
The persistence and transaction mechanisms in jBPM6 are not considered to be an externally consultable source of information; they provide a quick store and recovery mechanism, mainly to have a high-performance distributed platform. This means that the simplest way to configure the persistence in jBPM6 will have two characteristics:
- Only enough information to recreate the runtime is persisted. This means that we will have limited information about our process instances; only currently running processes will be stored, and only the information of the currently active nodes and used variables will be available. The rest of the information can be persisted as well, but through other mechanisms (see the History logs – extending the basic functionality section further in this chapter).
- The runtime information is persisted in the fastest way possible: serialized information in a byte array structure. This makes information for the basic persistence mechanism hard to read from external tools.
The persistence and transaction mechanisms for jBPM6 are directly applied from the KIE session. This means that not only the process runtime has a persistence mechanism for jBPM6, but also the rule runtime. This is because the same mechanism that is used by Drools to store content in a database is extended by jBPM6 to also store process instance information.
This is the best way to guarantee that the exact same environment that started running a process in one server or thread will be the one that will continue running it in another place. This is especially important if you're using rules that are invoking references to different process instances. We will see some examples of such types of rules in Chapter 9, Integration with Other Knowledge Definitions.
The configuration needed to create and load a JPA persistent KIE session with persistent process instances converges in code similar to the following:
KieServices ks = KieServices.Factory.get(); Environment env = ks.newEnvironment(); EntityManagerFactory emf = ...; TransactionManager tm = ...; env.set(EnvironmentName.ENTITY_MANAGER_FACTORY, emf); env.set(EnvironmentName.TRANSACTION_MANAGER, tm); KieBase kbase = ks.getKieClasspathContainer().getKieBase();
The preceding code section performs a series of steps needed to configure a persistent environment and load a KIE knowledge base. These components will be used while creating (and further down the line, loading) a KIE session that is persisted in a JPA persistence unit.
For brevity reasons, we skipped the creation of some of the components, such as the JPA EntityManagerFactory object, and the initialization of TransactionManager, leaving only the code relevant for the configuration of the Environment variable. If you want to see a full example of this code, it's available in the JPAPersistentProcessTest.java file in the persistent-process-examples project.
You can see that we have set special entries in the environment variable for the entity manager factory and transaction manager. These are the most basic properties a persistent environment defined with JPA will need. Later on, the KIE components will use the specified environment to determine how the persistence is configured in your environment.
Also, we are defining the KIE knowledge base. This is because, as we mentioned earlier, the persistence is only going to store minimal information for the runtime to be reloaded in another context. For this reason, the persistence mechanisms don't have the trouble of serializing the full knowledge base, and it must be provided each time we create or reload a persistent KIE session.
Once all environment components are created, we will not directly create the persistent KIE session implementation. Instead, we will use a special service to handle that creation for us. As a matter of fact, we will not even load the special service class directly; we will use the KieServices helper class to load it for us, as shown in the following line of code:
KieStoreServices kstore = KieServices.Factory.get().
getStoreServices();The
KieStoreServices interface will define two methods—one to create a new persistent KIE session and another to load an existing one, as shown in the following code:
KieSession ksession = kstore.newKieSession(kbase, null, env); Integer sessionId = ksession.getId(); ... //on a different part of your code KieSession reloadedKsession = kstore.loadKieSession(sessionId, kbase, null, env);
The KIE session ID is the only data that the application will need to remember to retrieve the same KIE session later on. Depending on how much we wish to reuse the KIE session, we might consider temporarily storing the ID, or maybe even registering it in a database reference or file to be reused all the time.
The actual implementation behind the KieStoreServices interface knows we have to use JPA to persist our runtime and create all the necessary components to make a persistent KIE session. In order to have the specific implementation of the service in the classpath, we will need to add a dependency to our projects that holds that implementation:
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-persistence-jpa</artifactId>
<version>6.1.0.Beta3</version>
</dependency>Different forms of persistence can be provided behind the KieStoreServices interface. Since the KieServices helper class will try to load the actual valid class from the service loader, we could implement our own persistence strategy and hide it behind the same interfaces, minimizing the changes needed in existing code to start using a different persistence mode. The runtime manager (explained in the previous chapter) uses the KieStoreServices class behind the scene so that users don't have to use it directly, and it will work for any part of the jBPM6 code that uses persistent processes.
