
Understanding Transaction Basics
The definition of a transaction is "a logical unit of work." In real terms, a transaction is one or more statements that are executed together as a group. SQL Server guarantees that a transaction will succeed or fail completely. You will never get a partial transaction.
When you go to an ATM to make a $50 withdrawal, that act is treated as a transaction. The transaction consists of two parts:
The debit of $50 from your bank account
The delivery of $50 cash into your hand
It's clear that both parts of the transaction should be completed, or neither should occur. If you get $50 but your account is not debited, the bank is unhappy. If your account is debited, but no money comes out of the machine, you are not happy. In the design of the ATM system, it was critical to implement transaction control.
Understanding Automatic Transactions and the Transaction Log
SQL Server automatically uses transaction management to ensure the completeness and consistency of all work performed on the server. Every SQL Server statement is a transaction.
This is a key point. You cannot step outside of the transaction management system. Even a simple insert statement or a select statement will be governed by transactions.
Consider this statement, that raises the unit price for all products by 10%:
update Products set UnitPrice = UnitPrice * 1.1
There is no where clause in the statement, so all rows in the table are affected. SQL Server guarantees that all rows in the Products table will be modified, or, if that fails, no changes will be written.
How does the server guarantee this? Through the use of a write-ahead transaction log and automatic commit and rollback mechanisms. Let's see how that works.
Understanding the Write-Ahead Log
SQL Server uses a write-ahead log to manage database consistency during transactions. It's a write-ahead log because the log entries are written first, before changes are made to the tables and indexes.
To understand this better, let's step through the process of changing a set of rows in the Products table. In Figure 13.1, I've set up four areas. On the left are disk areas for the transaction log and for permanent data storage. On the right are similar areas within the data cache. SQL Server performs work in cache first to improve performance. It is only when the work is complete, or when the work is too large to fit entirely into memory, that the server will write changes to disk.
Figure 13.1. Data modifications are made in RAM first, and then saved to disk.

When the server performs work on data, the first step is to retrieve that data into the cache. Data sets are retrieved gradually, as required. Figure 13.2 shows the data all in cache, where all modifications occur.
Figure 13.2. When rows are to be modified, the first step is to retrieve the data from disk into cache.
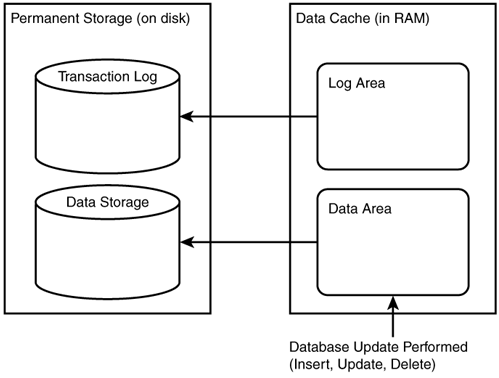
The first part of a transaction occurs when the server writes a Begin Transaction marker in the transaction log (see Figure 13.3). A time stamp identifies transaction markers. Time stamps don't include a time component. They are sequential hexadecimal keys for rows in the transaction log.
Figure 13.3. Before changing data, the server makes a transaction in the log. All subsequent changes will be associated with this transaction marker.

Note
The transaction marker log record does include date and time information, which the server can use to do "as-of" database restores. For instance, you could restore the database to its state on Thursday at 4 p.m. That would restore all transactions completed by that time.
Some updates can occur in place, when only the modified part of a row is replaced. Most updates occur in two steps—a delete followed by an insert. The server decides the method based on what is changing about the row. We'll look closely now at how the server performs the delete/insert sequence of an update statement.
Note
Don't get confused. The server deletes, and then reinserts the row, but it's not a regular DELETE or INSERT statement. For instance, you don't need the DELETE or INSERT permission on a table to perform an update.
When the server deletes the old version of the row, it first writes that version to the transaction log (see Figure 13.4). The old version of the row is a useful resource. If the update fails for any reason, the row in the transaction log can be reinserted to the table.
Figure 13.4. The next step is to save the original data values prior to modification. If something goes wrong, the server can restore those values.

As part of the deletion, the server also deletes all index entries that point to the row. The index deletions themselves are also logged.
When the deletions are complete, the server then inserts the modified values. The inserts are logged first, and then written to the table in cache (see Figure 13.5). Any index changes are written at this point.
Figure 13.5. Now the server records changes to the log and makes the changes to the data in cache.

The rows have been updated, and it's time to write the work to disk. The server writes a commit marker to the log in cache, and then flushes the changes to the log out of cache to the disk (see Figure 13.6).
Figure 13.6. The server writes a commit marker to the log in cache, and then flushes the changed log pages to disk. Notice that the data area on disk still contains the original data.

When you commit data, you are writing it to the database permanently, without any opportunity to back out.
That's all. The changes have been made, and the new values in the table are ready for use.
Rolling Back Changes
If something goes wrong when a transaction is partially completed, the server automatically rolls back the transaction. What might go wrong? You could have a constraint limiting the UnitPrice column to $150, and the update might attempt to set a UnitPrice higher than that value. You might violate a unique index, or insert an invalid foreign key.
When the server rolls back work, it re-creates the state of the data before the transaction started. If an update or delete was underway, any deleted rows are restored to the table. If an insert was underway, rows added to the table are removed. Indexes are restored. When all the changes are completely removed, a ROLLBACK TRANSACTION marker is written to the log to indicate that the work was backed out.
An automatic rollback is usually fast, unless the transaction was enormous. That's because almost all of the work associated with a rollback takes place in cache.