
Chapter 9
Code Generation Techniques
In keeping with the structure introduced in Chapter 1, we now want to address proven techniques that are the foundation for the selection or construction of MDSD tools – that is, those aspects that can be factored from domain architectures because they are of a more general nature. Yet a domain architecture cannot work without them: code generation techniques are an important foundation.
9.1 Code Generation – Why?
We have repeatedly mentioned that there is a close connection in MDSD between modeling, code generation and framework development – for example, framework completion code for the MDSD platform can be generated from a DSL. A rich, domain-specific platform, as described in Chapter 7, simplifies code generation and lessens the need for it. On the other hand, code generation offers advantages over purely generic approaches, or at least supplements them.
9.1.1 Performance
In many cases, code generation is used because one wishes to achieve a specific level of performance while maintaining a degree of flexibility. Traditional object-oriented techniques such as frameworks, polymorphism, or reflection are not always sufficient regarding their achievable performance. Using code generation, the configuration is stated abstractly – which also where its flexibility lies – and efficient code is generated.
9.1.2 Code Volume
Another reason for code generation is code size. If you know at compile time which features will be needed at runtime, the generator only needs to add those parts to the code. This can help to make the image smaller. Vice versa, the excessive expansion of constructs at the source code level can significantly enlarge the image. One example of this is C++ template instantiations.
9.1.3 Analyzability
Complex, generic frameworks or runtime systems tend to relocate programming language-related complexity to a proprietary configuration level. They usually make heavy use of interpretation, which hampers the possibilities for static analysis of program properties, and occasionally impairs error detection. In contrast, generated programming language source code possesses the analyzability of manually-programmed code. As we have pointed out, a sensible balancing of both approaches is ideal.
9.1.4 Early Error Detection
Flexible systems often use weak typing to allow decision-making at runtime (Object in Java, void* in C/C++). Thus error detection is deferred to program runtime, which is often undesirable, and which is one of the reasons why this kind of programming is not popular in embedded systems. Some of these disadvantages can be cured through the use of ‘static frameworks’. Configurations can be recognized as being flawed before compilation, and the compiler, too, usually has more information, so that it can report error messages.
9.1.5 Platform Compatibility
The classical case of using code generation in the context of MDA is that application logic can usually be programmed independently of the implementation platform. This enables an easier transition to newer and potentially better platforms.
9.1.6 Restrictions of the (Programming) Language
Most programming languages possess inconvenient restrictions in their expressiveness, which can be circumvented using code generation. Examples are type genericity in Java (at least before version 1.5), or the downcast to a variable class. Another example is the introduction of object-oriented concepts into a non-object-oriented language.
9.1.7 Aspects
Cross-cutting properties of a system such as logging or persistence can typically be implemented locally – that is, not scattered through the application – via code generation. We will further elaborate on this issue in the course of this chapter.
9.1.8 Introspection
The issue of introspection should not go unmentioned. Introspection describes a program’s (read-only) access to itself. This allows the program to obtain information about itself, for example about classes, their attributes and operations. In certain programming languages, such as Java, this mechanism is supported dynamically. Other languages such as C++ do not offer introspection. In such cases, code generation can create a substitute statically: instead of analyzing the program structure at runtime, the structure is analyzed at generation time – that is, before runtime – and code is generated that provides access to the respective structures.
9.2 Categorization
This section looks at various questions when dealing with metaprograms – programs that generate other programs. This includes the mixing/separation of the metaprogram and the base program (the generated program), as well as ways of integrating generated and non-generated code so that the metaprogram and the program are not mixed.
9.2.1 Metaprogramming
Code generators are metaprograms that process specifications (or models) as input parameters, and which generate source code as output.
Metaprograms can be run at different times in relation to the generated program:
- Completely independently of the base program – that is, before it.
- During compilation of the base program.
- While the base program runs.
Typical MDA/MDSD generators adhere to the first approach. Here, the metaprogram and the part of the base program to be created manually are usually specified separately. The generated code is also separated from the manually-created code, and both must be integrated by the developer (see Section 8.3.1).
Systems such as the C++ preprocessor or the C++ template mechanism can also be used for metaprogramming. Here, base program and metaprogram are mixed, and similarly the result of the generation process already contains manually-created as well as generated code, so it is also mixed. However, the created program no longer knows anything about the metaprogram. We refer to that as static metaprogramming.
