
CHAPTER 2
The Next Mountain
In design . . . the vision precedes the proof. A fine steel building is never designed by starting to figure the stresses and strains of the steel. We must get off the ground with an impulse strong enough to make our building stand up, high and shining and definite, in our mind’s eye, before we ever put pencil to paper in the matter. When we see it standing whole, it will be time enough to put its form on paper and begin to think about the steel that will hold it up.
—WALTER DORWIN TEAGUE
Chapter 1 was about some changes in the technology landscape that very likely will happen, and happen soon. We now turn to some potential consequences of those changes. These are things that certainly can happen, and in our judgment they should happen. In the long run, we are inclined to believe that they are inevitable (but then, we are optimists). There is, however, reason to fear that the long run may be unnecessarily slow in coming. In Chapter 3, we’ll address some of the things standing in the way of progress toward Trillions Mountain. It would be disingenuous to claim that the industry is obviously on a trajectory toward the trends we are about to describe. But this is merely to say that these changes are disruptive. It is part of the definition of disruptive technologies that they seem to the inattentive to come suddenly out of nowhere. But just because the trajectory isn’t obvious doesn’t mean that it isn’t discernible. There are long-term trends and fundamental processes at work, although the details are still very much in play. The prize to those who correctly discern the large-scale trends is the opportunity to influence and profit from those details.
In this chapter, we will sketch out a future computing landscape based upon the trillion-node network. This picture has three basic facets: (1) fungible devices, (2) liquid information, and (3) a genuine cyberspace. We will explore each in turn. All three of these facets are architectural in nature. They are dependent on the development and wide adoption of broad organizational principles and well-articulated standards and practices, developed and maintained by a community of designers.1 We will speak more about the “how” of this essential process in later chapters. This chapter focuses on the “what.”
FUNGIBLE DEVICES
The titles of both this section and the next involve terms borrowed from economics. This is no coincidence. There has only ever been one human-devised system with a level of complexity comparable to that of the coming trillion-node network, and that is the worldwide economy. In a real sense, the discipline of economics amounts to the study of unbounded complexity and how to manage it. It is thus no surprise that some of its basic concepts will show up in our study. Two such concepts are those of fungibility and liquidity. We will argue that device fungibility and information liquidity represent the holy grail of our search for a manageable future.
For the benefit of readers who may have slept through Econ 101, the term fungibility refers to the ability to freely interchange equivalent goods. An item is fungible to the extent that one instance is as good as another. If I lend you $1,000 (or, less plausibly, an ounce of gold), you do not expect to be paid back with the same actual dollars or gold. One dollar is as good as another. It is often assumed that fungibility depends on physical similarity. This may be true of gold, but it is certainly not true of dollars, even if we limit the discussion to U.S. dollars. No two dollar bills are physically identical, and many transactions don’t involve physical bills at all. It is not the physical similarity that is important; it is the functional equivalence that matters. Fungibility is a desirable trait for the obvious reason that it greases the skids of commerce. If you compare a market based upon fungible currency to a barter economy the difference is stark. You may trade a goat for two rolls of fabric today and trade one of those rolls for 100 pounds of flour tomorrow. While this works tolerably well in local enclaves, it doesn’t scale or interoperate very well. It’s very hard to separate the value of the good from the good itself. It is the fungibility of currency that makes it superior to barter as a medium of exchange.
Components and Information Architecture in the 21st Century
BAA: #99–07 (Information Technology Expeditions)
Dec 07, 1998
Our application of this concept to computing devices is slightly metaphorical and not quite precise. But the basic idea is the same. To the extent that building blocks of a system are fungible, that system is easier to build, easier to maintain over time, and more likely to benefit from the positive forces of free market processes. This is the point of modular architectures of all kinds. A toy structure built out of Lego bricks is vastly easier to build than a similar structure made out of hand-carved wood. Even better (at least from the consumer’s perspective), once any relevant patents have expired, a successful line of modular products invites competitors. There now exists a thriving market of Lego-compatible toys. Although it is true that some of these products directly compete with the real thing, many others represent extensions to new (often niche) markets—expanding the customer base into areas where the original innovator cannot or chooses not to go. There are businesses specializing in Lego-compatible ninja dolls; medieval weapons; custom colors; and on-demand customized graphics. It is unlikely that the existence of this market represents a net loss to The Lego Group. Fungibility builds markets and empowers users.
Where We Stand Today
How does the computer world score in terms of fungibility? At first glance, that answer appears to be “very well.” What is more interchangeable than the PC? If you can perform a task on one modern Window’s box, you can pretty much assume that you could do it on another one as well. And even the dreaded PC vs. Macintosh divide is not what it used to be. Modern development environments have vastly simplified the process of creating cross-platform applications, and robust “virtual PC” environments are available to fill in the gaps. However, this interchangeability was largely achieved at the expense of diversity. General-purpose computers are mostly interchangeable because they mostly all run the same software.