So far, we've seen how to start a persistent KIE session using helper classes from the jBPM6 API. We are now going to take some time to understand the components that are generated by those helper classes. Understanding the internal composition of a persistent KIE session will help you understand how and when the persistence is being used, and it will help you to easily detect problems in your persistence configuration.
Persistence is provided to a KIE session is through a specific set of adapters that use a command pattern implementation. Command pattern shows that every operation is encapsulated by a single contract (specifically, a Command interface with an execute method). Using this contract, you can implement different Command objects for all the different methods of a class (in our case, the KIE session). Then, you can decorate every method invocation by just deriving each command execution through another class, called a
CommandService, which will have the responsibility of knowing what you have to do before and/or after each command execution.
An example of how this is done to provide a persistent KIE session can be seen in the following class diagram:
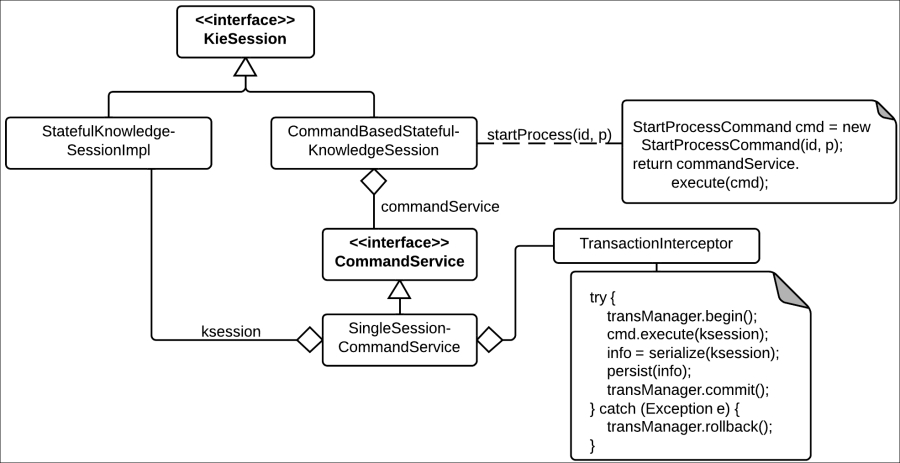
Here, we can see that we have two implementations of a KieSession interface: StatefulKnowledgeSessionImpl, which is the real implementation of a KIE session, and CommandBasedStatefulKnoweldgeSession, which is the command pattern adaptation of the KIE session interface. The latter will implement each method by creating a specific Command object and assigning its execution to a CommandService object.
The actual implementation used by the JPA persistent KIE session is called SingleSessionCommandService, and it provides a wrapper around the KIE session command execution that creates a database transaction before the command execution, serializes the actual KIE session object to a persistent object, and commits the transaction.
The
SingleSessionCommandService session doesn't directly implement the transaction management, but it has an Interceptor list that defines all the different method decorations needed, similar to the way the Human task component explained in Chapter 6, Human Interactions uses.
Eventually, the interaction between persistence and the KIE session activity happens on a per-method invocation basis, as shown in the following diagram:

We can infer the following points from the preceding diagram:
- The runtime won't be stored at every single change, but after a specific method invocation is completed. This means our runtime will only be storing itself when its internal execution reaches a static return point. Think of it as a very complex, configurable state machine, which will only be persisted after it reaches a defined state.
- Every process in the runtime will be persisted only when it reaches a safe state. That means, if we have multiple automatic steps and a few asynchronous steps in a process, the process runtime will only be persisted at the asynchronous step's wait states.
