
In the preceding two chapters, we saw how to encapsulate behavior and information with classes. Using the concepts of association, composition, aggregation, and derivation, we modeled relationships between those classes and looked at some of the benefits of polymorphism along with the use and abuse of virtual functions and their implied contracts with derived classes.
In this chapter, we’ll look at a functional (rather than class-based) approach to composition and extensibility, and see how we can use this to implement some of the patterns that have previously required us to burn our one and only base class and override virtual functions; and all with the added benefit of a looser coupling between classes.
Let’s start with another example. This time, we want to build a system that processes incoming (electronic) documents prior to publication. We might want to do an automated spellcheck, repaginate, perform a machine translation for a foreign-language website, or perform one of any other number of operations that our editors will devise during the development process and beyond.
After some business analysis, our platform team has given us a class
called Document, which is shown in Example 5-1. This is their baby, and we’re not allowed
to mess with it.
Example 5-1. The Document class
public sealed class Document
{
// Get/set document text
public string Text
{
get;
set;
}
// Date of the document
public DateTime DocumentDate
{
get;
set;
}
public string Author
{
get;
set;
}
}It has simple properties for its Text, the DocumentDate, and the Author, and no other methods.
Now we want to be able to process the document. At the very least, we
want to be able to Spellcheck, Repaginate, or Translate it (into French, say). Because we can’t
change the Document class, we’ll
implement these methods in a static utility class of common processes, as we
learned in Chapter 3.
Example 5-2 shows this class,
although the implementations are obviously just placeholders—we’re
illustrating how to structure the code here, and trying to write a real
spellchecker would be a rather large distraction.
Example 5-2. Some document processing methods
static class DocumentProcesses
{
public static void Spellcheck( Document doc )
{
Console.WriteLine("Spellchecked document.");
}
public static void Repaginate( Document doc)
{
Console.WriteLine("Repaginated document.");
}
public static void TranslateIntoFrench( Document doc )
{
Console.WriteLine("Document traduit.");
}
// ...
}Now we can build a simple example of a document processor that translates, spellchecks, and then repaginates the document (see Example 5-3).
Example 5-3. Processing a document
static class DocumentProcessor
{
public static void Process(Document doc)
{
DocumentProcesses.TranslateIntoFrench(doc);
DocumentProcesses.Spellcheck(doc);
DocumentProcesses.Repaginate(doc);
}
}And we can call on it from our main function, to process a couple of documents, as shown in Example 5-4.
Example 5-4. A program to test the document processing classes
class Program
{
static void Main(string[] args)
{
Document doc1 = new Document
{
Author = "Matthew Adams",
DocumentDate = new DateTime(2000, 01, 01),
Text = "Am I a year early?"
};
Document doc2 = new Document
{
Author = "Ian Griffiths",
DocumentDate = new DateTime(2001, 01, 01),
Text = "This is the new millennium, I promise you."
};
Console.WriteLine("Processing document 1");
DocumentProcessor.Process(doc1);
Console.WriteLine();
Console.WriteLine("Processing document 2");
DocumentProcessor.Process(doc2);
Console.ReadKey();
}
}Compile and run that, and you’ll see the following output:
Processing document 1 Document traduit. Spellchecked document. Repaginated document. Processing document 2 Document traduit. Spellchecked document. Repaginated document.
We encapsulated a particular set of processing instructions, executed
in a particular order, in this (static)
DocumentProcessor class so that we can
easily reuse it with different client applications that want a standard,
reliable means of performing our “translate into French” process. So far,
this should all be pretty familiar.
But what about a different set of processing operations, one that leaves the document in its native language and just spellchecks and repaginates?
We could just create a second DocumentProcessor-like class, and encapsulate the
relevant method calls in a process function:
static class DocumentProcessorStandard
{
public static void Process(Document doc)
{
DocumentProcesses.Spellcheck(doc);
DocumentProcesses.Repaginate(doc);
}
}And then we could add some calls to that processor in our Main method:
Console.WriteLine();
Console.WriteLine("Processing document 1 (standard)");
DocumentProcessorStandard.Process(doc1);
Console.WriteLine();
Console.WriteLine("Processing document 2 (standard)");
DocumentProcessorStandard.Process(doc2);Nothing is intrinsically wrong with any of this; it clearly works, and we have a nice enough design that neatly encapsulates our processing.
We note that each DocumentProcessor
is coupled to the Document class, and
also to each method that it calls on the DocumentProcesses class. Our client is coupled to
the Document and
each DocumentProcessor class that it
uses.
If we go back to the specification we showed earlier, we see that we are likely to be creating a lot of different functions to modify the document as part of the production process; they’ll slip in and out of use depending on the type of document, other systems we might have to work with, and the business process of the day.
Rather than hardcoding this process in an ever-increasing number of
processor classes (and coupling those to an ever-increasing number of
DocumentProcesses), it would obviously be
better if we could devolve this to the developers on our production team.
They could provide an ordered set of processes (of some kind) to the one and
only DocumentProcessor class that
actually runs those processes.
We can then focus on making the process-execution engine as efficient and reliable as possible, and the production team will be able to create sequences of processes (built by either us, them, contractors, or whoever), without having to come back to us for updates all the time.
Figure 5-1 represents that requirement as a diagram.
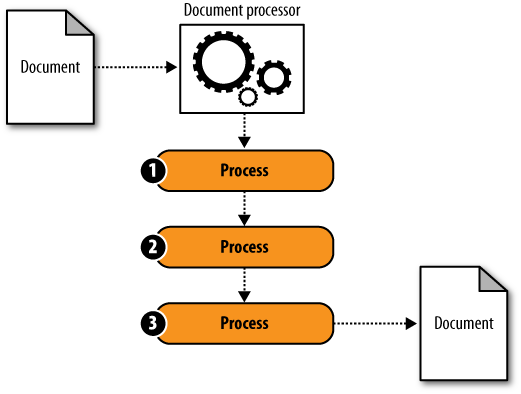
The document is submitted to the document processor, which runs it through an ordered sequence of processes. The same document comes out at the other end.
OK, let’s build a DocumentProcessor
class that implements that (see Example 5-5).
Example 5-5. An adaptable document processor
class DocumentProcessor
{
private readonly List<DocumentProcess> processes =
new List<DocumentProcess>();
public List<DocumentProcess> Processes
{
get
{
return processes;
}
}
public void Process(Document doc)
{
foreach(DocumentProcess process in Processes)
{
process.Process(doc);
}
}
}Our document processor has a List
of DocumentProcess objects (a
hypothetical type we’ve not written yet). A List<T> is an
ordered collection—that is to say that the item you Add at index 0 stays at index 0, and is first out
of the block when you iterate the list, and so on. That means our Process method can just iterate over the
collection of DocumentProcess objects,
and call some equally hypothetical Process method on each to do the
processing.
