
Social Sensing
A maximum likelihood estimation approach
Abstract
Considering the heuristic nature of fact-finding techniques, the quantified source truthfulness and claim correctness from Bayesian interpretation presented in the previous chapter remains to be a linear approximation. Moreover, results of Bayesian interpretation are shown to be sensitive to the priors given to the algorithm. To overcome these limitations, this chapter reviews the first optimal solution to the reliable social sensing problem we introduced in Chapter 1. Optimality, in the sense of maximum likelihood estimation (MLE), is attained through an expectation maximization approach that returns the best guess regarding the source reliability as well as the correctness of each claim. The algorithm jointly makes inferences regarding both source reliability and claim correctness by observing how sources corroborate the claims. The approach is shown to outperform the state-of-the-art fact-finding heuristics, as well as simple baselines such as majority voting under certain conditions.
5.1 The Social Sensing Problem
To formulate the reliable social sensing problem in a manner amenable to rigorous optimization, a social sensing application model was proposed by Wang et al. where a group of M sources, S1,…,SM, make individual observations about a set of N claims C1,…,CN in their environment [100]. For example, a group of individuals interested in the appearance of their neighborhood might join a sensing campaign to report all locations of offensive graffiti. Alternatively, a group of drivers might join a campaign to report freeway locations in need of repair. Hence, each claim denotes the existence or lack thereof of an offending condition at a given location.* In this effort, only binary variables are considered, and it is assumed, without loss of generality, that their “normal” state is negative (e.g., no offending graffiti on walls, or no potholes on streets). Hence, sources report only when a positive value is encountered.
Each source generally observes only a subset of all variables (e.g., the conditions at locations they have been to). The goal here is to determine which observations are correct and which are not. As mentioned in the introduction, this work differs from a large volume of previous sensing literature in that no prior knowledge is assumed about source reliability and no prior knowledge is assumed for the correctness of individual observations. Also note that the reviewed work in this chapter assumes imperfect reliability of sources and claims made by sources are mostly true, which is reasonable in a large category of social sensing applications. However, if those assumptions do not hold, the algorithm reviewed later in the chapter could converge to other stationary solutions (e.g., all sources are perfectly reliable or unreliable).
Besides the notations defined in the previous chapter, let us introduce a few new notations that will be used in this chapter. Let the probability that source Si makes an observation be si. Further, let the probability that source Si is right be ti and the probability that it is wrong be 1 − ti. Note that, this probability depends on the source’s reliability, which is not known a priori. Formally, ti is defined as the odds of a claim to be true given that source Si reports it:
Let ai represent the (unknown) probability that source Si reports a claim to be true when it is indeed true, and bi represent the (unknown) probability that source Si reports a claim to be true when it is in reality false. Formally, ai and bi are defined as follows:

From the definition of ti, ai, and bi, their relationship can be determined by using the Bayesian theorem:

The only input to the algorithm is the social sensing topology represented by a matrix SC, where SiCj = 1 when source Si reports that Cj is true, and SiCj = 0 otherwise. Let us call it the observation matrix.
The goal of the algorithm is to compute (i) the best estimate hj on the correctness of each claim Cj and (ii) the best estimate ei of the reliability of each source Si. The sets of the estimates are denoted by vectors H and E, respectively. The goal is to find the H* and E* vectors that are most consistent with the observation matrix SC. Formally, this is given by:
The background bias d will also be computed, which is the overall probability that a randomly chosen claim is true. For example, it may represent the probability that any street, in general, is in disrepair. It does not indicate, however, whether any particular claim about disrepair at a particular location is true or not. Hence, one can define the prior of a claim being true as ![]() . Note also that, the probability that a source makes an observation (i.e., si) is proportional to the number of claims observed by the source over the total number of claims observed by all sources, which can be easily computed from the observation matrix. Hence, one can define the prior P(SiCj) = si. Plugging these, together with ti into the definition of ai and bi, we get:
. Note also that, the probability that a source makes an observation (i.e., si) is proportional to the number of claims observed by the source over the total number of claims observed by all sources, which can be easily computed from the observation matrix. Hence, one can define the prior P(SiCj) = si. Plugging these, together with ti into the definition of ai and bi, we get:
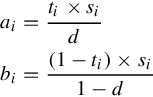
So that
5.2 Expectation Maximization
In this section, we review the solution to the problem formulated in the previous section using the expectation maximization (EM) algorithm. As we discussed in Chapter 3, EM is a general algorithm for finding the maximum likelihood estimates (MLEs) of parameters in a statistic model, where the data are “incomplete” or the likelihood function involves latent variables [93]. In the following, we first briefly review the basic ideas and steps of EM that will be used in this chapter.
5.2.1 Background
The EM algorithm is useful when the likelihood expression simplifies by the inclusion of a latent variable. Considering a latent variable Z, the likelihood function is given by:
where p(X,Z|θ) is L(θ|X,Z), which is uni-modal and easy to solve.
Once the formulation is complete, the EM algorithm finds the MLE by iteratively performing the following steps:
• E-step: Compute the expected log likelihood function where the expectation is taken with respect to the computed conditional distribution of the latent variables given the current settings and observed data.
• M-step: Find the parameters that maximize the Q function in the E-step to be used as the estimate of θ for the next iteration.
5.2.2 Mathematical Formulation
The social sensing problem fits nicely into the EM model. First, a latent variable Z is introduced for each claim to indicate whether it is true or not. Specifically, a corresponding variable zj is defined for the jth claim Cj such that: zj = 1 when Cj is true and zj = 0 otherwise. The observation matrix SC is denoted as the observed data X, and θ = (a1,a2,…,aM;b1,b2,…,bM;d) is defined as the parameter of the model that needs to be estimated. The goal is to obtain the MLE of θ for the model containing observed data X and latent variables Z.
The likelihood function L(θ;X,Z) is given by:
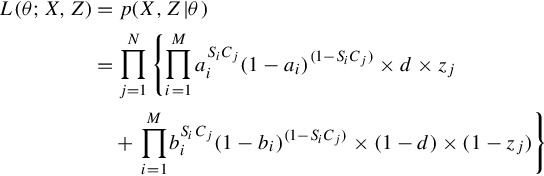
where, as we mentioned before, ai and bi are the conditional probabilities that source Si reports the claim Cj to be true given that Cj is true or false (i.e., defined in Equation (5.2)). SiCj = 1 when source Si reports that Cj is true, and SiCj = 0 otherwise. d is the background bias that a randomly chosen claim is true. Additionally, it is assumed that sources and claims are independent respectively. The likelihood function above describes the likelihood to have current observation matrix X and hidden variable Z given the estimation parameter θ.
5.2.3 Deriving the E-Step and M-Step
Given the above formulation, substitute the likelihood function defined in Equation (5.10) into the definition of Q function given by Equation (5.8) of EM. The Expectation step (E-step) becomes:

where Xj represents the jth column of the observed SC matrix (i.e., observations of the jth claim from all sources) and p(zj = 1|Xj,θ(t)) is the conditional probability of the latent variable zj to be true given the observation matrix related to the jth claim and current estimate of θ, which is given by:

where A(t,j) and B(t,j) are defined as:

A(t,j) and B(t,j) represent the conditional probability regarding observations about the jth claim and current estimation of the parameter θ given the jth claim is true or false, respectively.
Next Equation (5.11) is simplified by noting that the conditional probability of p(zj = 1|Xj,θ(t)) given by Equation (5.12) is only a function of t and j. Thus, it is represented by Z(t,j). Similarly, p(zj = 0|Xj,θ(t)) is simply:

Substituting from Equations (5.12) and 5.14 into Equation (5.11), we get:

The Maximization step (M-step) is given by Equation (5.9). θ* (i.e., ![]() ) is chosen to maximize the Q(θ|θ(t)) function in each iteration to be the θ(t+1) of the next iteration.
) is chosen to maximize the Q(θ|θ(t)) function in each iteration to be the θ(t+1) of the next iteration.
To get θ* that maximizes Q(θ|θ(t)), the derivatives are set to 0: ![]() ,
, ![]() ,
, ![]() which yields:
which yields:

Let us define SJi as the set of claims the source Si actually observes in the observation matrix SC, and ![]() as the set of claims source Si does not observe. Thus, Equation (5.16) can be rewritten as:
as the set of claims source Si does not observe. Thus, Equation (5.16) can be rewritten as:

Solving the above equations, the expressions of the optimal ![]() ,
, ![]() , and d* are:
, and d* are:

where Ki is the number of claims espoused by source Si and N is the total number of claims in the observation matrix.
Given the above, the E-step and M-step of EM optimization reduce to simply calculating Equations (5.12) and 5.18 iteratively until they converge. The convergence analysis has been done for EM scheme and it is beyond the scope of this chapter [108]. In practice, the algorithm runs until the difference of estimation parameter between consecutive iterations becomes insignificant. Since the claim is binary, the decision vector H* can be computed from the converged value of Z(t,j). Specially, hj is true if Z(t,j) ≥ 0.5 and false otherwise. At the same time, the estimation vector E* of source reliability can also be computed from the converged values of ![]() ,
, ![]() , and d(t) based on their relationship given by Equation (5.5). This completes the mathematical development. The resulting algorithm is summarized in the subsection below.
, and d(t) based on their relationship given by Equation (5.5). This completes the mathematical development. The resulting algorithm is summarized in the subsection below.
5.3 The EM Fact-Finding Algorithm
In summary of the EM scheme derived above, the input is the observation matrix SC from social sensing data, and the output is the MLE of source reliability and claim correctness (i.e., E* and H* vector defined in Equation (5.4)). In particular, given the observation matrix SC, the algorithm begins by initializing the parameter θ with random values between 0 and 1.† The algorithm then performs the E-steps and M-steps iteratively until θ converges. Specifically, the conditional probability of a claim to be true (i.e., Z(t,j)) is computed from Equation (5.12) and the estimation parameter (i.e., θ(t+1)) is computed from Equation (5.18). After the estimated value of θ converges, the decision vector H* (i.e., decide whether each claim Cj is true or not) is computed based on the converged value of Z(t,j) (i.e., ![]() ). The estimation vector E* (i.e., the estimated ti of each source) is computed from the converged values of θ(t) (i.e.,
). The estimation vector E* (i.e., the estimated ti of each source) is computed from the converged values of θ(t) (i.e., ![]() ,
, ![]() , and dc) based on Equation (5.5) as shown in the pseudocode of Algorithm 1.
, and dc) based on Equation (5.5) as shown in the pseudocode of Algorithm 1.
One should note that a theoretical quantification of accuracy of MLE is well-known in the literature, and can be done using the Cramer-Rao lower bound (CRLB) on estimator variance [109]. The estimator reviewed in this chapter is shown to asymptotically approach CRLB when the number of observations becomes infinite [102]. This observation makes it possible to quantify estimation accuracy, or confidence in results generated from EM scheme, using the CRLB.
We now present a toy example to help readers better understand the EM algorithm reviewed in this section. In this toy example, 10 sources generate observations about 20 claims. The first 10 claims (i.e., Claim ID: 1-10) are true and the remaining are false. The sources include both reliable and unreliable ones, whose reliability is shown in Table 5.1. The bipartite graph of the corresponding observation matrix SC representing “who said what” is shown in Figure 5.1, where a link between a source and a claim represents that the source reports the claim to be true. The results of using Voting and EM to classify the true claims from false ones in the toy example are shown in Table 5.2. For Voting, it is assumed that we have the prior knowledge on d (i.e., we know d = 0.5). Hence, voting takes the top half of the claims that receives the most number of “votes” as true and the remaining ones as false. For EM, ai is initialized to si and bi is initialized to 0.5 × si based on the assumption that most of sources are reliable. We showed the probability of each claim to be true (i.e., Z(t,j)) computed in every iteration of the algorithm until the estimation converges. We observe that EM correctly classifies all true and false claims while voting only correctly classifies half of the claims and mis-classifies the other half. The mis-classified claims of Voting are highlighted in the table. The reason is that EM jointly estimates both source reliability and claim correctness under the MLE framework while Voting simply counts the “votes” from every source equally without considering the difference in their reliability.
Table 5.1
The Source Reliability of the Toy Example
| Source ID | ||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Source reliability | 1 | 0.2 | 0.9 | 0.1 | 0.4 | 0.1 | 0.1 | 0.9 | 1 | 0.2 |


