
Chapter 10
Model Transformations with QVT
by Simon Helsen
Model-to-model transformations are a contentious topic, partly because they are not very well understood, and partly because their merit in practical model-driven development scenarios is not very clear. This is something of a ‘chicken and egg’ problem, of course, because the lack of understanding of the underlying problems and mechanisms to solve them is feeding the lack of understanding about where and how to apply these kinds of transformations.
Nevertheless, model-to-model transformations – referred to as M2M transformations – could become an important mechanism to bridge some of the abstraction gaps that occur in MSDS. Not surprisingly, countless attempts to develop M2M transformation languages have been made in academia, Open Source communities, and commercial companies.
In this chapter we focus on model-to-model transformations with the Query / View / Transformations standard of the OMG, also known as QVT. However, since the QVT standard has turned out to be a rather voluminous and complex specification, we only give a high-level overview of its architecture and features. An elaborated example is used to give you a sense of what QVT transformations look like. We also give a brief overview of its history and future, as well as a critical assessment.
A more comprehensive account is outside the scope of this book, but the adopted QVT specification document [QVT] is now publicly available from the OMG [OMG] Web site1. A very good discussion of the various model transformation techniques (beyond QVT) can be found in a paper by Czarnecki and Helsen [CH05].
10.1 History
The MDA guide as it is defined by the OMG [MDAG] often talks about transformations between different models at different levels of abstraction. For example, it assumes that a typical MDA-based development scenario entails the transformation of a platform-independent model (PIM) to a platform-specific model (PSM) before generating code from the latter. The MDA guide intentionally does not say how this is supposed to happen, and this is where QVT comes into play.
The OMG originally issued a Request for Proposal (usually referred to as an RFP) for model-to-model transformations in April 2002 [QVTR]. It took until November 2005 before the adopted specification was eventually released. The time required to come up with the QVT specification is relatively long even by OMG standards, and the standardization process is still not entirely finished (see Section 10.5). To address code generation from MOF models, the OMG issued an RFP in April 2004 [M2T], but that standardization process is currently on-going and outside the scope of this book.
The rather long standardization time can partly be explained by the intrinsic complexity of the problem. Although lots of people had good ideas on how to write programmatic model-to-model transformations in, say Java, it quickly became clear that realistic M2M scenarios required more sophisticated techniques. The QVT RFP nevertheless explicitly asked for proposals that addressed this level of sophistication, even though such requirements were largely unexplored and not understood at the time.
Another problem was that no or little prior experience existed with model-to-model transformations in the first place. This was not a very good starting position from which to come up with a standard, which ideally is a consolidation of existing technology. The situation was worsened by the fact that eight different groups submitted initial responses. Most of these RFP responses were so different that there was no clear basis for consolidation. As a result, it took a considerable amount of time to find common ground, and the result today still specifies three different QVT languages that are only loosely connected.
10.2 M2M Language Requirements
Before we delve into the details of QVT itself, it is helpful to discuss some of the more important and perhaps less obvious requirements for model-to-model transformation languages and their implementations:
- Most realistic model-to-model transformation scenarios require transformation rules to have the ability to look up what other transformation rules have calculated, because each rule usually addresses only one small aspect of the entire transformation. A look-up is only possible if the engine has the ability to do some book-keeping of the transformation trace. A transformation trace can be understood as a runtime footprint of a transformation execution. The exact form and user visibility of such a trace is widely different between different M2M languages. Usually, imperative transformation languages have a more explicit look-up procedure, while declarative languages have an implicit way of exploiting the trace.
Even the three QVT languages expose the trace in very different ways. Transformation traces are also required to implement all sorts of optimization and debugging scenarios. As with any practical programming language, the ability to debug is of critical importance to uncover difficult and subtle bugs. This is no different for model transformations. For example, sophisticated model-to-model transformations may behave subtly differently depending on the values of one small property in the source model. If the resulting target model shows anomalies, it is extremely helpful for a transformation writer to follow the execution trace and discover which rules are making the wrong decisions.
Apart from when M2M transformations are first run, users rarely generate models on a clean sheet. If a transformation is run again, it is important that it only makes required changes to the existing target model, and does not simply keep adding model elements for every transformation run. This kind of target model understanding is only possible if there is an identification mechanism on the target model. This can be achieved by intrinsic target metamodel properties, such as the name of a model element or even its uniquely identifying id, or alternatively, by encoding the identification in the actual relationship between a target model and its source model. Usually, the transformation trace contains this information. The requirement to have repeated transformation runs correctly update the target model is sometimes known as change propagation. - A transformation implicitly or explicitly defines a relationship between its source and target models. In some scenarios, both the source and target models exist before a transformation is executed and therefore, before their relationship was established. In this case, a transformation may be asked to verify if the relationship exists and optionally change the target model just enough to make the relationship happen. This problem is different from the change propagation scenario, because for the former one can assume the existence of a transformation trace, whereas in the latter scenario the transformation may not have ever run.
