
12
Distributed Machine Learning for IoT Applications in the Fog
Aluizio F. Rocha Neto1, Flavia C. Delicato2, Thais V. Batista1, and Paulo F. Pires2
1DIMAp, Federal University of Rio Grande do Norte, Natal, Brazil
2PGC/IC/UFF, Fluminense, Federal University, Niterói, Brazil
12.1 Introduction
The term Internet of Things (IoT) was coined by the British Kevin Aston in 1999 [1] and since then we have seen such a paradigm come about thanks to the evolution of several enabling technologies. IoT advocates a reality in which the physical and virtual worlds mingle through rich interactions. Its boundaries become almost invisible, so as to be possible on the one hand, the augment of the physical world with virtual information, and, on the other hand, the extension of the virtual world to encompass concrete objects. To do so, the first step is to instrument physical entities, through sensors, capable of acquiring various types of environmental variables, and actuators, capable of changing the state of physical objects. By instrumenting objects, they become endowed with the ability of perceiving the surrounding world and are generally denoted as intelligent or smart objects. However, the perception capability is only a small portion of what we call intelligence. Data on perceived phenomena can be partially processed locally (in the smart objects themselves) and then transmitted (usually through wireless interfaces) until eventually they are available on the Internet via virtual representations of the perceived physical phenomenon. This local processing characterizes another facet of intelligence in IoT objects, and its degree of complexity depends entirely on the amount of resources available in the device. Physical devices can communicate with their connected neighbors in order to exchange data on the monitored (common) phenomena, enriching the information before transmitting it. Once entering the virtual world, the data captured by the objects can serve as input to the most sophisticated processing and analysis systems in order to extract useful knowledge for a variety of purposes. This complex processing characterizes the ultimate degree of intelligence related to IoT systems.
Given the number of physical objects on Earth, if only a tiny fraction of them are instrumented by sensors/actuators, IoT will certainly have the potential to be the largest source of Big Data on the planet and as such, brings numerous research challenges to be solved to enjoy all the possible benefits of this paradigm. In this context, it is important to understand where these benefits really come from, and what challenges and avenues of research need to be explored to concretize the view of a fully connected, virtualized and Smart world.
First of all, although the IoT paradigm is focused on the connection of objects, its real potential lies not in the objects themselves, but in the ability to generate valuable knowledge from the data extracted from these objects. It can be said that IoT actually is not about things but about data. Therefore, the process of transforming the raw data collected through the perception of the physical environment in value-added information and, ultimately, in high-level knowledge capable of optimizing decision making, is crucial to obtaining the real benefit of IoT. At the heart of this transformation process are computational intelligence (CI) techniques. In particular, machine learning (ML) techniques are promising to process the data generated in order to transform them into information, knowledge, to predict trends, produce valuable insights, and guide automated decision-making processes. However, the use of machine learning (ML) techniques in IoT brings up several challenges, especially regarding the computational requirements demanded by them.
As discussed earlier, the IoT devices themselves may be part of this data transformation process. However, with their limited resources, they generally cannot perform very complex processing. With their vast computing capabilities, cloud platforms are the natural candidates as backend of IoT systems and perform computationally intensive analysis and long-term data storage. However, with the increasing growth in data generated by sensors and IoT devices, their discriminated transmission to the cloud began to generate a set of problems. Among them, the excessive use of network bandwidth has brought congestions and poor performance in the communication infrastructure. In addition, several IoT applications have critical response time requirements, and the high and unpredictable latency of the Internet for accessing remote data centers in the cloud is not acceptable in this context.
The challenge of minimizing network latency and improving computational performance in the context of IoT environments has been recognized among the main concerns of the IoT research community. In this context, the concept of fog computing was suggested by the industry and further extended by academic researchers. Cisco – one of the main pioneers on fog computing – states that the fog infrastructure (composed by smart switches, routers, and dedicated computing nodes) brings the cloud closer to the things that produce IoT data. The main idea in this approach is to put the computation resources closer to the data source – the IoT devices – so that they require less network traffic and are more cloud independent, reducing the application overall delays.
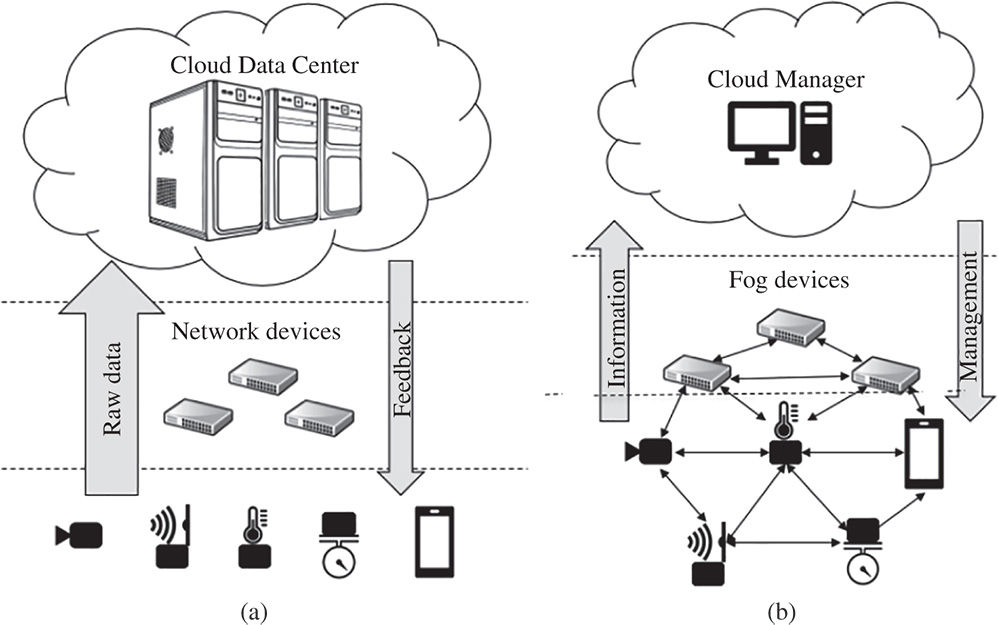
Figure 12.1 Three-tier architecture for IoT (a) and two-tier cloud assisted IoT (b).
In a similar way, the concept of edge computing is also used to refer to pushing the computation down to the end devices, i.e. toward the “edge” of the network. However, according to [2], edge is the first hop from the IoT devices. It enables that computations be executed on small datacenters close to the edge device itself. In this way, some advanced data analytics and processing can be performed near the devices, thus reducing system response time and network traffic. Figure 12.1 presents the differences between the traditional organization of IoT system architecture in three tiers and the novel vision, introduced by fog/edge computing paradigms. In the three-tier architecture (Figure 12.1a), IoT devices have to send a large amount of raw data to be processed on servers hosted typically in cloud data centers and wait for some feedback. With the two-tier fog/edge computing paradigm (Figure 12.1b), the edge and network devices collaboratively process the raw data and send only high-level information to a manager in the cloud.
In this two-tier architecture, the data produced by the IoT devices can then be processed: (1) in the data source itself (also called the Things tier/layer), (2) in cloud platforms, and (3) in the intermediate layer of fog/edge. Depending on the application requirements (such as response time) and the complexity of the required processing technique, each tier will be more suitable for performing the computation. The overhead that current ML techniques imposes on devices of the fog and things tiers, in which resources are scarce, hinders their widespread adoption in this context. In addition to the challenges of the processing complexity required by the ML techniques, the specific features of the data produced by IoT devices raise further requirements. Typically, data produced by IoT are time-series values, which are gathered during a period and transmitted to a gateway for further processing. Compared with Big Data produced by other sources, such as social data, sensor data streams have additional features that call for a shifting from the Big Data paradigm to the Big Data stream paradigm, which we discuss throughout this chapter.
Motivated by all the aforementioned issues, this chapter aims at presenting the reader with a broad view on the challenges of using ML techniques at the edge of the network, taking advantage of the capabilities of this tier while dealing with the computational constraints of fog devices. Due to the constant evolution of IoT devices and ML techniques, recent published researches in these fields are prone to become out of date quickly. Besides, there is a great rush in the technological scientific community to apply modern artificial intelligence techniques in their systems in order to increase their efficiency and provide better solutions for their problems. The ultimate goal of CI applied in context of IoT systems is to build valuable knowledge for supporting better decision-making processes in a wide range of application domains.
The next section presents the main challenges in processing IoT data, considering its peculiar features and the intersection of IoT and the Big Data paradigm. Section 12.3 gives a bird's-eye view on the employment of CI techniques at the edge of the networks, as a strategy to extract useful information from raw data and reduce the network overhead, as proposed by the fog computing paradigm. Section 12.4 describes the main challenges related to the execution of ML techniques within the resource constrained fog devices, analyzing different categories of devices according to their resources. Finally, we present some approaches to distribute intelligence on fog devices, with focus on distributed processing and information sharing.