Table 5.2
The Comparison Between Voting and EM in the Toy Example
| Claim ID | Voting Count | EM | Voting Results | EM Results | Ground Truth | ||||||
| t = 1 | t = 2 | t = 3 | t = 4 | t = 5 | t = 6 | t = 7 | |||||
| 1 | 5 | 0.5 | 0.5934 | 0.8754 | 1 | 1 | 1 | 1 | TRUE | TRUE | TRUE |
| 2 | 3 | 0.5784 | 0.6233 | 0.8793 | 1 | 1 | 1 | 1 | FALSE | TRUE | TRUE |
| 3 | 4 | 0.5394 | 0.5857 | 0.8504 | 0.9999 | 1 | 1 | 1 | FALSE | TRUE | TRUE |
| 4 | 5 | 0.5 | 0.5706 | 0.8905 | 1 | 1 | 1 | 1 | TRUE | TRUE | TRUE |
| 5 | 7 | 0.4216 | 0.4535 | 0.7053 | 0.9991 | 1 | 1 | 1 | TRUE | TRUE | TRUE |
| 6 | 5 | 0.5 | 0.5706 | 0.8905 | 1 | 1 | 1 | 1 | TRUE | TRUE | TRUE |
| 7 | 4 | 0.5394 | 0.6087 | 0.9134 | 1 | 1 | 1 | 1 | FALSE | TRUE | TRUE |
| 8 | 4 | 0.5394 | 0.6087 | 0.9134 | 1 | 1 | 1 | 1 | FALSE | TRUE | TRUE |
| 9 | 4 | 0.5394 | 0.6087 | 0.9134 | 1 | 1 | 1 | 1 | FALSE | TRUE | TRUE |
| 10 | 8 | 0.3837 | 0.4306 | 0.5234 | 0.8774 | 0.9996 | 1 | 1 | TRUE | TRUE | TRUE |
| 11 | 7 | 0.4216 | 0.3767 | 0.1194 | 0 | 0 | 0 | 0 | TRUE | FALSE | FALSE |
| 12 | 5 | 0.5 | 0.4524 | 0.1499 | 0 | 0 | 0 | 0 | TRUE | FALSE | FALSE |
| 13 | 4 | 0.5394 | 0.4452 | 0.156 | 0.0001 | 0 | 0 | 0 | FALSE | FALSE | FALSE |
| 14 | 5 | 0.5 | 0.4215 | 0.1375 | 0.0001 | 0 | 0 | 0 | TRUE | FALSE | FALSE |
| 15 | 3 | 0.5784 | 0.5465 | 0.2947 | 0.0007 | 0 | 0 | 0 | FALSE | FALSE | FALSE |
| 16 | 5 | 0.5 | 0.4215 | 0.1375 | 0.0001 | 0 | 0 | 0 | FALSE | FALSE | FALSE |
| 17 | 6 | 0.4606 | 0.3913 | 0.0866 | 0 | 0 | 0 | 0 | TRUE | FALSE | FALSE |
| 18 | 5 | 0.5 | 0.4295 | 0.1095 | 0 | 0 | 0 | 0 | FALSE | FALSE | FALSE |
| 19 | 5 | 0.5 | 0.4295 | 0.1095 | 0 | 0 | 0 | 0 | FALSE | FALSE | FALSE |
| 20 | 6 | 0.4606 | 0.4294 | 0.2003 | 0.0004 | 0 | 0 | 0 | TRUE | FALSE | FALSE |

5.4 Examples and Results
In this section, we review the experiments to evaluate the performance of the proposed EM scheme in terms of estimation accuracy of the probability that a source is right or a claim is true compared to other state-of-art solutions. The experiments begin by studying the algorithm performance for different abstract observation matrices (SC), then apply it to both an emulated participatory sensing scenario and a real world social sensing application. It is shown that the new algorithm outperforms the state of the art.
5.4.1 A Simulation Study
The simulator as described in the previous chapter was used in the simulation study. Remember that, as stated in the application model, sources do not report “lack of problems.” Hence, they never report a variable to be false. Let ti be uniformly distributed between 0.5 and 1 in the experiments. For initialization, the initial values of source reliability (i.e., ti) in the evaluated schemes are set to the mean value of its definition range. The performance of EM scheme is compared to Bayesian interpretation [39] and three state-of-art fact-finder schemes from prior literature that can function using only the inputs offered in the reliable social sensing problem formulation [35–37]. Results show a significant performance improvement of EM over all heuristics compared.
The first experiment compares the estimation accuracy of EM and the baseline schemes by varying the number of sources in the system. The number of reported claims was fixed at 2000, of which 1000 variables were reported correctly and 1000 were misreported. To favor the competition, the other baseline algorithms were given the correct value of bias d (in this case, d = 0.5). The average number of observations per source was set to 100. The number of sources was varied from 20 to 110. Reported results are averaged over 100 random source reliability distributions. Results are shown in Figure 5.2. Observe that EM has the smallest estimation error on source reliability and the least false positives among all schemes under comparison. For false negatives, EM performs similarly to other schemes when the number of sources is small and starts to gain improvements when the number of sources becomes large. This is because sources are assumed to espouse more true claims than false ones and more sources will provide better evidence for the algorithm to correctly classify claims. Note also that the performance gain of EM becomes large when the number of sources is small, illustrating that EM is more useful when the observation matrix is sparse.



