
jBPM6 uses a node-instance-based approach to determine what steps are being executed by the process instance. This means, for every active step in the process, a node instance object exists in the process instance. When the step is completed, the node instance is removed. This allows us to have a list of active steps in the process instance that are accessible by jBPM6 from the getNodeInstances method available from the NodeInstanceContainer interface. The following code shows a simplification of the methods of most of the node instance implementations:
public interface NodeInstance {
public ProcessInstance getProcessInstance() { ... }
public long getId() { ... }
public long getNodeId() { ... }
public void trigger(NodeInstance from, String type) { ... }
public void cancel() { ... }
}Here, you can see that node instance objects have methods to trigger the execution of a particular step or to cancel it from the outside. It also has an identifier for itself, the step definition, and the process instance it belongs to.
Finally, we can assert the internal status of the process instance by the getState method. Its implementation will return an integer value determined by constants in the ProcessInstance interface to any of the following states:
STATE_PENDING: The process instance hasn't started yetSTATE_ACTIVE: The process instance is runningSTATE_COMPLETED: The process instance has finished successfullySTATE_ABORTED: The process instance has been forcefully finishedSTATE_SUSPENDED: The process instance is paused
Process instances are created based on the process definitions using a special ProcessInstanceFactory implementation. This implementation contains the logic on how to create and initialize process instances according to a particular process definition and environment configuration. Since this factory is internally used by the exposed runtime, let's start learning about the said runtime to get a better picture of using processes in jBPM6.
In order to be able to use jBPM6, we need to create a specific runtime in which it can execute processes. Since Version 6, this runtime configuration has changed from being simple programmatic components to add BPMN files to a knowledge runtime to a complete API to create, interpret, and monitor Maven-based projects that contain BPMN resources in their structures. Maven is a Java-based tool for project integration, that is, from compilation to deployment time. It's widely supported by many different products that need to connect with specific deployments of objects, and this is why jBPM6 has embraced Maven as an internal representation of its modules. In order to provide ourselves with a runtime, we now need to obtain BPMN process definitions, rule definitions, and a full umbrella of different knowledge definitions from established structures.
There are enough components that surround jBPM6; it would take multiple books to cover each one of them in detail. There are planning frameworks for planning problems, probabilistic components, integrations with persistence frameworks, and many more that appear every day. We obviously won't be able to cover all of them, but we'll try to cover the ones that are most related to BPM systems in the following sections of this chapter.
A specific runtime allows you to have a wide variety of knowledge definitions to work together in a single environment. The following diagram shows how the runtime is constructed in an abstract way to allow us to understand how this is possible:
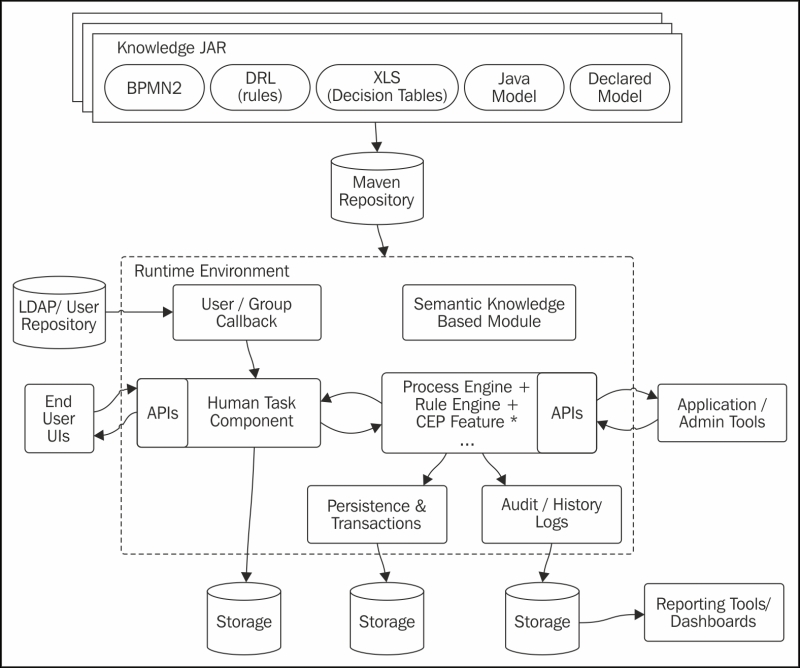
As you may notice, the rule engine (Drools, www.drools.org), the process engine, and complex event processing (CEP) features are merged to work together. This is very useful when it comes to defining processes; it's because the decision points that would make a very complex process definition are sometimes complemented by other knowledge representations such as business rules and decision tables. Having all the features running in a single environment allows the engine to communicate decisions made by rules or processes in a very direct way. Because of these features, it is important that we understand the knowledge-centric APIs to know how to interact with processes. The following section will cover the most important concepts so you can start using and understanding these APIs.
