
A data warehouse is primarily used to organize data so queries about the business can be answered quickly. As data warehouses grow in size, it is not uncommon to find a fact table several gigabytes or even terabytes in size. In order to obtain fast query response, it is extremely important for the database to retrieve and process such large amounts of data efficiently.
In Chapter 4, we discussed several physical design techniques, including partitioning, compression, and bitmapped indexing, that are suited for data warehouses. In this chapter, we’ll look at query optimizations, such as partition pruning, partition-wise join, and star transformation, that are specifically designed to improve query performance in a data warehouse. We will also describe how to use parallel execution for queries.
Finally, we will discuss several SQL functions that are useful for decision-support applications to answer business queries, which typically perform computations such as period-over-period comparisons and cumulative aggregations. These SQL functions allow users to express complex queries simply and process them efficiently. We will also look at the new spreadsheet technology in Oracle Database 10g.
We will begin with the query optimizer, which is the heart of query processing in a database.
Anyone who has worked with a database is familiar with the query optimizer. The job of the optimizer is to determine a plan to execute a query in the fastest possible time. For instance, the optimizer may decide to use an index, or, if the table is small, it might be faster to perform a full table scan. The query optimizer in Oracle Database 10g is known as the cost-based optimizer.
The cost-based optimizer uses various statistics, such as the cardinality of the table (i.e., number of rows), number of distinct values of a column and the distribution of column values, to determine the method and the cost of accessing a table. The method used to access a table is called its access path and can use one or more access structures, such as indexes and materialized views, or scan the entire table. The optimizer first identifies for each table, the access path with the least cost. It then determines the cheapest way to join the tables, includes the cost of other operations such as sorts, and in this manner picks the strategy to execute the query with the cheapest cost. We refer to this strategy as the query execution plan and the cost is a measure of how much I/O, CPU time, and memory will be required to execute the query using this execution plan. To use the cost-based optimizer effectively, statistics describing the cardinality and data distribution must be collected for each table, index, and materialized view. Chapter 11 will describe the use of the DBMS_STATS package to collect statistics and will explain how you can set up automatic statistics collection. Note that if a table does not have statistics, Oracle Database 10g employs a feature called dynamic sampling, which will automatically sample the data to collect statistics. This is also discussed in Chapter 11.
Note
Prior to Oracle Database 10g, there was an alternative approach of using the rule-based optimizer; however, this is not suitable for a data warehouse, and, in fact, starting in Oracle Database 10g, the rule-based optimizer is no longer supported by Oracle.
Next, we will talk about some of the features of the cost-based query optimizer and how they work for queries in a data warehouse. We will begin by reviewing the EXPLAIN PLAN facility to view the query execution plan generated by the query optimizer. This will be used extensively by the examples in this book.
Oracle provides several tools to display the execution plan. You can use the autotrace option of SQL*Plus to display the plan when you execute the query. Alternatively, to just get the query plan without executing the query, you can use EXPLAIN PLAN. The output of EXPLAIN PLAN is placed in a table called the PLAN_TABLE. Before you can start using EXPLAIN PLAN, you must create the PLAN_TABLE in the schema where you will execute the query by running the script ORACLE_HOME/rdbms/admin/utlxplan.sql. You can also ask EXPLAIN PLAN to place the output in some other table, but it must have the same columns as the PLAN_TABLE. To display the plan you would use the script ORACLE_HOME/rdbms/admin/utlxpls.sql.
Let us look at the output of an EXPLAIN PLAN statement. The output consists of the access path for each table, the cost of the access path, and the estimated number of rows retrieved. The plan output is indented so that tables that are being joined are shown at the same level of indentation; operations that are performed earlier are indented further.
EXPLAIN PLAN FOR
SELECT t.month, t.year, p.product_id,
SUM (purchase_price) as sum_of_sales,
COUNT (purchase_price) as total_sales,
COUNT(*) as cstar
FROM time t, product p, purchases f
WHERE t.time_key = f.time_key AND
f.product_id = p.product_id
GROUP BY t.month, t.year, p.product_id;
PLAN_TABLE_OUTPUT
------------------------------------------------------------------
Plan hash value: 419515211
------------------------------------------------------------------
|Id|Operation |Name |Rows |Bytes |Cost|Psta|Pstp|
------------------------------------------------------------------
| 0|SELECT STATEMENT | | 3936| 169K| 494| | |
| 1| SORT GROUP BY | | 3936| 169K| 494| | |
|*2| HASH JOIN | |81167| 3487K| 121| | |
| 3| TABLE ACCESS FULL |TIME | 731|12427 | 3| | |
|*4| HASH JOIN | |81167| 2140K| 115| | |
| 5| INDEX FULL SCAN |PRODUCT_PK| 164| 1148 | 1| | |
| 6| PARTITION RANGE ALL| _INDEX |81167| 1585K| 111| 1| 24|
| 7| TABLE ACCESS FULL |PURCHASES |81167| 1585K| 111| 1| 24|
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."TIME_KEY"="F"."TIME_KEY")
4 - access("F"."PRODUCT_ID"="P"."PRODUCT_ID")
20 rows selected.In this example, the innermost operation is a hash join between the tables, PURCHASES and PRODUCT (rows 4–7). Note that an index, PRODUCT_PK_INDEX (row 5), is used to access the table, PRODUCT. The output of this is joined with the table, TIME, using a hash join (rows 24). The final operation is a sort in order to perform the GROUP BY. The plan display also shows the predicates being applied during each operation. In the previous examples, the predicates being applied are the join predicates. Later in this chapter, we will discuss partition pruning, wherein Oracle will automatically avoid scanning partitions that are not needed by the query. The PARTITION RANGE clause (row 6) indicates the first and last partitions being scanned. The keyword ALL means that no partition pruning was done and all 24 partitions were scanned, which is shown by column values 1 for Pstart and 24 for Pstop. The plan also shows information about temporary space and estimated time for each operation, which are not shown here due to lack of space. The plan hash value shown at the top is used by various tuning tools to uniquely identify a specific execution plan for a query.
EXPLAIN PLAN can also be used to display the detailed query plan involving parallel execution, which we will discuss later in Chapter 10.
Next, we will discuss various query optimization techniques used to efficiently process queries in a data warehouse. We will start with the basic join methods used by the query optimizer, and then discuss some advanced techniques, such as star transformation, partition pruning, and partition-wise join.
One of the most common operations in a query is a join between two tables. A join operation combines data from two or more tables, based on a condition (known as the join predicate) involving columns from the tables.
The Oracle query optimizer uses one of the following three join methods to execute a join.
Nested Loops Join
Sort-Merge Join
Hash Join
In nested loops join, one table is chosen as the outer table and the other as the inner table. For each row in the outer table, all matching rows that satisfy the join condition in the inner table are found. A nested loop join can be extremely efficient if the inner table has an index on the join column and there are few rows in the outer table. However, if indexes are missing it can also be a very resource- and time-intensive method of performing joins.
A sort-merge join is useful when joining two large tables or when the join is based on an inequality predicate. In a sort-merge join, the data from each table is sorted by the values of the columns in the join condition. The sorted tables are then merged, such that each pair of rows with matching columns is joined. If there is an index on the join columns of either table, the optimizer may use it to directly retrieve the data in sorted order, thereby avoiding the sort for that table.
Given the ad hoc nature of decision-support queries, it is not always possible for the DBA to index all the columns the users may use to join tables together. Hash joins are especially useful when there are no indexes on the columns being joined and hence are a very commonly seen join technique in a data warehouse.
In a hash join, a hashing function is applied to the join columns of the smaller table to build a hash table. Then, the second table is scanned, and its join columns are hashed and compared with the hash table to look for matching rows. A hash join performs best if the hash table can fit entirely into memory. If the hash table does not fit into memory, then parts of it need to be written to disk, causing multiple passes over the data, which is not very efficient. Hash joins can only be used for joins based on equality predicates (i.e., table1.column1 = table2.column2).
You may be wondering how you would pick the join method—fortunately, you don’t need to pick one! The query optimizer will automatically choose the most efficient join method for each join within a query. In some cases, usually due to bad statistics or a skewed data distribution, the query optimizer may choose the incorrect join method. So it is extremely important to have accurate statistics on the data. It is possible to explicitly specify a join method to use by including an optimizer hint in the query; however, this is not recommended. Instead, we recommend running the SQL Tuning Advisor, described in Chapter 10, to tune slow-running queries. This will attempt to correct any mistakes made by the query optimizer and thereby improve the execution plan.
Another important point to note is that sort and hash joins are memory-intensive operations and may require temporary space if not enough memory is available. Chapter 10 also describes the PGA Memory Advisor, which can be used to automatically tune memory for these operations.
Next, we will look at some advanced query optimization techniques used in a data warehouse.
A star query is a typical query executed on a star schema. Each of the dimension tables is joined to the fact table using the primary-key/foreign-key relationship. If the fact table has bitmapped indexes on the foreign-key columns, Oracle can optimize the performance of such star queries using an algorithm known as the star transformation. Star transformation is based on combining bitmapped indexes on the fact table columns that correspond to the dimension tables in the query. First, bitmapped indexes are used to retrieve the necessary rows from the fact table. The result is then joined to the dimension tables to get any columns required in the final answer.
If your data warehouse has a star schema, you should enable star transformation. This is done by setting the initialization parameter, STAR_TRANSFORMATION_ENABLED, to TRUE. Alternatively, you can use the STAR_TRANSFORMATION hint on queries that join the fact and dimension tables. The optimizer will weigh the execution plans, with and without star transformation, and pick the most efficient plan.
Suppose there were bitmapped indexes on each of the foreign-key columns of the PURCHASES table (i.e., CUSTOMER_ID, TIME_KEY, and PRODUCT_ID). The following example shows a query that can benefit from star transformation. This query joins the fact (PURCHASES) table and dimension tables (PRODUCT, TIME, CUSTOMER) in a star schema and has selections on each of the dimension tables (MONTH = 200301, and STATE = ‘MA’, and CATEGORY = ‘HDRW’), representing a small fraction of the entire data.
EXPLAIN PLAN FOR
SELECT c.city, t.quarter, p.product_name,
SUM(f.purchase_price) sales
FROM purchases f, time t, customer c, product p
WHERE f.time_key = t.time_key and
f.customer_id = c.customer_id and
f.product_id = p.product_id and
t.month = 200301 and c.state = 'MA' and
p.category = 'HDRW'
GROUP BY c.city, t.quarter, p.product_name;The execution plan is as follows:
------------------------------------------------------------------ |ID | Operation | Name |Rows| Bytes|Cost| ------------------------------------------------------------------ | 0| SELECT STATEMENT | | 54| 3834| 715| | 1| SORT GROUP BY | | 54| 3834| 715| |* 2| HASH JOIN | | 328| 23288| 712| |* 3| TABLE ACCESS FULL |PRODUCT | 54| 1188| 2| |* 4| HASH JOIN | | 984| 48216| 709| | 5| MERGE JOIN CARTESIAN | | 3| 78| 4| |* 6| TABLE ACCESS FULL |CUSTOMER | 1| 12| 2| | 7| BUFFER SORT | | 1| 14| 2| |* 8| TABLE ACCESS FULL |TIME | 1| 14| 2| | 9| TABLE ACCESS BY INDEX ROWID |PURCHASES|7030| 157K| 703| | 10| BITMAP CONVERSION TO ROWIDS| | | | | | 11| BITMAP AND | | | | | | 12| BITMAP MERGE | | | | | | 13| BITMAP KEY ITERATION | | | | | |*14| TABLE ACCESS FULL |CUSTOMER | 1| 12| 2| |*15| BITMAP INDEX RANGE SCAN|CUST_IDX | | | | | 16| BITMAP MERGE | | | | | | 17| BITMAP KEY ITERATION | | | | | |*18| TABLE ACCESS FULL |TIME | 2| 28| 2| |*19| BITMAP INDEX RANGE SCAN|TIME_IDX | | | | | 20| BITMAP MERGE | | | | | | 21| BITMAP KEY ITERATION | | | | | |*22| TABLE ACCESS FULL |PRODUCT | 54| 1188| 2| |*23| BITMAP INDEX RANGE SCAN|PROD_IDX | | | | ------------------------------------------------------------------
To understand how star transformation works, notice that the rows corresponding to category = ‘HDRW’ can be retrieved using the following subquery (this is also known as a semijoin):
SELECT *
FROM purchases
WHERE product_id IN (SELECT product_id
FROM product
WHERE category = 'HDRW'),This query is executed to retrieve the product ids corresponding to the HDRW category, and then the PROD_IDX bitmapped index on PURCHASES.PRODUCT_ID is used to retrieve the rows from the PURCHASES table corresponding to these product id values. In star transformation, similar subqueries are generated for each of the dimension tables to obtain a bitmap for the rows of the PURCHASES table corresponding to that dimension table. Next, these bitmaps are combined using a bitmap AND operation into a single bitmap. This is shown in the execution plan in rows 10 through 23. This bitmap is then used to retrieve the relevant rows from the PURCHASES tables. Finally, a join is done back to the dimension tables (shown in plan rows 0 through 9) to obtain the other column values (CITY, QUARTER, and PRODUCT_NAME). Note that if the query did not select any columns from the dimension table, then the optimizer will not need to perform this join back. Star transformation turns out to be efficient when the fact table is large, because only a small subset of the table (in our example 7,030 rows out of 421K rows in the PURCHASES table) is now involved in the join.
Hint
Creating bitmapped indexes on foreign-key columns in the fact table will allow the optimizer to consider star transformation for your star queries.
A bitmapped join index can also be used instead of a combination of bitmapped indexes. Star transformation is also possible if only some of the foreign key columns have bitmapped indexes.
In Chapter 4, we mentioned that if a table is partitioned, the query optimizer could determine if a certain query can be answered by reading only specific partitions of the table. This can dramatically reduce the amount of data read to answer a query and hence speed up the query execution. This feature is known as Partition Elimination or Dynamic Partition Pruning.
We will now look at examples of partition pruning with different types of partitioning.
In range partitioning, data is partitioned into nonoverlapping ranges of data. In this case, the optimizer can perform partition pruning if the query has range, IN list, or LIKE predicates on the partition keys. For example, in the EASYDW schema, the PURCHASES table is partitioned on the TIME_KEY column, such that each partition corresponds to one month’s data. The following query asks for sales of November and December 2003. The optimizer will therefore eliminate from its search all partitions except those containing these two months.