Lisp and CLOS [Kos90] allow the execution of metaprograms at runtime via a meta object protocol. This works because in Lisp programs are represented as data (lists). Metaprograms can modify these lists and thus create or modify base programs at runtime. Changes of the metaprogram made from the base program enable the modification of the base program’s semantics.
9.2.2 Separation/Mixing of Program and Metaprogram
In the case in which metaprograms and base programs are mixed, a common (or at least integrated) language exists for programming and metaprogramming, and the source code components are not separated, but mixed. This can lead to invocation relationships between the two levels, in principle in both directions. C++ template metaprogramming can fall into this category, as well as Lisp and CLOS.
Mixing programs and metaprograms is a very powerful approach. However, the resulting system can easily become extremely complex, so its relevance to mainstream software development is very limited. A further implication of the mixed approach is that the target language is no longer a parameter of the code-generation process.
If program and metaprogram are separated, the system’s creation takes place in two distinct phases. The metaprogram is run and creates the base program (or parts of it) as output, then terminates. The program does not know that the metaprogram exists1. The separation is maintained throughout the (meta-)programming process, including the build process.
The question of whether program and metaprogram are written in the same language is irrelevant here. For example, one can easily write a metaprogram in Java that generates Java, C++, or C# as output.
The approach in which metaprogram and base program are separated does support meta object protocols, but due to its lower complexity it is better suited for typical architecture-centric, Model-Driven Software Development. The generator used in our book, openArchitectureWare [OAW], is a hybrid with respect to the metaprogramming language: parts of it are implemented in Java (metamodel of the application family), and parts in the template language Xpand. Thus one can combine the advantages of an expressive template language with the power of a ‘real’ programming language without overloading the templates with too much metaprogramming logic.
9.2.3 Implicit or Explicit Integration of Generated with Non-generated Code
Implicit integration of both program types results in code that already constitutes a mix of generated and non-generated code. As a result, one no longer has to worry about the integration of the two categories.
In the other case, the generated code is initially independent of handwritten code sections. The two kinds of code must be integrated in an appropriate way: this was described in the previous chapter.
9.2.4 Relationships
In general we can say that a relationship exists between the two aspects of generator categorization:
- Generators in which program and metaprogram are separated usually also create code that is separated from the manually-created code, and which must therefore be integrated manually.
- Generators with a mix of program and metaprogram do not require this manual integration – the generator already creates the combined system.
Separation of program and metaprogram, as well as the explicit integration of generated code and manually-created parts, is recommendable in practice. We will introduce the corresponding techniques in detail later on, but first we give a few examples for the second category.
9.2.5 Examples of the Mixing of Program and Metaprogram
The C++ preprocessor is a system that blends program and metaprogram. The languages applied here are independent of each other: one can also use the C++ preprocessor with other programming languages, as it works purely textually on the source code. Since the system is based on macro expansion, the preprocessor already produces source code that integrates both generated and manually-created code. The following is a simple C++ macro:
#define MAX(x, y) (x<y ? y : x)
If this macro is used in the source code, it is expanded by the preprocessor according to the rule cited above:
int a, b; int greaterValue = MAX(a, b);
becomes the following expression:
int greaterValue = (a<b ? a : b);
The generated code has been directly inserted where the macro to be expanded was originally located.
Another example, again from C++, are templates. Templates are a way first and foremost to implement type genericity in C++. Functions or classes can be parameterized with types. Due to the fact that this feature is realized in C++ using static code generation, this method can also be used for template metaprogramming [Ale01]. Here, generation takes place through the evaluation of templates2. This approach is primarily used for performance optimization, optimization of code volume, static program optimization, and in certain special cases, for the adaptation of interfaces, for generative programming or other interesting purposes described in [Ale01].
Here too program and metaprogram are mixed. Integration is clearly closer than in the case of the preprocessor, because the template mechanism knows and uses C++’s type system. Similarly, the resulting system consists of already-generated and manually-created code.
