
6
How Fog Computing Can Support Latency/Reliability-sensitive IoT Applications: An Overview and a Taxonomy of State-of-the-art Solutions
Paolo Bellavista1, Javier Berrocal2, Antonio Corradi1, Sajal K. Das3, Luca Foschini1, Isam Mashhour Al Jawarneh1, and Alessandro Zanni1
1Department of Computer Science and Engineering, University of Bologna, 40136 Bologna, Italy
2Department of Computer and Telematics Systems Engineering, University of Extremadura, 10003, Cáceres, Spain
3Department of Computer Science, Missouri University of Science and Technology, Rolla, MO, 65409, USA
6.1 Introduction
The widespread ubiquitous adoption of resource-constrained Internet of Things (IoT) devices has led to the collection of massive amounts of heterogeneous data on a continual basis, that when coupled with data coming from highly trafficked websites forms a challenge that exceeds the capacities of today's most powerful computational resources. Those avalanches of data coming from sensor-enabled and alike devices hides a great value that normally incorporates actionable insights if extracted in a timely fashion.
IoT is loosely defined as any network of connected devices spanning from home electronic appliances, connected vehicles, and sensor-enabled devices and actuators that interact and exchange data in a nonstationary fashion. It has been predicted that by 2020 the number of IoT devices could reach 50 billion connected to the Internet, and twice that number are anticipated within the next decade.
IoT devices are normally resource-constrained, limiting their ability to contribute toward advanced data analytics. However, nowadays with cloud infrastructures, the computations required to perform costly operations are hardly ever an issue. Cloud computing environments have gained an unprecedented spread and adoption in the last decade or so, aiming at deriving (near) real-time actionable insights from fully loaded ingestion pipelines. This is in part attributed to the fact that those environments are normally elastic in their offering for dynamic provisioning of data management resources on a per-need basis. Amazon Web Services (AWS) remains the most widely accepted competitor in the market and looks set to remain that way for some time. For those aims to be achieved, production-grade continuous applications must be launched, which typically raises several obstacles. Most important, however, is the ability to guarantee the end-to-end reliability of the overall structure, which is achieved by being resilient to failures such as those most common in upstream components, which ensures delivering highly dependable and available actionable insights in real time. Furthermore, the architecture should guarantee the correctness in handling late and out-of-order data, which is a fact in real-life scenarios.
Cloud computing environments offer a great ability to process highly trafficked loads of data. However, IoT applications have binding prerequisites. The vast majority of them are time-sensitive and require practically instant responsiveness while, in the meantime, quality of service (QoS), security, privacy, and location-awareness are well preserved [1]. With an expansive number of IoT devices continuously sending huge amounts of data, two-tier architectures fall short in meeting desired requirements [2].
There are several challenges that render solo-cloud deployments insufficient. From those, we focus on the case where there is an oscillation in data arrival rates, which is sometimes characterized as ephemeral, whereas in other circumstances it can be persistent and severe. Current cloud-based solutions highly depend either on elastic provisioning of resources on-the-fly or aggressively trading-off accuracy for latency by early discarding of some data or (worse) some processing stages. While those ad-hoc and glue-code solutions constitute conceptually appealing approaches in specific scenarios, they are undesirable in systems that are resistant to approximations and anticipate exact answers that, if not provided, can cause the system to become untrustworthy, thus requiring extra care when analysis of such data is essential. This does not detract from the values obtained by the two-layered cloud-edge architectures but rather complementing them in a manner that ensures reliability for scenarios that seek exact results on-the-fly. Scenarios where this applies are innumerable, e.g. smart traffic lights (STL), smart connected vehicles (SCV), and smart buildings to mention just a few. However, throughout our discussions we place due importance on both cloud-only and cloud-fog architectures. All that said, we next present an alternative in this chapter.
In the relevant literature, several works are proposed for facing up to the challenges introduced by the two-tiered architecture. Some of them merely depend on integrating lightweight sensors with the cloud, to counter common cloud issues such as latency, the capacity to support intermittent recurrent events, and the absence of flexibility when various remote sensors transmit information at the same time [3, 4]. Another solution focuses on increasing the number of layers in the architecture to push part of the processing load uphill to intermediate layers [5], subsequently reducing information traffic, reaction time, and the response location-awareness.
There is significant overload caused by spikes in network traffic, when data arrival rates grow at an unprecedented and mostly unpredictable pace. To meet this challenge, fog computing comes into play, which is simply treated as a programming and communication paradigm that conveys the cloud assets closer to the IoT devices. Stated another way, it fills in as an interface that associates cloud with IoT devices in a manner that improves their cooperation fundamentally by keeping the advantages of the two universes by broadening the application field of cloud computing and expanding the asset accessibility in IoT settings.
Fog importance stems from the fact that there are situations in which a little computation is performed just-near the edge, thus lightening the burden on the shoulders of network hops and the cloud. Fog computing is somewhat novel but is receiving elevated attention among researches and becoming a widely discussed topic. For example, fog nodes can handle some nonsubstantial computing loads to act as an intermediate caching system that stores some intermediate computational results (e.g. preserving the state of an online aggregation framework), thus preventing cold-start scenarios (those scenarios that mandates recomputation in case of state loss in stateful operations), so that a stream processing engine can resume from where it left off before the (non-)intentional continuous query restarts. However, one hindering challenge could be the fact that fog is still in its infancy. Nevertheless, there are a considerable number of works that focus on different aspects for fog optimization, ranging from communication requirements to security to privacy and to responsiveness, to mention just a few. Current efforts are mostly following layer stack-up trends. Older systems of the technology are maintained while a person or group is trying to adapt to new technologies. This serves as a new jumping-off point for incorporating newer approaches. As such, we here posit the importance of incorporating fog computing as a core player in the current two-tiered architecture in order to reap the benefits of fog. To better corroborate our conclusions, we justify the incorporation of six service layers that span all three worlds (fog, cloud, and edge). With this setting in mind, some may be misled by intuitively concluding that sudden data arrival spikes are no longer a problem when seeking reliable answers. More rigorously, by this division we aim at breaking the architecture into its granular constituent parts to simplify their comprehension.
In this chapter, we are flipping the switch on significant architectural changes that, most importantly, incorporate fog as a central player in a novel three-tiered architecture. We demystify the explanation of the three-tiered architecture that we dub as cloud-fog-edge by dividing into major sections the pattern defined herein for the stacked-up architecture. First, we establish some basic definitions before getting under the hood. Thereafter, we start detailing mechanisms required for fully building a convenient self-organized fog between cloud and edge devices that hides management details so to relieve the user from reasoning about the underlying technical details and focuses on analytics instead of the heavy lifting of resource management. Most this chapter is devoted to summarizing the underlying components that constitute our three-layered architecture and how each contributes toward a fast fault-tolerant low-latency IoT application's operation. We herein point out that several alternative designs and proposals for related architectural models are found in the relevant literature that differ significantly in the way they present the interplay between the three worlds. We specifically refer the interested reader to a recent survey by [6]. The downside, however, is that the authors focus mainly on comparing existing models without introducing a novel counterpart. A similar trend also follows in [7].
This chapter is organized as follows. We first start by defining major aspects of core players in the architecture, such as fog, IoT, and cloud. In what follows, we discuss the challenging requirements of fog when applied to IoT application domains. In a later section, we draw a taxonomy of fog computing for IoT. In the last section, we discuss challenges and recommended research frontiers. Finally, we close the chapter with some concluding remarks.
6.2 Fog Computing for IoT: Definition and Requirements
In this section, first, we give a depiction of what fog computing is, what it performs, and the upgrades it conceivably presents in IoT application areas and deployment environments. Then, we clarify the inspirations that lead to the presentation of the fog computing layer atop the stack and the inappropriateness of a two-tier architecture composed only by cloud computing and IoT. Finally, we propose an original reference architecture model with the aim of clarifying its structure and the interactions among all the elements, providing also a description of its components.
6.2.1 Definitions
Fog computing alludes to a distributed computing paradigm that off-loads calculation, for some parts, close to the edge nodes of the network system with the purpose of lightening their computational burden and thus speed up their responses. We stress the fact that fog is becoming increasingly focal in enriching the responsiveness of computations by intermediating the stacked-up architecture between the two IoT and cloud universes, bringing substantial computing power near the edge and helping time-intensive applications in their front-stage loads that may need instant reactions, which normally cannot wait for the whole cycle, from sending data upstream to cloud to getting results back. Fog can be considered as a significant extension of the cloud computing concept, capable of providing virtualized computation and storage resources and services with the essential difference of the distance from utilizing end-points. While cloud exploits virtualization to provide a global view of all available resources and consists of mostly homogeneous physical resources, far from users and devices, fog tends to exploit heterogeneous resources that are geographically distributed (often with the addition of mobility support) and situated in proximity of data sources and targeted devices.
Moreover, fog is based on a large-scale sensor network to monitor the environment and is composed of extremely heterogeneous nodes that can be deployed in different locations and must cooperate and combine services across domains. In fact, fog communicates, at the same time, with a wide range of nodes at different level of the stack, from constrained devices (with very restricted resources) to the cloud (which has virtually infinite resources). Many applications require, at the same time, both fog localization and cloud centralization: fog to perform real-time processes and actions, and cloud to store long-haul information, and thereby perform long-haul analytics.
A primary idea emerging from existing fog solutions in the literature is to deploy a common platform supporting a wide range of different applications, and the same support platform with multitenancy features, can be used also by a multiplicity of client organizations that anyway should perceive their resources as dedicated, without mutual interference [8]. Figure 6.1 shows a high-level architecture that summarizes the above vision by positioning the IoT, cloud, and fog computing layers.
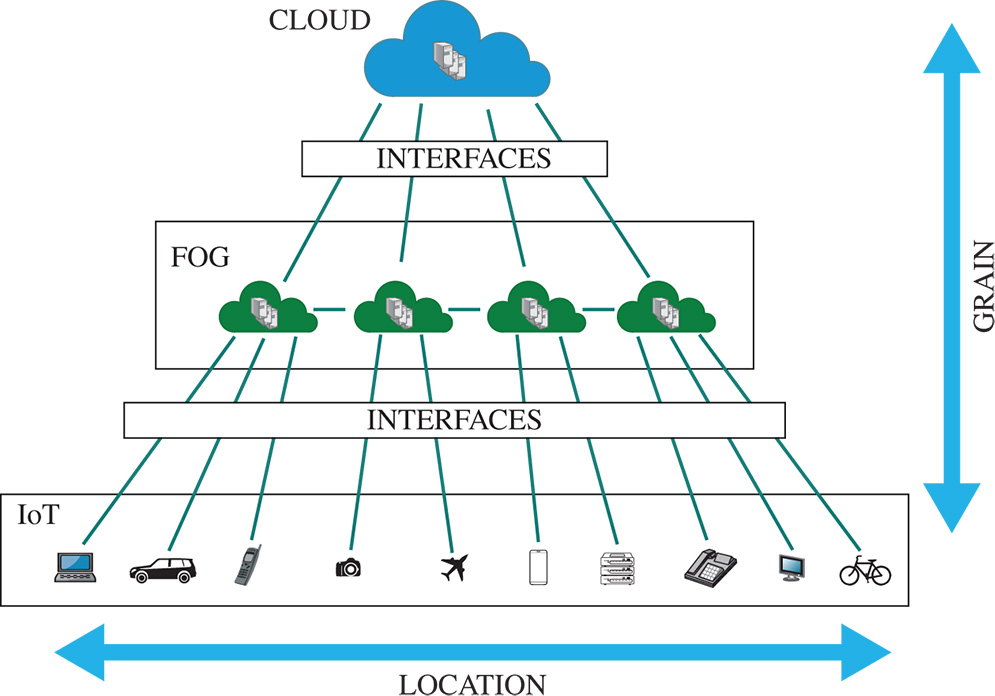
Figure 6.1 Cloud-fog-IoT architecture. (See color plate section for the color representation of this figure)
Fog interacts with the other layers through interfaces with different communication specifications, simplifying the connection among the different technologies. Due to cloud technology maturity and well-defined standardizations, cloud-side interfaces are more defined, and it is currently easier to make cloud service platforms interact with outside users. Cloud interfaces allow connecting the cloud with any device, anywhere, as a virtually unique huge component, and independently of where cloud services are located. On the contrary, IoT-side interfaces and, even more, fog ones are more various and heterogeneous, and much work should be done to homogenize the different approaches and implementations that are emerging.
6.2.2 Motivations
The incorporation of cloud in IoT applications is twofold, bringing significant preferences to the suppliers and end clients on one hand, yet bringing new unsuitableness in the integration with ubiquitous services on the other hand. In spite of its generous offering when it comes to the resource-rich assets that cloud may bring to an IoT setting, excessive misuse of cloud assets by ubiquitous IoT devices may present a few technical difficulties, such as network latency, traffic, and communication overhead, to mention a few. In particular, “dumbly” connecting a bunch of sensors legitimately to the cloud computing framework is resource-demanding, which are not designed, implemented, and deployed for high-frequency remote interactions, e.g. in the extreme case of one cloud invocation per each sensor duty cycle. Ubiquitous devices gather enormous quantity of data during normal operations, a condition that is worsened in crowded places during peak-load conditions or in future applications, because the purpose of IoT systems is to sense as much as possible and, thus, increasingly collecting more data, with the end result of exceeding the bandwidth capacity of the networks. In addition, IoT sensors usually use a high sampling rate, in particular for critical applications, to better monitor and act instantly, which typically generates a huge amount of data that need to be managed.
Interfacing a horde of sensors straightforwardly with cloud is incredibly demanding and potentially challenges the capacity of cloud resources. The result is a continuous iteration of cloud, which stays occupied per every sensor duty cycle, rendering cloud's “scale per sensor” property inefficient. To this end, we argue that an architecture that is based on a direct communication between cloud and IoT devices is infeasible. A direct rationale for this judgment is that a network's bandwidth is no longer able to support excessive data loads. In addition, the planned optimizations of networking and intercommunication capabilities are not promising for keeping up with the unprecedented avalanches of data, which are growing at a continuous rate and coming downstream at a fast pace. Such huge amounts of real-time data challenges the processing capabilities of any cloud deployment and potentially causes performance to take a severe dive in case the data are fed directly to the cloud layer, thus rendering the whole processing power a single point of failure and counteracting the benefits of parallelization.
Future web applications, which are arising from the advancement of IoT, are large-scale, latency-sensitive, and are never again meant to work in seclusion, but instead will potentially share foundation and inter-networking assets. These applications have stringent new requirements, such as mobility support, large-scale geographic distribution, location awareness, and low [9]. As a general idea, it begins to be broadly perceived that an architectural model that is just founded based on a direct interconnection between IoT devices and the cloud is unseemly for some IoT application situations [8, 9]. Cloud environments are too globally available and “far” from IoTs devices, which hinders meeting the IoT application's requirements and critical issues.
A distributed intelligent intermediate layer that adds extra functionalities to the system is required by, e.g. pushing some processing workloads into the data sources themselves, thus off-loading some heavy lifting that otherwise may cause congestion if sent abroad to the cloud. For this to happen, a support infrastructure is needed for the system to work properly and efficiently, thus providing QoS and capitalizing on the great potential of cloud. For a comprehensive survey that covers relevant literature methods that can be employed for off-loading time-sensitive tasks just-near the edge, in fog, we refer the interested reader to [10]. Authors basically discuss various methods and algorithms for off-loading, mostly by taking a utilitarian perspective that depicts the relevance of each method in achieving a streamlined off-loading conduct.
In the relevant literature, some works propose moving part of resources toward network edge to overcome limitations of cloud computing. In this chapter, we recapitulate main fog-related research directions including cloudlet, edge computing, and follow-me cloud (FMC).
The term cloudlet was first coined by [11] and describes small clouds. In simple terms, it is composed of a cluster of multicore computers with gigabit internal connectivity near endpoints that aim at bringing the computing power of cloud data centers closer to end devices in order to satisfy real-time and location-awareness requirements. An important distinction with what existed in traditional data centers is that a cloudlet has only soft state. In simpler terms, this means that management burden is kept considerably low and, once configured, a cloudlet can dynamically self-provision from remote data center [12]. Satyanarayanan et al. [13] highlights that usually cloudlet depends on a three-level stacking (mobile devices, cloudlet, and cloud) and is totally transparent under typical conditions, giving portable clients the deception that they are directly communicating with the cloud. Cloudlet stands as a possible realization of the resource-rich nodes, while those components deployed in the cloudlet are able to respond to requests coming from the resource-poor nodes in a timely manner [11].
Edge computing aims to move applications, data and services from cloud toward the edge of the network. Firdhous et al. [14] has summarized different advantages of edge computing, including a significant reduction in data movement across the network resulting in reduced congestion, cost and latency, elimination of bottlenecks, improved security of encrypted data (as it stays closer to the end-user, reducing exposure to hostile elements) and improved scalability arising from virtualized systems. Davy et al. [15] presents the idea of edge-as-a-service (EaaS), an idea that decouples the strict ownership relationship between network operators and their access network infrastructure that, through the development of a new novel network interface, allows virtual networks and functions to be requested on demand to support the delivery of more adaptive services.
FMC [16] is a technology developed to help novel mobile cloud processing applications, by giving both the capacity to move network end-points and adaptively relocating network services relying upon client's location, so as to ensure sufficient execution throughput and to have a fine-grained control over network resources. [16] analyses the scalability properties of an FMC-based system and proposes a role separation strategy based on distribution of control plane functions, which enable system's scale-out. [17] proposes a framework that aims at smoothing migration of an ongoing IP service between a data center and user equipment of a 3GPP mobile network to another optimal data center with no service disruption. [18] proposes and evaluates an implementation of FMC based on OpenFlow and underlines that services follow the user throughout his movements, always provided from data center locations that are optimal for the current locations of the users and the current conditions of the network. In a similar vein, [16] introduces an analytical model for FMC that provides the performance related to the user experience and to the cloud/mobile operator, stressing the importance of attention when triggering service migration.
In addition to these activities, some standardization efforts are geared toward improving interoperability and thus fostering fog and edge computing ecosystems. Recent initiatives include open edge computing [19], open fog computing [20], and mobile edge computing (MEC) [21].
The Open Edge Computing Consortium is a joint activity among industries and the scholarly community that calls for driving the advancement of an ecosystem around edge computing by giving open and internationally acknowledged standardized instruments, reference implementations, and live demonstrations. To that end, this community leverages cloudlets and provides a testbed environment for the deployment of cloudlet applications.
The OpenFog Computing Consortium aims mainly at defining standards in order to improve the interoperability of IoT applications. They indicate that cloud-only architectural approaches is not able to keep up with the fast data arrival rates and volume requirements of the IoT applications. Given this observation, efforts are geared toward a novel architectural view that emphasizes information processing and intelligence at logical edge. The upcoming reference architecture is a first step in creating standards for fog computing [22]. Being a multilayer architecture, where some are vertical while others are horizontal, it thus covers all aspects and requirements for achieving a multivendor interoperable fog computing ecosystem. The vertical layers, considering the cross-cutting properties, are as follows: (1) performance, including time critical computing, time-sensitive networking, network time protocols, etc.; (2) security, covering end-to-end security, and data integrity; (3) manageability, with remote access services (RAS), DevOps, Orchestration, etc.; (4) data analytics and control, containing machine learning, rules engines, and so on; and (5) IT business and cross fog applications, providing characteristic to properly operate applications at any level of the fog. The horizontal view, which aims at satisfying different stakeholder requirements is composed of (1) node view, including the protocol abstraction layer and sensors, actuators and control; (2) system view, providing support for the infrastructure and hardware virtualization; and (3) software view, providing services and supporting the deployment of applications.
MEC is a reference design and a standardization exertion by the European Telecommunication Standards Institute (ETSI). MEC gives a service environment and cloud-computing capabilities at the edge of the portable system, within the radio access network (RAN). Therefore, MEC environment is characterized by low latency, proximity, highly efficient network operation and service delivery, real-time insight into radio network information, and location awareness. Its key element is the MEC server, which is integrated at the RAN element and provides computing resources, storage capacity, connectivity, and access to user traffic and radio and network information. The MEC server's architecture comprises a facilitating framework and an application platform. The application platform gives the ability to facilitate applications and is composed of an application's virtualization administrator and application-platform services. MEC applications from third parties are deployed and executed within virtual machines (VMs) and managed by their related application manager. The application-platform services provide a set of middleware application services and infrastructure services to the hosted applications. Thus, ETSI is working on a standardized environment to enable the efficient and seamless integration of such applications across multivendor MEC platforms. This also guarantees ensure serving vast majority of the mobile operator's customers.
