
Based on the WS-HT specification, the current version of the Human task component is composed of multiple projects that can be found inside the master Git repository, where you can download the full code of the jBPM project. The following link will allow you to see the source code directly from the browser:
https://github.com/droolsjbpm/jbpm/tree/master/jbpm-human-task
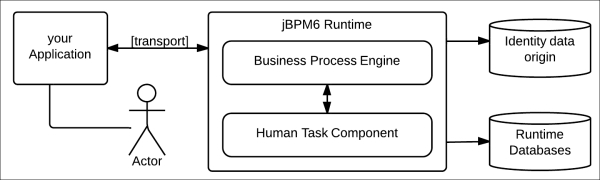
From the architectural perspective, this component can be configured to run in different ways, depending on your application needs. Because the Human task component is a very simple and lightweight component, the simplest way to start using it is to embed it in the same runtime with the process engine.
The following figure describes the different interactions with the Human task component:

This option instantiates the Human task component inside your application. The Human task component is a service that is implemented using
Java Persistence API (JPA) to persist information in a database. This implies adding special configurations to our application to make it work: a persistence provider must be specified (which by default is hibernate in jBPM6) and a persistence unit must be defined in order for JPA to understand specific objects as database table mappings.
An application that holds the Human task component as a library inside it will have a way to access information on our Human tasks from a database. As a con, we will need to add the database access configurations inside our application; if we have multiple applications embedding the Human task component features, we will have to maintain all the configurations for every application, which increases complexity.
The second option is to use this component as an external component. Our application will have to configure how to connect to the Human task component—located in a different server—through some specific communication protocol. In Chapter 10, Integrating KIE Workbench with External Systems, we will see ways in which KIE Workbench provides such an external Human task component and process engine.
The following figure shows how communication would happen with an external Human task component:
Before we get into any more details regarding how to externalize the Human task component, we should probably get into more detail about how it is implemented, its internal elements, and its exposed APIs.
For this particular case, we've extended the process definition with which we started working in the previous chapters. We added two new User tasks to test and bug fix the requirement, and we added a model class to it called requirement to handle all process variables, data inputs, and outputs.
The following screenshot shows the process definition we will be using in this chapter:

With these modifications, we now have two different groups in charge of Human tasks, namely, developers, and testers. This will enrich the process enough to give us a playroom for the next configuration steps.
The Human task component in jBPM6 follows the guidance of the WS-HT standard specification to construct a service that is accessible by both people and the process engine. This specification defines specific calls that must be made to switch the state of Human tasks. The main API for the Human task service is defined in the org.kie.api.task.TaskService interface, as shown in the following code:
public interface TaskService {
...
void claim(long taskId, String userId);
void start(long taskId, String userId);
void delegate(long taskId, String usrId, String tgtUsrId);
void fail(long taskId, String usrId, Map faultData);
void skip(long taskId, String usrId);
void forward(long taskId, String usrId, String tgtEntityId);
void complete(long taskId, String usrId, Map outputData);
List<TaskSummary> getTasksAssignedAsPotentialOwner(
String userId, String language);
List<TaskSummary> getTasksOwned(
String userId, String language);
...
}This is just a simplification with the most used methods of the TaskService interface. The behavior they provide is guided by the graph of the Human tasks' life cycle that we saw in the Human tasks' life cycle section. In order to use it, we must initialize an implementation of it.
In order to have our Human task component available inside our classpath, we need to add the dependencies necessary to get the task service classes working. In a Maven-based project, we can add those dependencies by adding the following three dependencies to your own Maven-based project's pom.xml file, just like the project in the code section of this book, which is in the chapter-06/human-task-components-api folder:
<dependency> <groupId>org.jbpm</groupId> <artifactId>jbpm-kie-services</artifactId> <version>6.1.0.Beta3</version> </dependency> <dependency> <groupId>org.jbpm</groupId> <artifactId>jbpm-human-task-core</artifactId> <version>6.1.0.Beta3</version> </dependency> <dependency> <groupId>org.jbpm</groupId> <artifactId>jbpm-human-task-audit</artifactId> <version>6.1.0.Beta3</version> </dependency>
Once we have these dependencies in our project, we can configure the persistence unit that will be used by our Human task component's implementation.
