
Recursive fact-finding
Abstract
As we discussed earlier in Chapter 5, expectation maximization (EM) is an iterative algorithm that provides the maximum likelihood estimation when the iteration converges. However, running the iterative algorithm is not necessarily efficient for the streaming data, especially when the estimation parameter θ remains stable over time. This observation motivates the development of a real-time version of the EM algorithm for streaming data to achieve a better tradeoff between the estimation accuracy and running time. In this chapter, we present a recursive fact-finding model developed based on EM approach that allows the applications to update their estimation on the fly as data stream in.
10.1 Real Time Social Sensing
This chapter presents a recursive fact-finding solution to the real-time social sensing problem. We introduced the reliable social sensing problem in Chapter 5. An iterative EM algorithm was developed to solve the reliable sensing problem under the assumption that all data are collected a priori. However, in many real world social sensing applications, data arrives as a stream. A key challenge emerge in this real-time context: how could we solve the reliable social sensing problem as data stream in? In particular, how could we develop an efficient scheme to update the estimation parameters of maximum likelihood estimation (MLE) model for the streaming data? We call this problem real time social sensing problem. A naive approach to solve the above problem is to re-run the iterative EM solution whenever new data arrive. The obvious deficiency of such an approach is that it is not scalable over the time dimension. In this chapter, we review a new recursive solution to solve this real time social sensing problem.
Reputation systems [18] have been successful at assessing quality of providers (e.g., the reliability of data sources) when the same providers repeatedly execute transactions that can be scored by others. In contrast to such scenarios, the reviewed work is specially interested in short-lived crowdsourcing campaigns (e.g., to support post-disaster recovery and rescue missions, which may last for only a few days), where anyone can volunteer and where there is not enough history to accumulate meaningful reputations. For example, consider the severe gas shortage around New York City in the aftermath of hurricane Sandy in November 2012. Social networks, such as Twitter carried tens of thousands of tweets on the availability of gas at different stations, but the reliability of the corresponding tweeters remained unknown.
Fact-finder algorithms [37, 44, 100] have been proposed that use unsupervised machine learning techniques to assess data reliability directly from multitudes of unreliable claims, whose sources may not have a known history in advance. The problem was also explored in data mining literature [35, 36, 133], with intuitions tracing back to Google’s original PageRank [34, 134]. These solutions iteratively rank claims and sources to jointly assess the reliability of both, without requiring sources to explicitly comment on each other’s performance. Unfortunately, they use batch algorithms, designed to run on a static dataset. As such, they are not well-suited to processing streaming data for applications such as crowdsourcing, where new observations continue to arrive over time. The batch algorithms will either need to operate on a growing data set as new data arrive (which does not scale), or ignore some previously computed results and run from scratch on a sliding recent data window (which does not exploit all available data).
In contrast, the main contribution of the reviewed model in this chapter is to develop a recursive fact-finder, based on expectation maximization (EM) that updates on new data, as it arrives, updating previous truth estimates (i.e., estimates of correctness of reported data) in a manner that approximates running an optimal batch algorithm on the entire augmented dataset [107]. The streaming EM scheme reviewed in this chapter is considered as one of the first on-line fact-finding approaches designed to solve the real time social sensing problem, where there is no prior knowledge on source reliability and no immediate way to verify the correctness of the collected data. The streaming EM scheme is derived by formulating an optimization problem (in the sense of maximum-likelihood estimation) and approximating the optimal solution using results from estimation theory.
10.2 A Streaming Truth Estimation Model