This lack of diversity has two very serious negative consequences: First, this kind of interchangeability implies generality, and generality implies complexity. Second, whenever we put all of our eggs in one basket, we are asking for trouble. A lack of diversity inevitably leads to fragile and vulnerable systems. In the case of the PC, this fragility is manifest in many ways, but most prominently in the utter absurdity of the current Internet virus situation. Books have been written on this topic, so we will restrain ourselves here. The following statistic seems sufficient: A PC plugged into the Internet without a firewall will almost certainly become infected with a virus (and thus become co-opted as a source of spam or worse) within a few minutes. The modern PC, it seems, is not a very wise choice as our only egg basket. This path to device fungibility is not going to get us much farther.
But what of less general devices? As we work our way down the computing food chain, does fungibility increase? In fact, the opposite is the case. The current crop of high-end mobile devices generally avoids the virus plague via a set of techniques known collectively as the walled garden approach. This means that the devices are “tethered” to their manufacturer so that even after the device is in its owner’s hands, the mother ship retains ultimate control over what software may or may not be run on the device. If, for example, Apple decides that a piece of software is insecure, of poor quality, or otherwise inappropriate, then that software cannot be run on a stock iPhone. Apple even retains the ability to delete software from all iPhones after the fact. Such arrangements are the rule and not the exception with contemporary smartphones, as well as DVRs, cable and satellite boxes, and most other subscription-based devices. This approach for the most part does an excellent job at keeping these devices safe in a way that PC users can only dream about. But it reduces the fungibility of these devices to almost zero. Your TiVo contains all of the hardware and most of the software to serve as a general-purpose computing device. Moreover, one can imagine many compelling uses of a computer constantly connected to your TV. But, unless you happen to be a very well informed tinkerer with a lot of time on your hands, you are out of luck. That powerful, video-enabled PC in your living room will only do what the TiVo people permit. Smartphones have apps and so are much more flexible, but they are not much more fungible. If you wish to switch from an iPhone to an Android device, you will pretty much be starting over. And, using that lovely touch screen for some ad hoc spur-of-the-moment purpose is simply out of the question.
So, how about really low-level products? Again, from a fungibility perspective, things only get worse. Your clock radio and your cordless phones and the half-dozen remote controls that have no doubt accumulated on your coffee table all contain reasonably powerful computers, and as we have seen, newer models may well have some kind of communications capability. And, just as with a TiVo, it is not difficult to imagine useful, convenient, and creative ways to customize or repurpose these devices to better fit the particulars of your life. But if you are tempted to try, be prepared to learn to use a soldering iron.2 Every device is an island, locked in to a very specific use that is almost impossible to change. This is particularly galling in the case of all those remote controls. Yes, most new remotes have “features” that purport to make them “universal,” yet somehow some necessary function always seems to fall between the cracks, and the collection on the coffee table continues to grow. In more than a quarter-century of trying, the technology industries have proven incapable of even making the half-dozen devices found in a typical entertainment center work together well enough to be tolerated by any sane consumer.
Where We Can Be Tomorrow
There is an exception to that last statement. A home theater can often be made to work seamlessly if you follow one simple rule: Just buy all your stuff from one manufacturer. This is essentially the moral equivalent of the walled-garden approach. Simply by ceding all decision-making power to a single corporation, most of our problems are solved. Another example of the viability of this approach can be found in a different industry: Imagine a world in which all of your doors and windows were automated; in which the security system was automatically and unobtrusively activated at all the right times; and in which you were instantly reminded if you leave your keys in the lock. This description is either futuristic science fiction or it is utterly mundane, depending upon whether it is describing your home or your car. What’s the difference? Simply that cars are designed and built as a unit and houses are not.
Unfortunately, a walled-garden home would leave something to be desired. It is one thing to be forced to choose between Apple and Android when buying a smartphone, it is quite another having to make a similar choice when buying a home. A consumer would be a fool to agree to a single-vendor commitment when investing in something as complex and long-lived as a home or an apartment. Imagine deciding five years into owning a home that you’d like to change something. Maybe you’d like to update the lighting, or the furniture, or the refrigerator, or the doors. Sorry, if the manufacturer doesn’t make those things or have a deal with someone who does, you are just out of luck. And don’t even think about trying to install that heirloom furniture from your childhood home. This, in a nutshell, is the challenge of pervasive computing: How do we build a world that hangs together well enough to be worth living in without giving up the ability to pick and choose among competing offerings? If the industry is going to find an answer to this question, it is going to involve a change of perspective, and the giving up of some very ingrained habits. Instead of using deliberately incompatible designs and protocols, manufacturers must begin to see themselves and their products as participating in an ecology—an ecology of information devices.