Internally, the JPA persistence strategy will store the process runtime separated in three different entities:
SessionInfo: This class is a serialization of the KIE session, and it is persisted exclusively from the command pattern whenever a method on the persistent KIE session is invoked. It basically stores a byte array with the deserialized information of the KIE session at a particular state and an integer ID.ProcessInstanceInfo: This class is a serialization of a specific process instance's runtime information. It stores a byte array with the deserialized information of the process instance runtime, its ID, state, and pending event information. There is a special manager class used by the persistent KIE session, calledJPAProcessInstanceManager, which takes care of notifying the persistence of any changes the KIE session does to each process instance's internal status.WorkItemInfo: This class stores information about a specific state in a process instance. It specifically stores a byte array with the input and output information of a step, its ID, a process instance it references, and the particular step's internal state flag. There is a special manager class used by the persistent KIE session, calledJPAWorkItemManager, which takes care of notifying the persistence of any changes in each step done by the KIE session.
In order for the JPA to be able to perform all the required steps to actually store the content of the KIE session and its components in a database, it requires certain configurations:
- JPA implementations and jBPM6-related dependencies
- A data source with access to an existing database
- A persistence unit with all the entity mappings
- A transaction manager configuration
We'll see all these configurations in detail during the next section of this chapter.
In order to configure the JPA persistence in our environment so that jBPM6 can create and load persistent KIE sessions and process instances, we need to configure a set of components and tie them together.
The first components we will need are the JAR files in our classpath to be able to use JPA directly from our code, and also directly from jBPM6. The dependencies we will use will be implementing JPA 2.0, and the Maven references to the relevant JAR files can be found in the persistent-process-examples project's pom.xml file:
<!-- JPA 2.0 standard library -->
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.0-api</artifactId>
<version>1.0.1.Final</version>
</dependency>
<!-- Hibernate implementation of the JPA 2.0 standard library -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.2.3.Final</version>
</dependency>
<!-- JPA management in jBPM6 -->
<dependency>
<groupId>org.jbpm</groupId>
<artifactId>jbpm-persistence-jpa</artifactId>
<version>6.1.0.Beta3</version>
</dependency>
<!-- in-memory database -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.2.128</version>
</dependency>
<!-- simple transaction manager -->
<dependency>
<groupId>org.codehaus.btm</groupId>
<artifactId>btm</artifactId>
<version>2.1.4</version>
</dependency>As you can see, each dependency has a different purpose. The hibernate-jpa-2.0-api defines the interfaces (the internal contract) of the JPA 2.0 specification. The actual implementation of said specification is provided by the hibernate-core dependency. We also need to provide a dependency for our data source and transaction manager (in our case, a simple test case, we can use h2 as an in-memory database and btm for the transaction manager). The jBPM6 management of the JPA persistence is done thanks to the classes we previously mentioned implemented in the jbpm-persistence-jpa dependency.
Once we have the dependencies, we need to define the required component configuration for each one of them. Let's start with JPA/hibernate, where the configuration we will need to add is the specific persistence unit that defines entities that should be mapped to our database. The most basic content that needs to be added to the META-INF/persistence.xml file in our classpath, as shown in the following code:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" ...>
<persistence-unit name="org.jbpm.persistence.jpa"
transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/testDS</jta-data-source>
<mapping-file>META-INF/JBPMorm.xml</mapping-file>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>
org.jbpm.persistence.processinstance.ProcessInstanceInfo
</class>
<class>
org.jbpm.persistence.correlation.CorrelationPropertyInfo
</class>
<class>
org.jbpm.persistence.correlation.CorrelationKeyInfo
</class>
<properties>
...
</properties>
</persistence-unit>
</persistence>Let's take some time to understand this file. It follows the JPA 2.0 standard XML notation to define five entities (SessionInfo, WorkItemInfo, ProcessInstanceInfo, CorrelationPropertyInfo, and CorrelationKeyInfo), a provider (which is defined in the hibernate-core dependency, called HibernatePersistence), and a JTA data source (which we will implement using btm).
Since we are using JTA to define a transaction manager for our data sources, we need to define a JNDI registry where the transactions are discovered. We can define that easily by having a jndi.properties file within our classpath that defines, in our case, the btm naming registry, with the following content:
java.naming.factory.initial=bitronix.tm.jndi.BitronixInitialContextFactory
From then onward, all other components are defined in our case through code. Specifically, we will start a data source, use btm to start a transaction manager around that data source, and start an entity manager factory (a class used by JPA to interact with our database in runtime).