- Generally, the source model of a transformation may be extremely large. After the first transformation execution, only comparatively small changes are usually made to the source model. In this case it should be possible to approximate which transformation rules have to be executed again and on what subset of the source model elements. An impact analysis on the transformation rules, as well as the availability of trace information, may be required to implement this. The need for such an optimization cannot be underestimated, as transformation users will expect reasonably fast turn-around cycles during development. This is comparable with non-MDSD development scenarios today in which entire builds of large projects are rare and usually happen overnight on a build server. This optimization requirement is sometimes referred to as incremental update.
- There are many use scenarios in which the target models, which are often platform-specific, may require manual changes by modelers. Such changes can often be avoided, as they might merely indicate a problem with the more abstract platform-independent model, or even with the transformation itself. Nevertheless, the PIM sometimes does not fix specific platform details on purpose and expects the platform modeler or developer to make controlled changes before another model transformation or code generation is applied. For this to be possible, the model transformation writer needs the ability to define where in the target model such changes are permitted. The transformation engine can then avoid overwriting these – and only these – manual changes. This is reminiscent of the protected area problem for code generation discussed in Section 8.3.1. The ability for a transformation writer to define how target models can be changed manually is sometimes known as the retainment policy.
- Model-to-model transformations often make substantial structural changes to the source model when they map it to a target model. Usually, this structures the transformation into multiple phases. In a typical M2M scenario, some of the classes in the source metamodel are mapped onto classes in the target metamodel in an initial phase. In a second phase, some of the source metamodel associations are mapped onto target metamodel associations. However, since the latter are usually encoded as properties, it might not be possible to construct one target model element in one operation. More generally, it is important that target model elements can be constructed incrementally. When this is the case, it is said that the language allows the definition of M x N transformations.
- It is contentious whether support for bidirectional transformations is a requirement. This can be achieved by writing two or more unidirectional transformations, or one transformation, which can be executed in both directions. The latter would only be possible in a declarative scenario. However, we question the usefulness of this requirement in practice. A bidirectional transformation can only be defined meaningfully when it describes an isomorphic relationship. In practice, this is almost never the case, as different metamodels usually describe aspects at different levels of abstraction with different completeness.
Even if a bidirectional transformation for a non-isomorphic problem is given (whether by two unidirectional transformations, or in one transformation that can be executed in two directions), it would be difficult to use in practice, as changes in both source and target model can easily oscillate in an unexpected and uncontrolled manner. In the worst case, changes in source and target models by different parties will render both models useless, as the transformation by necessity has to make defaulting assumptions because problem is not isomorphic. Such transformations would invalidate the architectural approach advocated in this book that architectural decisions should be made at the PIM level only.
The above are some of the more important reasons why it may not be sufficient to write model-to-model transformations in a general-purpose programming language like Java. If one does decide to write transformations in Java, a sophisticated framework would be required to support the transformation writer in managing the input and output models and the transformation trace: without the availability of an implicit or explicit trace, no useful transformations can be written. However, this would make the use of the Java debugger very hard, because users would have to deal with the internals of the framework. The ability to debug a transformation is however mandatory in practice.
One of the design goals of QVT was to either support, or at least not to prohibit, an implementation from fulfilling at least some of the requirements listed above. QVT ended up providing three domain-specific languages, each of which addresses model-to-model transformations in its own way. In Section 10.6 we give an assessment of whether QVT has lived up to its expectations and achieved its design goals.
You may wonder why QVT stands for ‘Queries, Views, and Transformations’, as it really only deals with model-to-model transformations. Queries are an intrinsic part of any model-to-model transformation, as they are used to gather model elements from the source model. In QVT, this is achieved with OCL [OCL]. The idea of a View, meanwhile, is to provide a means of looking at a specific aspect of a metamodel. It is thought that model transformations provide a mechanism to do so, although the currently-adopted specification explicitly avoids addressing the view problem. If the view needs to be editable, we bump into the bidirectional transformation requirement and its problematic consequences again. QVT claims to support bidirectional transformations because two of the three QVT languages have the ability to specify bidirectional rules, but it does not indicate how views could be defined with it.