This will involve a change in mind-set. In today’s market it is extremely common for the manufacturers of consumer electronics to go out of their way to make it difficult for third-party devices to interoperate with their products. But in an information ecosystem, interoperability must become a sacrament. The sheer scale and diversity of the world that we are in the midst of building implies that going it alone is a fool’s errand. Attempting to do so once this trend gains steam will represent a choice analogous to that made by the early online service providers such as Prodigy and CompuServe as the open Internet slowly but inexorably overtook their proprietary models—and the results will be the same.
How will this kind of universal interoperability be accomplished? Is it even feasible? This is a fair question. A straightforward extrapolation from today’s networking practice might lead to a certain pessimism. Will a trillion devices all be nodes on the Internet? Are we going to burden every light switch with the complexity required to speak the complex suite of Internet protocols plus some standardized home control protocol? And do we expect existing standards bodies to produce such a protocol and negotiate its universal adoption? Does our goal of device fungibility in an open market imply detailed published specifications and standards for every possible feature of every possible product?
The answer to all of these questions, fortunately, is “no.” First of all, a trillion-node network does not imply a trillion-node Internet. The vast majority of pervasive computing devices will only ever communicate with their immediate neighbors in a preconfigured peer-to-peer arrangement. This is not to say that there will not be data paths to and from the Internet to such devices. But in a great many cases those paths will be indirect, often involving numerous hops over much more primitive data paths. On the matter of protocols and standardization, the first thing to recognize is that very many devices have very little to say for themselves. Imagine putting all the complexity of a PC into a doorbell to get it “on” the Internet. Today, due to our lack of modularity, the most practical path often involves something nearly this complicated. A doorbell need communicate only one message, and that message is only a single bit long. This may be an extreme and atypical example, but if we go just one more step, to a protocol containing exactly two messages (which still requires a payload of only one bit), we will have captured the needs of a great many devices, including simple light switches, desk lamps, motion detectors, door locks, and many, many other devices. If we allow ourselves four bits (16 unique messages), we will have subsumed the needs of numeric keypads, simple telephone dialers, many security panels, and so on.
The previous paragraph may seem trivial and simplistic, but it is the key to the path forward. The trick is to recognize that the set of all devices requiring only, say, two messages forms a class. At MAYA we call such a class a realm. Once we have conceptualized the notion of realm, several key pieces of the puzzle quickly fall into place. First of all, although some realms—such as the Internet—have a great many different messages and so are quite complex, many others, including the ones just described, have very few different messages and so are extremely simple. The value of this observation lies in the fact that simple realms require only simple protocols, and simple protocols are easy to get people to agree to. If we can only manage to resist feature creep, there just isn’t very much to fight about.
The next realization is that if we avoid making unnecessary assumptions about how a realm will be used, we can get a great deal of interoperability for free. So, for example, if we are careful to define the two messages for our light switch not as “on” and “off,” but as “true” and “false” (or, equivalently, as “1” and “0”), then the same protocol can be used for all other two-valued devices, which means that any two such devices can speak directly to each other.3 This means that in one fell swoop, we have achieved universal interoperability among the vast number of devices—existing and potential—in the “True/False, On/Off, 1/0” realm. This in turn implies that, for example, all motion sensors will have achieved near-complete fungibility, and also that some blue-collar installer out in the field can be sure that any one of them can be used to control, say, any light fixture.
This is still pretty trivial. But we next observe that realms can be nested in the following sense: We can easily arrange for the 2-message realm to be represented as a proper subset of the 16-message realm (e.g., by agreeing that “1” means “True” and “0” means “False”). If we then add the simple requirement that all devices ignore any message they don’t understand, we now have a situation in which the simple 2-state devices can be directly mixed with members of the more capable 16-state realm. So, our simple light switch could serve as a source of messages for a controller that understands numeric commands, and vice versa. Moreover, even if we fail at coming to universal agreement on realm definitions, this will create a market for simple devices to bridge incompatible realms (we call such devices transducers).
The plausibility of this story clearly depends upon keeping things simple. It is one thing to talk to a light switch. But the list of messages we would need to control, say, a satellite TV set top box would be another matter. And what about device fungibility in the case of such a box? The features of such a device are so numerous and idiosyncratic that it would seem that we have made very little progress toward our goal. The answer to both problems involves one of the most basic patterns of nature: recursive decomposition. This is just a fancy way of saying that complex things should be built out of simple things. We can think of our satellite box as a wrapper around several simpler devices: a tuner box, a box that sends pictures to your TV, a user-interface box, a diagnostic box, a movie-ordering box, a video decryption box, and so on. Some of these boxes may be made up of even simpler boxes, perhaps down several levels. Thought of this way, no single part of the system needs to be all that complex—at least in terms of the messages we might want to exchange with it. If we can then figure out a way to expose the internal interconnections among these simple components to the outside world, we will be off and running. Figure 2.1 sketches this concept as applied to the components of a clock radio.
