
Chapter 10. Associative Containers
CONTENTS
Section 10.1 Preliminaries: the pair Type 356
Section 10.2 Associative Containers 358
Section 10.5 The multimap and multiset Types 375
Section 10.6 Using Containers: Text-Query Program 379
This chapter completes our review of the standard library container types by looking at the associative containers. Associative containers differ in a fundamental respect from the sequential containers: Elements in an associative container are stored and retrieved by a key, in contrast to elements in a sequential container, which are stored and accessed sequentially by their position within the container.
Although the associative containers share much of the behavior of the sequential containers, they differ from the sequential containers in ways that support the use of keys. This chapter covers the associative containers and closes with an extended example that uses both associative and sequential containers.
Associative containers support efficient lookup and retrieval by a key. The two primary associative-container types are map and set. The elements in a map are key–value pairs: The key serves as an index into the map, and the value represents the data that are stored and retrieved. A set contains only a key and supports efficient queries to whether a given key is present.
In general, a set is most useful when we want to store a collection of distinct values efficiently, and a map is most useful when we wish to store (and possibly modify) a value associated with each key. We might use a set to hold words that we want to ignore when doing some kind of text processing. A dictionary would be a good use for a map: The word would be the key, and its definition would be the value.
An object of the map or set type may contain only a single element with a given key. There is no way to add a second element with the same key. If we need to have multiple instances with a single key, then we can use multimap or multi set, which do allow multiple elements with a given key.
The associative containers support many of the same operations as do the sequential containers. They also provide specialized operations that manage or use the key. In the sections that follow, we look at the associative container types and their operations in detail. We’ll conclude the chapter by using the containers to implement a small text-query program.
Table 10.1. Associative Container Types

10.1 Preliminaries: the pair Type
Before we look at the associative containers, we need to know about a simple companion library type named pair, which is defined in the utility header.
Creating and Initializing pairs
A pair holds two data values. Like the containers, pair is a template type. Unlike the containers we’ve seen so far, we must supply two type names when we create a pair: A pair holds two data members, each of which has the corresponding named type. There is no requirement that the two types be the same.

When we create pair objects with no initializer, the default constructor value-initializes the members. Thus, anon is a pair of two empty strings, and line holds an empty string and an empty vector. The int value in word_count gets the value 0 and the string member is initialized to the empty string.
We can also provide initializers for each member:
pair<string, string> author("James", "Joyce");
creates a pair named author, in which each member has type string. The object named author is initialized to hold two strings with the values "James" and "Joyce".
The pair type can be unwieldy to type, so when we wish to define a number of objects of the same pair type, it is convenient to use a typedef (Section 2.6, p. 61):
typedef pair<string, string> Author;
Author proust("Marcel", "Proust");
Author joyce("James", "Joyce");
Table 10.2. Operations on pairs

Operations on pairs
Unlike other library types, the pair class gives us direct access to its data members: Its members are public. These members are named first and second, respectively. We can access them using the normal dot operator (Section 1.5.2, p. 25) member access notation:

The library defines only a limited number of operations on pairs, which are listed in Table 10.2 on the preceding page.
Generating a New pair
In addition to the constructors, the library defines the make_pair function, which generates a new pair from its two arguments. We might use this function to make a new pair to assign to an existing pair:

This loop processes a sequence of authors. The call to make_pair generates a new pair from the names read in the while condition. It is equivalent to the somewhat more complicated
// use pair constructor to make first and last into a pair
next_auth = pair<string, string>(first, last);
Because the data members of pair are public, we could read the inputeven more directly as

10.2 Associative Containers
Associative containers share many, but not all, of the operations on sequential containers. Associative containers do not have the front, push_front, pop_front, back, push_back, or pop_back operations.
The operations common to sequential and associative containers are:
• The first three constructors described in Table 9.2 (p. 307):

Associative containers cannot be defined from a size, because there would be no way to know what values to give the keys.
• The relational operations described in Section 9.3.4 (p. 321).
• The begin, end, rbegin, and rend operations of Table 9.6 (p. 317).
• The typedefs listed in Table 9.5 (p. 316). Note that for map, the value_type is not the same as the element type. Instead, value_type is a pair representing the types of the keys and associated values. Section 10.3.2 (p. 361) explains the typedefs for maps in more detail.
• The swap and assignment operator described in Table 9.11 (p. 329). Associative containers do not provide the assign functions.
• The clear and erase operations from Table 9.10 (p. 326), except that the erase operation on an associative container returns void.
• The size operations in Table 9.8 (p. 324) except for resize, which we cannot use on an associative container.
Elements Are Ordered by Key
The associative container types define additional operations beyond the ones just listed. They also redefine the meaning or return type of operations that are in common with the sequential containers. The differences in these common operations reflect the use of keys in the associative containers.