Transactions and persistence of the runtime status of the process execution engine are two extremely important topics to cover. BPM systems usually integrate systems and people to achieve a common goal. Deciding the next step could take milliseconds, but executing each step could take a lot more time. Persistence and transaction mechanisms allow for resource release in the process engine environment, load distribution, and fault recovery mechanisms.
Persistence is not meant, at least as provided by default, to make sessions and processes easily searchable from external tools. It is mostly used to provide a recovery strategy for the content that sessions and processes need in order to be able to continue them from different threads or even different servers. The persistence mechanisms, therefore, are simple serializations of the minimal content that the runtime needs to carry on the execution in a different environment.

Persistence works by wrapping the KieSession object's methods in a transactional environment where KieSession and all its internal components can be persisted after every call that is made inside a transaction boundary defined by the application. This provides us with a mechanism to define the following:
- How to handle long-running processes
- How and when can we store information about the status of the process and the information that the process is handling
- How and when do we need to create, commit, or roll back the process engine transactions
- Which business exceptions can roll back or compensate the already executed business actions
All these topics and its configuration mechanisms will be discussed in detail in Chapter 8, Implementing Persistence and Transactions.
Persistence for a process's execution is thought to be a recovery point between different environments. It wasn't thought of as a tool that provides a history of the process's execution or much readable information from external tools, but just to store its current state. Completed process instances are deleted from the runtime's database to maintain it at a steady size. For the same reason, only running steps are stored, and everything with regards to the runtime is simply serialized to the database to make restoring the process instance as efficient as possible. To keep historical information about our process executions separately, we need to use the Audit/History logs.
To provide searchable historical data of the process executions, a specific component stores the changes of the different process instances, its steps, and its variables. This information is known as the history logs of the process engine. Business Activity Monitoring (BAM) tools and dashboards are some of the most common clients for the information generated by this component. They display different aggregations and compositions of that data to different people (developers and business analysts, among others). It is heavily used during state 5 (monitoring) of the BPM cycle.
Some common applications that can be created using these components are as follows:
- Real-time dashboards
- Data-mining or data-analysis tools

The first line of analysis for the generated history logs are the real-time dashboards. They are usually composed of different widgets to display information from the last few hours to months of executions in our environment and present them in a way that assists users in making judgments about the environment's efficiency.
The jBPM6 BPM system provides a dashboard tool that we will start learning in Chapter 4, Understanding the KIE Workbench. In it, we can set different metrics and calculations that will define how the information will be aggregated and summarized for the end user. They provide tooling to make new indicators on the run and make a quick in-depth analysis of the historical information.
These kinds of tools provide a second level of analysis by allowing you to have huge amounts of information to be presented in a more detailed, cross-referenced way. Data mining and data analysis tools help us identify patterns, find hidden or hard-to-discover situations, and also improve the way information is being stored or generated.
Real-time dashboards are thought to typically query the data storage too often and do a lot of in-memory calculations in order to present summarized information. Data mining tools, on the other hand, are prepared to query huge amounts of information just once in an offline fashion. Usually, this sort of analysis requires a restructuring of the available information into different structures that are easier to query from data mining tools.
