
Most programs have to deal with multiple pieces of information. Payroll systems need to calculate the salary of every employee in a company; a space battle game has to track the position of all the ships and missiles; a social networking website needs to be able to show all of the user’s acquaintances. Dealing with large numbers of items is a task at which computers excel, so it’s no surprise that C# has a range of features dedicated to working with collections of information.
Sets of information crop up so often that we’ve already seen some of what C# has to offer here. So we’ll start with a more detailed look at the collection-based features we’ve already seen, and in the next chapter we’ll look at the powerful LINQ (Language Integrated Query) feature that C# offers for finding and processing information in potentially large sets of information.
The ability to work with collections is so important that the .NET Framework’s type system has a feature just for this purpose: the array. This is a special kind of object that can hold multiple items, without needing to declare a field for each individual item. Example 7-1 creates an array of strings, with one entry for each event coming up in one of the authors’ calendars over the next few days. You may notice a theme here (although one misfit appears to be a refugee from an earlier chapter’s theme, but that’s just how the author’s weekend panned out; real data is never tidy).
Example 7-1. An array of strings
string[] eventNames =
{
"Swing Dancing at the South Bank",
"Saturday Night Swing",
"Formula 1 German Grand Prix",
"Swing Dance Picnic",
"Stompin' at the 100 Club"
};Look at the variable declaration on the first line. The square
brackets after string indicate that
eventNames is not just a single
string; it’s an array of string values. These square brackets tie in with
the syntax for accessing individual elements in the array. Example 7-2 prints the first and fifth items
in the array. (So this will print out the text “Swing Dancing at the South
Bank”, followed by “Stompin’ at the 100 Club”.)
Example 7-2. Using elements in an array
Console.WriteLine(eventNames[0]); Console.WriteLine(eventNames[4]);
The number inside the square brackets is called the index, and as you can see, C# starts counting array elements from zero. As you may recall from Chapter 2, the index says how far into the array we’d like C# to look—to access the very first element, we don’t have to go any distance into the array at all, so its index is 0. Likewise, an index of 4 jumps past the first four items to arrive at the fifth.
To modify an array element you just put the same syntax on the lefthand side of an assignment. For example, noticing that I got one of the event names slightly wrong, I can update it, like so:
eventNames[1] = "Saturday Night Swing Club";
While you can change any element of an array like this, the number of elements is fixed for the lifetime of the array. (As we’ll see later, this limitation is less drastic than it first sounds.)
Note
If you try to use too high an index or a negative index when
accessing an array element, the code will throw an IndexOutOfRangeException. Since elements are
numbered from zero, the highest acceptable index is one less than the
number of elements. For example, eventNames[4] is the last item in our
five-item array, so trying to read or write eventNames[5] would throw an
exception.
The .NET Framework supports arrays whose first element is numbered
from something other than zero. This is to support languages such as
Visual Basic that have historically offered such a construct. However,
you cannot use such arrays with the C# index syntax shown here—you would
need to use the Array class’s
GetValue and SetValue helper methods to use such an
array.
Since the size of an array is fixed at the moment it is constructed, let’s look at the construction process in more detail.
There are two ways you can create a new array in C#. Example 7-1 showed the most straightforward approach—the array variable declaration was followed by a list of the array’s contents enclosed in braces, which is called an initializer list. But this requires you to know exactly what you want in the array when you write the code. You will often work with information that your program discovers at runtime, perhaps from a database or a web service. So C# offers an alternative mechanism that lets you choose the array’s size at runtime.
For example, suppose I decide I’d like to display the events in my calendar as a numbered list. I already have an array of event names, but I’d like to build a new string array that adds a number to the event text. Example 7-3 shows how to do this.
Example 7-3. Creating an array dynamically
static string[] AddNumbers(string[] names)
{
string[] numberedNames = new string[names.Length];
for (int i = 0; i < names.Length ; ++i)
{
numberedNames[i] = string.Format("{0}: {1}", i, names[i]);
}
return numberedNames;
}This AddNumbers method doesn’t
know up front what will be in the array it creates—it’s building a
modified copy of an existing array. So instead of creating a fixed list
of items, it uses this syntax: new
ElementType[arrayLength]. This specifies the two things that are
fixed when you create a new array: the type and number of
elements.
When you create an array with this minimal syntax, the elements
all start out with their default values. With the string type used here, the default is null; an array of numbers created this way
would contain all zeros. So Example 7-3 immediately goes on to
populate the newly created array with some useful values. In fact,
that’s also what happened in Example 7-1—when
you provide an array with a list of initial contents, the C# compiler
turns it into the sort of code shown in Example 7-4.
Example 7-4. How initializer lists work
string[] eventNames = new string[5]; eventNames[0] = "Swing Dancing at the South Bank"; eventNames[1] = "Saturday Night Swing"; eventNames[2] = "Formula 1 German Grand Prix"; eventNames[3] = "Swing Dance Picnic"; eventNames[4] = "Stompin' at the 100 Club";
The array initialization syntax in Example 7-1 is really just convenient shorthand—the .NET Framework itself always expects to be told the number and type of elements, so it’s just a matter of whether the C# compiler works out the element count for you.
The Example 7-1 shorthand works only at the point at which you declare a variable. If your program decides to put a new array into an existing variable, you’ll find that the syntax no longer works (see Example 7-5).
Example 7-5. Where array initializers fail
// Won't compile!
eventNames =
{
"Dean Collins Shim Sham Lesson",
"Intermediate Lindy Hop Lesson",
"Wild Times - Social Dancing at Wild Court"
};The reasons for this are somewhat arcane. In general, C# cannot
always work out what element type you need for an array, because it may
have more than one choice. For example, a list of strings doesn’t
necessarily have to live in an array of type string[]. An array of type object[] is equally capable of holding the
same data. And as we’ll see later, initializer lists don’t necessarily
have to initialize arrays—this list of strings could initialize a
List<string>, for
example.
As it happens, only one of those choices would work in Example 7-5—we’re assigning into the
eventNames variable, which is of type
string[], so you’d think the compiler
would know what we want. But since there are some situations which
really are ambiguous, Microsoft decided to require you to specify the
element type everywhere except for the one special case of initializing
a newly declared array variable.
The upshot is not so bad—if you specify the element type, you still get to use the initializer list syntax and have C# count the elements for you. Example 7-6 modifies Example 7-5 by explicitly stating the type of array we’d like before providing its contents. By the way, we could also have added this explicit array type in Example 7-1—it would have worked, it’s just more verbose than necessary in that particular case.
Example 7-6. Combining an explicit element type with an initializer list
// Will compile!
eventNames = new string[]
{
"Dean Collins Shim Sham Lesson",
"Intermediate Lindy Hop Lesson",
"Wild Times - Social Dancing at Wild Court"
};This syntax works anywhere you need an array-typed expression. For
example, we could use this to pass in an array to the AddNumbers method in Example 7-3, as shown in Example 7-7.
Example 7-7. Inline array initializer
string[] result = AddNumbers(new string[] { "The Jazz Devil", "Jitterbugs" });This inline array technique can occasionally be useful if you
need to call a method that demands to be passed an array, and you happen
not to have one handy. The String
class’s Split method illustrates an
interesting twist on this.
The String.Split method
breaks a string into multiple strings based on separator characters.
You tell it which characters to treat as separators by passing a
char array. Example 7-8 splits on spaces,
commas, and periods.
Example 7-8. Array arguments in the class library
string[] items = inputString.Split(
new char[] { ' ', ',', '.' },
StringSplitOptions.RemoveEmptyEntries);If inputString contained
"One,Two Three, Four. Five.", this
would put a five-element array into items containing the strings
"One", "Two", "Three", "Four", and "Five".
Example 7-8 asks
Split to ignore empty items so that
when we get both a period and a space in succession we don’t get an
empty string in the results to represent the fact that there were two
separators. If you don’t need to skip such things, there’s a simpler
overload of Split that illustrates
yet another way to initialize an array:
string[] items = inputString.Split(' ', ',', '.'),It looks like we’ve passed three char arguments to this method. But there’s
no such overload of Split—this ends
up calling an overload that looks like this:
public string[] Split(params char[] separator) ...
That params keyword is
significant. When an argument is marked with this keyword, C# lets you
use syntax that makes it look like a series of individual arguments,
and it will create an array from these for you. (You’re free to
provide the array explicitly if you prefer.) The params keyword can be used on only the very
last argument of a method, to avoid potential ambiguity about which
values go into arrays and which become arguments in their own right.
That’s why Example 7-8 had
to create the array explicitly.
The examples so far contain nothing but strings. This is a poor
way to represent events in a calendar—it would be useful to know when
each event occurs. We could add a second array of type DateTimeOffset[] whose elements correspond
to the event names in the original array. But spreading related data
across multiple arrays can make code awkward to write and hard to
maintain. Fortunately, there’s a better way.
You can create an array using any type for the element type—you’re not limited to types provided by the .NET Framework class library. You can use a class defined in the way shown in Chapter 3, such as the calendar event type in Example 7-9.
Example 7-9. Custom class to represent events in a calendar
class CalendarEvent
{
public string Title { get; set; }
public DateTimeOffset StartTime { get; set; }
public TimeSpan Duration { get; set; }
}This class holds the event’s title, start time, and duration in a single object. We can create an array of these objects, as shown in Example 7-10.
