
Chapter 17. Tools for Large Programs
CONTENTS
Section 17.1 Exception Handling 688
Section 17.3 Multiple and Virtual Inheritance 731
C++ is used on problems that have a wide range in complexity. It is used on problems small enough to be solved by a single programmer after a few hours’ work to problems requiring enormous systems consisting of tens of millions of lines of code developed and modified over many years. The facilities we covered in the earlier parts of this book are equally useful across this range of programming problems.
The language includes some features that are most useful on systems once problems get to be more complex than those that an individual can manage. These features—exception handling, namespaces, and multiple inheritance—are the topic of this chapter.
Large-scale programming places greater demands on programming languages than do the needs of systems that can be developed by small teams of programmers. Among the needs that distinguish large-scale applications are:
- Stricter up-time requirements and the need for more robust error detection and error handling. Error handling often must span independently developed subsystems.
- The ability to structure programs that are composed of libraries developed more or less independently.
- The need to deal with more complicated application concepts.
Three features in C++ are aimed at these needs: exception handling, namespaces, and multiple inheritance. This chapter looks at these three facilities.
17.1 Exception Handling
Exception handling allows independently developed parts of a program to communicate about and handle problems that arise during execution of the program. One part of the program can detect a problem that that part of the program cannot resolve. The problem-detecting part can pass the problem along to another part that is prepared to handle what went wrong.

Exceptions let us separate problem detection from problem resolution. The part of the program that detects a problem need not know how to deal with it.
In C++, exception handling relies on the problem-detecting part throwing an object to a handler. The type and contents of that object allow the two parts to communicate about what went wrong.
Section 6.13 (p. 215) introduced the basic concepts and mechanics of using exceptions in C++. In that section, we hypothesized that a more complex bookstore application might use exceptions to communicate about problems. For example, the Sales_item addition operator might throw an exception if the isbn members of its operands didn’t match:

Those parts of the program that added Sales_item objects would use a try block in order to catch an exception if one occured:

In this section we’ll expand our coverage of these basics and cover some additional exception-handling facilities. Effective use of exception handling requires understanding what happens when an exception is thrown, what happens when it is caught, and the meanings of the objects used to communicate what went wrong.
17.1.1 Throwing an Exception of Class Type
An exception is raised by throwing an object. The type of that object determines which handler will be invoked. The selected handler is the one nearest in the call chain that matches the type of the object.
Exceptions are thrown and caught in ways that are similar to how arguments are passed to functions. An exception can be an object of any type that can be passed to a nonreference parameter, meaning that it must be possible to copy objects of that type.
Recall that when we pass an argument of array or function type, that argument is automatically converted to an pointer. The same automatic conversion happens for objects that are thrown. As a consequence, there are no exceptions of array or function types. Instead, if we throw an array, the thrown object is converted to a pointer to the first element in the array. Similarly, if we throw a function, the function is converted to a pointer to the function (Section 7.9, p. 276).
When a throw is executed, the statement(s) following the throw are not executed. Instead, control is transferred from the throw to the matching catch. That catch might be local to the same function or might be in a function that directly or indirectly called the function in which the exception occurred. The fact that control passes from one location to another has two important implications:
- Functions along the call chain are prematurely exited. Section 17.1.2 (p. 691) discusses what happens when functions are exited due to an exception.
- In general, the storage that is local to a block that throws an exception is not around when the exception is handled.
Because local storage is freed while handling an exception, the object that is thrown is not stored locally. Instead, the throw expression is used to initialize a special object referred to as the exception object. The exception object is managed by the compiler and is guaranteed to reside in space that will be accessible to whatever catch is invoked. This object is created by a throw, and is initialized as a copy of the expression that is thrown. The exception object is passed to the corresponding catch and is destroyed after the exception is completely handled.

The exception object is created by copying the result of the thrown expression; that result must be of a type that can be copied.
Exception Objects and Inheritance
In practice, many applications throw expressions whose type comes from an inheritance hierarchy. As we’ll see in Section 17.1.7 (p. 697), the standard exceptions (Section 6.13, p. 215) are defined in an inheritance hierarchy. What’s important to know at this point is how the form of the throw expression interacts with types related by inheritance.
When an exception is thrown, the static, compile-time type of the thrown object determines the type of the exception object.
Ordinarily, the fact that the object is thrown using its static type is not an issue. When we throw an exception, we usually construct the object we are going to throw at the throw point. That object represents what went wrong, so we know the precise exception type.
Exceptions and Pointers
The one case where it matters that a throw expression throws the static type is if we dereference a pointer in a throw. The result of dereferencing a pointer is an object whose type matches the type of the pointer. If the pointer points to a type from an inheritance hierarchy, it is possible that the type of the object to which the pointer points is different from the type of the pointer. Regardless of the object’s actual type, the type of the exception object matches the static type of the pointer. If that pointer is a base-class type pointer that points to a derived-type object, then that object is sliced down (Section 15.3.1, p. 577); only the base-class part is thrown.
A problem more serious than slicing the object may arise if we throw the pointer itself. In particular, it is always an error to throw a pointer to a local object for the same reasons as it is an error to return a pointer to a local object (Section 7.3.2, p. 249) from a function. When we throw a pointer, we must be certain that the object to which the pointer points will exist when the handler is entered.
If we throw a pointer to a local object and the handler is in another function, then the object to which the pointer points will no longer exist when the handler is executed. Even if the handler is in the same function, we must be sure that the object to which the pointer points exists at the site of the catch. If the pointer points to an object in a block that is exited before the catch, then that local object will have been destroyed before the catch.
It is usually a bad idea to throw a pointer: Throwing a pointer requires that the object to which the pointer points exist wherever the corresponding handler resides.
17.1.2 Stack Unwinding
When an exception is thrown, execution of the current function is suspended and the search begins for a matching catch clause. The search starts by checking whether the throw itself is located inside a try block. If so, the catch clauses associated with that try are examined to see if one of them matches the thrown object. If a matching catch is found, the exception is handled. If no catch is found, the current function is exited—its memory is freed and local objects are destroyed—and the search continues in the calling function.
If the call to the function that threw is in a try block, then the catch clauses associated with that try are examined. If a matching catch is found, the exception is handled. If no matching catch is found, the calling function is also exited, and the search continues in the function that called this one.
This process, known as stack unwinding, continues up the chain of nested function calls until a catch clause for the exception is found. As soon as a catch clause that can handle the exception is found, that catch is entered, and execution continues within this handler. When the catch completes, execution continues at the point immediately after the last catch clause associated with that try block.
Destructors Are Called for Local Objects
During stack unwinding, the function containing the throw, and possibly other functions in the call chain, are exited prematurely. In general, these functions will have created local objects that ordinarily would be destroyed when the function exited. When a function is exited due to an exception, the compiler guarantees that the local objects are properly destroyed. As each function exits, its local storage is freed. Before releasing the memory, any local object that was created before the exception occurred is destroyed. If the local object is of class type, the destructor for this object is called automatically. As usual, the compiler does no work to destroy an object of built-in type.
During stack unwinding, the memory used by local objects is freed and destructors for local objects of class type are run.
If a block directly allocates a resource, and the exception occurs before that resource is freed, that resource will not be freed during stack unwinding. For example, a block might dynamically allocate memory through a call to new. If the block exits due to an exception, the compiler does not delete the pointer. The allocated memory will not be freed.
Resources allocated by an object of class type generally will be properly freed. Destructors for local objects are run; resources allocated by class-type objects ordinarily are freed by their destructor. Section 17.1.8 (p. 700) describes a programming technique that uses classes to manage resource allocation in the face of exceptions.
Destructors Should Never throw Exceptions
Destructors are often executed during stack unwinding. When destructors are executing, the exception has been raised but not yet handled. It is unclear what should happen if a destructor itself throws a new exception during this process. Should the new exception supersede the earlier exception that has not yet been handled? Should the exception in the destructor be ignored?
The answer is that while stack unwinding is in progress for an exception, a destructor that throws another exception of its own that it does not also handle, causes the library terminate function is called. Ordinarily, terminate calls abort, forcing an abnormal exit from the entire program.
Because terminate ends the program, it is usually a very bad idea for a destructor to do anything that might cause an exception. In practice, because destructors free resources, it is unlikely that they throw exceptions. The standard library types all guarantee that their destructors will not raise an exception.
Exceptions and Constructors
Unlike destructors, it is often the case that something done inside a constructor might throw an exception. If an exception occurs while constructing an object, then the object might be only partially constructed. Some of its members might have been initialized, and others might not have been initialized before the exception occurs. Even if the object is only partially constructed, we are guaranteed that the constructed members will be properly destroyed.
Similarly, an exception might occur when initializing the elements of an array or other container type. Again, we are guaranteed that the constructed elements will be destroyed.
Uncaught Exceptions Terminate the Program
An exception cannot remain unhandled. An exception is an important enough event that the program cannot continue executing normally. If no matching catch is found, then the program calls the library terminate function.
17.1.3 Catching an Exception
The exception specifier in a catch clause looks like a parameter list that contains exactly one parameter. The exception specifier is a type name followed by an optional parameter name.
The type of the specifier determines what kinds of exceptions the handler can catch. The type must be a complete type: It must either be a built-in type or a programmer-defined type that has already been defined. A forward declaration for the type is not sufficient.
An exception specifier can omit the parameter name when a catch needs to know only the type of the exception in order to handle it. If the handler needs information beyond what type of exception occurred, then its exception specifier will include a parameter name. The catch uses the name to get access to the exception object.
Finding a Matching Handler
During the search for a matching catch, thecatch that is found is not necessarily the one that matches the exception best. Instead, the catch that is selected is the first catch found that can handle the exception. As a consequence, in a list of catch clauses, the most specialized catch must appear first.
The rules for when an exception matches a catch exception specifier are much more restrictive than the rules used for matching arguments with parameter types. Most conversions are not allowed—the types of the exception and the catch specifier must match exactly with only a few possible differences:
• Conversions from nonconst to const are allowed. That is, a throw of a nonconst object can match a catch specified to take a const reference.
• Conversions from derived type to base type are allowed.
• An array is converted to a pointer to the type of the array; a function is converted to the appropriate pointer to function type.
No other conversions are allowed when looking for a matching catch. In particular, neither the standard arithmetic conversions nor conversions defined for class types are permitted.
Exception Specifiers
When a catch is entered, the catch parameter is initialized from the exception object. As with a function parameter, the exception-specifier type might be a reference. The exception object itself is a copy of the object that was thrown. Whether the exception object is copied again into the catch site depends on the exception-specifier type.
If the specifier is not a reference, then the exception object is copied into the catch parameter. The catch operates on a local copy of the exception object. Any changes made to the catch parameter are made to the copy, not to the exception object itself. If the specifier is a reference, then like a reference parameter, there is no separate catch object; the catch parameter is just another name for the exception object. Changes made to the catch parameter are made to the exception object.
Exception Specifiers and Inheritance
Like a parameter declaration, an exception specifier for a base class can be used to catch an exception object of a derived type. Again, like a parameter declaration, the static type of the exception specifier determines the actions that the catch clause may perform. If the exception object thrown is of derived-class type but is handled by a catch that takes a base-class type, then the catch cannot use any members that are unique to the derived type.

