
Chapter 7. Functions
CONTENTS
Section 7.1 Defining a Function 226
Section 7.2 Argument Passing 229
Section 7.3 The return Statement 245
Section 7.4 Function Declarations 251
Section 7.6 Inline Functions 256
Section 7.7 Class Member Functions 258
Section 7.8 Overloaded Functions 265
Section 7.9 Pointers to Functions 276
This chapter describes how to define and declare functions. We’ll cover how arguments are passed to and values are returned from a function. We’ll then look at three special kinds of functions: inline functions, class member functions, and overloaded functions. The chapter closes with a more advanced topic: function pointers.
A function can be thought of as a programmer-defined operation. Like the built-in operators, each function performs some computation and (usually) yields a result. Unlike the operators, functions have names and may take an unlimited number of operands. Like operators, functions can be overloaded, meaning that the same name may refer to multiple different functions.
7.1 Defining a Function
A function is uniquely represented by a name and a set of operand types. Its operands, referred to as parameters, are specified in a comma-separated list enclosed in parentheses. The actions that the function performs are specified in a block, referred to as the function body. Every function has an associated return type.
As an example, we could write the following function to find the greatest common divisor of two ints:

Here we define a function named gcd that returns an int and has two int parameters. To call gcd, we must supply two int values and we get an int in return.
Calling a Function
To invoke a function we use the call operator, which is a pair of parentheses. As with any operator, the call operator takes operands and yields a result. The operands to the call operator are the name of the function and a (possibly empty) comma-separated list of arguments. The result type of a call is the return type of the called function, and the result itself is the value returned by the function:

If we gave this program 15 and 123 as input, the output would be 3.
Calling a function does two things: It initializes the function parameters from the corresponding arguments and transfers control to the function being invoked. Execution of the calling function is suspended and execution of the called function begins. Execution of a function begins with the (implicit) definition and initialization of its parameters. That is, when we invoke gcd, the first thing that happens is that variables of type int named v1 and v2 are created. These variables are initialized with the values passed in the call to gcd. In this case, v1 is initialized by the value of i and v2 by the value of j.
Function Body Is a Scope
The body of a function is a statement block, which defines the function’s operation. As usual, the block is enclosed by a pair of curly braces and hence forms a new scope. As with any block, the body of a function can define variables. Names defined inside a function body are accessible only within the function itself. Such variables are referred to as local variables. They are “local” to that function; their names are visible only in the scope of the function. They exist only while the function is executing. Section 7.5 (p. 254) covers local variables in more detail.
Execution completes when a return statement is encountered. When the called function finishes, it yields as its result the value specified in the return statement. After the return is executed, the suspended, calling function resumes execution at the point of the call. It uses the return value as the result of evaluating the call operator and continues processing whatever remains of the statement in which the call was performed.
Parameters and Arguments
Like local variables, the parameters of a function provide named, local storage for use by the function. The difference is that parameters are defined inside the function’s parameter list and are initialized by arguments passed to the function when the function is called.
An argument is an expression. It might be a variable, a literal constant or an expression involving one or more operators. We must pass exactly the same number of arguments as the function has parameters. The type of each argument must match the corresponding parameter in the same way that the type of an initializer must match the type of the object it initializes: The argument must have the same type or have a type that can be implicitly converted (Section 5.12, p. 178) to the parameter type. We’ll cover how arguments match a parameter in detail in Section 7.8.2 (p. 269).
7.1.1 Function Return Type
The return type of a function can be a built-in type, such as int or double, a class type, or a compound type, such as int& or string*. A return type also can be void, which means that the function does not return a value. The following are example definitions of possible function return types:

A function may not return another function or a built-in array type. Instead, the function may return a pointer to the function or to a pointer to an element in the array:
![]()
This function returns a pointer to int and that pointer could point to an element in an array.
We’ll learn about function pointers in Section 7.9 (p. 276).
Functions Must Specify a Return Type
It is illegal to define or declare a function without an explicit return type:
![]()
Eariler versions of C++ would accept this program and implicitly define the return type of test as an int. Under Standard C++, this program is an error.

In pre-Standard C++, a function without an explicit return type was assumed to return an int. C++ programs compiled under earlier, non-standard compilers may still contain functions that implicitly return int.
7.1.2 Function Parameter List
The parameter list of a function can be empty but cannot be omitted. A function with no parameters can be written either with an empty parameter list or a parameter list containing the single keyword void. For example, the following declarations of process are equivalent:

A parameter list consists of a comma-separated list of parameter types and (optional) parameter names. Even when the types of two parameters are the same, the type must be repeated:
![]()
No two parameters can have the same name. Similarly, a variable local to a function may not use the same name as the name of any of the function’s parameters.
Names are optional, but in a function definition, normally all parameters are named. A parameter must be named to be used.
Parameter Type-Checking
C++ is a statically typed language (Section 2.3, p. 44). The arguments of every call are checked during compilation.
When we call a function, the type of each argument must be either the same type as the corresponding parameter or a type that can be converted (Section 5.12, p. 178) to that type. The function’s parameter list provides the compiler with the type information needed to check the arguments. For example, the function gcd, which we defined on page 226, takes two parameters of type int:

Each of these calls is a compile-time error. In the first call, the arguments are of type const char*. There is no conversion from const char* to int, so the call is illegal. In the second and third calls, gcd is passed the wrong number of arguments. The function must be called with two arguments; it is an error to call it with any other number.
But what happens if the call supplies two arguments of type double? Is this call legal?
gcd(3.14, 6.29); // ok: arguments are converted to int
In C++, the answer is yes; the call is legal. In Section 5.12.1 (p. 179) we saw that a value of type double can be converted to a value of type int. This call involves such a conversion—we want to use double values to initialize int objects. Therefore, flagging the call as an error would be too severe. Rather, the arguments are implicitly converted to int (through truncation). Because this conversion might lose precision, most compilers will issue a warning. In this case, the call becomes
gcd(3, 6);
and returns a value of 3.
A call that passes too many arguments, omits an argument, or passes an argument of the wrong type almost certainly would result in serious run-time errors. Catching these so-called interface errors at compile time greatly reduces the compile-debug-test cycle for large programs.
7.2 Argument Passing
Each parameter is created anew on each call to the function. The value used to initialize a parameter is the corresponding argument passed in the call.
Parameters are initialized the same way that variables are. If the parameter has a nonreference type, then the argument is copied. If the parameter is a reference (Section 2.5, p. 58), then the parameter is just another name for the argument.
Exercises Section 7.1.2
Exercise 7.1: What is the difference between a parameter and an argument?
Exercise 7.2: Indicate which of the following functions are in error and why. Suggest how you might correct the problems.

Exercise 7.3: Write a program to take two int parameters and generate the result of raising the first parameter to the power of the second. Write a program to call your function passing it two ints. Verify the result.
Exercise 7.4: Write a program to return the absolute value of its parameter.
7.2.1 Nonreference Parameters
Parameters that are plain, nonreference types are initialized by copying the corresponding argument. When a parameter is initialized with a copy, the function has no access to the actual arguments of the call. It cannot change the arguments. Let’s look again at the definition of gcd:

Inside the body of the while, we change the values of both v1 and v2. However, these changes are made to the local parameters and are not reflected in the arguments used to call gcd. Thus, when we call
gcd(i, j)
the values i and j are unaffected by the assignments performed inside gcd.
Nonreference parameters represent local copies of the corresponding argument. Changes made to the parameter are made to the local copy. Once the function terminates, these local values are gone.
Pointer Parameters
A parameter can be a pointer (Section 4.2, p. 114), in which case the argument pointer is copied. As with any nonreference type parameter, changes made to the parameter are made to the local copy. If the function assigns a new pointer value to the parameter, the calling pointer value is unchanged.
Recalling the discussion in Section 4.2.3 (p. 121), the fact that the pointer is copied affects only assignments to the pointer. If the function takes a pointer to a nonconst type, then the function can assign through the pointer and change the value of the object to which the pointer points:

After a call to reset, the argument is unchanged but the object to which the argument points will be 0:

If we want to prevent changes to the value to which the pointer points, then the parameter should be defined as a pointer to const:

Whether a pointer parameter points to a const or nonconst type affects the arguments that we can use to call the function. We can call use_ptr on either an int* or a const int*; we can pass only on an int* to reset. This distinction follows from the initialization rules for pointers (Section 4.2.5, p. 126). We may initialize a pointer to const to point to a nonconst object but may not use a pointer to nonconst to point to a const object.
const Parameters
We can call a function that takes a nonreference, nonconst parameter passing either a const or nonconst argument. For example, we could pass two const ints to our gcd function:
![]()
This behavior follows from the normal initialization rules for const objects (Section 2.4, p. 56). Because the initialization copies the value of the initializer, we can initialize a nonconst object from a const object, or vice versa.
If we make the parameter a const nonreference type:
void fcn(const int i) { /* fcn can read but not write to i */ }
then the function cannot change its local copy of the argument. The argument is still passed as a copy so we can pass fcn either a const or nonconst object.
What may be surprising, is that although the parameter is a const inside the function, the compiler otherwise treats the definition of fcn as if we had defined the parameter as a plain int:
![]()
This usage exists to support compatibility with the C language, which makes no distinction between functions taking const or nonconst parameters.
Limitations of Copying Arguments
Copying an argument is not suitable for every situation. Cases where copying doesn’t work include:
• When we want the function to be able to change the value of an argument.
• When we want to pass a large object as an argument. The time and space costs to copy the object are often too high for real-world applications.
• When there is no way to copy the object.
In these cases we can instead define the parameters as references or pointers.
7.2.2 Reference Parameters
As an example of a situation where copying the argument doesn’t work, consider a function to swap the values of its two arguments:

In this case, we want to change the arguments themselves. As defined, though, swap cannot affect those arguments. When it executes, swap exchanges the local copies of its arguments. The arguments passed to swap are unchanged:

Compiling and executing this program results in the following output:
Before swap(): i: 10 j: 20
After swap(): i: 10 j: 20
For swap to work as intended and swap the values of its arguments, we need to make the parameters references:

Like all references, reference parameters refer directly to the objects to which they are bound rather than to copies of those objects. When we define a reference, we must initialize it with the object to which the reference will be bound. Reference parameters work exactly the same way. Each time the function is called, the reference parameter is created and bound to its corresponding argument. Now, when we call swap
swap(i, j);
the parameter v1 is just another name for the object i and v2 is another name for j. Any change to v1 is actually a change to the argument i. Similarly, changes to v2 are actually made to j. If we recompile main using this revised version of swap, we can see that the output is now correct:
Before swap(): i: 10 j: 20
After swap(): i: 20 j: 10

Programmers who come to C++ from a C background are used to passing pointers to obtain access to the argument. In C++ it is safer and more natural to use reference parameters.
Using Reference Parameters to Return Additional Information
We’ve seen one example, swap, in which reference parameters were used to allow the function to change the value of its arguments. Another use of reference parameters is to return an additional result to the calling function.
Functions can return only a single value, but sometimes a function has more than one thing to return. For example, let’s define a function named find_val that searches for a particular value in the elements of a vector of integers. It returns an iterator that refers to the element, if the element was found, or to the end value if the element isn’t found. We’d also like the function to return an occurrence count if the value occurs more than once. In this case the iterator returned should be to the first element that has the value for which we’re looking.
How can we define a function that returns both an iterator and an occurrence count? We could define a new type that contains an iterator and a count. An easier solution is to pass an additional reference argument that find_val can use to return a count of the number of occurrences:

When we call find_val, we have to pass four arguments: a pair of iterators that denote the range of elements (Section 9.2.1, p. 314) in the vector in which to look, the value to look for, and a size_type (Section 3.2.3, p. 84) object to hold the occurrence count. Assuming ivec is a vector<int>, it is an iterator of the right type, and ctr is a size_type, we could call find_val as follows:
it = find_val(ivec.begin(), ivec.end(), 42, ctr);
After the call, the value of ctr will be the number of times 42 occurs, and it will refer to the first occurrence if there is one. Otherwise, it will be equal to ivec.end() and ctr will be zero.
Using (const) References to Avoid Copies
The other circumstance in which reference parameters are useful is when passing a large object to a function. Although copying an argument is okay for objects of built-in data types and for objects of class types that are small in size, it is (often) too inefficient for objects of most class types or large arrays. Moreover, as we’ll learn in Chapter 13, some class types cannot be copied. By using a reference parameter, the function can access the object directly without copying it.
As an example, we’ll write a function that compares the length of two strings. Such a function needs to access the size of each string but has no need to write to the strings. Because strings can be long, we’d like to avoid copying them. Using const references we can avoid the copy:

Each parameter is a reference to const string. Because the parameters are references the arguments are not copied. Because the parameters are const references, is Shorter may not use the references to change the arguments.
When the only reason to make a parameter a reference is to avoid copying the argument, the parameter should be const reference.
References to const Are More Flexible
It should be obvious that a function that takes a plain, nonconst reference may not be called on behalf of a const object. After all, the function might change the object it is passed and thus violate the constness of the argument.
What may be less obvious is that we also cannot call such a function with an rvalue (Section 2.3.1, p. 45) or with an object of a type that requires a conversion:

The problem is that a nonconst reference (Section 2.5, p. 59) may be bound only to nonconst object of exactly the same type.
Parameters that do not change the value of the corresponding argument should be const references. Defining such parameters as nonconst references needlessly restricts the usefulness of a function. As an example, we might write a program to find a given character in a string:

This function takes its string argument as a plain (nonconst) reference, even though it doesn’t modify that parameter. One problem with this definition is that we cannot call it on a character string literal:
if (find_char("Hello World", 'o')) // ...
This call fails at compile time, even though we can convert the literal to a string.
Such problems can be surprisingly pervasive. Even if our program has no const objects and we only call find_char on behalf of string objects (as opposed to on a string literal or an expression that yields a string), we can encounter compile-time problems. For example, we might have another function is_sentence that wants to use find_char to determine whether a string represents a sentence:

As written, the call to find_char from inside is_sentence is a compile-time error. The parameter to is_sentence is a reference to const string and cannot be passed to find_char, which expects a reference to a nonconst string.

Reference parameters that are not changed should be references to const. Plain, nonconst reference parameters are less flexible. Such parameters may not be initialized by const objects, or by arguments that are literals or expressions that yield rvalues.
Passing a Reference to a Pointer
Suppose we want to write a function that swaps two pointers, similar to the program we wrote earlier that swaps two integers. We know that we use * to define a pointer and & to define a reference. The question here is how to combine these operators to obtain a reference to a pointer. Here is an example:

The parameter
int *&v1
should be read from right to left: v1 is a reference to a pointer to an object of type int. That is, v1 is just another name for whatever pointer is passed to ptrswap.
We could rewrite the main function from page 233 to use ptrswap and swap pointers to the values 10 and 20:

When compiled and executed, the program generates the following output:
Before ptrswap(): *pi: 10 *pj: 20
After ptrswap(): *pi: 20 *pj: 10
What happens is that the pointer values are swapped. When we call ptrswap, pi points to i and pj points to j. Inside ptrswap the pointers are swapped so that after ptrswap, pi points to the object pj had addressed. In other words, pi now points to j. Similarly, pj points to i.
7.2.3 vector and Other Container Parameters
Ordinarily, functions should not have vector or other library container parameters. Calling a function that has a plain, nonreference vector parameter will copy every element of the vector.
In order to avoid copying the vector, we might think that we’d make the parameter a reference. However, for reasons that will be clearer after reading Chapter 11, in practice, C++ programmers tend to pass containers by passing iterators to the elements we want to process:

This function prints the elements starting with one referred to by beg up to but not including the one referred to by end. We print a space after each element but the last.
7.2.4 Array Parameters
Arrays have two special properties that affect how we define and use functions that operate on arrays: We cannot copy an array (Section 4.1.1, p. 112) and when we use the name of an array it is automatically converted to a pointer to the first element (Section 4.2.4, p. 122). Because we cannot copy an array, we cannot write a function that takes an array type parameter. Because arrays are automatically converted to pointers, functions that deal with arrays usually do so indirectly by manipulating pointers to elements in the array.
Defining an Array Parameter
Let’s assume that we want to write a function that will print the contents of an array of ints. We could specify the array parameter in one of three ways:
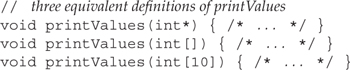
Even though we cannot pass an array directly, we can write a function parameter that looks like an array. Despite appearances, a parameter that uses array syntax is treated as if we had written a pointer to the array element type. These three definitions are equivalent; each is interpreted as taking a parameter of type int*.
It is usually a good idea to define array parameters as pointers, rather than using the array syntax. Doing so makes it clear that what is being operated on is a pointer to an array element, not the array itself. Because an array dimension is ignored, including a dimension in a parameter definition is particularly misleading.
Parameter Dimensions Can Be Misleading
The compiler ignores any dimension we might specify for an array parameter. Relying, incorrectly, on the dimension, we might write printValues as

Although this code assumes that the array it is passed has at least 10 elements, nothing in the language enforces that assumption. The following calls are all legal:

Even though the compiler issues no complaints, both calls are in error, and probably will fail at run time. In each case, memory beyond the array will be accessed because printValues assumes that the array it is passed has at least 10 elements. Depending on the values that happen to be in that memory, the program will either produce spurious output or crash.
When the compiler checks an argument to an array parameter, it checks only that the argument is a pointer and that the types of the pointer and the array elements match. The size of the array is not checked.
Array Arguments
As with any other type, we can define an array parameter as a reference or nonreference type. Most commonly, arrays are passed as plain, nonreference types, which are quietly converted to pointers. As usual, a nonreference type parameter is initialized as a copy of its corresponding argument. When we pass an array, the argument is a pointer to the first element in the array. That pointer value is copied; the array elements themselves are not copied. The function operates on a copy of the pointer, so it cannot change the value of the argument pointer. The function can, however, use that pointer to change the element values to which the pointer points. Any changes through the pointer parameter are made to the array elements themselves.
Functions that do not change the elements of their array parameter should make the parameter a pointer to const:
// f won't change the elements in the array
void f(const int*) { /* ... */ }
Passing an Array by Reference
As with any type, we can define an array parameter as a reference to the array. If the parameter is a reference to the array, then the compiler does not convert an array argument into a pointer. Instead, a reference to the array itself is passed. In this case, the array size is part of the parameter and argument types. The compiler will check that the size of the array argument matches the size of the parameter:

This version of printValues may be called only for arrays of exactly 10 ints, limiting which arrays can be passed. However, because the parameter is a reference, it is safe to rely on the size in the body of the function:

The parentheses around &arr are necessary because of the higher precedence of the subscript operator:
![]()
We’ll see in Section 16.1.5 (p. 632) how we might write this function in a way that would allow us to pass a reference parameter to an array of any size.
Passing a Multidimensioned Array
Recall that there are no multidimensioned arrays in C++ (Section 4.4, p. 141). Instead, what appears to be a multidimensioned array is an array of arrays.
As with any array, a multidimensioned array is passed as a pointer to its zeroth element. An element in a multidimenioned array is an array. The size of the second (and any subsequent dimensions) is part of the element type and must be specified:
![]()
declares matrix as a pointer to an array of ten ints.
We could also declare a multidimensioned array using array syntax. As with a single-dimensioned array, the compiler ignores the first dimension and so it is best not to include it:
![]()
declares matrix to be what looks like a two-dimensioned array. In fact, the parameter is a pointer to an element in an array of arrays. Each element in the array is itself an array of ten ints.
7.2.5 Managing Arrays Passed to Functions
As we’ve just seen, type checking for a nonreference array parameter confirms only that the argument is a pointer of the same type as the elements in the array. Type checking does not verify that the argument actually points to an array of a specified size.

It is up to any program dealing with an array to ensure that the program stays within the bounds of the array.
There are three common programming techniques to ensure that a function stays within the bounds of its array argument(s). The first places a marker in the array itself that can be used to detect the end of the array. C-style character strings are an example of this approach. C-style strings are arrays of characters that encode their termination point with a null character. Programs that deal with C-style strings use this marker to stop processing elements in the array.
Using the Standard Library Conventions
A second approach is to pass pointers to the first and one past the last element in the array. This style of programming is inspired by techniques used in the standard library. We’ll learn more about this style of programming in Part II.
Using this approach, we could rewrite printValues and call the new version as follows:

The loop inside printValues looks like other programs we’ve written that used vector iterators. We march the beg pointer one element at a time through the array. We stop the loop when beg is equal to the end marker, which was passed as the second parameter to the function.
When we call this version, we pass two pointers: one to the first element we want to print and one just past the last element. The program is safe, as long as we correctly calculate the pointers so that they denote a range of elements.
Explicitly Passing a Size Parameter
A third approach, which is common in C programs and pre-Standard C++ programs, is to define a second parameter that indicates the size of the array.
Using this approach, we could rewrite printValues one more time. The new version and a call to it looks like:

This version uses the size parameter to determine how many elements there are to print. When we call printValues, we must pass an additional parameter. The program executes safely as long as the size passed is no greater than the actual size of the array.
7.2.6 main: Handling Command-Line Options
It turns out that main is a good example of how C programs pass arrays to functions. Up to now, we have defined main with an empty parameter list:
int main() { ... }
However, we often need to pass arguments to main. Traditionally, such arguments are options that determine the operation of the program. For example, assuming our main program was in an executable file named prog, we might pass options to the program as follows:
prog -d -o ofile data0
The way this usage is handled is that main actually defines two parameters:
int main(int argc, char *argv[]) { ... }
The second parameter, argv, is an array of C-style character strings. The first parameter, argc, passes the number of strings in that array. Because the second parameter is an array, we might alternatively define main as
int main(int argc, char **argv) { ... }
indicating that argv points to a char*.
When arguments are passed to main, the first string in argv, if any, is always the name of the program. Subsequent elements pass additional optional strings to main. Given the previous command line, argc would be set to 5, and argv would hold the following C-style character strings:
argv[0] = "prog";
argv[1] = "-d";
argv[2] = "-o";
argv[3] = "ofile";
argv[4] = "data0";
7.2.7 Functions with Varying Parameters
Ellipsis parameters are in C++ in order to compile C programs that use varargs. See your C compiler documentation for how to use varargs. Only simple data types from the C++ program should be passed to functions with ellipses parameters. In particular, objects of most class types are not copied properly when passed to ellipses parameters.
Ellipses parameters are used when it is impossible to list the type and number of all the arguments that might be passed to a function. Ellipses suspend type checking. Their presence tells the compiler that when the function is called, zero or more arguments may follow and that the types of the arguments are unknown. Ellipses may take either of two forms:
void foo(parm_list, ...);
void foo(...);
The first form provides declarations for a certain number of parameters. In this case, type checking is performed when the function is called for the arguments that correspond to the parameters that are explicitly declared, whereas type checking is suspended for the arguments that correspond to the ellipsis. In this first form, the comma following the parameter declarations is optional.
Most functions with an ellipsis use some information from a parameter that is explicitly declared to obtain the type and number of optional arguments provided in a function call. The first form of function declaration with ellipsis is therefore most commonly used.
7.3 The return Statement
A return statement terminates the function that is currently executing and returns control to the function that called the now-terminated function. There are two forms of return statements:
return;
return expression;
7.3.1 Functions with No Return Value
A return with no value may be used only in a function that has a return type of void. Functions that return void are not required to contain a return statement. In a void function, an implicit return takes place after the function’s final statement.
Typically, a void function uses a return to cause premature termination of the function. This use of return parallels the use of the break (Section 6.10, p. 212) statement inside a loop. For example, we could rewrite our swap program to avoid doing any work if the values are identical:

This function first checks if the values are equal and if so exits the function. If the values are unequal, the function swaps them. An implicit return occurs after the last assignment statement.
A function with a void return type ordinarily may not use the second form of the return statement. However, a void function may return the result of calling another function that returns void:

Attempting to return any other expression is a compile-time error.
7.3.2 Functions that Return a Value
The second form of the return statement provides the function’s result. Every return in a function with a return type other than void must return a value. The value returned must have the same type as the function return type, or must have a type that can be implicitly converted to that type.
Although C++ cannot guarantee the correctness of a result, it can guarantee that every return from a function returns a result of the appropriate type. The following program, for example, won’t compile:

The return from within the while loop is an error because it fails to return a value. The compiler should detect this error.
The second error occurs because the function fails to provide a return after the while loop. If we call this function with one string that is a subset of the other, execution would fall out of the while. There should be are turn to handle this case. The compiler may or may not detect this error. If a program is generated, what happens at run time is undefined.
Failing to provide a return after a loop that does contain a return is particularly insidious because many compilers will not detect it. The behavior at run time is undefined.
Return from main
There is one exception to the rule that a function with a return type other than void must return a value: The main function is allowed to terminate without a return. If control reaches the end of main and there is no return, then the compiler implicitly inserts a return of 0.
Another way in which the return from main is special is how its returned value is treated. As we saw in Section 1.1 (p. 2), the value returned from main is treated as a status indicator. A zero return indicates success; most other values indicate failure. A nonzero value has a machine-dependent meaning. To make return values machine-independent, the cstdlib header defines two preprocessor variables (Section 2.9.2, p. 69) that we can use to indicate success or failure:

Our code no longer needs to use the precise machine-dependent values. Instead, those values are defined in cstdlib, and our code need not change.
Returning a Nonreference Type
The value returned by a function is used to initialize a temporary object created at the point at which the call was made. A temporary object is an unnamed object created by the compiler when it needs a place to store a result from evaluating an expression. C++ programmers usually use the term “temporary” as an abreviation of “temporary object.”
The temporary is initialized by the value returned by a function in much the same way that parameters are initialized by their arguments. If the return type is not a reference, then the return value is copied into the temporary at the call site. The value returned when a function returns a nonreference type can be a local object or the result of evaluating an expression.
As an example, we might want to write a function that, given a counter, a word, and an ending, gives us back the plural version of the word if the counter is greater than one:

