
Chapter 1
Introduction
1.1 Introduction
In experimental work, treatment or treatments are given to units and one or several observations are recorded from each unit. The experimental unit differs from problem to problem. In agricultural experiments, the unit is a plot of land; in preclinical trials, the unit is an animal; in clinical trials, the unit is a subject; in industrial experiments, the unit is a piece of equipment. Treatments are those introduced by the investigator into the experiment to study their effects. In certain experiments, only one observation will be taken on each unit, while in other experiments, several readings will be taken from each unit. In cases where several measurements are made, either they will all be taken at the same time as in a standard SAT consisting of essay/writing, critical reading, and math comprehension or they will be taken over a period of time as in several tests given in a course. In this monograph, we confine ourselves to the designs and analysis of experiments where several observations are taken from each unit.
While it is absolutely necessary to take several readings on a unit in some experiments, it is desirable to do so in other investigational settings. Consider an animal feeding experiment where four feeds, A, B, C, and D, are tested. One may plan an experiment using 16 cows in the total experiment in which each cow receives one of the four feeds, with four cows for each feed. Or the experiment may be planned with only four cows in the experiment with each cow receiving each of the four feeds at different time intervals. In the latter scenario, using only 4 cows rather than 16 cows is not only economical but also eliminates the cow-to-cow variability in testing the feeds. However, the experiment with four cows will take a longer time to complete.
The class of designs where several observations are taken on each unit can be broadly referred to as repeated measurement designs (RMD). These can be subclassified as
- One-sample RMD
- k-Sample RMD (or profile analysis)
- Cross-over designs (or change-over designs) without residual effects (CODWOR) of the treatments like Latin square designs, Youden square designs, and Lattice square designs
- Cross-over designs with residual effects (CODWR) of the treatments like two-period cross-over designs of Grizzle (1965) and balanced residual effects designs (BRED) of Williams (1949)
The standard split-plot design in certain situations can also be considered as an RMD. We will elaborate on these designs in the remaining chapters.
1.2 One-Sample RMD
In this setting, a random sample of N experimental units will be taken from a population and p responses will be taken at the same time or at different times on each experimental unit. Another scenario for this design is that N homogeneous units will be treated alike at the beginning of the experiment and p responses will be recorded on each unit at the same time or at different times.
Let Y′α = (Yα1, Yα2, …, Yαp) be the vector of the p responses on the αth experimental unit for α = 1, 2, …, N. Let us assume that Yα are independently and identically distributed as multivariate normal with mean vector μ′ = (μ1, μ2, …, μp) and positive definite dispersion matrix ∑. Both μ and ∑ are unknown.
The null hypothesis of interest in this case is
The matrix ∑ is said to satisfy the circularity condition or sphericity condition if
where d is a scalar, Ip–1 is an identity matrix of order p − 1, and P1 is a (p − 1) × p matrix such that

is an orthogonal matrix, Jm,n being an m × n matrix with 1’s everywhere. If α′ = (α1, α2, …, αp), ∑ of the form
clearly satisfies the sphericity condition. In particular, a complete symmetric matrix ∑ of the form aIp + bJp,p satisfies the sphericity condition. The matrix ∑ of Equation (1.2.4) is said to satisfy the Huynh–Feldt condition, which will be discussed in Section 2.5.
In Chapter 2, we will show that the null hypothesis (1.2.1) can be tested by the standard univariate procedures if ∑ satisfies the sphericity condition. If ∑ does not satisfy the sphericity condition, multivariate methods using Hotelling’s T2 will be used to test the null hypothesis (1.2.1), and these methods will also be described in Chapter 2.
We will now provide three practical problems:
1.3 k-Sample RMD
In this setting, we have k distinct populations and we draw k-independent random samples from these populations. Let Ni be the sample size of the sample taken from the ith population (i = 1, 2, …, k) and let ![]() . Let Y′ij = (Yij1, Yij2, …, Yijp) be the vector of p responses taken on the jth selected unit from the ith population (j = 1, 2, …, Ni; i = 1, 2, …, k).
. Let Y′ij = (Yij1, Yij2, …, Yijp) be the vector of p responses taken on the jth selected unit from the ith population (j = 1, 2, …, Ni; i = 1, 2, …, k).
