
CHAPTER 8
Life in an Information Ecology
If you wish to make an apple pie from scratch, you must first invent the Universe.
—CARL SAGAN
A humane and vibrant trillion-node world will result only from principled design, but not design in the sense that most people understand that term. Like the global financial economy, the trillion-node world will be a deeply complex ecology, not simply a collection or even a “patterned arrangement” of devices, information, power, and so on. An ecology carries with it a lot of embedded—often implicit—information about how things are related—not just what the things are. The ecology reveals who lives with whom, who eats whom, what happens to waste, how things are born and die, where the energy comes from, how things become aware of the other things around them, how new needs are recognized, opportunities to colonize, threats about being colonized . . . and much more.
An ecology has no “authority” serving as a central control. It is self-regulating in much the sense that a market economy is self-regulating. Yes, outside forces can tinker with it, resulting in a shift in the ecology’s equilibrium position. But too much tinkering results in its actually becoming a new or different ecology or, at the extreme, a catastrophic failure.
COMPONENTS
Any person or firm that desires to be an active participant in creating, influencing, or making money from the information ecology will have to become familiar with ecological principles and the properties of ecologies. It will be necessary to know how to recognize an ecology when you run into one—and to understand what’s missing when a claimed ecology is not working (too much fish food clouding the water?). It may be rightly claimed that the ordinary user in the ecology need not have such a level of understanding. We don’t want the technology to become a barrier to those who will enjoy its benefits, and the working of an ecology does not depend on conscious meta-thinking by all of its participants. But the players who will make money in such a world will be precisely those who do get good at such top-down awareness. What we should expect to see from such a vantage point are four main components of an ecology:
The Life Forms: Devices
In an information ecology, information devices are the equivalents of life forms. They are animate, and they consume energy and other resources. There will be simple life forms that perhaps do no more than announce their presence by the exchange of information. There will also be complex life forms that process information, transducers that convert energy into information or vice versa, and devices that represent information in such a way that humans can interact with it or simply be informed by it.
Devices don’t exactly eat each other, but they certainly do compete in the marketplace. Moreover, one lives off another by consuming or otherwise processing the information that the other produces or leaves behind. Over time more organizations will recognize that even their waste data can be aggregated, recycled, and turned into value for other life forms. For instance, a manufacturer of home appliances may have a sensor built into its washer and dryer to detect if someone has entered the laundry room. This small bit of information may be used to help conserve energy and turn on the appliances’ displays when a user is present. After this bit of data about presence is used, it may be thrown away. Imagine, however, an organization that provides eldercare services to homes. The waste data about movement in the laundry room may be highly valued information to them. Knowing whether an elderly parent has moved around in the last few hours could be the difference between life and death. The cost of exposing that information may be minimal to you, yet it could turn out to be a valuable asset to other members of the information ecology. Devices form an ecology when they all share, trade in, consume, and transform some common element, generically categorized as the currency.
The Currency: Information
Complex interconnected systems require a currency. In Joe’s fishpond, the currency comprises the carbon-based molecules that constitute the cells of plants, fish, and all the other critters. Those living devices process the molecules for energy, to grow new cells, and to discard waste.
A currency is something that embodies value, can be exchanged on the basis of its value, and can be transferred from place to place. In the world economy, the currency is money, not a thing of value in itself but a carrier of value, a surrogate of value.1 Finally, the currency must be fluid—easily flowing from place to place or situation to situation—in order to bind the ecology together. It is what makes the ecology a single system rather than a mere aggregation. If currency is hoarded, it is unproductive and does nothing to increase the overall value of the ecology. In a balanced ecology, nothing is wasted. Each actor has an essential freedom of action, and so is free to discover and exploit locally available resources that would have been overlooked and thus wasted by a system that relied upon centralized control. If you’re not fast, you become food. And there’s no begrudging the discarded waste that somebody else finds useful.