12.2 Challenges in Data Processing for IoT
In recent years, the number of IoT devices/sensors has increased exponentially and there is an estimation that by 2020 it will reach 26 billion.1 This network of devices/sensors encompasses an infrastructure of hardware, software, and services integrating the Internet with the physical world. This change in the physical world is giving a new shape in the way that individuals observe and interact with the environment. A plethora of applications can emerge, exploiting the diversity of real-time monitored data, and combining them in different ways to provide value-added information to users. Examples of advanced and intelligent applications are smart home, smart building, and smart city. The SmartSensor infrastructure [3] is an example of recent research initiatives aimed to support these applications and it was developed to manage a set of wireless sensor networks (WSNs), where sensors work collaboratively, extracting environmental data to be further processed and augmented with semantics information to provide value-added services to users.
At the heart of IoT ecosystems are the tiny sensors spread around the physical environment, possibly deployed in a large number, of the order of hundreds to thousands, depending on the size of the monitored region. Such sensors will create a data deluge encompassing different kinds of information with different values. How to handle these data and how to dig out the useful information from them are issues being tackled in recent researches. In [4], the authors suggest a simple taxonomy to classify the types of data in the IoT. According to the authors, “data about things” refers to data that describe the objects/things themselves (e.g. state, location, identity), while “data generated by things” refer to data generated or captured by things (e.g. room temperature, people counting, traffic condition). Data about things can be used to optimize the performance of the systems and infrastructures, whereas data generated by things contains useful information about interaction between humans and systems and among systems themselves; such data can be used to enhance the services provided by IoT [5].
In this section, we discuss the challenges introduced by IoT systems in three different dimensions: the generation, transmission, and processing of data. Such dimensions are typically related to and addressed by three well-known research fields, namely Big Data, Big Data stream, and data stream processing. Figure 12.2 shows a taxonomy for these challenges imposed by IoT system and the respective aspects addressed by each of the three dimensions.
12.2.1 Big Data in IoT
Big Data refers to voluminous and complex data sets that require advanced data processing application software. It involves several challenges that encompass capturing, storing, sharing, searching, transferring, analyzing, visualizing, updating, and protecting data. The IoT environment is one of the key areas responsible for this trend of data explosion. High data rate sensors, such as surveillance cameras, are one of the most relevant in this context.

Figure 12.2 IoT Data Challenges in three dimensions: generation, transmission, and processing of data.
Data scientists have defined six features to address all the issues related to Big Data:
- Volume. This is the key aspect to consider a data set to be “big,” as the size of the data is measured as volume.
- Velocity. This is related to the rate of data generation and transmission. The huge amount and speed of IoT Big Data coming from several sources demands the support for big data in real-time.
- Variety. With increasing volume and velocity comes increasing variety, which describes the huge diversity of data types any IoT system can produce.
- Veracity. Refers to how accurate and how truthful is the data set. It is more than reliability of the data source, it also involves the degree of confidence in the analysis of the data. This feature is quite important in IoT system that uses crowd-sensing data.
- Variability. This feature refers to the different rates of data flow, which may vary from time to time or place to place. For instance, in an IoT application for traffic management using sensors, the speed at which data is loaded in a database can have expressive variations depending on the heavy traffic hours.
- Value. Data must have value, i.e. all the infrastructure required to collect and interpret data on an IoT system must be justified by the insights you can gather to improve the user experience and services.
Another important aspect for the value of data is its temporariness. In many smart IoT systems that are time-sensitive, such as traffic accident monitoring or river flooding prediction, and where the system has to take some automatic action in a real-time manner, the potential value of data depends on data freshness that needs to be processed. Otherwise, the processing results and actions become less valuable or even worthless.
Qin et al. [6] present an IoT data taxonomy classifying the IoT data into three categories, regarding different characteristics of data: data generation, data quality, and data interoperability. Data generation is related to the Big Data features aforementioned such as velocity, scalability, dynamics, and heterogeneity. Data quality is related to the following characteristics:
- Uncertainty. In IoT data, uncertainty can refer to variance from the expected states of the data, due to several reasons such as transmission errors or sensing precision.
- Redundancy. Errors in sensor reading logic can produce multiple data that can interfere in the semantic of sensor data. For example, in radio-frequency identification (RFID) data, the same tag can be read multiple times at the same location when there are multiple RFID readers at the same spot to improve the sensing.
- Ambiguity. Refers to different ways of interpreting data from diverse things to distinct data consumers. This misunderstanding may interfere with the overall inference about the sensed environment.
- Inconsistency. Such as ambiguity, inconsistency may occur in the interpretation of data that may produce misunderstandings. It is common to detect inconsistency in sensing data in case of several sensors monitoring an environment.
Data interoperability is addressed by the following characteristics:
- Incompleteness. In many IoT applications that detect and react to events in real time, the combination of data from different sources is important to build a complete picture of the environment. However, in this cooperation of mobile and distributed things who are generating the data, some problem related to the data quality from any source may negatively interfere in the whole system.
- Semantics. Semantic technologies have been used to endow machines with the ability of processing and interpreting IoT data.
Despite presenting all the aforementioned characteristics, the data produced by IoT devices have additional features, not always observed in Big Data. Typically, data produced by IoT sensors consist of time-series values, which are sampled over a defined period and then transmitted to a gateway for further processing. Compared with Big Data produced by other sources, such as social data, sensor data streams have additional features that call for a shifting from the Big Data paradigm to the Big Data Stream paradigm, which we discuss in the next section.
12.2.2 Big Data Stream
Time-series data are not processed in the same way as the typical Big Data nor as easily interpretable such as, for instance, a document, video, or other data available on the Internet. Data items arrive continuously and sequentially as a stream and are usually ordered by a timestamp value besides including other additional attribute values about the data item. Differently from Big Data that is typically produced in controlled and owned data warehouses, data streams are usually generated by heterogeneous and scattered sources. In general, IoT systems do not have direct access or control over such data sources. Moreover, the input characteristics of a data stream are usually not controllable and typically unpredictable. Data streams are provided in different rates, for instance, from small number of bytes per second to several gigabits. The inherent nature of the input does not allow one to easily make multiple passes over a data stream while processing (and still retaining the usefulness of the data).
Finally, numerous important IoT scenarios, such as logistics, transportation, health monitoring, emergence response, require predictable latency, real-time support, and could dynamically and unexpectedly change their requirements (e.g. in terms of data sources). Big Data stream–oriented systems need to react effectively to changes and provide smart, semi-autonomous behavior to allocate resources for data processing, thus implementing scalable and cost-effective services. The inherent inertia of Big Data approaches, that commonly rely on batch-based processing, are not proper for data processing in IoT contexts with dynamism and real-time requirements.
The Big Data stream paradigm enables ad-hoc and real-time processing to connect streams of data and consumers, benefiting scalability, dynamic configuration, and management of heterogeneous data formats. In summary, although Big Data and Big Data stream cope with massive numerous heterogeneous data, Big Data centers on the batch analysis of data, Big Data stream deals with the management of data flows and real-time data analysis. This feature has an impact also on the data that are considered relevant to consumer applications. For instance, while for Big Data applications it is important to keep all sensed data in order to be able to perform any required computation, Big Data stream applications might decide to perform real-time data processing on the raw data produced by IoT devices to reduce the latency in transmitting the results to consumers, with no need to persist such raw data. IoT platforms such as Xively12 (former Cosm), EcodiF [7], or Nimbits23 are focused on handling Big Data stream produced by IoT devices. However, they basically allow only publishing and visualization of streaming data from sensor devices; they lack processing and analytic features. The data remain in the same raw state thus hindering the detection of valuable, insightful information, which could effectively produce knowledge for decision-making processes.
In this context, the issue of translating the huge amount of sensor generated data streams from their raw state into higher-level representations and making them accessible and understandable for humans or interpretable by machines and decision-making systems remains open. One promising approach to tackle this issue is by applying techniques of CI. CI refers to the ability of a computer system to learn a specific task from data or experimental observation. The methods used in CI are close to the human's way of reasoning, i.e. it combines inexact and incomplete knowledge to produce control actions in an adaptive way. The vast research on CI techniques can be of great help to generate useful knowledge from such massive amounts of data generated by a world of interconnected IoT resources.
12.2.3 Data Stream Processing
Data stream processing is a paradigm that deals with a sequence of data (a stream) and a series of operations being applied to each element in the stream [8]. The typical real-time stream processing should include solutions for five items:
- Integration with several data sources
- Live data discovery and monitoring
- Anomalies detection
- Events detection (collecting, filtering, prediction, etc.)
- Performance, scalability and real-time responsiveness
Item (1) is particularly relevant for time-sensitive IoT applications that deal with data provided by multiple data sources, and a timely fusion of data is needed to bring all pieces of data together. In this context, information fusion and sharing play a critical role for fast analysis and consequently providing reliable and accurate actionable insights [9]. According to [10], Information Fusion deals with three levels of data abstraction: measurement, feature, and decision, and it can be classified into these categories:
- Low-level fusion. Also referred to as signal (measurement) level fusion. Inputs are raw data that are joined with a new piece of more accurate data (with reduced noise) than the individual inputs.
