
Chapter 2. Variables and Basic Types
CONTENTS
Section 2.1 Primitive Built-in Types 34
Section 2.2 Literal Constants 37
Section 2.4 const Qualifier 56
Section 2.9 Writing Our Own Header Files 67
Types are fundamental to any program. They tell us what our data mean and what operations we can perform on our data.
C++ defines several primitive types: characters, integers, floating-point numbers, and so on. The language also provides mechanisms that let us define our own data types. The library uses these mechanisms to define more complex types such as variable-length character strings, vectors, and so on. Finally, we can modify existing types to form compound types. This chapter covers the built-in types and begins our coverage of how C++ supports more complicated types.
Types determine what the data and operations in our programs mean. As we saw in Chapter 1, the same statement
i =i +j;
can mean different things depending on the types of i and j. If i and j are integers, then this statement has the ordinary, arithmetic meaning of +. However, if i and j are Sales_item objects, then this statement adds the components of these two objects.
In C++ the support for types is extensive: The language itself defines a set of primitive types and ways in which we can modify existing types. It also provides a set of features that allow us to define our own types. This chapter begins our exploration of types in C++ by covering the built-in types and showing how we associate a type with an object. It also introduces ways we can both modify types and can build our own types.
2.1 Primitive Built-in Types
C++ defines a set of arithmetic types, which represent integers, floating-point numbers, and individual characters and boolean values. In addition, there is a special type named void. The void type has no associated values and can be used in only a limited set of circumstances. The void type is most often used as the return type for a function that has no return value.
The size of the arithmetic types varies across machines. By size, we mean the number of bits used to represent the type. The standard guarantees a minimum size for each of the arithmetic types, but it does not prevent compilers from using larger sizes. Indeed, almost all compilers use a larger size for int than is strictly required. Table 2.1 (p. 36) lists the built-in arithmetic types and the associated minimum sizes.
Table 2.1. C++: Arithmetic Types


Because the number of bits varies, the maximum (or minimum) values that these types can represent also vary by machine.
2.1.1 Integral Types
The arithmetic types that represent integers, characters, and boolean values are collectively referred to as the integral types.
There are two character types: char and wchar_t. The char type is guaranteed to be big enough to hold numeric values that correspond to any character in the machine’s basic character set. As a result, chars are usually a single machine byte. The wchar_t type is used for extended character sets, such as those used for Chinese and Japanese, in which some characters cannot be represented within a single char.
The types short, int, and long represent integer values of potentially different sizes. Typically, shorts are represented in half a machine word, ints in a machine word, and longs in either one or two machine words (on 32-bit machines, ints and longs are usually the same size).
Machine-Level Representation of The Built-in Types
The C++ built-in types are closely tied to their representation in the computer’s memory. Computers store data as a sequence of bits, each of which holds either 0 or 1. A segment of memory might hold
00011011011100010110010000111011 ...
At the bit level, memory has no structure and no meaning.
The most primitive way we impose structure on memory is by processing it in chunks. Most computers deal with memory as chunks of bits of particular sizes, usually powers of 2. They usually make it easy to process 8, 16, or 32 bits at a time, and chunks of 64 and 128 bits are becoming more common. Although the exact sizes can vary from one machine to another, we usually refer to a chunk of 8 bits as a “byte” and 32 bits, or 4 bytes, as a “word.”
Most computers associate a number—called an address—with each byte in memory. Given a machine that has 8-bit bytes and 32-bit words, we might represent a word of memory as follows:
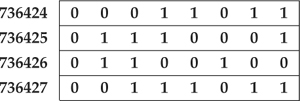
In this illustration, each byte’s address is shown on the left, with the 8 bits of the byte following the address.
We can use an address to refer to any of several variously sized collections of bits starting at that address. It is possible to speak of the word at address 736424 or the byte at address 736426. We can say, for example, that the byte at address 736425 is not equal to the byte at address 736427.
To give meaning to the byte at address 736425, we must know the type of the value stored there. Once we know the type, we know how many bits are needed to represent a value of that type and how to interpret those bits.
If we know that the byte at location 736425 has type “unsigned 8-bit integer,” then we know that the byte represents the number 112. On the other hand, if that byte is a character in the ISO-Latin-1 character set, then it represents the lower-case letter q. The bits are the same in both cases, but by ascribing different types to them, we interpret them differently.
The type bool represents the truth values, true and false. We can assign any of the arithmetic types to a bool. An arithmetic type with value 0 yields a bool that holds false. Any nonzero value is treated as true.
Signed and Unsigned Types
The integral types, except the boolean type, may be either signed or unsigned. As its name suggests, a signed type can represent both negative and positive numbers (including zero), whereas an unsigned type represents only values greater than or equal to zero.
The integers, int, short, and long, are all signed by default. To get an unsigned type, the type must be specified as unsigned, such as unsigned long. The unsigned int type may be abbreviated as unsigned. That is, unsigned with no other type implies unsigned int.
Unlike the other integral types, there are three distinct types for char: plain char, signed char, and unsigned char. Although there are three distinct types, there are only two ways a char can be represented. The char type is respresented using either the signed char or unsigned char version. Which representation is used for char varies by compiler.
How Integral Values Are Represented
In an unsigned type, all the bits represent the value. If a type is defined for a particular machine to use 8 bits, then the unsigned version of this type could hold the values 0 through 255.
The C++ standard does not define how signed types are represented at the bit level. Instead, each compiler is free to decide how it will represent signed types. These representations can affect the range of values that a signed type can hold. We are guaranteed that an 8-bit signed type will hold at least the values from –127 through 127; many implementations allow values from –128 through 127.
Under the most common strategy for representing signed integral types, we can view one of the bits as a sign bit. Whenever the sign bit is 1, the value is negative; when it is 0, the value is either 0 or a positive number. An 8-bit integral signed type represented using a sign-bit can hold values from –128 through 127.
Assignment to Integral Types
The type of an object determines the values that the object can hold. This fact raises the question of what happens when one tries to assign a value outside the allowable range to an object of a given type. The answer depends on whether the type is signed or unsigned.
For unsigned types, the compiler must adjust the out-of-range value so that it will fit. The compiler does so by taking the remainder of the value modulo the number of distinct values the unsigned target type can hold. An object that is an 8-bit unsigned char, for example, can hold values from 0 through 255 inclusive. If we assign a value outside this range, the compiler actually assigns the remainder of the value modulo 256. For example, we might attempt to assign the value 336 to an 8-bit signed char. If we try to store 336 in our 8-bit unsigned char, the actual value assigned will be 80, because 80 is equal to 336 modulo 256.
For the unsigned types, a negative value is always out of range. An object of unsigned type may never hold a negative value. Some languages make it illegal to assign a negative value to an unsigned type, but C++ does not.

