
Lock Fundamentals
So far, we've concentrated on the internal consistency maintained by a transaction. We've seen how the automatic begin, commit, and rollback transaction mechanisms make certain that entire transactions are completed or no work is done at all.
It's also important that a transaction be isolated from other activity. A transaction uses locks to prevent others from changing relevant data while the transaction is active.
In this section, you will learn about many characteristics of locks. Let's define some terms before we get started:
Lock mode defines how a lock interacts with other processes and locks. We'll look closely at shared, exclusive, update, shared intent, and exclusive intent locks.
Lock scope refers to how much data is locked. Locks can be acquired at the database, table, extent, page, and row levels.
Lock persistence describes how long a lock lasts.
Let's consider an example: My wife and I both carry ATM cards that access the same account. What if each of us makes a $50 withdrawal at the same time, but we have only $75 in the bank? If there were no locking to isolate each transaction, each of us could make a withdrawal at the same time and together we would overdraw the account. You can see in Figure 12.1 that the second withdrawal proceeded because the first withdrawal did not block its access to the account.
Figure 12.1. Without transaction isolation, the account is overdrawn.

The first transaction needs to lock the account to prevent further access. Only when the process is complete should another transaction be permitted to proceed. Figure 12.2 shows how transaction isolation prevents the overdraft problem discussed earlier.
Figure 12.2. Transaction isolation prevents simultaneously accessing the same data and an overdrawn account.

Just as with transactions, locks are automatically managed by SQL Server. The server decides when to lock data, how much to lock, and the type of lock to use. The server also determines when to release a lock. We will look at each of these aspects of locking to understand how your programs will interact with locks, and how you can influence how the server manages them.
Even though you don't actually create or drop locks in SQL Server, understanding how they work will help you avoid mistakes and understand better what's going on under the covers.
Understanding Lock Modes
There are two broad categories of locks: shared locks (also called read locks) and exclusive locks (also called write locks). Shared locks are obtained whenever a process reads data. Select statements obtain read locks, but so do update, delete, and insert statements when they use information in one table to update another.
Exclusive locks are obtained whenever a process modifies data. Typically, exclusive locks are assigned during insert, update, and delete processes. Select statements get exclusive locks on temporary worktables. Create, alter, and drop statements also get exclusive locks.
Shared and exclusive locks behave the way their names imply. Another user can read (select) through another user's shared lock. Both users will hold shared locks at that point. You cannot write through another user's shared lock because you would need an exclusive lock; you usually wait until the shared lock frees up, and then acquire the exclusive lock.
Exclusive locks permit only one user at a time to see a unit of data. Other users'shared and exclusive lock requests will fail until the exclusive lock is released.
Examining Lock Scope
SQL Server records and manages locks at many levels. Database locks are obtained to record activity and prevent certain maintenance operations until all users are out of the database. Table-level locks are used to manage large operations. A very common type of table-level lock is the extent lock, which prevents other table-level operations from occurring until the extent lock is released.
SQL Server also locks data at the eight-page level and at the row level. Page-level locks can be very efficient. Usually, page-level locks don't interfere with other users, especially where there is a large amount of data and a fairly small number of users updating the data. Where you have a unique index or primary key defined for a table, SQL Server can use row-level locks to manage multi-user concurrency one row at a time. This is the smallest lock that the server will obtain on a table.
During table creation and the allocation of space, SQL Server will also lock eight-page (64KB) extents. When tables or indexes require more space, SQL Server provides it one extent at a time (rather than one page at a time). During the allocation, other processes cannot access that space.
Note
Remember that an extent is made up of eight pages of storage.
SQL Server makes a decision during query optimization about the locking level that makes sense for each query. The server looks at the likely hit percentage (rows found per rows scanned) for the row retrieval method planned, and decides what level of locking would balance performance and concurrency. Some locking strategies minimize resource usage (table locks are cheap; row locks are expensive). Other strategies maximize concurrency (table locks block all users; row locks block almost nobody). In the section "Using Hints to Control Lock Types," you will learn to use table-level hints to suggest locking levels to SQL Server.
Examining Locks
Let's experiment with locks a little bit. To do that, we need to make the locks stay around long enough for us to see them. Ordinarily, and particularly on small tables such as those in the Northwind database, processes run so quickly that you can't see their locks.
