
Chapter 9. Sequential Containers
CONTENTS
Section 9.1 Defining a Sequential Container 307
Section 9.2 Iterators and Iterator Ranges 311
Section 9.3 Sequence Container Operations 316
Section 9.4 How a vector Grows 330
Section 9.5 Deciding Which Container to Use 333
Section 9.6 strings Revisited 335
Section 9.7 Container Adaptors 348
This chapter completes our discussion of the standard-library sequential container types. It expands on the material from Chapter 3, which introduced the most commonly used sequential container, the vector type. Elements in a sequential container are stored and accessed by position. The library also defines several associative containers, which hold elements whose order depends on a key. Associative containers are covered in the next chapter.
The container classes share a common interface. This fact makes the library easier to learn; what we learn about one type applies to another. Each container type offers a different set of time and functionality tradeoffs. Often a program using one type can be fine-tuned by substituting another container without changing our code beyond the need to change type declarations.
A container holds a collection of objects of a specified type. We’ve used one kind of container already: the library vector type. It is a sequential container. It holds a collection of elements of a single type, making it a container. Those elements are stored and accessed by position, making it a sequential container. The order of elements in a sequential container is independent of the value of the elements. Instead, the order is determined by the order in which elements are added to the container.
The library defines three kinds of sequential containers: vector, list, and deque (short for “double-ended queue” and pronounced “deck”). These types differ in how elements are accessed and the relative run-time cost of adding or removing elements. The library also provides three container adaptors. Effectively, an adaptor adapts an underlying container type by defining a new interface in terms of the operations provided by the original type. The sequential container adaptors are stack, queue, and priority_queue.
Containers define only a small number of operations. Many additional operations are provided by the algorithms library, which we’ll cover in Chapter 11. For those operations that are defined by the containers, the library imposes a common interface. The containers vary as to which operations they provide, but if two containers provide the same operation, then the interface (name and number of arguments) will be the same for both container types. The set of operations on the container types form a kind of hierarchy:
• Some operations are supported by all container types.
• Other operations are common to only the sequential or only the associative containers.
• Still others are common to only a subset of either the sequential or associative containers.
In the remainder of this chapter, we look at the sequential container types and their operations in detail.
Table 9.1. Sequential Container Types

9.1 Defining a Sequential Container
We already know a fair bit about how to use the sequential containers based on what we covered in Section 3.3 (p. 90). To define a container object, we must include its associated header file, which is one of
#include <vector>
#include <list>
#include <deque>
Each of the containers is a class template (Section 3.3, p. 90). To define a particular kind of container, we name the container followed by angle brackets that enclose the type of the elements the container will hold:
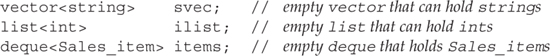
Each container defines a default constructor that creates an empty container of the specified type. Recall that a default constructor takes no arguments.

For reasons that shall become clear shortly, the most commonly used container constructor is the default constructor. In most programs, using the default constructor gives the best run-time performance and makes using the container easier.
9.1.1 Initializing Container Elements
In addition to defining a default constructor, each container type also supports constructors that allow us to specify initial element values.
Table 9.2. Container Constructors

Intializing a Container as a Copy of Another Container
When we initialize a sequential container using any constructor other than the default constructor, we must indicate how many elements the container will have. We must also supply initial values for those elements. One way to specify both the size and element values is to initialize a new container as a copy of an existing container of the same type:
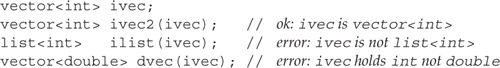
When we copy one container into another, the types must match exactly: The container type and element type must be the same.
Initializing as a Copy of a Range of Elements
Although we cannot copy the elements from one kind of container to another directly, we can do so indirectly by passing a pair of iterators (Section 3.4, p. 95). When we use iterators, there is no requirement that the container types be identical. The element types in the containers can differ as long as they are compatible. It must be possible to convert the element we copy into the type held by the container we are constructing.
The iterators denote a range of elements that we want to copy. These elements are used to initialize the elements of the new container. The iterators mark the first and one past the last element to be copied. We can use this form of initialization to copy a container that we could not copy directly. More importantly, we can use it to copy only a subsequence of the other container:

Recall that pointers are iterators, so it should not be surprising that we can initialize a container from a pair of pointers into a built-in array:

Here we use sizeof (Section 5.8, p. 167) to calculate the size of the array. We add that size to a pointer to the first element to get a pointer to a location one past the end of the array. The initializers for words2 are a pointer to the first element in words and a second pointer one past the last element in that array. The second pointer serves as a stopping condition; the location it addresses is not included in the elements to be copied.
Allocating and Initializing a Specified Number of Elements
When creating a sequential container, we may specify an explicit size and an (optional) initializer to use for the elements. The size can be either a constant or non-constant expression. The element initializer must be a valid value that can be used to initialize an object of the element type:
const list<int>::size_type list_size = 64;
list<string> slist(list_size, "eh?"); // 64 strings, each is eh?
This code initializes slist to have 64 elements, each with the value eh?.
As an alternative to specifying the number of elements and an element initializer, we can also specify only the size:

When we do not supply an element initializer, the library generates a value-initialized (Section 3.3.1, p. 92) one for us. To use this form of initialization, the element type must either be a built-in or compound type or be a class type that has a default constructor. If the element type does not have a default constructor, then an explicit element initializer must be specified.
The constructors that take a size are valid only for sequential containers; they are not supported for the associative containers,
9.1.2 Constraints on Types that a Container Can Hold
While most types can be used as the element type of a container, there are two constraints that element types must meet:
• The element type must support assignment.
• We must be able to copy objects of the element type.
There are additional constraints on the types used as the key in an associative container, which we’ll cover in Chapter 10.
Most types meet these minimal element type requirements. All of the built-in or compound types, with the exception of references, can be used as the element type. References do not support assignment in its ordinary meaning, so we cannot have containers of references.
Exercises Section 9.1.1
Exercise 9.1: Explain the following initializations. Indicate if any are in error, and if so, why.

Exercise 9.2: Show an example of each of the four ways to create and initialize a vector. Explain what values each vector contains.
Exercise 9.3: Explain the differences between the constructor that takes a container to copy and the constructor that takes two iterators.
With the exception of the IO library types (and the auto_ptr type, which we cover in Section 17.1.9 (p. 702)), all the library types are valid container element types. In particular, containers themselves satisfy these requirements. We can define containers with elements that are themselves containers. Our Sales_item type also satisifes these requirements.
The IO library types do not support copy or assignment. Therefore, we cannot have a container that holds objects of the IO types.
Container Operations May Impose Additional Requirements
The requirement to support copy and assignment is the minimal requirement on element types. In addition, some container operations impose additional requirements on the element type. If the element type doesn’t support the additional requirement, then we cannot perform that operation: We can define a container of that type but may not use that particular operation.
One example of an operation that imposes a type constraint is the constructors that take a single initializer that specifies the size of the container. If our container holds objects of a class type, then we can use this constructor only if the element type has a default constructor. Most types do have a default constructor, although there are some classes that do not. As an example, assume that Foo is a class that does not define a default constructor but that does have a constructor that takes an int argument. Now, consider the following declarations:
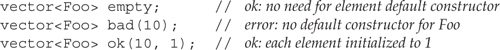
We can define an empty container to hold Foo objects, but we can define one of a given size only if we also specify an initializer for each element.
As we describe the container operations, we’ll note the constraints, if any, that each container operation places on the element type.
Containers of Containers
Because the containers meet the constraints on element types, we can define a container whose element type is itself a container type. For example, we might define lines as a vector whose elements are a vector of strings:
![]()
Note the spacing used when specifying a container element type as a container:
![]()
We must separate the two closing > symbols with a space to indicate that these two characters represent two symbols. Without the space, >> is treated as a single symbol, the right shift operator, and results in a compile-time error.
9.2 Iterators and Iterator Ranges
The constructors that take a pair of iterators are an example of a common form used extensively throughout the library. Before we look further at the container operations, we should understand a bit more about iterators and iterator ranges.
In Section 3.4 (p. 95), we first encountered vector iterators. Each of the library container types has several companion iterator types. Like the containers, these iterators have a common interface: If an iterator provides an operation, then the operation is supported in the same way for each iterator that supplies that operation. For example, all the iterators on the standard container types let us read an element from a container, and they all do so by providing the dereference operator. Similarly, the iterators for the library containers all provide increment and decrement operators to allow us to go from one element to the next. Table 9.3 lists the operations supported by the standard library container iterators.
Table 9.3. Standard Container Iterator Operations