But what type of thing is a DocumentProcess? Well, we already saw a solution
we can use—we could create a DocumentProcess abstract base, with a Process abstract method:
abstract class DocumentProcess
{
public abstract void Process(Document doc);
}We then need to create a derived class for every processing operation, as shown in Example 5-6.
Example 5-6. Implementations of the abstract DocumentProcess
class SpellcheckProcess : DocumentProcess
{
public override void Process(Document doc)
{
DocumentProcesses.Spellcheck(doc);
}
}
class RepaginateProcess : DocumentProcess
{
public override void Process(Document doc)
{
DocumentProcesses.Repaginate(doc);
}
}
class TranslateIntoFrenchProcess : DocumentProcess
{
public override void Process(Document doc)
{
DocumentProcesses.TranslateIntoFrench(doc);
}
}Now we can configure a processor in our client by adding some process objects to the list (see Example 5-7).
Example 5-7. Configuring a document processor with processes
static DocumentProcessorConfigure(){ DocumentProcessorrc =new DocumentProcessor();rc.Processes.Add(new TranslateIntoFrenchProcess());rc.Processes.Add(new SpellcheckProcess()); rc.Processes.Add(new RepaginateProcess()); return rc; }
See how we are adding the processes to the processor in the same order we had in our function calls previously? Our process objects are logically similar to function calls, and the order in which they appear is logically similar to a program, except that they are composed at runtime rather than compile time.
We can then use this configuration method in our client, and call on the processor to process our documents, as shown in Example 5-8.
Example 5-8. Using the dynamically configured processor
static void Main(string[] args)
{
Document doc1 = new Document
{
Author = "Matthew Adams",
DocumentDate = new DateTime(2000, 01, 01),
Text = "Am I a year early?"
};
Document doc2 = new Document
{
Author = "Ian Griffiths",
DocumentDate = new DateTime(2001, 01, 01),
Text = "This is the new millennium, I promise you."
};
DocumentProcessor processor = Configure();
Console.WriteLine("Processing document 1");
processor.Process(doc1);
Console.WriteLine();
Console.WriteLine("Processing document 2");
processor.Process(doc2);
Console.ReadKey();
}If you compile and run, you’ll see the same output as before:
Processing document 1 Document traduit. Spellchecked document. Repaginated document. Processing document 2 Document traduit. Spellchecked document. Repaginated document.
This is a very common pattern in object-oriented design—encapsulating a method in an object and/or a process in a sequence of objects.
What’s nice about it is that our DocumentProcessor is now coupled only to the
Document class, plus
the abstract base it uses as a contract for the individual processes. It is
no longer coupled to each and every one of those processes; they can vary
without requiring any changes to the processor itself, because they
implement the contract demanded by the abstract base class.
Finally, the processing sequence (the “program” for the DocumentProcessor) is now the responsibility of
the client app, not the processor library; so our different production teams
can develop their own particular sequences (and, indeed, new processes)
without having to refer back to the core team and change the document
processor in any way.
In fact, the only thing that is a bit of a pain about this whole approach is that we have to declare a new class every time we want to wrap up a simple method call. Wouldn’t it be easier just to be able to refer to the method call directly?
C# provides us with a tool to do just that: the delegate.
We just wrote some code that wraps up a method call inside an object. The call itself is wrapped up in another method with a well-known signature.
You can think of a delegate as solving that same sort of problem: it is an object that lets us wrap up a method call on another object (or class).
But while our DocumentProcess
classes have their methods hardcoded into virtual function overrides, a
delegate allows us to reference a specific function
(from a given class or object instance) at runtime, then use the delegate
to execute that function.
So, in the same way that a variable can be considered to contain a reference to an object, a delegate can be thought to contain a reference to a function (see Figure 5-2).

Before we get into the specific C# syntax, I just want to show you
that there isn’t anything mystical about a delegate; in fact, there is a
class in the .NET Framework called Delegate which encapsulates the behavior for
us.
As you might expect, it uses properties to store the reference to
the function. There are two, in fact: Method (which indicates which member function to
use) and Target (which tells us the
object on which the method should be executed, if any).
As you can see, the whole thing is not totally dissimilar in concept
from our previous DocumentProcess base
class, but we don’t need to derive from Delegate to supply the function to call. That
ability has moved into a property instead.
That’s all there is to a delegate, really.
However, it is such a powerful and useful tool that the C# language
designers have provided us with special language syntax to declare new
Delegate types, assign the appropriate
function, and then call it in a much more compact and expressive fashion.
It also allows the compiler to check that all the parameter and return
types match up along the way, rather than producing errors at runtime if
you get it wrong.
It is so compact, expressive, and powerful that you can probably get
through your entire C# programming career without ever worrying about the
classes the C# compiler emits which derive from that Delegate class and implement it all.
Note
So, why have we just spent a page or so discussing these implementation details, if we’re never going to see them again?
While you don’t usually need to use the
Delegate class directly, it is easy
to get confused by language-specific voodoo and lose track of what a
delegate really is: it is just an object, which in turn calls whichever
function we like, all specified through a couple of properties.
Let’s start by defining a new delegate type to reference our document processing functions.
As I mentioned earlier, rather than using that Delegate class, C# lets us define a delegate
type using syntax which looks pretty much like a function declaration,
prefixed with the keyword delegate:
delegate void DocumentProcess(Document doc);
That defines a delegate type for a method which returns void, and takes a single Document parameter. The
delegate’s type name is DocumentProcess.
Having added the delegate, we have two types called DocumentProcess, which is not going to work.
Let’s get rid of our old DocumentProcess abstract base class, and the
three classes we derived from it. Isn’t it satisfying, getting rid of
code? There is less to test and you are statistically likely to have fewer
bugs.
So how are we going to adapt our DocumentProcessor to use our new definition for
the DocumentProcess type? Take a look
at Example 5-9.
Example 5-9. Modifying DocumentProcess to use delegates
class DocumentProcessor
{
private readonly List<DocumentProcess> processes =
new List<DocumentProcess>();
public List<DocumentProcess> Processes
{
get
{
return processes;
}
}
public void Process(Document doc)
{
foreach(DocumentProcess process in Processes)
{
// Hmmm... this doesn't work anymore
process.Process(doc);
}
}
}We’re still storing a set of DocumentProcess objects, but those objects are
now delegates to member functions that conform to the signature specified
by the DocumentProcess delegate.
We can still iterate over the process collection, but we no longer
have a Process method on the object.
The equivalent function on the delegate type is a method called Invoke which matches the signature of our
delegated function:
process.Invoke(doc);
While this works just fine, it is such a common thing to need to do
with a delegate that C# lets us dispense with .Invoke entirely and treat the delegate as
though it really was the function to which it delegates:
process(doc);
Here’s the final version of our Process method:
public void Process(Document doc)
{
foreach(DocumentProcess process in Processes)
{
process(doc);
}
}Note
This can take a bit of getting used to, because our variable names are usually camelCased and our method names are usually PascalCased. Using function call syntax against a camelCased object can cause severe cognitive dissonance. I’ve still never really gotten used to it myself, and I always feel like I need a sit-down and a cup of coffee when it happens.
