
Chapter 14
Testing
Only in very few cases can software be verified completely based on specifications. Because of this, testing is extremely important in software development.
Up to this point we have not explicitly addressed the role of testing in the software development process. This is not because we believe that testing is unimportant or secondary, but because it essentially plays the same role in MDSD as in other methods. Agile processes [Coc01] [Bec02] can serve as role models in this case: testing constitutes a sort of safety net for the modifiability and extensibility of software. This is why tests should not be run at the end of a project, but frequently during the project.
Test automation [HT04] [Cla04] is a key element for enabling continuous and reproducible validation of the software during its construction. We don’t want to begin with Adam and Eve in regard to testing, but rather to concentrate on specifics in the context of MDSD in general and architecture-centric MDSD in particular.
We mentioned in the previous chapter that we divide a project into an architecture development thread and an application development thread. Both threads are synchronized via milestones; yet they produce different artifacts: The application development thread yields an application, the architecture development thread a domain architecture. We begin with the aforementioned, but before we get started, we wish to give a brief general introduction to the different types of tests.
14.1 Test Types
The discussion of which aspects of a software system are to be tested, when, and to what end, leads us to test types:
- Component tests (also called unit tests) are created by the developer in the course of their every-day work and serve to ensure the correct functioning of system parts (classes, modules, subsystems and so on).
- Integration tests ensure the correct interplay of various parts of the system.
- Acceptance tests show whether the system makes sense from the customer’s viewpoint and meets their requirements.
- GUI tests1 can either take on the role of acceptance tests (ergonomics) or of integration tests.
- Non-functional tests validate requirements for the target architecture, such as security, correct transaction management in multi-user environments, or robustness towards hardware failure.
- Load tests are a special subset of non-functional tests. They serve to measure performance (response times, data throughput) and scalability. Load tests are often quite sophisticated and thus only carried out at specific times in the course of a project.
- Regression tests are used to detect whether unwanted side-effects have emerged due to changes to the source code (additions or corrections). Regression tests are usually realized through repeated execution of other test types.
Test automation is a very important means for increasing the efficiency and effectiveness of tests. Only reproducible, automated tests can form the ‘safety net’ that allows software to stay changeable. Test automation helps to implement regression tests and is applicable for all test types except for tests of ergonomics. The most sophisticated kind of test automation is continuous integration [Cla04] [CRUI]. Here automated tests are carried out almost continuously in parallel to development on special test machines that inform the developer asynchronously about test failures, for example by e-mail.
In the context of MDSD, the domain architecture – due to its generative aspect – plays a similar role to a compiler. However, its correctness cannot always be taken for granted: more about this issue later. On the other hand, however, MDSD offers good opportunities for simplification of the test types listed above for the application development thread. This is what we will address in the following section.
14.2 Tests in Model-Driven Application Development
In the application development thread the same test types as in non-model-driven processes are relevant. The models are part of the code because they are formal and automatically transformed into 3GL code via transformations. From this perspective, the DSL is a programming language (with affinity to the domain) that can have semantic gaps. After generation, you will have exactly the same code as you would have had if you had not used MDSD, and so the code can be tested in the same manner. Even a test-first approach does not constitute a contradiction: nobody keeps the developer from writing test code prior to modeling if this is considered sensible.
The model-driven approach has a lot of potential that can also simplify the creation of test code. A black-box test is always a comparison between an is-state and a desired state: we do not differentiate between return values of methods and side-effects such as database changes. Thus a test secures the semantics behind a syntactically-defined interface2. In other words, the test ‘knows’ the signature and the semantics of the system to be tested – this can justifiably be called a design. In effect, a developer who writes test code specifies design information in doing so. Equally, no developer can write test code without having at least a rough idea of the design of the system to be tested.
In the context of MDSD, we now possess a more valuable means than a 3GL language to express designs: the DSL. Depending on the semantic depth of the DSL, it can be much more effective to specify design information first in the model rather than right away in the form of 3GL test code, in order to generate exactly that code or parts of it. The advantage of this approach lies in the abstraction and the simplified changeability of the test code: a part of it is moved into the domain architecture and can now be centrally maintained and modified. The domain architecture is thus extended to include the generation of testware. Whether this procedure is efficient (and if so, to what extent) depends very much on the expected degree of reusability.
14.2.1 Unit Tests
In the context of conventional software development, small but useful frameworks such as JUnit (or C#Unit, CppUnit, and so on) are available. We want to continue to use these tools in MDSD, and support the creation of tests as efficiently as possible with model-driven techniques.