Example 7-10. Creating an array with a custom element type
CalendarEvent[] events =
{
new CalendarEvent
{
Title = "Swing Dancing at the South Bank",
StartTime = new DateTimeOffset (2009, 7, 11, 15, 00, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(4)
},
new CalendarEvent
{
Title = "Saturday Night Swing",
StartTime = new DateTimeOffset (2009, 7, 11, 19, 30, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(6.5)
},
new CalendarEvent
{
Title = "Formula 1 German Grand Prix",
StartTime = new DateTimeOffset (2009, 7, 12, 12, 10, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(3)
},
new CalendarEvent
{
Title = "Swing Dance Picnic",
StartTime = new DateTimeOffset (2009, 7, 12, 15, 00, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(4)
},
new CalendarEvent
{
Title = "Stompin' at the 100 Club",
StartTime = new DateTimeOffset (2009, 7, 13, 19, 45, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(5)
}
};Notice that Example 7-10 uses the new keyword to
initialize each object. This highlights an important point about arrays:
individual array elements are similar to variables of the same type.
Recall from Chapter 3
that a custom type defined with the class keyword, such as the CalendarEvent type in Example 7-9, is a reference type. This means that when
you declare a variable of that type, the variable does not represent a
particular object—it’s a storage location that can
refer to an object. And the same is true of each
element in an array if the element type is a reference type. Figure 7-1 shows the objects
that Example 7-10 creates:
five CalendarEvent objects (shown on
the right), and an array object of type CalendarEvent[] (shown on the left) where each
element in the array refers to one of the event objects.

As you saw in Chapter 3, with reference types multiple different variables can all refer to the same object. Since elements in an array behave in a similar way to local variables of the element type, we could create an array where all the elements refer to the same object, as shown in Example 7-11.
Example 7-11. Multiple elements referring to the same object
CalendarEvent theOnlyEvent = new CalendarEvent
{
Title = "Swing Dancing at the South Bank",
StartTime = new DateTimeOffset (2009, 7, 11, 15, 00, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(4)
};
CalendarEvent[] events =
{
theOnlyEvent,
theOnlyEvent,
theOnlyEvent,
theOnlyEvent,
theOnlyEvent
};Figure 7-2 illustrates the result. While this particular example is not brilliantly useful, in some situations it’s helpful for multiple elements to refer to one object. For example, imagine a feature for booking meeting rooms or other shared facilities—this could be a useful addition to a calendar program. An array might describe how the room will be used today, where each element represents a one-hour slot for a particular room. If the same individual had booked the same room for two different slots, the two corresponding array elements would both refer to the same person.

Another feature that reference type array elements have in common
with reference type variables and arguments is support for polymorphism.
As you saw in Chapter 4, a
variable declared as some particular reference type can refer to any
object of that type, or of any type derived from
the variable’s declared type. This works for arrays too—using the
examples from Chapter 4, if an
array’s type is FirefighterBase[],
each element could refer to a Firefighter, or TraineeFirefighter, or anything else that
derives from FirefighterBase. (And
each element is allowed to refer to an object of a different type, as
long as the objects are all compatible with the element type.) Likewise,
you can declare an array of any interface type—for example, INamedPerson[], in which case each element can
refer to any object of any type that implements that interface. Taking
this to extremes, an array of type object[] has elements that can refer to any
object of any reference type, or any boxed value.
As you will remember from Chapter 3, the alternative to a reference type is a value type. With value types, each variable holds its own copy of the value, rather than a reference to some potentially shared object. As you would expect, this behavior carries over to arrays when the element type is a value type. Consider the array shown in Example 7-12.
Like all the numeric types, int
is a value type, so we end up with a rather different structure. As
Figure 7-3 shows, the array
elements are the values themselves, rather than references to
values.
Why would you need to care about where exactly the value lives?
Well, there’s a significant difference in behavior. Given the numbers array in Example 7-12, consider this code:
int thirdElementInArray = numbers[2];
thirdElementInArray += 1;
Console.WriteLine("Variable: " + thirdElementInArray);
Console.WriteLine("Array element: " + numbers[2]);which would print out the following:
Variable: 6 Array element: 5

Because we are dealing with a value type, the thirdElementInArray local variable gets a copy
of the value in the array. This means that the code can change the local
variable without altering the element in the array. Compare that with
similar code working on the array from Example 7-10:
CalendarEvent thirdElementInArray = events[2];
thirdElementInArray.Title = "Modified title";
Console.WriteLine("Variable: " + thirdElementInArray.Title);
Console.WriteLine("Array element: " + events[2].Title);This would print out the following:
Variable: Modified title Array element: Modified title
This shows that we’ve modified the event’s title both from the
point of view of the local variable and from the point of view of the
array element. That’s because both refer to the same CalendarEvent object—with a reference type,
when the first line gets an element from the array we don’t get a copy
of the object, we get a copy of the reference to that object. The object
itself is not copied.
The distinction between the reference and the object being
referred to means that there’s sometimes scope for ambiguity—what
exactly does it mean to change an element in an array? For value types,
there’s no ambiguity, because the element is the
value. The only way to change an entry in the numbers array in Example 7-12 is to assign a new value into an
element:
numbers[2] = 42;
But as you’ve seen, with reference types the array element is just a reference, and we may be able to modify the object it refers to without changing the array element itself. Of course, we can also change the element, it just means something slightly different—we’re asking to change which object that particular element refers to. For example, this:
events[2] = events[0];
causes the third element to refer to the same object as the first. This doesn’t modify the object that element previously referenced. (It might cause the object to become inaccessible, though—if nothing else has a reference to that object, overwriting the array element that referred to it means the program no longer has any way of getting hold of that object, and so the .NET Framework can reclaim the memory it occupies during the next garbage collection cycle.)
It’s often tempting to talk in terms of “the fourth object in the array,” and in a lot of cases, that’s a perfectly reasonable approximation in practice. As long as you’re aware that with reference types, array elements contain references, not objects, and that what you really mean is “the object referred to by the fourth element in the array” you won’t get any nasty surprises.
Regardless of what element type you choose for an array, all arrays provide various useful methods and properties.
An array is an object in its own right; distinct from any
objects its elements may refer to. And like any object, it has a type—as
you’ve already seen, we write an array type as
SomeType[]. Whatever type
SomeType may be, its corresponding array
type, SomeType[], will derive from a standard built-in type
called Array, defined in the System namespace.
The Array base class provides a
variety of services for working with arrays. It can help you find
interesting items in an array. It can reorder the elements, or move
information between arrays. And there are methods for working with the
array’s size.
Suppose we want to find out if an array of calendar items contains any events that start on a particular date. An obvious way to do this would be to write a loop that iterates through all of the elements in the array, looking at each date in turn (see Example 7-13).
Example 7-13. Finding elements with a loop
DateTime dateOfInterest = new DateTime (2009, 7, 12);
foreach (CalendarEvent item in events)
{
if (item.StartTime.Date == dateOfInterest)
{
Console.WriteLine(item.Title + ": " + item.StartTime);
}
}Note
Example 7-13 relies on a
useful feature of the DateTimeOffset type that makes it easy to
work out whether two DateTimeOffset values fall on the same
day, regardless of the exact time. The Date property returns a DateTime in which the year, month, and day
are copied over, but the time of day is set to the default time of
midnight.
Although Example 7-13 works
just fine, the Array class provides
an alternative: its FindAll method builds
a new array containing only those elements in the original array that
match whatever criteria you specify. Example 7-14 uses this method to do the
same job as Example 7-13.
Example 7-14. Finding elements with FindAll
DateTime dateOfInterest = new DateTime (2009, 7, 12); CalendarEvent[] itemsOnDateOfInterest = Array.FindAll(events, e => e.StartTime.Date == dateOfInterest); foreach (CalendarEvent item in itemsOnDateOfInterest) { Console.WriteLine(item.Title + ": " + item.StartTime); }
Notice that we’re using a lambda expression to tell FindAll which items match. That’s not
mandatory—FindAll requires a
delegate here, so you can use any of the alternatives discussed in
Chapter 5, including
lambda expressions, anonymous methods, method names, or any expression
that returns a suitable delegate. The delegate type here is Predicate<T>, where T is the array element type (Predicate<CalendarEvent> in this
case). We also discussed predicate delegates in Chapter 5, but in case
your memory needs refreshing, we just need to supply a function that
takes a CalendarEvent and returns
true if it matches, and false if it does not. Example 7-14 uses the same expression as
the if statement in Example 7-13.
This may not seem like an improvement on Example 7-13. We’ve not written any less code, and we’ve ended up using a somewhat more advanced language feature—lambda expressions—to get the job done. However, notice that in Example 7-14, we’ve already done all the work of finding the items of interest before we get to the loop. Whereas the loop in Example 7-13 is a mixture of code that works out what items we need and code that does something with those items, Example 7-14 keeps those tasks neatly separated. And if we were doing more complex work with the matching items, that separation could become a bigger advantage—code tends to be easier to understand and maintain when it’s not trying to do too many things at once.
The FindAll method becomes
even more useful if you want to pass the set of matching items on to
some other piece of code, because you can just pass the array of
matches it returns as an argument to some method in your code. But how
would you do that with the approach in Example 7-13, where the match-finding
code is intermingled with the processing code? While the simple
foreach loop in Example 7-13 is fine for trivial
examples, FindAll and similar
techniques (such as LINQ, which we’ll get to in the next chapter) are
better at managing the more complicated scenarios likely to arise in
real code.
