
Fact-finding in information networks
Abstract
This chapter reviews the state-of-the-art fact-finding schemes developed for trust and credibility analysis in information networks with a focus on a Bayesian interpretation of the basic fact-finding scheme. The fact-finding algorithms rank a list of claims and a list of sources by their credibility, which can be used toward solving the reliable social sensing problem. In particular, we review a Bayesian interpretation of the basic mechanism used in fact-finding from information networks in detail. This interpretation leads to a direct quantification of the accuracy of conclusions obtained from information network analysis. Such quantification scheme is of great value in deriving reliable information from unreliable sources in the context of social sensing.
4.1 Facts, Fact-Finders, and the Existence of Ground Truth
Fact-finders are an interesting class of algorithms whose purpose is to recognize “truth” from observations that are noisy, conflicting, and possibly incomplete. As such, they are quite fundamental to our quest to build reliable systems on unreliable data. The majority of fact-finders can be thought of as algorithms that combine two fundamental components, whose use is prevalent in data mining literature. Namely, fact-finders intertwine the use of clustering and ranking components. Informally, the clustering component combines together pieces of evidence in support of the same facts. The ranking component weights the trustworthiness, credibility, authority, or probability of correctness of different clusters of evidence. Different fact-finders vary in how they perform the ranking and clustering steps. While both ranking and clustering are well-researched areas in data mining, the fact-finding problem itself is a bit of a special case, because, unlike most other data mining problems, fact-finders typically deal with situations, where a unique externally defined ground truth exists.
To appreciate what the above statement means, let us first elaborate on what we mean by externally defined ground truth. This is a concept we inherit from sensing and data fusion, where the objective is always to estimate the state of some external system; the system being monitored. That system is assumed to have state that is independent of what the sensing and data fusion algorithms are doing. That state is unique and unambiguous. While the sensors may be noisy and the estimation algorithms might make simplifying assumptions about how the monitored system behaves, once an estimate of the state is obtained, this estimate can, in principle, be compared to a unique and unambiguous actual state. Any difference between the actual and estimated states would constitute a unique and unambiguous measure of estimation error.
Note that, many algorithms can define their own set of assumptions. Under this set of assumptions, they may reach optimal conclusions. While the algorithms may be optimal in that sense, they may or may not do well in terms of estimation error. It all depends on how well their simplifying assumptions approximate the real world.
Now, let us go back to our previous statement. We pointed out that the existence of a unique externally defined ground truth in fact-finding problems makes them different from many other clustering and ranking problems. Consider, for example, community detection. The goal is usually to identify different communities (clusters of nodes) based on node interaction patterns. The solution consists of the clusters that have been identified. It is generally hard to compare these clusters to a metric of ground truth. It could be, for example, that communities were split across belief boundaries, such as liberals versus conservatives. However, it is not straightforward to define what exactly constitutes a liberal and what exactly constitutes a conservative. Hence, it is hard to tell in an unambiguous way whether the resulting clusters are consistent with “ground truth” or not. In some sense, the formed clusters define their own ground truth. An optimal solution to a clustering problem simply says that according to the distance metric used for clustering, the resulting clusters are optimal and constitute the best answer to the problem.
The same lack of an externally defined ground truth can be said about many ranking problems as well, investigated in data mining literature. For example, recent work in data mining develops algorithms for combined ranking and clustering [86]. The algorithm is used to rank the top 10 conferences and the top 10 authors in several fields. The results are intuitive in that the best conferences and the most recognized authors indeed come on top. However, it is hard to define an objective measure of error because it is hard to quantify ground truth. After all, how would one define a top author? Is it the number of publications they have? Is it the number of citations to their work? Is it their success in technology transfer from published research? There is no single, unique, agreed-upon metric and therefore no single, unique, agreed-upon ground truth. The ranking algorithm defines its own ground truth based on some assumed model. For example, under the simplifying assumption that better authors have more papers, one can come up with a unique and unambiguous ranking. However, there is no unique external reference to compare this resulting ranking to in order to determine how accurate exactly the simplifying assumption underlying the ranking was. It is precisely the existence of an external reference (for what is considered “true”) versus the lack thereof that is the distinction we are trying to draw between problems for which an externally defined ground truth exists and problems for which it does not.
Now, by contrast, consider the problem of fact-finding. Let the goal of the fact-finder be to identify which of a set of facts claimed by some unreliable sources actually occurred in the physical world. The fact-finding algorithm can make simplifying assumptions about how sources behave. Based on those assumptions some answers are given. Once the answers are given, it is in principle possible to define an error based on a comparison of what the fact-finder believed and what was actually true in the external physical world. The distinction is important because it allows us to formulate fact-finding problems as ones of minimizing the difference between exact and estimated states of systems. In other words, we cast them as sensing problems and are thus able to apply results from traditional estimation theory.
It remains to make two more points clear. First, the assumption of the existence of an externally defined unique ground truth does not necessarily mean that this ground truth is available to the fact-finding algorithm. In fact, most of the time, it is not. By analogy with target tracking algorithms, when the position of a target is estimated, one can define the notion of an estimation error even if this error is not available in practice because the data fusion system does not know the exact location of the target. (After all, if it did, we would not need to do the estimation in the first place.) The point is that the target has a unique and unambiguous location in the physical world at any given time. The deviation of the estimate from that actual location is the error. Estimation theory quantifies bounds on that error under different conditions.
The second point is that the existence of ground truth versus lack thereof does not constitute an advantage of one set of problems or solutions over another. The discussion above simply sheds light on an interesting difference between many problems addressed in data mining and problems addressed in sensing. Philosophically speaking, data mining is about discovery of uncharted territory. Hence, by definition, no agreed upon models for ground truth need to exist. If anything, the goal is to discover what ground truth might be. Sensing, on the other hand, is about reconstruction of an existing physical world in cyberspace. Therefore, by definition, sensing is only as good as the accuracy to which it reconstructs world state, compared to ground truth. In this book, the problem addressed is fundamentally one of sensing, although it does use inspiration from data mining literature. We define a notion of error and set up the fact-finding problem as one of minimizing this error. First, however, we take a look at previous literature in the area.