Separation of Test Cases and Test Data
Unfortunately, unit tests are in most cases programmed in such a way that test cases and test data are mixed in the code. At first glance this seems to simplify matters, but in fact it harbors serious disadvantages for the further progress of the project:
- Test cases are not reusable for different test data.
- Test cases and test data lose their maintainability.
- Test data can only be modified or provided by the developers.
- The actual structure of test cases is obscured, which impairs readability.
It is therefore a good idea to separate test cases and test data when implementing component tests. This can be done for example by rendering the test data in the form of XML documents or Excel files, from which they can be read by the actual test case – for example a JUnit test method – at runtime. This not only works for the test input (the test stimuli), but also for the reference data.
In the context of MDSD, this separation also allows for dealing separately with test case generation. For example, you can only support the test cases generatively and solve the integration of the test data generically using a suitable framework.
The external format for formulating the test data becomes a part of the DSLs test partition – or in other words, test data can be MDSD models, regardless of whether they are transformed or directly interpreted by the (test) platform.
Test Infrastructure Generation
The simplest and most obvious support that MDSD offers for component tests is the generation of test infrastructure from the models. This can for example include (empty) test methods for all business operations of the application, as well as their compositions for test suites. One can also generate a default implementation into the test methods that causes the tests fail, thereby enforcing a real implementation by the developer.
Constraints Checking
The generation of test cases based on constraints in the models is a very powerful technique3. These declaratively specify properties of the system, but do not yield any information on how these properties are realized. Typically for such constraints one distinguishes between preconditions to describe the prerequisites for invoking an operation, post-conditions to describe the state of the system after the operation has been executed and invariants to describe such constraints that must always hold during system execution. If you have a suitable model, you can generate a unit test that creates the required test setup, provides valid test data (precondition), invokes the operation to be tested and afterwards checks the postcondition. In this context, the following questions arise:
- How can the set-up be created?
- How should the test data be composed?
- What environment must be present to enable the test to pass?
Since this is not always easy to define and implement, it often makes sense not to check the constraints using a special unit test, but simply to generate the constraint checks directly into the system, and also check the constraints during the integration tests. Figure 14.1 shows an example:
Figure 14.1 An example of a class diagram with constraints.

It is actually possible to generate code from these constraints:
class Vehicle {
…
public void setDriver( Person p ) {
if (p.getAge() < 18 )
throw new ConstraintViolated();
// … implementation code …
}
}
Two things need to be explained. First, the question arises of how one generates code from OCL constraints: suitable tools are available, for example [EMPO], [DRES]. Then there is the question of where and how the constraints can be integrated into the model and whether they would be available for subsequent tools, for example in the XMI export. A trick that works with all UML tools is to abuse the model elements’ documentation: for example, you can insert the following text for the setDriver() operation here:
The purpose of this operation is to assign a driver to a vehicle. Drivers are always Persons aged 18 or older. <Constraints> <pre id="driverAge"> <expr>p.getAge() >= 18</expr> <error>Driver must be 18 or older.<error> </pre> </Constraints>
In the MDSD transformation the documentation text can simply be searched for the Constraints tag. The XML can be parsed, and thus the constraints are ready for further processing. To simplify matters, we assume that the text inside <expr>…</expr> is a valid Boolean expression in the target language. This limits portability, but it is feasible if you need a pragmatic approach.
Another interesting question is how you realize this approach if the implementation of the actual method is done manually. How can you make sure that the constraint is nevertheless always checked? Here, the use of the Template Method pattern is advisable [GHJ+94]. An abstract class VehicleBase is generated that implements the operation setDriver() as follows:
abstract class VehicleBase {
…
public void setDriver( Person p ) {
// generated from precondition constraint
if (driver.getAge() > 18 )
throw new ConstraintViolated();
setDriverImpl( p );
// generated from postcondition constraint
if (driver == null) throw new ConstraintViolated();
}
protected abstract void setDriverImpl( Person p );
}
This operation invokes an abstract operation setDriverImpl(). The developer now writes the class Vehicle manually and implements only the abstract operations defined by the superclass:
class Vehicle extends VehicleBase{
protected abstract void setDriverImpl( Person p ) {
driver = p;
}
}
One can define the constraints with any required degree of complexity, for example via a protocol state machine that can be assigned to an interface. It is rather simple to generate code from this model that enforced adherence to the state machine during system execution.