Figure 2.1 Componentized clock radio: a common appliance re-imagined as a modular device
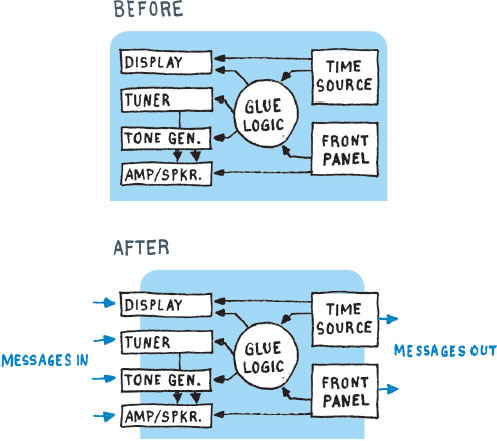
Please note that we are not necessarily suggesting that satellite boxes or clock radios should be physically modular—cost, space, and aesthetic considerations often preclude this. What is absolutely essential, though, is that we as the architects of Trillions start to think recursively and resolve to keep any given module simple enough and open enough that it could in principle serve as a fungible building block of new and unanticipated assemblies. Today, computing is largely thought of in terms of hardware versus software. The concept of fungible information devices drives a refactoring of this approach. Instead of thinking of hardware and software, we suggest that a more fruitful way of thinking about information systems would be to start with the distinction between devices and information. In essence the divide is between physical and metaphysical. Devices can then be further divided between hardware devices and software devices. These are built in very different ways, but they do exactly the same thing: They process information. In practice a particular building block may start out as a software module and, later, it may be replaced by hardware—or vice versa.4 This may happen because someone else in the market produced a version of the building block that was faster or more energy efficient or more robust along some other dimension. In a world of fungible components, such substitutions will become routine—they can be done without disrupting the basic architectural integrity of a design.
If we can make the transition to interchangeable information devices that are fungible between software and hardware, we will quickly see an explosion of innovation. We will discover that our customers will amaze us. Far from costing sales, interoperability will cause our products to be used in ways we could never have imagined, and in numbers we could only have dreamed of.
These ideas are simple, but they are not simplistic. This kind of thinking lights the way toward an open, competitive marketplace of incrementally evolving device families that collectively will deserve the label ecosystem.
LIQUID INFORMATION
Liquidity is the other side of the fungibility coin. In economics the term is used in various ways, all generally relating to the free flow of value in an economy. Similarly, our metaphorical usage refers to the ability of information to flow freely where and when it is needed. At one level of analysis, the Internet itself is a triumph of information liquidity. There are perhaps five billion or more devices connected to the Internet, and any one of them is capable of sending packets of data to any other one almost instantly. But users don’t care about packets; they care about meaningful units of information, and at that level, the liquidity scores are much more mixed.
Where We Stand Today
There is so much information available on the Internet, and there are so many different ways to measure quantities of information, that any statistic about how many petabytes, or exabytes, or whatever, of information on the Net is essentially meaningless. But there is a lot—eclipsing anything the world has seen by orders of magnitude. And a significant percentage of it can be summoned to a screen near you with a few clicks of a mouse. Doesn’t this count as liquidity? Not really. The term liquidity evokes images of a bubbling brook, with water finding its own course around boulders and down waterfalls; merging with other streams; being scooped up into buckets and poured into bottles and glasses. The flow of information from a web server to your screen is nothing like that. It is a highly regimented, rigidly engineered process by which largely predetermined chunks of data are dispensed in predetermined formats. Every website is like a discrete vending machine where we go to procure a certain particular kind of information. When we need a different kind, we move on to another machine. In this sense, it is less a matter of the data flowing to the user than the user traveling to the data.
There are modest exceptions to this pattern. The most obvious example involves what is known in web jargon as mashups. The term refers to the practice of gathering information from multiple sources around the Net and displaying them together on a single web page. The most common example involves using Google maps as “wallpaper” in front of which various geocoded data points may be displayed. This is indeed a big step forward, but in most cases the effect is more like the layering of one or more transparent acetates over a map than a true intermingling of independent data objects. A more aggressive plan for promoting information liquidity involves a family of protocols and interfaces that have been developed by the web technical community with the explicit goal of getting the data to flow. These include mechanisms with names like RSS (real simple syndication) and SOAP (simple object access protocol). These are parts of a broader framework going under the name of web services, and comprise techniques for sharing small amounts of information from one machine with another on demand. Again, such techniques represent real progress, but for the most part their designs assume a conventional client/server pattern of data flow, in which all aggregations of data ultimately reside in large servers controlled by single corporate entities. The data flow, but only begrudgingly.