4.2 Overview of Fact-Finders in Information Networks
In this section, we first review several state-of-the-art fact-finders used in information network analysis. Some early fact-finder models include Sums (Hubs and Authorities) [35], TruthFinder [36], Average Log, Investment, and Pooled Investment [37]. Sums developed a basic fact-finder where the belief in a claim c is Bi(c)=∑s∈ScTi(s)![]() and the truthfulness of a source s is Ti(s)=∑c∈CsB(i−1)(c)
and the truthfulness of a source s is Ti(s)=∑c∈CsB(i−1)(c)![]() , where Sc and Cs are the sources asserting a given claim and the claims asserted by a particular source, respectively. Both B(c) and T(s) are normalized by dividing by the maximum values in the respective vector to prevent them from going unbounded. TruthFinder is the first unsupervised fact-finder proposed by Yin et al. for trust analysis on a providers-facts network [36]. It models the fact-finding problem as a graph estimation problem where three types of nodes in the graph represent providers (sources), facts (claims), and objects, respectively. They assumed multiple mutual exclusive facts are associated with an object and providers assert facts of different objects. The proposed algorithm iterates between the computation of trustworthiness of sources and confidence of claims using heuristic based pseudo-probabilistic methods. In particular, the algorithm computes the “probability” of a claim by assuming that each source’s trustworthiness is the probability of it being correct and then average claim beliefs to obtain trustworthiness scores. Pasternack et al. extended the Sums framework by incorporating prior knowledge into the analysis and proposed several extended algorithms: Average Log, Investment, and Pooled Investment [37]. Average Log attempts to address the trustworthiness overestimation problem of a source who makes relatively few claims by explicitly considering the number of claims in the trustworthiness score computation. In particular, it adjusts the update rule to compute source trustworthiness score used in Sums as Ti(s)=log|Cs|∑c∈CsBi−1(c)|Cs|
, where Sc and Cs are the sources asserting a given claim and the claims asserted by a particular source, respectively. Both B(c) and T(s) are normalized by dividing by the maximum values in the respective vector to prevent them from going unbounded. TruthFinder is the first unsupervised fact-finder proposed by Yin et al. for trust analysis on a providers-facts network [36]. It models the fact-finding problem as a graph estimation problem where three types of nodes in the graph represent providers (sources), facts (claims), and objects, respectively. They assumed multiple mutual exclusive facts are associated with an object and providers assert facts of different objects. The proposed algorithm iterates between the computation of trustworthiness of sources and confidence of claims using heuristic based pseudo-probabilistic methods. In particular, the algorithm computes the “probability” of a claim by assuming that each source’s trustworthiness is the probability of it being correct and then average claim beliefs to obtain trustworthiness scores. Pasternack et al. extended the Sums framework by incorporating prior knowledge into the analysis and proposed several extended algorithms: Average Log, Investment, and Pooled Investment [37]. Average Log attempts to address the trustworthiness overestimation problem of a source who makes relatively few claims by explicitly considering the number of claims in the trustworthiness score computation. In particular, it adjusts the update rule to compute source trustworthiness score used in Sums as Ti(s)=log|Cs|∑c∈CsBi−1(c)|Cs|![]() . In Investment and Pooled Investment, sources “invest” their trustworthiness uniformly among claims and a non-linear function G was introduced to model the belief growth in each claim. Other fact-finders further enhanced the above basic framework by incorporating analysis on properties or dependencies within claims or sources. Galland et al. [38] took the notion of hardness of facts into consideration and proposed their algorithms: Cosine, 2-Estimates, and 3-Estimates. Dong et al. studied the source dependency and copying problem comprehensively and proposed several algorithms that give higher credibility to independent sources [41, 42, 97].
. In Investment and Pooled Investment, sources “invest” their trustworthiness uniformly among claims and a non-linear function G was introduced to model the belief growth in each claim. Other fact-finders further enhanced the above basic framework by incorporating analysis on properties or dependencies within claims or sources. Galland et al. [38] took the notion of hardness of facts into consideration and proposed their algorithms: Cosine, 2-Estimates, and 3-Estimates. Dong et al. studied the source dependency and copying problem comprehensively and proposed several algorithms that give higher credibility to independent sources [41, 42, 97].
More recent works came up with several new fact-finding algorithms toward building more generalized framework and using more rigorous statistic models. Pasternack et al. [44] provided a generalized fact-finder framework to incorporate the background knowledge such as the confidence of the information extractor, attributes of information sources and similarity between claims. Instead of considering the source claim network as an unweighted bipartite graph, they proposed a generalized k-partite weighted graph where different types of background knowledge and contextual details can be encoded as weight links. Specifically, they defined the uncertainty expressed by the source in the claim, the attributes of sources and similarity between claims as different weights in their lifted model. They also rewrote several basic fact-finders (e.g., Sums, Average Log, Investment, and TruthFinder) to incorporate the background knowledge as the link weights in the computation of source trustworthiness and claim beliefs. New “layers” of groups and attributes can be added to the source and claim graph to model meta-groups and meta-attributes. The generalized fact-finders were shown to outperform the basic ones by exploring the background knowledge through experiments on several real-world datasets. Following the above work, Pasternack et al. [47] proposed a probabilistic model by using Latent Credibility Analysis (LCA) for information credibility analysis. In their model, they introduced hidden variables to model the truth of claims and related the estimation parameters to source reliability. The LCA model provides semantics to the credibility scores of sources and claims that are computed by the proposed algorithms. However, sources and claims are assumed to be independent to keep the credibility analysis mathematically rigorous. Such assumptions may not always hold in real-world applications.
Zhao et al. [46] presented a Bayesian approach to model different types of errors made by sources and merge multi-valued attribute types of entities in data integration systems. They assumed the possible true values of a fact are not unique and a source can claim multiple values of a fact at the same time. They built a Latent Truth Model (LTM) based on maximum a posterior (MAP), which in general needs the prior on both source reliability and claim truthfulness. In particular, the LTM explicitly models two aspects of source quality by considering both false positive and false negative errors made by a source. They solved the MAP estimation problem by using the collapsed Gibbs sampling method. An incremental approximation algorithm was also developed to efficiently handle streaming data. There exists some limitations of LTM that originate from several assumptions made by the model. For example, the model assumes all sources are independent and the majority of data coming from each source is not erroneous. These assumptions may not be necessarily true in various real-world applications (e.g., social sensing) where data collection is often open to all.
