
C H A P T E R 7
Understanding T-SQL Programming Logic
Even though the primary purpose of T-SQL is to retrieve and manipulate data, like other programming languages it also contains logic elements. Most of the time you will write T-SQL statements that retrieve or update data, but you can also set up loops and write code with conditional flow. Often database administrators write scripts in T-SQL to perform maintenance tasks that require more than just retrieving or updating data. For example, you might need to write a script that checks the last backup date of all databases on the server or checks the free space of all the databases. Although most administrative tasks are beyond the scope of this book, you may find many uses in your environment for the techniques you learn in this chapter.
Variables
If you have programmed in any other language, you have probably used variables in your programs. Variables hold temporary values used to help you in designing programming logic. For example, you might use a variable to hold the results of a calculation, or the results of a string concatenation, or to control the number of times a loop executes.
Declaring and Initializing a Variable
To use a variable, you must first declare it. SQL Server 2012 also gives you the option to initialize a variable, that is, assign a value to the variable at the same time that you declare it. Versions earlier than SQL Server 2008 required that you assign a value on a separate line. Here is the syntax for declaring a variable and assigning a value at the same time and later in the code:
DECLARE @variableName <type>[(size)] = <value1>
SET @variableName = <value2>
You assign a value to a variable after you declare it by using the SET statement or by using the SELECT statement. The SET statement lets you work with only one variable at a time. The SELECT statement allows multiple variables to be modified in the same statement. Using a SELECT statement to assign values to multiple variables is more efficient than individual SET statements. In most cases, the difference is so small that you should just write your code using whichever technique you prefer. You can also assign a value to a variable from a column within a query. When doing so, that is the only thing the query can do; the query can’t return a result set. Type in and execute Listing 7-1 to learn how to declare and assign variables.
Listing 7-1. Declaring and Using Variables
USE AdventureWorks2012;
GO
--1
DECLARE @myNumber INT = 10;
PRINT 'The value of @myNumber';
PRINT @myNumber;
SET @myNumber = 20;
PRINT 'The value of @myNumber';
PRINT @myNumber;
GO
--2
DECLARE @myString VARCHAR(100), @myBit BIT;
SELECT @myString = 'Hello, World', @myBit = 1;
PRINT 'The value of @myString';
PRINT @myString;
PRINT 'The value of @myBit';
PRINT @myBit;
GO
--3
DECLARE @myUnicodeString NVARCHAR(100);
SET @myUnicodeString = N'This is a Unicode String';
PRINT 'The value of @myUnicodeString';
PRINT @myUnicodeString;
GO
--4
DECLARE @FirstName NVARCHAR(50), @LastName NVARCHAR(50);
SELECT @FirstName = FirstName, @LastName = LastName
FROM Person.Person
WHERE BusinessEntityID = 1;
PRINT 'The value of @FirstName';
PRINT @FirstName;
PRINT 'The value of @LastName';
PRINT @LastName;
GO
--5
PRINT 'The value of @myString';
PRINT @myString;
Figure 7-1 shows the results of the script. The script in Listing 7-1 consists of five batches after setting the database context. Batch 1 declares and initializes the local variable @myNumber in one line to the value 10. Local variables in T-SQL begin with the @ symbol and are in scope within the current connection and the current batch. Another line in the batch sets the value of the variable to 20 using the SET command. The SET command will set the value of only one variable at a time. Using the PRINT command, you can print the value of a variable.

Figure 7-1. The results of declaring and initializing a variable
Batch 2 demonstrates how you can declare more than one variable on the same line. The batch uses a SELECT statement to assign values to both the variables in the same statement. Batch 3 demonstrates that you set the value of an NVARCHAR string a bit differently. You must begin the string with the uppercase letter N. By doing so, SQL Server converts the string to Unicode. If you don’t begin the string with N, the string will remain as a non-Unicode string, and you may lose any special characters.
In batch 4, the SELECT statement assigns the value of the FirstName and LastName columns to two variables from one row of the Person.Person table. In this case, the WHERE clause restricts the SELECT statement to just one row. If the statement didn’t have a WHERE clause or a less restrictive one, the statement would assign the last value returned to the variable.
Batch 5 demonstrates that the variable declared in batch 2 is no longer in scope. Variables go out of scope when the batch completes. Even if there is only one batch in the script, once the code completes, the variable goes out of scope and is no longer in memory.
Using Expressions and Functions with Variables
The previous example demonstrated how to declare and assign a literal value or a value from a query. You can also use any expression and function to assign a value to a variable. For example, you may need to save the count of the rows of a query for later in the script, or you may need to save the value of a file name concatenated to a file path for a maintenance script. Type in and execute the code in Listing 7-2 to learn more about variables.
Listing 7-2. Using Expressions and Functions to Assign Variable Values
USE AdventureWorks2012;
GO
--1
DECLARE @myINT1 INT = 10, @myINT2 INT = 20, @myINT3 INT;
SET @myINT3 = @myINT1 * @myINT2;
PRINT 'Value of @myINT3: ' + CONVERT(VARCHAR,@myINT3);
GO
--2
DECLARE @myString VARCHAR(100);
SET @myString = 'Hello, ';
SET @myString += 'World';
PRINT 'Value of @myString: ' + @myString;
GO
--3
DECLARE @CustomerCount INT;
SELECT @CustomerCount = COUNT(*)
FROM Sales.Customer;
PRINT 'Customer Count: ' + CAST(@CustomerCount AS VARCHAR);
--4
DECLARE @FullName NVARCHAR(152);
SELECT @FullName = FirstName + ISNULL(' ' + MiddleName,'') + ' ' + LastName
FROM Person.Person
WHERE BusinessEntityID = 1;
PRINT 'FullName: ' + @FullName;
Figure 7-2 shows the results. Batch 1 declares three integer variables and assigns a value to two of them. The next line uses the SET statement to assign the sum of the two variables to the third one. Finally, to print the label explaining the value and the value on the same line, the code converts the @myINT3 variable to a string.