Alternatively, this design arises by taking N homogeneous experimental units and applying the ith treatment to Ni randomly selected units at the beginning of the experiment (i = 1, 2, …, k). The p-dimensional response vector Y′ij = (Yij1, Yij2, …, Yijp) can then be recorded on the jth unit receiving the ith treatment (j = 1, 2, …, Ni; i = 1, 2, …, k).
In each of these cases, we assume that Yij are independently and identically distributed multivariate normal with mean vector μ′i = (μi1, μi2, …, μip) and positive definite dispersion matrix ∑, for j = 1, 2, …, Ni, i = 1, 2, …, k. Both μi and ∑ are unknown.
In this problem, there are three different null hypotheses of interest to the experimenter and they are



Here, μi can be interpreted as the profile of the ith population (i = 1, 2, …, k). The null hypothesis H0c then implies that we are testing the parallelism of the k profiles. If H0c is retained, the parallelism hypothesis is not rejected and the profiles will appear as in Figure 1.3.1.

Figure 1.3.1 Parallel profiles.
When H0c is rejected, the profiles may be either intersecting one another (Figure 1.3.2) or the slopes may be different between the responses (Figure 1.3.3).

Figure 1.3.2 Intersecting nonparallel profiles.

Figure 1.3.3 Nonparallel profiles with different slopes.
In experimental work, H0c is the null hypothesis of testing the interaction effects between the treatments and the responses.
If H0c is not rejected, then one will be interested to test H0a and/or H0b. In H0a, we are testing the average of p responses to be constant from population to population (or treatment to treatment). In H0b, we are testing the average of the k populations (or treatments) to be the same for the responses. Testing H0a and H0b are, in essence, testing the main effects in a factorial experiment (see Padgett, 2011, for further details).
The analyses of these designs are discussed in Chapter 3. In this case, it is shown that the univariate analysis of variance (ANOVA) can be applied to make all inferences if ∑ satisfies the sphericity condition and multivariate methods are needed if ∑ violates the sphericity condition. Univariate methods can also be used by adjusting the degrees of freedom, when sphericity assumption is not valid and the necessary adjustment will also be given in Chapter 3. We will close this section with some examples of k-sample RMD given in the literature:
In this setting, one will be interested to test the parallelism of weight gain profiles for both groups of rats and then test for the differences of groups averaging over periods and for the differences of lactation periods averaging over the two groups following the methods discussed in Chapter 3. Gill and Hafs (1971) discussed different types of statistical analyses for this problem.
Lee was interested to test the hypothesis that all four groups are progressing equally and the hypothesis of no differences in ABS values from group to group and period to period. The numerical details of this type of analysis will be considered in Chapter 3.
1.4 Split-Plot Designs
Split-plot designs are widely used in agricultural experiments (see Gomez and Gomez, 1984; Raghavarao, 1983). The experimental material is first divided into main plots to accommodate main treatments. Each main plot is then subdivided into s subplots, and the s subplot treatments are randomly assigned to each main plot. The main plot treatments assigned to main plots can either form a randomized block design (RBD) or a completely randomized design (CRD). In the context of RMD, it is more appropriate to consider the main plot treatments to form a CRD. With three main plot treatments a0, a1, and a2 replicated on 3, 4, and 4 main plots and with four subplots treatments b0, b1, b2, and b3, the layout may appear as in Figure 1.4.1.

Figure 1.4.1 Split-plot layout.
In the RMD setting, one can consider three groups of experimental units a0, a1, and a2, respectively, of sizes 3, 4, and 4. Ignoring the subplot treatments, one considers the sequence of four subplot observations as the four-period observations. The model assumes equal correlation structure of period observations on each experimental unit. Further, the systematic arrangement of the subplot data somewhat violates the assumptions of split-plot analysis. However, this design is also widely used as RMD. We will not formally discuss this design in this monograph as this design is discussed in detail in several books on experimental designs; however, for completeness, we will provide the SAS program in Example 1.4.1.
