

4.8ShaderManagement 65
float sunShadow = 1.0;
#else
float sunShadow = 0.0;
#endif
// Fade sun shadow.
#if (defined(SOLID_SHADOW) || defined(SOFT_SHADOW)) &&
defined(SHADOW_FADE) && defined(SUN_LIGHT)
sunShadow = lerp(sunShadow, 1.0,
saturate(depth * shadowFadeScale + shadowFadeOffset));
#endif
// Apply sunlight.
#if defined(SUN_LIGHT) && !defined(SOLID_SHADOW)
float3 sunDiff, sunSpec;
Global_CalcDirectLighting(normal, view, sunShadow, specIntAndPow,
sunDiff, sunSpec);
oColor += (albedo * sunDiff) + sunSpec;
#endif
// Apply light scattering.
#ifdef LIGHT_SCATTERING
float3 colExtinction, colInscattering;
LightScattering(view, depth, lightDir, colExtinction,
colInscattering);
oColor = oColor * colExtinction + colInscattering;
#endif
Listing 4.7. This example shader code illustrates how we generate a shader for sunlight and soft
shadow only.
66 4.Screen‐SpaceClassificationforEfficientDeferredShading
4.9PlatformSpecifics
Xbox360
On the Xbox 360, downsampling pixel classification results and combining with
the depth-related classification results is performed inside the pixel classification
shader, and the final 7-bit classification IDs are written to a one-quarter resolu-
tion buffer in main memory using the
memexport API. We use memexport rather
than rendering to texture so we can output the IDs as nonlinear blocks, as shown
in Figure 4.3. This block layout allows us to speed up index buffer generation by
coalescing neighboring tiles with the same ID, as explained in Section 4.10. An-
other benefit of using
memexport is that it avoids a resolve to texture. Once
we’ve written out all final IDs to CPU memory, a GPU callback wakes up a CPU
thread to perform the index buffer generation.
Before we can allow tile rendering to begin, we must make sure that the CPU
index buffer generation has finished. This is done by inserting a GPU block that
waits for a signal from the CPU thread (using asynchronous resource locks). We
insert other GPU jobs before the block to avoid any stalls.
We use Xbox Procedural Synthesis (XPS) callbacks for tile rendering as they
allow us to dynamically generate draw calls inside the callback. We insert an
XPS callback after each shader activate during the CPU render submit, then
submit each draw call in the XPS callback using the index buffer offsets and
counts we calculated during index buffer generation.
Figure 4.4 shows how it all fits together, particularly the classification flow
between GPU and CPU. The dotted arrow represents other work that we do to
keep the GPU busy while the CPU generates the index buffer.
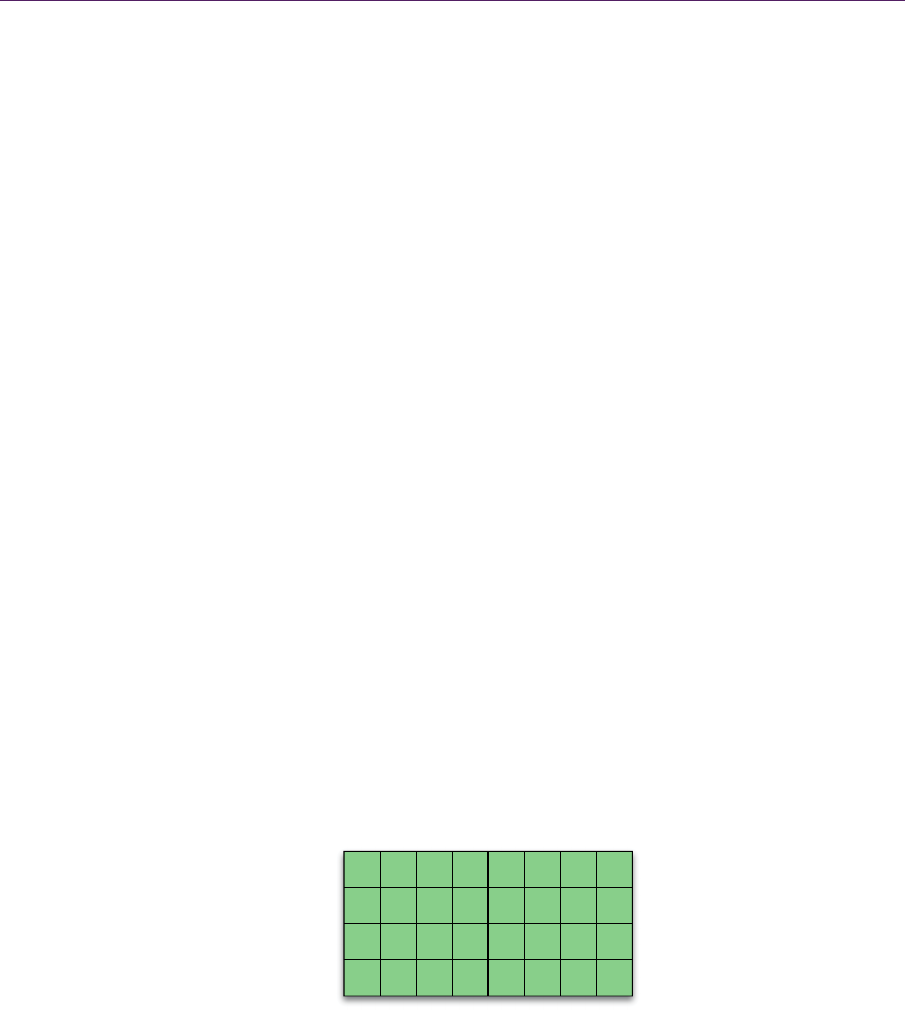
Figure 4.3.Xbox 360 tile classification IDs are arranged in blocks of
4
4
tiles, giving us
80 45 blocks in total. The numbers show the memory offsets, not the classification IDs.
0123
4567
891011
12 13 14 15
16 17 18 19
20 21 22 23
24 25 26 27
28 29 30 31