Note
This is an important principle that is not limited to arrays or collections. In general, you should try to construct your programs by combining small pieces, each of which does one well-defined job. Code written this way tends to be easier to maintain and to contain fewer bugs than code written as one big, sprawling mass of complexity. Separating code that selects information from code that processes information is just one example of this idea.
The Array class offers a few
variations on the FindAll theme. If
you happen to be interested only in finding the first matching item,
you can just call Find. Conversely,
FindLast returns the very last
matching item.
Sometimes it can be useful to know where in the array a matching
item was found. So as an alternative to Find and FindLast, Array also offers FindIndex and FindLastIndex, which work in the same way
except they return a number indicating the position of the first or
last match, rather than returning the matching item itself.
Finally, one special case for finding the index of an item turns out to crop up fairly often: the case where you know exactly which object you’re interested in, and just need to know where it is in the array. You could do this with a suitable predicate, for example:
int index = Array.FindIndex(events, e => e == someParticularEvent);
But Array offers the more
specialized IndexOf and LastIndexOf, so you only have to write
this:
int index = Array.IndexOf(events, someParticularEvent);
Sometimes it’s useful to modify the order in which entries appear in an array. For example, with a calendar, some events will be planned long in advance while others may be last-minute additions. Any calendar application will need to be able to ensure that events are displayed in chronological order, regardless of how they were added, so we need some way of getting items into the right order.
The Array class makes this
easy with its Sort method. We just
need to tell it how we want the events ordered—it can’t really guess,
because it doesn’t have any way of knowing whether we consider our
events to be ordered by the Title,
StartTime, or Duration property. This is a perfect job for
a delegate: we can provide a tiny bit of code that looks at two
CalendarEvent objects and says
whether one should appear before the other, and pass that code into
the Sort method (see Example 7-15).
Example 7-15. Sorting an array
Array.Sort(events,
(event1, event2) => event1.StartTime.CompareTo(event2.StartTime));The Sort method’s first
argument, events, is just the array
we’d like to reorder. (We defined that back in Example 7-10.) The second
argument is a delegate, and for convenience we again used the lambda
syntax introduced in Chapter 5. The Sort method wants to be able to know, for
any two events, whether one should appear before the other, It
requires a delegate of type Comparison<T>,
a function which takes two arguments—we called them event1 and event2 here—and which returns a number. If
event1 is before event2, the number must be negative, and if
it’s after, the number must be positive. We return zero to indicate
that the two are equal. Example 7-15 just
defers to the StartTime
property—that’s a DateTimeOffset,
which provides a handy CompareTo method that does exactly what
we need.
It turns out that Example 7-15 isn’t
changing anything here, because the events array created in Example 7-10 happens to be in
ascending order of date and time already. So just to illustrate that
we can sort on any criteria, let’s order them by duration
instead:
Array.Sort(events,
(event1, event2) => event1.Duration.CompareTo(event2.Duration));This illustrates how the use of delegates enables us to plug in
any number of different ordering criteria, leaving the Array class to get on with the tedious job
of shuffling the array contents around to match the specified
order.
Some data types such as dates or numbers have an intrinsic ordering. It would be irritating to have to
tell Array.Sort how to work out
whether one number comes before or after another. And in fact we don’t
have to—we can pass an array of numbers to a simpler overload of the
Sort method, as shown in Example 7-16.
Example 7-16. Sorting intrinsically ordered data
int[] numbers = { 4, 1, 2, 5, 3 };
Array.Sort(numbers);As you would expect, this arranges the numbers into ascending
order. We would provide a comparison delegate here only if we wanted
to sort the numbers into some other order. You might be wondering what
would happen if we tried this simpler method with an array of CalendarEvent objects:
Array.Sort(events); // Blam!
If you try this, you’ll find that the method throws an InvalidOperationException, because Array.Sort has no way of working out what
order we need. It works only for types that have an intrinsic order.
And should we want to, we could make CalendarEvent
self-ordering. We just have to implement an interface called
IComparable<CalendarEvent>, which
provides a single method, CompareTo. Example 7-17 implements this, and defers to
the DateTimeOffset value in
StartTime—the DateTimeOffset type implements IComparable<DateTimeOffset>. So all
we’re really doing here is passing the responsibility on to the property we
want to use for ordering, just like we did in Example 7-15. The one extra bit of work we do is to
check for comparison with null—the
IComparable<T> interface
documentation states that a non-null object should always compare as
greater than null, so we return a
positive number in that case. Without this check, our code would crash
with a NullReferenceException if
null were passed to CompareTo.
Example 7-17. Making a type comparable
class CalendarEvent : IComparable<CalendarEvent> { public string Title { get; set; } public DateTimeOffset StartTime { get; set; } public TimeSpan Duration { get; set; } public int CompareTo(CalendarEvent other) { if (other == null) { return 1; } return StartTime.CompareTo(other.StartTime); } }
Now that our CalendarEvent
class has declared an intrinsic ordering for itself, we are free to
use the simplest Sort
overload:
Array.Sort(events); // Works, now that CalendarEvent is IComparable<T>
Getting your array contents in order isn’t the only reason for
relocating elements, so Array
offers some slightly less specialized methods for moving data
around.
Suppose you want to build a calendar application that
works with multiple sources of information—maybe you use several
different websites with calendar features and would like to aggregate
all the events into a single list. Example 7-18 shows a method
that takes two arrays of CalendarEvent objects, and returns one array
containing all the elements from both.
Example 7-18. Copying elements from two arrays into one big one
static CalendarEvent[] CombineEvents(CalendarEvent[] events1,
CalendarEvent[] events2)
{
CalendarEvent[] combinedEvents =
new CalendarEvent[events1.Length + events2.Length];
events1.CopyTo(combinedEvents, 0);
events2.CopyTo(combinedEvents, events1.Length);
return combinedEvents;
}This example uses the CopyTo method, which
makes a complete copy of all the elements of the source array into the
target passed as the first argument. The second argument says where to
start copying elements into the target—Example 7-18 puts the first
array’s elements at the start (offset zero), and then copies the
second array’s elements directly after that. (So the ordering won’t be
very useful—you’d probably want to sort the results after doing
this.)
You might sometimes want to be a bit more selective—you might
want to copy only certain elements from the source into the target.
For example, suppose you want to remove the first event. Arrays cannot
be resized in .NET, but you could create a new array that’s one
element shorter, and which contains all but the first element of the
original array. The CopyTo method
can’t help here as it copies the whole array, but you can use the more
flexible Array.Copy method instead,
as Example 7-19 shows.
Example 7-19. Copying less than the whole array
static CalendarEvent[] RemoveFirstEvent(CalendarEvent[] events)
{
CalendarEvent[] croppedEvents = new CalendarEvent[events.Length - 1];
Array.Copy(
events, // Array from which to copy
1, // Starting point in source array
croppedEvents, // Array into which to copy
0, // Starting point in destination array
events.Length - 1 // Number of elements to copy
);
return croppedEvents;
}The key here is that we get to specify the index from which we want to start copying—1 in this case, skipping over the first element, which has an index of 0.
Note
In practice, you would rarely do this—if you need to be able
to add or remove items from a collection, you would normally use the
List<T> type that we’ll be
looking at later in this chapter, rather than a plain array. And
even if you are working with arrays, there’s an Array.Resize helper function that you
would typically use in reality—it calls Array.Copy for you. However, you often
have to copy data between arrays, even if it might not be strictly
necessary in this simple example. A more complex example would have
obscured the essential simplicity of Array.Copy.
The topic of array sizes is a little more complex than it first appears, so let’s look at that in more detail.
Arrays know how many elements they contain—several of the
previous examples have used the Length property to discover the size of an
existing array. This read-only property is defined by the base Array class, so it’s always present.[14] That may sound like enough to cover the simple task of
knowing an array’s size, but arrays don’t have to be simple sequential
lists. You may need to work with multidimensional data, and .NET
supports two different styles of arrays for that: jagged and rectangular
arrays.
As we said earlier, you can make an array using any type as the element type. And since arrays themselves have types, it follows that you can have an array of arrays. For example, suppose we wanted to create a list of forthcoming events over the next five days, grouped by day. We could represent this as an array with one entry per day, and since each day may have multiple events, each entry needs to be an array. Example 7-20 creates just such an array.
Example 7-20. Building an array of arrays
static CalendarEvent[][] GetEventsByDay(CalendarEvent[] allEvents,
DateTime firstDay,
int numberOfDays)
{
CalendarEvent[][] eventsByDay = new CalendarEvent[numberOfDays][];
for (int day = 0; day < numberOfDays; ++day)
{
DateTime dateOfInterest = (firstDay + TimeSpan.FromDays(day)).Date;
CalendarEvent[] itemsOnDateOfInterest = Array.FindAll(allEvents,
e => e.StartTime.Date == dateOfInterest);
eventsByDay[day] = itemsOnDateOfInterest;
}
return eventsByDay;
}We’ll look at this one piece at a time. First, there’s the method declaration:
static CalendarEvent[][] GetEventsByDay(CalendarEvent[] allEvents,
DateTime firstDay,
int numberOfDays)
{The return type—CalendarEvent[][]—is an array of arrays,
denoted by two pairs of square brackets. You’re free to go as deep as
you like, by the way—it’s perfectly possible to have an array of
arrays of arrays of arrays of anything.