There is one important consequence of the fact that elements are ordered by key: When we iterate across an associative container, we are guaranteed that the elements are accessed in key order, irrespective of the order in which the elements were placed in the container.
10.3 The map Type
A map is a collection of key–value pairs. The map type is often referred to as an associative array: It is like the built-in array type, in that the key can be used as an index to fetch a value. It is associative in that values are associated with a particular key rather than being fetched by position in the array.
10.3.1 Defining a map
To use a map, we must include the map header. When we define a map object, we must indicate both the key and value type:
// count number of times each word occurs in the input
map<string, int> word_count; // empty map from string to int
defines a map object word_count that is indexed by a string and that holds an associated int value.
Table 10.3. Constructors for map

Constraints on the Key Type
Whenever we use an associative container, its keys have not only a type, but also an associated comparison function. By default, the library uses the < operator for the key type to compare the keys. Section 15.8.3 (p. 605) will show how we can override the default and provide our own function.
Whichever comparison function we use must define a strict weak ordering over the key type. We can think of a strict weak ordering as “less than,” although we might choose to define a more complicated comparison function. However we define it, such a comparison function must always yield false when we compare a key with itself. Moreover, if we compare two keys, they cannot both be “less than” each other, and if k1 is “less than” k2, which in turn is “less than” k3, then k1 must be “less than” k3. If we have two keys, neither of which is “less than” the other, the container will treat them as equal. When used as a key to a map, either value could be used to access the corresponding element.
In practice, what’s important is that the key type must define the < operator and that that operator should “do the right thing.”
As an example, in our bookstore problem, we might add a type named ISBN that would encapsulate the rules for ISBNs. In our implementation, ISBNs are strings, which we can compare to determine which ISBN is less than another. Therefore, the ISBN type could support a < operation. Given that we had such a type, we could define a map that would allow us to efficiently search for a particular book held by a bookstore.
map<ISBN, Sales_item> bookstore;
defines a map object named bookstore that is indexed by an ISBN. Each element in the map holds an associated instance of our Sales_item class.
The key type needs to support only the < operator. There is no requirement that it support the other relational or equality operators.
10.3.2 Types Defined by map
The elements of a map are key–value pairs That is, each element has two parts: its key and the value associated with that key. The value_type for a map reflects this fact. This type is more complicated than those we’ve seen for other containers: value_type is a pair that holds the key and value of a given element. Moreover, the key is const. For example, the value_type of the word_count array is pair<const string, int>.
Table 10.4. Types Defined by the map Class

When learning the map interface, it is essential to remember that the value_type is a pair and that we can change the value but not the key member of that pair.
Dereferencing a map Iterator Yields a pair
When we dereference an iterator, we get a reference to a value of the container’s value_type. In the case of map, the value_type is a pair:

Dereferencing the iterator yields a pair object in which first member holds the const key and second member holds the value.
Additional map Typedefs
The map class defines two additional types, key_type and mapped_type, that let us access the type of either the key or the value. For word_count, the key_type is string and mapped_type is int. As with the sequential containers (Section 9.3.1, p. 317), we use the scope operator to fetch a type member—for example, map<string, int>::key_type.
10.3.3 Adding Elements to a map
Once the map is defined, the next step is to populate it with the key–value element pairs. We can do so either by using the insert member or by fetching an element using the subscript operator and then assigning a value to the element returned. In both cases, the fact that there can be only a single element for a given key affects the behavior of these operations.
10.3.4 Subscripting a map
When we write
map <string, int> word_count; // empty map
// insert default initialzed element with key Anna; then assign 1 to its value
word_count["Anna"] = 1;
the following steps take place:
word_countis searched for the element whose key isAnna. The element is not found.- A new key–value pair is inserted into
word_count. The key is aconst stringholdingAnna. The value is value initialized, meaning in this case that the value is 0. - The new key–value pair is inserted into
word_count. - The newly inserted element is fetched and is given the value 1.
Subscripting a map behaves quite differently from subscripting an array or vector: Using an index that is not already present adds an element with that index to the map.
As with other subscript operators, the map subscript takes an index (that is, a key) and fetches the value associated with that key. When we look for a key that is already in the map, then the behavior is the same for a map subscript or a vector subscript: The value associated with the key is returned. For maps only, if the key is not already present, a new element is created and inserted into the map for that key. The associated value is value-initialized: An element of class type is initialized using the default constructor for the element type; a built-in type is initialized to 0.
Using the Value Returned from a Subscript Operation
As usual, the subscript operator returns an lvalue. The lvalue it returns is the value associated with the key. We can read or write the element:
![]()
Unlike vector or string, the type returned by map subscript operator differs from the type obtained by dereferencing a map iterator.
As we’ve seen, a map iterator returns a value_type, which is a pair that contains a const key_type and mapped_type; the subscript operator returns a value of type mapped_type.
Programming Implications of the Subscript Behavior
The fact that subscript adds an element if it is not already in the map allows us to write surprisingly succinct programs:

This program creates a map that keeps track of how many times each word occurs. The while loop reads the standard input one word at a time. Each time it reads a new word, it uses that word to index word_count. If word is already in the map, then its value is incremented.
The interesting part is what happens when a word is encountered for the first time: A new element indexed by word, with an initial value of zero, is created and inserted into word_count. The value of that element is immediately incremented so that each time we insert a new word into the map it starts off with an occurrence count of one.
10.3.5 Using map::insert
The insert members operate similarly to the operations on sequential containers (Section 9.3.3, p. 318), with one important caveat: We must account for the effect of the key. The key impacts the argument types: The versions that insert a single element take a value that is a key–value pair. Similarly, for the version that takes an iterator pair, the iterators must refer to elements that are key–value pairs. The other difference is the return type from the version of insert that takes a single value, which we will cover in the remainder of this section.
Using insert Instead of Subscripting
When we use a subscript to add an element to a map, the value part of the element is value-initialized. Often we immediately assign to that value, which means that we’ve initialized and assigned the same object. Alternatively, we could insert the element directly by using the syntactically more intimidating insert member:
// if Anna not already in word_count, inserts new element with value 1
word_count.insert(map<string, int>::value_type("Anna", 1));
Table 10.5. insert Operations on maps

The argument to this version of insert
map<string, int>::value_type(anna, 1)
is a newly created pair that is directly inserted into the map. Remember that value_type is a synonym for the type pair<const K, V>, where K is the key type and V is the type of the associated value. The argument to insert constructs a new object of the appropriate pair type to insert into the map. By using insert, we can avoid the extraneous initialization of the value that happens when we insert a new map element as a side-effect of using a subscript.
The argument to insert is fairly unwieldy. There are two ways to simplify it. We might use make_pair:
word_count.insert(make_pair("Anna", 1));
Or use a typedef:
typedef map<string,int>::value_type valType;
word_count.insert(valType("Anna", 1));
Either approach improves readability by making the call less complicated.
Testing the Return from insert
There can be only one element with a given key in a map. If we attempt to insert an element with a key that is already in the map, then insert does nothing. The versions of insert that take an iterator or iterator pair do not indicate whether or how many elements were inserted.
However, the version of insert that takes a single key–value pair does return a value. That value is a pair that contains an iterator that refers to the element in the map with the corresponding key, and a bool that indicates whether the element was inserted. If the key is already in the map, then the value is unchanged, and the bool portion of the return is false. If the key isn’t present, then the element is inserted and the bool is true. In either case, the iterator refers to the element with the given key. We could rewrite our word count program to use insert:

For each word, we attempt to insert it with a value 1. The if test examines the bool in the return from the insert. If it is false, then the insertion didn’t happen and an element indexed by word was already in word_count. In this case we increment the value associated with that element.
Unwinding the Syntax
The definition of ret and the increment may be hard to decipher:
![]()
It should be easy to see that we’re defining a pair and that the second type of the pair is bool. The first type of that pair is a bit harder to understand. It is the iterator type defined by the map<string, int> type.
We can understand the increment by first parenthesizing it to reflect the precedence (Section 5.10.1, p. 168) of the operators:
++((ret.first)->second); // equivalent expression
Explaining this expression step by step, we have
• ret holds return value from insert, which is a pair. The first member of that pair is a map iterator referring to the key that was inserted.
• ret.first fetches the map iterator from the pair returned by insert.
• ret.first->second dereferences that iterator obtaining a value_type object. That object is also a pair, in which the second member is the value part of the element we added.
• ++ret.first->second increments that value.
Putting it back together, the increment statement fetches the iterator for the element indexed by word and increments the value part of that element.
10.3.6 Finding and Retrieving a map Element
The subscript operator provides the simplest method of retrieving a value:
map<string,int> word_count;
int occurs = word_count["foobar"];
As we’ve seen, using a subscript has an important side effect: If that key is not already in the map, then subscript inserts an element with that key.
Whether this behavior is correct depends on our expectations. In this example, if “foobar” weren’t already present, it would be added to the map with an associated value of 0. In this case, occurs gets a value of 0.
Our word-counting programs relied on the fact that subscripting a nonexistent element inserts that element and initializes the value to 0. There are times, though, when we want to know if an element is present but do not want the element inserted if it is not present. In such cases, we cannot use the subscript operator to determine whether the element is present.
There are two operations, count and find, that we can use to determine if a key is present without causing it to be inserted.
Table 10.6. Interrogating a map Without Changing It

