
11.2. Following Information Engineering Steps
The file cabinet is a good model for information engineering. Would you ask a cabinetmaker to tell you what information is important to you and how you should file it? Of course you wouldn't. You'd decide what and how much you thought you needed to store, and then describe it as clearly as possible. Would you then stand over his shoulder and tell him how to cut the wood or where to put every screw? Not if you ever hoped to hire him again. Don't expect to ask the IT folks to tell you what you want to store in your system. And don't tell them how to build your system. Business experts specify requirements and the IT team delivers solutions. When these roles get reversed (and it does happen), disaster is guaranteed.
For this chapter on information, we will also take a quick look at the IT department's perspectives. For the other CRM components, we will focus only on the two to three highest levels needed to ensure that the guiding information comes from the business functions that will use the system (see Table 11-2).
| Business View | Information View | File Cabinet View |
|---|---|---|
| Owner's Wants View | Data classes | File drawer labels |
| Owner's Needs View | Business subjects | Hanging file labels |
| Designer's View | Entity and relationship model | Individual folders |
| Builder's View | Physical data model | Document formats |
| Detailed Representation | Database: tables, columns, rows | Individual documents |
| Functioning System | Populated database | Filled filing cabinet |
It's important to generally understand both the business function and IT department's roles and especially to see how the early views drive the later views and ensure that what's built matches the business needs.
Of course, XYZ really started their information requirements definition as part of the strategic plan when they identified the program-wide scope for high level information needs (their inventory of strategic data classes).
|
During strategic planning, XYZ hadn't yet selected a project, so at the strategic highest level, they developed a picture across the whole CRM space. From the strategic internal interviews the team generated a list of business opportunities and business issues that they used to develop the program data classes. To demonstrate the approach, we'll use the summary of issues and opportunities from XYZ's strategic proposal in Chapter 8.
Team meetings and brainstorming sessions with the steering committee and others were some of the other good ways XYZ used to gather strategic perspectives. You may actually start with a list of 100 or more statements on your list, but plenty of these can be eliminated. Consolidate duplicates, and eliminate oddball comments. (Brainstorming sometimes encourages wacky ideas to expand thinking, but that doesn't mean you shouldn't eventually discard the ones that are not reasonable or useful.) Start with the list of issues, opportunities, and stupid things we do to customers that were identified during the internal interviews, and then eliminate/merge duplicate statements. XYZ used these steps to develop the first pass at their strategic data class inventory:
1. |
Go through the list with a highlighter and mark every noun. These are your candidate data classes. |
2. |
Identify and eliminate duplicate data classes as well as any unrealistic or unreasonable data classes. |
3. |
Write a definition of each of the remaining data classes on your list. |
4. |
Organize into global data classes for ease of communication. |
XYZ identified twelve data classes (there were really more like 30 at this point), which were organized into the four global data classes, as shown in Figure 11-4. Global data classes are not created for any scientific reason but because a short list is easier to remember. The XYZ strategic planning team said, “We only need to understand four things: who our customers are, the marketplace in which we operate, the investments we are making, and the returns we get from each investment.”
Figure 11-4. XYZ's global data classes