EXPLAIN PLAN FOR
SELECT t.time_key, SUM(f.purchase_price) as sales
FROM purchases f, time t
WHERE f.time_key = t.time_key
AND t.time_key BETWEEN TO_DATE('1-Nov-2003', 'DD-Mon-YYYY')
AND TO_DATE('31-Dec-2003', 'DD-Mon-YYYY')
GROUP BY t.time_key;
------------------------------------------------------------------
|Id|Operation |Name |Rows|Cost|Pstart|Pstop|
------------------------------------------------------------------
| 0|SELECT STATEMENT | | 62| 15| | |
| 1| SORT GROUP BY | | 62| 15| | |
|*2| HASH JOIN | | 585| 14| | |
|*3| INDEX FAST FULL SCAN |TIME_PK_ | | | | |
| | | INDEX| 62| 2| | |
| 4| PARTITION RANGE ITERATOR| |6893| 11| 11 | 12|
|*5| TABLE ACCESS FULL |PURCHASES |6893| 11| 11 | 12|
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("F"."TIME_KEY"="T"."TIME_KEY")
3 - filter("T"."TIME_KEY"<=TO_DATE('2003-12-31 00:00:00',
'yyyy-mm-dd hh24:mi:ss') AND
"T"."TIME_KEY">=TO_DATE('2003-11-01 00:00:00',
'yyyy-mm-dd hh24:mi:ss'))
5 - filter("F"."TIME_KEY"<=TO_DATE('2003-12-31 00:00:00',
'yyyy-mm-dd hh24:mi:ss'))
20 rows selected.Note that the output of EXPLAIN PLAN includes columns Pstart and Pstop, which indicate the range of partitions used to answer the query. Note that for multicolumn range partitioning, only predicates on the first column in the partition key are used for partition pruning.
Hash partitioning allows partition pruning only when a query involves equality or IN-list predicates on the partitioning column. This is because with hash partitioning, the values are distributed randomly among partitions and so contiguous values may not fall into a single partition.
If a table is list partitioned, the optimizer can perform partition pruning if the query asks for a range or list of partition-key values. For instance, the REGIONAL_SALES table in Chapter 4 (Figure 4.3) is partitioned by states in each region. Now, if a query asks for sales for states NH, MA, CT, CA, AZ, the optimizer can prune all partitions except the Northeast and West.
EXPLAIN PLAN FOR
SELECT store_number, dept_number, SUM(sales_amount) as q1_sales
FROM regional_sales
WHERE state in ('NH', 'MA', 'CT', 'CA', 'AZ')
GROUP BY store_number, dept_number;
------------------------------------------------------------------
|Id|Operation |Name |Rows|Cost|Pstart| Pstop|
------------------------------------------------------------------
| 0|SELECT STATEMENT | | 500| 4 | | |
| 1| SORT GROUP BY | | 500| 4 | | |
| 2| PARTITION LIST INLIST| | 500| 3 |KEY(I)|KEY(I)|
|*3| TABLE ACCESS FULL |REGIONAL_SALES| 500| 3 |KEY(I)|KEY(I)|
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("STATE"='AZ' OR "STATE"='CA' OR "STATE"='CT' OR
"STATE"='MA' OR "STATE"='NH')In case of a query with IN operator, you will see the KEY(I) term in the Pstart and Pstop columns in the output of EXPLAIN PLAN, rather than actual partition numbers.
Also note that in some cases the actual partitions to be accessed are determined only during the execution of the query, in which case you also will not see actual partition numbers but instead see the value KEY in the Pstart and Pstop columns in the EXPLAIN PLAN output.
For a composite-partitioned table, in addition to pruning at the partition level, the optimizer can also prune subpartitions within the partitions using predicates on the subpartitioning columns. This can further reduce the data accessed to answer a query.
For example, suppose we have a table, SALES, composite-partitioned using range partitioning on SALE_DATE and list subpartitioning on STATE. The following query asks for total sales for NH, MA, and CT states for a range of sales dates. The optimizer will determine that this query can be answered quickly by reading the partitions for February and March. Further, within these two partitions, only the first subpartition needs to be accessed. The Pstart and Pstop values in the output of EXPLAIN PLAN show the range of partitions used to answer the query, in this case partitions 2 and 3. Note that KEY keyword in the last line of the output indicates that the actual subpartition numbers will be determined at query execution time.
EXPLAIN PLAN FOR
SELECT store_number, dept_number, SUM(sales_amount) as q1_sales
FROM sales
WHERE sale_date between TO_DATE('15-Feb-2003', 'DD-Mon-YYYY')
AND TO_DATE('15-Mar-2003', 'DD-Mon-YYYY')
AND state in ('NH', 'MA', 'CT')
GROUP BY store_number, dept_number;
-----------------------------------------------------------------
|Id| Operation |Name |Rows|Cost| Pstart | Pstop |
-----------------------------------------------------------------
|0 | SELECT STATEMENT | | 1 | 41 | | |
|1 | SORT GROUP BY | | 1 | 41 | | |
|2 | PARTITION RANGE ITERATOR| | 1 | 40 | 2 | 3 |
|3 | PARTITION LIST INLIST | | 1 | 40 | KEY(I) | KEY(I)|
|4 | TABLE ACCESS FULL |SALES| 1 | 40 | KEY | KEY |
-----------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter(("STATE"='CT' OR "STATE"='MA' OR "STATE"='NH') AND
"SALE_DATE">=TO_DATE('2003-02-15 00:00:00',
'yyyy-mm-dd hh24:mi:ss') AND
"SALE_DATE"<=TO_DATE('2003-03-15 00:00:00',
'yyyy-mm-dd hh24:mi:ss'))If the query optimizer chooses an index to access the table, then, in addition to pruning on table partitions, Oracle will also prune index partitions. If the index is local and hence partitioned identically to the table, then Oracle will only access the index partitions corresponding to the table partitions being accessed. If the index is global and partitioned differently than the table, Oracle can still eliminate index partitions that are not needed provided there is a predicate on the partitioning key of the index.
Partition pruning is one of the many benefits of partitioning and can provide huge performance gains in a data warehouse. When designing your queries, include predicates on partitioning columns whenever possible to obtain the benefits of partition pruning.
When the tables being joined are partitioned, the optimizer may choose to perform a partition-wise join. Rather than performing a large join between two tables, the join operation is broken up into a series of smaller joins between the partitions or subpartitions. These smaller joins can be executed in parallel, which can make the entire join operation significantly faster. Note that a partition-wise join can use any of the join methods discussed earlier—sort merge, hash, or nested loops join. Recall that a hash join performs best when the hash tables fit into memory—with a partition, wise join, hash joins can be made more efficient, because the hash tables for each partition are much smaller and hence more likely to fit into memory.
A full partition-wise join, illustrated in Figure 6.1, can be done when the tables being joined are equipartitioned on the join key in the query. Equipartitioning means that the two tables have identical partitioning criteria (i.e., partition method and partition bounds), which means that there is a correspondence between the partitions (or subpartitions) or one table with the partitions (or subpartitions) of the other. So every partition (or subpartition) of the first table needs to be joined only to its corresponding partition (or subpartition) in the other table. In Figure 6.1, the PURCHASES and ORDERS tables are both partitioned by a date column, and each partition contains data for a month. In a full partition-wise join between these two tables, using the partition keys as the join columns, the January partition of PURCHASES will be joined to the January partition of ORDERS, the February partition of PURCHASES will be joined to the February partition of ORDERS, and so on. When executing the query in parallel, each piece of the join (separated by the dotted lines in the figure) can be executed on a separate processor.

If only one of the tables is partitioned on the join key, a partial partition-wise join can be done when executing the query in parallel. The table that is not partitioned by the join key is dynamically partitioned to match the partitioning criteria of the partitioned table. Each pair of partitions from the two tables is now joined, as in a full partition-wise join.
The decision to perform a partition-wise join or any of its variants is taken by the optimizer based on the cost of the execution plan. Note that if the query only requires some of the partitions of any table, then only those partitions will participate in the partition-wise join. Thus, a query execution can benefit from both partition pruning and partition-wise joins.
In this section, we mentioned executing queries in parallel. We will discuss the important technique of parallel execution in more detail next.
Many operations in a data warehouse involve processing large amounts of data. Bulk loads, large table scans, creating indexes and materialized views, sorting, and joining data from multiple tables can all take a considerable amount of time. Parallel execution can be used to reduce the time it takes to execute these operations.
With parallel execution certain SQL statements can be divided transparently into smaller concurrently executing operations. By dividing the work among several processes on different processors, the statement can be completed faster than with only a single process.
In Oracle, parallel execution is performed using a parallel execution coordinator process and a pool of parallel execution servers. The Oracle process that handles the user’s query becomes the coordinator process for that query. The coordinator process partitions the work to be done among the required number of parallel execution servers. It ensures that the load is balanced among the processes and redistributes work to any process that may have finished before the others. The coordinator receives the results from the parallel execution servers and assembles them into the final result. For example, in Figure 6.2, parallel execution is used to concurrently read partitions for four months from a table—for example, to calculate total sales.
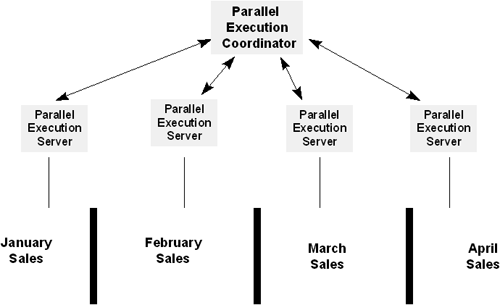
The operation to be executed in parallel is divided up into smaller units, known as granules of parallel execution. A granule corresponds to the work performed assigned to each parallel execution server. If a table or index is partitioned, the granule can be a partition or a subpartition. Alternatively, the granule can be a range of physical data blocks. Oracle will automatically determine the best granule to use to parallelize a statement.
Many operations can benefit from parallel execution. SELECT statements with various operations, such as joins, aggregation, sorts, set operations (e.g., UNION and UNION ALL), and SELECT DISTINCT, can use parallel execution. Partition pruning and partition-wise join in conjunction with parallel execution can provide huge performance improvements.
DML statements—INSERT, UPDATE, DELETE, and MERGE—can be done in parallel on partitioned as well as nonpartitioned tables. You must use the ALTER SESSION ENABLE PARALLEL DML in the session to allow DML statements to be parallelized. Bulk loads done using SQL*Loader can be parallelized using the PARALLEL=TRUE option.
Parallel execution is also possible for DDL statements, such as CREATE TABLE, CREATE INDEX and CREATE MATERIALIED VIEW, and partition maintenance operations, such as TRUNCATE, EXCHANGE, MERGE, and SPLIT PARTITION.
PL/SQL functions, user-defined aggregates, and table functions issued as part of SQL statements can also be parallelized.
At database startup, Oracle will start as many parallel execution servers as specified by the PARALLEL_MIN_SERVERS initialization parameter. These are available for use by any parallel operation. The query coordinator obtains the required number of parallel execution servers from the pool when needed to execute a parallel operation. When processing is complete, the coordinator returns the parallel execution servers to the pool. If there are a large number of concurrent users executing parallel statements, additional parallel execution servers can be created. The initialization parameter, PARALLEL_MAX_SERVERS, specifies the maximum number of server processes to create. When they are no longer needed, the parallel execution servers that have been idle for a period of time are terminated. The pool is never reduced below the PARALLEL_MIN_SERVERS parameter.
The number of units into which a statement gets divided is known as the degree of parallelism (DOP). You can set the DOP when creating or altering a table, index, or materialized view using the PARALLEL clause in the DDL statement, as shown in the following example:
-- set DOP to 4 for a table ALTER TABLE purchases PARALLEL 4;
For a given query the DOP of the query is defined as the maximum DOP of all tables and indexes involved in the execution of the query. You can override the value of DOP for a SQL statement with the PARALLEL hint or by setting it for the entire session using the ALTER SESSION FORCE PARALLEL statement. This is shown in the following examples.
--set DOP to 6 for a session for parallel DML or query ALTER SESSION FORCE PARALLEL DML PARALLEL 6; ALTER SESSION FORCE PARALLEL QUERY PARALLEL 6; -- set DOP to 2 for just this SQL statement SELECT /*+ PARALLEL (2)*/ * FROM purchases;
If the DOP is not specified using the previous methods, Oracle will calculate it automatically using the number of CPUs or number of partitions. For good performance, the number of partitions should be a multiple of the DOP. Otherwise, some parallel execution servers may remain idle waiting for others to complete a certain operation before beginning the next one.
During query execution, Oracle will try to use the requested degree of parallelism, but if several queries are competing for resources, it may adjust it to a lower value. Note that Oracle may use up to 2 × DOP number of execution servers for a query. If no parallel execution servers are available, the operation will execute serially. Sometimes a parallel operation cannot be executed efficiently unless a certain number of servers are available. The initialization parameter, PARALLEL_MIN_PERCENT, is used to specify the minimum percentage of requested parallel execution servers needed for the operation to succeed. If this percentage is not met, Oracle will return an error and you need to try the operation again later.
You may be wondering how to go about setting the different parallel execution parameters. Fortunately, since Oracle 9i, you can just set one initialization parameter, PARALLEL_AUTOMATIC_TUNING to TRUE, which will automatically set good defaults for all parallel execution—related parameters based on available resources on your system.
It is important to have the right hardware and system characteristics to get the benefits of parallel execution. The system must have adequate spare CPU time, memory, and I/O bandwidth to allow parallel execution. In Chapter 3, we discussed various hardware and storage architectures for a warehouse. SMP, MPP, and Cluster architectures make parallel execution possible. Obviously, uni-processor machines cannot make use of parallel processing, since there is only one CPU.
When using Oracle Real Application Clusters technology (RAC), parallel execution of a query may distribute the work across slave processes running on multiple database instances. Oracle will determine at run time whether to run the query on a single instance or multiple instances to keep internode communication to a minimum. Also, when possible, Oracle will try to assign a node to work on a tablespace or partition that is on a local device for that node—this is known as affinity. Using affinity improves performance by reducing the communication overhead and I/O latency, because a node only accesses local devices, and also by ensuring that multiple nodes do not try to access the same device at the same time.