The method’s arguments are fairly straightforward. This method expects to be passed a simple array containing an unstructured list of all the events. The method also needs to know which day we’d like to start from, and how many days we’re interested in.
The very first thing the method does is construct the array that it will eventually return:
CalendarEvent[][] eventsByDay = new CalendarEvent[numberOfDays][];
Just as new CalendarEvent[5]
would create an array capable of containing five CalendarEvent elements,
new CalendarEvent[5][] would create
an array capable of containing five arrays of CalendarEvent objects. Since our method lets
the caller specify the number of days, we pass that argument in as the
size of the top-level array.
Remember that arrays are reference types, and that whenever you
create a new array whose element type is a reference type, all the
elements are initially null. So although our new eventsByDay array is capable of referring to
an array for each day, what it holds right now is a null for each day. So the next bit of code
is a loop that will populate the array:
for (int day = 0; day < numberOfDays; ++day)
{
...
}Inside this loop, the first couple of lines are similar to the start of Example 7-14:
DateTime dateOfInterest = (firstDay + TimeSpan.FromDays(day)).Date;
CalendarEvent[] itemsOnDateOfInterest = Array.FindAll(allEvents,
e => e.StartTime.Date == dateOfInterest);The only difference is that this example calculates which date
to look at as we progress through the loop. So Array.FindAll will
return an array containing all the events that fall on the day for the
current loop iteration. The final piece of code in the loop puts that
into our array of arrays:
eventsByDay[day] = itemsOnDateOfInterest;
Once the loop is complete, we return the array:
return eventsByDay; }
Each element will contain an array with the events that fall on the relevant day.
Code that uses such an array can use the normal element access syntax, for example:
Console.WriteLine("Number of events on first day: " + eventsByDay[0].Length);Notice that this code uses just a single index—this means we want to retrieve one of the arrays from our array of arrays. In this case, we’re looking at the size of the first of those arrays. Or we can dig further by providing multiple indexes:
Console.WriteLine("First day, second event: " + eventsByDay[0][1].Title);This syntax, with its multiple sets of square brackets, fits right in with the syntax used to declare and construct the array of arrays.
So why is an array of arrays sometimes called a jagged array? Figure 7-4 shows the various objects you would end up with if you called the method in Example 7-20, passing the events from Example 7-10, asking for five days of events starting from July 11. The figure is laid out to show each child array as a row, and as you can see, the rows are not all the same length—the first couple of days have two items per row, the third day has one, and the last two are empty (i.e., they are zero-length arrays). So rather than looking like a neat rectangle of objects, the rows form a shape with a somewhat uneven or “jagged” righthand edge.
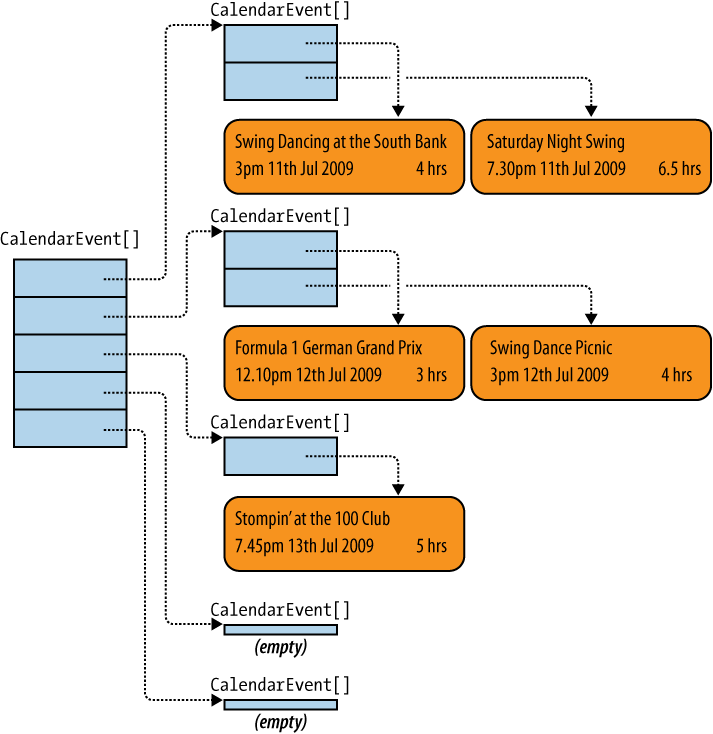
This jaggedness can be either a benefit or a problem, depending on your goals. In this example, it’s helpful—we used it to handle the fact that the number of events in our calendar may be different every day, and some days may have no events at all. But if you’re working with information that naturally fits into a rectangular structure (e.g., pixels in an image), rows of differing lengths would constitute an error—it would be better to use a data structure that doesn’t support such things, so you don’t have to work out how to handle such an error.
Moreover, jagged arrays end up with a relatively complicated structure—there are a lot of objects in Figure 7-4. Each array is an object distinct from the objects its element refers to, so we’ve ended up with 11 objects: the five events, the five per-day arrays (including two zero-length arrays), and then one array to hold those five arrays. In situations where you just don’t need this flexibility, there’s a simpler way to represent multiple rows: a rectangular array.
A rectangular array[15] lets you store multidimensional data in a single array, rather than needing to create arrays of arrays. They are more regular in form than jagged arrays—in a two-dimensional rectangular array, every row has the same width.
Note
Rectangular arrays are not limited to two dimensions, by the way. Just as you can have arrays of arrays of arrays, so you can have any number of dimensions in a “rectangular” array, although the name starts to sound a bit wrong. With three dimensions, it’s a cuboid rather than a rectangle, and more generally the shape of these arrays is always an orthotope. Presumably the designers of C# and the .NET Framework felt that this “proper” name was too obscure (as does the spellchecker in Word) and that rectangular was more usefully descriptive, despite not being technically correct. Pragmatism beat pedantry here because C# is fundamentally a practical language.
Rectangular arrays tend to suit different problems than jagged arrays, so we need to switch temporarily to a different example. Suppose you were writing a simple game in which a character runs around a maze. And rather than going for a typical modern 3D game rendered from the point of view of the player, imagine something a bit more retro—a basic rendering of a top-down view, and where the walls of the maze all fit neatly onto a grid. If you’re too young to remember this sort of thing, Figure 7-5 gives a rough idea of what passed for high-tech entertainment back when your authors were at school.

We don’t want to get too hung up on the details of the game
play, so let’s just assume that our code needs to know where the walls
are in order to work out where the player can or can’t move next, and
whether she has a clean shot to take out the baddies chasing her
through the maze. We could represent this as an array of numbers,
where 0 represents a gap and 1 represents a wall, as Example 7-21 shows. (We could
also have used bool instead of
int as the element type, as there
are only two possible options: a wall or no wall. However, using
true and false would have prevented each row of data
from fitting on a single row in this book, making it much harder to
see how Example 7-21
reflects the map in Figure 7-5.
Moreover, using numbers leaves open the option to add exciting game
features such as unlockable doors, squares of instant death, and other
classics.)
Example 7-21. A multidimensional rectangular array
int[,] walls = new int[,]
{
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 },
{ 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1 },
{ 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1 },
{ 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1 },
{ 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1 },
{ 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0 },
{ 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1 },
{ 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1 },
{ 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1 },
{ 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1 },
{ 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1 },
{ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1 }
};There are a couple of differences between this and previous
examples. First, notice that the array type has a comma between the
square brackets. The number of commas indicates how many dimensions we
want—no commas at all would mean a one-dimensional array, which is what we’ve
been using so far, but the single comma here specifies a
two-dimensional array. We could represent a cuboid layout with
int[,,], and so on, into as many
dimensions as your application requires.
The second thing to notice here is that we’ve not had to use the
new keyword for each row in the
initializer list—new appears only
once, and that’s because this really is just a single object despite
being multidimensional. As Figure 7-6 illustrates, this
kind of array has a much simpler structure than the two-dimensional
jagged array in Figure 7-4.
Note
While Figure 7-6 is accurate in the sense that just one object holds all the values here, the grid-like layout of the numbers is not a literal representation of how the numbers are really stored, any more than the position of the various objects in Figure 7-4 is a literal representation of what you’d see if you peered into your computer’s memory chips with a scanning electron microscope.
In reality, multidimensional arrays store their elements as a sequential list just like the simple array in Figure 7-3, because computer memory itself is just a big sequence of storage locations. But the programming model C# presents makes it look like the array really is multidimensional.
The syntax for accessing elements in a rectangular array is slightly different from that of a jagged array. But like a jagged array, the access syntax is consistent with the declaration syntax—as Example 7-22 shows, we use a single pair of square brackets, passing in an index for each dimension, separated by commas.

Example 7-22. Accessing an element in a rectangular array
static bool CanCharacterMoveDown(int x, int y, int[,] walls)
{
int newY = y + 1;
// Can't move off the bottom of the map
if (newY == walls.GetLength(0)) { return false; }
// Can only move down if there's no wall in the way
return walls[newY, x] == 0;
}Note
If you pass in the wrong number of indexes, the C# compiler
will complain. The number of dimensions (or
rank, to use the official term) is considered
to be part of the type: int[,] is
a different type than int[,,],
and C# checks that the number of indexes you supply matches the
array type’s rank.
