
Understanding Lock Persistence
You've already seen that exclusive locks are held throughout a transaction and are released when the transaction is committed or rolled back. Let's try a similar experiment with a select statement. We'll start with this query:
begin transaction select CustomerID from Orders where OrderID = 10258 CustomerID ---------- ERNSH
The first line of the query creates a transaction. The select statement acquires a shared lock on the row in the Orders table. Intent locks are acquired. Let's look at the locks held by this process:
spid dbid ObjId IndId Type Resource Mode Status
------ ------ ---------- ------ ---- -------- -------- ------
57 6 0 0 DB S GRANT
Even though the process acquired locks during the select process, the locks are gone. In its default mode, SQL Server releases shared locks after they are used, regardless of whether a transaction is running (the transaction state). This helps improve concurrency when many users are working.
This characteristic of locks is called persistence. Persistence is the length of time a lock is held. Locks can be held throughout the transaction, released after they are used, or never acquired. You will manipulate lock persistence with transaction isolation levels (which are covered later in the next section) and with table hints.
Working with Transaction Isolation Levels
The default transaction isolation level in SQL Server is called read committed. In that mode, exclusive locks persist throughout the transaction, but shared locks are released as soon as the page is no longer needed. If the process needs to refer to a page a second time, it acquires the select lock again. This is also known as isolation level 1.
The transaction isolation level determines lock persistence. The ANSI standard calls for databases to support four transaction isolation levels. We'll take a minute to review the four levels, and then experiment with them so that you understand how transaction isolation level might affect your applications.
The four transaction isolation levels refer to the way that shared locks are acquired and held. (Data modifications always obtain exclusive locks and the exclusive locks are always held throughout the transaction.) The isolation levels are listed here in order from least restrictive to most restrictive.
Read uncommitted—(Level 0) Read operations do not obtain locks. You can read through any lock (even an exclusive lock), known as a dirty read. Processes can modify data while it is being read. A dirty read is one that contains uncommitted data.
Read committed—(Level 1) Read operations obtain locks, but they release them immediately after the page is read. Exclusive locks are respected. If a page is read a second time, a new lock is obtained, but the data might have changed in the meantime. This is the SQL Server default.
Repeatable read—(Level 2) Read operations obtain locks and the locks are held through the transaction. This prevents other transactions from modifying values, in case they need to be read again (repeatable) or modified by the process later in the transaction.
Serializable—(Level 3) Read operations obtain locks and the locks are held through the transaction, making the read repeatable. Phantom inserts and updates are blocked using a range lock on the data set. This is the most restrictive level, and is most likely to create a blocking lock.
All the examples you have seen so far have demonstrated the default behavior of the server: using the read uncommitted isolation level. To change the isolation level, use one of these commands:
set transaction isolation level read uncommitted set transaction isolation level read committed set transaction isolation level repeatable read set transaction isolation level serializable
Let's look at how the other isolation levels work.
Experimenting with Dirty Reads
The read uncommitted isolation level, also called isolation level 0, implements dirty reads. Dirty reads allow select statements to read through a data set without creating or respecting locks. The reads are called "dirty" because the pages being read might be in the midst of being modified by a transaction.
We'll create another pending transaction and change the supplier, Escargot Nouveaux, to Joe's Rib Joint. Execute this script in your current window:
begin transaction
update Suppliers
/* two ''to store one in the string */
set CompanyName = 'Joe''s Rib Joint'
where SupplierID = 27
This process obtains exclusive locks in the table and indexes on the Suppliers table. As you've already seen, another process coming to look at supplier 27 will be blocked by the exclusive lock.
If you select the modified row without first changing the transaction isolation level, the update will block your select. This is the same situation we created earlier after a delete. Before you execute the select, set the transaction isolation level for dirty reads. Here's the command:
set transaction isolation level read uncommitted
Now execute a test query in the same session:
select CompanyName from Suppliers where SupplierID = 27
Results:
CompanyName ---------------------------------------- Joe's Rib Joint
Despite the exclusive lock, your process reads the modified data before the transaction is committed.
When should you use isolation level 0? Dirty reads are useful when you need to perform large queries on a table that is heavily updated. Any time you can accept an answer that's "close enough," you can use dirty reads.
If you need absolute precision, as with bank balances or inventory control, dirty reads will return data in a partial or inconsistent state. Avoid level 0 in those circumstances.