- Medium-level fusion. Attributes or features of an entity (e.g. shape, texture, position) are fused to obtain a feature map that may be used for other tasks (e.g. segmentation or detection of an object). This type of fusion is also known as feature/attribute level fusion.
- High-level fusion. Also known as symbol or decision level fusion. Inputs are decisions or symbolic representations that are joined to produce a more confident and/or a global decision.
- Multilevel fusion. This fusion involves data of different abstraction levels, i.e. multilevel fusion occurs when both input and output of fusion can be of any level (e.g. a measurement is fused with a feature to provide a decision).
In [11], the authors propose Olympus, a framework for supporting the paradigm known as Cloud of Sensors (CoS). According to the authors, CoS is a type of ecosystem within the broader domain of Cloud of Things (CoT). CoS systems exploit the potential advantages of WSNs along with smart sensors' specific features to provide Sensing as a Service to client applications. A CoS comprises virtual nodes built on top of physical WSN nodes and provides support to several applications following a service-based and on-demand provision model. In this context, Olympus is a virtualization model for CoS that uses information fusion for reducing data transmission and increasing the abstraction levels of the provided data for aiding application decision processes. In Olympus decentralized virtualization model, physical sensors and actuators are linked to virtual nodes (at the measurement level according to the earlier classification), which perform the low-level fusion of the sensing data. Theses nodes send the reduced data to the feature level virtual nodes, which in turn produce the feature data to the high level fusion virtual nodes in order to perform the decision-making processes.
Data stream mining is a technique that can extract useful information and knowledge from a sequence of data objects of which the number is potentially unbounded [12]. This mining (analysis) is important to address the aforementioned items of live data discovery (2) and anomalies detection (3) in stream processing. Some typical tasks for data stream mining are:
- Clustering. This task involves grouping a set of objects putting similar objects in a same group (called a cluster). This is a technique commonly used for statistical data analysis, in several fields, including pattern recognition, image analysis, information retrieval, data compression, and computer graphics.
- Classification. In statistics, classification is the task of identifying which, from a set of categories (subpopulations), a new observation belongs to, on the basis of a training set of data containing observations (or instances) whose category membership is known. In other words, classification uses prior knowledge to guide the partitioning process to construct a set of classifiers to represent the possible distribution of patterns. This means that each example fed into the algorithm is classified into a recognizable data class or type.
- Regression. In statistics, regression is a technique that allows exploring and inferring the relationship of a dependent variable (response variable) with specific independent variables (explanatory variables or “predictors”). Regression analysis can be used as a descriptive data analysis method (e.g. curve fitting) without requiring any assumptions about the processes that allowed data to be generated. Regression also designates a mathematical equation that describes the relationship between two or more variables.
- Outlier and anomaly detection. This is the task of finding data points that are the most different from the remaining points in a given data set. In general, outlier detection algorithms calculate the distance between every pair of points in a two-dimensional space. Outliers are the data points most distant from all other points.
Typically, in IoT applications, data streams from different sensors are real-time events that frequently form complex patterns. Each pattern represents a unique event that must be interpreted with minimal latency, to enable decision making in the context of current situation. The requirements of analyzing heterogeneous data streams and detecting complex patterns in near real time have formed the basis of a research area called complex event processing (CEP). CEP encompasses several tasks such as processing, analyzing, and correlating event streams from different data sources to infer more complex events almost in real time [13]. CEP lacks the predictive power provided by many ML data analysis methods. This is because most CEP applications relies on predefined rules to offer reactive solutions that correlate data streams but do not deal with historical data due to its limited memory. On the other hand, for some IoT applications, such as traffic management, prediction of a forthcoming event, for example, a congestion, is clearly more useful than detecting it after it has already occurred. This case is more notorious in applications for predicting natural disasters and epidemic diseases. ML techniques can complement the CEP data analysis methods to improve the inference and prediction process for such applications.
Finally, another important issue in the data stream processing is the real-time responsiveness (item 5 earlier) to perform data analysis with CEP and ML techniques. With its huge computing capacity and massive storage capacity, the cloud has traditionally been used to run the complex ML and event processing algorithms. However, it is well known that data transfer to the cloud and return of results are subject to unpredictable and potentially high latency of the Internet. To reduce the delay in processing all data streams and taking timely decisions, a promising approach is to perform the processing and decision tasks within end devices (IoT sensors and mobile devices), or at edge devices, thus leveraging their computational capabilities as proposed by the fog computing paradigm. The next section discusses the challenges to run CI techniques for processing IoT data in the fog context.
12.3 Computational Intelligence and Fog Computing
As mentioned before, in order to minimize the communication latency and improve the computational performance of IoT applications, the emerging paradigms of fog and edge computing have been advocated as potential and promising solutions. In this context, the compute nodes of the edge or fog tier will perform all or part of the various data stream processing steps. To tackle the issues related to performance, scalability, and real-time responsiveness, and considering the massive amount of data produced by large IoT systems, researchers have investigated the deployment of ML techniques in the fog computing paradigm.
12.3.1 Machine Learning
Recently, ML, a research field of CI, have been widely implemented in a number of domains that depend on complex and massive data processing such as medicine, biology, and engineering, providing solutions to gather the information hidden in the data [6]. The central goal of CI is to provide a set of algorithms and techniques that can be used to solve problems that humans perform intuitively and near automatically but are otherwise very challenging for computers. Combining ideas from many different fields, such as optimization theory, statistics, and cognitive science, ML algorithms are constantly improving. In addition, ML has benefited from the evolution in the capacity of the computational resources currently available even in IoT scenarios.
ML can be defined as the creation and use of models that are learned from data. In this context, a model is a specification of a mathematical (or probabilistic) relationship that exists between variables. Typically, in IoT scenarios the aim of adopting ML techniques is using historical and stream data to develop models able to predict various outcomes for new data or to provide insights. Examples of usage are below, just to name a few:
- Predicting the increase rate of energy consumption based on the current temperature and power status of an IoT system
- Predicting whether a set of events represents a dangerous situation in some environment (for instance a smart building)
- Predicting an intersection congestion when the number of vehicles increases in a smart road application
ML techniques can be divided into three subdomains: supervised learning, unsupervised learning, and reinforcement learning. The difference among them lies in the learning process of the intelligent algorithm. When the input data can be labeled with the desired outputs of the algorithm, supervised learning is applied because it is possible to supervise the accuracy of the training process. Unsupervised learning is applied when you can interpret data based only on input data trying to find some hidden pattern or intrinsic structure. Unsupervised learning is useful whenever one wants to explore the available data but does not have yet a specific goal or is not sure what information the data contains. Reinforcement learning differs from normal ML because it does not use training data set, but interactions with the external environment to constantly adapt and learn on given points as a kind of feedback. Supervised and unsupervised learning is suitable for data analysis while reinforcement learning is adequate for decision-making problems [14]. Table 12.1 presents these three classes of ML methods/techniques from different perspectives. Any of these ML techniques can be applied to a wide variety of IoT applications as we see in the next paragraph.
Table 12.1 Comparison of machine learningtechnologies [14].
| Learning types | Data processing tasks | Methodology | Learning algorithms | Example of IoT applications |
| Supervised learning | Classification/Regression/Estimation | Statistical classifiers | K-nearest neighbors Naïve Bayes Hidden Markov model Bayesian networks |
Fruit identification through classification of data patterns |
| Computational classifiers | Decision trees Support vector machine | |||
| Connectionist classifiers | Neural networks | |||
| Unsupervised learning | Clustering/Prediction | Parametric | K-means Gaussian mixture model |
Anomaly detection in IoT healthcare system |
| Nonparametric | Dirichlet pr. mix model X-means | |||
| Reinforcement learning | Decision-making | Model-free | Q-learning R-learning |
Urban traffic prediction |
| Model-based | TD learning Sarsa learning |
In [15], the authors analyze some of existing supervised and unsupervised learning techniques from the perspective of the challenges posed by processing IoT data. Their work aimed at helping to choose a suitable algorithm for some data analytic tasks. For example, to find unusual data points and anomalies in smart data, the support vector machine (SVM) algorithm is suggested. To predict the categories (labels) of data, neural networks use approximation functions to obtain the desired output. To find hidden patterns or intrinsic structure in data, unsupervised learning applies the clustering technique. K-means is the most widely used clustering algorithm for exploratory data analysis.
The K-nearest neighbors (KNN) is one of the most naive ML algorithms being used for classification and regression problems. For each new data point, KNN searches through all the training data for the K closest entries (nearest neighbors). Once the K closest data points are identified, a function will assess the distance (or degree of separation) between the new data point and its neighbors to determine the class of this new data point. Unlike KNN, Naïve Bayes (NB) does not need to store the training data. The NB algorithm learns the statistics for each predictor (attribute or feature) of the training data and applies the Bayes' Theorem (all predictors are independent from each other) to build the predictor-class probability. A mathematical function uses these probabilities to determine the class of the new data point according to its predictors. In [16], the author uses a Raspberry Pi to run the KNN and NB algorithms to predict the condition of a vehicle considering the information about the engine, coolant, etc.