In this chapter, so far we have discussed several query execution techniques that improve query performance in a data warehouse. Next, we will delve into SQL language features that Oracle provides specially for data warehousing applications. The following section would be most useful to application developers and readers who need to write SQL to issue business queries. If you use an end-user tool such as Discoverer, you may skip over the detailed SQL examples in this section.
The primary purpose of building a data warehouse is to obtain information about your business so that you can improve business processes and better understand the buying habits of your customers.
For instance, you may need to answer questions such as:
What were the top-10 selling products this year?
How do the sales this year compare against last year?
What are the cumulative sales numbers for each month this year?
What are the sales numbers for each region and subtotals for each city within it?
This type of analysis is referred to as business intelligence or decision support analysis. Although these questions sound quite simple, the SQL queries needed to answer these questions can be extremely complex. These queries are very hard to optimize and may require multiple scans over the data. They may perform poorly or may require application layer processing. A few years ago, several database vendors started an initiative to provide SQL extensions to concisely represent these types of queries and execute them efficiently. The extensions are now part of the SQL99 standard. Oracle’s BI tools, such as Discoverer, which are tightly integrated with the database, take advantage of the SQL functions in the database to deliver high performance for end-user queries.
The SQL extensions for business intelligence can be broadly classified into three categories—extensions for aggregation; such as calculating totals and subtotals; functions for analysis, such as finding the top-N products or cumulative sales and spreadsheet-like functionality for modeling (statistical analysis functions). We will provide a detailed look at each of these SQL extensions.
Aggregation is the most basic operation in a business intelligence query. Suppose we wanted to know the total sales by month for the current year. In this example, we are summing up the detailed data for each day, to give the total sales for each month. An operation where many detailed rows are combined using an operator such as SUM, to give a single value, is called aggregation. We have already seen several examples of aggregation in this chapter. You can recognize aggregation in a SQL query when you see a GROUP BY clause or operators such as SUM, AVG, COUNT, MIN, MAX, STDDEV, and VARIANCE.
The GROUP BY clause allows you to perform aggregation at a single level within a dimension, such as by month or by year. However, often you may want to see totals and subtotals in the same query—for instance, total sales by each month and further by quarter and by year. In the past, these types of operations were done using report-writing tools. Now, you can perform such multilevel aggregations within the database using the CUBE, ROLLUP, and GROUPING SETS operators. The ROLLUP operator is used to compute subtotals along a dimension hierarchy, and the CUBE operator is used to compute aggregations across all possible combinations for a set of GROUP BY columns (we refer to each combination as a grouping). The GROUPING SETS operator is used to compute aggregates for only specific groupings. By executing these aggregations within the database, they can be executed in parallel and benefit from the various query optimizations discussed earlier.
CUBE, ROLLUP, and GROUPING SETS can be used with all the supported aggregate operators in Oracle and also with other analysis functions discussed later in this chapter.
We will now take a detailed look at these extensions.
The CUBE operator computes aggregates for all possible combinations of the columns in the GROUP BY clause. For example, suppose you wanted to analyze the sales of your products according to the product category and the year and also see total sales by category, by year, and a grand total. This corresponds to a CUBE operation, as shown in the following example.
SELECT p.category, t.year, SUM(purchase_price) total_sales
FROM product p, purchases f, time t
WHERE p.product_id = f.product_id AND
t.time_key = f.time_key
GROUP BY CUBE (p.category, t.year);
CATE YEAR TOTAL_SALES
---- ---------- -------------------
ELEC 2003 9380600.38 <- (category, year)
ELEC 2004 9515598.19
HDRW 2003 105098.69
HDRW 2004 105130.03
MUSC 2003 107026.10
MUSC 2004 106399.30
ELEC 18896198.60 <- (category)
HDRW 210228.72
MUSC 213425.40
2003 9592725.17 <- (year)
2004 9727127.52
19319852.70 <- (grand total)
12 rows selected.As we can see, the answer to this query includes the total sales for the four groupings—(CATEGORY, YEAR), (CATEGORY), (YEAR)—and a grand total. We have highlighted with arrows the first row in each group.
As the number of columns increases, computing the CUBE operator can consume a lot of time and space. Notice that the number of groupings for a CUBE with two columns is four, with three columns eight, and so on. Often, you are only interested in totals along a specific dimension, which is accomplished by the ROLLUP operator.
The ROLLUP operator is useful for totaling data across a hierarchical dimension such as time. In a ROLLUP, you specify a list of columns and Oracle performs GROUP BY on steadily smaller subsets of the list, working from the rightmost column toward the left.
We will illustrate this operator using the following example, which computes the ROLLUP operation for category, year columns. To compute ROLLUP, we first group by (CATEGORY, YEAR) and then group by (CATEGORY), thereby aggregating over the rightmost column, YEAR, and finally produce a grand total. We have highlighted the first row of each grouping in the output with arrows.
SELECT p.category, t.year, SUM(purchase_price)
FROM product p, purchases f, time t
WHERE p.product_id = f.product_id AND
t.time_key = f.time_key
GROUP BY ROLLUP (p.category, t.year);
CATE YEAR SUM(PURCHASE_PRICE)
---- ----------- -------------------
ELEC 2003 9380600.38 <- (category, year)
ELEC 2004 9515598.19
HDRW 2003 105098.69
HDRW 2004 105130.03
MUSC 2003 107026.10
MUSC 2004 106399.30
ELEC 18896198.60 <- (category)
HDRW 210228.72
MUSC 213425.40
19319852.70 <- (grand total)
10 rows selected.To ROLLUP along a hierarchy correctly, we must order the columns from the highest to the lowest level of the hierarchy from left to right. For instance, to ROLLUP along a time hierarchy the column ordering would be (YEAR, MONTH, DAY).
If we compare the output of the CUBE and ROLLUP, you will notice that ROLLUP only computes some of the possible combinations of groupings in a CUBE. In the previous example, the grouping (YEAR) is present in the CUBE but not in the ROLLUP output. The output of a CUBE always includes the output of a ROLLUP. The ROLLUP is thus a much simpler and more efficient operation: for two columns, a rollup produces three groupings, for three columns, four, and so on.
GROUPING SETS is a generalization of the ROLLUP operator that allows you to specify which particular groupings you would like to compute.
In a data warehouse, aggregating data involves accessing a lot of detail data and therefore, to avoid repeating such expensive computations, it is common practice to precompute and store aggregations using materialized views. Now, if we were to store the result of a CUBE operator, computing all possible groupings, the space requirements could get too large. It is not uncommon for the output of a CUBE to be several times larger than the size of the fact table! This problem is overcome by using GROUPING SETS, which provide the capability to selectively compute only interesting combinations of groupings instead of the entire CUBE. Note that even though we introduced GROUPING SETS in the context of stored aggregates, it is a normal SQL operator and can be used in any query, just like the CUBE or ROLLUP operators.
For example, suppose we only wanted to calculate sales for the following groupings—(CATEGORY, YEAR), (CATEGORY, STATE), (YEAR, REGION)—and the grand total of sales, denoted by (). We choose not to calculate other combinations such as the detailed sales for each category, year, and state. This is accomplished in the following SQL query using a GROUPING SETS operator.
SELECT p.category as cat, t.year, c.region, c.state as st,
SUM(f.purchase_price) sales
FROM product p, purchases f, time t, customer c
WHERE p.product_id = f.product_id AND
t.time_key = f.time_key AND
c.customer_id = f.customer_id AND
c.country = 'USA' and c.region in ('AmerWest', 'AmerSouth')
GROUP BY GROUPING SETS ((p.category, c.state),
(t.year, c.region),
(p.category, t.year),());
CAT YEAR REGION ST SALES
---- ------ ---------- ---- -----------
ELEC AZ 1198445.49 <- (category, state)
ELEC CA 1392898.24
ELEC TX 1186616.83
HDRW AZ 15466.29
HDRW CA 12912.08
HDRW TX 12739.71
MUSC AZ 12771.05
MUSC CA 14870.83
MUSC TX 14886.50
2003 AmerWest 1317728.13 <- (year, region)
2003 AmerSouth 604485.20
2004 AmerWest 1329635.85
2004 AmerSouth 609757.84
ELEC 2003 1880405.77 <- (category, year)
ELEC 2004 1897554.79
HDRW 2003 20229.97
HDRW 2004 20888.11
MUSC 2003 21577.59
MUSC 2004 20950.79
3861607.02 <- (grand total)Note that ROLLUP is a special case of GROUPING SETS. For example, ROLLUP(CATEGORY, YEAR) is equivalent to GROUPING SETS ((CATEGORY, YEAR),(CATEGORY), ()).
You may specify multiple GROUPING SETS in a query. This offers a concise notation to specify a cross-product of groupings across multiple dimensions. For example, suppose we would like to compute sales for each product category along the (STATE, REGION) columns in the customer dimension and along the (YEAR, QUARTER) columns in the time dimension. Instead of specifying all combinations of groupings involving these four columns, we could simply use the following query. This is known as concatenated grouping sets.
SELECT p.category as cat, t.quarter as quart, t.year,
c.state as st, c.region, SUM(f.purchase_price) sales
FROM purchases f, time t, customer c, product p
WHERE p.product_id = f.product_id AND
t.time_key = f.time_key AND
c.customer_id = f.customer_id AND
c.country = 'USA' and c.region in ('AmerWest', 'AmerSouth')
GROUP BY p.category,
GROUPING SETS (c.state, c.region),
GROUPING SETS (t.quarter, t.year);
CAT QUART YEAR ST REGION SALES
---- ------- ------ ----- ---------- -----------
ELEC 200301 AZ 130219.58 <- (quarter,state)
ELEC 200302 AZ 154613.90
ELEC 200303 AZ 153216.43
....
HDRW 200402 TX 1770.71
HDRW 200403 TX 1504.32
HDRW 200404 TX 1661.02
...
ELEC 200301 AmerWest 296382.05 <- (quarter,region)
ELEC 200302 AmerWest 329691.54
ELEC 200303 AmerWest 338017.87
...
MUSC 200401 AmerSouth 1833.39
MUSC 200402 AmerSouth 1661.02
MUSC 200403 AmerSouth 1817.72
...
ELEC 2003 AZ 596005.79 <- (year, state)
ELEC 2004 AZ 602439.70
...
MUSC 2003 TX 7599.95
MUSC 2004 TX 7286.55
ELEC 2003 AmerWest 1289725.84 <- (year, region)
ELEC 2004 AmerWest 1301617.89
...
MUSC 2004 AmerSouth 7286.55
150 rows selected.The CATEGORY column that is outside the GROUPING SETS is present in all the groupings. Thus, the previous query computes the four groupings: (CATEGORY, QUARTER, STATE), (CATEGORY, QUARTER, REGION), (CATEGORY, YEAR, STATE), and (CATEGORY, YEAR, REGION).
We have seen how CUBE, ROLLUP, and GROUPING SETS operators all compute multiple levels of aggregations in one query. Now the problem is that in order to display the result appropriately for the end user, your application needs to know which rows in the answer correspond to which level. This is where the GROUPING and GROUPING_ID, functions come in handy. The SQL functions, GROUPING and GROUPING_ID provide a mechanism to identify the rows in the answer that correspond to each level of aggregation.
The following query illustrates the behavior of the GROUPING() function.
SELECT t.year, p.category as cat,
SUM(f.purchase_price) sales,
GROUPING(t.year) grp_y, GROUPING(p.category) grp_c
FROM product p, purchases f, time t
WHERE p.product_id = f.product_id AND
t.time_key = f.time_key
GROUP BY ROLLUP (t.year, p.category);
YEAR CAT SALES GRP_Y GRP_C
----- --------- --------------- ----- -----
2003 ELEC 9380600.38 0 0 <- (year,category)
2004 ELEC 9515598.19 0 0
2003 HDRW 105098.69 0 0
2004 HDRW 105130.03 0 0
2003 107026.10 0 0 *
2004 106399.30 0 0
2003 9592725.17 0 1 * <- (year)
2004 9727127.52 0 1
19319852.70 1 1 <- (grand total)
10 rows selected.For each grouping, the function GROUPING(CATEGORY) returns a value 0 if the CATEGORY column is in the group and 1 otherwise. Similarly, GROUPING(YEAR) returns a value 0 if the YEAR column is in the group and 1 otherwise. Thus, each level of aggregation can be identified from the values of the GROUPING function. The group (YEAR, CATEGORY) has grouping function values (0,0); the group (YEAR) has grouping function values (0,1). Note that the grand total row can be easily identified as the row where each grouping function column has the value 1.
The GROUPING function also serves another purpose. In the output of CUBE or ROLLUP, the rows that correspond to higher level of aggregation have value NULL for the columns that have been aggregated away. The GROUPING function can be used to distinguish this NULL from actual NULL values in the data itself. For example, look carefully at the two rows in the preceding output, marked with an asterisk. Both these rows have a value NULL in the TIME_KEY column. The first of these corresponds to products where the value of product category was unavailable (NULL). In the second one, we have aggregated away the category values and hence this row corresponds to aggregation at the year level. The GROUPING function distinguishes these two similar-looking rows. In the first case, the GROUPING(CATEGORY) is 0; in the second, it is 1.
Instead of using GROUPING for each column, you can use GROUPING_ID with all the columns together, as follows:
SELECT t.year, p.category as cat,
SUM(f.purchase_price) sales,
GROUPING_ID(p.category,t.year) gid
FROM product p, purchases f, time t
WHERE p.product_id = f.product_id AND
t.time_key = f.time_key
GROUP BY ROLLUP (t.year, p.category);
YEAR CAT SALES GID
----- --------- --------------- ---------
2003 ELEC 9380600.38 0 <- (year, category)
2004 ELEC 9515598.19 0
2003 HDRW 105098.69 0
2004 HDRW 105130.03 0
2003 107026.10 0
2004 106399.30 0
2003 9592725.17 1 <- (year)
2004 9727127.52 1
19319852.70 3 <- (grand total)
10 rows selected.If you concatenate the outputs of all the individual GROUPING functions, you create a binary number, which represents the complete grouping information for each row. The GROUPING_ID function performs this task and returns the decimal number corresponding to this binary value. Thus, in the previous example, if GROUPING(CATEGORY) is 0 and GROUPING(YEAR) is 1, then GROUPING_ID(CATEGORY, YEAR) is the binary number formed by 01, which is the decimal number 1. For the grand total row, GROUPING(CATEGORY) is 1 and GROUPING(YEAR) is 1; hence, the GROUPING_ID(CATEGORY, YEAR) is the binary number 11, which is the decimal number 3. The GROUPING_ID is thus a much more compact representation than individual GROUPING functions but is not as straightforward to interpret as separate GROUPING functions on each column.
