
Understanding physical dependencies
Social meets cyber-physical
Abstract
All of the models assumed up to point make two important assumptions: it is assumed (1) the claims are all independent and (2) the sources have the opportunity to observe all claims. However, the above assumptions may not always hold in various kinds of social sensing applications where physical dependencies exist among sources and claims. In this chapter, we present a new maximum likelihood estimation (MLE) model that is aware of such physical dependencies and derived the corresponding expectation maximization (EM) approaches to remove the above two assumptions from the basic MLE model. It turns out the new model and EM scheme outperforms the regular EM approach studied in Chapter 5 in the presence of physical dependencies on both sources and claims.
9.1 Correlations in the Physical World
In many social applications, there exists physical constraints on both sources and observed variables. For example, in a social sensing application to report disaster status in the aftermath of a earthquake, average people normally only have opportunity to observe situations physically close to them. As another example, if we look at hurricane risk prediction map of Hurricane Sandy on the east coast, we will find the communities in nearby neighborhoods have strong correlated risk predictions. Similar observations can be found on the speed map of a city where neighboring segments of the same road often have similar speed estimation. We refer to such constraints and correlations that exist in the physical world as physical dependencies.
This chapter presents a new expectation maximization (EM) model that investigates the exploitation of physical dependencies to improve the reliability of social sensing applications. In particular, two types of physical dependencies are exploited:
• Constraints on sources: A source constraint simply states that a source can only observe co-located physical variables. In other words, it can only report Cj if it visited location Lj. Furthermore, claim Cj = 1 means that a certain event occurs at location Lj (e.g., trash is located at Lj, etc., and Cj = 0 means the absence of that event). The granularity of locations is application specific. However, given location granularity in a particular application context, this constraint allows us to understand which variables a source had an opportunity to observe. Hence, for example, when a source does not report an event that others claim they observed, we can tell whether or not the silence should decrease the confidence in the reported observation, depending on whether or not the silent source was co-located with the alleged event.
• Constraints on observed variables: Observed variables may be correlated, which can be expressed by a joint probability distribution on the underlying variables. For example, traffic speed at different locations of the same freeway may be related by a joint probability distribution that favors similar speeds. This probabilistic knowledge gives us a basis for assessing how internally consistent a set of reported observations is.
Similar as before, let Si represent the ith source and Cj represent the jth variable. We say that Siobserved Cj if the source visited location Lj. We say that a source Si made a claim SiCj if the source reported that Cj was true. P(Cj = 1|x) and P(Cj = 0|x) represent the conditional probability that variable Cj is indeed true or false, given x, respectively. ti represents the (unknown) probability that a claim is correct given that source Si reported it, ti = P(Cj = 1|SiCj). Different sources may make different numbers of claims. The probability that source Si makes a claim is si. Formally, si = P(SiCj|Si observes Cj).
ai is redefined to be the (unknown) probability that source Si correctly reports a claim given that the underlying variable is indeed true and the source observed it. Similarly, bi is redefined the (unknown) probability that source Si falsely reports a claim when the underlying variable is in reality false and the source observed it. More formally:
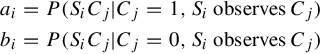
From the definitions above, the following relationships can be derived using the Bayesian theorem:

Let fi be the (unknown) probability that claim Cj is true conditioned on the fact that the ith source happens to observe its location, i.e., P(Cj = 1|Si observes Cj), and this value does not depend on the claim index j. Note that, the probability that a source makes a claim is proportional to the number of claims made by the source over the total number of variables observed by the source. Plugging these, together with ti, into the definition of ai and bi, given in Equation (9.2), the relationship between the terms we defined above can be obtained:

The input to the algorithm is: (i) the claim matrix SC, where SiCj = 1 when source Si reports that Cj is true, and SiCj = 0 otherwise; and (ii) the source’s opportunities to observe represented by a knowledge matrix SK, where SiKj = 1 when source Si has the opportunity to observe Cj and SiKj = 0 otherwise. The output of the algorithm is the probability that variable Cj is true, for each j and the reliability ti of source Si, for each i. More formally:

To account for non-independence among the observed variables, the set of all such constraints (expressed as joint distributions of dependent variables) are denoted by JD. The inputs to the algorithm become the SC, SK matrices and the set JD of constraints (joint distributions), mentioned above. The output is:

Below, we review the solution to the aforementioned problems using the EM algorithm. Following the approach described in Chapter 5, a latent variable zj denotes the estimated value of variable Cj, for each j (indicating whether it is true or not). Initially, p(zj = 1) is set to fj, which can be initialized to 0.5 in the absence of prior knowledge. This constitutes the latent vector Z above. X denotes the claim matrix SC, where Xj represents the jth column of the SC matrix (i.e., claims of the jth variable by all sources). The parameter vector to be estimated is θ = (a1,a2,…,aM;b1,b2,…,bM; f1,f2,…,fM). In the following sections, we review incorporation of the physical constraints into the new model.
9.2 Accounting for the Opportunity to Observe
In this section, we review the incorporation of the source constraints into the EM algorithm. We call this EM scheme, EM with opportunity to observe (OtO EM).
9.2.1 Deriving the Likelihood
When source constraints are considered in the likelihood function, it is assumed that sources only claim variables they observe, and hence the probability of a source claiming a variable he/she does not have an opportunity to observe is 0. For simplicity, it is assumed that all variables are independent, then this assumption is relaxed later in Section 9.3. Under these assumptions, the new likelihood function L(θ;X,Z) that incorporates the source constraints is given by:

where ![]() : Set of sources observed Cj
: Set of sources observed Cj
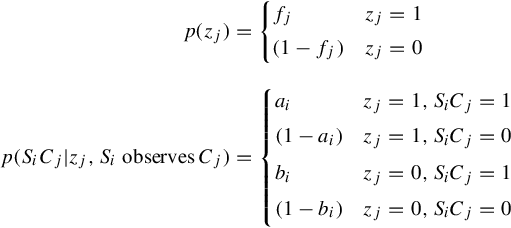
Note that, in the likelihood function, the probability contribution from sources who actually observe a variable (e.g., ![]() for Cj) is considered. This is an important change from the reviewed maximum likelihood estimation (MLE) model in Chapter 5. This change allows the new model to nicely incorporate the source constraints (name, source opportunity to observe) into the MLE framework.
for Cj) is considered. This is an important change from the reviewed maximum likelihood estimation (MLE) model in Chapter 5. This change allows the new model to nicely incorporate the source constraints (name, source opportunity to observe) into the MLE framework.
Using the above likelihood function, the corresponding E-step and M-step of OtO EM scheme can be derived. The detailed derivations are shown in Appendix of Chapter 9.
9.2.2 The OtO EM Algorithm
In summary, the inputs to the OtO EM algorithm are (i) the claim matrix SC from social sensing data and (ii) the knowledge matrix SK describing the source constraints. The output is the MLE of source reliability and the probability of claim correctness. Compared to the regular EM algorithm from Chapter 5, source constraints are provided as a new input into the framework and imposed them on the E-step and M-step. The algorithm begins by initializing the parameter θ with random values between 0 and 1. The algorithm then performs the new derived E-steps and M-steps iteratively until θ converges. Since each observed variable is binary, variables can be classified as either true or false based on the converged value of Z(t,j). Specifically, Cj is considered true if ![]() goes beyond some threshold (e.g., 0.5) and false otherwise. The estimated ti of each source can also be computed from the converged values of θ(t) (i.e.,
goes beyond some threshold (e.g., 0.5) and false otherwise. The estimated ti of each source can also be computed from the converged values of θ(t) (i.e., ![]() ,
, ![]() , and
, and ![]() ) based on Equation (9.3). Algorithm 5 provides the pseudocode of OtO EM.
) based on Equation (9.3). Algorithm 5 provides the pseudocode of OtO EM.
9.3 Accounting for Physical Dependencies
In this section, we review the incorporation of the constraints on observed variables (i.e., claims) into the EM algorithm. We refer to this EM scheme as EM with dependent variables (DV EM). For clarity, we first ignore the source constraints from the previous section (i.e., assume that each source observes all variables). Then, we consider the combination of the two extensions of the regular EM (i.e., OtO EM and DV EM) to obtain a comprehensive EM scheme (OtO+DV EM) that incorporates constraints on both sources and observed variables into the estimation framework.
9.3.1 Deriving the Likelihood
In order to derive a likelihood function that considers constraints in the form of dependencies between observed variables, N observed variables in the social sensing model are divided into G independent groups, where each independent group contains variables that are related by some local constraints (e.g., gas price of stations in the same neighborhood could be highly correlated). Consider group g, where there are k dependent variables g1,…,gk. Let ![]() represent the joint probability distribution of the k variables and let
represent the joint probability distribution of the k variables and let ![]() represent all possible combinations of values of g1,…,gk. For example, when there are only two variables,
represent all possible combinations of values of g1,…,gk. For example, when there are only two variables, ![]() . Note that, it is assumed that
. Note that, it is assumed that ![]() is known or can be estimated from prior knowledge. The new likelihood function L(θ;X,Z) that considers the aforementioned constraints is:
is known or can be estimated from prior knowledge. The new likelihood function L(θ;X,Z) that considers the aforementioned constraints is:

where αi,j is the same as defined in Equation (9.7) and cg represents the set of variables belonging to the independent group g. Compared to the regular EM from Chapter 5, the new likelihood function is formulated with independent groups as units (instead of single independent variables). The joint probability distribution of all dependent variables within a group is used to replace the distribution of a single variable. This likelihood function is therefore more general, but reduces to the previous form in the special case where each group is composed of only one variable.
Using the above likelihood function, the corresponding E-step and M-step of DV EM and OtO+DV EM schemes can be derived. The detailed derivations are shown in Appendix of Chapter 9.
9.3.2 The OtO+DV Algorithm
In summary, the OtO+DV EM scheme incorporates constraints on both sources and observed variables. The inputs to the algorithm are (i) the claim matrix SC, (ii) the knowledge matrix SK, and (iii) the joint distribution for each group of dependent variables, collectively represented by set JD. The output is the MLE of source reliability and claim correctness. The OtO+DV EM pseudocode is shown in Algorithm 6.
9.4 Real-World Case Studies
In this section, we evaluate the performance of the new reliable social sensing schemes that incorporate “opportunity to observe” constraints on sources (OtO EM) and dependency constraints on observed variables (DV EM), as well as the comprehensive scheme (OtO+DV EM) that combines both. Their performance is compared to the state of the art regular EM scheme (see Chapter 5) through a real world social sensing application. The purpose of the application is to map locations of traffic lights and stop signs on the campus of the University of Illinois (in the city of Urbana-Champaign).
The SmartRoad dataset [114] is reused, where vehicle-resident Android smartphones record their GPS location traces as the cars are driven around by participants. The GPS readings include samples of the instantaneous latitude-longitude location, speed and bearing of the vehicle, with a sampling rate of 1 s. The goal was to show that even very unreliable sensing of traffic lights and stop signs can result in a good final map once the fact-finding algorithms are applied to these claims to determine their odds of correctness. Hence, an intentionally simple-minded application scenario was designed to identify stop signs and traffic lights from GPS data.
Let us briefly review the experiment mentioned earlier: if a vehicle waits at a location for 15-90 s, the application concludes that it is stopped at a traffic light and issues a traffic-light claim (i.e., a claim that a traffic light is present at that location and bearing). Similarly if it waits for 2-10 s, it concludes that it is at a stop sign and issues a stop-sign claim (i.e., a claim that a stop sign is present at that location and bearing). If the vehicle stops for less than 2 s, for 10-15 s, or for more than 90 s, no claim is made. Claims were reported by each source to a central data collection point.
Clearly the claims defined above are very error-prone due to the simple-minded nature of the “sensor” and the complexity of road conditions and driver’s behaviors. Moreover, it is hard to quantify the reliability of sources without a training phase that compares measurements to ground truth. For example, a car can stop elsewhere on the road due to a traffic jam or crossing pedestrians, not necessarily at locations of traffic lights and stop signs. Also, a car does not stop at traffic lights that are green and a careless driver may pass stop signs without stopping. The question addressed in the evaluation is whether knowledge of constraints helps improve the accuracy of stop sign and traffic light estimation from such unreliable measurements in this case study.
Hence, different estimation approaches reviewed in this chapter were applied along with the constraints from the physical world on the noisy data to identify the correct locations of traffic lights and stop signs and compute the reliability of participants. One should note that location granularity here is of the order of half a city block. This ensures that stop sign and traffic light claims are attributed to the correct intersections. Most GPS devices easily attain such granularity. Therefore, the authors do not expect location errors to be of concern. For evaluation purposes, the ground truth locations of traffic lights and stop signs were manually collected.
In the experiment, 34 people (sources) were invited to participate and 1,048,572 GPS readings (around 300 h of driving) were collected. A total of 4865 claims were generated by the phones, of which 3303 were for stop signs and 1562 were for traffic lights, collectively identifying 369 distinct locations where claims were generated. The elements SiCj of the claim matrix were set according to the claims extracted from each source vehicle.
It is observed that traffic lights at an intersection are always present in all directions. Hence, when processing traffic light claims, vehicle bearing was ignored. However, stop signs at an intersection have a few possible scenarios. For example, (i) a stop sign may be present in each possible direction (e.g., All-Way stop); (ii) two stop signs may exist on one road whereas no stop sign exist on the other road (e.g., a main road intersecting with a small road); or (iii) two stop signs may exist for one road and one stop sign for the other road (e.g., a two-way road intersecting with a one way road). Hence, in claims regarding stop signs the bearing is important. Bearing was classified into four main directions. A different Boolean variable is created for each direction.
9.4.1 Opportunity to Observe
In this subsection, we first evaluate the performance of the OtO EM scheme. For the OtO EM scheme, the recorded GPS traces of each vehicle were used to determine whether it actually went to a specific location or not (i.e., decide whether a source has an opportunity to observe a given variable or not). There are 54 actual traffic lights and 190 stop signs covered by the data traces collected.
Figure 9.1 compares the source reliability estimated by both the OtO EM and regular EM schemes to the actual source reliability computed from ground truth. The source IDs are sorted by the ground truth reliability. We observed that the OtO EM scheme stays closer to the actual results for most of the sources (i.e., OtO EM estimation error is smaller than regular EM for about 74% of sources).