Usually, a catch clause that handles an exception of a type related by inheritance ought to define its parameter as a reference.
If the catch parameter is a reference type, then the catch object accesses the exception object directly. The static type of the catch object and the dynamic type of the exception object to which it refers might differ. If the specifier is not a reference, then the catch object is a copy of the exception object. If the catch object in an object of the base type and the exception object has derived type, then the exception object is sliced down (Section 15.3.1, p. 577) to its base-class subobject.
Moreover, as we saw in Section 15.2.4 (p. 566), objects (as opposed to references) are not polymorphic. When we use a virtual function on an object rather than through a reference, the object’s static and dynamic type are the same; the fact that the function is virtual makes no difference. Dynamic binding happens only for calls through a reference or pointer, not calls on an object.
Ordering of Catch Clauses Must Reflect Type Hierarchy
When exception types are organized in class hierarchies, users may choose the level of granularity with which their applications will deal with an exception. For example, an application that merely wants to do cleanup and exit might define a single try block that encloses the code in main with a catch such as the following:

Other programs with more rigorous uptime requirements might need finer control over exceptions. Such applications will clear whatever caused the exception and continue processing.
Because catch clauses are matched in the order in which they appear, programs that use exceptions from an inheritance hierarchy must order their catch clauses so that handlers for a derived type occurs before a catch for its base type.
Multiple catch clauses with types related by inheritance must be ordered from most derived type to least derived.

17.1.4 Rethrow
It is possible that a single catch cannot completely handle an exception. After some corrective actions, a catch may decide that the exception must be handled by a function further up the chain of function calls. A catch can pass the exception out to another catch further up the list of function calls by rethrowing the exception. A rethrow is a throw that is not followed by a type or an expression:
throw;
An empty throw rethrows the exception object. An empty throw can appear only in a catch or in a function called (directly or indirectly) from a catch. If an empty throw is encountered when a handler is not active, terminate is called.
Although the rethrow does not specify its own exception, an exception object is still passed up the chain. The exception that is thrown is the original exception object, not the catch parameter. When a catch parameter is a base type, then we cannot know the actual type thrown by a rethrow expression. That type depends on the dynamic type of the exception object, not the static type of the catch parameter. For example, a rethrow from a catch with a parameter of base type might actually throw an object of the derived type.
In general, a catch might change its parameter. If, after changing its parameter, the catch rethrows the exception, then those changes will be propagated only if the exception specifier is a reference:

17.1.5 The Catch-All Handler
A function may want to perform some action before it exits with a thrown exception, even though it cannot handle the exception that is thrown. Rather than provide a specific catch clause for every possible exception, and because we can’t know all the exceptions that might be thrown, we can use a catch-all catch clause. A catch-all clause has the form (...). For example:

A catch-all clause matches any type of exception.
A catch(...) is often used in combination with a rethrow expression. The catch does whatever local work can be done and then rethrows the exception:

A catch(...) clause can be used by itself or as one of several catch clauses.
If a catch(...) is used in combination with other catch clauses, it must be last; otherwise, any catch clause that followed it could never be matched.
17.1.6 Function Try Blocks and Constructors
In general, exceptions can occur at any point in the program’s execution. In particular, an exception might occur in a constructor, or while processing a constructor initializer. Constructor initializers are processed before the constructor body is entered. A catch clause inside the constructor body cannot handle an exception that might occur while processing a constructor initializer.
To handle an exception from a constructor initializer, we must write the constructor as a function try block. A function try block lets us associate a group of catch clauses with the function as a whole. As an example, we might wrap our Handle constructor from Chapter 16 in a try block to detect a failure in new:

Exercises Section 17.1.5
Exercise 17.4: Given a basic C++ program,
![]()
modify main to catch any exception thrown by functions in the C++ standard library. The handlers should print the error message associated with the exception before calling abort (defined in the header cstdlib) to terminate main.
Exercise 17.5: Given the following exception types and catch clauses, write a throw expression that creates an exception object that could be caught by each catch clause.
(a) class exceptionType { };
catch(exceptionType *pet) { }
(b) catch(...) { }
(c) enum mathErr { overflow, underflow, zeroDivide };
catch(mathErr &ref) { }
(d) typedef int EXCPTYPE;
catch(EXCPTYPE) { }
Notice that the keyword try precedes the member initialization list, and the compound statement of the try block encompasses the constructor function body. The catch clause can handle exceptions thrown either from within the member initialization list or from within the constructor body.
The only way for a constructor to handle an exception from a constructor initializer is to write the constructor as a function try block.
17.1.7 Exception Class Hierarchies
Section 6.13 (p. 215) introduced the standard-library exception classes. What that section did not cover is that these classes are related by inheritance. The inheritance hierarchy is portrayed in Figure 17.1 on the following page.
Figure 17.1. Standard exception Class Hierarchy
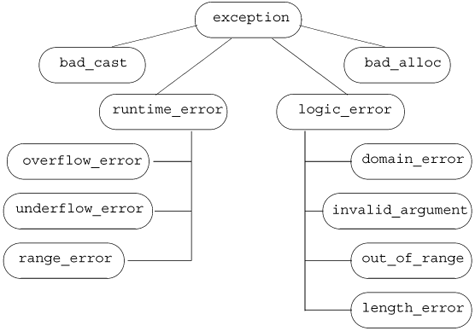
The only operation the exception types define is a virtual member named what. That function returns a const char*. It typically returns the message used when constructing the exception object at the throw site. Because what is virtual if we catch a base-type reference, a call to the what function will execute the version appropriate to the dynamic type of the exception object.
Exception Classes for a Bookstore Application
The standard exception classes can be used for quite a number of applications. In addition, applications often extend the exception hierarchy by deriving additional types from exception or one of the intermediate base classes. These newly derived classes can represent exception types specific to the application domain.
If we were building a real bookstore application, our classes would have been much more complex than the ones presented in this primer. One way in which they might be more elaborate would be in their handling of exceptions. In fact, we probably would have defined our own hierarchy of exceptions to represent application-specific problems that might arise. Our design might include classes such as

Here we defined our application-specific exception types by deriving them from the standard exception classes. As with any hierarchy, we can think of the exception classes as being organized into layers. As the hierarchy becomes deeper, each layer becomes a more specific exception. For example, the first and most general layer of the hierarchy is represented by class exception. All we know when we catch an object of this type is that something has gone wrong.
The second layer specializes exception into two broad categories: run-time or logic errors. Our bookstore exception classes represent an even more specialized layer. The class out_of_stock represents something that can go wrong at run time that is particular to our application. It would be used to signal that an order cannot be fulfilled. The isbn_mismatch exception is a more particular form of logic_error. In principle, a program could detect that the ISBNs don’t match by calling same_isbn.
Using Programmer-Defined Exception Types
We use our own exception classes in the same way that we use one of the standard library classes. One part of the program throws an object of one of these types, and another part catches and handles the indicated problem. As an example, we might define the overloaded addition operator for our Sales_item class to throw an error of type isbn_mismatch if it detected that the ISBNs didn’t match:

Code that uses the addition operator could then detect this error, write an appropriate error message, and continue:

17.1.8 Automatic Resource Deallocation
In Section 17.1.2 (p. 691) we saw that local objects are automatically destroyed when an exception occurs. The fact that destructors are run has important implication for the design of applications. It also is one (among many) reasons why we encourage the use of the standard library classes. Consider the following function:

This function defines a local vector and dynamically allocates an array. Under normal execution, both the array and the vector are destroyed before the function exits. The array is freed by the last statement in the function, and the vector is automatically destroyed when the function ends.
However, if an exception occurs inside the function, then the vector will be destroyed but the array will not be freed. The problem is that the array is not freed automatically. An exception that occurs after the new but before the corresponding delete leaves the array undestroyed. No matter when an exception occurs, we are guaranteed that the vector destructor is run.
Using Classes to Manage Resource Allocation
The fact that destructors are run leads to an important programming technique that makes programs more exception safe. By exception safe, we mean that the programs operate correctly even if an exception occurs. In this case, the “safety” comes from ensuring that any resouce that is allocated is properly freed if an exception occurs.
We can guarantee that resources are properly freed by defining a class to encapsulate the acquisition and release of a resource. This technique is often referred to as “resource allocation is initialization,” often abreviated as RAII.
The resource-managing class should be designed so that the constructor acquires the resource and the destructor frees it. When we want to allocate the resource, we define an object of that class type. If no exception occurs, then the resource will be freed when the object that acquired the resource goes out of scope. More importantly, if an exception occurs after the object is created but before it goes out of scope, then the compiler ensures that the object is destroyed as part of unwinding the scope in which the object was defined.
The following class is a prototypical example in which the constructor acquires a resource and the destructor releases it:

The Resource class is a type that allocates and deallocates a resource. It holds data member(s) that represent that resource. The constructor for Resource allocates the resource, and the destructor frees it. When we use this class

the resource is automatically freed. If the function terminates normally, then the resource is freed when the Resource object goes out of scope. If the function is exited prematurely by an exception, the destructor for Resource is run by the compiler as part of the exception handling process.
Programs in which exceptions are possible and that allocate resources should use classes to manage those resources. As described in this section, using classes to manage acquisition and deallocation ensures that resources are freed if an exception occurs.
Exercises Section 17.1.8
Exercise 17.6: Given the following function, explain what happens when the exception occurs.

