
Errors happen all the time; they’re a fact of life:
Despite the best efforts of Microsoft Word, an army of highly skilled reviewers and editors, and even your authors, it would be surprising if there wasn’t a typographical error in a book of this length.
Although they are relatively few and far between, there are bugs in the .NET Framework—hence the need for occasional service packs.
You might type your credit card number for an online transaction and accidentally transpose two digits; or forget to type in the expiration date.
Like it or not, we’re going to have to face up to the fact that there are going to be errors of all kinds to deal with in our software too. In this chapter, we’ll look at various types of errors, the tools that C# and the .NET Framework give us to deal with them, and some strategies for applying those tools.
First, we need to recognize that all errors are not made the same. We’ve classified a few of the more common ones in Table 6-1.
Table 6-1. A far-from-exhaustive list of some common errors
Although bugs are probably the most obvious type of error, we won’t actually be dealing with them directly in this chapter. We will, however, look at how our error-handling techniques can make it easier (or harder!) to find the bugs that are often the cause of the other, better defined issues.
Let’s get started with an example we can use to look at error-handling techniques. We’re going to branch out into the world of robotics for this one, and build a turtle-controlling application. The real-world turtle is a rectangular piece of board on which are mounted two motors that can drive two wheels. The wheels are located in the middle of the left and right edges of the board, and there are nondriven castor wheels at the front and back to give it a bit of stability. We can drive the two motors independently: we can move forward, move backward, or stop. And by moving the wheels in different directions, or moving one wheel at time, we can steer it about a bit like a tank.
Let’s create a class to model our turtle (see Example 6-1).
Example 6-1. The Turtle class
class Turtle
{
// The width of the platform
public double PlatformWidth
{
get; set;
}
// The height of the platform
public double PlatformHeight
{
get; set;
}
// The speed at which the motors drive the wheels,
// in meters per second. For ease, we assume that takes account
// of the distance traveled by the tires in contact
// with the ground, and any slipping
public double MotorSpeed
{
get; set;
}
// The state of the left motor
public MotorState LeftMotorState
{
get; set;
}
// The state of the right motor
public MotorState RightMotorState
{
get; set;
}
// The current position of the turtle
public Point CurrentPosition
{
get; private set;
}
// The current orientation of the turtle
public double CurrentOrientation
{
get; private set;
}
}
// The current state of a motor
enum MotorState
{
Stopped,
Running,
Reversed
}In addition to the motor control, we can define the size of the platform and the speed at which the motors rotate the wheels. We also have a couple of properties that tell us where the turtle is right now, relative to its point of origin, and the direction in which it is currently pointing.
To make our turtle simulator actually do something, we can add a method which makes time pass. This looks at the state of the different motors and applies an appropriate algorithm to calculate the new position of the turtle. Example 6-2 shows our first, somewhat naive, go at it.
Example 6-2. Simulating turtle motion
// Run the turtle for the specified duration
public void RunFor(double duration)
{
if (LeftMotorState == MotorState.Stopped &&
RightMotorState == MotorState.Stopped)
{
// If we are at a full stop, nothing will happen
return;
}
// The motors are both running in the same direction
// then we just drive
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Running) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Reversed))
{
Drive(duration);
return;
}
// The motors are running in opposite directions,
// so we don't move, we just rotate about the
// center of the rig
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Reversed) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Running))
{
Rotate(duration);
return;
}
}If both wheels are pointing in the same direction (forward or reverse), we drive (or reverse) in the direction we are pointing. If they are driving in opposite directions, we rotate about our center. If both are stopped, we will remain stationary.
Example 6-3 shows the
implementations of Drive and Rotate. They use a little bit of trigonometry to
get the job done.
Example 6-3. Simulating rotation and movement
private void Rotate(double duration)
{
// This is the total circumference of turning circle
double circum = Math.PI * PlatformWidth;
// This is the total distance traveled
double d = duration * MotorSpeed;
if (LeftMotorState == MotorState.Reversed)
{
// And we're going backwards if the motors are reversed
d *= -1.0;
}
// So we've driven it this proportion of the way round
double proportionOfWholeCircle = d / circum;
// Once round is 360 degrees (or 2pi radians), so we have traveled
// this far:
CurrentOrientation =
CurrentOrientation + (Math.PI * 2.0 * proportionOfWholeCircle);
}
private void Drive(double duration)
{
// This is the total distance traveled
double d = duration * MotorSpeed;
if (LeftMotorState == MotorState.Reversed)
{
// And we're going backwards if the motors are reversed
d *= -1.0;
}
// Bit of trigonometry for the change in the x,y coordinates
double deltaX = d * Math.Sin(CurrentOrientation);
double deltaY = d * Math.Cos(CurrentOrientation);
// And update the position
CurrentPosition =
new Point(CurrentPosition.X + deltaX, CurrentPosition.Y + deltaY);
}Let’s write a quick test program to see whether the code we’ve written actually does what we expect (see Example 6-4).
Example 6-4. Testing the turtle
static void Main(string[] args)
{
// Here's our turtle
Turtle arthurTheTurtle =
new Turtle {PlatformWidth = 10.0, PlatformHeight = 10.0, MotorSpeed = 5.0};
ShowPosition(arthurTheTurtle);
// We want to proceed forwards
arthurTheTurtle.LeftMotorState = MotorState.Running;
arthurTheTurtle.RightMotorState = MotorState.Running;
// For two seconds
arthurTheTurtle.RunFor(2.0);
ShowPosition(arthurTheTurtle);
// Now, let's rotate clockwise for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
// PI / 2 seconds should do the trick
arthurTheTurtle.RunFor(Math.PI / 2.0);
ShowPosition(arthurTheTurtle);
// And let's go into reverse
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
// And run for 5 seconds
arthurTheTurtle.RunFor(5);
ShowPosition(arthurTheTurtle);
// Then rotate back the other way
arthurTheTurtle.RightMotorState = MotorState.Running;
// And run for PI/4 seconds to give us 45 degrees
arthurTheTurtle.RunFor(Math.PI / 4.0);
ShowPosition(arthurTheTurtle);
// And finally drive backwards for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
arthurTheTurtle.RunFor(Math.Cos(Math.PI / 4.0));
ShowPosition(arthurTheTurtle);
Console.ReadKey();
}
private static void ShowPosition(Turtle arthurTheTurtle)
{
Console.WriteLine(
"Arthur is at ({0}) and is pointing at angle {1:0.00} radians.",
arthurTheTurtle.CurrentPosition,
arthurTheTurtle.CurrentOrientation);
}We chose the times for which to run quite carefully so that we end up going through relatively readable distances and angles. (Hey, someone could design a more usable facade over this API!) If we compile and run, we see the following output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 1.57 radians. Arthur is at (-25,10) and is pointing at angle 1.57 radians. Arthur is at (-25,10) and is pointing at angle 0.79 radians. Arthur is at (-27.5,7.5) and is pointing at angle 0.79 radians.