We might use such a function to print a message with either a plural or singular ending.
This function either returns a copy of its parameter named word or it returns an unnamed temporary string that results from adding word and ending. In either case, the return copies that string to the call site.
Returning a Reference
When a function returns a reference type, the return value is not copied. Instead, the object itself is returned. As an example, consider a function that returns a reference to the shorter of its two string parameters:

The parameters and return type are references to const string. The strings are not copied either when calling the function or when returning the result.
Never Return a Reference to a Local Object
There’s one crucially important thing to understand about returning a reference: Never return a reference to a local variable.
When a function completes, the storage in which the local objects were allocated is freed. A reference to a local object refers to undefined memory after the function terminates. Consider the following function:

This function will fail at run time because it returns a reference to a local object. When the function ends, the storage in which ret resides is freed. The return value refers to memory that is no longer available to the program.
One good way to ensure that the return is safe is to ask: To what pre-existing object is the reference referring?
Reference Returns Are Lvalues
A function that returns a reference returns an lvalue. That function, therefore, can be used wherever an lvalue is required:

It may be surprising to assign to the return of a function, but the return is a reference. As such, it is just a synonym for the element returned.
If we do not want the reference return to be modifiable, the return value should be declared as const:
const char &get_val(...
Never Return a Pointer to a Local Object
The return type for a function can be most any type. In particular, it is possible for a function to return a pointer. For the same reasons that it is an error to return a reference to a local object, it is also an error to return a pointer to a local object. Once the function completes, the local objects are freed. The pointer would be a dangling pointer (Section 5.11, p. 176) that refers to a nonexistent object.
7.3.3 Recursion
A function that calls itself, either directly or indirectly, is a recursive function. An example of a simple recursive function is one that computes the factorial of a number. The factorial of a number n is the product of the numbers from 1 to n. The factorial of 5, for example, is 120.
1 * 2 * 3 * 4 * 5 = 120
Exercises Section 7.3.2
Exercise 7.17: When is it valid to return a reference? A const reference?
Exercise 7.18: What potential run-time problem does the following function have?

Exercise 7.19: Indicate whether the following program is legal. If so, explain what it does; if not, make it legal and then explain it:

A natural way to solve this problem is recursively:

A recursive function must always define a stopping condition; otherwise, the function will recurse “forever,” meaning that the function will continue to call itself until the program stack is exhausted. This is sometimes called an “infinite recursion error.” In the case of factorial, the stopping condition occurs when val is 1.
As another example, we can define a recursive function to find the greatest common divisor:

In this case the stopping condition is a remainder of 0. If we call rgcd with the arguments (15, 123), then the result is three. Table 7.1 on the next page traces the execution.
Table 7.1. Trace of rgcd(15,123)

rgcd(3,0)
satisfies the stopping condition. It returns the greatest common denominator, 3. This value successively becomes the return value of each prior call. The value is said to percolate upward until the execution returns to the function that called rgcd in the first place.
7.4 Function Declarations
Just as variables must be declared before they are used, a function must be declared before it is called. As with a variable definition (Section 2.3.5, p. 52), we can declare a function separately from its definition; a function may be defined only once but may be declared multiple times.
A function declaration consists of a return type, the function name, and parameter list. The parameter list must contain the types of the parameters but need not name them. These three elements are referred to as the function prototype. A function prototype describes the interface of the function.
Function prototypes provide the interface between the programmer who defines the function and programmers who use it. When we use a function, we program to the function’s prototype.
Parameter names in a function declaration are ignored. If a name is given in a declaration, it should serve as a documentation aid:
void print(int *array, int size);
Function Declarations Go in Header Files
Recall that variables are declared in header files (Section 2.9, p. 67) and defined in source files. For the same reasons, functions should be declared in header files and defined in source files.
It may be tempting—and would be legal—to put a function declaration directly in each source file that uses the function. The problem with this approach is that it is tedious and error-prone. By putting function declarations into header files, we can ensure that all the declarations for a given function agree. If the interface to the function changes, only one declaration must be changed.
Including the header that contains a function’s declaration in the same file that defines the function lets the compiler check that the definition and declaration are the same. In particular, if the definition and declaration agree as to parameter list but differ as to return type, the compiler will issue a warning or error message indicating the discrepancy.
Exercises Section 7.4
Exercise 7.22: Write the prototypes for each of the following functions:
(a) A function named compare with two parameters that are references to a class named matrix and with a return value of type bool.
(b) A function named change_val that returns a vector<int> iterator and takes two parameters: one is an int and the other is an iterator for a vector<int>.
Hint: When you write these prototypes, use the name of the function as an indicator as to what the function does. How does this hint affect the types you use?
Exercise 7.23: Given the following declarations, determine which calls are legal and which are illegal. For those that are illegal, explain why.

7.4.1 Default Arguments
A default argument is a value that, although not universally applicable, is the argument value that is expected to be used most of the time. When we call the function, we may omit any argument that has a default. The compiler will supply the default value for any argument we omit.
A default argument is specified by providing an explicit initializer for the parameter in the parameter list. We may define defaults for one or more parameters. However, if a parameter has a default argument, all the parameters that follow it must also have default arguments.
For example, a function to create and initialize a string intended to simulate a window can provide default arguments for the height, width, and background character of the screen:

A function that provides a default argument for a parameter can be invoked with or without an argument for this parameter. If an argument is provided, it overrides the default argument value; otherwise, the default argument is used. Each of the following calls of screenInit is correct:

Arguments to the call are resolved by position, and default arguments are used to substitute for the trailing arguments of a call. If we want to specify an argument for background, we must also supply arguments for height and width:
![]()
Note that the second call, which passes a single character value, is legal. Although legal, it is unlikely to be what the programmer intended. The call is legal because ’?’ is a char, and a char can be promoted to the type of the leftmost parameter. That parameter is string::size_type, which is an unsigned integral type. In this call, the char argument is implicitly promoted to string::size_type, and passed as the argument to height.
Because char is an integral type (Section 2.1.1, p. 34), it is legal to pass a char to an int parameter and vice versa. This fact can lead to various kinds of confusion, one of which arises in functions that take both char and int parameters—it can be easy for callers to pass the arguments in the wrong order. Using default arguments can compound this problem.
Part of the work of designing a function with default arguments is ordering the parameters so that those least likely to use a default value appear first and those most likely to use a default appear last.
Default Argument Initializers
A default argument can be any expression of an appropriate type:

When the default argument is an expression, and the default is used as the argument, then the expression is evaluated at the time the function is called. For example, screenDefault is called to obtain a value for background every time screenInit is called without a third argument.
Constraints on Specifying Default Arguments
We can specify default argument(s) in either the function definition or declaration. However, a parameter can have its default argument specified only once in a file. The following is an error:

Default arguments ordinarily should be specified with the declaration for the function and placed in an appropriate header.
If a default argument is provided in the parameter list of a function definition, the default argument is available only for function calls in the source file that contains the function definition.
7.5 Local Objects
In C++, names have scope, and objects have lifetimes. To understand how functions operate, it is important to understand both of these concepts. The scope of a name is the part of the program’s text in which that name is known. The lifetime of an object is the time during the program’s execution that the object exists.
The names of parameters and variables defined within a function are in the scope of the function: The names are visible only within the function body. As usual, a variable’s name can be used from the point at which it is declared or defined until the end of the enclosing scope.
Exercises Section 7.4.1
Exercise 7.24: Which, if any, of the following declarations are errors? Why?
![]()
Exercise 7.25: Given the following function declarations and calls, which, if any, of the calls are illegal? Why? Which, if any, are legal but unlikely to match the programmer’s intent? Why?