Next, we review the accuracy of identifying traffic lights by the new scheme. It may be tempting to confuse the problem with one of classification and plot ROC curves or confusion matrices. This would not be appropriate, however, because the output of the algorithm is not a classification label, but rather a probability that the labeled entity (e.g., a traffic light) exists at a given location. Some locations are associated with a higher probability than others. Hence, what is needed is an estimate of how well the computed probabilities match ground truth.
Accordingly, Figures 9.2 and 9.3 show the accuracy of identifying traffic lights by the OtO EM scheme (Figure 9.2) and the regular EM scheme (Figure 9.3). The horizontal axis shows location IDs where lights were indicated by the respective schemes, sorted by their probability (as computed from the corresponding EM variant) from high to low. Hence, one should expect that lower-numbered locations be true positives, whereas high-numbered locations may contain increasingly more false positives as the scheme assigns a lower probability that those contain traffic lights.




Figure 9.2(a) shows the actual status of each location. A green (light gray in print versions) bar is a true positive, whereas a red (dark gray in print versions) one is a false positive. As expected, we observe that most of the traffic light locations identified by the OtO EM scheme are true positives. False positives occur only later on at higher-numbered (i.e., lower probability) locations. Additionally, it is interesting to compare the probability of finding traffic lights at the indicated locations, as computed by the algorithms, to the probability computed empirically for the same locations by counting how many of them have actual lights. Figure 9.2(b) shows this comparison. Specifically, it compares the average probability to the empirical probability, computed for the first n locations to have traffic lights, where n is the location index on the horizontal axis. We observe that the estimation results of OtO EM follow quite well the empirical ones.
Similarly, results for the regular EM scheme are reported in Figure 9.3. We observe that the OtO EM scheme is able to find five more traffic light locations compared to the regular EM scheme. We also note that the red curve (dark gray in print versions) in Figure 9.2(b) is larger than that of Figure 9.3(b) for the same location ID, which indicates a better match of the estimated credibility of the claim. The detailed comparison results between two schemes are given in Table 9.1.
Table 9.1
Performance Comparison Between Regular EM Versus OtO EM in Case of Traffic Lights
| Regular EM | OtO EM | |
| Average source reliability estimation error | 10.19% | 7.74% |
| Number of correctly identified traffic lights | 31 | 36 |
| Number of mis-identified traffic lights | 2 | 3 |