In addition to the built-in aggregate functions, such as SUM or AVG, you can define your own custom aggregate functions, which we will discuss next.
Some applications, usually financial ones, may use proprietary aggregation algorithms that cannot be computed using the built-in SQL aggregate operators. Or the data representation may be complex, involving objects or LOB columns. In such situations, you can define custom aggregate functions, which can be used in SQL queries just like regular aggregates.
User-defined aggregates are part of Oracle’s extensibility framework. To define a user-defined aggregate, you must first define a type that implements the ODCIAggregate interface. You then declare a function that uses this type to perform aggregation. The implementation of the aggregate functions can be in any procedural language, such as C, PL/SQL, or Java.
The ODCIAggregate interface consists of the following functions:
ODCIAggregateInitialize() initializes the aggregate value at the start of processing.
ODCIAggregateIterate() updates the aggregate for new row of data.
ODCIAggregateTerminate() returns the aggregate value and ends processing.
ODCIAggregateMerge() is used to support parallel computation of the aggregation. The aggregate is computed on different pieces of the data and finally the ODCIAggregateMerge() is called to combine the results. The PARALLEL_ENABLE clause must be specified on the aggregate function to enable this.
For instance, suppose you have a proprietary sales forecasting algorithm that takes the sales numbers for the past five years and comes up with an estimate for sales for the next year. You can define a user-defined aggregate for this as follows. The SalesForecastFunction type implements the ODCIAggregate interface. (We omit the implementation here for lack of space. Please see the Appendix for instructions to obtain the full example.) The function SalesForecast() is declared as an aggregate function using the SalesForecastFunction.
CREATE OR REPLACE TYPE SalesForecastFunction AS OBJECT ( data number, STATIC FUNCTION ODCIAggregateInitialize (ctx IN OUT SalesForecastFunction) RETURN number, MEMBER FUNCTION ODCIAggregateIterate (self IN OUT SalesForecastFunction, value IN number) RETURN number, MEMBER FUNCTION ODCIAggregateTerminate (self IN OUT SalesForecastFunction, returnValue OUT number, flags IN number) RETURN number, MEMBER FUNCTION ODCIAggregateMerge (self IN OUT SalesForecastFunction, ctx2 IN OUT SalesForecastFunction) RETURN number ); / CREATE OR REPLACE TYPE BODY SalesForecastFunction IS ... END; / CREATE or REPLACE FUNCTION SalesForecast(x number) RETURN number PARALLEL_ENABLE AGGREGATE USING SalesForecastFunction; /
This function can then be used in a SQL query in place of any aggregate, as follows. You can also use the DISTINCT flag to remove duplicate column values prior to aggregation.
SELECT p.category, SUM(f.purchase_price) sales,
SalesForecast(f.purchase_price) as salesforecast
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.category;
CATE SALES SALESFORECAST
---- ----------- -------------
ELEC 33327213.90 36659935.30
HDRW 2962332.61 3258565.87
MUSC 3223204.06 3545524.47Hint
Before you implement a user-defined aggregate, check if your aggregate can be handled by existing SQL aggregates, since they would give better performance. The CASE function can be used to handle a wide variety of complex computations.
If aggregation were all we needed, life would be simple. However, business intelligence queries usually involve more complex analysis than just aggregation. For example, if you wanted to find the top-selling products or compare sales of one month with the previous one, you will need to use SQL functions for analysis; these are discussed next.
The analytical functions in Oracle provide very powerful SQL constructs to represent many typical decision-support queries. By using the analytical functions in the database, these calculations can take advantage of parallelism and other optimization techniques in the database.
Analytical functions fall into many categories, some of which are:
Ranking functions can be used to answer queries for top-N items, such as: What were the top-10 best-selling products this year? Examples of ranking functions include RANK, DENSE_RANK, and NTILE.
Moving window aggregates can be used to answer queries such as: What were the cumulative sales for Asia for each month this year? These functions calculate quantities, such as cumulative sum or moving average, that involve continuous computations over a period of time.
Reporting aggregates can be used to see the aggregated value side by side with the detailed rows that contributed to it. You would use a reporting aggregate if you wanted to compare sales of each product with the average sales of all products.
Lag and Lead functions can be used to do period-over-period comparisons—for example, comparing sales of one year to the previous year.
We will now look at these SQL functions in more detail with some examples.
Ranking functions allow you to answer queries such as: Who are my top 15 percent customers? or What were my worst- or best-selling products? Take, for example, that we are trying to streamline our product line and would like to take the 10 worst-selling products off the market at the end of the year. To answer this question, we must first compute the sales for each product and order the products according to their sales (least sales first) and finally pick the first 10.
The following SQL statement identifies the worst-selling 10 products using the RANK function. The RANK function assigns ranks from 1 to N, skipping ranks in case of ties. Thus, if there were two products with the same sales with rank 3, then the next rank would be 5.
SELECT *
FROM
(SELECT p.product_id p_id, SUM(f.purchase_price) as sales,
RANK() OVER (ORDER BY SUM(f.purchase_price)) as rank
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.product_id)
WHERE rank <= 10;
P_ID SALES RANK
-------- ---------- ----------
SP1247 7082.84 1
SP1264 7145.52 2
SP1220 7223.87 3 <- tie for rank 3
SP1260 7223.87 3
SP1224 7239.54 5
SP1245 7302.22 6
SP1262 7333.56 7
SP1238 7364.90 8
SP1256 7380.57 9
SP1243 7474.59 10
SP1257 7474.59 10
11 rows selected.This query has two parts—an inner subquery ranks the products by their sales and the outer query selects the rows corresponding to the first 10 ranks. Let us concentrate on the inner subquery for the moment. If you ignore the RANK function, this subquery simply performs the familiar aggregation SUM(f.purchase_price) to determine the total sales for each product. The RANK function then ranks the result according to the ordering criteria SUM(f.purchase_price) (i.e., the sales for that product).
If, instead of the worst-selling products, you wanted to determine the best-selling products, you simply need to change the ORDER BY clause from the default (ascending) to descending using the DESC keyword. However, you need to be aware of a small nuance due to NULL values. In the SQL ORDER BY clause, you can specify whether NULL values should be ordered before (FIRST) or after (LAST) any non-null values. NULLS LAST is the default for ascending order and NULLS FIRST for descending order. Obviously, in our case, we don’t want products with NULL sales (perhaps they were damaged and had to be written off) to appear first in the list, so we must specify NULLS LAST. The resulting SQL is as follows:
SELECT p.product_id p_id, SUM(f.purchase_price) as sales,
RANK() OVER (ORDER BY SUM(f.purchase_price)
DESC NULLS LAST) as rank
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.product_id;
P_ID SALES RANK
-------- --------- -------
SP1052 675785.37 1
SP1056 669445.92 2
SP1036 668178.03 3
SP1040 665642.25 4
SP1060 655499.13 5
...
SP1300 56.02 164
SP1255 165 <- nulls lastA variant of RANK is the DENSE_RANK function that assigns contiguous ranks despite ties. For instance, if two products had the same rank, 3, DENSE_RANK would assign the next rank to be 4. Thus, the DENSE_RANK function does not skip ranks, whereas the RANK function does. The following query illustrates the difference between RANK and DENSE_RANK. We could have decided to use one or the other depending on the business policy.
SELECT p.product_id p_id, SUM(f.purchase_price) as sales,
RANK() OVER (ORDER BY SUM(f.purchase_price)) as rank,
DENSE_RANK() OVER (ORDER BY SUM(f.purchase_price)) as drank
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.product_id;
P_ID SALES RANK DRANK
-------- ---------- ---------- -----------
SP1247 7082.84 1 1
SP1264 7145.52 2 2
SP1220 7223.87 3 3 <- tie for rank 3
SP1260 7223.87 3 3
SP1224 7239.54 5 4 <- note the difference
SP1245 7302.22 6 5
...All analytical functions follow a similar syntax, consisting of the OVER() clause, which can include an ORDER BY condition. To understand analytic functions better, it helps to remember that these functions are applied after the WHERE, GROUP BY, and HAVING clauses of the query have been computed and before ORDER BY and SQL Model clauses (explained in section 6.4.5). Consequently, any aggregate functions such as SUM(f.purchase_price), computed by the query, are available as ordering criteria to the analytical function.
Now that we have computed the worst-selling products overall, we would like to identify the worst-selling products in each product category. This can be achieved by making a slight change to the OVER() clause in the earlier example, to include the PARTITION BY clause, as follows:
SELECT p.category, p.product_id, SUM(f.purchase_price) as sales,
RANK() OVER (PARTITION BY p.category
ORDER BY SUM(f.purchase_price)) as rank
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.category, p.product_id;
CATE PRODUCT_ SALES RANK
---- -------- ---------- -----------
ELEC SP1078 11695.32 1
ELEC SP1065 11820.27 2
ELEC SP1063 11823.29 3
ELEC SP1066 11845.26 4
...
HDRW SP1220 7223.87 1
HDRW SP1224 7239.54 2
HDRW SP1238 7364.90 3
...
MUSC SP1247 7082.84 1
MUSC SP1264 7145.52 2
MUSC SP1260 7223.87 3
...
164 rows selected.In this example, the query first computes the sales for each product. The PARTITION BY clause then divides the result into groups according to the CATEGORY column. Note that we must select category in the GROUP BY clause so that it is available to the PARTITION BY clause. Finally, for each category, the RANK function assigns a rank to the products within that category, ordered according to their sales. The rank is reset to 1 within each product category. Figure 6.3 illustrates the computation of RANK with the PARTITION BY clause.

You can use the RANK function multiple times using different PARTITION and ORDER BY expressions in the same query. Note that the PARTITION BY clause used by analytical functions is completely unrelated to partitioning for tables, discussed in Chapter 4.
In the previous section, we computed the worst-selling products, however, we did not get a sense of the relative standing of a product with respect to all of the products. For instance, if we had 1,000 products, then a rank of 10 would be pretty close to the top of the worst-selling list. However, if we only had 15 products, then a rank of 10 is not that bad—in fact, if we removed the 10 worst-selling products from our store, we would have eliminated 75 percent of our products, which may not be what we set out to do! The analytical functions PERCENT_RANK, CUME_DIST, and NTILE give us a way to interpret where any given product stands in comparison to the entire set. You can think of these functions as relative ranking functions whereas RANK and DENSE_RANK are absolute ranking functions. Relative ranking functions help us understand the placement of values in the distribution of data, so they are also known as distribution functions.
Suppose we wanted to answer the question: Show me the 25 percent worst-selling products with sales less than $7,500? To answer this question we need to compute the NTILE(4) of sales within each product category. The NTILE(N) function orders the data using a specified criterion and then divides the result into N buckets, assigning the bucket number to all rows in each bucket. Thus, NTILE(4) assigns a number (also called the quartile) between 1 and 4 to each row. You can use quartile to determine whether a value falls within the ranges of 0–25 percent, 25–50 percent, 50–75 percent or 75–100 percent with respect to all values in the set. You may be familiar with the term percentile used to compare test scores for school admissions. This is a special case of the NTILE function where N is 100, so if a student is in the 98 percentile, then only 2 percent of students performed better than this student.
The following query answers the business question we posed earlier. The 25 percent worst-selling products correspond to the first quartile—that is, those with an NTILE value of 1 (marked with an asterisk in the following output). Note that the condition sales <7,500 specified in the HAVING clause will be evaluated before the analytical function.
SELECT p.category, p.product_id, SUM(f.purchase_price) as sales,
NTILE(4) OVER (PARTITION BY p.category
ORDER BY SUM(f.purchase_price)) as quartile
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.category, p.product_id
HAVING SUM(f.purchase_price) < 7500;
CATE PRODUCT_ SALES QUARTILE
---- -------- ---------- -----------
HDRW SP1220 7223.87 1 *
HDRW SP1224 7239.54 2
HDRW SP1238 7364.90 3
MUSC SP1247 7082.84 1 *
MUSC SP1264 7145.52 1 *
MUSC SP1260 7223.87 2
MUSC SP1245 7302.22 2
MUSC SP1262 7333.56 3
MUSC SP1256 7380.57 3
MUSC SP1243 7474.59 4
MUSC SP1257 7474.59 4The buckets generated by the NTILE(4) function all have almost the same number of rows: The function allocates rows so the count per bucket differs by no more than one. However, the range between the lowest and highest value in each bucket may differ. This is called an equiheight histogram.
Note that with NTILE(4), you only got a coarse distribution of the product, such as whether it was in the top 25 percent, the bottom 50 percent, and so on. Instead, if you wanted to see the finer-grained ranking of each product relative to the whole set, you could use a high number, such as 1,000, as the argument to NTILE or use the CUME_DIST or PERCENT_RANK functions.
The CUME_DIST function computes the cumulative distribution of product sales, which answers the question: What percentage of products have sales less than a given product? For instance, in the following example, 37.5 percent of products have sales value less than or equal to SP1260 in the music category. PERCENT_RANK answers the question: What percentage of products rank lower than a given product based on their total sales? For instance, in the following example, 28.5 percent of products rank lower than SP1260.