Now we need to deal with the Configure method that
sets up our processes. Rather than creating all those process classes, we
need to create the delegate instances instead.
You can construct a delegate instance just like
any other object, using new, and
passing the name of the function to which you wish to delegate as a
constructor parameter:
static DocumentProcessor Configure()
{
DocumentProcessor rc = new DocumentProcessor();
rc.Processes.Add(new DocumentProcess(DocumentProcesses.TranslateIntoFrench));
rc.Processes.Add(new DocumentProcess(DocumentProcesses.Spellcheck));
rc.Processes.Add(new DocumentProcess(DocumentProcesses.Repaginate));
return rc;
}However, C# has more syntactic shorthand that can do away with a lot of that boilerplate code. It can work out which delegate type you mean from context, and you only need to provide the method name itself:
static DocumentProcessor Configure()
{
DocumentProcessor rc = new DocumentProcessor();
rc.Processes.Add(DocumentProcesses.TranslateIntoFrench);
rc.Processes.Add(DocumentProcesses.Spellcheck);
rc.Processes.Add(DocumentProcesses.Repaginate);
return rc;
}Not only have we achieved the same end in much less code, but we’ve
actually reduced coupling between our subsystems still further—our
DocumentProcessor doesn’t depend on any
classes other than the Document itself;
it will work with any class, static or otherwise, that can provide a
method that conforms to the appropriate signature, as defined by our
delegate.
So far, we’ve only provided delegates to static functions, but this works just as well for an instance method on a class.
Let’s imagine we need to provide a trademark filter for our
document, to ensure that we pick out any trademarks in an appropriate
typeface. Example 5-10 shows our TrademarkFilter
class.
Example 5-10. Another processing step
class TrademarkFilter
{
readonly List<string> trademarks = new List<string>();
public List<string> Trademarks
{
get
{
return trademarks;
}
}
public void HighlightTrademarks(Document doc)
{
// Split the document up into individual words
string[] words = doc.Text.Split(' ', '.', ','),
foreach( string word in words )
{
if( Trademarks.Contains(word) )
{
Console.WriteLine("Highlighting '{0}'", word);
}
}
}
}It maintains a list of Trademarks
to pick out, and has a HighlightTrademarks
method that does the actual work. Notice that it is coupled only to the
Document—it knows nothing about our
processor infrastructure. Neither have we burned our base; we didn’t have
to inherit from any particular class to fit in with the processor
framework, leaving it free for, say, our forthcoming “highlighter
framework.”
Example 5-11 shows how we add it to our configuration code.
Example 5-11. Adding a processing step with a nonstatic method
static DocumentProcessor Configure()
{
DocumentProcessor rc = new DocumentProcessor();
rc.Processes.Add(DocumentProcesses.TranslateIntoFrench);
rc.Processes.Add(DocumentProcesses.Spellcheck);
rc.Processes.Add(DocumentProcesses.Repaginate);
TrademarkFilter trademarkFilter = new TrademarkFilter();
trademarkFilter.Trademarks.Add("O'Reilly");
trademarkFilter.Trademarks.Add("millennium");
rc.Processes.Add(trademarkFilter.HighlightTrademarks);
return rc;
}We create our TrademarkFilter
object and add a few “trademarks” to its list. To specify a delegate to
the method on that instance we use our reference to
the instance and the name of the function on that instance. Notice that
the syntax is very similar to a method call on an object, but without the
parentheses.
If we compile and run, we get the expected output:
Processing document 1 Document traduit. Spellchecked document. Repaginated document. Processing document 2 Document traduit. Spellchecked document. Repaginated document. Highlighting 'millennium'
This pattern is very common in object-oriented design: an overall
process encapsulated in a class is customized by allowing a client to
specify some action or actions for it to execute somewhere within that
process. Our DocumentProcess delegate
is typical for this kind of action—the function takes a single parameter
of some type (the object our client wishes us to process), and returns
void.
Because we so often need delegates with this kind of signature, the framework provides us with a generic type that does away with the need to declare the delegate types explicitly, every time.
Action<T> is a
generic type for a delegate to a function that
returns void, and takes a single
parameter of some type T. We used a
generic type before: the List<T>
(List-of-T) where T represents the type
of the objects that can be added to the list. In this case, we have an
Action-of-T where T represents the type
of the parameter for the function.
So, instead of declaring our own delegate:
delegate void DocumentProcess( Document doc );
we could just use an Action<> like this:
Action<Document>
Warning
A quick warning: although these are functionally equivalent, you
cannot use an Action<Document>
polymorphically as a DocumentProcess—they are, of course, different
classes under the covers.
We’re choosing between an implementation that uses a type we’re declaring ourselves, or one supplied by the framework. Although there are sometimes good reasons for going your own way, it is usually best to take advantage of library code if it is an exact match for your requirement.
So, we can delete our own delegate definition, and update our
DocumentProcessor to use an Action<Document> instead, as shown in
Example 5-12.
Example 5-12. Modifying the processor to use the built-in Action<T> delegate type
class DocumentProcessor
{
private readonly List<Action<Document>> processes =
new List<Action<Document>>();
public List<Action<Document>> Processes
{
get
{
return processes;
}
}
public void Process(Document doc)
{
foreach (Action<Document> process in Processes)
{
process(doc);
}
}
}Compile and run, and you’ll see that we still get our expected output.
If you were watching the IntelliSense as you were typing in that
code, you will have noticed that there are several Action<> types in the framework: Action<T>, Action<T1,T2>, Action<T1,T2,T3>, and so on. As you might
expect, these allow you to define delegates to methods which return
void, but which take two, three, or
more parameters. .NET 4 provides Action<> delegate types going all the way
up to 16 parameters. (Previous versions stopped at four.)
OK, let’s suppose that everything we’ve built so far has been deployed to the integration test environment, and the production folks have come back with a new requirement. Sometimes they configure a processing sequence that fails against a particular document—and it invariably seems to happen three hours into one of their more complex processes. They have some code which would let them do a quick check for some of their more compute-intensive processes and establish whether they are likely to fail. They want to know if we can implement this for them somehow.
One way we might be able to do this is to provide a means of supplying an optional “check” function corresponding to each “action” function. We could then iterate all of the check functions first (they are supposed to be quick), and look at their return values. If any fail, we can give up (see Figure 5-3).

We could implement that by rewriting our DocumentProcessor as shown in Example 5-13.