Note
The transaction isolation level settings are specific to a connection. They characterize the way that a session (a window in Query Analyzer) will obtain and keep locks. The easiest way to reset the transaction isolation level when you are working in Query Analyzer is to close the window and reconnect to the server. I suggest that you close any open transactions by exiting all your open connections before continuing.
Understanding More Restrictive Isolation Levels
The isolation levels that support repeatable reads and serialized work are also known as levels 2 and 3. These higher isolation levels obtain and keep shared locks throughout a transaction.
In a new window, execute this query:
set transaction isolation level repeatable read begin transaction select CompanyName from Suppliers where SupplierID = 27
Here are the locks that sp_lock reported for this process:
dbid ObjId IndId Type Resource Mode Status
------ ----------- ------ ---- ---------------- ----- ------
6 0 0 DB S GRANT
6 2137058649 1 PAG 1:292 IS GRANT
6 2137058649 1 KEY (1b007df0a359) S GRANT
6 2137058649 0 TAB IS GRANT
There are four locks.
The database lock indicates that a user is working in this database. It is a shared lock.
The table-level shared intent lock (mode IS) reports that a user holds a shared lock somewhere in this table. This lock prevents another user from obtaining a table-level exclusive lock until it is released. Another process could obtain a table-level exclusive intent lock (mode IX), indicating that the process is updating something in the table.
A shared key lock (mode S) indicates a real lock on this row. Other users may read the row, but no one may modify it until the transaction completes.
The page-level shared intent lock (mode IS) reports that a user holds a shared lock on a key within the page. This prevents other users from obtaining an exclusive page-level lock until this transaction completes.
Because the transaction is running at this transaction isolation level, shared locks are held instead of being released immediately. We can now see three shared locks on the table, page, and key.
What is the value of holding shared locks? If a process needs to reread or modify information about a row later in the transaction, the repeatable read setting guarantees that the data will not change. Without this setting, another user could modify the data or even delete the row.
Listing 12.1 deletes an order and all of its associated order detail rows if the total value of the order is less than $2000.
Code Listing 12.1. Deleting Rows for Order Less Than $2000
In this query, lines 5 through 7 read from the Order Details table. Based on this result, the process either quits or deletes the rows from Orders and Order Details. The sequence read-validate-write is specifically what transaction isolation levels are meant to handle.
Listing 12.2 is a query that another user is trying to run at the same time. We'll look closely at the interaction between these operations to understand transaction isolation better.
Code Listing 12.2. Updating the Value of a Row in the Order Details Table
01:begin transaction 02:update [Order Details] 03: set Quantity = 100 04: where OrderID = 10258 05: and ProductID = 2 06:commit transaction |
Using the default isolation level, read committed, can cause significant consistency problems in this situation. What happens if the first user gets the total dollar value of the order, but before he has a chance to delete the rows, a second user increases the total value of the order? In Figure 12.8, Step 1_ is the external user performing a data modification. Without a persistent shared lock, other users can change data conditions while you are working, making a later update invalid.
Figure 12.8. Using the read committed isolation level, the first query releases the shared lock on the Order Details table before the transaction is complete.

If the transaction isolation level is raised to repeatable read, shared locks are held throughout the transaction. In Figure 12.9, you can see how the shared locks block the other user, preventing him from obtaining an exclusive lock. In this case, the data is safe from modification after it has been read.
Figure 12.9. Using the repeatable read isolation level, the first query holds the shared lock on the Order Details table throughout the transaction.

There is a weakness in the repeatable read method. What if a user adds new rows for the order instead of modifying Order Details rows already in the table? This query could cause the value of the order to exceed $2000 without modifying any rows that are currently locked:
insert [order details] (
orderid,
productid,
unitprice,
quantity,
discount
) values (
10258,
7,
25,
10,
.2
)
Note
The orderid that is used in this example must exist in the Orders table. If it does not exist in the Orders table, you will receive an error.
The insert would need an exclusive intent lock on the table and a page, and a key lock on the new row. After it is in the table, further operations with this order will include the new order detail row. Figure 12.10 illustrates the addition of a new row, known as a phantom because it appears mysteriously in the midst of a transaction.
Figure 12.10. Using the repeatable read transaction isolation level, the first query holds the shared lock on specific rows in the Order Details table throughout the transaction.