SELECT p.category, p.product_id, SUM(f.purchase_price) as sales,
CUME_DIST() OVER (PARTITION BY p.category
ORDER BY SUM(f.purchase_price)) as cume_dist,
PERCENT_RANK() OVER (PARTITION BY p.category
ORDER BY SUM(f.purchase_price)) as pct_rank
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.category, p.product_id
HAVING SUM(f.purchase_price) < 7500 ;
CATE PRODUCT_ SALES CUME_DIST PCT_RANK
---- -------- ---------- ---------- -----------
HDRW SP1220 7223.87 .333333333 0
HDRW SP1224 7239.54 .666666667 .5
HDRW SP1238 7364.90 1 1
MUSC SP1247 7082.84 .125 0
MUSC SP1264 7145.52 .25 .142857143
MUSC SP1260 7223.87 .375 .285714286 *
MUSC SP1245 7302.22 .5 .428571429
MUSC SP1262 7333.56 .625 .571428571
MUSC SP1256 7380.57 .75 .714285714
MUSC SP1243 7474.59 1 .857142857
MUSC SP1257 7474.59 1 .857142857Both these functions are calculated with respect to all the elements in the set and have a value between 0 and 1. To convert to a percentage, you simply need to multiply it by 100. One characteristic of PERCENT_RANK is that the first value will always be 0 (since there are no ranks lower than the first rank!), and the last value will always be less than or equal to 1. On the other hand, CUME_DIST will always have the first entry greater than 0 and the last entry equal to 1. Note that in case of a tie (i.e., when two rows have the same value of sales), they will get the identical value of CUME_DIST and PCT_RANK—for example, the last two rows, SP1243 and SP1257 in the preceding output. If you are interested, PERCENT_RANK of an element with rank R is computed as (R–1) / (Total Ranks–1) and CUME_DIST of an element with value V is computed as (Number of values before V in the given order) / (Total number of values).
Note that the examples in this section use the PARTITION BY clause, which means that the analytical function would be applied to each partition, or in this case each product category.
Other functions in the RANK family are FIRST_VALUE, LAST_VALUE, and ROW_NUMBER. All of these provide different ways to choose data from ordered groups.
We have seen how we can do comparative analysis using ranking functions. Another common form of comparative analysis is frequency distribution (i.e., to classify items into different categories based on some quantity and then count how many would fall into each category). For instance, we would like to classify products that have sales between $0 and $100,000 into five equal-sized buckets, as shown in Figure 6.4.
This type of classification called as an equiwidth histogram, because each bucket has roughly the same range but can have differing number of rows. The WIDTH_BUCKET function can be used to generate this classification, as shown in the following example. This function takes a range (in this example, 0–10,000) and number of buckets (in this example, four) and assigns a bucket from 1 to 4 to each value. Any values lower than the lower bound will go into an underflow bucket, numbered 0, and any values higher than the upper bound go into an overflow bucket, numbered 5. To get the frequency distribution, we have an outer query that counts all values with a given bucket number using a GROUP BY on the width_bucket value. We also show the minimum and maximum actual sales value, in each bucket.
SELECT width_bucket, min(sales) , max(sales), COUNT(*)
FROM
(SELECT p.product_id, SUM(f.purchase_price) as sales,
WIDTH_BUCKET(SUM(f.purchase_price), 0, 100000, 4)
as width_bucket
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.product_id)
GROUP BY width_bucket;
WIDTH_BUCKET MIN(SALES) MAX(SALES) COUNT(*)
------------ ---------- ---------- ----------
1 56.02 24854.91 95
2 25333.81 37236.57 30
3 73531.50 4783.10 4
4 75252.45 83387.85 9
5 573086.28 675785.37 26
1 <- no salesFrom this analysis, we can tell that most of our products (95) had total sales less than $25,000. We also see that we have a significant number of products (26) that had total sales over $100,000. Note also that products with NULL sales value do not get counted in this analysis and get a bucket number NULL.
This type of analysis can also be used to concisely report statistics such as customer demographics or income-level surveys. The WIDTH_BUCKET function only allows you to create buckets of equal sizes. If you need a more customized distribution of buckets, you should take a look at the CASE expression discussed in section 6.4.4.
Period-over-period comparisons, such as comparing sales to those a year ago, are often part of business reporting. The two simple analytic functions, LAG and LEAD, allow you to perform such comparisons. For instance, suppose we need to compare monthly sales to the sales six months ago. In this case we would use the LAG function, as shown in the following query:
SELECT t.month, SUM(f.purchase_price) as monthly_sales,
LAG(SUM(f.purchase_price),6)
OVER (ORDER BY t.month) as sales_6_months_ago
FROM purchases f, time t
WHERE f.time_key = t.time_key
GROUP BY t.year, t.month;
MONTH MONTHLY_SALES SALES_6_MONTHS_AGO
---------- ------------- ------------------
200301 747376.33
200302 677746.09
...
200306 847609.93
200307 905908.19 747376.33 <- LAG(sales,6) = 200301
200308 762608.21 677746.09
...
200401 883351.03 905908.19
200402 841068.94 762608.21
200403 779704.31 745532.66
200404 833190.58 886877.84
200405 906714.58 733383.72
200406 736279.04 754124.30
200407 758762.01 883351.03 <- LAG(sales,6) = 200401
200408 900208.87 841068.94
200409 732996.94 779704.31
...For each row returned by a query, LAG and LEAD functions provide the values at a row at a known offset from the current row. In this example, since each row corresponds to one month, the term 6 months ago would translate to a LAG offset of 6. For example, LAG(sales,6) for July 2004 is the sales for January 2004. Similarly, monthly sales last quarter would translate to LAG(sales,3) and monthly sales for the following year would translate to LEAD(sales, 12).
Note that if the lagging (or leading) row specified by the function is not present, LAG (or LEAD) returns the NULL value or a default you specify. In the EASYDW data warehouse, we keep data for two years, 2003 and 2004, and hence LAG(sales,6) for 200301 through 200306 will have a value of NULL, because data for six months prior is unavailable.
These functions are extremely simple to use and very powerful. Without these functions, such apparently simple computations would require a join of a table to itself, possibly multiple times, or a number of subqueries, which would make the query extremely inefficient.
One of the most powerful tools provided by the analytical functions is to aggregate over a moving window. These functions allow you to answer questions such as: What are the cumulative sales numbers for each month this year? Window aggregate functions let you compute a function such as SUM over a specified window of rows relative to the current row.
The following example calculates the monthly cumulative sales for the year 2003. The query first computes the SUM(purchase_price) (i.e., sales for each month in 2003). Then, for each month, it sums up the sales for all months up to and including the current month. This is indicated by the expression SUM(SUM(f.purchase_price)). Note that the ORDER BY clause indicates how to order the rows to determine the window; in this example the window is determined by the order of the months. The ROWS UNBOUNDED PRECEDING clause specifies that the window is all rows before and including the current row. A window specified using number of rows preceding or following the current row is known as a physical window.
SELECT t.month, SUM(f.purchase_price) as sales,
SUM(SUM(f.purchase_price))
OVER (ORDER BY t.month ROWS UNBOUNDED PRECEDING)
as cumulative_sales
FROM purchases f, time t
WHERE f.time_key = t.time_key and t.year = 2003
GROUP BY t.month;
MONTH SALES CUMULATIVE_SALES
------- --------- ----------------
200301 747376.33 747376.33
200302 678003.47 1425379.80
200303 899322.05 2324701.85
200304 871402.28 3196104.13
200305 758742.80 3954846.93
200306 848080.03 4802926.96
200307 906190.25 5709117.21
200308 762764.91 6471882.12
200309 745689.36 7217571.48
200310 887175.57 8104747.05
200311 733383.72 8838130.77
200312 754594.40 9592725.17Another common example of a moving window function is a moving average. In the next example, we are computing, for each month, the moving average of the sales for that month and the two months preceding it. This is specified by the ROWS 2 PRECEDING clause.
SELECT t.month, SUM(f.purchase_price) as sales,
AVG(SUM(f.purchase_price))
OVER (ORDER BY t.month ROWS 2 PRECEDING) as mov_avg
FROM purchases f, time t
WHERE f.time_key = t.time_key and t.year = 2003
GROUP BY t.month;
MONTH SALES MOV_AVG
------- --------- ----------
200301 747376.33 747376.330
200302 678003.47 712689.900
200303 899322.05 774900.617
200304 871402.28 816242.600
200305 758742.80 843155.710
200306 848080.03 826075.037
200307 906190.25 837671.027
200308 762764.91 839011.730
200309 745689.36 804881.507
200310 887175.57 798543.280
200311 733383.72 788749.550
200312 754594.40 791717.897If, instead, we wanted the window to include the current month and two months following it, the window expression would simply change to ROWS 2 FOLLOWING.
One of the most common moving window analyses is a time-series analysis, where the ordering expression is a date. For this special case, you can specify the window using logical entities such as INTERVAL DAY, MONTH, or YEAR. Such window expressions are called logical windows and are only allowed when the ORDER BY expression has a numeric, date, or interval data types. For instance, suppose you wanted to know the daily sales totaled over a moving five-day window including two days before and two days after the current date. The SQL to answer this query is as follows. The window is specified using a RANGE BETWEEN clause and INTERVAL DAY expressions for the upper and lower bounds.
SELECT t.time_key, SUM(f.purchase_price) as sales,
SUM(SUM(f.purchase_price)) OVER (ORDER BY t.time_key
RANGE BETWEEN INTERVAL '2' DAY PRECEDING AND
INTERVAL '2' DAY FOLLOWING) as sales_5_day
FROM purchases f, time t
WHERE f.time_key = t.time_key and t.year = 2003
GROUP BY t.time_key
HAVING SUM(f.purchase_price) < 25000;
TIME_KEY SALES SALES_5_DAY
--------- ---------- -----------
01-JAN-03 23345.03 71195.91
02-JAN-03 24572.88 94636.72
03-JAN-03 23278 119209.60 ---
04-JAN-03 23440.81 119142.57 |
05-JAN-03 24572.88 118010.50 <- current row |logical window
06-JAN-03 23278 1193058.00 |
07-JAN-03 23440.81 119142.50 ---
08-JAN-03 24572.88 118010.50
09-JAN-03 23278 119305.38
10-JAN-03 23440.81 119142.57
...
27-JAN-03 23278 72423.76
29-JAN-03 24572.88 71128.88 ---
30-JAN-03 23278 69999.47 <- current row | logical window
01-FEB-03 22148.59 70191.14 ---
03-FEB-03 24764.55 68977.70
...
152 rows selected.In this example, the computation for the date 5-Jan-03 consists of sales from five consecutive dates from 3-Jan-03 through 7-Jan-03. However, the calculation for 30-Jan-03 consists only of three dates: 29-Jan-03, 30-Jan-03, and 01-Feb-03, because dates 28-Jan-03 and 31-Jan-03 are missing. Instead, if this were a physical window, the window would have included 27-Jan-03 and 01-Feb-03, which is not really what we want. This highlights an important issue with using physical windows, which is that a physical window is good only if you have dense data (i.e., no gaps in the ordering values). Fortunately, the Oracle Database 10g provides a solution to this problem, which is what we will discuss next.
A logical window can only be used for a restricted set of data types. A physical window is often the most convenient for time-series calculations, such as comparing year over year or quarterly sales. However, as mentioned earlier if the data is not dense we cannot use a physical window for analysis. For instance, the following query shows sales for each product by month. In this example, a product, CD LX1 was not sold in February 2003, and so the result would be missing a row for 200302, CD LX1. Therefore, a physical window expression such as a three-month moving average would give incorrect results.
SELECT t.month, p.product_name, SUM(f.purchase_price) as sales
FROM purchases f, time t, product p
WHERE f.time_key = t.time_key
AND f.product_id = p.product_id
GROUP BY p.product_name, t.month;
MONTH PRODUCT_NAME SALES
---------- --------------- ----------
200301 CD LX1 485.77
<- missing 200302
200303 CD LX1 470.10
200304 CD LX1 313.40
200305 CD LX1 313.40
200306 CD LX1 313.40
200307 CD LX1 470.10
200308 CD LX1 501.44
200309 CD LX1 470.10
200310 CD LX1 250.72
200311 CD LX1 56.70
...
3417 rows selected.Would it not be easier if, instead of having no row, we had a “dummy” row for 200302, CD LX1 with sales of 0? We could then simply use a physical window, such as ROWS PRECEDING 1, for the previous month or ROWS FOLLOWING 1 for the next month. Oracle Database 10g introduced a new operation, known as a PARTITION OUTER JOIN, which can be used to convert sparse data into dense data, thus enabling the use of physical windows even with sparse data. Before we discuss, let us briefly review what an outer join is.
In this chapter, we have seen several queries where we calculate the total sales by product. The joins used in these examples were inner joins, where rows appear in the result only if the joining column value is present in both tables. However, if we also wanted to see those products that did not sell at all, we would need to use an outer join. These products would have PRODUCT_ID values that appear in the PRODUCT table but not in the PURCHASES table. For such rows, a NULL value is output instead of columns in the PURCHASES table. The SQL statement for this query is as follows. As you can see, this query has two rows marked with an asterisk, corresponding to products that did not sell, which would not be in the inner join. These extra rows are called the antijoin.
SELECT p.product_name, SUM(f.purchase_price) as sales FROM purchases f RIGHT OUTER JOIN product p ON (f.product_id = p.product_id) GROUP BY p.product_name; PRODUCT_NAME SALES ------------------------------ ----------- APS Camera 17064.33 CD LX1 7772.32 ... XYZ 56.02 Tents Half Dome 1999 * Tents Half Dome 2000 *
Note that this query uses a RIGHT OUTER JOIN clause, which is the ANSI standard syntax for a join. Here the join is represented in the FROM clause rather than in the WHERE clause, which is an Oracle specific syntax. An outer join can be a LEFT OUTER JOIN or RIGHT OUTER JOIN. The RIGHT OUTER JOIN between PURCHASES and PRODUCT gave us rows from the PRODUCTS (right) table, which had no corresponding rows in the PURCHASES (left) table. If we used a LEFT OUTER JOIN in the previous example, we would get those rows in the PURCHASES (left) table, for which PRODUCT_ID was not in the PRODUCTS (right) table. For instance, these may be transactions for discontinued or special products or maybe where the actual products sold was not known.
Now that we know what an outer join is, we can see how the partition outer join is used.
Recall the problem we are trying to solve: We would like to find sales by product and month for each product; if there were no sales for that product in some month, we would like to generate a row with sales of 0 for that product and month. This is done by the following SQL statement, which uses the PARTITION OUTER JOIN. The PARTITION OUTER JOIN is an extension of the outer join where the outer join is done against each partition identified by a PARTITION BY clause. (Note that we are talking about the PARTITION BY clause shown in Figure 6.5 and not physical data partitioning.) We will explain this SQL in more detail in a moment, but for now notice that rows marked with an asterisk indicate that we have filled in the missing rows with a sales value of 0.