OK, that seems fine for basic operation. But what happens if we change the width of the platform to zero?
Turtle arthurTheTurtle =
new Turtle { PlatformWidth = 0.0, PlatformHeight = 10.0, MotorSpeed = 5.0 };Not only does that not make much sense, but the output is not very useful either; clearly we have divide-by-zero problems:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angleInfinityradians. Arthur is at (NaN,NaN) and is pointing at angleInfinityradians. Arthur is at (NaN,NaN) and is pointing at angleNaNradians. Arthur is at (NaN,NaN) and is pointing at angleNaNradians.
Clearly, our real-world turtle could go badly wrong if we told it to
rotate through an infinite angle. At the very least, we’d get bored waiting
for it to finish. We should prevent the user from running it if the PlatformWidth is less than or equal to zero.
Previously, we used the following code:
// Run the turtle for the specified duration
public void RunFor(double duration)
{
if (PlatformWidth <= 0.0)
{
// What to do here?
}
// ...
}That detects the problem, but what should we do if our particular turtle is not set up correctly? Previously, we silently ignored the problem, and returned as though everything was just fine. Is that really what we want to do?
For this application it might be perfectly safe, but what if another
developer uses our turtle with a paintbrush strapped to its back, to paint
the lines on a tennis court? The developer added a few extra moves at the
beginning of his sequence, and he didn’t notice that he had inadvertently
done so before he initialized the PlatformWidth. We could have a squiggly paint
disaster on our hands!
Choosing when and how to fail is one of the big debates in software development. There is a lot of consensus about what we do, but things are much less clear-cut when it comes to failures.
You have a number of choices:
Try to plow on regardless.
Try to make sense of what has happened and work around it.
Return an error of some kind to your caller, and hope the caller knows what to do with it.
Stop.
At the moment, we’re using option 1: try to plow on regardless; and you can see that this might or might not be dangerous. The difficulty is that we can be sure it is safe only if we know why our client is calling us. Given that we can’t possibly have knowledge of the continuum of all possible clients (and their clients, and their clients’ clients), plugging on regardless is, in general, not safe. We might be exposing ourselves to all sorts of security problems and data integrity issues of which we cannot be aware at this time.
What about option 2? Well, that is really an extension of the contract: we’re saying that particular types of data outside the range we previously defined are valid, it is just that we’ll special-case them to other values. This is quite common with range properties, where we clamp values outside the range to the minimum and maximum permitted values. Example 6-5 shows how we could implement that.
Example 6-5. Range checking
class Turtle
{
// The width of the platform must be between 1.0 and 10.0 inclusive
// Values outside this range will be coerced into the range.
private double platformWidth;
public double PlatformWidth
{
get { return platformWidth; }
set
{
platformWidth = value;
EnsurePlatformSize();
}
}
// The height of the platform must be between 1.0 and 10.0 inclusive
// Values outside this range will be coerced into the range.
private double platformHeight;
public double PlatformHeight
{
get { return platformHeight; }
set
{
platformHeight = value;
EnsurePlatformSize();
}
}
// The new constructor initializes the platform size appropriately
public Turtle()
{
EnsurePlatformSize();
}
// This method enforces the newly documented constraint
// we added to the contract
private void EnsurePlatformSize()
{
if (PlatformWidth < 1.0)
{
PlatformWidth = 1.0;
}
if (PlatformWidth > 10.0)
{
PlatformWidth = 10.0;
}
if (PlatformHeight < 1.0)
{
PlatformHeight = 1.0;
}
if (PlatformHeight > 10.0)
{
PlatformHeight = 10.0;
}
}
// ...
}Here we documented a constraint in our contract, and enforced that constraint first at construction, and then whenever clients attempt to modify the value.
We chose to enforce that constraint at the point when the value can
be changed because that makes the effect of the constraint directly
visible. If users set an out-of-bounds value and read it back they can
immediately see the effect of the constraint on the property. That’s not
the only choice, of course. We could have done it just before we used
it—but if we changed the implementation, or added features, we might have
to add lots of calls to EnsurePlatformSize, and you can be certain that
we’d forget one somewhere.
When we run the application again, we see the following output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 15.71 radians. Arthur is at (-1.53075794227797E-14,35) and is pointing at angle 15.71 radians. Arthur is at (-1.53075794227797E-14,35) and is pointing at angle 7.85 radians. Arthur is at (-3.53553390593275,35) and is pointing at angle 7.85 radians.
Although this is a very useful technique, and it has clearly
banished those less-than-useful NaNs,
we have to consider: is this the right solution for this particular
problem? Let’s think about our tennis-court-painting robot again. Would we
really want it to paint the court as though it were a 1-meter-wide robot,
just because we forgot to initialize it? Looking at the distances traveled
and the angles through which it has turned, the answer is clearly
no!
Note
Constraints such as this are useful in lots of cases. We might want to ensure that some UI element not extend off the screen, or grow too big or small, for example. But equally, an online banking application that doesn’t permit transactions less than $10 shouldn’t just clamp the amount the user entered from $1 to $10 and carry on happily!
So let’s backtrack a little and look at another option: returning a value that signifies an error.