Example 7-22
performs two checks: before it looks to see if there’s a wall in the
way of the game character, it first checks to see if the character is
up against the edge of the map. To do this, it needs to know how big
the map is. And rather than assuming a fixed-size grid, it asks the
array for its size. But it can’t just use the Length property we saw earlier—that returns
the total number of elements. Since this is a 12×12 array, Length will be 144. But we want to know the
length in the vertical dimension. So instead, we use the GetLength method,
which takes a single argument indicating which dimension you want—0
would be the vertical dimension and 1 in this case is
horizontal.
Note
Arrays don’t really have any concept of horizontal and vertical. They simply have as many dimensions as you ask for, and it’s up to your program to decide what each dimension is for. This particular program has chosen to use the first dimension to represent the vertical position in the maze, and the second dimension for the horizontal position.
This rectangular example has used a two-dimensional array of
integers, and since int is a value
type, the values get to live inside the array. You can also create
multidimensional rectangular arrays with reference type elements. In
that case, you’ll still get a single object containing all the
elements of the array in all their dimensions, but these individual
elements will be null references—you’ll need to create objects for
them to refer to, just like you would with a single-dimensional
array.
While jagged and rectangular multidimensional arrays give us
flexibility in terms of how to specify the size of an array, we have
not yet dealt with an irritating sizing problem mentioned back at the
start of the chapter: an array’s size is fixed. We saw that it’s
possible to work around this by creating new arrays and copying some
or all of the old data across, or by getting the Array.Resize method to do that work for us.
But these are inconvenient solutions, so in practice, we rarely work
directly with arrays in C#. There’s a far easier way to work with
changing collection sizes, thanks to the List<T> class.
The List<T> class,
defined in the System.Collections.Generic namespace, is
effectively a resizable array. Strictly speaking, it’s just a generic
class provided by the .NET Framework class library, and unlike arrays,
List<T> does not get any special
treatment from the type system or the CLR. But from a C# developer’s
perspective, it feels very similar—you can do most of the things you
could do with an array, but without the restriction of a fixed
size.
Note
You may be wondering why .NET offers arrays when List<T> appears to be more useful. The
answer is that it wouldn’t be possible for List<T> to exist if there were no
arrays: List<T> uses an array
internally to hold its elements. As you add elements, it allocates new,
larger arrays as necessary, copying the old contents over. It employs
various tricks to minimize how often it needs to do this.
List<T> is one of the most
useful types in the .NET Framework. If you’re dealing with multiple pieces
of information, as programs often do, it’s very common to need some
flexibility around the amount of information—fixed-size lists are the
exception rather than the rule. (An individual’s calendar tends to change
over time, for example.) So have we just wasted your time with the first
half of this chapter? Not at all—not only do arrays crop up a lot in APIs,
but List<T> collections are very
similar in use to arrays.
We could migrate most of the examples seen so far in this chapter
from arrays to lists. Returning to our earlier, nonrectangular example, we
would need to modify only the first line of Example 7-10, which creates an
array of CalendarEvent objects. That
line currently reads:
CalendarEvent[] events =
It is followed by the list of objects to add to the array, contained within a pair of braces. If you change that line to this:
List<CalendarEvent> events = new List<CalendarEvent>
the initializer list can remain the same. Notice that besides
changing the variable declaration to use the List<T> type (with the generic type
argument T set to the element type
CalendarEvent, of course) we also need
an explicit call to the constructor. (Normally, you’d expect parentheses
after the type name when invoking a constructor, but those are optional
when using an initializer list.) As you saw earlier, the use of new is optional when assigning a value to a
newly declared array, but C# does not extend that courtesy to other
collection types.
While we can initialize the list in much the same way as we would an
array, the difference is that we are free to add and remove elements
later. To add a new element, we can use the Add method:
CalendarEvent newEvent = new CalendarEvent
{
Title = "Dean Collins Shim Sham Lesson",
StartTime = new DateTimeOffset (2009, 7, 14, 19, 15, 00, TimeSpan.Zero),
Duration = TimeSpan.FromHours(1)
};
events.Add(newEvent);This appends the element to the end of the list. If you want to put
the new element somewhere other than at the end, you can use Insert:
events.Insert(2, newEvent);
The first argument indicates the index at which you’d like the new
item to appear—any items at or after this index will be moved down to make
space. You can also remove items, either by index, using the RemoveAt method, or by
passing the value you’d like to remove to the Remove method (which will remove the first
element it finds that contains the specified value).
Note
List<T> does not have a
Length property, and instead offers a
Count. This may seem
like pointless inconsistency with arrays, but there’s a reason. An
array’s Length property is guaranteed
not to change. A List<T> cannot
make that guarantee, and so the behavior of its Count property is necessarily different from
an array’s Length. The use of
different names signals the fact that the semantics are subtly
different.
List<T> also offers
AddRange, which lets you
add multiple elements in a single step. This makes it much easier to
concatenate lists—remember that with arrays we ended up writing the
CombineEvents method in Example 7-18 to concatenate a
couple of arrays. But with lists, it becomes as simple as the code shown
in Example 7-23.
Warning
The one possible downside of List<T> is that this kind of operation
modifies the first list. Example 7-18 built a brand-new
array, leaving the two input arrays unmodified, so if any code happened
still to be using those original arrays, it would carry on working. But
Example 7-23 modifies the
first list by adding in the events from the second list. You would need
to be confident that nothing in your code was relying on the first list
containing only its original content. Of course, you could always build
a brand-new new List<T> from
the contents of two existing lists. (There are various ways to do this,
but one straightforward approach is to construct a new List<T> and then call AddRange twice, once for each list.)
You access elements in a List<T> with exactly the same syntax as
for an array. For example:
Console.WriteLine("List element: " + events[2].Title);Note
As with arrays, a List<T>
will throw an IndexOutOfRangeException if you use too high
an index, or a negative index. This applies for writes as well as
reads—a List<T> will not
automatically grow if you write to an index that does not yet
exist.
There is a subtle difference between array element access and list
element access that can cause problems with custom value types (structs).
You may recall that Chapter 3 warned that when
writing a custom value type, it’s best to make it immutable if you plan to
use it in a collection. To understand why, you need to know how List<T> makes the square bracket syntax
for element access work.
Arrays are an integral part of the .NET type system, so C#
knows exactly what to do when you access an array element using the
square bracket syntax. However, as List<T> demonstrates, it’s also possible
to use this same syntax with some objects that are not arrays. For this
to work, the object’s type needs to help C# out by defining the behavior
for this syntax. This takes the form of a slightly unusual-looking
property, as shown in Example 7-24.
Example 7-24. A custom indexer
class Indexable
{
public string this[int index]
{
get
{
return "Item " + index;
}
set
{
Console.WriteLine("You set item " + index + " to " + value);
}
}
}This has the get and set parts we’d expect in a normal property,
but the definition line is a little unusual: it starts with the
accessibility and type as normal, but where we’d expect to see the
property name we instead have this[int
index]. The this keyword signifies
that this property won’t be accessed by any name. It is followed by a
parameter list enclosed in square brackets, signifying that this is an
indexer property, defining what should happen if we use the square
bracket element access syntax with objects of this type. For example,
look at the code in Example 7-25.
Example 7-25. Using a custom indexer
Indexable ix = new Indexable(); Console.WriteLine(ix[10]); ix[42] = "Xyzzy";
After constructing the object, the next line uses the same element
access syntax you’d use to read an element from an array. But this is
not an array, so the C# compiler will look for a property of the kind
shown in Example 7-24. If you try this on a type
that doesn’t provide an indexer, you’ll get a compiler error, but since
this type has one, that ix[10]
expression ends up calling the indexer’s get accessor. Similarly, the third line has
the element access syntax on the lefthand side of an assignment, so C#
will use the indexer’s set
accessor.
Note
If you want to support the multidimensional rectangular array
style of index (e.g., ix[10, 20]),
you can specify multiple parameters between the square brackets in
your indexer. Note that the List<T> class does not do this—while
it covers most of the same ground as the built-in array types, it does
not offer rectangular multidimensional behavior. You’re free to create
a jagged list of lists, though. For example, List<List<int>> is a list of
lists of integers, and is similar in use to an int[][].
The indexer in Example 7-24 doesn’t really
contain any elements at all—it just makes up a value in the get, and prints out the value passed into
set without storing it anywhere. So
if you run this code, you’ll see this output:
Item 10 You set item 42 to Xyzzy
It may seem a bit odd to provide array-like syntax but to discard
whatever values are “written,” but this is allowed—there’s no rule that
says that indexers are required to behave in an array-like fashion. In
practice, most do—the reason C# supports indexers is to make it possible
to write classes such as List<T> that feel like arrays without
necessarily having to be arrays. So while Example 7-24 illustrates that you’re free to do
whatever you like in a custom indexer, it’s not a paragon of good coding
style.
What does any of this have to do with value types and immutability, though? Look at Example 7-26. It has a public field with an array and also an indexer that provides access to the array.