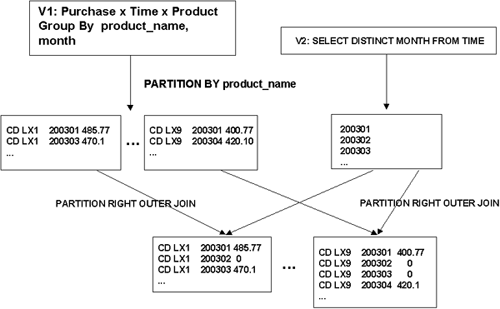
SELECT v2.month, v1.product_name, nvl(v1.sales,0) FROM (SELECT t.month, p.product_name, SUM(f.purchase_price) as sales FROM purchases f, time t, product p WHERE f.time_key = t.time_key AND f.product_id = p.product_id GROUP BY p.product_name, t.month) v1 PARTITION BY (product_name) RIGHT OUTER JOIN (SELECT DISTINCT t.month FROM time t) v2 ON v1.month = v2.month; MONTH PRODUCT_NAME NVL(V1.SALES,0) ---------- ------------------------------ ---------------- 200301 CD LX1 485.77 200302 CD LX1 0 * 200303 CD LX1 470.10 200304 CD LX1 313.40 200305 CD LX1 313.40 200306 CD LX1 313.40 200307 CD LX1 470.10 200308 CD LX1 501.44 200309 CD LX1 470.10 200310 CD LX1 250.72 200311 CD LX1 156.70 200312 CD LX1 0 * ... 3816 rows selected.
Now let us try to understand this query. The query has two views in the FROM clause, v1 and v2. The first view, v1, is simply the query for sales by product and month we saw earlier. The second view, v2, obtains the distinct values of month in the table, TIME. The PARTITION BY clause on PRODUCT_NAME will take the result of v1 and divide it into partitions one for each product. The query then joins each such partition of v1 to the view v2 using a RIGHT OUTER JOIN. For each product, the antijoin portion will correspond to rows (months) from v2 that do not join with any rows in the partition of v1 for that product. This exactly corresponds to the months where there were no sales for the particular product! The expression nvl(sales,0) will put a value of 0, rather than NULL for such rows. And, Voilà—we have converted the sparse data into a dense form. Figure 6.5 can help visualize this PARTITION OUTER JOIN operation.
If you are wondering why we need the PARTITION OUTER JOIN and cannot do this with just an OUTER JOIN, remember that we would be joining v1 and v2 on month. As long as every value of month in v2 appears in v1 for some product, a simple outer join will be same as an inner join and will leave the result of v1 unchanged. If some value of month does not appear in v1 at all, it means that in this month we did not sell any products at all, which is not what we were looking for in this example! The interested reader may find it to be an instructive exercise to use outer joins to find those months where we did not sell any products and those products that did not sell in any month. Hint: The query is very similar to the example given here but you do not need the PARTITION OUTER join to do this.
Continuing on with our product analysis, suppose we want to answer the question: What is the percentage contribution of each product category to the overall sales? You can visualize this result as a pie chart, with each slice being sales of one product category. To generate this pie chart, what we need to compute is the ratio of each product category’s sales to the total sales of all categories combined.
You will find that with conventional SQL it is very cumbersome to do this type of calculation. This is because when you ask for a simple aggregate such as SUM or MAX in SQL, you lose the individual rows contributing to the aggregate. Only one row, which is the aggregate, is returned. So you will need to do two queries: one to get the sales for each individual category and another to compute the total sales of all categories and then calculate the ratio within the application outside of SQL. Reporting aggregates solve this problem by reporting the computed aggregate value side by side with all the detail rows that contributed to it.
The following query uses a reporting aggregate to answer our question. In this example, the aggregate sales is a regular aggregate, whereas sales_total is a reporting aggregate that computes the total sales for all products. You can identify a reporting aggregate by its use of an OVER() clause. Notice how the same value 19312425.1 appears in all the rows. To generate the pie chart we simply use the ratio between sales and total_sales for each category, computed as ratio_sales in this example.
SELECT category, SUM(f.purchase_price) as sales,
SUM(SUM(f.purchase_price)) OVER () as sales_total,
SUM(f.purchase_price)/SUM(SUM(f.purchase_price)) OVER()
as ratio_sales
FROM product p, purchases f
WHERE f.product_id = p.product_id
GROUP BY p.category;
CATE SALES SALES_TOTAL RATIO_SALES
---- ---------- --------------- ------------
ELEC 18896198.6 19312425.1 .978447733
HDRW 210228.72 19312425.1 .010885672
MUSC 205997.82 19312425.1 .010666595In fact, there is a built-in reporting aggregate called RATIO_TO_ REPORT, which does this particular computation automatically. Thus, we could have written the query as follows to get the same ratio as the previous query:
SELECT category, RATIO_TO_REPORT(SUM(f.purchase_price))
OVER () as ratio_sales
FROM product p, purchases f
WHERE f.product_id = p.product_id
GROUP BY p.category;
CATE RATIO_SALES
---- ------------
ELEC .978447733
HDRW .010885672
MUSC .010666595The preceding examples used an empty OVER() clause, which simply means that the reporting aggregate is being computed without any PARTITION BY clause (i.e., over all rows). However, as with other analytical functions, you can use the PARTITION BY clauses to divide the data into partitions before computing the reporting aggregate. For example, if we wanted to see the products whose sales are below the average sales in their category, we would use the following query:
SELECT *
FROM (SELECT p.category, p.product_id prod_id,
SUM(f.purchase_price) prod_sales,
AVG(SUM(f.purchase_price))
OVER (PARTITION BY p.category) category_avg
FROM product p, purchases f
WHERE f.product_id = p.product_id
GROUP BY p.category, p.product_id)
WHERE prod_sales < category_avg;
CATE PROD_ID PROD_SALES CATEGORY_AVG
---- -------- ---------- ------------
ELEC SP1000 34085.61 170237.033
ELEC SP1001 17064.33 170237.033
ELEC SP1010 22699.86 170237.033
...
HDRW SP1217 7740.98 7786.24889
HDRW SP1220 7223.87 7786.24889
HDRW SP1221 7552.94 7786.24889
...
MUSC SP1242 7772.32 7922.99308
MUSC SP1243 7474.59 7922.99308
MUSC SP1244 7740.98 7922.99308
...In this example, the inner query computes the sales of each product as a regular aggregate and the average sales for each category as a reporting aggregate using the PARTITION BY category. The outer query then simply selects the products with sales below the category average.
While we are streamlining our product portfolio, we have decided to revamp our pricing model as well and to do so we must determine how prices affect our sales. For instance, we would like to find the number of purchases made for the costliest and cheapest products in each category. This involves first ranking all products, by their selling price, picking the cheapest and costliest products and then aggregating using COUNT(*) all the purchases made for these products. The FIRST and LAST aggregation functions allow you to do such operations in a concise manner, as illustrated in the following query. In our example, we find that total sales for the costliest items are about the same as for the cheaper ones.
SELECT p.category cat, SUM(f.purchase_price) total_sales,
MIN(p.sell_price) cheap_prod,
COUNT(*) KEEP (DENSE_RANK FIRST
ORDER BY p.sell_price) cheap_sales,
MAX(p.sell_price) costly_prod,
COUNT(*) KEEP (DENSE_RANK LAST
ORDER BY p.sell_price) costly_sales
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.category;
CAT TOTAL_SALES CHEAP_PROD CHEAP_SALES COSTLY_PROD COSTLY_SALES
---- ----------- ---------- ----------- ----------- ------------
ELEC 18896198.60 24.99 13888 1267.89 12770
HDRW 210228.72 15.67 13416 15.67 13416
MUSC 205997.82 15.67 13620 15.67 13620Note that the ranking of an item as FIRST or LAST is done using the DENSE_RANK function we discussed earlier.
A common use of FIRST and LAST is to return the value of a column other than the column used to order the group. For instance, you can order by column A yet return the MIN(column B). This approach increases query performance by avoiding subqueries or other processing that is required without FIRST and LAST. The FIRST and LAST functions can also be used as reporting aggregates.
Previously, we mentioned the CUME_DIST function, which can be used to determine the cumulative distribution of a quantity, also known as its percentile. Given this distribution, an inverse percentile function looks up the data value that corresponds to a given percentile value in an ordered set of rows. You can use this to ask the question—what product falls into the 50th percentile?
To illustrate this function, we will use the output of the following query, which we saw previously. Recall that the rows are ordered by SUM(purchase_price) and each row is assigned a value between 0 and 1.
SELECT p.category, p.product_id, SUM(f.purchase_price) as sales,
CUME_DIST() over (PARTITION BY p.category
ORDER BY SUM(f.purchase_price))
as cume_dist
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.category, p.product_id
HAVING SUM(f.purchase_price) < 7500 ;
CATE PRODUCT_ SALES CUME_DIST
---- -------- ----------- ----------
HDRW SP1220 7223.87 .333333333
HDRW SP1224 7239.54 .666666667 <- PERCENTILE_DISC(0.5)
HDRW SP1238 7364.90 1
MUSC SP1247 7082.84 .125
MUSC SP1264 7145.52 .25
MUSC SP1260 7223.87 .375
MUSC SP1245 7302.22 .5 <- PERCENTILE_DISC(0.5)
MUSC SP1262 7333.56 .625
MUSC SP1256 7380.57 .75
MUSC SP1243 7474.59 1
MUSC SP1257 7474.59 1There are two flavors of inverse percentile. PERCENTILE_DISC assumes that the sales values are discrete and returns the value that corresponds to the nearest CUME_DIST value greater than the percentile specified. PERCENTILE_CONT assumes that the values are continuous and returns the interpolated value corresponding to the given percentile. In the previous example, the sales value that corresponds to PERCENTILE_DISC(0.5) for the HDRW category is 7239.54 and for MUSC category it is 7302.22.
The following example illustrates the use of the inverse percentile functions. This example returns the median sales amount for products within each category. Note that PERCENTILE_DISC and PERCENTILE_CONT functions always return a single data value. An ORDER BY criterion must be specified and must consist of a single expression.
SELECT p.category, p.product_id, SUM(f.purchase_price) as sales,
PERCENTILE_DISC(0.5) WITHIN GROUP
(ORDER BY SUM(f.purchase_price))
OVER (PARTITION BY p.category) as pct_disc,
PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY SUM(f.purchase_price))
OVER (PARTITION BY p.category) as pct_cont
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.category, p.product_id
HAVING SUM(f.purchase_price) < 7500;
CATE PRODUCT_ SALES PCT_DISC PCT_CONT
---- -------- ---------- ---------- ----------
HDRW SP1220 7223.87 7239.54 7239.54
HDRW SP1224 7239.54 7239.54 7239.54
HDRW SP1238 7364.90 7239.54 7239.54
MUSC SP1247 7082.84 7302.22 7317.89
MUSC SP1264 7145.52 7302.22 7317.89
MUSC SP1260 7223.87 7302.22 7317.89
MUSC SP1245 7302.22 7302.22 7317.89
MUSC SP1262 7333.56 7302.22 7317.89
MUSC SP1256 7380.57 7302.22 7317.89
MUSC SP1243 7474.59 7302.22 7317.89
MUSC SP1257 7474.59 7302.22 7317.89In this example, PERCENTILE_DISC and PERCENTILE_CONT have been used as reporting aggregates.
Business intelligence often involves what-if analysis, where you make a hypothetical change to the business and analyze its impact. For instance, we are introducing a new product in the HDRW category and have a projected sales figure of $7,600 based on market surveys. Based on this information, we would like to know how this product would rank among other products in its category. Oracle provides a family of hypothetical rank and distribution functions for this purpose. With these functions, you can ask to compute the RANK, PERCENT_RANK, or CUME_DIST of a given value, as if it were hypothetically inserted into a set of values.
To illustrate this, we will use the following query, showing the sales for different products in the HDRW category in ascending order of sales and their respective ranks.
SELECT p.product_id, SUM(f.purchase_price) sales,
RANK() OVER (ORDER BY SUM(f.purchase_price)) as rank
FROM purchases f, product p
WHERE f.product_id = p.product_id and p.category = 'HDRW'
GROUP BY p.product_id;
PRODUCT_ SALES RANK
-------- ---------- ----------
SP1220 7223.87 1
SP1224 7239.54 2
SP1238 7364.90 3
SP1221 7552.94 4
SP1222 7568.61 5
SP1237 7568.61 5
SP1239 7568.61 5
<- Insert hypothetical value 7600.00
SP1230 7646.96 8
SP1235 7725.31 9
SP1217 7740.98 10
SP1223 7787.99 11
SP1233 7787.99 11
SP1218 7819.33 13
...Now, suppose we want to find the hypothetical rank of a product with sales of $7,600. From the previous output, we can see that this value, if inserted into the data would get a rank of 8. The following query asks for the hypothetical rank:
SELECT RANK(7600.00)
WITHIN GROUP (ORDER BY SUM(f.purchase_price)) as hrank
FROM purchases f, product p
WHERE f.product_id = p.product_id and p.category = 'HDRW'
GROUP BY p.product_id;
HRANK
----------
8Hypothetical rank functions take an ordering condition and a constant data value to be inserted into the ordered set. The way to recognize a hypothetical rank function in a query is the WITHIN GROUP clause and a constant expression within the RANK function. Similarly, you can use CUME_DIST or PERCENT_RANK to find the distribution or percentile of a quantity inserted hypothetically into a result.
Statistical analysis is a key tool for business intelligence. Business decisions may often be influenced by relationships between various quantities. For instance, earlier we wanted to know if the price of an item influences how many items are sold. A common technique used in such analyses is linear regression analysis, which is a statistical technique used to quantify how one quantity affects or determines the value of another. The idea is to fit the data for two quantities along a straight line, as accurately as possible. This line is called the regression line. Some of the quantities of interest are the slope of the line, y-intercept of the line and the coefficient of determination (which is how closely the line fits the points). Oracle provides various diagnostic functions commonly used for this analysis, such as standard error and regression sum of squares.
The linear regression functions are all computed simultaneously in a single pass through the data. They can be treated as regular aggregate functions or reporting aggregate functions.