Table 1.4.1 Artificial data for profile analysis
| Lactation period (days) | Pregnant rats | Nonpregnant rats | ||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| 8–12 | 3.4 | 1.6 | 5.7 | 7.3 | 6.3 | 8.1 | 7.2 | 12.1 | 8.9 | 9.8 | 7.9 | 8.6 | 10.8 | 11.7 |
| 12–16 | 8.1 | 9.6 | 12.9 | 11.9 | 9.8 | 10.4 | 9.4 | 12.3 | 9.4 | 10.7 | 7.9 | 8.5 | 10.6 | 12.3 |
| 16–20 | 4.7 | 7.8 | 10.8 | 9.2 | 6.4 | 7.7 | 8.3 | 12.4 | 9.4 | 13.2 | 7.9 | 8.3 | 9.9 | 9.8 |
| 20–24 | 1.1 | 2.9 | 3.6 | 5.6 | 0.6 | 2.9 | 3.4 | 10.1 | 7.3 | 9.7 | 4.6 | 5.7 | 7.5 | 8.4 |
The following SAS program provides the necessary output:
data a; input days $ treatment ratnumber value @@;cards;
8-12 1 1 3.4 8-12 1 2 1.6 8-12 1 3 5.7 8-12 1 4 7.3 8-12 1 5 6.38-12 1 6 8.1 8-12 1 7 7.2 8-12 2 1 12.1 8-12 2 2 8.9 8-12 2 3 9.8
8-12 2 4 7.9 8-12 2 5 8.6 8-12 2 6 10.8 8-12 2 7 11.712-16 1 1 8.1 12-16 1 2 9.6 12-16 1 3 12.9 12-16 1 4 11.9 12-16 1 5 9.8
12-16 1 6 10.4 12-16 1 7 9.4 12-16 2 1 12.3 12-16 2 2 9.4 12-16 2 3 10.7
12-16 2 4 7.9 12-16 2 5 8.5 12-16 2 6 10.6 12-16 2 7 12.316-20 1 1 4.7 16-20 1 2 7.8 16-20 1 3 10.8 16-20 1 4 9.216-20 1 5 6.4 16-20 1 6 7.7 16-20 1 7 8.3 16-20 2 1 12.416-20 2 2 9.4 16-20 2 3 13.2 16-20 2 4 7.9 16-20 2 5 8.316-20 2 6 9.9 16-20 2 7 9.820-24 1 1 1.1 20-24 1 2 2.9 20-24 1 3 3.6 20-24 1 4 5.6 20-24 1 5 0.620-24 1 6 2.9 20-24 1 7 3.4 20-24 2 1 10.1 20-24 2 2 7.3
20-24 2 3 9.7 20-24 2 4 4.6 20-24 2 5 5.7 20-24 2 6 7.5 20-24 2 7 8.4
;
data final;set a;
if days='8-12' then period=1;
else if days='12-16' then period=2;
else if days='16-20' then period=3;
else if days='20-24' then period=4;
proc sort;by days ratnumber;
proc glm; class ratnumber treatment period;
model value=treatment treatment(ratnumber) period treatment*period ;
*If the main treatments are arranged in a RBD, we will use ‘blocks’ and ‘blocks * interaction’ in the model statement and remove treatment (rat number) term. We will also use ‘blocks’ instead of ‘rat numbers’ in the class statement.;
test h=treatment e=treatment(ratnumber);
*In the RBD case, we will use e=blocks*interaction;run;
means period/snk;
means treatment/snk e=treatment(ratnumber); run;
***
The GLM Procedure
Dependent Variable: value
Sum of
| Source | DF | Squares | Mean Square | F Value | Pr > F |
| Model | 19 | 480.3192857 | 25.2799624 | 20.91 | <.0001 |
| Error | 36 (a6) | 43.5150000 | 1.2087500 (a4) | ||
| Corrected Total | 55 | 523.8342857 |
| R-Square | Coeff Var | Root MSE | value Mean |
| 0.916930 | 13.60923 | 1.099432 | 8.078571 |
| Source | DF | Type I SS | Mean Square | F Value | Pr > F |
| treatment | 1 | 111.4464286 | 111.4464286 | 92.20 | <.0001 |
| treatment(ratnumber) | 12(a7) | 125.7478571 | 10.4789881 (a5) | 8.67 | <.0001 |
| period | 3 | 192.3971429 | 64.1323810 | 53.06 | <.0001 (a2) |
| treatment*period | 3 | 50.7278571 | 16.9092857 | 13.99 | <.0001 (a1) |
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| treatment | 1 | 111.4464286 | 111.4464286 | 92.20 | <.0001 |
| treatment(ratnumber) | 12 | 125.7478571 | 10.4789881 | 8.67 | <.0001 |
| period | 3 | 192.3971429 | 64.1323810 | 53.06 | <.0001 |
| treatment*period | 3 | 50.7278571 | 16.9092857 | 13.99 | <.0001 |
Tests of Hypotheses Using the Type III MS for treatment(ratnumber) as an Error Term
| Source | DF | Type III SS | Mean Square | F Value | Pr > F |
| treatment | 1 | 111.4464286 | 111.4464286 | 10.64 | 0.0068 (a3) |
The GLM Procedure
Student-Newman-Keuls Test for value
***
Means with the same letter are not significantly different.