As we have already seen, the low-level Internet is a marvel of liquidity. If you can represent something digitally, you can transport it using the Internet. Word processing files, photos, web pages, spreadsheets, music, movies, computer programs, encrypted files whose contents are a total mystery—it makes no difference. If your target device is on the Net and it has enough room, the Internet can get it there for you. We’ve come to take this fact for granted, but if you think about it, it is quite a trick. How is the trick done? How did a small group of designers working in a day when CNN on a computer was an ironic joke manage to anticipate all this diversity? The answer is very simple: The Internet slices everything up into a bunch of little data containers called packets. The problem thus reduces to a relatively simple one of creating mechanisms for moving around packets. The strategy is the same as that seen in the use of standardized shipping containers for the transport of physical goods. Instead of having one system for moving machinery and another one for moving dry goods and so on, we simply put everything into standard containers, and then design all our cranes and trucks and ships and railcars to efficiently move those containers.
Figure 2.2 The intermodal shipping container: a standardized interface between shippers and carriers
The concept of containerization is further explored online at http://trillions.maya.com/Containerization.
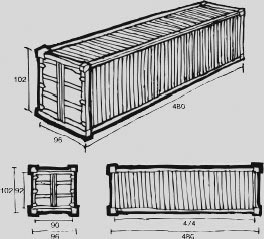
Packets are small, they are simple, and most importantly they are (at least so far) non-negotiable. If you want to be part of the Internet, you need to deal with packets, and if you want to use the Internet, you need to turn your payload into packets. This is not to say that packets are always the best way to represent data. For any given task, a clever engineer can usually conceive of a bespoke representation that would be more efficient and/or convenient. But almost never is this worth the trade-off.
Regrettably, nothing like the packet exists at higher levels of our information infrastructure. Our semantic stack progresses nicely from the bit to the byte to the packet. After that, however, standard practice degenerates to a chaos of “just so” protocols that bear a closer resemblance to longshoremen with nets than to the structured simplicity of shipping containers. The emergence of a uniform data container is in the critical path to the world of Trillions.
Where We Can Be Tomorrow
Suppose we did have a “container” for data. Nothing fancy like XML or its ilk. Just one small step up from the packet. Think of it as a little box into which you could fit an e-mail message, or a single image, or a chapter of a book, or a single scene from a movie. Let’s add just one more feature: On the outside of each “box” we could put a unique number. Not a name or a date code or an owner or anything like that (those things will be inside the box), just a number that is different on every box.5 Think of this number as being like the barcodes that we routinely put on the outsides of virtually all shipping containers. Such numbers aren’t names because they don’t identify the contents of the box, only the box itself. (This is important: It encourages all boxes to be treated on an equal basis. Plus, in most cases, it is none of the transporter’s business what is in the box, anyway.) We could then use these numbers as pointers that allow the contents of one box to refer to other boxes. In this way, for example, there could be a box that in effect refers to an entire book or movie, simply by containing a list of other boxes’ numbers.
Such a concept (except for the unique identifier) was proposed in 1997 by Michael Dertouzos, then head of the MIT Laboratory for Computer Science. He prefaced the proposal with the following quotation:
Achieving some basic degree of understanding among different computers to make automatization possible is not as technically difficult as it sounds. However, it does require one very difficult commodity: human consensus.
As Dertouzos suggests, this idea is, from a technical perspective, really quite trivial. Making it happen in practice is quite another matter. The problem is that the way of thinking implied by this simple little idea is completely at odds with the way the web deals with content. For this reason (and this reason alone), the challenges are significant. But let’s fantasize for a moment and assume that in the future all content is shipped around the Net in our little boxes. What would such a world be like?
For starters, it would be a much simpler world. Even though the Net is based only on packets, if we go up a level we discover that it is replete with special-purpose protocols and standards, all of which do pretty much the same thing. There is a protocol called SMTP that is only used for sending e-mail. There is a different protocol for fetching e-mail (actually, there are two: POP and IMAP). There is HTTP for web pages, NTP for the time of day, the aforementioned SOAP and RSS (among others) for “web services.” We will not belabor the point, except to note that as of this writing, the Wikipedia list of such so-called application layer protocols contains 51 items. There is no doubt that every one of these protocols has some handy features and optimizations that were important back when computers were orders of magnitude slower and when the Internet was accessed via dial-up lines, but we can assure you that with today’s technology there is no data payload being transported by any of them that couldn’t be successfully put into our little boxes.
Thus, all 51 protocols could be replaced by a single protocol. (Let’s call it LBTP—Little Box Transport Protocol). Such a change would be guaranteed to vastly increase information liquidity. This is true for several reasons. For starters, both data transport and data storage would become much more standardized and general. Instead of requiring devices to have the complexity of a relational database or some one-off remote access protocol to fetch and store information, we just ask for a trivial ability to get little boxes and give little boxes. This becomes increasingly important in the age of Trillions, since it permits relatively simple devices to retain generality. If a device can transport and store one little box, it can do so with another. The computers in your car might or might not be able to display pictures from your camera or save the state of a video game, but in our hypothetical world they will surely be able to back them up in a network dead zone and pass them on whenever service is restored.