The following example illustrates the use of some of these functions. Here, we are analyzing, for each manufacturer, whether the price of a product has a relationship to the number of items sold. To do so we compute the slope, intercept, and coefficient of determination of the regression line for the quantities sell_price and total_purchases.
SELECT manufacturer,
REGR_SLOPE(sell_price, total_purchases) slope,
REGR_INTERCEPT(sell_price, total_purchases) intercept,
REGR_R2(sell_price, total_purchases) coeff_determination
FROM
(
SELECT p.manufacturer , p.product_id,
f.purchase_price sell_price,
count(f.purchase_price) as total_purchases
FROM purchases f, product p
WHERE f.product_id = p.product_id
GROUP BY p.manufacturer, p.product_id, f.purchase_price
)
GROUP BY manufacturer;
MANUFACTURER SLOPE INTERCEPT COEFF_DETERMINATION
--------------- ---------- ---------- -------------------
Dell 2.39415728 89.6207996 0.946392646
RTG -.00712584 35.922917 0.000745027
Ricoh .86111111 -369.35333 1
...From this analysis, we can see that a straight line can closely model the relationship between selling price and total purchases for the products manufactured by Dell but not for those made by RTG.
Oracle also provides aggregate functions to compute other quantities of interest to a linear regression analysis, such as covariance of a population (COVAR_POP) or sample (COVAR_SAMP) and correlation (CORR) between variables.
In Oracle Database 10g, there is a new package, DBMS_STATS_FUNC, that includes several statistical functions. One function that is particularly convenient is the SUMMARY function, which computes several useful statistics, such as mode, median, TOP 5, and so on, on a given column in a table. The results are returned in a PL/SQL record of type SummaryType.
The following example shows the SUMMARY function on the PURCHASE_PRICE column of the PURCHASES table and prints the values that correspond to various quantiles and the median.
set serveroutput on;
DECLARE
srec dbms_stat_funcs.summaryType;
BEGIN
dbms_stat_funcs.summary(p_ownername=>'EASYDW',
p_tablename=>'PURCHASES',
p_columnname=>'PURCHASE_PRICE',
s=>srec);
dbms_output.put_line('Quantile 5 => ' || srec.quantile_5);
dbms_output.put_line('Quantile 25 => ' || srec.quantile_25);
dbms_output.put_line('Median => ' || srec.median);
dbms_output.put_line('Quantile 75 => ' || srec.quantile_75);
dbms_output.put_line('Quantile 95 => ' || srec.quantile_95);
END;
/
Quantile 5 => 15.67
Quantile 25 => 15.67
Median => 24.99
Quantile 75 => 72.87
Quantile 95 => 1267.89
PL/SQL procedure successfully completed.Other functions in this package allow you to test if your data conforms to a particular distribution, such as Uniform, Exponential, Poisson, or Normal. Detailed explanation of these statistical concepts can be found in any textbook on statistics and is beyond the scope of this book.
Earlier, we saw how we can generate a frequency distribution using the WIDTH_BUCKET function. However, instead of equally sized buckets, if we wanted a more customized classification, you could use a CASE expression. The CASE expression allows you to return different expressions based on various conditions. The simple CASE statement is identical to a DECODE statement, where you can return different values depending on the value of an expression. The searched CASE statement allows you more flexibility, as illustrated by this example:
SELECT f.product_id, SUM(f.purchase_price) as sales,
CASE WHEN SUM(f.purchase_price) > 150000 THEN 'High'
WHEN SUM(f.purchase_price)
BETWEEN 100000 and 150000 THEN 'Medium'
WHEN SUM(f.purchase_price)
BETWEEN 50000 and 100000 THEN 'Low'
ELSE 'Other' END as sales_value
FROM purchases f
GROUP BY f.product_id;
PRODUCT_ SALES SALES_VALUE
-------- ---------- -----------
SP1023 75252.45 Low
SP1024 82136.25 Low
...
SP1053 613658.76 High
SP1054 654231.24 High
...
SP1268 7584.28 Other
SP1269 14197.02 Other
164 rows selected.You can use the CASE expression anywhere you use a column or expression, including inside aggregate functions. The combination of aggregates and CASE expressions can be used to compute complex aggregations and for what-if analysis. For instance, suppose we wanted to provide free shipping on orders greater than $50. However, for customers who live in California the minimum order would be $100 and for customers who live in the United Kingdom the minimum order would be $250, and they would only get 10 percent off shipping. The following statement computes the current and projected shipping costs paid by a customer:
SELECT AVG(f.shipping_charge) as current_avg_shipcosts,
AVG(CASE WHEN c.state = 'CA' and f.purchase_price > 100
THEN 0
WHEN c.country = 'UK' and f.purchase_price > 250
THEN 0.9 * f.shipping_charge
WHEN f.purchase_price > 50 THEN 0
ELSE f.shipping_charge
END) projected_shipping_costs
FROM purchases f, customer c
WHERE f.customer_id = c.customer_id;
CURRENT_AVG_SHIPCOSTS PROJECTED_SHIPPING_COSTS
--------------------- ------------------------
4.55426569 2.45110852Thus, we can see that with this scheme, on the average, customers will end up paying around $2 less for shipping.
Even with all the analytical functions, business intelligence queries could be very complex and contain complex subqueries. In fact, the same subquery can appear multiple times in the query. The WITH clause, introduced in Oracle 9i, can improve the readability of such complex queries and also improve performance for queries needing repeated computation.
For example, suppose we wanted to determine for each product category the month for which the sales were the highest. One way of doing this is by using the following query:
SELECT s.category, s.month, s.monthly_prod_sales
FROM (SELECT p.category, t.month,
SUM(f.purchase_price) as monthly_prod_sales
FROM product p, purchases f, time t
WHERE f.product_id = p.product_id
AND f.time_key = t.time_key
GROUP BY p.category, t.month) s
WHERE s.monthly_prod_sales
IN (SELECT MAX(v.monthly_sales)
FROM (SELECT p.category, t.month,
SUM(f.purchase_price) as monthly_sales
FROM product p, purchases f, time t
WHERE f.product_id = p.product_id
AND f.time_key = t.time_key
GROUP BY p.category, t.month) v
GROUP BY v.month);We can see that this is a very complex SQL statement, and, moreover, the subqueries with alias s and v are identical. The WITH clause can be used to simplify such queries, as we will demonstrate shortly.
The WITH clause allows you to name a subquery and then subsequently use the name instead of that sub-query within a statement. If the same sub-query appears multiple times in a query, then Oracle will automatically materialize that subquery into a temporary table and reuse it when executing the query. The temporary table will live only for the duration of the query and will be automatically deleted when the execution is complete.
Let us rewrite the preceding SQL statement to use the WITH clause. First, we will pull out the common subquery and give it a name, such as PRODUCT_SALES_BY_MONTH. Then, wherever we used this subquery before, we will instead use this name, resulting in the following statement:
WITH product_sales_by_month <- name the subquery
AS
(
SELECT p.category, t.month,
SUM(f.purchase_price) as monthly_prod_sales
FROM product p, purchases f, time t
WHERE f.product_id = p.product_id
AND f.time_key = t.time_key
GROUP BY p.category, t.month
)
SELECT s.category, s.month, s.monthly_prod_sales
FROM product_sales_by_month s <- use name here
WHERE s.monthly_prod_sales
IN (SELECT MAX(v.monthly_prod_sales)
FROM product_sales_by_month v <- use name here
GROUP BY v.month);This makes the query execute more efficiently, since Oracle can choose to materialize the result of the subquery into a temporary table and reuse it in both places, thereby saving repeated computation. Also, the query is now much easier to read. The careful reader may have noted that this particular query could also have been done efficiently using reporting aggregates, discussed previously, or using the FIRST or LAST functions of Section First and Last Functions, as also discussed previously. Analytical functions provide great flexibility in expressing business queries.
Every one of us has used a spreadsheet such as Excel to perform calculations. Often, calculations that may be extremely simple to do in a spreadsheet can be surprisingly difficult and slow in SQL. For example, you can add the second column of the third row to the fifth column of the fifth row as C2 + E5. This is very cumbersome to do in conventional SQL. Some such calculations could be performed with SQL but not without using several self-joins and union operations with abysmal performance. The underlying reason for this is that a spreadsheet allows you to address every row and column of data and use it in a formula. Conventional SQL completely lacks this very simple but extremely powerful interrow and intercell calculation functionality. Hence, it is not uncommon to find that many businesses pull data out of the database into myriad spreadsheets just to perform calculations required for modeling their business performance or revenue forecasts. When it is time to upgrade the accounting model, all users of the spreadsheets must be notified to use the newer version. Even a small discrepancy could lead to serious accounting inconsistencies. In this era of financial accounting scandals, compliance laws are getting stricter and so managing their accounting procedures is becoming a major concern for businesses.
Oracle Database 10g introduced a new feature known as the SQL Model Clause, which adds this calculation capability into SQL. The SQL Model Clause gives you all the power of a conventional spreadsheet. Some of the benefits of this feature are as follows:
Within this clause you can address the result of a query as if it were a multidimensional array. In fact, instead of the ordinal addressing scheme (using row and column number) in a spreadsheet, you use dimension values. For example, instead of saying C5 or D3, which can be very error-prone, you can simply say sales[May] or purchases[March].
Calculations are done in the database and therefore have the added benefit of a scalable data processing engine, which can optimize and parallelize the calculations.
The result of calculations done using the model produce rows like any SQL query and so you can do further processing on this result or save it into a table.
Last, but not least, you can store the model itself in the same database as the data, using a view. So when it is time to change the model, just change the view and all users automatically run with the newer model!
Let us now look at how to do a simple calculation.
The following query calculates the total sales by each month and produces an additional row for “Holidays,” which gives the total sales for November and December. This is quite like a calculation you may have done in a spreadsheet previously.
SELECT month_name, sales
FROM (SELECT t.month, t.month_name, SUM(f.purchase_price) sales
FROM purchases f, time t
WHERE f.time_key = t.time_key AND t.year = 2003
GROUP BY t.month, t.month_name)
MODEL
MAIN holiday_sales_model
DIMENSION BY (month_name)
MEASURES (sales)
RULES
(sales['Holidays'] = sales['November'] + sales['December']);
MONTH_NAME SALES
----------- ----------
January 747376.33
February 677690.07
March 899008.65
April 870947.85
May 758257.03
June 847609.93
July 905908.19
August 762608.21
September 745532.66
October 886877.84
November 733383.72
December 754124.30
Holidays 1487508.02 <- new row computed by the model clauseThe SQL looks quite complex and has a lot of new syntax; however, we will break it down into simpler pieces as we move along. The careful reader will notice that the answer to this calculation has a value of “Holidays” under month, which obviously did not come from the month table. This row was created by execution of the RULES section of the model clause. The rule defines a calculation to add the sales for November and December and assign it under a new value, “Holidays.” This type of calculation is referred to as a calculated member. The notation sales[‘November’] is used to identify a specific element in the result of the query. The quantity, sales, which is used in numerical calculations, is called a measure and is conceptually the same as a measure from a fact table. The elements within square brackets, specified within the DIMENSION BY clause, are called dimensions. In this example, we have a single dimension, month. For those of you who have worked with a MOLAP product or even arrays in any programming language, this notation should be very intuitive to you. Finally, notice that the MODEL has an optional name, holiday_sales_model.
In addition to this, a model clause can also specify a PARTITION BY clause. This is the same concept as we discussed previously. If a PARTITION clause is present, the calculation is done for each partition. If it is not present, the entire query is treated like one partition.
Figure 6.6 shows the operation of a model pictorially. Imagine the result of the query without the model clause. For each partition created by the partition by clause, picture an array of the measure columns, addressed by dimensions. Rules are then applied to each array to produce the calculations.

The following example shows the SQL query for Figure 6.6. As in the previous example, the query shown in the figure calculates the sales for the holiday season for each region. After applying the model clause, you can choose to return only the new rows that were inserted or updated by the rules using the RETURN UPDATED ROWS option. If not specified, the default behavior is RETURN ALL ROWS, which will return the rows from the original query in addition to those computed by the rules.
SELECT region, month_name, sales
FROM (SELECT t.month_name, c.region, SUM(f.purchase_price) sales
FROM purchases f, time t, customer c
WHERE f.time_key = t.time_key
AND c.customer_id = f.customer_id
GROUP BY c.region, t.month_name)
MODEL
RETURN UPDATED ROWS <- returns only the updated rows
MAIN holiday_sales_model
PARTITION BY (region)
DIMENSION BY (month_name)
MEASURES (sales)
RULES
(sales['Holiday'] = sales['November'] + sales['December'])
ORDER BY region;
REGION MONTH_NAME SALES
--------------- ---------- ----------
AMerNorthEast Holiday 207454.07
AmerMidWest Holiday 435140.11
AmerNorthEast Holiday 611232.13
AmerNorthWest Holiday 185404.61
AmerSouth Holiday 197293.73
AmerWest Holiday 435254.48
EuroWest Holiday 1027255.94Note that the SQL Model Clause is executed after the SELECT, WHERE GROUP BY, and HAVING clauses but before the ORDER BY clause. Hence, any aggregates and analytic functions computed by the query may be used in the DIMENSION BY, PARTITION BY, and MEASURES clauses of the SQL Model Clause. One restriction with the SQL Model clause is that the query block containing the model clause must not contain any aggregation in the SELECT list, so we need to use a subquery (or view) in the FROM clause to do the aggregation.
Hint
If you have several SQL models that use the same base query, you could create a materialized view for this query (see Chapter 7) to avoid repeat computation. Further, you can create regular database views to store the definition of each model.
Now that we understand the basics, let us see what else we can do with RULES.
The SQL Model Clause uses an array-like notation to identify an element at a given row and column in the result of the query. This is called a cell-reference. There can be several different ways of addressing cells, as we shall see. Each RULE is an assignment expression, where the cell(s) referenced on the left-hand side of the = are assigned the result of the expression on the right-hand side. Thus, in the previous example, the rule assigns to the cell sales[‘Holiday’] the value of sales[‘November’] + sales[‘December’].
For the following examples, we will define a view, which computes sales by month and region, which we will use as our base query.