From inside our test cases, we define a method marked with the @Before JUnit annotation in our JPAPersistentProcessTest class by using the following content:
private PoolingDataSource ds = null;
...
@Before
public void startUp() throws Exception {
ds = new PoolingDataSource();
ds.setUniqueName("jdbc/testDS");
ds.setClassName(
"bitronix.tm.resource.jdbc.lrc.LrcXADataSource");
ds.setAllowLocalTransactions(true);
ds.setMaxPoolSize(3);
ds.getDriverProperties().put("driverClassName",
"org.h2.Driver");
ds.getDriverProperties().put("Url", "jdbc:h2:mem:mydb");
ds.getDriverProperties().put("password", "sasa");
ds.getDriverProperties().put("user", "sa");
ds.init();
}The preceding code section will do two different things. First, which is easy to infer, is the creation of the PoolingDataSource class (a data source class provided by btm). What is hard to understand first-hand is that this is not our real data source, but just a wrapper that we will use to provide transaction management around the LrcXADataSource class (the actual in-memory database data source). Secondly, the preceding code section will also publish the created data source in the JNDI context. That way, the persistence unit that we previously configured in the persistence.xml file is going to be able to take the connection from the jta-data-source parameter configuration:
<jta-data-source>jdbc/testDS</jta-data-source>
This way, the persistence unit will be using the specific data source information that we define in our unit test. We just need to make sure that we create the data source wrapper before instantiating the persistence unit's entity manager factory. This is something that the code you create to start the persistence unit needs to do beforehand, and it is the main reason we create the persistence unit's EntityManagerFactory object in the test method, and start the data source wrapper in the @Before section:
@Test
public void testPersistentKieSessionInstantiation() throws Exception {
KieServices ks = KieServices.Factory.get();
KieStoreServices kstore = ks.getStoreServices();
Environment environment = ks.newEnvironment();
EntityManagerFactory emf = Persistence.
createEntityManagerFactory("org.jbpm.persistence.jpa");
TransactionManager tm = TransactionManagerServices.
getTransactionManager();
environment.set(EnvironmentName.ENTITY_MANAGER_FACTORY, emf);
environment.set(EnvironmentName.TRANSACTION_MANAGER, tm);
KieBase kbase = ks.getKieClasspathContainer().getKieBase();
KieSessionConfiguration ksconf = ks.
newKieSessionConfiguration();
KieSession ksession = kstore.newKieSession(
kbase, ksconf, environment);
...
}We will go into detail about each of the steps we saw in the previous code section, in the order they appear:
- We created the data source wrapper to handle the connection transactions for us. This initialization code is usually provided by the JEE container or by a context initialization framework such as CDI or Spring. We will need to obtain a
TransactionManagerobject once we have initialized this. In our case, we do it with the following code:TransactionManager tm = TransactionManagerServices. getTransactionManager(); - We first created the
EntityManagerFactoryobject by calling the following code:EntityManagerFactory emf = Persistence. createEntityManagerFactory( "org.jbpm.persistence.jpa"); - We provided both the transaction manager and the entity manager factory to an
Environmentvariable, as shown in the following code:Environment env = KieServices.Factory.get(). newEnvironment(); env.set(EnvironmentName.TRANSACTION_MANAGER, tm); env.set(EnvironmentName.ENTITY_MANAGER_FACTORY, emf);
Once we have this information, we simply use the previously explained KieStoreServices interface to access a persistent KIE session.
While all these components will provide enough information to make a KIE session recoverable from another thread or server node, it is just the most basic information we can store inside a database. If we want to store and/or retrieve extra information, such as specific tables related to our domain model or statistical information, we can extend our configuration in multiple ways. We will concentrate on two of the most popular components for extending the persisted information:
- History logs: This component is used to store extra historical information about our process executions
- Object marshalling strategies: This component is used to store extra entities in specific ways in our model
We previously mentioned that jBPM6 stores the minimal information to be able to recover a KIE session and its process executions in another place. Most of the time in productive environments, we want to keep information that is not directly required by the runtime, but is instead used by KPIs. These KPIs can be used to know about which tasks took longer, how many process instances are completed or pending, and many other inquiries.