The second experiment compares EM with baseline schemes when the average number of observations per source changes. As before, the number of correctly and incorrectly reported variables was fixed to 1000 respectively. Again, the competition favored by giving the baseline algorithms the correct value of background bias d (here, d = 0.5). The number of sources was set to 30. The average number of observations per source is varied from 100 to 1000. Results are averaged over 100 experiments. The results are shown in Figure 5.3. Observe that EM outperforms all baselines in terms of both source reliability estimation accuracy and false positives as the average number of observations per source changes. For false negatives, EM has similar performance as other baselines when the average number of observations per source is small and starts to gain advantage as the average number of observations per source becomes large. This is because most observations are assumed to be true and more observations will provide better evidence for the algorithm to correctly classify claims. As before, the performance gain of EM is higher when the average number of observations per source is low, verifying once more the high accuracy of EM for sparser observation matrices.



The third experiment examines the effect of changing the claim mix on the estimation accuracy of all schemes. The ratio of the number of correctly reported variables to the total number of reported variables was varied from 0.1 to 0.6, while fixing the total number of such variables to 2000. To favor the competition, the background bias d is given correctly to the other algorithms (i.e., d = varying ratio). The number of sources is fixed at 30 and the average number of observations per source is set to 150. Results are averaged over 100 experiments. These results are shown in Figure 5.4. We observe that EM has almost the same performance as other fact-finder baselines when the fraction of correctly reported variables is relatively small. The reason is that the small amount of true claims are densely observed and most of them can be easily differentiated from the false ones by both EM and baseline fact-finders. However, as the number of variables (correctly) reported as true grows, EM is shown to have a better performance in both source reliability and claim estimation. Additionally, we also observe that the Bayesian interpretation scheme predicts less accurately than other heuristics under some conditions. This is because the estimated posterior probability of a source to be reliable or a claim to be true in Bayesian interpretation is a linear transform of source and claim credibility values. Those values obtained from a single or sparse observation matrix may not be very accurate and must be refined [39].



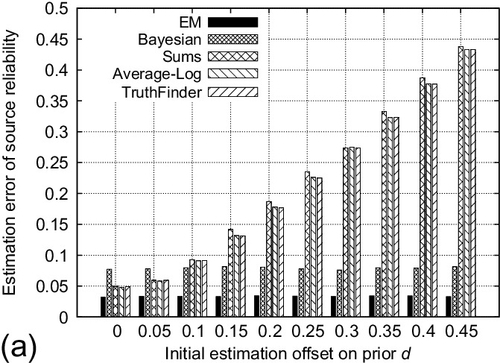
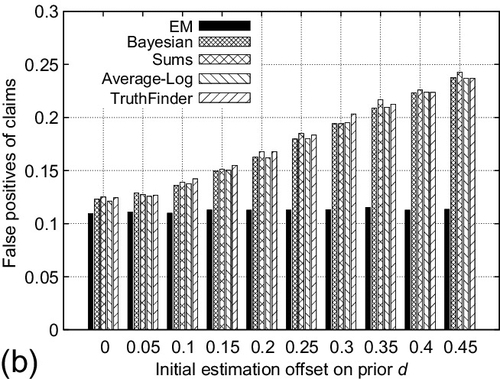
The fourth experiment evaluates the performance of EM and other schemes when the offset of the initial estimation on the background bias d varies. The offset is defined as the difference between initial estimation on d and its ground-truth. The number of correctly and incorrectly reported variables was set to 1000 respectively (i.e., d = 0.5). The absolute value of the initial estimate offset on d was varied from 0 to 0.45. The reported results are averaged for both positive and negative offsets of the same absolute value. The number of sources is fixed at 50 and the average number of observations per source is set to 150. Reported results are averaged over 100 experiments. Figure 5.5 shows the results. We observe that the performance of EM scheme is stable as the offset of initial estimate on d increases. On the contrary, the performance of other baselines degrades significantly when the initial estimate offset on d becomes large. This is because the EM scheme incorporates the d as part of its estimation parameter and provides the MLE on it. However, other baselines depend largely on the correct initial estimation on d (e.g., from the past history) to find out the right number of correctly reported claims. These results verify the robustness of the EM scheme when the accurate estimate on the prior d is not available to obtain.

