough room to be thrown back out of harm’s way, and thus avoid electrocution.
A building contractor will never build an emergency exit door that opens inward toward the interior of a building. Why? Because in an emergency, a panicking crowd might surge forward toward the exit with enough force as to make it impossible to open an inward-swinging door.
A computer programmer, faced with a mission-critical design decision—such as a mechanism for providing network access to the control systems of a municipal waterworks—will do, well, whatever pops into his head.
So, what’s the difference? The difference, in a word, is professionalism.8 And we don’t mean the professionalism of the computer programmer. Plumbers, electricians, and builders are all members of mature communities of practice. These communities are participants in a complex ecology that also includes architects and other designers, standards organizations, insurance companies, lawmakers, enforcement bureaucracies, and the general public. One of the essential roles of communities of practice of all kinds is to serve as reservoirs of the accumulated wisdom of their communities. This is accomplished in many ways, but in the case of the building trades, the process is centered on a set of wholly remarkable documents known collectively as building codes. Maintained by various trade and standards organizations, these manuals essentially comprise a long litany of “thou shalts . . .” and “thou shalt nots . . .” They don’t tell us what to build, and they don’t place significant constraints on the process of building. What they do say is “if you are going to do thus, this is how you shall do it.” They do so with remarkable clarity and specificity, while also recognizing the realities of the job site. For example, the electrical code is very specific about what color wires are to be used for what purposes. But, they also allow substitutions, provided that the ends of the nonconformant wires are wrapped with the correct color of electrical tape. These documents are masterful examples of practical wisdom.
Building codes do not themselves have force of law (although they are often included by reference in municipal building laws and regulations). However, apprentice tradespeople are trained from the beginning to treat them with sacramental reverence. They are not matters of opinion, and tradespeople don’t argue about whether or not a given rule is “stupid.” You don’t question them; you don’t even think about them; you just do them. This training is reinforced by tying the process of obtaining an occupancy permit to a series of inspections by government bureaucrats. If you go to the electrical panel in your basement, you will find a series of initialed and dated inspection stickers that were placed there by a county or city building inspector at certain well-defined stages of the construction process. Although (as in all large-scale human activity) there is a certain amount of give-and-take in this process, and the exchange of cash is not unheard of, for the most part the system works remarkably well.
We doubt that very many computer professionals have ever even seen a building code. The thought processes that these codes reflect are alien to their way of doing business. Computers have long since become an essential part of our built world, and that part most certainly has health and safety implications. So, why isn’t there a National Computer Code? Perhaps it is just a result of the immaturity of the industry—after all, we are at the early stages of computerization. Well, maybe. But, here’s a data point: The first National Electric Code was completed in the year 1897, 15 years after the opening of the first commercial power plant—Edison’s Pearl Street Station in Manhattan.
And yet, as we enter the second half-century of the Information Age, one would be hard-pressed to point to any widely honored standards of practice governing the deployment (as opposed to the manufacture) of computerized devices. No inspectors come around with clipboards to verify that a piece of software is “up to code,” even though a great deal of programming is as directly relevant to public health and safety as are the creations of civil engineers.
It is not that nobody thinks about such things. Our own Carnegie Mellon University hosts a Department of Defense (DOD)-funded center called the Software Engineering Institute, which routinely develops and promotes standards and practices of a very high quality. More generally, researchers from areas ranging from academic computer science to industrial engineering do excellent work in this area. And, of course, there are a great many well-trained and highly skilled software engineers in the industry. What is lacking is any kind of organized professionalism out in the field.
Why? For starters, this is an area of activity to which there are almost no barriers to entry. Anybody can play, and so anybody does, and the field is full of amateurs with no engineering training or experience. Yes, you might have some trouble getting a full-time job as a coder in a major corporation without some kind of a college degree—preferably one involving some programming courses. But a large and increasing amount of the code that finds itself in computerized products (remember Pete’s Plasma TV) comes from the so-called open source community. Their standards for entry are somewhat lower.