Information Architecture and Device Architecture
The architecture of an ecology sets the rules of the game by which the life forms or devices exchange and process the currency. If the currency of the ecology is thought of as a sort of a language for communicating among the life forms, then the architecture is the syntax of that language. In biology, the architecture has two facets: On one hand there is an architecture based upon DNA, chromosomes, and genes (among many other structures). This is basically an information architecture (IA), in that it comprises a structure for the storage, replication, and interpretation of the patterns necessary for the creation of new organisms. On the other hand is what we might call an organism architecture, comprising the patterns of physical structure—cells, organs, bilateral symmetry, and all the other usual techniques used by biology to build the machinery of the living world.
A true ecology of information devices will inevitably exhibit the same two-faceted structure. It starts, as we have seen, with an IA based upon a well-defined notion of information objects, mediated by universally unique identifiers (UUIDs). Out of these primitives, it is quite possible—even relatively easy—to rebuild all of the standard data structures that have evolved over 50 years of writing code for stand-alone computers. This involves not so much invention as reinterpretation of standard patterns, but liberated from the computers into the larger ecology. The equivalent of organism architecture is what we call device architecture (DA). Made up of things like application program interfaces (APIs), modular packaging standards, and the like, the DA guides the evolution of the ever larger and more complex systems that will evolve within this new ecology.
These architectures are not laws or any other kind of coercive mechanism. They work with carrots, not with sticks. They operate like the lines painted in a parking lot. Their mere presence tends to result in drivers doing the right thing all on their own. You don’t need traffic cops or physical barriers. You just need to establish the proper patterns. People then (mostly) follow them in their own self-interest. In the case of the parking lot, the evidence of the architecture is boldly there for all to see. Such is not always the case. Sometimes the architecture is hidden or subtle. Such architectures depend upon professional training and the existence of healthy communities of practice for their effectiveness. The evolution of such communities is an indispensable component of our expedition up Trillions Mountain.
A Strange Loop
The Environment: Human Culture
All of this interplay among life forms, currency, and architecture takes place in the context of an environment. In a bio-ecology, the environment is a multivariate aggregation of natural elements, temperature, acidity, radiation, an abundance or scarcity of chemical resources, and so on. In the information ecology, the environment is rather different: It is nothing less than all of human culture. For all of its similarities with Nature, this ecology was created (or at least initiated) by human artifice, and it exists to serve human needs.
But just as the environment affects the ecology that it hosts, so does the ecology affect its environment. Life has been molded by conditions on Earth, but it has also transformed the Earth beyond reckoning. Just so, the emerging information ecology will transform human culture profoundly. The ultimate nature of that transformation is a story not yet written. But, if the shifts in human social intercourse wrought by the relatively trivial social networking technologies deployed to date are any indication, the story of life in the age of Trillions will prove to be a profound and exciting narrative.
Much of the good news of this book proceeds from the ecological nature of the trillion-node world. Learning to describe, understand, and participate in a global information ecology represents a tremendous opportunity. The new research, experimentation, and education implicit in this next stage of our technological development will spark a second knowledge revolution in which many of our readers and their children will participate.
CHALLENGES IN THE INFORMATION ECOLOGY
This book has two themes that are somewhat in tension. On one hand, we claim that the information ecology is upon us whatever we do or don’t do. On the other hand, we say that it is critical to apply the principles of design science to guide its emergence. This may strike some readers as contradictory. But it is really just an example of the familiar tension between trusting our fate to self-determining, natural forces and centralized, rational efforts to bend such forces to our will. This is the tension underlying the conservative/liberal axis in politics; the subtle balance between free-market economics and government regulation intended to reign in the excesses of unbridled capitalism. The skills involved are those of the surfer who sizes up patterns in a wave’s unalterable energy and rides them toward her own goals. They are the skills of the entrepreneur with the insight to foresee a high-leverage branch-point in the chaotic but nonrandom processes of the marketplace and to capitalize upon it for self-profit and social progress.