10.3 Overall Architecture
The QVT specification comprises three different model-to-model transformation languages: two, the Relations language and the Core language are declarative, one, the Operational Mappings language, is imperative. The hybrid nature of QVT was introduced to accommodate different types of users who have different needs, requirements, and habits. This strategy may not come as a surprise if you consider the numerous initial submitters to the RFP, each with different expectations on the use and functionality of QVT:
- The Relations language is a declarative user-friendly transformation language that is primarily built around the concept of object patterns. The user is not responsible for the creation and deletion of objects, nor for the management of transformation traces. The language expects a user to describe the relationships between parts of the source and target metamodels by means of object patterns and OCL expressions. It provides a mechanism to identify target model elements, which is required to support change propagation. The QVT Relations language also defines a simple graphical syntax. We discuss the Relations language by means of an example in Section 10.4.1.
- The Core language is defined as an absolutely minimal extension to EMOF2 and OCL. Here too the user is not responsible for object creation and deletion, but traces are not automatically generated. The user is instead expected to define transformation rules and trace information as a MOF metamodel. The Core language does not provide patterns, nor any direct mechanism for the identification of target model elements.
This absolutely minimal approach makes the Core language beautiful in its simplicity, but almost impossible to use in practice. This is partly caused by the absence of automatic trace management, as well as the difficulty of dealing with target model element identification. The latter has to be explicitly encoded in rules and subrules, requiring a complex transformation specification for relatively simple transformation problems. Because of this, we do not elaborate the Core language any further. - The Operational Mappings language is the imperative cornerstone of QVT. It provides a domain-specific imperative language for describing transformations. OCL is used as its query language, but extended with imperative features to describe computations. The Operational Mappings language can be used in two different ways. First, it is possible to specify a transformation purely in the operational mappings language. We illustrate this possibility by means of our example in Section 10.4.2.
Alternatively, it is possible to work in a hybrid mode. The user then has to specify some aspects of the transformation in the Relations (or Core) language, and implement individual rules in the Operational Mappings language as black-box mappings.
Although the QVT standard specifies three transformation languages, they are not entirely disconnected. Figure 10.1 illustrates the relationships between the different QVT languages.
Figure 10.1 QVT language architecture.

The Relations language is semantically defined in terms of the Core language. In the specification, this is modeled by a model-to-model transformation from the MOF metamodel of the Relations language to the MOF metamodel of the Core language. This semantic transformation is itself specified in the Relations language. A discussion of this mapping would be beyond the scope of this book, but if you’re interested, you can find this transformation in the QVT specification document, where it is also extensively commented [QVT].
This explicit transformation between the Relations and Core languages suggests that a Relations language could be implemented on top of a Core language engine by translating a Relations transformation with the above transformation. Although this is possible in theory, it seems hardly a practical approach. It is clearly more viable to develop an optimized QVT engine for the Relations language, which better supports the different requirements for model-to-model transformations, than taking a detour via the Core language.
In connection with this relationship between the Relations and Core languages, the QVT document makes an analogy to the JVM and the Java programming language: the Core language is more like Java byte code, whereas the Relations language is a little like the Java language itself. You must judge the value of this analogy for yourself.
In practice it may not always be possible to specify all aspects of a transformation in the Relations (or Core) language because the user has only OCL to express computational problems. For example, it is possible that model-to-model transformations are required to use complex or legacy libraries that it would not be economical to re-implement in pure QVT. To accommodate this, the QVT specification explicitly allows for black-box mappings. As Figure 10.1 suggests, these black-box mappings may be written in the Operational Mappings language, which is then used in hybrid mode. As an alternative, it is also possible to use external programming languages such as Java.
In the sections that follow we investigate a concrete transformation problem and discuss its implementation in both the Relations and Operational Mappings languages. However, since it is not possible to discuss all the features and intricacies of these two M2M transformation languages, we recommend that interested readers work with the prototypes of these languages as soon as they are available (see Section 10.5).
10.4 An Example Transformation
In Section 6.11 we discussed the ALMA metamodel example, which can be used to model astronomic observational data. It provides a platform-independent abstraction over all the possible artifacts required for the ALMA software infrastructure. One possible platform-specific incarnation of ALMA data could be a relational database. In this section, we discuss a transformation from the ALMA metamodel to a simple relational database metamodel, referred to as DB.
Before discussing the actual transformation, we have to specify the input (or source) and output (or target) metamodels of the QVT transformation accurately. Since QVT assumes MOF-based metamodels for its input and output, we show a MOF rendition of the ALMA metamodel. Note that it is in theory possible to specify a QVT transformation directly on the UML profile, where the source metamodel would then have to be UML itself. However, because the UML metamodel as an instance of MOF is extremely large and complex, such transformations are often difficult to understand, let alone write. The QVT transformation writer is then required to understand the UML metamodel as an instance of MOF, which may not be straightforward and, more importantly, may distract from the domain-specific intentions of the metamodel.
