
Chapter 3. Library Types
CONTENTS
Section 3.1 Namespace using Declarations 78
Section 3.2 Library string Type 80
Section 3.3 Library vector Type 90
Section 3.4 Introducing Iterators 95
Section 3.5 Library bitset Type 101
In addition to the primitive types covered in Chapter 2, C++ defines a rich library of abstract data types. Among the most important library types are string and vector, which define variable-sized character strings and collections, respectively. Associated with string and vector are companion types known as iterators, which are used to access the characters in a string or the elements in a vector. These library types are abstractions of more primitive types—arrays and pointers—that are part of the language.
Another library type, bitset, provides an abstract way to manipulate a collection of bits. This class provides a more convenient way of dealing with bits than is offered by the built-in bitwise operators on values of integral type.
This chapter introduces the library vector, string, and bitset types. The next chapter covers arrays and pointers, and Chapter 5 looks at built-in bitwise operators.
The types that we covered in Chapter 2 are all low-level types: They represent abstractions such as numbers or characters and are defined in terms of how they are represented on the machine.
In addition to the types defined in the language, the standard library defines a number of higher level abstract data types. These library types are higher-level in that they mirror more complex concepts. They are abstract because when we use them we don’t need to care about how the types are represented. We need to know only what operations they support.
Two of the most important library types are string and vector. The string type supports variable-length character strings. The vector type holds a sequence of objects of a specified type. These types are important because they offer improvements over more primitive types defined by the language. Chapter 4 looks at the language-level constructs that are similar to, but less flexible and more error-prone than, the library string and vector types.
Another library type that offers a more convenient and reasonably efficient abstraction of a language level facility is the bitset class. This class lets us treat a value as a collection of bits. It provides a more direct way of operating on bits than do the bitwise operators that we cover in Section 5.3 (p. 154).
Before continuing our exploration of the library types, we’ll look at a mechanism for simplifying access to the names defined in the library.
3.1 Namespace using Declarations
The programs we’ve seen so far have referred to names from the library by explicitly noting that the name comes from the std namespace. For example, when we want to read from the standard input, we write std::cin. Such names use the :: operator, which is the scope operator (Section 1.2.2, p. 8). This operator says that we should look for the name of the right-hand operand in the scope of the left-hand operand. Thus, std::cin says that we want the name cin that is defined in the namespace std. Referring to library names through this notation can be cumbersome.
Fortunately, there are easier ways to use namespace members. In this section we’ll cover the safest mechanism: using declarations. We will see other ways to simplify the use of names from a namespace in Section 17.2 (p. 712).
A using declaration allows us to access a name from a namespace without the prefix namespace_name::. A using declaration has the following form:
using namespace::name;
Once the using declaration has been made, we can access name directly without reference to its namespace:

Using the unqualified version of a namespace name without a using declaration is an error, although some compilers may fail to detect this error.
A Separate Using Declaration Is Required for Each Name
A using declaration introduces only one namespace member at a time. It allows us to be very specific regarding which names are used in our programs. If we want to use several names from std—or any other namespace—then we must issue a using declaration for each name that we intend to use. For example, we could rewrite the addition program from page 6 as follows:

The using declarations for cin, cout, and endl mean that we can use those names without the std:: prefix, making the code easier to read.
From this point on, our examples will assume that using declarations have been provided for the names we use from the standard library. Thus, we will refer to cin, not std::cin, in the text and in code examples. To keep the code examples short, we won’t show the using declarations that are needed to compile the examples. Similarly, our code examples will not show the necessary #include directives. Table A.1 (p. 810) in Appendix A lists the library names and corresponding headers for standard-library names we use in this primer.

Readers should be aware that they must add appropriate #include and using declarations to our examples before compiling them.
Class Definitions that Use Standard Library Types
There is one case in which we should always use the fully qualified library names: inside header files. The reason is that the contents of a header are copied into our program text by the preprocessor. When we #include a file, it is as if the exact text of the header is part of our file. If we place a using declaration within a header, it is equivalent to placing the same using declaration in every program that includes the header whether that program wants the using declaration or not.
3.2 Library string Type
The string type supports variable-length character strings. The library takes care of managing the memory associated with storing the characters and provides various useful operations. The library string type is intended to be efficient enough for general use.
As with any library type, programs that use strings must first include the associated header. Our programs will be shorter if we also provide an appropriate using declaration:
#include <string>
using std::string;
3.2.1 Defining and Initializing strings
The string library provides several constructors (Section 2.3.3, p. 49). A constructor is a special member function that defines how objects of that type can be initialized. Table 3.1 on the facing page lists the most commonly used string constructors. The default constructor (Section 2.3.4, p. 52) is used “by default” when no initializer is specified.
Table 3.1. Ways to Initialize a string

3.2.2 Reading and Writing strings
As we saw in Chapter 1, we use the iostream library to read and write values of built-in types such as int, double, and so on. Similarly, we can use the iostream and string libraries to allow us to read and write strings using the standard input and output operators:

This program begins by defining a string named s. The next line,
cin >> s; // read whitespace-separated string into s
reads the standard input storing what is read into s. The string input operator:
• Reads and discards any leading whitespace (e.g., spaces, newlines, tabs)
• It then reads characters until the next whitespace character is encountered
So, if the input to this program is “Hello World!”, (note leading and trailing spaces) then the output will be “Hello” with no extra spaces.
The input and output operations behave similarly to the operators on the builtin types. In particular, the operators return their left-hand operand as their result. Thus, we can chain together multiple reads or writes:
string s1, s2;
cin >> s1 >> s2; // read first input into s1, second into s2
cout << s1 << s2 << endl; // write both strings
If we give this version of the program the same input as in the previous paragraph, our output would be
HelloWorld!
To compile this program, you must add #include directives for both the iostream and string libraries and must issue using declarations for all the names used from the library: string, cin, cout, and endl.
The programs presented from this point on will assume that the needed #include and using declarations have been made.
Reading an Unknown Number of strings
Like the input operators that read built-in types, the string input operator returns the stream from which it read. Therefore, we can use a string input operation as a condition, just as we did when reading ints in the program on page 18. The following program reads a set of strings from the standard input and writes what it has read, one string per line, to the standard output:

In this case, we read into a string using the input operator. That operator returns the istream from which it read, and the while condition tests the stream after the read completes. If the stream is valid—it hasn’t hit end-of-file or encountered an invalid input—then the body of the while is executed and the value we read is printed to the standard output. Once we hit end-of-file, we fall out of the while.
Using getline to Read an Entire Line
There is an additional useful string IO operation: getline. This is a function that takes both an input stream and a string. The getline function reads the next line of input from the stream and stores what it read, not including the newline, in its string argument. Unlike the input operator, getline does not ignore leading newlines. Whenever getline encounters a newline, even if it is the first character in the input, it stops reading the input and returns. The effect of encountering a newline as the first character in the input is that the string argument is set to the empty string.
The getline function returns its istream argument so that, like the input operator, it can be used as a condition. For example, we could rewrite the previous program that wrote one word per line to write a line at a time instead:

Because line does not contain a newline, we must write our own if we want the strings written one to a line. As usual, we use endl to write a newline and flush the output buffer.
3.2.3 Operations on strings
Table 3.2 on the next page lists the most commonly used string operations.
Table 3.2. string Operations

The string size and empty Operations
The length of a string is the number of characters in the string. It is returned by the size operation:

If we compile and execute this program it yields
The size of The expense of spirit
is 22 characters, including the newline
Often it is useful to know whether a string is empty. One way we could do so would be to compare size with 0:
if (st.size() == 0)
// ok: empty
In this case, we don’t really need to know how many characters are in the string; we are only interested in whether the size is zero. We can more directly answer this question by using the empty member:
if (st.empty())
// ok: empty
The empty function returns the bool (Section 2.1, p. 34) value true if the string contains no characters; otherwise, it returns false.
string::size_type
It might be logical to expect that size returns an int, or, thinking back to the note on page 38, an unsigned. Instead, the size operation returns a value of type string::size_type. This type requires a bit of explanation.
The string class—and many other library types—defines several companion types. These companion types make it possible to use the library types in a machine-independent manner. The type size_type is one of these companion types. It is defined as a synonym for an unsigned type—either unsigned int or unsigned long—that is guaranteed to be big enough to hold the size of any string. To use the size_type defined by string, we use the scope operator to say that the name size_type is defined in the string class.

Any variable used to store the result from the string size operation ought to be of type string::size_type. It is particularly important not to assign the return from size to an int.
Although we don’t know the precise type of string::size_type, wedo know that it is an unsigned type (Section 2.1.1, p. 34). We also know that for a given type, the unsigned version can hold a positive value twice as large as the corresponding signed type can hold. This fact implies that the largest string could be twice as large as the size an int can hold.
Another problem with using an int is that on some machines the size of an int is too small to hold the size of even plausibly large strings. For example, if a machine has 16-bit ints, then the largest string an int could represent would have 32,767 characters. A string that held the contents of a file could easily exceed this size. The safest way to hold the size of a string is to use the type the library defines for this purpose, which is string::size_type.
The string Relational Operators
The string class defines several operators that compare two string values. Each of these operators works by comparing the characters from each string.

