
How SQL Server Uses Indexes
Indexes are used to provide fast access to data. An index in a database is much like an index in a book. When you are looking for a specific topic in a book, you would use the index to find the page or pages where the topic is located. In a database, when you are looking for a specific row of data in a table, SQL Server uses an index to find where that row is physically located. There are two main differences between a book index and one that exists in SQL Server. First, with a book, you decide whether or not to use the book index. This option does not exist in SQL Server. The database system itself decides whether to use an existing index or not. Second, a book index is edited together with the book and does not change after the book has been printed. This means that each topic is exactly where the index says it is on the page. In contrast, a SQL Server index changes every time the data referenced in the index is modified.
There is one other method for accessing data in a database table, which is called sequential access. Sequential access means that each row of data is retrieved and examined in sequence and returned in the result set if the condition in the WHERE clause is true. All the rows in the table are read according to their physical position in the table. (Sequential access is sometimes called a table scan.)
Using an index to access the data is the preferred method for accessing tables with many rows. By using an index, SQL Server will usually take only a few I/O operations to find any row within a table, in a very short time. Sequential access, on the other hand, requires much more time to find a row in the table.
Why Use Indexes?
If you haven't already figured it out, indexes speed up the processing of your SQL query. There are really three main reasons for SQL Server to make use of an index. These are
Organizing data
Improving performance of all data retrieval and data modification queries
Enforcing uniqueness of data
To see this, we are going to look at the different types of indexes that SQL Server uses, how the data is organized within them, and how the server uses them to improve performance. When you create a table, SQL Server will create it without adding any indexes to the table. The reason for this omission is that unless you specify a primary key or unique constraint (these will be discussed later in this lesson), the table is created with no indexes. Every time a query references this table, the server has no choice but to examine every row to find the required data using tables scan.
As an example, if you were to submit the following query to an orders table with no indexes, the server would perform a table scan to determine which rows meet the criteria:
Select Count(*)
From [Order Detail]
Where Quantity > 50 and
ProductID = 41
As the server reads each page of data into memory and retrieves a row, it inspects the values for quantity and productID, to determine which rows should be included in the final result set.
Note
It doesn't matter if 10 rows or 1 million rows are returned. Without an index, the server must inspect every row in the table to build the result set.
This increased performance does come with a cost. Tables that have indexes require more storage space in the database. In addition, any commands that insert, update, or delete data can take longer and require more processing to maintain the indexes. When designing and creating an index, you should make sure that the performance benefits you get outweigh the extra cost.
Understanding Optimization
Optimization is the process of selecting the best access path for resolving a SQL query. To understand what this means, let's look at what the server does when it processes a SQL query. When you execute a query, SQL Server performs the following four-step process:
1. | Parse—SQL Server verifies the syntax of the SQL query and all the objects referenced in it. |
2. | Optimize—SQL Server chooses how to execute the query. |
3. | Compile—An executable module or plan is created. |
4. | Execute—The compiled module or plan is executed by SQL Server. |
In step 2 of this process, the server will make several decisions regarding how the query should be processed and which if any indexes will be used to enable the query to run more efficiently. Now that you have seen the different types of indexes and how SQL Server actually uses them when executing a query, we will take a look at how the process of optimization really works.
Note
Understanding that SQL Server decides when and where to use indexes to optimize the execution of a query will be the hardest thing for you to do. As we look at the decision process, you will see how it is affected by the data you are accessing. You will see that the server is far more flexible and efficient over time than you could be when writing the actual SQL code.
Remember, that the server is seldom wrong about which path is the most efficient when retrieving data, but this increase in efficiency brings with it a loss of control to the programmer.
To decide how to optimize a query, SQL Server uses a method called cost-based optimization. This means that the server will focus on the cost (in terms of the physical resources needed—disk and memory reads) of performing a query using a certain plan. The optimization process itself consists of the following four steps:
1. | Find the current Search ARGuments (SARGs). |
2. | Match the SARGs to one or more indexes. |
3. | Estimate the work required by the server to resolve the query using each of the identified indexes (as well as without using an index). |
4. | Choose the most effective way to resolve the query from the list of indexes or table search found by the server as described in the previous 3 steps. |
The following example demonstrates how the optimization process works:
Use northwind
select count(*) as 'Count',
sum(Quantity) as 'Total Sold'
From [Order Details]
Where orderid between 10250 and 10700
and ProductID like '6%'
Finding the SARGs
SQL Server will first try to find the elements of a query that will allow the server to use an index. These are the search arguments, or SARGs.
A SARG is the portion of a WHERE clause that contains the actual condition in the form of
<column name> <operator> <constant | expression>
An example of this is
orderid between 10250 and 10700
Only SARGs can take advantage of indexes.
Tip
Whenever possible, you should use constants instead of expressions or variables in the WHERE clause to increase the use of indexes.
Also, try not to use functions with columns in a WHERE clause. Of course, there will be many times when you must use functions and expressions. SQL Server will do its best to optimize the query.
Getting back to our original example, there are two SARGs that the server will use to locate an index. These are the BETWEEN and LIKE keywords that were discussed on Day 2, "Filtering and Sorting Data."