Additionally, since the boxes are assumed to be relatively small, designers will be forced to break up large blocks of data (such as web pages and large databases) into smaller units. Although it is true that this could be done stupidly (e.g., by breaking the data up into semantically meaningless blocks at arbitrary cut-points) this is not what competent engineers will do. Rather, they will tend to make their slices at semantic boundaries. So, for example, if a web page comprises a list of travel information about 50 cities, each city will tend to be given its own box. This, in turn, will tend to support the evolution of user interfaces that make it possible to tear off parts of visualizations that are of interest to the user. Such fragments of data could be mixed and matched and caused to flow into tight spaces of the pervasive computing world, performing functions that today would require the cost and complexity of a PC or an iPhone.
The liquidity resulting from this kind of containerization of data is an essential step in the emergence of the trillion-node network. The traditional Internet serves as the arteries and veins of the worldwide information circulatory system, and it will continue to do so. The advent of a network of many billions of cheaper, less-capable, but far more ubiquitous devices represents the emergence of a system of capillaries, reaching all the cells of our technology and of our society. This is only going to work if the viscosity of our information lifeblood is reduced to a minimum.
CYBERSPACE FOR REAL
The word cyberspace has not fared well in recent years. Its common usage has devolved into a geeky synonym for “Internet.” This is a shame, because it originally referred to a distinct idea that is both nonobvious and important. It was coined by science-fiction writer William Gibson in 1982—a time in which the idea of a public information network was not even on most people’s radar. Gibson’s cyberspace was in effect a parallel reality, a “place” filled with “things” made of bits rather than atoms. Most importantly, it was a place where people “went” to interact. The idea was captured evocatively by author and sometime Gibson collaborator Bruce Sterling in the following:
Cyberspace is the “place” where a telephone conversation appears to occur. Not inside your actual phone, the plastic device on your desk. Not inside the other person’s phone, in some other city. The place between the phones. The indefinite place out there, where the two of you, two human beings, actually meet and communicate.
In Gibson’s stories, cyberspace is accessed via a “consensual hallucination” produced by a machine involving the attachment of electrodes to one’s head. Although the real Internet may or may not someday come to that, the mode of access is beside the point. For present purposes, the inconvenient presence of a plastic screen between user and cyberspace is incidental. What is not incidental is that cyberspace is a (almost) literal place where people can “go” to find and interact with digital “things” and also with other people.
In writing these words, we are painfully aware of the triteness that many readers will perceive upon first reading. Everybody talks about the Net this way. What we are trying to say, though, is that these ideas are not metaphors. The places between our telephones where we have our conversations are not physical but they are quite real. They exist, and they have done so for the century and a half since the invention of the telephone. Also real is the one-dimensional “path” defined by the radio dial, along which one can travel and occasionally bump into “objects” in the form of radio channels. The computer and the Internet have expanded the scope of these places almost beyond imagination. So, a little imagination is called for.
Where We Stand Today
What exactly do we mean by place? The idea is related to what mathematicians call manifolds. This notion generalizes the idea of coordinate system and lets us talk about “where” things are and “how far apart” they may be. The surface of the Earth is a manifold, and so the world has “places” where we can go and where we can put things. If you use a modern personal computer, its so-called desktop is a manifold. It is a place where you can put icons representing your digital stuff. You can drag them around and group them in ways that you find meaningful or pleasing—just as on your physical desktop. This desktop metaphor has been with us since the early 1980s, when it was introduced at the Xerox Palo Alto Research Center and popularized by Apple with the original Macintosh computer. It was a toe in the water of a true cyberspace.
At the time, there was a great deal of research in a field called Information Visualization6 on how this metaphor could be extended from the desktop out into the Internet so as to form the basis of a single, worldwide collaborative information space—a true cyberspace. But there was a competing vision. Its name was “hypertext.” This term was coined in the 1960s by an eccentric visionary named Ted Nelson in the context of an extremely ambitious plan for a distributed, text-based information system known as Xanadu. Nelson’s vision was sweeping and largely beyond our scope, but the core idea was that of the hypertext link—a technique by which disparate units of text could be associated such that a single click of a mouse can take the reader instantly from one place to another. In cyberspace terms, hypertext links can be thought of as “magic wormholes” from one point in space directly to any other.
Thanks to Nelson and a small community of researchers exploring the technical and human factors of hypertexts, the idea was in the air as the World Wide Web emerged in the early 1990s, and it was a very appealing one. If it lacked the new frontier romance of the cyberspace vision, it made up for it with relatively straightforward answers to pressing questions concerning how users were going to find their way around the vast new world of data that was rapidly forming itself. Moreover, being essentially text based, hypertext techniques were better suited to the graphically primitive personal computers that were commercially viable for consumer purchase at the time.