The adaptation of code volume can serve as an example of template metaprogramming here. Specifically, we want to use the smallest possible data type (short or int) adequate for the maximum value of a variable defined here so that we can decrease the memory footprint at runtime. The following code fragment illustrates this:
#define MAXVALUE 200 IF|(MAXVALUE<255), short, int>::RET i; // type of i is short
The IF statement in the example above is evaluated at compile time. It is implemented using templates, clearly visible from the use of the ‘<’ and ‘>’ brackets. Specifically, we apply partial template specialization. We first define a template that has three parameters: a Boolean value, as well as classes (types) for the true case and the false case.
template<bool condition, class Then, class Else>
struct IF {
typedef Then RET;
};
In the context of the C++ template definition, we now define a new type using typedef. Based on a commonly-accepted convention, this type is called RET. It serves as the template evaluation’s return value. In the default case, we define the return type – the value of the template instance – as the type that has been defined as the true case above, that is, the template parameter of the name Then.
Next, the template is partially specialized for the case in which the Boolean expression is false. Now the template has only two parameters, since the Boolean expression has been set to false.
//specialization for condition==false
template<class Then, class Else>
struct IF<false, Then, Else> {
typedef Else RET;
};
The return value RET is now the type parameter that was specified for the false case (the parameter Else). If the compiler finds an instance of this template, like in the short/int example given above, it will use the template that is the most specific – the false case in this context. RET is then defined with the type Else and is thus short.
9.3 Generation Techniques
In this section we introduce proven code generation techniques, including some code examples. We have organized the generation techniques into various categories:
- Templates + filtering
- Template + metamodel
- Frame processors
- API-based generators
- In-line generation
- Code attributes
- Code weaving
We briefly introduce all these techniques and illustrate them with examples. Except for in-line generation (and to some degree, code attributes), all these approaches require explicit integration.
Independent of the – in some cases important – differences between the various generation techniques, they all have the following in common:
- A metamodel or respectively an abstract syntax always exists, at least implicitly.
- Transformations that build on the metamodel always exist.
- Some kind of front-end that reads the model (the specification) and makes it available to the transformations exists.
9.3.1 Templates and Filtering
This generation technique describes the simplest case of code generation. As shown in Figure 9.1, we use templates to iterate over the relevant parts of a textually-represented model, for example using XSLT via XML.
Figure 9.1 Templates and filtering.
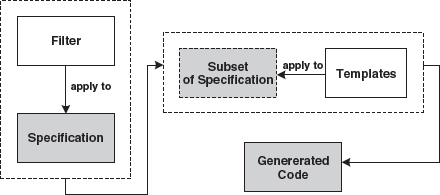
The code to be generated is found in the templates. Variables in the templates can be bound to values from the model. Below, we will present a simple example in which a Java Bean Person is generated from an XML specification (for simplification purposes, we do not use XMI as the model representation, instead we use a custom schema). This is the specification:
<class name=“Person” package=“com.mycompany”> <attribute name=“name” type=“String”/> <attribute name=“age” type=“int”/> </class>
The generated code should look like the following:
package com.mycompany;
public class Person {
private String name;
private int age;
public String get_name() {return name;}
public void set_name( String name) {this.name = name;}
public int get_age() {return age;}
public void set_age( int age ) {this.age = age;}
}
The XSLT stylesheet that performs this transformation looks roughly like the following:
<xsl:template match=“/class">
package <xsl:value-of select=“@package”/>;
public class <xsl:value-of select=“@name”/> {
<xsl:apply-templates select=“attribute”/>
}
</xsl:template>
<xsl:template match=“attribute">
private <xsl:value-of select=“@type”/>
<xsl:value-of select=“@name”/>;
public <xsl:value-of select=“@type”/>
get_<xsl:value-of select=“@name”/>() {
return <xsl:value-of select=“@name”/>;
}
public void set_<xsl:value-of select=“@name”/> (
<xsl:value-of select=“@type”/>
<xsl:value-of select=“@name”/>) {
this.<xsl:value-of select=“@name”/> =
<xsl:value-of select=“@name”/>;
}
</xsl:template>
The generation using templates and filtering is fairly straightforward and portable, but the stylesheets soon become very complex. For this reason, this approach is totally unsuitable for larger systems, particularly if the specification is based on XMI.