string comparisons are case-sensitive—the upper- and lowercase versions of a letter are different characters. On most computers, the uppercase letters come first: Every uppercase letter is less than any lowercase letter.
The equality operator compares two strings, returning true if they are equal. Two strings are equal if they are the same length and contain the same characters. The library also defines != to test whether two strings are unequal.
The relational operators <, <=, >, >= test whether one string is less than, less than or equal, greater than, or greater than or equal to another:
string big = "big", small = "small";
string s1 = big; // s1 is a copy of big
if (big == small) // false
// ...
if (big <= s1) // true, they're equal, so big is less than or equal to s1
// ...
The relational operators compare strings using the same strategy as in a (case-sensitive) dictionary:
• If two strings have different lengths and if every character in the shorter string is equal to the corresponding character of the longer string, then the shorter string is less than the longer one.
• If the characters in two strings differ, then we compare them by comparing the first character at which the strings differ.
As an example, given the strings
string substr = "Hello";
string phrase = "Hello World";
string slang = "Hiya";
then substr is less than phrase, and slang is greater than either substr or phrase.
Assignment for strings
In general the library types strive to make it as easy to use a library type as it is to use a built-in type. To this end, most of the library types support assignment. In the case of strings, we can assign one string object to another:
// st1 is an empty string, st2 is a copy of the literal
string st1, st2 = "The expense of spirit";
st1 = st2; // replace st1 by a copy of st2
After the assignment, st1 contains a copy of the characters in st2.
Most string library implementations go to some trouble to provide efficient implementations of operations such as assignment, but it is worth noting that conceptually, assignment requires a fair bit of work. It must delete the storage containing the characters associated with st1, allocate the storage needed to contain a copy of the characters associated with st2, and then copy those characters from st2 into this new storage.
Adding Two strings
Addition on strings is defined as concatenation. That is, it is possible to concatenate two or more strings through the use of either the plus operator (+) or the compound assignment operator (+=) (Section 1.4.1, p. 13). Given the two strings
string s1("hello, ");
string s2("world
");
we can concatenate the two strings to create a third string as follows:
string s3 = s1 + s2; // s3 is hello, world
If we wanted to append s2 to s1 directly, then we would use +=:
s1 += s2; // equivalent to s1 = s1 + s2
Adding Character String Literals and strings
The strings s1 and s2 included punctuation directly. We could achieve the same result by mixing string objects and string literals as follows:
string s1("hello");
string s2("world");
string s3 = s1 + ", " + s2 + "
";
When mixing strings and string literals, at least one operand to each + operator must be of string type:

The initializations of s3 and s4 involve only a single operation. In these cases, it is easy to determine that the initialization of s3 is legal: We initialize s3 by adding a string and a string literal. The initialization of s4 attempts to add two string literals and is illegal.
The initialization of s5 may appear surprising, but it works in much the same way as when we chain together input or output expressions (Section 1.2, p. 5). In this case, the string library defines addition to return a string. Thus, when we initialize s5, the subexpression s1 + ", " returns a string, which can be concatenated with the literal "world
". It is as if we had written
string tmp = s1 + ", "; // ok: + has a string operand
s5 = tmp + "world"; // ok: + has a string operand
On the other hand, the initialization of s6 is illegal. Looking at each subexpression in turn, we see that the first subexpression adds two string literals. There is no way to do so, and so the statement is in error.
Fetching a Character from a string
The string type uses the subscript ([ ]) operator to access the individual characters in the string. The subscript operator takes a size_type value that denotes the character position we wish to fetch. The value in the subscript is often called “the subscript” or “an index.”
Subscripts for strings start at zero; if s is a string, then if s isn’t empty, s[0] is the first character in the string, s[1] is the second if there is one, and the last character is in s[s.size() - 1].
It is an error to use an index outside this range.
We could use the subscript operator to print each character in a string on a separate line:
string str("some string");
for (string::size_type ix = 0; ix != str.size(); ++ix)
cout << str[ix] << endl;
On each trip through the loop we fetch the next character from str, printing it followed by a newline.
Subscripting Yields an Lvalue
Recall that a variable is an lvalue (Section 2.3.1, p. 45), and that the left-hand side of an assignment must be an lvalue. Like a variable, the value returned by the subscript operator is an lvalue. Hence, a subscript can be used on either side of an assignment. The following loop sets each character in str to an asterisk:
for (string::size_type ix = 0; ix != str.size(); ++ix)
str[ix] = '*';
Computing Subscript Values
Any expression that results in an integral value can be used as the index to the subscript operator. For example, assuming someval and someotherval are integral objects, we could write
str[someotherval * someval] = someval;
Although any integral type can be used as an index, the actual type of the index is string::size_type, which is an unsigned type.
The same reasons to use string::size_type as the type for a variable that holds the return from size apply when defining a variable to serve as an index. A variable used to index a string should have type string::size_type.
When we subscript a string, we are responsible for ensuring that the index is “in range.” By in range, we mean that the index is a number that, when assigned to a size_type, is a value in the range from 0 through the size of the string minus one. By using a string::size_type or another unsigned type as the index, we ensure that the subscript cannot be less than zero. As long as our index is an unsigned type, we need only check that it is less than the size of the string.
The library is not required to check the value of the index. Using an index that is out of range is undefined and usually results in a serious run-time error.
3.2.4 Dealing with the Characters of a string
Often we want to process the individual characters of a string. For example, we might want to know if a particular character is a whitespace character or whether the character is alphabetic or numeric. Table 3.3 on the facing page lists the functions that can be used on the characters in a string (or on any other char value). These functions are defined in the cctype header.
Table 3.3. cctype Functions

These functions mostly test the given character and return an int, which acts as a truth value. Each function returns zero if the test fails; otherwise, they return a (meaningless) nonzero value indicating that the character is of the requested kind.
For these functions, a printable character is a character with a visible representation; whitespace is one of space, tab, vertical tab, return, newline, and formfeed; and punctuation is a printable character that is not a digit, a letter, or (printable) whitespace character such as space.
As an example, we could use these functions to print the number of punctuation characters in a given string:

The output of this program is
3 punctuation characters in Hello World!!!
Rather than returning a truth value, the tolower and toupper functions return a character—either the argument unchanged or the lower- or uppercase version of the character. We could use tolower to change s to lowercase as follows:

which generates
hello world!!!
3.3 Library vector Type
A vector is a collection of objects of a single type, each of which has an associated integer index. As with strings, the library takes care of managing the memory associated with storing the elements. We speak of a vector as a container because it contains other objects. All of the objects in a container must have the same type. We’ll have much more to say about containers in Chapter 9.
To use a vector, we must include the appropriate header. In our examples, we also assume an appropriate using declaration is made:
#include <vector>
using std::vector;
A vector is a class template. Templates let us write a single class or function definition that can be used on a variety of types. Thus, we can define a vector that holds strings, or a vector to hold ints, or one to hold objects of our own class types, such as Sales_items. We’ll see how to define our own class templates in Chapter 16. Fortunately, we need to know very little about how templates are defined in order to use them.
To declare objects of a type generated from a class template, we must supply additional information. The nature of this information depends on the template. In the case of vector, we must say what type of objects the vector will contain. We specify the type by putting it between a pair of angle brackets following the template’s name:
![]()
As in any variable definition, we specify a type and a list of one or more variables. In the first of these definitions, the type is vector<int>, which is a vector that holds objects of type int. The name of the variable is ivec. In the second, we define Sales_vec to hold Sales_item objects.
vector is not a type; it is a template that we can use to define any number of types. Each of vector type specifies an element type. Hence, vector<int> and vector<string> are types.
3.3.1 Defining and Initializing vectors
The vector class defines several constructors (Section 2.3.3, p. 49), which we use to define and initialize vector objects. The constructors are listed in Table 3.4.
Table 3.4. Ways to Initialize a vector

Creating a Specified Number of Elements
When we create a vector that is not empty, we must supply value(s) to use to initialize the elements. When we copy one vector to another, each element in the new vector is initialized as a copy of the corresponding element in the original vector. The two vectors must hold the same element type:
![]()
We can initialize a vector from a count and an element value. The constructor uses the count to determine how many elements the vector should have and uses the value to specify the value each of those elements will have:
![]()
Key Concept: vectorS Grow Dynamically
A central property of vectors (and the other library containers) is that they are required to be implemented so that it is efficient to add elements to them at run time. Because vectors grow efficiently, it is usually best to let the vector grow by adding elements to it dynamically as the element values are known.
As we’ll see in Chapter 4, this behavior is distinctly different from that of built-in arrays in C and for that matter in most other languages. In particular, readers accustomed to using C or Java might expect that because vector elements are stored contiguously, it would be best to preallocate the vector at its expected size. In fact, the contrary is the case, for reasons we’ll explore in Chapter 9.
Although we can preallocate a given number of elements in a vector, it is usually more efficient to define an empty vector and add elements to it (as we’ll learn how to do shortly).
Value Initialization
When we do not specify an element initializer, then the library creates a value initialized element initializer for us. This library-generated value is used to initialize each element in the container. The value of the element initializer depends on the type of the elements stored in the vector.
If the vector holds elements of a built-in type, such as int, then the library creates an element initializer with a value of 0:
vector<int> ivec(10); // 10 elements, each initialized to 0
If the vector holds elements of a class type, such as string, that defines its own constructors, then the library uses the value type’s default constructor to create the element initializer:
vector<string> svec(10); // 10 elements, each an empty string
As we’ll see in Chapter 12, some classes that define their own constructors do not define a default constructor. We cannot initialize a vector of such a type by specifying only a size; we must also specify an initial element value.
There is a third possibility: The element type might be of a class type that does not define any constructors. In this case, the library still creates a value-initialized object. It does so by value-initializing each member of that object.
3.3.2 Operations on vectors
The vector library provides various operations, many of which are similar to operations on strings. Table 3.5 lists the most important vector operations.
Table 3.5. vector Operations

The size of a vector
The empty and size operations are similar to the corresponding string operations (Section 3.2.3, p. 83). The size member returns a value of the size_type defined by the corresponding vector type.
To use size_type, we must name the type in which it is defined. A vector type always includes the element type of the vector:
![]()
Adding Elements to a vector
The push_back operation takes an element value and adds that value as a new element at the back of a vector. In effect it “pushes” an element onto the “back” of the vector:

This loop reads a sequence of strings from the standard input, appending them one at a time onto the back of the vector. We start by defining text as an initially empty vector. Each trip through the loop adds a new element to the vector and gives that element the value of whatever word was read from the input. When the loop completes, text will have as many elements as were read.
Subscripting a vector
Objects in the vector are not named. Instead, they can be accessed by their position in the vector. We can fetch an element using the subscript operator. Subscripting a vector is similar to subscripting a string (Section 3.2.3, p. 87).
The vector subscript operator takes a value and returns the element at that position in the vector. Elements in a vector are numbered beginning with 0. The following example uses a for loop to reset each element in the vector to 0:
// reset the elements in the vector to zero
for (vector<int>::size_type ix = 0; ix != ivec.size(); ++ix)
ivec[ix] = 0;
Like the string subscript operator, the vector subscript yields an lvalue so that we may write to it, which we do in the body of the loop. Also, as we do for strings, we use the size_type of the vector as the type for the subscript.
Even if ivec is empty, this for loop executes correctly. If ivec is empty, the call to size returns 0 and the test in the for compares ix to 0. Because ix is itself 0 on the first trip, the test would fail and the loop body would not be executed even once.
Subscripting Does Not Add Elements
Programmers new to C++ sometimes think that subscripting a vector adds elements; it does not:
vector<int> ivec; // empty vector
for (vector<int>::size_type ix = 0; ix != 10; ++ix)
ivec[ix] = ix; // disaster: ivec has no elements
This code intended to insert new 10 elements into ivec, giving the elements the values from 0 through 9. However, ivec is an empty vector and subscripts can only be used to fetch existing elements.
The right way to write this loop would be
for (vector<int>::size_type ix = 0; ix != 10; ++ix)
ivec.push_back(ix); // ok: adds new element with value ix
An element must exist in order to subscript it; elements are not added when we assign through a subscript.
3.4 Introducing Iterators
While we can use subscripts to access the elements in a vector, the library also gives us another way to examine elements: We can use an iterator. An iterator is a type that lets us examine the elements in a container and navigate from one element to another.
The library defines an iterator type for each of the standard containers, including vector. Iterators are more general than subscripts: All of the library containers define iterator types, but only a few of them support subscripting. Because iterators are common to all containers, modern C++ programs tend to use iterators rather than subscripts to access container elements, even on types such as vector that support subscripting.
Caution: Only Subscript Elements that Are Known to Exist!
It is crucially important to understand that we may use the subscript operator, (the [] operator), to fetch only elements that actually exist. For example,
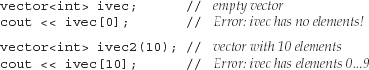
Attempting to fetch an element that doesn’t exist is a run-time error. As with most such errors, there is no assurance that the implementation will detect it. The result of executing the program is uncertain. The effect of fetching a nonexisting element is undefined—what happens will vary by implementation, but the program will almost surely fail in some interesting way at run time.
This caution applies any time we use a subscript, such as when subscripting a string and, as we’ll see shortly, when subscripting a built-in array.
Attempting to subscript elements that do not exist is, unfortunately, an extremely common and pernicious programming error. So-called “buffer overflow” errors are the result of subscripting elements that don’t exist. Such bugs are the most common cause of security problems in PC and other applications.
The details of how iterators work are discussed in Chapter 11, but we can use them without understanding them in their full complexity.
Container iterator Type
Each of the container types, such as vector, defines its own iterator type:
vector<int>::iterator iter;
This statement defines a variable named iter, whose type is the type named iterator defined by vector<int>. Each of the library container types defines a member named iterator that is a synonym for the actual type of its iterator.
The begin and end Operations
Each container defines a pair of functions named begin and end that return iterators. The iterator returned by begin refers to the first element, if any, in the container:
vector<int>::iterator iter = ivec.begin();
This statement initializes iter to the value returned by the vector operation named begin. Assuming the vector is not empty, after this initialization, iter refers to the same element as ivec[0].
The iterator returned by the end operation is an iterator positioned “one past the end” of the vector. It is often referred to as the off-the-end iterator indicating that it refers to a nonexistent element “off the end” of the vector. If the vector is empty, the iterator returned by begin is the same as the iterator returned by end.
The iterator returned by the end operation does not denote an actual element in the vector. Instead, it is used as a sentinel indicating when we have processed all the elements in the vector.
Dereference and Increment on vector Iterators
The operations on iterator types let us retrieve the element to which an iterator refers and let us move an iterator from one element to another.
Iterator types use the dereference operator (the * operator) to access the element to which the iterator refers:
*iter = 0;
The dereference operator returns the element that the iterator currently denotes. Assuming iter refers to the first element of the vector, then *iter is the same element as ivec[0]. The effect of this statement is to assign 0 to that element.
Iterators use the increment operator (++) (Section 1.4.1, p. 13) to advance an iterator to the next element in the container. Incrementing an iterator is a logically similar operation to the increment operator when applied to int objects. In the case of ints, the effect is to “add one” to the int’s value. In the case of iterators, the effect is to “advance the iterator by one position” in the container. So, if iter refers to the first element, then ++iter denotes the second element.
Because the iterator returned from end does not denote an element, it may not be incremented or dereferenced.
Other Iterator Operations
Another pair of useful operations that we can perform on iterators is comparison: Two iterators can be compared using either == or !=. Iterators are equal if they refer to the same element; they are unequal otherwise.
A Program that Uses Iterators
Assume we had a vector<int> named ivec and we wanted to reset each of its elements to zero. We might do so by using a subscript:
![]()
This program uses a for loop to iterate through the elements in ivec. The for defines an index, which it increments on each iteration. The body of the for sets each element in ivec to zero.
A more typical way to write this loop would use iterators:

The for loop starts by defining iter and initializing it to refer to the first element in ivec. The condition in the for tests whether iter is unequal to the iterator returned by the end operation. Each iteration increments iter. The effect of this for is to start with the first element in ivec and process in sequence each element in the vector. Eventually, iter will refer to the last element in ivec. After we process the last element and increment iter, it will become equal to the value returned by end. At that point, the loop stops.
The statement in the for body uses the dereference operator to access the value of the current element. As with the subscript operator, the value returned by the dereference operator is an lvalue. We can assign to this element to change its value. The effect of this loop is to assign the value zero to each element in ivec.
Having walked through the code in detail, we can see that this program has exactly the same effect as the version that used subscripts: We start at the first element in the vector and set each element in the vector to zero.
This program, like the one on page 94, is safe if the vector is empty. If ivec is empty, then the iterator returned from begin does not denote any element; it can’t, because there are no elements. In this case, the iterator returned from begin is the same as the one returned from end, so the test in the for fails immediately.
const_iterator
The previous program used a vector::iterator to change the values in the vector. Each container type also defines a type named const_iterator, which should be used when reading, but not writing to, the container elements.
When we dereference a plain iterator, we get a nonconst reference (Section 2.5, p. 59) to the element. When we dereference a const_iterator, the value returned is a reference to a const (Section 2.4, p. 56) object. Just as with any const variable, we may not write to the value of this element.
For example, if text is a vector<string>, we might want to traverse it, printing each element. We could do so as follows:

This loop is similar to the previous one, except that we are reading the value from the iterator, not assigning to it. Because we read, but do not write, through the iterator, we define iter to be a const_iterator. When we dereference a const_iterator, the value returned is const. We may not assign to an element using a const_iterator:
![]()
When we use the const_iterator type, we get an iterator whose own value can be changed but that cannot be used to change the underlying element value. We can increment the iterator and use the dereference operator to read a value but not to assign to that value.
A const_iterator should not be confused with an iterator that is const. When we declare an iterator as const we must initialize the iterator. Once it is initialized, we may not change its value:

A const_iterator may be used with either a const or nonconst vector, because it cannot write an element. An iterator that is const is largely useless: Once it is initialized, we can use it to write the element it refers to, but cannot make it refer to any other element.

// an iterator that cannot write elements
vector<int>::const_iterator
// an iterator whose value cannot change
const vector<int>::iterator
3.4.1 Iterator Arithmetic
In addition to the increment operator, which moves an iterator one element at a time, vector iterators (but few of the other library container iterators) also support other arithmetic operations. These operations are referred to as iterator arithmetic, and include:
iter - n
We can add or subtract an integral value to an iterator. Doing so yields a new iterator positioned n elements ahead of (addition) or behind (subtraction) the element to which iter refers. The result of the addition or subtraction must refer to an element in the vector to which iter refers or to one past the end of that vector. The type of the value added or subtracted ought ordinarily to be the vector’s size_type or difference_type (see below).
• iter1 - iter2
Computes the difference between two iterators as a value of a signed integral type named difference_type, which, like size_type, is defined by vector. The type is signed because subtraction might have a negative result. This type is guaranteed to be large enough to hold the distance between any two iterators. Both iter1 and iter2 must refer to elements in the same vector or the element one past the end of that vector.
We can use iterator arithmetic to move an iterator to an element directly. For example, we could locate the middle of a vector as follows:
vector<int>::iterator mid = vi.begin() + vi.size() / 2;
This code initializes mid to refer to the element nearest to the middle of ivec. It is more efficient to calculate this iterator directly than to write an equivalent program that increments the iterator one by one until it reaches the middle element.
Any operation that changes the size of a vector makes existing iterators invalid. For example, after calling push_back, you should not rely on the value of an iterator into the vector.
3.5 Library bitset Type
Some programs deal with ordered collections of bits. Each bit can contain either a 0 (off) or a 1 (on) value. Using bits is a compact way to keep yes/no information (sometimes called flags) about a set of items or conditions. The standard library makes it easy to deal with bits through the bitset class. To use a bitset we must include its associated header file. In our examples, we also assume an appropriate using declaration for std::bitset is made:
#include <bitset>
using std::bitset;
3.5.1 Defining and Initializing bitsets
Table 3.6 lists the constructors for bitset. Like vector, the bitset class is a class template. Unlike vector, objects of type bitset differ by size rather than by type. When we define a bitset, we say how many bits the bitset will contain, which we do by specifying the size between a pair of angle brackets.
Table 3.6. Ways to Initialize a bitset