Finally, the fog vision was conceived to address applications and services that do not fit well the paradigm of the cloud [8]. Fog computing is pushed between IoT and cloud, leveraging the best from both worlds in enabling IoTs applications to become established as future enabling technologies. Along the same lines, [23] emphasizes that, as indicated by IoT developing paradigm, everything will be seamlessly associated to structure a virtual continuum of interconnected and addressable items in a global networking system. The outcome will be a strong hidden structure on which clients may create novel applications helpful for the whole community. Fog computing is considered a driver for enterprise/industrial-based IoTs that brings connections to the real world in an unprecedented way and aims at interfacing with new business models introduced by IoTs, rethinking about how to create and capture value.
6.2.3 Fog Computing Requirements When Applied to Challenging IoTs Application Domains
IoTs systems raise requirements that burden fog and cloud computing to accomplish the right activity and fulfill the client's expectations. The following subsections discuss these highlights and elucidate their definitions.
6.2.3.1 Scalability
Scalability is a core requirement, not only for big data management, but also a proper geo-distribution of devices. To state the obvious, [8] proposes to add geo-distributed property as a further data dimension in big data analysis, in order to manage the information distributed nature as a coherent whole. In this scenario, fog plays an important role, thanks to its proximity to the edge and, thus provides information's location-awareness.
By considering scalability referred to big data processes, we feature the characteristic of the framework to scale, depending on the amount of data and, if necessary, being able to manage great amount of data. On the other side, regarding “scalability” of device geo-distribution, we underline the ability of fog computing to manage a large number of nodes in a highly distributed system.
Big data scalability is a fundamental necessity for IoT applications, where a developing number of devices must be interconnected. Geo-distributed scalability is a demand that underlines the paradigm of fog computing to have a capacity of overseeing distributed services and applications, even profoundly distributed frameworks, which falls in stark contrast with the more centralized cloud settings. In exceptionally conveyed systems, fog is dealing with a huge number of nodes across the board in geographic zones, and nodes can likewise be spread out with different degrees of density on the ground. Fog computing is thus dealing with various sorts of topology and distributed configurations systems and have the capacity to scale and adjust so as to meet the demands for every scenario.
6.2.3.2 Interoperability
The IoT is a very heterogeneous setting that is normally found in real-life situations, in light of a wide scope of various devices that gather heterogeneous data from the encompassing geography. Sensors differs when it comes to range coverage, from short- to long-distance coverage. Bonomi et al. [8] lists various heterogeneity inside the fog: (1) fog nodes extend from high-end servers, edge switches, access points, set-top boxes and, even, end devices such as vehicles and cell phones; (2) the different hardware platform has varying levels of RAM memory, secondary storage, and real estate to support new functionalities; (3) the platforms run various kinds of operating systems and software applications resulting in a wide variety of hardware and software capabilities; (4) the fog network infrastructure is also heterogeneous, ranging from high-speed links, connecting enterprise data centers and the core, to multiple wireless access technologies, toward the edge. In addition, inside fog computing, services must be unified on the grounds that they require the participation of various suppliers [9]. Fog computing is a very virtualized setting that needs heterogeneous devices and their running services to be unified under one umbrella in a homogeneous way.
In complex settings, heterogeneity can influence technical interoperability, in addition to semantic interoperability. Technical interoperability concerns communication norms, components executions, or parts interfaces with various information formats or diverse media sorts of data streams. Whereas semantic interoperability is more concerned with the information inside data interleaved and the likelihood that two components comprehend and share similar data in an unexpected way. A standard method to portray and exchange data, together with an abstraction layer that anonymizes physical diversities among components are thus required to make interoperability possible. Diallo et al. [24] explains under which conditions systems are interoperable, proving definitions and classifications and many approaches to address interoperability at different levels.
Fog computing is there for empowering interoperability, so as to make an exceptional information stream to be later handled by sensing and information analytics parts or to host conventional application programming interfaces (APIs) that can be utilized by various applications, without the costly need to move calculations to the cloud layer.
6.2.3.3 Real-Time Responsiveness
Real-time responsiveness is a principle empowering agent for IoT applications and their organization in real-life situations. Fog computing is vital to accomplish low-latency prerequisite in cases where cloud-IoT collaborations are not able to achieve the target latency for several reasons including the distance. (1) IoT and cloud are, in practice, geometrically distant and information requires considerable time in the loop, arriving as an input to cloud and thereafter returning as results (final or intermediate) to IoT devices. Fog is a promising field that alleviates the overhead costs caused by long-distance traveling of information; instead it is clear that performing computations near the edge costs less than sending data all the way downstream to cloud nodes. For some jobs, which do not require high computational power or are less demanding, fog promotes instant computation. (2) Real-time interactions loosely mean processing the unbounded streams of fresh data that arrive continuously in the cloud. Moments where data arrival rates exceed the processing capacities of cloud resources, in addition to Internetwork communication overheads, are not unheard of. Such conditions normally challenge the capacities of fully resource-loaded cloud deployments, where neither reactive nor proactive solutions make a difference. The promising (near) real-time operation of cloud environments is hindered by such facts. To top that off, in a highly dynamic and real-time scenario, such as those in Industry 4.0 (I4.0) or smart cities, data from IoT is fed very quickly to cloud, and because different chunks follow different networking routes, so that it arrives, sometimes, out of order, thus negatively affecting the overall accuracy. Fog diminishes this by sensing information, processing it, and acting in real-time using data that reflect instantly the situation. (3) Sensors accumulate a tremendous amount of continuously arriving data that if sent to the cloud potentially causes system congestion and consequently causing system's performance to hit a wall. On the contrary, fog acts as a front-stage that locates data traffic in a defined space surrounding sensors and preprocesses information before uploading data to the cloud, with lower focused loads and reduced core network load.
6.2.3.4 Data Quality
Data quality is a pertinent demand in real-life scenarios, making it essential for high-performing systems' operations. Also, this element essentially performs initial data filtering so as to early discard unnecessary duplicate and noisy loads, thus improving significantly the overall system quality and performance.
Data quality support is provided by the fog layer with the aim of early discarding useless data, aiming at relieving the burden on subsequent computational stages and consequently decreasing network data traffic by confining traffic near the edge, and reducing the amount of data pushed toward the cloud. Data quality depends on the association of various strategies. The mix of data filtering, aggregation, standardization and analytics, big data and small data analysis is fundamental to understand the surrounding environment, thus performing proactive maintenance and anomaly detection in real time, among a huge amount of data gathered from IoT sensors. In a ubiquitous environment, finding noisy data is challenging, especially in nonstationary settings where data is arriving fast and may thus challenge a front-stage system's resources.
6.2.3.5 Security and Privacy
An essential challenge in ubiquitous settings and fog computing is to harmonize security and reliability of systems, citizens' privacy concerns and personal data control, with the possibility to access data to provide better services. Particularly, with multitenancy support, fog offers policies to specify security, isolation, and privacy management that are required for different applications.
Fog computing is utilized in real applications that appear in critical settings, so reliability and safety are basic requirements. Moreover, it must consider that actuator's operations may be irreversible. Subsequently, the presence of unforeseen conduct, even due to bugs in applications, must be minimized with precautionary measures. Security is a key issue that must be solved to help industrial organizations and it concerns the entire system's architecture, from IoT devices reaching down to cloud. We need to provide important features such as (1) confidentiality, ensuring that the data arrives to the target spot, thus counteracting divulgence of data to unapproved objects with access limitations; (2) integrity, detecting, and preventing unauthorized alteration of the system by steps that control the preserving of consistency, accuracy, and trustworthiness of data over its entire life-cycle; (3) availability, ensuring that services are available when requested by authorized users, and performing repairs, if necessary, to maintain a correct functioning of the system.
A rich arrangement of security features that empowers essential security for every condition for the entire framework is thus required to avoid implementing security mechanisms on a node-by-node basis. Many controls are needed at all levels, including network and communications, from the physical and computational points of view. In fact, intelligence, data processing, analysis, and other computing workloads move toward the edge but, on the downside, many devices will be located in low-security locations, thus protecting devices, and their data becomes a big challenge.
Distributed and internetworked security arrangements are required to ensure complete and superior intelligence and for responsiveness reactions with automated decisions based on M2M communications and M2M security control without human interventions.
What is more, privacy is an undeniably critical issue that is growing in importance with ubiquitous and pervasive settings, where clients are aware concerning the privacy of their private information. Storing encrypted sensitive data in traditional clouds for privacy is not a suitable option as it causes many processing problems when applications have to access these data. In fog computing, personal information is kept in the system for better protection of privacy. It is imperative to characterize the responsibility for information inside the fog, since applications must utilize o information that they have access to [1]. In particular, we must consider the geographic diversity of information and certain data. For example, sensitive military or government data cannot be sent outside of certain geometrical areas. Fog can anonymize and aggregate user data and is thus useful for localizing intelligence and preventing the discovery of protected data. Anyway, it is necessary to introduce additional ways to protect data privacy and thereby to incentive the utilization of fog computing in privacy-critical contexts.
6.2.3.6 Location-Awareness
In dynamic real-world scenario, such as IoT applications, the location-awareness is the property of fog computing, due to its proximity to the edge, to own a widespread knowledge of its subnetwork and to comprehend the outer setting in which it is submerged. Fog improves adaptability because of its behavior adjustability in response to different events, where it adapts itself to better suit certain circumstances, assisted by the awareness of the context.
6.2.3.7 Mobility
Extending the concept of availability and trying to satisfy novel IoT application requirements, fog adapts itself in accordance with geographical distribution of its devices, thus providing mobility support. MIoT (Mobile Internet of Things) is proving itself to be a challenge for distributed supports [25, 26]. The ubiquity of mobile devices raises the need to present mobility support in fog computing, which allows sensing information and reacting while they are moving around the environment. Fog computing, in order to be effective, even with systems that have mobility as a peculiarity, must adjust to oversee high mobility devices. In addition, fog computing supports the likelihood that devices can move between fog nodes without causing issues that may bring the system into halts.
6.2.4 IoT Case Studies
At present, there are diverse IoT scenarios that are broadly promoted in the relevant literature to inspire the distinctive prerequisites of these frameworks and fog computing settings. Likewise, numerous researches are dealing with those situations so as to propose novel arrangements hybridizing the three worlds – IoT, fog and cloud – to address the demands [8, 27]. We herein provide a brief description of most important case studies. Those scenarios are used throughout the rest of this chapter to present how different approaches and solutions are applied in fog-enabled environments.
- Smart traffic light (STL). STLs focus on better handling of traffic congestion in metropolitan cities. These frameworks depend on camcorders and sensors distributed along the streets to detect vehicles and components in streets, distinguishing the nearness of bikers, vehicles, or ambulances. To decrease errors, these frameworks can be fine-tuned to sense when traffic lights must be turned green or red depending on vehicles congestion in a single direction. Similarly, when an ambulance with blazing lights is distinguished, the STLs change road lights to open paths for the emergency vehicle. In this situation, traffic lights are fog devices.
- Smart connected vehicle (SCV). SCVs are systems located inside a vehicle controlling every sensor and actuator in the vehicle, such as tires pressure, temperature inside the car, and the street lane in which the car is located. All the information collected by different sensors and sent to the closest fog node, which is usually located in the vehicle, so that all information can be quickly processed, and a real-time response can be given to any dangerous situation, e.g. stopping the car if a puncture is detected in a tire. In addition, different information can be exchanged between vehicles (vehicle-to-vehicle [V2V] communication), with the road infrastructure (through the roadside units [RSUs]) or with the Internet at large (through Wi-Fi, 3G, etc.).
- Wind farm. These are systems that aim at improving the capture of wind power as well as preserving the wind tower structure under adverse condition. Diverse sensors to distinguish the turbine speed, the produced power, or the weather conditions are essential. These data can be given to a nearby fog node situated in every turbine to tune it in order to build the effectiveness and to decrease the probabilities of harm because of wind conditions. Furthermore, wind farms may comprise several individual turbines that must be facilitated to achieve the highest possible efficiency. The optimization of a single turbine can likewise lessen the effectiveness of different turbines in a row at the back of a farm.
- Smart grid frameworks are promoted to counteract the waste of electrical energy. Those frameworks analyze energy requests and evaluate the accessibility and the cost to adaptively switch to green powers such as sun and wind. For this to occur, distinctive fog nodes are deployed on system edge devices hosting software responsible for balancing the equations.
- Smart building systems are one of the most demanding IoT applications. In this scenario, different sensors are deployed throughout a house or a building to get information about different parameters, such as temperature, humidity, light, or levels of various gases. In addition, a fog node could be deployed in-house for collecting and combining all that information in order to react to different situations (e.g. turning the air conditioning on if the temperature is too high or activating a fan depending on gas level). With fog computing applied in those systems, they can better control the waste of energy and water in order to execute actions to better conserve them.
For an overwhelming review that better sheds light on more case studies, we refer the interested reader to a recent survey by [28], which focuses mainly on smart city scenarios and compares more than 30 related research efforts. For another six more scenarios, we point to a recent survey by [29].
6.3 Fog Computing: Architectural Model
This section explains an architectural framework dubbed as cloud-fog-IoT for interwoven application scenarios (see Figure 6.2). It depicts a high-level view of the composing essential elements and their associations. These elements form the ground for our taxonomy of IoT fog computing that we present hereafter. They have been identified considering both the different solutions and approaches surveyed, and the requirements presented in Section 6.2.3. First, the architecture is divided into three areas: cloud, fog, and IoT. These areas mirror the diverse types of nodes that could normally execute activities and tasks of components comprised within those areas. A component can be completely performed by a specific kind of nodes or by diverse nodes relying on the granularity of tasks (for instance, the IoT layer may contain some activities done by fog nodes and others performed by IoT devices). Second, the architecture consists of six layers that span the three worlds (fog, cloud, and IoT). For example, the communication layer must act on improving the interconnection between IoT devices and fog nodes, among fog nodes themselves, and between fog nodes and cloud environments. We expand the explanation of those layers as follows.
6.3.1 Communication
The communication layer is in charge of the communication among the constituent nodes of the network. It contains different techniques for a proper communication between those nodes, including standardization mechanisms for facilitating the exchange of information between different nodes of the network or between different subsystems of the IoT application. These techniques directly address the infrastructure interoperability requirement (see Section 6.2.3.2 for more details). Furthermore, IoT applications are typically described by a high mobility of a portion of its IoT devices. To this end, this layer should contain methods permitting the relocation of a device from a subnetwork to a different one without corrupting a system's normal operation. Meanwhile, this layer is significant for accomplishing real-time responsiveness, which can be obstructed by the inefficiency of communication protocols. In this manner, it additionally incorporates diverse procedures for decreasing communications latency. As a final perspective to consider, this layer needs to guarantee the dependability of communications, ensuring that data will not be lost in the system and that each node or subsystem expecting a particular information ingestion is getting it properly, subsequently improving information quality.

Figure 6.2 Our proposed architecture for cloud-fog-IoT integration.
6.3.2 Security and Privacy
The security and privacy layer influences the entire design, since all interconnections, information, and activities must be done in ways that guarantee the safety of the system and its clients. This layer achieves security on three unique dimensions: security, privacy, and safety. In the first place, security focuses on various methods to guarantee the dependability, confidentiality and integrity of the interconnections between diverse nodes of the setting. Second, unreliable privacy-awareness strategies normally render the whole framework trustworthy. Hence, this layer incorporates access control component to submit data to just-approved clients. As a final consideration, IoT frameworks act in critical environments where safety matters a lot. Fog computing settings encourage the promotion of such approaches just near the edge.
6.3.3 Internet of Things
IoT applications consist of interconnected objects, embedded with sensors, gathering information from the surrounding world, and actuators, and acting upon the environment. The IoT layer is included by each one of those devices responsible for sensing the surroundings and adaptively acting in specific circumstances. This is implanted in IoT and fog worlds. Sensing straightforwardly influences the quality of generated data. Actuation is mostly important in IoT settings, as these are naturally required to interactively respond to flaws so as to avoid disasters. Fog computing can improve the actuation with convenient responses to data.
6.3.4 Data Quality
The data quality layer oversees the processing of all sensed and gathered data so as to build their quality and to diminish the size of data to be stored in the fog nodes or to be transmitted to the cloud environments. This layer comprises three different phases that are successively executed: data normalization, filtering, and aggregation. To start with, data normalization techniques get raw data sensed by heterogeneous devices in order to unify it in a common homogeneous language. Thereafter, since many of the data collected are useless (in the sense that they are not contributing to the final result) and only a part of them are valuable, different data-filtering techniques are employed to get just the contributing subsets, relevantly discarding worthless information, aiming at better exploiting scarce computational resources during subsequent steps. Finally, data aggregation is a process through which fog nodes take filtered data to construct a unique information stream and thereby improve its analysis. Fog should be able to follow aggregation rules in order to identify homogeneous information and, thus, produces a uniform data flow. Architectural components have long been utilized by various settings; they are rather essential for connecting heterogeneous sensors' data with computational assets spread out within the premises of the architecture remainder, thus improving significantly the quality, the scalability, and the general responsiveness of the framework.
6.3.5 Cloudification
The cloudification layer forms tiny cloud-analogy inside a fog. It helps to close the gap by bringing a defined set of cloud services just-near the edge of the targeted deployment environment or temporarily storing a portion of data and recurrently uploading them to a remote cloud setting, thus diminishing overwhelmed remote communications with the cloud. In order to achieve distributed clouds in the fog nodes, virtualization techniques must be provided so that different applications can be deployed in the same node. In addition, diverse services deployed on fog nodes should be composed and coordinated with the target of orchestrating challenging services for supporting higher-level business processes. Finally, the storage subcomponent is in charge of orchestrating distributed data, which are normally stored in diverse fog nodes, thus managing their processing when applications have to access these data and controlling their privacy. Different and non-irrelevant advantages are normal with that framework in light of the fact that each task is normally achieved in a location-aware setting with better analytics, responsiveness, and results. Moreover, it is not unheard of to confine traffic near IoT devices, without overwhelming traffic load on the shoulders of the network interconnections, improving also privacy, since users have their data in-proximity and can control them. Therefore, this layer provides important benefits in the parlance of responsiveness and user experience quality.
6.3.6 Analytics and Decision-Making
The analytics and decision-making segment are accountable for getting insights from the stored information to create distinctive analytics and to identify various situations. These analytics can lead to making specific decisions that systems should perform. In analogy with previously explained layers, this layer spans the three components of the architecture. In ubiquitous settings, where an immense number of sensors always accumulate data and forward it to fog, the mix of short and long-haul analytics, in fog and cloud respectively, normally accomplishes reactive and proactive decision-making, in a row.
The multifaceted nature of IoT environments prompts the need of a precise introductory conduct of the surroundings to characterize a substantial model to use in system. In fog computing, the prediction of input/output is favored by the proximity to end-users that allows a greater location-awareness of the environments where they execute. This enables further processes, performed by the system, to the external context and, thus improve every future task.
While short-lived analytics and lightweight processing with constrained data amounts are recommended to be handled by fog, cloud are normally performing long-haul and overwhelming asset-demanding activities in Big Data as underpinned in [30] for, specifically, health-care applications, these capabilities transfer over to any similar IoT scenario. Often within a Big Data analysis and processing cycle, significant resource assets are utilized for supporting data-intensive resource-demanding operations, which mostly cannot be satisfied by constrained devices with few available resources near IoT environment. However, big data processing algorithms that perform efficiently even with constrained-resources devices is not a situation that is unheard of. This specifically rationale our decision to expand this layer so that it covers the edge component. Ultimately, in case of resource incapability near the edge, cloud computing is taking the lead and offering great amount of computing power, relieving scalability, cost and performance issues. Moreover, those long-lived analysis cycles are normally utilized for performing orchestrated and proactive decisions processes.
6.4 Fog Computing for IoT: A Taxonomy
In this section, we propose a novel taxonomy for elucidating the principal constituent parts found normally in fog for IoT computing application scenarios. We specifically aim at explaining our categorization, which flows naturally from our previously sketched architectural model. Aiming at facilitating a comprehension of our taxonomy, we introduce a breed of over-the-shelf proposals that support specific elements or traits similar to those appearing in our architectural model. Thus, the proposed classification is populated with different approaches.
Instead of analyzing a complete list of solutions proposed for each characteristic of the taxonomy, we also detail different approaches, applying parts of them to different scenarios, as introduced in Section 6.2.4. We argue that this conceptualization serves as a comprehensive guideline, assisting IoT application designers in deploying effective cloud-fog-edge computing environments.