The XMI problem can be somewhat alleviated if one works in several steps: an initial transformation transforms the XMI into a concrete, domain-specific XML schema. Further transformation steps can now generate code based on this schema. One gains a certain decoupling of the templates from the concrete XMI syntax, and the actual code generation – the second step – becomes much easier. However, one still works on the abstraction level of the XML metamodel – a problem that can clearly be solved using the approach presented next.
9.3.2 Templates and Metamodel
To avoid the problems of direct code generation from (XML) models, one can implement a multi-stage generator that first parses the XML, then instantiates a metamodel (which is adaptable by the user), and finally uses it together with the templates for generation. Figure 9.2 demonstrates the principle.
Figure 9.2 Templates and metamodel.

The advantage of this approach is that on the one hand one gains greater independence from the model’s concrete syntax, for example UML and its different XMI versions. On the other hand, one can integrate more powerful logic for the verification of the model – constraints – into the metamodel. In contrast to the templates, this can be implemented in a real programming language, such as Java. This kind of code generation is of special significance in the context of MDSD, as we pointed out in Chapter 6.
One interesting implementation aspect of the openArchitectureWare generator that falls in this tool category should not go unmentioned: from the perspective of compiler construction, metamodel implementation (for example in Java) and templates are part of the transformation. The metamodel assumes the role of the abstract syntax. Since the abstract syntax and the transformation are parameters of the compiler, we are in fact dealing with an open compiler framework. What is remarkable is that the constructs of the syntax – that is, the metamodel elements – compile themselves. Put another way, the compiler is object-oriented, which helps to avoid, among other things, tedious type switches. The templates are – from a conceptual point of view – compiler methods of the metamodel, just like the help methods implemented in Java. You can see this from the template definitions («DEFINE method FOR metaclass»). Just like Java, the template language also supports polymorphism and overwriting – both are necessary to build an object-oriented compiler – and only the definition of classes is delegated to the Java part. This is why we consider the template language to be object-oriented, even though no classes can be defined directly in the template language.
9.3.3 Frame Processors
Frames, the central element of frame processors, are basically specifications of code that should be generated. Like classes in object-oriented languages, frames can be instantiated, multiple times. During this instantiation, the variables (which are called slots) are bound to concrete values. Each instance can possess its own values for the slots, just like classes. In a subsequent step, the frame instances can be generated, so that the actual source code is generated.
Figure 9.3 Frame processors.

The values that are assigned to slots can be everything from strings to other frame instances. At runtime, this results in a tree structure of frame instances that finally represents the structure of the program to be generated. Figure 9.4 shows an example.
Figure 9.4 An example frame hierarchy.
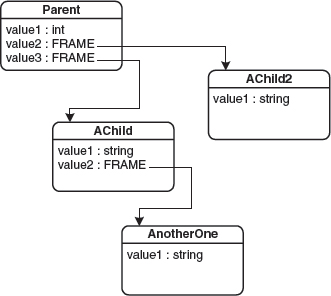
The following example uses the ANGIE processor [DSTG]. First, we show the generation of a simple member declaration that looks like the following:
short int aShortNumber = 100;
This code fragment already contains quite a number of variable aspects: the variable’s name, its type, as well as an optional initialization parameter. The following frame generates this piece of code:
.Frame GenNumberElement(Name, MaxValue) .Dim vIntQual = (MaxValue > 32767) ? “long” : “short” .Dim sNumbersInitVal <!vIntQual!> int <Name!> <? = <!sNumbersInitVal!>?>; .End Frame
The first line declares the frame, which is basically a constructor with two parameters: the name of the NumberElement and the maximum value. Based on this maximum value, the second line decides whether we need a short int, a long int, or simply an ordinary int. Line four defines the host code that is eventually generated in the course of code generation. The <!…!> syntax accesses the value of a slot of the frame instance. The code between <?…?> is only generated if the value of the slot contained in it is not undefined. The following piece of code instantiates the frame:
.myNumbElm = CreateFrame(“GenNumberElement”, “aShortNumber”, 100)
It should be noted that this instantiation does not yet generate any code – only a frame instance is created and assigned to the variable .myNumbElm. The instance is kept in the generator-internal instance repository. If one finally executes:
.Export(myNumbElm)
the instance is ‘executed’ and the code generated. Instead of exporting the instance directly (and thus immediately generating the code), it can also be assigned to another frame instance’s slot as a value, to construct more complex structures. The next frame, which generates a simple Java class, serves as an example:
.Frame ClassGenerator(fvClassName)
.Dim fvMembers = CreateCollection()
public class <!fvClassName!> {
<!fvMembers!>
}
.End Frame
This frame accepts the names of the class to be generated as a parameter. Moreover, a multi-value slot (a collection) is created. An external script (or another frame) can now set values, such as other frame instances. For example, the NumberElements from above can be set.