This experiment will help you understand lock persistence, or how long locks stick around. Under different circumstances, different kinds of locks last for more or less time. We'll actually take advantage of that to inspect locks.
Later in the lesson, you will learn to use BEGIN TRANSACTION and COMMIT TRANSACTION to group sets of statements together into a single transaction. You will also learn to use ROLLBACK TRANSACTION to reverse the work in a pending transaction. We'll use those statements now to hold open a transaction so that we can query the locks created by various operations. We'll also see how locks affect other processes.
We'll start by deleting rows from the Order Details and Orders tables. The delete operation requires an exclusive lock to guarantee the consistency of its own operations. Open a window in the Query Analyzer and execute this query:
begin transaction delete [Order Details] where OrderID = 10258 delete Orders where OrderID = 10258
The first line starts a transaction, but the transaction is not completed. That would require a COMMIT TRANSACTION statement at the end. Until you commit the transaction, SQL Server holds any locks obtained during the deletion. After you execute this query, you can examine the locks it created.
Examining Locks with the Enterprise Manager
You can examine locks in SQL Enterprise Manager or using sp_lock in the Query Analyzer. We'll start with SQL-EM, and then look at sp_lock output. Both return the same information.
To observe lock information in SQL-EM, use the tree control to open the current server. Under Management, Current Activity, you will find two locking options. You can observe locks by process ID or by object. Let's look at locks by object first.
Figure 12.3 shows the lock information for the Orders table after the delete has occurred. By default, the list is sorted on the ProcessID column. By clicking twice at the top of the Lock Type column, I've resorted the list of locks in descending order by lock type. This will help you more easily understand the list.
Figure 12.3. Enterprise Manager enables you to look at locks by process ID or object. This list of locks on the Orders table was obtained during a delete statement.

Note
Most of the time, when you look for locks on the server, you won't find many. That's because locks are maintained only as long as the transaction takes. Most simple transactions take hundredths of a second, so your chances of finding locks aren't too good. We found these locks because we executed a transaction and did not commit our work. Don't do this in real life.
The first lock in the list—after the list is sorted in reverse order by lock type—is a table lock (lock type TAB) on the Orders table. Don't worry! SQL Server won't lock an entire table to delete one row unless there are no indexes on the table, or if you delete all the rows. This lock is an intent lock, which you can determine because of the mode, IX. An intent lock tells other processes that this process intends to do work somewhere in this table. The mode IX means that the process intends to do exclusive work (I for intent, X for eXclusive); that is, the process intends to update one or many rows in the table.
Intent locks block other processes from getting table-level locks that would conflict with the work being done somewhere inside the table. Many processes can all hold a mix of exclusive and shared intent locks for a single table. (Shared intent locks are identified with the mode IS.) The intent locks only indicate that many processes are working in the table, but nobody else can obtain an exclusive table-level lock until the intent locks are cleared.
SQL Server can also obtain an intent lock on a page. These locks warn other processes that work is going on within the page. The nine page locks in the list (lock type PAG) are all intent locks. Why nine locks? There is one page lock for each index on the Orders table. Each index is stored in a separate allocation structure and requires a lock on the page where the entry for OrderID 10258 is stored, and will be deleted. The actual page number is displayed in the Resource column.
|
Exploring Page Headers Why are all the page entries marked with the index value PK_Orders? Each page entry should have the name of a different index. It might be a bug or a deficiency in the table in the master database that stores locking information, syslockinfo. I wondered about it, so I asked the server to display the header for each page. In the page header, you can find the object ID and index number. This is a little technical, but there's an undocumented command to display page headers. To display the header from the fifth item in the list, page 1:252, I ran this query: dbcc traceon (3604)
dbcc page ('Northwind', 1, 252, 0)
dbcc traceoff (3604)
The dbcc, or Database Console Commands, enable you to check the physical and logical consistency of a database. Many DBCC statements can even fix detected problems. Here is the page header displayed by the dbcc page command: 1: Page @0x1B9B0000 2: ---------------- 3: m_pageId = (1:252) m_headerVersion = 1 m_type = 2 4: m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x0 5: m_objId = 1781581385 m_indexId = 5 m_prevPage = (0:0) 6: m_nextPage = (1:206) pminlen = 9 m_slotCnt = 290 7: m_freeCnt = 4036 m_freeData = 7092 m_reservedCnt = 0 8: m_lsn = (106:396:31) m_xactReserved = 0 m_xdesId = (0:59945) 9: m_ghostRecCnt = 1 m_tornBits = 2 Line 5 includes both the object ID and the index ID. As you saw back on Day 3, "Working with Columns," metadata functions can convert these numeric IDs into meaningful names. This query converts the object ID to an object name: select
object_name(1781581385) 'Object Name'
As you would expect, this query returns the name Orders. The easiest way to get the index name for index 5 is to query the sysindexes system table: select
indid, name
from
sysindexes
where
id = 1781581385
Results: indid name
------ ----------------------------------------
1 PK_Orders
2 CustomerID
3 CustomersOrders
4 EmployeeID
5 EmployeesOrders
6 OrderDate
7 ShippedDate
8 ShippersOrders
9 ShipPostalCode
I've displayed the complete list of indexes. There are nine real indexes, which corresponds to the number of page locks in the lock display. Index 5 is Employee Orders. |
Caution
You must be a system administrator to use dbcc page. If you have a local instance of the server on your machine, you can try it there.