When they began working on each of the project specific levels of detail, efforts would be focused on just what's needed for Valencia, the selected project. Identifying the program-wide component scope during strategic planning, and starting each project there, ensures that individual projects will fit together to create a successful total program. No more information silos!
11.2.1. Owner's Wants View: Data Classes
Now we're ready to start working on the project-specific views for the first piece of XYZ's customer identity system (El Cid). As you know the project team chose Valencia as the name for the first project. The owner's wants view for the information component was defined during the project launch. At that time XYZ reviewed the list of strategic data classes and narrowed the scope to those that they felt were relevant the Valencia project. The team identified the two data classes shown in Table 11-3.
| Data Class | Definition |
|---|---|
| Customers | A customer is a person (or a group of persons) who influences or decides on the acquisition of one of our products or services, or who uses one of these products or services. |
| Installed Products | Products or services owned or used by a customer |
They also developed definitions for each of the data classes (and of course leveraged any previous common terms such as the one for CUSTOMERS which was given in Chapter 1).
11.2.2. Owner's Needs View: Business Subjects
We always start creating a view with the results from the previous level. Each step builds on the preceding step. If new information is discovered that doesn't logically fit anyplace in the preceding view, we have to go back and add them.
|
After we have defined our data classes (file drawers) we need to identify the major topics that we want to store in each drawer. Business subjects are the hanging files that are used to separate the drawer labeled Customer into its main components so that it's easier to find what is needed. We determine our list of business subjects by deciding what things we want to keep in each drawer. Business subjects represent real things that have different facts that describe them. Like an architect's model, subjects begin to take shape, but there still isn't much detail. These steps can help you develop the list of subjects that will be part of Valencia:
1. |
Start with the data classes that are were identified as relevant for this project. |
2. |
Identify the major divisions (business subjects) for the data classes. |
3. |
Write a definition for each business subject. |
XYZ immediately identified two important subjects within the CUSTOMERS data class, but found none for INSTALLED PRODUCTS, so the subject just carried the same name as the data class as shown in Table 11-4 which lists the subjects that XYZ identified and defined to support Valencia business goals. The subjects were defined independent of where they were captured or stored.
| Data Class | Business Subject | Definition |
|---|---|---|
| Customers | Customer Companies | An organization that acquires one of our products or services |
| Customer Contacts | A person who acquires one of our products or services | |
| Installed Products | Installed Products | A product or service owned or used by a customer company or contact |
We never organize data around any of its uses—only on what the thing actually is. Next, we will decide how to organize the facts that we want to collect and store. Company is one thing, but what do we want to know about companies?
11.2.3. Designer's View: Entities, Attributes, and Relationships
The designer's view is where the hand-off between business knowledge and IT knowledge takes place. This is the view where the responsibility switches from being primarily business function to primarily Information Technology's responsibility.
Don't think this means that everyone needs to learn how to draw blueprints. This is not required at all. But everyone needs to understand what the blueprints mean, or some very unpleasant surprises may be in store. The blueprint for a database, called an Entity-Relationship Diagram, covers all three elements of the designer's view: entities, attributes, and relationships.
But where do we start? Not surprisingly, we start with the subjects we have just identified. Let's review the steps that XYZ used to identify the entities, attributes, and relationships for Valencia:
1. |
Assign each fact that is currently used (or desired) by the business teams to the specific business subject that it best describes; these are candidate entities. |
2. |
Identify the KEY attribute (label) for each candidate entity. |
3. |
Apply entity rules to determine the final structure of each entity. |
4. |
Identify entity relationships. |
5. |
Define entities, attributes, and relationships. |
We will go through each of these steps in Appendix D, just as XYZ did during its planning for Valencia. Entities represent real stuff; they are concrete enough that we can actually describe them.
|

Entities have characteristics we want to capture (what is the customer's name), and they have links to other entities (what customer placed this order). Data classes and subjects are very conceptual, like labels on file drawers and dividers. But an entity with its unique attributes is more like a single folder that contains a number of similar forms. An entity (sometimes called entity-type) represents a group of real people, companies, etc. Each real thing (such as a particular consumer), is represented by a single physical form, is called an entity instance. The form design describes what we need to capture about each entity.
Attributes
Attributes are all the blanks that need to be filled in or checked on each form. We can generate a list of potential attributes through a number of avenues, such as interviews and brainstorming. The best source of information about attributes is all the documents (forms, reports, computer screens) the company already uses. XYZ has used cardboard product registration cards for years to collect information about its customers. Figure 11-5 shows an example of one of XYZ's product registration cards.
Figure 11-5. Sample XYZ product registration card
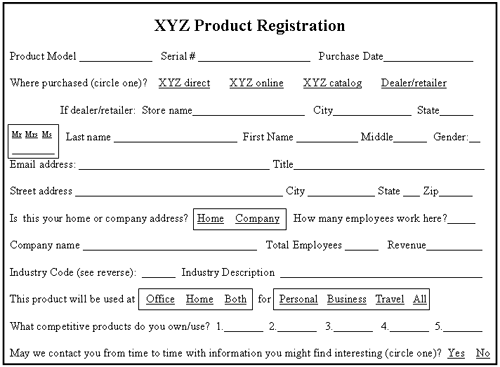
XYZ used this card to generate a list of important facts it needed to store about customers; then the company assigned each attribute to an appropriate entity. For a well-organized computer file, each form type would be designed to hold attributes that describe only one type of data entity, and those attributes would not be repeated anywhere else. Figure 11-6 shows XYZ's street address entity (folder).
Figure 11-6. Street address entity