Figure 7-2. The results of using variables with expressions
Batch 2 assigns the value Hello (with a space after it) to the @myString variable. The next line uses the += operator to concatenate another string, World, to the variable. The += operator is available in many programming languages as a shorter way to write an assignment. Without the shortcut, the code would look like this:
SET @myString = @myString + 'World';
Batch 3 assigns the result of the aggregate expression COUNT(*) to the variable @CustomerCount. When assigning a value to a variable from a query, you will assign only one value to a variable. In this case, the query returns only one value, the count of all the rows from the table. The query in Batch 4 also returns one row because of the criteria in the WHERE clause. The query assigns a value to the @FullName variable for one row only.
Using Variables in WHERE and HAVING Clauses
So far, the examples in this book have used literal values in the expressions, also known as predicates, in WHERE and HAVING clauses. You will often not know ahead of time what values will be needed, so it makes sense to use variables. Type in and execute the code in Listing 7-3 to learn more about using a variable instead of a literal value in a WHERE or HAVING clause.
Listing 7-3. Using a Variable in a WHERE or HAVING Clause Predicate
USE AdventureWorks2012;
GO
--1
DECLARE @ID INT;
SET @ID = 1;
SELECT BusinessEntityID, FirstName, LastName
FROM Person.Person
WHERE BusinessEntityID = @ID;
GO
--2
DECLARE @FirstName NVARCHAR(50);
SET @FirstName = N'Ke%';
SELECT BusinessEntityID, FirstName, LastName
FROM Person.Person
WHERE FirstName LIKE @FirstName
ORDER BY BusinessEntityID;
GO
--3
DECLARE @ID INT = 1;
--3.1
SELECT BusinessEntityID, FirstName, LastName
FROM Person.Person
WHERE @ID = CASE @ID WHEN 0 THEN 0 ELSE BusinessEntityID END;
SET @ID = 0;
--3.2
SELECT BusinessEntityID, FirstName, LastName
FROM Person.Person
WHERE @ID = CASE @ID WHEN 0 THEN 0 ELSE BusinessEntityID END;
GO
--4
DECLARE @Amount INT = 10000;
SELECT SUM(TotalDue) AS TotalSales, CustomerID
FROM Sales.SalesOrderHeader
GROUP BY CustomerID
HAVING SUM(TotalDue) > @Amount;
Figure 7-3 shows the results. Batch 1 declares a variable @ID and assigns the value 1. The query uses the variable in the WHERE clause to restrict the results to just the row from the Person.Person table where the BusinessEntityID is 1. Batch 2 demonstrates how pattern matching with LIKE can be used. The variable contains the wildcard %. The query returns all rows where the FirstName begins with Ke.
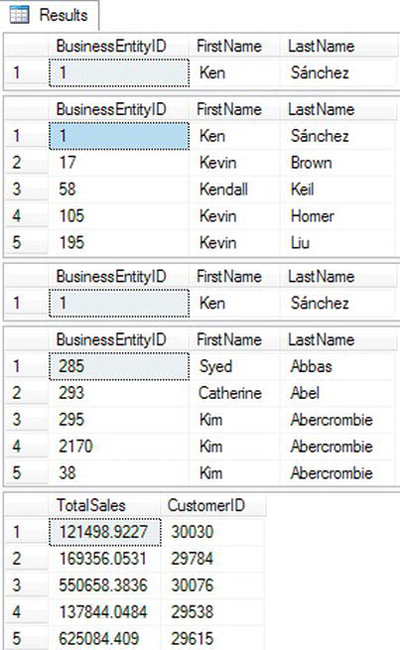
Figure 7-3. The partial results of using a variable in the WHERE and HAVING clauses
Batch 3 uses the variable @ID within a CASE expression in the WHERE clause. The variable starts out with the value 1. Query 3.1 returns only the row in which BusinessEntityID equals 1. Take a closer look at the CASE expression. The variable does not equal 0, so the CASE expression returns the column BusinessEntityID. The variable @ID equals the BusinessEntityID in only one row. In query 3.2, the value of @ID is 0. The CASE expression returns 0 because @ID is equal to 0. Since @ID is equal to 0 and the CASE expression returns 0, the query returns every row. Zero is always equal to zero.
Batch 4 demonstrates that the variables can also be used in the HAVING clause of an aggregate query. Recall from Chapter 5 that you use the HAVING clause to filter the rows after the database engine processes the GROUP BY clause. The query returns only the rows from the Sales.SalesOrderHeader table where the TotalSales value by CustomerID exceeds the value stored in @Amount.
Now that you understand some of the things you can do with variables, practice working with them by completing Exercise 7-1.
The IF… ELSE Construct
Use IF along with the optional ELSE keyword to control code flow in your T-SQL scripts. Use IF just as you would in any other programming language to execute a statement or group of statements based on an expression that must evaluate to TRUE or FALSE. For example, you might need to display an error message if the count of the rows in a table is too low. If the count exceeds a given value, your code repopulates a production table.
Using IF
Always follow the keyword IF with a condition that evaluates to TRUE or FALSE. You can follow the condition with the next statement to run on the same line or on the next line. If the condition applies to a group of statements, you will use BEGIN and END to designate which statements are within the IF block. Here is the syntax:
IF <condition> <statement>
IF <condition>
<statement>
IF <condition> BEGIN
<statement1>
[<statement2>]
END
To make my code more readable and avoid mistakes, I use the first and third methods but avoid the second. For example, I might decide later to add a PRINT statement before the line to execute when the condition is true. In that case, I might accidentally cause the IF to apply just to the PRINT statement by forgetting to go back and add BEGIN and END. Type in and execute the code in Listing 7-4 to learn how to use IF.
Listing 7-4. Using IF to Control Code Execution
USE AdventureWorks2012;
GO
--1
DECLARE @Count INT;
SELECT @Count = COUNT(*)
FROM Sales.Customer;
IF @Count > 500 BEGIN
PRINT 'The customer count is over 500.';
END;
GO
--2
DECLARE @Name VARCHAR(50);
SELECT @Name = FirstName + ' ' + LastName
FROM Person.Person
WHERE BusinessEntityID = 1;
--2.1
IF CHARINDEX('Ken',@Name) > 0 BEGIN
PRINT 'The name for BusinessEntityID = 1 contains "Ken"';
END;
--2.2
IF CHARINDEX('Kathi',@Name) > 0 BEGIN
PRINT 'The name for BusinessEntityID = 1 contains "Kathi"';
END;
Figure 7-4 shows the results. Batch 1 retrieves the count of the rows in the Sales.Customer table. If the count exceeds 500, then the PRINT statement executes. You can use any valid statements within the IF block. These code examples use PRINT statements so that you can easily see the results. Batch 2 assigns the value returned by the expression FirstName + ' ' + LastName to the variable. The 2.1 IF block executes the PRINT statement if the value contains Ken. The 2.2 IF block executes the PRINT statement if the value contains Kathi. Since the value doesn’t contain Kathi, nothing prints.

Figure 7-4. The results of using IF
Using ELSE
Often you will need to perform an alternate option if the condition you are checking is false. If you are using the BEGIN and END keywords in the IF block, you must close the block first before adding ELSE. Just like IF, you can use BEGIN and END to designate the ELSE block. You can also type the statement on the same line or the next line if you choose. Here is the syntax for many of the ways you can use ELSE:
IF <condition> <statement>
ELSE <statement>
IF <condition> BEGIN
<statement1>
[<statement2>]
END
ELSE <statement>
IF <condition> BEGIN
<statement1>
[<statement2>]
END
ELSE BEGIN
<statement1>
[<statement2>]
END
The syntax examples show some of the ways you can use ELSE along with IF. You can use BEGIN and END with both or either parts of the construct. Type in and execute Listing 7-5 to learn how to use ELSE.
Listing 7-5. Using ELSE
USE AdventureWorks2012;
GO
--1
DECLARE @Count INT;
SELECT @Count = COUNT(*)
FROM Sales.Customer;
IF @Count < 500 PRINT 'The customer count is less than 500.';
ELSE PRINT 'The customer count is 500 or more.';
GO
--2
DECLARE @Name NVARCHAR(101);
SELECT @Name = FirstName + ' ' + LastName
FROM Person.Person
WHERE BusinessEntityID = 1;
--2.1
IF CHARINDEX('Ken', @Name) > 0 BEGIN
PRINT 'The name for BusinessEntityID = 1 contains "Ken"';
END;
ELSE BEGIN
PRINT 'The name for BusinessEntityID = 1 does not contain "Ken"';
PRINT 'The name is ' + @Name;
END;
--2.2
IF CHARINDEX('Kathi', @Name) > 0 BEGIN
PRINT 'The name for BusinessEntityID = 1 contains "Kathi"';
END;
ELSE BEGIN
PRINT 'The name for BusinessEntityID = 1 does not contain "Kathi"';
PRINT 'The name is ' + @Name;
END;
Figure 7-5 shows the results. This listing looks almost like Listing 7-4 except that it contains the ELSE blocks. Batch 1 saves the count of the customers in a variable. This time, if the count is less than 500, the PRINT statement in the IF block executes. In this case, the count exceeds 500, so the PRINT statement in the ELSE block executes. Batch 2 executes the PRINT statement in the IF block of the 2.1 section of code because the value of the variable contains Ken. The 2.2 section of code executes the PRINT statement in the ELSE block because the value of the variable does not contain Kathi.

Figure 7-5. The results of using ELSE
Using Multiple Conditions
So far, the examples have shown only one condition along with each IF or ELSE. You can include multiple conditions along with AND and OR just like within a WHERE clause. You can also control the logic with parentheses. For example, you may need to execute a statement only if the current day is Monday and the count of the rows in a table exceeds a certain value. Type in and execute the code in Listing 7-6.
Listing 7-6. Using Multiple Conditions with IF and ELSE
USE AdventureWorks2012;
GO
--1
DECLARE @Count INT;
SELECT @Count = COUNT(*)
FROM Sales.Customer;
IF @Count > 500 AND DATEPART(dw,getdate()) = 2 BEGIN
PRINT 'The count is over 500.';
PRINT 'Today is Monday.';
END
ELSE BEGIN
PRINT 'Either the count is too low or today is not Monday.';
END;
--2
IF @Count > 500 AND (DATEPART(dw,getdate()) = 2 OR DATEPART(m,getdate())= 5) BEGIN
PRINT 'The count is over 500.'
PRINT 'It is either Monday or the month is May.'
END
Figure 7-6 shows the results. This listing contains just one batch after setting the database context. IF block 1 checks to see whether the count exceeds 500 and whether the current day of the week is Monday. You may get different results depending on the day of the week you run the code. IF block 2 checks first to see whether the day of the week is Monday or whether the current month is May. The block then checks the count, which must exceed 500. Since both the count exceeds 500 and I executed the code in May, the statements print. Again, you may get different results depending on when you run the code example.