.Static myGeneratedClass As ClassGenerator .Function Main(className) .myGeneratedClass = CreateFrame(“ClassGenerator”, className) .Add(myGeneratedClass.fvMembers, CreateFrame(“GenNumberElement”, “i”, 1000)) .Add(myGeneratedClass.fvMembers, CreateFrame(“GenNumberElement”, “j”, 1000000)) .End Function
During the export of myGeneratedClass, a simple Java class is generated that contains the two members i and j.
9.3.4 API-based Generators
Probably the most popular type of code generators are the API-based ones. These simply provide an API with which the elements of the target platform or language can be generated. Conceptually, these generators are based on the abstract syntax (the metamodel) of the target language, and are therefore always specific to one language, or more precisely to the target language’s abstract syntax.
Figure 9.5 Functional principle of API-based generators.

For a change, the following example is taken from the .NET world. The following code should be generated:
public class Vehicle : object {
}
The following fragment of C# code generates it:
CodeNamespace n = … CodeTypeDeclaration c = new CodeTypeDeclaration (“Vehicle”); c.IsClass = true; c.BaseTypes.Add (typeof (System.Object) ); c.TypeAttributes = TypeAttributes.Public; n.Types.Add(c);
The code shown above builds an internal representation of the code, typically in the shape of an abstract syntax tree (AST). A call to a helper function initiates the actual code generation, which is not shown here.
This kind of generator is fairly intuitive and easy to use. Furthermore, it is also easy to enforce that only syntactically correct code can be generated, guaranteed by the compiler of the generator code in combination with the API. However, the problem with this kind of generator is that the potentially large amounts of constant code – the code that does not depend on the model – must be programmed instead of simply being copied into the templates.
The use of such generators becomes efficient when you build domain-specific generator classes by using well-known OO concepts on the generator level. In the following example, a Java class as well as an (empty) main method are defined using the tool Jenerator:
public class HelloJenerator {
public static void main( String[] args ) {
CClass createdClass =
new CClass(“demo”, “HelloWorld” );
CMethod mainMethod =
new CMethod( CVisibility.PUBLIC,
CType.VOID, “main” );
mainMethod.addParameter(
new CParameter( CType.user( “String[]” ), “args” )
);
mainMethod.setOwnership( COwnership.STATIC );
createdClass.addMethod( mainMethod );
}
}
This program is very long. A useful refactoring would consist of a generator class MainMethod – Java’s main methods by definition always have the same signature:
public class MainMethod extends CMethod {
public MainMethod() {
super(CVisibility.PUBLIC, CType.VOID, “main” );
setOwnership( COwnership.STATIC );
addParameter(
new CParameter( CType.user( “String[]” ),
“args” ) );
}
}
As you can see, the HelloJenerator example from above is simplified considerably:
public class HelloJenerator {
public static void main( String[] args ) {
CClass createdClass =
new CClass( “demo”, “HelloWorld” );
createdClass.addMethod( new MainMethod() );
}
}
You can imagine that efficient, domain-specific generators can be built with these generator classes. Flexibility is achieved through suitable parametrization of the generator classes.
Such generators are clearly specific to the abstract syntax of the target language, not necessarily to their concrete syntax. If one had different languages with the same abstract syntax, one could generate different target languages simply by exchanging the code generator backend. This is possible, for example in the context of the .NET framework. Using CodeDOM, one defines an abstract syntax tree based on the abstract syntax that is predefined for .NET languages in the context of the common-language runtime (CLS). One can generate the concrete syntax for any .NET language (C#, VB, C++) by selecting a suitable implementation of ICode-Generator.