As previously mentioned, the Human task component is basically a JPA-backed application that will handle the stateful nature of Human tasks with a database. For it to work, it needs a persistence unit configured in the META-INF/persistence.xml file in our classpath, pointing to all the database entity class mappings and data source configurations. In the human-task-components-api project inside this chapter's code, you will find the persistence.xml file in the src/main/resources folder. The content of this file is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
...>
<persistence-unit name="org.jbpm.services.task"
transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/testDS</jta-data-source>
<mapping-file>META-INF/Taskorm.xml</mapping-file>
<class>org.jbpm.services.task.impl.model.AttachmentImpl</class>
<class>org.jbpm.services.task.impl.model.ContentImpl</class>
<class>org.jbpm.services.task.impl.model.BooleanExpressionImpl
</class>
<class>org.jbpm.services.task.impl.model.CommentImpl</class>
<class>org.jbpm.services.task.impl.model.DeadlineImpl</class>
<class>org.jbpm.services.task.impl.model.DelegationImpl</class>
<class>org.jbpm.services.task.impl.model.EscalationImpl</class>
<class>org.jbpm.services.task.impl.model.GroupImpl</class>
<class>org.jbpm.services.task.impl.model.I18NTextImpl</class>
<class>org.jbpm.services.task.impl.model.NotificationImpl
</class>
<class>org.jbpm.services.task.impl.model.EmailNotificationImpl
</class>
<class>
org.jbpm.services.task.impl.model.EmailNotificationHeaderImpl
</class>
<class>org.jbpm.services.task.impl.model.PeopleAssignmentsImpl
</class>
<class>org.jbpm.services.task.impl.model.ReassignmentImpl
</class>
<class>org.jbpm.services.task.impl.model.TaskImpl</class>
<class>org.jbpm.services.task.impl.model.TaskDataImpl</class>
<class>org.jbpm.services.task.impl.model.UserImpl</class>
<class>org.jbpm.services.task.audit.impl.model.BAMTaskSummaryImpl
</class>
<properties>
<property name="hibernate.dialect"
value="org.hibernate.dialect.H2Dialect" />
...
</properties>
</persistence-unit>
</persistence>Also, the said persistence unit will need a transactional data source to work against the database. In our test file called HumanTaskSampleTest.java, you will find its configuration in the method marked by the @Before annotation called setUp. This is a JUnit (http://junit.org/) markup to let the test runtime know that this method will initialize components for every test run:
@Before
public void setUp() {
this.ds = new PoolingDataSource();
this.ds.setUniqueName("jdbc/testDS");
this.ds.setClassName("org.h2.jdbcx.JdbcDataSource");
this.ds.setMaxPoolSize(3);
this.ds.setAllowLocalTransactions(true);
this.ds.getDriverProperties().setProperty("URL",
"jdbc:h2:mem:db");
this.ds.getDriverProperties().setProperty("user", "sa");
this.ds.getDriverProperties().setProperty("password", "sasa");
this.ds.init();
}The test will start a Bitronix (http://www.bitronix.be) transactional data source to be used by the persistence unit. Bitronix is the framework that defines the PoolingDataSource class, which is used to wrap a data source with a transaction manager.
In order for all these components to compile, we will need to add a few extra dependencies to our pom.xml file. We do this so that our classpath can have the JPA APIs, an implementation of those APIs (we will use hibernate for our case), and the Bitronix transaction manager dependency as well, as shown in the following code:
<dependency> <groupId>org.hibernate.javax.persistence</groupId> <artifactId>hibernate-jpa-2.0-api</artifactId> <version>1.0.1.Final</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>4.2.0.Final</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>4.2.0.Final</version> </dependency> <dependency> <groupId>org.codehaus.btm</groupId> <artifactId>btm</artifactId> <version>2.1.3</version> </dependency>
Finally, because we will be working with an H2 database as the persistence accessed through JPA, we will also need to add the H2 dependency:
<dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <version>1.2.128</version> </dependency>
Once we have started our data source and configured our persistence unit, we can start the JPA persistence by just creating an EntityManagerFactory object with the persistence unit name, as follows:
EntityMananagerFactory entityManagerFactory = Persistence.
createEntityManagerFactory("org.jbpm.services.task");Another thing we need to configure before we create and use our task service is a way for it to understand who the valid users are and the groups they belong to. Depending on the way your software or organization defines these structures, you might need to connect to one of the many different identity software components. These range from something as simple as a file with users and roles to a database or to an LDAP or Active Directory (AD) server.