A UML Profile is in many ways a concrete syntax model. From practical experience, we have observed that well-structured and adaptable transformations3 written directly against a UML profile tend to first transform the profile into an implicit MOF-like metamodel before implementing the actual transformation logic. This is particularly important when the transformation is the basis for reuse and adaptation4.
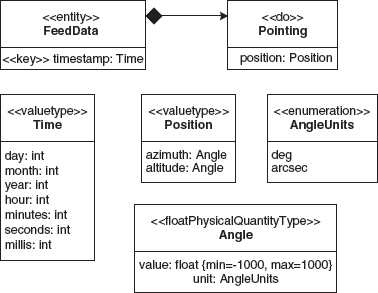
Figure 10.2 shows the ALMA metamodel as an instance of MOF.
Figure 10.2 ALMA metamodel as an instance of MOF.

The main differences with the UML profile are that we introduce the abstract class Record and the concrete class Field, instead of hanging on to UML’s Class and Attribute metaclass. We also introduce specific metaclasses for the PhysicalQuantityType and its different incarnations for each primitive type. This reduces a large number of constraints on the metamodel that were required in the definition of the UML profile.
Figure 10.3 shows the example of Figure 6.28 with some slight adaptations to show the use of a physical quantity type. Note that this example is not quite an instance of the UML profile of Section 6.11, which illustrates that there is some freedom in how to map a metamodel onto a profile.
Figure 10.3 An example ALMA model instance.
Our target DB metamodel is a simple rendition of relational database tables. Figure 10.4 shows its MOF instance.
Figure 10.4 Simple DB metamodel as an instance of MOF.
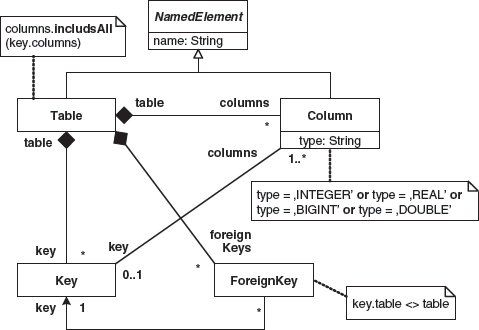
A DB model may contain any number of tables, each having one primary key, any number of columns, and any number of possible foreign keys. The key refers to one or more columns, where a constraint requires those columns to be owned by the table of the key. Each foreign key of a specific table refers to the primary key of another table, and we disallow a foreign key to refer to its own table. Finally, both tables and columns have names and each column has a primitive type, for which we only allow numeral types.
The example transformation from the ALMA metamodel to the DB metamodel can be described informally as follows:
- All fields of a record are mapped to one ore more columns depending on the field type:
- Each ALMA entity is mapped to a DB table:
- Each ALMA-dependent part that is owned by an entity is mapped to a DB table as well, where its name is a concatenation of the entity name and the dependent part name:
- All ALMA-dependent parts that h are parts of other dependent parts have all their columns (for each of their fields) expanded into the table of the topmost dependent part. This happens recursively as well.
The simple example of Figure 10.3, transformed with the above transformation description, would lead to the following two tables5:
10.4.1 The Example in the QVT Relations language
The QVT Relations language is a declarative member of the QVT trio. A user of QVT Relations has to describe the transformation of a source metamodel to a target metamodel6 as a set of relations. A transformation execution means that these relations are verified and then, if necessary, enforced by manipulating the target model.
For our example, we describe how an instance of ALMA relates to an instance of DB. A transformation declaration looks like this:
transformation alma2db(alma : AlmaMM, db : DbMM) {
…
}
The direction of an execution is not fixed when the transformation is defined which means that in theory both alma and db can be the source and target model and vice versa. Only when invoking the transformation must the user specify in which direction the transformation has to be executed. This direction alters the interpretation of the individual relations, as we explain below.
Here is the relation rule that maps an entity to a table:
top relation EntityToTable {
prefix, eName : String;
checkonly domain alma entity:Entity {
name = eName
};
enforce domain db table:Table {
name = eName
};
where {
prefix = ’ ‘;
RecordToColumns(entity, table, prefix);
}
}
A relation rule always has as many domain declarations as there are models involved in the transformation. A domain is bound to a model (for example alma) and declares a pattern that will be matched with elements from the model to which the domain is bound. Such patterns consist of a variable and a type declaration, which in itself may specify some of the properties of that type, and recursively so for the types of those properties. Such patterns simply constrain the model elements and properties in which we are interested for this relation rule.
For example, in the relation EntityToTable, the domain binding the alma model will match all elements of type Entity in the alma model to the variable entity, provided they at least define a property name, which has to be bound to the string variable eName. Similarly, in the domain for db, the pattern binds the variable table of type Table, while property name is bound to the variable eName. Observe that both patterns refer to the same variable eName, which implicitly is a cross-domain constraint. Additional cross-domain constraints can be specified in the where clause of a relation rule.