| SNK Grouping | Mean | N | period |
| A | 10.2714 | 14 | 2 |
| B | 8.9857 | 14 | 3 |
| C | 7.8143 | 14 | 1 |
| D | 5.2429 | 14 | 4 |
The GLM Procedure
Student-Newman-Keuls Test for value
***
Means with the same letter are not significantly different.
| SNK Grouping | Mean | N | treatment |
| A | 9.4893 | 28 | 2 |
| B | 6.6679 | 28 | 1 |
From the ANOVA output, we can see that the p-value for testing the treatments and periods interaction given at (a1) of the output is <0.0001 and the interaction is significant. Since the interaction is significant, we will not be discussing the treatment and period differences. However, if this interaction is not significant, the p-value at (a3) will be used to test the treatment differences, and the p-value at (a2) will be used to test the period effects. When the interaction is not significant, the Student–Neuman–Keuls procedure given in the output can be used for multiple comparisons of the treatments and the periods.
When the interaction between treatments and periods is significant as in our case, we will test the difference in periods for each treatment and test the difference in treatments for each period. Let us define υ2 as the error degrees of freedom given at (a6), υ1 as the treatment (rat number) degrees of freedom given at (a7), E2 as the error mean square given at (a4), and E1 as the treatment (rat number) MS given at (a5). The standard error for the difference between the two periods at a given treatment level is
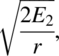
where r is the number of replications, and the standard error for the difference between two treatments at the same period level is

where s is the number of periods. The standard t-statistic will be formed and compared against the critical values

respectively, where tα(.) is the upper 100α percentile point of the t distribution with the degrees of freedom given in the parentheses.
This same analysis can also be carried out in SAS using the PROC MIXED procedure. The following are the programming lines:
data a; input days $ treatment ratnumber value @@;cards;
*Use data from previous analysis;
data final;set a;
if days='8-12' then period=1;
else if days='12-16' then period=2;
else if days='16-20' then period=3;
else if days='20-24' then period=4;
proc sort;by days ratnumber;
proc mixed;
class ratnumber treatment period ;
model value=treatment period treatment*period ;
random treatment(ratnumber) ;*if the main treatments are in randomized block, the blocks and the interaction between blocks and main treatments should be shown as random effects;
lsmeans treatment period/adjust=tukey;run;
***
Type 3 Tests of Fixed Effects
Num Den
| Effect | DF | DF | F Value | Pr > F |
| treatment | 1 | 12 | 10.64 | 0.0068 |
| period | 3 | 36 | 53.06 | <.0001 |
| treatment*period | 3 | 36 | 13.99 | <.0001 |
***
The Mixed Procedure
Differences of Least Squares Means (a8)
| Effect | treatment | period _treatment | _period | Adjustment | Adj P |
| treatment | 1 | 2 | Tukey | 0.0068 | |
| period | 1 | 2 | Tukey-Kramer | <.0001 | |
| period | 1 | 3 | Tukey-Kramer | 0.0373 | |
| period | 1 | 4 | Tukey-Kramer | <.0001 | |
| period | 2 | 3 | Tukey-Kramer | 0.0190 | |
| period | 2 | 4 | Tukey-Kramer | <.0001 | |
| period | 3 | 4 | Tukey-Kramer | <.0001 |
The conclusions and the test statistics are the same using the PROC MIXED procedure as was initially discussed using the PROC GLM procedure. The contrasts of main or subtreatment effects can be tested from the last part of the output indicated by (a8).