Byte code modifiers, a type of tool that is especially popular in the Java universe, are usually also API-based generators. They usually operate on the abstraction level of the JVM byte code, although some provide higher-level abstractions while technically still manipulating the byte code. .NET IL code can also be generated directly with .NET’s CodeDOM.
9.3.5 In-line Generation
In-line generation refers to the case in which ‘regular’ source code contains constructs that generate more source code or byte/machine code during compilation or some kind of preprocessing. Examples are C++ preprocessor instructions or C++ templates.
Figure 9.6 In-line generation.

A trivial example based on the C++ preprocessor could look as follows:
#if defined (ACE_HAS_TLI) static ssize_t t_snd_n (ACE_HANDLE handle, const void *buf, size_t len, int flags, const ACE_Time_Value *timeout = 0, size_t *bytes_transferred = 0); #endif /* ACE_HAS_TLI */
Here, the code between the #if and the #endif is only compiled if the flag ACE_HAS_TLI has been defined. More complex expressions with parameter passing are also possible:
#define MAX(x, y) (x<y ? y : x) #define square(x) x*x
If application code contains the statement MAX (v1, v2), this is textually replaced according to the rule defined before. Thus, MAX (v1, v2) is replaced with (v1<v2 ? v1 : v2) by the preprocessor. All of this is purely based on text substitution and no type constraints or precedence rules are observed. As a consequence, this approach is only useful for simple cases.
In comparison, template metaprogramming allows a more structured approach, because the processing of templates by the compiler provide a Turing-complete functional programming language that operates on C++ types and literals. One can therefore write entire programs that run during the compilation process. The following calculates the factorial of an integer at compile time:
#include <iostream>
using namespace std;
#include “../meta/meta.h”
using namespace meta;
struct Stop
{ enum { RET = 1 };
};
template<int n>
struct Factorial
{ typedef IF<n==0, Stop, Factorial<n-1> >::RET
PreviousFactorial;
enum { RET = (n==0) ? PreviousFactorial::RET :
PreviousFactorial::RET * n };
};
void main()
{ cout « Factorial<3>::RET « endl;
}
To find out how this works is an exercise we leave to our readers – if you want to cheat, you can look it up in [EC00]. Due to the clumsy syntax and the occasionally very strange error messages, using this approach is only advisable in exceptional cases, and is not suitable for more complex model-driven projects. This is mainly because the compilers that actually run the metaprograms were neither created nor optimized for these purposes.
9.3.6 Code Attributes
We continue with another mechanism that is very popular in the Java field: code attributes. In the Java world these were first used by JavaDoc, where special comments were used to enable automatic generation of HTML documentation. The extensible architecture of JavaDoc, makes it possible to plug in custom tags and code generators. Probably the most popular example is XDoclet [XDOC]. XDoclet serves, among other purposes, to generate EJB Remote/Local Interfaces as well as deployment descriptors. The developer writes the implementation class manually and adds the required XDoclet comments to the class, which are then read by the XDoclet code generator. Furthermore, the generator has access to the source code’s syntax tree, to which the comments are added. In this way, the generator can derive information from the comments as well as from the code itself.
The following is an example of a Java class that has been supplemented with XDoclet comments.
/**
* @ejb:bean type="Stateless”
* name=“vvm/VVMQuery”
* local-jndi-name=“/ejb/vvm/VVMQueryLocal”
* jndi-name=“/ejb/vvm/VVMQueryRemote”
* view-type=“both”
*/
public abstract class VVMQueryBean
/**
* @ejb:interface-method view-type=“both”
*/
public List getPartsForVehicle( VIN theVehicle ) {
return super.getPartsForVehicle( theVehicle );
}
}
The central idea behind this method is that much of the information needed by the generator is already present in the code. The developer only has to add a few special comments. The generator has the AST of the code as well as the additional comments at its disposal.
An often-heard criticism in this context is that such tools are necessary only because J2EE (and primarily EJB) require so much redundancy in the code that it can no longer be handled manually. This is certainly true – nevertheless, generation via code attributes is not restricted to the generation of EJB infrastructure code. One can quite elegantly create persistence mappings for Hibernate [HIBE], or similar frameworks with XDoclet.