As this configuration can be so varied, the Human task component provides a specific interface (with multiple available implementations) to connect itself to any of these data sources called
UserGroupCallback:
public interface UserGroupCallback {
boolean existsUser(String userId);
boolean existsGroup(String groupId);
List<String> getGroupsForUser(String userId,
List<String> groupIds,
List<String> allExistingGroupIds);
}For our test case, we will use a properties file, and an implementation called JBossUserGroupCallbackImpl, which will allow us to define our users and groups at runtime through a Properties object:
Properties userGroups = new Properties();
userGroups.setProperty("john", "developers");
userGroups.setProperty("mary", "testers");
JBossUserGroupCallbackImpl userGroupCallback =
new JBossUserGroupCallbackImpl(userGroups);There are other implementations of this interface that are already available for use, such as DBUserGroupCallbackImpl that allows you to configure a couple of queries to validate users and groups, or LDAPGroupCallbackImpl that can be used to connect to an LDAP/AD server to validate users and groups. You can even implement your own to connect to any legacy system you might have to validate users within your organization.
Finally, once we have our JPA persistence started and our identity data source configured, we can start our task service. Doing so is very simple, and the Human task component provides a factory class called HumanTaskServiceFactory to quickly create a task service instance, as follows:
TaskService taskService = HumanTaskServiceFactory.
newTaskServiceConfigurator().
entityManagerFactory(entityManagerFactory).
userGroupCallback(userGroupCallback).getTaskService();At this point, we can start using our task service that is backed up by JPA-based persistence, which is connected to our users and groups' data source. This task service will give us the possibility to create new tasks; interact with them, one user at a time; complete them; and so on. The next step in our configuration will be to connect it to the actual process runtime.
By now, we have a task service instance running against a database and a user data source. We now need to connect it to the process runtime so that each process instance can create tasks in the Human task component and the Human task component can notify the process runtime when a Human task has been completed.
The connector, as we saw in Chapter 2, BPM Systems' Structure, is based on the WorkItemHandler interface, and for our particular case, it is going to be the NonManagedLocalHTWorkItemHandler implementation, as shown in the following code:
WorkItemHandler htHandler = new NonManagedLocalHTWorkItemHandler(
ksession, taskService);
ksession.getWorkItemManager().registerWorkItemHandler(
"Human Task", htHandler);Using the Human Task reserved key, we can register a work item handler specific to handling User tasks. In this opportunity, the instance we selected is prepared to create a new task every time a process instance enters a new task. At the same time, this handler will register a listener on the task service to receive notification when the created task is completed, skipped, or failed, in order to call the completeWorkItem method on the work item manager.
The most interesting thing about the interaction between the process runtime and the task service is that it minimizes the interaction with the process runtime. The more the systems take care of notifying the process instance that it should continue, the less you have to do it. You'll find out that the only interaction with the KIE session for the test available in human-task-components-api is to start the process; all the subsequent activities are handled directly through the task service. We request specific tasks available for a developer or a tester and complete them using the available methods:
List<TaskSummary> tasks = taskService.
getTasksAssignedAsPotentialOwner("john", "en-UK");
TaskSummary firstTask = tasks.iterator().next();
taskService.claim(firstTask.getId(), "john");
taskService.start(firstTask.getId(), "john");
Map<String, Object> results1 = new HashMap<String, Object>();
results1.put("reqResult", req);
taskService.complete(firstTask.getId(), "john", results1);The calls that we see in the preceding code snippet are made after a process is started to get the tasks available for the user, john (one of the developers defined in the user data source). Once we have the task available, we claim it, start it, and complete it. After this is done, the process will be notified about the task completion and it will move to the next wait state. This will be a User task owned by testers, so mary will be able to get a task now to work on, as follows:
List<TaskSummary> marysTasks = taskService.