Figure 7-6. The results of using multiple conditions with IF
Nesting IF…ELSE
You can nest IF and ELSE blocks inside other IF and ELSE blocks to create even more complex logic. For example, you may need to check to make sure the current date is not a Sunday and execute a statement. Then within the IF block, check to make sure the table has at least a certain number of rows before executing another statement. The BEGIN and END keywords are sometimes optional, but I suggest you include them to make sure that the code is correct and readable. Here are two of the possible syntax examples:
IF <condition> BEGIN
[<statement1>]
IF <condition> BEGIN
<statement2>
END
END
IF <condition> BEGIN
<statement1>
END
ELSE BEGIN
[statment2]
IF <condition> BEGIN
<statement3>
[<statement4>]
END
ELSE <statement5>
END
As you can probably tell, nesting IF blocks can cause your code to become complicated. Be sure to use comments and consistent formatting to aid in your understanding of the code when you come back to it a few months or years after you write it. Type in and execute the code in Listing 7-7 to learn how to nest IF blocks.
Listing 7-7. Using a Nested IF Block
USE AdventureWorks2012;
GO
DECLARE @Count INT;
SELECT @Count = COUNT(*)
FROM Sales.Customer;
IF @Count > 500 BEGIN
PRINT 'The count is over 500.';
IF DATEPART(dw,getdate())= 2 BEGIN
PRINT 'Today is Monday.';
END;
ELSE BEGIN
PRINT 'Today is not Monday.';
END;
END;
Figure 7-7 shows the results. Since the count exceeds 500, the code executes the first PRINT statement. Then depending on the day that you execute the code, one of the statements inside the nested IF…ELSE block will print. When writing nested IF blocks, make sure that the logic actually acts in the way you intended.

Figure 7-7. The results of using a nested IF block
Using IF EXISTS
You can use IF EXISTS to check for the results of a SELECT statement before executing the statements within the IF block. For example, you could check to see whether a certain part number is listed in the parts table. If it is, then based on the results you can choose to begin or end the script or raise an error . You may have noticed IF EXISTS being used in Chapter 6 to check the system tables to make sure a table exists before dropping it. Here is the syntax:
IF [NOT] EXISTS(SELECT * FROM <TABLE1> [WHERE <condition>]) BEGIN
<statement1>
[<statement2>]
END
This is one of the cases where using the asterisk (*) is perfectly acceptable. The database engine just checks to see whether the query will return even one row but doesn’t return any rows at all. The EXISTS function returns only TRUE or FALSE. Type in and execute Listing 7-8 to learn how to use IF EXISTS.
Listing 7-8. Using IF EXISTS
USE AdventureWorks2012;
GO
--1
IF EXISTS(SELECT * FROM Person.Person WHERE BusinessEntityID = 1) BEGIN
PRINT 'There is a row with BusinessEntityID = 1';
END
ELSE BEGIN
PRINT 'There is not a row with BusEntityID = 1';
END;
--2
IF NOT EXISTS(SELECT * FROM Person.Person WHERE FirstName = 'Kathi') BEGIN
PRINT 'There is not a person with the first name "Kathi".';
END;
Figure 7-8 shows the results. Listing 7-8 contains one batch after setting the database context. IF block 1 checks to see whether there is a row in the Person.Person table with BusinessEntityID = 1. You can also use ELSE along with IF EXISTS. IF block 2 uses the NOT keyword to make sure that there isn’t a row with the FirstName of Kathi and executes the PRINT statements since there isn’t a row with that name.

Figure 7-8. The results of using IF EXISTS
You should now know how to use IF and ELSE in a number of situations. Practice what you have learned by completing Exercise 7-2.
WHILE
Use the WHILE construct to set up loops, or code that executes a number of times, in T-SQL. For example, you might have a script that updates 10,000 rows each time within the loop because updating 10,000 rows at a time is more efficient than updating millions of rows at once.
Using a WHILE Loop
The WHILE loop requires a condition (an expression that evaluates to true or false) to determine when the looping should stop. If you don’t specify a condition, the loop will run until you stop it or some error condition causes it to stop. Here is the syntax:
You can use several different techniques to create the condition that the database engine checks to determine when to exit the loop. One technique is to declare a variable, usually an integer, to be used as a counter. At the beginning of the loop, the code compares the variable to a value. Inside the loop, the code increments the variable. Another common way to control the loop is by using the EXISTS keyword. This might be used if a statement within the loop modifies data in the table used in the EXISTS condition. Type in and execute Listing 7-9 to learn how to use WHILE.
Listing 7-9. Using WHILE
USE AdventureWorks2012;
GO
--1
DECLARE @Count INT = 1;
WHILE @Count < 5 BEGIN
PRINT @Count;
SET @Count += 1;
END;
GO
--2
IF EXISTS (SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'dbo.demoContactType')
AND type in (N'U'))
DROP TABLE dbo.demoContactType;
GO
CREATE TABLE dbo.demoContactType(ContactTypeID INT NOT NULL PRIMARY KEY,
Processed BIT NOT NULL);
GO
INSERT INTO dbo.demoContactType(ContactTypeID,Processed)
SELECT ContactTypeID, 0
FROM Person.ContactType;
DECLARE @Count INT = 1;
WHILE EXISTS(SELECT * From dbo.demoContactType WHERE Processed = 0) BEGIN
UPDATE dbo.demoContactType SET Processed = 1
WHERE ContactTypeID = @Count;
SET @Count += 1;
END;
PRINT 'Done!';
Figure 7-9 shows the partial results. Batch 1 declares a variable and sets the value to 1 to use as a counter. Once the value of @Count reached 5, the execution exited the loop. It is very important that you set the value of the counter before the WHILE statement. If the value is NULL, then the statement incrementing the value of the counter will not actually do anything since adding one to NULL returns NULL. In this case, the loop will run indefinitely. The other option is to check for a NULL counter variable inside the loop and set the value at that point. The code prints the value of the counter each time through the loop.