Decision tree algorithms are used to develop classification models in the form of a tree structure. They are quite popular among data analysts because they are easy to read and understand. A decision tree algorithm chooses the outputs according to the possible decision paths represented in a hierarchical tree structure. To construct the tree structure, a data set is decomposed into smaller subsets based on the available predictors. The goal is to obtain subsets that contain only one class of outcomes. Unlike the other models, decision trees can easily handle a mix of numeric (e.g. room temperature) and categorical (e.g. user's perception of temperature – hot/cold) predictors and can even classify data for which attributes are missing. As an example of application, in [17], the authors used a wearable device equipped with motion and orientation sensors (accelerometer and gyroscope) to detect several activities of a person when in the living room. Some activities were: watching TV, reading newspaper, chatting, taking a nap, listening to music, and walking around. They used the decision tree and Hidden Markov model (HMM) algorithms to build the model for activity detection.
An artificial neural network (ANN), or neural network for short, is a technique inspired by the way the brain operates – a collection of neurons wired together. The neurons that represent processing units are organized in layers – input layer, one or more hidden layers and output layer. Each neuron in a layer receives the outputs of the previous layer neurons, does a calculation with an activation function, and then forwards the results to the next layer neurons. Figure 12.3 shows an example of feed-forward neural network with two hidden layers. The algorithms used in neural networks form a framework for many ML techniques capable of dealing with complex data inputs. An example of application of this technique is described in [18]. The authors developed an intelligent IoT-based hydroponics system for tomato plants. The system gathers several data about the monitored plant such as pH, temperature, humidity, and light intensity. Then, employing ANN to analyze such data, the system can predict the appropriate actions to automatically control the hydroponic system.

Figure 12.3 A multilayer feed-forward neural network.
Reinforcement learning is an ML method based on trial and error technique. A processing unit called agent develops his learning experience according to the actions he takes in an interactive environment, which returns a value indicating whether an action was right or wrong. Unlike supervised learning, where the desired output is the correct answer for performing a data analysis, reinforcement learning uses rewards and punishment as signals for positive and negative behavior. In the IoT context, for example, there are various researches on applying reinforcement learning to actuators embedded in urban traffic signals with the purpose of alleviating traffic congestion in the Smart City domain application. The authors in [19] present a thorough literature survey of adaptive traffic signal control (ATSC) approaches using three reinforcement learning algorithms, namely: TD-learning, Q-learning, and Sarsa learning.
An important issue for applying ML in the IoT context regards the capacity of the algorithms to learn from data streams that evolve over time and are generated by nonstationary distributions. Many ML algorithms are designed for data processing tasks in which data is completely available and can be loaded any time into memory. Such a condition does not hold most cases of IoT systems that produce large data streams. Such a problem requires incremental learning algorithms, which can modify the current model whenever new data is obtained [20]. In this case, the objective is to permanently maintain a precise decision model consistent with the current state of the process that generates data. In [21], the authors identify the following four computational model properties for such learning systems:
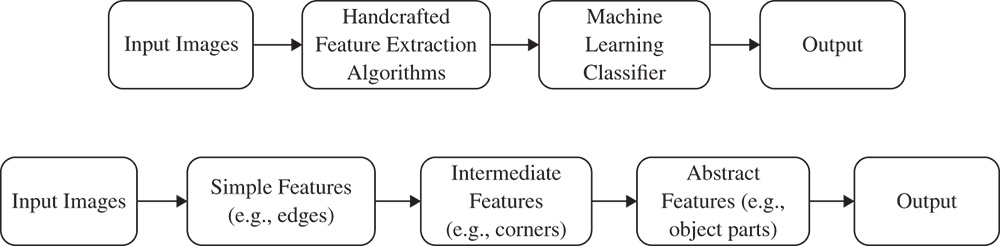
Figure 12.4 Traditional machine learning (a) and deep learning (b) approaches to image classification.
- Incremental and real-time learning;
- Capacity to process data in constant time and using limited memory;
- Limited access to data already processed;
- Ability to detect and adapt the decision model to concept changes.
In [22], the authors evaluate a lightweight method based on incremental learning algorithms for fast classification in real-time data stream. They use the proposed method to do outlier detection via several popular learning algorithms, like decision tree, Naïve Bayes, and others.
12.3.2 Deep Learning
In recent years, with the increasing computational capacities, new generation IoT devices have been able to apply more advanced neural networks to capture and understand their environments. For example, in a smart home application, the security system can unlock the door when it recognizes its user's face. Using a cascade of nonlinear processing units (layers) for feature extraction and transformation, a deep learning (DL) method can extract from an image a hierarchy of concepts that correspond to different levels of abstraction. Figure 12.4 depicts the main aspects of this technique that distinguish it from traditional ML feature extraction and classification methods [23].
DL architectures such as Deep Neural Network (DNN) and Convolutional Neural Network (CNN) have been applied to many fields including computer vision, audio recognition, speech transcription, and natural language processing, where they have produced results comparable to human experts. A DNN is basically a feed-forward neural network with several hidden layers of interconnected neurons (or processing units). Collectively, the neurons of the hidden layers are responsible for transforming the data of the input layer into the desired output data (inference classes) of the output layer. Each hidden layer neuron has a vector of weights with a size equal to the number of inputs as well as a bias. These weights are optimized during the training process. The hidden layer neuron receives the inputs from the previous layer, calculates a weighted summation of these inputs, and calls an activation function to produce the output, passing the resulting sum as a parameter. These weights are what make each neuron unique. They are fixed during the test of the network, but during the supervised training these weights are changed in order to teach the network how to produce the expected output for the respective data inputs.

Figure 12.5 Typical CNN architecture [25].
A CNN is a class of ANN and an alternative to DNN when applied to analyzing visual imagery due to scalability issues (e.g. high resolution images imply thousands of neurons) and the translation-invariance property of such models. DNN might not learn the features that undergo minor changes in some images, like a rotation of the face. CNN has solved these problems by supporting sparse interactions, parameter sharing, and translation-equivariance computations [24]. As any ANN, a CNN also consists of input layer, multiple hidden layers, and an output layer. The hidden layers of a CNN typically consist of one or more convolutional and pooling layers, and finally a fully connected layer equivalent to those used in DNNs. Convolutional layers apply convolution operations to the input, called filters, extracting the features from data, reducing the number of parameters and passing the result to the next layer. In the training process, a CNN automatically learns the values for these filters, which represent hierarchical feature maps (e.g. edges, corners and object parts) of the input images. The pooling layers operate on the feature maps produced by the filters combining the outputs of neuron clusters at one layer into a single neuron in the next layer. Max and average pooling uses the maximum and average value, respectively, from output of a cluster of neurons at the prior layer causing dimensionality reduction and the representations to be invariant to translations. The last layers (i.e. a DNN fully connected) are applied to complete classification. Figure 12.5 presents a typical CNN architecture for image classification.
Many modern devices, such as smart phones, drones, and smart cars, are equipped with cameras. The deployment of embedded CNN architecture on such devices is enabling a variety of smart applications. For example, using the smart phone's camera to detect plant disease, drone aerial images to detect traffic congestion, and collision prediction using vehicle's camera, just to name a few. In [9], the authors present a complete survey on applying DL for IoT data and streaming analytics, analyzing different DL architectures for different IoT scenarios. They also analyze how DL was embedded in solutions using intelligent IoT devices, as well as compare deployment approaches in the fog and cloud.
Besides the complexity of ML algorithms, other issues to be addressed are where and how to deploy the CI techniques considering the high volume of data and computational resources required to run the algorithms, especially on resource constrained fog devices. The next section presents some approaches recently researched on this regard.
12.4 Challenges for Running Machine Learning on Fog Devices
Traditionally, ML algorithms run on powerful computers hosted in cloud data centers to accommodate their high demand for computation, memory, and power resources. In the context of IoT and fog computing, data streams are generated (and eventually processed) by devices located at the edge of the network that have limited power and hardware resources. Smart applications that use large sets of sensing data, such as audio and images, aggravate the memory demand and bandwidth consumption. Therefore, applying modern data analytics processing using ML techniques without imposing communication overheads is a challenge, and researchers have recently investigated how to deploy CI on fog devices in an efficient way.
In this context, the challenges for running any resource demanding program on fog devices are related to the following aspects: processing time, memory demand, bandwidth, and power consumption. Generally, processing time and bandwidth consumption are directly related to the performance and the energy required to run the application, so any reduction in these two factors is important to save energy and increase the overall efficiency of the system. Besides, there are many other aspects to be analyzed when designing a hardware solution for an IoT system. Energy efficiency is one of the key characteristics for IoT products (nobody wants to recharge a smartwatch three times a day). System boards that consume a lot of power hamper battery autonomy and impose an increase in product size. On the other hand, low power system boards that are generally low performance may not be able to run applications that are sensitive to delays. Thus, the hardware industry has continually researched how to balance these various aspects to better deliver system boards for future technological solutions.