The state machine in Figure 14.2 states, for example, that you can only start to drive (drive()) if a driver is seated in the car. The generated code can automatically track these states. Should the drive() operation be invoked while the vehicle is empty, a ConstraintViolation exception can be thrown.
Figure 14.2 An example of a protocol state machine.

Generation of Extreme Value Tests
If no constraints are given for an operation, of course no functionally useful tests can be generated automatically: they must be implemented by hand. However, you can see this situation differently: if no constraints are stated, this means that any input parameter (combination) is valid for the operation. This means that you can generate test cases that use arbitrary test data. You cannot verify the result of the operation (since you don’t know what it does) but you can check that it does not fail fatally, for example with a null pointer exception. This is a practicable approach, especially for operations with primitive types. Common values for int parameters are for example 0, -1, 87684335: for object parameters, null is recommended. Note that this approach does not replace real tests that check that the operation performs its task correctly, but the approach does hint at typical programming bugs such as not checking for null values or negative numbers.
Mock Objects
Mock objects are a useful instrument for software testing. They serve to decouple test code and application infrastructure that is relevant from a testing perspective. To this end, the corresponding interfaces are implemented by mock objects that behave as required for a test scenario, even without a complex infrastructure. Let’s assume we want to check whether a client treats the exceptions thrown by a remote object correctly:
public Object doSomething( RemoteObject o ) throws SomeEx {
try {
return o.anOperation();
} catch ( RemoteException ex ) {
log( ex );
throw new SomeEx();
}
}
How can we now make sure that the RemoteObject really throws an exception for test purposes when the client invokes the operation anOperation()? Of course, we can implement the interface RemoteObject manually and throw a corresponding exception – but for other test scenarios, we have to implement the same thing again and again.
In addition to generic approaches, such as EasyMock [EASY], code generation can also help here. For one thing, you can very easily generate implementation classes with it that demonstrate a specific behavior. As a specification, you can use the following XML code:
<MockConfig type="examplepackage.RemoteObject” name="RemoteObjectTestImpl"> <operation names="anotherOperation, thirdOperation"> <return value="null” occurrence="1"/> </operation> <operation names="anOperation"> <throw type="RemoteException” occurrence="all"/> </operation> </MockConfig>
This specifies that a class RemoteObjectTestImpl should be generated that implements the examplepackage.RemoteObject interface. The operation anotherOperation and thirdOperation are implemented in such a way that null is returned. For anOperation it is defined that a RemoteException is thrown. This class can now be used in a test.
You can also define such mock objects implicitly, which requires even less effort – see Figure 14.3):
Figure 14.3 An example for the use of mock objects.
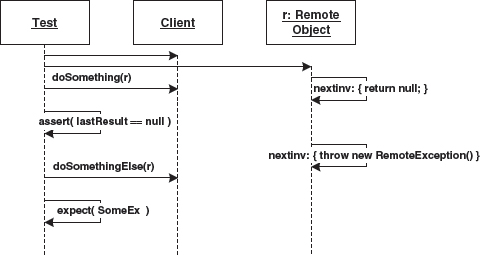
Here a RemoteObject is created. We specify that null is returned on the next method call (the implementation code for the method is simply placed in braces). We check if the doSomething() method returns this correctly, then we define on RemoteObject that it throws an exception when the next invocation occurs. Next, we invoke doSomethingElse() on the client and expect it to throw a SomeEx exception.
To implement this scenario, the code generator can simply generate a matching implementation of the RemoteObject interface that behaves as specified in the diagram.
14.2.2 Acceptance Tests
These tests must be defined independently of the application model. It would be useless to generate acceptance tests from the same model from which the application is generated, because in that case it would never fail, as long as the domain architecture is correct. This leads us to the two-channel principle: one needs a second, independent ‘channel’ to specify tests that are independent of the original specification. However, the second channel can also be supported by MDSD – see Figure 14.4.
Figure 14.4 An examples of the two-channel principle.

As you can see, it is possible to model test scenarios in the same manner as the application itself, but in a separate acceptance test model. Constraints on operations of the test scripts provide the validation rules that are needed in the tests.
When a suitable DSL is used, a domain expert can understand the test cases much better and work more productively on their definition compared to programming the integration tests. Figure 14.5 is an example of this that uses a sequence diagram. First, the test client creates a new Vehicle and a new Person. It then sets the person’s age to twenty and defines the person as the driver of the car. An Assertion follows that ensures that the driver of the car is exactly the one that has just been set. Then a new person is created who is ten years old. If this new person is set as a driver, a ConstraintViolated exception must be thrown that is evaluated with expect(). This guarantees that the implementation code actually checks the respective constraint. Finally, we verify that the driver is still the original driver.