getTasksAssignedAsPotentialOwner("mary", "en-UK");
TaskSummary marysTask = marysTasks.iterator().next();
taskService.claim(marysTask.getId(), "mary");
taskService.start(marysTask.getId(), "mary");
Map<String, Object> results2 = new HashMap<String, Object>();
req.addBug("bug 1");
results2.put("reqResult", req);
taskService.complete(marysTask.getId(), "mary", results2);As you can see, these interactions are done exclusively through the Human task component. This translates to an actual application where you have people who only need to worry about working directly with Human tasks and let the application run the process in the background, creating new tasks according to what the process dictates. The interfaces needed for such a user perspective of the process runtime is defined in the following section.
A good way to finish the understanding of APIs provided by the Human task component is to understand what kind of generic UIs will relate to it. These task-oriented user interfaces should be generic enough to work for any kind of User task, but descriptive enough to show sufficient information to the users to determine the task they should be working with.
These screens will contain and handle Human tasks in two different ways usually:
- Through the task lists
- Through the task forms
When a user needs to check pending tasks, they need a screen that displays these tasks and have an initial interaction with them. The list should contain enough information to understand the pending task, but the information should be generic enough to be available for most of the tasks.
The Tasks List view provided by tools such as KIE Workbench allows the user to choose which tasks in the list to start working on first. A Tasks List view is an entry point for users to understand what needs to be done. Users should have enough information from the list to understand the nature of the tasks at hand and be able to prioritize them in order to know which one to do first.
Some of the common pieces of information displayed in the Tasks List view are as follows:
- Task Name: This is a short and descriptive name of the task.
- Priority: This can help us sort tasks depending on their urgency.
- Status: A task could be in many different statuses and available to a user. It could be reserved to that user, ready for one of its groups, or in progress when it is already started.
- Created On: This is the date when the task was created.
- Due On: This is the date and time for when the task is due.
- Description: This is some textual description of the task that can contain contextual information to clarify its purpose.
- Last Update: This is the last date when it was modified.
The Human task component clients should build a UI to represent this information for many tasks at a time; they should do this to let the users decide which task to work on.
This view, whether you use KIE Workbench or a custom UI, should be generic enough to show information of any kind of tasks. However, when we have to work on a specific task, standardization becomes complicated, and specialization is what we will need for each specific task. To provide said specialization for each task type at a time, we will use task forms.
A Tasks List screen looks like the following screenshot in KIE Workbench, where we can see some of the properties we previously mentioned:

Once we are able to view, discriminate, and prioritize the pending tasks, we need a way to work with the full representation of each task, one task at a time.
Each type of task needs to have a different task form that enables user interaction. These forms can be created from the process designer's contextual menu in KIE Workbench. This menu will allow us to create and edit both the forms used by User tasks as well as the form that can be used to create a new process instance, as we can see in the following screenshot:

Each specific User task should have a specialized task form to show the exact information the user needs to perform their job. The task forms usually have the following requirements:
- Reviewing and approving information
- Gathering information required by the task
- Doing manual work and reporting the outcome
Each task form needs to be created to handle the information managed on each task. An example of a task form is shown in the following screenshot:

The Hiring a Developer task form provides the user with all the components to determine the name of the developer to be hired. Like almost all the task forms, this one contains information that is only relevant to the specific domain of this task. When the user needs to do the real work, they need specific tools to make the decisions involved in said job. However, when it comes to listing tasks, we want to be able to assess multiple cases simultaneously. The formula to get both the things working in the same environment is to provide abstract task lists and specific domain task forms. The other cool thing about task forms is that multiple processes that require this functionality can reuse them.
Keeping an external reference inside the process can be enough for most cases. There is no need to keep all the content of a document as a process variable, especially if there are external services to access, query, or even modify the said documents from outside the process scope. You will find it a common practice to keep documents in a content repository and have a process variable that points to the actual document. If for some reason the business process requires some bits of information from inside the document to make some decisions, you can usually store the metadata about the document inside the repository and use that information inside the process' context.