Real time social sensing addresses the challenge of estimating some pertinent “state of the world” from source’s reported observations that come continuously over time. The streaming model represents the state of the world by a set of true/false statements (e.g., “The Golden Gate bridge is on fire,” “The 435 Main Street gas station is out of power,” or “The 5th Avenue and 34th Street intersection is flooded”). Such a binary approach, while simple, is a powerful tool to articulate arbitrarily complex conditions. It is also well-suited to geotagging campaigns that mark locations of some conditions of interest (e.g., locations of street flooding after a thunderstorm). For example, each location may be associated with a number of Booleans indicating the presence or absence of different types of damage. A report from a source conveys one or more claims, each presenting the value of one of these Booleans. The values of claims are assumed to not change over the period of study. The “ground truth” state is unknown and needs to be reconstructed as accurately as possible from claims by different sources, whose reliability is unknown.
More formally, let us first review the social sensing application model discussed in Chapter 5, where a group of M sources (sources), S1,…,SM, collectively make observations about N measured Boolean variables, C1,…,CN, which are of interest to the application. It is assumed, without loss of generality, that the “normal” state of each (Boolean) variable is negative (e.g., a place is not damaged). Hence, sources only report when the positive state of the claim (repair is needed) is encountered. Each source generally reports only a subset of the variables (e.g., those at the places they have been to). The goal of reliable social sensing is to jointly calculate the reliability of sources (i.e., the probability that a source reports correct observations) and the correctness of observations, given only the record of who reported what.
Importantly, in crowdsourcing applications, the observations from sources do not come all at once. Instead, updates are reported over the course of the campaign, lending themselves better to the abstraction of a data stream arriving from the community of sources. In Chapter 5, we reviewed a batch EM (expectation maximization) algorithm to solve the reliable sensing problem based on a MLE hypothesis [100]. As its name suggests, the batch EM scheme is designed to run in a batch mode, which is not suitable for continuously arriving data. This is because, every time a new report arrives, the batch EM algorithm needs to be re-run on the whole data set from scratch. Considering such inefficiency, this chapter reviews a new fact-finding approach based on a recursive EM algorithm to update estimation results on the fly in view of newly arriving data.
Following the terminology of previous chapters, let us review a few notations we will use in the following sections. Let Si denote the ith source and Cj denote the jth claim. Let Xi,j denote whether source Si reports claim Cj. The matrix representing who reported what is called the observation matrix X, where Xi,j = 1 when source Si reports that Cj is true, and Xi,j = 0 otherwise. Let Tj represent the ground truth value of Cj (i.e., Tj is 1 if Cj is true and 0 otherwise). Source reliability ti is defined as the probability that the source is right in a randomly chosen claim he/she reported. Formally, ti is defined as:
Let us also review two more important conditional probabilities: ai is the (unknown) probability that source Si reports a variable to be true when it is indeed true, and bi is the (unknown) probability that source Si reports a variable to be true when it is in reality false. Formally, ai and bi are defined as follows:
As we discussed before, the relationship between ti, ai, and bi can be derived by the Bayes’ theorem:
where d is the overall background prior that a randomly chosen claim is true. Note that, this value does not indicate, however, whether any particular report about a specific claim is true or not. d can be either chosen from the prior knowledge or jointly estimated in the EM scheme [100]. Finally, si denotes the probability that source Si reports an observation.
Starting with a log-likelihood function that describes the likelihood of the observed data (i.e., who said what) given the estimation parameter defined in Equation (10.2), the batch EM algorithm converges to the MLE of the variables in question (in this case, the truth values of claims and the reliability of sources). The likelihood function can be given by:

where N and M are the numbers of claims and sources, respectively, zj is 1 if claim Cj is true (and 0 otherwise). The optimal estimation of the parameters in the batch EM algorithm [100] are given by:

where SJi is the set of claims the source Si actually observes and Ki is its size. Zj is the probability of Cj to be true given current estimation and observed data.
In this chapter, we review a new streaming fact-finder based on a recursive EM algorithm to accurately estimate the above parameters in real time from streaming data.
10.3 Dynamics and the Recursive Algorithm
In the following subsections, we derive the recursive formulas for the fact-finder to account for the staggered data in the stream and provide the resulting algorithm.
10.3.1 The Derivation
In estimation theory, a recursive formula of the EM scheme estimates parameters of the model in consecutive time intervals as follows [91]:
where ![]() is the estimation parameter by observing the data up to the time interval k,
is the estimation parameter by observing the data up to the time interval k, ![]() represents the “complete” Fisher information matrix, which is the expected value of Fisher information matrix average over the missing data at time k. In this work, we take the asymptotic CRLB from Chapter 6, which is slightly different than the inverse of the “complete” Fisher information matrix. This is one of the key distinctions of the approach in [91] vice using the actual Fisher information.
represents the “complete” Fisher information matrix, which is the expected value of Fisher information matrix average over the missing data at time k. In this work, we take the asymptotic CRLB from Chapter 6, which is slightly different than the inverse of the “complete” Fisher information matrix. This is one of the key distinctions of the approach in [91] vice using the actual Fisher information. ![]() is the score function (defined in Equation (3.10)) of the observed data at time interval k + 1 w.r.t. the estimation parameter
is the score function (defined in Equation (3.10)) of the observed data at time interval k + 1 w.r.t. the estimation parameter ![]() . Authors in [91] state that we can take expectation of the score function over the missing data instead of the score function itself. The above formula basically provides us a recursive way to compute the estimation parameter in the new time interval (i.e.,
. Authors in [91] state that we can take expectation of the score function over the missing data instead of the score function itself. The above formula basically provides us a recursive way to compute the estimation parameter in the new time interval (i.e., ![]() ) based on its estimation value in the previous time interval (i.e.,
) based on its estimation value in the previous time interval (i.e., ![]() ), the complete CRLB of the estimation (i.e.,
), the complete CRLB of the estimation (i.e., ![]() ) and the score function of the updated data observed in the new interval (i.e.,
) and the score function of the updated data observed in the new interval (i.e., ![]() ). Based on the results are from Chapter 6 (under the assumption that the number of sources is sufficiently large to reach this asymptotic results) of the EM scheme,
). Based on the results are from Chapter 6 (under the assumption that the number of sources is sufficiently large to reach this asymptotic results) of the EM scheme, ![]() is the estimation vector defined as
is the estimation vector defined as ![]() .
. ![]() and
and ![]() are given by the asymptotic CRLB from Chapter 6 (see Equation (6.16)):
are given by the asymptotic CRLB from Chapter 6 (see Equation (6.16)):

and the score function is:

where ![]() is the probability of the jth claim to be true in the k + 1 time interval. Plugging Equations (10.7) and (10.8) into (10.6), the recursive formula to update the estimation parameters is given by:
is the probability of the jth claim to be true in the k + 1 time interval. Plugging Equations (10.7) and (10.8) into (10.6), the recursive formula to update the estimation parameters is given by:

From above equations, one can observe that the estimation of the parameters related with reliability of each source in current time interval can be computed from their estimations in the past and the observed data in the new interval. Moreover, ![]() is unknown and can be estimated by its approximation
is unknown and can be estimated by its approximation ![]() , which can be computed as follows:
, which can be computed as follows:

where

where ![]() and
and ![]() are the frequencies of source Si reports a claim after iteration k + 1 and k (i.e., at time k + 1 and k). Note that
are the frequencies of source Si reports a claim after iteration k + 1 and k (i.e., at time k + 1 and k). Note that ![]() can be computed as the percentage of all claims made by Si relative to the total number of claims that it could have made, which is known from the observed data. For the above equation to hold, it is assumed that source reliability changes slowly over time and can be treated unchanged over two consecutive time intervals.
can be computed as the percentage of all claims made by Si relative to the total number of claims that it could have made, which is known from the observed data. For the above equation to hold, it is assumed that source reliability changes slowly over time and can be treated unchanged over two consecutive time intervals.
Based on the definition of ![]() , it can be further represented as a function of
, it can be further represented as a function of ![]() , the values of which are known at time interval k + 1:
, the values of which are known at time interval k + 1:

where
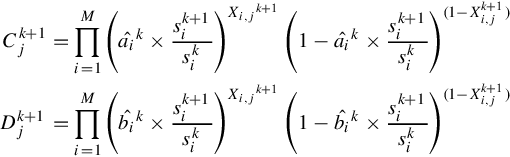
Plugging Equation (10.11) into Equation (10.9), the following recursive computation of the estimation parameters can be obtained:

Additionally, the updated correctness of claims (i.e., ![]() ) can also be computed as follows:
) can also be computed as follows:
where function f is the same as the one in Equation (10.10).
This gives us the recursive equations to compute the estimation parameters of the model in the current time interval based on the estimations from the previous time interval and the observed data up to now. Therefore, Equation (10.12) can be utilized to keep track of the estimation parameter of the sources that report new observations consecutively over time. We also note that the estimation parameter change of the updated sources will affect the credibility of claims they report, which in turn will affect the credibility of other sources asserting the same claim. We call this credibility update propagation “ripple effect.” To capture such an effect, a simple trick was designed: only run one EM iteration after applying the recursive formula (as compared to running the full version of EM from scratch). This turns out to be an efficient heuristic based on the following observations: (i) the recursive estimation already offers us a reasonably good initialization on the estimation parameter; (ii) the credibility change of sources by a few updates in a short time interval is usually slight. This allows the recursive EM to converge much faster than the batch algorithm that starts from a random point.
10.3.2 The Recursive EM Algorithm
In summary of the recursive EM algorithm derived above, the pseudocode of the algorithm is given in Algorithm 7. The algorithm runs when a new update Xk+1 arrives and it first computes the recursive update on the estimation parameter (i.e., ![]() ) based on Equation (10.12). The correctness of claims are consequently updated from the estimation parameters based on Equation (10.13). The recursive algorithm runs one EM iteration to capture the “ripple effect” of the credibility prorogation as we discussed in the previous subsection. Thus the iteration only consider who are making the claims as the current time. After that, once can decide the truthfulness of each claim Cj at current time slot based on the updated value of
) based on Equation (10.12). The correctness of claims are consequently updated from the estimation parameters based on Equation (10.13). The recursive algorithm runs one EM iteration to capture the “ripple effect” of the credibility prorogation as we discussed in the previous subsection. Thus the iteration only consider who are making the claims as the current time. After that, once can decide the truthfulness of each claim Cj at current time slot based on the updated value of ![]() (i.e.,
(i.e., ![]() ). One can also compute the reliability of each source from the updated values of
). One can also compute the reliability of each source from the updated values of ![]() (i.e.,
(i.e., ![]() and
and ![]() ) based on Equation (10.3).
) based on Equation (10.3).
Algorithm 7
Recursive Expectation Maximization Algorithm
1: while new update Xk+1 arrives do
2: for i = 1 : M do
3: compute ![]() based on Equation (10.12)
based on Equation (10.12)
4: update ![]() with
with ![]()
5: end for
6: for j = 1 : N do
7: compute ![]() based on Equation (10.13)
based on Equation (10.13)
8: end for
9: run one EM iteration to capture the “ripple effect”
10: Let Zjr = the value of ![]() after the iteration
after the iteration
11: Let air = the value of ![]() after the iteration
after the iteration
12: Let bir = the value of ![]() after the iteration
after the iteration
13: for j = 1 : N do