Of course one would separate the test data from the test code, as mentioned above. We omitted this here to keep our example simple.
Figure 14.5 An example for the definition of a test scenario using a UML sequence diagram.

14.2.3 Load Tests
In principle load tests follow this schema: a set of clients that usually run on a number of computers are simulated. These clients run test scripts. The clients’ timing behavior is measured relative to the load – that is, the number of clients and their call frequency. The server’s resource consumption is also logged.
The environment’s setup (for example, server, network, databases) must be created manually. The following aspects must be defined:
- The test script(s)
- The number of clients
- Their internal parallelism, that is, the number of processes and threads
In most cases the last two aspects are handled by tools that also measure the timing behavior and monitor the application(s). The test scripts are well-suited for generation. A sequence diagram or a state chart constitute a good basis, as can be seen in Figure 14.6.
Figure 14.6 State diagram with timeouts for load test definition.

14.2.4 Non-functional Tests
Testing non-functional requirements such as reliability, transactional consistency, or deadlock freedom cannot be done in a simple environment, such as in JUnit. Realistic scenarios are needed here. Failures of networks or databases must be simulated, or forced to actually occur. Similarly, security tests can only be conducted manually. Model-driven development does not offer any specific help here.
14.2.5 Model Validation
Model validation is a type of test that is possible only when using MDSD. It offers totally new options for testing. We must distinguish between three different subtypes:
- Acceptance tests on the model level to validate the model semantics
- Well-formedness tests to check whether the modeling rules are observed (DSL constraints)
- Simulation of models
Acceptance Tests on the Model Level
MDSD models have the potential to be validated in direct communication with customers or experts (unless they create the tests themselves), particularly if the MDSD domain and its DSL are business-oriented. This approach can provide additional certainty, especially when code or configuration files are created from the model. The meaning of this code or configuration can thus be checked beforehand on a more abstract level.
Well-Formedness Tests
We have already studied the importance of modeling rules in the context of MDSD from the example of the first case study in Chapter 3. We also saw that such rules take on the role of the DSL’s static semantics (Chapter 4) and showed how they are defined in the context of metamodeling (Chapter 6).
From the test perspective, such modeling rules are invariants that are valid for all instances of a DSL – that is, for all models. They must be checked before the actual MDSD transformations can take place, otherwise the transformation result is undefined. The well-formedness test can be carried out by the modeling tool (if it is able to) or a by subsequent MDSD tool – see Sections 3.2 and 11.1.2. From a technical point of view, these tests are nothing more than a check of the static semantics of a classic programming language by the respective compiler. However, from the developer’s point of view, they are far more effective: the compiler of a classic programming language doesn’t know anything about the domain, so it can only issue error messages about the solution space – the programming language. In contrast, modeling rules are specifically created for the domain and can therefore report error messages using the terminology of the problem space.
A specific class of errors that in conventional development are typically not detected even by the compiler, but only show up at runtime, can be detected very early with the MDSD approach – during modeling or prior to code generation. Here is a simple example: the metamodel in Figure 14.7 defines that a configuration parameter (a special type of attribute) that must always have the type String.
Figure 14.7 An example of constraints in the metamodel.

For all models that are specified using this DSL, the given constraint must hold. If a configuration parameter is not of type String, a corresponding and meaningful error message can be issued, such as ‘ConfigParam must be of type String’, instead of getting an exception at runtime because somewhere somebody tried to assign an Integer to a String.
Simulation of the Model
If the dynamic aspects of a system are thoroughly described in a model, they can be validated by simulation of the model. This approach is quite popular for embedded systems, but only for rather specific types of behavior definition, specifically finite state automata. The UML 2.0 and action semantics are also a step in that direction – see Chapter 12. In general practice, the model simulation approach is either not economical or not possible because the dynamic system behavior is not specified in the model.
14.3 Testing the Domain Architecture
The domain architecture is software, too, and thus must be tested adequately. Fortunately, one can break down this problem into single aspects for which well-known testing solutions are available.
14.3.1 Testing the Reference Implementation and the MDSD Platform
The reference implementation plays a central role – at least during the bootstrapping phase of the domain architecture. Since one typically uses a small expert team for this purpose, agile, test-driven methods are quite useful here. The same is true for the MDSD platform.