Before discussing the contents of the where clause, we want to draw your attention to the domain qualifiers checkonly and enforce. These qualifiers constrain how a relation can be executed for a given direction. For example, if the alma2db transformation is executed in the direction of db, the QVT engine will try to match all domain patterns of a rule that are not part of the direction (conveniently called source domains). For each source domain match, the engine will search for matches in the domains of the direction (called target domains). If there is no or only a partial match and the target domain is qualified with enforce, the engine will alter or create the model elements of the target domain to (re-)enforce the relation. If, on the other hand, the target domain is qualified with checkonly, the engine will notify the user of an inconsistency, but will not try to correct the model in the target domain.
In our example, when alma2db is executed in the direction of db, the entityToTable rule will match elements in alma of type Entity and check if a corresponding element of type Table with the same name exists in db. If not, the QVT engine will change or create a table in db.
The QVT Relations engine will also delete any tables that have no corresponding entity in the alma model. The other way around, whenever we execute alma2db in the direction of alma, the entityToTable rule will match elements in db of type Table and check if a corresponding element of type Entity exists in alma. If this is not the case, the user will be notified, but no changes will be made in the alma model.
In theory it is possible to qualify all domains of a relation with enforce, which amounts to a bidirectional or even multidirectional transformation rule. However, as we pointed out in Section 10.2, this does not work well in practice. Moreover, the QVT relation language constrains the format of expressions involved in the enforced domain to guarantee executability. It is considerably more difficult to express all the required computations when all domains are enforced.
After a successful match of the source domain pattern, the target domain pattern is checked and enforced with the constraints of the where clause. In the example, the entityToTable rule demands that the variable prefix is bound to the empty string and demands that the relation RecordToColumns, with the given arguments exists or is constructed. In a way, the predicate RecordToColumns(entity, table, prefix) can be interpreted as a rule call.
Relation rules can either be top-level or non-top-level. The former are qualified with the keyword top and are executed automatically as soon as a match exists for the source domain patterns. In contrast, non-top-level relation rules are only executed when explicitly called from the where clause of another relation. The above entityToTable rule is an example top-level relation, whereas the RecordToColumns rule, which is called from the where clause of entityToTable, is non-top-level:
relation RecordToColumns {
checkonly domain alma record:Record {
fields = field:Field {}
};
enforce domain db table:Table {};
primitive domain prefix:String;
where {
FieldToColumns(field, table);
}
}
This relation rule matches records and their fields in alma and tables in db. It also defines a special primitive domain. This mechanism allows non-top level relations to specify parameters of primitive type. They can only meaningfully occur in non-top-level relations, because primitive domains have an infinite number of instances.
You may have wondered how the QVT engine repairs broken elements in an in an enforced target domain. A simple answer could be that for each failing target domain pattern match, the engine simply deletes the entire match and replaces it with a correctly-calculated match. Although semantically correct, this strategy would be very inefficient and, worse, would destroy the underlying identities in the target model, which is very problematic in practice.
For example, consider the following relation rule of the alma2db example:
relation PhysicalQuantityTypeToColumn {
pqName, pqUnit, fieldName : String;
checkonly domain alma field:Field {
name = fieldName,
type = pq:PhysicalQuantityType {
name = pqName,
units = pqUnit
}
};
enforce domain db table:Table {
columns = column:Column {
name = prefix + fieldName + ‘_as_’ +
pqName + ‘_in_’ + pqUnit,
type = AlmaPhysicalQuantityTypeToDbType(pq)
}
};
primitive domain prefix:String;
}
In the alma domain, this rule matches a Field of type PhysicialQuantityType with the properties name and units bound to the variables pqName and pqUnit respectively. In the db model, the engine would therefore want to match or repair a column of a table with a name based on pqName and a type calculated from the fieldType.
Suppose now that for a match in alma, a corresponding column is found in db, but with a non-matching name: hopefully only the name property of Column is recalculated and not the entire Column object. In QVT Relations, this is achieved with key definitions, which a transformation writer has to provide at the beginning of a transformation. As an example, consider:
key Column {table, name};
This key definition says that columns are uniquely defined by their name and the table to which they belong. If in the above example both the table and the name property of the column had changed in the enforced target domain, a new column object would have been created.