Qi et al. [43] proposed an integrated group reliability and true data value inference approach in collective intelligence applications to aggregate information from large crowds. The aggregation results in such applications are often negatively affected by the unreliable information sources with low quality data. To address this critical challenge, they developed a multi-source sensing model to jointly estimate source reliability and data correctness with explicit consideration of source dependency. High source dependency makes the collective intelligence systems vulnerable to overuse redundant and possibly incorrect information from dependent sources. The key insight of their model is to infer the source dependency by revealing latent group structures among dependent sources and analyze the source reliability at group levels. They studied two types of source reliability of their model: the general reliability that represents the overall performance of a group and the specific reliability on each individual object. The true data value is extracted from reliable groups to minimize the negative impacts of unreliable groups. They demonstrated the performance improvement of their model over other existing fact-finders through experiments on two real-world datasets.
Yu et al. [48] presented an unsupervised multi-dimensional truth finding framework to study credibility perceptions in the context of information extraction (IE). The proposed framework incorporates signals from multiple sources and multiple systems through knowledge graphs that are constructed from multiple evidences using multi-layer deep linguistic analysis. In particular, the proposed multi-dimensional truth-finding model (MTM) is constructed based on a tripartite graph where nodes in the graph represent sources, responses, and systems, respectively. The response in the model is defined as a claim and evidence pair, which is automatically generated from unstructured natural language texts by a Slot Filling system. The response is trustworthy if its claim is true and its evidence supports the claim. A trusted source is assumed to always support true claims by offering convincing evidence and a good system is assumed to extract trustworthy responses from trusted sources. They then computed the credibility scores of sources, responses, and systems by using a set of similar heuristics adapted from TruthFinder [36]. They also demonstrated a better accuracy and efficiency of their approach compared to baselines through case studies of Slot Filling Validation tasks.
Complementary to the above fact-finders that target to discover the truthfulness/correctness of claims, Sikdar et al. [98] defined credibility as the believability of claims, which can be different from truthfulness of claims in certain contexts. They developed machine learning based methods to find features or indicators (e.g., network location of sources, textual content of the claims) to assess the credibility of claims. These methods normally need to have sufficient training data that is representative of the current problem in order to work well. Such conditions may not hold in scenarios where no good features can be found for future predictions or the identified features are manipulated by others. To overcome this limitation, they recently conducted some interesting Twitter based case studies to demonstrate how data fusion techniques can be used to combine the credibility results from the machine learning based methods with the truthfulness analysis results from fact-finders to capture the trade off between discovering true versus credible information [99].
Toward an optimal fact-finding solution to address data reliability problem in social sensing, Wang et al. developed a maximum likelihood estimation (MLE) framework that jointly estimates both source reliability and claim correctness based on a set of general simplifying assumptions in the context of social sensing [100, 101]. The derived solutions are optimal in the sense that they are most consistent with the data observed without prior knowledge of source reliability and without independent ways to verify the correctness of claims. They also derived accuracy bounds by leveraging results from estimation theory and statistics to correctly assess the quality of the estimation results [102–104]. They further relaxed the assumptions they made in their basic model to address source dependency [105], claim dependency [106], and streaming data [107]. We will review this thread of research work in great details starting from the next chapter of the book. Before that, let us first review a Bayesian interpretation scheme for the basic fact-finders in information networks in the remaining sections of this chapter.
4.3 A Bayesian Interpretation of Basic Fact-Finding
Starting from this section, we will review a Bayesian interpretation of the basic fact-finding scheme that leads to a direct quantification of the accuracy of conclusions obtained from information network analysis [39]. When information sources are unreliable, information networks have been used in data mining literature to uncover facts from large numbers of complex relations between noisy variables. The approach relies on topology analysis of graphs, where nodes represent pieces of (possibly unreliable) information and links represent abstract relations. More specifically, let there be s sources, S1,…,Ss who collectively assert c different pieces of information, C1,…,Cc. Each such piece of information is called a claim. All sources and claims are represented by a network, where these sources and claims are nodes, and nodes, and where an observation, Ci,j (denoting that a source Si makes claim Cj) is represented by a link between the corresponding source and claim nodes. It is assumed that a claim can either be true or false. An example is “John Smith is CEO of Company X” or “Building Y is on Fire.” Cred(Si) is defined as the credibility of source Si, and Cred(Cj) as the credibility of claim Cj.
Ccred is defined as a c × 1 vector that represents the claim credibility vector [Cred(C1)…Cred(Cc)]T and Scred is a s × 1 vector that represents the source credibility vector [Cred(S1)…Cred(Ss)]T. CS is defined as a c × s array such that element CS(j,i) = 1 if source Si makes claim Cj, and is zero otherwise.
Cestcred![]() is defined as a vector of estimated claim credibility, defined as (1/α)[CS]Scred. One can pose the basic fact-finding problem as one of finding a least squares estimator (that minimizes the sum of squares of errors in source credibility estimates) for the following system:
is defined as a vector of estimated claim credibility, defined as (1/α)[CS]Scred. One can pose the basic fact-finding problem as one of finding a least squares estimator (that minimizes the sum of squares of errors in source credibility estimates) for the following system:
Cestcred=1α[CS]Scred
Scred=1β[CS]TCestcred+e
where the notation XT denotes the transpose of matrix X. It can further be shown that the condition for it to minimize the error is that α and β be chosen such that their product is an Eigenvalue of [CS]T[CS]. The algorithm produces the credibility values Cred(Si) and Cred(Cj) for every source Si and for every claim Cj. These values are used for ranking. The question is, does the solution have an interpretation that allows quantifying the actual probability that a given source is truthful or that a given claim is true?
Let Sti![]() denote the proposition that “Source Si speaks the truth.” Let Ctj
denote the proposition that “Source Si speaks the truth.” Let Ctj![]() denote the proposition that “claim Cj is true.” Also, let Sfi
denote the proposition that “claim Cj is true.” Also, let Sfi![]() and Cfj
and Cfj![]() denote the negation of the above propositions, respectively. The objective is to estimate the probabilities of these propositions. SiCj means “Source Si made claim Cj.”
denote the negation of the above propositions, respectively. The objective is to estimate the probabilities of these propositions. SiCj means “Source Si made claim Cj.”
It is useful to define Claimsi as the set of all claims made by source Si, and Sourcesj as the set of all sources who claimed claim Cj. In the subsections below, we review the derivation of the posterior probability that a claim is true, followed by the derivation of the posterior probability that a source is truthful.
4.3.1 Claim Credibility
Consider some claim Cj, claimed by a set of sources Sourcesj. Let ik be the kth source in Sourcesj, and let |Sourcesj| = Kj. (For notational simplicity, the subscript j from Kj shall be occasionally omitted in the discussion below, where no ambiguity arises.) According to Bayes theorem:
P(Ctj|Si1Cj,Si2Cj,…,SiKCj)=P(Si1Cj,Si2Cj,…,SiKCj|Ctj)P(Si1Cj,Si2Cj,…,SiKCj)P(Ctj)