The fifth experiment shows the convergence property of the EM iterative algorithm in terms of the estimation error on source reliability, as well as the false positives and false negatives on claims. The number of correctly and incorrectly reported variables was fixed to 1000 respectively and the initial estimate offset on d was set to 0.3. The number of sources is fixed at 50 and the average number of observations per source is set to 250. Reported results are averaged over 100 experiments. Figure 5.6 shows the results. We observe that both the estimation error on source reliability and false positives/negatives on claim converge reasonably fast (e.g., less than 10 iterations) to stable values as the number of iterations of EM algorithm increases. It verifies the efficiency of applying EM scheme to solve the MLE problem formulated. Note that the false negatives increase as the number of iteration increases. This is because the initial d was set to 0.8 which is larger than its true value (i.e., 0.5). Hence, the initial estimate of false negatives by the algorithm is smaller than its converged value (e.g., the algorithm could initially take true claims that very few sources reported as true and later classify them as false).



5.4.2 A Geotagging Case Study
In this subsection, we reviewed the application the EM scheme to a typical social sensing application: Geotagging locations of litter in a park or hiking area. In this application, litter may be found along the trails (usually proportionally to their popularity). Sources visiting the park geotag and report locations of litter. Their reports are not reliable however, erring both by missing some locations, as well as misrepresenting other objects as litter. The goal of the application is to find where litter is actually located in the park, while disregarding all false reports.
To evaluate the performance of different schemes, two metrics of interest were defined: (i) false negatives defined as the ratio of litter locations missed by a scheme to the total number of litter locations in the park, and (ii) false positives defined as the ratio of the number of incorrectly labeled locations by a scheme, to the total number of locations in the park. The EM scheme was compared to the Bayesian interpretation scheme and to voting, where locations are simply ranked by the number of times people report them.
A simplified trail map of a park represented by a binary tree was created and shown in Figure 5.7. The entrance of the park (e.g., where parking areas are usually located) is the root of the tree. Internal nodes of the tree represent forking of different trails. It is assumed trails are quantized into discretely labeled locations (e.g., numbered distance markers). In the emulation, at each forking location along the trails, sources have a certain probability Pc to continue walking and 1 − Pc to stop and return. Sources who decide to continue have equal probability to select the left or right path. The majority of sources are assumed to be reliable (i.e., when they geotag and report litter at a location, it is more likely than not that the litter exists at that location).

The first experiment studied the effect of the number of people visiting the park on the estimation accuracy of different schemes. A binary tree with a depth of 4 was chosen as the trail map of the park. Each segment of the trail (between two forking points) is quantized into 100 potential locations (leading to 1500 discrete locations in total on all trails). We define the pollution ratio of the park to be the ratio of the number of littered locations to the total number of locations in the park. The pollution ratio is fixed at 0.1 for the first experiment. The probability that people continue to walk past a fork in the path is set to be 95% and the percent of reliable sources is set to be 80%. The reliability of unreliable sources is uniformly distributed over (0,0.5). Reliable sources will report all pollution that they see. The number of sources visiting the park was varied from 5 to 50. The corresponding estimation results of different schemes are shown in Figure 5.8. Observe that both false negatives and false positives decrease as the number of sources increases for all schemes. This is intuitive: the chances of finding litter on different trails increase as the number of people visiting the park increases. Note that, the EM scheme outperforms others in terms of false negatives, which means EM can find more pieces of litter than other schemes under the same conditions. The improvement becomes significant (i.e., around 20%) when there is a sufficient number of people visiting the park. For the false positives, EM performs similarly to Bayesian interpretation and Truth Finder scheme and better than voting. Generally, voting performs the worst in accuracy because it simply counts the number of reports complaining about each location but ignores the reliability of individuals who make them.


The second experiment showed the effect of park pollution ratio (i.e., how littered the park is) on the estimation accuracy of different schemes. The number of individuals visiting the park is set to be 40. The pollution ratio of the park was varied from 0.05 to 0.15. The estimation results of different schemes are shown in Figure 5.9. Observe that both the false negatives and false positives of all schemes increase as the pollution ratio increases. The reason is that: litter is more frequently found and reported at trails that are near the entrance point. The amount of unreported litter at trails that are far from entrance increases more rapidly compared to the total amount of litter as the pollution ratio increases. Note that, the EM scheme continues to find more actual litter compared to other baselines. The performance of false positives is similar to other schemes.