Exercise 17.7: There are two ways to make the previous code exception-safe. Describe them and implement them.
17.1.9 The auto_ptr Class
The standard-library auto_ptr class is an example of the exception-safe “resource allocation is initialization” technique described in the previous subsection. The auto_ptr class is a template that takes a single type parameter. It provides exception safety for dynamically allocated objects. The auto_ptr class is defined in the memory header.
auto_ptr can be used only to manage single objects returned from new. It does not manage dynamically allocated arrays.
As we’ll see, auto_ptr has unusual behavior when copied or assigned. As a result, auto_ptrs may not be stored in the library container types.
An auto_ptr may hold only a pointer to an object and may not be used to point to a dynamically allocated array. Using an auto_ptr to point to a dynamically allocated array results in undefined run-time behavior.
Each auto_ptr is either unbound or it points to an object. When an auto_ptr points to an object, it can be said to “own” that object. When the auto_ptr goes out of scope or is otherwise destroyed, then the dynamically allocated object to which the auto_ptr points is automatically deallocated.
Using auto_ptr for Exception-Safe Memory Allocation
If memory is acquired through a normal pointer and an exception occurs before a delete is executed, then that memory won’t be freed automatically:

If an exception happens between the new and the delete, and if that exception is not caught locally, then the delete will not be executed. The memory will never be returned.
If we use an auto_ptr instead, the memory will be freed automatically, even if the block is exited prematurely:

In this case, the compiler ensures that the destructor for ap is run before the stack is unwound past f.
Table 17.1. Class auto_ptr

auto_ptr Is a Template and Can Hold Pointers of Any Type
The auto_ptr class is a template taking a single type parameter. That type names the type of the object to which the auto_ptr may be bound. Thus, we can create auto_ptrs of any type:
auto_ptr<string> ap1(new string("Brontosaurus"));
Binding an auto_ptr to a Pointer
In the most common case, we initialize an auto_ptr to the address of an object returned by a new expression:
auto_ptr<int> pi(new int(1024));
This statement initializes pi to the address of the object created by the new expression. This new expression initializes that int to the value 1,024.
The constructor that takes a pointer is an explicit (Section 12.4.4, p. 462) constructor, so we must use the direct form of initialization to create an auto_ptr:
// error: constructor that takes a pointer is explicit and can't be used implicitly
auto_ptr<int> pi = new int(1024);
auto_ptr<int> pi(new int(1024)); // ok: uses direct initialization
The object created by the new expression to which pi refers is deleted automatically when pi goes out of scope. If pi is a local object, the object to which pi refers is deleted at the end of the block in which pi is defined. If an exception occurs, then pi also goes out of scope. The destructor for pi will be run automatically as part of handling the exception. If pi is a global object, the object to which pi refers is deleted at the end of the program.
Using an auto_ptr
Suppose we wish to access a string operation. With an ordinary string pointer, we’d do the following:
![]()
The auto_ptr class defines overloaded versions of the dereference (*) and arrow (->) operators (Section 14.6, p. 523). Because auto_ptr defines these operators, we can use an auto_ptr in some ways that are similar to using a built-in pointer:

The primary purpose of auto_ptr is to support ordinary pointerlike behavior while ensuring that the object to which an auto_ptr object refers is automatically deleted. As we’ll see, the fact that objects are automatically deleted leads to significant differences between auto_ptrs and ordinary pointers with respect to how we copy and access their address value.
Copy and Assignment on auto_ptr Are Destructive Operations
There is a crucially important difference between how auto_ptr and built-in pointers treat copy and assignment. When we copy an auto_ptr or assign its value to another auto_ptr, ownership of the underlying object is transferred from the original to the copy. The original auto_ptr is reset to an unbound state.
Copying (or assigning) ordinary pointers copies (assigns) the address. After the copy (assignment), both pointers point to the same object. After copying (or assigning) auto_ptrs, the original points to no object and the new auto_ptr (left-hand auto_ptr) owns the underlying object:
auto_ptr<string> ap1(new string("Stegosaurus"));
// after the copy ap1 is unbound
auto_ptr<string> ap2(ap1); // ownership transferred from ap1 to ap2
When we copy or assign an auto_ptr, the right-hand auto_ptr relinquishes all responsibility for the underlying object and is reset to be an unbound auto_ptr. In our example, it is ap2 that deletes the string object, and not ap1. After the copy, ap1 no longer refers to any object.
Unlike other copy or assignment operations, auto_ptr copy and assignment change the right-hand operand. As a result, both the left- and right-hand operands to assignment must be modifiable lvalues.
Assignment Deletes the Object Pointed To by the Left Operand
In addition to transferring ownership from the right-hand to the left-hand operand, assignment also deletes the object to which the left-hand operand originally referred—provided that the two objects are different. As usual, self-assignment has no effect.
auto_ptr<string> ap3(new string("Pterodactyl"));
// object pointed to by ap3 is deleted and ownership transferred from ap2 to ap3;
ap3 = ap2; // after the assignment, ap2 is unbound
After the assignment of ap2 to ap3,
• the object to which ap3 had pointed is deleted;
• ap3 is set to point to the object to which ap2 pointed; and
• ap2 is an unbound auto_ptr.
Because copy and assignment are destructive operations, auto_ptrs cannot be stored in the standard containers. The library container classes require that two objects be equal after a copy or assignment. This requirement is not met by auto_ptr. If we assign ap2 to ap1, then after the assignment ap1 != ap2. Similarly for copy.
The Default auto_ptr Constructor
If no initializer is given, the auto_ptr is unbound; it doesn’trefertoanobject:
auto_ptr<int> p_auto; // p_autodoesn't refer to any object
By default, the internal pointer value of an auto_ptr is set to 0. Dereferencing an unbound auto_ptr has the same effect as dereferencing an unbound pointer—the program is in error and what happens is undefined:
*p_auto = 1024; // error: dereference auto_ptr that doesn't point to an object
Testing an auto_ptr
To check whether a pointer is unbound, we can test the pointer directly in a condition, which has the effect of determining whether the pointer is 0. In contrast, we cannot test an auto_ptr directly.
![]()
The auto_ptr type does not define a conversion to a type that can be used as a condition. Instead, to test the auto_ptr, we must use its get member, which returns the underlying pointer contained in the auto_ptr:
![]()
To determine whether the auto_ptr object refers to an object, we can compare the return from get with 0.
get should be used only to interrogate an auto_ptr or to use the returned pointer value. get should not be used as an argument to create another auto_ptr.
Using get member to initialize another auto_ptr violates the class design principle that only one auto_ptr holds a given pointer at any one time. If two auto_ptrs hold the same pointer, then the pointer will be deleted twice.
The reset Operation
Another difference between auto_ptr and a built-in pointer is that we cannot assign an address (or other pointer) directly to an auto_ptr:
p_auto = new int(1024); // error: cannot assign a pointer to an auto_ptr
Instead, we must call reset to change the pointer:

To unset the auto_ptr object, we could pass 0 to reset.
Calling reset on an auto_ptr deletes the object (if any) to which the auto_ptr refers before binding the auto_ptr to another object. However, just as self-assignment has no effect, if we call reset on the same pointer that the auto_ptr already holds, then there is no effect; the object is not deleted.
17.1.10 Exception Specifications
When looking at an ordinary function declaration, it is not possible to determine what exceptions the function might throw. However, it can be useful to know whether and which exceptions a function might throw in order to write appropriate catch clauses. An exception specification specifies that if the function throws an exception, the exception it throws will be one of the exceptions included in the specification, or it will be a type derived from one of the listed exceptions.
Defining an Exception Specification
An exception specification follows the function parameter list. An exception specification is the keyword throw followed by a (possibly empty) list of exception types enclosed in parentheses:
void recoup(int) throw(runtime_error);
This declaration says that recoup is a function taking an int, and returningvoid. If recoup throws an exception, that exception will be a runtime_error or an exception of a type derived from runtime_error.
An empty specification list says that the function does not throw any exception:
void no_problem() throw();
An exception specification is part of the function’s interface. The function definition and any declarations of the function must have the same specification.
If a function declaration does not specify an exception specification, the function can throw exceptions of any type.
Violating the Exception Specification
Unfortunately, it is not possible to know at compile time whether or which exceptions a program will throw. Violations of a function’s exception specification can be detected only at run time.
If a function throws an exception not listed in its specification, the library function unexpected is invoked. By default, unexpected calls terminate, which ordinarily aborts the program.
Even if a casual reading of a function’s code indicates that it might throw an exception missing from the specification, the compiler will not complain:
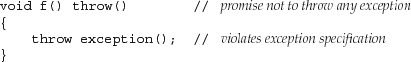
Instead, the compiler generates code to ensure that unexpected is called if an exception violating the exception specification is thrown.
Specifying that the Function Does Not Throw
Because an exception specification cannot be checked at compile time, the practical utility of exception specifications is often limited.
One important case when an exception specification is useful is if a function can guarantee that it will not throw any exceptions.
Specifying that a function will not throw any exceptions can be helpful both to users of the function and to the compiler: Knowing that a function will not throw simplifies the task of writing exception-safe code that calls that function. We can know that we need not worry about exceptions when calling it. Moreover, if the compiler knows that no exceptions will be thrown, it can perform optimizations that are suppressed for code that might throw.
Exception Specifications and Member Functions
As with nonmember functions, an exception specification on a member function declaration follows the function parameter list. For example, the class bad_alloc from the C++ standard library is defined so that all its member functions have an empty exception specification. These members promise not to throw an exception:

Notice that the exception specification follows the const qualifier in const member function declarations.
Exception Specifications and Destructors
In Section 17.1.7 (p. 697) we showed two hypothetical bookstore application exception classes. The isbn_mismatch class defines its destructor as

and said that we would explain this usage here.
The isbn_mismatch class inherits from logic_error, which is one of the standard exception classes. The destructors for the standard exception classes include an empty throw() specifier; they promise that they will not throw any exceptions. When we inherit from one of these classes, then our destructor must also promise not to throw any exceptions.
Our out_of_stock class had no members, and so its synthesized destructor does nothing that might throw an exception. Hence, the compiler can know that the synthesized destructor will abide by the promise not to throw.
The isbn_mismatch class has two members of class string, which means that the synthesized destructor for isbn_mismatch calls the string destructor. The C++ standard stipulates that string destructor, like any other library class destructor, will not throw an exception. However, the library destructors do not define exception specifications. In this case, we know, but the compiler doesn’t, that the string destructor won’t throw. We must define our own destructor to reinstate the promise that the destructor will not throw.
Exception Specifications and Virtual Functions
A virtual function in a base class may have an exception specification that differs from the exception specification of the corresponding virtual in a derived class. However, the exception specification of a derived-class virtual function must be either equally or more restrictive than the exception specification of the corresponding base-class virtual function.
This restriction ensures that when a pointer to a base-class type is used to call a derived virtual function, the exception specification of the derived class adds no new exceptions to those that the base said could be thrown. For example,