Iterators on vector and deque Support Additional Operations
There are two important sets of operations that only vector and deque support: iterator arithmetic (Section 3.4.1, p. 100) and the use of the relational operators (in addition to == and !=) to compare two iterators. These operations are summarized in Table 9.4 on the facing page.
Table 9.4. Operations Supported by vector and deque Iterators

The reason that only vector and deque support the relational operators is that only vector and deque offer fast, random access to their elements. These containers are guaranteed to let us efficiently jump directly to an element given its position in the container. Because these containers support random access by position, it is possible for their iterators to efficiently implement the arithmetic and relational operations.
For example, we could calculate the midpoint of a vector as follows:
vector<int>::iterator iter = vec.begin() + vec.size()/2;
On the other hand, this code

is an error. The list iterator does not support the arithmetic operations—addition or subtraction—nor does it support the relational (<=, <, >=, >) operators. It does support pre- and postfix increment and decrement and the equality (inequality) operators.
In Chapter 11 we’ll see that the operations an iterator supports are fundamental to using the library algorithms.
Exercises Section 9.2
Exercise 9.7: What is wrong with the following program? How might you correct it?

Exercise 9.8: Assuming vec_iter is bound to an element in a vector that holds strings, what does this statement do?
if (vec_iter->empty()) /* . . . */
Exercise 9.9: Write a loop to write the elements of a list in reverse order.
Exercise 9.10: Which, if any, of the following iterator uses are in error?

9.2.1 Iterator Ranges
An iterator range is denoted by a pair of iterators that refer to two elements, or to one past the last element, in the same container. These two iterators, often referred to as first and last, or beg and end, mark a range of elements from the container.
Although the names last and end are common, they are a bit misleading. The second iterator never refers to the last element of the range. Instead, it refers to a point one past the last element. The elements in the range include the element referred to by first and every element from first through the element just before last. If the iterators are equal, then the range is empty.
This element range is called a left-inclusive interval. The standard notation for such a range is
// to be read as: includes first and each element up to but not including last
[ first, last )
indicating that the range begins with first and ends with, but does not include, last. The iterator in last may be equal to the first or may refer to an element that appears after the one referred to by first. The last iterator must not refer to an element ahead of the one referred to by first.
Requirements on Iterators Forming an Iterator Range
Two iterators, first and last, form an iterator range, if
• They refer to elements of, or one-past-the-end of, the same container.
• If the iterators are not equal, then it must be possible to reach last by repeatedly incrementing first. In other words, last must not precede first in the container.
Programming Implications of Using Left-Inclusive Ranges
The library uses left-inclusive ranges because such ranges have two convenient properties. Assuming first and last denote a valid iterator range, then
- When
firstequalslast, the range is empty. - When
firstis not equal tolast, there is at least one element in the range, andfirstrefers to the first element in that range. Moreover, we can advancefirstby incrementing it some number of times untilfirst == last.
These properties mean that we can safely write loops such as the following to process a range of elements by testing the iterators:

Assuming first and last form a valid iterator range, then we know that either first == last, in which case the loop is exited, or the range is non-empty and first refers to an element. Because the condition in the while handles the case where the range is empty, there is no need for a special case to handle an empty range. When the range is non-empty, the loop will execute at least once. Because the loop body increments first, we know the loop will eventually terminate. Moreover, if we are in the loop, then we know that *first is safe: It must refer to an element in the non-empty range between first and last.
9.2.2 Some Container Operations Invalidate Iterators
In the sections that follow, we’ll see that some container operations change the internal state of a container or cause the elements in the container to be moved. Such operations invalidate all iterators that refer to the elements that are moved and may invalidate other iterators as well. Using an invalidated iterator is undefined, and likely to lead to the same kinds of problems as using a dangling pointer.
For example, each container defines one or more erase functions. These functions remove elements from the container. Any iterator that refers to an element that is removed has an invalid value. After all, the iterator was positioned on an element that no longer exists within the container.

When writing programs that use iterators, we must be aware of which operations can invalidate the iterators. It is a serious run-time error to use an iterator that has been invalidated.
There is no way to examine an iterator to determine whether it has been invalidated. There is no test we can perform to detect that it has gone bad. Any use of an invalidated iterator is likely to yield a run-time error, but there is no guarantee that the program will crash or otherwise make it easy to detect the problem.

When using iterators, it is usually possible to write the program so that the range of code over which an iterator must stay valid is relatively short. It is important to examine each statement in this range to determine whether elements are added or removed and adjust iterator values accordingly.
9.3 Sequence Container Operations
Each sequential container defines a set of useful typedefs and supports operations that let us
• Add elements to the container
• Delete elements from the container
• Determine the size of the container
• Fetch the first and last elements from the container, if any
9.3.1 Container Typedefs
We’ve used three of the container-defined types: size_type, iterator, and const_iterator. Each container defines these types, along with several others shown in Table 9.5.
Table 9.5. Container-Defined Typedefs

We’ll have more to say about reverse iterators in Section 11.3.3 (p. 412), but briefly, a reverse iterator is an iterator that goes backward through a container and inverts the iterator operations: For example, saying ++ on a reverse iterator yields the previous element in the container.
The last three types in Table 9.5 on the facing page let us use the type of the elements stored in a container without directly knowing what that type is. If we need the element type, we refer to the container’s value_type. If we need a reference to that type, we use reference or const_reference. The utility of these element-related typedefs will be more apparent when we define our own generic programs in Chapter 16.
Expressions that use a container-defined type can look intimidating:
// iter is the iterator type defined by list<string>
list<string>::iterator iter;
// cnt is the difference_type type defined by vector<int>
vector<int>::difference_type cnt;
The declaration of iter uses the scope operator to say that we want the name on the right-hand side of the :: from the scope of the left-hand side. The effect is to declare that iter has whatever type is defined for the iterator member from the list class that holds elements of type string.
9.3.2 begin and end Members
The begin and end operations yield iterators that refer to the first and one past the last element in the container. These iterators are most often used to form an iterator range that encompasses all the elements in the container.
Table 9.6. Container begin and end Operations