Example 5-13. Adding quick checking to the document processor
class DocumentProcessor
{
class ActionCheckPair
{
public Action<Document> Action { get; set; }
public Check QuickCheck { get; set; }
}
private readonly List<ActionCheckPair> processes = new List<ActionCheckPair>();
public void AddProcess(Action<Document> action)
{
AddProcess(action, null);
}
public void AddProcess(Action<Document> action, Check quickCheck)
{
processes.Add(
new ActionCheckPair { Action = action, QuickCheck = quickCheck });
}
public void Process(Document doc)
{
// First time, do the quick check
foreach( ActionCheckPair process in processes)
{
if (process.QuickCheck != null && !process.QuickCheck(doc))
{
Console.WriteLine("The process will not succeed.");
return;
}
}
// Then perform the action
foreach (ActionCheckPair process in processes)
{
process.Action(doc);
}
}
}There are quite a few new things to look at here.
First, we declared a new class inside our
DocumentProcessor definition, rather
than in the namespace scope. We call this a nested class.
We chose to nest the class because it is private to the DocumentProcessor, and we can avoid polluting
the namespace with implementation details. Although you can make nested
classes publicly accessible, it is unusual to do so and is considered a
bad practice.
This nested class just associates a pair of delegates: the Action<Document> that does the work, and
the corresponding Check that performs
the quick check.
We removed the public property for our list of processes, and
replaced it with a pair of AddProcess method
overloads. These allow us to add processes to the sequence; one takes both
the action and the check, and the other is a convenience overload that
allows us to pass the action only.
Note
Notice how we had to change the public contract for our class
because we initially exposed the list of processes directly. If we’d
made the list an implementation
detail and provided the single-parameter AddProcess method in the first place, we
wouldn’t now need to change our clients as we’d only be extending the
class.
Our new Process function first
iterates the processes and calls on the QuickCheck delegate (if it is not null) to see if all is OK. As soon as one of
these checks returns false, we return
from the method and do no further work. Otherwise, we iterate through the
processes again and call the Action
delegate.
What type is a Check? We need a
delegate to a method that returns a Boolean and takes a Document:
delegate bool Check(Document doc);
We call this type of “check” method a predicate: a function that operates on
a set of parameters and returns either true or false
for a given input. As you might expect, given the way things have been
going so far, this is a sufficiently useful idea for it to appear in the
framework (again, as of .NET 3.5).
Unlike the many variants of Action<>, the framework provides us with a
single Predicate<T> type, which defines a
delegate to a function that takes a single parameter of type T and returns a Boolean.
Note
Why only the one parameter? There are good computer-science-philosophical reasons for it. In mathematical logic, a predicate is usually defined as follows:
P : X → { true, false }
That can be read as “a Predicate of some entity X maps to ‘true’ or ‘false’”. The single parameter in the mathematical expression is an important limitation, allowing us to build more complex systems from the simplest possible building blocks.
This formal notion gives rise to the single parameter in the .NET
Predicate<T> class, however
pragmatically useful it may be to have more than one parameter in your
particular application.
We can delete our Check delegate
(Hurrah! More code removed!), and replace it with a Predicate<T> that
takes a Document as its type
parameter:
Predicate<Document>
And we can update the DocumentProcessor to make use of Predicate<T>, as shown in Example 5-14.
Example 5-14. DocumentProcessor updated to use Predicate<T>
class DocumentProcessor
{
class ActionCheckPair
{
public Action<Document> Action { get; set; }
public Predicate<Document> QuickCheck { get; set; }
}
private readonly List<ActionCheckPair> processes =
new List<ActionCheckPair>();
public void AddProcess(Action<Document> action)
{
AddProcess(action, null);
}
public void AddProcess(Action<Document> action,
Predicate<Document> quickCheck)
{
processes.Add(
new ActionCheckPair { Action = action, QuickCheck = quickCheck });
}
// ...
}We can now update our client code to use our new DocumentProcessor API, calling AddProcess now that the list of processes is
private (see Example 5-15).
Example 5-15. Updating Configure to use modified DocumentProcessor
static DocumentProcessor Configure()
{
DocumentProcessor rc = new DocumentProcessor();
rc.AddProcess(DocumentProcesses.TranslateIntoFrench);
rc.AddProcess(DocumentProcesses.Spellcheck);
rc.AddProcess(DocumentProcesses.Repaginate);
TrademarkFilter trademarkFilter = new TrademarkFilter();
trademarkFilter.Trademarks.Add("Ian");
trademarkFilter.Trademarks.Add("Griffiths");
trademarkFilter.Trademarks.Add("millennium");
rc.AddProcess(trademarkFilter.HighlightTrademarks);
return rc;
}For the time being, we’re using the overload of AddProcess that doesn’t supply a quickCheck, so if we
compile and run, we get the same output as before:
Processing document 1 Document traduit. Spellchecked document. Repaginated document. Processing document 2 Document traduit. Spellchecked document. Repaginated document. Highlighting 'millennium'
OK, the idea here was to allow our production team to quickly
configure a check to see if the process was likely to fail, before
embarking on a resource-intensive task. Let’s say DocumentProcesses.TranslateIntoFrench is a very
time-consuming function, and they’ve discovered that any document whose
text contains a question mark (?) will
fail.
They’ve raised a bug with the machine translation team, but they don’t want to hold up the entire production process until it is fixed—only 1 in 10 documents suffer from this problem.
They need to add a quick check to go with the TranslateIntoFrench process. It is only one line
of code:
return !doc.Contains("?");They could create a static class, with a static utility function to use as their predicate, but the boilerplate code would be about 10 times as long as the actual code itself. That’s a barrier to readability, maintenance, and therefore the general well-being of the developer. C# comes to our rescue with a language feature called the anonymous method.
An anonymous method is just like a regular function, except that it is inlined in the code at the point of use.
Let’s update the code in our Configure function to include a delegate to an
anonymous method to perform the check:
rc.AddProcess(
DocumentProcesses.TranslateIntoFrench,
delegate(Document doc)
{
return !doc.Text.Contains("?");
});The delegate to the anonymous method (i.e., the anonymous delegate)
is passed as the second parameter to our AddProcess method. Let’s pull it out so that we
can see it a little more clearly (there’s no need to make this change in
your code; it is just for clarity):
Predicate<Document> predicate =
delegate(Document doc)
{
return !doc.Text.Contains("?");
}Written like this, it looks recognizably like a function definition,
except that we use the delegate keyword
to let the compiler know we are providing a delegate. There’s no need to
specify the return type—that is inferred from the context. (In this case,
the delegate type is Predicate<T>, so the compiler knows the
return type is bool.) Any parameters in
our parameter list are accessible only inside the body of the anonymous
method itself.
Why do we call it an anonymous method? Because it doesn’t have a name that can be referenced elsewhere! The variable that references the delegate to the anonymous method has a name, but not the anonymous delegate type, or the anonymous method itself.
If you compile and run the code you’ll see the new output:
Processing document 1 The processing will not succeed Processing document 2 Document traduit. Spellchecked document. Repaginated document.