In 2015, the authors in [26] published an initial study aimed to analyze the development of embedded and mobile devices that could run some DL techniques. They experimented some device kits running two DNNs and two CNNs models to process audio and image sensor data, respectively. The DNNs assessed in the experiments were: Deep Keyword Spotting (KWS) [27], which was used to perceive voice specific phrases (e.g. “Hey Siri”), and DeepEar (Lane et al., [28]), which was composed of three coupled DNNs offering separate recognition tasks – emotion recognition, speaker identification, and ambient sound classification. The two CNNs were: AlexNet [29], an object recognition model supporting more than 1,000 object classes (e.g. dog, car), which in 2012 obtained state-of-the-art levels of accuracy for the well-known data set ImageNet4; and SVHN [30], a specialized model for recognizing numbers in complex and noisy scenes like Google Streetview images. They tested these models in three device kits:
- Intel Edison. The smallest and the weakest computing power of all experimented kit (500 MHz dual-core Atom “Silvermont” central processing unit [CPU] assisted by a 100 MHz Quark processor, 1 GB of RAM).
- Qualcomm Snapdragon 800. Widely used in smartphones and tablets (three processors: a Krait 4-core 2.3 GHz CPU, an Adreno 330 GPU and a 680 MHz Hexagon DSP, 1 GB of RAM).
- Nvidia Tegra K1. Developed for extreme GPU performance in IoT context (Kepler 192-core GPU, 2.3 GHz 4-core Cortex CPU, 2 GB of RAM).
The authors measured the execution time and energy consumption of each hardware platform for every model performing 1,000 separate inference tasks. Table 12.2 shows the average execution time for each model using the processing units of the hardware platforms. The first insight is about the feasibility for running such models on these devices, specially the weakest of the processors – Intel Edison. AlexNet has 60.9 million parameters, five convolutional layers, three pooling layers, and two hidden layers summing 4,096 neurons. Running AlexNet on Edison and Snapdragon toke 238 and 159 seconds, respectively, and consumed 110 and 256 J, respectively, from a 2,000 mAH battery. On the other hand, running AlexNet on Tegra's GPU took only 49 ms and 0.232 J from the battery. Other good results were the Deep KWS, the smaller model, consuming only 12.1 mJ on Edison and 10.2 Mj on Snapdragon's DSP with execution times below 64 ms.
Those experiments showed that running a heavy DL model like AlexNet on low-capacity computer is still possible, but the response time and energy consumption will probably make the solution infeasible for most Smart IoT applications. One way to overcome this problem is to use GPUs. CNN algorithms require a huge number of mathematical operations using large matrices of floating-point numbers that are intensive time-consuming if performed in pipeline mode by the CPU. However, the hundreds or thousands of processing cores of GPUs can easily speed up the execution of a huge set of mathematical operations such as the ones required by CNN algorithms, as we can see in experiments using AlexNet running on Tegra's GPU compared to its CPU.
Table 12.2 Execution time (ms) for running DL models in three hardware platforms.
| Tegra | Snapdragon | Edison | ||||||
| Model | Type | Qty. parameters | Architecturea) | CPU | GPU | CPU | DSP | CPU |
| DeepKWS | DNN | 241 K | h :3; n:128 | 0.8 | 1.1 | 7.1 | 7.0 | 63.1 |
| DeepEar | DNN | 2.3 M | h :3; n:512 or 256 | 6.7 | 3.2 | 71.2 | 379.2 | 109.0 |
| SVHN | CNN | 313 K | c :2; p:2; h:2; n:1728 | 15.1 | 2.8 | 1615.5 | — | 3352.3 |
| AlexNet | CNN | 60.9 M | c:5; p:3; h:2; n:4096 | 600.2 | 49.1 | 159 383.1 | — | 283 038.6 |
a) c: convolution layers; p: pooling layers; h: hidden layers; n: neurons in hidden layers.
Considering the continuous evolution of the IoT and Edge devices and how they can be deployed for executing various applications that demand intelligent processing, our research group developed a study about the hardware resources found in most of these devices, analyzing their capacities for running ML algorithms [14]. The result of this study was a classification that matches hardware resources with learning algorithms. Table 12.3 presents the proposed classes of devices with the respective suitable algorithms. Devices class 1 are the smallest and least computational powerful of them, and its role is only to produce data. From this perspective, class 1 devices are known as the IoT sensors by the research community, with some basic computational resources. At the other end, class 5 devices are the highest powerful computational equipment and can be considered as the unlimited resources available in cloud data centers. The experiments done with the devices of class 2, 3, and 4 showed that they have capacity to perform the three levels of information fusion: measurement, feature, and decision, respectively. Unlike class 1 devices that have microcontrollers, they have true CPU, RAM memory and a multitask operating system. Devices class 3 and 4 are the ones really used for running ML algorithms on the fog. The main difference between them is that class 4 devices have a powerful GPU for parallel processing, which is very important for the execution of algorithms for training DNNs, for instance. Class 3 device can use a trained neural network to make the mid-level data fusion and extract the relevant features of the data, like a detection of an object. Class 4 device can go further and taking decisions using a set of higher-level data fusion.
Table 12.3 Classification of smart IoT devices according to their capacities [23].
| Class | Hardware capacity | Power consumption | Suitable algorithms | Main application |
| 1 | No storage Low CPU and memory |
≤1 W | Basic computation | Data generation |
| 2 | Storage ≤4 GB Memory ≤512 MB CPU single-core |
≤2 W | Basic statistic | Measurement level fusion |
| 3 | Storage ≤8 GB Memory ≤2 GB CPU quad-core |
≤4 W | Classification/ Regression / Estimation | Feature level fusion |
| 4 | Storage ≥16 GB Memory ≥4 GB CPU and GPU |
≤8 W | Prediction/ Decision-making |
Decision level fusion |
| 5 | Very large | Very high | Any | Autonomous system |
Another important aspect is the power consumption of the devices. On the one hand, IoT devices are to be deployed in nonrefrigerated environments and with limited power sources, less computation requires less power and yields less heat. On the other hand, devices with high computational power are more expensive, require a lot of energy to work and yield more heat, so that they should be used with care in IoT projects. The next section presents some solutions brought by industry to address these issues in IoT system design.
12.4.1 Solutions Available on the Market to Deploy ML on Fog Devices
Thinking about the potential that ML can bring to IoT applications, the industry has created new hardware specifically tailored to develop ML-based solutions. For example, OpenMV5 is a tiny open hardware kit for IoT developers with an embedded camera that can detect face and find eyes using built-in feature detection algorithms and expending less than 200 mA of energy. This kit facilitates, for instance, the development of smart applications that require authenticating users by their faces.

Figure 12.6 OpenMV, a machine vision kit for IoT developers.
The OpenMV kit runs an operating system based on MicroPython,6 a version of Python 3 to run on microcontrollers and constrained devices that includes a small subset of the Python standard library. It also comes with an IDE (integrated development environment) that organizes in tiled windows the code, the image from camera, some graphs and a terminal to interact with its operating system. Figure 12.6 shows one of the OpenMV model kits.
In [31], the authors presented a method to improve the line-finding algorithm to control a self-tracking smart car using OpenMV as the main development platform. The improved method uses Hough line transformation to plan the best path solution based on detecting two black lines under white background as the driving road. The OpenMV used was equipped with an OV7725 camera that is capable of taking 640 × 480 8-bit images at 60 FPS (frames per second) or 320 × 240 at 120 FPS, which is very suitable for smart car algorithms based on image processing. The results showed that the improved algorithm performs better than the traditional one, especially when cruising a continuous bend road.
Recently, the Raspberry Pi,7 a palm-sized single-board computer (SBC), has been used as the edge device to process IoT complex data and streams. In [32], the authors developed a facial recognition system for use by police officers in smart cities. This system uses a wireless camera mounted on the police officer's uniform to capture images of the environment, which is passed to a Raspberry Pi 3 in the officer's car for face detection and recognition. To accomplish the facial recognition, they initially use the Viola-Jones object detection framework8 to find all the faces present in the live video stream sent by the camera. Then, the ORB9 (Oriented FAST and Rotated BRIEF) method is executed to extract from the identified faces all their features, which are transmitted to a trained SVM classifier in the cloud. For the purpose of saving transmission power and bandwidth, only the features extracted from the face are sent to the cloud.

Figure 12.7 NCS based on Intel Movidius Myriad 2 Vision Processing Unit (VPU).