1.5 Growth Curves
Often, we come across situations where responses are taken over a period of time on each experimental unit. These responses can be modeled using linear or nonlinear models. The linear model may be a polynomial on time. The model on the unit is called the growth curve, as it represents the growth or decay of the response over a period of time. The difference with this setting is that the experimenter may be interested in testing the model parameters for the demographic variables of the units and/or the treatments applied to the units. Some of the earlier work on this topic is given by Potthoff and Roy (1964). We will now provide some examples:
The mathematical model for these problems differs from the standard model formulations, and we will discuss some of these problems in Chapter 4. It is possible to do a hierarchial model in this setting, and this will also be discussed in Chapter 4.
1.6 Cross-Over Designs
The commonly used cross-over designs are the Latin square designs. If v treatments are used in an experiment, one may construct a v × v square array such that every treatment occurs once in each row and once in each column to get a Latin square design. Given such a design, one may identify the columns to the experimental units and rows to different periods of administering the treatments. A k-sample RMD and cross-over designs both use several treatments. However, in the k-sample RMD, each unit is given only one of the treatments at the beginning of the experiment and the data are collected over several periods, while in cross-over designs, each unit receives a subset or all of the treatments used in the experiment.
Let us consider a feeding experiment on four cows using four feeds A, B, C, and D in a Latin square design of Table 1.6.1.
Table 1.6.1 A Latin square design for four treatments
| Cow number | ||||
| Period | 1 | 2 | 3 | 4 |
| 1 | A | B | C | D |
| 2 | B | C | D | A |
| 3 | D | A | B | C |
| 4 | C | D | A | B |
The experimenter first decides the length of time each feed will be given to each animal, say, 2 weeks. Cow 1 receives feed A for 2 weeks, followed by feed B for 2 weeks, followed by feed D for 2 weeks, and finally followed by feed C for 2 weeks. A similar interpretation can be made to the feeding assignment of the other cows. In this situation, a treatment produces a direct effect in the period of application. The treatment effect may still persist to the subsequent periods after the treatment has been discontinued, and such effects are called residual or carryover effects. Residual effect of the ith order is the residual effect of the treatment effect in the ith period after its discontinuance. Usually, the residual effects of the ith order will be smaller than the residual effects of the (i − 1)th order for i = 2, 3, …, v. While conducting the experiment, either we have to account for the residual effects by introducing them in the linear model or provide a washout period between switching the treatments so that the residual effect of the previously administered treatment will disappear before the new treatment is applied. Cross-over designs providing washout periods and using no residual effects in the model will be called CODWOR, and the design of Table 1.6.1 may then appear as in Table 1.6.2, interpreting ![]() as a washout period.
as a washout period.
Table 1.6.2 CODWOR for four treatments
| Cow number | ||||
| Period | 1 | 2 | 3 | 4 |
| 1 | A | B | C | D |
| 2 | B | C | D | A |
| 3 | D | A | B | C |
| 4 | C | D | A | B |
The designs, properties, and the analysis of CODWOR will be discussed in Chapter 5. It may be noted that for these designs it is not necessary to have every cell of the design filled with a treatment. One may leave an experimental unit untreated in a period. Further, if washout period is impractical, then the response for the treatments may be taken in the middle of the period of application of the treatment, and this practice assumes that there will be no carryover effects when responses are taken.
When it is not possible to leave a washout period in an experiment due to the time constraint or due to the nature of the experimentation, the analysis will be conducted accounting for residual effects in the linear model, and such designs are called CODWR. The literature for CODWR is well developed for designs accounting first-order residual effects. Using one or two Latin squares, depending on even or odd number of treatments, Williams (1949) gave CODWR where elementary contrasts of direct effects are estimated with the same variance and also the elementary contrasts of first-order residual effects are estimated with the same variance. Following the block design terminology, such designs are called BRED. BREDs not arising from Latin square designs are also known in the literature (cf. Patterson, 1952). While CODWR usually consists of distinct treatments in successive periods, it is also possible to use the treatment repeatedly in successive periods assuming that each treatment produces a carryover effect on itself. We will discuss these designs along with their analysis in Chapters 6 and 8. Some examples for cross-over designs given in the literature are the following:
In this experiment, it is not possible to leave washout periods between treatment administrations. Thus, this design will be analyzed as a CODWR. This design is Williams’ type of BRED and can be analyzed by the methods given in Chapter 6 or Cochran and Cox (1966).