The above equation makes the implicit assumption that the probability that a source makes any given claim is sufficiently low that no appreciable change in posterior probability can be derived from the lack of a claim (i.e., lack of an edge between a source and a claim). Hence, only existence of claims is taken into account. Assuming further that sources are conditionally independent (i.e., given a claim, the odds that two sources claim it are independent), Equation (4.3) is rewritten as:
P(Ctj|Si1Cj,Si2Cj,…,SiKCj)=P(Si1Cj|Ctj)…P(SiKCj|Ctj)P(Si1Cj,Si2Cj,…,SiKCj)P(Ctj)

It is further assumed that the change in posterior probability obtained from any single source or claim is small. This is typical when using evidence collected from many individually unreliable sources. Hence
P(SikCj|Ctj)P(SikCj)=1+δtikj

where |δtikj|≪1![]() . Similarly
. Similarly
P(SikCj|Cfj)P(SikCj)=1+δfikj

where |δfikj|≪1![]() . Under the above assumptions, the proof is provided in Appendix of Chapter 4 to show that the denominator of the right hand side in Equation (4.4) can be rewritten as follows:
. Under the above assumptions, the proof is provided in Appendix of Chapter 4 to show that the denominator of the right hand side in Equation (4.4) can be rewritten as follows:
P(Si1Cj,Si2Cj,…,SiKCj)≈∏Kjk=1P(SikCj)

Please see Appendix of Chapter 4 for a proof of Equation (4.7). Note that, the proof does not rely on an independence assumption of the marginals, P(SikCj)![]() . Those marginals are, in fact, not independent but approximately so. The proof merely shows that, under the assumptions stated in Equations (4.5) and 4.6, the above approximation holds true. Substituting in Equation (4.4):
. Those marginals are, in fact, not independent but approximately so. The proof merely shows that, under the assumptions stated in Equations (4.5) and 4.6, the above approximation holds true. Substituting in Equation (4.4):
P(Ctj|Si1Cj,Si2Cj,…,SiKCj)=P(Si1Cj|Ctj)…P(SiKCj|Ctj)P(Si1Cj)…P(SiKCj)P(Ctj)

which can be rewritten as:
P(Ctj|Si1Cj,Si2Cj,…,SiKCj)=P(Si1Cj|Ctj)P(Si1Cj)×…×P(SiKCj|Ctj)P(SiKCj)×P(Ctj)

Substituting from Equation (4.5):
P(Ctj|Si1Cj,Si2Cj,…,SiKCj)=P(Ctj)∏Kjk=1(1+δtikj)=P(Ctj)(1+∑Kjk=1δtikj)