For many years, programmers have written methods that detect
errors, and which report those errors by returning an error
code. Typically, this is a Boolean value of some kind, with True representing success and False failure. Or you might use either an
int or an enum if you need to distinguish lots of
different types of errors.
Note
Before we add an error return value, we should remove the code we
just added that silently enforces the constraints. We can delete
EnsurePlatformSize and any references
to it. (Or if you’re following along in Visual Studio and don’t want to
delete the code, just comment out all the relevant lines.)
So where are we going to return the error from? Our first instinct
might be to put it in the RunFor
method, where we suggested earlier; but look at the code—there’s nothing
substantive there. The problem actually occurs in Rotate. What happens if we change the Rotate method later so that it depends on
different properties? Do we also update RunFor to check the new constraints? Will we
remember?
It is Rotate that actually uses
the properties, so as a rule of thumb we should do the checking there. It
will also make the debugging easier later—we can put breakpoints near the
origin of the error and see what is going
wrong.
Let’s change the Rotate method
and see what happens (see Example 6-6).
Example 6-6. Indicating errors through the return value
private bool Rotate(double duration)
{
if (PlatformWidth <= 0.0)
{
return false;
}
// This is the total circumference of turning circle
double circum = Math.PI * PlatformWidth;
// This is the total distance traveled
double d = duration * MotorSpeed;
if (LeftMotorState == MotorState.Reversed)
{
// And we're going backwards if the motors are reversed
d *= -1.0;
}
// So we've driven it this proportion of the way round
double proportionOfWholeCircle = d / circum;
// Once round is 360 degrees (or 2pi radians), so we have traveled
CurrentOrientation =
CurrentOrientation + (Math.PI * 2.0 * proportionOfWholeCircle);
return true;
}If we compile and run with our all-new error checking added, we see the following output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Arthur is at (0,-15) and is pointing at angle 0.00 radians. Arthur is at (0,-15) and is pointing at angle 0.00 radians. Arthur is at (0,-18.5355339059327) and is pointing at angle 0.00 radians.
Hmmm; that’s not very good. Rotate has indeed failed, but we’ve carried on
driving the turtle up and down that line because we didn’t do anything
with the return value.
Note
This is the great benefit, and great downside, of error return values: you can just ignore them.
Let’s look at where we call Rotate and see what we can do with that error
(see Example 6-7).
Example 6-7. Detecting failure and then wondering what to do with it
// Run the turtle for the specified duration
public void RunFor(double duration)
{
// ...
// The motors are running in opposite directions,
// so we don't move, we just rotate about the
// center of the rig
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Reversed) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Running))
{
if (!Rotate(duration))
{
// It failed, so what now?
}
return;
}
}It is simple enough to check to see if it failed, but what are we
actually going to do about it? Is there any action we can take? Not
surprisingly, the answer is no—we know no more about the needs of our
caller than we did when we were discussing the other options. So we are
going to have to pass the error on up. Example 6-8
shows an implementation of Run that
does that.
Example 6-8. Passing the buck
// Run the turtle for the specified duration
// Returns false if there was a failure
// Or true if the run succeeded
public bool RunFor(double duration)
{
if (LeftMotorState == MotorState.Stopped &&
RightMotorState == MotorState.Stopped)
{
// If we are at a full stop, nothing will happen
return true;
}
// The motors are both running in the same direction
// then we just drive
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Running) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Reversed))
{
Drive(duration);
return true;
}
// The motors are running in opposite directions,
// so we don't move, we just rotate about the
// center of the rig
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Reversed) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Running))
{
return Rotate(duration);
}
// We didn't expect to get here
return false;
}Notice that we updated our documentation for the public method as we changed the contract. We
also have to return values from all of the exit points of our
method.
That has exposed another problem with our implementation: we never supported one motor at the stop condition, and the other at the driving or reversing condition. Well, that’s fine—we can return an error if we hit those conditions now.
One problem with this contract is that we can’t tell
why our error occurred. Was it due to the state of
the motors, or a problem with Rotate?
We could create an enum that lets us
distinguish between these error types:
enum TurtleError
{
OK,
RotateError,
MotorStateError
}Then we could use the enum as shown in Example 6-9.
Example 6-9. Indicating errors with an enum
// Run the turtle for the specified duration
// Returns one of the TurtleError values if a failure
// occurs, or TurtleError.OK if it succeeds
public TurtleError RunFor(double duration)
{
if (LeftMotorState == MotorState.Stopped &&
RightMotorState == MotorState.Stopped)
{
// If we are at a full stop, nothing will happen
return TurtleError.OK;
}
// The motors are both running in the same direction
// then we just drive
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Running) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Reversed))
{
Drive(duration);
return TurtleError.OK;
}
// The motors are running in opposite directions,
// so we don't move, we just rotate about the
// center of the rig
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Reversed) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Running))
{
if (!Rotate(duration))
{
return TurtleError.RotateError;
}
}
return TurtleError.MotorStateError;
}OK so far, although it is starting to get a bit tortuous, and we’re going up only one call in the stack. But let’s build and run anyway:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Arthur is at (0,-15) and is pointing at angle 0.00 radians. Arthur is at (0,-15) and is pointing at angle 0.00 radians. Arthur is at (0,-18.5355339059327) and is pointing at angle 0.00 radians.
Yup; we’re no better off than before, because all we’ve done is to pass the responsibility up to the client, and they are still free to ignore our pleadings. Given that the problem is a result of our oversight in the first place, what is the likelihood that we’ll remember to check the error message?
Things would be even worse if this was in a library; we could recompile against this new version, and everything would seem fine, while in the background everything would quietly be going horribly wrong.
It is probably about time we did something with the error message, so let’s see what happens in our client code (see Example 6-10).