The third experiment evaluated the effect of the initial estimation offset of the pollution ratio on the performance of different schemes. The pollution ratio is fixed at 0.1 and the number of individuals visiting the park is set to be 40. The absolute value of initial estimation offset of the pollution ratio was varied from 0 to 0.09. Results are averaged over both positive and negative offsets of the same absolute value. The estimation results of different schemes are shown in Figure 5.10. Observe that EM finds more actual litter locations and reports less falsely labeled locations than other baselines as the initial estimation offset of pollution ratio increases. Additionally, the performance of EM scheme is stable while the performance of other baselines drops substantially when the initial estimation offset of the pollution ratio becomes large.


The above evaluation demonstrates that the new EM scheme generally outperforms the current state of the art in inferring facts from social sensing data. This is because the state of the art heuristics infer the reliability of sources and correctness of facts based on the hypothesis that their relationship can be approximated linearly [36, 37, 39]. However, EM scheme makes its inference based on a maximum likelihood hypothesis that is most consistent with the observed sensing data, thus it provides an optimal solution.
5.4.3 A Real World Application
In this subsection, we reviewed the evaluation of the performance of the EM scheme through a real-world social sensing application, based on Twitter. The objective was to see whether the EM scheme would distill from Twitter feeds important events that may be newsworthy and reported by media. Specifically, the news coverage of Hurricane Irene was followed and 10 important events reported by media during that time were manually selected as ground truth. Independently from that collection, more than 600,000 tweets originating from New York City during Hurricane Irene were obtained using the Twitter API (by specifying keywords as “hurricane,” “Irene,” and “flood”, and the location to be New York). These tweets were collected from August 26 until September 2nd, roughly when Irene struck the east coast. Retweets were removed from the collected data to keep sources as independent as possible.
An observation matrix was generated from these tweets by clustering them based on the Jaccard distance metric (a simple but commonly used distance metric for micro-blog data [110]). Each cluster was taken as a statement of claim about current conditions, hence representing a claim in the MLE model. Sources contributing to the cluster were connected to that variable forming the observation matrix. In the formed observation matrix, sources are the twitter users who provided tweets during the observation period, claims are represented by the clusters of tweets and the element SiCj is set to 1 if the tweets of source Si belong to cluster Cj, or to 0 otherwise. The matrix was then fed to the EM scheme. The scheme ran on the collected data and picked the top (i.e., most credible) tweet in each hour. It was then checked if 10 “ground truth” events were reported among the top tweets. Table 5.3 compares the ground truth events to the corresponding top hourly tweets discovered by EM. The results show that indeed all events were reported correctly, demonstrating the value of EM scheme in distilling key information from large volumes of noisy data. Voting was observed to have similarly good performance in this case study. However, in other case studies, the EM scheme was shown to have a better coverage of events than the voting scheme [50].
Table 5.3
Ground Truth Events and Related Tweets Found by EM in Hurricane Irene
| # | Media | Tweet Found by EM |
| 1 | East Coast Braces For Hurricane Irene; Hurricane Irene is expected to follow a path up the East Coast | @JoshOchs A #hurricane here on the east coast |
| 2 | Hurricane Irene’s effects begin being felt in NC, The storm, now a Category 2, still has the East Coast on edge. | Winds, rain pound North Carolina as Hurricane Irene closes in http://t.co/0gVOSZk |
| 3 | Hurricane Irene charged up the U.S. East Coast on Saturday toward New York, shutting down the city, and millions of Americans sought shelter from the huge storm. | Hurricane Irene rages up U.S. east coast http://t.co/u0XiXow |
| 4 | The Wall Street Journal has created a way for New Yorkers to interact with the location-based social media app Foursquare to find the nearest NYC hurricane evacuation center. | Mashable - Hurricane Irene: Find an NYC Evacuation Center on Foursquare … http://t.co/XMtpH99 |
| 5 | Following slamming into the East Coast and knocking out electricity to more than a million people, Hurricane Irene is now taking purpose on largest metropolitan areas in the Northeast. | 2M lose power as Hurricane Irene moves north - Two million homes and businesses were without power … http://t.co/fZWkEU3 |
| 6 | Irene remains a Category 1, the lowest level of hurricane classification, as it churns toward New York over the next several hours, the U.S. National Hurricane Center said on Sunday. | Now its a level 1 hurricane. Let’s hope it hits NY at Level 1 |
| 7 | Blackouts reported, storm warnings issued as Irene nears Quebec, Atlantic Canada. | DTN Canada: Irene forecast to hit Atlantic Canada http://t.co/MjhmeJn |