All the test types introduced in Section 14.1 can be applied here – of course first without model-driven, generative support. Nevertheless, the reference implementation can contain a partition for prototype testware to discover its potential for generation.
14.3.2 Acceptance Test of the DSL
The validation of the modeling language (DSL) is also very important. This happens through its use in the reference model (see Section 13.2.2). The latter is primarily an (acceptance) test of the DSL in terms of its suitability and ergonomics. Since the reference implementation and the reference model try to cover all of the DSL’s constructs as minimalistically as possible – the minimum of testing that completely tests every feature once – the reference model should be considered a rather significant tests. After bootstrapping, the application model from the development thread is the next DSL test – you can use the ‘real’ application models as a test case for the suitability of the DSL.
14.3.3 Test of the MDSD Transformations
In the architecture development thread, the formalization of the reference implementation’s aspects and its casting in a computer-processable form – mostly generator templates or similar transformation rules that are bound to the DSL’s metamodel – is accomplished. As a rule, the transformation rules build on a generic MDSD tool whose correctness we assume for our purposes4. This leaves us only with the test of the domain- and platform-specific transformations. How can this be carried out in a sensible manner?
A fairly obvious test method is a by-product of bootstrapping the domain architecture: since the transformation rules were derived from both reference implementation and reference model, they should be able to reproduce exactly that part of the reference implementation that is covered by the DSL. In other words, if you apply the newly-created transformations to the reference model, you get – depending on the scope of the architecture – either the complete reference implementation or just its implementation skeleton. If you complement this skeleton with code fragments from the original reference implementation, a complete and testable application should be the result. All the tests that were created during the reference implementation’s construction should still work successfully! As a side-effect, one gets a generative reference implementation, and the bootstrapping of the domain architecture is finished.
In the further course of the project, this initial test of the domain architecture is extended for testing the actual application. The architecture is thus implicitly validated by the applications created – that is, by their tests. This is extremely effective and totally sufficient in practice.
What would an explicit test of the transformation rules look like? After all, a generator is a metaprogram – a program that generates programs from models. Its inputs are models, its outputs are programs or program parts (source code fragments). Thus an explicit test of for example a single transformation rule would use a relevant piece of a model as the test set-up, apply the rule to it, and finally compare the result to a specification: that is, to the corresponding desired generated code or source code fragment. Figure 14.8 explains this principle.
Figure 14.8 An explicit transformation test.

When the generators are constructed from modules, such an approach, and the construction of respective test suites is entirely possible. Let’s consider the consequences.
A (black-box) test supplies the system under test with specific stimuli (set-up and parameters) and compares the output or side-effects of the executing system with a specification. Abstraction takes place from the implementation of the system to be tested. How does abstraction work in the case of the explicit transformation tests described in this section? Is it helpful to commit to a specific and textually fixed version of the generated code, or aren’t the semantics of the generated code more relevant? Imagine a test suite with explicit transformation tests for a domain architecture in practice: what happens if the architects realize that another implementation is much better suited for a generative software architecture aspect than the existing one? The test suite would not allow the change – even though it would perhaps be totally transparent from the client applications’ perspective! Equally, this means that explicit transformation tests constitute a counterproductive over-specification. Transformation tests should not take place on the metalevel (testing of the generator), but on the concrete level (testing of the generated code).
What about modularization of transformation tests? The reference implementation (including its concrete test suite) and the reference model provide one rather powerful test case for generative software architecture, while each client application provides another. Depending on the combinatorics of the modeling constructs, it can make sense to generate a test suite from a number of smaller test cases for the domain architecture. This can work as follows: a transformation test case focuses on a specific construct of the DSL (for example, associations between persistent entities) – that is, the set-up consists of a model that is minimal in this respect and if necessary also contains pre-implemented domain logic. The test run includes running the transformations, resulting in code generated from the model that embeds the existing domain logic, if applicable. The runnable generated code is then validated on the concrete level via test cases. A test suite from such transformation tests that covers the DSL validates the generative part of the domain architecture.
1 Tests of graphical user interfaces (GUIs).
2 This can either be an API or a GUI, depending on the test type.
3 These should not be mistaken for modeling constraints at the metalevel (see Chapter 6) which define valid models in terms of the DSL.
4 Our scenario would look different if the generator needed to be certified, for example for a safety-critical system. However, we do not address such a scenario.