There are two different versions of each of these operations: One is a const member (Section 7.7.1, p. 260) and the other is nonconst. The return type of these operations varies on whether the container is const. In each case, if the container is nonconst, then the result’s type is iterator or reverse_iterator. If the object is const, then the type is prefixed by const_, that is, const_iterator or const_reverse_iterator. We cover reverse iterators in Section 11.3.3 (p. 412).
9.3.3 Adding Elements to a Sequential Container
In Section 3.3.2 (p. 94) we saw one way to add elements: push_back. Every sequential container supports push_back, which appends an element to the back of the container. The following loop reads one string at a time into text_word:

The call to push_back creates a new element at the end of container, increasing the size of container by one. The value of that element is a copy of text_word. The type of container can be any of list, vector, or deque.
In addition to push_back, the list and deque containers support an analogous operation named push_front. This operation inserts a new element at the front of the container. For example,
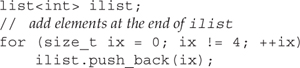
uses push_back to add the sequence 0, 1, 2, 3 to the end of ilist.
Alternatively, we could use push_front
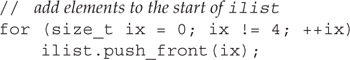
to add the elements 0, 1, 2, 3 to the beginning of ilist. Because each element is inserted at the new beginning of the list, they wind up in reverse order. After executing both loops, ilist holds the sequence 3,2,1,0,0,1,2,3.
Table 9.7. Operations that Add Elements to a Sequential Container

Adding Elements at a Specified Point in the Container
The push_back and push_front operations provide convenient ways to insert a single element at the end or beginning of a sequential container. More generally, insert allows us to insert elements at any particular point in the container. There are three versions of insert. The first takes an iterator and an element value. The iterator refers to the position at which to insert the value. We could use this version of insert to insert an element at the beginning of a container:

The value is inserted before the position referred to by the iterator. The iterator can refer to any position in the container, including one past the end of the container. Because the iterator might refer to a nonexistent element off the end of the container, insert inserts before the position rather than after it. This code
slist.insert(iter, spouse); // insert spouse just before iter
inserts a copy of spouse just before the element referred to by iter.
This version of insert returns an iterator referring to the newly inserted element. We could use the return value to repeatedly insert elements at a specified position in the container:

It is important to understand thoroughly how this loop operates—in particular to understand why we say that the loop is equivalent to calling push_front.
Before the loop, we initialize iter to lst.begin(). Because the list is empty, lst.begin() and lst.end() are equal, so iter refers one past the end of the (empty) list. The first call to insert puts the element we just read in front of the element referred to by iter. The value returned by insert is an iterator referring to this new element, which is now the first, and only, element in lst. We assign that iterator to iter and repeat the while, reading another word. As long as there are words to insert, each trip through the while inserts a new element ahead of iter and reassigns to iter the value of the newly inserted element. That element is always the first element, so each iteration inserts an element ahead of the first element in the list.
Inserting a Range of Elements
A second form of insert adds a specified number of identical elements at an indicated position:
svec.insert(svec.end(), 10, "Anna");
This code inserts ten elements at the end of svec and initializes each of those elements to the string "Anna".
The final form of insert adds a range of elements denoted by an iterator pair into the container. For example, given the following array of strings
string sarray[4] = {"quasi", "simba", "frollo", "scar"};
we can insert all or a subset of the array elements into our list of strings:

Inserting Elements Can Invalidate Iterators
As we’ll see in Section 9.4 (p. 330), adding elements to a vector can cause the entire container to be relocated. If the container is relocated, then all iterators into the container are invalidated. Even if the vector does not have to be relocated, any iterator to an element after the one inserted is invalidated.
Iterators may be invalidated after doing any insert or push operation on a vector or deque. When writing loops that insert elements into a vector or a deque, the program must ensure that the iterator is refreshed on each trip through the loop.
Avoid Storing the Iterator Returned from end
When we add elements to a vector or deque, some or all of the iterators may be invalidated. It is safest to assume that all iterators are invalid. This advice is particularly true for the iterator returned by end. That iterator is always invalidated by any insertion anywhere in the container.
As an example, consider a loop that reads each element, processes it and adds a new element following the original. We want the loop to process each original element. We’ll use the form of insert that takes a single value and returns an iterator to the element that was just inserted. After each insertion, we’ll increment the iterator that is returned so that the loop is positioned to operate on the next original element. If we attempt to “optimize” the loop, by storing an iterator to the end(), we’ll have a disaster:

The behavior of this code is undefined. On many implementations, we’ll get an infinite loop. The problem is that we stored the value returned by the end operation in a local variable named last. In the body of the loop, we add an element. Adding an element invalidates the iterator stored in last. That iterator neither refers to an element in v nor any longer refers to one past the last element in v.
Don’t cache the iterator returned from end. Inserting or deleting elements in a deque or vector will invalidate the cached iterator.
Rather than storing the end iterator, we must recompute it after each insertion:

9.3.4 Relational Operators
Each container supports the relational operators (Section 5.2, p. 152) that can be used to compare two containers. The containers must be the same kind of container and must hold elements of the same type. We can compare a vector<int> only with another vector<int>. We cannot compare a vector<int> with a list<int> or a vector<double>.
Exercises Section 9.3.3
Exercise 9.18: Write a program to copy elements from a list of ints into two deques. The list elements that are even should go into one deque and those that are odd into the second.
Exercise 9.19: Assuming iv is a vector of ints, what is wrong with the following program? How might you correct the problem(s)?

Comparing two containers is based on a pairwise comparison of the elements of the containers. The comparison uses the same relational operator as defined by the element type: Comparing two containers using != uses the != operator for the element type. If the element type doesn’t support the operator, then the containers cannot be compared using that operator.
These operators work similarly to the string relationals (Section 3.2.3, p. 85):
• If both containers are the same size and all the elements are equal, then the two containers are equal; otherwise, they are unequal.
• If the containers have different sizes but every element of the shorter one is equal to the corresponding element of the longer one, then the shorter one is considered to be less than the other.
• If neither container is an initial subsequence of the other, then the comparison depends on comparing the first unequal elements.
The easiest way to understand these operators is by studying examples:

Relational Operators Use Their Element’s Relational Operator
We can use a relational operator to compare two containers only if the operator is also defined for the element types.
Each container relational operator executes by comparing pairs of elements from the two containers:
ivec1 < ivec2
Assuming ivec1 and ivec2 are vector<int>, then this comparison uses the built-in int less-than operator. If the vectors held strings, then the string less-than operator would be used.
If the vectors held objects of the Sales_item type that we used in Section 1.5 (p. 20), then the comparison would be illegal. We did not define the relational operators for Sales_item. If we have two containers of Sales_items, we could not compare them:
vector<Sales_item> storeA;
vector<Sales_item> storeB;
if (storeA < storeB) // error: Sales_item has no less-than operator
9.3.5 Container Size Operations
Each container type supports four size-related operations. We used size and empty in Section 3.2.3 (p. 83): size returns the number of elements in the container; empty returns a bool that is true if size is zero and false otherwise.
The resize operation changes the number of elements in the container. If the current size is greater than the new size, then elements are deleted from the back of the container. If the current size is less than the new size, then elements are added to the back of the container:

The resize operation takes an optional element-value argument. If this argument is present, then any newly added elements receive this value. If this argument is absent, then any new elements are value initialized (Section 3.3.1, p. 92).
resize can invalidate iterators. A resize operation on a vector or deque potentially invalidates all iterators.
For any container type, if resize shrinks the container, then any iterator to an element that is deleted is invalidated.
Table 9.8. Sequential Container Size Operations

9.3.6 Accessing Elements
If a container is not empty, then the front and back members return references bound to the first or last elements in the container:

This program uses two different approaches to fetch a reference to the first and last elements in ilist. The direct approach is to call front or back. Indirectly, we can obtain a reference to the same element by dereferencing the iterator returned by begin or the element one before the iterator returned by end. Two things are noteworthy in this program: The end iterator refers “one past the end” of the container so to fetch the last element we must first decrement that iterator. The other important point is that before calling front or back or dereferencing the iterators from begin or end we check that ilist isn’t empty. If the list were empty all of the operations in the if would be undefined.
When we introduced subscripting in Section 3.3.2 (p. 94), we noted that the programmer must ensure that an element exists at the indicated subscript location. The subscript operator itself does not check. The same caution applies to using the front or back operations. If the container is empty, these operations yield an undefined result. If the container has only one element, then front and back each return a reference to that element.
Using a subscript that is out-of-range or calling front or back on an empty container are serious programming errors.
Table 9.9. Operations to Access Elements in a Sequential Container

An alternative to subscripting is to use the at member. This function acts like the subscript operation but if the index is invalid, at throws an out_of_range exception (Section 6.13, p. 215):

9.3.7 Erasing Elements
Recall that there is both a general insert operation that inserts anywhere in the container and specific push_front and push_back operations to add elements only at the front or back. Similarly, there is a general erase and specific pop_front and pop_back operations to remove elements.
Removing the First or Last Element
The pop_front and pop_back functions remove the first and last elements in the container. There is no pop_front operation for vectors. These operations remove the indicated element and return void.
One common use of pop_front is to use it together with front to process a container as a stack:

This loop is pretty simple: We use front to get a value to operate on and then call pop_front to remove that element from the list.
The pop_front and pop_back return void; they do not return the value of the element popped. To examine that value, it is necessary to call front or back prior to popping the element.
Table 9.10. Operations to Remove Elements from a Sequential Container

Removing an Element From within the Container
The more general way to remove an element, or range of elements, is through erase. There are two versions of erase: We can delete a single element referred to by an iterator or a range of elements marked by a pair of iterators. Both forms of erase return an iterator referring to the location after the element or range that was removed. That is, if element j is the element immediately after i and we erase element i from the container, then the iterator returned will refer to j.
As usual, the erase operations don’t check their argument(s). It is up to the programmer to ensure that the iterator or iterator range is valid.
The erase operation is often used after finding an element that should be removed from the container. The easiest way to find a given element is to use the library find algorithm. We’ll see more about find in Section 11.1 (p. 392). To use find or any other generic algorithm, we must include the algorithm header. The find function takes a pair of iterators that denote a range in which to look, and a value to look for within that range. find returns an iterator referring to the first element with that value or the off-the-end iterator:

Note that we check that the iterator is not the end iterator before erasing the element. When we ask erase to erase a single element, the element must exist—the behavior of erase is undefined if we ask it to erase an off-the-end iterator.
Removing All the Elements in a Container
To delete all the elements in a container, we could either call clear or pass the iterators from begin and end to erase:
slist.clear(); // delete all the elements within the container
slist.erase(slist.begin(), slist.end()); // equivalent
The iterator-pair version of erase lets us delete a subrange of elements:

This code starts by calling find twice to obtain iterators to two elements. The iterator elem1 refers to the first occurrence of val1 or to the off-the-end iterator if val1 is not present in the list. The iterator elem2 refers to the first occurrence of val2 that appears after val1 if that element exists, otherwise, elem2 is an off the-end iterator. The call to erase removes the elements starting from the referred to by elem1 up to but not including elem2.
The erase, pop_front, and pop_back functions invalidate any iterators that refer to the removed elements. For vectors, iterators to elements after the erasure point are also invalidated. For deque, if the erase does not include either the first or last element, all iterators into the deque are invalidated.
9.3.8 Assignment and swap
The assignment-related operators act on the entire container. Except for swap, they can be expressed in terms of erase and insert operations. The assignment operator erases the entire range of elements in the left-hand container and then inserts the elements of the right-hand container object into the left-hand container:

After the assignment, the left- and right-hand containers are equal: Even if the containers had been of unequal size, after the assignment both containers have the size of the right-hand operand.
Assignment and the assign operations invalidate all iterators into the left-hand container. swap does not invalidate iterators. After swap, iterators continue to refer to the same elements, although those elements are now in a different container.
Using assign
The assign operation deletes all the elements in the container and then inserts new elements as specified by the arguments. Like the constructor that copies elements from a container, the assignment operator (=) can be used to assign one container to another only if the container and element type are the same. If we want to assign elements of a different but compatible element type and/or from a different container type, then we must use the assign operation. For example, we could use assign to assign a range of char* values from a vector into a list of string.
Table 9.11. Sequential Container Assignment Operations

Because the original elements are deleted, the iterators passed to assign must not refer to elements in the container on which assign is called.
The arguments to assign determine how many elements are inserted and what values the new elements will have. This statement:
// equivalent to slist1 = slist2
slist1.assign(slist2.begin(), slist2.end());
uses the version of assign that takes a pair of iterators. After deleting the elements in slist1, the function copies the elements in the range denoted by the iterators into slist2. Thus, this code is equivalent to assigning slist2 to slist1.
The assign operator that takes an iterator pair lets us assign elements of one container type to another.
A second version of assign takes an integral value and an element value. It replaces the elements in the container by the specified number of elements, each of which has the specified element value
// equivalent to: slist1.clear();
// followed by slist1.insert(slist1.begin(), 10, "Hiya!");
slist1.assign(10, "Hiya!"); // 10 elements; each one is Hiya!
After executing this statement, slist1 has 10 elements, each of which has the value Hiya!.
Using swap to Avoid the Cost of Deleting Elements
The swap operation swaps the values of its two operands. The types of the containers must match: The operands must be the same kind of container, and they must hold values of the same type. After the call to swap, the elements that had been in the right-hand operand are in the left, and vice versa:

After the swap, svec1 contains 24 string elements and svec2 contains 10.
The important thing about swap is that it does not delete or insert any elements and is guaranteed to run in constant time. No elements are moved, and so iterators are not invalidated.
The fact that elements are not moved means that iterators are not invalidated. They refer to the same elements as they did before the swap. However, after the swap, those elements are in a different container. For example, had iter referred to the string at position svec1[3] before the swap it will refer to the element at position svec2[3] after the swap.
9.4 How a vector Grows
When we insert or push an element onto a container object, the size of that object increases by one. Similarly, if we resize a container to be larger than its current size, then additional elements must be added to the container. The library takes care of allocating the memory to hold these new elements.
Ordinarily, we should not care about how a library type works: All we should care about is how to use it. However, in the case of vectors, a bit of the implementation leaks into its interface. To support fast random access, vector elements are stored contiguously—each element is adjacent to the previous element.
Given that elements are contiguous, let’s think about what happens when we add an element to a vector: If there is no room in the vector for the new element, it cannot just add an element somewhere else in memory because the elements must be contiguous for indexing to work. Instead, the vector must allocate new memory to hold the existing elements plus the new one, copy the elements from the old location into the new space, add the new element, and deallocate the old memory. If vector did this memory allocation and deallocation each time we added an element, then performance would be unacceptably slow.
There is no comparable allocation issue for containers that do not hold their elements contiguously. For example, to add an element to a list, the library only needs to create the new element and chain it into the existing list. There is no need to reallocate or copy any of the existing elements.
One might conclude, therefore, that in general it is a good idea to use a list rather than a vector. However, the contrary is usually the case: For most applications the best container to use is a vector. The reason is that library implementors use allocation strategies that minimize the costs of storing elements contiguously. That cost is usually offset by the advantages in accessing elements that contiguous storage allows.
The way vectors achieve fast allocation is by allocating capacity beyond what is immediately needed. The vector holds this storage in reserve and uses it to allocate new elements as they are added. Thus, there is no need to reallocate the container for each new element. The exact amount of additional capacity allocated varies across different implementations of the library. This allocation strategy is dramatically more efficient than reallocating the container each time an element is added. In fact, its performance is good enough that in practice a vector usually grows more efficiently than a list or a deque.
9.4.1 capacity and reserve Members
The details of how vector handles its memory allocation are part of its implementation. However, a portion of this implementation is supported by the interface to vector. The vector class includes two members, capacity and reserve, that let us interact with the memory-allocation part of vector’s implementation. The capacity operation tells us how many elements the container could hold before it must allocate more space. The reserve operation lets us tell the vector how many elements it should be prepared to hold.
It is important to understand the difference between capacity and size. The size is the number of elements in the vector; capacity is how many it could hold before new space must be allocated.
To illustrate the interaction between size and capacity, consider the following program:

When run on our system, this program produces the following output:
ivec: size: 0 capacity: 0
ivec: size: 24 capacity: 32
We know that the size of an empty vector is zero, and evidently our library also sets capacity of an empty vector to zero. When we add elements to the vector, we know that the size is the same as the number of elements we’ve added. The capacity must be at least as large as size but can be larger. Under this implementation, adding 24 elements one at a time results in a capacity of 32. Visually we can think of the current state of ivec as

We could now reserve some additional space:
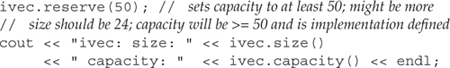
As the output indicates, doing so changes the capacity but not the size:
ivec: size: 24 capacity: 50
We might next use up that reserved capacity as follows:
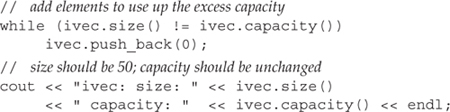
Because we used only reserved capacity, there is no need for the vector to do any allocation. In fact, as long as there is excess capacity, the vector must not reallocate its elements.
The output indicates that at this point we’ve used up the reserved capacity, and size and capacity are equal:
ivec: size: 50 capacity: 50
If we now add another element, the vector will have to reallocate itself:

The output from this portion of the program
ivec: size: 51 capacity: 100
indicates that this vector implementation appears to follow a strategy of doubling the current capacity each time it has to allocate new storage.
Each implementation of vector is free to choose its own allocation strategy. However, it must provide the reserve and capacity functions, and it must not allocate new memory until it is forced to do so. How much memory it allocates is up to the implementation. Different libraries will implement different strategies.
Moreover, every implementation is required to follow a strategy that ensures that it is efficient to use push_back to populate a vector. Technically speaking, the execution time of creating an n-element vector by calling push_back n times on an initially empty vector is never more than a constant multiple of n.
Exercises Section 9.4.1
Exercise 9.29: Explain the difference between a vector’s capacity and its size. Why is it necessary to support the notion of capacity in a container that stores elements contiguously but not, for example, in a list?
Exercise 9.30: Write a program to explore the allocation strategy followed by the library you use for vector objects.
Exercise 9.31: Can a container have a capacity less than its size? Is a capacity equal to its size desirable? Initially? After an element is inserted? Why or why not?
Exercise 9.32: Explain what the following (contrived) program fragment does:

If the program reads 256 words, what is its likely capacity after it is resized? What if it reads 512? 1,000? 1,048?
9.5 Deciding Which Container to Use
As we saw in the previous section, allocating memory to hold elements in contiguous storage has impacts on the memory allocation strategies and overhead of a container. By using clever implementation techniques, library authors minimize this allocation overhead. Whether elements are stored contiguously has other significant impacts on:
• The costs to add or delete elements from the middle of the container
• The costs to perform nonsequential access to elements of the container
The degree to which a program does these operations should be used to determine which type of container to use. The vector and deque types provide fast non-sequential access to elements at the cost of making it expensive to add or remove elements anywhere other than the ends of the container. The list type supports fast insertion and deletion anywhere but at the cost of making nonsequential access to elements expensive.
How Insertion Affects Choice of Container
A list represents noncontiguous memory and allows for both forward and backward traversal one element at a time. It is efficient to insert or erase an element at any point. Inserting or removing an element in a list does not move any other elements. Random access, on the other hand, is not supported. Accessing an element requires traversing the intervening elements.
Inserting (or removing) anywhere except at the back of a vector requires that each element to the right of the inserted (or deleted) element be moved. For example, if we have a vector with 50 elements and we wish to erase element number 23, then each of the elements after 23 have to be moved forward by one position. Otherwise, there’d be a hole in the vector, and the vector elements would no longer be contiguous.
A deque is a more complicated data structure. We are guaranteed that adding or removing elements from either end of the deque is a fast operation. Adding or removing from the middle will be more expensive. A deque offers some properties of both list and vector:
• Like vector, it is inefficient to insert or erase elements in the middle of the deque.
• Unlike vector, a deque offers efficient insert and erase at the front as well as at the back.
• Unlike list and like vector, a deque supports fast random access to any element.
• Inserting elements at the front or back of a deque does not invalidate any iterators. Erasing the front or back element invalidates only iterators referring to the element(s) erased. Inserting or erasing anywhere else in the deque invalidates all iterators referring to elements of the deque.
How Access to the Elements Affects Choice of Container
Both vector and deque support efficient random access to their elements. That is, we can efficiently access element 5, then 15, then 7, and so on. Random access in a vector can be efficient because each access is to a fixed offset from the beginning of the vector. It is much slower to jump around in a list. the only way to move between the elements of a list is to sequentially follow the pointers. Moving from the 5th to the 15th element requires visiting every element between them.
In general, unless there is a good reason to prefer another container, vector is usually the right one to use.
Hints on Selecting Which Container to Use
There are a few rules of thumb that apply to selecting which container to use:
- If the program requires random access to elements, use a
vectoror adeque. - If the program needs to insert or delete elements in the middle of the container, use a
list. - If the program needs to insert or delete elements at the front and the back, but not in the middle, of the container, use a
deque. - If we need to insert elements in the middle of the container only while reading input and then need random access to the elements, consider reading them into a
listand then reordering thelistas appropriate for subsequent access and copying the reorderedlistinto avector.
What if the program needs to randomly access and insert and delete elements in the middle of the container?
This decision will depend on the relative cost of doing random access to list elements versus the cost of copying elements when inserting or deleting elements in a vector or deque. In general, the predominant operation of the application (whether it does more access or more insertion or deletion) should determine the choice of container type.
Deciding which container to use may require profiling the performance of each container type doing the kinds of operations the application requires.