Example 6-10. Handling an error
static void Main(string[] args)
{
Turtle arthurTheTurtle =
new Turtle {
PlatformWidth = 0.0,
PlatformHeight = 10.0,
MotorSpeed = 5.0 };
ShowPosition(arthurTheTurtle);
// We want to proceed forwards
arthurTheTurtle.LeftMotorState = MotorState.Running;
arthurTheTurtle.RightMotorState = MotorState.Running;
// For two seconds
TurtleError result = arthurTheTurtle.RunFor(2.0);
if (result != TurtleError.OK)
{
HandleError(result);
return;
}
ShowPosition(arthurTheTurtle);
// Now, let's rotate clockwise for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
// PI / 2 seconds should do the trick
result = arthurTheTurtle.RunFor(Math.PI / 2.0);
if (result != TurtleError.OK)
{
HandleError(result);
return;
}
ShowPosition(arthurTheTurtle);
// And let's go into reverse
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
// And run for 5 seconds
result = arthurTheTurtle.RunFor(5);
if (result != TurtleError.OK)
{
HandleError(result);
return;
}
ShowPosition(arthurTheTurtle);
// Then rotate back the other way
arthurTheTurtle.RightMotorState = MotorState.Running;
// And run for PI/4 seconds to give us 45 degrees
result = arthurTheTurtle.RunFor(Math.PI / 4.0);
if (result != TurtleError.OK)
{
HandleError(result);
return;
}
ShowPosition(arthurTheTurtle);
// And finally drive backwards for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
result = arthurTheTurtle.RunFor(Math.Cos(Math.PI / 4.0));
if (result != TurtleError.OK)
{
HandleError(result);
return;
}
ShowPosition(arthurTheTurtle);
Console.ReadKey();
}
private static void HandleError(TurtleError result)
{
Console.WriteLine("We hit turtle error {0}", result);
Console.ReadKey();
}Every time we call the RunFor
method, we have to stash away the error message that is returned, check it
for problems, and then decide what we’re going to do.
In this instance, we decided to quit the application, after showing an error message to the user, because it isn’t safe to continue.
If we compile and run, here’s the output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. We hit turtle error RotateError
From an application point of view, this is much better behavior than before: we were able to stop when we hit our first problem. Unfortunately, we had to write quite a lot of boilerplate code to achieve that end, and our code is much less readable than it was before. We also created a huge number of potential exit points out of our function, which decreases its maintainability. So while it is better, I’m not totally happy with it; this is catching just one potential error from one function, and we have almost as many lines of code dealing with that as we do our success scenario, scattered throughout our whole program!
So we finally spotted the problem, and stopped it from causing trouble. How do we find out what is wrong? Well, first we should take a look at the error message. That tells us that it has something to do with rotating the turtle, which gives us a bit of a clue. The easiest way to see what is really going on, though, might be to set a breakpoint in our error handler and see what state the system is in when the error occurs.
To set a breakpoint, we can put the cursor on the line where we want to break into the debugger, and press F9. Figure 6-1 shows the code with a breakpoint set.

If we run this now, the application will break into the debugger when we hit our error handler. If we press Ctrl-Alt-C, we can inspect the call stack to see where we went wrong, as shown in Figure 6-2.

As you can see, there’s not an awful lot to help us; we lost context in which the error occurred because we returned out of the method that had the actual problem, and wound back up to our calling function.
It isn’t completely useless—we now know which call had the problem (this time), so we can put a breakpoint on the relevant line and run again; but what if this was a hard-to-reproduce, intermittent error? We may have lost our one chance this week to identify and fix the problem!
These are not the only problems with a return-value-based approach
to error handling. What if we already need to use the return value on
the method? We’re heading into the realm of “magic” values that mean an
error has occurred, or we could add out or ref
parameters to allow our method to return both a useful output and an
error code.
And what about property setters; we don’t have the option of a return value, but we might well like to return an error of some kind if the value is out of range.
If you’re thinking “surely there has to be a better way,” you’re right. C# (like most modern languages) supports an alternative means of signaling errors: exceptions.
Rather than return an
error code from a method, we can instead throw an instance of any type derived from
Exception. Let’s rewrite our Rotate method to do that (see Example 6-11).
Example 6-11. Indicating an error with an exception
private void Rotate(double duration)
{
if (PlatformWidth <= 0.0)
{
throw new InvalidOperationException(
"The PlatformWidth must be initialized to a value > 0.0");
}
// This is the total circumference of turning circle
double circum = Math.PI * PlatformWidth;
// This is the total distance traveled
double d = duration * MotorSpeed;
if (LeftMotorState == MotorState.Reversed)
{
// And we're going backwards if the motors are reversed
d *= −1.0;
}
// So we've driven it this proportion of the way round
double proportionOfWholeCircle = d / circum;
// Once round is 360 degrees (or 2pi radians), so we have traveled
CurrentOrientation =
CurrentOrientation + (Math.PI * 2.0 * proportionOfWholeCircle);
// return true; (This is now redunant, so you can delete it)
}Notice that we changed the return specification back to void, and removed the unnecessary return at the
end. The interesting bit, though, is in our test at the beginning of the
method.
Rather than return an instance of
an enum, we throw an instance of the InvalidOperationException class.
InvalidOperationException is one
of several types derived from Exception. It is intended to be used when an
operation fails because the current state of the object itself doesn’t
allow the method to succeed (rather than, say, because a parameter passed
in to the method was incorrect). That seems to fit this case quite nicely,
so we can make use of it.
Note
Back before C# 3.0, you could throw an instance of any type you
liked (e.g., a string). In C# 3.0, a constraint was added that only
types derived from Exception can be
thrown.
If we take a look at the Exception class (see
http://msdn.microsoft.com/library/system.exception)
we’ll see that it has a Message property. That’s
what we’re setting with the string we
pass to the constructor, and it can be any text we like—preferably
something that will help us (or one of our clients) debug the problem in
the future.
There’s also a property called Data. This is a dictionary of key/value pairs
that lets us associate more information with the exception, and it can be
extremely useful for debugging or logging purposes.
Replacing the return value with an exception, we will need to perform a bit of surgery on our application to get it to compile.
First, let’s change the Turtle.RunFor method so that it no longer
returns a value, and delete the TurtleError enumeration (see Example 6-12).