We have spoken much about the opportunities appertaining to these evolutionary processes, but the risks and challenges are always there, too. Some of these challenges will arrive unanticipated, but others are readily discernible or already upon us. It is worth discussing a few of the most obvious of the latter. Of these, three goals stand out: resiliency, trust, and what we might call human rightness or perhaps felicitousness.
Resiliency
Every psychology student learns the story of the celebrated Phineas Gage, the nineteenth century railroad gandy dancer who, having had a 13-pound iron bar propelled directly through his brain by an ill-timed blast of powder, was able to speak and walk within a few minutes, and led a reasonably normal life for 12 more years (Figure 8.1). Gage did not escape wholly unscathed, but given the magnitude of his injuries, his recovery was striking.
Figure 8.1 Phineas Gage and his iron bar

Now, imagine an analogous amount of damage to a modern PC or smartphone. No. Imagine a vastly smaller amount of damage—say, some kind of microscopic lesion through the device’s circuitry involving only a few hundred transistors. How would the device survive such damage? The chances are that it would not survive at all. In all probability, the device would be junk. It is a credit to modern engineering that we have learned how to make such fragile devices reliable. But they are not very resilient, which is a different thing entirely. The reliability of modern electronic devices depends upon ultrareliability of the devices’ components. The failure of any one of the billions of transistors in a modern CPU chip has a good chance of rendering the chip useless, so reliability of that CPU depends on the assumption that every transistor will work perfectly every time. An animal brain, on the other hand, has an architecture that makes no such assumption. Quite the opposite. Individual neurons are slow, noisy, and unreliable devices. And yet, a human brain is capable of functioning nonstop for a century or more, while sustaining serious abuse along the way. This is resiliency at work.
We see from these examples that there are two different approaches to achieving robust systems: bottom-up ultrareliability, and top-down resiliency. The computer industry has so far mostly relied on the former.3 But in the coming information ecology, the former will not work. None of the techniques that have allowed manufacturers to make it work—centrally controlled choices of components; uniform manufacturing environments; mass-replication of nearly identical vertically integrated systems; factory-level unit testing—will characterize the age of Trillions. Creating large, complex systems will be less like factory manufacturing and more like growing a garden. One will plant, cultivate and prune—not expecting every sprout to blossom.
So, the cultivation of resilient systems will be a major thrust as we learn how to build in the new technological landscape. Where does resiliency come from? There are many answers to this question, but three characteristics have particular importance. These are redundancy, diversity, and stochastic processes.
Redundancy
In Nature, there are no singletons—there is never just one of anything. Everything is massively replicated. Andrew Carnegie advised that one should “put all your eggs into one basket—and watch that basket.” This may have been good advice for a nineteenth-century robber baron, but it is not Nature’s way, and it is not good advice for a twenty-first-century information ecologist.
Component redundancy can effectively protect against some failure modes, but it is powerless against certain others. In particular, if a design flaw or systematic manufacturing defect introduces a vulnerability into a component, the redundant deployment of that component will just make matters worse. As an obvious example of this, the extreme amount of standardization within the PC world on the Windows operating system—for all its advantages—is largely responsible for the sorry state of security on today’s Internet.
Diversity
Protecting against this class of threat requires not just redundancy, but also diversity. Actually, diversity is itself a kind of redundancy—a redundancy not just of deployed components, but also of the design of those components. It is redundancy up a level of metaness. No ecology—natural or technological—can thrive for long without genetic diversity. Relying on a single vendor’s solution—whether it be a particular integrated circuit or an entire operating system—as a de facto standard is the “cheap” and dangerous path toward standardization—we follow it at our peril. A trillion nodes with a high incidence of common defects would be setting us up for a disaster of unprecedented proportions. We must learn how to preserve and encourage diversity as we build toward the pervasive future. But here too, ham-handed attempts to follow this advice are likely to lead to new problems. The challenge is to preserve diversity while simultaneously achieving the uniformity of experience—both for end users and for those who deploy and maintain systems on their behalf—that will become a practical and economic necessity in the age of Trillions.