In order to provide that information to the database and also to publish any piece of process information to external tools, we will use a specific implementation of the ProcessEventListener interface.
Process event listeners will expose all the process execution information through different methods that expose process starts, completions, and node and variable changes. We explored them previously in Chapter 7, Defining Your Environment with the Runtime Manager. In this case, we use the interface as a connection point to expose all that information in a different set of entities: the
NodeInstanceLog, ProcessInstanceLog, and VariableInstanceLog classes. All the information can be checked later through a series of services. Summarizing all things needed to work with the history logs, we need the following four components:
- The
jbpm-auditdependency added to the classpath:<dependency> <groupId>org.jbpm</groupId> <artifactId>jbpm-audit</artifactId> <version>6.1.0.Beta3</version> </dependency> - The history log entities added to the persistence unit (the three classes enumerated previously,
ProcessInstanceLog,NodeInstanceLog, andVariableInstanceLog) - Adding the specific
ProcessEventListenerimplementation to our KIE session:ksession.addEventListener( AuditLoggerFactory.newJPAInstance(environment)); - Instantiating and using the audit log service to query the generated history logs:
AuditLogService service = new JPAAuditLogService(emf);
Once we have a version of the AuditLogService class (and some process executions to feed the history logs), we can start checking some of its information directly from the already provided methods:
List<ProcessInstanceLog> findProcessInstances();
List<ProcessInstanceLog> findProcessInstances(String procId);
List<ProcessInstanceLog> findActiveProcessInstances(
String procId);
List<NodeInstanceLog> findNodeInstances(long processInstanceId);
List<VariableInstanceLog> findVariableInstances(
long processInstanceId, String variableId);
...You can also extend these methods quite easily, since they're only JPA queries executed against the existing entities. You can see an example of using the audit service in the testHistoryLogs() method of the JPAPersistentProcessTest class.
Object marshalling strategies are used to configure our persistent KIE session to understand that specific objects are going to be persisted or loaded into the KIE session in a very specific way. By default, the persistent KIE session will try to serialize every object in the working memory, process variables, and task inputs and outputs to a series of byte arrays. However, if you have a specific way of storing certain objects in a data storage, you can use a persistence strategy to let the KIE session know how to persist such objects. This is a very common way of simplifying interaction- and domain-based monitoring of the process engine. To be able to provide such functionality, the Drools and jBPM6 API define an interface called ObjectMarshallingStrategy to specify different strategies of storing your model:
public interface ObjectMarshallingStrategy {
boolean accept(Object object);
void write(ObjectOutputStream os, Object object);
Object read(ObjectInputStream os);
byte[] marshal( Context context, ObjectOutputStream os,
Object object);
Object unmarshal( Context context, ObjectInputStream is,
byte[] object, ClassLoader classloader );
Context createContext();
}The implementations are rather simple. The accept method will determine whether a specific object is suitable for the specific persistence strategy. If accepted, writing and reading the objects will involve two things:
- Storing or reading an ID or any other way of referencing the object in the provided byte array
- Reading and/or writing the object in a specific persistence strategy
There are a few implementations provided and they are ready to be utilized. The SerializablePlaceholderResolverStrategy implementation is the one used by default, and it simply attempts to write the full object to the byte array. The JPAPlaceholderResolverStrategy implementation is used to read objects from a JPA database. It only stores the ID in the byte array, and it doesn't store the objects if something changes. We extend it in the testProcessModelStorage method of the JPAPersistentProcessTest class by creating the JPAReadAndWriteStrategy object and adding it to the corresponding environment variable:
Environment environment = kservices.newEnvironment();
...
environment.set(EnvironmentName.OBJECT_MARSHALLING_STRATEGIES,
new ObjectMarshallingStrategy[] {
new JPAReadAndWriteStrategy(emf),
new SerializablePlaceholderResolverStrategy(
ClassObjectarshallingStrategyAcceptor.DEFAULT)
});This configuration works by providing an array of the ObjectMarshallingStrategy objects, and the engine will try to find the first strategy in the provided array that accepts each specific object and uses it to persist or read the correspondent objects. This configuration needs to be the same when restoring a specific KIE session; otherwise, you might get marshalling problems.