The presentation order of our taxonomy follows the same pattern as proposed in our logical architecture. Therefore, six parts of our taxonomy are drawn as one for each architectural element in a row. Section 6.4.1 presents the various interconnection aspects that should be considered for the interaction between IoT devices and fog and cloud nodes. Section 6.4.2 elucidates the various security and privacy measures required by IoT scenarios. Section 6.4.3 details interactions between fog nodes and IoT devices. Section 6.4.4 classifies how gathered data is processed. Section 6.4.5 spots the light on various aspects that need to be managed to enable off-loading some cloud loads to fog nodes. Finally, Section 6.4.6 sums up by explaining the taxonomy for data analytics and decision-making perspectives.
6.4.1 Communication
The communication layer offers four distinctive parts, providing help to the diverse attributes and prerequisites of IoT applications with respect to the communication between edge devices and fog and cloud nodes (see Figure 6.3). First, the standardization component, Section 6.4.1.1, explains various protocols that are used in standardizing the intercommunication aspects among the IoT devices ands fog and cloud nodes. Second, not only the communication between network elements should be standardized; rather, in critical IoT applications, the reliability of the transmitted information is essential for correct operation of the system. Section 6.4.1.2 details some of the main techniques to achieve the communication reliability. Likewise, the latency of transmitted information must also be considered in those applications requiring real-time communication. Section 6.4.1.3 analyzes some protocols and techniques focused on reducing communication latency. Finally, the mobility component is discussed in Section 6.4.1.4, which reviews some of the most important mechanism to reduce the mobility issues in IoT applications. For simplicity, Figure 6.3 sums up the proposed taxonomy elements. Some communication protocols actualize diverse methods to support the above parts. However, each method has its pros and cons, making it appropriate for various conditions.

Figure 6.3 Taxonomy for the classification of the communication layer.
6.4.1.1 Standardization
A standout amongst the most basic focuses for the right coordination and intercommunication between IoT devices and IoT applications is the networking protocol utilized. Those protocols standardize the communication among sensors, actuators, and fog and cloud nodes, allowing programmers to accomplish proper levels of infrastructure interoperability in IoT settings. Various authors [31, 32] partition the infrastructure interoperability into two diverse arrangements of protocols: application protocols and infrastructure protocols. Application protocols are utilized to guarantee communicating messages among applications and their devices (Constrained Application Protocol [CoAP] [33], Message Queuing Telemetry Transport [MQTT] [34], Advanced Message Queuing Protocol (AMQP) [35], HTTP, Data Distribution Service [DDS] [36], ZigBee [37], Universal Plug and Play (UPnP) [38]). The latter are required to launch the underlying interconnection among various networks (RPL [39], 6LoWPAN [IPv6 low-power wireless personal area network] [40], IEEE 802.15.4, BLE [Bluetooth Low Energy] [41], LTE-A [Long-Term Evolution – Advanced] [42], Locator/ID Separation Protocol [LISP] [43]). Each system is to utilize a layered-up stack of protocols relevant to a set of requirements and the sensate traits of every application.
For instance, IEEE 802.15.4 offers a generally very secure wireless personal area network (WPAN), which focuses on low-cost, low-power usage, low-speed ubiquitous communication among devices, and with support to facilitate very large-scale management with a dense number of fixed endpoints [44]. On the top of the IEEE 802.15.4 standard, the ZigBee protocol takes advantage of the lower layers in order to facilitate the interoperability between wireless low-power devices, the optimization for time-critical environment, and the discoverability support for mobile devices. In addition, it is possible to extend the IEEE 802.15.4 standard, with 6LoWPAN network protocol that creates an adaptation layer that fits IPv6 packets, improving header compression with up to 80% compression rate, packet fragmentation, and thus direct end-to-end Internet integration [44].
The smart grid is composed of frameworks made out of an enormous number of distributed and heterogeneous devices spread out in various networks. Wang and Lu [45] represents Smart Grid communication network onto a hierarchical network composed by backbone network and millions of different local-area networks with ad-hoc nodes. Infrastructure interoperability is needed to allow devices and networks to cooperate in order to create a unique vision of the system state or to execute a common task. In smart building applications, in addition to the devices, the integration and communication among buildings allow managers to share the infrastructure and management costs, thus reducing the capital and operational expenses [46]. ZigBee is specifically utilized in smart building and smart grid applications because of its short-range and robustness under noise traits [47]. In [48], ZigBee is utilized in smart grid applications for associating sensors with smart meters, considering the overarching characteristic of its low bandwidth prerequisites and minimal-effort deployment.
ZigBee can also be used in vehicular applications, especially to perform short intra-vehicles communications among all the devices inside a vehicle and, for certain specific applications, to communicate outside the vehicle, as shown in [49], where it is used to improve the safety short-range system requirements. SCV acts in a heterogeneous scenario, with the involvement of a swarm of in-built sensors inside the vehicle that communicate, as well as many types of vehicles, externally seen as macro-endpoints, and access point stations that must cooperate among themselves. Several wireless technologies are used to communicate in the network environment [50]. Hence, infrastructure interoperability must be provided in order to allow V2V communications, access-point-to-vehicle and access-point to access-point.
Another well-known kind of WPAN connection is that of Bluetooth tech, characterized by an exceptionally low transmission range and a poor transmission rate, but on the upside with low power consumption. In IoT situations, BLE has gained momentum. This version extends the Bluetooth technology to face and support connections among constrained devices, optimizing lightweight coverage (about 100 m), latency (about 15 times lower than that of a classic Bluetooth), and energy requirements, with a transmission power range of 0.01–10 mW. BLE provides a good trade-off between energy requirements, communication range and flexibility, and a lower bit rate, combined with a low latency and reduced transmitting power, allows developers to transmit beacons beyond 100 m. For these reasons, BLE has several advantages that make it suitable for V2V applications, and thus could be successfully adopted in SCV systems [51].
Moreover, in heterogeneous environments, OSGi framework is widely adopted as a lightweight application container that defines dynamic managements of software components, allowing deployment of bundles that expose services' discoverability and accessibility. As examples, [52, 53] present platforms for SCV where the middleware is based on OSGi services and modules in order to improve the interaction between devices. In [54, 55] the proposal architecture, utilized in Smart Grid and Smart Building scenarios, capitalizes OSGi as a component platform, which enables to activate, deactivate, or deploy system modules easily, to provide a platform on which new components can be integrated in a plug-and-play fashion, keeping the design as flexible and technology independent as possible.
6.4.1.2 Reliability
Another imperative property of the communication protocols is that of the intercommunication reliability. This property guarantees the gathering of the information transmitted by diverse nodes of the setting. Presently, various systems can be utilized to guarantee the quality of the communications, e.g.: retransmission, handshake, and multicasting.
First, retransmission requires the acknowledgment of every packet and thereby retransmitting each lost packet. Several application protocols, like CoAP, MQTT, AMQP, DDS, concentrate on communication's dependability and are founded on retransmission schemes that are designed to handle the packet loss in lower layers. For example, the scheme per-hop retransmission (often called automatic repeat request [ARQ] at the mandatory access control [MAC] layer) tries to retransmit a packet several times before reaching a defined level before the packet is declared lost. Losses are on-the-spot realized and corrected, and even a few per-link retransmissions can substantially enhance end-to-end dependability [56, 57]. CoAP is based on UDP, an unreliable transport layer protocol, but it promotes the utilization of confirmable messages, that require an acknowledgment message, and non-confirmable messages, that does not need an acknowledgment [58].
Second, the handshake mechanism is designed so that two nodes or devices attempting to communicate can agree on parameters of the interconnection before data transmission. MQ Telemetry Transport (MQTT) and Advanced Message Queuing Protocol (AMQP) support three different layers of reliability that are used based on the domain-specific needs: (1) level 0, where a message is delivered at most once, with no acknowledgment of reception; (2) level 1, where every message is delivered at least once with a confirmation message; and (3) level 2, where the message is delivered exactly once and uses a four-way handshake mechanism.
Third, the publish/subscribe technique permits a device to publish some specific information. Other devices or nodes can be subscribed to that information. To state the obvious, each time the publisher posts new information, it is forwarded to the subscribers. Multiple nodes can subscribe to the same information; therefore, the information would be multicast to all of them. DDS uses multicasting for bringing excellent QoS and high reliability to its applications, with the support of various QoS approaches in connection with a wide scope of adjustable communication paradigms [59]: network scheduling policies (e.g. end-to-end network latency), timeliness policies (e.g. time-based filters to control data delivery rate), temporal aspects for specifying a rate at which recurrent data is refreshed (stated another way, timelines between data sampling), network transport priority policies, and other policies that influence how data is processed alongside the communication in relative to its reliability, urgency, importance, and durability [60].
In SVC and STL case studies, with huge increase in the number of connected vehicles, the number of sensors they incorporate, and with their unprecedented mobility, the support for low latency and unobstructed communication among sensors and fog nodes is crucial to guarantee a correct flow of applications [61]. DDS has been used as basis for building an intra-vehicle communication network. To that end, the vehicle was divided into six modules constituting the intra-vehicle network; the vehicle controller, inverter/motor controller, transmission, battery, brakes, and the driver interface and control panel. Fifty-three signals were shared among the different modules, some of them periodic and some sporadic. The test showed that this protocol improves the reliability and the QoS [60].
6.4.1.3 Low-Latency
As fog computing is implemented at the edge of the network, it is easier to provide low latency response, but it is also necessary to use the right protocol. Distinctive protocols can be utilized to improve the interplay between fog or cloud nodes or among devices and nodes. For instance, [59] utilizes MQTT publish/subscribe protocol to acknowledge continuous and low-latency streams of data, in a real-time setting dependent on fog computing capabilities toward cloud and IoT, utilizing fog layer in the meantime as broker and message interpreter: MQTT conveys data stream among fog and cloud and MQTT-SN, while the lightweight variant transports information from edge devices to the fog layer. CoAP [33] is yet another application protocol specifically utilized in IoT scenarios to provide low-latency cycles. In addition, [58] explains performance differences between MQTT and CoAP, focusing on the response delay variation in association with reliability and the QoS provided for communication: lower packet loss or bigger message size implies that MQTT outperforms CoAP; the opposite holds, reversing the conditions. So, deciding the protocol to use is essential depending on the type of application. In other terms, this means employing MQTT for reliable communications or for communication of large packets, and CoAP elsewhere for decreasing latency and thereby increasing the system's performance accordingly.
Finally, DDS [36] is a brokerless publish/subscribe protocol, recursively used for real-time M2M communication scenarios among resource-constrained devices [59]. Amel et al. [60] consider DDS as a favorable solution for real-time distributed industrial deployments and applies the protocol for improving the performance of vehicular application scenarios, evaluating the performance with tests that encapsulate hard real-time applications benchmark. Hakiri et al. [62] suggests utilizing DDS for enterprise-distributed real-time scenarios and embedded systems, those common in smart grid and smart building applications, for the efficient and predictable circulation of time-critical data.
In smart grid and smart building scenarios, most control capacities have strict latency prerequisites and need instant responses. Low-latency activities are fundamental to improve the framework's adaptability on the two sides of the electricity market. In smart grid scenarios, electricity markets expect to utilize demand-response instance pricing and charge clients for time-fluctuating costs that mirror the time-changing savings for power obtained at the discount level [63]. Wang and Lu [45] highlights the importance of low-latency actions in order to collect correlated data samples from local-area systems to enable a global power signal quality at a particular time instant. All samples must be collected by the phasor measurement unit (PMU) in a timely fashion to estimate the power signal quality for a certain instant and, depending on applications, the frequency of synchronization is usually 15–60 Hz, leading to delay requirements of tens of milliseconds for PMU data delivery. For modern power distribution automation, the IEDs (intelligent electronic devices) that are implanted in substations are sending their measurements to data collectors within 4 ms ranges in row, while intercommunications between data collectors and utility control centers need a network latency that falls roughly within the 8–12 ms range [32]; and for the standard communication protocol IEC 61850, maximum acceptable delay requirements vary from 3 ms; for fault isolation and protection purposes messages, to 500 ms; for less time-critical information exchange, such as monitoring and readings [45].
6.4.1.4 Mobility
One of the characteristics of IoT applications is the high mobility of some of their devices [9]. Currently, there are different protocols applying different techniques to support such mobility, such as routing and resource discovery mechanism.
Routing mechanisms oversee constructing and maintaining paths among remote nodes. Few protocols are responsible for building such routes, despite the need of some nodes for mobility peculiarities. For example, the LISP [43] indicates a design for decoupling host identity from its locational data in the present address scheme. This division is accomplished by supplanting the addresses utilized in the Internet with two separate name spaces: endpoint identifiers (EIDs), and routing locators (RLOCs). Isolating the host identity from its locations allows good improvements to its mobility, by enabling the applications to tie to a perpetual address, which is dubbed as the host's EID. Host location changes commonly amid an active connection. RPL is yet another routing protocol for constrained communications, utilizing insignificant routing necessities through structuring a strong topology over light connections and supporting straightforward and complex traffic models such as multipoint-to-point, point-to-multipoint, and point-to-point [31].
In STL and SCV case studies, mobility and routing support are essential needs for creating dependable applications ready for high rates of mobility of vehicles edges. Vehicles must be managed as macro-endpoints, allowing them to switch from one fog subnetwork to another. SCV must incorporate a routing mechanism for supporting vehicles' mobility externally but it does not require these mechanisms internally, since the swarm of sensors normally act statically inside the vehicle. RPL is adaptable for a multi-hop-to-infrastructure design, as a protocol that enables huge area coverage in real geometries, hosting connected vehicles with minimal deployment of infrastructure [64]. This protocol has practical applications in SCV and STL systems, and it is emerging as the reference Internet-related routing protocol for advanced metering infrastructure applications, since it can meet the requirements of a wide range of monitoring and control applications, such as building automation, smart grid, and environmental monitoring [65].
Resource discovery techniques strategies concentrate on recognizing adjacent nodes when a device relocates, so as to build up new communications. For instance, CoAP is able to discover nodes resources in a subnetwork, through URI that host a rundown of assets given by the server. On the other hand, MQTT does not offer out-of-the-box support resources discovery, and thus clients must understand the message design and associated topics to enable the communication. UPnP is a discovery protocol widely used in many application contexts that enables automatic devices' discovery in distributed environments. Fog solutions use UPnP+ [66], which is complementary to IoT applications. This version encapsulates light-tailed protocols and architectural parts (e.g. REST interface, JSON data format instead of XML) aimed at enhancing communication levels with resource-constrained devices. Moreover, Kim et al. [54] proposes an architectural view encompassing both smart building and smart grid utilizing UPnP for further detecting and adding new devices dynamically with no user intervention, unless the system wants additional information about the user's environment. Likewise, Seo et al. [67] propose using UPnP in vehicular applications, to allow external smart devices to communicate with an in-vehicle network, sharing data over a single network with the services provided by each device.
In other scenarios, like wind farm, smart grid, and smart building, the mobility of devices is not a priority in building the application, due to the static nature of the systems.
6.4.2 Security and Privacy Layer
The Security and Privacy layer encompasses three essential elements constituting parts of the IoT settings: those are safety, security, and privacy (see Figure 6.4). In the shown use cases, security and privacy essentially span the whole cycle from computational all the way down to physical aspects. First, few IoT systems are providing minimal safety policies for their users. Section 6.4.2.1 analyses few of the most significant safety mechanisms used in different fog computing–IoT applications. Second, security is a key element for every industrial development. Section 6.4.2.2 details the most important techniques and approaches in IoT systems. Finally, Section 6.4.2.3 presents the most important mechanism to preserve the privacy of the data. As detailed above, this is a vertical layer in the architecture because different kind security and privacy policies can be implemented throughout the data life cycle, from the gathering of the data to their storage in the fog nodes or the cloud environments. For the sake of clarity, Figure 6.4 sums up our taxonomy with all alternatives of modular constituting components.
6.4.2.1 Safety
Safety is fundamental for critical IoT systems. Safety is most often found in a lawful society and the corresponding business logic of IoT systems. That is, these systems must be designed to maximize the safety of any element, entity, good, or user of the system.
The most widely adopted safety practices are activity coordination for orchestrating actions with a concentration on maximizing the users' safety or even those of goods; activity monitoring for ensuring a streamlined and correct execution of actions; and, action planning for controlling the actions required in hazardous situations by either one of deterministic or stochastic designs [68].
Evaluating the application of these techniques in the different use cases, for instance, in STL, different applications can execute coordinated activities to construct green waves for assisting emergency vehicles in avoiding traffic jams or to reduce noise and fuel consumption [69]. SCV systems also rely on action control techniques for monitoring each and every operation, through acquisition of images or vehicles' movement patterns. More often, all users' actions are traced utilizing targeted surveillances.
As a final consideration, in wind farm scenarios, the framework must face fluctuating weather conditions, compare them with a predefined set of thresholds, and apply a lot of arranged activities, e.g. stopping the turbines in the event of a strong wind, for safety reasons. In [70], the authors survey diverse ways to deal with location vulnerability in wind control generation in the unit commitment issue, with fascinating results that demonstrate the presence of models that can adequately adjust expenses, revenue, and safety in a balanced fashion. What's more, as it is demonstrated in [68], the use of stochastic models for unit commitment, instead of deterministic models, can expand the penetration of wind power without any trade-off of safety.
6.4.2.2 Security
Security is a fundamental perspective that must be confronted by industrial settings. The security of IoT systems is usually supported by at least four basic pillars: the confidentiality of the information, ensuring the arrival of data to safe locations, thus preventing their circulation among unauthorized parties. Data encryption and the use of sandboxes to isolate executions, data, and communications are standard methods of ensuring confidentiality [71, 72]. Data loss, can occur; information can be lost throughout circulation or in the different nodes of the fog environment. Normally, these situations are controlled by various protocols utilized for sending data to fog nodes or to cloud settings, through the channels of version control, and configuration management [73]. The integrity of the data must be ensured, discovering and disallowing nonauthorized dissemination of information throughout the whole cycle. Common ways to ensure integrity are file permissions, user-access controls, checksum, and hashing [74] methods. Intrusion detection allows a system to identify if an nonauthorized client is intending to access protected data [27]. Data analytics techniques are used to detect intrusions (observing the behavior of the system), to check for anomalies, and to discover fault recognitions. Finally, pattern detection techniques can be used to compare the users' behaviors with already known patterns, or with the prediction of the system's behavior. Notwithstanding, adapting intrusion detection mechanisms for each IoT setting is challenging as it requires domain-specific knowledge in addition to the technical aspects.
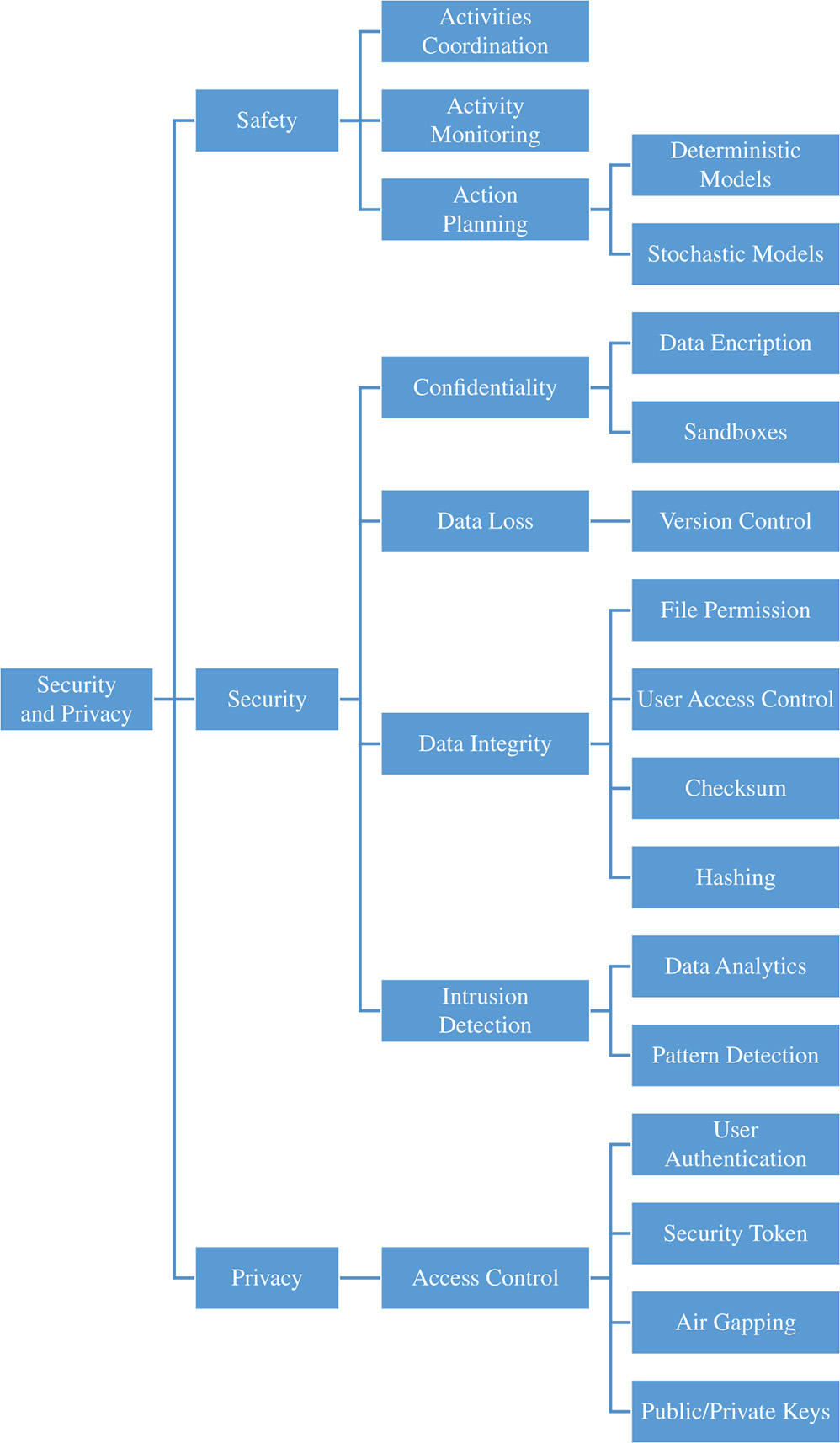
Figure 6.4 Taxonomy for the classification of the security and privacy layer.