The last line above is true because higher products of δtikj![]() can be neglected, since it is assumed that |δtikj|≪1
can be neglected, since it is assumed that |δtikj|≪1![]() . The above equation can be re-written as:
. The above equation can be re-written as:
P(Ctj|Si1Cj,Si2Cj,…,SiKCj)−P(Ctj)P(Ctj)=∑Kjk=1δtikj

where from Equation (4.5):
δtikj=P(SikCj|Ctj)−P(SikCj)P(SikCj)

4.3.2 Source Credibility
Next, consider some source Si, who makes the set of claims Claimsi. Let jk be the kth claim in Claimsi, and let |Claimsi| = Li. (For notational simplicity, the subscript i from Li shall occasionally be omitted in the discussion below, where no ambiguity arises.) According to Bayes theorem:
P(Sti|SiCj1,SiCj2,…,SiCjL)=P(SiCj1,SiCj2,…,SiCjL|Sti)P(SiCj1,SiCj2,…,SiCjL)P(Sti)

As before, assuming conditional independence:
P(Sti|SiCj1,SiCj2,…,SiCjL)=P(SiCj1|Sti)…P(SiCjL|Sti)P(SiCj1,SiCj2,…,SiCjL)P(Sti)

Once more the assumption that the change in posterior probability caused from any single claim is very small is invoked:
P(SiCjk|Sti)P(SiCjk)=1+ηtijk
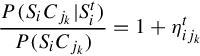
where |ηtijk|≪1![]() . Similarly to the proof in Appendix of Chapter 4, this leads to:
. Similarly to the proof in Appendix of Chapter 4, this leads to:
P(Sti|SiCj1,SiCj2,…,SiCjL)=P(SiCj1|Sti)P(SiCj1)×…×P(SiCjL|Sti)P(SiCjL)×P(Sti)

The above can be re-written as follows:
P(Sti|SiCj1,SiCj2,…,SiCjL)=P(Sti)∏Lik=1(1+ηtijk)=P(Sti)(1+∑Lik=1ηtijk)

The above equation can be further re-written as:
P(Sti|SiCj1,SiCj2,…,SiCjL)−P(Sti)P(Sti)=∑Lik=1ηtijk

where from Equation (4.15):
ηtijk=P(SiCjk|Sti)−P(SiCjk)P(SiCjk)

4.4 The Iterative Algorithm
In the sections above, we reviewed the derivation of the expressions of posterior probability that a claim is true or that a source is truthful. These expressions were derived in terms of δtikj![]() and ηtijk
and ηtijk![]() . It remains to show how these quantities are related. Let us first consider the terms in Equation (4.12) that defines δtikj
. It remains to show how these quantities are related. Let us first consider the terms in Equation (4.12) that defines δtikj![]() . The first is P(SiCj|Ctj)
. The first is P(SiCj|Ctj)![]() , the probability that Si claims claim Cj, given that Cj is true. (For notation simplicity, subscripts i and j shall be used to denote the source and the claim.) We have:
, the probability that Si claims claim Cj, given that Cj is true. (For notation simplicity, subscripts i and j shall be used to denote the source and the claim.) We have:
P(SiCj|Ctj)=P(SiCj,Ctj)P(Ctj)
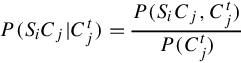
where
P(SiCj,Ctj)=P(Sispeaks)=P(SiclaimsCj|Sispeaks)=P(Ctj|Sispeaks,SiclaimsCj)

In other words, the joint probability that link SiCj exists and Cj is true is the product of the probability that Si speaks, denoted P(Sispeaks), the probability that it claims Cj given that it speaks, denoted P(Siclaims Cj|Sispeaks), and the probability that the claim is true, given that it is claimed by Si, denoted P(Ctj|Sispeaks,SiclaimsCj)![]() . Here, P(Sispeaks) depends on the rate at which Si makes claims. Some sources may be more prolific than others. P(Siclaims Cj|Sispeaks) is simply 1/c, where c is the total number of claims. Finally, P(Ctj|Sispeaks,SiclaimsCj)
. Here, P(Sispeaks) depends on the rate at which Si makes claims. Some sources may be more prolific than others. P(Siclaims Cj|Sispeaks) is simply 1/c, where c is the total number of claims. Finally, P(Ctj|Sispeaks,SiclaimsCj)![]() is the probability that Si is truthful. Since the ground truth is not known, that probability is estimated by the best information we have, which is P(Sti|SiCj1,SiCj2,…,SiCjL)
is the probability that Si is truthful. Since the ground truth is not known, that probability is estimated by the best information we have, which is P(Sti|SiCj1,SiCj2,…,SiCjL)![]() . Thus:
. Thus:
P(SiCj,Ctj)=P(Sispeaks)P(Sti|SiCj1,SiCj2,…,SiCjL)c

Substituting in Equation (4.20) from Equation (4.22) and noting that P(Ctj)![]() is simply the ratio of true claims, ctrue to the total claims, c, we get:
is simply the ratio of true claims, ctrue to the total claims, c, we get:
P(SiCj|Ctj)=P(Sispeaks)P(Sti|SiCj1,SiCj2,…,SiCjL)ctrue

Similarly,
P(SiCj)=P(Sispeaks)c
Substituting from Equations (4.23) and 4.24 into Equation (4.12) and re-arranging, we get:
δtikj=P(SikCj|Ctj)−P(SikCj)P(SikCj)=P(Sti|SiCj1,SiCj2,…,SiCjL)ctrue/c−1