14: if Zjr ≥ 0.5 then
15: Cj is true
16: else
17: Cj is false
18: end if
19: end for
20: for i = 1 : M do
21: calculate tir from air, bir based on Equation (10.3)
22: end for
23: k = k + 1
24: end while
10.4 Performance Evaluation
In this section, we review the evaluation of the performance of the proposed recursive EM algorithm compared to the batch EM algorithm (see Chapter 5) and three state-of-art fact-finders; namely, Sums [35], Average-Log [37], and Truthfinder [36]. For the batch EM algorithm, there are two ways for parameter initialization: one way is to statically initialize the estimation parameters based on the observed data and run EM from scratch for each time epoch [100] and the other way is to use the values computed from the previous updates for the current initialization (denoted as EM-P). Below, We first review the evaluation of estimation accuracy and algorithm execution time through an extensive simulation study. The recursive EM algorithm is shown to achieve a better performance tradeoff compared to the batch EM algorithm and other state-of-art baselines. Then, we present an empirical study that demonstrates convergence of the recursive EM algorithm to results of the (optimal but slower) batch EM algorithm through a real-world social sensing application.
10.4.1 Simulation Study
We begin by reviewing the evaluation of the performance of the proposed recursive EM algorithm in simulation by measuring (i) the accuracy of source reliability estimation, (ii) the false positive and false negative rates (i.e., claims misclassified as true or false), and (iii) the average time the algorithm takes to process an update in different conditions.
A similar simulator as the one we discussed in Chapter 5 was built to generate a random number of sources and measured (Boolean) variables. A random probability Pi is assigned to each source Si representing his/her reliability (i.e., the ground truth probability that they report correct observations). A “reporting rate” of a source is defined as the probability that the source reports an observation at a given time slot, reflecting the source’s willingness to report. At a given time slot, for each source Si, the simulator decides whether or not the source reports an observation based on its reporting rate. If a measured variable is true, the Si reports with probability Pi ×reporting rate and if it is false then Si speaks with (1 − Pi) ×reporting rate. Pi is uniformly distributed between 0.5 and 1 in the experiments.* The fact-finder is executed as reports arrive to update estimates of source reliability and truth values of reported data. Each point on the following curves is an average of 50 experiments.
The first experiment evaluated the performance of recursive EM, the batch EM, and other baselines while varying the number of sources in the system. The total number of reported variables was set to 2000, half of which were reported correctly. The reporting rate of sources was fixed at 0.5. The number of sources was varied from 60 to 150. 100 time slots were simulated for the data stream generation. The observation updates of the last 20 slots were used to evaluate the algorithm performance. Reported results were averaged 50 experiments that differ in source reliability distributions. Results are shown in Figure 10.1. Observe that the recursive EM algorithm takes the shortest time to process an update while keeping the estimation accuracy (in terms of both source reliability estimation and claim classification) only slightly worse than the batch EM algorithm.