Every entity must have one attribute that identifies each page in the folder. These are called key attributes, and they are the primary way that the computer finds and retrieves a single specific page.
XYZ identified a total of nine entities, two each for the three project subjects and three whose subject area was outside the original project scope. Schedule and resource investments had to be considered when the scope grew. The XYZ team had to take a step back and identify the subjects and data classes for these new entities.
By the way, the naming convention commonly used in information engineering uses plural names for the two highest-level views (class and subject) and a singular form for the rest of the views. This convention is illustrated in Table 11-5, which shows the entities and attributes XYZ identified for Valencia.
| Class | Subject | Entity | Attribute |
|---|---|---|---|
| INSTALLED PRODUCTS | Installed Products | XYZ Installed Product | product model serial number |
| purchase date | |||
| where purchased | |||
| primary use | |||
| where used | |||
| Competitive Installed Product | person identifier competitive product | ||
| product quantity | |||
| CHANNEL PARTNERS | Stores | Store | store identifier |
| store name | |||
| store location city | |||
| store location state | |||
| CUSTOMERS | Customer Contacts | Contact Person | person identifier |
| person last name | |||
| person first name | |||
| person address title | |||
| person business title | |||
| person gender | |||
| ok to contact? | |||
| Customer Companies | Company Site | company identifier address identifier | |
| employee count here | |||
| Company Organization | company identifier | ||
| company name | |||
| total employees | |||
| revenue | |||
| LOCATERS | Locaters | E-mail Address | person identifier e-mail address |
| e-mail inactive date | |||
| Street Address | address identifier | ||
| street | |||
| city | |||
| state | |||
| postal code | |||
| country | |||
| INDUSTRIES | Industries | Industry | industry code |
| industry description |
Even if XYZ had decided not to expand scope to work on the new data entities, they needed to capture the additional knowledge they had uncovered about the two new business subjects (Stores and Locaters) and one previously unidentified class (LOCATERS).
Relationships
Relationships describe how an entity is related to any other entities: which entities are related to each other, the purpose of the relationship, and how they are related. Relationships allow us to avoid repeating the same information over and over throughout the database. This is where computers really have an advantage over filing cabinets; computers support automatic links between entities so that all the related data looks as if it is physically stored in every linked entity. For paper files, we'd have to search through each of our folders, pull out the related forms, and then tape them all together to get the full picture. That's why we put every piece of information we might need on one single form. (I didn't say the form was only one page.) Because much of the same information is repeated, paper forms get out of date and are usually laden with errors and inconsistencies. But we're used to paper files and very often make the same mistake with computer filing systems.
We know we don't want to clutter our computers with all this redundant and consistent data, but how do we get it organized and linked. In a paper filing system, you might try tying a piece of string between all of the files that have related information about, say, the same customer. Can you imagine? Take a look at Figure 11-7. What a nightmare!
Figure 11-7. Filing cabinet relationships?

Early computer systems followed the file drawer method: store everything in one big computer file. This approach had the same inherent wasted space, inconsistency, and poor quality as the filing cabinet method. Although computers are faster and bigger than filing cabinets, database software hadn't been designed to take advantage of the computer's potential. The early computer file designs forced programmers to tie figurative strings between related files.
But that has changed. The database management systems most prevalent today (relational, object-oriented) are designed to manage relationships between entities such that, after the relationships are defined, the computer does the work of linking everything together so it looks like one big form, with the advantage of eliminating all that redundant data. Software engineers put all this together using a Computer Aided Software Engineering (CASE) tool (trust me, graphics software is NOT the way), and we get the Entity Relationship Diagram for Valencia, which you can find in Appendix D. This is the technical team's blueprint for constructing the new system. As promised, not very many people need to understand how to actually create this model, not even everyone in the IT department. But everyone needs to have some idea of what it represents about the information component.
These first three views are all that the business needs to even think about. But you can see that even getting this far takes a delicate balance of business knowledge and technical knowledge. This is one area in which organizations often need help from outside the company to ensure that all three steps are completed and that business requirements have been clearly articulated, but not to make the decisions of course. Now the rest of the steps are up to the IT department.
11.2.4. Following the Rest of the Steps
The two remaining views are the responsibility of the IT organization. Still the business function participation is important to answer detailed questions and review specifications.
Builder's View: Physical Data Model
Just as in each preceding view, the IT designers started with the entity relationship diagram (ERD). It will be reviewed for technical performance issues, and modifications may be suggested to support faster updates, retrievals, and sorting. Each modification recommended should be explained to the business team with pros and cons, and the exception should be documented. System performance is always improving; there may be a reason to go back to the original design sometime in the future. The people who have to make that future change need to know why the database looks the way it does.
The physical data model includes the physical characteristics of the data to be stored, such as type of data (numbers, text) and size (how much space needs to be set aside). These characteristics are generally required for “decision support” data that is used for sorting and searching. There are also many excellent products that support storing formatted and variable-length text for quick retrieval, but this is not a requirement of Valencia.
Subcontractor's View: Individual Tables, Rows, and Columns
Now the Information Technology department can actually build the database. Many CASE tools create code that can be used to generate the physical (empty) database straight from the project design. These reproduce the physical data model in a database management system by creating one table for each entity. The database table is made up of a series of columns, one for each attribute, as shown in Table 11-6.
| Data Model | Physical Database |
|---|---|
| Entity | Data table |
| Attribute | Column |
| Entity instance | Row |
The database is empty when it is first built. Just like creating a new computer spreadsheet, you have only the empty spreadsheet and a list of labeled columns.
Finally, the IT department will get the physical database up and running so that data can be loaded, managed and retrieved. Each individual record (set of information about an entity instance) that is added creates a new row in the data table. A specific row is retrieved based on the value of its key. Once accessed, all the data for the entity instance is available, whether it is physically in that table or linked by a foreign key.
11.2.5. The Transition to Information Technology
The Designer's View is where primary responsibility shifts from the business functions to the IT function as shown in Figure 11-8.
Figure 11-8. Information Handoff

There is considerable risk of losing momentum and continuity when a responsibility shift between two separate organizations occurs. The “transition” view is always an extremely critical view and one that must be understood and managed very well.