As a result, the vision (if not the term) of cyberspace basically disappeared from the industry’s road map. The first web browsers presented the Internet primarily as columns of clickable lists leading to other such lists. Soon, those columns were to give way to billboards of clickable images, but the basic model remains the same. The World Wide Web is literally a tangle of arbitrary links. There is no sense of “distance” in the web model. One can ask how many clicks it takes to get from one web page to another, but beyond that, it makes little sense to ask how “far apart” they are.7 It is analogous to living in a town arranged randomly, completely without neighborhoods. We have made up for this randomness with the miracle of Google. This approach has gotten us a long way. But it is not the end of the story.
In the mid-1970s, an interesting piece of software was making the rounds in the computer community. Its name was ADVENT, which was short for Adventure (file names were limited to six characters back then). If you happened to stumble upon this program without knowing anything about it, it was a fascinating and disorienting experience. After the briefest of introductions, your terminal (most likely a teletype machine) would type the following:
You are standing at the end of a road before a small brick building. Around you is a forest. A small stream flows out of the building and down a gully.
>
A user at that time would recognize the “>” character as a prompt that it was his or her turn to type. After some fumbling, it became clear that you could type things like “GO SOUTH” or “ENTER.” Typing the latter would result in the following:
You are inside a building, a well house for a large spring.
There are some keys on the ground here.
There is a shiny brass lamp nearby.
There is food here.
There is a bottle of water here.
It turned out that the well house stood near the entrance to “Colossal Cave,” a huge underground labyrinth filled with treasures to be found and puzzles to be solved. Not only could you move around in and near the cave, you could pick up, carry, use, and drop objects like the keys, lamp, food, and bottle. And, if you dropped something at a particular location and then came back later, the object would still be there!
Users of Second Life will be unimpressed, but in 1975 this was a revelation. Perceptive observers (whether or not they had any interest in the novel idea of playing games on computers) were quick to extrapolate this relatively simple stunt to something very new. This was the computer, not as the realization of Charles Babbage’s vision of “calculating by steam,” but computer as medium—a medium sufficiently expressive for the creation of what amounted to real places8—places where you could put what amounted to real things. It didn’t take a lot of imagination to picture multiuser versions of the game in which people could “go” to meet and collaborate (this was not long in coming). Those familiar with the nascent Internet could extrapolate from a virtual model of a Kentucky cave to a virtual model of an office building or hospital; or of a city; or . . . of the world.
As we have seen, this represents a path not (yet) taken. We have been distracted by the low-hanging fruit of the hypertext-based World Wide Web. But it is too compelling a path to believe that we will not get back to it soon. It is as if every piece of real estate in the world somehow had an undiscovered companion lot right next to it, waiting for development. How valuable would some of those lots be?
And, then there are those keys, the lamp, the food, and the bottle. The really important difference between the hypertext and the cyberspace models lies here: Virtual places imply virtual things, that is to say, digital objects. What do we mean by this term? What counts as a thing? Philosophers have earned good livings attempting to answer this question ever since Plato, and anything we say on the topic will annoy somebody. So, let’s keep it simple: Things have identities that persist over space and time. If this is what we mean by digital objects, then it is fair to say that not a lot of the stuff out there on the Net qualifies. Is a web page a digital object? Well, a page is defined by a URL (the thing that starts with “HTTP:”). But, a URL does not actually point to the contents of a page. Rather, it points to the place in some server (or server farm) where the page can be found. This is more than a semantic distinction. It means that the content itself has no real identity. There is no precise way to point to the content without also pointing to the location. And if the content is moved (if, say, it is taken over by another custodian), its identity changes. These are not characteristics of objects. Anyone who has clicked on a dead link immediately wonders what that thing was and if she can find it somewhere else. We, and our ancestors, all grew up in a world of objects, so we try to treat web pages as digital objects; we fool ourselves into thinking they are. Until they disappear with a click.
Where We Can Be Tomorrow
Think back to those little boxes of data that we discussed earlier. Each box has a unique number on its outside. The numbers are called universally unique identifiers (UUIDs). The number identifies the container, regardless of where it is located, and regardless of whether the contents of the box change. Such containers thus meet our minimal definition of digital object. We now have everything we need to start to build a truly public information space. We say public because the little boxes are capable of maintaining their identity independently of where they are stored or of who owns them.