4.9PlatformSpecifics 67
Figure 4.4. Xbox 360 classification flow.
PlayStation3
On the PlayStation 3, the pixel classification pass is piggybacked on top of an
existing depth and normal restore pass as an optimization to avoid needing a spe-
cific pass. This pass creates non-antialiased, full-width depth and normal buffers
for later non-antialiased passes, such as local lights, particles, post-processing,
etc., and we write the classification results to the unused
w component of the
normal buffer.
Once we’ve rendered the normals and pixel classification to a full-resolution
texture, we then trigger a series of SPU downsample jobs to convert this texture
into a one-quarter resolution buffer containing only the pixel classification re-
sults. Combination with the depth-related classification results is performed later
on during the index buffer generation because those results aren’t ready yet. This
is due to the fact that we start the depth-related classification work on the GPU at
GPU
G-buffer render
Depth-related classification
Pixel classification
GPU callback
Wait on signal
Tile render
CPU Worker Thread
Wake
XPS Callback
XPS render submit
Index buffer generation
Signal
Sleep

68 4.Screen‐SpaceClassificationforEfficientDeferredShading
the same time as these SPU downsample jobs to maximize parallelization be-
tween the two.
We spread the work across four SPUs. Each SPU job takes 64 6
4
pixels of
classification data (one main memory frame buffer tile), ORs each
4
4 pixel
area together to create a
1
61
6
block of classification IDs, and streams them
back to main memory. Figure 4.5 shows how output IDs are arranged in main
memory. We take advantage of this block layout to speed up index buffer genera-
tion by coalescing neighboring tiles with the same ID, as explained in Section
4.10. Using
1
61
6
tile blocks also allows us to send the results back to main
memory in a single DMA call. Once this SPU work and the depth related classi-
fication work have both finished, a GPU callback triggers SPU jobs to combine
both sets of classification results together and perform the index buffer genera-
tion and draw call patching.
The first part of tile rendering is to fill the command buffer with a series of
shader activates interleaved with enough padding for the draw calls to be inserted
later on, once we know their starting indices and counts. This is done on the CPU
during the render submit phase.
Index buffer generation and tile rendering is spread across four SPUs, where
each SPU runs a single job on a quarter of the screen. The first thing we do is
combine the depth-related classification with the pixel classification. Remember
that we couldn’t do it earlier because the depth-related classification is rendered
on the GPU at the same time as the pixel classification downsample jobs are run-
ning on the SPUs. Once we have final 7-bit IDs, we can create the final draw
calls. Listings 4.5 and 4.6 show how we calculate starting indices and counts for
each shader, and we use these results to patch the command buffer with each
draw call.
Figure 4.5. PlayStation 3 tile classification IDs are arranged in blocks of
1
616 tiles,
giving us
20 12 blocks in total. The numbers show the memory offsets, not the classifi-
cation IDs.
01 15
16
255
256 257 271
272
496 511240
Block 1 Block 2
...
...
...
...

4.10Optimizations 69
Figure 4.6. PlayStation 3 classification flow.
Figure 4.6 shows how it all fits together, particularly the classification flow
between GPU and SPU jobs. The dotted arrow represents other work that we do
to keep the GPU busy while the SPU generates the index buffer.
4.10Optimizations
ReducingShaderCount
We realized that some of the 7-bit classification combinations are impossible,
such as sun light and solid shadow together, no sunlight and soft shadow togeth-
er, etc., and we were able to optimize these seven bits down to five by collapsing
the four sun and shadow bits into two. This reduced the number of shaders from
128 to 32 and turned out to be a very worthwhile optimization.
GPU
G-buffer render
Pixel classification
GPU callback
Depth-related classification
Wait on signal
Tile render
Wait on signal
GPU callback
SPU Jobs
Classification downsample
SPU Jobs
Classification combine
Signal
Index buffer generation
Draw call patching
Signal
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.