Some techniques are utilized for the shown case studies. For example, in smart grid and smart building, security levels needs are obviously high, because any potential breach could result in a blackout. In [45], the authors highlight that these attacks commonly come through intercommunication networks, from intruders with the motive and ability to perform malicious attacks, such as the following. (1) Denial-of-service (DoS) attacks can be targeted toward a variety of communication layers (applications, network/transport, MAC, physical) to degrade intercommunication performance and thus obstruct the normal operation of associated electronic devices. (2) Attacks can target integrity and confidentiality of data, trying to acquire/manipulate information. The great number of devices and providers connected to these systems require the implementation of different security policies to prevent and face any possible cyberattack. Those systems have to ensure that devices are protected against physical attacks, utilizing user-access control policies, and also that sensitive data will never be altered throughout their transmission life cycles, using data encryption and sandboxes techniques [32]. Additionally, fault-tolerant and integrity-check mechanisms are normally operated hand-in-hand with power systems for protecting data integrity and for thereby defending and anonymizing user's actions and their associated localizations.
In relation to protocols used in critical applications, the widely adopted solution is to use different protocols for different parts of the system. MQTT benefits in terms of security and privacy from encryption through secure socket layer (SSL)/transport layer security (TLS), but, at the same time, it has a weak authentication phase (e.g. short usernames and passwords) and inappropriate security/privacy policies (e.g. global namespaces that produce global topics). Hence, MQTT in particularly is used to connect local elements in private networks, e.g. connections between a fog node and sensors in the subnetwork. AMQP extends the security and privacy of MQTT with sandboxes for the authentication phase and proxy servers to protect the servers with additional security levels (e.g. firewall protection). In addition, ADQP separates the message and the delivery information, providing metadata management and encrypted message. ADQP is normally used to connect public elements, e.g. connections between fog and cloud. Finally, CoAP enhances the security/privacy match using DTLS (datagram transport layer security) aimed at preventing eavesdropping, tampering, or message forgery toward integrity and confidentiality of exchanged messages.
6.4.2.3 Privacy
In fog computing, personal data are circulated throughout the fog's nervous system and not centralized in some components, which normally improves privacy. Controlling data access remains the top method for ensuring the privacy of personal data that must be protected from unauthorized parties. Few strategies such as user authentication, security token, or air gapping are normally utilized for increasing the privacy of data for privacy-sensitive applications [75]. Moreover, Stojmenovic and Wen [27] emphasize authentication at various stages yet it remains a security issue of high importance in fog settings. Every network device has an IP address and a hacker is able to tamper with a device and send false readings or imitate the IP addresses. To avoid this, a few authentication techniques, based on public key infrastructures or key exchange, are utilized.
In STL, e.g. privacy plays an important role and its concerns are related to the images acquisition of the vehicles approaching the intersection and the close-circuit cameras for vehicle presence detection and monitoring of traffic conditions, which also analyze patterns of vehicles' movements. Likewise, in SCV, the vehicles store information about the drivers' habits, their actions, and their driving patterns. Different user control techniques should be implemented to prevent unauthorized users to access that information.
In smart grid and smart building scenarios, privacy aspects mainly concern a mistaken spread of users' private data (e.g. monetary information and account balance) or information related to energy, from voltage/power readings to device running status to nonauthorized parties. This information is valuable and the system should seek to keep it safe and out of reach of malicious users. Ancillotti et al. [65] classifies the main smart grid vulnerabilities as the following: (1) device vulnerabilities, where attackers tamper with IEDs, which are normally utilized for monitoring electricity production/distribution, with probable not-to-be-underestimated consequences in the language of stealing data or destroying operations, or even aggravating by an unsafe WiFi communications between edge devices; (2) network vulnerabilities, where the adoption of architectures comprising open network is risky and open gates for routing modification attacks, DNS hacking, different DoS; (3) data vulnerabilities, where data is attacked aiming compromising the private data of customers, e.g. man-in-the-middle (MiM) attacks. Out-of-the-box smart grid applications normally ensure stringent access control with minimized levels of abilities performed by every node, which are usually resource-constrained nodes. As fog computing joined the play, smart grid nodes are now off-loading access control to the fog layer, which provides more computational resources and thus boosts more accurate and faster analysis near the edge.
6.4.3 Internet of Things
The IoT layer is of central relevance since the successful ability of the integrated system to be compliant with the possibly stringent requirements of the application domain, e.g. in terms of scalability and latency, highly depends on the appropriate behavior of IoT. This layer incorporates all components sensing data from the surrounding environments and launching actuators correspondingly to alter the environments in an appropriate reaction manner. It can be divided into two main modules. The first one, the sensors component, presented in Section 6.4.2.1, considers all these elements, gathering information from the environments. The second module, actuators, takes into account all those elements that can actuate or somehow change the environment. Figure 6.5 elucidates our taxonomy, highlighting the most significant alternatives for each of these elements.
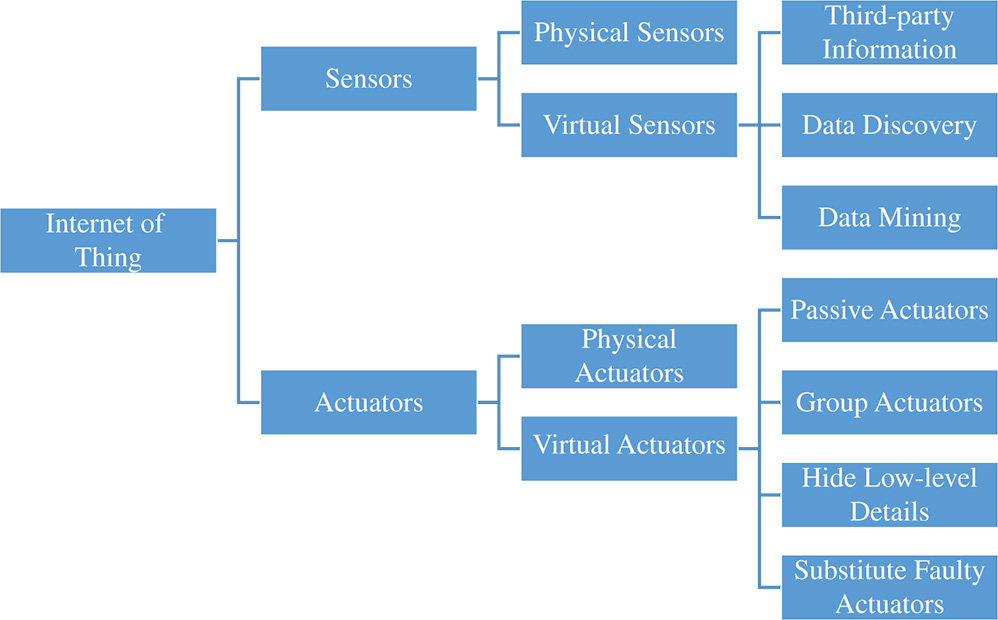
Figure 6.5 Taxonomy for the classification of the Internet of Things layer.
6.4.3.1 Sensors
Sensing is a capacity that normally IoT devices are performing. This element is concerned with two types of sensors: physical sensors, those that get data dynamically as directly connected and implanted within the environment utilizing specific hardware devices, and virtual sensors, those that indirectly acquire data through indirect channels (e.g. using a third-party system web service) [76, 77].
In STL and SCV, sensing is a main element that collects data for helping in accident prevention and maintaining a fluid flow of traffic. Sensing is important to understand the state of the road, and the internal state of the vehicle in SCV. For example, a smart vehicle may have physical sensors to identify wheel pressure, the distance to the nearby vehicles, or the lighting conditions. It can also have different virtual sensors to gather data on forecasting meteorology in its route or different traffic alerts obtained directly from the traffic authority [78]. Regarding wind farm systems, physical sensors gather real-time data related to fluctuations in weather, the wind speed, or the electrical power generated [8]. On the other hand, virtual sensors are fundamental for collecting relevant data and assisting in forecasting weather conditions [79]. Therefore, various reports are composed to confront weather conditions with generated power or even a deviation from forecasted loads.
In smart grid and smart building applications, physical sensor networks are required to sense the whole area pervasively and virtual sensors can provide information on networks incidents and system load. Thus, different statistics and reports are normally generated for comparing data from real-time operations in connection with data related to network incidents, loading, and connectivity. In smart building, sensors sense and share information among different rooms/floors of the building and obtain dynamic information about users' activities and energy supply conditions [46].
Few settings have only a sensing part, since they just watch the environment without concentrating on any actuation act. Business intelligence (BI) applications are a prominent case of this sort of frameworks dependent on sensing. BI applications utilizes procedures such as data discovery [80], data mining [81], business performance, analytics and processing, to convert sensed raw data into valuable insights for subsequent strategic decision-making or for solely visualizing results [82, 83]. In real-world settings, using BI in real-time scenarios in support of knowledge delivery is normally the act [84, 85], thus enhancing the strategic decision-making cycle and maximizing on the cost/profit cycles of the enterprise resources.
6.4.3.2 Actuators
Other systems provide relevant sensing and actuation phases; thus, they actively modify the environment, reacting to current events. Most real use cases are dependent on a sensing phase alongside a robust actuation phase. Henceforth, actuators are normally changing surrounding environments in an automatic or semi-automatic fashion.
This element comprises two types of actuators: physical actuators, which normally produce a physical modification that affects the surrounding entities via specific hardware; and virtual actuators, which are utilized for controlling a group of physical actuators [86], aiming at anonymizing the unnecessarily complicated peculiarities of low-level layers communicating with the physical actuators or otherwise substituting faulty actuators and preventing the system from thereby taking a severe dive [87, 88].
In STL and SCV, the actuation is fundamental in preventing accidents and maintain a fluid traffic flow. In STL, different reaction can be provided in relation of the circumstances. For instance, physical actuators may launch an alarm or alternate a traffic light so that it turns to red so as to slow down near vehicles. On the same side, virtual actuators are utilized for better controlling big areas and thus creating green waves of traffic lights to decrease pollution or for the passage of emergency vehicles. Likewise, SCV provides many virtual and physical reactions for sending warning messages to actuate passively on the driver showing visible or audible signals. Also, it can physically activate a warning or specific piece of hardware for recovering from anomalies as quickly as possible (e.g. slowing down the vehicle or turning some lights on) [89].
In wind farm scenarios, physical actuators are utilized for starting and possibly stopping turbines in response to a forecast and wind speed, thus preventing the system from breaking down [8]. In general we can resume some typical operational scenarios related to weather conditions: (1) in low wind speed, turbines switched off to avoid economic losses; (2) in normal wind speed, normal operation conditions, and blade optimized to maximized the electrical production; (3) in high wind speed, turbines, and power limited in order to avoid exceeding electrical and mechanical load limits; (4) in very high wind speed, turbines switched off to prevent electrical and mechanical breakdowns, due to the high possibility of exceeding allowable values. Also, in the recent literature, researchers of wind turbines replace faulty actuators through corresponding virtual actuators [87].
As a final consideration herein, in smart grid, operational planning and optimization actors employ simulation of network operations, put switching actions on schedule, dispatch repair crews, inform affected customers, and schedule the importing of power [90]. In smart building, the systems handle the energy consumption issue through a strong autonomous and continuous interaction sensing-actuation. Sensors sense and share information among different rooms/floors of the building and then make distributed decisions and activate physical actuators such as lowering the temperature, injecting fresh air, turning lights on and off, opening windows, or removing moisture from the air [91].
6.4.4 Data Quality
The data quality layer is in charge of processing the collected data so as to give a uniform specification for all information, on-the-fly discarding useless data elements, and thus reducing the amount of data sent to the fog or cloud nodes. The data quality layer comprises three essential elements for data processing: data normalization, data filtering and data aggregation (see Figure 6.6). First, data normalization is the process in which all the information is homogenized. Section 6.4.4.1 analyzes some of the most important approaches for the normalization of data. Second, data filtering focuses on eliminating any duplicate and erroneous data in order to reduce dataset size. Section 6.4.4.2 details the most important data-filtering solution. Finally, data aggregation is the process of merging large data set in a single flow. Section 6.4.4.3 presents some of the techniques used for aggregating collected information coming from heterogeneous sources.

Figure 6.6 Taxonomy for the classification of the data quality layer.
6.4.4.1 Data Normalization
As detailed in Section 6.2.1, IoT is an extremely heterogeneous environment that is built upon a comprehensive range of devices that gather information, often heterogeneous, from surrounding environments. Sensors have normally different reachability ranges, fluctuating from weak to robust sensors, with significant differences in power consumption, data rate, and available resources. In the same vein, fog nodes are naturally heterogeneous, with the different levels of services they provide. Hence, all senses are normalized so as to facilitate data dissemination among various devices or between fog nodes. Data normalization is a main data preprocessing procedure for learning data forms [92].
Currently, there are different approaches to normalize all the exchanged data in order to improve the semantic interoperability between devices. In general, interoperability affects the system at different levels. Different approaches tackle this issue using different cross-applications, languages, and data homogenization and serialization mechanisms. Specification languages allow developers to transform all sensed data to a common format. Data homogenization mechanism unify data from different sensors and services. Even though semantic data and open standard middleware can homogenize data, the great variety of data sources leads to the need for new mechanisms. Each IoT application should adopt the technique that best fits their requirements [93]. Data serialization techniques convert and compact data to various formats to transmit them effectively.
Often these mechanics are combined to enhance data normalization. For instance, Zao et al. [59] employ two-level mechanisms for data normalization: first, they utilize a global specification language called Pigi [94] to gather data/metadata fields; secondly, they use the Google Protocol Buffers [95] to perform the data serialization for streaming and archiving the information with a compact binary data encoding.
STL and SCV are systems composed of heterogeneous components that should work appropriately together. Though multiple providers give different specifications, they must exhibit common interfaces and interoperability abilities. Data normalization is highly important in these environments. For example, in SCV, all sensed data are converted to a common language and serialized in order to be efficiently transmitted to a local fog node in the vehicle or to other vehicles or road infrastructures requiring that information.
Smart Grid systems usually comprise a huge mass of distributed and naturally heterogeneous devices, thus demanding the use of protocols so as to achieve the inter-communication between them. Greer et al. [90] indicates eight layers of the degrees of interoperation necessary to enable different transactions on the smart grid, divided among three drivers: (1) an informational driver, which focuses on what information is exchanged and its meaning (using specific languages); (2) an organizational driver, which emphasizes the pragmatic (business and policy) aspects of interoperation, especially those pertaining to the management of electricity; and (3) a technical driver, which involves technical aspects, such as mechanisms to establish physical and logical connections and to exchange messages between multiple systems across various networks. In addition, [90] promotes a few guidelines for identifying standards and protocol in support for interoperability throughout the smart grid, coupled with definitions of architectures for incorporating and supporting a wide spectrum of technologies, spanning from legacy to novel. Also, standard languages are common for performing interoperability between smart meters, smart devices, charging interfaces, and in exchanging information for all smart grid scenarios [96].
In smart building applications, data normalization is a critical activity due to the huge number of devices that must communicate [46]. In addition, these applications could be integrated with smart grid systems with the intention to manage consumption in response to supply conditions by selectively turning off appliances or reducing nonessential or non-time-critical services, with many benefits for suppliers (e.g. avoiding costly capital investments) and customers (e.g. sharing the savings resulting from the lower operational cost of energy production) [46]. In this situation, the language used to transmit the information between different systems is essential in order to achieve the required coordination. These iterations issues are exacerbated by the range of producers that build devices and smart building systems that generally use different type of implementations and with different policies. Hence, smart building applications must define and/or enforce standardized data normalization techniques and guidelines. In this scenario, Chen et al. [46] propose reference semantic models (RSMs) implementing the smart-building related industry standards to facilitate the exchange of information among different subsystems, through a variety of functions including measurements, planning/scheduling, and life cycle management.
Along these lines, a wind farm system is mainly responsible for sensing weather conditions, wind speed, and the turbine power and react interactively with a number of different actuators, thus, data normalization can be achieved. Nevertheless, the most appropriate techniques for data homogenization and serialization are selected so as to exchange information efficiently.
6.4.4.2 Data Filtering
IoT frameworks with several sensors continually sending data to the fog nodes and to the cloud could quickly clog the system and overwhelm the nodes' constrained assets. Data filtering is in part responsible for decreasing the quantity of data transmitted by taking out any information that is repetitive, mistaken, or broken [97]. Data filtering procedures ought to be actualized as close to the edge as possible to decrease information traffic. In spite of the fact that sensors may execute lightweight filtering to evacuate some noise at information accumulation stage, increasingly vigorous and complex data filtering is as yet required at the fog layer. The principal data-filtering techniques consists of duplicate detection, errors detection, and data prioritization. Normally, due to its location near to the edge, fog nodes do not have a widespread knowledge of the whole system, thus, they cannot perform advanced data-filtering operations, so they are left to subsequent stages.
Duplicate detection techniques focus on analyzing received data, from either a specific sensor or a set of sensors, so as to detect duplicated data that can be safely discarded. The Bloom algorithm [98], for instance, detects the redundant data via a buffer that stores the received data and periodically controls whether newly arrival data is present in the buffer. Different algorithms utilize the locality property of IoT systems. They indicate that there is a strong spatial-temporal interconnection between various sensors, with an elevated probability that they collect same data at times and that the same information will probably be gathered by those sensors soon.
Error detection mechanisms are used for identifying flaw data generated by incorrect measures obtained through sensors or noise. [99]. The knowledge of the system, the relation input-output, and the use of secondary data features of data gathered to compare several additional information are basic to detect faulty data. To detect these data, different techniques can be applied. For instance, Statistical model approaches can assist in creating models for predicting data distribution and thus detecting those data which do not fit the model (known as outliers).
Finally, data prioritization techniques filter time-critical data aiming at prioritizing and forwarding them to be processed early by the data analytics component. This is in stark contrast to the aim of reducing data size that is of the other filtering techniques mentioned earlier.
In the STL and SCV case studies, the variance and standard deviation for the vehicles observed speed compared to the average data received at same contexts, with same location, time, weather, and type of vehicle, metrics are normally utilized for identifying outliers and detecting an accurate speed of an approaching vehicle. Consequently, with the definition of data thresholds, it is possible to discard outliers and refine the information collected.
In addition, it is possible to introduce various management control system (e.g. Six Sigma, Lean, etc.) usually adopted in manufacturing or business processing, adapting them to be effective to face the specific problem of data quality improvements. These control systems extend variance/standard deviation measures and are based on a set of advanced statistical methods and techniques, trying to identify and remove all the causes of errors and waste in order to maximize the quality level in relation to the specific application where they act.
In smart building, there are works that focus on reducing the inaccurate sensed information by identifying outliers. The authors indicate that outlier's detection is important in application processing since these erroneous data can lead to abnormal behavior of an application, e.g. turning on the air conditioning when an erroneous measure of the building temperature has been identified. In [47], the authors use the Hodrick-Prescott and moving average techniques to identify the outliers. The Hodrick-Prescott filter is a mathematical tool used to remove the cyclical components of a time series from raw data. The moving average technique is a calculation to analyze data points by creating a series of averages of different subsets of the full data set [100]. The authors applied those techniques to minimize the fluctuation of the temperature/humidity parameters in smart buildings.