It is here, once again, that architecture becomes important. A properly layered architectural approach to systems design tends to focus attention not merely upon making something work, but upon functionally specified subcomponents with well-defined requirements and interfaces. Such specifications are, as we have seen, essential to device fungibility; and fungibility among independently developed equivalent implementations in the context of a free market of components is the royal path to diversity.
Stochastic Processes
Mainstream computing can trace its ancestry directly back to the giant calculator era of computers. As a result, numerical accuracy is an integral part of the DNA of the industry. If anything can be said about computers of virtually all stripes it is that they don’t make errors in arithmetic. Getting the same answer every time is axiomatic. This may seem like a strange constraint to relax, but trading off precision and determinacy for resiliency will become an increasingly important part of the systems designer’s repertoire of techniques as ecological computing takes hold. Stochastic processes—those that have some random component and thus are nondeterministic—are forced upon us by the tyranny of large numbers and by certain computational operations that are unavoidably expensive. A prime example of the latter involves what is known as “transactional consistency.” To make a long story short, this refers to the operation of making sure that some piece of replicated information has consistent values in all of the places it is stored. This turns out to be a very expensive guarantee to make, computationally speaking. As a result, it needs to be avoided when possible, and that usually means compromising moment-to-moment consistency.
An example of this can be found in the massive server farms that lie behind giant, high-volume websites. If you watch carefully the behavior of a large, rapidly changing site—cnn.com, for example—you might notice that if you access the site using two identical web browsers at roughly the same time, you will occasionally see different information. This, as you probably know, is because such websites are not served from a single giant server, but rather from farms of thousands of independent machines. Updating all those machines takes time, and exactly what you get at any given instant depends upon the luck of the draw. These machines could be explicitly synchronized every time a change is made, but this would be at the expense of bringing everything to a screeching halt during every change. We would find ourselves back to the days of the World-Wide-Wait. The designers of these server farms chose to sacrifice a bit of consistency (a kind of accuracy) for a lot of performance. Similar tradeoffs will become an inevitable part of a successful information ecology.
Trust
Our willingness to embrace a technology or a source of information (and therefore their market viability) is completely dependent on our willingness to trust them. We fly in airliners because we trust that they will not fall out of the sky. We rely upon physical reference books found in the library because we trust that they are not elaborate forgeries and that their publishers have properly vetted their authors. But trust is a relative thing. We trust—more or less—well-known websites when we are shopping for appliances or gadgets. But we are more careful about things we read on the Internet when the consequences are high. We consider web-based sources of medical information, but we do so with caution. We tend to discount random political rants found on personal blogs. We trust not at all e-mail from widows of former Nigerian ministers of finance. Wikipedia has earned our trust for many routine purposes, but would we be willing to have our taxes calculated based upon numbers found there? Similarly, we trust consumer computing devices5 for surfing the web, for TiVoing our television programs, and perhaps for turning on our porch light every evening, but we do not trust them to drive our cars or to control our cities.
As these examples illustrate, our requirements for trust vary proportionately with the criticality of the applications. The average level of trust of the Internet or of consumer computing devices is fairly low, but this is acceptable since we do not yet use them for the things that really matter. As we have seen, this is about to change, and so the stakes with respect to trust are going up.
Where does trust in a technology come from? This is yet another question with many answers, but some obvious ones involve reputation, provenance, and security. These three are intimately related. Reputation is practically synonymous with trust itself. Other than personal experiences, which are inevitably limited, what basis do we have for forming trust besides reputation? But, there can be no reputation without provenance. An anonymous note scribbled on a wall can almost never be trusted, simply because we know so little about its origin. Similarly, material obtained from today’s peer-to-peer file sharing services is inherently untrustworthy. There is, in general, no way of knowing whether a file is what it claims to be, or whether it has been subtly altered from its original. Which brings us, inevitably, to security. Our confidence in the provenance of an item in the real world depends critically on one of two things: We believe that an object is what it seems to be either because it is technically difficult to duplicate, or because its history is accounted for. Dollar bills are an example of the former, and a fork once owned by George Washington might be an example of the latter.