The highest level of transaction isolation, serializable, blocks phantom rows by locking not only individual rows but also the range of rows represented by a query. The select query that obtains the shared locks uses this condition:
where OrderID = @OrderID
With serializable transactions, the server guarantees that the query will return the same result set if it is run again later in the transaction. Figure 12.11 illustrates the blocking of phantom rows.
Figure 12.11. Using the serializable transaction isolation level, the first query holds the shared lock on specific rows in the Order Details table and holds a range lock throughout the transaction.
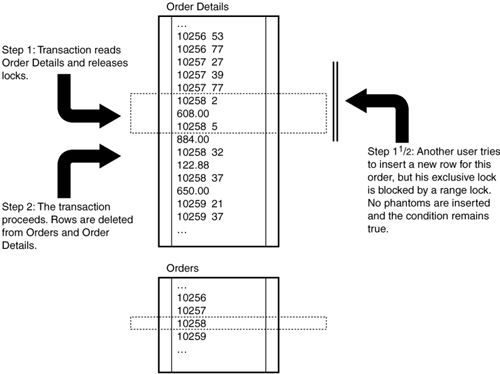
You can see the range locks created by serializable transactions. Execute this query from a new session, and then look at the locks on the Order Details table.
1:set transaction isolation level serializable 2:declare @OrderID int 3:select @OrderID = 10258 4:begin transaction 5:if ( 6: select sum(Quantity * UnitPrice * (1 - Discount)) 7: from [Order Details] 8: where OrderID = @OrderID 9: ) < $2000 10:print 'lower' 11:else 12:print 'higher'
Here are the locks for this process from sp_lock:
ObjId IndId Type Resource Mode Status
----------- ------ ---- ---------------- -------- ------
0 0 DB S GRANT
325576198 1 PAG 1:148 IS GRANT
325576198 0 TAB IS GRANT
325576198 1 KEY (280008c67cf3) RangeS-S GRANT
325576198 1 KEY (1400b0a918f2) RangeS-S GRANT
325576198 1 KEY (320005ce23f8) RangeS-S GRANT
325576198 1 KEY (17000991cf6f) RangeS-S GRANT
The range locks prevent other users from modifying the rows matching the search condition, but they also prevent users from adding new rows that would match the condition. If you try to insert a new order detail row for OrderID 10258, the insert will wait for this transaction to complete.
Caution
Don't forget to rollback this transaction when you are finished.
Using Higher Transaction Isolation Levels
The default isolation level works well and is very efficient in most circumstances. You will seldom write applications that need repeatable reads or protection against phantoms. Level 2 is used infrequently because the phantom problem is hard to manage. If you need repeatable reads, you probably need serializable reads as well.
You need to recognize the situations when higher transaction isolation levels are required and consider ways to code around them. For example, a read-reread or read-validate-write sequence creates the need for higher isolation levels. Instead, use a locking hint (see the section "Using Hints to Control Lock Types") to obtain exclusive locks instead of shared locks in a query.
You'll see in the section "Deadlocks" that higher isolation levels frequently lead to deadlocks. First, you need to learn about using table hints to control lock types.
Using Hints to Control Lock Types
You saw on Day 9, "Indexes and Performance," how to use table hints to specify an index or table scan for a table in a query. Locking hints provide the programmer with the flexibility to manage the locking behavior for individual tables in a query.
For example, in this query, the Orders table is read without locks (dirty reads), but the Order Details table uses read committed (the default isolation level):
select o.OrderID, o.CustomerID, od.ProductID
from Orders o with (readuncommitted)
inner join
[Order Details] od with (readcommitted)
on o.OrderID = od.OrderID
where o.OrderID = 10258
and od.OrderID = 10258
Here is a list of locking hints regarding isolation level and the behavior they specify:
readuncommitted (or nolock)—This implements dirty reads for a table (isolation level 0). Locks on this table held by other processes are ignored. This process places no locks on the table.
readcommitted—The default transaction isolation level (isolation level 1). Exclusive locks will be held throughout a transaction, and shared locks will be released. Use this hint only when you are set to a different isolation level and require default behavior for this table.
repeatableread—Exclusive and shared locks are held throughout a transaction, but phantoms can still appear (isolation level 2).
serializable (or holdlock)—Exclusive and shared locks are held throughout a transaction, and phantoms are prevented (isolation level 3).
readpast—This hint tells the query to skip locked rows (isolation level 4). In this query, the server requests all orders between 10256 and 10260, but if any specific rows are locked, return only the available rows:
select OrderID, CustomerID from Orders with (readpast) where OrderID between 10256 and 10260.