Figure 7-9. The results of using a WHILE loop
The next example contains more than one batch because it creates and populates a table to be updated within the loop. This example also contains a variable called @Count, but the value of @Count doesn’t control the execution. This WHILE loop checks to see whether any rows in table dbo.demoContactType have a zero value in the Processed column. Each time through the loop, the code updates any rows with a ContactTypeID equal to the current value of @Count. (I removed all but two of the statements reporting that one row has been updated to save space in Figure 7-9.) When no more rows exist with Processed = 0, the code completes, and the PRINT statement executes. I purposely chose a small table for this example because processing a table row by row is very inefficient.
![]() Note Keep in mind that row-by-row (or RBAR, “row-by-agonizing-row,” as it is known in the SQL community) is inefficient because of the amount of locks SQL Server needs to create and the number of commits. There is no “correct” number in regards to the amount of rows you should commit at any one time. Committing too many rows in one transaction could delay your processing during the commit while growing the transaction log; too few could also slow down execution. The answer is always somewhere in the middle. Plan on testing your batch jobs to judge the best performance.
Note Keep in mind that row-by-row (or RBAR, “row-by-agonizing-row,” as it is known in the SQL community) is inefficient because of the amount of locks SQL Server needs to create and the number of commits. There is no “correct” number in regards to the amount of rows you should commit at any one time. Committing too many rows in one transaction could delay your processing during the commit while growing the transaction log; too few could also slow down execution. The answer is always somewhere in the middle. Plan on testing your batch jobs to judge the best performance.
Using ROWCOUNT
When you run a T-SQL statement, your statement will return, update, insert, or delete all rows meeting the criteria or join condition. By turning on the ROWCOUNT setting, you can specify the number of rows affected by each execution of the statements. The setting stays in effect for the current connection until it is turned off. This technique may be used in a WHILE loop to process a smaller portion of the rows at a time. Recall the car key analogy in Chapter 6 where the solution was to move all the keys at once instead of one at a time. If the pile of keys is too large to transfer at once, you might make two or three transfers but you wouldn’t resort to moving one key at a time. Here is the syntax:
SET ROWCOUNT <number|@variable>
SET ROWCOUNT 0
To turn off ROWCOUNT, set the value to 0. Type in and execute the code in Listing 7-10 to learn how to use ROWCOUNT.
Listing 7-10. Using SET ROW COUNT to Limit the Number of Rows Affected
USE AdventureWorks2012;
GO
IF EXISTS (SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'dbo.demoSalesOrderDetail')
AND type in (N'U'))
DROP TABLE dbo.demoSalesOrderDetail;
GO
CREATE TABLE dbo.demoSalesOrderDetail(SalesOrderID INT NOT NULL,
SalesOrderDetailID INT NOT NULL, Processed BIT NOT NULL);
GO
SET ROWCOUNT 0;
INSERT INTO dbo.demoSalesOrderDetail(SalesOrderID,SalesOrderDetailID,Processed)
SELECT SalesOrderID, SalesOrderDetailID, 0
FROM Sales.SalesOrderDetail;
PRINT 'Populated work table';
SET ROWCOUNT 50000;
WHILE EXISTS(SELECT * From dbo.demoSalesOrderDetail WHERE Processed = 0) BEGIN
UPDATE dbo.demoSalesOrderDetail SET Processed = 1
WHERE Processed = 0;
PRINT 'Updated 50,000 rows';
END;
PRINT 'Done!';
Figure 7-10 shows the results. The code first creates and populates a copy of the Sales.SalesOrderDetail table. A statement changes the ROWCOUNT to 50,000 so the UPDATE statement inside the loop will update only 50,000 rows at a time. Once there are no rows left with the value zero in the Processed column, the loop completes. Be careful when writing a loop like this. If the WHERE clause that makes sure that the statement includes only the rows that need to be updated is missing, the loop will continue indefinitely. That’s because it will otherwise keep updating the same rows over and over. Notice that I include the SET ROWCOUNT 0 line before the code to create the table. By default, ROWCOUNT is turned off, so the insert works as expected the first time. Without turning off ROWCOUNT, the INSERT statement inserts only 50,000 rows the second time you run it.
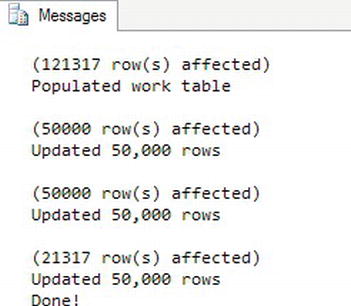
Figure 7-10. The results of using the ROWCOUNT setting
Nesting WHILE Loops
Just as you can nest IF blocks, you can create WHILE loops within WHILE loops. You can also nest IF blocks within WHILE loops and WHILE loops within IF blocks. The important thing to remember when your T-SQL scripts become more complex is to keep your formatting consistent and add comments to your code. You may understand what your code does when you write it, but you may have a hard time figuring it out months or years later when you need to troubleshoot a problem or make a change. Type in and execute Listing 7-11 to learn how to nest WHILE loops.
Listing 7-11. Using a Nested WHILE Loop
DECLARE @OuterCount INT = 1;
DECLARE @InnerCount INT;
WHILE @OuterCount < 10 BEGIN
PRINT 'Outer Loop';
SET @InnerCount = 1;
WHILE @InnerCount < 5 BEGIN
PRINT ' Inner Loop';
SET @InnerCount += 1;
END;
SET @OuterCount += 1;
END;
Figure 7-11 shows the results. The PRINT statements show which loop is executing at the time. Make sure that you reset the value of the inner loop counter in the outer loop right before the inner loop. Otherwise, the inner loop will not run after the first time because the counter is already too high.
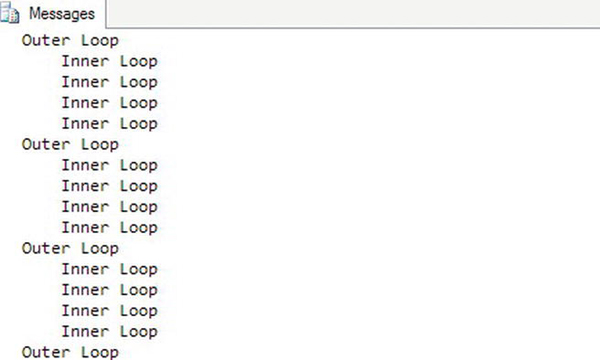
Figure 7-11. The results of running a nested WHILE loop
Exiting a Loop Early
Most of the time a WHILE loop continues until the controlling condition returns false. You can also cause code execution to exit early by using the BREAK statement. Usually you will include a nested IF statement that controls when the BREAK statement will execute. One reason you might want to use BREAK is if you decide not to include a controlling condition at the top of the loop and include the condition in an IF block instead. The condition may be a query checking to see whether any rows remain to be updated. Type in and execute the code in Listing 7-12 to learn how to use BREAK.
Listing 7-12. Using BREAK
DECLARE @Count INT = 1;
WHILE @Count < 50 BEGIN
PRINT @Count;
IF @Count = 10 BEGIN
PRINT 'Exiting the WHILE loop';
BREAK;
END;
SET @Count += 1;
END;
Figure 7-12 shows the results. If the code didn’t include the BREAK statement, the loop would print the numbers from 1 to 49. Instead, the loop exits when it reaches 10.

Figure 7-12. The results of using the BREAK command
Using CONTINUE
The CONTINUE command causes the loop to continue at the top. In other words, the code following the CONTINUE statement doesn’t execute. Generally, you will find the CONTINUE within an IF block nested inside the WHILE loop. Type in and execute Listing 7-13 to learn how to use CONTINUE.
Listing 7-13. Using CONTINUE in a WHILE Loop
DECLARE @Count INT = 1;
WHILE @Count < 10 BEGIN
PRINT @Count;
SET @Count += 1;
IF @Count = 3 BEGIN
PRINT 'CONTINUE';
CONTINUE;
END;
PRINT 'Bottom of loop';
END;
Figure 7-13 shows the results. Each time though the loop, the PRINT statement at the bottom of the loop executes except for the time when the counter equals 3. Notice that the counter increments before the IF block. If the counter incremented at the bottom of the loop, then the loop would execute indefinitely.

Figure 7-13. The results of using CONTINUE in a WHILE loop
Now that you know how to write code with a WHILE loop, practice what you have learned by completing Exercise 7-3.
Error Handling
No matter what language you are programming in, there is always the possibility of error conditions that your code must handle. T-SQL has two ways to deal with errors, both of which you will learn about in this section. If you are writing T-SQL code within an application (for example, with a .NET language), your program will probably deal with the errors. If, however, you are writing a T-SQL script, you will handle errors at the T-SQL level. You can do both; you can handle errors within T-SQL and decide what you want sent back to the calling application.
Often the source of an error in T-SQL is a problem with an update or insert. For example, you might try to insert a row into a table that violates the primary key constraint by inserting a row with a duplicate key value. Other errors occur because of nondata reasons, such as divide-by-zero errors, for example.
Using @@ERROR
The traditional way to trap errors in T-SQL is to check the value of the @@ERROR function, formerly called a global variable. The @@ERROR function returns a number greater than zero if an error exists. Type in and execute the code in Listing 7-14 to learn how to use this method of error handling.
Listing 7-14. Using @@ERROR to Handle Errors
USE AdventureWorks2012;
GO
--1
DECLARE @errorNo INT;
PRINT 1/0;
SET @errorNo = @@ERROR;
IF @errorNo > 0 BEGIN
PRINT 'An error has occurred.'
PRINT @errorNo;
PRINT @@ERROR;
END;
GO
--2
DECLARE @errorNo INT;
DROP TABLE testTable;
SET @errorNo = @@ERROR;
IF @errorNo > 0 BEGIN
PRINT 'An error has occurred.'
PRINT @errorNo;
PRINT @@ERROR;
END;
GO
--3
DECLARE @errorNo INT;
SET IDENTITY_INSERT Person.ContactType ON;
INSERT INTO Person.ContactType(ContactTypeID,Name,ModifiedDate)
VALUES (1,'Accounting Manager',GETDATE());
SET @errorNo = @@ERROR;
IF @errorNo > 0 BEGIN
PRINT 'An error has occurred.';
PRINT @errorNo;
END;
Figure 7-14 shows the results. Even if you don’t use the error trapping, the error prints on the screen in red, and the database engine returns an error message to the client. Notice that the code saves the value of the @@ERROR function before doing anything else. That is because, once another statement runs, the value of @@ERROR changes. Just by accessing it, the value goes back to zero. By saving the value in a local variable, you can check to see whether the value exceeds zero and deal with the error, in this case, just printing the value. You could roll back a transaction or halt the execution of the batch.
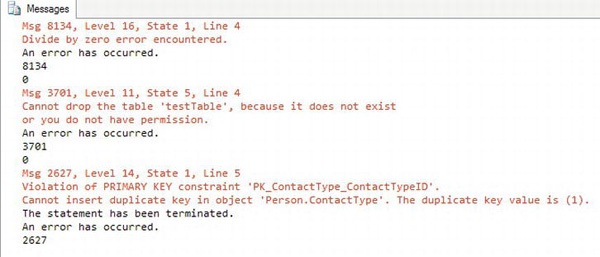
Figure 7-14. The results of using @@ERROR to trap errors
Batch 1 attempts to divide by zero. Batch 2 tries to drop a table that doesn’t exist. Batch 3 inserts a row into the Person.ContactType table but violates the primary key so the row can’t be inserted.
Using GOTO
T-SQL allows you to use GOTO statements to cause code execution to jump to a label in another part of the code where processing continues after the label. I recommend that you reserve GOTO for handling errors and don’t turn your T-SQL batches into “spaghetti code” with GOTO. Type in and execute the code in Listing 7-15 to learn how to use GOTO.
Listing 7-15. Using GOTO
DECLARE @errorNo INT;
PRINT 'Beginning of code.'
PRINT 1/0;
SET @errorNo = @@ERROR;
IF @errorNo > 0 GOTO ERR_LABEL;
PRINT 'No error';
ERR_LABEL:
PRINT 'At ERR_LABEL';
Figure 7-15 shows the results. Because of the divide-by-zero error, the code skips over one of the PRINT statements and jumps to the label. T-SQL doesn’t have a “return” statement, so at that point, you could include other GOTO statements and labels to control handling errors.