The production team is happy; but is the job done?
Not quite; although this inline syntax for an anonymous method is a lot more compact than a static class/function declaration, we can get more compact and expressive still, using lambda expression syntax, which was added in C# 3.0 (anonymous methods having been around since C# 2.0).
In the 1930s (a fertile time for computing theory!) two mathematicians named Church and Kleene devised a formal system for investigating the properties of functions. This was called lambda calculus, and (as further developed by Curry and others) it is still a staple part of computational theory for computer scientists.
Fast-forward 70 or so years, and we see just a hint of this theory peeking through in C#’s lambda expressions—only a hint, though, so bear with it.
As we saw before, you can think of a function as an expression that maps a set of inputs (the parameters) to an output (the return value).
Mathematicians sometimes use a notation similar to this to define a function:
(x,y,z) → x + y + z
You can read this as defining a function that operates on three
parameters (x, y, and z).
The result of the function is just the sum of the three parameters, and,
by definition, it can have no side effects on the system. The
parameters themselves aren’t modified by the function; we just map from
the input parameters to a result.
Lambda expressions in C# use syntax very similar to this to define functional expressions. Here’s the C# equivalent of that mathematical expression we used earlier:
(x,y,z) => x + y + z;
Note
Notice how it rather cutely uses => as the programming language equivalent
of →. C++ users should not mistake this
for the -> operator—it is quite
different!
This defines a lambda expression that takes three parameters and returns the sum of those three parameters.
Some languages enforce the no side effects constraint; but in C# there is nothing to stop you from writing a lambda expression such as this one:
(x,y,z) =>
{
SomeStaticClass.CrashAndBurnAndMessWithEverything();
x.ModifyInternalState();
return x + y + z;
}(Incidentally, this form of lambda expression, using braces to help define its body, is called a statement-form lambda.) In C#, a lambda is really just a concise way to write an anonymous method. We’re just writing normal code, so we can include operations that have side effects.
So, although C# brings along some functional techniques with lambda syntax, it is not a “pure” functional language like ML or F#. Nor does it intend to be.
So, what use is a lambda, then?
We’ll see some very powerful techniques in Chapter 8 and Chapter 14, where lambdas play an important role in LINQ. Some of the data access features of the .NET Framework use the fact that we can convert lambdas into data structures called expression trees, which can be composed to create complex query-like expressions over various types of data.
For now, we’re merely going to take advantage of the fact that we can implicitly create a delegate from a lambda, resulting in less cluttered code.
How do we write our anonymous delegate as a lambda? Here’s the original:
Predicate<Document> predicate =
delegate(Document doc )
{
return !doc.Text.Contains("?");
}And here it is rewritten using a lambda expression:
Predicate<Document> predicate = doc => !doc.Text.Contains("?");Compact, isn’t it!
For a lot of developers, this syntax takes some getting used to, because it is completely unlike anything they’ve ever seen before. Where are the type declarations? Is this taking advantage of some of these dynamic programming techniques we’ve heard so much about?
The short answer is no (but we’ll get to dynamic typing in Chapter 18, don’t worry). One of the nicer features of lambda
expression syntax is that it takes care of working out what types the
various parameters need to be, based on the context. In this case, the
compiler knows that it needs to produce a Predicate<Document>, so it can infer that
the parameter type for the lambda must be a Document. You even get full IntelliSense on your lambda parameters in Visual
Studio.
Note
It is well worth getting used to reading and writing lambdas; you’ll find them to be a very useful and expressive means of defining short functions, especially when we look at various aspects of the LINQ technologies and expression composition in later chapters.
Most developers, once they get over the initial comprehension hurdles, fall in love with lambdas—I promise!
The delegates we’ve seen so far have taken one or more
parameters, and returned either void
(an Action<>) or a bool (a Predicate<T>).
But we can define a delegate to any sort of function we like. What if we want to provide a mechanism that allows the client to be notified when each processing step has been completed, and provide the processor with some text to insert into a process log?
Our callback delegate might look like this:
delegate string LogTextProvider(Document doc);
We could add a property to our DocumentProcessor so that we can get and set the
callback function (see Example 5-16).
Example 5-16. A property that holds a delegate
class DocumentProcessor
{
public LogTextProvider LogTextProvider
{
get;
set;
}
// ...
}And then we could make use of it in our Process method, as shown in Example 5-17.
Example 5-17. Using a delegate in a property
public void Process(Document doc)
{
// First time, do the quick check
foreach (ActionCheckPair process in processes)
{
if (process.QuickCheck != null && !process.QuickCheck(doc))
{
Console.WriteLine("The process will not succeed.");
if (LogTextProvider != null)
{
Console.WriteLine(LogTextProvider(doc));
}
return;
}
}
// Then perform the action
foreach (ActionCheckPair process in processes)
{
process.Action(doc);
if (LogTextProvider != null)
{
Console.WriteLine(LogTextProvider(doc));
}
}
}Notice that we’re checking that our property is not null, and then we use standard delegate syntax
to call the function that it references.
Let’s set a callback in our client (see Example 5-18).
Example 5-18. Setting a property with a lambda
static void Main(string[] args)
{
// ...
DocumentProcessor processor = Configure();
processor.LogTextProvider = (doc => "Some text for the log...");
// ...
}Here we used a lambda expression to provide a delegate that takes a
Document parameter called doc, and returns a string. In this case, it is just a constant
string. Later, we’ll do some work to emit a more useful message.
Take a moment to notice again how compact the lambda syntax is, and how the compiler infers all those parameter types for us. Remember how much code we had to write to do this sort of thing back in the world of abstract base classes?
Compile and run, and we see the following output:
Processing document 1 The processing will not succeed. Some text for the log... Processing document 2 Document traduit. Some text for the log... Spellchecked document. Some text for the log... Repaginated document. Some text for the log... Highlighting 'millennium' Some text for the log...
That’s an example of a delegate for a function that returns
something other than void or a bool. As you might have already guessed, the
.NET Framework provides us with a generic type so that we don’t have to
declare those delegates by hand, either.
The .NET Framework exposes a generic class called Func<T, TResult>,
which you can read as “Func-of T and TResult.”
As with Predicate<T> and
Action<T> the first type
parameter determines the type of the first parameter of the function
referenced by the delegate.
Unlike Predicate<T> or
Action<T> we also get to specify
the type of the return value, using the last type parameter: TResult.
Note
Just like Action<T>,
there is a whole family of Func<> types which take one, two, three,
and more parameters. Before .NET 4, Func<> went up to four parameters, but
now goes all the way up to 16.
So we could replace our custom delegate type with a Func<>. We can delete the delegate
declaration:
delegate string LogTextProvider(Document doc);
and update the property:
public Func<Document,string> LogTextProvider
{
get;
set;
}We can build and run without any changes to our client code because the new property declaration still expects a delegate for a function with the same signature. And we still get a bit of log text:
Processing document 1 The processing will not succeed. Some text for the log... Processing document 2 Document traduit. Some text for the log... Spellchecked document. Some text for the log... Repaginated document. Some text for the log... Highlighting 'millennium' Some text for the log...