Finally, in smart grid, the signals are typically sampled and communicated at high rates – several tens or hundreds of times per second – to augment or even replace the conventional supervisory control and data acquisition system. In [101], the authors indicate that this situation creates some congestion problems, preventing the most critical information to be received at the right time at the nodes where decisions are made and hindering a real-time response. Therefore, they propose the technique of distributed execution with filtered data forwarding to assign more importance to time-critical applications compared to other, less time-critical monitoring applications, prioritizing data for applications having more stringent timeliness requirements compared to ones having lenient QoS.
6.4.4.3 Data Aggregation
The data aggregation element further focuses on minimizing collected information by means of aggregating them into groups based on some keys and constraints for some variables of interest. To such an end, it combines all the gathered information in order to form a unified picture and a unique flow of data. In addition, this component also improves the system interoperability, since it aggregates and merges data from various sensors, ensuring reliable data collected from sensors [102].
Data aggregation can be done using diverse integral perspectives focused on: merging large data sets, hierarchically aggregating data in different nodes and improving the degree of safety via data aggregation. Data fusion methods attempt to combine diverse sorts of information to diminish data size and acquire a novel data stream. Keeping that in mind, a distinctive number of arithmetic operations can be used to get increasingly steady and representative estimations from a big data sample. Spatial methods can be utilized to aggregate data relying upon the sample's geographical location. Hierarchical data aggregation promotes the idea of identifying whether the information can be aggregated on a single node or simultaneously on many nodes. In fog environments that incorporate middle nodes with diverse capacities, this technique normally allows the consequent application of aggregation techniques to enforce location-awareness property for every node. Safety data aggregation centers around gathering similar data from various sensors to have alternate points of view of a similar context with the objective of improving the security and safety of the IoT applications.
The application of these techniques is evaluated in the different cases of uses. For instance, both SCV and STL systems are highly distributed applications with numerous geo-distributed information gatherers that must impart and collect data so as to make productive traffic strategies to draw paths for vehicles.
In SCV, some approaches use data aggregation to monitor the roughness of road surfaces. In [14], the authors propose to collect and fuse different information from accelerometer and GPS sensors and progressively thin it at different levels through sampling and spatial/temporal aggregation techniques. Each collected point is mapped onto a map database and aggregated according to specific geometric constraints. This makes it possible to consistently map the sensed physical quantities of several adjacent points into a single aggregate data. Then, a temporal aggregation is performed. The stored points are kept updated with the last significant changes (incrementally down-weighting older points). Finally, by applying a linear predictive coding (LPC) algorithm to the collected samples, the roughness of the road surface upon which the vehicle travels are estimated as their arithmetic average. This estimate provides significant information on the quality of road surface, given the capability of the LPC algorithm of filtering out (to a certain degree) spurious components of the acceleration signals (engine vibrations, gravitation, inertial forces, etc.).
In STL, the control of the diverse states of the vehicles and the streets is basic to give the ideal safety to the drivers. Currently, different approaches rely on safety data aggregation methods to identify and trace vehicles via observation cameras and diverse sensors (for instance, BOLO Vehicle Tracking Algorithm [103]).
In smart grid, the data produced by the diverse elements of smart grid network is huge. Therefore, in [97], the author proposes the hierarchical aggregation of the data. Power consumption data from different meters are collected and aggregated at prespecified aggregator meters hierarchically. All collected data is aggregated at data aggregation points of power generation plants, distributed energy resource stations, substations, transmission and distribution grids, control centers, and so on. The aggregator meters perform the aggregation by using some arithmetic and temporal operations. The aggregator meter waits for the arrival of data packets associated with the same timestamp from lower meters. For time-aligning the packets from multiple nodes, it temporarily buffers the extracted data, and once all the data with the same timestamp arrive, they are aggregated to create a single data packet. Then, the data are transmitted to the next aggregator meter.
In wind farms, wind turbines transmit data to the base station using multiple hops. Intermediate fog nodes can operate as aggregators reducing the number of direct links from the wind turbines to the base station. In [79], authors apply different data fusion techniques to aggregate the sensed data in the intermediate nodes depending on the physical components, timestamp of the sensed information, sampling rate, and sensor type.
6.4.5 Cloudification
The cloudification layer permits the operation of various IoT settings within the layers of fog nodes, serving as a small-version cloud within the fog. This layer offers four fundamental components: virtualization, composition, orchestration, and storage. First, a virtualization component permits developers to incorporate IoT applications and deploy them in a fog node. Second, the composition component facilitates the mash-up of small services deployed in the fog nodes in order to provide higher-level and better adapted services. The orchestration module allows IoT systems manager to control the different IoT instances deployed in a fog node. Finally, a storage element supports the permanent storage of data that is sent or requested by users so as to increase system's responsiveness. Despite being geared toward fog components, cloudification by definition spans all the three components of our architecture, being a shrink volume of cloud deployed in fog or even in the edge itself.
In this section, we mainly focused in the virtualization and storage components because they are the most important ones and the areas in which a higher number of solutions and technologies have been proposed. Section 6.4.5.1 details the most important platforms, allowing virtualization and deployment of IoT settings in fog nodes. Section 6.4.5.2 presents some of the most important mechanisms providing support to the storage of data in the fog nodes. For the sake of clarity, Figure 6.7 summarizes the proposed taxonomy with the possible choices for any of the components.
6.4.5.1 Virtualization
Virtualization permits fog nodes to make VMs. Virtualization considers two principle attributes. Tho=ese are the technology utilized to epitomize the IoT framework and how the virtual images are relocated between fog nodes, supporting the clients and framework mobility needs. Currently, the main technologies for creating virtual images are hypervisor and container. Hypervisor is a virtualization approach, where since a virtual image not only contains a final output but, rather, it delivers an operating system required for executing it. OpenStack and OpenNebula [104] are some of the frameworks supporting this virtualization technique. Instead, containers is a lightweight solution for the deployment of isolated execution context in top of an already defined operating system (i.e. it contains the applications, but not the operating systems). Not supporting the emulation of various operating platforms, it improves the execution and the relocation of the containerization parts. LinuX Containers (LXC) [105] or Docker [106] are some representative examples of this technology.
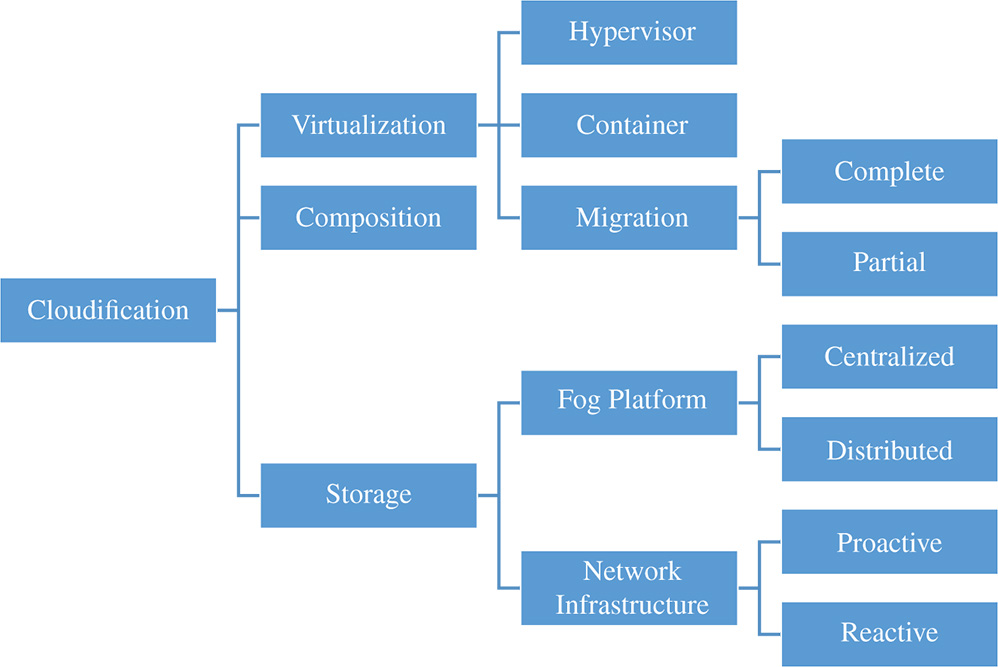
Figure 6.7 Taxonomy for the classification of the cloudification layer.
Migration is yet another key characteristic in virtualization. VM migration is essential in fog computing to address the mobility requirement. When a user leaves the area covered by the current fog node, the VMs or the container may need to be migrated to another node covering the user's destination. This process should be fast enough for maintaining real-time and location-awareness needs of IoT settings. Two principal migration approaches are used; a complete migration, in which the entire virtual image is migrated from one node to another (using Internet Suspend/Resume [ISR] [107] or Xen live migration [108], for instance) or partial migration, in which only specific pieces of the virtual image are transferred (utilizing, for instance, alternatives for the previous methods [109]).
Currently, there are many approaches employing those virtualization methods in fog computing settings. Cloudlet was proposed before fog computing, but both share the same concept. Actually, as it is indicated in Section 6.2.2, the Open Edge Computing Consortium promotes its use. Cloudlet comprises a three-layered-up stack, with the base layer containing a working OS, such as Linux, in addition to the information cache from the cloud. The center layer incorporates a hypervisor to isolate the transient guest software environment from the cloudlet infrastructure. Concretely, this layer is based on OpenStack++ [110], which is a specific extension of OpenStack including a set of cloudlet-specific APIs. The third upper layer constitutes applications separated by various VMs. Finally, cloudlets again deploys a specific method for the subtotal relocation of VM instances, dubbed as dynamic VM synthesis. Each cloudlet node comprises a basic VM and every mobile device constitutes a tiny VM overlay. Hence, when a mobile device relocates, a source node stops the overlay and saves it in the mobile device. When the mobile device hits the destination, it transmits the VM overlay into the destination node, subsequently applying it to its base, and thereby beginning its running in a precise state where it left off.
In [71, 72], the authors characterize an exploratory fog processing platform. This stage utilizes a hypervisor virtualization method so as to give adaptability. Solidly, they utilize OpenStack together with the Glance module for the administration of VM images. Likewise, they additionally execute two diverse migration schemes to encourage the meander of VM images among fog nodes. In the main technique, they take a snapshot of the VM to be relocated, compress it, and afterward exchange the compacted data to the target fog. In the second strategy, the VM has a base snapshot entrenched on the two fogs with the goal that they just exchange the incremental part of the VM's snapshot. IOx [111] is the Cisco implementation of fog computing, providing uniform and consistent hosting capabilities for fog applications across its own network infrastructure. IOx works by hosting applications in a guest operating system running a hypervisor directly on the connected grid router. The platform also supports programmers in running applications embedded on Docker and LXC, packaged as a VM, compiled and run as Java or Python bytecodes.
In addition, different platforms have been developed specifically focused on supporting some of the case studies evaluated in this paper.
Truong et al. [50] proposes a platform using software-defined networking (SDN) and fog computing to reduce the latency and improve the responsiveness of SCV applications. Concretely, the authors deploy a fog infrastructure on the roadside-unit controller (RSUC) and on the cellular base station (BS), allowing the computation and storage of some information from the vehicles in these elements. For supporting the virtualization, they use the hypervisor technique. Then, different vehicular and traffic services can be hosted in the VMs allowing service migration and replication.
In smart building, [112] proposes the platform ParaDrop to exploit the underused resources of WiFi access point or cable set-top box, provided by the network operators, with the aim of making them smarter and reducing the information transmitted to the cloud. To that end, ParaDrop uses the LXC abstraction for providing resource isolation and allowing third-party developers to deploy their services using this container. The containers retain user state and can move with the users as the latter changes their points of attachment. This platform has been used to support the control of environmental sensors (humidity and temperature) and security cameras, improving the privacy and the latency and providing local networking context to the system, since all the information is computed in the local node and only the data requested by end-users are transmitted through Internet.
6.4.5.2 Storage
Given the huge amount of data generated by smartphones and IoT devices, data must be allocated as close as possible to users. Information is first stored on fog nodes so as to accelerate its processing, decreasing thereby the information exchange latency and increasing the systems QoS.
Various approaches include storing that data on fog nodes or on different components of the network.
From one viewpoint, the fog system is able to handle local storage for keeping data in a disk-residence fashion. Based on priority, data are stored locally in a compressed manner, thus improving their security and privacy. Typically, these OSs store information on a single node (similar to a semi-centralized mode) or on various nodes (thus similar to a distributed mode).
Every virtualization mechanism and solid framework used by the operating system can implement one or both models. As detailed above, one of the widely used Hypervisor frameworks is OpenStack. The basic implementation of OpenStack can complements different modules providing different storage capabilities. The most important modules are Cinder and Swift. Cinder gives persistent block storage to guest VMs. This module encourages the storage of information on a given fog node, utilizing a centralized mode. Cinder virtualizes the administration of block storage devices and gives end clients a self-managed API to ask for and expend those assets. Swift functions as a distributed, API-open storage system that can be incorporated straightforwardly into IoT applications or used for storing VM images.
The fog platform presented in [89] is based on OpenStack, including the module Cinder for data storage. Therefore, this platform allows the centralized data storage in a specific fog node. Cloudlet is built on OpenStack++, which is mainly focused on improving the cloudlet deployment. Nevertheless, as OpenStack++ is plugging on top of OpenStack, it supports the addition of Cinder or Swift components. In addition, in [113], the authors present CoSMiC, a cloudlet-based implementation of a hierarchical cloud storage system for mobile devices based on multiple I/O caching layers. The solution relies on Memcached as a cache system, preserving its powerful capacities, such as performance, scalability, and quick and portable deployment. The solution aims to be hierarchical by deploying memcached-based I/O cache servers across all the I/O infrastructure data paths.
Containers, such as Docker or LXC, again provide various functionalities for caching and storing data. For instance, in [114], the authors evaluate Dockers as an edge computing platform. Every Docker container is separated and comprises its network subsystem in addition to memory and file systems. For data storage, Docker utilizes a lightweight file system dubbed as UnionFS to provide the building blocks for containers, allowing the caching of data to decrease user local access and to improve overall application performance. Concretely, Flocker is a container data-volume manager. It allows state-full container, e.g. production database data, to be protected. Any container regardless of its location can use Flocker.
On the other hand, other relevant works consider caching users' information on network infrastructure. Suchinformation is typically stored in a reactive fashion, thus caching data as users request it; or proactively, analyzing users' requirements on data and precaching accordingly.
The content delivery network (CDN) [115] serves as a representative for caching networks. CDN acts as an Internet-based cache network by disseminating cache servers at Internet edge so as to reduce upstream lateness caused by contents arriving from remote sites.
Information centric network (ICN) [116] is a wireless cache infrastructure that provides content distribution services to mobile users with distributed cache servers. Different from the cache servers in ICN, the fog servers are intelligent computing units. The fog servers can be connected to the cloud and leverage the scalable computing power and big data tools for rich applications other than content distribution, such as IoT, vehicular communications, and smart grid applications [9, 117].
Bastug et al. [118] detail that the information demand patterns of mobile users are predictable to an extent and propose to proactively precache the desirable information before users request it. The social relations and device-to-device communications are leveraged. The proactive caching framework described by Bastug et al. can be applied in fog computing.
6.4.6 Analytics and Decision-Making Layer
This layer promotes two principal components for decision-making in IoT settings. Those are decision management and data analytics (see Figure 6.8). First, all gathered data must be analyzed so as to detect varying trends and contexts. Section 6.4.6.1 details some of the main data analytics approaches. Second, from the data obtained by the sensors and the knowledge obtained processing them, different decisions are made in order to execute the appropriate business rules at the right time. Section 6.4.6.2 analyzes the main decision-making approaches for fog computing. For simplicity, Figure 6.8 depicts our taxonomy, elucidating all alternative components. Notice that this layer potentially spans the three components (fog, cloud, and edge) as it is a matter of fact that those kinds of advanced processing are nowadays being conducted at any of those layers with various degrees of load capacity. For example, some decisions are to be made in real-time near the edge nodes so as for the system to be able to feed actuators with appropriate decisions that guide their instant operation.

Figure 6.8 Taxonomy for the classification of the analytics and decision-making layer.
6.4.6.1 Data Analytics
Data analytics is an advanced analytics techniques application to data loads, aiming basically at gaining deep insights [61]. Concentrating basically on the location where data is analyzed, this component is normally divided into big data analytics and small data analytics. Big data analytics relies completely on cloud settings in order to perform complex operations for huge avalanches of fast-arriving big data loads, being able to identify complex associations, patterns, and trends [119]. On the contrary, small data analytics are performed near the edge, and thereby close to the IoT devices, suited to be handled by fog nodes. Small data analytics can handle only small amounts of fine-grained data that naturally provide beneficial information for a system, thus enabling real-time decisions near the edge in an as-fast-as-possible manner. The centralized model is perfectly suitable for orchestrating data generated by many applications with an appropriate response time. Likewise, a decentralized model provides real-time information for fast and short-term decision-making. Nevertheless, when many geographically distributed devices produce data requiring analysis alongside on-the-fly decisions, hierarchical data analytics models seem to respond better to different scenarios. Instead of sending all gathered data to the cloud, information can be stored, and small data analytics can be executed in the fog nodes. Then, relevant or complex data can be aggregated and posted to the cloud environment. In doing so, more complex and resource-demanding analytical techniques can be performed, and medium or long-term decisions can follow, depending on their outcomes [5].
Methods herein are employed for our aforementioned case studies. For instance, in STL and SCV systems, small data analytics are used for constructing a nearly exact picture of the surrounding current situation and thus assisting decision-maker components in reacting spontaneously. Both STL and SCV act in a critical context where the quickness of the decisions plays a key role in these systems than can even save many lives. These systems collect data regarding traffic density, vehicle-related data (for instance, speed, traces, internal condition), movements of different vehicles or bicyclists in lanes and emergency routing. The fog node should store this data and execute fast analysis to recognize certain events on the street, e.g. which vehicles are coming closer, crossing, or traveling along the road, and foresee where they will likely move. In this way, a basic setting for actuation must be able to prevent systems from crashing and improve safety. In this sense, Hong et al. [103] promoted the MCEP system for overseeing traffic via several patterns.
In the case of a wind farm, big data analytics are more often used, because not only are instant actions significant but also insights into future events are useful. A common issue in wind darm applications is to gather enough real-time data of good quality and, therefore, some ISO/RTO introduce mandatory data reporting requirements for wind power producers, with penalties for noncompliance [70]. As a general consideration, it is of great importance to ensure a specific exactness level when applying wind forecasting methods, especially those that are short-lived, so as to improve the quality of a wind power generator that the system offers to markets and to schedule appropriate levels of operating reserves needed to perform the different regulation tasks [68].
In smart grid and smart building use cases, layered-up data analytics are essential to guarantee that systems are working effectively and to accurately oversee dynamic end-client requests and distributed producing sources, supporting instant responses if an occurrence of unforeseen occasions should arise. Chen et al.'s [46] stacked-up data analytics are central to confront sustainable power source supply capriciousness that might be a important factor in connection to weather fluctuations, since each middle node serves as a functioning control unit, processing and responding to passing information [96]. In this scenario, many utility companies, with the intention to improve coordination and control techniques, have introduced smart meter readings to remotely meter-gathered data. As an example, consider consumption records, electricity production, and alarms [32].
6.4.6.2 Decision-Making
As the speed at which the collected information must be transmitted and processed in IoT scenarios increases, the readiness to settle on decisions to trigger explicit business procedures and standards in the correct minute is pivotal and it plainly influences the asset usage and consumer loyalty levels essentially [120]. Depending on how fast a decision is to be considered, the decision-making element is thus divided into predictive and reactive.
The predictive model stores all the data gathered by the sensors, the system's behaviors, its performance, etc., to get a profound learning of the surroundings and the framework so as to trigger the most suitable responses for every context and to surmise conceivable system advancement. These models focus on data calculation and gaining insights, thus constructing clear and predictive models from extensive volumes of data gathered so as to predict the relationship between settings' data. Despite what might be expected, reactive models react in the briefest conceivable time to various occasions that occur in the environment so as to endeavor to create corrections as early as possible. These models serve in a way that enables it to accomplish an ideal objective while interfacing with an environment.
More often, however, systems have diverse dimensions in the decision-making process consolidating at various degree the two models, yet our proposal depends on which part is progressively created and on which functionality the system is increasingly cantered around.
Few systems work in settings where predictions are vital, and they perform comprehensive data calculation and analytics.
Predictive Systems In numerous applications, the interaction among fog and cloud is straightforwardly related with the decision-making model desired. Predictive systems depend more on cloud so as to gather a lot of information and perform long-haul analytics to distinguish the distinctive policies that ought to be executed.
