
Drools is a rule engine framework that provides the possibility of creating rules in a script language called Drools Rule Language (DRL) and running the rules inside an in-memory inference engine that provides great performance. Rule languages have a declarative nature, which means that the next action to be taken is determined by the input data that triggers specific conditions in the rules, unlike the imperative nature of languages such as Java, where the next action to be taken is determined by the sequence of actions written in the code.
Rules written in DRL follow a very specific syntax for constraints and a configurable syntax for the actions of the rule (which we will keep as plain Java for simplicity). The constraint part of the rule shouldn't be interpreted as regular imperative code such as a Java code, where we specifically tell the system what to do at a particular point in time. Instead, it should be considered as a declarative statement, similar to a SQL query, where we will search anything that matches a specific criterion. For every match, we will execute the consequence of the rule (the "then" part of the rule). The structure of a DRL rule is similar to the following code:
rule "prioritize requirements with lots of bugs"
lock-on-active
when
r: Requirement(bugs.size() > 3)
then
r.setPriority(20 / r.getBugs().size());
update(r);
endIn the preceding rule, we searched for all Requirement objects that have a bugs list with more than three elements. For each one of them, we set the priority to a calculated value and update the reference in the rule engine memory to evaluate other possible rules. The lock-on-active attribute is there to make sure we don't re-evaluate the same rule for the same object after we update it.
The power of rules grows as we add more rules. The internal algorithm of the rule engine (called PHREAK on the current version) will optimize the structure of all rules and make sure that all added objects evaluate rules in the shortest execution path possible. Afterwards, using rules is very simple, and it uses the same runtime component we already learned in order to use processes, that is, the KIE session:
KieServices ks = KieServices.Factory.get();
KieSession ksession = ks.getKieClasspathContainer().newKieSession();
ksession.insert(new Requirement("req1", "description"));
...
ksession.fireAllRules();The preceding code uses two new methods: insert (that adds objects to the rule engine memory for evaluation) and fireAllRules (that executes all the rules that are ready to be triggered by the engine). The full code can be seen in the drools-simple-example project in the chapter's code bundle.
The preceding code uses the same API that is used to invoke process executions through the startProcess method. However, some configuration considerations need to be taken to have both processes and rules interacting together. The next sections explain those considerations in detail.
To start with, all that Drools needs to work is a KIE session. In order for it to work with rules, we need to include the DRL files in the KIE base that will be used, either through the kmodule.xml configuration or through the programmatic API.
The following four methods are the most important calls that we need to know in the KIE session to interact with the rules:
FactHandle insert(Object fact)FactHandle update(FactHandle handle, Object fact)void delete(FactHandle handle)int fireAllRules()
The first three methods allow you to insert, update, and remove objects from the rule execution memory. The FactHandle class is a reference to the internal status of an object in said memory. Finally, the fireAllRules method allows you to fire any rules that matched any rule constraints for the inserted objects.
Every time we add, change, or remove objects from the internal memory of the KIE session, evaluations of these objects are created that determine what rules should execute. The fireAllRules method later invokes the following flow of execution:

The previously mentioned methods are enough to interact with the rules. However, to simplify process and rule interaction, we will see a few other components of the DRL language and the KIE session.
The DRL language allows us to define attributes to our rules. Three of these attributes allow us to define groupings for our rules in order to activate small groups of rules at a time instead of activating all of them at the same time. These attributes are as follows:
agenda-group: This attribute has a string parameter. It defines a group of rules that can be manually set through code using the following method:ksession.getAgenda().getAgendaGroup("group-x").setFocus();When this group is activated, only the rules inside of it will be matched or fired.
activation-group: This attribute is similar to the agenda group, except it marks a group of rules where only one should be executed. The decision of which rule is executed is determined by the conflict resolution strategy of the rule engine.ruleflow-group: This attribute is the one we will see the most. It determines a group of rules that will not be activated manually, but instead will be activated by a specific process instance execution. It is one of the most used points for process/rule interaction.