CREATE VIEW sales_region_month
AS
SELECT t.month, t.month_name, c.region, t.year,
SUM(f.purchase_price) sales
FROM purchases f, time t, customer c
WHERE f.time_key = t.time_key
AND c.customer_id = f.customer_id
GROUP BY t.month, t.month_name, c.region, t.year;A cell-reference that uses only constant values of each dimension to identify a cell is called a positional reference. For instance, if the model had DIMENSION BY (month_name), then sales[‘November’] is a positional reference. Similarly, if the model clause had DIMENSION BY (region, month_name), then sales[‘Northeast’, ‘January’] is also a positional reference. The ordering of dimensions is specified by the DIMENSION BY clause.
On the other hand, you can use a symbolic reference, where you specify an expression involving each dimension column. For example, sales[month IN (‘January’, ‘February’), region IN (‘NorthEast’, ‘NorthWest’)]. This actually translates into four cells: sales[‘NorthEast’, ‘January’], sales[‘NorthEast’, ‘February’], sales[‘NorthWest’, ‘January’], and sales[‘NorthWest’, ‘February’]. Note that when a cell reference expression refers to one cell, for example, sales[‘November’]—it is called a single-cell reference. When it refers to multiple cells—for example, sales[month in (‘November’, ‘December’)], it is called multicell reference.
In any cell-reference on the left hand side of a rule, you can use the ANY keyword as a wildcard to refer to all values of a dimension, as illustrated in the following example. The CV function on the right-hand side refers to the current value of the dimension on the left-hand side. This shorthand notation allows us to specify the same rule for all region values, rather than repeating the rule for each region value. In this example, the rule computes, for every region, the percentage growth in sales in that region in the year 2004, compared with the sales in that region in 2003.
SELECT region, year, sales
FROM (SELECT region, year, SUM(sales) as sales
FROM sales_region_month
GROUP BY region, year)
MODEL
RETURN UPDATED ROWS
MAIN sales_growth_2004
DIMENSION BY (region, year)
MEASURES (sales)
RULES
(sales[region IS ANY, 2004]
= (sales[CV(region), 2004] - sales[CV(region), 2003])*100
/sales[CV(region), 2003])
ORDER BY region;
REGION YEAR SALES
--------------- ---------- -----------
AMerNorthEast 2004 1.734760870
AmerMidWest 2004 1.103745720
AmerNorthEast 2004 1.529564870
AmerNorthWest 2004 2.465897740
AmerSouth 2004 .872252952
AmerWest 2004 .903655293
EuroWest 2004 1.466177920If your rule requires multiple-cell references on the right-hand side to compute a single-cell value on the left-hand side, you must use an aggregation operator to collapse the multiple values to a single value. For instance, in the previous example, if you wanted to compute sales growth for all regions combined, you would use the following rule. The SUM operator is used to aggregate the multicell reference on the right-hand side to one value, which is then assigned to sales[‘All Regions’, 2004]. Note that the ANY keyword here is used to specify all values for the region on the right-hand side.
sales['All Regions', 2004] = (SUM(sales) [region IS ANY, 2004)] - SUM(sales) [region IS ANY, 2003)]) *100/SUM(sales) [region IS ANY, 2003]
In the case of positional references used on the left-hand side, the rules can have either UPDATE or UPSERT semantics. With UPSERT semantics, if the cell does not exist, it is inserted; otherwise, the existing value is updated. However, if the rule is specified with UPDATE semantics, the cell is updated only if it already exists; otherwise, no action is taken. For instance, suppose we had a rule that computed sales[‘All Regions’] as the sum of sales of each region. If we specified update semantics for this rule, then unless there already exists a cell named ‘All Regions’, this rule will not do anything, as shown in the following example! If, on the other hand, we had a region value called ‘All Regions’, its value would have been updated.
SELECT region, sales
FROM (SELECT region, SUM(sales) as sales
FROM sales_region_month
GROUP BY region)
MODEL
RETURN UPDATED ROWS
MAIN holiday_sales_model
DIMENSION BY (region)
MEASURES (sales)
RULES UPDATE <- update semantics
(sales['All Regions'] = SUM(sales) [region is ANY])
ORDER BY region;
no rows selected <- does nothingAlternatively, if you used the upsert semantics, you would get a new row for “All Regions” as shown in the following example.
SELECT region, sales
FROM (SELECT region, SUM(sales) as sales
FROM sales_region_month
GROUP BY region)
MODEL
RETURN UPDATED ROWS
MAIN holiday_sales_model
DIMENSION BY (region)
MEASURES (sales)
RULES UPSERT <- upsert semantics
(sales['All Regions'] = SUM(sales) [region is ANY])
ORDER BY region;
REGION SALES
--------------- ---------
All Regions 19312425.1Note that while symbolic references are a powerful construct in a model clause, if you specify a symbolic reference on the left-hand side of a rule, you will only get UPDATE semantics, even if you say RULES UPSERT. This can be cumbersome in some cases. One case when you may want UPSERT semantics with a symbolic reference is as a shorthand notation to combine multiple identical or similar rules into one rule. Fortunately, this can be achieved using the FOR keyword, as shown in the example that follows.
SELECT region, month_name,sales
FROM (SELECT region, month_name, sales
FROM sales_region_month
WHERE year = 2003)
MODEL
RETURN UPDATED ROWS
MAIN holiday_sales_model
DIMENSION BY (region, month_name)
MEASURES (sales)
RULES UPSERT
(sales[FOR region IN ('AmerNorthEast', 'AmerMidWest'), 'Winter']
= SUM(sales) [CV(region),
month_name IN ('November', 'December',
'January', 'February', 'March')],
sales[FOR region IN ('AmerWest', 'AmerSouth'), 'Winter']
= SUM(sales) [CV(region),
month_name IN ('January', 'February')])
ORDER BY region, month_name;
REGION MONTH_NAME SALES
--------------- ---------- ----------
AmerMidWest Winter 539398.81
AmerNorthEast Winter 747304.58
AmerSouth Winter 81210.68
AmerWest Winter 182327.29Instead of writing the same rule for each region separately, we have written one rule. If you omitted the FOR keyword in the rules, you will get no rows returned.
If your SQL model specifies multiple rules, there may be dependencies among the rules. You can specify the AUTOMATIC ORDER option to indicate that Oracle should automatically determine in which order to apply the rules. In the following example, we want to compute the total sales for Americas, and Europe, and also the grand total. We can see that RULE 1 depends on RULE 2 and RULE 3, and by specifiying AUTOMATIC ORDER we let Oracle decide to first evaluate RULES 2 and 3 and then RULE 1.
SELECT region, sales
FROM (SELECT region, SUM(sales) sales
FROM sales_region_month
WHERE year = 2003
GROUP BY region)
MODEL
RETURN UPDATED ROWS
MAIN holiday_sales_model
DIMENSION BY (region)
MEASURES (sales)
RULES AUTOMATIC ORDER
(sales['Total']
= sales['TotalAmericas']
+ sales['TotalEurope'], <- RULE 1
sales['TotalAmericas']
= SUM(sales)[region like 'Amer%'], <- RULE 2
sales['TotalEurope']
= SUM(sales)[region like 'Eur%']) <- RULE 3
ORDER BY region;
REGION SALES
--------------- ----------
Total 8938839.16
TotalAmericas 5758817.19
TotalEurope 3180021.97On the other hand, you can also specify that the rules must be executed in the order specified, using the SEQUENTIAL ORDER option.
The rules in a SQL Model Clause can be applied multiple times. You can specify the exact number of iterations to apply the rules or specify that the rules be applied until a given stopping condition is satisfied. You can use the ITERATION_NUMBER keyword in a rule to refer to the current iteration number. Note that ITERATION_NUMBER starts from 0. The following example shows a sales forecasting model for 10 years. It iterates the rule 10 times. Each iteration computes the forecast for the next year using the values computed in the previous iteration.
SELECT year, sales
FROM (SELECT year, SUM(sales) sales
FROM sales_region_month
WHERE year = 2003
GROUP BY year)
MODEL
RETURN ALL ROWS
MAIN forecast_over_10_years
DIMENSION BY (year)
MEASURES (sales)
RULES ITERATE (10) <- # of iterations
(sales[2003+ITERATION_NUMBER+1]
= sales[2003+ITERATION_NUMBER] * 0.15
+ AVG(sales)[year in (2003+ITERATION_NUMBER,
2003+ITERATION_NUMBER-1)]);
YEAR SALES
---------- ----------
2003 9589380.8
2004 11027787.9
2005 11962752.5
2006 13289683.1
2007 14619670.3
2008 16147627.3
2009 17805792.9
2010 19647579.0
2011 21673822.8
2012 23911774.3
2013 26379564.7Instead of the number of iterations, you can also specify a condition such that the iteration stops when that condition is satisfied.
In the following section, we will look at couple of complex examples of using the SQL Model Clause.
The first example uses the SQL Model Clause to do a pivot operation. This is a very common operation in decision-support applications. In a pivot operation, you take the dimension values along one column of data and convert them into columns in a report. This is useful to display a result in a cross-tabulation along two or more dimensions. For example, the following query combines the monthly sales for each region by quarter and then pivots the result so that each quarter appears as a column. We have declared a measure variable, Q1sales, Q2sales, and so on, for sales of each quarter. The rules assign values to each of these measures for each region. Recall that the ANY keyword precludes the upsert semantics for rules. Hence, we use the existing cell for the month January, since we are really only interested in the final values.
SELECT region, Q1sales, Q2sales, Q3sales, Q4sales
FROM
(SELECT region,month_name, Q1sales, Q2sales, Q3sales, Q4sales
FROM (SELECT region, month_name, SUM(sales) sales
FROM sales_region_month WHERE year = 2003
GROUP BY region, month_name)
MODEL
RETURN ALL ROWS
MAIN holiday_sales_model
DIMENSION BY (region, month_name)
MEASURES (sales,
0 as Q1sales, 0 as Q2sales, 0 as Q3sales, 0 as q4sales)
RULES AUTOMATIC ORDER
(
Q1sales[region is ANY, 'January']
= SUM(sales)[CV(region), month_name
IN ('January', 'February', 'March')],
Q2sales[region is ANY, 'January']
= SUM(sales)[CV(region), month_name
IN ('April', 'May', 'June')],
Q3sales[region is ANY, 'January']
= SUM(sales)[CV(region), month_name
IN ('July', 'August', 'September')],
Q4sales[region is ANY, 'January']
= SUM(sales)[CV(region), month_name
IN ('October', 'November','December')]
)
) WHERE month_name = 'January'
ORDER BY region;
REGION Q1SALES Q2SALES Q3SALES Q4SALES
--------------- ---------- ---------- ---------- ----------
AMerNorthEast 168666.12 163446.74 164542.86 153829.90
AmerMidWest 336162.46 352213.10 340611.21 329105.92
AmerNorthEast 447266.04 477220.90 464554.97 471557.18
AmerNorthWest 158393.71 163313.59 147821.03 148383.75
AmerSouth 140683.64 162605.99 151958.09 149237.48
AmerWest 303449.22 336507.99 345210.40 332560.52
EuroWest 769453.86 821506.50 799350.50 789711.11The next example uses a SQL Model Clause to compute the net sales for the year 2003 for various states based on different state tax rates. This example uses a feature called a REFERENCE model to identify the sales tax rates for each state. The reference model also uses the DIMENSION BY and MEASURE clauses; however, its cells cannot be modified and hence it serves the purpose of a read-only lookup table which can be used in the calculations in the main model. The reference model cannot have a PARTITION by clause.
SELECT year, state, sales, net_sales
FROM (SELECT t.year, c.state, SUM(f.purchase_price) sales
FROM purchases f, time t, customer c
WHERE f.time_key = t.time_key
AND c.customer_id = f.customer_id
AND c.country = 'USA'
GROUP BY t.year, c.state)
MODEL
REFERENCE state_tax_model
ON (SELECT distinct state, tax_rate FROM customer)
DIMENSION BY (state) MEASURES (tax_rate) IGNORE NAV
MAIN
DIMENSION BY (year, state)
MEASURES (sales, 0 as net_sales) IGNORE NAV
RULES SEQUENTIAL ORDER
(net_sales[ANY, ANY] = sales[CV(year), CV(state)] *
(1 - state_tax_model.tax_rate[CV(state)]/100));
YEAR STATE SALES NET_SALES
---------- ---------- ---------- ---------
2004 AZ 616558.37 585730.45
2004 CA 713077.48 656031.28
2004 CT 627492.12 596117.51
2004 IL 740107.36 703101.99
2004 MA 661769.99 628681.49
2004 NH 628569.43 628569.43
2004 NY 632996.61 588686.85
2004 OH 632975.22 601326.46
2004 TX 609757.84 609757.84
2004 WA 633149.16 633149.16
2003 AZ 610124.46 579618.24
2003 CA 707603.67 650995.38
2003 CT 613003.5 582353.32
2003 IL 740373.37 703354.70
2003 MA 650485.62 617961.34
2003 NH 622458.88 622458.88
2003 NY 625136.71 581377.14
2003 OH 617719.32 586833.35
2003 TX 604485.2 604485.20
2003 WA 617912.08 617912.08The IGNORE NAV option allows you to treat missing cell values as 0 for purposes of calculations. For instance, the CUSTOMERS table does not store states with no tax rate, and this option will set the cells for tax rates for these states to 0.
We have only skimmed the surface of what we can do with the SQL Model Clause, but we can already see the power it can bring to business intelligence applications. Obviously, there are a lot of concepts and new syntax to learn here and it may take you some time to master it; however, once you do, you will find that this feature can indeed be very convenient and useful. So the next time you plan to use a spreadsheet, consider using the SQL Model Clause instead and reap the benefits of a scalable and more manageable modeling solution.
In this chapter, we looked at several features in the Oracle database for querying and analysis in a data warehouse. Oracle provides several mechanisms to improve query performance, such as star transformation, partition-wise join, partition pruning, and parallel execution. Complex aggregation and reporting needs can be met through the new aggregation and analytical functions in the database. The new SQL Model Clause can be used instead of conventional spreadsheets for calculations and modeling applications.
With good physical design and proper use of these querying features, a data warehouse can deliver excellent query performance for large amounts of data. In the next chapter, we will discuss materialized views, which are indispensable when it comes to boosting query performance in a data warehouse.