If another process were holding a lock on OrderID 10258, the server would return 10256, 10257, 10259, and 10260.
You can also request specific locking levels by using hints:
rowlock—If the process would normally obtain shared page- or table-level locks, you can request shared row locks instead.
paglock—If the process would normally obtain a shared table-level lock, you can request page locks.
tablock—This requests a shared table-level lock to be held throughout a transaction. This hint enables you to get a snapshot in time of a table, but the table lock will slow down other users.
Finally, you can request locking modes by using hints. You can escalate locks only with hints. (Shared locks can be promoted to exclusive locks, but not vice versa.)
updlock—This hint causes a query to obtain update locks instead of shared locks. Update locks are locks indicating an intent to modify data. They are used to prevent deadlocks. (For more on update locks, see the next section, "Deadlocks.")
xlock—This hint requests exclusive locks instead of shared locks. Using the xlock hint will help you avoid deadlocks and should be considered as an alternative to higher isolation levels.
tablockx—This hint tells the server to acquire an exclusive lock on the table. It is the equivalent of combining the tablock and xlock hints.
Deadlocks
What is a deadlock? A deadlock occurs when two or more users are stuck waiting for resources held by each other. None of the processes can proceed until a lock is released. Let's look at an example. In earlier database systems, deadlocks were a serious problem that required administrative intervention to resolve. SQL Server detects deadlocks before they occur and automatically resolves them. You need to understand deadlocks for two reasons:
First, deadlocks generate error states that you need to understand and respond to. This is a programming problem. Normally, when you get a deadlock error (server error 1205), your application should just go ahead and retry the query.
Second, deadlocks have a definite performance impact. The more deadlocks your application encounters, the slower work will proceed. (One client years ago was dealing with a 95% deadlock rate. 95% of all attempted updates were failing on deadlocks!) Deadlock avoidance is a separate programming challenge. That's what we'll focus on here.
Examining Deadlocks
Most of the time, you can create a deadlock by imagining two users, each running the same program. The program needs to use the read-validate-write sequence you saw earlier, with repeatable read or serializable isolation level.
Listing 12.3 is a copy of Listing 12.1 with the serializable locking hint added to the query. In addition, the OrderID is hard-coded in each statement.
Code Listing 12.3. Code for Testing Deadlocks
To perform the test, you will need to simulate concurrent execution. I do that by executing a small part of the query at a time from each of two windows. Figure 12.12 shows how my Query Analyzer looks as I prepare to execute this test. To do deadlock testing, I single-step each query to keep the queries synchronized.
Figure 12.12. In the Query Analyzer, the same query is run from two separate windows.

To single-step the query, highlight the portion you want to run, and then execute. In the figure, I've highlighted the BEGIN TRANSACTION statement and the select query. Execute the select statement from both sessions, and then check the locks on the Order Details table. You should find persistent shared intent locks on the table and page, and shared range locks on individual keys. If the locks don't appear in the list, you might have forgotten to execute the BEGIN TRANSACTION statement as well.
Now, skip the if condition and just highlight the delete statement on Order Details (lines 9 and 10 in the Query Analyzer). When you execute the delete in one of the windows, that window will go into a lock sleep state, waiting for the lock on the Order Details table to release. Figure 12.13 shows the locking sequence on the Order Details table.
Figure 12.13. Almost ready for the deadlock. Each user holds a shared lock on the Order Details rows, and both users need exclusive access to delete the rows. When the second user executes a delete statement, the deadlock will be detected.