In order to run DL models on devices like Raspberry Pi, Movidius, a company acquired by Intel in 2016 that designs specialized low-power processor chips for computer vision, has launched the Neural Compute Stick (NCS) [33],10 a USB device (Figure 12.7) containing Intel's Myriad 2 VPU (vision processing unit). The Neural Compute Engine in conjunction with the 16 SHAVE11 cores and an ultra-high throughput memory fabric makes Myriad VPU, a consistent option for on-device DNNs and computer vision applications. Most drones in the market have used this technology to interpret the images they capture and trigger actions like following an object in movement or take a picture when the user makes some gestures. Intel has distributed the OpenVINO toolkit12 for developers to profile, tune, and deploy CNNs on DL applications that require real-time inferencing.
To probe the power of this NCS as a replacement of a GPU card, the authors in [34] designed a CNN model to detect humans in images for a low-cost video surveillance system. To run the pretrained model on a desktop PC, they tested two SBC: Raspberry Pi 3 (1GB RAM) and Rock6413 that has the same CPU (ARM Cortex-A53) but 4GB RAM. The model used to extract the features and classify the images was the MobileNet [35] that uses the technique known as Single Shot MultiBox Detector (SSD) [36]. MobileNet was proposed by Google as a lightweight CNN suitable for Android mobile devices and embedded systems. It uses an architecture called depthwise separable convolutions, which significantly reduces the number of parameters when compared to the network with normal convolutions with the same depth in the neural networks. They used the software development kit (SDK) of NCS to load the pretrained CNN onto the USB device in order to speed up the human detection processing of the images captured from a camera connected to the SBC. The detected image of a human is then sent to another CNN model to distinguish specific persons from strangers. The image data set used in this second model has 10,000 photos of five persons in different angles. This second model was created and pretrained in Tensorflow [37] on the desktop PC as well. In the end, they present the execution time of human detection (first CNN used) on Rock64 and Raspberry Pi 3, first using only the CPU and later with the NCS running the model. On Raspberry Pi 3, the execution time is five times faster with the NCS, reducing from 0.9 to 0.18 seconds. On Rock64 this time drops from 0.5 to 0.15 seconds with the NCS, six times faster.
12.5 Approaches to Distribute Intelligence on Fog Devices
In a large-scale system, such as Smart Cities, thousands of IoT devices will continuously generate huge amounts of data. In order to extract valuable information for applications, all this data has to be collected and processed in a timely and efficient way. As we pointed out in the Section 12.1, in the traditional three-tier architecture for IoT systems, data must be sent and processed in cloud data centers, what can be infeasible especially for time-sensitive multimedia applications due to the overhead of communications and delays. Therefore, applying ML techniques close to the data sources for extracting useful information and reducing the bandwidth consumption and delay is a promising approach to mitigate these issues. Other important advantages related to the distributed data learning process are presented by [38]:
- In a large-scale system, a possible approach to improve the accuracy in inferences is adopting different learning processes to train multiple classifiers in distributed data sets. Each classifier will be using different learning biases and joining them in the same inference process can soften the inefficient characteristics of these biases.
- For large-scale smart applications where the data volume is huge as well as processing is challenging, the divide-and-conquer approach may be the best strategy. Due to memory, storage, and processing time limitations, each processing unit can work collaboratively with different data partitions, thus reducing the overall computational cost. In addition, this strategy improves the availability of classifiers since smaller processing units can be more easily replaced in case of failures.
To investigate the advantages of distributed learning for extracting knowledge from a data set collected from sensors in multiple locations, the authors in [39] proposed and developed a novel framework. Specifically, they exploit the technique called hypothesis transfer learning (HTL) [40] where each data producer performs an initial learning process yielding a partial model (knowledge) from its own data set. In order to obtain a unique model (global inference), the partial models have to be shared among the data producers to refine their partial models “embedding knowledge” from the other partial models. On the one hand, the benefit of this approach is that the amount of data to be transmitted over the network is minimized since the partial models are much smaller than the raw data. On the other hand, the accuracy of the final model has to be as close as possible to a model trained directly over all data sets. In order to experiment the approach, they used a data set of human activities (standing, sitting, lying, walking, stand-to-sit, etc.) collected through smart-phones' sensors (accelerometer and gyroscope) wore on the waist of 30 volunteers. The results showed that they reached both goals of minimizing the network traffic while keeping a high accuracy. With the HTL solution, the accuracy of the final model using only smart-phones was comparable to a cloud-trained model with all data sets, but with the network overhead having a drastic reduction up to 77%. In a later article [47], the same authors explore the three-tier architecture of fog computing introducing data collectors (DCs) to perform the partial learnings on the fog. The aim of the research was to evaluate the trade-off between accuracy and network traffic when varying the number of data collectors (DCs) located on the fog. The obtained results showed that increasing the number of data collectors decreases the network traffic and the accuracy of the HTL solution does not vary significantly with the number of DCs. Therefore, they conclude that a distributed HTL solution using the fog computing approach is the most promising technique.
In [41], the authors introduced EdgeSGD, a variation of the stochastic gradient descent (SGD) algorithm to provide analytics and decentralized ML on nodes at the edge of the network. With this algorithm, they could estimate on each node the feature vector for linear regression using multiple training subset of the entire data set. They used the proposed algorithm to learn and predict seismic anomalies through seismic imaging from sensors placed in different locations. They evaluated the performance of the algorithm on an edge computing testbed – a cluster composed of 16 SBC BeagleBone.14 They also compared the performance of the proposed solution with other distributed computation frameworks such as MapReduce, decentralized gradient descent (DGD) [42], and EXTRA [43], examining the aspects of fault tolerance and communication overhead. Such a comparative analysis showed that edge processing with EdgeSGD outperformed the other frameworks in terms of execution time while having the same robustness of them.
There is a consensus that with the rapid evolution of hardware, which is being smaller and more energy-efficient, edge/fog devices will be increasingly powerful. In [44], the authors try to explore this potential by creating an architecture for distributed stream processing. The proposed architecture creates a cluster of edge devices to process stream images (video) in parallel for a faster response time when compared to off-loading data to cloud platforms. They implement the proposed solution using the open source framework Apache NiFi,15 where a data flow represents a chain of processing tasks with data streamed in a “flow-based programming” (FSB). The processing units are called processors, and each processor can perform any data operation and has an input and an output port, which serve to interconnect the processors creating a data flow topology. There are more than 100 built-in processors in NiFi and it is possible to develop and plug in custom-made processors. To probe the proposed approach, the authors applied a CCTV-based intelligent surveillance system (ISS) to recognize persons by their faces from the camera images. For this application, they developed three processors:
- CaptureVideo (CV). The data flow starts with this processor. It uses a camera to capture the video stream continuously. At a given frequency, this processor splits the video stream into separate frames and sends them to cluster nodes. Thus, this processor orchestrate the tasks off-loaded to the cluster as a coordinator;
- DetectFaces (DF). For each frame received from the CV processor, this processor execute a facial detection algorithm, cropping the detected faces and placing them on other objects. Then, these objects are sent to the next processor;
- RecogniseFaces (RF). Upon arrival of a new object containing a face, this processor performs a facial recognition algorithm to identify the detected person. This processor is trained with a data set with a small group of human faces and outputs a prediction value (10,000 indicates a match) for each face in this group.
They deployed the application on a laptop (CPU Intel i7-4510U quadcore, 16GB RAM) running the CV processor and a local virtual cluster consisting of five VirtualBox instances of the Raspberry Pi acting as edge nodes. Each node is an virtual machine running the Raspbian OS with 1GB RAM and up to 20% of the host CPU. The edge nodes execute the DF and RF processors. In the first tested topology, all edge nodes have the same training data set and the coordinator sends each frame to a unique cluster node for face detection and further recognition. Another topology tested was splitting the training images in separate subsets given to each cluster node and the coordinator sends the frames to all nodes, expecting at least one of them to recognize the face in each image. This second topology was designed to bring parallelism and some performance benefits compared to the first one, since the larger the training set, the greater the time to reach an inference. They also run the experiment with a third setup running a software to detect and recognize faces on a cloud-based computer containing the whole data set of the trained images. For each experiment they measure the time delay – the total time for the coordinator to receive an inference (result of the face recognition task) starting when a frame is captured by CV processor. According to the authors, this period of time encompasses all possible delays related to network latency and data serialization. The solution designed with the proposed architecture of an edge cluster had a far superior performance compared to processing in the cloud. The results shown that, when using the complete training set, it performed up to five times faster, and nine times faster with the split training set. Thus, they conclude that splitting the training set is a good strategy for gaining performance since with a training set five times smaller they have achieved a performance 40% faster (compared to cloud-only solutions).
Analyzing this last discussed work [44] and aiming at improving some aspects of their proposed architecture, our research group developed a novel approach to define the topology of Fog devices for executing ML techniques. As we discussed in Section 12.4, the hardware resources required by different ML algorithms can vary from a single CPU and few megabytes of RAM to a powerful GPU and gigabytes of RAM. Our approach hierarchically organizes the fog devices in three clusters considering the classification of the devices presented in Table 12.3. Combining the devices of classes 2, 3, and 4 with the three levels of information fusion (presented in Section 12.2.3) – measurement, feature, and decision – each cluster of devices will extract valuable information from IoT data streams through these respective data abstraction layers (Figure 12.8). On the bottom of the hierarchy there are the IoT devices with their sensors generating data. This raw data is collected by the fog device responsible for measurement level fusion (class 2) that, by running some statistical algorithms, remove the noise and outputs to the upper layer new pieces of data that are more accurate/valuable than its data input. In the next layer, the class 3 device extracts the feature maps of the data using some classification, regression, or estimation algorithm passing them to the upper layer. In the decision level, a prediction algorithm yields knowledge from its input data allowing the device to execute decision-making processes in order to take some actions.