Another component that we previously mentioned in Chapter 8, Implementing Persistence and Transactions, is called event listeners. There are three types of event listeners we can add to a KIE session through the addEventListener method:
ProcessEventListener: This event listener, as previously mentioned, exposes methods to add specific hooks to all changes in a process instance internal stateAgendaEventListener: This event listener exposes methods to notify when a match to a rule constraint is detected or negated, changes in the activated groups of rules, and when each rule is fired within the KIE sessionRuleRuntimeEventListener: This event listener allows us to follow all changes done to the objects in the rule execution memory (insertions, updates, and deletions)
Now that we have mentioned these components, we can see them in action in the process-rules-examples project in the next section.
Invoking business rules from inside a business process and vice versa can provide a lot of power to our knowledge representation. Both components deal with decisions in two very different ways; rules provide simple ways of representing complex solutions, where the order to find said solution is not always relevant. Processes, on the other hand, focus on the order of the steps that need to be taken to reach a goal.
Inside jBPM6, you can invoke rules and processes or even perform nested invocations, where rules invoke processes that can then invoke other rules with very little configuration.
We will start by learning the different ways to execute rules in our business processes. In the process-rules-examples project, you will find a test that will be used in the rest of this section called RulesAndProcessesTest, where processes are invoked from rules and rules from processes as well.
The simplest way to define conditions in our processes is inside an exclusive or inclusive gateway's outgoing sequence flows. Inside sequence flows, you can determine a condition expression to decide whether that flow should be followed or not. This condition is defined as Java code by default in the web process designer used in Chapter 3, Using BPMN 2.0 to Model Business Scenarios. However, if you select Drools in the expression language attribute of the sequence flow, you can define a condition expression that will be evaluating the rule memory with a DRL-based condition. This is quite useful to evaluate complex conditions, but it depends on that all the relevant objects being "inserted" in the KIE session's rule memory.
The most common way of invoking rules from a process is through Business Rule tasks, which was explained briefly in Chapter 3, Using BPMN 2.0 to Model Business Scenarios. In a Business Rule task, you will have to define two important things: input mappings for the task that will determine what process variables should be made available in the KIE session's rule memory, and a RuleFlow Group attribute that will define what group of rules are to be invoked. In the RulesAndProcessesTest class, we invoke a process with a Business Rule task, such as the one shown in the following diagram:
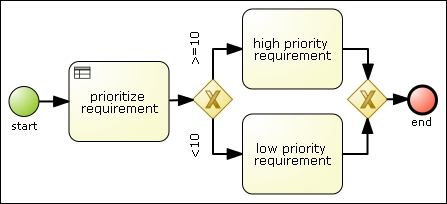
The preceding process diagram has a Business Rule task called
prioritize requirement. The task has an input mapping of a Requirement object, such as the one we saw in the model of Chapter 6, Human Interactions, and Chapter 7, Defining Your Environment with the Runtime Manager. It also defines establish-reqs-priority as the RuleFlow Group attribute value. This attribute will define that when the process instance reaches the prioritize requirement task, only rules that define the same RuleFlow group variable will be activated. You can see examples of such rules in the reqRules.drl file. The following code snippet is a small skeleton of a rule that defines such group:
rule "prioritize requirements"
lock-on-active
ruleflow-group "establish-reqs-priority"
when
r: Requirement(priority == -1)
then
r.setPriority(5);
endAs you can see in the examples, you can have multiple rules that evaluate the model and change values to different objects in it. The output of the rules in a Business Rule task is usually a modification or addition in the model that will be easily checked by a gateway later on. In our case, the elements we check in each of the gateways' outgoing connections is the requirement's priority value, and determine two paths based on the values of the priority.