Example 6-12. Passing the buck is no longer required
// Run the turtle for the specified duration
public void RunFor(double duration)
{
if (LeftMotorState == MotorState.Stopped &&
RightMotorState == MotorState.Stopped)
{
// If we are at a full stop, nothing will happen
return;
}
// The motors are both running in the same direction
// then we just drive
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Running) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Reversed))
{
Drive(duration);
}
// The motors are running in opposite directions,
// so we don't move, we just rotate about the
// center of the rig
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Reversed) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Running))
{
Rotate(duration);
}
}Then, we can update the calling program, and strip out the code that deals with the return value (see Example 6-13).
Example 6-13. Main no longer checking explicitly for errors
static void Main(string[] args)
{
Turtle arthurTheTurtle = new Turtle {
PlatformWidth = 0.0, PlatformHeight = 10.0, MotorSpeed = 5.0 };
ShowPosition(arthurTheTurtle);
// We want to proceed forwards
arthurTheTurtle.LeftMotorState = MotorState.Running;
arthurTheTurtle.RightMotorState = MotorState.Running;
// For two seconds
arthurTheTurtle.RunFor(2.0);
ShowPosition(arthurTheTurtle);
// Now, let's rotate clockwise for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
// PI / 2 seconds should do the trick
arthurTheTurtle.RunFor(Math.PI / 2.0);
ShowPosition(arthurTheTurtle);
// And let's go into reverse
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
// And run for 5 seconds
arthurTheTurtle.RunFor(5);
ShowPosition(arthurTheTurtle);
// Then rotate back the other way
arthurTheTurtle.RightMotorState = MotorState.Running;
// And run for PI/4 seconds to give us 45 degrees
arthurTheTurtle.RunFor(Math.PI / 4.0);
ShowPosition(arthurTheTurtle);
// And finally drive backwards for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
arthurTheTurtle.RunFor(Math.Cos(Math.PI / 4.0));
ShowPosition(arthurTheTurtle);
Console.ReadKey();
}Finally, we can delete the HandleError method.
OK, what happens if you compile and run (make sure you press F5 or choose Debug→Start Debugging so that you run in the debugger)? Well, you drop very rapidly into the debugger, as you can see in Figure 6-3.

As the debugger implies, we’ve broken in here because the exception is unhandled; but notice that we’ve broken right at the point at which the exception actually occurred. Even if we hadn’t provided some nice descriptive error text, we can clearly see why we failed, unlike with error codes, where by the time the debugger got involved, we had already lost track of the root cause of the failure.
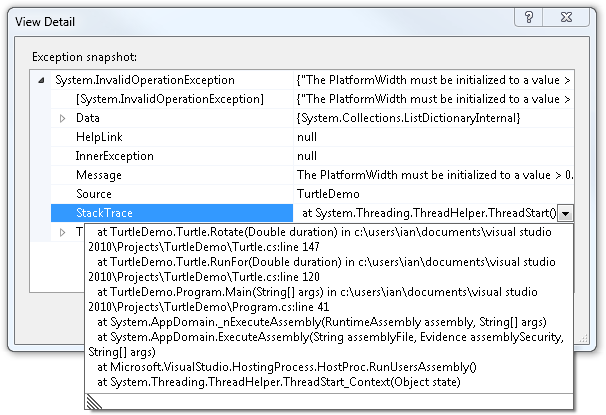
If we want an even closer look, we can click the View Detail link on
the callout. This produces a dialog containing a property grid view of the
exception object that was thrown. We can examine this to help us debug the
problem. (You can see the Message and Data properties that we previously looked at,
and I’ve popped open the StackTrace for
the exception, in the example in Figure 6-4.)
That’s already a huge improvement over the return value approach; but are there any obvious downsides to throwing an exception?
Well, the first downside is that throwing an exception is way more expensive than simply returning a value. You don’t really want to throw an exception just to manage your normal flow of control. Passing parameters and looking at internal state is always going to be a better choice for anything you might call “the success path.”
That being said, expense is, of course, relative, and as usual, you should use the best tool for the job. Plus, exceptions are actually lower cost than return values if you don’t actually throw them. In our previous example, we allocated and copied return values even if everything was OK. With the exception model, the success path is basically free.
Note
The debate about when to use exceptions versus return values continues to rage in our industry. I don’t expect it to let up anytime soon. As I said at the beginning of the chapter, it is almost like we’re not really on top of the whole error-handling situation.
We’ve seen what happens if we don’t handle an exception that we throw (i.e., it percolates up until eventually we crash); and while that behavior is far more satisfactory than the situation when we ignored a return value, we would like to do much better. We want to handle the error and exit gracefully, as we did before.
As you might expect, C# provides us with language features to do
just that: try, finally, and catch.
When we handled our return values, we had to propagate them up the call stack by hand, adding appropriate return values to each and every method, checking the result, and either passing it up or transforming and passing it as we go.
Exceptions, on the other hand, propagate up the stack
automatically. If we don’t want to add a handler, we don’t have to, and
the next call site up gets its chance instead, until eventually we pop
out at the top of Main and either
break into the debugger or Windows Error Handling steps in.
This means we can take a more structured approach to error handling—identifying points in our application control flow where we want to handle particular types of exceptions, and gathering our error-handling code into easily identified blocks.
The try, catch, and finally keywords help
us to define those blocks (along with the ubiquitous braces).
In our example, we have no need to handle the potential errors
from each and every call to RunFor
separately. Instead, we can wrap the whole set into a single set of
try, catch, and finally blocks, as shown in Example 6-14.