The open source movement romanticizes this democratization of computer code in much the way that the culture at large romanticizes the lack of training or proficiency among musicians in punk rock bands. “Anybody can play.” The difference is that punk rock is a folk art, and software development is—or should be—an engineering discipline. Its purpose is the creation of machines made of code that run on networked processors. The future of humanity is quickly coming to depend upon the reliability and interoperability of such networked code-machines.
In this Internet era, the creation of software is now one of the most far-reaching and consequential of all human activities, yet it’s not a profession or even a trade. It’s much closer to a free-for-all. Personal computing pioneer Alan Kay says flatly that we no longer have real computer science or real software engineering. “Most software today,” Kay commented in 2004, “is very much like an Egyptian pyramid with millions of bricks piled on top of each other, with no structural integrity, but just done by brute force and thousands of slaves.”
It wasn’t always this way. There was a time when computer science was taken seriously by work-a-day developers, and software development was as rigorous as any other branch of engineering. Thirty years ago, the world ran on minicomputers that booted in seconds, not minutes, and ran flawlessly from power failure to power failure with no memory leaks or performance degradation. It is true that they didn’t have fancy graphics and they couldn’t stream CNN, but for most routine textual and numerical work they were every bit as good (and from the user’s perspective, as fast) as what we have today. Every academic science and engineering lab depended upon them, and if you had to reboot one of those machines due to an operating-system bug, you’d consider it a professional disgrace, and you wouldn’t stand for it. Today, the phenomenon of a laptop slowing to a crawl if it has been up too long doesn’t even bear comment.9
As computing moves forward on certain fronts, its ill-managed complexity is causing it to regress on others. In the “professions” of computer science and software engineering, almost all the rules have somehow devolved into matters of opinion. As the screenwriter William Goldman famously said about Hollywood, “Nobody knows anything.” Practitioners have wars about the most basic assumptions of the field. If you log onto a discussion forum and make the least controversial statement possible about any aspect of computing, some practicing “professional” from somewhere will surface to tell you that you’re stupid. You might be instructed in the wisdom of “creative waste,” and you will probably be reminded that cycles are cheap but programmers are expensive and that you don’t understand the future and that you had best get over it.
The Internet itself was designed so that it would scale gracefully—that is, grow arbitrarily without deforming or breaking its architecture. It could do that because its architecture was rigorously modular and because its designers did the math before they wrote the code. But the Internet era has now passed into the hands of a pop culture that is neither formally trained nor intellectually rigorous, and doesn’t particularly care whether its “solutions” have a rigorous engineering basis—as long as they accomplish the task at hand. Programmers have been pampered by Moore’s law for their entire working lives, and have every reason to believe that this will continue. As the herd stampedes from one social networking site to the next, for example, it’s abundantly clear that fashion and other superficial, self-regarding considerations are the real drivers of technology adoption in this era.
Many authors have discussed the sensations of power and control that coding can confer upon anyone with an inexpensive PC and the patience to master the syntax of a programming language. Programmers are the gods of the microworlds they create, and this status, along with the puzzle-solving appeal of the work itself, has produced a global culture of devotees who hunger for influence and approval, and who know just enough to create code that others find useful.
Software Pop Culture and Bad Abstraction
Software designer/programmers currently have unprecedented power, since they have craftsperson-like control over products that are destined for mass production. Programming is like a craft in that design decisions tend to be made by individuals with access to a wide range of alternatives, and their choices are often idiosyncratic. But it’s unlike a craft in that the resulting product is often mass-produced, and typically has extremely high lifetime support and maintenance costs. These costs are perhaps comparable in magnitude to the upfront tooling costs that help motivate careful design in traditional manufacturing, but, since they mostly occur after the product has shipped, they are insidious and lose their power to motivate a sense of engineering discipline. This pseudocraft character of programming does much to account for the poor quality of much production software: In handicraft, the origin of quality lies in repeated production and gradual perfection of the product. In mass production, the high cost of upfront tooling and commitment to large production runs motivates discipline and investment in design. Programming has neither. It is fair to say that a large percentage of production software comes into existence via a process that shares many of the worst aspects of both traditional craft-based production and of serial manufacture. Most software is produced by a small group or even an individual, with little separation between conception and realization. But it shares with serial production the fact that, unlike the craftsperson, the programmer tends to produce a given product only once.