When you are not certain which container the application should use, try to write your code so that it uses only operations common to both vectors and lists: Use iterators, not subscripts, and avoid random access to elements. By writing your programs this way, it will be easier to change the container from a vector to a list if necessary.
9.6 strings Revisited
We introduced the string type in Section 3.2 (p. 80). Table 9.12 (p. 337) recaps the string operations covered in that section.
Table 9.12. string Operations Introduced in Section 3.2

In addition to the operations we’ve already used, strings also supports most of the sequential container operations. In some ways, we can think of a string as a container of characters. With some exceptions, strings support the same operations that vectors support: The exceptions are that string does not support the operations to use the container like a stack: We cannot use the front, back, and pop_back operations on strings.
The container operations that string supports are:
• The typedefs, including the iterator types, listed in Table 9.5 (p. 316).
• The constructors listed in Table 9.2 (p. 307) except for the constructor that takes a single size parameter.
• The operations to add elements listed in Table 9.7 (p. 319) that vector supports. Note: Neither vector nor string supports push_front.
• The size operations in Table 9.8 (p. 324).
• The subscript and at operations listed in Table 9.9 (p. 325); string does not provide back or front operations listed in that table.
• The begin and end operations of Table 9.6 (p. 317).
• The erase and clear operations of Table 9.10 (p. 326); string does not support either pop_back or pop_front.
• The assignment operations in Table 9.11 (p. 329).
• Like the elements in a vector, the characters of a string are stored contiguously. Therefore, string supports the capacity and reserve operations described in Section 9.4 (p. 330).
When we say that string supports the container operations, we mean that we could take a program that manipulates a vector and rewrite that same program to operate on strings. For example, we could use iterators to print the characters of a string a line at a time to the standard output:

Not surprisingly, this code looks almost identical to the code from page 163 that printed the elements of a vector<int>.
In addition to the operations that string shares with the containers, string supports other operations that are specific to strings. We will review these string-specific operations in the remainder of this section. These operations include additional versions of container-related operations as well as other, completely new functions. The additional functions that string provides are covered starting on page 341.
The additional versions of the container operations that string provides are defined to support attributes that are unique to strings and not shared by the containers. For example, several operations permit us to specify arguments that are pointers to character arrays. These operations support the close interaction between library strings and character arrays, whether null-terminated or not. Other versions let us use indices rather than iterators. These versions operate positionally: We specify a starting position, and in some cases a count, to specify the element or range of elements which we want to manipulate.
The string library defines a great number of functions, which use repeated patterns. Given the number of functions supported, this section can be mind-numbing on first reading.
Readers might want to skim the remainder of Section 9.6. Once you know what kinds of operations are available, you can return for the details when writing programs that need to use a given operation.
9.6.1 Other Ways to Construct strings
The string class supports all but one of the constructors in Table 9.2 (p. 307). The constructor that takes a single size parameter is not supported for string. We can create a string: as the empty string, by providing no argument; as a copy of another string; from a pair of iterators; or from a count and a character:

In addition to these constructors, the string type supports three other ways to create a string. We have already used the constructor that takes a pointer to the first character in a null-terminated, character array. There is another constructor that takes a pointer to an element in a character array and a count of how many characters to copy. Because the constructor takes a count, the array does not have to be null-terminated:

We define s1 using the constructor that takes a pointer to the first character of a null-terminated array. All the characters in that array, up to but not including the terminating null, are copied into the newly created string.
The initializer for s2 uses the second constructor, taking a pointer and a count. In this case, we start at the character denoted by the pointer and copy as many characters as indicated in the second argument. s2, therefore, is a copy of the first five characters from the array c_array. Remember that when we pass an array as an argument, it is automatically converted to a pointer to its first element. Of course, we are not restricted to passing a pointer to the beginning of the array. We initialize s3 to hold four exclamation points by passing a pointer to the first exclamation point in c_array.
The initializers for s4 and s5 are not C-style strings. The definition of s4 is an error. This form of initialization may be called only with a null-terminated array. Passing an array that does not contain a null is a serious error (Section 4.3, p. 130), although it is an error that the compiler cannot detect. What happens at run time is undefined.
The initialization of s5 is fine: That initializer includes a count that says how many characters to copy. As long as the count is within the size of the array, it doesn’t matter whether the array is null-terminated.
Table 9.13. Additional Ways to Construct strings

Using a Substring as the Initializer
The other pair of constructors allow us to create a string as a copy of a substring of the characters in another string:
string s6(s1, 2); // s6 == "ya"
string s7(s1, 0, 2); // s7 == "Hi"
string s8(s1, 0, 8); // s8 == "Hiya"
The first two arguments are the string from which we want to copy and a starting position. In the two-argument version, the newly created string is initialized with the characters from that position to the end of the string argument. We can also provide a third argument that specifies how many characters to copy. In this case, we copy as many characters as indicated (up to the size of the string), starting at the specified position. For example, when we create s7, we copy two characters from s1, starting at position zero. When we create s8, we copy only four characters, not the requested eight. Regardless of how many characters we ask to copy, the library copies up to the size of the string, but not more.
9.6.2 Other Ways to Change a string
Many of the container operations that string supports operate in terms of iterators. For example, erase takes an iterator or iterator range to specify which element(s) to remove from the container. Similarly, the first argument to each version of insert takes an iterator to indicate the position before which to insert the values represented by the other arguments. Although string supports these iterator-based operations, it also supplies operations that work in terms of an index. The index is used to indicate the starting element to erase or the position before which to insert the appropriate values. Table 9.14 lists the operations that are common to both string and the containers; Table 9.15 on the facing page lists the string-only operations.
Table 9.14. string Operations in Common with the Containers

Table 9.15. string-Specific Versions

Position-Based Arguments
The string-specific versions of these operations take arguments similar to those of the additional constructors covered in the previous section. These operations let us deal with strings positionally and/or let us use arguments that are pointers to character arrays rather than strings.
For example, all containers let us specify a pair of iterators that denote a range of elements to erase. For strings, we can also specify the range by passing a starting position and count of the number of elements to erase. Assuming s is at least five characters long, we could erase the last five characters as follows:
s.erase(s.size() - 5, 5); // erase last five characters from s
Similarly, we can insert a given number of values in a container before the element referred to by an iterator. In the case of strings, we can specify the insertion point as an index rather than using an iterator:
s.insert(s.size(), 5, '!'), // insert five exclamation points at end of s
Specifying the New Contents
The characters to insert or assign into the string can be taken from a character array or another string. For example, we can use a null-terminated character array as the value to insert or assign into a string:

Similarly, we can insert a copy of one string into another as follows:

9.6.3 string-Only Operations
The string type provides several other operations that the containers do not:
• The substr function that returns a substring of the current string
• The append and replace functions that modify the string
• A family of find functions that search the string
The substr Operation
The substr operation lets us retrieve a substring from a given string. We can pass substr a starting position and a count. It creates a new string that has that many characters, (up to the end of the string) from the target string, starting at the given position:
string s("hello world");
// return substring of 5 characters starting at position 6
string s2 = s.substr(6, 5); // s2 = world
Alternatively, we could obtain the same result by writing:
// return substring from position 6 to the end of s
string s3 = s.substr(6); // s3 = world
Table 9.16. Substring Operation