As of Version 6, both jBPM and Drools (the parent project of jBPM that establishes an inference engine and runtime for both rules and processes) have changed their umbrella name from Drools/jBPM to KIE.
KIE stands for Knowledge Is Everything; this change was made to encompass all the new components that keep on getting added to the Drools and jBPM family, such as OptaPlanner for planning problems or Predictive Model Mark-up Language (PMML), an import functionality. It also uses the KIE name to group generic parts of the unified API, such as building, deploying, and loading knowledge-related projects.
The main aspect that you should pay attention to is that KIE runtimes work by taking the knowledge definitions not just from a group of knowledge files like previous versions did. They instead work by reading their knowledge definitions from the Maven-based JAR files (Maven: http://maven.apache.org) that could contain anything a JAR file could contain, from classes and configuration files to processes, rules, and much more. This means that building and loading applications can align with Maven and Maven repositories by adhering to a standardized way of managing code and configuration updates through JAR publications in specific repositories.
It also includes a declarative configuration in an XML file for KIE projects called kmodule.xml; for this configuration, we will create different components to define knowledge definitions and runtimes, along with the kbase and ksession tags. It must be located inside the META-INF folder. Here's an example of a kmodule.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns="http://jboss.org/kie/6.0.0/ kmodule">
<kbase name="namedKieBase">
<ksession name="ksession1">
</kbase>
</kmodule>Before we get to understand this configuration, we need to cover what structures we will use to actually access the Maven dependencies that define our knowledge runtime. We will start with a few main concepts, as follows:
- KIE services
- The KIE module
- The KIE container
- The KIE base
- The KIE session
In the KIE API, there are a lot of different services for the instantiation of components that could be implemented in different ways. Luckily, a helper method to access those instantiations is provided by the KieServices class, which serves as a simple starting point for the generation and access of the KIE components. It is accessible through the following method:
KieServices ks = KieServices.Factory.get();
This method will be used in the next pieces of code.
Any Maven dependency that contains a kmodule.xml file (like the one we showed at the beginning of this section) is considered a KIE module. They can be loaded from the classpath, dynamically from any knowledge resource, or can be built programmatically, shown as follows:
//Create a virtual file system for our generated project
KieFileSystem kfs = ks.newKieFileSystem();
//Write content in a maven project structure
kfs.write("src/main/resources/my-process.bpmn2",
getFile("my-process.bpmn2"));
//Set a specific maven release ID for a pom.xml in the file system
kfs.generateAndWritePomXML("com.wordpress.marianbuenosayres", "test", "1.0-SNAPSHOT");
//Use a Kie Builder to generate a Kie Module
KieBuilder kbuilder = ks.newKieBuilder(kfs);
//build the content
kbuilder.buildAll();
KieModule kmodule = Kbuilder.getKieModule();In the previous code, you first created a filesystem representation where you will write a specific Maven module. This is pretty much the same method you should use when creating a new project using maven, but here you'll use the KIE API to do it for you. You then add a BPMN2 file to it (whose content will be loaded from the getFile (my-process.bpmn2) invocation) and set the release ID of the project (composed of the group ID, artefact ID, and version). Afterwards, a KieBuilder instance is used to build a specific KieModule object from that filesystem representation.
The KIE container provides an accessory to utilize the KIE module. It will provide versioning and building through maven, and you can dynamically update the version of a KIE container to work with other KIE modules.