.NET offers the attribute mechanism as an integral concept of the .NET platform. Various source code elements – methods, attributes, classes – can be assigned attributes, as shown in the following example:
[QoSServicePriority(Prio.HIGH)]
class SomeService : ServiceBase {
[QoSTimeLimit(100, Quantity.MS)]
public void processRequest( Request r ) {
.…
}
}
Here we specify in a purely declarative way that the instances of this class have a service priority HIGH and that the execution of the operation processRequest() may take a maximum of 100 ms. The idea behind this is that the service is executed in a framework that measures parameters such as the execution time of the service operation. It can then make, for example, a log entry if the limits set by the attributes are exceeded, or alternatively stop accepting client requests, to lower the system load, and throw an exception to the client.
The framework’s access to the attribute (and thus to the defined time limit) is achieved using reflection. Technically this is realized as follows: attributes are simply serializable .NET classes that are instantiated by the compiler during compilation and serialized into the respective Assembly. These objects can then be accessed via reflection. Code generators can read this information from the compiled .NET Assembly and – as with XDoclet – use it as a basis for generation.
Note that such features are also available in Java, starting with Version 5. Annotations can be added to many source elements, such as classes, attributes, or operations. Technically, this works the same way as in .NET, in that the compiler instantiates data that is stored with the byte code and can subsequently be queried using reflection.
9.3.7 Code Weaving
Code weaving describes the intermixing of separate but syntactically complete, and therefore independent, pieces of code. To this end, one must define how these various parts can be put together: such locations are called join points or hooks. AspectJ [ASPJ] is a well-known example of this kind of generator: regular OO program code and aspect code are interwoven, either on the source code or byte code level. Aspects describe cross-cutting concerns – that is, functionality that cannot be adequately described and localized using the available constructs of object-oriented programming.
The following example illustrates an aspect that inserts log statements at all code locations at which methods on instances of the Account class are invoked For each method call, the log states from which method the respective Account method has been called3:
aspect Logger {
public void log( String className, String methodName ) {
System.out.println( className+”."+methodName );
}
pointcut accountCall(): call(* Account.*(*));
before() calling: accountCall() {
log( thisClass.getName(), thisMethod.getName() );
}
}
After this aspect has been applied to a system – that is, interwoven with the regular code via the weaver – code along the following lines is created, assuming the weaving happens on source level:
public class SomeClass {
private Account someAccount = …;
public someMethod( Account account2, int d ) {
// aspect Logger
System.out.println(“SomeClass.someMethod”);
someAccount.add( d );
// aspect Logger
System.out.println(“SomeClass.someMethod”);
account2.subtract(d );
}
public void anotherMethod() {
//aspect Logger
System.out.println(“SomeClass.anotherMethod”);
int bal = someAccount.getBalance();
}
}
Another example of this invasive composition of source code is the Compost Library [COMP]. This ultimately provides an API to change the structure of programs based on their AST. Compost is implemented in Java and also operates on Java source code. An additional library, the Boxology Framework, allows systematic modification of source code via hooks. We have to distinguish here between explicit hooks declared by the original developer of the source code to be modified, and implicit hooks. Implicit hooks are specific, well-defined locations in the AST of a program, such as the implements hook. Through the extension of that hook, further interfaces can be implemented. This framework can therefore serve as a basis for a wide variety of source code modification tools.
9.3.8 Combining Different Techniques
Combinations of the different code generation techniques are also possible. The Open Source tool AndroMDA [ANDR] creates source code via templates. This source code again contains code attributes. The template-based generation of this code takes place using Velocity [VELO], and further processing with XDoclet. The following is an example of a Velocity template with XDoc comments:
// -------------- attributes --------------
#foreach ( $att in $class.attributes )
#set ($atttypename = transform.findFullyQualifiedName($att.type))
private $atttypename ${att.name};
/**
#generateDocumentation ($att “ “)
*
#set ($attcolname = $str.toDatabaseAttriName(${att.name}, “_”))
#set ($attsqltype = $transform.findAttributeSQLType($att))
#if ($transform.getStereotype($att.id) == “PrimaryKey”)
* @hibernate.id
* generator-class=“uuid.string”
#else
* @hibernate.property
#end
* column=“$attcolname”
*
* @hibernate.column
* sql-type=“$attsqltype”
Another popular combination are API-based generators that can optionally read templates to simplify handling of the API.