The append and replace Functions
There are six overloaded versions of append and ten versions of replace. The append and replace functions are overloaded using the same set of arguments, which are listed in Table 9.18 on the next page. These arguments specify the characters to add to the string. In the case of append, the characters are added at the end of the string. In the replace function, these characters are inserted in place a specified range of existing characters in the string.
The append operation is a shorthand way of inserting at the end:

The replace operations remove an indicated range of characters and insert a new set of characters in their place. The replace operations have the same effect as calling erase and insert.
The ten different versions of replace differ from each other in how we specify the characters to remove and in how we specify the characters to insert in their place. The first two arguments specify the range of elements to remove. We can specify the range either with an iterator pair or an index and a count. The remaining arguments specify what new characters to insert.
We can think of replace as a shorthand way of erasing some characters and inserting others in their place:
Table 9.17. Operations to Modify strings (args defined in Table 9.18)

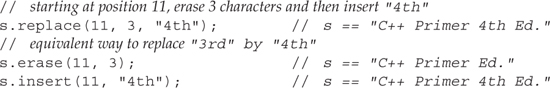
In the previous call to replace, the text we inserted happens to be the same size as the text we removed. We could insert a larger or smaller string:
s.replace(11, 3, "Fourth"); // s == "C++ Primer Fourth Ed."
In this call we remove three characters but insert six in their place.
Table 9.18. Arguments to append and replace

9.6.4 string Search Operations
The string class provides six search functions, each named as a variant of find. The operations all return a string::size_type value that is the index of where the match occurred, or a special value named string::npos if there is no match. The string class defines npos as a value that is guaranteed to be greater than any valid index.
There are four versions of each of the search operations, each of which takes a different set of arguments. The arguments to the search operations are listed in Table 9.20. Basically, these operations differ as to whether they are looking for a single character, another string, a C-style, null-terminated string, or a given number of characters from a character array.
Table 9.19. string Search Operations (Arguments in Table 9.20)

Table 9.20. Arguments to string find Operations

Finding an Exact Match
The simplest of the search operations is the find function. It looks for its argument and returns the index of the first match that is found, or npos if there is no match:
![]()
Returns 0, the index at which the substring "Anna" is found in "AnnaBelle".
By default, the find operations (and other string operations that deal with characters) use the built-in operators to compare characters in the string. As a result, these operations (and other string operations) are case sensitive.
When we look for a value in the string, case matters:
![]()
This code will set pos1 to npos—the string Anna does not match anna.
The find operations return a string::size_type. Use an object of that type to hold the return from find.
Find Any Character
A slightly more complicated problem would be if we wanted to match any character in our search string. For example, the following locates the first digit within name:

In this example, pos is set to a value of 1 (the elements of a string, remember, are indexed beginning at 0).
Specifying Where to Start the Search
We can pass an optional starting position to the find operations. This optional argument indicates the index position from which to start the search. By default, that position is set to zero. One common programming pattern uses this optional argument to loop through a string finding all occurrences. We could rewrite our search of "r2d2" to find all the numbers in name:

In this case, we initialize pos to zero so that on the first trip through the while name is searched, beginning at position 0. The condition in the while resets pos to the index of the first number encountered, starting from the current value of pos. As long as the return from find_first_of is a valid index, we print our result and increment pos.
Had we neglected to increment pos at the end of this loop, then it would never terminate. To see why, consider what would happen if we didn’t. On the second trip through the loop. we start looking at the character indexed by pos. That character would be a number, so find_first_of would (repeatedly) returns pos!
It is essential that we increment pos. Doing so ensures that we start looking for the next number at a point after the number we just found.
Looking for a Nonmatch
Instead of looking for a match, we might call find_first_not_of to find the first position that is not in the search argument. For example, to find the first non-numeric character of a string, we can write

Searching Backward
Each of the find operations that we’ve seen so far executes left to right. The library provides an analogous set of operations that look through the string from right to left. The rfind member searches for the last—that is, rightmost—occurrence of the indicated substring:

find returns an index of 1, indicating the start of the first "is", while rfind returns an index of 4, indicating the start of the last occurrence of "is".
The find_last Functions
The find_last functions operate like the corresponding find_first functions, except that they return the last match rather than the first:
• find_last_of searches for the last character that matches any element of the search string.
• find_last_not_of searches for the last character that does not match any element of the search string.
Each of these operations takes an optional second argument indicating the position within the string to begin searching.
9.6.5 Comparing strings
As we saw in Section 3.2.3 (p. 85), the string type defines all the relational operators so that we can compare two strings for equality (==), inequality (!=), and the less- or greater-than operations (<, <=, >, >=). Comparison between strings is lexicographical—that is, string comparison is the same as a case-sensitive, dictionary ordering:
string cobol_program_crash("abend");
string cplus_program_crash("abort");
Exercises Section 9.6.4
Exercise 9.38: Write a program that, given the string
"ab2c3d7R4E6"
finds each numeric character and then each alphabetic character. (The program may assume that the string contains only alphabetic or numeric characters.) Write two versions of the program. The first should use find_first_of, and the second find_first_not_of.
Exercise 9.39: Write a program that, given the strings

counts the number of words in sentence and identifies the largest and smallest words. If several words have the largest or smallest length, report all of them.
Here cobol_program_crash is less than the cplus_program_crash. The relational operators compare two strings character by character until reaching a position where the two strings differ. The overall comparison of the strings depends on the comparison between these unequal characters. In this case, the first unequal characters are ’e’ and ’o’. The letter ’e’ occurs before (is less than) ’o’ in the English alphabet and so "abend" is less than "abort". If the strings are of different length, and one string is a substring of the other, then the shorter string is less than the longer.
The compare Functions
In addition to the relational operators, string provides a set of compare operations that perform lexicographical comparions. The results of these operations are similar to the C library strcmp function (Section 4.3, p. 132). Given
s1.compare (args);
compare returns one of three possible values:
- A positive value if
s1is greater than thestringrepresented by args - A negative value if
s1is less than thestringrepresented by args - 0 if
s1is equal to thestringrepresented by args
For example
// returns a negative value
cobol_program_crash.compare(cplus_program_crash);
// returns a positive value
cplus_program_crash.compare(cobol_program_crash);
Table 9.21. string compare Operations

The overloaded set of six compare operations allows us to compare a substring of either one or both strings for comparison. They also let us compare a string to a character array or portion thereof:

The second call to compare is the most interesting. This call uses the version of compare that takes five arguments. We use find to locate the position of the beginning of the substring "4th". We compare three characters starting at that position to a substring from third_ed. That substring begins at the position returned from find when looking for "3rd" and again we compare three characters. Essentially, this call compares "4th" to "3rd".
9.7 Container Adaptors
In addition to the sequential containers, the library provides three sequential container adaptors: queue, priority_queue, and stack. An adaptor is a general concept in the library. There are container, iterator, and function adaptors. Essentially, an adaptor is a mechanism for making one thing act like another. A container adaptor takes an existing container type and makes it act like a different abstract type. For example, the stack adaptor takes any of the sequential containers and makes it operate as if it were a stack. Table 9.22 (p. 350) lists the operations and types that are common to all the container adaptors.
Table 9.22. Common Adaptor Operations and Types