From inside the KIE container, we will have access to the knowledge definitions and runtimes defined for each KIE module:
KieContainer kcontainer = ks.newKieContainer( kmodule.getReleaseId());
You can also get the container from the current project classpath:
KieContainer defaultKcontainer = ks.getKieClasspathContainer();
Then, you can get the default knowledge definitions and runtimes from the container:
//Getting default knowledge definitions from the container KieBase kbase = Kcontainer.getKieBase(); //Creating knowledge runtimes directly from the container KieSession ksession = Kcontainer.newKieSession();
A KIE base is a repository for a particular group of knowledge definitions. It will contain rules, processes, functions, and type models. They don't contain data. Runtime environments are created from KieBase and wrapped in the KieSession objects. They're represented in the kmodule.xml file by the kbase tag. Constructing a KieBase repository can be quite heavy, so if they're built programmatically, it's recommended to have them cached. They can be obtained from KieContainer by getting the default KIE base:
KieBase kbase = kcontainer.getKieBase();
Alternatively, we can get a specific KieBase repository by name:
KieBase kbase = kcontainer.getKieBase("namedKieBase");In contrast to the KieBase objects, KieSession objects store and execute all the runtime data. They're represented in the kmodule.xml file by the ksession tag. They can be created from KieBase or, as we saw in the The KIE container section, from the KieContainer object directly. This object is the point of contact to start, signal, and complete process instances:
KieSession namedKsession = kcontainer.newKieSession("ksession1");
KieSession newKsession = kbase.newKieSession();There is another flavor of KieSession called StatelessKieSession that can run isolated one-time-use-and-dispose executions, but since they don't support process executions, we will skip them in this book.
From the process's perspective, we are interested in the following methods that are exposed by the KieSession interface:
public ProcessInstance startProcess(String processId); public ProcessInstance startProcess(String processId, Map<String, Object> params); public void signalEvent(String type, Object event); public void signalEvent(String type, Object event, Long processInstanceId);
We will use these methods (and other services implemented with these methods) to interact with our process instances at the runtime. You can see a quick example of these configurations in the testKieAPIConfigurations method of the KieAPIProcessExecutionTest class, as shown in the following code:
KieServices ks = KieServices.Factory.get();
KieFileSystem kfs = ks.newKieFileSystem();
Kfs.write("src/main/resources/my-process.bpmn2", getFile("my-process.bpmn2"));
kfs.generateAndWritePomXML(ks.newReleaseId( "com.wordpress.marianbuenosayres", "test", "1.0"));So far, we have created a new filesystem to start writing our project programmatically. It will have one process (since it is a maven project, it should be located by default at src/main/resources); then, we set a group, artefact, and version for the POM file of the maven project. Once we've done this, we have to validate its content using a KieBuilder instance:
KieBuilder kbuilder = ks.newKieBuilder(kfs);
kbuilder.buildAll();
if (kbuilder.getResults().hasMessages(Level.ERROR)) {
System.out.println("Errors compiling Kie Module");
System.out.println(kbuilder.getResults().getMessages());
throw new IllegalStateException("Errors compiling KieModule");
}
KieModule kmodule = kbuilder.getKieModule();
ks.getRepository().addKieModule(kmodule);This will create a KieBuilder instance that will try to construct a KieModule object from a filesystem that contains maven files. If the building of the KieModule object encounters any errors, all messages related to the build will be printed through the system output, and an exception is thrown to stop the system from continuing with the load. Otherwise, we obtain the KieModule object from the KieBuilder instance and add it to the in-memory repository.
Once the module is added to the repository, we can use a KieContainer instance to obtain the knowledge definitions and knowledge runtimes that are defined in it:
KieContainer kcontainer = ks.newKieContainer(kmodule.getReleaseId()); KieBase kbase = kcontainer.getKieBase() KieSession ksession = kbase.newKieSession();
We obtain the default KieBase object for the container and create a simple stateful session from the said KieBase; we could have also requested it directly from the container. Once we have a session, we can use it to start process instances:
ProcessInstance pI = Ksession.startProcess("myDesignedProcess");Since the my-process.bpmn2 file contained a process definition with the myDesignedProcess ID, we can use that ID to create a new process instance. We store its reference in the pI variable. Since it is a completely automated process with no external interactions or wait states, the process instance will be completed by the time the variable is assigned. So there is nothing more you can do with it.
Now that we understand the core of the process engine, we can continue looking at how other components around the process engine fit inside jBPM6.