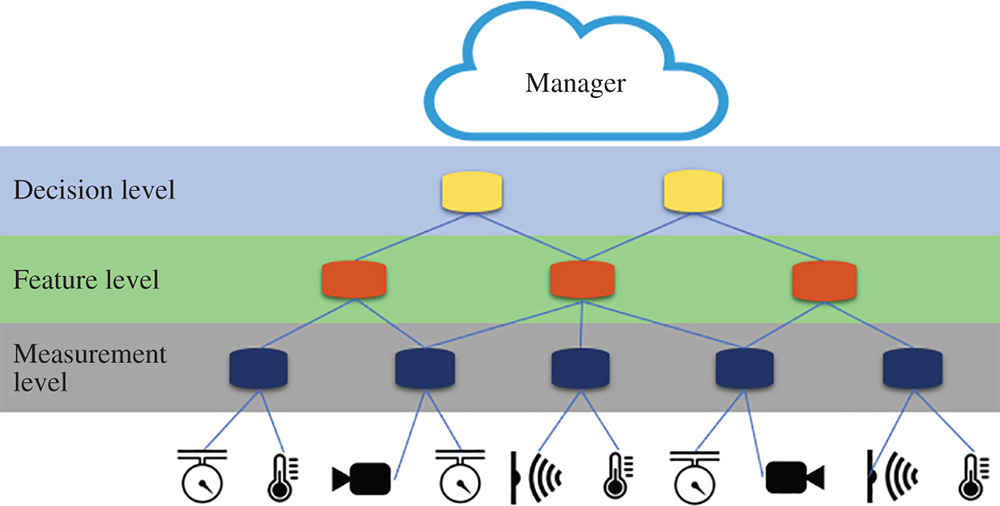
Figure 12.8 Fog topology with devices grouped by levels.
To illustrate our approach, let us consider, for example, its application to an ISS in a Smart City scenario. The CCTV-cameras are the class 1 devices generating the videos as the raw data. Devices of classes 2, 3, and 4 can be single-board computers (e.g. Raspberry Pi, Nvidia Jetson,16) placed in the network close to the cameras (i.e. in the fog layer) in order to reduce bandwidth and latency. A class 2 device in this scenario is responsible for detecting objects in the video through their movements in the images (i.e. pattern variation in the pixels of the background image) taking snapshots of them, which represents the more valuable data. In turn, a class 3 device receives the pictures with the objects detected and runs a DNN or CNN to classify them based on their feature maps. Finally, a class 4 device can run a deeper classifier to identify the object within a set of objects of interest. To speed up the inference process running the DL algorithm a Raspberry Pi could be equipped with the NCS presented in Section 12.4.1. Figure 12.9 presents a possible example of this multilevel data fusion for video processing from CCTV-cameras in a Smart City ISS application.
This distributed processing approach considerably reduces the amount of data to be sent over the network, and, in each level, the information yielded can feed different applications in the same context. For instance, using the example of ISS presented in Figure 12.8, the class 3 device could feed an application that counts the number of cars, buses, motorcycles passed by the camera region, whereas the class 4 device could feed another application by checking whether the detected car is a stolen vehicle. This way, all data exchanged among devices must be tagged with the sensor identification along other metadata of application control (e.g. direction of the object movement).
In terms of processing load, the devices of classes 3 and 4 are the ones that will run the DL models, and so will be the most powerful and consume more energy but will be in smaller numbers. This does not seem to be a problem, since class 3 and 4 devices can serve more than one device of the lower class in sporadic classification tasks. If the volume of classifications increases greatly, new instances of the devices should be added to address the new demand. A micro-service execution platform that can be instantiated on-demand would be a good way to deliver this distributed processing approach.

Figure 12.9 Multilevel data fusion for video processing.
12.6 Final Remarks
In the research community, there is a consensus that IoT is the leading technology to enable advanced, ubiquitous and intelligent systems. Using all kinds of data, provided by a growing number of heterogeneous devices (from wearables to cameras), a huge diversity of information can be extracted and interpreted to enhance the user experience. The gathering and analysis of this Big Data is one of the main challenges faced by the community nowadays. As we have seen throughout this chapter, ML techniques have been applied to perform advanced data analysis in a very efficient way in order to allow for valuable inferences even in resource-constrained devices. Looking at the opportunities of a new market, the industry has developed new hardware to overcome the limitations of running heavy ML algorithms on edge devices.
However, the limited hardware of edge/fog device is only part of the problem, and there are further issues that have been addressed by researchers developing IoT intelligent systems:
- Accuracy vs. energy consumption. When designing applications to run on devices with limited power, energy consumption is always a concern. In [45], the authors analyzed several recent and advanced DNN models to investigate how their accuracy, memory demands, and the time for the inference may interfere with energy consumption. They demonstrated that there is a hyperbolic relationship between the inference time (processing time of the entire neural network to reach a classification/prediction) and the inference accuracy. Some minor increments in accuracy may lead to long processing times and consequently a substantial increase in energy consumption. Thus, this indicated that energy constraint will limit the best achievable accuracy. They also pointed out that there is a linear relationship between the number of operations a neuron does and the inference time. Therefore, there is an obvious trade-off that must be carefully handled.
- Lack of complete training data set for each domain. It is well known that a neural network model is only really good when it has a large training data set as close as possible to all data to be interpreted. Having a complete training set is not an easy task especially in applications that use audio and image data sets from different domains. There are initiatives to create public data sets, like the ImageNet with 14 million images of 21,000 categories, to facilitate the deployment and tests of the ML algorithms developed by community. But in the context of a Smart City application, for example, car images in ImageNet are often useless because they do not reflect the images captured by the cameras normally positioned on poles. In voice recognition applications, a single human voice can vary greatly or be very similar to the voice of others, which makes their neural network training difficult.
- Security and privacy. The processing of personal data captured by the user's device sensors always opens up a discussion about users' privacy and security. Mechanisms to let the user know that their sensitive or personal data is being used to improve their experience are not always well understood. The main concern is the capture of this data by hackers and attackers who may exploit vulnerabilities in communications or processing and then blackmail users. Recently, Chinese startups have developed computer vision systems to capture and identify the face of any citizen in public spaces, demanded by the Chinese government.17 This has sparked controversy in other countries regarding the privacy of people by governments and companies.
Finally, another important issue in developing smart IoT systems is the topology and communication protocols suite of the devices and networks. In [46], the authors present Edge Mesh as a novel paradigm to enable distributed intelligence in IoT through edge devices. This new paradigm integrates the best features of cloud, fog, and cooperative computing into a mesh network of edge devices and routers. Despite the advances toward a collaborative approach at the edge, the authors claim that there are many open research challenges for implementing Edge Mesh. Among them, we can mention the communication between different types of devices, to promote data sharing and to allow executing the intelligence of the application at the edge of the network.
Therefore, we can conclude with a final thought that the ML algorithms will evolve along with IoT devices, pushing forward the development of new hardware, software, and network protocols to address all the challenges presented in this chapter.
Acknowledgments
This work is partially supported by São Paulo Research Foundation – FAPESP, through grant number 2015/24144-7. Flávia C. Delicato, Paulo F. Pires, and Thais Batista are CNPq Fellows.
References
- 1 K. Ashton, That “Internet of Things” thing: in the real workd things matter more than ideas, RFID Journal, https://www.rfidjournal.com/articles/view?4986, 2009.
- 2 Yousefpour, A., Fung, C., Nguyen, T. et al. (2019). All one needs to know about fog computing and related edge computing paradigms: a complete survey. Journal of Systems Architecture, 98: 289–330.
- 3 Delicato, F.C., Pires, F.P., and Batista, V.T. (2013). Middleware Solutions for the Internet of Things. Springer.
- 4 Ali, N. and Abu-Elkheir, M. (2012). Data management for the Internet of Things: green directions. In: IEEE Globecom Workshops, 386–390.
- 5 Tsai, C., Lai, C., Chiang, M., and Yang, L.T. (2014). Data Mining for Internet of things: a survey. IEEE Communication Surveys and Tutorials 16 (1): 77–97.
- 6 Qiu, J., Wu, Q., Ding, G. et al. (2016). A survey of machine learning for big data processing. EURASIP Journal on Advances in Signal Processing 1: 67.
- 7 P. F. Pires, E. Cavalcante, T. Barros et al., A platform for integrating physical devices in the Internet of Things, 12th IEEE International Conference on Embedded and Ubiquitous Computing, 1. Washington, DC, 2014.