Figure 7-15. The results of using GOTO
Using TRY … CATCH
I recommend using the TRY…CATCH error handling construct over the older method of checking the value of @@ERROR. The TRY…CATCH error handling method is similar to the error handling in other programming languages such as C# and VB .NET. Along with this new method, you use several functions that provide information about the error. You can also avoid sending an error message to the client if you choose. Here is the syntax:
BEGIN TRY
<statements that might cause an error>
END TRY
BEGIN CATCH
<statements to access error information and deal with the error>
END CATCH
Table 7-1 lists the new functions you use along with TRY…CATCH. One benefit is that the functions retain their values while in the CATCH block. You can access the values as many times as needed. Once outside of the CATCH block, the values of the error functions revert to NULL.

Listing 7-16 demonstrates how to use TRY…CATCH. Type in and execute the code to learn how to use it.
USE AdventureWorks2012;
GO
--1
BEGIN TRY
PRINT 1/0;
END TRY
BEGIN CATCH
PRINT 'Inside the Catch block';
PRINT ERROR_NUMBER();
PRINT ERROR_MESSAGE();
PRINT ERROR_NUMBER();
END CATCH
PRINT 'Outside the catch block';
PRINT ERROR_NUMBER()
GO
--2
BEGIN TRY
DROP TABLE testTable;
END TRY
BEGIN CATCH
PRINT 'An error has occurred.'
PRINT ERROR_NUMBER();
PRINT ERROR_MESSAGE();
END CATCH;
Figure 7-16 shows the results. One difference between TRY…CATCH and @@ERROR is that you can print the error numbers and messages multiple times within the CATCH block. The values reset to NULL once execution leaves the CATCH block. When using TRY…CATCH, the error will not print at all unless you purposely print it. It is possible to just ignore the error.
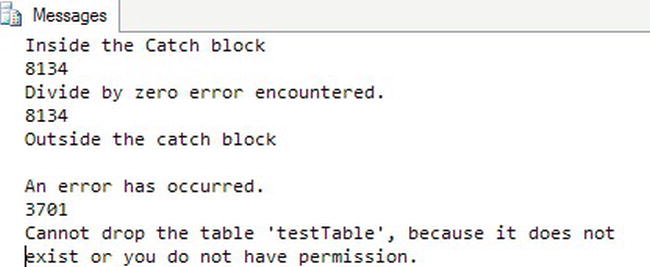
Figure 7-16. The results of using TRY…CATCH
Viewing Untrappable Errors
TRY…CATCH can’t trap some errors. For example, if the code contains an incorrect table or column name or a database server is not available, the entire batch of statements will fail, and the error will not be trapped. One interesting way to work around this problem is to encapsulate calls within stored procedures and then call the stored procedure inside the TRY block. You will learn about stored procedures in Chapter 8. Database administrators might use the stored procedure technique for management jobs, for example, checking the job history on each server. If one server is down, the database administrator would want the code to continue to check the other servers. Type in and execute Listing 7-17 to see some examples.
Listing 7-17. Untrappable Errors
USE AdventureWorks2012;
GO
--1
PRINT 'Syntax error.';
GO
BEGIN TRY
SELECT FROM Sales.SalesOrderDetail;
END TRY
BEGIN CATCH
PRINT ERROR_NUMBER();
END CATCH;
GO
--2
PRINT 'Invalid column.';
GO
BEGIN TRY
SELECT ABC FROM Sales.SalesOrderDetail;
END TRY
BEGIN CATCH
PRINT ERROR_NUMBER();
END CATCH;
Figure 7-17 shows the results. I put the PRINT statements before each TRY…CATCH block in separate batches because they wouldn’t print along with these incorrect statements. Example 1 is a syntax error; the SELECT list is empty. Example 2 contains an invalid column name.

Figure 7-17. The results of running untrappable errors
Using RAISERROR
By using TRY…CATCH, you can avoid having an error message return to the client application, basically “trapping” the error. Sometimes you might want to return a different error or return an error to the client when one doesn’t exist. For example, you might want to return an error message to a client when the code tries to update a nonexistent row. This wouldn’t cause a database error, but you might want to cause an error to fire anyway from SQL Server to the client application. You can use the RAISERROR function to raise an error back to the client. Here is the syntax:
RAISERROR(<message>,<severity>,<state>)
The RAISERROR function has several other optional parameters that provide additional functionality, but for a first look, these three parameters may be all you need. You can create reusable custom error messages by using the sp_addmessage stored procedure or just use a variable or hard-coded string with RAISERROR. Type in and execute Listing 7-18 to learn how to use RAISERROR.
Listing 7-18. Using RAISERROR
USE master;
GO
--1 This code section creates a custom error message
IF EXISTS(SELECT * FROM sys.messages where message_id = 50002) BEGIN
EXEC sp_dropmessage 50002;
END
GO
PRINT 'Creating a custom error message.'
EXEC sp_addmessage 50002, 16,
N'Customer missing.';
GO
USE AdventureWorks2012;
GO
--2
IF NOT EXISTS(SELECT * FROM Sales.Customer
WHERE CustomerID = -1) BEGIN
RAISERROR(50002,16,1);
END
GO
--3
BEGIN TRY
PRINT 1/0;
END TRY
BEGIN CATCH
IF ERROR_NUMBER() = 8134 BEGIN
RAISERROR('A bad math error!',16,1);
END;
END CATCH;
Figure 7-18 shows the results. You can provide either a message number or a message string for the message parameter. Batch 1 sets up a custom error message that you can use later when raising an error as in Batch 2. Batch 3 returns a different error to the client than the one that actually happened. Since the code returned an ad hoc error message, the database engine supplied the default number, 50000. The second parameter, severity, ranges from 1 to 25. When under 11, the message is a warning or information. You might want to build a dynamic error based on what happened in your code. If you would like to do this, make sure you save the message in a variable. You can’t build the message dynamically inside the RAISERROR function. See the Books Online article “Database Engine Error Severities” to learn more about error severities, but you will generally use 16 for errors correctable by the user. The state parameter is an integer between 1 and 255. You can use state to define where in the code the error occurred.

Figure 7-18. The results of using RAISERROR
Using TRY…CATCH with Transactions
You can use TRY…CATCH to make sure that transactions complete successfully so that the transaction may be rolled back if necessary. Include the transaction in the TRY block. Type in and execute Listing 7-19, which shows a simple example.
Listing 7-19. Using TRY…CATCH with a Transaction
--1
CREATE TABLE #Test (ID INT NOT NULL PRIMARY KEY);
GO
--2
BEGIN TRY
--2.1
BEGIN TRAN
--2.1.1
INSERT INTO #Test (ID)
VALUES (1),(2),(3);
--2.1.2
UPDATE #Test SET ID = 2 WHERE ID = 1;
--2.2
COMMIT
END TRY
--3
BEGIN CATCH
--3.1
PRINT ERROR_MESSAGE();
--3.2
PRINT 'Rolling back transaction';
ROLLBACK;
END CATCH;
Figure 7-19 shows the error message and the transaction rolled back. Statement 2.1.2 attempts to set the value ID to 2 in the row where it equals 1. This violates the primary key; you can’t have two rows with the value 2. If the entire transaction had been successful, the COMMIT statement would have committed the transaction. Instead, the CATCH block fired, giving you the chance to handle the error.