OK, let’s go back and have a look at that log function. As we noted earlier, it isn’t very useful right now. We can improve it by logging the name of the file we have processed after each output stage, to help the production team diagnose problems.
Example 5-19 shows an
update to the Main function to do
that.
Example 5-19. Doing more in our logging callback
static void Main(string[] args)
{
Document doc1 = new Document
{
Author = "Matthew Adams",
DocumentDate = new DateTime(2000, 01, 01),
Text = "Am I a year early?"
};
Document doc2 = new Document
{
Author = "Ian Griffiths",
DocumentDate = new DateTime(2001, 01, 01),
Text = "This is the new millennium, I promise you."
};
Document doc3 = new Document
{
Author = "Matthew Adams",
DocumentDate = new DateTime(2002, 01, 01),
Text = "Another year, another document."
};
string documentBeingProcessed = null;
DocumentProcessor processor = Configure();
processor.LogTextProvider = (doc => documentBeingProcessed);
documentBeingProcessed = "(Document 1)";
processor.Process(doc1);
Console.WriteLine();
documentBeingProcessed = "(Document 2)";
processor.Process(doc2);
Console.WriteLine();
documentBeingProcessed = "(Document 3)";
processor.Process(doc3);
Console.ReadKey();
}We added a third document to the set, just so that we can see more
get processed. Then we set up a local variable called documentBeingProcessed. As we move through the
documents we update that variable to reflect our current status.
How do we get that information into the lambda expression? Simple: we just use it!
Compile and run that code, and you’ll see the following output:
The processing will not succeed. (Document 1) Document traduit. (Document 2) Spellchecked document. (Document 2) Repaginated document. (Document 2) Highlighting 'millennium' (Document 2) Document traduit. (Document 3) Spellchecked document. (Document 3) Repaginated document. (Document 3)
We took advantage of the fact that an anonymous method has access to variables declared in its parent scope, in addition to anything in its own scope. For more information about this, see the sidebar below.
We’ve seen how to read variables in our containing scope, but what about writing back to them? That works too. Let’s create a process counter that ticks up every time we execute a process, and add it to our logging function (see Example 5-20).
Example 5-20. Modifying surrounding variables from a nested method
static void Main(string[] args)
{
// ... (document setup)
DocumentProcessor processor = Configure();
string documentBeingProcessed = "(No document set)";
int processCount = 0;
processor.LogTextProvider = (doc => {
processCount += 1;
return documentBeingProcessed;
});
documentBeingProcessed = "(Document 1)";
processor.Process(doc1);
Console.WriteLine();
documentBeingProcessed = "(Document 2)";
processor.Process(doc2);
Console.WriteLine();
documentBeingProcessed = "(Document 3)";
processor.Process(doc3);
Console.WriteLine();
Console.WriteLine("Executed " + processCount + " processes.");
Console.ReadKey();
}We added a processCount variable
at method scope, which we initialized to zero. We’ve switched our lambda
expression into the statement form with the braces so that
we can write multiple statements in the function body. In addition to
returning the name of the document being processed, we also increment our
processCount.
Finally, at the end of processing, we write out a line that tells us how many processes we’ve executed. So our output looks like this:
The processing will not succeed. (Document 1) Document traduit. (Document 2) Spellchecked document. (Document 2) Repaginated document. (Document 2) Highlighting 'millennium' (Document 2) Document traduit. (Document 3) Spellchecked document. (Document 3) Repaginated document. (Document 3) (Document 3) Executed 9 processes.
OK, our production team is very happy with all of that, but they have another requirement. Apparently, they have one team working on some diagnostic components that are going to track the time taken to execute some of their processes, and another team developing some real-time display of all the processes as they run through the system. They want to know when a process is about to be executed and when it has completed so that these teams can execute some of their own code.
Our first thought might be to implement a couple of additional callbacks: one called as processing starts, and the other as it ends; but that won’t quite meet their needs—they have two separate teams who both want, independently, to hook into it.
We need a pattern for notifying several clients that something has occurred. The .NET Framework steps up with events.
An event is raised (or sent) by a publisher (or sender) when something of interest occurs (such as an action taking place, or a property changing). Clients can subscribe to the event by providing a suitable delegate, rather like the callbacks we used previously. The method wrapped by the delegate is called the event handler. The neat thing is that more than one client can subscribe to the event.
Here’s an example of a couple of events that we can add to the
DocumentProcessor to help our
production team:
class DocumentProcessor
{
public event EventHandler Processing;
public event EventHandler Processed;
// ...
}Notice that we use the keyword event to indicate
that what follows is an event declaration. We then specify the delegate
type for the event (EventHandler) and
the name of the event (using PascalCasing). So, this is just like a
declaration for a public field of type EventHandler, but annotated with the event keyword.
What does this EventHandler
delegate look like? The framework defines it like this:
delegate void EventHandler(object sender, EventArgs e);Notice that our delegate takes two parameters. The first is a
reference to the publisher of the event so that subscribers can tell who
raised it. The second is some data associated with the event. The EventArgs class is defined in the framework, and
is a placeholder for events that don’t need any extra information. We’ll
see how to customize this later.
Note
Almost all events follow this two-argument pattern. Technically, they’re not required to—you can use any delegate type for an event. But in practice, this pattern is almost universal.
So, how do we raise an event? Well, it really is just like a delegate, so
we can use the delegate calling syntax as shown in the OnProcessing and OnProcessed methods in Example 5-21.
Example 5-21. Raising events
public void Process(Document doc)
{
OnProcessing(EventArgs.Empty);
// First time, do the quick check
foreach (ActionCheckPair process in processes)
{
if (process.QuickCheck != null && !process.QuickCheck(doc))
{
Console.WriteLine("The process will not succeed.");
if (LogTextProvider != null)
{
Console.WriteLine(LogTextProvider(doc));
}
OnProcessed(EventArgs.Empty);
return;
}
}
// Then perform the action
foreach (ActionCheckPair process in processes)
{
process.Action(doc);
if (LogTextProvider != null)
{
Console.WriteLine(LogTextProvider(doc));
}
}
OnProcessed(EventArgs.Empty);
}
private void OnProcessing(EventArgs e)
{
if (Processing != null)
{
Processing(this, e);
}
}
private void OnProcessed(EventArgs e)
{
if (Processed != null)
{
Processed(this, e);
}
}Notice how we pulled out the code to check for null and execute the delegate into functions
called OnXXX. This isn’t strictly
necessary, but it is a very common practice.
Note
If we are designing our class as a base, we often mark this kind
of method as a protected virtual so
that derived classes can override the event-raising function instead of
subscribing to the event.