Matching the SARGs to Available Indexes
The next step is for the server to look for any indexes that might be useful for the query. Each column that is referenced by a SARG might have one or more relevant indexes. For our example, the server finds two candidate indexes, one for each SARG.
Note
An index is used only if one of the search arguments is the First column in the index. Most programmers expect that an index will be effective for a query because a column is included in an index. This, of course, is not true unless that column is the First column.
Estimating the Work Using Each Index
In order for the server to estimate the work needed to perform a query, it checks several of the statistics about the table and the indexes. First, it determines how many pages and rows are in the table. Second, it looks in a distribution page for each index to determine about how many rows will fit the condition for each SARG.
An index has a distribution page that enables the server to estimate the selectivity of a WHERE clause. These pages allow the server to quickly scan the values contained in the index and determine exactly how many rows might match the condition.
Tip
The distribution page statistics are set up one time, when the index is created. There is no automatic method to get SQL Server to rebuild the information on the distribution page. On a periodic basic, someone (probably the database administrator) should execute the following statement for every table in the database.
Update Statistics <table name>
When executing this command, the process might take a while to complete when run on larger tables. You should plan to do this work after hours, when the tables are not being used.
Using the distribution page, the server would determine that about 9% of the table's rows matched the WHERE clause conditions. A table itself might contain more than 500,000 rows on 9,572 pages. If a clustered index on the OrderID is used, on the same percentage, it might find about 10,567 rows on approximately 425 pages. Finally, if a non- clustered index on the ProductID is used, the server might find 975 rows on about 1000 pages.
Note
The numbers used in this example are completely fictional and do not represent actual values in the Northwind database.
Choosing the Optimal Way to Resolve the Query
The server will use the statistics calculated in the previous step to decide on the most efficient approach. In addition to the index methods, the cost of performing the query with a table scan is also considered. Based on this information, the server does a comparison of estimated cost, as shown in Table 9.1.
| Execution Method | Estimated Cost |
|---|---|
| Table scan | 9,572 pages |
| Clustered index on OrderID | 425 pages |
| Nonclustered index on ProductID | 1,000 pages |
Although the nonclustered index approach is less costly than a table scan, the clustered index scan is the fastest method to use for this query.
Of course, this is a very simple overview of how the server determines the best way to execute a query, and which index or indexes to use. In the remaining sections of this lesson, we will be learning about the different indexes available, how to create them, and how to use the tools provided in SQL Server 2000 to enhance their performance.
Understanding Clustered and Nonclustered Indexes
There are two main types of indexes used by the server to organize data: clustered and nonclustered. A clustered index sorts the actual rows of data by the index key specified, whereas a nonclustered index creates a separate, sorted list of keys that contains pointer to the actual rows in the table.
Clustered Indexes
A clustered index actually determines the physical order of the data in a table. Only a single clustered index is allowed per table in SQL Server because the rows of data in the table cannot be physically ordered more than one way. If you define a primary key for a table when you create it, a clustered index is automatically created for that table.
The first thing that the server does when you create a clustered index is to sort the existing rows in the order specified in the clustered index. If you created an index for last name on a telephone directory, the server would automatically re-sort all the rows in the directory by the values in the last name column. If you then dropped that index, and created a new clustered index based on the telephone number, the server would again re-sort the table. Although the system or database administrator controls most index maintenance, everyone who might perform maintenance on an index should be aware of some of the maintenance issues associated with indexes. Some of these questions are
How often should the indexes be rebuilt to remove fragmentation?
How long does it take to re-sort the data on a large table?
Can presorting the data before loading it speed up the creation of the index?
The clustered index on OrderID forces SQL Server to sort the table by OrderID and to maintain that sort throughout any other operations that might be performed on that table. Figure 9.1 shows the first level of the clustered index on Order Details. After sorting the rows by the index key (orderID), the server will build the index by recording the first value of orderID on each data page, along with a pointer to that page. In the figure, the orderID value on the first page in the table (page 7420) is 17. The first value on the first page of the clustered index is also 17. The row in the index includes a pointer value to the page number in the table.
Figure 9.1. An Order Detail table and its Level 1 clustered index.

Note
In SQL Server 2000, a page is defined as an 8kb area of storage that is used both on disk and in memory to contain rows of data in a SQL table and index.
Depending on the size of a row of data, many rows can fit into one page of storage. As an example, if your data row is 200 bytes, then you would be able to fit 40 rows on one page.
Because the data in the table is already sorted by orderID, the server does not need to store a pointer to each row to know what values are on each page. Because of this, the number of rows in the first level of a clustered index is dramatically lower than the number of rows in a table.
Clustered indexes use several levels to reduce the amount of searching the server must perform to find a particular set of data. Figure 9.2 displays the rest of the structure for the clustered index. Level 1 includes one row per page which is faster to search than the actual data pages. The server continues to generate additional index levels until it is able to store pointers to all the pages at the next index level on a single page, which is called the root page.
Figure 9.2. A Level 3 clustered index structure.