In C++ it is perfectly legal to assign a negative number to an object with unsigned type. The result is the negative value modulo the size of the type. So, if we assign –1 to an 8-bit unsigned char, the resulting value will be 255, which is –1 modulo 256.
When assigning an out-of-range value to a signed type, it is up to the compiler to decide what value to assign. In practice, many compilers treat signed types similarly to how they are required to treat unsigned types. That is, they do the assignment as the remainder modulo the size of the type. However, we are not guaranteed that the compiler will do so for the signed types.
2.1.2 Floating-Point Types
The types float, double, and long double represent floating-point single-, double-, and extended-precision values. Typically, floats are represented in one word (32 bits), doubles in two words (64 bits), and long double in either three or four words (96 or 128 bits). The size of the type determines the number of significant digits a floating-point value might contain.
The float type is usually not precise enough for real programs—float is guaranteed to offer only 6 significant digits. The double type guarantees at least 10 significant digits, which is sufficient for most calculations.
2.2 Literal Constants
A value, such as 42, in a program is known as a literal constant: literal because we can speak of it only in terms of its value; constant because its value cannot be changed. Every literal has an associated type. For example, 0 is an int and 3.14159 is a double. Literals exist only for the built-in types. There are no literals of class types. Hence, there are no literals of any of the library types.
Rules for Integer Literals
We can write a literal integer constant using one of three notations: decimal, octal, or hexadecimal. These notations, of course, do not change the bit representation of the value, which is always binary. For example, we can write the value 20 in any of the following three ways:
20 // decimal
024 // octal
0x14 // hexadecimal
Literal integer constants that begin with a leading 0 (zero) are interpreted as octal; those that begin with either 0x or 0X are interpreted as hexadecimal.
By default, the type of a literal integer constant is either int or long. The precise type depends on the value of the literal—values that fit in an int are type int and larger values are type long. By adding a suffix, we can force the type of a literal integer constant to be type long or unsigned or unsigned long. We specify that a constant is a long by immediately following the value with either L or l (the letter “ell” in either uppercase or lowercase).

When specifying a long, use the uppercase L: the lowercase letter l is too easily mistaken for the digit 1.
In a similar manner, we can specify unsigned by following the literal with either U or u. We can obtain an unsigned long literal constant by following the value by both L and U. The suffix must appear with no intervening space:
![]()
There are no literals of type short.
Rules for Floating-Point Literals
We can use either common decimal notation or scientific notation to write floating-point literal constants. Using scientific notation, the exponent is indicated either by E or e. By default, floating-point literals are type double. We indicate single precision by following the value with either F or f. Similarly, we specify extended precision by following the value with either L or l (again, use of the lowercase l is discouraged). Each pair of literals below denote the same underlying value:
![]()
Boolean and Character Literals
The words true and false are literals of type bool:
bool test = false;
Printable character literals are written by enclosing the character within single quotation marks:
'a' '2' ',' ' ' // blank
Such literals are of type char. We can obtain a wide-character literal of type wchar_t by immediately preceding the character literal with an L, as in
L'a'
Escape Sequences for Nonprintable Characters
Some characters are nonprintable. A nonprintable character is a character for which there is no visible image, such as backspace or a control character. Other characters have special meaning in the language, such as the single and double quotation marks, and the backslash. Nonprintable characters and special characters are written using an escape sequence. An escape sequence begins with a backslash. The language defines the following escape sequences:
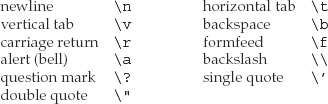
We can write any character as a generalized escape sequence of the form
ooo
where ooo represents a sequence of as many as three octal digits. The value of the octal digits represents the numerical value of the character. The following examples are representations of literal constants using the ASCII character set:
![]()
The character represented by ’�’ is often called a “null character,” and has special significance, as we shall soon see.
We can also write a character using a hexadecimal escape sequence
xddd
consisting of a backslash, an x, and one or more hexadecimal digits.
Character String Literals
All of the literals we’ve seen so far have primitive built-in types. There is one additional literal—string literal—that is more complicated. String literals are arrays of constant characters, a type that we’ll discuss in more detail in Section 4.3 (p. 130).
String literal constants are written as zero or more characters enclosed in double quotation marks. Nonprintable characters are represented by their underlying escape sequence.
For compatibility with C, string literals in C++ have one character in addition to those typed in by the programmer. Every string literal ends with a null character added by the compiler. A character literal
'A' // single quote: character literal
represents the single character A, whereas
"A" // double quote: character string literal
represents an array of two characters: the letter A and the null character.
Just as there is a wide character literal, such as
L'a'
there is a wide string literal, again preceded by L, such as
L"a wide string literal"
The type of a wide string literal is an array of constant wide characters. It is also terminated by a wide null character.
Concatenated String Literals
Two string literals (or two wide string literals) that appear adjacent to one another and separated only by spaces, tabs, or newlines are concatenated into a single new string literal. This usage makes it easy to write long literals across separate lines:

When executed this statement would print:
a multi-line string literal using concatenation
What happens if you attempt to concatenate a string literal and a wide string literal? For example:
// Concatenating plain and wide character strings is undefined
std::cout << "multi-line " L"literal " << std::endl;
The result is undefined—that is, there is no standard behavior defined for concatenating the two different types. The program might appear to work, but it also might crash or produce garbage values. Moreover, the program might behave differently under one compiler than under another.
Multi-Line Literals
There is a more primitive (and less useful) way to handle long strings that depends on an infrequently used program formatting feature: Putting a backslash as the last character on a line causes that line and the next to be treated as a single line.
As noted on page 14, C++ programs are largely free-format. In particular, there are only a few places that we may not insert whitespace. One of these is in the middle of a word. In particular, we may not break a line in the middle of a word. We can circumvent this rule by using a backslash:
// ok: A before a newline ignores the line break
std::cou
t << "Hi" << st
d::endl;
is equivalent to
std::cout << "Hi" << std::endl;
We could use this feature to write a long string literal:

Note that the backslash must be the last thing on the line—no comments or trailing blanks are allowed. Also, any leading spaces or tabs on the subsequent lines are part of the literal. For this reason, the continuation lines of the long literal do not have the normal indentation.
2.3 Variables
Imagine that we are given the problem of computing 2 to the power of 10. Our first attempt might be something like

This program solves the problem, although we might double- or triple-check to make sure that exactly 10 literal instances of 2 are being multiplied. Otherwise, we’re satisfied. Our program correctly generates the answer 1,024.
We’re next asked to compute 2 raised to the power of 17 and then to the power of 23. Changing our program each time is a nuisance. Worse, it proves to be remarkably error-prone. Too often, the modified program produces an answer with one too few or too many instances of 2.
An alternative to the explicit brute force power-of-2 computation is twofold:
- Use named objects to perform and print each computation.
- Use flow-of-control constructs to provide for the repeated execution of a sequence of program statements while a condition is true.
Here, then, is an alternative way to compute 2 raised to the power of 10:

value, pow, result, and cnt are variables that allow for the storage, modification, and retrieval of values. The for loop allows for the repeated execution of our calculation until it’s been executed pow times.
2.3.1 What Is a Variable?
A variable provides us with named storage that our programs can manipulate. Each variable in C++ has a specific type, which determines the size and layout of the variable’s memory; the range of values that can be stored within that memory; and the set of operations that can be applied to the variable. C++ programmers tend to refer to variables as “variables” or as “objects” interchangeably.
Lvalues and Rvalues
We’ll have more to say about expressions in Chapter 5, but for now it is useful to know that there are two kinds of expressions in C++:
- lvalue (pronounced “ell-value”): An expression that is an lvalue may appear as either the left-hand or right-hand side of an assignment.
- rvalue (pronounced “are-value”): An expression that is an rvalue may appear on the right- but not left-hand side of an assignment.
Variables are lvalues and so may appear on the left-hand side of an assignment. Numeric literals are rvalues and so may not be assigned. Given the variables:
int units_sold = 0;
double sales_price = 0, total_revenue = 0;
it is a compile-time error to write either of the following:
// error: arithmetic expression is not an lvalue
units_sold * sales_price = total_revenue;
// error: literal constant is not an lvalue
0 = 1;
Some operators, such as assignment, require that one of their operands be an lvalue. As a result, lvalues can be used in more contexts than can rvalues. The context in which an lvalue appears determines how it is used. For example, in the expression
units_sold = units_sold + 1;
the variable units_sold is used as the operand to two different operators. The + operator cares only about the values of its operands. The value of a variable is the value currently stored in the memory associated with that variable. The effect of the addition is to fetch that value and add one to it.
The variable units_sold is also used as the left-hand side of the = operator. The = operator reads its right-hand side and writes to its left-hand side. In this expression, the result of the addition is stored in the storage associated with units_sold; the previous value in units_sold is overwritten.
In the course of the text, we’ll see a number of situations in which the use of an rvalue or lvalue impacts the behavior and/or the performance of our programs—in particular when passing and returning values from a function.
2.3.2 The Name of a Variable
The name of a variable, its identifier, can be composed of letters, digits, and the underscore character. It must begin with either a letter or an underscore. Upper- and lowercase letters are distinct: Identifiers in C++ are case-sensitive. The following defines four distinct identifiers:
// declares four different int variables
int somename, someName, SomeName, SOMENAME;