This can be more efficient than going through the event, and it allows us (optionally) to decline to raise the event by not calling on the base implementation.
Be careful to document whether derived classes are allowed not to call the base, though!
Now we need to subscribe to those events. So let’s create a couple of classes to simulate what the production department would need to do (see Example 5-22).
Example 5-22. Subscribing to and unsubscribing from events
class ProductionDeptTool1
{
public void Subscribe ( DocumentProcessor processor )
{
processor.Processing += processor_Processing;
processor.Processed += processor_Processed;
}
public void Unsubscribe(DocumentProcessor processor)
{
processor.Processing -= processor_Processing;
processor.Processed -= processor_Processed;
}
void processor_Processing(object sender, EventArgs e)
{
Console.WriteLine("Tool1 has seen processing.");
}
void processor_Processed(object sender, EventArgs e)
{
Console.WriteLine("Tool1 has seen that processing is complete.");
}
}
class ProductionDeptTool2
{
public void Subscribe( DocumentProcessor processor )
{
processor.Processing +=
(sender, e) => Console.WriteLine("Tool2 has seen processing.");
processor.Processed +=
(sender, e) =>
Console.WriteLine("Tool2 has seen that processing is complete.");
}
}To subscribe to an event we use the += operator, with a suitable delegate. You can
see in ProductionDeptTool1.Subscribe
that we used the standard delegate syntax, and in ProductionDeptTool2.Subscribe we used the lambda
expression syntax.
Note
Of course, you don’t have to subscribe to events in methods called
Subscribe—you can do it anywhere you
like!
When you’re done watching an event for any reason, you can
unsubscribe using the -= operator and
another delegate to the same method. You can see that in the ProductionDeptTool1.Unsubscribe
method.
When you subscribe to an event your subscriber implicitly holds a reference to the publisher. This means that the garbage collector won’t be able to collect the publisher if there is still a rooted reference to the subscriber. It is a good idea to provide a means of unsubscribing from events you are no longer actively observing, to avoid growing your working set unnecessarily.
Let’s add some code to our Main
method to make use of the two new tools, as shown in Example 5-23.
Example 5-23. Updated Main method
static void Main(string[] args)
{
// ...
ProductionDeptTool1 tool1 = new ProductionDeptTool1();
tool1.Subscribe(processor);
ProductionDeptTool2 tool2 = new ProductionDeptTool2();
tool2.Subscribe(processor);
documentBeingProcessed = "(Document 1)";
// ...
Console.ReadKey();
}If we compile and run, we now see the following output:
Tool1 has seen processing. Tool2 has seen processing. The processing will not succeed. (Document 1) Too11 has seen that processing is complete. Tool2 has seen that processing is complete. Tool1 has seen processing. Tool2 has seen processing. Document traduit. (Document 2) Spellchecked document. (Document 2) Repaginated document. (Document 2) Highlighting 'millennium' (Document 2) Too11 has seen that processing is complete. Tool2 has seen that processing is complete. Tool1 has seen processing. Tool2 has seen processing. Document traduit. (Document 3) Spellchecked document. (Document 3) Repaginated document. (Document 3) (Document 3) Too11 has seen that processing is complete. Tool2 has seen that processing is complete. Executed 9 processes.
Warning
You might notice that the event handlers have been executed in the order in which we added them. This is not guaranteed to be the case, and you cannot depend on this behavior.
If you need deterministic ordering (as we did for our processes, for example) you should not use an event.
Earlier, I alluded to the fact that we can customize the data we
send through with the event. We do this by deriving our own class from
EventArgs, and adding extra properties
or methods to it. Let’s say we want to send the current document through
in the event; we can create a class like the one shown in Example 5-24.
Example 5-24. Custom event arguments class
class ProcessEventArgs : EventArgs
{
// Handy constructor
public ProcessEventArgs(Document document)
{
Document = document;
}
// The extra property
// We don't want subscribers to be able
// to update this property, so we make
// it private
// (Of course, this doesn't prevent them
// from changing the Document itself)
public Document Document
{
get;
private set;
}
}We also need to create a suitable delegate for the event, one that
takes a ProcessEventArgs as its second
parameter rather than the EventArgs
base class. We could do this by hand, sticking to the convention of
calling the first parameter sender and
the data parameter e:
delegate void ProcessEventHandler(object sender, ProcessEventArgs e);
Once again, this is such a common thing to need that the framework
provides us with a generic type, EventHandler<T>, to
save us the boilerplate code. So we can replace the ProcessEventHandler with an EventHandler<ProcessEventArgs>.
Let’s update our event declarations (see Example 5-25).
Example 5-25. Updated event members
public event EventHandler<ProcessEventArgs> Processing; public event EventHandler<ProcessEventArgs> Processed;
and then our helper methods which raise the event that will need to
take a ProcessEventArgs (see Example 5-26).
Example 5-26. Updated code for raising events
private void OnProcessing(ProcessEventArgs e)
{
if (Processing != null)
{
Processing(this, e);
}
}
private void OnProcessed(ProcessEventArgs e)
{
if (Processed != null)
{
Processed(this, e);
}
}And finally, our calls to those methods will need to create an
appropriate ProcessEventArgs object, as
shown in Example 5-27.
Example 5-27. Creating the event arguments object
public void Process(Document doc)
{
ProcessEventArgs e = new ProcessEventArgs(doc);
OnProcessing(e);
// First time, do the quick check
foreach (ActionCheckPair process in processes)
{
if (process.QuickCheck != null && !process.QuickCheck(doc))
{
Console.WriteLine("The process will not succeed.");
if (LogTextProvider != null)
{
Console.WriteLine(LogTextProvider(doc));
}
OnProcessed(e);
return;
}
}
// Then perform the action
foreach (ActionCheckPair process in processes)
{
process.Action(doc);
if (LogTextProvider != null)
{
Console.WriteLine(LogTextProvider(doc));
}
}
OnProcessed(e);
}Notice how we happen to reuse the same event data for each event we
raise. That’s safe to do because our event argument instance cannot be
modified—its only property has a private setter. If it were possible for event
handlers to change the event argument object, it would be risky to use the
same one for both events.
We could offer our colleagues on the production team another
facility using these events. We already saw how they need to perform a
quick check before each individual process to determine whether they
should abort processing. We can take advantage of our Processing event to give them the option of
canceling the whole process before it even gets off the
ground.
The framework defines a class called CancelEventArgs which adds a Boolean property called Cancel to the basic EventArgs. Subscribers can set the property to
True, and the publisher is expected to
abort the operation.
Let’s add a new EventArgs class
for that (see Example 5-28).
Example 5-28. A cancelable event argument class
class ProcessCancelEventArgs : CancelEventArgs
{
public ProcessCancelEventArgs(Document document)
{
Document = document;
}
public Document Document
{
get;
private set;
}
}We’ll update the declaration of our Processing event, and its corresponding helper,
as shown in Example 5-29 (but we’ll leave the
Processed event as it is—if the
document has already been processed, it’s too late to cancel it).