Web Process Designer also provides us with an option in the aforementioned menu to automatically generate all the task forms. This will create a generic implementation of the task forms. The main responsibility of generic implementations of task forms is to get the task's input and output information. Based on this mapping, provided by the BPMN file, we can construct a dynamic form that will display all of the input and provide simple form fields to fill all of the task output. The kinds of output a mechanism like this could handle are as follows:
- Text input fields
- Password/hidden text fields
- Calendar components to handle dates
- Select lists (list of values)
- Multiselection lists
- Checkboxes/radio buttons
The previously mentioned visual components are available in most of the UI-related frameworks. They can be enough to start working on a generic initial form display, but eventually, we will want to provide as much real-world information to the end user as they need to do their job more efficiently. This is one of the most important steps toward improving the performance of business processes. Depending on the nature of the task, we need to create custom components to deal with the interactions of domain-specific users.
External components can be used to render our forms, so we need to search and decide which component is best for each one of our forms' needs. Also, each of these task forms can be handled as a knowledge asset, which will be used as a bridge between the process and the users. The eventual task form that the user sees is the combination of a form definition used as a template and input data from the task to populate the said template.
We need to understand that this is just one possible solution to enable the user interaction. We need to be open minded about how we can expose the task lists and task forms so that users can easily access the information required to complete their tasks.
The following are some of the things that we can do to improve how the end users access the information related to Human tasks:
- Provide mobile implementations for task lists and task forms
- E-mail-based services
- SMS-based services
- Social networking client interfaces (such as Twitter and Facebook implementations)
- Excel-based task forms
The more options the users have to work on their tasks, the easier it is for them to adapt to the new services provided by the process engine.
The following section discusses how we can extend the functionality of the Human task component.
Now that we've understood the APIs provided by the Human task component, we can start discussing the possible extension points that the API provides to allow users to extend its functionality and connect the component to other tools. This proves most useful when you think of the Human task component as a piece of a big puzzle, for example, the overall enterprise architecture of an organization. In such contexts, the possibility of handling human tasks is not the only thing that is important, but how information from those tasks can also impact other components.
The main responsibility of the Human task component is to handle the life cycle of tasks, and leave many connection points for other pieces of software to be notified about the changes in said life cycle or affect it in a simple way. In the following subsections, we will see some details on how to configure different pieces of software that can provide a lot of added value to you. We will concentrate on three main extension points:
- Task life cycle event listeners
- Task service interceptors
- Task model providers
In jBPM6, the task service provides a configuration facility to expose the behavior of tasks to external components. This configuration allows you to construct all sorts of publishing for task operations. In a way, every time a task is changed from one state to another, the current status of said task could be exposed. This is achieved through a specific listener class called TaskLifeCycleEventListener that can be implemented in virtually any way you see fit, as shown in the following code:
public interface TaskLifeCycleEventListener extends EventListener {
public void beforeTaskActivatedEvent(TaskEvent event);
public void beforeTaskAddedEvent(TaskEvent event);
//omitted methods
public void afterTaskActivatedEvent(TaskEvent event);
public void afterTaskAddedEvent(TaskEvent event);
//omitted methods
}In the current status of the API, the methods provided by this listener interface allow you to implement your own code before and after any changes made to a task. The TaskEvent class used to describe the occurrence of each event gives you a reference to the task instance and a TaskContext object that will hold a few useful references, as shown in the following code:
public interface TaskContext extends Context {
TaskPersistenceContext getPersistenceContext();
void setPersistenceContext(TaskPersistenceContext context);
UserGroupCallback getUserGroupCallback();
}A TaskPersistenceContext object gives you data access methods to query and/or change the task persistence, especially tasks, groups, users, and task data. It also has methods to control the status of the database connection and the transaction, so they do provide a lot of power when deciding to alter the persistence of our model.
In the project human-task-extension-points, you will find a test file called HumanTaskListenersTest.java. In this file, you will find an example of using a listener to keep an in-memory list of all the activities done in the tasks. We create a special listener implementation called LogTaskChangeListener and add a very simple TaskLog object for each after method of the listener, as follows:
public void afterTaskClaimedEvent(TaskEvent event) {
logs.add(new TaskLog(event.getTask().getId(), "TaskClaimed"));
}After this, we provide a get method for the logs we create and validate it from the test.