The second experiment compares the recursive EM to baseline algorithms when the source reporting rate changes from 0.1 to 1. Reported results are averaged over 50 experiments. The results are shown in Figure 10.2. We observe that the recursive EM algorithm continues to achieve a better trade-off between estimation accuracy and execution time: it runs fastest while offering comparable quality to the batch algorithm. Note also that both estimation accuracy and execution time of the studied algorithms improve as the source reporting rate increases. The reason is that a higher reporting rate leads to more data, which eventually allows faster convergence of the algorithm to a more accurate point.




The third and last experiment examined the effect of changing the claim mix on the performance of all algorithms. The total number of claims to was fixed at 2000 and the ratio of the number of correctly reported claims to the total number of reported variables was varied from 0.1 to 0.6. The number of sources is set to 120 and source reporting rate is fixed at 0.5. Reported results are averaged over 50 experiments. The results are shown in Figure 10.3. As before, one can observe that the recursive EM algorithm has the shortest execution time and does almost as well as the batch EM algorithm.




The simulation results show that the proposed recursive EM algorithm succeeds at offering similar estimation accuracy to its best batch counterpart while running significantly faster.
10.4.2 A Real World Case Study
In this section, we review the evaluation of the performance of the proposed recursive EM algorithm compared to the batch EM algorithm through a real world social sensing application. The application targets at finding the free parking lots on the campus of University of Illinois at Urbana-Champaign (UIUC). The “free parking lots” are defined as the parking lots that are free of charge after 5pm daily in this application. The goal here was to see if the recursive EM algorithm can track the performance of the batch EM algorithm and correctly find the real locations of free parking lot on campus. Specially, 106 parking lots on campus were selected and volunteers were asked to mark the ones they believe as “Free.” Sources marked those parking lots they have been to or are familiar with. Various types of parking lots were observed to exist on campus: enforced parking lots with time limits, parking meters, permit parking, street parking, etc. Different parking lots have different regulations for free parking. Moreover, instructions and permit signs often read similar and easy to miss. Hence, sources are prone to make mistakes in their marks. For the purpose of evaluation, the ground truth were manually collected.
In the experiment, 30 sources were invited to provide their “free parking lot” marks on the 106 parking lots (46 of which are indeed free). There were 340 marks collected from sources in total. Both the recursive and batch EM algorithms were ran on the collected marks and their performance on identifying the correct free parking lots were compared. Results are shown in Figure 10.4. Once can observe that the recursive EM algorithm is able to track the performance of the batch EM algorithm and converge to the number of free parking lots found by the batch algorithm as the amount of marks used by the algorithm increases. This result verified the nice convergence property of the developed recursive EM algorithm using real world data.

It should be emphasized that the choice of application of the reviewed work is intended to be a proxy for other more pertinent uses of the reviewed fact-finding tool that are harder to experiment with in a paper (due to absence of ground truth). For example, “free parking lots” may stand for “operational gas stations” in a post-disaster scenario (such as the New York gas crisis in the aftermath of recent hurricane Sandy).
It should also highlight that the reviewed evaluation chose an application where ground truth does not change. This is claimed to be intentional, in order to favor their competition (the batch algorithms) that operate on the entire data set at once and hence have difficulty handling dynamic changes. It is expected the advantages of the recursive algorithm to be more pronounced if ground truth did change during the experiment (e.g., a gas station runs out of gas), since it is easy to adapt them to give more weight to more recent measurements.
Finally, one should note that the reviewed work kept its data sets small enough such that running the batch algorithm upon every update remained feasible (for evaluation purposes, where each point needs 50 runs). The real advantage of the recursive scheme, however, becomes clear when the input volume is scaled up. For example, hundreds of thousands of tweets may be received in the aftermath of real disaster events. Interpreting individual tweets as claims, a recursive fact-finder can rank the claims by credibility in real-time as events unfold, which would be much less time consuming than if a batch fact-finder is re-run continuously as new tweets arrive.
10.5 Discussion
This chapter reviewed a streaming fact-finding approach to address the real time social sensing problem on the fly. Several limitations exist that offer directions for future work.
The recursive EM algorithm is sensitive to the dynamics in the source membership (e.g., new sources join and old sources leave). This is because the recursive model is continuously updating the estimation vector, which is related to the set of sources who are involved in the application. When few sources join or leave the applications, the algorithm is able to infer the reliability of new sources based on the corroboration between their claims and claims made by other sources who are already in the system. However, in the case where a large number of sources change their membership over a short period of time, it is challenging for the recursive algorithm to converge to a stable point quickly. One possible solution is to re-run the batch algorithm when such large dynamics in sources happen. Then, the next challenge is to find the appropriate threshold to invoke the batch algorithm so that the algorithm achieves a nice tradeoff between time and estimation accuracy. It would also be interesting to extend the reviewed recursive model to enhance its robustness against the membership changes in participating sources.
The values of claims are not assumed to change over time. However, in some real world social sensing applications, such assumption may not hold. For example, in a geotagging application to find litter locations in a neighborhood, the litter could be cleaned up periodically by a group of cleaning crew. Hence, the claim of a certain place to have litter may change over time. It is very interesting to further extend our model to consider the dynamics in the values of the same claim. The authors have recently applied the DV EM algorithm discussed in Chapter 9 to handle the dependency between instances of the same claim over different time slots [135]. In this way, one could leverage the results of DV EM to solve this interesting real time social sensing problem where the values of claims change over time. It would also be interesting to further extend this recursive model to consider more complex dynamics. For example, how could one extend the recursive model to apply in the cases where the dependency between sources and correlations between claims also evolve as time proceeds?