As these examples suggest, most traditional approaches to security are tied to physical attributes such as complex structures of various kinds or brute-force barriers to entry. These familiar approaches have also formed the basis for the security of information systems in the great majority of cases. It is true that “private places” in cyberspace such as web-based services are “protected” by passwords, but as a practical matter, most private data are protected via physical security. We protect the contents of our PCs by keeping strangers away from them. We keep our cell phones and our credit cards securely in our pockets and purses. Large corporations keep their data crown jewels locked away in data center fortresses.
But there’s a new sheriff in town. His name is “encryption.” Of course, there is nothing really new about encryption. It has been around for millennia. But modern computing, combined with modern mathematics and modern networking, has raised the art of code making to both critical importance and—if properly deployed—near perfect trustworthiness.6 This is fortunate, because on Trillions Mountain nothing else will work. In a world moving irrevocably into cyberspace, and in which cyberspace itself will be implemented in a radically distributed manner, how could it be otherwise?
Encryption is already indispensable to the functioning of the Internet. The channels along which our data flow are and should be considered intrinsically insecure. Any attempt to “fix” this situation would involve throwing out the baby with the bathwater. A safe Internet would be a sterile Internet—innovation would cease. Fortunately, this is unnecessary. End-to-end encryption is fully capable of providing secure communication over insecure channels. The same technologies are also capable of meeting the needs of data provenance. Techniques going under the name of cryptographic signatures allow even plaintext data to be reliably identified as to its source in a way such that any tampering can be reliably detected. These techniques are mature, and they are reliable. The problem is that they are at present only deployed in very limited settings and for very narrow purposes. A successful information ecology will require the use of these techniques to become universal and routine. They will be the only practical means of security in the future.
Let us be clear about this point: The time will soon come in which it will be necessary to almost completely abandon physical security as a component of our system of trust. In a world of immaterial, promiscuously replicated data objects, all secrets must be encrypted and most nonsecrets must be digitally signed. In this world, if you would not be willing to hand copies of your most important data to your mortal enemies (properly encrypted, of course), then any sense of security you may have will be illusory. For all practical purposes, this is already true. If you are a user of any of the so-called cloud computing services, or any other network service for that matter, your precious data pass through many hands on the way to that service, and not all of them are necessarily friendly. The world we describe simply takes the next small steps of using encryption routinely during storage as well as during transport, and then giving up the illusion of physical security.
These issues of trust, provenance, reputation, and security don’t apply only to information. In the age of Trillions, they will be equally important when dealing with physical devices. This is a relatively minor issue today. If you go to your local Apple Store and buy something that looks and acts like an iPhone, you have reason to believe that it is indeed an iPhone, exactly as Apple designed it. And so your level of trust in the device should pretty much equal your level of trust in the Apple brand (whatever that level may be). On the other end of the spectrum, if you buy a four-banger pocket calculator at the dollar store, it may well have no brand at all—certainly no brand that you will have heard of. You don’t know or care who designed or built it. As long as it does correct arithmetic (which in all likelihood it will), what harm can it do?
But, in the age of Trillions, things won’t be so cut and dried. When every piece of bric-a-brac will have enough computing power to do real mischief, the provenance of trivial things will come to be of concern. Even today, how would you know if deep inside the CPU chip of your new Internet-connected TV there was some tiny bit of unnoticed logic—the result of some secret mandate of some unscrupulous foreign government—implementing a latent back-door Trojan horse, waiting for an innocent-looking automatic firmware update to begin doing god-knows-what? Has such a thing ever been done? We have no idea. Is it implausible? Obviously, not in the least. The odds may be small in any given case. But, as we may have mentioned before, a trillion is a large number. There will soon be a great many places to hide, and malicious functionality hiding in insignificant hardware is going to be a whole lot more insidious than malicious code hiding in information objects. In the future, the provenance of mundane objects is going to become of real interest.