Figure 7-19. The results of using TRY…CATCH with a transaction
Using THROW Instead of RAISERROR
New in SQL Server 2012 is the THROW statement. You’ll find using THROW to be much simpler than using RAISERROR. For example, the error number in the THROW statement doesn’t have to exist in sys.messages. Also, the formatting for the error string can be any string format. Here is the syntax:
THROW [ { error_number | message | state } ] [ ; ]
Keep in mind the statement prior to the THROW command must end in a semicolon. Any error occurring in the THROW statement will cause the batch execution to end. Listing 7-20 shows a basic THROW command. The severity will always be 16. Figure 7-20 shows the output.
Listing 7-20. Simple THROW statement
THROW 999999, 'This is a test error.', 1

Figure 7-20. Results of THROW statement
Now let’s see how to use the THROW statement in a transaction. For this example, you’ll attempt to insert a duplicate row into the Person.PersonPhone table. Run the script in Listing 7-21. Figure 7-21 shows the output. Feel free to change the error message to anything you want.
Listing 7-21. Using THROW in a transaction
BEGIN TRY
INSERT INTO Person.PersonPhone (BusinessEntityID, PhoneNumber, PhoneNumberTypeID)
VALUES (1, '697-555-0142', 1);
END TRY
BEGIN CATCH
THROW 999999, 'I will not allow you to insert a duplicate value.', 1;
END CATCH
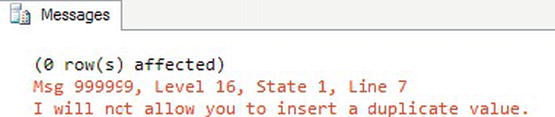
Figure 7-21. Results of THROW statement in a transaction
As you can see, the THROW statement is easy to use and extremely customizable. The command is especially useful for those unusual application errors that SQL Server may not be aware of or may not explain with a clearly expressive message indicating the content of the error. As always, though, try to keep your error messages easily understandable and detailed enough to help diagnose the error.
Trapping and handling errors is a very important part of T-SQL. If anything can go wrong, it often will. Practice what you have learned by completing Exercise 7-4.
Temporary Tables and Table Variables
Temporary, or temp, tables and table variables allow you to save data in short-lived table structures that you can use in your scripts. For example, you may need to save the results of complicated calculations for further processing. The use of temp tables and table variables is controversial. You can find many articles and newsgroup discussions stating that no one should ever use these structures. In my opinion, temp tables and table variables are just more tools that you can use if you need them. I have found that they often allow me to break extremely complicated queries into smaller, more manageable pieces—sometimes with better performance.
Creating Local Temp Tables
Temp tables look and behave just like regular tables except that they live in the tempdb database instead of a user database like AdventureWorks2012. The tempdb database is one of the system databases required for SQL Server. SQL Server also uses tempdb as a work area for sorting and other behind-the-scene tasks.
To create a local temp table, preface the table name with the number sign (#). Only the connection in which the table was created can see a local temp table. Chapter 9 covers creating tables with the CREATE TABLE command, but you have learned how to use the SELECT INTO syntax to create a table. You have also typed in numerous CREATE TABLE statements to create work tables for examples and exercises in Chapter 6. Here is the minimum syntax to create a local temp table using the CREATE TABLE command:
CREATE TABLE #tableName (<col1> <data type>,<col2> <data type>)
Temp tables can have anything that a regular table has, such as primary keys, defaults, and indexes. Type in and execute the code from Listing 7-22 to learn how to create a temp table.
Listing 7-22. Creating and Populating Local Temp Table
USE AdventureWorks2012;
GO
CREATE TABLE #myCustomers(CustomerID INT, FirstName VARCHAR(25),
LastName VARCHAR(25));
GO
INSERT INTO #myCustomers(CustomerID,FirstName,LastName)
SELECT C.CustomerID, FirstName, LastName
FROM Person.Person AS P INNER JOIN Sales.Customer AS C
ON P.BusinessEntityID = C.PersonID;
SELECT CustomerID, FirstName, LastName
FROM #myCustomers;
DROP TABLE #myCustomers;
Figure 7-22 shows the results. The code first uses the CREATE TABLE command to create the table, #myCustomers. This example is very simple. The command could define a primary key, CustomerID, and define that the FirstName and LastName columns should not contain NULL values. The script could include an ALTER TABLE command to add an index. The script populates the table with a regular insert statement, inserting the rows from a join on two tables. The SELECT statement looks like any other SELECT statement. Finally, the DROP TABLE command destroys the table. Even though the table will drop automatically when the connection closes, it’s a good practice to drop temp tables when you are done using them.

Figure 7-22. The partial results of creating and populating a temp table
Creating Global Temp Tables
You can create two kinds of temp tables: local and global. When creating a local temp table, you can access the table only within the connection where it was created. When the connection closes, the database engine destroys the temp table. When creating a global temp table, any connection can see the table. When the last connection to the temp table closes, the database engine destroys the temp table. Global temp tables begin with two number signs. Type in and execute the code from Listing 7-23 to learn how to create a global temp table. Don’t close the query window when you’re done.
Listing 7-23. Creating and Populating a Global Temp Table
USE AdventureWorks2012;
GO
CREATE TABLE ##myCustomers(CustomerID INT, FirstName VARCHAR(25),
LastName VARCHAR(25));
GO
INSERT INTO ##myCustomers(CustomerID,FirstName,LastName)
SELECT C.CustomerID, FirstName,LastName
FROM Person.Person AS P INNER JOIN Sales.Customer AS C
ON P.BusinessEntityID = C.PersonID;
SELECT CustomerID, FirstName, LastName
FROM ##myCustomers;
--Run the drop statement when you are done
--DROP TABLE ##myCustomers;
By using two number signs (##) in the name, you create a global temp table. Open another query window, and type the same SELECT statement to see that you can access the table from another connection. The results will look the same as Figure 7-22. Be sure to drop temp tables, especially global temp tables, when you no longer need them.
You won’t find many reasons to use global temp tables. For example, suppose that an application creates a global temp table. If another user runs the same code to create the global temp table with the same name while the first temp table exists, an error will occur. I have actually seen this error happen in a commercially available application!
Creating Table Variables
Table variables became available in SQL Server 2000. At that time, many T-SQL developers decided they should always use table variables instead of temp tables because of a myth about them. Many developers believe that table variables exist in memory instead of tempdb, but that is not the case. Table variables do live in tempdb. Here is the syntax for creating a table variable:
DECLARE @tableName TABLE (<col1> <data type>,<col2> <data type>)
Because a table variable is a variable, it follows the same scoping rules as other variables. Table variables go out of scope at the end of the batch, not when the connection closes, and you can’t perform an ALTER TABLE command to give the table variable nonclustered indexes or make any changes to the definition of a table variable once it is declared. Table variables are fine for small tables that you won’t need after running the batch. Temp tables are the better choice for tables with large numbers of rows that could benefit from nonclustered indexes or when you need to use the table after the batch is done. Type in and execute Listing 7-24 to learn how to use a table variable.
Listing 7-24. Creating and Populating Table Variable
USE AdventureWorks2012;
DECLARE @myCustomers TABLE (CustomerID INT, FirstName VARCHAR(25),
LastName VARCHAR(25))
INSERT INTO @myCustomers(CustomerID,FirstName,LastName)
SELECT C.CustomerID, FirstName,LastName
FROM Person.Person AS P INNER JOIN Sales.Customer AS C
ON P.BusinessEntityID = C.PersonID;
SELECT CustomerID, FirstName, LastName
FROM @myCustomers;
The results are identical to those in Figure 7-22. Again, if you need to save a very large number of rows temporarily, you may find that a temporary table is a better choice. Another reason you might want to use a temp table is that you can create it with a SELECT INTO statement, which is not possible with a table variable. The advantage of a SELECT INTO is that you don’t need to know the column names and data types up front. See the “Creating and Populating a Table in One Statement” section in Chapter 6 for more information.
Using a Temp Table or Table Variable
You may be wondering why you might need to use a temporary table. For example, in many human resource system databases, most of the tables have history and future rows. The tables have effective dates and effective sequences. The effective sequences determine the valid row for a given date for a given employee. Instead of figuring out the effective date and effective sequence for each employee over and over in my scripts, I create a temporary table to hold that information.
Another way I use temp tables is to store a list of values for filtering queries. For example, suppose a user can select one value or more values to filter a report. The reporting application sends a comma-delimited list of values to a stored procedure. You can add each value from the comma-delimited list to a temp table or table variable and then use that table to filter the report results. You will learn about stored procedures in Chapter 9. Listing 7-25 shows how to use a table variable populated from a list of values. Type in and execute the code.
Listing 7-25. Using a Temp Table to Solve a Query Problem
USE AdventureWorks2012;
GO
--1
DECLARE @IDTable TABLE (ID INT);
DECLARE @IDList VARCHAR(2000);
DECLARE @ID INT;
DECLARE @Loc INT;
--2
SET @IDList = '16496,12506,11390,10798,2191,11235,10879,15040,3086';
--3
SET @Loc = CHARINDEX(',',@IDList);
--4
WHILE @Loc > 0 BEGIN
--4.1
SET @ID = LEFT(@IDList,@Loc-1);
--4.2
SET @IDList = SUBSTRING(@IDList,@Loc +1,2000);
--4.3
INSERT INTO @IDTable(ID)
VALUES (@ID);
--4.4
SET @Loc = CHARINDEX(',',@IDList);
END;
--5
IF LEN(@IDList) > 0 BEGIN
SET @ID = @IDList;
INSERT INTO @IDTable(ID)
VALUES (@ID);
END;
--6
SELECT BusinessEntityID, FirstName, LastName
FROM Person.Person AS p
INNER JOIN @IDTable ON p.BusinessEntityID = ID;
Figure 7-23 shows the results. Code section 1 declares four variables: @IDTable, which is a table variable; @IDList to hold the comma-delimited list sent from the application; @ID to hold one individual value from the list; and @Loc to hold the location of the comma. Statement 2 sets the value of @IDList, which represents the list of values sent by the application.