Thus, we have the worst of both worlds: Lacking the rigor of careful a priori designs that the requirements of toolmaking and production engineering impose, the producer of software is free to behave like a folk artist, melding design and production into a single creative act. But, unlike handicraft, this creative act is not expected to be repeated until mastery is attained. A working piece of code is almost never reimplemented from scratch the way a potter repeatedly throws ceramic vessels on a wheel. Computer programs are certainly modified incessantly: Errors will be corrected (and new ones introduced), features may be added (but rarely removed), interfaces updated. But rare is the software product that has the occasion for even a single complete rewrite, far less a long tradition of iterative refinement and perfection.
In this regard, software is more like literature than like a physical artifact: Its quality varies widely with the talents of the individual creator. But unlike literature, the result of such an effort is a product that is destined to be used over and over again by an end user whose motivation for its use is typically not recreational. Indeed, software often runs without anyone’s conscious choice; it’s just part of what happens in the world.
Ask a software “engineer” to tell you the minimum number of bytes of memory necessary for her latest program to run, and she will look at you like you’re crazy. Coders are generally completely unaware of the low-level computing resources needed to make their creations run. They’ve been spared all that. Real engineers, however, know these things. Buckminster Fuller was fond of noting that the designer of a sailing vessel could tell you almost exactly how much a new ship weighed. Why? Because it mattered. Today’s software developers don’t think about the analogous aspects of their creations because too many things about the systems they work in have been hidden from them in order to make their lives easier. Abstraction can be a powerful tool, but it can also lead to heads buried in the sand.
In many facets of the industry, most notably web development, software development no longer even pretends to be engineering. Nothing is specifiable anymore. Supposedly, Moore’s Law makes such “compulsiveness” unnecessary: Computation and bandwidth are now “approaching free,” and we can just use as much of them as we want. If these resources really were free, then there might be some truth to this position. But they are not. As we have seen, the use of these resources implies the creation of complexity, and complexity is never free. Moore’s Law simply gives us more and more rope with which to hang ourselves. Or, if you will, more and more acceleration toward the complexity cliff.
It would be an exaggeration, but not a great one, to claim that the premier technologies of our time are in the hands of amateurs. A loose federation of teenaged hobbyists is on the verge of running the world. They are writing the codebase of humanity’s future. Worse, they’re doing it in an ad hoc, arbitrary manner that many people romanticize. These children are not scientists or architects, or artists for that matter. They are not trained, experienced, seasoned, or even necessarily very disciplined. They are good at math and have an appetite for coding, and this is their credential and the source of their authority. The world has handed them the keys because the need for the services that they offer is boundless, and real engineers are scarce and expensive. The children often work for free.
Geek Culture Doesn’t Care about People
In many respects, the world of the computer avant-garde is exotic and wonderful in ways that are little understood or appreciated outside the fraternity of its initiates. The digerati and geek culture are the vanguard of a computer-dominated future10 in which technology is a pleasurable end in itself. They live with a passion for computing machines and their possibilities. The term hobbyist scarcely does it justice. They see digital devices not as tools for accomplishing tasks but rather as the quintessentially malleable, infinitely flexible devices that, in fact, they are. Grasping their power and their possibilities can forever alter one’s perceptions of life and work. How can you be content to use a computer like a typewriter when it could do anything? The digerati are like the star child at the end of Arthur C. Clarke’s 2001: A Space Odyssey: “For though he was master of the world, he was not quite sure what to do next. But he would think of something.”
We understand the romance and the futuristic thrill of computing machines. We know how the digital adepts feel about the limitless potential of their skills. We’re technologists, too. We just happen to be technologists who put people first and technology second, because that’s the way it ought to be. We get the enchantment of computing; we just don’t expect our neighbors or our children’s classmates’ parents to get it. We get excited by the prospect of all of them coming to the conclusion that these machines are less trouble than they are worth.