Example 6-14. Handling exceptions
static void Main(string[] args)
{
Turtle arthurTheTurtle = new Turtle {
PlatformWidth = 0.0, PlatformHeight = 10.0, MotorSpeed = 5.0 };
ShowPosition(arthurTheTurtle);
try
{
// We want to proceed forwards
arthurTheTurtle.LeftMotorState = MotorState.Running;
arthurTheTurtle.RightMotorState = MotorState.Running;
// For two seconds
arthurTheTurtle.RunFor(2.0);
ShowPosition(arthurTheTurtle);
// Now, let's rotate clockwise for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
// PI / 2 seconds should do the trick
arthurTheTurtle.RunFor(Math.PI / 2.0);
ShowPosition(arthurTheTurtle);
// And let's go into reverse
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
// And run for 5 seconds
arthurTheTurtle.RunFor(5);
ShowPosition(arthurTheTurtle);
// Then rotate back the other way
arthurTheTurtle.RightMotorState = MotorState.Running;
// And run for PI/4 seconds to give us 45 degrees
arthurTheTurtle.RunFor(Math.PI / 4.0);
ShowPosition(arthurTheTurtle);
// And finally drive backwards for a bit
arthurTheTurtle.RightMotorState = MotorState.Reversed;
arthurTheTurtle.LeftMotorState = MotorState.Reversed;
arthurTheTurtle.RunFor(Math.Cos(Math.PI / 4.0));
ShowPosition(arthurTheTurtle);
}
catch (InvalidOperationException e)
{
Console.WriteLine("Error running turtle:");
Console.WriteLine(e.Message);
}
finally
{
Console.ReadKey();
}
}If any of the code in the try
block throws an exception, the runtime looks to see if there are any
catch blocks whose exception type
matches the type of that exception. It matches successfully if the
catch parameter is either of the same
type, or of a less-derived (base) type than that of the
exception.
You can have any number of catch blocks for different types of
exceptions, and it will look through them in the order they are defined;
the first one that matches wins (even if there is a “better” match
farther down).
If it doesn’t find a suitable match, the exception will be
propagated on up the call stack, just as though there was no try block.
To see how this works in practice, let’s quickly modify the code
in Example 6-14 to catch Exception as well, as shown in Example 6-15.
Example 6-15. Poorly placed catch block
try
{
...
}
catch (Exception e2)
{
Console.WriteLine("Caught generic exception...");
}
catch (InvalidOperationException e)
{
Console.WriteLine("Error running turtle:");
Console.WriteLine(e.Message);
}
finally
{
Console.WriteLine("Waiting in the finally block...");
Console.ReadKey();
}If you try to compile this, you’ll see the following error:
A previous catch clause already catches all exceptions of this or of a
super type ('System.Exception')This occurs because Exception
is an ancestor of InvalidOperationException, and the clause
appears first in the list of catch
blocks. If we switch those around, we compile successfully, as shown in
Example 6-16.
Example 6-16. Catching exceptions in the right order
try
{
...
}
catch (InvalidOperationException e)
{
Console.WriteLine("Error running turtle:");
Console.WriteLine(e.Message);
}
catch (Exception e2)
{
Console.WriteLine("Caught generic exception...");
}
finally
{
Console.WriteLine("Waiting in the finally block...");
Console.ReadKey();
}When the flow of control leaves the try block successfully,
or the flow of control exits the last catch block if an exception occurred in the
try block, the code in the finally block is executed. In other words, the
code in the finally block is
always executed, regardless of whether there was an
exception.
If you designed your exception-handling code nicely, you’ll almost
certainly use far more finally blocks
than you do catch blocks. The
finally block is a good place for
cleaning up your resources, or winding back internal state if an error
occurs, to ensure that your pre- and post conditions are still valid,
whereas a catch block allows you to
deal with an error condition you, as a client, understand in some
way—even if it is only to present a message to the user (as in this
case).
If we compile and run our code again, we’ll see the following output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Error running turtle: The PlatformWidth must be initialized to a value > 0.0 Waiting in the finally block...
Notice how the error-handling code is now consolidated neatly into clearly defined blocks, rather than scattered throughout our code, and we’ve been able to cut down substantially on the number of points of return from our method.
At the moment, we’re not handling any exceptions in our Turtle itself. Let’s imagine that our Turtle is being provided to clients in a
library, and we (as the leading vendors of turtle simulators) want the
library to do some internal logging when errors occur: maybe we have an
opt-in customer experience program that sends telemetry back to our
team.
We still want the errors to propagate up to the client for them to deal with; we just want to see them on the way past.
C# gives us the ability to catch, and then transparently rethrow, an exception, as shown in Example 6-17.
Example 6-17. Rethrowing an exception
// Run the turtle for the specified duration
public void RunFor(double duration)
{
try
{
if (LeftMotorState == MotorState.Stopped &&
RightMotorState == MotorState.Stopped)
{
// If we are at a full stop, nothing will happen
return;
}
// The motors are both running in the same direction
// then we just drive
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Running) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Reversed))
{
Drive(duration);
}
// The motors are running in opposite directions,
// so we don't move, we just rotate about the
// center of the rig
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Reversed) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Running))
{
Rotate(duration);
}
}
catch (Exception ex)
{
Console.WriteLine("Log message: " + ex.Message);
// Rethrow
throw;
}
}The first thing to notice is that we caught the base Exception type, having just said that we
almost never do that. We want to log every exception, and because we’re
rethrowing rather than eating it, we won’t simply ignore exceptions we
weren’t expecting.
After we execute our handler code (just writing the message to the
console in this case), we use the throw keyword, without
any object, to rethrow the exception we just caught.
If you compile and run that, you’ll see the following output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Log error: The PlatformWidth must be initialized to a value > 0.0 Error running turtle: The PlatformWidth must be initialized to a value > 0.0 Waiting in the finally block
Notice that we get the output from both of the exception handlers.
That’s not the only way to throw from a catch block: it is perfectly reasonable to
throw any exception from our exception handler! We often do this to wrap
up an exception that comes from our implementation in another exception
type that is more appropriate for our context. The original exception is
not thrown away, but stashed away in the InnerException property
of the new one, as shown in Example 6-18.