Top-level relations may need additional cross-domain constraints before a successful source domain pattern match is allowed to happen. This is illustrated in the following rule:
top relation EntityKeyToTableKey {
checkonly domain alma entity:Entity {
key = entityKeyField:Field {}
};
enforce domain db table:Table {
key = tableKey:Key {}
};
when {
EntityToTable(entity, table);
}
where {
KeyRecordToKeyColumns(entityKeyField, table);
}
}
This top-level relation specifies a when clause. It requires that the pattern bound to entity in the alma domain is only considered successful whenever there exists an instance of EntityToTable with entity and table as arguments. Only then do we match or construct a Key object in the enforced target domain with a link to the Column object that was previously calculated and call the non-top-level relation KeyRecordToKeyColumns.
Sometimes, it is also useful to write auxiliary functions that do simple calculations. Consider the function AlmaTypeToDbType from the alma2db example:
function AlmaTypeToDbType(almaType : String) : String {
if (almaType = ‘int’) then ‘INTEGER’
else if (almaType = ‘float’) then ‘REAL’
else if (almaType = ‘long’) then ‘BIGINT’
else ‘DOUBLE’
}
This calculates the correct string name for the primitive types in db for each primitive type of alma. This type of function should be understood as a macro: that is, it does not contribute to the transformation trace, and behaves as if it was in-lined.
The QVT Relations language also provides a graphical notation, which extends UML object diagrams. As an example, Figure 10.5 shows the EntityKeyToTableKey relation rule in the graphical notation.
Figure 10.5 Graphical notation of a QVT rule.

The notation is relatively straightforward. Each rule has its own frame with the name at the top-left corner. The two patterns are drawn as object graphs in which the domain variable and type are given the stereotype «domain». The domain bindings and their qualifications are drawn in the middle with a new symbol, where C indicates checkonly and E means enforce. Both the when and where clauses are drawn as compartments of the rule frame. Their contents is then inserted as text.
Unfortunately, the current-adopted QVT specification is not complete with regard to the graphical notation of all possible QVT relation rules. For example, it does not define how primitive domains are to be specified. More generally, it is not clear how much of an advantage the graphical notation gives over the textual representation. Graphical rules are comparatively large and require a lot of work to specify. Moreover, unlike UML or MOF, which are languages for defining structural information, it is not clear how much more readable rules of a behavioral language such QVT become in a graphical form.
You can find the entire alma2db example in its QVT-relational textual form in Appendix A.1.
10.4.2 The Example in the QVT Operational Mappings language
The Operational Mappings language (OM) is the imperative member of the QVT language specification. It can be used in conjunction with QVT Relations in a hybrid manner, or stand-alone. For the sake of the example, we only consider the stand-alone method.
An Operational Mappings transformation starts with the transformation header, which specifies the input and output models of the transformation. An OM transformation can only be executed in the statically-declared direction, as it generally does not address multidirectional transformations. For the alma2db example, we have:
transformation alma2db(in alma : AlmaMM, out db : DbMM);
OM transformations consist primarily of mapping operations, which are attached to source metamodel classes. For example, consider the following mapping example from the alma2db example:
mapping DependentPart::part2table(in prefix : String) : Table
inherits fieldColumns {
var dpTableName := prefix + recordName;
name := dpTableName;
columns := mainColumns +
object Column {
name := ‘key_’ + dpTableName;
type := ‘INTEGER’;
inKey := true;
}
end { self.parts->map part2columns(result, dpTableName + ‘_’); }
}
The mapping part2table is attached to the DependentPart metaclass. It has one input parameter prefix of type String and, when invoked, either leads to a new Table instance or, if the rule is called with a table binding already, updates that table.
The body of the mapping contains property assignments as well as temporary variables (qualified with the keyword var). Additionally, mappings may declare an init- and end-clause. These contain statements that have to be executed before and after the instantiation of the metaclass respectively.
All statements in the body and its clauses are specified in an imperative extension of OCL. We don’t discuss this extension in any detail, as it is mostly self-explanatory. Within expressions of mapping statements, one commonly has to refer to the containing object, as an instance of a source metaclass. This object can be referenced with the self keyword.
Expressions may also contain in-lined mappings, which are qualified with the object keyword. In the example, the columns property assignment contains such an in-lined mapping. It constructs a Column instance, which in its turn is assigned some properties7.
You may wonder where the property inKey came from. In OM transformations, it is possible to extend metaclasses with auxiliary properties. For the example it is sufficient to add the following statement:
intermediate property Column::inKey : Boolean;
The end- clause of the part2table mapping example exploits two features that deserve explanation. The parts property of the self object is fed to the map operation. This operation simply applies its argument mapping to each element in the collection assigned to the property. Moreover, the mapping part2columns, which results in a table, is passed, next to a normal String argument, the special variable result. As a consequence, mapping part2columns will not create a new table, but merely use the result of the part2table mapping and update properties as specified in the part2columns mapping. The special variable result stores the result of the mapping implicitly8.