Ad hoc processes are processes whose sequence of actions cannot be predefined. When we define an ad hoc process, we do know what tasks will be needed to be performed, but the order and sequence of said tasks is either too complex to be defined in a flow or too variable to be considered fixed. As a diagram, they just seem as a bag of tasks with no connection between them. The following diagram shows a representation of the adhocProcess.bpmn2 file:
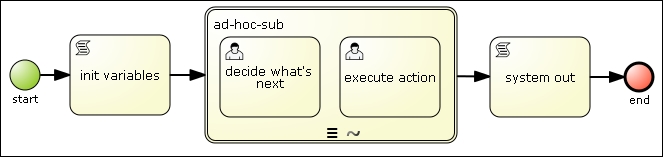
In jBPM6, ad hoc processes are supported in a way that makes it similar to a Business Rule task: the name of the ad hoc process will be a ruleflow group that will be activated when you reach the start the process. Using rules, you can determine which task needs to be created and you can start one of those tasks manually using a class called DynamicUtils. You can also determine the conditions to exit the ad hoc process using rules. In the process-rules-examples project, you can find a test called AdHocProcessTest, which uses this functionality to run an ad hoc subprocess called adHocProcess and uses the rules defined in the ad-hoc-sub ruleflow group to determine the next task. The rules are defined in a file called adhocRules.drl, and on finding specific conditions, fires a new work item to execute a specific task within the ad hoc process as the following rule shows:
rule "init rule"
salience 100
ruleflow-group "ad-hoc-sub"
when
wf: WorkflowProcessInstance($nodes: nodeInstances)
dn: DynamicNodeInstance() from $nodes
eval(wf.getVariable("processVar1") == null)
then
System.out.println(drools.getRule().getName());
KieRuntime kr = kcontext.getKnowledgeRuntime();
Map params = new HashMap();
params.put("inVar1", wf.getVariable("processVar1"));
params.put("TaskName", "decide what's next");
DynamicUtils.addDynamicWorkItem(dn, kr, "Human Task", params);
endIn the preceding rule, we are looking for a process instance, which has an active dynamic node (which is jBPM6's internal representation for an ad hoc process) and has no process variable assigned with the name processVar1. This is done by checking for the WorkflowProcessInstance objects we might have in the rule engine memory, and checking whether its nodeInstances attribute (which we will assign to a $nodes variable) contains a DynamicNodeInstance object. Finally, we evaluate whether a process variable is not yet present in the process instance. When those conditions are met, we start a dynamic Human task (with a WorkItemHandler registered in the KIE session with the Human Task key). It is a responsibility of the "then" part of this rule to provide all the information to the work item generated, including all parameters and references to the KIE session and the node.
One more important step to know is which is the best way to start a process or invoke a process signal inside a rule consequence. To do so, we need to understand a specific predefined variable in the rules consequence called kcontext. This variable will have a reference to the KIE session so that we can use it to invoke our process executions. Using this variable, we can also call all the process related methods in the KIE session, such as signalEvent, getProcessInstance, abortProcessInstance, and so on.
Even though rules and processes share the same runtime, they have very different memory scopes. The process instance memory (called process variables) and the rule memory (called working memory) do not share information unless it is specified that they should do so. In order to communicate information back and forth from the process memory to the rule memory, we need to configure event listeners to populate relevant information changes from one component to the other. Luckily for us, if we want to automatically add a process instance to the working memory (and communicate its internal changes to it for reevaluation when necessary), you can add a particular event listener called RuleAwareProcessEventLister:
ksession.addEventListener(new RuleAwareProcessEventLister());
This listener will make sure that when a process instance is added, changed, or removed, it gets inserted, updated, or deleted from the rule memory. Note that it finishes with the word Lister and not Listener. This is not a typo in the book, but in the code itself, and it has been maintained like this for backward compatibility issues.
Another important configuration that we need to be aware of is related to the use of ruleflow groups. Whenever we enter a Business Rule task or an ad hoc process, the KIE session will not fire all the rules associated with those ruleflow groups automatically. All it will do is notify the internal structure of the KIE session that the ruleflow group is activated, and the user needs to decide whether and when they should fire all the rules. In the majority of cases, we want to fire all rules activated in a ruleflow group when we reach a Business Rule task or an ad hoc subprocess. In order to do so, we have a method in the AgendaEventListener interface to take specific actions after a ruleflow group is activated, and we can invoke a fireAllRules method inside it:
ksession.addEventListener(new DefaultAgendaEventListener() {
public void afterRuleFlowGroupActivated(RuleFlowGroupActivatedEvent event) {
KieSession kses = (KieSession) event.getKieRuntime();
kses.fireAllRules();
}
});With these event listeners, rules from a ruleflow group can be invoked and fired from a process instance.
On a side node, the previous event listener implementation is built in the jBPM6 code, in a class called org.jbpm.process.instance.event.listeners.TriggerRulesEventListener. However, the previous anonymous class was left intentionally to show that you can create your own event listeners as you see fit, and don't need to stick to built-in event listeners.
This covers the main interactions between rules and processes. The next section deals with some advanced rule concepts that allow for tracking different operations along a specific timeline.