Exercise 7.26: Write a version of make_plural with a default argument of ’s’. Use that version to print singular and plural versions of the words “success” and “failure”.
7.5.1 Automatic Objects
By default, the lifetime of a local variable is limited to the duration of a single execution of the function. Objects that exist only while a function is executing are known as automatic objects. Automatic objects are created and destroyed on each call to a function.
The automatic object corresponding to a local variable is created when the function control path passes through the variable’s definition. If the definition contains an initializer, then the object is given an initial value each time the object is created. Uninitialized local variables of built-in type have undefined values. When the function terminates, the automatic objects are destroyed.
Parameters are automatic objects. The storage in which the parameters reside is created when the function is called and is freed when the function terminates.
Automatic objects, including parameters, are destroyed at the end of the block in which they were defined. Parameters are defined in the function’s block and so are destroyed when the function terminates. When a function exits, its local storage is deallocated. After the function exits, the values of its automatic objects and parameters are no longer accessible.
7.5.2 Static Local Objects
It is can be useful to have a variable that is in the scope of a function but whose lifetime persists across calls to the function. Such objects are defined as static.
A static local object is guaranteed to be initialized no later than the first time that program execution passes through the object’s definition. Once it is created, it is not destroyed until the program terminates; local statics are not destroyed when the function ends. Local statics continue to exist and hold their value across calls to the function. As a trivial example, consider a function that counts how often it is called:

This program will print the numbers from 1 through 10 inclusive.
Before count_calls is called for the first time, ctr is created and given an initial value of 0. Each call increments ctr and returns its current value. Whenever count_calls is executed, the variable ctr already exists and has whatever value was in the variable the last time the function exited. Thus, on the second invocation, the value is 1, on the third it is 2, and soon.
7.6 Inline Functions
Recall the function we wrote on page 248 that returned a reference to the shorter of its two string parameters:

The benefits of defining a function for such a small operation include:
• It is easier to read and understand a call to shorterString than it would be to read and interpret an expression that used the equivalent conditional expression in place of the function call.
• If a change needs to be made, it is easier to change the function than to find and change every occurrence of the equivalent expression.
• Using a function ensures uniform behavior. Each test is guaranteed to be implemented in the same manner.
• The function can be reused rather than rewritten for other applications.
There is, however, one potential drawback to making shorterString a function: Calling a function is slower than evaluating the equivalent expression. On most machines, a function call does a lot of work: registers are saved before the call and restored after the return; the arguments are copied; and the program branches to a new location.
inline Functions Avoid Function Call Overhead
A function specified as inline (usually) is expanded “in line” at each point in the program in which it is invoked. Assuming we made shorterString an inline function, then this call
cout << shorterString(s1, s2) << endl;
would be expanded during compilation into something like
![]()
The run-time overhead of making shorterString a function is thus removed.
We can define shorterString as an inline function by specifying the keyword inline before the function’s return type:

The inline specification is only a request to the compiler. The compiler may choose to ignore this request.
In general, the inline mechanism is meant to optimize small, straight-line functions that are called frequently. Many compilers will not inline a recursive function. A 1,200-line function is also not likely to be explanded inline.
Put inline Functions in Header Files
To expand the code of an inline function at the point of call, the compiler must have access to the function definition. The function prototype is insufficient.
An inline function may be defined more than once in a program as long as the definition appears only once in a given source file and the definition is exactly the same in each source file. By putting inline functions in headers, we ensure that the same definition is used whenever the function is called and that the compiler has the function definition available at the point of call.
Whenever an inline function is added to or changed in a header file, every source file that uses that header must be recompiled.
7.7 Class Member Functions
In Section 2.8 (p. 63) we began the definition of the Sales_item class used in solving the bookstore problem from Chapter 1. Now that we know how to define ordinary functions, we can continue to fill in our class by defining the member functions of this class.
We define member functions similarly to how we define ordinary functions. As with any function, a member function consists of four parts:
• A return type for the function
• The function name
• A (possibly empty) comma-separated list of parameters
• The function body, which is contained between a pair of curly braces
As we know, the first three of these parts constitute the function prototype. The function prototype defines all the type information related to the function: what its return type is, the function name, and what types of arguments may be passed to it. The function prototype must be defined within the class body. The body of the function, however, may be defined within the class itself or outside the class body.
With this knowledge, let’s look at our expanded class definition, to which we’ve added two new members: the member functions avg_price and same_isbn. The avg_price function has an empty parameter list and returns a value of type double. The same_isbn function returns a bool and takes a single parameter of type reference to const Sales_item.

We’ll explain the meaning of the const that follows the parameter lists shortly, but first we need to explain how member functions are defined.
7.7.1 Defining the Body of a Member Function
We must declare all the members of a class within the curly braces that delimit the class definition. There is no way to subsequently add any members to the class. Members that are functions must be defined as well as declared. We can define a member function either inside or outside of the class definition. In Sales_item, we have one example of each: same_isbn is defined inside the Sales_item class, whereas avg_price is declared inside the class but defined elsewhere.
A member function that is defined inside the class is implicitly treated as an inline function (Section 7.6, p. 256).
Let’s look in more detail at the definition of same_isbn:
![]()
As with any function, the body of this function is a block. In this case, the block contains a single statement that returns the result of comparing the value of the isbn data members of two Sales_item objects.
The first thing to note is that the isbn member is private. Even though these members are private, there is no error.
More interesting is understanding from which Sales_item objects does the function get the values that it compares. The function refers both to isbn and rhs.isbn. Fairly clearly, rhs.isbn uses the isbn member from the argument passed to the function. The unqualified use of isbn is more interesting. As we shall see, the unqualified isbn refers to the isbn member of the object on behalf of which the function is called.
Member Functions Have an Extra, Implicit Parameter
When we call a member function, we do so on behalf of an object. For example, when we called same_isbn in the bookstore program on page 26, we executed the same_isbn member on the object named total:
if (total.same_isbn(trans))
In this call, we pass the object trans. As part of executing the call, the object trans is used to initialize the parameter rhs. Thus, in this call, rhs.isbn is a reference to trans.isbn.
The same argument-binding process is used to bind the unqualified use of isbn to the object named total. Each member function has an extra, implicit parameter that binds the function to the object on which the function was called. When we call same_isbn on the object named total, that object is also passed to the function. When same_isbn refers to isbn, it is implicitly referring to the isbn member of the object on which the function was called. The effect of this call is to compare total.isbn with trans.isbn.
Introducing this
Each member function (except for static member functions, which we cover in Section 12.6 (p. 467)) has an extra, implicit parameter named this. When a member function is called, the this parameter is initialized with the address of the object on which the function was invoked. To understand a member function call, we might think that when we write
total.same_isbn(trans);
it is as if the compiler rewrites the call as
// pseudo-code illustration of how a call to a member function is translated
Sales_item::same_isbn(&total, trans);
In this call, the data member isbn inside same_isbn is bound to the one belonging to total.
Introducing const Member Functions
We now can understand the role of the const that follows the parameter lists in the declarations of the Sales_item member functions: That const modifies the type of the implicit this parameter. When we call total.same_isbn(trans), the implicit this parameter will be a const Sales_Item* that points to total. It is as if the body of same_isbn were written as

A function that uses const in this way is called a const member function. Because this is a pointer to const, a const member function cannot change the object on whose behalf the function is called. Thus, avg_price and same_isbn may read but not write to the data members of the objects on which they are called.
A const object or a pointer or reference to a const object may be used to call only const member functions. It is an error to try to call a nonconst member function on a const object or through a pointer or reference to a const object.
Using the this Pointer
Inside a member function, we need not explicitly use the this pointer to access the members of the object on which the function was called. Any unqualified reference to a member of our class is assumed to be a reference through this:
![]()
Here, the right-hand operand of the == operator explicitly uses the isbn member of the parameter rhs. The left-hand operand implicitly uses the isbn of the object on which the function is called. It is as if we had written this->isbn.
The this parameter is defined implicitly, so it is unnecessary and in fact illegal to include the this pointer in the function’s parameter list. However, in the body of the function we can refer to the this pointer explicitly. It is legal, although unnecessary, to define same_isbn as follows:
![]()
7.7.2 Defining a Member Function Outside the Class
Member functions defined outside the class definition must indicate that they are members of the class:

This definition is like the other functions we’ve seen: It has a return type of double and an empty parameter list enclosed in parentheses after the function name. What is new is the const following the parameter list and the form of the function name. The function name
Sales_item::avg_price
uses the scope operator (Section 1.2.2, p. 8) to say that we are defining the function named avg_price that is defined in the scope of the Sales_item class.
The const that follows the parameter list reflects the way we declared the member funcion inside the Sales_item header. In any definition, the return type and parameter list must match the declaration, if any, of the function. In the case of a member function, the declaration is as it appears in the class definition. If the function is declared to be a const member function, then the const after the parameter list must be included in the definition as well.
We can now fully understand the first line of this code: It says we are defining the avg_price function from the Sales_item class and that the function is a const member. The function takes no (explicit) parameters and returns a double.
The body of the function is easier to understand: It tests whether units_sold is nonzero and, if so, returns the result of dividing revenue by units_sold. If units_sold is zero, we can’t safely do the division—dividing by zero has undefined behavior. In this program, we return 0, indicating that if there were no sales the average price would be zero. Depending on the sophistication of our error-handling strategy, we might instead throw an exception (Section 6.13, p. 215).
7.7.3 Writing the Sales_item Constructor
There’s one more member that we need to write: a constructor. As we learned in Section 2.8 (p. 65), class data members are not initialized when the class is defined. Instead, data members are initialized through a constructor.
Constructors Are Special Member Functions
A constructor is a special member function that is distinguished from other member functions by having the same name as its class. Unlike other member functions, constructors have no return type. Like other member functions they take a (possibly empty) parameter list and have a function body. A class can have multiple constructors. Each constructor must differ from the others in the number or types of its parameters.
The constructor’s parameters specify the initializers that may be used when creating objects of the class type. Ordinarily these initializers are used to initialize the data members of the newly created object. Constructors usually should ensure that every data member is initialized.
The Sales_item class needs to explicitly define only one constructor, the default constructor, which is the one that takes no arguments. The default constructor says what happens when we define an object but do not supply an (explicit) initializer:
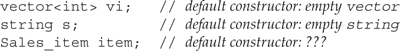
We know the behavior of the string and vector default constructors: Each of these constructors initializes the object to a sensible default state. The default string constructor generates an empty string, the one that is equal to "". The default vector constructor generates a vector with no elements.
Similarly, we’d like the default constructor for Sales_items to generate an empty Sales_item. Here “empty” means an object in which the isbn is the empty string and the units_sold and revenue members are initialized to zero.
Defining a Constructor
Like any other member function, a constructor is declared inside the class and may be defined there or outside the class. Our constructor is simple, so we will define it inside the class body:

Before we explain the constructor definition, note that we put the constructor in the public section of the class. Ordinarily, and certainly in this case, we want the constructor(s) to be part of the interface to the class. After all, we want code that uses the Sales_item type to be able to define and initialize Sales_item objects. Had we made the constructor private, it would not be possible to define Sales_item objects, which would make the class pretty useless.
As to the definition itself
// default constructor needed to initialize members of built-in type
Sales_item(): units_sold(0), revenue(0.0) { }
it says that we are defining a constructor for the Sales_item class that has an empty parameter list and an empty function body. The interesting part is the colon and the code between it and the curly braces that define the (empty) function body.
Constructor Initialization List
The colon and the following text up to the open curly is the constructor initializer list. A constructor initializer list specifies initial values for one or more data members of the class. It follows the constructor parameter list and begins with a colon. The constructor initializer is a list of member names, each of which is followed by that member’s initial value in parentheses. Multiple member initializations are separated by commas.
This initializer list says that both the units_sold and revenue members should be initialized to 0. Whenever a Sales_item object is created, these members will start out as 0. We need not specify an initial value for the isbn member. Unless we say otherwise in the constructor initializer list, members that are of class type are automatically initialized by that class’ default constructor. Hence, isbn is initialized by the string default constructor, meaning that isbn initially is the empty string. Had we needed to, we could have specified a default value for isbn in the initializer list as well.
Having explained the initializer list, we can now understand the constructor: Its parameter list and the function body are both empty. The parameter list is empty because we are defining the constructor that is run by default, when no initializer is present. The body is empty because there is no work to do other than initializing units_sold and revenue. The initializer list explicitly initializes units_sold and revenue to zero and implicitly initializes isbn to the empty string. Whenever we create a Sales_item object, the data members will start out with these values.
Synthesized Default Constructor
If we do not explicitly define any constructors, then the compiler will generate the default constructor for us.
The compiler-created default constructor is known as a synthesized default constructor. It initializes each member using the same rules as are applied for variable initializations (Section 2.3.4, p. 50). Members that are of class type, such as isbn, are initialized by using the default constructor of the member’s own class. The initial value of members of built-in type depend on how the object is defined. If the object is defined at global scope (outside any function) or is a local static object, then these members will be initialized to 0. If the object is defined at local scope, these members are uninitialized. As usual, using an uninitialized member for any purpose other than giving it a value is undefined.
The synthesized default constructor often suffices for classes that contain only members of class type. Classes with members of built-in or compound type should usually define their own default constructors to initialize those members.
Because the synthesized constructor does not automatically initialize members of built-in type, we had to define the Sales_item default constructor explicitly.
7.7.4 Organizing Class Code Files
As we saw in Section 2.9 (p. 67), class declarations ordinarily are placed in headers. Usually, member functions defined outside the class are put in ordinary source files. C++ programmers tend to use a simple naming convention for headers and the associated class definition code. The class definition is put in a file named type .h or type .H, where type is the name of the class defined in the file. Member function definitions usually are stored in a source file whose name is the name of the class. Following this convention we put the Sales_item class definition in a file named Sales_item.h. Any program that wants to use the class must include that header. We should put the definition of our Sales_item functions in a file named Sales_item.cc. That file, like any other file that uses the Sales_item type, would include the Sales_item.h header.
7.8 Overloaded Functions
Two functions that appear in the same scope are overloaded if they have the same name but have different parameter lists.
If you have written an arithmetic expression in a programming language, you have used an overloaded function. The expression
1 + 3
invokes the addition operation for integer operands, whereas the expression
1.0 + 3.0
invokes a different operation that adds floating-point operands. It is the compiler’s responsibility, not the programmer’s, to distinguish between the different operations and to apply the appropriate operation depending on the operands’ types.
Similarly, we may define a set of functions that perform the same general action but that apply to different parameter types. These functions may be called without worrying about which function is invoked, much as we can add ints or doubles without worrying whether integer arithmetic or floating-point arithmetic is performed.
Function overloading can make programs easier to write and to understand by eliminating the need to invent—and remember—names that exist only to help the compiler figure out which function to call. For example, a database application might well have several lookup functions that could do the lookup based on name, phone number, account number, and so on. Function overloading allows us to define a collection of functions, each named lookup, that differ in terms of what values they use to do the search. We can call lookup passing a value of any of several types:

Here, all three functions share the same name, yet they are three distinct functions. The compiler uses the argument type(s) passed in the call to figure out which function to call.
To understand function overloading, we must understand how to define a set of overloaded functions and how the compiler decides which function to use for a given call. We’ll review these topics in the remainder of this section.
Distinguishing Overloading from Redeclaring a Function
If the return type and parameter list of two functions declarations match exactly, then the second declaration is treated as a redeclaration of the first. If the parameter lists of two functions match exactly but the return types differ, then the second declaration is an error:
![]()
Functions cannot be overloaded based only on differences in the return type.
Two parameter lists can be identical, even if they don’t look the same:

In the first pair, the first declaration names its parameter. Parameter names are only a documentation aid. They do not change the parameter list.
In the second pair, it looks like the types are different, but Telno is not a new type; it is a synonym for Phone. A typedef name provides an alternative name for an existing data type; it does not create a new data type. Therefore, two parameters that differ only in that one uses a typedef and the other uses the type to which the typedef corresponds are not different.
In the third pair, the parameter lists differ only in their default arguments. A default argument doesn’t change the number of parameters. The function takes two arguments, whether they are supplied by the user or by the compiler.
The last pair differs only as to whether the parameter is const. This difference has no effect on the objects that can be passed to the function; the second declaration is treated as a redeclaration of the first. The reason follows from how arguments are passed. When the parameter is copied, whether the parameter is const is irrelevant—the function executes on a copy. Nothing the function does can change the argument. As a result, we can pass a const object to either a const or nonconst parameter. The two parameters are indistinguishable.
It is worth noting that the equivalence between a parameter and a const parameter applies only to nonreference parameters. A function that takes a const reference is different from one that takes a nonconst reference. Similarly, a function that takes a pointer to a const type differs from a function that takes a pointer to the nonconst object of the same type.
Advice: When Not to Overload a Function Name
Although overloading can be useful in avoiding the necessity to invent (and remember) names for common operations, it is easy to take this advantage too far. There are some cases where providing different function names adds information that makes the program easier to understand. Consider a set of member functions for a Screen class that move Screen’s cursor.
Screen& moveHome();
Screen& moveAbs(int, int);
Screen& moveRel(int, int, char *direction);
It might at first seem better to overload this set of functions under the name move:
Screen& move();
Screen& move(int, int);
Screen& move(int, int, *direction);
However, by overloading these functions we’ve lost information that was inherent in the function names and by doing so may have rendered the program more obscure.
Although cursor movement is a general operation shared by all these functions, the specific nature of that movement is unique to each of these functions. moveHome, for example, represents a special instance of cursor movement. Which of the two calls is easier to understand for a reader of the program? Which of the two calls is easier to remember for a programmer using the Screen class?
7.8.1 Overloading and Scope
We saw in the program on page 54 that scopes in C++ nest. A name declared local to a function hides the same name declared in the global scope (Section 2.3.6, p. 54). The same is true for function names as for variable names:

Normal scoping rules apply to names of overloaded functions. If we declare a function locally, that function hides rather than overloads the same function declared in an outer scope. As a consequence, declarations for every version of an overloaded function must appear in the same scope.
In general, it is a bad idea to declare a function locally. Function declarations should go in header files.
To explain how scope interacts with overloading we will violate this practice and use a local function declaration.
As an example, consider the following program:

The declaration of print(int) in the function fooBar hides the other declarations of print. It is as if there is only one print function available: the one that takes a single int parameter. Any use of the name print at this scope—or a scope nested in this scope—will resolve to this instance.
When we call print, the compiler first looks for a declaration of that name. It finds the local declaration for print that takes an int. Once the name is found, the compiler does no further checks to see if the name exists in an outer scope. Instead, the compiler assumes that this declaration is the one for the name we are using. What remains is to see if the use of the name is valid
The first call passes a string literal but the function parameter is an int. A string literal cannot be implicitly converted to an int, so the call is an error. The print(const string&) function, which would have matched this call, is hidden and is not considered when resolving this call.
When we call print passing a double, the process is repeated. The compiler finds the local definition of print(int). The double argument can be converted to an int, so the call is legal.
Had we declared print(int) in the same scope as the other print functions, then it would be another overloaded version of print. In that case, these calls would be resolved differently:

Now when the compiler looks for the name print it finds three functions with that name. On each call it selects the version of print that matches the argument that is passed.
7.8.2 Function Matching and Argument Conversions
Function overload resolution (also known as function matching) is the process by which a function call is associated with a specific function from a set of overloaded functions. The compiler matches a call to a function automatically by comparing the actual arguments used in the call with the parameters offered by each function in the overload set. There are three possible outcomes:
- The compiler finds one function that is a best match for the actual arguments and generates code to call that function.
- There is no function with parameters that match the arguments in the call, in which case the compiler indicates a compile-time error.
- There is more than one function that matches and none of the matches is clearly best. This case is also an error; the call is ambiguous.
Most of the time it is straghtforward to determine whether a particular call is legal and if so, which function will be invoked by the compiler. Often the functions in the overload set differ in terms of the number of arguments, or the types of the arguments are unrelated. Function matching gets tricky when multiple functions have parameters that are related by conversions (Section 5.12, p. 178). In these cases, programmers need to have a good grasp of the process of function matching.
Exercises Section 7.8.1
Exercise 7.34: Declare a set of overloaded functions named error that would match the following calls:

Exercise 7.35: Explain the effect of the second declaration in each one of the following sets of declarations. Indicate which, if any, are illegal.

7.8.3 The Three Steps in Overload Resolution
Consider the following set of functions and function call:

Candidate Functions
The first step of function overload resolution identifies the set of overloaded functions considered for the call. The functions in this set are the candidate functions. A candidate function is a function with the same name as the function that is called and for which a declaration is visible at the point of the call. In this example, there are four candidate functions named f.
Determining the Viable Functions
The second step selects the functions from the set of candidate functions that can be called with the arguments specified in the call. The selected functions are the viable functions. To be viable, a function must meet two tests. First, the function must have the same number of parameters as there are arguments in the call. Second, the type of each argument must match—or be convertible to—the type of its corresponding parameter.
When a function has default arguments (Section 7.4.1, p. 253), a call may appear to have fewer arguments than it actually does. Default arguments are arguments and are treated the same way as any other argument during function matching.
For the call f(5.6), we can eliminate two of our candidate functions because of a mismatch on number of arguments. The function that has no parameters and the one that has two int parameters are not viable for this call. Our call has only one argument, and these functions have zero and two parameters, respectively.
On the other hand, the function that takes two doubles might be viable. A call to a function declaration that has a default argument (Section 7.4.1, p. 253) may omit that argument. The compiler will automatically supply the default argument value for the omitted argument. Hence, a given call might have more arguments than appear explicitly.
Having used the number of arguments to winnow the potentially viable functions, we must now look at whether the argument types match those of the parameters. As with any call, an argument might match its parameter either because the types match exactly or because there is a conversion from the argument type to the type of the parameter. In the example, both of our remaining functions are viable.
• f(int) is a viable function because a conversion exists that can convert the argument of type double to the parameter of type int.
• f(double, double) is a viable function because a default argument is provided for the function’s second parameter and its first parameter is of type double, which exactly matches the type of the parameter.
Finding the Best Match, If Any
The third step of function overload resolution determines which viable function has the best match for the actual arguments in the call. This process looks at each argument in the call and selects the viable function (or functions) for which the corresponding parameter best matches the argument. The details of “best” here will be explained in the next section, but the idea is that the closer the types of the argument and parameter are to each other, the better the match. So, for example, an exact type match is better than a match that requires a conversion from the argument type to the parameter type.
In our case, we have only one explicit argument to consider. That argument has type double. To call f(int), the argument would have to be converted from double to int. The other viable function, f(double, double), is an exact match for this argument. Because an exact match is better than a match that requires a conversion, the compiler will resolve the call f(5.6) as a call to the function that has two double parameters.
Overload Resolution with Multiple Parameters
Function matching is more complicated if there are two or more explicit arguments. Given the same functions named f, let’s analyze the following call:
f(42, 2.56);
The set of viable functions is selected in the same way. The compiler selects those functions that have the required number of parameters and for which the argument types match the parameter types. In this case, the set of viable functions are f(int, int) and f(double, double). The compiler then determines argument by argument which function is (or functions are) the best match. There is a match if there is one and only one function for which
- The match for each argument is no worse than the match required by any other viable function.
- There is at least one argument for which the match is better than the match provided by any other viable function.
If after looking at each argument there is no single function that is preferable, then the call is in error. The compiler will complain that the call is ambiguous.
In this call, when we look only at the first argument, we find that the function f(int, int) is an exact match. To match the second function, the int argument 42 must be converted to a double. A match through a built-in conversion is “less good” than one that is exact. So, considering only this parameter, the function that takes two ints is a better match than the function that takes two doubles.
However, when we look at the second argument, then the function that takes two doubles is an exact match to the argument 2.56. Calling the version of f that takes two ints would require that 2.56 be converted from double to int. When we consider only the second parameter, then the function f(double, double) is the better match.
This call is therefore ambiguous: Each viable function is a better match on one of the arguments to the call. The compiler will generate an error. We could force a match by explicitly casting one of our arguments:
![]()
In practice, arguments should not need casts when calling over-loaded functions: The need for a cast means that the parameter sets are designed poorly.
7.8.4 Argument-Type Conversions
In order to determine the best match, the compiler ranks the conversions that could be used to convert each argument to the type of its corresponding parameter. Conversions are ranked in descending order as follows:
- An exact match. The argument and parameter types are the same.
- Match through a promotion (Section 5.12.2, p. 180).
- Match through a standard conversion (Section 5.12.3, p. 181).
- Match through a class-type conversion. (Section 14.9 (p. 535) covers these conversions.)
Promotions and conversions among the built-in types can yield surprising results in the context of function matching. Fortunately, well-designed systems rarely include functions with parameters as closely related as those in the following examples.
These examples bear study to cement understanding both of function matching in particular and of the relationships among the built-in types in general.
Matches Requiring Promotion or Conversion
Promotions or conversions are applied when the type of the argument can be promoted or converted to the appropriate parameter type using one of the standard conversions.
One important point to realize is that the small integral types promote to int. Given two functions, one of which takes an int and the other a short, the int version will be a better match for a value of any integral type other than short, even though short might appear on the surface to be a better match:

A character literal is type char, and chars are promoted to int. That promoted type matches the type of the parameter of function ff(int). A char could also be converted to short, but a conversion is a “less good” match than a promotion. And so this call will be resolved as a call to ff (int).
A conversion that is done through a promotion is preferred to another standard conversion. So, for example, a char is a better match for a function taking an int than it is for a function taking a double. All other standard conversions are treated as equivalent. The conversion from char to unsigned char, for example, does not take precedence over the conversion from char to double. As a concrete example, consider:
extern void manip(long);
extern void manip(float);
manip(3.14); // error: ambiguous call
The literal constant 3.14 is a double. That type could be converted to either long or float. Because there are two possible standard conversions, the call is ambiguous. No one standard conversion is given precedence over another.
Parameter Matching and Enumerations
Recall that an object of enum type may be initialized only by another object of that enum type or one of its enumerators (Section 2.7, p. 63). An integral object that happens to have the same value as an enumerator cannot be used to call a function expecting an enum argument:

The call that passes the literal 128 matches the version of ff that takes an int.
Although we cannot pass an integral value to a enum parameter, we can pass an enum to a parameter of integral type. When we do so, the enum value promotes to int or to a larger integral type. The actual promotion type depends on the values of the enumerators. If the function is overloaded, the type to which the enum promotes determines which function is called:

The enum Tokens has only two enumerators, the largest of which has a value of 129. That value can be represented by the type unsigned char, and many compilers would store the enum as an unsigned char. However, the type of VIRTUAL is not unsigned char. Enumerators and values of an enum type, are not promoted to unsigned char, even if the values of the enumerators would fit.
When using overloaded functions with enum parameters, remember: Two enumeration types may behave quite differently during function overload resolution, depending on the value of their enumeration constants. The enumerators determine the type to which they promote. And that type is machine-dependent.
Overloading and const Parameters
We can overload a function based on whether a reference parameter refers to a const or nonconst type. Overloading on const for a reference parameter is valid because the compiler can use whether the argument is const to determine which function to call:

If the parameter is a plain reference, then we may not pass a const object for that parameter. If we pass a const object, then the only function that is viable is the version that takes a const reference.
When we pass a nonconst object, either function is viable. We can use a nonconst object to initializer either a const or nonconst reference. However, initializing a const reference to a nonconst object requires a conversion, whereas initializing a nonconst parameter is an exact match.
Pointer parameters work in a similar way. We may pass the address of a const object only to a function that takes a pointer to const. We may pass a pointer to a nonconst object to a function taking a pointer to a const or nonconst type. If two functions differ only as to whether a pointer parameter points to const or nonconst, then the parameter that points to the nonconst type is a better match for a pointer to a nonconst object. Again, the compiler can distinguish: If the argument is const, it calls the function that takes a const*; otherwise, if the argument is a nonconst, the function taking a plain pointer is called.
It is worth noting that we cannot overload based on whether the pointer itself is const:
![]()
Here the const applies to the pointer, not the type to which the pointer points. In both cases the pointer is copied; it makes no difference whether the pointer itself is const. As we noted on page 267, when a parameter is passed as a copy, we cannot overload based on whether that parameter is const.
Exercises Section 7.8.4
Exercise 7.38: Given the following declarations,
void manip(int, int);
double dobj;
what is the rank (Section 7.8.4, p. 272) of each conversion in the following calls?
(a) manip('a', 'z'), (b) manip(55.4, dobj);
Exercise 7.39: Explain the effect of the second declaration in each one of the following sets of declarations. Indicate which, if any, are illegal.

Exercise 7.40: Is the following function call legal? If not, why is the call in error?
enum Stat { Fail, Pass };
void test(Stat);
test(0);
7.9 Pointers to Functions
A function pointer is just that—a pointer that denotes a function rather than an object. Like any other pointer, a function pointer points to a particular type. A function’s type is determined by its return type and its parameter list. A function’s name is not part of its type:
![]()
This statement declares pf to be a pointer to a function that takes two const string& parameters and has a return type of bool.
Using Typedefs to Simplify Function Pointer Definitions
Function pointer types can quickly become unwieldy. We can make function pointers easier to use by defining a synonym for the pointer type using a typedef (Section 2.6, p. 61):
typedef bool (*cmpFcn)(const string &, const string &);
This definition says that cmpFcn is the name of a type that is a pointer to function. That pointer has the type “pointer to a function that returns a bool and takes two references to const string.” When we need to use this function pointer type, we can do so by using cmpFcn, rather than having to write the full type definition each time.
Initializing and Assigning Pointers to Functions
When we use a function name without calling it, the name is automatically treated as a pointer to a function. Given
![]()
any use of lengthCompare, except as the left-hand operand of a function call, is treated as a pointer whose type is
bool (*)(const string &, const string &);
We can use a function name to initialize or assign to a function pointer:

Using the function name is equivalent to applying the address-of operator to the function name:
cmpFcn pf1 = lengthCompare;
cmpFcn pf2 = &lengthCompare;
A function pointer may be initialized or assigned only by a function or function pointer that has the same type or by a zero-valued constant expression.
Initializing a function pointer to zero indicates that the pointer does not point to any function.
There is no conversion between one pointer to function type and another:

Calling a Function through a Pointer
A pointer to a function can be used to call the function to which it refers. We can use the pointer directly—there is no need to use the dereference operator to call the function
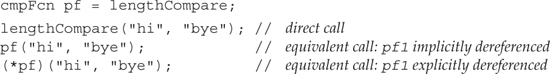
If the pointer to function is uninitialized or has a value of zero, it may not be used in a call. Only pointers that have been initialized or assigned to refer to a function can be safely used to call a function.
Function Pointer Parameters
A function parameter can be a pointer to function. We can write such a parameter in one of two ways:

Returning a Pointer to Function
A function can return a pointer to function, although correctly writing the return type can be a challenge:
// ff is a function taking an int and returning a function pointer
// the function pointed to returns an int and takes an int* and an int
int (*ff(int))(int*, int);
The best way to read function pointer declarations is from the inside out, starting with the name being declared.
We can figure out what this declaration means by observing that
ff(int)
says that ff is a function taking one parameter of type int. This function returns
int (*)(int*, int);
a pointer to a function that returns an int and takes two parameters of type int* and an int.
Typedefs can make such declarations considerably easier to read:

We can define a parameter as a function type. A function return type must be a pointer to function; it cannot be a function.
An argument to a parameter that has a function type is automatically converted to the corresponding pointer to function type. The same conversion does not happen when returning a function:

Pointers to Overloaded Functions
It is possible to use a function pointer to refer to an overloaded function:

The type of the pointer and one of the overloaded functions must match exactly. If no function matches exactly, the initialization or assignment results in a compile-time error:

Chapter Summary
Functions are named units of computation and are essential to structuring even modest programs. They are defined by specifying a return type, a name, a (possibly empty) list of parameters, and a function body. The function body is a block that is executed when the function is called. When a function is called, the arguments passed to the function must be compatible with the types of the corresponding parameters.
Passing an argument to a function follows the same rules as initializing a variable. Each parameter that has nonreference type is initialized as a copy of the corresponding argument. Any changes made to a (nonreference) parameter are made to the local copy, not to the argument itself.
Copying large, complex values can be expensive. To avoid the overhead of passing a copy, parameters can be specified as references. Changes made to reference parameters are reflected in the argument itself. A reference parameter that does not need to change its argument should be const reference.
In C++, functions may be overloaded. The same name may be used to define different functions as long as the number or types of the parameters in the functions differ. The compiler automatically figures out which function to call based the arguments in a call. The process of selecting the right function from a set of overloaded functions is referred to as function matching.
C++ provides two special kinds of functions: inline and member functions. Specifying inline on a function is a hint to the compiler to expand the function into code directly at the call point. Inline functions avoid the overhead associated with calling a function. Member functions are just that: class members that are functions. This chapter introduced simple member functions. Chapter 12 will cover member functions in more detail.
Defined Terms
Compile-time error that results when there is not a single best match for a call to an overloaded function.
Values supplied when calling a function. These values are used to initialize the corresponding parameters in the same way that variables of the same type are initialized.
Objects that are local to a function. Automatic objects are created and initialized anew on each call and are destroyed at the end of the block in which they are defined. They no longer exist once the function terminates.
The single function from a set of overloaded functions that has the best match for the arguments of a given call.
The operator that causes a function to be executed. The operator is a pair of parentheses and takes two operands: The name of the function to call and a (possibly empty) comma-separated list of arguments to pass to the function.
The set of functions that are considered when resolving a function call. The candidate functions are all the functions with the name used in the call for which a declaration is in scope at the time of the call.
Function that is member of a class and that may be called for const objects of that type. const member functions may not change the data members of the object on which they operate.
Member function that has the same name as its class. A constructor says how to initialize objects of its class. Constructors have no return type. Constructors may be overloaded.
List used in a constructor to specify initial values for data members. The initializer list appears in the definition of a constructor between the parameter list and the constructor body. The list consists of a colon followed by a comma-separated list of member names, each of which is followed by that member’s initial value in parentheses.
The constructor that is used when no explicit initializer is supplied. The compiler will synthesize a default constructor if the class defines no other constructors.
A callable unit of computation.
Block that defines the actions of a function.
Compiler process by which a call to an overloaded function is resolved. Arguments used in the call are compared to the parameter list of each overloaded function.
Synonym for function declaration. The name, return type, and parameter types of a function. To call a function, its prototype must have been declared before the point of call.
Function that is expanded at the point of call, if possible. Inline functions avoid the normal function-calling overhead by replacing the call by the function’s code.
Local object that is created and initialized once before the function is first called and whose value persists across invocations of the function.
Variables defined inside a function. Local variables are accessible only within the function body.
Every object has an associated lifetime. Objects that are defined inside a block exist from when their definition is encountered until the end of the block in which they are defined. Local static objects and global objects defined outside any function are created during program startup and are destroyed when the main function ends. Dynamically created objects that are created through a new expression exist until the memory in which they were created is freed through a corresponding delete.
A synonym for function matching.
A function that has the same name as at least one other function. Overloaded functions must differ in the number or type of their parameters.
Variables local to a function whose initial values are supplied when the function is called.
Function that calls itself directly or indirectly.
The type of the value returned from a function.
synthesized default constructor
If there are no constructors defined by a class, then the compiler will create (synthesize) a default constructor. This constructor default initializes each data member of the class.
Unnamed object automatically created by the compiler in the course of evaluating an expression. The phrase temporary object is usually abreviated as temporary. A temporary persists until the end of the largest expression that encloses the expression for which it was created.
Implicit parameter of a member function. this points to the object on which the function is invoked. It is a pointer to the class type. In a const member function the pointer is a pointer to const.
The subset of overloaded functions that could match a given call. Viable functions have the same number of parameters as arguments to the call and each argument type can potentially be converted to the corresponding parameter type.