The geeks actively desire to live in a technical milieu. They like the obscurity of technologies that sets them apart from the masses. But ordinary people have no such relationship with technology. Though the worldview of the digerati is fundamentally unlike that of “ordinary” users, their worldview drives the agenda for everyone. Walt Mossberg of the Wall Street Journal has written of the widespread phenomenon of technology columns that are written by geeks for geeks. How about geeks restructuring the whole world only for other geeks? That’s the world we’re heading into.
But computers aren’t really the point. Complexity is. The real agent of change is not computers per se but rather the computation that we are installing into even the most mundane constituents of our everyday surroundings. As we have seen, we are at the point that it is now often cheaper to manufacture digital information processing into an object than it to leave it out. Microelectronics permit even trivial products to be deeply complex and connectible—and that is both the promise and the problem.
That complexity is the domain of the machines. People cannot directly cope with it. Therefore, it should be the job of the machines to shield humans from machine complexity rather than mercilessly exposing them to its harsh glare. That is precisely what we mean by taming complexity. You don’t have to dumb down machines and sacrifice their potential to make the future work. Nor should you expect people to smarten up in ways that are not human. The alternative? Design the whole thing much better than we do today.
Open Source Is Not the World’s Salvation
The undeniable success of the open source movement in facilitating collaborative software projects has led many people to believe that it changes the rules of the game for technological innovation, and maybe everything else that human beings do, too. This belief is incorrect and represents a misunderstanding of the phenomenon.
Open source can be a wonderful, surprising, even magical way to grow and deploy ideas that are already well understood and accepted. But it is emphatically not a good way to create new ideas or to promote genuine innovation. Almost without exception, the highly touted success stories of the open source process represent derivative re-implementations of existing successful designs.11 One is hard-pressed to point to significant cases where the open source process as such resulted in the creation of something genuinely new.
Open source is widely perceived as a radical, paradigm-shifting phenomenon. There’s some truth in this, but the innovations are primarily economic and political, not technological. Technologically, open source is inherently conservative. Its efficacy lies in forwarding sustaining technologies, not disruptive ones. Open source has been disruptive in the marketplace, but not in the technological landscape. Further, the promulgation of “free” versions of mainstream tools—Linux for Unix, MySQL for Microsoft SQL Server, and so on—reduces the economic incentives for people to attempt disruptive innovation. Thus even the market mechanisms of open source tend to reinforce the status quo.
There have been a small number of truly significant innovations coming out of the open source community. One that we consider particularly important is Guido van Rossum’s Python programming language. It is absolutely true that the open source status of the Python project has provided dramatic amplification of van Rossum’s efforts. But our reading of the long and complex history of the project leads us to the conclusion that the true innovations associated with Python are in almost all cases traceable back to the vision of van Rossum himself, and not the open source process as such. This is a pattern that we believe characterizes the few other examples of true innovation coming from the open source community. It is worth noting that van Rossum ended up working for Google, under terms that permit him to spend half of his time on Python.
Open source is characteristically about herd behavior and local hill climbing. There is such a thing as the wisdom of crowds, but it is an inherently conservative wisdom. A crowd can tread a meandering cowpath into a highway. What it will never do, however, is decide to dig a tunnel through the mountain to shorten the path, or to leave the mountain altogether for a better one.
THE PEER-TO-PEER BOGEY
Occasionally, an important new technology for one reason or another gets off on the wrong foot. Nuclear technology, for all of its revolutionary medical and scientific applications, is forever burdened by its initial introduction in the form of the atomic bomb. Stem cell research is currently entangled with reproductive politics. Similarly, peer-to-peer (P2P) communications architectures have been sullied by their association with the theft of music recordings and other intellectual property.