The above experiments were repeated for stop sign identification, and it is observed that the OtO EM scheme achieves a more significant performance gain in both participant reliability estimation and stop sign classification accuracy compared to the regular EM scheme. The reason is: stop signs are scattered in town and the odds that a vehicle’s path covers most of the stop signs are usually small. Hence, having the knowledge of whether a source had an opportunity to observe a variable is very helpful. However, the identification of stop signs in general is found to be more challenging than that of traffic lights. There are several reasons for that. Namely, (i) the claims for stop signs are sparser because stops signs are typically located on smaller streets, so the chances of different cars visiting the same stop sign are lower than that for traffic lights, (ii) cars often stop briefly at non-stop sign locations, which the reviewed scheme mis-interpret for stop signs, and (iii) when cars want to make a turn after the stop sign, cars’ bearings are often not well aligned with the directions of stop signs, which causes errors since stop-sign claims are bearing-sensitive.
Figure 9.4 compares source reliability computed by the OtO EM and regular EM schemes. The actual reliability is computed from similar experiments as traffic lights. We observe that source reliability is better estimated by the OtO EM scheme compared to the regular EM scheme.

Figures 9.5 and 9.6 show the true positives and false positives in recognizing stop signs. We observe the OtO EM scheme actually finds twelve more correct stop sign locations and reduces one false positive location compared to the regular EM scheme. The detailed comparison results are given in Table 9.2. Additionally, we observe that, for both EM schemes, the actual probability of finding stop signs at the indicated locations stays close to but slightly less than the estimated probability by the reviewed algorithms. The reasons of such deviation can be explained by the aforementioned short wait behaviors at non-stop sign locations in real world scenarios.





9.4.2 Dependent Variables
In this subsection, we evaluate the extensions that consider dependency constraints (DV EM), and the comprehensive OtO+DV EM scheme. While the earlier discussion treated stop signs as independent variables, this is not strictly so. The existence of stop signs in different directions (bearings) is in fact quite correlated. The correlations for Urbana-Champaign were empirically computed and assumed to be known in advance. Clearly, the more “high-order” correlations are considered, the more information is given to improve performance of algorithm. To assess the effect of “minimal” information (which would be a “worst-case” improvement for the reviewed scheme), only pairwise correlations were used. Hence, the joint distribution of co-existence of (two) stop signs in opposite directions at an intersection was computed. It is presented in Table 9.3, and was used as input to the DV EM scheme.
Table 9.3
Distribution of Stop Signs in Opposite Directions
| A = stop sign 1 exists; B = stop sign 2 exists | Percentage |
| p(A,B) | 36% |
| p(not A, not B) | 49% |
| p(A,not B) = p(not A, B) | 7.5% |
Figure 9.7 shows the accuracy of source reliability estimation, when these constraints are used. We observe that both DV EM and DV+OtO EM scheme track the source reliability very well (the estimation error of the two EM schemes improved 9.4% and 13.4%, respectively, compared to the regular EM scheme).