Figure 7-23. The results of using a table variable
The code finds each ID value from the comma-delimited string and stores the value in the table variable. Statement 3 finds the location of the first comma in the list and stores the location in @Loc. Code section 4 is a WHILE loop. Inside the WHILE loop, statement 4.1 stores the first value in the @ID variable, and statement 4.2 removes that value along with the comma from @IDList based on the value of @Loc. Statement 4.3 inserts the value stored in @ID into the table variable, @IDTable. Finally, at the bottom of the loop, statement 4.4 locates the next comma, resetting the value of @Loc. The loop continues as long as the code continues to find a comma in @IDList. Once the loop completes, the last value is most likely still in @IDList. Code section 5 checks the length of @IDList and inserts the last value into the table variable. Query 6 joins the @IDTable to the Person.Person table, effectively using @IDTable as a filter.
Using a Temp Table or Table Variable as an Array
An array is a collection of values used in many programming languages. T-SQL doesn’t have an array structure, but programmers sometimes use temp tables or table variables as arrays. I often use this method in my administrative scripts to perform a backup or check the space used on each database on a server, for example. Listing 7-26 demonstrates how you might use a table variable as an array. Type in and execute the code to learn how to use this technique.
Listing 7-26. Using an “Array”
--1
SET NOCOUNT ON;
GO
--2
DECLARE @IDTable TABLE(ArrayIndex INT NOT NULL IDENTITY,
ID INT);
DECLARE @RowCount INT;
DECLARE @ID INT;
DECLARE @Count INT = 1;
--3
INSERT INTO @IDTable(ID)
VALUES(500),(333),(200),(999);
--4
SELECT @RowCount = COUNT(*)
FROM @IDTable;
--5
WHILE @Count <= @RowCount BEGIN
--5.1
SELECT @ID = ID
FROM @IDTable
WHERE ArrayIndex = @Count;
--5.2
PRINT CAST(@COUNT AS VARCHAR) + ': ' + CAST(@ID AS VARCHAR);
--5.3
SET @Count += 1;
END;
Figure 7-24 shows the results. Statement 1 sets the NOCOUNT property to ON. This will remove the messages showing how many each statement affects. In this case, the messages just get in the way. Code section 2 declares the variables used in this example. The table variable, @IDTable, contains an identity column called ArrayIndex. See Chapter 6 for more information about identity columns. Statement 3 populates @IDTable with several values. Since the database engine populates the INDEX column automatically, you now have a two-dimensional “array.” Statement 4 populates the @RowCount variable with the number of rows in @IDTable. Code section 5 is a WHILE loop that runs once for each row in @IDTable. During each iteration of the loop, statement 5.1 sets the value of @ID with the ID column from @IDTable corresponding to the ArrayIndex column matching @Count. Statement 5.2 prints the @Count and @ID values, but you could do whatever you need to do instead of just printing the values. Statement 5.3 increments the @Count.
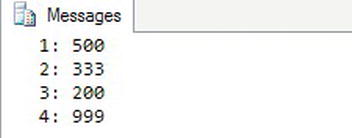
Figure 7-24. The results of using an “array”
Temp tables and table variables are just more tools in your T-SQL tool belt, but use them wisely.
Using a Cursor
Another way to loop through a result set is by using a cursor. This is a very controversial topic, especially for beginners. Developers frequently overuse cursors and end up writing poorly performing code. I’ll cover cursors so that you are familiar with them and so that you understand the example in the “Thinking About Performance” section. Type in and execute the code from Listing 7-27, which shows a simple example.
Listing 7-27. Using a Cursor
USE AdventureWorks2012;
GO
--1
DECLARE @ProductID INT;
DECLARE @Name NVARCHAR(25);
--2
DECLARE products CURSOR FAST_FORWARD FOR
SELECT ProductID, Name
FROM Production.Product;
--3
OPEN products;
--4
FETCH NEXT FROM products INTO @ProductID, @Name;
--5
WHILE @@FETCH_STATUS = 0 BEGIN
--5.1
PRINT @ProductID;
PRINT @Name;
--5.2
FETCH NEXT FROM products INTO @ProductID, @Name;
END
--6
CLOSE products;
DEALLOCATE products;
Figure 7-25 shows the results. Code section 1 declares variables that will be used later in the code. Statement 2 declares the cursor. The cursor must have a name and a SELECT statement. I included the option FAST_FORWARD to improve the performance. See Books Online if you are interested in learning more about cursor options. Statement 3 opens the cursor so that it is ready for access. Statement 4 reads the first row from the cursor into the variables. There must be one variable for each column selected in the cursor definition. The WHILE loop checks the status of the last read of the cursor. As long as the value is zero, the loop continues. Section 5.1 prints out the variables, but you could do anything you need to do at this point. Statement 5.2 is very important; it reads the next row. Without statement 5.2, the WHILE loop would continue indefinitely. Finally, section 6 cleans up the cursor. Cursors are another tool at your disposal, but use them only when another better-performing option is not available. Developers often use cursors to update one row at a time, which is usually a very bad idea.