Some of these IoT systems rely on evolutionary or genetic algorithms to optimize the system operations. In Wind Farm, for instance, prediction has been identified as an important tool to address the increasing variability and uncertainty, and to more efficiently operate power systems with large wind power penetration. They are based on the analysis of the atmospheric stability and wind patterns at different time scales in order to increase the efficiency of the overall system: (1) monthly yearly basis predictions are used to improve the deployment process of the system; (2) daily forecast to submit bids to the independent system operators ISO/RTO; (3) hourly forecast to adjust the commitments, responding to contingencies that may occur in the operating conditions (e.g. forced outages of generators, transmission lines, deviation from the forecast loads, and so on); (4) few-minutes forecast to dynamically optimize the wind farm operations [70]. Unit commitment components relay on evolutionary techniques [121, 122] to limit operating expenses while satisfying the total needs offered in the market. This is normally done by a controller that decides global or customized arrangements and enforces them for each subsystem. Obviously, they additionally have some reactive methodology so as to build productivity and to counteract harm, closing down the turbines if wind is excessively low or hitting hard. Other approaches apply agent-based model, multivariate Gaussian model, hidden Markov model, and neural networks as predictive strategies to foresee behaviors of the various parts of systems. For example, in smart grid and smart building systems, [123, 124] highlight that predictive strategies meet user demand better than typical baseline strategies, showing better energy-savings performance and even significantly better QoS than typical reactive strategies. Prediction-based methods are able to predict the indoor comfort level and the QoS of a specific user by learning the user's behaviors and comfort zone, and to satisfy a user's needs by managing the efficient use of available resources. In [125], Erickson et al. make use of an agent-based and multivariate Gaussian model to evaluate the inhabitancy in a huge multipurpose building and for foreseeing client mobility designs so as to effectively control energy use in a smart building. In [123], the authors employ hidden Markov to model the behavior of the individual in relation to the temporal nature of the occupancy changes, the interroom correlations, and occupant usage of the areas in order to generate probabilistic instructions, achieving significant energy savings while still maintaining service quality, or even improving upon it.
Response approaches in these environments usually need more time to achieve the target quality required by the user, since there is a delay from the occurrence of an event and the system stabilization and, thus, they require more energy. Reactive methods can be utilized at the same time with the predictive methods so as to refine the system if there should arise a need and get the best results for every circumstance. In this context, [124] proposes a procedure, in view of neural networks methods, that consolidates distributed production, storage, and demand-side load management techniques, accomplishing a superior coordination of demand and supply.
Reactive Systems Reactive systems exploit the capabilities of fog environments in order to decide as early as the data are gathered in order to produce (near) real-time responses. Real-time support is a key trait in fog that is particularly essential in those systems that require an instant action. In general, real-time response is directly related to the reactive part of the system. Nonetheless, in some systems there must also be a balance between fog and cloud in order to optimize real-time responses.
To obtain a sufficient response time, as a rule-of-thumb a fog node closer to the edge means a better response time. Therefore, these systems exploit the close-to-the-edge [117] and location-awareness [9] methods. For instance, in STL and SCV applications, low-latency actions are essential demands crucial for safety. In both systems, low-latency reactions must be provided to be able to prevent vehicle collisions or for timely emergency ambulance vehicles passage. Bonomi et al. estimates that reaction time must fall in the premises of minimal milliseconds and, maybe most notably significant, less than 10 ms to be considered effective and thus satisfying safety hard bounds. In such a context, fog's role is critical in sensing the situation, process data, and thereby identify the required actuation in significantly limited time bounds. As such, those systems should use the trait of fog moving close to sensors/actuators so as to diminish the latency on a scale. In SCV, the fog layer has a massive role in changing information among vehicles in order to make better, more dynamic decisions, and outside vehicles, to provide information to the RSUs (stationary infrastructure elements that are installed along the road [50], and can be envisaged as higher-level fog nodes in a multilevel architecture), reducing latency and communication overhead. In both contexts, there is a relevant different time scale in relation to the purpose of the action. Fog nodes must be sufficiently powerful to be able to allow low-latency communication, inside the vehicles and between decision makers and traffic lights, in order to perform real-time reactions. At the same time, elevated amounts of data are forwarded to the cloud for long-haul analytics to evaluate the impact on traffic jams and to monitor city pollution, to mention just a few factors. Finally, the location-awareness strategy enhances system's responsiveness, providing advance knowledge of the environment amid applications execution with a few advantages; e.g. an RSU can infer whether a vehicle is in danger (because it is approaching too fast to a bend), and react to the nearby traffic light cycle to alter the circumstance or notify the driver accordingly.
In addition, STL systems may cross boundaries of several authorities. Thus, many critical application APIs around the whole system are coordinating and organizing their policies across the whole system, creating the control policies to send to the individual traffic lights and, inversely, collecting data from traffic lights [8].
6.5 Comparisons of Surveyed Solutions
In this section, we contrast the studied methodologies with a stress on the principle benefits and the inadequacies of the conceivable arrangement that can be adopted for structuring successful fog computing environments for IoT applications. As in the previous section, we organize our comparison alongside our logical architecture (see Figure 6.2).
6.5.1 Communication
Table 6.1 shows approaches surveyed for communication support, and cross-matching them with the categories and subcategories of relevancy. Further details about each follows in subsequent sections.
Table 6.1 Comparison between surveyed communication approaches.
| Standardization | Reliability | Latency | Mobility | |||||
| Application | Infrastructure | Retransmission | Handshake | Publish/subscribe | Latency | Routing | Resource Discovery | |
| CoAP [33] | X | X | X | X | ||||
| MQTT [34] | X | X | X | X | ||||
| Oasis [35] | X | X | X | |||||
| DDS [36] | X | X | X | X | ||||
| Zigbee [37] | X | |||||||
| ISO [38] | X | X | ||||||
| Tim Winter et al. [39] | X | X | ||||||
| IEFT WG [40] | X | |||||||
| IEEE 802.15.4 [126] | X | |||||||
| Bluetooth SIG [41] | X | X | ||||||
| Qualcomm [42] | X | |||||||
| Farinacci et al. [43] | X | X | ||||||
6.5.1.1 Standardization
The first step is selecting a protocol for communicating different system devices. This allow developers to standardize the communication between the different elements of the system and, at the same time, to choose the one that best suits the system's requirements. The selection of communication protocols is very dependent on the specific requirements of the application. Right now, various protocols can be chosen to improve the communication at network level, or between various devices or parts of the system. To state the obvious, numerous protocols at the application level depend on explicit protocols at the foundation level. Hence, certain attributes of the latter are acquired by the former. For instance, the ZigBee protocol depends on the IEEE 802.15.4 standard.
Specifically, by analyzing our case studies, we have noticed that ZigBee is especially recognized in IoT scenarios such as smart grid, smart building, and smart vehicle. This may be attributed in part to its short range and robustness with present noise conditions. In addition, especially in smart building and smart vehicle environments, the BLE has also gained momentum recently, in part due to its low-power energy consumption, short-range communication, and elasticity.
6.5.1.2 Reliability
The communication standardization is important for the correct exchange of information, but its reliability is also critical. This requires a system that confirms that appropriate data levels are being received instead of being lost, thus ensuring a correct flow of the system in most circumstances. Therefore, the protocols for communicating the different parts of the applications must contain techniques ensuring such reliability. As can be seen in Table 6.1, protocols such as CoAP, MQTT, AMQP, and DDS are based on retransmission techniques, allowing message retransmission a certain number of times until it is received. Algorithms such as MQTT and AMPQ also encompass handshake methods to establish the most appropriate parameters to ensure such communication. In addition, in order to further increase the reliability of the communications, other protocols implement multicasting techniques, so that different nodes can get the transmitted information.
Those techniques are commonly found in cases studies encompassing critical environments, such as smart vehicle and STL, since reliability is an essential requirement.
Nevertheless, as Table 6.1 shows, all the reliability methods found in the surveyed proposals are adopted by application protocols.
6.5.1.3 Low-latency Communication
A low-latency communication is important in IoT applications so that the system can respond adequately to certain situations. Low-latency must be accomplished among fog nodes, in addition to fog nodes and those in the cloud. CoAP, MQTT y DDS are protocols in support for low-latency of communication among various nodes. In addition, MQTT proposes the usage of various versions, a version for the communication between devices and fog nodes, and the other one is for the exchanging information between fog and cloud nodes. In the case studies evaluated, DDS is promoted in different situations associated with smart grid, smart building, and smart vehicle as it provides efficient and predictable distributions for time-critical data.
Similar to reliability, in the surveyed methods, low latency is focally accounted for by protocols of the applications (Table 6.1).
6.5.1.4 Mobility
The protocols figured beforehand normally encompass various techniques, such as routing and discovery mechanisms to improve and facilitate the mobility of the different nodes of the system. As indicated in Section 6.2, this is a fundamental requirement of IoT systems.
According to the analyzed solutions, mobility support is essential for infrastructure and application protocols in row. Two of the protocols that support this feature are RPL and LISP, making it easy for a device to migrate from one subnetwork to another. In addition, when a device changes from one context to another, it must facilitate the device in discovering services and resources disponible in that context. Normally, this characteristic is provided by application protocols. CoAP and UPnP are two of the analyzed protocols supporting this type of mobility.
Again, STL and SCV are the case studies where a correct implementation of the mobility techniques is crucial, since vehicles may be constantly moving from one fog node to another and the system operations should not be diminished by it. RTL is being adopted in other settings in addition to those described herein. In these same environments, the resource discovery techniques are used to identify and interact with new devices automatically.
6.5.2 Security and Privacy
Table 6.2 summarizes surveys works that fall in the security and privacy layer, with a matching to the correspondent categories.
6.5.2.1 Security
IoT systems are environments where data is normally scattered between different elements. Thus, the communication between them is constant. Therefore, techniques ensuring the security of such communications are essential.
This security is fundamentally given by the communication protocols. As can be seen in Table 6.2, some of them implement different techniques to encrypt the data transmitted between the different elements of the system. In addition, other protocols, such as CoAP, encapsulate techniques for improving integrity of data, ensuring that the exchanged messages have not been manipulated during the communication.
Table 6.2 Comparison between surveyed security and privacy approaches.
| Security | Privacy | Safety | ||||||
| Confidentiality | Data loss | Data integrity | Intrusion detection | Access control | Activities coordination | Activity monitoring | Action planning | |
| Wang et al. [4] | X | X | ||||||
| Botterud et al. [70] | X | |||||||
| Bouffard and Galiana [68] | X | |||||||
| Wang and Lu [45] | X | X | ||||||
| Ancillotti et al. [32] | X | X | X | |||||
| MQTT [34] | X | |||||||
| Oasis [35] | X | |||||||
| CoAP [33] | X | X | ||||||
On the other hand, security has also to be provided by every system. As Table 6.2 shows, the methodologies and case studies assessed basically focus on privacy and integrity of the information to guarantee that all communications are made by approved people and to ensure that the exchanged data is not altered.
Nonetheless, distributed and interlinked security mechanisms are urgent to integrate supreme solutions with a superior intelligence for responsiveness reactions and automated decisions based on M2M communications and M2M security control, without human interventions.
6.5.2.2 Privacy
For all case studies, privacy is considered a focal job. They store and analyze privacy-sensitive data and any unapproved access involves an incredible hazard for the IoT frameworks and for their clients. Nevertheless, as can be seen in Table 6.2, few of the analyzed solutions include mechanisms for the data privacy control, concentrating mainly on applications security and safety.
6.5.2.3 Safety
Many IoT applications work in critical environments where safety techniques must exist for ensuring the correct operation in suspected situations.
While analyzing the reviewed methodologies, we have distinguished that those case studies including an incredible number of devices and requiring an instant actuation more often than not employ one of two methods: activity monitoring and coordination. The former is utilized to precisely know the condition of every component, while the previous is applied to trigger facilitated activities to act over the environment and meet the system's objectives.
But, on the case studies where the reaction ought not be continuous such as those cases found in wind farm, there is a more noteworthy emphasis on the utilization of planned action techniques, since this permits a fine planning of each activity so as to augment the system benefits and safety.
6.5.3 Internet of Things
Table 6.3 summarizes a comparison of the surveyed solutions related to the Internet of Things layer. In the following subsections, we elaborate each layer, explaining the behavior of related systems.
6.5.3.1 Sensors
Sensing is a capacity performed by all those case studies. They all gather sense the surroundings gathering that assist in obtaining credible results, analyze the circumstance and make decisions accordingly. Both virtual and physical sensors are used herein.
Table 6.3 Comparison of the surveyed solution related to the Internet of Things layer.
| Sensors | Actuators | |||
| Physical sensors | Virtual sensors | Physical actuators | Virtual actuators | |
| Ronnie Burns [78] | X | X | ||
| Bonomi et al. [8] | X | X | X | |
| Chen et al. [46] | X | |||
| Duan and Xu [83] | X | X | ||
| Baars et al. [82] | X | X | ||
| Watson and Wixom [85] | X | X | ||
| Azvine et al. [84] | X | X | ||
| Ahmed and Kim [79] | X | X | ||
| Rotondo et al. [88] | X | X | X | X |
| Blesa et al. [87] | X | X | X | X |
| Al-Sultan et al. [89] | X | X | ||
| Greer et al. [90] | X | X | ||
| Stojmenovic [91] | x | X | ||
Few systems just require a sensing element, as an actuation phase is simply not there serving no purpose. More often than not, those systems acquire such data solely for analyzing the surrounding environment, or visualizing reports, or for conducting executive-level strategic decision making, such as establishing a company strategy for upcoming years.
6.5.3.2 Actuators
Real-time responsiveness requires more than sensing. Here is where actuators come into play. They work normally by changing the environments aiming at automatically or semi-automatically achieving desired goals. All case study systems clearly demand physical actuators. However, few of them use virtual actuators.
6.5.4 Data Quality
Table 6.4 shows a comparison of the surveyed solutions related to the Data Quality layer. We next explain the relationship between the surveyed solutions and each component of the layer.
Table 6.4 Comparison of the surveyed solution related to the data quality layer.
| Data normalization | Data filtering | Data aggregation | |||||||
| Language | Homogenization | Serialization | Duplicate | Erroneous | Prioritization | Fusion | Hierarchical | Safety | |
| Zao et al. [59] | X | X | |||||||
| Greer et al. [90] | X | X | |||||||
| Ancillotti et al. [32] | X | ||||||||
| Chen et al. [46] | X | ||||||||
| Gupta et al. [47] | X | X | |||||||
| Khandeparkar et al. [101] | X | ||||||||
| Freschi et al. [127] | X | X | |||||||
| Hong et al. [103] | X | X | |||||||
| Ho et al. [97] | X | X | |||||||
| Tyagi et al. [98] | X | X | |||||||
| Ahmed and Kim [79] | X | ||||||||
6.5.4.1 Data Normalization
Normalization collected is essential in unifying all heterogeneous data coming from different sources under one umbrella. In the case studies analyzed, we have recognized that present solutions are typically founded on proposing normal dialects improving the communication between various devices or nodes or some serialization instruments diminishing the asset consumption that is caused by exchanging data.
6.5.4.2 Data Filtering
Data filtering is a widely spread approach for reducing the sizes of data loads arriving in avalanches. Currently, many solutions employ methods for specifying duplicates and, detecting outliers. On the other part of the story, data prioritization is less famous and receives less attention specifically used in settings where different components of a system receive diverse priorities.
However, filtering critical data can be off-loaded to fog nodes, thus, prioritizing them on the fog environment level.
6.5.4.3 Data Aggregation
Data aggregation can normally be performed by fog nodes with certain computing and storage capacities. The vast majority of the techniques analyzed focus on fusing data, because it is the focal constituent part of this element. Various techniques also exploit a layered-up aggregation, on the price that this implies that common aggregation methods are deployed in each fog node or systems' coordinators have to perfectly know the resources for every fog node and its location so as to establish the aggregation method that is to be employed.
Also, data aggregation safety is yet another aspect widely accepted in critical scenarios. Nevertheless, they also require to know the different fog nodes in order to establish specific encryption and access control mechanisms.
6.5.5 Cloudification
Table 6.5 lists a comparison of the surveyed solution related to the Cloudification layer. In the next subsections, we explain how each component of the Cloudification layer is accommodated by the surveyed systems.
6.5.5.1 Virtualization
To create a fog platform capable of supporting different IoT applications, designers must analyze and clearly define the virtualization technology to use. As can be seen in Table 6.5, Hypervisor is the most extended technology, because is flexible and a wider range of IoT applications are exploiting it for their deployments, because the required OS is emerged in the VM. However, for settings where fog nodes have lower computing resources, or the type of deployed applications, and their requirements, are known and more or less fixed, containers can provide additional advantages, because it is a lightweight solution. Specifically, analyzing the surveyed solutions, those approaches proposing general fog platforms usually implement the hypervisor technology or both. More specific approaches, such as ParaDrop, use containers.
Table 6.5 Comparison of the surveyed solution related to the cloudification layer.
| Virtualization | Storage | ||||
| Hypervisor | Container | Migration | Fog platform | Network infrastructure | |
| Al Ali et al. [11] | X | X | X | ||
| S. Yi et al. [71, 72] | X | X | X | ||
| Cisco [111] | X | X | X | X | |
| Truong et al. [50] | X | X | X | ||
| Willis et al. [112] | X | X | X | ||
| Peng [115] | X | ||||
| Ahlgren et al. [116] | X | ||||
| Bastug et al. [118] | X | ||||
Also, all platforms allow the relocation of VMs. Often, containerized applications are totally relocatable, while platforms depending on the hypervisor technology permit a complete move of the VM images or complete and partial relocation. This is in part due to a large size of hypervisor-based VM images. It worth noting that some approaches propose few efficient algorithms for effectively migrating VMs images using IoT devices for transmitting information without overburdening network shoulders.
6.5.5.2 Storage
When it comes to storage, all fog nodes are welcoming. Naturally, data storage respects a centralized model, storing data in the same fog node that receives it. However, different approaches also implement the distributed storage of information, thus enhancing users' mobility alongside network and capacity of storage but increasing network overload.
Moreover, other approaches are working on directly storing data on the network infrastructure. These solutions allow the deployment of a large number of servers to cache the information in a distributed way. In addition, some proposals are working on predicting the information that will be required by users in order to store it in the network infrastructure close to the users that will request it. These approaches usually do not implement any method for the deployment of IoT applications on these servers, but they can be used to store the information produced by the IoT applications deployed on near fog nodes or incorporated in the fog platform.
6.5.6 Analytics and Decision-Making Layer
Table 6.6 shows a comparison of the surveyed solutions related to the Analytics and Decision-Making layer. In the subsections that follow, we detail the way that related systems are designed to handle each component of the layer.
6.5.6.1 Data Analytics
IoT systems aim mainly at analyzing massive amounts of sensor-collected datasets from diverse contextual conditions, and consecutively extracting a knowledge-base that serves top tiers in stacked-up architectures mainly for visualization and reporting in support for strategic decision making. Adopted data deep analytical techniques depend highly on the volume of the data in addition to its being time-sensitive, safety-sensitive or alike. Those techniques, often, consider the geo-locality of the arrived data so as to decide keeping it in fog or turning it on to a remote resource-rich cloud. Thus, the stringent the temporal constrains and the smaller the data set to analyze, the greater the number of techniques that should be relegated to the fog nodes. Instead, if the data set is very large, the analytics techniques are resource consuming, and the temporal requirements are not very strict, a higher number of these techniques should be executed in the cloud.
Table 6.6 Comparison of the surveyed solution related to the analytics and decision-making layer.
| Data analytics | Decision-making | ||
| Geo-distribution | Predictive | Reactive | |
| Hong et al. [103] | x | ||
| Botterud et al. [70] | X | X | X |
| Bouffard and Galiana [68] | X | ||
| Chen et al. [46] | X | ||
| Allalouf et al. [96] | X | ||
| Ancillotti et al. [32] | X | ||
| Uyar and Türkay [122] | X | ||
| Huang et al. [121] | X | ||
| Erickson et al. [123] | X | ||
| Molderink et al. [124] | X | X | X |
| Erickson et al. [125] | X | ||
| Truong et al. [50] | X | ||
| Bonomi et al. [8] | X | X | X |
Referring to our case studies, we know intuitively that most of them require instant decision making, thus are relying highly on processing some tasks near the edge, in fog specifically. However, some systems, such as those of wind farms, which normally require long-haul forecasting analytics more than often delegate such compute-intensive tasks to a resourceful cloud. It worth mentioning however that hybridizing capacities of the both worlds, small data analytics and big data analytics, is capable of providing the system with a performance boost.