Before we go ahead, you should look at the list of locks for the table. Here is the output from sp_lock for these two sessions:
spid ObjId IndId Type Resource Mode Status
------ ----------- ------ ---- ----------- -------- ------
51 325576198 0 TAB IS GRANT
55 325576198 0 TAB IX GRANT
51 325576198 1 PAG 1:148 IS GRANT
55 325576198 1 PAG 1:148 IU GRANT
55 325576198 3 PAG 1:185 IU GRANT
51 325576198 1 KEY (280008c6 RangeS-S GRANT
55 325576198 1 KEY (280008c6 RangeS-S GRANT
51 325576198 1 KEY (1400b0a9 RangeS-S GRANT
55 325576198 1 KEY (1400b0a9 RangeS-U GRANT
55 325576198 1 KEY (1400b0a9 X CNVT
55 325576198 3 KEY (1400b0a9 U GRANT
51 325576198 1 KEY (320005ce RangeS-S GRANT
55 325576198 1 KEY (320005ce RangeS-S GRANT
51 325576198 1 KEY (17000991 RangeS-S GRANT
55 325576198 1 KEY (17000991 RangeS-S GRANT
I've manually sorted the output to make it easier to read. Each process holds an intent lock on the table, although the first process (spid 55) has escalated the lock to an exclusive intent lock. It plans to modify data in the table.
The page locks are also modified. Process 55 holds two page locks, one for the clustered primary key index and one for a second, nonclustered index. These are update intent locks. Update intent locks are held when the server plans to perform exclusive work but needs to wait for another lock to clear. These update locks are specifically used to prevent deadlocks. (Update locks are special shared locks: Other users can read through an update lock.)
At the key level, we can also see update locks on one key, resource number 1400b0a9…. The original shared range lock has been converted to an update range lock (RangeS-U), an update lock has been added for this row, and an exclusive lock is waiting to be acquired. Note the status of the exclusive lock (CNVT). The server is waiting for the shared locks from process 51 to clear so that it can convert a prior shared lock to an exclusive lock.
Normally all this work takes place in the blink of an eye. We've slowed it down to see the details. Now let's push this forward one last step.
To complete the deadlock chain, highlight and execute the delete statement in the second window. The second process (process 51) will try to obtain an update lock on the same row, but that lock will be blocked by process 55. The server sees the blocking chain (55 blocks 51, 51 blocks 55) and detects a deadlock before it occurs.
Two things happen immediately:
First, one of the processes will report success (3 rows deleted). (The transaction will still be alive, so you can roll back the deleted rows if you don't want to make changes to the sample database.)
Second, the other process will report error 1205, a deadlock. Here's the actual error message:
Server: Msg 1205, Level 13, State 50, Line 1 Your transaction (Process ID 51) was deadlocked on {lock} resources with another process and has been chosen as the deadlock victim. Rerun your transaction.
Which process will succeed and which will fail? The choice of a deadlock victim is essentially chosen at random.
What happens when you are the deadlock victim? The server terminates your current command, rolls back any current work, and releases all locks. If you are running a multi-statement batch or a stored procedure, deadlock detection will abort your work immediately. The process will not go on to the next step. The logical next step for the application is simply to try again.
Avoiding Deadlocks
To avoid deadlocks, try to obtain exclusive locks in the first step of a batch. For instance, modify the data before you read it. Here is a typical programming problem that can be easily solved with a simple change in the code.
In Listing 12.4, the user checks the balance in the account before deducting $50.
Code Listing 12.4. An Example of Incorrect Transaction Usage
The query validates the balance first, and then updates the checking account. Because this follows the read-validate-write sequence, you need to use the serializable hint to prevent data consistency problems.
Listing 12.5 shows an alternative approach, where the update is performed, and then the resulting balance is checked. Notice that the balance must be greater than $0 after the withdrawal occurs.
Code Listing 12.5. Updating the Account and then Validating the Modification
If the withdrawal was successful, the transaction is committed. If the withdrawal failed, the transaction is rolled back. This "shoot first, ask questions later" approach acquires an exclusive lock in the first step. Other users wait for the entire transaction to complete. There is no danger of deadlock.
This approach is supported in an alternative form of the update statement, which returns the modified value of a column to a variable. Here is the same example, this time using the @Balance variable to store the contents of the modified Balance column.
declare @Balance money
begin transaction
update Checking
set @Balance = Balance = Balance - $50
where AccountNum = 12345
if @Balance >= $0
begin
print 'Withdrawal approved'
commit transaction
end
else
begin
print 'Account balance insufficient'
rollback transaction
end
Whenever possible, use this approach to avoid locking problems and improve performance. Here is an example of a query that retrieves the next value in a sequential counter:
declare @NextKey int update CounterTable set @NextKey = NextKey = NextKey + 1 where TableName = 'Ledger'
Normally, getting the next key requires a read and a write. By writing both the read and the write at once, the query can be performed in a single step with no transactional coding at all and no danger of deadlock.