There is no language-imposed limit on the permissible length of a name, but out of consideration for others that will read and/or modify our code, it should not be too long.
For example,
gosh_this_is_an_impossibly_long_name_to_type
is a really bad identifier name.
C++ Keywords
C++ reserves a set of words for use within the language as keywords. Keywords may not be used as program identifiers. Table 2.2 on the next page lists the complete set of C++ keywords.
Table 2.2. C++ Keywords

C++ also reserves a number of words that can be used as alternative names for various operators. These alternative names are provided to support character sets that do not support the standard set of C++ operator symbols. These names, listed in Table 2.3, also may not be used as identifiers:
Table 2.3. C++ Operator Alternative Names
![]()
In addition to the keywords, the standard also reserves a set of identifiers for use in the library. Identifiers cannot contain two consecutive underscores, nor can an identifier begin with an underscore followed immediately by an upper-case letter. Certain identifiers—those that are defined outside a function—may not begin with an underscore.
Conventions for Variable Names
There are a number of generally accepted conventions for naming variables. Following these conventions can improve the readability of a program.
• A variable name is normally written in lowercase letters. For example, one writes index, not Index or INDEX.
• An identifier is given a mnemonic name—that is, a name that gives some indication of its use in a program, such as on_loan or salary.
• An identifier containing multiple words is written either with an underscore between each word or by capitalizing the first letter of each embedded word. For example, one generally writes student_loan or studentLoan, not studentloan.
2.3.3 Defining Objects
The following statements define five variables:
int units_sold;
double sales_price, avg_price;
std::string title;
Sales_item curr_book;
Each definition starts with a type specifier, followed by a comma-separated list of one or more names. A semicolon terminates the definition. The type specifier names the type associated with the object: int, double, std::string, and Sales_item are all names of types. The types int and double are built-in types, std::string is a type defined by the library, and Sales_item is a type that we used in Section 1.5 (p. 20)and will define in subsequent chapters. The type determines the amount of storage that is allocated for the variable and the set of operations that can be performed on it.
Multiple variables may be defined in a single statement:
double salary, wage; // defines two variables of type double
int month,
day, year; // defines three variables of type int
std::string address; // defines one variable of type std::string
Initialization
A definition specifies a variable’s type and identifier. A definition may also provide an initial value for the object. An object defined with a specified first value is spoken of as initialized. C++ supports two forms of variable initialization: copy-initialization and direct-initialization. The copy-initialization syntax uses the equal (=) symbol; direct-initialization places the initializer in parentheses:
int ival(1024); // direct-initialization
int ival = 1024; // copy-initialization
In both cases, ival is initialized to 1024.
Although, at this point in the book, it may seem obscure to the reader, in C++ it is essential to understand that initialization is not assignment. Initialization happens when a variable is created and gives that variable its initial value. Assignment involves obliterating an object’s current value and replacing that value with a new one.
Many new C++ programmers are confused by the use of the = symbol to initialize a variable. It is tempting to think of initialization as a form of assignment. But initialization and assignment are different operations in C++. This concept is particularly confusing because in many other languages the distinction is irrelevant and can be ignored. Moreover, even in C++ the distinction rarely matters until one attempts to write fairly complex classes. Nonetheless, it is a crucial concept and one that we will reiterate throughout the text.
There are subtle differences between copy- and direct-initialization when initializing objects of a class type. We won’t completely explain these differences until Chapter 13. For now, it’s worth knowing that the direct syntax is more flexible and can be slightly more efficient.
Using Multiple Initializers
When we initialize an object of a built-in type, there is only one way to do so: We supply a value, and that value is copied into the newly defined object. For built-in types, there is little difference between the direct and the copy forms of initialization.
For objects of a class type, there are initializations that can be done only using direct-initialization. To understand why, we need to know a bit about how classes control initialization.
Each class may define one or more special member functions (Section 1.5.2, p. 24) that say how we can initialize variables of the class type. The member functions that define how initialization works are known as constructors. Like any function, a constructor can take multiple arguments. A class may define several constructors, each of which must take a different number or type of arguments.
As an example, we’ll look a bit at the string class, which we’ll cover in more detail in Chapter 3. The string type is defined by the library and holds character strings of varying sizes. To use strings, we must include the string header. Like the IO types, string is defined in the std namespace.
The string class defines several constructors, giving us various ways to initialize a string. One way we can initialize a string is as a copy of a character string literal:
#include <string>
// alternative ways to initialize string from a character string literal
std::string titleA = "C++ Primer, 4th Ed.";
std::string titleB("C++ Primer, 4th Ed.");
In this case, either initialization form can be used. Both definitions create a string object whose initial value is a copy of the specified string literal.
However, we can also initialize a string from a count and a character. Doing so creates a string containing the specified character repeated as many times as indicated by the count:
std::string all_nines(10, '9'), // all_nines= "9999999999"
In this case, the only way to initialize all_nines is by using the direct form of initialization. It is not possible to use copy-initialization with multiple initializers.
Initializing Multiple Variables
When a definition defines two or more variables, each variable may have its own initializer. The name of an object becomes visible immediately, and so it is possible to initialize a subsequent variable to the value of one defined earlier in the same definition. Initialized and uninitialized variables may be defined in the same definition. Both forms of initialization syntax may be intermixed:

An object can be initialized with an arbitrarily complex expression, including the return value of a function:
double price = 109.99, discount = 0.16;
double sale_price = apply_discount(price, discount);
In this example, apply_discount is a function that takes two values of type double and returns a value of type double. We pass the variables price and discount to that function and use its return value to initialize sale_price.
2.3.4 Variable Initialization Rules
When we define a variable without an initializer, the system sometimes initializes the variable for us. What value, if any, is supplied depends on the type of the variable and may depend on where it is defined.
Initialization of Variables of Built-in Type
Whether a variable of built-in type is automatically initialized depends on where it is defined. Variables defined outside any function body are initialized to zero. Variables of built-in type defined inside the body of a function are uninitialized. Using an uninitialized variable for anything other than as the left-hand operand of an assignment is undefined. Bugs due to uninitialized variables can be hard to find. As we cautioned on page 42, you should never rely on undefined behavior.
We recommend that every object of built-in type be initialized. It is not always necessary to initialize such variables, but it is easier and safer to do so until you can be certain it is safe to omit an initializer.
Initialization of Variables of Class Type
Each class defines how objects of its type can be initialized. Classes control object initialization by defining one or more constructors (Section 2.3.3, p. 49). As an example, we know that the string class provides at least two constructors. One of these constructors lets us initialize a string from a character string literal and another lets us initialize a string from a character and a count.
Each class may also define what happens if a variable of the type is defined but an initializer is not provided. A class does so by defining a special constructor, known as the default constructor. This constructor is called the default constructor because it is run “by default;” if there is no initializer, then this constructor is used. The default constructor is used regardless of where a variable is defined.
Most classes provide a default constructor. If the class has a default constructor, then we can define variables of that class without explicitly initializing them. For example, the string type defines its default constructor to initialize the string as an empty string—that is, a string with no characters:
std::string empty; // empty is the empty string; empty =""
Some class types do not have a default constructor. For these types, every definition must provide explicit initializer(s). It is not possible to define variables of such types without giving an initial value.
Exercises Section 2.3.4
Exercise 2.17: What are the initial values, if any, of each of the following variables?