Example 5-29. A cancelable event
public event EventHandler<ProcessCancelEventArgs> Processing; private void OnProcessing(ProcessCancelEventArgse) { if (Processing != null) { Processing(this, e); } }
Finally, we need to update the Process method to create
the right kind of event argument object, and to honor requests for
cancellation (see Example 5-30).
Example 5-30. Supporting cancellation
public void Process(Document doc)
{
ProcessEventArgs e = new ProcessEventArgs(doc);
ProcessCancelEventArgs ce = new ProcessCancelEventArgs(doc);
OnProcessing(ce);
if (ce.Cancel)
{
Console.WriteLine("Process canceled.");
if (LogTextProvider != null)
{
Console.WriteLine(LogTextProvider(doc));
}
return;
}
// ...
}Now we’ll make use of this in one of our production tools, as shown in Example 5-31.
Example 5-31. Taking advantage of cancelability
class ProductionDeptTool1
{
public void Subscribe(DocumentProcessor processor)
{
processor.Processing += processor_Processing;
processor.Processed += processor_Processed;
}
public void Unsubscribe(DocumentProcessor processor)
{
processor.Processing -= processor_Processing;
processor.Processed -= processor_Processed;
}
void processor_Processing(object sender, ProcessCancelEventArgs e)
{
Console.WriteLine("Tool1 has seen processing, and not canceled.");
}
void processor_Processed(object sender, EventArgs e)
{
Console.WriteLine("Tool1 has seen that processing is complete.");
}
}
class ProductionDeptTool2
{
public void Subscribe(DocumentProcessor processor)
{
processor.Processing += (sender, e) =>
{
Console.WriteLine("Tool2 has seen processing and canceled it");
if(e.Document.Text.Contains("document"))
{
e.Cancel = true;
}
};
processor.Processed += (sender, e) =>
Console.WriteLine("Tool2 has seen that processing is complete.");
}
}Notice how we don’t have to update the event
data parameter—we can take advantage of polymorphism and just refer to it
through its base type, unless we want to take advantage of its new
features. In the lambda expression syntax, of course, the new type
parameter is inferred and we don’t have to change anything; we can just
update the handler in ProductionDeptTool2 to cancel if it sees the
text "document".
If we compile and run, we now see the following output:
The process will not succeed. (Document 1) Tool1 has seen that processing is complete. Tool2 has seen that processing is complete. Tool1 has seen processing, and not canceled. Tool2 has seen processing, and not canceled. Document traduit. (Document 2) Spellchecked document. (Document 2) Repaginated document. (Document 2) Highlighting 'millennium' (Document 2) Tool1 has seen that processing is complete. Tool2 has seen that processing is complete. Tool1 has seen processing, and not canceled. Tool2 has seen processing and canceled. Process canceled. (Document 3) Executed 6 processes.
So we have our cancellation behavior, but we have to be very
careful. Notice that Tool1 happened to
see the event first, and it happily executed its handler, before Tool2 got in and canceled the whole thing. When
you write handlers for cancelable events, you must
ensure that it doesn’t matter if some or all of those handlers never get
called and that they behave correctly if the action they expect never
actually occurs. Cancelable events need very careful documentation to
indicate how they relate to the actions around them, and the exact
semantics of cancellation. It is therefore (in general) a bad idea to do
what we have just done, and convert a noncancelable event into a
cancelable one, if your code has already shipped; you stand a very good
chance of breaking any clients that just recompile successfully against
the new version.
Some classes (particularly those related to user interactions) need to expose a very large number of events. If you use the normal event syntax shown in the preceding examples, storage is allocated for every single event you declare, even if the events have no subscribers. This means that objects of this type can get very large, very quickly.
To avoid this situation, C# provides you with the ability to manage storage for the events yourself, using syntax similar to a property getter and setter, with your own backing storage:
public event EventHandler MyEvent
{
add
{
// Code to add handler here
}
remove
{
// Code to remove handler here
}
}Typically, you use a Dictionary<Key,Val> to create the
backing storage for the event only when it gets its first subscriber.
(Dictionaries are described in Chapter 9.)
Example 5-32 updates the
DocumentProcessor we’re developing in
this chapter to use a dictionary for the backing storage for its
events.
Example 5-32. Custom event storage
class DocumentProcessor
{
private Dictionary<string, Delegate> events;
public event EventHandler<ProcessCancelEventArgs> Processing
{
add
{
Delegate theDelegate =
EnsureEvent("Processing");
events["Processing"] =
((EventHandler<ProcessCancelEventArgs>)
theDelegate) + value;
}
remove
{
Delegate theDelegate =
EnsureEvent("Processing");
events["Processing"] =
((EventHandler<ProcessCancelEventArgs>)
theDelegate) - value;
}
}
public event EventHandler<ProcessEventArgs> Processed
{
add
{
Delegate theDelegate =
EnsureEvent("Processed");
events["Processed"] =
((EventHandler<ProcessEventArgs>)
theDelegate) + value;
}
remove
{
Delegate theDelegate =
EnsureEvent("Processed");
events["Processed"] =
((EventHandler<ProcessEventArgs>)
theDelegate) - value;
}
}
private Delegate EnsureEvent(string eventName)
{
// Construct the dictionary if it doesn't already
// exist
if (events == null)
{
events = new Dictionary<string, Delegate>();
}
// Add a placeholder for the delegate if we don't
// have it already
Delegate theDelegate = null;
if (!events.TryGetValue(
eventName, out theDelegate))
{
events.Add(eventName, null);
}
return theDelegate;
}
private void OnProcessing(ProcessCancelEventArgs e)
{
Delegate eh = null;
if( events != null &&
events.TryGetValue("Processing", out eh) )
{
EventHandler<ProcessCancelEventArgs> pceh =
eh as EventHandler<ProcessCancelEventArgs>;
if (pceh != null)
{
pceh(this, e);
}
}
}
private void OnProcessed(ProcessEventArgs e)
{
Delegate eh = null;
if (events != null &&
events.TryGetValue("Processed", out eh))
{
EventHandler<ProcessEventArgs> pceh =
eh as EventHandler<ProcessEventArgs>;
if (pceh != null)
{
pceh(this, e);
}
}
}
// ...
}Obviously, that’s a lot more complex than the automatic method, and you would not normally use it for a class that exposes just a couple of events, but it can save a lot of working set for classes that are either large in number, or publish a large number of events but have few subscribers.
In this chapter, we saw how functional techniques provide powerful reuse and extensibility mechanisms for our programs, in ways that can be more flexible and yet simpler than class-based approaches. We also saw how events enabled a publisher-to-multiple-subscribers relationship. In the next chapter, we’ll look at how we deal with unexpected situations: errors, failures, and exceptions.