The true positives and false positives for stop signs are shown in Figures 9.8 and 9.9. Observe that the DV EM scheme finds 14 more correct stop sign locations. The DV+OtO EM scheme performed the best, it finds the most stop sign locations (i.e., 19 more than regular EM, 5 more than DV EM) while keeping the false positives the least (i.e., the same as regular EM and 4 less than DV EM). The detailed comparison results are given in Table 9.2.




Additionally, we observe that, for the DV+OtO EM scheme, the estimated probability of finding stop signs is much closer to the empirically computed probability, compared to other EM schemes we discussed. Also, the red curve (dark gray in print versions) is higher for the DV+OtO EM than the DV EM. This is because the new model explicitly considered both dependency constraints and the “opportunity to observe” for sources in the DV+OtO EM scheme.
9.5 Discussion
This chapter reviewed a generalization of the MLE framework for exploiting the physical world constraints (i.e., source locations and observed variable dependencies) to improve the reliability of social sensing. Some limitations exist that offer directions that deserve further discussions.
First, the framework did not explicitly model the time dimension of the problem. This is mainly because their current application involves the detection of fixed infrastructure (e.g., stop signs and traffic lights). Time is less relevant in such context. Hence, opportunity to observe is only a function of source location, and observed variable dependencies are not likely to change over time. It would be interesting to consider time constraints in future models. In systems where the state of the environment may change over time, when we consider the opportunity to observe, it is not enough for the source to have visited a location of interest. It is also important that the source visits that location within a certain time bound during which the state of the environment has not changed. Similarly, when we consider observed variable dependencies, it is crucial that dependencies of observed variables remain stable within a given time interval and that we have an efficient way to quickly update the estimation on such dependencies as time proceeds.
Second, it is assumed that sources will only report claims for the places they have been to (e.g., cars only generate stop sign claims on the streets their GPS traces covered). Hence, it makes sense to “penalize” sources for not making claims for some clearly observable variables based on their locations. However, many other factors might also influence the opportunity of users to generate claims in real-world social sensing applications. Some of these factors are out of user’s control. For example, in some geo-tagging applications, participants use their phones to take photos of locations of interest. However, this approach might not work at some places due to “photo prohibited” signs or privacy concerns. Source reliability penalization based on visited locations might not be appropriate in such context. It is interesting to extend the notion of location-based opportunity-to-observe in the model to consider different types of source constrains in other social sensing applications.
Third, “Byzantine” sources are not assumed in the reviewed model (e.g., cars will not cheat in reporting the their GPS coordinates). However, in some crowd-sensing applications, sources can intentionally report incorrect locations (e.g., Google’ Ingress). Different techniques have been developed to detect and address location cheating attacks on both mobile sensing applications [130] and social gaming systems [131]. These techniques can be used along with the reviewed schemes to solve the truth estimation problem in social sensing applications where source’s reliability is closely related to their locations. Moreover, it is also interesting to further investigate the robustness of the scheme with respect to the percentage of cheating sources in the system.
Last, the joint probability distribution of dependent variables and knowledge about the opportunity to observe is assumed to be known or can be estimated from prior knowledge. This might not be possible for all social sensing applications. Clearly, the approach in the current paper would not apply if nothing was known about spatial correlations in environmental state. Additionally, the scale of reviewed experiment is relatively small. Recent work has developed a generative model to estimate the opportunity to observe in truth finding for spatial events [132]. More work is necessary to determine when and when not structure learning is possible within fact-finding methods for adaptive DV and OtO methods.
Appendix
Derivation of the E-Step and M-Step of OtO EM
After the formulation of the new likelihood function to account for the source constraints, the likelihood function can be plugged into the Q function defined in Equation (5.8) of EM. The E-step can be derived as follows:

where p(zj = 1|Xj,θ(t)) represents the conditional probability of the variable Cj to be true given the claim matrix related to the jth claim and current estimate of θ. p(zj = 1|Xj,θ(t)) is represented by Z(t,j) since it is only a function of t and j. Z(t,j) can be further computed as:
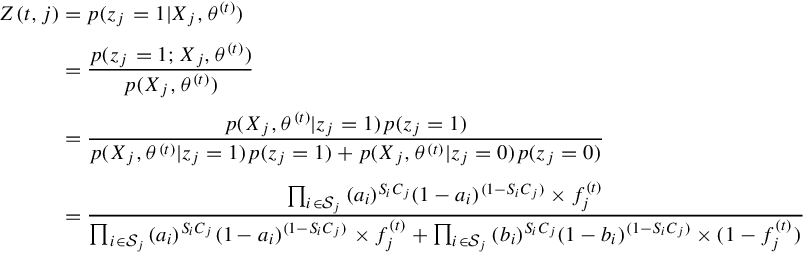
Note that, in the E-step, only sources who observe a given variable are considered while computing the likelihood of reports regarding that variable.
In the M-step, the derivatives are set to 0: ![]() ,
, ![]() , and
, and ![]() . This gives us the θ* (i.e.,
. This gives us the θ* (i.e., ![]() ;
;![]() ;
;![]() ) that maximizes the Q(θ|θ(t)) function in each iteration and is used as the θ(t+1) of the next iteration.
) that maximizes the Q(θ|θ(t)) function in each iteration and is used as the θ(t+1) of the next iteration.

where ![]() is set of variables source Si observes according to the knowledge matrix SK and Z(t,j) is defined in Equation (9.10). SJi is the set of variables the source Si actually claims in the claim matrix SC. We note that, in the computation of ai and bi, the silence of source Si regarding some variable Cj is interpreted differently depending on whether Siobserved it or not. This reflects that the opportunity to observe has been incorporated into the M-step when the estimation parameters of sources are computed. The resulting OtO EM algorithm is summarized in the subsection below.
is set of variables source Si observes according to the knowledge matrix SK and Z(t,j) is defined in Equation (9.10). SJi is the set of variables the source Si actually claims in the claim matrix SC. We note that, in the computation of ai and bi, the silence of source Si regarding some variable Cj is interpreted differently depending on whether Siobserved it or not. This reflects that the opportunity to observe has been incorporated into the M-step when the estimation parameters of sources are computed. The resulting OtO EM algorithm is summarized in the subsection below.
Derivation of E-Step and M-Step of DV and OtO+DV EM
Given the new likelihood function of the DV EM scheme defined in Equation (9.8), the E-step becomes:

where ![]() represents the conditional joint probability of all variables in independent group g (i.e., g1,…,gk) given the observed data regarding these variables and the current estimation of the parameters.
represents the conditional joint probability of all variables in independent group g (i.e., g1,…,gk) given the observed data regarding these variables and the current estimation of the parameters. ![]() can be further computed as follows:
can be further computed as follows:

We note that p(zj = 1|Xj,θ(t)) (i.e., Z(t,j)), defined as the probability that Cj is true given the observed data and the current estimation parameters, can be computed as the marginal distribution of the joint probability of all variables in the independent claim group g that variable Cj belongs to (i.e., ![]() ). We also note that, for the worst case where N variables fall into one independent group, the computational load to compute this marginal grows exponentially with respect to N. However, as long as the constraints on observed variables are localized, the reviewed approach stays scalable, independently of the total number of estimated variables.
). We also note that, for the worst case where N variables fall into one independent group, the computational load to compute this marginal grows exponentially with respect to N. However, as long as the constraints on observed variables are localized, the reviewed approach stays scalable, independently of the total number of estimated variables.
In the M-step, as before, θ* is chosen to maximize the Q(θ|θ(t)) function in each iteration to be the θ(t+1) of the next iteration. Hence:

where Z(t,j) = p(zj = 1|Xj,θ(t)). We note that for the estimation parameters, ai and bi, the same expression as for the case of independent variables is obtained. The reason is that sources report variables independently of the form of constraints between these variables.
Next, the two EM extensions (i.e., OtO EM and DV EM) derived so far are combined to obtain a comprehensive EM scheme (OtO+DV EM) that considers constraints on both sources and observed variables. The corresponding E-step and M-step are shown below:

where ![]() : Set of sources observes Cj
: Set of sources observes Cj

where ![]() is set of variables source Si observes.
is set of variables source Si observes.