Using count to Determine Whether a Key is in the map
The count member for a map always returns either 0 or 1. A map may have only one instance of any given key, so count effectively indicates whether the key is present. The return from count is more useful for multimaps, which we cover in Section 10.5 (p. 375). If the return value is nonzero, we can use the subscript operator to fetch the value associated with the key without worrying that doing so will insert the element into the map:
int occurs = 0;
if (word_count.count("foobar"))
occurs = word_count["foobar"];
Of course, executing count followed by the subscript effectively looks for the element twice. If we want to use the element if it is present, we should use find.
Retrieving an Element Without Adding It
The find operation returns an iterator to the element or the end iterator if the element is not present:

We should use find when we want to obtain a reference to the element with the specified key if it exists, and do not want to create the element if it does not exist.
10.3.7 Erasing Elements from a map
There are three variants of the erase operation to remove elements from a map. As with the sequential containers, we can erase a single element or a range of elements by passing erase an iterator or an iterator pair. These versions of erase are similar to the corresponding operations on sequential containers with one exception: The map operations return void, whereas those on the sequential containers return an iterator to the element following the one that was removed.
The map type supplies an additional erase operation that takes a value of the key_type and removes the element with the given key if the element exists. We could use this version to remove a specific word from word_count before printing the results:

The erase function returns a count of how many elements were removed. In the case of a map, that number is either zero or one. If the return value is zero, then the element we wanted to erase was not in the map.
Table 10.7. Removing Elements from a map

10.3.8 Iterating across a map
Like any other container, map provides begin and end operations that yield iterators that we can use to traverse the map. For example, we could print the map named word_count that we built on page 363 as follows:

The while condition and increment for the iterator in this loop look a lot like the programs we wrote that printed the contents of a vector or a string. We initialize an iterator, map_it, to refer to the first element in word_count. As long as the iterator is not equal to the end value, we print the current element and then increment the iterator. The body of the loop is more complicated than those earlier programs because we must print both the key and value for each element.
The output of our word-count program prints the words in alphabetical order. When we use an iterator to traverse a map, the iterators yield elements in ascending key order.
10.3.9 A Word Transformation Map
We’ll close this section with a program to illustrate creating, searching, and iterating across a map. Our problem is to write a program that, given one string, transforms it into another. The input to our program is two files. The first file contains several word pairs. The first word in the pair is one that might be in the input string. The second is the word to use in the output. Essentially, this file provides a set of word transformations—when we find the first word, we should replace it by the second. The second file contains the text to transform. If the contents of the word transformation file is

and the text we are given to transform is
nah i sez tanx cuz i wuz pos to
not cuz i wuz gratz
then the program should generate the following output:
no I said thanks because I was supposed to
not because I was grateful
The Word Transformation Program
Our solution, which appears on the next page, stores the word transformation file in a map, using the word to be replaced as the key and the word to use as the replacement as its corresponding value. We then read the input, looking up each word to see if it has a transformation. If so, we do the transformation and then print the transformed word. If not, we print the original word.
Our main program takes two arguments (Section 7.2.6, p. 243): the name of the word transformation file and the name of the file to transform. We start by checking the number of arguments. The first argument, argv[0], is always the name of the command. The file names will be in argv[1] and argv[2].
Once we know that argv[1] is valid, we call open_file (Section 8.4.3, p. 299) to open the word transformation file. Assuming the open succeeded, we read the transformation pairs. We call insert using the first word as the key and the second as the value. When the while concludes, trans_map contains the data we need to transform the input. If there’s a problem with the arguments, we throw (Section 6.13, p. 215) an exception and exit the program.
Next, we call open_file to open the file we want to transform. The second while uses getline to read that file a line at a time. We read by line so that our output will have line breaks at the same position as our input file. To get the words from each line we use a nested while loop that uses an istringstream. This part of the program is similar to the sketch we wrote on page 300.
The inner while checks each word to see if it is in the transformation map. If it is, then we replace the word by its corresponding value from the map. Finally, we print the word, transformed or not. We use the bool firstword to determine whether to print a space. If it is the first word in the line, we don’t print a space.


10.4 The set Type
A map is a collection of a key–value pairs, such as an address and phone number keyed to an individual’s name. In contrast, a set is simply a collection of keys. For example, a business might define a set named bad_checks, to hold the names of individuals who have issued bad checks to the company. A set is most useful when we simply want to know whether a value is present. Before accepting a check, for example, that business would query bad_checks to see whether the customer’s name was present.
With two exceptions, set supports the same operations as map:
• All the common container operations listed in Section 10.2 (p. 358).
• The constructors described in Table 10.3 (p. 360).
• The insert operations described in Table 10.5 (p. 365).
• The count and find operations described in Table 10.6 (p. 367).
• The erase operations described in Table 10.7 (p. 369).
The exceptions are that set does not provide a subscript operator and does not define mapped_type. In a set, the value_type is not a pair; instead it and key_type are the same type. They are each the type of the elements stored in the set. These differences reflect the fact that set holds only keys; there is no value associated with the key. As with map, the keys of a set must be unique and may not be changed.
10.4.1 Defining and Using sets
To use a set, we must include the set header. The operations on sets are essentially identical to those on maps.
As with map, there can be only one element with a given key in a set. When we initialize a set from a range of elements or insert a range of elements, only one element with a given key is actually added:

We first create a vector of ints named ivec that has 20 elements: two copies of each of the integers from 0 through 9 inclusive. We then use all the elements from ivec to initialize a set of ints. That set has only ten elements: one for each distinct element in ivec.
Adding Elements to a set
We can add elements to a set by using the insert operation:

Alternatively, we can insert a range of elements by providing a pair of iterators to insert. This version of insert works similarly to the constructor that takes an iterator pair—only one element with a given key is inserted:
![]()
Like the map operations, the version of insert that takes a key returns a pair containing an iterator to the element with this key and a bool indicating whether the element was added. The one that takes an iterator pair returns void.
Fetching an Element from a set
There is no subscript operator on sets. To fetch an element from a set by its key, we use the find operation. If we just want to know whether the element is present, we could also use count, which returns the number of elements in the set with a given key. Of course, for set that value can be only one (if the element is present) or zero (if it is not):
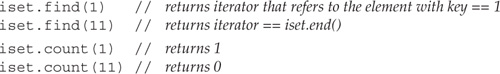
Just as we cannot change the key part of a map element, the keys in a set are also const. If we have an iterator to an element of the set, all we can do is read it; we cannot write through it:
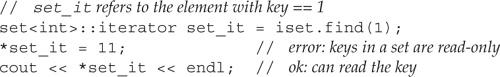
10.4.2 Building a Word-Exclusion Set
On page 369 we removed a given word from our word_count map. We might want to extend this approach to remove all the words in a specified file. That is, our word-count program should count only words that are not in a set of excluded words. Using set and map, this program is fairly straightforward:

This program is similar to the word-count program on page 363. The difference is that we do not bother to count the common words.
The function starts by reading the file it was passed. That file contains the list of excluded words, which we store in the set named excluded. When the first while completes, that set contains an entry for each word in the input file.
The next part of the program looks a lot like our original word-count program. The important difference is that before counting each word, we check whether the word is in the exclusion set. We do this check in the if inside the second while:
// increment counter only if the word is not in excluded
if (!excluded.count(word))
The call to count returns one if word is in excluded and zero otherwise. We negate the return from count so that the test succeeds if word is not in excluded. If word is not in excluded, we update its value in the map.
As in the previous version of our word count program, we rely on the fact that subscripting a map inserts an element if the key is not already in the map. Hence, the effect of
++word_count[word];
is to insert word into word_count if it wasn’t already there. If the element is inserted, its value is initially set to 0. Regardless of whether the element had to be created, the value is then incremented.
10.5 The multimap and multiset Types
Both map and set can contain only a single instance of each key. The types multiset and a multimap allow multiple instances of a key. In a phone directory, for example, someone might wish to provide a separate listing for each phone number associated with an individual. A listing of available texts by an author might provide a separate listing for each title. The multimap and multiset types are defined in the same headers as the corresponding single-element versions: the map and set headers, respectively.
The operations supported by multimap and multiset are the same as those on map and set, respectively, with one exception: multimap does not support subscripting. We cannot subscript a multimap because there may be more than one value associated with a given key. The operations that are common to both map and multimap or set and multiset change in various ways to reflect the fact that there can be multiple keys. When using either a multimap or multiset, we must be prepared to handle multiple values, not just a single value.
10.5.1 Adding and Removing Elements
The insert operations described in Table 10.5 (p. 365) and the erase operations described in Table 10.7 (p. 369) are used to add and remove elements of a multimap or multiset.
Because keys need not be unique, insert always adds an element. As an example, we might define a multimap to map authors to titles of the books they have written. The map might hold multiple entries for each author:

The version of erase that takes a key removes all elements with that key. It returns a count of how many elements were removed. The versions that take an iterator or an iterator pair remove only the indicated element(s). These versions return void:

10.5.2 Finding Elements in a multimap or multiset
We noted that maps and sets store their elements in order. The multimap and multiset types do so as well. As a result, when a multimap or multiset has multiple instances of a given key, those instances will be adjacent elements within the container.
We are guaranteed that iterating across a multimap or multiset returns all the elements with a given key in sequence.
Finding an element in a map or a set is a simple matter—the element is or is not in the container. For multimap and multiset the process is more complicated: the element may be present many times. For example, given our map from author to titles, we might want to find and print all the books by a particular author.
It turns out that there are three strategies we might use to find and print all the books by a given author. Each of these strategies relies on the fact that we know that all the entries for a given author will be adjacent within the multimap.
We’ll start by presenting a strategy that uses only functions we’ve already seen. This version turns out to require the most code, so we will continue by exploring more compact alternatives.
Using find and count
We could solve our problem using find and count. The count function tells us how many times a given key occurs, and the find operation returns an iterator that refers to the first instance of the key we’re looking for:

We start by determining how many entries there are for the author by calling count and getting an iterator to the first element with this key by calling find. The number of iterations of the for loop depends on the number returned from count. In particular, if the count was zero, then the loop is never executed.
A Different, Iterator-Oriented Solution
Another, more elegant strategy uses two associative container operations that we haven’t seen yet: lower_bound and upper_bound. These operations, listed in Table 10.8 (p. 379), apply to all associative containers. They can be used with (plain) maps or sets but are most often used with multimaps or multisets. Each of these operations takes a key and returns an iterator.
Calling lower_bound and upper_bound on the same key yields an iterator range (Section 9.2.1, p. 314) that denotes all the elements with that key. If the key is in the container, the iterators will differ: the one returned from lower_bound will refer to the first instance of the key, whereas upper_bound will return an iterator referring just after the last instance. If the element is not in the multimap, then lower_bound and upper_bound will return equal iterators; both will refer to the point at which the key could be inserted without disrupting the order.
Of course, the iterator returned from these operations might be the off-the-end iterator for the container itself. If the element we look for has the largest key in the multimap, then upper_bound on that key returns the off-the-end iterator. If the key is not present and is larger than any key in the multimap, then the return from lower_bound will also be the off-the-end iterator.
The iterator returned from lower_bound may or may not refer to an element with the given key. If the key is not in the container, then lower_bound refers to the first point at which this key could be inserted while preserving the element order within the container.
Using these operations, we could rewrite our program as follows:

This program does the same work as the previous one that used count and find but accomplishes its task more directly. The call to lower_bound positions beg so that it refers to the first element matching search_item if there is one. If there is no such element, then beg refers to first element with a key larger than search_item. The call to upper_bound sets end to refer to the element with the key just beyond the last element with the given key.
These operations say nothing about whether the key is present. The important point is that the return values act like an iterator range.
If there is no element for this key, then lower_bound and upper_bound will be equal: They will both refer to the same element or they will both point one past the end of the multimap. They both will refer to the point at which this key could be inserted while maintaining the container order.
If there are elements with this key, then beg will refer to the first such element. We can increment beg to traverse the elements with this key. The iterator in end will signal when we’ve seen all the elements. When beg equals end, we have seen every element with this key.
Given that these iterators form a range, we can use the same kind of while loop that we’ve used to traverse other ranges. The loop is executed zero or more times and prints the entries, if any, for the given author. If there are no elements, then beg and end are equal and the loop is never executed. Otherwise, we know that the increment to beg will eventually reach end and that in the process we will print each record associated with this author.
Table 10.8. Associative Container Operations Returning Iterators

The equal_range Function
It turns out that there is an even more direct way to solve this problem: Instead of calling upper_bound and lower_bound, we can call equal_range. This function returns a pair of iterators. If the value is present, then the first iterator refers to the first instance of the key and the second iterator refers one past the last instance of the key. If no matching element is found, then both the first and second iterator refer to the position where this key could be inserted.
We could use equal_range to modify our program once again:

This program is essentially identical to the previous one that used upper_bound and lower_bound. Instead of using local variables, beg and end, to hold the iterator range, we use the pair returned by equal_range. The first member of that pair holds the same iterator as the one lower_bound would have returned. The iterator that upper_bound would have returned is in the second member.
Thus, in this program pos.first is equivalent to beg, and pos.second is equivalent to end.
10.6 Using Containers: Text-Query Program
To conclude this chapter, we’ll implement a simple text-query program.
Our program will read a file specified by the user and then allow the user to search the file for words that might occur in it. The result of a query will be the number of times the word occurs and a list of lines on which it appears. If a word occurs more than once on the same line, our program should be smart enough to display that line only once. Lines should be displayed in ascending order—that is, line 7 should be displayed before line 9, and so on.
Exercises Section 10.5.2
Exercise 10.26: Write a program that populates a multimap of authors and their works. Use find to find an element in the multimap and erase that element. Be sure your program works correctly if the element you look for is not in the map.
Exercise 10.27: Repeat the program from the previous exercise, but this time use equal_range to get iterators so that you can erase a range of elements.
Exercise 10.28: Using the multimap from the previous exercise, write a program to generate the list of authors whose name begins with the each letter in the alphabet. Your output should look something like:

Exercise 10.29: Explain the meaning of the operand pos.first->second used in the output expression of the final program in this section.
For example, we might read the file that contains the input for this chapter and look for the word “element.” The first few lines of the output would be:

followed by the remaining 120 or so lines in which the word “element” occurs.
10.6.1 Design of the Query Program
A good way to start the design of a program is to list the program’s operations. Knowing what operations we need to provide can then help us see what data structures we’ll need and how we might implement those actions. Starting from requirements, the tasks our program needs to support include:
- It must allow the user to indicate the name of a file to process. The program will store the contents of the file so that we can display the original line in which each word appears.
- The program must break each line into words and remember all the lines in which each word appears. When it prints the line numbers, they should be presented in ascending order and contain no duplicates.
- The result of querying for a particular word should be the line numbers on which that word appeared.
- To print the text in which the word appeared, it must be possible to fetch the line from the input file corresponding to a given line number.
Data Structure
We’ll implement our program as a simple class that we’ll name TextQuery. Our requirements can be met quite neatly by using various containers:
- We’ll use a
vector<string>to store a copy of the entire input file. Each line in the input file will be an element in thisvector. That way, when we want to print a line, we can fetch it by using the line number as an index. - We’ll store each word’s line numbers in a
set. Using asetwill guarantee that there is only one entry per line and that the line numbers will be automatically stored in ascending order. - We’ll use a
mapto associate each word with thesetof line numbers on which the word appears.
Our class will have two data members: a vector to hold the input file and a map to associate each input word with the set of line numbers on which it appears.
Operations
The requirements also lead fairly directly to an interface for our class. However, we have one important design decision to make first: The function that does the query will need to return a set of line numbers. What type should it use to do so?
We can see that doing the query will be simple: We’ll index into the map to obtain the associated set. The only question is how to return the set that we find. The safest design is to return a copy of that set. However, doing so means that each element in the set must be copied. Copying the set could be expensive if we process a very large file. Other possible return values are a pair of iterators into the set, or a const reference to the set. For simplicity, we’ll return a copy, noting that this decision is one that we might have to revisit if the copy is too expensive in practice.
The first, third, and fourth tasks are actions programmers using our class will perform. The second task is internal to the class. Mapping these tasks to member functions, we’ll have three public functions in the class interface:
• read_file takes an ifstream&, which it reads a line at a time, storing the lines in the vector. Once it has read all the input, read_file will create the map that associates each word to the line numbers on which it appears.
• run_query takes a string and returns the set of line numbers on which that string appears.
• text_line takes a line number and returns the corresponding text for that line from the input file.
Neither run_query nor text_line changes the object on which it runs, so we’ll define these operations as const member functions (Section 7.7.1, p. 260).
To do the work of read_file, we’ll also define two private functions to read the input file and build the map:
• store_file will read the file and store the data in our vector.
• build_map will break each line into words and build the map, remembering the line number on which each word appeared.
10.6.2 TextQuery Class
Having worked through our design, we can now write our TextQuery class:

The class directly reflects our design decisions. The only part we hadn’t described is the typedef that defines an alias for size_type of vector.
For the reasons described on page 80, this class definition uses fully qualified std:: names for all references to library entities.
The read_file function is defined inside the class. It calls store_file to read and store the input file and build_map to build the map from words to line numbers. We’ll define the other functions in Section 10.6.4 (p. 385). First, we’ll write a program that uses this class to solve our text-query problem.
10.6.3 Using the TextQuery Class
The following main program uses a TextQuery object to perform a simple query session with the user. Most of the work in this program involves managing the interaction with the user: prompting for the next search word and calling the print_results function—which we shall write next—to print the results.

Preliminaries
This program checks that argv[1] is valid and then uses the open_file function (Section 8.4.3, p. 299) to open the file we’re given as an argument to main. We test the stream to determine whether the input file is okay. If not, we generate an appropriate message and exit, returning EXIT_FAILURE (Section 7.3.2, p. 247) to indicate that an error occurred.
Once we have opened the file, it is a simple matter to build up the map that will support queries. We define a local variable named tq to hold the file and associated data structures:
![]()
We call the read_file operation on tq, passing it the file opened by open_file.
After read_file completes, tq holds our two data structures: the vector that corresponds to the input file and the map from word to set of line numbers. That map contains an entry for each unique word in the input file. The map associates with each word the set of line numbers on which that word appeared.
Doing the Search
We want the program to let the user look for more than one word in each session, so we wrap the prompt in a while loop:

The test in the while is the boolean literal true, which means that the test always succeeds. We exit the loop through the break after the test on cin and the value read into sought. The loop exits when cin hits an error or end-of-file or when the user enters a ’q’ to quit.
Once we have a word to look for, we ask tq for the set of line numbers on which that word appears. We pass that set along with the word we are looking for and the TextQuery object to the print_results function. That function will write the output of our program.
Printing the Results
What remains is to define the print_results function:

The function starts by defining a typedef to simplify the use of the line number set. Our output first reports how many matches were found, which we know from the size of the set. We call make_plural (Section 7.3.2, p. 248) to print time or times, depending on whether that size is equal to one.
The messiest part of the program is the for loop that processes locs to print the line numbers on which the word was found. The only subtlety here is remembering to change the line numbers into more human-friendly counting. When we stored the text, we stored the first line as line number zero, which is consistent with how C++ containers and arrays are numbered. Most users think of the first line as line number 1, so we systematically add one to our stored line numbers to convert to this more common notation.
10.6.4 Writing the Member Functions
What remains is to write the definitions of the member functions that were not defined inside the class.
Storing the Input File
Our first task is to read the file that our user wishes to query. Using string and vector operations, this task is handled easily:

Because we want to store the file a line at a time, we use getline to read our input. We push each line we read onto the lines_of_text vector.
Building the Word map
Each element in the vector holds a line of text. To build the map from words to line numbers, we need to break each line into its individual words. We again use an istringstream in ways outlined in the program on page 300:

The for loop marches through lines_of_text a line at a time. We start by binding an istringstream object named line to the current line and use the istringstream input operator to read each word on the line. Remember that that operator, like the other istream operators, ignores whitespace. Thus, the while reads each whitespace-separated word from line into word.
The last part of this function is similar to our word-count programs. We use word to subscript the map. If word was not already present, then the subscript operator adds word to the word_map, giving it an inital value that is the empty set. Regardless of whether word was added, the return value from the subscript is a set. We then call insert to add the current line number. If the word occurs more than once in the same line, then the call to insert does nothing.
Supporting Queries
The run_query function handles the actual queries:

The run_query function takes a reference to a const string and uses that value to index the word_map. Assuming the string is found, it returns the set of line numbers associated with the string. Otherwise, it returns an empty set.
Using the Return from run_query
Once we’ve run the run_query function, we get back a set of line numbers on which the word we sought appears. In addition to printing how many times each word appears, we also want to print the line on which the word appeared. The text_line function lets us do so:

This function takes a line number and returns the input text line corresponding to that line number. Because the code using our TextQuery class cannot do so— lines_of_text is private—we first check that the line we are asked for is in range. If it is, we return the corresponding line. If it is not, we throw an out_of_range exception.
Chapter Summary
The elements in an associative container are ordered and accessed by key. The associative containers support efficient lookup and retrieval of elements by key. The use of a key distinguishes them from the sequential containers, in which elements are accessed positionally.
The map and multimap types store elements that are key–value pairs. These types use the library pair class, defined in the utility header, to represent these pairs. Dereferencing a map or multimap iterator yields a value that is a pair. The first member of the pair is a const key, and the second member is a value associated with that key. The set and multiset types store keys. The map and set types allow only one element with a given key. The multimap and multiset types allow multiple elements with the same key.
The associative containers share many operations with the sequential containers. However, the associative containers define some new operations and redefine the meaning or return types of some operations that are in common with the sequential containers. The differences in the operations reflect the use of keys in associative containers.
Elements in an associative container can be accessed by iterators. The library guarantees that iterators access elements in order by key. The begin operation yields the element with the lowest key. Incrementing that iterator yields elements in nondescending order.
Defined Terms
Array whose elements are indexed by key rather than positionally. We say that the array maps a key to its associated value.
A type that holds a collection of objects that supports efficient lookup by key.
Type defined by the associative containers that is the type for the keys used to store and retrieve values. For a map, key_type is the type used to index the map. For set, key_type and value_type are the same.
Associative container type that defines an associative array. Like vector, map is a class template. A map, however, is defined with two types: the type of the key and the type of the associated value. In a map a given key may appear only once. Each key is associated with a particular value. Dereferencing a map iterator yields a pair that holds a const key and its associated value.
Type defined by map and multimap that is the type for the values stored in the map.
Associative container similar to map except that in a multimap, a given key may appear more than once.
Associative container type that holds keys. In a multiset, a givenkey may appear more than once.
Type that holds two public data members named first and second. The pair type is a template type that takes two type parameters that are used as the types of these members.
Associative container that holds keys. In a set, a given key may appear only once.
Relationship among the keys used in an associative container. In a strict weak ordering, it is possible to compare any two values and determine which of the two is less than the other. If neither value is less than the other, then the two values are considered equal. See Section 10.3.1 (p. 360).
The type of the element stored in a container. For set and multiset, value_type and key_type are the same. For map and multimap, this type is a pair whose first member has type const key_type and whose second member has type mapped_type.
The dereference operator when applied to a map, set, multimap, or multiset iterator yields a value_type. Note, that for map and multimap the value_type is a pair.
Subscript operator. When applied to a map, [] takes an index that must be a key_type (or type that can be converted to key_type) value. Yields a mapped_type value.