6.5.6.2 Decision-Making
Upon analyzing collected data, the resulting information is normally used for making different decisions. If the decision-making process is automated or semi-automated, it can be performed in both the cloud and the fog nodes. As mentioned earlier, this depends, for the most parts, on the target response time, in such a way that those that are time-sensitive can perform some parts of their jobs near the edge (in fog), whereas those with more relaxed time constraints can wait normally for the whole cycle to complete, from sending collected data remotely to cloud all the way back to visualization and reporting In this sense, the data analytics and the decision-making elements are mostly related, since their distribution between fog and cloud nodes is usually similar.
Wind Farm, smart building, and smart grid are those scenarios such that the temporal requirements are normally eased, so many of their decision-making functionalities can be relegated to the cloud.
On the other hand, in critical systems, such as STL and SCV, the low-latency reaction is a key necessity and is pivotal for ensuring safety. These environments are predominantly reactive.
Nevertheless, most systems comprise various levels constituting the decision-making process hybridizing both models at different degrees.
6.6 Challenges and Recommended Research Directions
Fog is a promising powerful computational model that is expected to highly boost IoT applications' performance by scales of magnitudes. However, many challenges remain still in the path for a production-grade fog setting. Prioritizing their research is essential for taking current initiatives way steps further. We recommend the following prioritization list in this domain, to be considered as potential future research frontiers that characterize significantly the way that this paradigm may spread out within the premises of the next decade:
- Multilevel organization. Depending on the target application and the associated scenarios where an IoT setting is deployed, one can define a multilevel structure that is constituting of groups of nodes and interwoven and their constituent subgroups. In such a staggered organization, every fog node serves a particular job and responsibility. More often than not, in real-case applications, fog nodes ought to be organized into a hierarchical structure with a potential elasticity and scalability.
- Node specialization. In hierarchical structures or mesh typologies, each fog node is specialized to perform a specific work and it is optimized to handle each specific issue or weakness, with significant performance improvements. In addition, each node can be composed differently, with specific and concentrate resources in order to enhance its ability to perform the tasks assigned. Every setting should design fog in a way that optimizes the overall system's performance. For example, in wide-scale vehicular applications, fog nodes may be really heterogeneous, with very strong mobility and geo-distributed abilities outside the vehicle because they normally administer quick mobility endpoints in widespread real geometries and, on the contrary, inside the car, nodes concentrate resources on strong sensing and actuation phases to take the right decisions, timely, among static sensors.
- Actuation capacity. Fog computing is characterized by the interplay with cloud computing and many use cases are strongly based on it to analyze the situation and take the best decisions. An overarching trait of fog computing is that of its ability to sense whether an instant actuation is urgent, which triggers an action directly by fog itself, or otherwise the data can be sent safely all the trip down to a cloud where its slowly sending back results for a noninstant decision making. Depending on the environment where a fog setting is implanted, a set of rules should be able to define instant actuations and other cloud-depending relatively slow reactions. Moreover, each application has to define the level of fog-cloud interwoven. To take a more utilitarian perspective, in a vehicular IoT setting, cloud analytical capacities are normally employed for evaluating traffic patterns, thus detecting favorable ways for reaching out a destination. On the other hand, fog is responsible for real-time analysis related to the vehicle insides.
- Efficient fog-cloud communications. Fog computing often upload data to the cloud and similarly the cloud can send data and actuation commands/strategies to the fog. We aim to transmit as much data as possible, without generating traffic congestion and performance degradation that can slow down the system or too many iterations that can raise cost. It would be interesting to detect algorithms that are able to optimize these communications and improve fog computing components toward an efficient fog-cloud interface. Regarding the specific scenario, it is possible to choose the type of interactions that better suits the specific use case: in (1) latency-tolerant applications, the interplay with cloud communication can be reinforced and more frequent, with intensive batching communications that exchange heavy data and increase the focus on big data processing even to react to a current situation; in (2) latency-sensitive applications, the interplay between fog and cloud must be accurately planned and make the most of it with few interactions and raising small data processing importance for those systems. Moreover, independently to the specific application, the implementation of lightweight and efficient M2M protocols improving the communication and optimizing the resources used to exchange data are required.
- Efficient distributed data processing. Fog computing is responsible for managing the handling of massive amounts of fast arriving sensor real-time data, thus conforming to the hard requirements of real-time insights analytics. Sensing, data aggregation, data filtering, data analytics, fault detection techniques, Big Data and Small Data processing at different roles, must understand which data are useful and which can be wasted because are only “ground noise,” process data and, if required, be able to store only a minimal quantity of them. All these phases should be improved to speed-up performance and systems accuracy, for instance, with balancing the load computations or, if necessary, delegating few computing and storage jobs for resource-rich nodes.
- Interworking of different Fog localities. Fog deployments are widespread into environment localities and each fog locally coordinates a subgroup of IoT devices. Demand are raised for ways that are able to coordinate fog efforts in ways that enables achieving unified global objectives via the interwoven of various networks that share different information among different multi-level fog nodes or nodes spread out in various locations that have the awareness of several application scenarios. In this way, it could be possible to aggregate data from sensors located in different networks and with the possibility to use actuators spread in different networks too, extending the sensing-actuation cycle within larger areas, thus offering services in a more distributed fashion, with more complete functionalities and, thus, creating more sophisticated analysis and processing information more effectively.
In conclusion, we believe fog computing is a promising concept that has the potentiality to be an enabler and a significant driver for IoT environments. Further research is needed, and many challenges must be solved to establish the fog role practically and to enable industrially deployed IoT, in particular in critical and dynamic real-world applications.
6.7 Concluding Remarks
Cloud computing provides an elastic on-demand resource provisioning that is capable of achieving high big data processing throughputs in a fashion that was impossible before. Acting in parallel, Cloud deployments compete with server-based beefed architectures, gathering colloquial power in a recipe that is driven by appropriate share of computing resources. Having said that, IoT have been driven by such an evolution, which motivates and incentivize gathering huge amounts of data in the front-ends, knowing that back-end powers are available to process them in timely fashion aiming at actionable real-time insights. However, the past decade or so has witnessed an unprecedented adoption of IoT devices in all aspects of life, presenting the current two-tier cloud-IoT architectures with new challenges that exceeds their capacities.
Consider real-life end-to-end scenarios that integrate storage back-ends with serving systems and batch jobs in a fault-tolerant and consistent fashion that aims at keeping decision makers in the know. Those pipelines normally run into multiple complications that are not affecting traditional database management systems (DBMSs) or beefed-up server-based architectures. Those are complications that fog sets out to solve. By pushing down some processing loads toward edge or fog nodes, so as for those to serve as quick-and-clean sieve that filters unnecessarily downstream-loaded data (those that do not contribute to a critical result). This normally comes at the cost of higher consolidation requirements that spans multiple layers of the envisioned cloud-fog-IoT architecture. Works in the relevant literature have focused mainly on discrete aspects of fog-enabled IoT deployments.
Beyond its theoretical impact, fog technologies are gaining momentum and regarded more appropriate for scenarios that seek exact results. Healthcare, city planning, industrial IoT and Industry 4.0 (I4.0) are just few examples.
Relevant literature has mainly geared efforts toward cloud-only architectures, which easily become a bottleneck in sudden data arrival spike scenarios, where it become brittle and prone to failures. A situation that is mostly solved by approximation, which does not play well with fault tolerance.
We provide a high-level perspective pictured in a multilayer architecture. However, functionalities are nowadays hidden in black boxes so that a user does not have to reason about low-level aspects of communication and near-edge light processing. To our knowledge, there no conclusive work that gathers technologies developed for IoT requirement's support in a systematic manner. Also, there is no work that colloquially define (or at best are ill-defined) the role that each participated component of each layer plays in the background of the interconnected components that constitute our architecture. To this end, this chapter aims at analyzing the main IoT applications needs. We have conceptualized a global model of a fog architectural model satisfying the analyzed needs and a taxonomy so as to compare and contrast various proposals and elucidate their applicability in IoT domains to specific domains.
Stated another way, we herein draw a map that constitutes a reference guideline that assists practitioners in designing multilayered fog-enabled deployments, thus fostering and incentivizing a faster adoption. Our proposed architecture is modular and seamlessly allows incorporating elements in a hot-swappable manner. We mainly aim at achieving an overarching objective of better exploiting fog computing in accomplishing a seamless transition from a loosely coordinated set of existing cloud-based solutions to a fit-for-purpose fog-enabled architectures, which granularly aims at filling existing in-situ cloud-based architectural gaps.
We detail an explanation for all enabling technologies in order for this vision to see the light. From communication hardware-assisted levels all the way downhill to complex analytics.
This serves as a conclusive study that demonstrates systemically ways of interleaving the three worlds into an entwined architecture such as the one we propose in this chapter. We further expand on an “alchemy” behind a successful hybridization among the three elements. The purpose of this chapter is unveiling a rollout of a new working architecture through which we analyze and discuss our approach. We demonstrated it in a systematic way that aims at enabling it to serve as a compass for research and practice in the field of fog computing.
References
- 1 Vaquero, L.M. and Rodero-Merino, L. (2014). Finding your way in the fog: towards a comprehensive definition of fog computing. SIGCOMM Computer Communication Review 44: 27–32. https://doi.org/10.1145/2677046.2677052.
- 2 Bellavista, P., Cinque, M., Cotroneo, D., and Foschini, L. (2005). Integrated support for handoff management and context awareness in heterogeneous wireless networks. In: Proceedings of the 3rd International Workshop on Middleware for Pervasive and Ad-Hoc Computing, MPAC'05, 1–8. New York, NY, USA: ACM https://doi.org/10.1145/1101480.1101495.
- 3 Podnar Zarko, L., Antonic, A., and Pripužic, K. (2013). Publish/subscribe middleware for energy-efficient Mobile Crowdsensing. In: Proceedings of the 2013 ACM Conference on Pervasive and Ubiquitous Computing Adjunct Publication, UbiComp '13 Adjunct, 1099–1110. New York, NY, USA: ACM https://doi.org/10.1145/2494091.2499577.
- 4 Wang, W., Lee, K., and Murray, D. (2012). Integrating sensors with the cloud using dynamic proxies. In: 2012 IEEE 23rd International Symposium on Personal, Indoor and Mobile Radio Communications – (PIMRC), 1466–1471. Sydney, NSW, Australia: IEEE https://doi.org/10.1109/PIMRC.2012.6362579.
- 5 Yannuzzi, M., Milito, R., Serral-Gracià, R. et al. (2014). Key ingredients in an IoT recipe: fog computing, cloud computing, and more fog computing. In: 2014 IEEE 19th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), 325–329. Athens, Greece: IEEE https://doi.org/10.1109/CAMAD.2014.7033259.
- 6 Li, C., Xue, Y., Wang, J. et al. (2018). Edge-oriented computing paradigms: a survey on architecture design and system management. ACM Computing Surveys 51, pp. 39:1–39:34 doi: 10.1145/3154815.
- 7 Ferrer, A.J., Marquès, J.M., and Jorba, J. (2019). Towards the decentralised cloud: survey on approaches and challenges for Mobile, ad hoc, and edge computing. ACM Computing Surveys 51, pp. 111:1–111:36 https://doi.org/10.1145/3243929.
- 8 Bonomi, F., Milito, R., Natarajan, P., and Zhu, J. (2014). Fog computing: a platform for Internet of things and analytics. In: Big Data and Internet of Things: A Roadmap for Smart Environments, Studies in Computational Intelligence, 169–186. Cham: Springer https://doi.org/10.1007/978-3-319-05029-4_7.
- 9 Bonomi, F., Milito, R., Zhu, J., and Addepalli, S. (2012). Fog computing and its role in the Internet of things. In: Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, MCC '12, 13–16. New York, NY, USA: ACM https://doi.org/10.1145/2342509.2342513.
- 10 Wang, J., Pan, J., Esposito, F. et al. (2019). Edge cloud off-loading algorithms: issues, methods, and perspectives. ACM Computing Surveys 52, pp. 2:1–2:23 doi: 10.1145/3284387.
- 11 Al Ali, R., Gerostathopoulos, I., Gonzalez-Herrera, I. et al. (2014). An architecture-based approach for compute-intensive pervasive systems in dynamic environments. In: Proceedings of the 2nd International Workshop on Hot Topics in Cloud Service Scalability, HotTopiCS'14. New York, NY, USA, pp. 3:1–3:6: ACM https://doi.org/10.1145/2649563.2649577.
- 12 Satyanarayanan, M., Bahl, P., Caceres, R., and Davies, N. (2009). The case for VM-based cloudlets in mobile computing. IEEE Pervasive Computing 8: 14–23. https://doi.org/10.1109/MPRV.2009.82.
- 13 Satyanarayanan, M., Lewis, G., Morris, E. et al. (2013). The role of cloudlets in hostile environments. IEEE Pervasive Computing 12: 40–49. https://doi.org/10.1109/MPRV.2013.77.
- 14 Firdhous, M., Ghazali, O., Hassan, S., and Publications, S.D.I.W.C. (2014). Fog computing: will it be the future of cloud computing? In: The Third International Conference on Informatics & Applications (ICIA2014). Malaysia: Kuala Terengganu.
- 15 Davy, S., Famaey, J., Serrat, J. et al. (2014). Challenges to support edge-as-a-service. IEEE Communications Magazine 52: 132–139. https://doi.org/10.1109/MCOM.2014.6710075.
- 16 Bifulco, R., Brunner, M., Canonico, R. et al. (2012). Scalability of a mobile cloud management system. In: Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing, MCC '12, 17–22. New York, NY, USA: ACM https://doi.org/10.1145/2342509.2342514.
- 17 Taleb, T. and Ksentini, A. (2013). Follow me cloud: interworking federated clouds and distributed mobile networks. IEEE Network 27: 12–19. https://doi.org/10.1109/MNET.2013.6616110.
- 18 Taleb, T., Hasselmeyer, P., and Mir, F.G. (2013). Follow-me cloud: An OpenFlow-based implementation. In: 2013 IEEE International Conference on Green Computing and Communications (GreenCom) and IEEE Internet of Things (iThings) and IEEE Cyber, Physical and Social Computing(CPSCom), 240–245. Beijing, China: IEEE https://doi.org/10.1109/GreenCom-iThings-CPSCom.2013.59.
- 19 OEC, Open edge computing [WWW document], 2019. http://openedgecomputing.org (accessed October 29, 2019).
- 20 OFC, OpenFog Consortium, 2019. https://www.openfogconsortium.org (accessed February 14, 2019).
- 21 S. Dahmen-Lhuissier, Multi-access edge computing [WWW document], 2019. ETSI. http://www.etsi.org/technologies-clusters/technologies/multi-access-edge-computing (accessed October 29, 2019).
- 22 OF Reference, OpenFog Reference Architecture for Fog Computing, OpenFog Consortium, 2019. https://www.openfogconsortium.org/wp-content/uploads/OpenFog_Reference:Architecture_2_09_17-FINAL.pdf (accessed September 5, 2019).
- 23 Borgia, E. (2014). The Internet of things vision: key features, applications and open issues. Computer Communications 54: 1–31. https://doi.org/10.1016/j.comcom.2014.09.008.
- 24 Diallo, S., Herencia-Zapana, H., Padilla, J.J., and Tolk, A. (2011). Understanding interoperability, Proceedings of the 2011 Emerging M&S Applications in Industry and Academia Symposium, Boston, MA, 84–91. New York, NY, USA: ACM.
- 25 Bellavista, P., Corradi, A., and Magistretti, E. (2005). REDMAN: an optimistic replication middleware for read-only resources in dense MANETs. Pervasive and Mobile Computing 1: 279–310. https://doi.org/10.1016/j.pmcj.2005.06.002.
- 26 Toninelli, A., Pantsar-Syväniemi, S., Bellavista, P., and Ovaska, E. (2009). Supporting context awareness in smart environments: a scalable approach to information interoperability. In: Proceedings of the International Workshop on Middleware for Pervasive Mobile and Embedded Computing, M-PAC '09. New York, NY, USA, pp. 5:1–5:4: ACM https://doi.org/10.1145/1657127.1657134.
- 27 Stojmenovic, I. and Wen, S. (2014). The fog computing paradigm: scenarios and security issues. In: 2014 Federated Conference on Computer Science and Information Systems, FedCSIS 2014, 1–8. Warsaw, Poland: IEEE https://doi.org/10.15439/2014F503.
- 28 Perera, C., Qin, Y., Estrella, J.C. et al. (2017). Fog computing for sustainable smart cities: a survey. ACM Computing Surveys 50, pp. 32:1–32:43 https://doi.org/10.1145/3057266.
- 29 Puliafito, C., Mingozzi, E., Longo, F. et al. (2019). Fog computing for the Internet of things: a survey. ACM Transactions on Internet Technology 19, pp. 18:1–18:41 https://doi.org/10.1145/3301443.
- 30 Ferrer-Roca, O., Tous, R., and Milito, R. (2014). Big and small data: the fog. In: Presented at the 2014 International Conference on Identification, Information and Knowledge in the Internet of Things, 260–261. Beijing, China: IEEE https://doi.org/10.1109/IIKI.2014.60.
- 31 Al-Fuqaha, A., Guizani, M., Mohammadi, M. et al. (2015). Internet of things: a survey on enabling technologies, protocols, and applications. IEEE Communication Surveys and Tutorials 17: 2347–2376. https://doi.org/10.1109/COMST.2015.2444095.
- 32 Ancillotti, B.R. and Conti, M. (2013). The role of communication systems in smart grids: architectures, technical solutions and research challenges. Computer Communications 36: 1665–1697. https://doi.org/10.1016/j.comcom.2013.09.004.
- 33 CoAP, CoAP – Constrained Application Protocol [WWW document], 2019. http://coap.technology (accessed October 24, 2019).
- 34 MQTT, MQTT – Message Queue Telemetry Transport, 2019. http://mqtt.org (accessed October 24, 2019).
- 35 Oasis, AMQP – Advanced Message Queuing Protocol [WWW document], 2019. https://www.amqp.org (accessed October 24, 2019).
- 36 DDS, DDS – Data Distribution Services [WWW document], 2019. http://portals.omg.org/dds (accessed October 24, 2019).
- 37 Zigbee, Zigbee, 2019. http://www.zigbee.org (accessed October 24, 2019).
- 38 ISO, UPnP – ISO/IEC 29341–1:2011 Device Architecture [WWW document], 2019. https://www.iso.org/standard/57195.html (accessed October 24, 2019).
- 39 T. Winter, P. Thubert, A. Brandt et al., RPL: IPv6 Routing Protocol for Low-Power and Lossy Networks [WWW document], 2019. https://tools.ietf.org/html/rfc6550 (accessed October 24, 2019).
- 40 IEFT WG, 6LoWPAN – IPv6 over Low-Power Wireless Area Networks [WWW document], 2019. http://6lowpan.tzi.org (accessed Octoer 24, 2019).
- 41 Bluetooth SIG, BLE – Bluetooth Low Energy [WWW document], 2019. www.bluetooth.com (accessed October 24, 2019).
- 42 Qualcomm, LTE Advanced [WWW document]. Qualcomm, 2014. https://www.qualcomm.com/invention/technologies/lte/advanced (accessed October 24, 2019).
- 43 D. Farinacci, D. Lewis, D. Meyer, and V. Fuller, LISP – The Locator/ID Separation Protocol [WWW document], 2019. https://tools.ietf.org/html/rfc6830 (accessed October 24, 2019).
- 44 Bartoli, A., Dohler, M., Hernández-Serrano, J. et al. (2011). Low-power low-rate goes long-range: the case for secure and cooperative machine-to-machine communications. In: NETWORKING 2011 Workshops, Lecture Notes in Computer Science (eds. V. Casares-Giner, P. Manzoni and A. Pont), 219–230. Springer Berlin Heidelberg.
- 45 Wang, W. and Lu, Z. (2013). Survey cyber security in the smart grid: survey and challenges. Computer Networks 57: 1344–1371. https://doi.org/10.1016/j.comnet.2012.12.017.
- 46 Chen, H., Chou, P., Duri, S. et al. (2009). The design and implementation of a smart building control system. In: 2009 IEEE International Conference on e-Business Engineering, 255–262. Macau, China: IEEE https://doi.org/10.1109/ICEBE.2009.42.
- 47 Gupta, M., Krishnanand, K.R., Chinh, H.D., and Panda, S.K. (2015). Outlier detection and data filtering for wireless sensor and actuator networks in building environment. In: 2015 IEEE International Conference on Building Efficiency and Sustainable Technologies, 95–100. Singapore: IEEE https://doi.org/10.1109/ICBEST.2015.7435872.
- 48 Gungor, V.C., Sahin, D., Kocak, T. et al. (2011). Smart grid technologies: communication technologies and standards. IEEE Transactions on Industrial Informatics 7: 529–539. https://doi.org/10.1109/TII.2011.2166794.