Example 7-26. Arrays versus indexers
// This class's purpose is to illustrate a difference between
// arrays and indexers. Do not use this in real code!
class ArrayAndIndexer<T>
{
public T[] TheArray = new T[100];
public T this[int index]
{
get
{
return TheArray[index];
}
set
{
TheArray[index] = value;
}
}
}You might think that it would make no difference whether we use this class’s indexer, or go directly for the array. And some of the time that’s true, as it is in this example:
ArrayAndIndexer<int> aai = new ArrayAndIndexer<int>(); aai.TheArray[10] = 42; Console.WriteLine(aai[10]); aai[20] = 99; Console.WriteLine(aai.TheArray[20]);
This swaps freely between using the array and the indexer, and as the output shows, items set through one mechanism are visible through the other:
42 99
However, things are a little different if we make this class store a mutable value type. Here’s a very simple modifiable value type:
struct CanChange
{
public int Number { get; set; }
public string Name { get; set; }
}The Number and Name properties both have setters, so this is
clearly not an immutable type. This might not seem like a problem—we can
do more or less exactly the same with this type as we did with int just a moment ago:
ArrayAndIndexer<CanChange> aai = new ArrayAndIndexer<CanChange>();
aai.TheArray[10] = new CanChange { Number = 42 };
Console.WriteLine(aai[10].Number);
aai[20] = new CanChange { Number = 99, Name = "My item" };
Console.WriteLine(aai.TheArray[20].Number);That works fine. The problem arises when we try to modify a property of one of the values already inside the array. We can do it with the array:
aai.TheArray[10].Number = 123; Console.WriteLine(aai.TheArray[10].Number);
That works—it prints out 123 as you’d expect. But this does not work:
aai[20].Number = 456;
If you try this, you’ll find that the C# compiler reports the following error:
error CS1612: Cannot modify the return value of 'ArrayAndIndexer<CanChange>.this[int]' because it is not a variable
That’s a slightly cryptic message. But the problem becomes clear when we think about what we just asked the compiler to do. The intent of this code:
aai[20].Number = 456;
seems clear—we want to modify the Number property of the item whose index is 20.
And remember, this line of code is using our ArrayAndIndexer<T> class’s indexer.
Looking at Example 7-26, which of the two
accessors would you expect it to use here? Since we’re modifying the
value, you might expect set to be
used, but a set accessor is an all or
nothing proposition: calling set
means you want to replace the whole element. But we’re not trying to do
that here—we just want to modify the Number property of the value, leaving its
Name property unmodified. If you look
at the set code in Example 7-26, it simply doesn’t offer that as an
option—it will completely replace the element at the specified index in
the array. The set accessor can come
into play only when we’re providing a whole new value for the element,
as in:
aai[20] = new CanChange { Number = 456 };That compiles, but we end up losing the Name property that the element in that
location previously had, because we overwrote the entire value of the
element.
Since set doesn’t work, that
leaves get. The C# compiler could interpret this code:
aai[20].Number = 456;
as being equivalent to the code in Example 7-27.
And in fact, that’s what it would have done if we were using a
reference type. However, it has noticed that CanChange is a value type, and has therefore
rejected the code. (The error message says nothing about value types,
but you can verify that this is the heart of the problem by changing the
CanChange type from a struct to a class. That removes the compiler error, and
you’ll find that the code aai[20].Number =
456 works as expected.)
Why has the compiler rejected this seemingly obvious solution?
Well, remember that the crucial difference between reference types and
value types is that values usually involve copies—if you retrieve a
value from an indexer, the indexer returns a copy. So in Example 7-27 the elem variable holds a copy of the item at
index 20. Setting elem.Number to 456 has an effect on only
that copy—the original item in the array remains unchanged. This makes
clear why the compiler rejected our code—the only thing it can do with
this:
aai[20].Number = 456;
is to call the get accessor,
and then set the Number property on
the copy returned by the array, leaving the
original value unaltered. Since the copy would then immediately be
discarded, the compiler has wisely determined that this is almost
certainly not what we meant. (If we really want that copy-then-modify
behavior, we can always write the code in Example 7-27 ourselves, making the
fact that there’s a copy explicit. Putting the copy into a named
variable also gives us the opportunity to go on and do something with
the copy, meaning that setting a property on the copy might no longer be
a waste of effort.)
Note
You might be thinking that the compiler could read and modify a
copy like Example 7-27, and
then write that value back using the set indexer accessor. However, as Example 7-24 showed, indexer accessors are not
required to work in the obvious way, and more generally, accessors can
have side effects. So the C# compiler cannot assume that such a
get-modify-set sequence is necessarily safe.
This problem doesn’t arise with reference types, because in that
case, the get accessor returns a
reference rather than a value—no copying occurs because that reference
refers to the same object that the corresponding array entry refers
to.
But why does this work when we use the array directly? Recall that the compiler didn’t have a problem with this code:
aai.TheArray[10].Number = 123;
It lets that through because it’s able to make that behave like we
expect. This will in fact modify the Number property of the element in the array.
And this is the rather subtle difference between an array and an
indexer. With an array you really can work directly with the element
inside the array—no copying occurs in this example. This works because
the C# compiler knows what an array is, and is able to generate code
that deals directly with array elements in situ.
But there’s no way to write a custom indexer that offers the same
flexibility. (There are reasons for this, but to explain them would
require an exploration of the .NET Framework’s type safety rules, which
would be lengthy and quite outside the scope of this chapter.)
Having established the root of the problem, let’s look at what
this means for List<T>.
The List<T>
class gets no special privileges—it may be part of the .NET Framework
class library, but it is subject to the same restrictions as your
code. And so it has the same problem just described—the following code
will produce the same compiler error you saw in the preceding
section:
List<CanChange> numbers = new List<CanChange> { new CanChange() };
numbers[0].Number = 42; // Will not compileOne way of dealing with this would be to avoid using custom
value types in a collection class such as List<T>, preferring custom reference
types instead. And that’s not a bad rule of thumb—reference types are
a reasonable default choice for most data types. However, value types
do offer one compelling feature if you happen to be dealing with very
large volumes of data. As Figure 7-1 showed earlier, an
array with reference type elements results in an object for the array
itself, and one object for each element in the array. But when an
array has value type elements, you end up with just one object—the
values live inside the array, as Figure 7-3 illustrates. List<T> has similar characteristics
because it uses an array internally.
For an array with hundreds of thousands of elements, the simpler
structure of Figure 7-3 can have a
noticeable impact on performance. For example, I just ran a quick test
on my computer to see how long it would take to create a List<CanChange> with 500,000 entries,
and then run through the list, adding the Number values together. Example 7-28 shows the
code—it uses the Stopwatch class
from the System.Diagnostics
namespace, which provides a handy way to see how long things are
taking.
Example 7-28. Microbenchmarking values versus references in lists
Stopwatch sw = new Stopwatch();
sw.Start();
int itemCount = 500000;
List<CanChange> items = new List<CanChange>(itemCount);
for (int i = 0; i < itemCount; ++i)
{
items.Add(new CanChange { Number = i });
}
sw.Stop();
Console.WriteLine("Creation: " + sw.ElapsedTicks);
sw.Reset();
sw.Start();
int total = 0;
for (int i = 0; i < itemCount; ++i)
{
total += items[i].Number;
}
sw.Stop();
Console.WriteLine("Total: " + total);
Console.WriteLine("Sum: " + sw.ElapsedTicks);With CanChange as a value
type, it takes about 150 ms on my machine to populate the list, and
then about 40 ms to run through all the numbers, adding them together.
But if I change CanChange from a
struct to a class (i.e., make it a reference type) the
numbers become more like 600 ms and 50 ms, respectively. So that’s
about 25 percent longer to perform the calculations but a staggering
four times longer to create the collection in the first place. And
that’s because with CanChange as a
reference type, we now need to ask the .NET Framework to create half a
million objects for us instead of just one object when we initialize
the list. From the perspective of an end user, this is the difference
between a tiny hiatus and an annoyingly long delay—when an application
freezes for more than half a second, users begin to wonder if it has
hung, which is very disruptive.
Warning
Please don’t take away the message that value types are four times faster than reference types—they aren’t. A micro benchmark like this should always be taken with a very strong pinch of salt. All we’ve really measured here is how long it takes to do something contrived in an isolated and artificial experiment. This example is illuminating only insofar as it demonstrates that the choice between value types and reference types can sometimes have a profound effect. It would be a mistake to draw a generalized conclusion from this.
Notice that even in this example we see significant variation: the first part of the code slowed down by a factor of four, but in the second part, the impact was much smaller. In some scenarios, there will be no measurable difference, and as it happens there are situations in which value types can be shown to be slower than reference types.
The bottom line is this: the only important performance measurements are ones you make yourself on the system you are building. If you think your code might get a useful speedup by using a value type instead of a reference type in a large collection, measure the effect of that change, rather than doing it just because some book said it would be faster.
Since the use of value types in a collection can sometimes offer
very useful performance benefits, the rule of thumb we suggested
earlier—always use reference types—looks too restrictive in practice.
So this is where immutability comes into play. As we saw earlier in
this section, the fact that a get
accessor can only return a copy of a value type causes problems if you
ever need to modify a value already in a collection. But if your value
types are immutable, you will never hit this problem. And as we’ll see
in Chapter 16, there are other
benefits to immutable types.
So we now know how List<T> is able to make itself
resemble an array. Having understood some of the subtle differences
between array element access and custom indexers, let’s get back to
some of the other functionality of List<T>.