The declaration of f1 in the derived class is an error because its exception specification adds an exception to those listed in the version of f1 in the base class. The reason that the derived class may not add to the specfication list is users of the hierarchy should be able to write code that depends on the specification list. If a call is made through a base pointer or reference, then only the exceptions specified in the base should be of concern to a user of these classes.
By restricting which exceptions the derived classes will throw to those listed by the base class, we can write our code knowing what exceptions we must handle. Our code can rely on the fact that the list of exceptions in the base class is a superset of the list of exceptions that a derived-class version of the virtual might throw. As an example, when calling f3, we know we need to handle only logic_error or runtime_error:

The function compute uses the specification in the base class in deciding what exceptions it might need to catch.
17.1.11 Function Pointer Exception Specifications
An exception specification is part of a function type. As such, exception specifications can be provided in the definition of a pointer to function:
void (*pf)(int) throw(runtime_error);
This declaration says that pf points to a function that takes an int, returns avoid, and that can throw exceptions only of type runtime_error. If no specification is provided, then the pointer may point at a function with matching type that could throw any kind of exception.
When a pointer to function with an exception specification is initialized from (or assigned to) another pointer (or to the address of a function), the exception specifications of both pointers do not have to be identical. However, the specification of the source pointer must be at least as restrictive as the specification of the destination pointer
void recoup(int) throw(runtime_error);
// ok: recoup is as restrictive as pf1
void (*pf1)(int) throw(runtime_error) = recoup;
// ok: recoup is more restrictive than pf2
void (*pf2)(int) throw(runtime_error, logic_error) = recoup;
// error: recoup is less restrictive than pf3
void (*pf3)(int) throw() = recoup;
// ok: recoup is more restrictive than pf4
void (*pf4)(int) = recoup;
The third initialization is an error. The pointer declaration says that pf3 points to a function that will not throw any exceptions. However, recoup says it can throw exceptions of type runtime_error. The recoup function throws exception types beyond those specified by pf3. The recoup function is not a valid initializer for pf3, and a compile-time error is issued.
17.2 Namespaces
Every name defined in a given scope must be unique within that scope. This requirement can be difficult to satisfy for large, complex applications. Such applications tend to have many names defined in the global scope. Complex programs composed of independently developed libraries are even more likely to encounter name collisions—the same name is used in our own code or (more often) in the code supplied to us by independent producers.
Libraries tend to define a large number of global names—primarily names of templates, types and functions. When writing an application using libraries from many different vendors, it is almost inevitable that some of these names will clash. This name-clashing problem is known as the namespace pollution problem.
Traditionally, programmers avoided namespace pollution by making names of global entities very long, often prefixing the names in their program with specific character sequences:
class cplusplus_primer_Query { ... };
ifstream&
cplusplus_primer_open_file(ifstream&, const string&);
This solution is far from ideal: It can be cumbersome for programmers to write and read programs that use such long names. Namespaces provide a much more controlled mechanism for preventing name collisions. Namespaces partition the global namespace, making it easier to use independently produced libraries. A namespace is a scope. By defining a library’s names inside a namespace, library authors (and users) can avoid the limitations inherent in global names.
17.2.1 Namespace Definitions
A namespace definition begins with the keyword namespace followed by the namespace name.

This code defines a namespace named cplusplus_primer with four members: three classes and an overloaded + operator.
As with other names, the name of a namespace must be unique within the scope in which the namespace is defined. Namespaces may be defined at global scope or inside another namespace. They may not be defined inside a function or a class.
Following the namespace name is a block of declarations and definitions delimited by curly braces. Any declaration that can appear at global scope can be put into a namespace: classes, variables (with their initializations), functions (with their definitions), templates, and other namespaces.
Each Namespace Is a Scope
The entities defined in a namespace are called namespace members. Just as is the case for any scope, each name in a namespace must refer to a unique entity within that namespace. Because different namespaces introduce different scopes, different namespaces may have members with the same name.
Names defined in a namespace may be accessed directly by other members of the namespace. Code outside the namespace must indicate the namespace in which the name is defined:

If another namespace (say, AddisonWesley) also provides a TextQuery class and we want to use that class instead of the one defined in cplusplus_primer, we can do so by modifying our code as follows:
AddisonWesley::Query q = AddisonWesley::Query("hello");
q.display(cout);
// ...
Using Namespace Members from Outside the Namespace
Of course, always referring to a namespace member using the qualified name
namespace_name::member_name
can be cumbersome. Just as we’ve been doing for names defined in the std namespace, we can write a using declaration (Section 3.1, p. 78) to obtain direct access to names we know we’ll use frequently:
using cplusplus_primer::Query;
After this using declaration, our program can use the name Query directly without the cplusplus_primer qualifier. We’ll see other ways to simplify access in Section 17.2.4 (p. 720).
Namespaces Can Be Discontiguous
Unlike other scopes, a namespace can be defined in several parts. A namespace is made up of the sum of its separately defined parts; a namespace is cumulative. The separate parts of a namespace can be spread over multiple files. Namespace definitions in different text files are also cumulative. Of course, the usual restriction continues to apply that names are visible only in the files in which they are declared. So, if one part of the namespace requires a name defined in another file, that name must still be declared.
Writing a namespace definition
namespace namespace_name {
// declarations
}
either defines a new namespace or adds to an existing one.
If the name namespace_name does not refer to a previously defined namespace, then a new namespace with that name is created. Otherwise, this definition opens an existing namespace and adds these new declarations to that namespace.
Separation of Interface and Implementation
The fact that namespace definitions can be discontiguous means that we can compose a namespace from separate interface and implementation files. Thus, a namespace can be organized in the same way that we manage our own class and function definitions:
- Namespace members that define classes and declarations for the functions and objects that are part of the class interface can be put into header files. These headers can be included by files that use namespace members.
- The definitions of namepsace members can be put in separate source files.
Organizing our namespaces this way also satisfies the requirement that various entities—non-inline functions, static data members, variables, and so forth—may be defined only once in a program. This requirement applies equally to names defined in a namespace. By separating the interface and implementation, we can ensure that the functions and other names we need are defined only once, but the same declaration will be seen whenever the entity is used.
Namespaces that define multiple, unrelated types should use separate files to represent each type that the namespace defines.
Defining the Primer Namespace
Using this strategy for separating interface and implementation, we might define the cplusplus_primer library in several separate files. The declarations for Sales_item and its related functions that we built in Part I (p. 31) would be placed in Sales_item.h, those for the Query classes of Chapter 15 (p. 557) in Query.h, and so on. The corresponding implementation files would be in files such as Sales_item.cc and Query.cc:

This program organization gives both the developers and users of our library the needed modularity. Each class is still organized into its own interface and implementation files. A user of one class need not compile names related to the others. We can hide the implementations from our users, while allowing the files Sales_item.cc and user.cc to be compiled and linked into one program without causing any compile-time or link-time error. Developers of the library can work independently on the implementation of each type.
A program using our library would include whichever headers it needed. The names in those headers are defined inside the cplusplus_primer namespace:

Defining Namespace Members
Functions defined inside a namespace may use the short form for names defined in the same namespace:

It is also possible to define a namespace member outside its namespace definition. We do so in ways that are similar to defining class members outside a class: The namespace declaration of the name must be in scope, and the definition must specify the namespace to which the name belongs:

This definition should look similar to class member functions defined outside a class. The return type and function name are qualified by the namespace name. Once the fully qualified function name is seen, we are in the scope of the namespace. Thus, references to namespace members in the parameter list and the function body can use unqualified names to reference Sales_item.
Members May Not Be Defined in Unrelated Namespaces
Although a namespace member can be defined outside its namespace definition, there are restrictions on where this definition can appear. Only namespaces enclosing the member declaration can contain its definition. For example, operator+ could be defined in either the cplusplus_primer namespace or at global scope. It may not be defined in an unrelated namespace.
The Global Namespace
Names defined at global scope—names declared outside any class, function, or namespace—are defined inside the global namespace. The global namespace is implicitly declared and exists in every program. Each file that defines entities at global scope adds those names to the global namespace.
The scope operator can be used to refer to members of the global namespace. Because the global namespace is implicit, it does not have a name; the notation
::member_name
refers to a member of the global namespace.
17.2.2 Nested Namespaces
A nested namespace is a nested scope—its scope is nested within the namespace that contains it. Names in nested namespaces follow the normal rules: Names declared in an enclosing namespace are hidden by declarations of the same name in a nested namespace. Names defined inside a nested namespace are local to that namespace. Code in the outer parts of the enclosing namespace may refer to a name in a nested namespace only through its qualified name.
Nested namespaces can improve the organization of code in a library:

The cplusplus_primer namespace now contains two nested namespaces: the namespaces named QueryLib and Bookstore.
Nested namespaces are useful when a library provider needs to prevent names in each part of a library from colliding with names in other parts of the library.
The name of a member in a nested namespace is formed from the names of the enclosing namespace(s) and the name of the nested namespace. For example, the name of the class declared in the nested namespace QueryLib is
cplusplus_primer::QueryLib::Query
17.2.3 Unnamed Namespaces
A namespace may be unnamed. An unnamed namespace is a namespace that is defined without a name. An unnamed namespace begins with the keyword namespace. Following the namespace keyword is a block of declarations delimited by curly braces.
Unnamed namespaces are not like other namespaces; the definition of an unnamed namespace is local to a particular file and never spans multiple text files.
An unnamed namespace may be discontiguous within a given file but does not span files. Each file has its own unnamed namespace.
Unnamed namespaces are used to declare entities that are local to a file. Variables defined in an unnamed namespace are created when the program is started and exist until the program ends.
Names defined in an unnamed namespace are used directly; after all, there is no namespace name with which to qualify them. It is not possible to use the scope operator to refer to members of unnamed namespaces.
Names defined in an unnamed namespace are visible only to the file containing the namespace. If another file contains an unnamed namespace, the namespaces are unrelated. Both unnamed namespaces could define the same name, and the definitions would refer to different entities.
Names defined in an unnamed namespace are found in the same scope as the scope at which the namespace is defined. If an unnamed namespace is defined at the outermost scope in the file, then names in the unnamed namespace must differ from names defined at global scope:

An unnamed namespace, like any other namespace, may be nested inside another namespace. If the unnamed namespace is nested, then names in it are accessed in the normal way, using the enclosing namespace name(s):

If a header defines an unnamed namespace then the names in that namespace will define different local entities in each file that includes the header.
In all other ways, the members of an unnamed namespace are normal program entities.
Unnamed Namespaces Replace File Statics
Prior to the introduction of namespaces in standard C++, programs had to declare names as static to make them local to a file. The use of file statics is inherited from C. In C, a global entity declared static is invisible outside the file in which it is declared.
Exercises Section 17.2.3
Exercise 17.18: Why would you define your own namespace in your programs? When might you use an unnamed namespace?
Exercise 17.19: Suppose we have the following declaration of the operator* that is a member of the nested namespace cplusplus_primer::MatrixLib:

How would you define this operator in global scope? Provide only the prototype for the operator’s definition.
17.2.4 Using Namespace Members
Referring to namespace members as namespace_name::member_name is admittedly cumbersome, especially if the namespace name is long. Fortunately, there are ways to make it easier to use namespace members. Our programs have used one of these ways, using declarations (Section 3.1, p. 78). The others, namespace aliases and using directives, will be described in this section.
Header files should not contain using directives or using declarations except inside functions or other scopes. A header that includes a using directive or declaration at its top level scope has the effect of injecting that name into the file that includes the header. Headers should define only the names that are part of its interface, not names used in its own implementation.
using Declarations, a Recap
The programs in this book that use names from the standard library generally assume that an appropriate using declaration has been made:
map<string, vector< pair<size_t, size_t> > > word_map;
assumes that the following using declarations have been made:
using std::map;
using std::pair;
using std::size_t;
using std::string;
using std::vector;
A using declaration introduces only one namespace member at a time. It allows us to be very specific regarding which names are used in our programs.
Scope of a using Declaration
Names introduced in a using declaration obey normal scope rules. The name is visible from the point of the using declaration to the end of the scope in which the declaration is found. Entities with the same name defined in an outer scope are hidden.
The shorthand name may be used only within the scope in which it is declared and in scopes nested within that scope. Once the scope ends, the fully qualified name must be used.
A using declaration can appear in global, local, or namespace scope. A using declaration in class scope is limited to names defined in a base class of the class being defined.
Namespace Aliases
A namespace alias can be used to associate a shorter synonym with a namespace name. For example, a long namespace name such as
namespace cplusplus_primer { /* ... */ };
can be associated with a shorter synonym as follows:
namespace primer = cplusplus_primer;
A namespace alias declaration begins with the keyword namespace, followed by the (shorter) name of the namespace alias, followed by the = sign, followed by the original namespace name and a semicolon. It is an error if the original namespace name has not already been defined as a namespace.
A namespace alias can also refer to a nested namespace. Rather than writing
cplusplus_primer::QueryLib::Query tq;
we could define and use an alias for cplusplus_primer::QueryLib:
namespace Qlib = cplusplus_primer::QueryLib;
Qlib::Query tq;
A namespace can have many synonyms, or aliases. All the aliases and the original namespace name can be used interchangeably.
using Directives
Like a using declaration, a using directive allows us to use the shorthand form of a namespace name. Unlike a using declaration, we retain no control over which names are made visible—they all are.
The Form of a using Directive
A using directive begins with the keyword using, followed by the keyword namespace, followed by a namespace name. It is an error if the name is not a previously defined namespace name.
A using directive makes all the names from a specific namespace visible without qualification. The short form names can be used from the point of the using directive to the end of the scope in which the using directive appears.
A using directive may appear in namespace, function, or block scope. It may not appear in a class scope.
It can be tempting to write programs with using directives, but doing so reintroduces all the problems inherent in name collisions when using multiple libraries.
using Directives and Scope
The scope of names introduced by a using directive is more complicated than those for using declarations. A using declaration puts the name directly in the same scope in which the using declaration itself appears. It is as if the using declaration is a local alias for the namespace member. Because the declaration is localized, the chance of collisions is minimized.
A using directive does not declare local aliases for the namespace member names. Rather, it has the effect of lifting the namespace members into the nearest scope that contains both the namespace itself and the using directive.
In the simplest case, assume we have a namespace A and a function f, both defined at global scope. If f has a using directive for A, then in f it will be as if the names in A appeared in the global scope prior to the definition of f:


One place where using directives are useful is in the implementation files for the namespace itself.
using Directives Example
Let’s look at an example:

The using directive in manip makes all the names in blip directly accessible to manip: The function can refer to the names of these members, using their short form.
The members of blip appear as if they were defined in the scope in which both blip and manip are defined. Given that blip is defined at global scope, then the members of blip appear as if they were declared in global scope. Because the names are in different scopes, local declarations within manip may hide some of the namespace member names. The local variable bk hides the namespace member blip::bk. Referring to bk within manip is not ambiguous; it refers to the local variable bk.
It is possible for names in the namespace to conflict with other names defined in the enclosing scope. For example, the blip member bj appears to manip as if it were declared at global scope. However, there is another object named bj in global scope. Such conflicts are permitted; but to use the name, we must explicitly indicate which version is wanted. Therefore, the use of bj within manip is ambiguous: The name refers both to the global variable and to the member of namespace blip.
To use a name such as bj, we must use the scope operator to indicate which name is wanted. We would write ::bj to obtain the variable defined in global scope. To use the bj defined in blip, we must use its qualified name, blip::bj.
Exercises Section 17.2.4
Exercise 17.20: Explain the differences between using declarations and using directives.
Exercise 17.21: Consider the following code sample:

What are the effects of the declarations and expressions in this code sample if using declarations for all the members of namespace Exercise are located at the location labeled position 1? At position 2 instead? Now answer the same question but replace the using declarations with a using directive for namespace Exercise.
17.2.5 Classes, Namespaces, and Scope
As we’ve noted, namespaces are scopes. As in any other scope, names are visible from the point of their declaration. Names remain visible through any nested scopes until the end of the block in which they were introduced.
Name lookup for names used inside a namespace follows the normal C++ lookup rules: When looking for a name, we look outward through the enclosing scopes. An enclosing scope for a name used inside a namespace might be one or more nested namespaces ending finally with the all-encompassing global namespace. Only names that have been declared before the point of use that are in blocks that are still open are considered:

Names used in a class member definition are resolved in much the same way, with one important difference: If the name is not local to the member function, we first try to resolve the name to a class member before looking in the outer scopes.
As we saw in Section 12.3 (p. 444), members defined inside a class may use names that appear textually after the definition. For example, a constructor defined inside the class body may initialize the data members even if the declaration of those members appears after the constructor definition. When a name is used in a class scope, we look first in the member itself, then in the class, including any base classes. Only after exhausting the class(es) do we examine the enclosing scopes. When a class is wrapped in a namespace, the same lookup happens: Look first in the member, then the class (including base classes), then look in the enclosing scopes, one or more of which might be a namespace:

With the exception of member definitions, scopes are always searched upward: A name must be declared before it can be used. Hence, the return in f2 will not compile. It attempts to reference the name h from namespace A, but h has not yet been defined. Had that name been defined in A before the definition of C1, the use of h would be legal. Similarly, the use of h inside f3 is okay, because f3 is defined after A::h has been defined.
The order in which scopes are examined to find a name can be inferred from the qualified name of a function. The qualified name indicates, in reverse order, the scopes that are searched.
The qualifiers A::C1::f3 indicate the reverse order in which the class scopes and namespace scopes are to be searched. The first scope searched is that of the function f3. Then the class scope of its enclosing class C1 is searched. The scope of the namespace A is searched last before the scope containing the definition of f3 is examined.
Argument-Dependent Lookup and Class Type Parameters
Consider the following simple program:
std::string s;
// ok: calls std::getline(std::istream&, const std::string&)
getline(std::cin, s);
The program uses the std::string type, yet it refers without qualification to the getline function. Why can we use this function without a specific std:: qualifier or a using declaration?
It turns out that there is an important exception to the rule that namespace names are hidden.
Functions, including overloaded operators, that take parameters of a class type (or pointer or reference to a class type), and that are defined in the same namespace as the class itself, are visible when an object of (or reference or pointer to) the class type is used as an argument.
When the compiler sees the use of the getline function
getline(std::cin, s);
it looks for a matching function in the current scope, the scopes enclosing the call to getline, and in the namespace(s) in which the type of cin and the string type are defined. Hence, it looks in the namespace std and finds the getline function defined by the string type.
The reason that functions are made visible if they have a parameter of the class type is to allow nonmember functions that are conceptually part of a class’ interface to be used without requiring a separate using declaration. Being able to use nonmember operations is particularly useful for operator functions.
For example, consider the following simple program:
std::string s;
cin >> s;
In absence of this exception to the lookup rules, we would have to write either:
![]()
Either of these declarations is awkward and would make simple uses of strings and the IO library more complicated.
Implicit Friend Declarations and Namespaces
Recall that when a class declares a friend function (Section 12.5, p. 465), a declaration for the function need not be visible. If there isn’t a declaration already visible, then the friend declaration has the effect of putting a declaration for that function or class into the surrounding scope. If a class is defined inside a namespace, then an otherwise undeclared friend function is declared in the same namespace:

Because the friend takes an argument of a class type and is implicitly declared in the same namespace as the class, it can be used without using an explicit name-space qualifier:

17.2.6 Overloading and Namespaces
As we’ve seen, each namespace maintains its own scope. As a consequence, functions that are members of two distinct namespaces do not overload one another. However, a given namespace can contain a set of overloaded function members.
In general, function matching (Section 7.8.2, p. 269) within a namespace happens in the same manner as we’ve already seen:
- Find the set of candidate functions. A function is a candidate if a declaration for it is visible at the time of the call and if it has the same name as the called function.
- Select the viable functions from the set of candidates. A function is viable if it has the same number of parameters as the call has arguments and if each parameter could be matched by the corresponding argument.
- Select the single best match from the viable set and generate code to call that function. If the viable set is empty, then the call is in error, having no match. If the viable set is nonempty and there is no best match, then the call is ambiguous.
Candidate Functions and Namespaces
Namespaces can have two impacts on function matching. One of these should be obvious: A using declaration or directive can add functions to the candidate set. The other is much more subtle.
As we saw in the previous section, name lookup for functions that have one or more class-type parameters includes the namespace in which each parameter’s class is defined. This rule also impacts how we determine the candidate set. Each namespace that defines a class used as a parameter (and those that define its base class(es)) is searched for candidate functions. Any functions in those namespaces that have the same name as the called function are added to the candidate set. These functions are added even though they otherwise are not visible at the point of the call. Functions with the matching name in those namespaces are added to the candidate set:

The argument, book1, to the display function has class type Bulk_item. The candidate functions for the call to display are not only the functions with declarations that are visible where the function display is called, but also the functions in the namespace where the class Bulk_item and its base class Item_base are declared. The function display(const Item_base&) declared in namespace NS is added to the set of candidate functions.
Overloading and using Declarations
A using declaration declares a name. As we saw in Section 15.5.3 (p. 592), there is no way to write a using declaration to refer to a specific function declaration:
![]()
If a function is overloaded within a namespace, then a using declaration for the name of that function declares all the functions with that name. If there are print functions for int and double in the namespace NS, then a using declaration for NS::print makes both functions visible in the current scope.
A using declaration incorporates all versions of an overloaded function to ensure that the interface of the namespace is not violated. The author of a library provided different functions for a reason. Allowing users to selectively ignore some but not all of the functions from a set of overloaded functions could lead to surprising program behavior.
The functions introduced by a using declaration overload any other declarations of the functions with the same name already present in the scope where the using declaration appears.
If the using declaration introduces a function in a scope that already has a function of the same name with the same parameter list, then the using declaration is in error. Otherwise, the using declaration defines additional overloaded instances of the given name. The effect is to increase the set of candidate functions.
Overloading and using Directives
A using directive lifts the namespace members into the enclosing scope. If a namespace function has the same name as a function declared in the scope at which the namespace is placed, then the namespace member is added to the overload set:

Overloading across Multiple using Directives
If many using directives are present, then the names from each namespace become part of the candidate set:

The overload set for the function print in global scope contains the functions print(int), print(double), and print(long double). These functions are all part of the overload set considered for the function calls in main, even though these functions were originally declared in different namespace scopes.
Exercises Section 17.2.6
Exercise 17.22: Given the following code, determine which function, if any, matches the call to compute. List the candidate and viable functions. What type conversion sequence, if any, is applied to the argument to match the parameter in each viable function?

What would happen if the using declaration were located in main before the call to compute? Answer the same questions as before.
17.2.7 Namespaces and Templates
Declaring a template within a namespace impacts how template specializations (Section 16.6, p. 671) are declared: An explicit specialization of a template must be declared in the namespace in which the generic template is defined. Otherwise, the specialization would have a different name than the template it specialized.
There are two ways to define a specialization: One is to reopen the namespace and add the definition of the specialization, which we can do because namespace definitions are discontiguous, Alternatively, we could define the specialization in the same way that we can define any namespace member outside its namespace definition: by defining the specialization using the template name qualified by the name of the namespace.
To provide our own specializations of templates defined in a namespace, we must ensure that the specialization definition is defined as being in the namespace containing the original template definition.
17.3 Multiple and Virtual Inheritance
Most C++ applications use public inheritance from a single base class. In some cases, however, single inheritance is inadequate, either because it fails to model the problem domain or the model it imposes is unnecessarily complex.
In these cases, multiple inheritance may model the application more directly. Multiple inheritance is the ability to derive a class from more than one immediate base class. A multiply derived class inherits the properties of all its parents. Although simple in concept, the details of intertwining multiple base classes can present tricky design-level and implementation-level problems.
17.3.1 Multiple Inheritance
This section uses a pedagogical example of a zoo animal hierarchy. Our zoo animals exist at different levels of abstraction. There are the individual animals, distinguished by their names, such as Ling-ling, Mowgli, and Balou. Each animal belongs to a species; Ling-Ling, for example, is a giant panda. Species, in turn, are members of families. A giant panda is a member of the bear family. Each family, in turn, is a member of the animal kingdom—in this case, the more limited kingdom of a particular zoo.
Each level of abstraction contains data and operations that support a wider category of users. We’ll define an abstract ZooAnimal class to hold information that is common to all the zoo animals and provides the public interface. The Bear class will contain information that is unique to the Bear family, and so on.
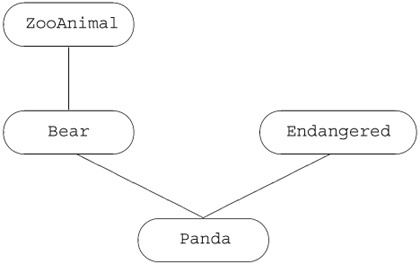
In addition to the actual zoo-animal classes, there are auxiliary classes that encapsulate various abstractions such as endangered animals. In our implementation of a Panda class, for example, a Panda is multiply derived from Bear and Endangered.
Defining Multiple Classes
To support multiple inheritance, the derivation list
class Bear : public ZooAnimal {
};
is extended to support a comma-separated list of base classes:
class Panda : public Bear, public Endangered {
};
The derived class specifies (either explicitly or implicitly) the access level— public, protected, or private— for each of its base classes. As with single inheritance, a class may be used as a base class under multiple inheritance only after it has been defined. There is no language-imposed limit on the number of base classes from which a class can be derived. A base class may appear only once in a given derivation list.
Multiply Derived Classes Inherit State from Each Base Class
Under multiple inheritance, objects of a derived class contain a base-class subobject (Section 15.2.3, p. 565) for each of its base classes. When we write
Panda ying_yang("ying_yang");
the object ying_yang is composed of a Bear class subobject (which itself contains a ZooAnimal base-class subobject), an Endangered class subobject, and the nonstatic data members, if any, declared within the Panda class (see Figure 17.2).
Figure 17.2. Multiple Inheritance Panda Hierarchy
Derived Constructors Initialize All Base Classes
Constructing an object of derived type involves constructing and initializing all its base subobjects. As is the case for inheriting from a single base class (Section 15.4.1, p. 580), derived constructors may pass values to zero or more of their base classes in the constructor initializer:

Order of Construction
The constructor initializer controls only the values that are used to initialize the base classes, not the order in which the base classes are constructed. The base-class constructors are invoked in the order in which they appear in the class derivation list. For Panda, the order of base-class initialization is:
ZooAnimal, the ultimate base class up the hierarchy fromPanda’s immediate base classBearBear, the first immediate base classEndangered, the second immediate base, which itself has no base classPanda; the members ofPandaitself are initialized, and then the body of its constructor is run.
The order of constructor invocation is not affected by whether the base class appears in the constructor initializer list or the order in which base classes appear within that list.
For example, in Panda’s default constructor, the Bear default constructor is invoked implicitly; it does not appear in the constructor initializer list. Even so, Bear’s default constructor is invoked prior to the explicitly listed constructor of Endangered.
Order of Destruction
Destructors are always invoked in the reverse order from which the constructors are run. In our example, the order in which the destructors are called is ~Panda, ~Endangered, ~Bear, ~ZooAnimal.
17.3.2 Conversions and Multiple Base Classes
Under single inheritance, a pointer or a reference to a derived class can be converted automatically to a pointer or a reference to a base class. The same holds true with multiple inheritance. A pointer or reference to a derived class can be converted to a pointer or reference to any of its base classes. For example, a Panda pointer or reference could be converted to a pointer or a reference to ZooAnimal, Bear, or Endangered:

Under multiple inheritance, there is a greater possibility of encountering an ambiguous conversion. The compiler makes no attempt to distinguish between base classes in terms of a derived-class conversion. Converting to each base class is equally good. For example, if there was an overloaded version of print
void print(const Bear&);
void print(const Endangered&);
an unqualified invocation of print with a Panda object
![]()
results in a compile-time error that the call is ambiguous.
Virtual Functions under Multiple Inheritance
To see how the virtual function mechanism is affected by multiple inheritance, let’s assume that our classes define the virtual members listed in Table 17.2.
Table 17.2. Virtual Function in the ZooAnimal/Endangered Classes
Lookup Based on Type of Pointer or Reference
As with single inheritance, a pointer or reference to a base class can be used to access only members defined (or inherited) in the base. It cannot access members introduced in the derived class.
When a class inherits from multiple base classes, there is no implied relationship between those base classes. Using a pointer to one base does not allow access to members of another base.
As an example, we could use a pointer or reference to a Bear, ZooAnimal, Endangered, or Panda to access a Panda object. The type of the pointer we use determines which operations are accessible. If we use a ZooAnimal pointer, only the operations defined in that class are usable. The Bear-specific, Panda-specific, and Endangered portions of the Panda interface are inaccessible. Similarly, a Bear pointer or reference knows only about the Bear and ZooAnimal members; an Endangered pointer or reference is limited to the Endangered members:

If the Panda object had been assigned to a ZooAnimal pointer, this set of calls would resolve exactly the same way.
When a Panda is used via an Endangered pointer or reference, the Panda-specific and Bear portions of the Panda interface are inaccessible:

Determining Which Virtual Destructor to Use
Assuming all the root base classes properly define their destructors as virtual, then the handling of the virtual destructor is consistent regardless of the pointer type through which we delete the object:

Assuming each of these pointers points to a Panda object, the exact same order of destructor invocations occurs in each case. The order of destructor invocations is the reverse of the constructor order: The Panda destructor is invoked through the virtual mechanism. Following execution of the Panda destructor, the Endangered, Bear, then ZooAnimal destructors are invoked in turn.
17.3.3 Copy Control for Multiply Derived Classes
The memberwise initialization, assignment and destruction (Chapter 13) of a multiply derived class behaves in the same way as under single inheritance. Each base class is implicitly constructed, assigned or destroyed, using that base class’ own copy constructor, assignment operator or destructor.
Let’s assume that Panda uses the default copy control members. Using the default copy constructor, the initialization of ling_ling
![]()
invokes the Bear copy constructor, which in turn runs the ZooAnimal copy constructor prior to executing the Bear copy constructor. Once the Bear portion of ling_ling is constructed, the Endangered copy constructor is run to create that part of the object. Finally, the Panda copy constructor is run.
The synthesized assignment operator behaves similarly to the copy constructor. It assigns the Bear (and through Bear, the ZooAnimal) parts of the object first. Next, it assigns the Endangered part, and finally the Panda part.
The synthesized destructor destroys each member of the Panda object and calls the destructors for the base class parts, in reverse order from construction.
As is the case for single inheritance (Section 15.4.3, p. 584), if a class with multiple bases defines its own destructor, that destructor is responsible only for cleaning up the derived class. If the derived class defines its own copy constructor or assignment operator, then the class is responsible for copying (assigning) all the base class subparts. The base parts are automatically copied or assigned only if the derived class uses the synthesized versions of these members.
17.3.4 Class Scope under Multiple Inheritance
Class scope (Section 15.5, p. 590) is more complicated in multiple inheritance because a derived scope may be enclosed by multiple base class scopes. As usual, name lookup for a name used in a member function starts in the function itself. If the name is not found locally, then lookup continues in the member’s class and then searches each base class in turn. Under multiple inheritance, the search simultaneously examines all the base-class inheritance subtrees—in our example, both the Endangered and the Bear/ZooAnimal subtrees are examined in parallel. If the name is found in more than one subtree, then the use of that name must explicitly specify which base class to use. Otherwise, the use of the name is ambiguous.
When a class has multiple base classes, name lookup happens simultaneously through all the immediate base classes. It is possible for a multiply derived class to inherit a member with the same name from two or more base classes. Unqualified uses of that name are ambiguous.
Multiple Base Classes Can Lead to Ambiguities
Assume both Bear and Endangered define a member named print. If Panda does not define that member, then a statement such as the following
ying_yang.print(cout);
results in a compile-time error.
The derivation of Panda, which results in Panda having two members named print, is perfectly legal. The derivation results in only a potential ambiguity. That ambiguity is avoided if no Panda object ever calls print. The error would also be avoided if each call to print specifically indicated which version of print was wanted—Bear::print or Endangered::print. An error is issued only if there is an ambiguous attempt to use the member.
If a declaration is found only in one base-class subtree, then the identifier is resolved and the lookup algorithm concludes. For example, class Endangered might have an operation to return the given estimated population of its object. If so, the following call
ying_yang.population();
would compile without complaint. The name population would be found in the Endangered base class and does not appear in Bear or any of its base classes.
Name Lookup Happens First
Although the ambiguity of the two inherited print members is reasonably obvious, it might be more surprising to learn that an error would be generated even if the two inherited functions had different parameter lists. Similarly, it would be an error even if the print function were private in one class and public or protected in the other. Finally, if print were defined in ZooAnimal and not Bear, the call would still be in error.
As always, name lookup happens in two steps (Section 7.8.1, p. 268): First the compiler finds a matching declaration (or, in this case, two matching declarations, which causes the ambiguity). Only then does the compiler decide whether the declaration it found is legal.
Avoiding User-Level Ambiguities
We could resolve the print ambiguity by specifying which class to use:
ying_yang.Endangered::print(cout);
The best way to avoid potential ambiguities is to define a version of the function in the derived class that resolves the ambiguity. For example, we should give our Panda class a print function that chooses which version of print to use:


Exercises Section 17.3.4
Exercise 17.29: Given the class hierarchy in the box on this page and the following MI::foo member function skeleton,
int ival;
double dval;
void MI::foo(double dval) { int id; /* ... */ }
(a) identify the member names visible from within MI. Are there any names visible from more than one base class?
(b) identify the set of members visible from within MI::foo.
Exercise 17.30: Given the hierarchy in the box on page 739, why is this call to print an error?
MI mi;
mi.print(42);
Revise MI to allow this call to print to compile and execute correctly.
Exercise 17.31: Assume we added a function named bar to class MI in the hierarchy in the box on page 739. Identify which of the following assignments, if any, are in error:

Exercise 17.32: Assume we added a function named foobar to class MI from the hierarchy defined in the box on page 739. Using the following skeleton of MI::foobar

(a) assign to the local instance of dval the sum of the dval member of Base1 and the dval member of Derived.
(b) assign the value of the last element in MI::dvec to Base2::fval.
(c) assign cval from Base1 to the first character in sval from Derived.
17.3.5 Virtual Inheritance
Under multiple inheritance, a base class can occur multiple times in the derivation hierarchy. In fact, our programs have already used a class that inherits from the same base class more than once through its inheritance hierarchy.
Each of the IO library classes inherits from a common abstract base class. That abstract class manages the condition state of the stream and holds the buffer that the stream reads or writes. The istream and ostream classes inherit directly from this common base class. The library defines another class, named iostream, that inherits from both istream and ostream. The iostream class can both read and write a stream. A simplified version of the IO inheritance hierarchy is illustrated in Figure 17.3 on the facing page.
Figure 17.3. Virtual Inheritance iostream Hierarchy (Simplified)
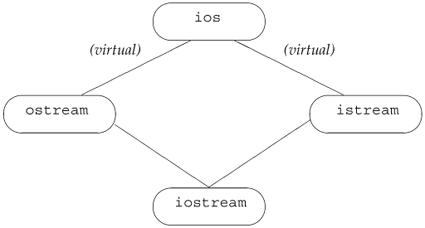
As we know, a multiply inherited class inherits state and action from each of its parents. If the IO types used normal inheritance, then each iostream object would contain two ios subobjects: one instance contained within its istream subobject and the other within its ostream subobject. From a design perspective, this implementation is just wrong: The iostream class wants to read to and write from a single buffer; it wants the condition state to be shared across input and output operations. If there are two separate ios objects, this sharing is not possible.
In C++ we solve this kind of problem by using virtual inheritance. Virtual inheritance is a mechanism whereby a class specifies that it is willing to share the state of its virtual base class. Under virtual inheritance, only one, shared base-class subobject is inherited for a given virtual base regardless of how many times the class occurs as a virtual base within the derivation hierarchy. The shared base-class subobject is called a virtual base class.
The istream and ostream classes inherit virtually from their base class. By making their base class virtual, istream and ostream specify that if some other class, such as iostream, inherits from both of them, then only one copy of their common base class will be present in the derived class. We make a base class virtual by including the keyword virtual in the derivation list:
class istream : public virtual ios { ... };
class ostream : virtual public ios { ... };
// iostream inherits only one copy of its ios base class
class iostream: public istream, public ostream { ... };
A Different Panda Class
For the purposes of illustrating virtual inheritance, we’ll continue to use the Panda class as a pedagogical example. Within zoological circles, for more than 100 years there has been an occasionally fierce debate as to whether the Panda belongs to the Raccoon or the Bear family. Because software design is primarily a service industry, our most practical solution is to derive Panda from both:
![]()
Our virtual inheritance Panda hierarchy is pictured in Figure 17.4. If we examine that hierarchy, we notice a nonintuitive aspect of virtual inheritance: The virtual derivation (in our case, of Bear and Raccoon) has to be made prior to any actual need for it to be present. Virtual inheritance becomes necessary only with the declaration of Panda, but if Bear and Raccoon are not already virtually derived, the designer of the Panda class is out of luck.
Figure 17.4. Virtual Inheritance Panda Hierarchy

In practice, the requirement that an intermediate base class specify its inheritance as virtual rarely causes any problems. Ordinarily, a class hierarachy that uses virtual inheritance is designed at one time by either one individual or a project design group. It is exceedingly rare for a class to be developed independently that needs a virtual base in one of its base classes and in which the developer of the new base class cannot change the existing hierarchy.
17.3.6 Virtual Base Class Declaration
A base class is specified as being derived through virtual inheritance by modifying its declaration with the keyword virtual. For example, the following declarations make ZooAnimal a virtual base class of both Bear and Raccoon:
// the order of the keywords public and virtual is not significant
class Raccoon : public virtual ZooAnimal { /* ... */ };
class Bear : virtual public ZooAnimal { /* ... */ };
Specifying virtual derivation has an impact only in classes derived from the class that specifies a virtual base. Rather than affecting objects of the derived class’ own type, it is a statement about the derived class’ relationship to its own, future derived class.
The virtual specifier states a willingness to share a single instance of the named base class within a subsequently derived class.
Any class that can be specified as a base class also could be specified as a virtual base class. A virtual base may contain any class element normally supported by a nonvirtual base class.
Normal Conversions to Base Are Supported
An object of the derived class can be manipulated as usual through a pointer or a reference to a base-class type even though the base class is virtual. For example, all of the following Panda base class conversions execute correctly even though Panda inherits its ZooAnimal part as a virtual base:

Visibility of Virtual Base-Class Members
Multiple-inheritance hierarchies using virtual bases pose fewer ambiguity problems than do those without virtual inheritance.
Members in the shared virtual base can be accessed unambiguously and directly. Similarly, if a member from the virtual base is redefined along only one derivation path, then that redefined member can be accessed directly. Under a nonvirtual derivation, both kinds of access would be ambiguous.
Assume a member named X is inherited through more than one derivation path. There are three possibilities:
- If in each path
Xrepresents the same virtual base class member, then there is no ambiguity because a single instance of the member is shared. - If in one path
Xis a member of the virtual base class member and in another pathXis a member of a subsequently derived class, there is also no ambiguity—the specialized derived class instance is given precedence over the shared virtual base class instance. - If along each inheritance path
Xrepresents a different member of a subsequently derived class, then the direct access of the member is ambiguous.
As in a nonvirtual multiple inheritance hierarchy, ambiguities of this sort are best resolved by the class providing an overriding instance in the derived class.
Exercises Section 17.3.6
Exercise 17.33: Given the following class hierarchy, which inherited members can be accessed without qualification from within the VMI class? Which require qualification? Explain your reasoning.