For a detailed discussion on cross-over designs, the reader is referred to Bose and Dey (2009), Jones and Kenward (2003), and Stufken (1996).
Another class of cross-over designs is the frequency square or F-square design. In this design, v treatments will be tested in n periods on n subjects where n > v. The ith treatment will occur in ri periods on each of the ri subjects. Here, ∑ ri = n. An example of an F-square design with v = 3, n = 6, r1 = 3, r2 = 2, and r3 = 1 is given in Table 1.6.3.
Table 1.6.3 F-square design with v = 3 and n = 6
| 1 | 1 | 1 | 2 | 2 | 3 |
| 3 | 1 | 1 | 1 | 2 | 2 |
| 1 | 1 | 2 | 2 | 3 | 1 |
| 2 | 3 | 1 | 1 | 1 | 2 |
| 1 | 2 | 2 | 3 | 1 | 1 |
| 2 | 2 | 3 | 1 | 1 | 1 |
This F-square design can be analyzed as CODWOR by leaving washout periods between administration of treatments. This F-square design is more useful when some treatments have to be applied more often than other treatments.
Another class of CODWOR are Youden square designs in which v treatments are tested on v subjects in k periods where no treatment is repeated on a subject, k subjects receive each of the v treatments, and λ subjects receive every distinct pair of treatments. Here, λ(v − 1) = k(k − 1). An example of a Youden square design with v = 7, k = 3, and λ = 1 is given in Table 1.6.4.
Table 1.6.4 Youden square design with v = 7, k = 3, and λ = 1
| A | B | C | D | E | F | G |
| B | C | D | E | F | G | A |
| D | E | F | G | A | B | C |
1.7 TWO-PERIOD CROSS-OVER DESIGNS
Two-period, two-treatment cross-over designs introduced by Grizzle (1965) enjoyed wide popularity in clinical trials. If A and B are two treatments, on N1 experimental units, the treatment pair {A, B} will be administered in the two periods, and on N2 experimental units, the treatment pair {B, A} will be given in the two periods. Usually, one of the treatments is placebo (or the standard commonly used drug) and the other is the experimental drug. In clinical trials, it appears unethical to switch a treatment showing good response to another treatment, which may or may not be effective. Furthermore, this design in particular and cross-over designs in general are severely criticized for not accounting the interaction between the periods and sequences of treatments used in the experiment. For a detailed discussion on the controversy of this design, the interested reader is referred to Brown (1978, 1980). Ignoring the controversy, the design has interesting statistical problems, and we will discuss them in Chapter 7. Balaam (1968) gave two-period designs for t treatments in t2 experimental units. These will also be considered in Chapter 7. We will now discuss some applications of two-period cross-over designs.
Methods of Chapter 7 can be used to analyze the data by assuming normality. Koch (1972) gave the analysis using nonparametric methods, and those methods will also be discussed in Chapter 7.
1.8 Modifications in Cross-Over Designs
Cunningham and Owen (1971) discussed four methods of analyzing performance data from a dairy cattle feeding experiment. The design involved a preexperimental, an experimental, and a postexperimental period. Periods I and III were essentially controls during which all cows were fed the same. Each of the active treatments was used in Period II. In their experiment, 36 cows were used consisting of 6 cows for each of the following sequences:

In this design, A and H are controls, and B, C, D, E, F, and G are active treatments. The four methods of analysis used were
- Analysis of average performance for Period II
- Analysis of average performance for Period II with average performance for Period I as a concomitant variable
- Analysis of average performance for Period II with both average performances for Period I and body weight at the end of Period I as concomitant variables
- Analysis of twice the average performance for Period II (Y) minus the sum of the average performance for Periods I (X) and III (Z) (i.e., 2Y - X - Z)
They found that method (iv) gave the smallest coefficient of variation.