- 8 Garofalakis, M.N., Gehrke, J., and Rastogi, R. (2016). Data Stream Management - Processing High-Speed Data Streams. Springer.
- 9 Mohammadi, M., Al-Fuqaha, A., Sorour, S., and Guizani, M. (2018). Deep learning for IoT big data and streaming analytics: a survey. IEEE Communication Surveys and Tutorials 20 (4): 2923–2960.
- 10 Nakamura, E.F., Loureiro, A.A., and Frery, A.C. (2007). Information fusion for wireless sensor networks: methods, models, and classifications. ACM Computing Surveys 39 (3): 9.
- 11 Santos, I.L., Pirmez, L., Delicato, F.C. et al. (2015). Olympus: the cloud of sensors. IEEE Cloud Computing 2 (2): 48–56.
- 12 Qin, Y., Sheng, Q.Z., Falkner, N.J. et al. (2016). When things matter: a survey on data-centric internet of things. Journal of Network and Computer Applications 64: 137–153.
- 13 Akbar, A., Khan, A., Carrez, F., and Moessner, K. (2016). Predictive analytics for complex IoT data streams. IEEE Internet of Things Journal 4 (5): 1571–1582.
- 14 Neto, A.R., Soares, B., Barbalho, F. et al. (2018). Classifying smart IoT devices for running machine learning algorithms. In: 45° Seminário Integrado de Software e Hardware 2018 (SEMISH), 18–29. Natal – Brazil.
- 15 Mahdavinejad, M.S., Rezvan, M., Barekatain, M. et al. (2018). Machine learning for Internet of Things data analysis: a survey. Digital Communications and Networks 4 (3): 161–175.
- 16 Srinivasan, A. (2018). IoT cloud based real time automobile monitoring system. In: 2018 3rd IEEE International Conference on Intelligent Transportation Engineering (ICITE), 231–235. Singapore.
- 17 Lee, S.-Y. and Lin, F.J. (2016). Situation awareness in a smart home environment. In: 2016 IEEE 3rd World Forum on Internet of Things (WF-IoT), 678–683.
- 18 Mehra, M., Saxena, S., Sankaranarayanan, S. et al. (2018). IoT based hydroponics system using deep neural networks. Computers and Electronics in Agriculture 155: 473–486.
- 19 El-Tantawy, S., Abdulhai, B., and Abdelgawad, H. (2014). Design of Reinforcement Learning Parameters for seamless application of adaptive traffic signal control. Journal of Intelligent Transportation Systems: 227–245.
- 20 Faceli, K., Lorena, A.C., Gama, J., and Carvalho, A.C. (2015). Inteligência Artificial: Uma Abordagem de Aprendizado de Máquina. Rio de Janeiro: LTC.
- 21 Domingos, P. and Hulten, G. (2001). A general method for scaling up machine learning algorithms and its application to clustering. In: Proceedings of 18th International Conference on Machine Learning, 106–113. San Francisco, CA: Morgan Kaufmann.
- 22 Fong, S., Luo, Z., and Yap, B.W. (2013). Incremental learning algorithms for fast classification in data stream. In: 2013 International Symposium on Computational and Business Intelligence, 186–190.
- 23 A. Rosebrock, Deep learning for computer vision with Python, PyImageSearch, http://PyImageSearch.com, 2018.
- 24 Goodfellow, I., Bengio, Y., and Courville, A. (2016). Deep Learning, www.deeplearningbook.org:. MIT Press.
- 25 G. Carlsson, Using topological data analysis to understand the behavior of convolutional neural networks. Retrieved from AYASDI: https://www.ayasdi.com/blog/artificial-intelligence/using-topological-data-analysis-understand-behavior-convolutional-neural-networks, June 21, 2018.
- 26 N. D. Lane, S. Bhattacharya, P. Georgiev et al., An early resource characterization of deep learning on Wearables, smartphones and internet-of-things devices, pp. 7–12, Seoul, South Korea: ACM, 2015.
- 27 Chen, G., Parada, C., and Heigold, G. (4091, 2014). Small-footprint keyword spotting using deep neural networks. In: 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 4087. IEEE.
- 28 Lane, N.D., Georgiev, P., and Qen, L. (2015). DeepEar: robust smartphone audio sensing in unconstrained acoustic environments using deep learning. In: International Joint Conference on Pervasive and Ubiquitous Computing, 283–294. Osaka, Japan: ACM.
- 29 Krizhevsky, A., Sutskever, I., and Hinton, G.E. (2012). ImageNet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems, 1106–1114. Lake Tahoe, Nevada.
- 30 Y. Netzer, T. Wang, A. Coates, R. Bissacco, B. Wu, and A. Y. Ng, Reading digits in natural images with unsupervised feature learning, NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011.
- 31 Mu, Z. and Li, Z. (2018). Intelligent tracking car path planning based on Hough transform and improved PID algorithm. In: 2018 5th International Conference on Systems and Informatics (ICSAI), 24–28.
- 32 Sajjad, M., Nasir, M., Min Ullah, F. et al. (2019). Raspberry Pi assisted facial expression recognition framework for smart security in law-enforcement services. Inf. Sci. 479: 416–431.
- 33 Intel Developer Zone, Neural compute stick, Retrieved from Intel Movidius: https://developer.movidius.com, 2018.
- 34 Yang, L.W. and Su, C.Y. (2018). Low-cost CNN Design for Intelligent Surveillance System. In: 2018 International Conference on System Science and Engineering (ICSSE), 1–4.
- 35 A. G. Howard, M. Zhu, B. Chen et al., MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, arXiv:1704.04861, 2017.
- 36 Liu, W., Anguelov, D., Erhan, D. et al. (2016). SSD: single shot multiBox detector. In: Computer Vision – ECCV 2016, 21–37.
- 37 M. Abadi, A. Agarwal, P. Barham et al., TensorFlow: large-scale machine learning on heterogeneous distributed systems, CoRR, 2016.
- 38 Peteiro-Barral, D. and Guijarro-Berdiñas, B. (2013). A survey of methods for distributed machine learning. Progress in Artificial Intelligence 2 (1): 1–11.
- 39 Valerio, L., Passarella, A., and Conti, M. (2016). Hypothesis transfer learning for efficient data computing in smart cities environments. In: 2016 IEEE International Conference on Smart Computing (SMARTCOMP), 1–8. IEEE Computer Society.
- 40 Kuzborskij, I., Orabona, F., and Caputo, B. (2015). Transfer learning through greedy subset selection. In: International Conference on Image Analysis and Processing, 3–14. Springer.
- 41 Kamath, G., Agnihotri, P., Valero, M. et al. (2016). Pushing analytics to the edge. In: GLOBECOM, 1–6. IEEE.
- 42 Yuan, K., Ling, Q., and Yin, W. (2016). On the convergence of decentralized gradient descent. SIAM Journal on Optimization: 1835–1854.
- 43 Ling, Q., Wu, G., and Yin, W. (2015). EXTRA: an exact first-order algorithm for decentralized consensus optimization. SIAM Journal on Optimization 25 (2): 944–966.
- 44 Dautov, R., Distefano, S., Bruneo, D. et al. (2017). Pushing intelligence to the edge with a stream processing architecture. In: 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), 792–799. Exeter, United Kingdom: IEEE Computer Society.
- 45 Canziani, A., Paszke, A., Culurciello, E. An analysis of deep neural network models for practical applications, CoRR, 2016.
- 46 Sahni, Y., Cao, J., Zhang, S., and Yang, L. (2017). Edge mesh: a new paradigm to enable distributed intelligence in internet of things. IEEE Access 5: 16441–16458.
- 47 L. Valerio, A. Passarella and M. Conti, Accuracy vs. traffic trade-off of learning IoT data patterns at the edge with hypothesis transfer learning, 2016 IEEE 2nd International Forum on Research and Technologies for Society and Industry Leveraging a better tomorrow (RTSI), Bologna, 2016, 1–6. doi: 10.1109/RTSI.2016.7740634.
Notes
- 1 http://www.gartner.com/newsroom/id/2636073
- 2 https://xively.com
- 3 https://www.crunchbase.com/organization/nimbits
- 4 http://www.image-net.org
- 5 https://openmv.io
- 6 http://micropython.org
- 7 https://www.raspberrypi.org
- 8 https://en.wikipedia.org/wiki/Viola-Jones_object_detection_framework
- 9 https://en.wikipedia.org/wiki/Oriented_FAST_and_rotated_BRIEF
- 10 https://developer.movidius.com
- 11 https://en.wikichip.org/wiki/movidius/microarchitectures/shave_v2.0
- 12 https://software.intel.com/openvino-toolkit
- 13 https://www.pine64.org
- 14 https://beagleboard.org/black
- 15 https://nifi.apache.org
- 16 https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules
- 17 https://www.businessinsider.com/china-facial-recognition-tech-company-megvii-faceplusplus-2018-5