The part2table mapping has expressions that refer to the variables recordName and mainColumns, which don’t seem to be declared anywhere. These variables were in fact inherited from the abstract mapping fieldColumns:
abstract mapping Record::fieldColumns(in prefix : String) : Table {
init {
var mainColumns := self.fields->map(f)
field2Columns(prefix, self.key = f);
var recordName := self.name;
}
}
The inheritance semantics of mappings implies that the sub-mapping implicitly calls the super-mapping, passing its own result. The call happens before the body of the sub-mapping is executed. In the example, some intermediate results only are calculated. The fact that fieldColumns is abstract merely implies that it cannot be called explicitly.
The result of a mapping cannot always be implicitly assigned, as has been the case with our previous sample mappings. This is typically the case when the result of a mapping is a collection. Consider the following example from alma2db:
mapping PhysicalQuantityType::pqType2Columns (in prefix : String, in iskey : Boolean)
: Sequence(Column) {
init {
result := self.units->map(u)
object Column {
name := prefix + ‘_as_’ + self.name + ‘_in_’ + u;
type := self->convertPQType();
inKey := iskey;
};
}
}
The pqType2Columns mapping results in a sequence of Column objects and the result variable is explicitly assigned in the init- clause. Also notice that the map operation can bind each of the collection elements to a parameter. In the example, each unit from self.units is bound to the parameter u.
OM transformations also have a means of specifying functions, which do not contribute to the runtime footprint of a transformation. Consider the example:
query PrimitiveType::convertPrimitiveType() : String = if self.name = “int” then ‘INTEGER’ else if self.name = “float” then ‘FLOAT’ else if self.name = “long” then ‘BIGINT’ else ‘DOUBLE’ endif endif endif;
Operational Mappings queries are comparable with functions in QVT relations.
Finally, we have to tell the transformation where and how to start transforming. This is achieved with the main declaration, which in the case of alma2db looks like this:
main() {
alma.objectsOfType(Entity)->map entity2table(“);
}
The operation objectsOfType(Entity) simply returns all model elements of metaclass Entity from the alma input model. The entity2table mapping is called on each of these with the prefix bound to the empty string.
This exposition only covered some of the very basic OM language aspects, which are a small (but useful) subset of entire OM language feature collection. It is beyond the scope of this book to delve into the details of OM’s numerous possibilities. Some language features are purely for convenience or address scalability issues (for example library usage). Others allow the user to inspect the transformation trace.
One of the more curious OM language properties is the support for integrating it more tightly with a QVT Relations engine. For example, it is possible to include when and where clauses within mapping definitions. In this case, a transformation writer has to be aware that a mapping invocation may fail and return the null value when the when clause evaluates to false. Such when and where clauses function as pre- and post-conditions respectively.
The entire alma2db OM language example is given in Appendix A.2.
10.5 The OMG Standardization Process and Tool Availability
As we mentioned at the beginning of this chapter, the QVT specification as it is currently adopted by the OMG Architecture Board is not yet finalized. This means that the current specification is open to the public for issue reporting to allow participants from inside and outside the OMG to point out potential problems and errors, or suggest small improvements. The deadline for issue reporting is 20th March 2006.
Subsequently, a small group of OMG members involved in the QVT language definition will process all the reported issues and either change the adopted specification, or explain why specific issues do not have to be addressed. This process leads to a finalization report, which is then presented to the Architecture Board. In the case of QVT, this report is due by 7th July 2006.
If the Architecture Board is happy with the finalization report, they will issue a recommendation to the OMG Board of Directors, which usually follows the Architecture Board’s recommendation to publish the specification. In the case of QVT, this may happen by the end of 2006.
In the meantime, however, tool developers are free to use the adopted specification and provide the MDA community with prototype implementations. Unfortunately, at the time of writing, hardly any prototypes for a QVT language are publicly available. TCS9 has promised a public non-open-source prototype for QVT Relations by early 2006. France Telecom10 expects a prototype for the QVT Operational Mappings language by April 2006. Borland has already announced a QVT-based model-to-model language prototype implementation in its Together Architect 2006 product. This QVT prototype is essentially a small subset of the QVT Operational Mappings language with small deviations from the adopted standard.
In the near future we expect an increased number of available QVT tools, both commercial and Open Source. However, you should be aware that the OMG is not very strict about standards compliance. In fact, the OMG has no official way of verifying the level of compliance for a tool11. In the case of QVT, this will almost certainly lead to a large number of vendors claiming support for QVT without really being standards-compliant.