If the fraction of all true claims to the total number of claims is taken as the prior probability that a source is truthful, P(Sti)![]() (which is a reasonable initial guess in the absence of further evidence), then the above equation can be re-written as:
(which is a reasonable initial guess in the absence of further evidence), then the above equation can be re-written as:
δtikj=P(Sti|SiCj1,SiCj2,…,SiCjL)P(Sti)−1

Substituting for δtikj![]() in Equation (4.11), we get:
in Equation (4.11), we get:
P(Ctj|Si1Cj,Si2Cj,…,SiKCj)−P(Ctj)P(Ctj)=∑Kji=1P(Sti|SiCj1,SiCj2,…,SiCjL)−P(Sti)P(Sti)

The following can be similarly proven:
ηtijk=P(Ctj|Si1Cj,Si2Cj,…,SiKCj)P(Ctj)−1

and
P(Sti|SiCj1,SiCj2,…,SiCjL)−P(Sti)P(Sti)=∑Lij=1P(Ctj|Si1Cj,Si2Cj,…,SiKCj)−P(Ctj)P(Ctj)

Comparing the above equations to the iterative formulation of the basic fact-finder, described in this section, the sought interpretation of the credibility rank of sources Rank(Si) and credibility rank of claims Rank(Cj) in iterative fact-finding is:
Rank(Cj)=P(Ctj|Si1Cj,Si2Cj,…,SiKCj)−P(Ctj)P(Ctj)

Rank(Si)=P(Sti|SiCj1,SiCj2,…,SiCjL)−P(Sti)P(Sti)

In other words, Rank(Cj) is interpreted as the increase in the posterior probability that a claim is true, normalized by the prior. Similarly, Rank(Si) is interpreted as the increase in the posterior probability that a source is truthful, normalized by the prior. Substituting from Equations (4.30) and 4.31 into Equations (4.27) and 4.29, we then get:
Rank(Cj)=∑k∈SourcesjRank(Sk)Rank(Si)=∑k∈ClaimsiRank(Ck)

One should note that the credibility ranks are normalized in each iteration to keep the values in bound. The above equations make similar linear approximation as Sums (Hubs and Authorities) [35] as we reviewed in the previous section. However, we will review another set of work using a more principled approach (i.e., MLE) to avoid this approximation in the next chapter. Once the credibility ranks are computed such that they satisfy the above equations (and any other problem constraints), Equations (4.30) and 4.31, together with the assumption that prior probability that a claim is true is initialized to pta=ctrue/c![]() , give us the main contribution of this effort, Namely1 :
, give us the main contribution of this effort, Namely1 :
P(Ctj|network)=pta(Rank(Cj)+1)
Similarly, it is shown that if pts![]() is the prior probability that a randomly chosen source tells the truth, then:
is the prior probability that a randomly chosen source tells the truth, then:
P(Sti|network)=pts(Rank(Si)+1)
Hence, the above Bayesian analysis presents, for the first time, a basis for estimating the probability that each individual source, Si, is truthful and that each individual claim, Cj, is true. These two vectors are computed based on two scalar constants: pta![]() and pts
and pts![]() , which represent estimated statistical averages over all claims and all sources, respectively.
, which represent estimated statistical averages over all claims and all sources, respectively.
4.5 Examples and Results
In this section, we review the experiments that were carried to verify the correctness and accuracy of the probability that a source is truthful or a claim is true estimated from the Bayesian interpretation of fact-finding in information networks. The Bayesian interpretation was compared to several state-of-the-art algorithms in fact-finder literature.
A simulator was built in Matlab 7.14.0 to simulate the source and claim information network. To test the results, the simulator generates a random number of sources and claims, and partition these claims into true and false ones. A random probability, Pi, is assigned to each source Si representing the ground truth probability that the source speaks the truth. For each source Si, Li observations are generated. Each observation has a probability Pi of being true and a probability 1 − Pi of being false. A true observation links the source to a randomly chosen true claim (representing that the source made that claim). A false observation links the source to a randomly chosen false claim. This generates an information network.
Let Pi be uniformly distributed between 0.5 and 1 in the experiments.2 An assignment of credibility values that satisfies Equation (4.32) is then found for the topology of the generated information network. Finally, the estimated probability that a claim is true or a source is truthful is computed from the resulting credibility values of claims and sources based on Equations (4.33) and 4.34. Since it is assumed that claims are either true or false, each claim is viewed as “true” or “false” based on whether the probability that it is true is above or below 50%. Then the computed results are compared against the ground truth to report the estimation accuracy.
For sources, the computed probability is simply compared to the ground truth probability that they tell the truth. For claims, we define two metrics to evaluate classification accuracy: false positives and false negatives. The false positives are defined as the ratio of the number of false claims that are classified as true over the total number of claims that are false. The false negatives are defined as the ratio of the number of true claims that are classified as false over the total number of claims that are true. Reported results are averaged over 100 random source correctness probability distributions.
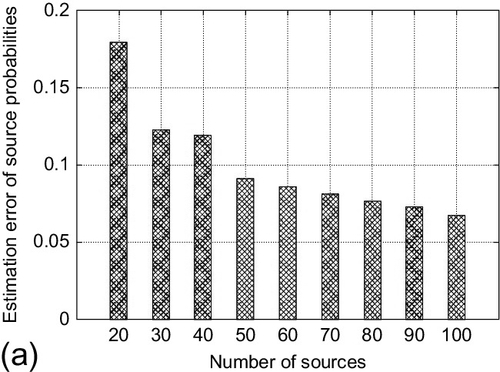
The first experiment showed the effect of the number of sources on prediction accuracy. The number of true and false claims was fixed at 1000 respectively. The average number of observations per source was set to 100. The number of sources is varied from 20 to 100. The estimation accuracy for both sources and claims is shown in Figure 4.1. We note that both estimation accuracy of source probabilities to be truthful and the claim classification accuracy (i.e., false positives and false negatives) improves as the number of sources increases. This is intuitive: more sources provide more corroborating observations about the claims, which helps the Bayesian approach to get better estimations. The usefulness of the Bayesian interpretation increases for large networks.