Earlier we saw that the Array class offers a variety of helper methods
for finding elements in arrays. If you try to use these directly on a
List<T>, it won’t work. The
following code from Example 7-14
will not compile if events is a
List<CalendarEvents>, for
example:
DateTime dateOfInterest = new DateTime (2009, 7, 12);
CalendarEvent[] itemsOnDateOfInterest = Array.FindAll(events,
e => e.StartTime.Date == dateOfInterest);This will cause an error, because Array.FindAll expects
an array, and we’re now giving it a List<T>. However, all the finding and
sorting functionality we saw earlier is still available; you just have
to use the methods provided by List<T> instead of Array:
DateTime dateOfInterest = new DateTime(2009, 7, 12);
List<CalendarEvent> itemsOnDateOfInterest = events.FindAll(
e => e.StartTime.Date == dateOfInterest);Notice a slight stylistic difference—whereas with arrays, FindAll is a static method provided by the
Array class, List<T> chooses to make its FindAll method an instance member—so we invoke
it as events.FindAll. Style aside, it
works in exactly the same way. As you might expect, it returns its
results as another List<T>
rather than as an array.
This same stylistic difference exists with all the other
techniques we looked at before. List<T> provides Find, FindLast, FindIndex, FindLastIndex, IndexOf, LastIndexOf, and Sort methods that all work in almost exactly
the same way as the array equivalents we looked at earlier, but again,
they’re instance methods rather than static methods.
Since List<T> offers
almost everything you’re likely to want from an array and more besides,
List<T> will usually be your
first choice to represent a collection of data. (The only common
exception is if you need a rectangular array.) Unfortunately, you will
sometimes come up against APIs that simply require you to provide an
array. In fact, we already wrote some code that does this: the
AddNumbers method back
in Example 7-3 requires its input
to be in the form of an array. But even this is easy to deal with:
List<T> provides a handy
ToArray() method for
just this eventuality, building a copy of the list’s contents in array
form.
But wouldn’t it be better if we could write our code in such a way
that it didn’t care whether incoming information was in an array, a
List<T>, or some other kind of
collection? It is possible to do exactly this, using the polymorphism
techniques discussed in Chapter 4.
Polymorphic code is code that is able to work on a variety
of different forms of data. The foreach keyword has this
characteristic. For example:
foreach (CalendarEvent ev in events)
{
Console.WriteLine(ev.Title);
}This code works if events is an
array—CalendarEvent[]—but it works
equally well if events is a List<CalendarEvent>. And in fact, there
are many more specialized collection types in the .NET Framework class
library that we’ll look at in a later chapter that foreach can work with. You can even arrange for it to work with custom collection
classes you may have written yourself. All this is possible because the
.NET Framework defines some standard interfaces for representing collections of things. The
foreach construct depends on a pair of
interfaces: IEnumerable<T> and
IEnumerator<T>. These derive from
a couple of nongeneric base interfaces, IEnumerable and IEnumerator. These interfaces are defined in the
class library, and they are reproduced in Example 7-29.
Example 7-29. Enumeration interfaces
namespace System.Collections.Generic
{
public interface IEnumerable<out T> : IEnumerable
{
new IEnumerator<T> GetEnumerator();
}
public interface IEnumerator<out T> : IDisposable, IEnumerator
{
new T Current { get; }
}
}
namespace System.Collections
{
public interface IEnumerable
{
IEnumerator GetEnumerator();
}
public interface IEnumerator
{
bool MoveNext();
object Current { get; }
void Reset();
}
}The split between the generic and nongeneric interfaces here is a
historical artifact. Versions 1.0 and 1.1 of .NET did not support
generics, so only the base IEnumerable
and IEnumerator interfaces existed.
When .NET 2.0 shipped in 2005, generics were introduced, making it
possible to provide versions of these interfaces that were explicit about
what type of objects a collection contains, but in order to maintain
backward compatibility the old version 1.x interfaces had to remain. You
will normally use the generic versions, because they are easier to work
with.
Conceptually, if a type implements IEnumerable<T> it is declaring that it
contains a sequence of items of type T.
To get hold of the items, you can call the GetEnumerator method,
which will return an IEnumerator<T>. An enumerator is an object
that lets you work through the objects in an enumerable collection one at
a time.[16] The split between enumerables and enumerators makes it
possible to have different parts of your program working their way through
the same collection at the same time, without all of them needing to be in
the same place. This can be useful in multithreaded applications (although
as we’ll see in a later chapter, you have to be extremely careful about
letting multiple threads use the same data structure
simultaneously).
Note
Some enumerable collections, such as List<T>, can be modified. (.NET defines
an IList<T> interface to
represent the abstract idea of a modifiable, ordered collection.
List<T> is just one
implementation IList<T>.) You
should avoid modifying a collection while you’re in the process of
iterating through it. For example, do not call Add on a List<T> in the middle of a foreach loop that uses that list. List<T> detects when this happens, and
throws an exception.
Note that unlike IList<T>, IEnumerable<T> does not provide any
methods for modifying the sequence. While this provides less flexibility
to the consumer of a sequence, it broadens the range of data that can be
wrapped as an IEnumerable<T>.
For some sources of data it doesn’t make sense to provide consumers of
that data with the ability to reorder it.
These interfaces make it possible to write a function that uses a
collection without having any idea of the collection’s real type—you only
need to know what type of elements it contains. We could rewrite Example 7-3 so that it works with any
IEnumerable<string> rather than
just an array of strings, as shown in Example 7-30.
Example 7-30. Using IEnumerable<T> and IEnumerator<T>
static string[] AddNumbers(IEnumerable<string> names)
{
List<string> numberedNames = new List<string>();
using (IEnumerator<string> enumerator = names.GetEnumerator())
{
int i = 0;
while (enumerator.MoveNext())
{
string currentName = enumerator.Current;
numberedNames.Add(string.Format("{0}: {1}", i, currentName));
i += 1;
}
}
return numberedNames.ToArray();
}Since List<T> and arrays
both implement IEnumerable<T>,
this modified code in Example 7-30 will now work with
List<string>, as well as arrays,
or any other collection class that implements IEnumerable<string>. For more information
on the subtleties of type compatibility and enumerations, see the sidebar
on the next page.
Example 7-30 works
much harder than it needs to—it creates the enumerator explicitly, and
walks through the objects by calling MoveNext in a loop, retrieving the Current value each time around. (A newly created
enumerator needs us to call MoveNext
before first reading Current. It
doesn’t automatically start on the first item because there might not be
one—collections can be empty.) As it happens, that’s exactly what
foreach does, so we can
get that to do the work for us. Example 7-31 does the same thing as
Example 7-30, but lets the
C# compiler generate the code.
Example 7-31. Using an IEnumerable<T> with foreach
static string[] AddNumbers(IEnumerable<string> names)
{
List<string> numberedNames = new List<string>();
int i = 0;
foreach (string currentName in names)
{
numberedNames.Add(string.Format("{0}: {1}", i, currentName));
i += 1;
}
return numberedNames.ToArray();
}This example only half enters into the spirit of things—it can
accept any IEnumerable<string>,
but it stubbornly continues to return an array. This isn’t necessarily a
problem; after all, arrays implement IEnumerable<T>. However, our code is a
little inelegant in the way that it creates a List<string> and then converts that into
an array at the end. There’s a better way—C# makes it very easy to provide
a sequence of objects directly as an IEnumerable<T>.
Before version 2 of C# (which shipped with Visual Studio 2005),
writing your own enumerable types was tedious—you had to write a class
that implemented IEnumerator, and
that would usually be a separate class from the one that implemented
IEnumerable,
because multiple enumerators can be active simultaneously for any single
collection. It wasn’t hugely tricky, but it was enough of a hassle to
put most people off. But C# 2 made it extremely easy to provide
enumerations. Example 7-32 shows yet another
reworking of the AddNumbers
method.
Example 7-32. Implementing IEnumerable<T> with yield return
static IEnumerable<string> AddNumbers(IEnumerable<string> names)
{
int i = 0;
foreach (string currentName in names)
{
yield return string.Format("{0}: {1}", i, currentName);
i += 1;
}
}Instead of using the normal return statement, this method uses yield return. This
special form of return statement can only be used inside a method that
returns either an enumerable or an enumerator object—you’ll get a
compiler error if you try to use it anywhere else. It works rather
differently from a normal return. A normal return statement indicates that the method has
finished, and would like to return control to the caller (returning a
value, if the method’s return type was not void). But yield
return effectively says: “I want to return this value as an
item in the collection, but I might not be done yet—I could have more
values to return.”
The yield return in Example 7-32 is in the middle
of a foreach loop. Whereas a normal
return would break out of the loop,
in this case the loop is still running, even though the method has
returned a value. This leads to some slightly surprising flow of
execution. Let’s look at the order in which this code runs. Example 7-33 modifies the AddNumbers method from
Example 7-32 by adding a
few calls to Console.Writeline, so we
can see exactly how the code runs. It also includes a Main method with a foreach loop iterating over the collection
returned by AddNumbers, again with
some Console.WriteLine calls to keep
track of what’s going on.