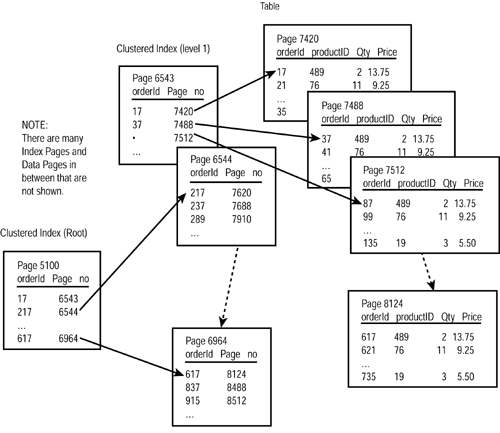
The root page is the index page where all the rows in a single index level are stored. Almost all index-based searches will start at the root page.
To understand how a clustered index really works, let's consider how the server actually uses the index to resolve the following query.
Select ProductID From [Order Details] Where OrderId = 10260
Using the index shown in Figure 9.2, the server looks at the root page to see where the value 41 falls. You can see that it is between the first entry and the second entry on the page. The server uses the page pointer 6543 to find the right page at the next level of the index, Again, it decides the 41 would fall between the second and the third entries on that page, so it follows the chain for 41 to page 7488, which is the table itself.
After the server has found the correct page, it will scan each row on the page. As soon as a row is retrieved that has a value that does not match 41, the server will stop the search immediately. As you can see in the previous example shown in Figure 9.2, the server scanned two index pages and one table page to retrieve the data.
Note
To give you an idea of how this all saves time for the server, a clustered index on a 1 billion-row table that has a 4-byte key will only have six levels in the index.
Nonclustered Indexes
A nonclustered index is a bit different from the clustered index. Remember that you can only have one clustered index on a table because of this restriction; a nonclustered index will build a separate table of key values. When you create a nonclustered index, the server always starts by building a sorted list of the values in the specified index column, with page and row pointers to each value. Figure 9.3 displays a completed nonclustered index.
Figure 9.3. Data and index levels of a nonclustered index.

You can see that the diagram looks almost the same as a clustered index. The only real difference is that the leaf or final level of the nonclustered index contains one row for each row in the table.
Using the following query, let's take a quick look at the search process using the nonclustered index.
Select count(*) From [Order Details] Where productID = 21
The server starts at the root page of the index, and then follows the chain to pages 6543 and 7420. Page 7420 displays the values for the productID value, 21.
Here is where the real difference between a clustered and nonclustered index becomes clear. Instead of going to a single page in the table and doing a table scan for occurrences of productID 21, the server scans the index leaf page, reading one data page per row on the index leaf page.
You are probably asking yourself, "How do I know which type of index to use?" The following list can help you to answer that question.
Clustered indexes are best at range searches, mostly for larger quantities of data.
Clustered indexes are most likely to help with a query requesting sorted data.
Nonclustered indexes are almost as fast as clustered indexes at finding a single row of data.
Nonclustered indexes enable the server to use an index containing all the columns required to resolve the query without accessing the table itself. This can run substantially faster than a query accessing a table, even with a clustered index.
Understanding Unique Indexes
A unique index ensures that the indexed column contains no duplicate values. In the case of multicolumn unique indexes, the index ensures that each combination of values in the indexed column is unique. For example, if a unique index fullname is created on a combination of lname, and fname columns, no two people could have the same full name in the table.
Both clustered and nonclustered indexes can be unique. Therefore, provided that the data in the column is unique, you can create both a unique clustered index and nonclustered indexes on the same table. Specifying a unique index makes sense only when uniqueness is a characteristic of the data itself. If uniqueness must be enforced to ensure data integrity, create a UNIQUE or PRIMARY KEY constraint on the column, rather than a unique index.
Note
Creating a PRIMARY KEY or UNIQUE constraint will automatically create a unique index on the specified columns in the table.
Indexing Computed Columns
A computed column is nothing more than a column in a table that is used to store the result of a computation of a table's data. The following example shows the creation of a table with computed columns:
Create Table OrderDemo (
Orderid Int Not Null,
Price Money Not Null,
Qty Int Not Null,
SaleTotal AS Price * qty,
OrderDate DateTime Not Null,
ShippedDate AS Dateadd(DAY,7,OrderDate))
You can see that this table contains two computed columns; SaleTotal and ShippedDate. They are both computed using other columns in the table.
New to SQL Server 2000, you can now define indexes on a computed column if the following conditions are true:
The computed column must always return the same result for a given set of inputs.
The result value of the computed column cannot evaluate to a text or image data type.
Forcing Index Selection
One of the last topics I want to discuss is how to tell the server which index to use. Take a look at the following example:
Use pubs
Select count(*) as 'Count',
sum(qty) as 'Total Sold'
From Sales
Where Stor_id between 6000 and 7000
and Title_id like 'PS2%'
Normally, SQL Server chooses to use the clustered index that is defined for the Sales table. If you wanted to override that choice, you would specify an optimizer hint by using the following syntax in the FROM clause:
From Sales (index = <index name>)
This will tell the server the actual index you want to use instead of what was selected.