The process of configuring listeners for the Task Service can be done through the HumanTaskServiceFactory class, as shown in the following code snippet:
TaskService taskService = HumanTaskServiceFactory.
newTaskServiceConfigurator().
entityManagerFactory(emf).
userGroupCallback(ugCallback).
listener(new LogTaskChangeListener()).
getTaskService();You can also add a new listener to an existing task service instance by executing the following code:
( (EventService<TaskLife cycleEventListener>) taskService)
.registerTaskEventListener(listener)The preceding code section first casts the taskService instance to an EventService interface and then registers the listener. The HumanTaskServiceFactory helper class will do this for us if we use it to build the task service.
However, sometimes configuring information about the tasks themselves is not enough. We might be interested in not just the task change, but any sort of invocation for the Human task component. For those cases, the Human task component provides another set of interactions called interceptors, which will be discussed in the following section.
One more extension point provided by the Human task component is what is called the interceptors. In order to explain the nature of interceptors, we must first understand the way that the task service is internally implemented, and to do so, we will need to explain the command pattern.
The command pattern is based on having every method in a particular service represented by the exact same call to a command object. An adapter class between the interface and the invocation of those command objects need to be created. The resulting class structure for the task service implemented through a command pattern looks like the following screenshot:
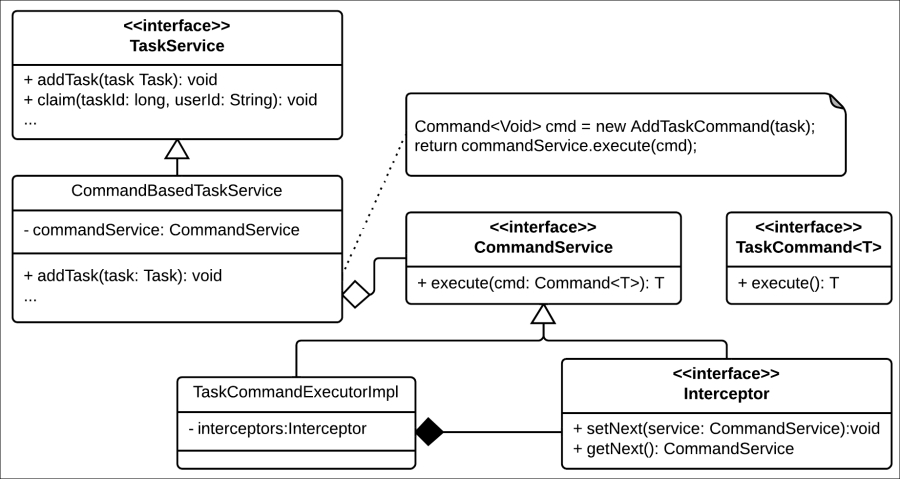
In the preceding class diagram, we can see that the addTask method is translated to a command invocation as follows:
public void addTask(Task task) {
Command<Void> cmd = new AddTaskCommand(task);
return commandService.execute(cmd);
}A similar structure is followed for every single method invocation in the task service API. As you can see, the commandService.execute() method invocation will be the one done for every method.
The next step to understand the interceptors is to understand the
CommandService class. This class will have the responsibility of invoking the actual execute method in the Command object. The idea behind the interceptors is that you can decorate the class by creating wrappers for it. Each one of the wrappers can invoke special pieces of code before and/or after the method invocation. The result is the creation of different components that can do anything you want before or after every method that is called on top of the task service.
The following sequence diagram shows how the interceptor pattern allows you to add steps before and after the execution of commands:

Now that we have understood a bit more about what the interceptors do and how they influence the behavior of a command pattern's application, we can get into the details of specific interceptors you can build for the task service, how to configure them, and what classes constitute our model to create these interceptors.
Interceptors for the task service can extend an abstract class with some helper methods called
AbstractInterceptor. It provides basic implementations for all the methods, except for the execute method, and provides an executeNext method to invoke the next interceptor in line. With it, it becomes very simple to create a new interceptor.