This is a serious issue that has not received nearly as much attention as the protection of information via encryption. Short of X-raying a chip and accounting for every transistor, it is really not clear how the authenticity of a chip that has ever been out in the wild can really be established. The seriousness of this issue has recently been brought into focus by a series of incidents involving the discovery of “counterfeit” (actually recycled) chips in U.S. military electronics. Although it is not clear that these incidents involved anything beyond an attempt to make extra profit, the potential consequences of the appearance of enemy Trojan horses embedded deep into military hardware needs no elaboration. How these risks can be addressed is an open question. Fortunately, the very problem may prove to contain the seeds to its own solution. There already exist electronic shipping tags that, when attached to crates containing high-value cargo, monitor them for rough handling and other physical abuse, and in some cases even track exactly where the items have been and when. It seems plausible that the kind of supply-chain transparency that such technologies make possible may become a routine and essential part of establishing and maintaining the provenance of even commodity products.
Felicitousness: Designing for People
The information ecology that we have been sketching involves a kind of automation, but it is not the automation of a lights-out robotically controlled factory, or of the missile system in Pete’s story. Far from being a system apart from humanity, it will be a seamless symbiosis between human and machine systems.7 In this respect, it is more like a home or a city than it is like a factory. This is a crucial point, because it gets to the heart of why pulling off the next 50 years is going to be a challenge. In a nutshell, the challenge is this: We are facing an engineering project as big as any that humanity has ever faced, but the system being engineered will be as much human as it is machine. The trick will be to insure that it is also humane.
At the time we are writing, the current next big thing (that is to say, the thing for which it is currently easiest to obtain venture capital) is any Internet business plan containing the words social networking. This is just the latest in what will prove to be a very long row of profit-making dominos that the industry will knock down more or less one at a time, but at an ever-increasing rate. But it is a fortunate one at the present juncture, since it focuses the industry on the basic issues of human interaction, which is where the important developments are going to lie from now on.
Networks of Trust
Before we leave the topic of trust, we should explore the increasingly important notion of networks of trust. People have always participated in multiple, overlapping communities of various kinds. But prior to the mass Internet, the number of such communities available to any individual was as a practical matter very limited, and usually very local. There was family, and neighborhood, and work, and perhaps church or fraternal lodge or knitting club or Boy Scout troop. All of these were community based, which basically means that everybody pretty much knew everybody else—at least well enough to size them up for trust purposes. If your interests spilled out beyond your local community, then you were more or less reduced to magazine subscriptions or mail-order society memberships, both of which were largely one-way read-only relationships.
But, from its earliest days, the Net has been changing all of that. Arguably, the very first practical use to which the early ARPAnet was put was to support a dozen or so “mailing lists,” which were in fact topically grouped networks of people who used mass-emailings to form something new in the world: persistent, intimate, real-time discussion groups made up of total strangers.8 In other words, the very first computer networking was social networking. And, suddenly, the number of social networks that one could belong to was no longer limited by geography, but only by one’s enthusiasms, energy, and willingness to stay up late.
What was striking about these early online communities, and all that have followed, is that they quickly lead to new kinds of interpersonal relationships. Instead of gaining a broad understanding of other people, one gains a very deep understanding about very narrow slices of other lives. You may have one circle of friends whom you would trust intimately if you were repairing your antique motorcycle, and another whose advice about New York City nightlife is beyond reproach. On all other topics, you wouldn’t know these people from Adam and would trust them even less. And yet, for the matters for which you do trust them, the level of trust is often far higher than would be the case with generic friends. And, it must be remembered that these kinds of microcommunities-of-interest exist in vast numbers and on just about every conceivable topic. This democratization of access to specialized knowledge is where the real significance of social networking lies. Just as mobile access to Google has destroyed the bar bet by giving everyone instant access to any fact, the emerging vast web of trust networks has given everyone access to expert opinion and judgment.