2.3.5 Declarations and Definitions
As we’ll see in Section 2.9 (p. 67), C++ programs typically are composed of many files. In order for multiple files to access the same variable, C++ distinguishes between declarations and definitions.
A definition of a variable allocates storage for the variable and may also specify an initial value for the variable. There must be one and only one definition of a variable in a program.
A declaration makes known the type and name of the variable to the program. A definition is also a declaration: When we define a variable, we declare its name and type. We can declare a name without defining it by using the extern keyword. A declaration that is not also a definition consists of the object’s name and its type preceded by the keyword extern:
extern int i; // declares but does not define i
int i; // declares and defines i
An extern declaration is not a definition and does not allocate storage. In effect, it claims that a definition of the variable exists elsewhere in the program. A variable can be declared multiple times in a program, but it must be defined only once.
A declaration may have an initializer only if it is also a definition because only a definition allocates storage. The initializer must have storage to initialize. If an initializer is present, the declaration is treated as a definition even if the declaration is labeled extern:
extern double pi = 3.1416; // definition
Despite the use of extern, this statement defines pi. Storage is allocated and initialized. An extern declaration may include an initializer only if it appears outside a function.
Because an extern that is initialized is treated as a definition, any subseqent definition of that variable is an error:
extern double pi = 3.1416; // definition
double pi; // error: redefinition of pi
Similarly, a subsequent extern declaration that has an initializer is also an error:
extern double pi = 3.1416; // definition
extern double pi; // ok: declaration not definition
extern double pi = 3.1416; // error: redefinition of pi
The distinction between a declaration and a definition may seem pedantic but in fact is quite important.
Any variable that is used in more than one file requires declarations that are separate from the variable’s definition. In such cases, one file will contain the definition for the variable. Other files that use that same variable will contain declarations for—but not a definition of—that same variable.
2.3.6 Scope of a Name
Every name in a C++ program must refer to a unique entity (such as a variable, function, type, etc.). Despite this requirement, names can be used more than once in a program: A name can be reused as long as it is used in different contexts, from which the different meanings of the name can be distinguished. The context used to distinguish the meanings of names is a scope. A scope is a region of the program. A name can refer to different entities in different scopes.
Most scopes in C++ are delimited by curly braces. Generally, names are visible from their point of declaration until the end the scope in which the declaration appears. As an example, consider this program, which we first encountered in Section 1.4.2 (p. 14):

This program defines three names and uses two names from the standard library. It defines a function named main and two variables named sum and val. The name main is defined outside any curly braces and is visible throughout the program. Names defined outside any function have global scope; they are accessible from anywhere in the program. The name sum is defined within the scope of the main function. It is accessible throughout the main function but not outside of it. The variable sum has local scope. The name val is more interesting. It is defined in the scope of the for statement (Section 1.4.2, p. 14). It can be used in that statement but not elsewhere in main. It has statement scope.
Scopes in C++ Nest
Names defined in the global scope can be used in a local scope; global names and those defined local to a function can be used inside a statement scope, and so on. Names can also be redefined in an inner scope. Understanding what entity a name refers to requires unwinding the scopes in which the names are defined:

This program defines three variables: a global string named s1, a local string named s2, and a local int named s1. The definition of the local s1 hides the global s1.
Variables are visible from their point of declaration. Thus, the local definition of s1 is not visible when the first output is performed. The name s1 in that output expression refers to the global s1. The output printed is hello world. The second statement that does output follows the local definition of s1. The local s1 is now in scope. The second output uses the local rather than the global s1. It writes 42 world.
Programs such as the preceeding are likely to be confusing. It is almost always a bad idea to define a local variable with the same name as a global variable that the function uses or might use. It is much better to use a distinct name for the local.
We’ll have more to say about local and global scope in Chapter 7 and about statement scope in Chapter 6. C++ has two other levels of scope: class scope, which we’ll cover in Chapter 12 and namespace scope, which we’ll see in Section 17.2.
2.3.7 Define Variables Where They Are Used
In general, variable definitions or declarations can be placed anywhere within the program that a statement is allowed. A variable must be declared or defined before it is used.
Defining an object where the object is first used improves readability. The reader does not have to go back to the beginning of a section of code to find the definition of a particular variable. Moreover, it is often easier to give the variable a useful initial value when the variable is defined close to where it is first used.
One constraint on placing declarations is that variables are accessible from the point of their definition until the end of the enclosing block. A variable must be defined in or before the outermost scope in which the variable will be used.
Exercises Section 2.3.6
Exercise 2.19: What is the value of j in the following program?

Exercise 2.20: Given the following program fragment, what values are printed?
Exercise 2.21: Is the following program legal?

2.4 const Qualifier
There are two problems with the following for loop, both concerning the use of 512 as an upper bound.
![]()
The first problem is readability. What does it mean to compare index with 512? What is the loop doing—that is, what makes 512 matter? (In this example, 512 is known as a magic number, one whose significance is not evident within the context of its use. It is as if the number had been plucked by magic from thin air.)
The second problem is maintainability. Imagine that we have a large program in which the number 512 occurs 100 times. Let’s further assume that 80 of these references use 512 to indicate the size of a particular buffer but the other 20 use 512 for different purposes. Now we discover that we need to increase the buffer size to 1024. To make this change, we must examine every one of the places that the number 512 appears. We must determine—correctly in every case—which of those uses of 512 refer to the buffer size and which do not. Getting even one instance wrong breaks the program and requires us to go back and reexamine each use.
The solution to both problems is to use an object initialized to 512:
int bufSize = 512; // input buffer size
for (int index = 0; index != bufSize; ++index) {
// ...
}
By choosing a mnemonic name, such as bufSize, we make the program more readable. The test is now against the object rather than the literal constant:
index != bufSize
If we need to change this size, the 80 occurrences no longer need to be found and corrected. Rather, only the one line that initializes bufSize requires change. Not only does this approach require significantly less work, but also the likelihood of making a mistake is greatly reduced.
Defining a const Object
There is still a serious problem with defining a variable to represent a constant value. The problem is that bufSize is modifiable. It is possible for bufSize to be changed—accidentally or otherwise. The const type qualifier provides a solution: It transforms an object into a constant.
const int bufSize = 512; // input buffer size
defines bufSize to be a constant initialized with the value 512. The variable bufSize is still an lvalue (Section 2.3.1, p. 45), but now the lvalue is unmodifiable. Any attempt to write to bufSize results in a compile-time error.
bufSize = 0; // error: attempt to write to const object
Because we cannot subsequently change the value of an object declared to be const, we must initialize it when it is defined:
const std::string hi = "hello!"; // ok: initialized
const int i, j = 0; // error: i is uninitialized const
const Objects Are Local to a File By Default
When we define a nonconst variable at global scope (Section 2.3.6, p. 54), it is accessible throughout the program. We can define a nonconst variable in one file and—assuming an appropriate declaration has been made—can use that variable in another file:

Unlike other variables, unless otherwise specified, const variables declared at global scope are local to the file in which the object is defined. The variable exists in that file only and cannot be accessed by other files.
We can make a const object accessible throughout the program by specifying that it is extern:

In this program, file_1.cc defines and initializes bufSize to the result returned from calling the function named fcn. The definition of bufSize is extern, meaning that bufSize can be used in other files. The declaration in file_2.cc is also made extern. In this case, the extern signifies that bufSize is a declaration and hence no initializer is provided.
We’ll see in Section 2.9.1 (p. 69) why const objects are made local to a file.
Nonconst variables are extern by default. To make a const variable accessible to other files we must explicitly specify that it is extern.
2.5 References
A reference serves as an alternative name for an object. In real-world programs, references are primarily used as formal parameters to functions. We’ll have more to say about reference parameters in Section 7.2.2 (p. 232). In this section we introduce and illustrate the use of references as independent objects.
A reference is a compound type that is defined by preceding a variable name by the & symbol. A compound type is a type that is defined in terms of another type. In the case of references, each reference type “refers to” some other type. We cannot define a reference to a reference type, but can make a reference to any other data type.
A reference must be initialized using an object of the same type as the reference:

A Reference Is an Alias
Because a reference is just another name for the object to which it is bound, all operations on a reference are actually operations on the underlying object to which the reference is bound:
refVal += 2;
adds 2 to ival, the object referred to by refVal. Similarly,
int ii = refVal;
assigns to ii the value currently associated with ival.
When a reference is initialized, it remains bound to that object as long as the reference exists. There is no way to rebind a reference to a different object.
The important concept to understand is that a reference is just another name for an object. Effectively, we can access ival either through its actual name or through its alias, refVal. Assignment is just another operation, so that when we write
refVal = 5;
the effect is to change the value of ival to 5. A consequence of this rule is that you must initialize a reference when you define it; initialization is the only way to say to which object a reference refers.
Defining Multiple References
We can define multiple references in a single type definition. Each identifier that is a reference must be preceded by the & symbol:

const References
A const reference is a reference that may refer to a const object:
![]()
We can read from but not write to refVal. Thus, any assignment to refVal is illegal. This restriction should make sense: We cannot assign directly to ival and so it should not be possible to use refVal to change ival.
For the same reason, the initialization of ref2 by ival is an error: ref2 is a plain, nonconst reference and so could be used to change the value of the object to which ref2 refers. Assigning to ival through ref2 would result in changing the value of a const object. To prevent such changes, it is illegal to bind a plain reference to a const object.
A const reference can be initialized to an object of a different type or to an rvalue (Section 2.3.1, p. 45), such as a literal constant:
int i = 42;
// legal for const references only
const int &r = 42;
const int &r2 = r + i;
The same initializations are not legal for nonconst references. Rather, they result in compile-time errors. The reason is subtle and warrants an explanation.
This behavior is easiest to understand when we look at what happens when we bind a reference to an object of a different type. If we write
double dval = 3.14;
const int &ri = dval;
the compiler transforms this code into something like this:
![]()
If ri were not const, then we could assign a new value to ri. Doing so would not change dval but would instead change temp. To the programmer expecting that assignments to ri would change dval, it would appear that the change did not work. Allowing only const references to be bound to values requiring temporaries avoids the problem entirely because a const reference is read-only.
A nonconst reference may be attached only to an object of the same type as the reference itself.
A const reference may be bound to an object of a different but related type or to an rvalue.
2.6 Typedef Names
A typedef lets us define a synonym for a type:
![]()
A typedef name can be used as a type specifier:
![]()
A typedef definition begins with the keyword typedef, followed by the data type and identifier. The identifier, or typedef name, does not introduce a new type but rather a synonym for the existing data type. A typedef name can appear anywhere in a program that a type name can appear.
Typedefs are commonly used for one of three purposes:
• To hide the implementation of a given type and emphasize instead the purpose for which the type is used
• To streamline complex type definitions, making them easier to understand
• To allow a single type to be used for more than one purpose while making the purpose clear each time the type is used
2.7 Enumerations
Often we need to define a set of alternative values for some attribute. A file, for example, might be open in one of three states: input, output, and append. One way to keep track of these state values might be to associate a unique constant number with each. We might write the following:
const int input = 0;
const int output = 1;
const int append = 2;
Although this approach works, it has a significant weakness: There is no indication that these values are related in any way. Enumerations provide an alternative method of not only defining but also grouping sets of integral constants.
Defining and Initializing Enumerations
An enumeration is defined using the enum keyword, followed by an optional enumeration name, and a comma-separated list of enumerators enclosed in braces.
![]()
By default, the first enumerator is assigned the value zero. Each subsequent enumerator is assigned a value one greater than the value of the enumerator that immediately precedes it.
Enumerators Are const Values
We may supply an initial value for one or more enumerators. The value used to initialize an enumerator must be a constant expression. A constant expression is an expression of integral type that the compiler can evaluate at compile time. An integral literal constant is a constant expression, as is a const object (Section 2.4, p. 56) that is itself initialized from a constant expression.
For example, we might define the following enumeration:
// shape is 1, sphere is 2, cylinder is 3, polygon is 4
enum Forms {shape = 1, sphere, cylinder, polygon};
In the enum Forms we explicitly assigned shape the value 1. The other enumerators are implicitly initialized: sphere is initialized to 2, cylinder to 3, and polygon to 4.
An enumerator value need not be unique.
![]()
In this example, the enumerator point2d is explicitly initialized to 2. The next enumerator, point2w, is initialized by default, meaning that its value is one more than the value of the previous enumerator. Thus, point2w is initialized to 3. The enumerator point3d is explicitly initialized to 3, and point3w, again is initialized by default, in this case to 4.
It is not possible to change the value of an enumerator. As a consequence an enumerator is itself a constant expression and so can be used where a constant expression is required.
Each enum Defines a Unique Type
Each enum defines a new type. As with any type, we can define and initialize objects of type Points and can use those objects in various ways. An object of enumeration type may be initialized or assigned only by one of its enumerators or by another object of the same enumeration type:
Points pt3d = point3d; // ok: point3d is a Points enumerator
Points pt2w = 3; // error: pt2w initialized with int
pt2w = polygon; // error: polygon is not a Points enumerator
pt2w = pt3d; // ok: both are objects of Points enum type
Note that it is illegal to assign the value 3 to a Points object even though 3 is a value associated with one of the Points enumerators.
2.8 Class Types
In C++ we define our own data types by defining a class. A class defines the data that an object of its type contains and the operations that can be executed by objects of that type. The library types string, istream, and ostream are all defined as classes.
C++ support for classes is extensive—in fact, defining classes is so important that we shall devote Parts III through V to describing C++ support for classes and operations using class types.
In Chapter 1 we used the Sales_item type to solve our bookstore problem. We used objects of type Sales_item to keep track of sales data associated with a particular ISBN. In this section, we’ll take a first look at how a simple class, such as Sales_item, might be defined.
Class Design Starts with the Operations
Each class defines an interface and implementation. The interface consists of the operations that we expect code that uses the class to execute. The implementation typically includes the data needed by the class. The implementation also includes any functions needed to define the class but that are not intended for general use.
When we define a class, we usually begin by defining its interface—the operations that the class will provide. From those operations we can then determine what data the class will require to accomplish its tasks and whether it will need to define any functions to support the implementation.
The operations our type will support are the operations we used in Chapter 1. These operations were outlined in Section 1.5.1 (p. 21):
• The addition operator to add two Sales_items
• The input and output operators to read and write Sales_item objects
• The assignment operator to assign one Sales_item object to another
• The same_isbn function to determine if two objects refer to the same book
We’ll see how to define these operations in Chapters 7 and 14 after we learn how to define functions and operators. Even though we can’t yet implement these functions, we can figure out what data they’ll need by thinking a bit about what these operations must do. Our Sales_item class must
- Keep track of how many copies of a particular book were sold
- Report the total revenue for that book
- Calculate the average sales price for that book
Looking at this list of tasks, we can see that we’ll need an unsigned to keep track of how many books are sold and a double to keep track of the total revenue. From these data we can calculate the average sales price as total revenue divided by number sold. Because we also want to know which book we’re reporting on, we’ll also need a string to keep track of the ISBN.
Defining the Sales_item Class
Evidently what we need is the ability to define a data type that will have these three data elements and the operations we used in Chapter 1. In C++, the way we define such a data type is to define a class:

A class definition starts with the keyword class followed by an identifier that names the class. The body of the class appears inside curly braces. The close curly must be followed by a semicolon.
It is a common mistake among new programmers to forget the semicolon at the end of a class definition.
The class body, which can be empty, defines the data and operations that make up the type. The operations and data that are part of a class are referred to as its members. The operations are referred to as the member functions (Section 1.5.2, p. 24) and the data as data members.
The class also may contain zero or more public or private access labels. An access label controls whether a member is accessible outside the class. Code that uses the class may access only the public members.
When we define a class, we define a new type. The class name is the name of that type. By naming our class Sales_item we are saying that Sales_item is a new type and that programs may define variables of this type.
Each class defines its own scope (Section 2.3.6, p. 54). That is, the names given to the data and operations inside the class body must be unique within the class but can reuse names defined outside the class.
Class Data Members
The data members of a class are defined in somewhat the same way that normal variables are defined. We specify a type and give the member a name just as we do when defining a simple variable:
std::string isbn;
unsigned units_sold;
double revenue;
Our class has three data members: a member of type string named isbn, an unsigned member named units_sold, and a member of type double named revenue. The data members of a class define the contents of the objects of that class type. When we define objects of type Sales_item, those objects will contain a string, an unsigned, and a double.
There is one crucially important difference between how we define variables and class data members: We ordinarily cannot initialize the members of a class as part of their definition. When we define the data members, we can only name them and say what types they have. Rather than initializing data members when they are defined inside the class definition, classes control initialization through special member functions called constructors (Section 2.3.3, p. 49). We will define the Sales_item constructors in Section 7.7.3 (p. 262).
Access Labels
Access labels control whether code that uses the class may use a given member. Member functions of the class may use any member of their own class, regardless of the access level. The access labels, public and private, may appear multiple times in a class definition. A given label applies until the next access label is seen.
The public section of a class defines members that can be accessed by any part of the program. Ordinarily we put the operations in the public section so that any code in the program may execute these operations.
Code that is not part of the class does not have access to the private members. By making the Sales_item data members private, we ensure that code that operates on Sales_item objects cannot directly manipulate the data members. Programs, such as the one we wrote in Chapter 1, may not access the private members of the class. Objects of type Sales_item may execute the operations but not change the data directly.
Using the struct Keyword
C++ supports a second keyword, struct, that can be used to define class types. The struct keyword is inherited from C.
If we define a class using the class keyword, then any members defined before the first access label are implicitly private; ifwe usethe struct keyword, then those members are public. Whether we define a class using the class keyword or the struct keyword affects only the default initial access level.
We could have defined our Sales_item equivalently by writing

There are only two differences between this class definition and our initial class definition: Here we use the struct keyword, and we eliminate the use of public keyword immediately following the opening curly brace. Members of a struct are public, unless otherwise specified, so there is no need for the public label.
The only difference between a class defined with the class keyword or the struct keyword is the default access level: By default, members in a struct are public; those in a class are private.
Exercises Section 2.8
Exercise 2.28: Compile the following program to determine whether your compiler warns about a missing semicolon after a class definition:

If the diagnostic is confusing, remember the message for future reference.
Exercise 2.29: Distinguish between the public and private sections of a class.
Exercise 2.30: Define the data members of classes to represent the following types:
(a) a phone number (b) an address
(c) an employee or a company (d) a student at a university
2.9 Writing Our Own Header Files
We know from Section 1.5(p. 20)that ordinarily class definitions go into a header file. In this section we’ll see how to define a header file for the Sales_item class.
In fact, C++ programs use headers to contain more than class definitions. Recall that every name must be declared or defined before it is used. The programs we’ve written so far handle this requirement by putting all their code into a single file. As long as each entity precedes the code that uses it, this strategy works. However, few programs are so simple that they can be written in a single file. Programs made up of multiple files need a way to link the use of a name and its declaration. In C++ that is done through header files.
To allow programs to be broken up into logical parts, C++ supports what is commonly known as separate compilation. Separate compilation lets us compose a program from several files. To support separate compilation, we’ll put the definition of Sales_item in a header file. The member functions for Sales_item, which we’ll define in Section 7.7 (p. 258), will go in a separate source file. Functions such as main that use Sales_item objects are in other source files. Each of the source files that use Sales_item must include our Sales_item.h header file.
2.9.1 Designing Our Own Headers
A header provides a centralized location for related declarations. Headers normally contain class definitions, extern variable declarations, and function declarations, about which we’ll learn in Section 7.4 (p. 251). Files that use or define these entities include the appropriate header(s).
Proper use of header files can provide two benefits: All files are guaranteed to use the same declaration for a given entity; and should a declaration require change, only the header needs to be updated.
Some care should be taken in designing headers. The declarations in a header should logically belong together. A header takes time to compile. If it is too large programmers may be reluctant to incur the compile-time cost of including it.
To reduce the compile time needed to process headers, some C++ implementations support precompiled header files. For more details, consult the reference manual of your C++ implementation.
Headers Are for Declarations, Not Definitions
When designing a header it is essential to remember the difference between definitions, which may only occur once, and declarations, which may occur multiple times (Section 2.3.5, p. 52). The following statements are definitions and therefore should not appear in a header:
extern int ival = 10; // initializer, so it's a definition
double fica_rate; // no extern, so it's a definition
Although ival is declared extern, it has an initializer, which means this statement is a definition. Similarly, the declaration of fica_rate, although it does not have an initializer, is a definition because the extern keyword is absent. Including either of these definitions in two or more files of the same program will result in a linker error complaining about multiple definitions.
Compiling and Linking Multiple Source Files
To produce an executable file, we must tell the compiler not only where to find our main function but also where to find the definition of the member functions defined by the Sales_item class. Let’s assume that we have two files: main.cc, which contains the definition of main, and Sales_item.cc, which contains the Sales_item member functions. We might compile these files as follows:

where $ is our system prompt and # begins a command-line comment. We can now run the executable file, which will run our main program.
If we have only changed one of our .cc source files, it is more efficient to recompile only the file that actually changed. Most compilers provide a way to separately compile each file. This process usually yields a .o file, where the .o extension implies that the file contains object code.
The compiler lets us link object files together to form an executable. On the system we use, in which the compiler is invoked by a command named CC, we would compile our program as follows:

You’ll need to check with your compiler’s user’s guide to understand how to compile and execute programs made up of multiple source files.
Because headers are included in multiple source files, they should not contain definitions of variables or functions.
There are three exceptions to the rule that headers should not contain definitions: classes, const objects whose value is known at compile time, and inline functions (Section 7.6 (p. 256) covers inline functions) are all defined in headers. These entities may be defined in more than one source file as long as the definitions in each file are exactly the same.
These entities are defined in headers because the compiler needs their definitions (not just declarations) to generate code. For example, to generate code that defines or uses objects of a class type, the compiler needs to know what data members make up that type. It also needs to know what operations can be performed on these objects. The class definition provides the needed information. That const objects are defined in a header may require a bit more explanation.
Some const Objects Are Defined in Headers
Recall that by default a const variable (Section 2.4, p. 57) is local to the file in which it is defined. As we shall now see, the reason for this default is to allow const variables to be defined in header files.
In C++ there are places where constant expression (Section 2.7, p. 62) is required. For example, the initializer of an enumerator must be a constant expression. We’ll see other cases that require constant expressions in later chapters.
Generally speaking, a constant expression is an expression that the compiler can evaluate at compile-time. A const variable of integral type may be a constant expression when it is itself initialized from a constant expression. However, for the const to be a constant expression, the initializer must be visible to the compiler. To allow multiple files to use the same constant value, the const and its initializer must be visible in each file. To make the initializer visible, we normally define such consts inside a header file. That way the compiler can see the initializer whenever the const is used.
However, there can be only one definition (Section 2.3.5, p. 52) for any variable in a C++ program. A definition allocates storage; all uses of the variable must refer to the same storage. Because, by default, const objects are local to the file in which they are defined, it is legal to put their definition in a header file.
There is one important implication of this behavior. When we define a const in a header file, every source file that includes that header has its own const variable with the same name and value.
When the const is initialized by a constant expression, then we are guaranteed that all the variables will have the same value. Moreover, in practice, most compilers will replace any use of such const variables by their corresponding constant expression at compile time. So, in practice, there won’t be any storage used to hold const variables that are initialized by constant expressions.
When a const is initialized by a value that is not a constant expression, then it should not be defined in header file. Instead, as with any other variable, the const should be defined and initialized in a source file. An extern declaration for that const should be made in the header, enabling multiple files to share that variable.
2.9.2 A Brief Introduction to the Preprocessor
Now that we know what we want to put in our headers, our next problem is to actually write a header. We know that to use a header we have to #include it in our source file. In order to write our own headers, we need to understand a bit more about how a #include directive works. The #include facility is a part of the C++ preprocessor. The preprocessor manipulates the source text of our programs and runs before the compiler. C++ inherits a fairly elaborate preprocessor from C. Modern C++ programs use the preprocessor in a very restricted fashion.
A #include directive takes a single argument: the name of a header. The pre-processor replaces each #include by the contents of the specified header. Our own headers are stored in files. System headers may be stored in a compiler-specific format that is more efficient. Regardless of the form in which a header is stored, it ordinarily contains class definitions and declarations of the variables and functions needed to support separate compilation.
Headers Often Need Other Headers
Headers often #include other headers. The entities that a header defines often use facilities from other headers. For example, the header that defines our Sales_item class must include the string library. The Sales_item class has a string data member and so must have access to the string header.
Including other headers is so common that it is not unusual for a header to be included more than once in the same source file. For example, a program that used the Sales_item header might also use the string library. That program wouldn’t—indeed shouldn’t—know that our Sales_item header uses the string library. In this case, the string header would be included twice: once by the program itself and once as a side-effect of including our Sales_item header.
Accordingly, it is important to design header files so that they can be included more than once in a single source file. We must ensure that including a header file more than once does not cause multiple definitions of the classes and objects that the header file defines. A common way to make headers safe uses the preprocessor to define a header guard. The guard is used to avoid reprocessing the contents of a header file if the header has already been seen.
Avoiding Multiple Inclusions
Before we write our own header, we need to introduce some additional preprocessor facilities. The preprocessor lets us define our own variables.
Names used for preprocessor variables must be unique within the program. Any uses of a name that matches a preprocessor variable is assumed to refer to the preprocessor variable.
To help avoid name clashes, preprocessor variables usually are written in all uppercase letters.
A preprocessor variable has two states: defined or not yet defined. Various preprocessor directives define and test the state of preprocessor variables. The #define directive takes a name and defines that name as a preprocessor variable. The #ifndef directive tests whether the specified preprocessor variable has not yet been defined. If it hasn’t, then everything following the #ifndef is processed up to the next #endif.
We can use these facilities to guard against including a header more than once:
#ifndef SALESITEM_H
#define SALESITEM_H
// Definition of Sales_itemclass and related functions goes here
#endif
The conditional directive
#ifndef SALESITEM_H
tests whether the SALESITEM_H preprocessor variable has not been defined. If SALESITEM_H has not been defined, the #ifndef succeeds and all the lines following #ifndef until the #endif is found are processed. Conversely, if the variable SALESITEM_H has been defined, then the #ifndef directive is false. The lines between it and the #endif directive are ignored.
To guarantee that the header is processed only once in a given source file, we start by testing the #ifndef. The first time the header is processed, this test will succeed, because SALESITEM_H will not yet have been defined. The next statement defines SALESITEM_H. That way, if the file we are compiling happens to include this header a second time, the #ifndef directive will discover that SALESITEM_H is defined and skip the rest of the header file.
Headers should have guards, even if they aren’t included by another header. Header guards are trivial to write and can avoid mysterious compiler errors if the header subsequently is included more than once.
This strategy works well provided that no two headers define and use a pre-processor constant with the same name. We can avoid problems with duplicate preprocessor variables by naming them for an entity, such as a class, that is defined inside the header. A program can have only one class named Sales_item. By using the class name to compose the name of the header file and the preprocessor variable, we make it pretty likely that only one file will use this preprocessor variable.
Using Our Own Headers
The #include directive takes one of two forms:
#include <standard_header>
#include "my_file.h"
If the header name is enclosed by angle brackets (< >), it is presumed to be a standard header. The compiler will look for it in a predefined set of locations, which can be modified by setting a search path environment variable or through a command line option. The search methods used vary significantly across compilers. We recommend you ask a colleague or consult your compiler’s user’s guide for further information. If the header name is enclosed by a pair of quotation marks, the header is presumed to be a nonsystem header. The search for nonsystem headers usually begins in the directory in which the source file is located.
Chapter Summary
Types are fundamental to all programming in C++.
Each type defines the storage requirements and the operations that may be performed on all objects of that type. The language provides a set of fundamental built-in types such as int and char. These types are closely tied to their representation on the machine’s hardware.
Types can be nonconst or const; a const object must be initialized and its value may not be changed. In addition, we can define compound types, such as references. A reference provides another name for an object. A compound type is a type that is defined in terms of another type.
The language lets us define our own types by defining a class. The library uses the class facility to provide a set of higher-level abstractions such as the IO and string types.
C++ is a statically typed language: Variables and functions must be declared before they are used. A variable can be declared many times but defined only once. It is almost always a good idea to initialize variables when you define them.
Defined Terms
Members in a class may be defined to be private, which protects them from access from code that uses the type. Members may also be defined as public, which makes them accessible code throughout the program.