- 49 Selvarajah, K., Tully, A., and Blythe, P.T. (2008). ZigBee for intelligent transport system applications. In: IET Road Transport Information and Control – RTIC 2008 and ITS United Kingdom Members' Conference, 1–7. Manchester, UK: IEEE https://doi.org/10.1049/ic.2008.0814.
- 50 Truong, N.B., Lee, G.M., and Ghamri-Doudane, Y. (2015). Software-defined networking-based vehicular ad hoc network with fog computing. In: 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM), 1202–1207. Ottawa, Canada: IEEE https://doi.org/10.1109/INM.2015.7140467.
- 51 Frank, R., Bronzi, W., Castignani, G., and Engel, T. (2014). Bluetooth low energy: an alternative technology for VANET applications. In: 2014 11th Annual Conference on Wireless on-Demand Network Systems and Services (WONS), 104–107. Obergurgl, Austria: IEEE https://doi.org/10.1109/WONS.2014.6814729.
- 52 Lee, B., An, S., and Shin, D. (2011). A remote control service for OSGi-based unmanned vehicle using SmartPhone in ubiquitous environment. In: 2011 Third International Conference on Computational Intelligence, Communication Systems and Networks, 158–163. Bali, Indonesia: IEEE https://doi.org/10.1109/CICSyN.2011.43.
- 53 Park, P., Yim, H., Moon, H., and Jung, J. (2009). An OSGi based in-vehicle gateway platform architecture for improved sensor extensibility and interoperability. In: 2009 33rd Annual IEEE International Computer Software and Applications Conference, 140–147. Seattle, WA: IEEE https://doi.org/10.1109/COMPSAC.2009.203.
- 54 Kim, J.E., Boulos, G., Yackovich, J. et al. (2012). Seamless integration of heterogeneous devices and access control in smart homes. In: 2012 Eighth International Conference on Intelligent Environments, 206–213. Guanajuato, Mexico: IEEE https://doi.org/10.1109/IE.2012.57.
- 55 Koß, D., Bytschkow, D., Gupta, P.K. et al. (2012). Establishing a smart grid node architecture and demonstrator in an office environment using the SOA approach. In: 2012 First International Workshop on Software Engineering Challenges for the Smart Grid (SE-SmartGrids), 8–14. Switzerland: IEEE, Zurich https://doi.org/10.1109/SE4SG.2012.6225710.
- 56 Bharghavan, V., Demers, A., Shenker, S., and Zhang, L. (1994). MACAW: a media access protocol for wireless LAN's. In: Proceedings of the Conference on Communications Architectures, Protocols and Applications, SIGCOMM'94, 212–225. New York, NY, USA: ACM https://doi.org/10.1145/190314.190334.
- 57 Gnawali, O., Yarvis, M., Heidemann, J., and Govindan, R. Interaction of retransmission, blacklisting, and routing metrics for reliability in sensor network routing. In: 2004 First Annual IEEE Communications Society Conference on Sensor and Ad Hoc Communications and Networks, 2004. IEEE SECON 2004, 34–43. Santa Clara, CA: IEEE https://doi.org/10.1109/SAHCN.2004.1381900.
- 58 Thangavel, D., Ma, X., Valera, A. et al. (2014). Performance evaluation of MQTT and CoAP via a common middleware. In: 2014 IEEE Ninth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), 1–6. Singapore: IEEE https://doi.org/10.1109/ISSNIP.2014.6827678.
- 59 Zao, J.K., Gan, T.T., You, C.K. et al. (2014). Augmented brain computer interaction based on fog computing and linked data. In: 2014 International Conference on Intelligent Environments, 374–377. Shanghai, China: IEEE https://doi.org/10.1109/IE.2014.54.
- 60 Amel, B.N., Rim, B., Houda, J. et al. (2014). Flexray versus Ethernet for vehicular networks. In: 2014 IEEE International Electric Vehicle Conference (IEVC), 1–5. Florence, Italy: IEEE https://doi.org/10.1109/IEVC.2014.7056123.
- 61 Varun, Menon, G. (2017). Moving from vehicular cloud computing to vehicular fog computing:issues and challenges. International Journal of Computational Science and Engineering 9: 14–18.
- 62 Hakiri, A., Berthou, P., Gokhale, A. et al. (2014). Supporting SIP-based end-to-end data distribution service QoS in WANs. Journal of Systems and Software 95: 100–121. https://doi.org/10.1016/j.jss.2014.03.078.
- 63 Rusitschka, S., Eger, K., and Gerdes, C. (2010). Smart grid data cloud: a model for utilizing cloud computing in the smart grid domain. In: 2010 First IEEE International Conference on Smart Grid Communications, IEEE, Gaithersburg, MD, USA, 483–488. https://doi.org/10.1109/SMARTGRID.2010.5622089.
- 64 Lee, K.C., Sudhaakar, R., Ning, J. et al. (2012, 2012). A comprehensive evaluation of RPL under mobility. International Journal of Vehicular Technology: 1–10. https://doi.org/10.1155/2012/904308.
- 65 Ancillotti, B.R. and Conti, M. (2013). The role of the RPL routing protocol for smart grid communications. IEEE Communications Magazine 51: 75–83. https://doi.org/10.1109/MCOM.2013.6400442.
- 66 UPNP Forum, Leveraging UPNP+. The next generation of universal interoperability, 2015. [online] Available at http://upnp.org/resources/whitepapers/UPnP_Plus_Whitepaper_2015.pdf.
- 67 Seo, H.S., Kim, B.C., Park, P.S. et al. (2013). Design and implementation of a UPnP-can gateway for automotive environments. International Journal of Automotive Technology 14: 91–99. https://doi.org/10.1007/s12239-013-0011-5.
- 68 Bouffard, F. and Galiana, F.D. (2008). Stochastic security for operations planning with significant wind power generation. IEEE Transactions on Power Apparatus and Systems 23: 306–316. https://doi.org/10.1109/TPWRS.2008.919318.
- 69 Gupta, H., Chakraborty, S., Ghosh, S.K., and Buyya, R. (2017). Fog computing in 5G networks: an application perspective. In: Cloud and Fog Computing in 5G Mobile Networks (eds. E. Markakis, G. Mastorakis, C.X. Mavromoustakis and E. Pallis), 23–56. London: The Institution of Engineering and Technology https://doi.org/10.1049/PBTE070E_ch2.
- 70 Botterud, A., Wang, J., Monteiro, C., and Mir, V. (2009). Wind Power Forecasting and Electricity Market Operations. Argonne National Laboratory.
- 71 Yi, S., Hao, Z., Qin, Z., and Li, Q. (2015). Fog computing: platform and applications. In: Presented at the 2015 Third IEEE Workshop on Hot Topics in Web Systems and Technologies (HotWeb), 73–78. Washington, DC: IEEE https://doi.org/10.1109/HotWeb.2015.22.
- 72 Shanhe Yi, Z. and Qin, Q.L. (2015). Security and privacy issues of fog computing: a survey. In: Wireless Algorithms, Systems, and Applications: 10th International Conference, WASA 2015, Qufu, China, August 10–12, 2015, Proceedings (eds. K. Xu and H. Zhu), 685–695. Cham: Springer International Publishing https://doi.org/10.1007/978-3-319-21837-3_67.
- 73 Kumari, M. and Nath, R. (2015). Security concerns and countermeasures in cloud computing paradigm. In: Proceedings of 2015 Fifth International Conference on Advanced Computing & Communication Technologies (ACCT 2015), 534–540. IEEE https://doi.org/10.1109/ACCT.2015.80.
- 74 Sivathanu, G., Wright, C.P., and Zadok, E. (2005). Ensuring data integrity in storage: techniques and applications. In: Proceedings of the 2005 ACM Workshop on Storage Security and Survivability, StorageSS '05, 26–36. New York, NY, USA: ACM https://doi.org/10.1145/1103780.1103784.
- 75 Stojmenovic, I., Wen, S., Huang, X., and Luan, H. (2016). An overview of fog computing and its security issues. Concurrency and Computation: Practice and Experience 28: 2991–3005. https://doi.org/10.1002/cpe.3485.
- 76 Aazam, M. and Huh, E.N. (2015). Dynamic resource provisioning through fog micro datacenter. In: 2015 IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops), 105–110. St. Louis, MO, USA: IEEE https://doi.org/10.1109/PERCOMW.2015.7134002.
- 77 Kabadayi, S., Pridgen, A., and Julien, C. (2006). Virtual sensors: abstracting data from physical sensors. In: 2006 International Symposium on a World of Wireless, Mobile and Multimedia Networks(WoWMoM'06), vol. 592, 6. Buffalo–Niagara Falls, NY, USA: IEEE https://doi.org/10.1109/WOWMOM.2006.115.
- 78 Ronnie Burns, Method and system for providing personalized traffic alerts,. US Patent 6590507 B2, 2003.
- 79 Ahmed, M.A. and Kim, Y.-C. (2016). Wireless communication architectures based on data aggregation for internal monitoring of large-scale wind turbines. International Journal of Distributed Sensor Networks 12 https://doi.org/10.1177/1550147716662776.
- 80 Di Liping (2007). Geospatial sensor web and self-adaptive earth predictive systems (SEPS). In: Proceedings of the Earth Science Technology Office (ESTO)/Advance Information Systems Technology (AIST) Sensor Web Principal Investigator (PI). Presented at the NASA AIST PI Conference, San Diego, CA, 1–4.
- 81 Srivastava, A.N., Oza, N.C., and Stroeve, J. (2005). Virtual sensors: using data mining techniques to efficiently estimate remote sensing spectra. IEEE Transactions on Geoscience and Remote Sensing 43: 590–600. https://doi.org/10.1109/TGRS.2004.842406.
- 82 Baars, H., Kemper, H.G., Lasi, H., and Siegel, M. (2008). Combining RFID technology and business intelligence for supply chain #x0A0: optimization scenarios for retail logistics. In: Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS 2008), 73–73. Waikoloa, HI, USA: IEEE https://doi.org/10.1109/HICSS.2008.93.
- 83 Duan, L. and Xu, L.D. (2012). Business intelligence for enterprise systems: a survey. IEEE Transactions on Industrial Informatics 8: 679–687. https://doi.org/10.1109/TII.2012.2188804.
- 84 Azvine, B., Cui, Z., and Nauck, D.D. (2005). Towards real-time business intelligence. BT Technology Journal 23: 214–225. https://doi.org/10.1007/s10550-005-0043-0.
- 85 Watson, H.J. and Wixom, B.H. (2007). The current state of business intelligence. Computer 40: 96–99. https://doi.org/10.1109/MC.2007.331.
- 86 Azzara, A. and Mottola, L. (2015). Virtual resources for the Internet of Tthings. In: 2015 IEEE 2nd World Forum on Internet of Things (WF-IoT), 245–250. Milan, Italy: IEEE https://doi.org/10.1109/WF-IoT.2015.7389060.
- 87 Blesa, J., Rotondo, D., Puig, V., and Nejjari, F. (2014). FDI and FTC of wind turbines using the interval observer approach and virtual actuators/sensors. Control Engineering Practice 24: 138–155. https://doi.org/10.1016/j.conengprac.2013.11.018.
- 88 Rotondo, D., Nejjari, F., and Puig, V. (2014). A virtual actuator and sensor approach for fault tolerant control of LPV systems. Journal of Process Control 24: 203–222. https://doi.org/10.1016/j.jprocont.2013.12.016.
- 89 Al-Sultan, S., Al-Doori, M.M., Al-Bayatti, A.H., and Zedan, H. (2014). A comprehensive survey on vehicular ad hoc network. Journal of Network and Computer Applications 37: 380–392. https://doi.org/10.1016/j.jnca.2013.02.036.
- 90 C. Greer, D.A. Wollman, D.E. Prochaska et al., NIST framework and roadmap for smart grid interoperability standards, Release 3.0. Special Publication NIST SP 1108r3, National Institute of Standards and Technology, 2014. https://doi.org/916755
- 91 Stojmenovic, I. (2014). Fog computing: a cloud to the ground support for smart things and machine-to-machine networks. In: 2014 Australasian Telecommunication Networks and Applications Conference (ATNAC), 117–122. Southbank, VIC, Australia: IEEE https://doi.org/10.1109/ATNAC.2014.7020884.
- 92 Nayak, S., Misra, B.B., and Behera, H.S. (2013). Impact of data normalization on stock index forecasting. International Journal of Computer Information Systems and Industrial Management Applications 6: 257–269.
- 93 Díaz, M., Martín, C., and Rubio, B. (2016). State-of-the-art, challenges, and open issues in the integration of internet of things and cloud computing. Journal of Network and Computer Applications 67: 99–117. https://doi.org/10.1016/j.jnca.2016.01.010.
- 94 Piqi, Pigi – The Piqi Project, 2019. http://piqi.org (accessed October 25, 2019).
- 95 Google, Protocol buffers [WWW Document]. Google Developers, 2019. https://developers.google.com/protocol-buffers (accessed October 25, 2019).
- 96 Allalouf, M., Gershinsky, G., Lewin-Eytan, L., and Naor, J. (2011). Data-quality-aware volume reduction in smart grid networks. In: 2011 IEEE International Conference on Smart Grid Communications (SmartGridComm), 120–125. IEEE https://doi.org/10.1109/SmartGridComm.2011.6102302.
- 97 Ho, Q.D., Gao, Y., and Le-Ngoc, T. (2013). Challenges and research opportunities in wireless communication networks for smart grid. IEEE Wireless Communication 20: 89–95. https://doi.org/10.1109/MWC.2013.6549287.
- 98 Tyagi, S., Ansari, A.Q., and Khan, M.A. (2010). Dynamic threshold based sliding-window filtering technique for RFID data. In: 2010 IEEE 2nd International Advance Computing Conference (IACC), 115–120. Patiala, India: IEEE https://doi.org/10.1109/IADCC.2010.5423025.
- 99 Tang, L.-A., Han, J., and Jiang, G. (2014). Mining sensor data in cyber-physical systems. Tsinghua Science and Technology 19: 225–234. https://doi.org/10.1109/TST.2014.6838193.
- 100 Smith, S. (2013). Digital Signal Processing: A Practical Guide for Engineers and Scientists. Elsevier.
- 101 Khandeparkar, K., Ramamritham, K., and Gupta, R. (2017). QoS-driven data processing algorithms for smart electric grids. ACM Transactions on Cyber-Physical Systems 1, pp. 14:1–14:24 https://doi.org/10.1145/3047410.
- 102 Sang, Y., Shen, H., Inoguchi, Y. et al. (2006). Secure data aggregation in wireless sensor networks: a survey. In: 2006 Seventh International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT'06), 315–320. Taipei, Taiwan: IEEE https://doi.org/10.1109/PDCAT.2006.96.
- 103 Hong, K., Lillethun, D., Ramachandran, U. et al. (2013). Mobile fog: a programming model for large-scale applications on the internet of things. In: Proceedings of the Second ACM SIGCOMM Workshop on Mobile Cloud Computing, MCC '13, 15–20. New York, NY, USA: ACM https://doi.org/10.1145/2491266.2491270.
- 104 OpenNebula, OpenNebula – flexible enterprise cloud made simple, 2019. https://opennebula.org (accessed October 26, 2019).
- 105 Canonical, Linux containers [WWW document], 2019. https://linuxcontainers.org (accessed October 26, 2019).
- 106 Docker, Docker [WWW document], 2019. Docker. https://www.docker.com (accessed October 26, 2019).
- 107 Kozuch, M. and Satyanarayanan, M. (2002). The internet suspend/resume (ISR). In: 4th IEEE Workshop Mobile Computing Systems and Applications. IEEE CS Press.
- 108 Clark, C., Fraser, K., Hand, S. et al. (2005). Live migration of virtual machines. In: Proceedings of the 2Nd Conference on Symposium on Networked Systems Design & Implementation – Volume 2, NSDI'05., 273–286. Berkeley, CA, USA: USENIX Association.
- 109 Kozuch, M., Satyanarayanan, M., Bressoud, T. et al. (2004). Seamless mobile computing on fixed infrastructure. Computer 37: 65–72. https://doi.org/10.1109/MC.2004.66.
- 110 Ha Kiryong and Mahadev Satyanarayanan, OpenStack++ for cloudlet deployment [WWW document], 2015. (accessed October 26, 2019).
- 111 Cisco, IOx [WWW document], 2019. https://developer.cisco.com/site/iox/docs (accessed October 26, 2019).
- 112 Willis, D., Dasgupta, A., and Banerjee, S. (2014). ParaDrop: a multi-tenant platform to dynamically install third party services on wireless gateways. In: Proceedings of the 9th ACM Workshop on Mobility in the Evolving Internet Architecture, MobiArch '14, 43–48. New York, NY, USA: ACM https://doi.org/10.1145/2645892.2645901.
- 113 Rodrigo Duro, F., Garcia Blas, J., Higuero, D. et al. (2015). CoSMiC: a hierarchical cloudlet-based storage architecture for mobile clouds. Simulation Modelling Practice and Theory 50: 3–19. https://doi.org/10.1016/j.simpat.2014.07.007.
- 114 Ismail, B.I., Goortani, E.M., Karim, M.B.A. et al. (2015). Evaluation of Docker as edge computing platform. In: 2015 IEEE Conference on Open Systems (ICOS), Bandar Melaka, Malaysia, 130–135. IEEE https://doi.org/10.1109/ICOS.2015.7377291.
- 115 G. Peng, CDN: Content Distribution Network, 2004. arXiv:cs/0411069
- 116 Ahlgren, B., Dannewitz, C., Imbrenda, C. et al. (2012). A survey of information-centric networking. IEEE Communications Magazine 50: 26–36. https://doi.org/10.1109/MCOM.2012.6231276.
- 117 T.H. Luan, L. Gao, Z. Li et al., Fog computing: focusing on mobile users at the edge, 2015. ArXiv150201815 Cs.
- 118 Bastug, E., Bennis, M., and Debbah, M. (2014). Living on the edge: the role of proactive caching in 5G wireless networks. IEEE Communications Magazine 52: 82–89. https://doi.org/10.1109/MCOM.2014.6871674.
- 119 Raghupathi, W. and Raghupathi, V. (2014). Big data analytics in healthcare: promise and potential. Health Information Science and Systems 2 https://doi.org/10.1186/2047-2501-2-3.
- 120 Isaai, M.T. and Cassaigne, N.P. (2001). Predictive and reactive approaches to the train-scheduling problem: a knowledge management perspective. IEEE Transactions on Systems, Man, and Cybernetics Part C: Applications and Reviews 31: 476–484. https://doi.org/10.1109/5326.983931.
- 121 Huang, Y., Pardalos, P.M., and Zheng, Q.P. (2017). Deterministic unit commitment models and algorithms. In: Electrical power unit commitment: Deterministic and two-stage stochastic programming models and algorithms, SpringerBriefs in Energy. Springer USA, Boston, MA (eds. Y. Huang, P.M. Pardalos and Q.P. Zheng), 11–47. https://doi.org/10.1007/978-1-4939-6768-1_2.
- 122 Uyar, H. and Türkay, B. (2008). Evolutionary algorithms for the unit commitment problem. Turkish Journal of Electrical Engineering 16 (3).
- 123 Erickson, V.L., Carreira-Perpiñán, M.A., and Cerpa, A.E. (2011). OBSERVE: occupancy-based system for efficient reduction of HVAC energy. In: Proceedings of the 10th ACM/IEEE International Conference on Information Processing in Sensor Networks, 258–269. Chicago, IL, USA: IEEE.
- 124 Molderink, A., Bakker, V., Bosman, M.G.C. et al. (2010). Management and control of domestic smart grid technology. IEEE Transactions on Smart Grid 1: 109–119. https://doi.org/10.1109/TSG.2010.2055904.
- 125 Erickson, V.L., Lin, Y., Kamthe, A. et al. (2009). Energy efficient building environment control strategies using real-time occupancy measurements. In: Proceedings of the First ACM Workshop on Embedded Sensing Systems for Energy-Efficiency in Buildings, BuildSys '09, 19, 2009–24. New York, NY, USA: ACM https://doi.org/10.1145/1810279.1810284.
- 126 IEEE 802.15.4 – IEEE Standard for Information technology – Local and metropolitan area networks – Specific requirements – Part 15.4: Wireless Medium Access Control (MAC) and Physical Layer (PHY) Specifications for Low Rate Wireless Personal Area Networks (WPANs) [WWW document], 2006. https://standards.ieee.org/standard/802_15_4-2006.html (accessed February 14, 2019).
- 127 Freschi, V., Delpriori, S., Klopfenstein, L.C. et al. (2014). Geospatial data aggregation and reduction in vehicular sensing applications: the case of road surface monitoring. In: 2014 International Conference on Connected Vehicles and Expo (ICCVE), 711–716. Vienna, Austria: IEEE https://doi.org/10.1109/ICCVE.2014.7297643.