The next experiment shows the effect of changing the claim mix on estimation accuracy. The ratio of the number of true claims to the total number of claims in the network was varied. Assuming that there is usually only one variant of the truth, whereas rumors have more versions, one might expect the set of true claims to be smaller than the set of false ones. Hence, the total number of claims was fixed to be 2000 and change the ratio of true to total claims from 0.1 to 0.5. The ctrue/c is set accordingly to the correct ratio used for the experiment. The number of sources in the network is set to 50 and the average observations per source is set to 100. The estimation accuracy for both sources and claims is shown in Figure 4.2. Observe that both the estimation error of source probabilities to be truthful and the error of claim classification increase as the ratio of true claims increases. This is because the true claim set becomes less densely claimed and more true and false claims are misclassified as each other as the number of true claims grows.



Finally, the Bayesian interpretation scheme was compared to three other fact-finder schemes: Sums (Hubs and Authorities) [35], Average-Log [37], and TruthFinder [36]. These algorithms were selected because, unlike other state-of-art fact-finders (e.g., 3-Estimates [38]), they do not require the knowledge about what mutual exclusion, if any, exists among the claims. In this experiment, the number of true and false claims is 1000 respectively, the number of observations per source is 150, and the number of sources is set to 50. The initial estimation offset on prior claim correctness was varied from 0.05 to 0.45. The initial claim beliefs of all fact-finders were set to the initial prior (i.e., 0.5) plus the offset used for the experiment. Each baseline fact-finder was ran for 20 iterations, and the 1000 highest-belief claims were selected as those predicted to be correct. The estimated probability of each source making a true claim was thus calculated as the proportion of predicted-correct claims asserted relative to the total number of claims asserted by source.
The compared results are shown in Figure 4.3. Observe that the prediction error of source correctness probability by the Bayesian interpretation scheme is significantly lower than all baseline fact-finder schemes. The reason is that Bayesian analysis estimates the source correctness probability more accurately based on Equation (4.34) derived in this chapter rather than using heuristic methods adopted by the baseline schemes that depends on the correct estimation on prior claim correctness. We also note that the prediction performance for claims in the Bayesian scheme is generally as good as the baselines. This is good since the other techniques excel at ranking, which (together with the hint on the number of correct claims) is sufficient to identify which ones these are. The results confirm the advantages of the Bayesian approach over previous ranking-based work at what the Bayesian analysis does best: estimation of probabilities of conclusions from observed evidence.



4.6 Discussion
This chapter presented a Bayesian interpretation of the most basic fact-finding algorithm. The question was to understand why the algorithm is successful at ranking, and to use that understanding to translate the ranking into actual probabilities. Several simplifying assumptions were made that offer opportunities for future extensions.
No dependencies were assumed among different sources or different claims. In reality, sources could be influenced by other sources. Claims could fall into mutual exclusion sets, such as when one is the negation of the other. Taking such relations into account can further improve quality of fact-finding. The change in posterior probabilities due to any single edge in the source-claim network was assumed to be very small. In other words, it is assumed that |δtikj|≪1![]() and |ηtijk|≪1
and |ηtijk|≪1![]() . It is interesting to extend the scheme to situations where a mix of reliable and unreliable sources is used. In this case, claims from reliable sources can help improve the determination of credibility of other sources.
. It is interesting to extend the scheme to situations where a mix of reliable and unreliable sources is used. In this case, claims from reliable sources can help improve the determination of credibility of other sources.
The probability that any one source makes any one claim was assumed to be low. Hence, the lack of an edge between a source and a claim did not offer useful information. There may be cases, however, when the absence of a link between a source and a claim is important. For example, when a source is expected to bear on an issue, a source that “withholds the truth” exhibits absence of a link that needs to be accounted for.
In this chapter, we reviewed a novel analysis technique for information networks that uses a Bayesian interpretation of the network to assess the credibility of facts and sources. Prior literature that uses information network analysis for fact-finding aims at computing the credibility rank of different facts and sources. This work, in contrast, proposes an analytically founded technique to convert rank to a probability that a fact is true or that a source is truthful. This chapter therefore lays out a foundation for quality of information assurances in iterative fact-finding, a common branch of techniques used in data mining literature for analysis of information networks. The fact-finding techniques addressed in this chapter are particularly useful in environments where a large number of sources are used whose reliability is not a priori known (as opposed collecting information from a small number of well-characterized sources). Such situations are common when, for instance, crowd-sourcing is used to obtain information, or when information is to be gleaned from informal sources such as Twitter messages. The reviewed Bayesian approach shows that accurate information may indeed be obtained regarding facts and sources even when we do not know the credibility of each source in advance, and where individual sources may generally be unreliable.
Appendix
Consider an assertion Cj made be several sources Si1,…,SiK![]() . Let SikCj
. Let SikCj![]() denote the fact that source Sik
denote the fact that source Sik![]() made assertion Cj. It is further assumed that Equations (4.5) and 4.6 hold. In other words:
made assertion Cj. It is further assumed that Equations (4.5) and 4.6 hold. In other words:
P(SikCj|Ctj)P(SikCj)=1+δtikjP(SikCj|Cfj)P(SikCj)=1+δfikj