Number by which a byte in memory can be found.
The arithmetic types represent numbers: integers and floating point. There are three types of floating point values: long double, double, and float. These represent extended, double, and single precision values. It is almost always right to use double. In particular, float is guaranteed only six significant digits— too small for most calculations. The integral types include bool, char, wchar_t, short, int, and long. Integer types can be signed or unsigned. It is almost always right to avoid short and char for arithmetic. Use unsigned for counting. The bool type may hold only two values: true or false. The whcar_t type is intended for characters from an extended character set; char type is used for characters that fit in 8 bits, such as Latin-1 or ASCII.
Data structure that holds a collection of unnamed objects that can be accessed by an index. This chapter introduced the use of character arrays to hold string literals. Chapter 4 will discuss arrays in much more detail.
Typically the smallest addressable unit of memory. On most machines a byte is 8 bits.
C++ mechanism for defining data types. Classes are defined using either the class or struct keyword. Classes may have data and function members. Members may be public or private. Ordinarily, function members that define the operations on the type are made public; data members and functions used in the implementation of the class are made private. By default, members in a class defined using the class keyword are private; members in a class defined using the struct keyword are public.
A part of a class. Members are either data or operations.
A type, such as a reference, that is defined in terms of another type. Chapter 4 covers two additional compound types: pointers and arrays.
A reference that may be bound to a const object, a nonconst object, or to an rvalue. A const reference may not change the object to which it refers.
An integral expression whose value can be evaluated at compile-time.
Special member function that is used to initialize newly created objects. The job of a constructor is to ensure that the data members of an object have safe, sensible initial values.
Form of initialization that uses the = symbol to indicate that variable should be initialized as a copy of the initializer.
The data elements that constitute an object. Data members ordinarily should be private.
Asserts the existence of a variable, function, or type defined elsewhere in the program. Some declarations are also definitions; only definitions allocate storage for variables. A variable may be declared by preceeding its type with the keyword extern. Names may not be used until they are defined or declared.
The constructor that is used when no explicit values are given for an initializer of a class type object. For example, the default constructor for string initializes the new string as the empty string. Other string constructors initialize the string with characters specified when the string is created.
Allocates storage for a variable of a specified type and optionally initializes the variable. Names may not be used until they are defined or declared.
Form of initialization that places a comma-separated list of initializers inside a pair of parentheses.
A type that groups a set of named integral constants.
The named members of an enumeration. Each enumerator is initialized to an integral value and the value of the enumerator is const. Enumerators may be used where integral constant expressions are required, such as the dimension of an array definition.
Alternative mechanism for representing characters. Usually used to represent nonprintable characters such as newline or tab. An escape sequence is a backslash followed by a character, a three-digit octal number, or a hexadecimal number. The escape sequences defined by the language are listed on page 40. Escape sequences can be used as a literal character (enclosed in single quotes) or as part of a literal string (enclosed in double quotes).
Scope that is outside all other scopes.
A mechanism for making class definitions and other declarations available in multiple source files. User-defined headers are stored as files. System headers may be stored as files or in some other system-specific format.
The preprocessor variable defined to prevent a header from being included more than once in a single source file.
A name. Each identifier is a nonempty sequence of letters, digits, and underscores that must not begin with a digit. Identifiers are case-sensitive: Upper- and lowercase letters are distinct. Identifiers may not use C++ keywords. Identifiers may not contain two adjacent underscores nor may they begin with an underscore followed by a uppercase letter.
The (usually private) members of a class that define the data and any operations that are not intended for use by code that uses the type. The istream and ostream classes, for example, manage an IO buffer that is part of their implementation and not directly accessible to users of those classes.
A variable that has an initial value. An initial value may be specified when defining a variable. Variables usually should be initialized.
See arithmetic type.
The operations supported by a type. Well-designed classes separate their interface and implementation, defining the interface in the public part of the class and the implementation in the private parts. Data members ordinarily are part of the implementation. Function members are part of the interface (and hence public) when they are operations that users of the type are expected to use and part of the implementation when they perform operations needed by the class but not defined for general use.
Compilation step in which multiple object files are put together to form an executable program. The link step resolves interfile dependencies, such as linking a function call in one file to a function definition contained in a second file.
A value such as a number, a character, or a string of characters. The value cannot be changed. Literal characters are enclosed in single quotes, literal strings in double quotes.
Term used to describe function scope and the scopes nested inside a function.
A value that may appear on the left-hand of an assignment. A nonconst lvalue may be read and written.
A literal number in a program whose meaning is important but not obvious. It appears as if by magic.
A reference that may be bound only to a nonconst lvalue of the same type as the reference. A nonconst reference may change the value of the underlying object to which it refers.
A character with no visible representation, such as a control character, a backspace, newline, and so on.
A region of memory that has a type. A variable is an object that has a name.
The preprocessor is a program that runs as part of compilation of a C++ program. The preprocessor is inherited from C, and its uses are largely obviated by features in C++. One essential use of the preprocessor remains: the #include facility, which is used to incorporate headers into a program.
Member that is inaccessible to code that uses the class.
Member of a class that can be used by any part of the program.
An alias for another object. Defined as follows:
type &id = object;
Defines id to be another name for object. Any operation on id is translated as an operation on object.
Refers to the time during which the program is executing.
A value that can be used as the right-hand, but not left-hand side of an assignment. An rvalue may be read but not written.
A portion of a program in which names have meaning. C++ has several levels of scope:
global— names defined outside any other scope.
class— names defined by a class.
namespace— names defined within a namespace.
local— names defined within a function.
block— names defined within a block of statements, that is, within a pair of curly braces.
statement— names defined within the condition of a statement, such as an if, for, or while.
Scopes nest. For example, names declared at global scope are accessible in function and statement scope.
Ability to split a program into multiple separate source files.
Integer type that holds negative or positive numbers, including zero.
Term used to refer to languages such as C++ that do compile-time type checking. C++ verifies at compile-time that the types used in expressions are capable of performing the operations required by the expression.
Keyword that can be used to define a class. By default, members of a struct are public until specified otherwise.
Term used to describe the process by which the compiler verifies that the way objects of a given type are used is consistent with the definition of that type.
The part of a definition or declaration that names the type of the variables that follow.
Introduces a synonym for some other type. Form:
typedef type synonym;
defines synonym as another name for the type named type.
A usage for which the language does not specify a meaning. The compiler is free to do whatever it wants. Knowingly or unknowingly relying on undefined behavior is a great source of hard-to-track run-time errors and portability problems.
Variable with no specified initial value. An uninitialized variable is not zero or “empty;” instead, it holds whatever bits happen to be in the memory in which it was allocated. Uninitialized variables are a great source of bugs.
Integer type that holds values greater than or equal to zero.
Term used to describe the rules for initializing variables and array elements when no explicit initializer is given. For class types, objects are initialized by running the class’s default constructor. If there is no default constructor, then there is a compile-time error: The object must be given an explicit initializer. For built-in types, initialization depends on scope. Objects defined at global scope are initialized to 0; those defined at local scope are uninitialized and have undefined values.
Special-purpose type that has no operations and no value. It is not possible to define a variable of type void. Most commonly used as the return type of a function that does not return a result.
The natural unit of integer computation on a given machine. Usually a word is large enough to hold an address. Typically on a 32-bit machine machine a word is 4 bytes.