Example 6-18. Wrapping one exception in another
// Run the turtle for the specified duration
public void RunFor(double duration)
{
try
{
if (LeftMotorState == MotorState.Stopped &&
RightMotorState == MotorState.Stopped)
{
// If we are at a full stop, nothing will happen
return;
}
// The motors are both running in the same direction
// then we just drive
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Running) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Reversed))
{
Drive(duration);
}
// The motors are running in opposite directions,
// so we don't move, we just rotate about the
// center of the rig
if ((LeftMotorState == MotorState.Running &&
RightMotorState == MotorState.Reversed) ||
(LeftMotorState == MotorState.Reversed &&
RightMotorState == MotorState.Running))
{
Rotate(duration);
}
}
catch (InvalidOperationException iox)
{
throw new Exception("Some problem with the turtle...", iox);
}
catch (Exception ex)
{
// Log here
Console.WriteLine("Log message: " + ex.Message);
// Rethrow
throw;
}
}Notice how we passed the exception to be wrapped as a parameter to
the new exception when we constructed it. Let’s make a quick
modification to the exception handler in Main to take advantage of this new feature
(see Example 6-19).
Example 6-19. Reporting an InnerException
static void Main(string[] args)
{
Turtle arthurTheTurtle = new Turtle {
PlatformWidth = 0.0, PlatformHeight = 10.0, MotorSpeed = 5.0 };
ShowPosition(arthurTheTurtle);
try
{
// ...
}
catch (InvalidOperationException e)
{
Console.WriteLine("Error running turtle:");
Console.WriteLine(e.Message);
}
catch (Exception e1)
{
// Loop through the inner exceptions, printing their messages
Exception current = e1;
while (current != null)
{
Console.WriteLine(current.Message);
current = current.InnerException;
}
}
finally
{
Console.WriteLine("Waiting in the finally block");
Console.ReadKey();
}
}If we compile and run again, we can see the following output, including the messages from both the outer and inner exceptions:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Arthur is at (0,10) and is pointing at angle 0.00 radians. Some problem with the turtle has occurred The PlatformWidth must be initialized to a value > 0.0 Waiting in the finally block
Clearly, wrapping an implementation-detail exception with something explicitly documented in our public contract can simplify the range of exception handlers you require. It also helps to encapsulate implementation details, as the exceptions you throw can be considered part of your contract.
On the other hand, are there any disadvantages to throwing a
wrapped exception (or indeed rethrowing the original exception
explicitly, rather than implicitly with throw;)? As programming tends to be a series
of compromises, the answer is, as you might expect, yes.
If you explicitly (re)throw an exception, the call stack in the
exception handler starts at the new throw statement, losing the original context
in the debugger (although you can still inspect it in the inner
exception in the object browser). This makes debugging noticeably less
productive.
Because of this, you should consider carefully whether you need to wrap the exception, and always ensure that you implicitly (rather than explicitly) rethrow exceptions that you have caught and then wish to pass through.
It is worth clarifying exactly when the finally block gets executed, under a few edge
conditions.
First, let’s see what happens if we run our example application
outside the debugger. If we do that (by pressing
Ctrl-F5) we’ll see that Windows Error Handling[12] materializes, and presents the user with an error dialog
before we actually hit our finally block at all! It is like the runtime
has inserted an extra catch block in
our own (top-level) exception handler, rather than percolating up
another level (and hence out of our scope, invoking the code in the
finally block).
And what happens when exceptions are thrown out of the exception handlers?
Let’s add a finally block to
our RunFor method (see Example 6-20).
Example 6-20. Seeing when finally blocks run
// Run the turtle for the specified duration
public void RunFor(double duration)
{
try
{
// ...
}
catch (InvalidOperationException iox)
{
throw new Exception("Some problem with the turtle has occurred", iox);
}
catch (Exception ex)
{
// Log here
Console.WriteLine("Log error: " + ex.Message);
// Rethrow
throw;
}
finally
{
Console.WriteLine("In the Turtle finally block");
}
}If you compile and run this code, you’ll see the following output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. In the Turtle finally block Arthur is at (0,10) and is pointing at angle 0.00 radians. In the Turtle finally block Some problem with the turtle has occurred The PlatformWidth must be initialized to a value > 0.0 Waiting in the finally block
So our finally block executes
after the exception is thrown, but
before it executes the exception handlers farther
up the stack.
One important question remains: how did we know what exception type to catch from our code? Unlike some other languages (e.g., Java) there is no keyword which allows us to specify that a method can throw a particular exception. We have to rely on good developer documentation. The MSDN documentation for the framework itself carefully documents all the exceptions that can be thrown from its methods (and properties), and we should endeavor to do the same.
The .NET Framework provides a wide variety of exception types that you can catch (and often use). Let’s revisit Table 6-1 (the common error types) and see what is available for those situations (see Table 6-2).
Table 6-2. Some common errors and their exception types
Error | Description | Examples |
|---|---|---|
Unexpected input | A client passes data to a method that is outside some expected range. |
|
Unexpected data type | A client passes data to a method that is not of the expected type. |
|
Unexpected data format | A client passes data to a method in a format that is not recognized. |
|
Unexpected result | A client receives
information from a method that it did not expect for the given
input (e.g., |
|
Unexpected method call | The class wasn’t expecting you to call a particular method at that time; you hadn’t performed some required initialization, for example. |
|
Unavailable resource | A method tried to access a resource of some kind and it failed to respond in a timely fashion; a hardware device was not plugged in, for instance. |
|
Contended resource | A method tried to access a scarce resource of some kind (memory or a hardware device that cannot be shared) and it was not available because someone else was using it. |
|
Obviously, that’s a much abbreviated list, but it contains some of
the most common exceptions you’ll see in real applications. One of the
most useful that you’ll throw yourself is the ArgumentException. You
can use that when parameters passed to your methods fail to
validate.
Let’s make use of that in our RunFor method. Say that a “feature” of our
turtle hardware is that it crashes and becomes unresponsive if we try to
run it for zero seconds. We can work around this in our software by
checking for this condition in the RunFor method, and throwing an exception if
clients try this, as shown in Example 6-21.
Example 6-21. Throwing an exception when arguments are bad
public void RunFor(double duration)
{
if (duration <= double.Epsilon)
{
throw new ArgumentException(
"Must provide a duration greater than 0",
"duration");
}
try
{
// ...
}
catch (InvalidOperationException iox)
{
throw new Exception("Some problem with the turtle has occurred", iox);
}
catch (Exception ex)
{
// Log here
Console.WriteLine("Log error: " + ex.Message);
// Rethrow
throw;
}
finally
{
Console.WriteLine("In the Turtle finally block");
}
}The second parameter in this constructor should match the name of the parameter that is in error. The first represents the exception message.