The notion of networks of trust is also important in the implementation of systems of data provenance. As we have already seen, the ability to judge the trustworthiness of a document is dependent on the ability to have trustworthy knowledge of who wrote it. But, most documents are written by strangers, so the problem reduces to deciding whether you can trust a stranger. How do you do this? Basically, you need to find a path through a network of trust. If the document is written by a friend of a friend whom you trust, that is often enough. But theories of “six degrees of separation” notwithstanding, finding such a path on the interpersonal level is often not practical. What is needed is connectors—aggregators of trust. There is a name for such aggregators. They are called publishers. If you strip out incidental (and increasingly irrelevant) functions like printing and warehousing physical books, the essential residue of what commercial publishers do has everything to do with vouching for authors. Given two books by equally obscure authors, are you more likely to trust the one that was self-published, or the one that was published by a major publishing house? This function of vouching for authors will be at least as important in the new information ecology as it has been historically.
Privacy
This is a tough one. On one hand, there is the position epitomized by Sun Microsystems’ CEO Scott McNealey’s infamous 1999 pronouncement that “You have zero privacy anyway. Get over it.” When video cameras are the size of pinheads and cost approximately nothing, it is sometimes difficult not to conclude that the jig is up. And, it can’t be denied that everyone from subway riders to FedEx delivery men are thinking twice these days before misbehaving. On the other hand, we have all read 1984, and it is hard to get that one out of your head. Maybe the path we are on is just not acceptable. We just don’t know. But, what we do know is that whether or not we choose to treat a modicum of privacy as a basic human right, we have to acknowledge it as a basic human need. And even if not, it still seems obvious that simple prudence dictates that we cede control of much personal information to the individual to whom it appertains. Sooner or later, we think, there is going to be pushback from consumers, and purveyors of information products and services will ignore privacy issues at their peril.
For all the wonders that pervasive computing will bring, it must be admitted that it will not in the natural course of things be very good for privacy. These negative side effects of a generally positive technological trend are analogous to the air and water pollution that inevitably accompanied industrialization. They can’t be entirely avoided, but they can and must be mitigated.
Amid the circus of the O.J. Simpson murder trial, a lot of people were more than a bit startled to discover that every swipe of those hotel room keycards is recorded and subject to subpoena. Similarly, if you lose your ticket when parking in an airport parking lot, you might be surprised to learn that the management will know how many days you have been parked, courtesy of the automatic OCR (Optical Character Recognition) performed on your license plate. Both of these examples are old news. The new situational awareness technologies that are becoming practical every year are beginning to boggle the mind. And, of course, we have been focusing only on the physical world. The ability to surreptitiously collect data in cyberspace is too obvious and too well known to require comment here.
As in every other technological revolution, some kind of middle ground will have to be carved out over time, and doing so will very likely require the force of law in at least some cases. But once the consequences of these new capabilities begins to sink in, we suspect that there will be enough consumer objections with enough negative effect on the corporate bottom line that, even without government action, being privacy friendly will soon acquire as much cash value as being environmentally friendly already has.
Empowering Power Users
The early days of the PC were a classic case of a solution in search of a problem. It was pretty obvious that a computer-on-your-desk was an exciting prospect and had to be good for something. But what? Storing recipes perhaps? We were in a hunt for a killer app. When we finally found one in the late 1970s, it was at first a bit surprising. It turned out to be something called VisiCalc. VisiCalc was basically a glorified financial calculator, but it had two features that are critical to our story: First, it had an architecture. Better yet, it had an architecture tied to a good metaphor. The metaphor was that of a financial spreadsheet—a grid of rows and columns forming cells. These cells were (literally) little boxes into which one could put numbers and text. If this sounds familiar, it is not coincidental. Spreadsheets are a microcosm of the data container idea that we have been discussing throughout this book. By labeling columns with letters and rows with numbers, each cell was given a unique identity (albeit only unique within a given spreadsheet) that permitted it to be referred to independently of its contents. It was a simple, powerful concept that made sense to business users. Second—and critically—VisiCalc was scriptable. It wasn’t so much an application as a box of Lego blocks. It did almost nothing out of the box, but it was relatively easy to build highly specific appliances that fit like a glove into the workflows of particular offices and did a far better job of meeting the myriad needs of those offices than could any canned accounting package.