where |δtikj|≪1![]() and |δfikj|≪1
and |δfikj|≪1![]() .
.
Under these assumptions, it can be proved that the joint probability P(Si1Cj,Si2Cj,![]() …,SiKCj)
…,SiKCj)![]() , denoted for simplicity by P(Sourcesj), is equal to the product of marginal probabilities P(Si1Cj),…,P(SiKCj)
, denoted for simplicity by P(Sourcesj), is equal to the product of marginal probabilities P(Si1Cj),…,P(SiKCj)![]() .
.
First, note that, by definition:
P(Sourcesj)=P(Si1Cj,Si2Cj,…,SiKCj)=P(Si1Cj,Si2Cj,…,SiKCj|Ctj)P(Ctj)+P(Si1Cj,Si2Cj,…,SiKCj|Cfj)P(Cfj)

Using the conditional independence assumption, we get:
P(Sourcesj)=P(Ctj)∏Kk=1P(SikCj|Ctj)+P(Cfj)∏Kk=1P(SikCj|Cfj)

Using Equations (4.5) and 4.6, the above can be rewritten as:
P(Sourcesj)=P(Ctj)∏Kjk=1(1+δtikj)∏Kjk=1P(SikCj)+P(Cfj)∏Kjk=1(1+δfikj)∏Kjk=1P(SikCj)

and since |δtikj|≪1![]() and |δfikj|≪1
and |δfikj|≪1![]() , any higher-order terms involving them can be ignored. Hence, ∏Kjk=1(1+δtikj)=1+∑Kjk=1δtikj
, any higher-order terms involving them can be ignored. Hence, ∏Kjk=1(1+δtikj)=1+∑Kjk=1δtikj![]() , which results in:
, which results in:
P(Sourcesj)=P(Ctj)(1+∑Kjk=1δtikj)∏Kk=1P(SikCj)+P(Cfj)(1+∑Kjk=1δfikj)∏Kk=1P(SikCj)

Distributing multiplication over addition in Equation (4.38), then using the fact that P(Ctj)+P(Cfj)=1![]() and rearranging, we get:
and rearranging, we get:
P(Sourcesj)=∏Kjk=1P(SikCj)(1+Termsj)

where
Termsj=P(Ctj)∑Kjk=1δtikj+P(Cfj)∑Kjk=1δfikj

Next, it remains to compute Termsj.
Consider δtikj![]() as defined in Equation (4.5). The equation can be rewritten as follows:
as defined in Equation (4.5). The equation can be rewritten as follows:
δtikj=P(SikCj|Ctj)−P(SikCj)P(SikCj)

where by definition, P(SikCj)=P(SikCj|Ctj)P(Ctj)+P(SikCj|Cfj)P(Cfj)![]() . Substituting in Equation (4.41), we get:
. Substituting in Equation (4.41), we get:
δtikj=P(SikCj|Ctj)(1−P(Ctj))−P(SikCj|Cfj)P(Cfj)P(SikCj|Ctj)P(Ctj)+P(SikCj|Cfj)P(Cfj)

Using the fact that 1−P(Ctj)=P(Cfj)![]() in the numerator, and rearranging, we get:
in the numerator, and rearranging, we get:
δtikj=(P(SikCj|Ctj)−P(SikCj|Cfj))P(Cfj)P(SikCj|Ctj)P(Ctj)+P(SikCj|Cfj)P(Cfj)

We can similarly show that:
δfikj=P(SikCj|Cfj)−P(SikCj)P(SikCj)=P(SikCj|Cfj)(1−P(Cfj))−P(SikCj|Ctj)P(Ctj)P(SikCj|Ctj)P(Ctj)+P(SikCj|Cfj)P(Cfj)=(P(SikCj|Cfj)−P(SikCj|Ctj))P(Ctj)P(SikCj|Ctj)P(Ctj)+P(SikCj|Cfj)P(Cfj)
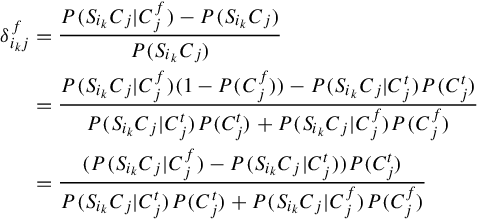
Dividing Equation (4.43) by Equation (4.44), we get:
δtikjδfikj=−P(Cfj)P(Ctj)

Substituting for δtikj![]() from Equation (4.45) into Equation (4.40), we get Termsj = 0. Substituting with this result in Equation (4.39), we get:
from Equation (4.45) into Equation (4.40), we get Termsj = 0. Substituting with this result in Equation (4.39), we get:
P(Sourcesj)=∏Kjk=1P(SikCj)

The above result completes the proof. We have shown that the joint probability P(Si1Cj,Si2Cj,…,SiKCj)![]() , denoted for simplicity by P(Sourcesj), is well approximated by the product of marginal probabilities P(Si1Cj),…,P(SiKCj)
, denoted for simplicity by P(Sourcesj), is well approximated by the product of marginal probabilities P(Si1Cj),…,P(SiKCj)![]() . Note that, the proof did not assume independence of the marginals. Instead, it proved the result under the small δikj
. Note that, the proof did not assume independence of the marginals. Instead, it proved the result under the small δikj![]() assumption.
assumption.