To use an adaptor, we must include its associated header:
#include <stack> // stack adaptor
#include <queue> // both queue and priority_queue adaptors
Initializing an Adapator
Each adaptor defines two constructors: the default constructor that creates an empty object and a constructor that takes a container and makes a copy of that container as its underlying value. For example, assuming that deq is a deque<int>, we could use deq to initialize a new stack as follows:
stack<int> stk(deq); // copies elements from deq into stk
Overriding the Underlying Container Type
By default both stack and queue are implemented in terms of deque, and a priority_queue is implemented on a vector. We can override the default container type by naming a sequential container as a second type argument when creating the adaptor:
// empty stack implemented on top of vector
stack< string, vector<string> > str_stk;
// str_stk2 is implemented on top of vector and holds a copy of svec
stack<string, vector<string> > str_stk2(svec);
There are constraints on which containers can be used for a given adapator. We can use any of the sequential containers as the underlying container for a stack. Thus, a stack can be built on a vector, list, or deque. The queue adapator requires push_front in its underlying container, and so could be built on a list but not on a vector. A priority_queue requires random access and so can be built on a vector or a deque but not on a list.
Relational Operations on Adaptors
Two adaptors of the same type can be compared for equality, inequality, less-than, greater-than, less-than-equal, and greater-than-equal relationships, provided that the underlying element type supports the equality and less-than operators. For these operations, the elements are compared in turn. The first pair of unequal elements determines the less-than or greater-than relationship.
9.7.1 Stack Adaptor
The operations provided by a stack are listed in Table 9.23 on the facing page. The following program exercises this set of five stack operations:
Table 9.23. Operations Supported by the Stack Container Adaptor


stack<int> intStack; // empty stack
defines intStack to be an empty stack that holds integer elements. The for loop adds stk_size elements initializing each to the next integer in sequence starting from zero. The while loop iterates through the entire stack, examining the top value and popping it from the stack until the stack is empty.
Each container adaptor defines its own operations in terms of operations provided by the underlying container type. By default, this stack is implemented using a deque and uses deque operations to implement the operations of a stack. For example, when we execute
// use postfix increment; want to push old value onto intStack
intStack.push(ix++); // intStack holds 0...9 inclusive
this operation executes by calling the push_back operation of the deque object on which intStack is based. Although stack is implemented by using a deque, we have no direct access to the deque operations. We cannot call push_back on a stack; instead, we must use the stack operation named push.
9.7.2 Queue and Priority Queue
The library queue uses a first-in, first-out (FIFO) storage and retrieval policy. Objects entering the queue are placed in the back. The next object retrieved is taken from the front of the queue. There are two kinds of queues: the FIFO queue, which we will speak of simply as a queue, and a priority queue.
A priority_queue lets us establish a priority among the elements held in the queue. Rather than place a newly entered item at the back of the queue, the item is placed ahead of all those items with a lower priority. By default, the library uses the < operator on the element type to determine relative priorities.
A real-world example of a priority queue is the line to check luggage at an airport. Those whose flight is going to leave within the next 30 minutes are generally moved to the front of the line so that they can finish the check-in process before their plane takes off. A programming example of a priority queue is the scheduler of an operating system determining which, of a number of waiting processes, should execute next.
To use either queue or priority_queue, we must include the queue header. Table 9.24 lists the operations supported by queue and priority_queue.
Table 9.24. Operations Supported by Queues and Priority Queues

Chapter Summary
The C++ library defines a number of sequential container types. A container is a template type that holds objects of a given type. In a sequential container, elements are ordered and accessed by position. The sequential containers share a common, standardized interface: If two sequential containers offer a particular operation, then the operation has the same interface and meaning for both containers. All the containers provide (efficient) dynamic memory management. We may add elements to the container without worrying about where to store the elements. The container itself manages its storage.
The most commonly used container, vector, supports fast, random access to elements. Elements can be added and removed efficiently from the end of a vector. Inserting or deleting elements elsewhere can be expensive. The deque class is like a vector, but also supports fast insertion and deletion at the front of the deque. The list class supports only sequential access to elements, but it can be quite fast to insert or remove elements anywhere within the list.
The containers define surprisingly few operations. Containers define constructors, operations to add or remove elements, operations to determine the size of the container, and operations to return iterators to particular elements. Other useful operations, such as sorting or searching, are defined not by the container types but by the standard algorithms, which we shall cover in Chapter 11.
Container operations that add or remove elements can invalidate existing iterators. When mixing actions on iterators and container operations, it is essential to keep in mind whether a given container operation could invalidate the iterators. Many operations that invalidate an iterator, such as insert or erase, return a new iterator that allows the programmer to maintain a position within the container. Loops that use container operations that change the size of a container should be particularly careful in their use of iterators.
Defined Terms
A library type, function, or iterator that given a type, function, or iterator, makes it act like another. There are three sequential container adaptors: stack, queue, and priority_queue. Each of these adaptors defines a new interface on top of an underlying sequential container.
Container operation that returns an iterator referring to the first element in the container, if there is one, or the off-the-end iterator ff the container is empty.
A type that holds a collection of objects of a given type. Each library container type is a template type. To define a container, we must specify the type of the elements stored in the container. The library containers are variable-sized.
Sequential container. Elements in a deque are accessed by their positional index. Like a vector in all respects except that it supports fast insertion at the front of the container as well as at the end and does not relocate elements as a result of insertions or deletions at either end.
Container operation that returns an iterator referring to the element one past the end of the container.
An iterator that refers to an element that no longer exists. Using an invalidated iterator is undefined and can cause serious run-time problems.
A type whose operations support navigating among the elements of a container and examining values in the container. Each of the library containers has four companion iterator types listed in Table 9.5 (p. 316). The library iterators all support the dereference (*) and arrow (->) operators to examine the value to which the iterator refers. They also support prefix and postfix increment (++) and decrement (--) and the equality (==) and inequality (!=) operators.
A range of elements denoted by a pair of iterators. The first iterator refers to the first element in the sequence, and the second iterator refers one past the last element. If the range is empty, then the iterators are equal (and vice versa—if the iterators are equal, they denote an empty range). If the range is non-empty, then it must be possible to reach the second iterator by repeatedly incrementing the first iterator. By incrementing the iterator, each element in the sequence can be processed.
A range of values that includes its first element but not its last. Typically denoted as [i, j) meaning the sequence starting at and including i up to but excluding j.
Sequential container. Elements in a list may be accessed only sequentially—starting from a given element, we can get to another element by incrementing or decrementing across each element between them. Supports fast insertion (or deletion) anywhere in the list. Adding elements does not affect other elements in the list; iterators remain valid when new elements are added. When an element is removed, only the iterators to that element are invalidated.
Adaptor for the sequential containers that yields a queue in which elements are inserted, not at the end but according to a specified priority level. By default, priority is determined by using the less-than operator for the element type.
Adaptor for the sequential containers that yields a type that lets us add elements to the back and remove elements from the front.
A type that holds an ordered collection of objects of a single type. Elements in a sequential container are accessed by position.
Adaptor for the sequential containers that yields a type that lets us add and remove elements from one end only.
Sequential container. Elements in a vector are accessed by their positional index. We add elements to a vector by calling push_back or insert. Adding elements to a vector might cause it be reallocated, invalidating all iterators into the vector. Adding (or removing) an element in the middle of a vector invalidates all iterators to elements after the insertion (or deletion) point.