This is a good story, but it may strike you as being out of place in a section about social processes in pervasive computing. But the story is essentially social. To see why, we need to point out one more fact about spreadsheet programs: Many users who routinely employ spreadsheets really don’t understand them very well. Although developing new spreadsheet appliances is relatively easy when compared with writing a computer program from scratch, it is still a somewhat arcane process requiring certain specialized skills and a certain temperament. Most people prefer to just get on with their jobs. The true breakthrough of the spreadsheet program was that it empowered the former to support the latter (Figure 8.2). Many people would rather have a root canal than create an elaborate spreadsheet. But everybody knows the wizard down the hall who is great at it and loves the challenge. These aren’t programmers, they are scriptors—paraprogrammers.
Figure 8.3 Developers serving scriptors serving users
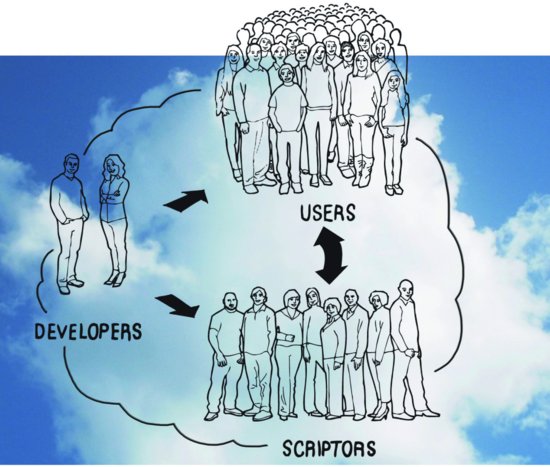
This story of Architecture empowering people to help each other in intimate local settings is of crucial importance in envisioning how the coming information ecology will operate. Both the sheer scale of the systems we will be deploying and their vast diversity and sensitivity to local conditions simply precludes any deployment and support system that does not have the essential characteristics of locality and interpersonal communications that is epitomized by the end-user/power-user axis. No Geek Squad is going to suffice to come into your house every time you want to rearrange your furniture (which, being information devices like everything else, will be part of the fabric of your local information environment). A lot of that kind of thing will have to take care of itself. For most of the rest, it is your geek nephew, or your friendly next-door neighbor that will be your go-to person. This is a fundamentally social process, but one that is enabled by subtle and deliberate design decisions by the device and information architects who conceive and cultivate the DNA of these new life-forms.
1 Indeed, in the final analysis, money is a carrier of information.
2 Note by Pete: I first learned this game during my juvenile infatuation with James Bond novels. Ian Fleming used it as a high-drama plot device in the opening pages of You Only Live Twice. The effectiveness of the game for this purpose in Fleming’s capable hands relies upon the psychological subtleties to which Mick alludes.
3 The original architecture of the Internet being a notable exception.
4 186,282 miles/second divided by 4,900 miles (round trip).
5 By this we mean computers not tightly controlled by IT professionals, as opposed, say, to those located in a bank’s data center.
6 It is true that the development of a practical quantum computer would compromise this trustworthiness, but such a breakthrough is not imminent; and, if and when it does happen, the same technology will no doubt provide new tools for the code makers as well as the code breakers. Moreover, the significantly more mature techniques of quantum key distribution, which rely on the process of quantum entanglement, are believed to be fundamentally impervious to any possible attack.
7 If you doubt this, walk down a busy street in any city in the world and estimate the percentage of young people who are visibly attached to some piece of information technology. Then, make a similar estimate for the percentage with some kind of body modification. Can there be any doubt that when the day comes that implantable iPhones become feasible (and that day is not distant), a nontrivial number of people will opt-in?
8 Google Groups has indexed many messages from these days—going back as far as 1981. It is disorienting and sometimes embarrassing to come across one’s own footprints in that lost world.