Example 7-33. Exploring yield return
class Program
{
static IEnumerable<string> AddNumbers(IEnumerable<string> names)
{
Console.WriteLine("Starting AddNumbers");
int i = 0;
foreach (string currentName in names)
{
Console.WriteLine("In AddNumbers: " + currentName);
yield return string.Format("{0}: {1}", i, currentName);
i += 1;
}
Console.WriteLine("Leaving AddNumbers");
}
static void Main(string[] args)
{
string[] eventNames =
{
"Swing Dancing at the South Bank",
"Saturday Night Swing",
"Formula 1 German Grand Prix",
"Swing Dance Picnic",
"Stompin' at the 100 Club"
};
Console.WriteLine("Calling AddNumbers");
IEnumerable<string> numberedNames = AddNumbers(eventNames);
Console.WriteLine("Starting main loop");
foreach (string numberedName in numberedNames)
{
Console.WriteLine("In main loop: " + numberedName);
}
Console.WriteLine("Leaving main loop");
}
}Here’s the output:
Calling AddNumbers Starting main loop Starting AddNumbers In AddNumbers: Swing Dancing at the South Bank In main loop: 0: Swing Dancing at the South Bank In AddNumbers: Saturday Night Swing In main loop: 1: Saturday Night Swing In AddNumbers: Formula 1 German Grand Prix In main loop: 2: Formula 1 German Grand Prix In AddNumbers: Swing Dance Picnic In main loop: 3: Swing Dance Picnic In AddNumbers: Stompin' at the 100 Club In main loop: 4: Stompin' at the 100 Club Leaving AddNumbers Leaving main loop
Even though the main method calls AddNumbers only once, before the start of the
loop, you can see from the output that the code flits back and forth
between the main loop and AddNumbers
for each item in the list.
That’s how yield return
works—it returns from the method temporarily. Execution will continue
from after the yield return as soon
as the code consuming the collection asks for the next element. (More
precisely, it will happen when the client code calls MoveNext on the enumerator.) C# generates some
code that remembers where it had got to on the last yield return so that it can carry on from
where it left off.
Note
You might be wondering what happens if the consumer
abandons the loop halfway through. If that happens, execution will not
continue from the yield return.
However, as you saw in Example 7-30, code that
consumes an enumeration should have a using statement to ensure that the
enumerator is always disposed of—a foreach loop will always do this for you.
The enumerator generated by C# to implement yield return relies on this to ensure that
any using or finally blocks inside your enumerator method
run correctly even when the enumeration is abandoned halfway
through.
This causes a slight wrinkle in the story regarding exception handling. You’ll find that you cannot use
yield return inside a try block that is followed by a catch block, for example, because it’s not
possible for the C# compiler to guarantee that exceptions will be
handled consistently in situations where enumerations are
abandoned.
This ability to continue from where we left off as the consumer
iterates through the loop illustrates a subtler benefit of yield return: it doesn’t just make the code
slightly neater; it lets the code be lazy.
The AddNumbers method
in Example 7-31 creates all
of its output before it returns anything. We could describe it as
being eager—it does all the work it might need to
do right up front. But the modified version in Example 7-32, which uses
yield return, is not so eager: it
generates items only when it is asked for them, as you can see from
the output of Example 7-33. This approach
of not doing work until absolutely necessary is often referred to as a
lazy style. In fact, if you look closely at the
output you’ll see that the AddNumbers method in Example 7-33 is so lazy,
it doesn’t seem to run any code at all until we start asking it for
items—the Starting AddNumbers
message printed out at the beginning of the AddNumbers method (before it starts its
foreach loop) doesn’t appear when
we call AddNumbers—as you can see,
the Starting main loop message
appears first, even though Main
doesn’t print that out until after AddNumbers returns. This illustrates that
none of the code in AddNumbers runs
at the point when we call AddNumbers. Nothing happens until we start
retrieving elements.
Note
Support for lazy collections is the reason that IEnumerable<T> does not provide a
Count property. The only way to
find out how many items are in an enumeration is to enumerate the
whole lot and see how many come out. Enumerable sequences don’t
necessarily know how many items they contain until you’ve asked for
all the items.
Lazy enumeration has some benefits, particularly if you are
dealing with very large quantities of information. Lazy enumeration
makes it possible to start processing data as soon as the first item
becomes available. Example 7-34 illustrates
this. Its GetAllFilesInDirectory returns an
enumeration that returns all the files in a folder, including all
those in any subdirectories. The Main method here uses this to enumerate all
the files on the C: drive. (In fact, the Directory class can save us from writing all
this code—there’s an overload of Directory.EnumerateFiles that will do a
lazy, recursive search for you. But writing our own version is a good
way to see how lazy enumeration works.)
Example 7-34. Lazy enumeration of a large, slow data set
class Program
{
static IEnumerable<string> GetAllFilesInDirectory(string directoryPath)
{
IEnumerable<string> files = null;
IEnumerable<string> subdirectories = null;
try
{
files = Directory.EnumerateFiles(directoryPath);
subdirectories = Directory.EnumerateDirectories(directoryPath);
}
catch (UnauthorizedAccessException)
{
Console.WriteLine("No permission to access " + directoryPath);
}
if (files != null)
{
foreach (string file in files)
{
yield return file;
}
}
if (subdirectories != null)
{
foreach (string subdirectory in subdirectories)
{
foreach (string file in GetAllFilesInDirectory(subdirectory))
{
yield return file;
}
}
}
}
static void Main(string[] args)
{
foreach (string file in GetAllFilesInDirectory(@"c:"))
{
Console.WriteLine(file);
}
}
}If you run this, you’ll find it starts printing out filenames
immediately, even though it clearly won’t have had time to discover
every single file on the hard disk. (That’s why we’re not using the
overload of Directory.GetFiles that
recursively searches subdirectories for us. As you’ll see in Chapter 8, the Directory
class can save us from writing all this code, but it insists on
finding all the files before starting to return any of them.)
It’s possible to chain enumerations together. For example, we can combine
Example 7-34 with the
AddNumbers function, as shown in
Example 7-35.
Example 7-35. Chaining lazy enumerators together
IEnumerable<string> allFiles = GetAllFilesInDirectory(@"c:");
IEnumerable<string> numberedFiles = AddNumbers(allFiles);
foreach (string file in numberedFiles)
{
Console.WriteLine(file);
}If we’re using the version of AddNumbers from Example 7-32—the one that
uses yield return—this will start
printing out filenames (with added numbers) immediately. However, if
you try it with the version from Example 7-31, you’ll see
something quite different. The program will sit there for as many
minutes as it takes to find all the filenames on the hard disk—it
might print out some messages to indicate that you don’t have
permission to access certain folders, but it won’t print out any
filenames until it has all of them. And it ends up consuming quite a
lot of memory—on my system it uses more than 130 MB of memory, as it
builds up a huge List<string>
containing all of the filenames, whereas the lazy version makes do
with a rather more frugal 7 MB.
So in its eagerness to do all of the necessary work up front, Example 7-31 actually slowed us down. It didn’t return any information until it had collected all of the information. Ironically, the lazy version in Example 7-32 enabled us to get to work much faster, and to work more efficiently.
Note
This style of enumeration, in which work is done no sooner than necessary, is sometimes called deferred execution. While that’s more of a mouthful, it’s probably more fitting in cases where the effect is the opposite of what lazy suggests.
Lazy enumeration also permits an interesting technique whereby
infinite loops aren’t necessarily a problem. A method can yield an
infinite collection, leaving it up to the caller to decide when to
stop. Example 7-36 returns an
enumeration of numbers in the Fibonacci series. That’s an infinite
series, and since this example uses the BigInteger type introduced in .NET 4, the
quantity of numbers it can return is limited only by space and
time—the amount of memory in the computer, and the impending heat
death of the universe, respectively (or your computer’s next reboot,
whichever comes sooner).
Example 7-36. An infinite sequence
using System.Numerics; // Required for BigInteger
...
static IEnumerable<BigInteger> Fibonacci()
{
BigInteger current = 1;
BigInteger previous = 1;
yield return 1;
while (true)
{
yield return current;
BigInteger next = current + previous;
previous = current;
current = next;
}
}Because consumers of enumerations are free to stop enumerating at any time, in practice this sort of enumeration will just keep going until the calling code decides to stop. We’ll see some slightly more practical uses for this when we explore parallel execution and multithreading later in the book.
The concept of chaining lazy enumerations together shown in Example 7-35 is a very useful technique—it’s the basis of the most powerful feature that was added in version 3 of C#: LINQ. LINQ is such an important topic that the next chapter is devoted to it. But before we move on, let’s review what we’ve seen so far.
The .NET Framework’s type system has intrinsic support for
collections of items in the form of arrays. You can make arrays out of any
type. They can be either simple single-dimensional lists, nested arrays of
arrays, or multidimensional “rectangular” arrays. The size of an array is
fixed at the moment you create it, so when we need a bit more flexibility
we use the List<T> generic
collection class instead. This works more or less like an array, except we
can add and remove items at will. (It uses arrays internally, dynamically
allocating new arrays and copying elements across as necessary.) Both
arrays and lists offer various services for finding and sorting elements.
Thanks to the IEnumerable<T>
interface, it’s possible to write polymorphic code that can work with any
kind of collection. And as we’re about to see, LINQ takes that idea to a
whole new level.
[14] There’s also a LongLength,
which is a 64-bit version of the property, which theoretically
allows for larger arrays than the 32-bit Length
property. However, .NET currently imposes an upper limit on the size
of any single array: it cannot use more than 2 GB of memory, even in
a 64-bit process. So in practice, LongLength isn’t very useful in the
current version of .NET (4). (You can use a lot more than 2 GB of
memory in total in a 64-bit process—the 2 GB limit applies only to
individual arrays.)
[15] Rectangular arrays are also sometimes called multidimensional arrays, but that’s a slightly confusing name, because jagged arrays also hold multidimensional data.
[16] If you’re familiar with C++ and its Standard Template Library, an enumerator is broadly similar in concept to an iterator in the STL.