17.3.7 Special Initialization Semantics
Ordinarily each class initializes only its own direct base class(es). This initialization strategy fails when applied to a virtual base class. If the normal rules were used, then the virtual base might be initialized multiple times. The class would be initialized along each inheritance path that contains the virtual base. In our ZooAnimal example, using normal initialization rules would result in both Bear and Raccoon attempting to initialize the ZooAnimal part of a Panda object.
To solve this duplicate-initialization problem, classes that inherit from a class that has a virtual base have special handling for initialization. In a virtual derivation, the virtual base is initialized by the most derived constructor. In our example, when we create a Panda object, the Panda constructor alone controls how the ZooAnimal base class is initialized.
Although the virtual base is initialized by the most derived class, any classes that inherit immediately or indirectly from the virtual base usually also have to provide their own initializers for that base. As long as we can create independent objects of a type derived from a virtual base, that class must initialize its virtual base. These initializers are used only when we create objects of the intermediate type.
In our hierarchy, we could have objects of type Bear, Raccoon, or Panda. When a Panda is created, it is the most derived type and controls initialization of the shared ZooAnimal base. When a Bear (or a Raccoon) is created, there is no further derived type involved. In this case, the Bear (or Raccoon) constructors directly initialize their ZooAnimal base as usual:

The Panda constructor also initializes the ZooAnimal base, even though it is not an immediate base class:

When a Panda is created, it is this constructor that initializes the ZooAnimal part of the Panda object.
How a Virtually Inherited Object Is Constructed
Let’s look at how objects under virtual inheritance are constructed.
![]()
When a Panda object is created,
- The
ZooAnimalpart is constructed first, using the initializers specified in thePandaconstructor initializer list. - Next, the
Bearpart is constructed. The initializers forZooAnimal Bear’s constructor initializer list are ignored. - Then the
Raccoonpart is constructed, again ignoring theZooAnimalinitializers. - Finally, the
Pandapart is constructed.
If the Panda constructor does not explicitly initialize the ZooAnimal base class, then the ZooAnimal default constructor is used. If ZooAnimal doesn’t have a default constructor, then the code is in error. The compiler will issue an error message when the definition of Panda’s constructor is compiled.
Constructor and Destructor Order
Virtual base classes are always constructed prior to nonvirtual base classes regardless of where they appear in the inheritance hierarchy.
For example, in the following whimsical TeddyBear derivation, there are two virtual base classes: the ToyAnimal base class and the indirect ZooAnimal base class from which Bear is derived:

Figure 17.5. Virtual Inheritance TeddyBear Hierarchy
The immediate base classes are examined in declaration order to determine whether there are any virtual base classes. In our example, the inheritance subtree of BookCharacter is examined first, then that of Bear, and finally that of ToyAnimal. Each subtree is examined starting at the root class down to the most derived class.
The order in which the virtual base classes are constructed for TeddyBear is ZooAnimal followed by ToyAnimal. Once the virtual base classes are constructed, the nonvirtual base-class constructors are invoked in declaration order: BookCharacter, which causes the Character constructor to be invoked, and then Bear. Thus, to create a TeddyBear, the constructors are invoked in the following order:

where the initializers used for ZooAnimal and ToyAnimal are specified by the most derived class— TeddyBear.
The same construction order is used in the synthesized copy constructor; the base classes also are assigned in this order in the synthesized assignment operator. The order of base-class destructor calls is guaranteed to be the reverse order of constructor invocation.
Exercises Section 17.3.7
Exercise 17.34: There is one case in which a derived class need not supply initializers for its virtual base class(es). What is this case?
Exercise 17.35: Given the following class hierarchy,

(a) What is the order of constructor and destructor for the definition of a Final object?
(b) How many Base subobjects are in a Final object? How many Class subobjects?
(c) Which of the following assignments is a compile-time error?

Exercise 17.36: Given the previous hierarchy, and assuming that Base defines the following three constructors, define the classes that inherit from Base, giving each class the same three constructors. Each constructor should use its argument to initialize its Base part.

Chapter Summary
Most of C++ is applicable to a wide range of problems—from those solvable in a few hour’s time to those that take years of development by large teams. Some features in C++ are most applicable in the context of large-scale problems: exception handling, namespaces, and multiple or virtual inheritance.
Exception handling lets us separate the error-detection part of the program from the error-handling part. Section 6.13 (p. 215) introduced exception handling and this chapter completes our coverage of exceptions. When an exception is thrown, the current executing function is suspended and a search is started to find the nearest catch clause. Local variables defined inside functions that are exited while searching for a catch clause are destroyed as part of handling the exception. The fact that objects are destroyed gives rise to an important programming technique known as “resource allocation is initialization” (RAII).
Namespaces are a mechanism for managing large complex applications built from code produced by independent suppliers. A namespace is a scope in which objects, types, functions, template, and other namespaces may be defined. The standard library is defined inside the namespace named std.
Names in a namespace may be made available to the current scope one at a time via a using declaration. Alternatively, but much less safely, all the names in a namespace may be brought into the current scope via a using directive.
Conceptually, multiple inheritance is a simple notion: A derived class may inherit from more than one direct base class. The derived object consists of the derived part and a base part contributed by each of its base classes. Although conceptually simple, the details can be more complicated. In particular, inheriting from multiple base classes introduces new possibilities for name collisions and resulting ambiguous references to names from the base part of an object.
When a class inherits from more than one immediate base class, it is possible that those classes may themselves share another base class. In cases such as this, the intermediate classes can opt to make their inheritance virtual, which states a willingness to share its virtual base class with other classes in the hierarchy that inherit virtually from that same base class. In this way there is only one copy of the shared virtual base in a subsequently derived class.
Defined Terms
Library function that abnormally terminates a program’s execution. Ordinarily, abort is called by terminate. Programs may also call abort directly. It is defined in the cstdlib header.
Library class template that provides exception-safe access to dynamically allocated objects. An auto_ptr cannot be bound to an array or a pointer to a variable. Copying and assigning an auto_ptr is a destructive operation: Ownership of the object is transferred from the right-hand operand to the left. Assigning to an auto_ptr deletes the object in the left-hand operand. As a result, auto_ptrs may not be stored in containers.
A catch clause in which the exception specifier is (...). A catch-all clause catches an exception of any type. It is typically used to catch an exception that is detected locally in order to do local cleanup. The exception is then rethrown to another part of the program to deal with the under-lying cause of the problem.
The part of the program that handles an exception. A catch clause consists of the keyword catch followed by an exception specifier and a block of statements. The code inside a catch does whatever is necessary to handle an exception of the type defined in its exception specifier.
Ordinarily, base classes are constructed in the order in which they are named in the class derivation list. A derived constructor should explicitly initialize each base class through the constructor initializer list. The order in which base classes are named in the constructor initializer list does not affect the order in which the base classes are constructed. In a virtual inheritance, the virtual base class(es) are constructed before any other bases. They are constructed in the order in which they appear (directly or indirectly) in the derivation list of the derived type. Only the most derived type may initialize a virtual base; constructor initializers for that base that appear in the intermediate base classes are ignored.
Derived objects are destroyed in the reverse order from which they were constructed—the derived part is destroyed first, then the classes named in the class derivation list are destroyed, starting with the last base class. Classes that serve as base classes in a multiple-inheritance hierarchy ordinarily should define their destructors to be virtual.
Another way to refer to a catch clause.
Language-level support for managing run-time anomalies. One independently developed section of code can detect and “raise” an exception that another independently developed part of the program can “handle.” The error-detecting part of the program throws an exception; the error-handling part handles the exception in a catch clause of a try block.
Object used to communicate between the throw and catch sides of an exception. The object is created at the point of the throw and is a copy of the thrown expression. The exception object exists until the last handler for the exception completes. The type of the object is the type of the thrown expression.
Term used to describe programs that behave correctly when exceptions are thrown.
Used on a function declaration to indicate what (if any) exception types a function throws. Exception types are named in a parenthesized, comma-separated list following the keyword throw, which appears after a function’s parameter list. An empty list means that the function throws no exceptions. A function that has no exception specification may throw any exception.
Specifies the types of exceptions that a given catch clause will handle. An exception specifier acts like a parameter list, whose single parameter is initialized by the exception object. Like parameter passing, if the exception specifier is a nonreference type, then the exception object is copied to the catch.
Name local to a file that is declared with the static keyword. In C and pre-Standard versions of C++, file statics were used to declare objects that could be used in a single file only. File statics are deprecated in C++, having been replaced by the use of unnamed namespaces.
A try block that is a function body. The keyword try occurs before the opening curly of the function body and closes with catch clause(s) that appear after the close curly of the function body. Function try blocks are used most often to wrap constructor definitions in order to catch exceptions thrown by constructor initializers.
The (implicit) name-space in each program that holds all global definitions.
Inheritance in which a class has more than one immediate base class. The derived class inherits the members of all its base classes. Multiple base classes are defined by naming more than one base class in the class derivation list. A separate access label is required for each base class.
Mechanism for gathering all the names defined by a library or other collection of programs into a single scope. Unlike other scopes in C++, a namespace scope may be defined in several parts. The namepsace may be opened and closed and reopened again in disparate parts of the program.
Mechanism for defining a synonym for a given namespace:
namespace N1 = N;
defines N1 as another name for the name-space named N. A namespace can have multiple aliases, and the namespace name or one of its aliases may be used interchangeably.
Term used to describe what happens when all the names of classes and functions are placed in the global namespace. Large programs that use code written by multiple independent parties often encounter collisions among names if these names are global.
Often used as a synonym for throw. C++ programmers speak of “throwing” or “raising” an exception interchangably.
An empty throw—a throw that does not specify an expression. A rethrow is valid only from inside a catch clause, or in a function called directly or indirectly from a catch. Its effect is to rethrow the exception object that it received.
Operator used to access names from a namespace or a class.
Term used to describe the process whereby the functions leading to a thown exception are exited in the search for a catch. Local objects constructed before the exception are destroyed before entering the corresponding catch.
Library function that is called if an exception is not caught or if an exception occurs while a handler is in process. Usually calls abort to end the program.
Expression that interrupts the current execution path. Each throw transfers control to the nearest enclosing catch clause that can handle the type of exception that is thrown. The expression e is copied into the exception object.
A block of statements enclosed by the keyword try and one or more catch clauses. If the code inside the try block raises an exception and one of the catch clauses matches the type of the exception, then the exception is handled by that catch. Otherwise, the exception is passed out of the try to a catch further up the call chain.
Library function that is called if an exception is thrown that violates the exception specification of a function.
A namespace that is defined without a name. Names defined in an unnamed namespace may be accessed directly without use of the scope operator. Each file has its own unique unnamed namespace. Names in the file are not visible outside that file.
Mechanism to inject a single name from a namespace into the current scope:
using std::cout;
makes the name cout from the namespace std available in the current scope. The name cout can be used without the std:: qualifier.
Mechanism for making all the names in a namespace available in the nearest scope containing both the using directive and the namespace itself.
A base class that was inherited using the virtual keyword. A virtual base part occurs only once in a derived object even if the same class appears as a virtual base more than once in the hierarchy. In nonvirtual inheritance a constructor may only initialize its immediate base class(es). When a class is inherited virtually, that class is initialized by the most derived class, which therefore should include an initializer for all of its virtual parent(s).
Form of multiple inheritance in which derived classes share a single copy of a base that is included in the hierarchy more than once.