In the project, human-task-extension-points, you will find that we created an interceptor called UserLogInterceptor. It is just for demonstration purposes. The main activity it provides around every method is the process of finding out whether it is a user-related operation according to the type of the invoked command. If it is, it stores a log of the operation that is called, inferred from the command name as well. The execute method for UserLogInterceptor looks like the following code:
public <T> T execute(Command<T> command) {
String userId = getUserId(command);
String operation = getOperationName(command);
if (userId != null) {
logs.add(new OperationLog(userId, operation));
}
return executeNext(command);
}Later on, in the HumanTaskInterceptorTest class, we can see that we register it and check its logs after every user action to see that they are correctly populated. The HumanTaskServiceFactory class provides a method to configure interceptor objects inside your task service's implementation. The code to configure them looks like the following code snippet:
TaskService taskService = HumanTaskServiceFactory.
newTaskServiceConfigurator().
entityManagerFactory(emf).
userGroupCallback(ugCallback).
interceptor(priority, new UserLogInterceptor()).
getTaskService();In the preceding code, the priority variable is an integer that defines in what place this interceptor will be in the chain of interceptors that a task service instance could have.
Whether to use interceptors or task life cycle event listeners is a tough discussion, but the best rule of thumb to make a decision in that aspect is to consider transaction management.
Task life cycle event listeners provide a simple connection point. However, this extension point is usually detached from the invocation stack. It will be solely invoked from inside the task service when the task service finds a change in a task. It is great to connect external systems to the internal information of the task, but not a great place to make once-per-method-invocation operation inside the task service.
Interceptors, on the other hand, will be invoked for each method's invocation and will be able to wrap a lot more of execution than each method of the listener; for one invocation in a task service method, many different task life cycle event listeners might be fired, all detached from one another. However, the interceptor will be able to handle what happens before and after that whole invocation and even take care of exception handling if some of the actions taken in the proprietary code need to roll back the task service operation if there is an error.
For some cases, using both on a single class could be an alternative. For example, let's consider a cache for tasks. Whenever a task is changed, we want to mark it to update the cache. However, we don't want the cache to be updated until we finish the method's invocation. A good way to manage such a case would be to implement an interceptor to handle the cache update and a life cycle event listener to control which tasks are being changed by a particular method's invocation in the task service.
Many more possible cases might trigger the necessity of one over the other. The important thing to understand is that they are not mutually exclusive, and each deal with a different aspect of the task management, something we can take advantage of.
One final extension point that we will discuss in this chapter is the possibility of changing the JPA entity model used by the application. This will be an advanced feature that users can use that will allow people to add extra attributes (and therefore, extra columns) to the domain model to make it easier for you to create your own queries on the persistence.
You could have the possibility of adding, for example, an external entity ID passed to the task as a data input to your task objects. Later on, you could use this ID to create queries with your particular model, provided that they are both working in the same persistence unit.
This is possible because no components of the core of the Human task component construct any of the model objects directly. Instead, they use a factory called TaskModelFactory. This factory provides a concrete implementation of the interfaces that compose the core model of the task service, as follows:
public void TaskModelFactory {
public Task newTask();
public TaskData newTaskData();
public Content newContent();
//omitted methods
}The TaskModelFactory class has an implementation called JPATaskModelFactory that defines JPA-based implementations for the interfaces defined in the model. What the task model provider does is that it discovers the JPATaskModelFactory implementation through Java's ServiceLoader and uses it to create its own components.
Therefore, you can configure the actual TaskModelFactory class that your project will use by adding a file called META-INF/services/org.kie.internal.task.api.TaskModelFactory, with the actual name of the implementation in it. You can see an example of this configuration in the human-task-extension-points project in the code section of this book, which just defines the default implementation class for the interface. If any of its methods is constructed to return a different type of object, it will replace the actual JPA implementation by the one you need. The only thing you will have to be careful is to make sure you replace the classes that will be persisted in the META-INF/persistence.xml file as well as in the newly registered implementation of the TaskModelFactory interface.