9.3.9 Commonalities and Differences Between the Different Approaches
First, we classify the different approaches based on the criteria listed in Section 9.2:
Table 9-1 Commonalities and Differences
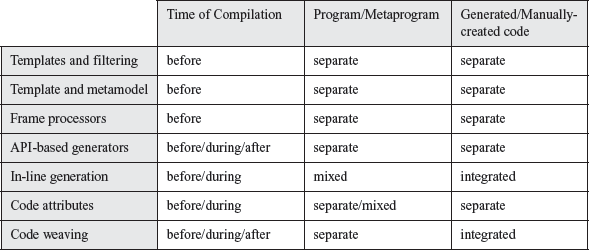
This table needs to be explained, particularly those parts where more than one option is listed:
- API-based generation can occur either prior to actual compilation via an integrated preprocessor, or during compilation using compile-time meta object protocols, as well as at runtime using runtime meta object protocols.
- In-line generation can take place either before actual compilation via an integrated preprocessor, or during compilation, for example via Lisp’s quoting mechanisms, C++ templates and so on.
- Code attributes are either evaluated during compilation, as for example in .NET, or beforehand using a preprocessor such as XDoclet. Depending on the generator, the generated code can be embedded directly in the source code or written to separate artifacts.
- Code weaving can also take place during a separate run prior to compilation, during compilation (with fully aspect-oriented languages) and at runtime (with dynamic aspect-weaving). In Java, interweaving at load time via special class loaders is common.
At this point we need to address a number of additional characteristics, differences, and commonalities. In principle, frame processors and API-based generators build an AST of the system to be created. For both approaches, the alignment with the problem domain – and thus the abstraction level and efficiency – can be increased by inserting domain-specific generator constructs, for example a frame that generates a JavaBeans property. As a rule, one always starts with the AST of the target language/platform.
If the ‘templates and metamodel’ approach is used, the generator builds an AST of the model at runtime – a representation of the problem space, depending on the metamodel, thus starting on a higher abstraction level. The templates do the translation work toward the target platform. This kind of generator is particularly suited for application in cases where the problem space’s metamodel is already complex.
A question that often comes up is whether API- or template-based generators are better in this context. In our opinion, template-based systems are better suited when large amounts of identical code are created. API-based generators are more efficient when finely granular code is to be created, for example state machines or algorithms. In the context of architecture-centric MDSD, template-based generators are preferable.
Code attributes can be considered as a form of in-line generation. The code can be generated directly into the location where the specification (the attribute) in the base program source code is located. However, in almost all cases this does not happen: the code generated from the base program and the attributes is in most case external and complete and does not have to be integrated with handwritten code, because it usually covers technical aspects such as persistence or EJB ‘glue’ code. Code attributes are recommended if you do not work completely model-driven, but you still want to generate specific artifacts. The approach is limited in that it only works if the necessary input for the generator can be reasonably specified using source code structures plus the additional information in the attributes.
The main difference between in-line generation and code weaving is that the latter approach can be used to localize cross-cutting concerns in a non-invasive way: the code to be modified need not be changed manually: it is modified from the outside by the weaver instead. Both approaches are specifically useful if you work exclusively with code and not with models.
9.3.10 Other Systems
A number of other systems exist in the field of code generation. However, they are not very relevant for MDSD. A short overview of such systems can be found in [Voe03]. We will list only two examples here:
- Meta object protocols (MOPs) allow access to compiler structures – compile-time MOPs such as OpenC++ [OC++] change the compiled program, while runtime system MOPs such as CLOS [KRB91] change the running program.
- A number of tools exist primarily in the context of Java that allow the modification of generated byte code. For example, transparent accesses to an OO database can be generated into the relevant locations in the byte code. Examples of this include BCEL [BCEL] and Javassist [JASS].
1 The program can partially learn about the metaprogram’s existence through descriptive meta objects.
2 Because this step takes place in the course of the C++ compilation process, source code is not the inevitable result, but rather direct machine code or corresponding intermediate representations in the compiler.
3 The syntax of AspectJ is evolving constantly. It is therefore quite likely that the syntax shown here will not work with the latest version.