This command is mostly used by Microsoft's technical people to diagnose problems and find bugs.
The next nine rows are key locks. Key locks are locks on individual rows in the database. The mode of the key locks is X, which means that they are (finally) real locks, not intent locks. These exclusive locks block other readers and writers attempting to access these individual rows in the database.
Each of the nine key locks points to the deleted row in one of the nine indexes. Notice that the indexes are properly named in this case. The key resource identifiers are hexadecimal identifiers, used internally by the server.
Examining Locks with sp_lock
You can also use the stored procedure sp_lock to get locking information. You can exe cute the stored procedure on its own, or you can pass one or two server process IDs (spids) to limit the results to display locks for only specific processes.
Note
Server process IDs are assigned when you log in to the server. They are managed in the system table sysprocesses in the master database.
To get your current server process ID, use
select @@spid
------
57
You can get a list of current users from the Current Activity, Process Info tab in SQL-EM. To get a list of current users and their process IDs from a stored procedure, use sp_who. Figure 12.4 displays the output from sp_who for my test server. When many sessions are logged in for a single user name, it can be difficult to tell processes apart.
Figure 12.4. The stored procedure sp_who reports a list of current users and their process identifiers. The only runnable process is the sp_who query itself (process 52).
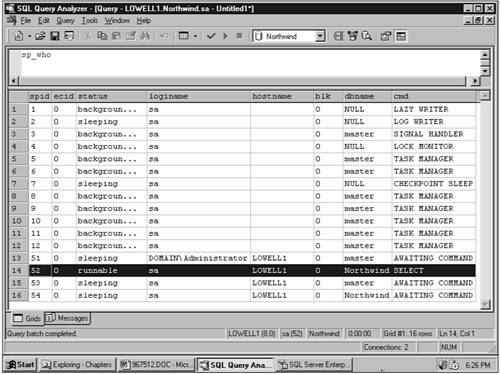
One important note about sp_who: Whenever you look at the list of processes, there will always be at least one runnable process; that is, a process currently executing. That runnable process is the sp_who query itself. I have seen people spend hours trying to eliminate the running process, only to have it reappear every time they run the query again.
This is a partial result set from sp_lock command:
sp_lock 53
Results:
spid dbid ObjId IndId Type Resource Mode Status ---- ---- ----------- ------ ---- ----------- ----- ------ 53 6 0 0 DB S GRANT 53 6 325576198 1 PAG 1:148 IX GRANT 53 6 325576198 1 PAG 1:183 IX GRANT 53 6 325576198 1 PAG 1:189 IX GRANT 53 6 325576198 1 PAG 1:187 IX GRANT 53 6 325576198 3 PAG 1:185 IX GRANT 53 6 325576198 1 PAG 1:199 IX GRANT 53 6 325576198 1 PAG 1:198 IX GRANT 53 6 1781581385 1 PAG 1:207 IX GRANT 53 6 1781581385 1 KEY (1200… X GRANT … 53 6 325576198 3 KEY (1700… X GRANT 53 6 325576198 1 KEY (1700… X GRANT 53 6 325576198 4 KEY (1700… X GRANT 53 6 325576198 5 KEY (1700… X GRANT
This is the same information you saw in SQL-EM. Table names and index names are displayed as object and index IDs, and database names are listed as numbers. The data is not as carefully sorted as in SQL-EM, but the information about each lock is the same.