While using invasive procedures as treatments, it is desirable to leave some experimental units untreated in certain periods. This also becomes necessary when data collection in each period is costly or time consuming. Mercado (1976) discussed designs allowing for untreated periods. One can use seven treatments A, B, C, D, E, F, and G in seven periods on seven units using the design given in Table 1.8.1, where “–” denotes that no treatment was applied on the unit in that period.
Table 1.8.1 GRED for seven treatments
| Unit number | |||||||
| Period | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1 | A | — | — | E | — | C | B |
| 2 | C | B | — | — | F | — | D |
| 3 | E | D | C | — | — | G | — |
| 4 | — | F | E | D | — | — | A |
| 5 | B | — | G | F | E | — | — |
| 6 | — | C | — | A | G | F | — |
| 7 | — | — | D | — | B | A | G |
Mercado called such designs as generalized residual effects designs (GRED) and classified them into two types:
Type I (GRED-I) – designs in which observations are taken only on treated cells
Type II (GRED-II) – designs in which observations are taken on all cells, treated or untreated.
GRED-I and GRED-II will be discussed in Chapter 6.
In most settings, the residual effects of higher orders are less than the residual effects of smaller orders; however, in some cases, the residual effects of all orders are the same in the experimental period. Lakatos and Raghavarao (1987) discussed designs where the residual effects are the same for all orders of a treatment. Such designs can be used to order sensitive questions in a questionnaire. These results will be considered in Chapter 8.
In some experiments, interest centers on the simultaneous comparison of several test treatments to a control treatment rather than on all pairwise comparisons. Dunnett (1964) developed a multiple comparison procedure for comparing several treatments with a control in a CRD. Bechhofer and Tamhane (1981) gave incomplete block designs for comparing treatments with a control. Treatment balanced residual effects designs (TBRED) are the cross-over designs for comparing active treatments with a control, and they were discussed by Pigeon and Raghavarao (1987). These results will also be presented in Chapter 8. The optimality of these designs was discussed by Majumdar (1988).
Sometimes, the treatments may be a factorial combination of two factors F1 and F2. We need longer period of application for levels of factor F1, whereas we can easily change the levels of factor F2. In this case, the levels of factor F1 will be applied to experimental units following a cross-over design. The periods of application of levels of factor F1 are called whole-plot periods. The whole-plot periods will be subdivided into subplot periods, and the levels of factor F2 will be applied in a cross-over design to the whole-plot periods of the levels of factor F1. Such designs may be called split-plot type carryover designs and are discussed by Raghavarao and Xie (2003).
Sometimes, each treatment may be giving a carryover effect when applied to the next period by the same treatment. Designs studying these type of carryover effects contain replications of the treatments in adjacent periods on the same subject. Designs of this type are discussed by Laska, Meisner, and Kushner (1983) and will be discussed in Chapter 8.
1.9 NONPARAMETRIC METHODS
Using univariate and bivariate Wilcoxon tests, Koch (1972) gave the analysis of a two-period, two-treatment cross-over design and illustrated the analysis on the example discussed in Section 1.7.
Poisson data often arises in experiments as described in the following examples:
For a given patient, the nausea count is approximately Poisson distributed. We will use nonparametric methods to analyze this data as described in Chapter 7.
In conclusion, we direct the interested reader to the paper by Koch et al. (1980) for some views on repeated measurement analysis.
References
- Balaam LN. A two-period design with t2 experimental units. Biometrics 1968;24:61–73.
- Bechhofer RE, Tamhane AC. Incomplete block designs for comparing treatment with a control: general theory. Technometrics 1981;23:45–57.
- Bose M, Dey A. Optimal Crossover Designs. Singapore: World Scientific; 2009.
- Brown BW. Statistical controversies in the design of clinical trials. Technical Report 37. Stanford, CA: Division of Biostatistics, Stanford University; 1978.
- Brown BW. The crossover experiment for clinical trials. Biometrics 1980;36:69–79.
- Cochran WG, Cox GM. Experimental Designs. 2nd ed. New York: Wiley; 1966.