bitset<32> bitvec; // 32 bits, all zero
The size must be a constant expression (Section 2.7, p. 62). It might be defined, as we did here, using an integral literal constant or using a const object of integral type that is initialized from a constant.
This statement defines bitvec as a bitset that holds 32 bits. Just as with the elements of a vector, the bits in a bitset are not named. Instead, we refer to them positionally. The bits are numbered starting at 0. Thus, bitvec has bits numbered 0 through 31. The bits starting at 0 are referred to as the low-order bits, and those ending at 31 are referred to as high-order bits.
Initializing a bitset from an unsigned Value
When we use an unsigned long value as an initializer for a bitset, that value is treated as a bit pattern. The bits in the bitset are a copy of that pattern. If the size of the bitset is greater than the number of bits in an unsigned long, then the remaining high-order bits are set to zero. If the size of the bitset is less than that number of bits, then only the low-order bits from the unsigned value are used; the high-order bits beyond the size of the bitset object are discarded.
On a machine with 32-bit unsigned longs, the hexadecimal value 0xffff is represented in bits as a sequence of 16 ones followed by 16 zeroes. (Each 0xf digit is represented as 1111.) We can initialize a bitset from 0xffff:

In all three cases, the bits 0 to 15 are set to one. For bitvec1, the high-order bits in the initializer are discarded; bitvec1 has fewer bits than an unsigned long. bitvec2 is the same size as an unsigned long, so all the bits are used to initialize that object. bitvec3 is larger than an unsigned long, so its high-order bits above 31 are initialized to zero.
Initializing a bitset from a string
When we initialize a bitset from a string, the string represents the bit pattern directly. The bits are read from the string from right to left:
string strval("1100");
bitset<32> bitvec4(strval);
The bit pattern in bitvec4 has bit positions 2 and 3 set to 1, while the remaining bit positions are 0. If the string contains fewer characters than the size of the bitset, the high-order bits are set to zero.
The numbering conventions of strings and bitsets are inversely related: The rightmost character in the string—the one with the highest subscript—is used to initialize the low-order bit in the bitset—the bit with subscript 0. When initializing a bitset from a string, it is essential to remember this difference.
We need not use the entire string as the initial value for the bitset. Instead, we can use a substring as the initializer:
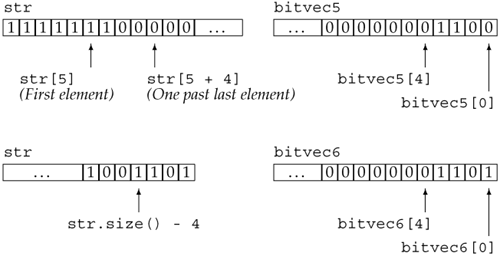
string str("1111111000000011001101");
bitset<32> bitvec5(str, 5, 4); // 4 bits starting at str[5], 1100
bitset<32> bitvec6(str, str.size() - 4); // use last 4 characters
Here bitvec5 is initialized by a substring of str starting at str[5] and continuing for four positions. As usual, we start at the rightmost end of this substring when initializing the bitset, meaning that bitvec5 is initialized with bit positions 0 through 3 set to 1100 while its remaining bit positions are set to 0. Leaving off the third parameter says to use characters from the starting position to the end of the string. In this case, the characters starting four from the end of str are used to initialize the lower four bits of bitvec6. The remainder of the bits in bitvec6 are initialized to zero. We can view these initializations as
3.5.2 Operations on bitsets
The bitset operations (Table 3.7) define various operations to test or set one or more bits in the bitset.
Table 3.7. bitset Operations

Testing the Entire bitset
The any operation returns true if one or more bits of the bitset object are turned on—that is, are equal to 1. Conversely, the operation none returns true if all the bits of the object are set to zero.
![]()
If we need to know how many bits are set, we can use the count operation, which returns the number of bits that are set:
size_t bits_set = bitvec.count(); // returns number of bits that are on
The return type of the count operation is a library type named size_t. The size_t type is defined in the cstddef header, which is the C++ version of the stddef.h header from the C library. It is a machine-specific unsigned type that is guaranteed to be large enough to hold the size of an object in memory.
The size operation, like the one in vector and string, returns the total number of bits in the bitset. The value returned has type size_t:
size_t sz = bitvec.size(); // returns 32
Accessing the Bits in a bitset
The subscript operator lets us read or write the bit at the indexed position. As such, we can use it to test the value of a given bit or to set that value:
![]()
This loop turns on the even-numbered bits of bitvec.
As with the subscript operator, we can use the set, test, and reset operations to test or set a given bit value:
![]()
To test whether a bit is on, we can use the test operation or test the value returned from the subscript operator:

The result of testing the value returned from a subscript is true if the bit is 1 or false if the bit is 0.
Setting the Entire bitset
The set and reset operations can also be used to turn on or turn off the entire bitset object, respectively:
![]()
The flip operation reverses the value of an individual bit or the entire bitset:
![]()
Retrieving the Value of a bitset
The to_ulong operation returns an unsigned long that holds the same bit pattern as the bitset object. We can use this operation only if the size of the bitset is less than or equal to the size of an unsigned long:
unsigned long ulong = bitvec3.to_ulong();
cout << "ulong = " << ulong << endl;
The to_ulong operation is intended to be used when we need to pass a bitset to a C or pre-Standard C++ program. If the bitset contains more bits than the size of an unsigned long, a run-time exception is signaled. We’ll introduce exceptions in Section 6.13 (p. 215) and look at them in more detail in Section 17.1 (p. 688).
Printing the Bits
We can use the output operator to print the bit pattern in a bitset object:
bitset<32> bitvec2(0xffff); // bits 0 ... 15 are set to 1; 16 ... 31 are 0
cout << "bitvec2: " << bitvec2 << endl;
will print
bitvec2: 00000000000000001111111111111111
Using the Bitwise Operators
The bitset class also supports the built-in bitwise operators. As defined by the language, these operators apply to integral operands. They perform operations similar to the bitset operations described in this section. Section 5.3 (p. 154) describes these operators.
Chapter Summary
The library defines several higher-level abstract data types, including strings and vectors. The string class provides variable-length character strings, and the vector type manages a collection of objects of a single type.
Iterators allow indirect access to objects stored in a container. Iterators are used to access and navigate between the elements in strings and vectors.
In the next chapter we’ll cover arrays and pointers, which are types built into the language. These types provide low-level analogs to the vector and string libraries. In general, the library classes should be used in preference to low-level array and pointer alternatives built into the language.
Defined Terms
A type whose representation is hidden. To use an abstract type, we need know only what operations the type supports.
Standard library class that holds a collection of bits and provides operations to test and set the bits in the collection.
Header inherited from C that contains routines to test character values. See page 88 for a listing of the most common routines.
A blueprint from which many potential class types can be created. To use a class template, we must specify what actual type(s) or value(s) to use. For example, a vector is a template that holds objects of a given type. When we create a vector, we must say what type this vector will hold. vector<int> holds ints, vector<string> holds strings, and so on.
A type whose objects hold a collection of objects of a given type.
A signed integral type defined by vector that is capable of holding the distance between any two iterators.
Function defined by the string and vector types. empty returns a bool indicating whether the string has any characters or whether the vector has any elements. Returns true if size is zero; false otherwise.
Function defined in the string header that takes an istream and a string. The function reads the stream up to the next newline, storing what it read into the string, and returns the istream. The newline is read and discarded.
Bits in a bitset with the largest indices.
Value used in the subscript operator to denote the element to retrieve from a string or vector.
A type that can be used to examine the elements of a container and to navigate between them.
The arithmetic operations that can be applied to some, but not all, iterator types. An integral type can be added to or subtracted from an iterator, resulting in an iterator positioned that many elements ahead of or behind the original iterator. Two iterators can be subtracted, yielding the distance between the iterators. Iterator arithmetic is valid only on iterators that refer to elements in the same container or the off-the-end iterator of the container.
Bits in a bitset with the lowest indices.
The iterator returned by end. It is an iterator that refers to a nonexistent element one past the end of a container.
Function defined by vector that appends elements to the back of a vector.
Programming technique that uses a value as a guard to control processing. In this chapter, we showed the use of the iterator returned by end as a guard to stop processing elements in a vector once we had processed every element in the vector.
Function defined by the library types string, vector, and bitset that returns the number of characters, elements, or bits respectively. The string and vector functions return a value of the size_type for the type. For example, size of a string returns a string::size_type. The bitset operation returns a value of type size_t.
Machine-dependent unsigned integral type defined in cstddef header that is large enough to hold the size of the largest possible array.
Type defined by the string and vector classes that is capable of containing the size of any string or vector, respectively. Library classes that define size_type define it as an unsigned type.
Make a name from a namespace accessible directly.
using namespace::name;
makes name accessible without the namespace:: prefix.
Initialization that happens for container elements when the container size is specified but there is no explicit element initializer. The elements are initialized as a copy of a compiler-generated value. If the container holds built-in types, then the value copied into the elements is zero. For class types, the value is generated by running the class’s default constructor. Container elements that are of class type can be value-initialized only if the class has a default constructor.
The iterator types define the increment operator to “add one” by moving the iterator to refer to the next element.
The scope operator. It finds the name of its right-hand operand in the scope of its left-hand operand. Used to access names in a namespace, such as std::cout, which represents the name cout from the namespace std. Similarly, used to obtain names from a class, such as string::size_type, which is the size_type defined by the string class.
An overloaded operator defined by the string, vector, and bitset types. It takes two operands: The left-hand operand is the name of the object and the right-hand operand is an index. It fetches the element whose position matches the index. Indices count from zero—the first element is element 0 and the last is element indexed by obj.size() - 1. Subscript returns an lvalue, so we may use a subscript as the left-hand operand of an assignment. Assigning to the result of a subscript assigns a new value to the indexed element.
The iterator types define the dereference operator to return the object to which the iterator refers. Dereference returns an lvalue, so we may use a dereference operator as the left-hand operand of an assignment. Assigning to the result of a dereference assigns a new value to the indexed element.
The string and bitset library types define an output operator. The string operator prints the characters in a string. The bitset operator prints the bit pattern in the bitset.
The string and bitset library types define an input operator. The string operator reads whitespace delimited chunks of characters, storing what is read into the right-hand (string) operand. The bitset operator reads a bit sequence into its bitset operand.