This may sound like a minor point, but it is not. Let’s fantasize a little more: Suppose we assigned a UUID to everything in the world that we wanted to talk about: every place, every organization, every product, every document, every dubious claim, every abstract concept—everything (there are plenty of numbers to go around, trust us). We don’t have to assign the numbers all at once, and we don’t have to be completely consistent—we can fix up the problems as we go along. Nor do we need some central authority to assign these numbers. If you need a number for some entity, you would simply check something like Google to see if somebody else already gave it one, and if not, you just make one up. (It is not quite as simple as that, but pretty close.) There is no need to fight over who gets to decide—they are just numbers—one is as good as another.
![]()
Once we have these numbers, we can start to have fun. Let’s say you have a nice experience at a restaurant and you want to write a review. First, you create a note on your phone, describing the experience. The phone will automatically generate a new little box with a unique identifier for the note. You publish the note wherever you like—your favorite blogging site, some Yahoo! Group, Facebook . . . whatever. In fact, you can send it to all of those places. They will all remember the UUID, so there will be no confusion. In fact, if you prefer, you could publish the note yourself, cutting out the middleman, if you are willing to run a simple server on your PC—peer-to-peer style. Next, you send a little message to a Google-like indexing service, which associates the number of your review with the unique number of the restaurant (compared to what Google can already do, this is duck soup). If you wish to identify yourself, you can also include a third UUID identifying you as the author (after all, you are certainly unique). That way your friends can find your reviews in particular.
And that, except for some not-very-hard details, is pretty much it. Of course, this is just one example. Obviously, the Google-like service will associate the UUID of the restaurant with the identity of its location (all the search engines do this kind of thing already). All the publishers will have UUIDs, too, so it will be easy to find the note, or to update it if the publisher allows it. There will be UUIDs identifying the intellectual property status of your note, so people and machines can tell whether and how they may use your review. You can give your UUID to friends, so they can search for all of your reviews, and so on and so forth.
What we have essentially done in this story is to turn the web inside out. Today, everything on the web is organized by publisher—if you want to read something, you need to go to a (usually single) website that contains it. In cyberspace, things can be organized by topic. Information objects make this possible by separating the identity of the object from its location (and, thus, its effective owner). The search engines try to do this with today’s web, but it is a losing battle, since the hints they have to work with are obtuse and unreliable. In cyberspace, things are much easier, since the creator of a piece of information gets to decide where to put it. And by where we don’t mean places like Yahoo! or Facebook. Rather, we mean places like “at the restaurant to which the review pertains,” or “the appliance that this user manual describes.” This will not put Yahoo! or Facebook out of business—quite the opposite. But it will cause their business models to evolve—no doubt in interesting ways.
As evidence that this capability has vast business potential consider the explosion in the number of location-based services of late. They allow you to do something that may appear on the surface to be similar to our story. However, they are regrettably tied to each company’s own servers and systems and in many cases custom-designed database schemes. When (not if) those companies change business models, fall prey to malicious attacks, or go out of business, all your carefully curated information will disappear, and you will find that those web things you considered information objects didn’t in reality pass the test for true objectness.
Taken together, device fungibility, information liquidity, and a true cyberspace suggest a new and radical path forward in the evolution of computing. Once we have liberated the world’s data from their proprietary silos, they will be free to flow downward into the rapidly emerging capillary web of devices, where they can start to interact via a trillion sensors and transducers with the ground-truth of the real world. The promise of such interactions is not just about computing as such, but about the blending of the digital and physical world into one seamless whole. Cyberspace becomes much more compelling when it reflects, informs, and is informed by the real world.
The rest of this book is in essence an exploration of the prospect and problems of this process.
1 The word designer is used to label practitioners of activities that range from the ridiculous to the sublime. Later on we will give significant attention to the concept of “design.” For now, suffice it to say that our use of the term is broad. Engineers, for example, are certainly designers in our book.
2 This is no exaggeration. It is common, for example, for professional home-theater installers to physically modify consumer devices in a heroic effort to lash together disparate products into a system with a modicum of usability.
3 We are simplifying here just a bit. In addition to agreeing on the messages, we also have to agree to how those messages are actually transported, but this is only a little harder.
4 It is important to note that, although software is often thought of as data rather than as mechanism, this is incorrect. Computer code indeed comprises data, but a piece of code is in fact merely a plan (a blueprint, if you will) for the creation of a running computer program. The latter, although existing inside the memory of a computer, is an operational mechanism—taking up space in memory and consuming energy. It is in every essential respect a machine.
5 If you are worried that there aren’t enough numbers to go around, just do the math: 34 bytes would be enough to label each atom in the known universe.
6 Our late colleague and fellow MAYAn Steve Roth was one of the founders of this field.
7 For math geeks: Distances on the web are “topological” in nature. A true cyberspace can support “topographic” distances.
8 Significantly, Colossal Cave is a real place. The author of Adventure, a computer scientist named Will Crowther, was also a caver, and he based the game’s topology on a particular cave in Mammoth Cave National Park in Kentucky. It has been claimed that cavers who knew the cave could find their way around the game, and vice versa.