| 8 | President Barack Obama declared New York a disaster area Wednesday, The New York Times reports, allowing the release of federal aid to the state’s government and individuals. | Hurricane Irene: New York State Declared A Disaster Area By President Obama |
| 9 | Hurricane Irene’s rampage up the East Coast has become the tenth billion-dollar weather event this year, breaking a record stretching back to 1980, climate experts said Wednesday. | Irene is 10th billion-dollar weather event of 2011. |
| 10 | WASHINGTON—On Sunday, September 4, the President will travel to Paterson, New Jersey, to view damage from Hurricane Irene. | White House: Obama to visit Paterson, NJ Sunday to view damage from Hurricane Irene |
5.5 Discussion
This chapter reviewed a MLE approach to solve the reliable social sensing problem. Some simplifying assumptions are made to the model that offer opportunities for future work.
Sources are assumed to be independent from each other in the current EM scheme. However, sources can sometimes be dependent. That is, they copy observations from each other in real life (e.g., retweets of Twitter). Regarding possible solutions to this problem, one possibility is to remove duplicate observations from dependent sources and only keep the original ones. This can be achieved by applying copy detection schemes between sources [41, 42]. Another possible solution is to cluster dependent sources based on some source-dependency metric [40]. In other words, sources in the same cluster are closely related with each other but independent from sources in other clusters. Then EM scheme can be modified and be applied on top of the clustered sources. More importantly, we will review a direct extension of the MLE framework presented in this chapter in Chapter 2 that discusses social networks. The extended work nicely integrates source dependency information learned from social network into the MLE framework without sacrificing the rigor of the analytical model.
Observations from different sources on a given claim are assumed to be corroborating in this chapter. This happens in social sensing applications where people do not report “lack of problems.” For example, a group of sources involved in a geotagging application to find litter of a park will only report locations where they observe litter and ignore the locations they do not find litter. However, sources can also make conflicting observations in other types of applications. For example, comments from different reviewers in an on-line review system on the same product often contradict with each other. Fortunately, the reviewed MLE model can be flexibly extended to handle conflicting observations. The idea is to extend the estimation vector to incorporate the conflicting states of a claim and rebuild the likelihood function based on the extended estimation vector. The general outline of the EM derivation still holds.
The EM scheme reviewed in this chapter is mainly designed to run on static data sets, where the computation overhead stays reasonable even when the dataset scales up (e.g., the Irene dataset). However, such computation may become less efficient for streaming data because we need to re-run the algorithm on the whole dataset from scratch every time the dataset gets updated. Instead, it will be more efficient for the algorithm to process only novel data by exploiting the previously results in an optimal (or suboptimal) way. One possibility is to develop a scheme that can compute the estimated parameters of interest recursively over time using incoming measurements and a mathematical process model. The challenge here is that the relationship between the estimation from the updated dataset and the complete dataset may not be linear. Hence, linear regression might not be generally plausible. Rather, recursive estimation schemes, such as the Recursive EM estimation, would be a better fit.
The reviewed EM scheme is an unsupervised scheme, where no data samples are assumed to be used to train the estimation model. What happens if we do have some training samples available? For example, we might have some prior knowledge on either source reliability or the correctness of claims from other independent ways of data verification. One possible way to incorporate such prior knowledge into the MLE model is to reset the known variables in each iteration of EM to their correct values, which may help the algorithm to converge much faster and also reduce the estimation error. Some techniques exist in machine learning community that try to incorporate the prior knowledge (e.g., source and claim similarity, common-sense reasoning, etc.) into the fact-finding framework by using linear programming [37] or k-partite graph generalization [44]. It would be interesting to investigate if it would be possible to borrow some of these techniques and leverage the training data to further improve the accuracy of the MLE estimation.
This chapter reviewed a MLE approach to solve the reliable social sensing problem. The approach can determine the correctness of reported observations given only the measurements sent without knowing the trustworthiness of sources. The optimal solution is obtained by solving an EM problem and can directly lead to an analytically founded quantification of the correctness of measurements as well as the reliability of sources. Evaluation results show that non-trivial estimation accuracy improvements can be achieved by the MLE approach compared to other state of the art solutions.