Actually, it isn’t quite right to characterize P2P as new. The term refers to communications patterns characterized by symmetrical transactions among more-or-less equally privileged entities. That is a bit of a mouthful, but the concept is simple and extremely common. Two humans carrying on a conversation—in person, via telephone, or writing letters—are engaged in P2P. The interlibrary loan system is a P2P network. Nor is it new or unusual in the context of computer networking. The aforementioned beaming capability of Palm Pilots was P2P. The World Wide Web as it was originally conceived was arguably P2P. The Internet itself is, of course, P2P. And not just in some theoretical sense. The file transfer protocol (FTP) is one of the oldest tools in the suite of basic capabilities of the Net. Using it (or its more secure successors), any two PCs for which this capability has not been explicitly blocked, can copy any files from each other’s hard drives. There is no need for Napster, BitTorrent, or any pirate website in order for two consenting adults to share computer files.
So, what is it about Napster and its successors that so terrifies the entertainment industry? The answer is convenience. This is no small matter. It is true that most people are basically honest and don’t tend to steal each other’s money. But that doesn’t mean that it is a good idea to leave piles of unwatched cash on your front porch. In the view of the record industry, that is just about what Napster was forcing them to do. Their response—and that of other powerful holders of IP—was predictable. They have done everything they can think of to obfuscate, cripple, demonize, and criminalize all things P2P.
This impulse is at the core of many of the most familiar aspects of the contemporary computing landscape. It is why the web evolved away from P2P and toward the antiquated client-server model. It is why home Internet connections are engineered to be asymmetrical—with most of the bandwidth devoted to incoming data while the ability of consumers to be a source of data is crippled, if not outright prohibited. It is why you can’t use your iPod or iPhone as a generic container for exchanging information with your friends.
Books quite a bit thicker than this one have been written on the difficult legal, economic, and ethical issues underlying this response and we are not about to enter the fray—at least not here. But whether one assumes that our current approach to compensating for creative effort needs to be rethought, or conversely that existing IP rights need to be protected at all costs, one conclusion seems to us to be inescapable: Attempting to solve the problem by outlawing P2P is doomed to failure.
We will see in the following chapters that the wholesale avoidance of the P2P communication pattern is quite literally unnatural. Life on Trillions Mountain simply cannot be made to work without the embracing of a fundamentally decentralized mode for many kinds of routine local communications. There are solutions for the protection of information in a P2P world—even if you believe in the status quo with respect to IP issues. But attempting to stop the evolution of a peer-to-peer world amounts to spitting into the wind.
1 After all, the whole point of services like Hometown was to provide web authoring abilities to users who lack knowledge of the alphabet-soup of low-level Internet machinery.
2 A Google search will reveal many similar messages posted elsewhere on the web.
3 “Permalinks” are a web convention for specifying web page addresses that will never change. We are writing this with a straight face.
4 We will get to the state-of-the-art alternative of “cloud computing” a little later.
5 Such incidents have become so commonplace that our originally planned litany of such examples has become superfluous.
6 If this seems overblown, try the following math exercise: How many light switches and fluorescent fixtures are there in an 80-story skyscraper? How long would it take if each of them had to be manually removed and reinstalled?
7 Many of the web references included in first drafts of this book have already gone dead and have had to be replaced. No doubt, others will have done so by the time you are reading this. Our apologies.
8 Professionalism is not actually quite the right word. Plumbing is a trade, not a profession. But, interestingly, the analogous word does not seem to appear in English. Tradecraft comes to mind, but that term has come to be closely tied to the espionage trade.
9 We are well aware of the argument that these machines were orders of magnitude simpler than today’s PC, but is that a bad thing? We will argue that much of the additional complexity is gratuitous, and that it is quite possible to deal with the complexity we do need in ways that do not doom us to perpetual flakiness.
10 As opposed to a “human-enabled” future, which will be a lot more interesting to many of us.
11 Indeed, many of the proponents of open source do not pretend otherwise. It is worth noting that the mother of all open-source projects, Richard Stallman’s exhaustive effort to re-implement Unix bears the self-consciously ironic moniker “GNU,” which is a self-referential acronym standing for “GNUs Not Unix!”