- Cochran WG, Autrey KM, Cannon CY. A double change-over design for dairy cattle feeding experiments. J Dairy Sci 1941;24:937–951.
- Cunningham PJ, Owen FG. Statistical methods for improving sensitivity in dairy cattle feeding experiments. J Dairy Sci 1971;54:503–508.
- Danford MB, Hughes HM, McNee RC. On the analysis of repeated measurements experiments. Biometrics 1960;16:547–565.
- Dunnett CW. New tables for multiple comparisons with a control. Biometrics 1964;20:482–491.
- Gill JL, Hafs HD. Analysis of repeated measurements of animals. J Anim Sci 1971;33:331–336.
- Gomez KA, Gomez AA. Statistical Procedures for Agricultural Research. New York: Wiley & Sons; 1984.
- Grizzle JE. The two-period change-over design and its use in clinical trials. Biometrics 1965;21:467–480.
- Henderson PL. Methods of Research in Marketing. Application of the Double Change-Over Design to Measure Carry-Over Effects of Treatments in Controlled Experiments. Mimeo Department of Agricultural Economics MB:A672–MB:A758. Ithaca, NY: Cornell University; 1952.
- Jones B, Kenward MG. Design and Analysis of Cross-Over Trials. 2nd ed. London: Chapman & Hall; 2003.
- Koch GG. The use of nonparametric methods in the statistical analysis of the two-period change-over design. Biometrics 1972;28:577–584.
- Koch GG, Amara IA, Stokes ME, Gillings DB. Some views on parametric and non-parametric analysis for repeated measurements. Int Statist Rev 1980;48:249–265.
- Lakatos E, Raghavarao D. Undiminished residual effects designs and their suggested applications. Comm Statist—Theor Meth 1987;16:1345–1359.
- Laska E, Meisner M, Kushner HB. Optimal crossover designs in the presence of carryover effects. Biometrics 1983;39:1087–1091.
- Layard MW, Arvesen JN. Analysis of Poisson data in crossover experimental design. Biometrics 1978;34:421–428.
- Lee RM. Evaluation of the matrix of Woodhaven ABS values. Data Analysis Laboratory Project. Philadelphia, PA: Temple University; 1977.
- Majumdar D. Optimal repeated measurements designs for comparing test treatments with a control. Comm Statist—Theor Meth 1988;17:3687–3703.
- Mercado R. Generalized residual effects designs [unpublished Ph.D. dissertation]. Philadelphia, PA: Temple University; 1976.
- Paape MJ, Tucker HA. Mammary nucleic acid, hydroxyproline, and hexosamine of pregnant rats during lactation and post lactational involution. J Dairy Sci 1969;52:380–385.
- Padgett LV. Practical Statistical Methods: A SAS Programming Approach. Boca Raton, FL: CRC Press/Chapman & Hall; 2011.
- Patterson HD. The construction of balanced designs for experiments involving sequences of treatments. Biometrika 1952;39:32–48.
- Pigeon JG, Raghavarao D. Crossover designs for comparing treatments with a control. Biometrika 1987;74:321–328.
- Potthoff RF, Roy SN. A generalized multivariate analysis of variance model useful especially for growth curve problems. Biometrika 1964;51:313–326.
- Raghavarao D. Statistical Techniques in Agricultural and Biological Research. New Delhi: Oxford and IBH Publishing Company; 1983.
- Raghavarao D, Xie Y. Split-plot type cross-over designs. J Statist Plan Inf 2003;116:197–207.
- Rao CR. Linear Statistical Inference and its Applications. 2nd ed. New York: Wiley; 1973.
- Stufken J. Optimal crossover designs. In: Ghosh S, Rao CR, editors. Handbook of Statistics, Vol. 13. Amsterdam: North-Holland; 1996. p 63–90.
- Varma AO, Chilton NW. Crossover designs involving two treatments. J Periodontal Res 1974;9:160–165.
- Williams EJ. Experimental designs balanced for the estimation of residual effects of treatments. Aust J Sci Res 1949;2:149–168.
- Zinner DD, Duany LF, Chilton NW. Controlled study of the clinical effectiveness of a new oxygen gel on plaque, oral debris and gingival inflammation. Pharmacol Therapeut Dentist 1970;1:7–15.