It is also interesting to consider what it means to be QVT-compliant. According to the specification, a tool ought to indicate which of the three QVT languages it supports. For each supported language, a tool has to indicate whether it can import or export a specification either in its abstract syntax (for example via XMI) or its concrete syntax. Moreover, the ability to use black-box rules has to be explicitly stated as well. Clearly, this leads to a large number of possible ways of being QVT-compliant.
10.6 Assessment
Whether the QVT standard as it stands today will survive the turbulent and fast evolution of new techniques and methodologies within MDSD, only time will tell. The fact that the standard specifies three different languages indicates that model-to-model transformations remain an ill-understood domain. There is also a multitude of non-QVT model-to-model transformation languages and tools available, some proprietary, some Open Source, but all tackling the problem in their own way.
Obviously, the intentions of the QVT standard were to avoid wild growth of such systems, but the problem is that nobody knows today what is really required to make M2M work in practice. This is partly because few projects have used M2M on a large scale in industrial project settings, and partly because model-driven development is an ‘early’ market.
The M2M requirements in Section 10.2 only scratch the surface of what is really required for an M2M transformation language to become practical and usable. The difficulty of developing a new M2M language is to find the balance between a usable language for the transformation writer and the possibility of properly implementing the language reasonably efficiently and well-integrated in an MDA tool landscape. While a standard should not specify how to build tools for the language, it should define a language that can be reasonably implemented. In the case of QVT, it should not be forgotten that a transformation works on models that ‘live’ in some kind of MDSD repository environment. Users of the transformation expect a smooth integration of a QVT engine into such an environment, as the transformation is only a means, not an end, after all.
But even with the most basic requirements from Section 10.2, it is not clear how the current QVT languages address them all. For example, QVT Relations has no way of specifying a retainment policy. QVT Operational Mappings is an imperative language, it is not clear at all how an incremental update mechanism can be supported, as its impact analysis would be horrendously complex.
In terms of language use, it seems that both QVT Relations and QVT Core have paid a high price for wanting to support bidirectional mappings, something that we believe has no practical value. Moreover, these two declarative languages do not have mechanisms for working with exception conditions, which is an important omission. The QVT Operational Mappings language was only touched on in this chapter, but the full language is fantastically complex: it almost seems that object orientation here has been driven too far to remain usable. An M2M transformation is an intrinsically functional problem that does not seem to integrate easily into the object-oriented paradigm.
We also believe that M2M transformation development will only be able to take off when M2M development environments have become available and are as good as modern programming language IDEs. However, this requires sophisticated tools with intelligent editors and advanced debugging facilities. Considering the fact that at the time of writing hardly any QVT tools are on the market in the first place, we are not anticipating QVT transformation writing to become a mainstream activity in the near future. Moreover, the lack of one standardized QVT language is a further hindrance for the acceptance and usage of QVT-style M2M transformation writing.
Finally, it should be mentioned that the QVT specification is a complex document that underwent countless revisions. It is difficult, if not impossible, to verify whether the language standard is consistent and sound. This can partly be explained by the fact that the OMG has little experience in language definitions with a behavioral bias. Another reason is probably that too many people were involved in its specification over a long period of time. However, a sound language standard is a must for widespread acceptance and easy implementation. We anticipate that revisions and follow-up versions of QVT will appear in the near future, provided the standard is not bypassed by the possible emergence of a defacto model-to-model transformation standard.
1 The adopted specification is not yet finalized, which means minor changes may be made to it. See also Section 10.5.
2 EMOF is a minimal subset of MOF 2.0 akin, but not identical to Ecore, the meta meta model defined as part of the Eclipse Modeling Framework (EMF).
3 These observations stem primarily from model-to-text transformations: however, we believe that they equally apply to M2M transformations.
4 The attentive reader might wonder how we relate a UML profile with a MOF metamodel. In theory, this could also be achieved with an M2M transformation, but in practice, it is more likely the job of the hosting MDA tool because to be practical, the connection between the profile and metamodel has to be live and bidirectional. More importantly, the tool may want to put restrictions on the permitted mappings from the metamodel to the profile, and thus might have to provide its own mechanism or language to express this relationship.
5 One might define a UML profile as a concrete syntax for DB models, but since this is not relevant for the transformation we do not discuss it further.
6 All QVT languages allow for multiple input and output models.
7 In fact, a mapping body that directly assigns properties is merely a syntactic simplification of an in-lined mapping, bound to the result of the mapping. For details, we advise you to consult the specification.
8 This is again a syntactic convenience. The assignment to result can be explicit whenever the mapping defines an explicit object creation. Consult the specification for details on this.
9 TCS (Tata Consulting Services) is one of the main QVT Relations language contributors.
10 France Telecom leads a group of companies committed to the QVT Operational Mappings language.
11 Standard compliance could be verified with a test suite or a reference implementation, or, as is the case with J2EE, with both.