Figure 7-25. The partial results of using a cursor
Complete Exercise 7-5 to practice what you have learned about temporary tables and table variables.
Thinking About Performance
This chapter focuses on the logic features available T-SQL instead of retrieving or updating data. Depending on the task at hand, you may or may not need to use this functionality. Often you may need to write or support very complex T-SQL scripts that run once each night. The performance of these scripts is not as critical as that of the performance of T-SQL code in an application or a report, but over time you may have to rewrite several to perform better. For example, a programmer from a software vendor writes a custom program that creates a denormalized table of information from a financial system. That table is needed by many other systems in the enterprise. The program as originally written takes more than an hour to run. Luckily, you have access to the original source code and find that the program populated this table one row and one column at a time. Another way of writing the code and having it run much faster is by using a set-based approach and inserting or updating all the rows at once from each source table instead of one row at a time.
The following example compares two ways to solve a typical problem. The first uses a cursor solution and the second a set-based approach. The requirements are to calculate sales totals by order year, order month, and TerritoryID. The report must also show the total sales for the previous month in the same row. Every territory, year, and month possible must appear on the report even if there are no sales for a particular combination. To save typing, you might want to download the code from this book’s page at www.apress.com. Listing 7-28 uses a cursor and two nested WHILE loops to create a temp table with the totals. On my laptop, the code took 19 seconds to run.
Listing 7-28. Using a Cursor to Populate a Report
USE AdventureWorks2012;
GO
DECLARE @Year INT;
DECLARE @Month INT;
DECLARE @TerritoryID INT;
DECLARE @Total MONEY;
DECLARE @PreviousTotal MONEY;
DECLARE @FirstYear INT;
DECLARE @LastYear INT;
DECLARE @BeginDate DATETIME;
DECLARE @EndDate DATETIME;
CREATE TABLE #Totals(OrderYear INT, OrderMonth INT,
TerritoryID INT, TotalSales MONEY,
PreviousSales MONEY);
SELECT @FirstYear = MIN(YEAR(OrderDate)),
@LastYear = MAX(YEAR(OrderDate))
FROM Sales.SalesOrderHeader;
DECLARE Territory CURSOR FAST_FORWARD FOR
SELECT TerritoryID
FROM Sales.SalesTerritory;
OPEN Territory;
FETCH NEXT FROM Territory INTO @TerritoryID;
WHILE @@FETCH_STATUS = 0 BEGIN
SET @Year = @FirstYear;
WHILE @Year <= @LastYear BEGIN
SET @Month = 1;
WHILE @Month <= 12 BEGIN
SET @BeginDate = CAST(@Year AS VARCHAR) + '/' +
CAST(@Month AS VARCHAR) + '/1';
SET @EndDate = DATEADD(M,1,@BeginDate);
SET @Total = 0;
SELECT @Total = SUM(LineTotal)
FROM Sales.SalesOrderDetail AS SOD
INNER JOIN Sales.SalesOrderHeader AS SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE TerritoryID = @TerritoryID
AND OrderDate >= @BeginDate AND OrderDate < @EndDate;
SET @PreviousTotal = 0;
SET @EndDate = @BeginDate;
SET @BeginDate = DATEADD(M,-1,@BeginDate);
SELECT @PreviousTotal = SUM(LineTotal)
FROM Sales.SalesOrderDetail AS SOD
INNER JOIN Sales.SalesOrderHeader AS SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE TerritoryID = @TerritoryID
AND OrderDate >= @BeginDate AND OrderDate < @EndDate;
INSERT INTO #Totals(TerritoryID, OrderYear,
OrderMonth,TotalSales, PreviousSales)
SELECT @TerritoryID, @Year, @Month,
ISNULL(@Total,0), ISNULL(@PreviousTotal,0);
SET @Month +=1;
END; -- Month loop
SET @Year += 1;
END; -- Year Loop
FETCH NEXT FROM Territory INTO @TerritoryID;
END; -- Territory cursor
CLOSE Territory;
DEALLOCATE Territory;
SELECT OrderYear, OrderMonth, TerritoryID,
TotalSales, PreviousSales
FROM #Totals
ORDER BY OrderYear, OrderMonth, TerritoryID;
SELECT OrderYear, OrderMonth, TerritoryID,
TotalSales, PreviousSales
FROM #Totals
WHERE TerritoryID = 1 AND TotalSales <> 0 AND PreviousSales <> 0
ORDER BY OrderYear, OrderMonth;
DROP TABLE #Totals;
The code in Listing 7-28 uses a cursor-based approach to populate a temp table for the report. The code creates a cursor that loops through the TerritoryID values. Inside the cursor loop, a WHILE loop of months is nested inside a WHILE loop of possible years. The code performs the calculations and inserts a row within the innermost loop. Finally, after the loops complete, two SELECT statements display the results. This code actually performs better than other code I have seen. It is not unusual to see code that not only loops through the territories but also loops through all the sales. Now try the example in Listing 7-29, which produces the same results much faster (about 1 second on my laptop).
Listing 7-29. Populating a Report with a Set-Based Approach
USE AdventureWorks2012;
GO
--1
CREATE TABLE #Totals(TerritoryID INT, OrderYear INT, OrderMonth INT,
TotalSales MONEY, PreviousSales MONEY
);
--2
CREATE TABLE #SalesMonths(MonthNo INT);
--3
INSERT INTO #SalesMonths(MonthNo)
VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12);
--4
WITH SalesYears AS (
SELECT YEAR(OrderDate) AS OrderYear
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate)
)
INSERT INTO #Totals(OrderYear, OrderMonth, TerritoryID,
TotalSales, PreviousSales)
SELECT OrderYear, MonthNo,TerritoryID, 0 AS TotalSales,0 AS PreviousSales
FROM SalesYears, Sales.SalesTerritory, #SalesMonths
ORDER BY OrderYear, MonthNo, TerritoryID;
--5
WITH Totals AS (
SELECT SUM(LineTotal) AS TotalSales,
YEAR(OrderDate) AS OrderYear,
MONTH(OrderDate) AS OrderMonth, TerritoryID
FROM Sales.SalesOrderDetail AS SOD
INNER JOIN Sales.SalesOrderHeader AS SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
GROUP BY YEAR(OrderDate), MONTH(OrderDate), TerritoryID
)
UPDATE #Totals SET TotalSales = Totals.TotalSales
FROM #Totals INNER JOIN Totals ON #Totals.OrderYear = Totals.OrderYear
AND #Totals.OrderMonth = Totals.OrderMonth
AND #Totals.TerritoryID = Totals.TerritoryID;
--6
WITH Totals AS (
SELECT SUM(LineTotal) AS TotalSales,
YEAR(DATEADD(M,1,OrderDate)) AS OrderYear,
MONTH(DATEADD(M,1,OrderDate)) AS OrderMonth, TerritoryID
FROM Sales.SalesOrderDetail AS SOD
INNER JOIN Sales.SalesOrderHeader AS SOH
ON SOD.SalesOrderID = SOH.SalesOrderID
GROUP BY YEAR(DATEADD(M,1,OrderDate)),
MONTH(DATEADD(M,1,OrderDate)), TerritoryID
)
UPDATE #Totals SET PreviousSales = Totals.TotalSales
FROM #Totals INNER JOIN Totals ON #Totals.OrderYear = Totals.OrderYear
AND #Totals.OrderMonth = Totals.OrderMonth
AND #Totals.TerritoryID = Totals.TerritoryID;
--7
SELECT OrderYear, OrderMonth, TerritoryID,
TotalSales, PreviousSales
FROM #Totals
ORDER BY OrderYear, OrderMonth, TerritoryID;
--8
SELECT OrderYear, OrderMonth, TerritoryID,
TotalSales, PreviousSales
FROM #Totals
WHERE TerritoryID = 1 AND TotalSales <> 0 AND PreviousSales <> 0
ORDER BY OrderYear, OrderMonth;
DROP TABLE #Totals;
DROP TABLE #SalesMonths;
Figure 7-26 shows the results of Listing 7-29. Statement 1 creates a temp table to hold the results. Statement 2 creates a temp table, #SalesMonths. Statement 3 populates the #SalesMonths table with the numbers 1 through 12. Statement 4 contains a CTE, SalesYears, listing all the unique years in the Sales.SalesOrderHeader table. The SELECT statement in statement 4 joins the SalesYears, #SalesMonths, and Sales.SalesTerritory tables in a Cartesian product that inserts every possible combination into a temp table, #Totals. It fills in zeros for the TotalSales and PreviousSales columns. Statement 5 updates the TotalSales column of the #Totals table with the sum of the LineTotal column. Statement 6 updates the PreviousSales column of the #Totals table. Statement 7 displays all the rows in the #Totals table. Statement 8 displays a subset of the rows that actually have some sales.

Figure 7-26. The partial results of the set-based approach
The point of this example is to show that most of the time a set-based approach can be found and is more efficient. It may take more practice and experience before you come up with this solution, but the more you work with T-SQL, the better you will get.
Summary
If you know one programming language, you will probably find the second and third language even easier to learn because the logic is the same. You will generally have ways to execute or avoid executing lines of code based on certain criteria. You will have ways to repeatedly execute lines code of code by looping. Whether or not you decide to implement this logic in T-SQL scripts will depend on the design of your application, the standards in your shop, or your personal preferences.
This chapter covered using variables, conditional logic, looping, and temporary table structures. In Chapter 9, you will use what you have learned in this chapter to create stored procedures, user-defined functions, and more.