Note
When you come to use ArgumentNullException (which you throw when
you are erroneously passed a null argument) you’ll find that the error
message and parameter arguments are swapped around in the constructor.
This irritating inconsistency has been with us since .NET 1.0, and too
much code depends on it to fix it now.
The code in Example 6-22
updates Main, to sneak in an attempt
to run it for zero seconds.
Example 6-22. Testing for the expected exception
static void Main(string[] args)
{
Turtle arthurTheTurtle = new Turtle {
PlatformWidth = 0.0, PlatformHeight = 10.0, MotorSpeed = 5.0 };
ShowPosition(arthurTheTurtle);
try
{
arthurTheTurtle.RunFor(0.0);
// ...
}
catch (InvalidOperationException e)
{
Console.WriteLine("Error running turtle:");
Console.WriteLine(e.Message);
}
catch (Exception e1)
{
// Loop through the inner exceptions, printing their messages
Exception current = e1;
while (current != null)
{
Console.WriteLine(current.Message);
current = current.InnerException;
}
}
finally
{
Console.WriteLine("Waiting in the finally block");
Console.ReadKey();
}
}If we compile and run, we’ll see the following output:
Arthur is at (0,0) and is pointing at angle 0.00 radians. Must provide a duration greater than 0 Parameter name: duration Waiting in the finally block
Notice how the error message automatically includes the details of the problem parameter.
You might want to create your own exceptions for a couple of reasons:
My exception is a special snowflake.
I want to group my exceptions together for layered exception handling.
The first of these is the most problematic. You should think very carefully about whether your exception is really special, or whether you can just reuse an existing exception type.
When you introduce new exceptions, you’re asking clients to understand and deal with a new type of problem, and you’re expecting them to handle it in a special way. There are occasional instances of this, but more often the differences are in the context (i.e., that it was thrown from your code) rather than the exception itself (i.e., something was out of range, invalid, null, or unavailable, or it timed out).
Slightly more often, you provide custom exception types when you
want to provide a convenient API over some additional information that
comes along with the exception. The Exception.Data property we discussed earlier
might be a better solution—it gives you somewhere to put information
without needing to add a new kind of exception. But the convenience of a
dedicated property might outweigh the costs of introducing a custom
exception.
Finally, you might wish to create a custom exception class to
allow you to conceptually group some subsystem’s exceptions together.
DbException is an example of this in
the .NET Framework; it represents the various errors that can occur when
using a database. There are various specialized errors that derive from
this, such as the SqlException thrown by the SQL Server
subsystem, but the common base class enables you to write a single catch for all database errors, rather than
having to handle provider-specific errors.
Again, you should think carefully about this before doing it: what client exception-handling scenarios are you enabling, and why do you need the custom type?
However, having been through all of this, creating your own
exception type is very simple. Let’s create a TurtleException for our exception wrapper (see
Example 6-23).
Note
Whether we really want a TurtleException is another matter. I’m not
sure I really would in these circumstances, but your mileage may
vary.
Example 6-23. A custom exception
[Serializable]
class TurtleException : Exception
{
public TurtleException()
{}
public TurtleException(string message)
: base(message)
{ }
public TurtleException(string message, Exception innerException)
: base(message, innerException)
{}
// For serialization support
protected TurtleException(SerializationInfo info, StreamingContext context)
: base(info, context)
{}
}The first thing to notice is that we derive from Exception.
If you’ve plowed through the MSDN documentation you might have
noticed the ApplicationException type, which derives
from Exception, and was provided as a
base class for application-defined exceptions. Why, you might ask, are
we not deriving from ApplicationException?
Well, ApplicationException adds
no functionality to Exception, and
the .NET designers could not come up with a scenario where it was useful
to catch ApplicationException (as
opposed to Exception). Sadly, they
only realized this after .NET 1.0 had shipped, so it is in the library,
but it is now deprecated. You should neither derive from nor catch
ApplicationException.
Also, we provide a bunch of standard constructors: a default parameterless constructor, one that takes a message, and one that takes a message and an inner exception. Even if you add more properties to your own exception that you wish to initialize in the constructor, you should still provide constructors that follow this pattern (including the default, parameterless one).
The final constructor supports serialization. We do this because
Exception itself is marked as a
serializable class, which means that derived classes have to be too.
This enables exceptions to cross appdomain boundaries.[13] We’re just calling the base class’s constructor here.
Because there is no constructor inheritance in C#, we need to provide a
matching constructor which calls the one in our base. If we didn’t do
this, any code that polymorphically used our TurtleException as its base Exception might break.
In this chapter, we reviewed the various types of errors that might
occur in our software and looked at several strategies for handling them.
These include ignoring the problem, aborting the application, returning
errors, and throwing exceptions. We also saw some of the benefits and
pitfalls of returning errors, and how exceptions can often provide a more
robust and flexible means of alerting your clients to problems. We saw how
we can handle exceptions in layers, sometimes catching, using, and then
rethrowing an exception, sometimes wrapping an implementation exception in
a public exception type, and sometimes allowing exceptions to bubble up to
the next layer of handlers. We saw what happens when an unhandled
exception pops out at the top of the stack, and how we can use finally blocks at each layer to ensure that
application state remains consistent, and resources can be released,
whether exceptions occur or not. We then took a quick review of some of
the most common exceptions provided by the framework, and how we might use
them. Finally, we looked at creating our own exception types and why we
might (and might not) wish to do so.
We’ve come a long way in the past few chapters, covering all of the everyday C# programming concepts you’ll need. In the next few chapters, we’ll look at features of the .NET Framework in more detail, and how we can best use them in C#; starting with the collection classes.
[12] Or “Dr. Watson” as the crash handler was more colorfully named on older versions of Windows.
[13] An appdomain is a kind of process within a process. We’ll talk about them a little more in Chapter 11 and Chapter 15, but they’re mainly used by systems that need to host code, such as ASP.NET.